diff --git a/latest/.buildinfo b/latest/.buildinfo
index e399b071ba..98392361a4 100644
--- a/latest/.buildinfo
+++ b/latest/.buildinfo
@@ -1,4 +1,4 @@
# Sphinx build info version 1
# This file hashes the configuration used when building these files. When it is not found, a full rebuild will be done.
-config: 5c850ce0a6f2d0ce79a91d25fbeeb241
+config: 6d408ca198781361fe3feb19254966dc
tags: 645f666f9bcd5a90fca523b33c5a78b7
diff --git a/latest/_cpp_gen/executor.html b/latest/_cpp_gen/executor.html
index f1700a377d..df6fb636d1 100644
--- a/latest/_cpp_gen/executor.html
+++ b/latest/_cpp_gen/executor.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -12925,9 +12925,9 @@
diff --git a/latest/_cpp_gen/runtime.html b/latest/_cpp_gen/runtime.html
index a6ee809136..bf16716c4d 100644
--- a/latest/_cpp_gen/runtime.html
+++ b/latest/_cpp_gen/runtime.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -9589,24 +9589,21 @@ one more than decoding draft tokens for prediction from primary head
@@ -13770,9 +13708,9 @@ one more than decoding draft tokens for prediction from primary head
diff --git a/latest/_downloads/b509390ba70e52fabb10dbd9d15d5118/attention.py b/latest/_downloads/b509390ba70e52fabb10dbd9d15d5118/attention.py
index 32dcea9fff..cc9031bc28 100644
--- a/latest/_downloads/b509390ba70e52fabb10dbd9d15d5118/attention.py
+++ b/latest/_downloads/b509390ba70e52fabb10dbd9d15d5118/attention.py
@@ -1,11 +1,11 @@
import math
import weakref
-from enum import IntEnum
from typing import Optional, Union, cast
import torch
from torch import nn
+from tensorrt_llm.logger import logger
from tensorrt_llm.mapping import Mapping
from ..attention_backend import (AttentionInputType, AttentionMetadata,
@@ -23,15 +23,6 @@ from .rms_norm import RMSNorm
from .rotary_embedding import RotaryEmbedding
-class QkNormType(IntEnum):
- """
- The type of QK normalization.
- """
- none = 0 # No normalization applied to Q and K
- pre_rope = 1 # Apply normalization before Rope
- post_rope = 2 # Apply normalization after Rope
-
-
class Attention(nn.Module):
def __init__(
@@ -43,7 +34,7 @@ class Attention(nn.Module):
max_position_embeddings: int,
bias: bool,
pos_embd_params: Optional[PositionalEmbeddingParams] = None,
- qk_norm_type: QkNormType = QkNormType.none,
+ rope_fusion: Optional[bool] = None,
layer_idx: Optional[int] = None,
dtype: torch.dtype = None,
dense_bias: Optional[bool] = None,
@@ -60,14 +51,14 @@ class Attention(nn.Module):
num_key_value_heads (int): The number of key value heads.
max_position_embeddings (int): The maximum position embeddings.
bias (bool): Whether to use bias in the linear layers.
- pos_embd_params (PositionalEmbeddingParams): The positional embedding parameters.
- qk_norm_type (QkNormType): The type of QK normalization.
- layer_idx (int): The layer index.
+ pos_embd_params (Optional[PositionalEmbeddingParams]): The positional embedding parameters.
+ rope_fusion (Optional[bool]): Whether to fuse RoPE into the attention OP and skip applying unfused RoPE. If None, whether to fuse is decided by the capability of the attention backend.
+ layer_idx (Optional[int]): The layer index.
dtype (torch.dtype): The data type.
- dense_bias (bool): Whether to use bias in the output projection layer.
- config (ModelConfig): The model configuration.
+ dense_bias (Optional[bool]): Whether to use bias in the output projection layer.
+ config (Optional[ModelConfig]): The model configuration.
q_scaling (float): The scaling factor for the qk_scale. The definition is $O = softmax(QK^T * qk_scale) * V, qk_scale = 1 / (sqrt(head_dim) * q_scaling)$. The default value is 1.0.
- attention_chunk_size (int): See [Chunked Attention] below.
+ attention_chunk_size (Optional[int]): See [Chunked Attention] below.
"""
super().__init__()
self.layer_idx = layer_idx
@@ -81,7 +72,6 @@ class Attention(nn.Module):
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
self.max_position_embeddings = max_position_embeddings
self.pos_embd_params = pos_embd_params
- self.qk_norm_type = qk_norm_type
self.dense_bias = dense_bias
self.q_scaling = q_scaling
@@ -169,14 +159,21 @@ class Attention(nn.Module):
self.o_lora = LoraLayer([LoraModuleType.ATTENTION_DENSE],
[self.hidden_size])
- # enable_rope_fusion: Whether to fuse RoPE into the attention OP.
+ # Whether to fuse RoPE into the attention OP.
# If true, RoPE will be applied in self.attn.forward.
# If false, RoPE will be applied in self.apply_rope.
- self.enable_rope_fusion = attn_cls.support_fused_rope(
- ) and self.qk_norm_type != QkNormType.post_rope
+ self.rope_fusion = rope_fusion
+ if self.rope_fusion and not attn_cls.support_fused_rope():
+ logger.warning(
+ "rope_fusion is true but the attention backend does not support it. Will disable rope_fusion."
+ )
+ self.rope_fusion = False
+ # If rope_fusion is not specified, enable if the attention backend supports it.
+ if self.rope_fusion is None:
+ self.rope_fusion = attn_cls.support_fused_rope()
self.rotary_emb = None
- if not self.enable_rope_fusion and self.pos_embd_params is not None:
+ if not self.rope_fusion and self.pos_embd_params is not None:
self.rotary_emb = RotaryEmbedding(
self.pos_embd_params.rope,
head_dim=self.head_dim,
@@ -189,8 +186,7 @@ class Attention(nn.Module):
self.num_heads,
self.head_dim,
self.num_key_value_heads,
- pos_embd_params=self.pos_embd_params
- if self.enable_rope_fusion else None,
+ pos_embd_params=self.pos_embd_params if self.rope_fusion else None,
quant_config=self.quant_config,
skip_create_weights_in_init=config.skip_create_weights_in_init,
q_scaling=self.q_scaling,
@@ -198,6 +194,7 @@ class Attention(nn.Module):
)
self.support_fused_qkv = self.attn.support_fused_qkv()
+ self.support_nvfp4_output = self.attn.support_nvfp4_output()
if not config.skip_create_weights_in_init:
self.create_weights()
@@ -222,7 +219,7 @@ class Attention(nn.Module):
def forward(
self,
- position_ids: Optional[torch.LongTensor],
+ position_ids: Optional[torch.IntTensor],
hidden_states: Union[torch.Tensor, Fp4QuantizedTensor],
attn_metadata: AttentionMetadata,
attention_mask: PredefinedAttentionMask = PredefinedAttentionMask.
@@ -237,7 +234,7 @@ class Attention(nn.Module):
Forward pass for the Attention module.
Args:
- position_ids (Optional[torch.LongTensor]): The position IDs.
+ position_ids (Optional[torch.IntTensor]): The position IDs.
hidden_states (torch.Tensor): The hidden states.
attn_metadata (AttentionMetadata): The attention metadata.
attention_mask (PredefinedAttentionMask): The attention mask type.
@@ -262,11 +259,16 @@ class Attention(nn.Module):
if qkv_lora is not None:
qkv = qkv + qkv_lora
- q, k, v = self.apply_rope(qkv, position_ids)
+ q, k, v = qkv, None, None
+
+ q, k, v = self.apply_rope(q, k, v, position_ids)
out_scale = None
+ out_scale_sf = None
if self.o_proj.has_fp8_qdq or self.o_proj.has_nvfp4 or self.o_proj.has_fp8_block_scales:
out_scale = self.o_proj.inv_input_scale
+ if self.o_proj.has_nvfp4 and self.support_nvfp4_output:
+ out_scale_sf = self.o_proj.input_scale
q, k, v = self.convert_qkv(q, k, v)
attn_output = self.attn.forward(
@@ -275,6 +277,7 @@ class Attention(nn.Module):
v,
attn_metadata,
out_scale=out_scale,
+ out_scale_sf=out_scale_sf,
attention_mask=attention_mask,
mrope_config=mrope_config,
attention_window_size=attention_window_size)
@@ -285,32 +288,25 @@ class Attention(nn.Module):
layer_idx=self.layer_idx)
return attn_output
- def apply_qk_norm(self, q, k):
- raise NotImplementedError(
- f"QK norm is not implemented for {self.__class__.__name__}."
- "Please override the `apply_qk_norm` method in the subclass.")
-
- def apply_rope(self, qkv: torch.Tensor, position_ids: torch.Tensor):
+ def apply_rope(self, q: torch.Tensor, k: Optional[torch.Tensor],
+ v: Optional[torch.Tensor], position_ids: torch.Tensor):
"""
- Apply RoPE to the query and key, possibly including QK norm.
+ Apply RoPE to the query and key.
+ Depending on the implementation, q, k, v could be either fused (q, k, v = concat(q, k, v), None, None) or unfused (none of q, k, v is None).
+ Before self.attn.forward, convert_qkv will be called to make sure that the format of (q, k, v) satisfies the requirement of self.attn.
+ This method could be overridden in the subclass, in which extra functionalities such as q_norm/k_norm could be added.
Args:
- qkv (torch.Tensor): The query, key, and value tensor.
+ q (torch.Tensor): The query tensor.
+ k (Optional[torch.Tensor]): The key tensor.
+ v (Optional[torch.Tensor]): The value tensor.
position_ids (torch.Tensor): The position IDs of each token for RoPE.
Returns:
tuple: A tuple of (q, k, v).
- This method could be overridden in the subclass, it is possible that k/v is None and q is the concatenated qkv tensor, up to the implementation.
- Before self.attn.forward, convert_qkv will be called to make sure that the format of (q, k, v) satisfies the requirement of self.attn.
"""
- q, k, v = qkv, None, None
- if self.qk_norm_type == QkNormType.pre_rope:
- q, k, v = self.split_qkv(q, k, v)
- q, k = self.apply_qk_norm(q, k)
- if not self.enable_rope_fusion and position_ids is not None:
- q, k, v = self.split_qkv(q, k, v)
+ q, k, v = self.split_qkv(q, k, v)
+ # If RoPE is fused into the attention OP, do not apply RoPE here.
+ if not self.rope_fusion and position_ids is not None:
q, k = self.rotary_emb(position_ids, [q, k])
- if self.qk_norm_type == QkNormType.post_rope:
- q, k = self.apply_qk_norm(q, k)
-
return q, k, v
@@ -595,14 +591,14 @@ class MLA(nn.Module):
self.aux_stream = aux_stream
self.ln_events = [torch.cuda.Event(), torch.cuda.Event()]
- self.enable_rope_fusion = self.mha.support_fused_rope()
+ self.rope_fusion = self.mha.support_fused_rope()
self.support_fused_qkv = self.mha.support_fused_qkv()
self.rotary_emb = RotaryEmbedding(
pos_embd_params.rope,
head_dim=self.qk_rope_head_dim,
is_neox=pos_embd_params.is_neox,
)
- self.apply_rotary_emb = not self.enable_rope_fusion
+ self.apply_rotary_emb = not self.rope_fusion
if not config.skip_create_weights_in_init:
self.create_weights()
@@ -687,7 +683,7 @@ class MLA(nn.Module):
Forward pass for the MLA module.
Args:
- position_ids (Optional[torch.LongTensor]): The position IDs.
+ position_ids (Optional[torch.IntTensor]): The position IDs.
hidden_states (torch.Tensor): The hidden states.
attn_metadata (AttentionMetadata): The attention metadata.
all_reduce_params (Optional[AllReduceParams]): The all reduce parameters.
@@ -841,7 +837,7 @@ class MLA(nn.Module):
compressed_kv: torch.Tensor,
k_pe: torch.Tensor,
attn_metadata: AttentionMetadata,
- position_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.IntTensor] = None,
) -> torch.Tensor:
trtllm_attention = cast(TrtllmAttention, self.mha)
# split current q into q_nope and q_pe
@@ -949,7 +945,7 @@ class MLA(nn.Module):
k_pe: torch.Tensor,
attn_metadata: AttentionMetadata,
latent_cache: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.IntTensor] = None,
) -> torch.Tensor:
if isinstance(self.mha, TrtllmAttention):
assert isinstance(attn_metadata, TrtllmAttentionMetadata)
diff --git a/latest/_downloads/cba6509356738d5d6b4dcb3b7f52cf39/llm_args.py b/latest/_downloads/cba6509356738d5d6b4dcb3b7f52cf39/llm_args.py
index 0835058eda..42a5bc282b 100644
--- a/latest/_downloads/cba6509356738d5d6b4dcb3b7f52cf39/llm_args.py
+++ b/latest/_downloads/cba6509356738d5d6b4dcb3b7f52cf39/llm_args.py
@@ -42,7 +42,6 @@ from ..bindings.executor import (
PeftCacheConfig as _PeftCacheConfig,
SchedulerConfig as _SchedulerConfig) # isort: skip
# isort: on
-from transformers import PreTrainedTokenizerBase
# yapf: enable
from ..builder import BuildConfig, EngineConfig
@@ -1087,7 +1086,7 @@ class BaseLlmArgs(BaseModel):
self.speculative_model
) if self.speculative_model is not None else None
if model_obj.is_local_model and self.backend not in [
- 'pytorch', 'autodeploy'
+ 'pytorch', '_autodeploy'
]:
# Load parallel_config from the engine.
self.model_format = get_model_format(self.model)
@@ -1191,7 +1190,7 @@ class BaseLlmArgs(BaseModel):
self.build_config.max_draft_len = self.speculative_config.max_draft_len
- if self.backend != 'pytorch':
+ if self.backend not in ['pytorch', '_autodeploy']:
eagle_config = _EagleConfig(
self.speculative_config.eagle_choices,
self.speculative_config.greedy_sampling,
@@ -1211,7 +1210,7 @@ class BaseLlmArgs(BaseModel):
eagle3_one_model)
elif isinstance(self.speculative_config, NGramDecodingConfig):
self.build_config.speculative_decoding_mode = SpeculativeDecodingMode.NGRAM
- assert self.backend == 'pytorch'
+ assert self.backend in ['pytorch', '_autodeploy']
assert self.speculative_config.prompt_lookup_num_tokens > 0 and self.speculative_config.max_matching_ngram_size > 0
self.build_config.max_draft_len = self.speculative_config.max_draft_len
from tensorrt_llm._torch.speculative import NGramConfig
@@ -1259,9 +1258,11 @@ class BaseLlmArgs(BaseModel):
"lora_dir is empty, so custom embedding or lm head will not be applied."
)
- if self.enable_lora and self.lora_config is not None and self.backend == 'pytorch':
+ if self.enable_lora and self.lora_config is not None and self.backend in [
+ 'pytorch', '_autodeploy'
+ ]:
logger.warning(
- "enable_lora is ignored when lora_config is provided for pytorch backend."
+ f"enable_lora is ignored when lora_config is provided for {self.backend} backend."
)
if self.lora_config is not None:
@@ -1634,11 +1635,6 @@ class TorchLlmArgs(BaseLlmArgs):
def get_pytorch_backend_config(self) -> "PyTorchConfig":
from tensorrt_llm._torch.pyexecutor.config import PyTorchConfig
- # TODO: Remove this after the PyTorch backend is fully migrated to TorchLlmArgs from ExecutorConfig
- # Just a WAR to support the auto_deploy
- if self.auto_deploy_config is not None:
- return self.auto_deploy_config
-
return PyTorchConfig(
extra_resource_managers=self.extra_resource_managers,
use_cuda_graph=self.use_cuda_graph,
@@ -1718,7 +1714,7 @@ class TorchLlmArgs(BaseLlmArgs):
2. If cuda_graph_batch_sizes is not provided, it is generated based on cuda_graph_max_batch_size
3. If both are provided, cuda_graph_batch_sizes must match the generated values
"""
- if self.cuda_graph_batch_sizes is not None:
+ if self.cuda_graph_batch_sizes:
self.cuda_graph_batch_sizes = sorted(self.cuda_graph_batch_sizes)
if self.cuda_graph_max_batch_size != 0:
if self.cuda_graph_batch_sizes != self._generate_cuda_graph_batch_sizes(
@@ -1743,6 +1739,109 @@ class TorchLlmArgs(BaseLlmArgs):
return self
+class _AutoDeployLlmArgs(TorchLlmArgs):
+ """LLM arguments specifically for AutoDeploy backend.
+
+ This class extends TorchLlmArgs with AutoDeploy-specific configuration options.
+ AutoDeploy provides automatic deployment and optimization of language models
+ with various attention backends and optimization strategies.
+ """
+
+ model_factory: Literal[
+ "AutoModelForCausalLM", "AutoModelForImageTextToText"] = Field(
+ default="AutoModelForCausalLM",
+ description="The model factory to use for loading the model.",
+ )
+
+ model_kwargs: Dict[str, Any] = Field(
+ default_factory=dict,
+ description=
+ "Extra kwargs for the model config class to customize the model config. "
+ "These arguments take precedence over default values or config values in the model config "
+ "file. Arguments are resolved in order: 1) Default values in model config class, 2) Values "
+ "in model config file, 3) Values in model_kwargs. Note: if a kwarg doesn't exist in the "
+ "model config class, it will be ignored.",
+ )
+
+ mla_backend: Literal["MultiHeadLatentAttention"] = Field(
+ default="MultiHeadLatentAttention",
+ description="The Multi-Head Latent Attention backend to use.",
+ )
+
+ skip_loading_weights: bool = Field(
+ default=False,
+ description=
+ "Whether to skip loading model weights during initialization. "
+ "If True, only the model architecture is loaded.",
+ )
+
+ free_mem_ratio: float = Field(
+ default=0.8,
+ description="The fraction of available memory to allocate for cache. "
+ "Must be between 0.0 and 1.0.",
+ )
+
+ simple_shard_only: bool = Field(
+ default=False,
+ description=
+ "If True, force simple sharding (all_gather) in tensor parallelism. "
+ "If False, auto-detect and use column+row (all_reduce) sharding when possible.",
+ )
+
+ # TODO: Remove this field once tokens_per_block is properly passed through
+ attn_page_size: int = Field(
+ default=64,
+ description=
+ "Page size for attention (tokens_per_block). For TritonWithFlattenedInputs "
+ "backend, this should equal max_seq_len. Temporary field until tokens_per_block gets "
+ "properly passed through.",
+ )
+
+ @field_validator("free_mem_ratio")
+ @classmethod
+ def validate_free_mem_ratio(cls, v):
+ """Validate that free_mem_ratio is between 0.0 and 1.0."""
+ if not 0.0 <= v <= 1.0:
+ raise ValueError(
+ f"free_mem_ratio must be between 0.0 and 1.0, got {v}")
+ return v
+
+ @print_traceback_on_error
+ def model_post_init(self, __context):
+ # Modify default values that differ from TorchLlmArgs
+ new_defaults = {
+ "max_batch_size": 8,
+ "max_seq_len": 512,
+ "attn_backend": "FlashInfer",
+ # TODO: Remove this when overlap scheduler is supported (https://github.com/NVIDIA/TensorRT-LLM/issues/4364)
+ "disable_overlap_scheduler": True,
+ }
+ for k, v_default in new_defaults.items():
+ if k not in self.__pydantic_fields_set__:
+ setattr(self, k, v_default)
+
+ # NOTE: Only call super() after setting the default values since default values should be
+ # set first.
+ super().model_post_init(__context)
+
+ # Handle attn_page_size for TritonWithFlattenedInputs backend
+ if self.attn_backend == "TritonWithFlattenedInputs":
+ self.attn_page_size = self.max_seq_len
+
+ # Add max_position_embeddings to model_kwargs
+ # TODO (lucaslie): this is more HF specific than a generic model_kwargs. Ideally, we can
+ # move this to the HF model factory but we don't have access to max_seq_len there right now.
+ self.model_kwargs["max_position_embeddings"] = min(
+ self.max_seq_len,
+ self.model_kwargs.get("max_position_embeddings", self.max_seq_len),
+ )
+
+ # TODO: Remove this after the PyTorch backend is fully migrated to TorchLlmArgs from ExecutorConfig
+ def get_pytorch_backend_config(self) -> "_AutoDeployLlmArgs":
+ """Return the _AutoDeployLlmArgs (self) object."""
+ return self
+
+
def update_llm_args_with_extra_dict(
llm_args: Dict,
llm_args_dict: Dict,
diff --git a/latest/_modules/index.html b/latest/_modules/index.html
index d43b59af11..2809ca5be1 100644
--- a/latest/_modules/index.html
+++ b/latest/_modules/index.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -687,9 +687,9 @@
diff --git a/latest/_modules/tensorrt_llm/builder.html b/latest/_modules/tensorrt_llm/builder.html
index 7d244c86a4..9eb769ac2e 100644
--- a/latest/_modules/tensorrt_llm/builder.html
+++ b/latest/_modules/tensorrt_llm/builder.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1993,9 +1993,9 @@
diff --git a/latest/_modules/tensorrt_llm/disaggregated_params.html b/latest/_modules/tensorrt_llm/disaggregated_params.html
index d717c7998e..c5efe951c0 100644
--- a/latest/_modules/tensorrt_llm/disaggregated_params.html
+++ b/latest/_modules/tensorrt_llm/disaggregated_params.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -668,9 +668,9 @@
diff --git a/latest/_modules/tensorrt_llm/executor/result.html b/latest/_modules/tensorrt_llm/executor/result.html
index 5d2f55c78f..095a0eeac3 100644
--- a/latest/_modules/tensorrt_llm/executor/result.html
+++ b/latest/_modules/tensorrt_llm/executor/result.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -721,10 +721,6 @@
else:output.token_ids.extend(response_tensors.output_token_ids[src_idx])
- # In PD, the first token should be ignored in streaming mode, since it's already been returned by the context server
- ifself.disaggregated_paramsisnotNoneandself.disaggregated_params.request_type=="generation_only"andself._streamingandself.decoding_iter==2:
- output._last_token_ids_len=1
-
ifresponse_tensors.cum_log_probsisnotNone:output.cumulative_logprob=response_tensors.cum_log_probs[src_idx]
@@ -1273,9 +1269,9 @@
diff --git a/latest/_modules/tensorrt_llm/executor/utils.html b/latest/_modules/tensorrt_llm/executor/utils.html
index eeced86c7f..92b9bd23ad 100644
--- a/latest/_modules/tensorrt_llm/executor/utils.html
+++ b/latest/_modules/tensorrt_llm/executor/utils.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -519,7 +519,6 @@
fromtensorrt_llm._utilsimportmpi_rankfromtensorrt_llm.bindings.executorimportResponsefromtensorrt_llm.llmapi.utilsimportprint_colored_debug
-fromtensorrt_llm.loggerimportloggerfrom..llmapi.mpi_sessionimport(MpiCommSession,MpiPoolSession,MpiSession,RemoteMpiCommSessionClient)
@@ -536,10 +535,6 @@
TLLM_EXECUTOR_PERIODICAL_RESP_IN_AWAIT="TLLM_EXECUTOR_PERIODICAL_RESP_IN_AWAIT"
-PERIODICAL_RESP_IN_AWAIT=os.getenv(
- LlmLauncherEnvs.TLLM_EXECUTOR_PERIODICAL_RESP_IN_AWAIT)=="1"
-
-
defget_spawn_proxy_process_ipc_addr_env()->str|None:''' Get the IPC address for the spawn proxy process dynamically. '''returnos.getenv(LlmLauncherEnvs.TLLM_SPAWN_PROXY_PROCESS_IPC_ADDR)
@@ -556,10 +551,6 @@
returnos.getenv(LlmLauncherEnvs.TLLM_SPAWN_PROXY_PROCESS)=="1"
-ifPERIODICAL_RESP_IN_AWAIT:
- logger.info("Using periodical responses in await_responses")
-
-
defcreate_mpi_comm_session(n_workers:int)->RemoteMpiCommSessionClient|MpiPoolSession:assertmpi_rank(
@@ -658,7 +649,7 @@
classWorkerCommIpcAddrs(NamedTuple):''' IPC addresses (str) and HMAC keys (bytes) for communication with the worker processes. '''request_queue_addr:tuple[str,Optional[bytes]]
- request_error_queue_addr:tuple[str,Optional[bytes]]
+ worker_init_status_queue_addr:tuple[str,Optional[bytes]]result_queue_addr:tuple[str,Optional[bytes]]stats_queue_addr:tuple[str,Optional[bytes]]kv_cache_events_queue_addr:tuple[str,Optional[bytes]]
@@ -781,9 +772,9 @@
diff --git a/latest/_modules/tensorrt_llm/functional.html b/latest/_modules/tensorrt_llm/functional.html
index e9badfb41b..8988c0cabd 100644
--- a/latest/_modules/tensorrt_llm/functional.html
+++ b/latest/_modules/tensorrt_llm/functional.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -8681,9 +8681,9 @@
diff --git a/latest/_modules/tensorrt_llm/layers/activation.html b/latest/_modules/tensorrt_llm/layers/activation.html
index 6f42b49a0b..1bfdce8ca5 100644
--- a/latest/_modules/tensorrt_llm/layers/activation.html
+++ b/latest/_modules/tensorrt_llm/layers/activation.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -646,9 +646,9 @@
diff --git a/latest/_modules/tensorrt_llm/layers/attention.html b/latest/_modules/tensorrt_llm/layers/attention.html
index d1d370eaf2..8287f7efcf 100644
--- a/latest/_modules/tensorrt_llm/layers/attention.html
+++ b/latest/_modules/tensorrt_llm/layers/attention.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -3511,9 +3511,9 @@
diff --git a/latest/_modules/tensorrt_llm/layers/cast.html b/latest/_modules/tensorrt_llm/layers/cast.html
index 8a50d31b0e..ccd71c5ece 100644
--- a/latest/_modules/tensorrt_llm/layers/cast.html
+++ b/latest/_modules/tensorrt_llm/layers/cast.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -653,9 +653,9 @@
diff --git a/latest/_modules/tensorrt_llm/layers/conv.html b/latest/_modules/tensorrt_llm/layers/conv.html
index 83fc9ea691..6ddea3d38c 100644
--- a/latest/_modules/tensorrt_llm/layers/conv.html
+++ b/latest/_modules/tensorrt_llm/layers/conv.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -902,9 +902,9 @@
diff --git a/latest/_modules/tensorrt_llm/layers/embedding.html b/latest/_modules/tensorrt_llm/layers/embedding.html
index aacfd70035..c883945de8 100644
--- a/latest/_modules/tensorrt_llm/layers/embedding.html
+++ b/latest/_modules/tensorrt_llm/layers/embedding.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1369,9 +1369,9 @@
diff --git a/latest/_modules/tensorrt_llm/layers/linear.html b/latest/_modules/tensorrt_llm/layers/linear.html
index f399188379..c2bb0d63d5 100644
--- a/latest/_modules/tensorrt_llm/layers/linear.html
+++ b/latest/_modules/tensorrt_llm/layers/linear.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1217,9 +1217,9 @@
diff --git a/latest/_modules/tensorrt_llm/layers/mlp.html b/latest/_modules/tensorrt_llm/layers/mlp.html
index e5bfd99f21..64b52880fe 100644
--- a/latest/_modules/tensorrt_llm/layers/mlp.html
+++ b/latest/_modules/tensorrt_llm/layers/mlp.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1243,9 +1243,9 @@
diff --git a/latest/_modules/tensorrt_llm/layers/normalization.html b/latest/_modules/tensorrt_llm/layers/normalization.html
index 39cca5e8ac..175ba76108 100644
--- a/latest/_modules/tensorrt_llm/layers/normalization.html
+++ b/latest/_modules/tensorrt_llm/layers/normalization.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1007,9 +1007,9 @@
diff --git a/latest/_modules/tensorrt_llm/layers/pooling.html b/latest/_modules/tensorrt_llm/layers/pooling.html
index 3b9b232be7..61b50b28fc 100644
--- a/latest/_modules/tensorrt_llm/layers/pooling.html
+++ b/latest/_modules/tensorrt_llm/layers/pooling.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -662,9 +662,9 @@
diff --git a/latest/_modules/tensorrt_llm/llmapi/build_cache.html b/latest/_modules/tensorrt_llm/llmapi/build_cache.html
index 211ec0ce6a..764852987d 100644
--- a/latest/_modules/tensorrt_llm/llmapi/build_cache.html
+++ b/latest/_modules/tensorrt_llm/llmapi/build_cache.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -946,9 +946,9 @@
diff --git a/latest/_modules/tensorrt_llm/llmapi/llm.html b/latest/_modules/tensorrt_llm/llmapi/llm.html
index 9f22875735..45e38c1767 100644
--- a/latest/_modules/tensorrt_llm/llmapi/llm.html
+++ b/latest/_modules/tensorrt_llm/llmapi/llm.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -511,7 +511,9 @@
importjsonimportosimportshutil
+importsocketimporttempfile
+importtimeimportweakreffrompathlibimportPathfromtypingimportAny,List,Literal,Optional,Sequence,Union
@@ -538,7 +540,7 @@
from..loggerimportloggerfrom..sampling_paramsimportSamplingParamsfrom.llm_argsimport(LLMARGS_EXPLICIT_DOCSTRING,PybindMirror,TorchLlmArgs,
- TrtLlmArgs)
+ TrtLlmArgs,_AutoDeployLlmArgs)from.llm_utilsimport(CachedModelLoader,KvCacheRetentionConfig,LlmBuildStats,ModelLoader,_ModelRuntimeContext)from.mpi_sessionimportMpiPoolSession,external_mpi_comm_available
@@ -601,6 +603,7 @@
Attributes: tokenizer (tensorrt_llm.llmapi.tokenizer.TokenizerBase, optional): The tokenizer loaded by LLM instance, if any. workspace (pathlib.Path): The directory to store intermediate files.
+ llm_id (str): The unique ID of the LLM instance."""
@@ -629,10 +632,16 @@
**kwargs:Any)->None:self._executor_cls=kwargs.pop("executor_cls",GenerationExecutor)
+ self._llm_id=Nonetry:
- llm_args_cls=TorchLlmArgsifkwargs.get(
- 'backend',None)=='pytorch'elseTrtLlmArgs
+ backend=kwargs.get('backend',None)
+ ifbackend=='pytorch':
+ llm_args_cls=TorchLlmArgs
+ elifbackend=='_autodeploy':
+ llm_args_cls=_AutoDeployLlmArgs
+ else:
+ llm_args_cls=TrtLlmArgsself.args=llm_args_cls.from_kwargs(model=model,
@@ -706,6 +715,16 @@
defworkspace(self)->Path:returnPath(self._workspace.name)ifself._on_trt_backendelseNone
+ @property
+ defllm_id(self)->str:
+ ifself._llm_idisNone:
+ hostname=socket.gethostname()
+ pid=os.getpid()
+ timestamp=int(time.time()*1000)
+ self._llm_id=f"{hostname}-{pid}-{timestamp}"
+
+ returnself._llm_id
+
[docs]defgenerate(
@@ -989,7 +1008,7 @@
)sampling_params._setup(self.tokenizer)# auto enabled context and/or generation logits flags, as they are required by logprob computation for TRT backend.
- ifself.args.backendnotin["pytorch","autodeploy"]:
+ ifself.args.backendnotin["pytorch","_autodeploy"]:ifsampling_params.prompt_logprobsandnotsampling_params.return_context_logits:sampling_params.return_context_logits=Truesampling_params._context_logits_auto_enabled=True
@@ -1006,7 +1025,7 @@
def_check_arguments(self,prompt_len:int,query_len:int,sampling_params:SamplingParams)->None:
- ifself.args.backend=="pytorch":
+ ifself.args.backendin["pytorch","_autodeploy"]:# TODO: remove these checks after PyTorch backend# fully support TopK prompt and generation logprobs.ifsampling_params.prompt_logprobs:
@@ -1018,7 +1037,7 @@
f"PyTorch backend currently only supports `logprobs=1`. Received `logprobs={sampling_params.logprobs}` (Top{sampling_params.logprobs} logprobs). Please set `logprobs=1` in `sampling_params` instead.")return
- elifself.args.backend=="autodeploy":
+ elifself.args.backend=="_autodeploy":returnbuild_config=self.args.build_config
@@ -1171,7 +1190,7 @@
executor_config,backend=self.args.backend,pytorch_backend_config=self.args.get_pytorch_backend_config()
- ifself.args.backend=="pytorch"elseNone,
+ ifself.args.backendin["pytorch","_autodeploy"]elseNone,mapping=self.args.parallel_config.to_mapping(),build_config=self.args.build_configifself._on_trt_backendelseNone,
@@ -1218,9 +1237,9 @@
# TODO smor- need to refine what is the desired behavior if lora is enabled# in terms of the tokenizer initialization process
- ifhasattr(
- self.args,"backend"
- )andself.args.backend=="pytorch"andself.args.lora_configisnotNone:
+ ifhasattr(self.args,"backend")andself.args.backendin[
+ "pytorch","_autodeploy"
+ ]andself.args.lora_configisnotNone:num_lora_dirs=len(self.args.lora_config.lora_dir)ifnum_lora_dirs==1:tokenizer_path=self.args.lora_config.lora_dir[0]
@@ -1427,9 +1446,9 @@
diff --git a/latest/_modules/tensorrt_llm/llmapi/llm_args.html b/latest/_modules/tensorrt_llm/llmapi/llm_args.html
index 3e41a4e02b..c7e10cded3 100644
--- a/latest/_modules/tensorrt_llm/llmapi/llm_args.html
+++ b/latest/_modules/tensorrt_llm/llmapi/llm_args.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -551,7 +551,6 @@
PeftCacheConfigas_PeftCacheConfig,SchedulerConfigas_SchedulerConfig)# isort: skip# isort: on
-fromtransformersimportPreTrainedTokenizerBase# yapf: enablefrom..builderimportBuildConfig,EngineConfig
@@ -1668,7 +1667,7 @@
self.speculative_model)ifself.speculative_modelisnotNoneelseNoneifmodel_obj.is_local_modelandself.backendnotin[
- 'pytorch','autodeploy'
+ 'pytorch','_autodeploy']:# Load parallel_config from the engine.self.model_format=get_model_format(self.model)
@@ -1772,7 +1771,7 @@
self.build_config.max_draft_len=self.speculative_config.max_draft_len
- ifself.backend!='pytorch':
+ ifself.backendnotin['pytorch','_autodeploy']:eagle_config=_EagleConfig(self.speculative_config.eagle_choices,self.speculative_config.greedy_sampling,
@@ -1792,7 +1791,7 @@
eagle3_one_model)elifisinstance(self.speculative_config,NGramDecodingConfig):self.build_config.speculative_decoding_mode=SpeculativeDecodingMode.NGRAM
- assertself.backend=='pytorch'
+ assertself.backendin['pytorch','_autodeploy']assertself.speculative_config.prompt_lookup_num_tokens>0andself.speculative_config.max_matching_ngram_size>0self.build_config.max_draft_len=self.speculative_config.max_draft_lenfromtensorrt_llm._torch.speculativeimportNGramConfig
@@ -1840,9 +1839,11 @@
"lora_dir is empty, so custom embedding or lm head will not be applied.")
- ifself.enable_loraandself.lora_configisnotNoneandself.backend=='pytorch':
+ ifself.enable_loraandself.lora_configisnotNoneandself.backendin[
+ 'pytorch','_autodeploy'
+ ]:logger.warning(
- "enable_lora is ignored when lora_config is provided for pytorch backend."
+ f"enable_lora is ignored when lora_config is provided for {self.backend} backend.")ifself.lora_configisnotNone:
@@ -2231,11 +2232,6 @@
defget_pytorch_backend_config(self)->"PyTorchConfig":fromtensorrt_llm._torch.pyexecutor.configimportPyTorchConfig
- # TODO: Remove this after the PyTorch backend is fully migrated to TorchLlmArgs from ExecutorConfig
- # Just a WAR to support the auto_deploy
- ifself.auto_deploy_configisnotNone:
- returnself.auto_deploy_config
-
returnPyTorchConfig(extra_resource_managers=self.extra_resource_managers,use_cuda_graph=self.use_cuda_graph,
@@ -2321,7 +2317,7 @@
2. If cuda_graph_batch_sizes is not provided, it is generated based on cuda_graph_max_batch_size 3. If both are provided, cuda_graph_batch_sizes must match the generated values """
- ifself.cuda_graph_batch_sizesisnotNone:
+ ifself.cuda_graph_batch_sizes:self.cuda_graph_batch_sizes=sorted(self.cuda_graph_batch_sizes)ifself.cuda_graph_max_batch_size!=0:ifself.cuda_graph_batch_sizes!=self._generate_cuda_graph_batch_sizes(
@@ -2348,6 +2344,109 @@
+class_AutoDeployLlmArgs(TorchLlmArgs):
+"""LLM arguments specifically for AutoDeploy backend.
+
+ This class extends TorchLlmArgs with AutoDeploy-specific configuration options.
+ AutoDeploy provides automatic deployment and optimization of language models
+ with various attention backends and optimization strategies.
+ """
+
+ model_factory:Literal[
+ "AutoModelForCausalLM","AutoModelForImageTextToText"]=Field(
+ default="AutoModelForCausalLM",
+ description="The model factory to use for loading the model.",
+ )
+
+ model_kwargs:Dict[str,Any]=Field(
+ default_factory=dict,
+ description=
+ "Extra kwargs for the model config class to customize the model config. "
+ "These arguments take precedence over default values or config values in the model config "
+ "file. Arguments are resolved in order: 1) Default values in model config class, 2) Values "
+ "in model config file, 3) Values in model_kwargs. Note: if a kwarg doesn't exist in the "
+ "model config class, it will be ignored.",
+ )
+
+ mla_backend:Literal["MultiHeadLatentAttention"]=Field(
+ default="MultiHeadLatentAttention",
+ description="The Multi-Head Latent Attention backend to use.",
+ )
+
+ skip_loading_weights:bool=Field(
+ default=False,
+ description=
+ "Whether to skip loading model weights during initialization. "
+ "If True, only the model architecture is loaded.",
+ )
+
+ free_mem_ratio:float=Field(
+ default=0.8,
+ description="The fraction of available memory to allocate for cache. "
+ "Must be between 0.0 and 1.0.",
+ )
+
+ simple_shard_only:bool=Field(
+ default=False,
+ description=
+ "If True, force simple sharding (all_gather) in tensor parallelism. "
+ "If False, auto-detect and use column+row (all_reduce) sharding when possible.",
+ )
+
+ # TODO: Remove this field once tokens_per_block is properly passed through
+ attn_page_size:int=Field(
+ default=64,
+ description=
+ "Page size for attention (tokens_per_block). For TritonWithFlattenedInputs "
+ "backend, this should equal max_seq_len. Temporary field until tokens_per_block gets "
+ "properly passed through.",
+ )
+
+ @field_validator("free_mem_ratio")
+ @classmethod
+ defvalidate_free_mem_ratio(cls,v):
+"""Validate that free_mem_ratio is between 0.0 and 1.0."""
+ ifnot0.0<=v<=1.0:
+ raiseValueError(
+ f"free_mem_ratio must be between 0.0 and 1.0, got {v}")
+ returnv
+
+ @print_traceback_on_error
+ defmodel_post_init(self,__context):
+ # Modify default values that differ from TorchLlmArgs
+ new_defaults={
+ "max_batch_size":8,
+ "max_seq_len":512,
+ "attn_backend":"FlashInfer",
+ # TODO: Remove this when overlap scheduler is supported (https://github.com/NVIDIA/TensorRT-LLM/issues/4364)
+ "disable_overlap_scheduler":True,
+ }
+ fork,v_defaultinnew_defaults.items():
+ ifknotinself.__pydantic_fields_set__:
+ setattr(self,k,v_default)
+
+ # NOTE: Only call super() after setting the default values since default values should be
+ # set first.
+ super().model_post_init(__context)
+
+ # Handle attn_page_size for TritonWithFlattenedInputs backend
+ ifself.attn_backend=="TritonWithFlattenedInputs":
+ self.attn_page_size=self.max_seq_len
+
+ # Add max_position_embeddings to model_kwargs
+ # TODO (lucaslie): this is more HF specific than a generic model_kwargs. Ideally, we can
+ # move this to the HF model factory but we don't have access to max_seq_len there right now.
+ self.model_kwargs["max_position_embeddings"]=min(
+ self.max_seq_len,
+ self.model_kwargs.get("max_position_embeddings",self.max_seq_len),
+ )
+
+ # TODO: Remove this after the PyTorch backend is fully migrated to TorchLlmArgs from ExecutorConfig
+ defget_pytorch_backend_config(self)->"_AutoDeployLlmArgs":
+"""Return the _AutoDeployLlmArgs (self) object."""
+ returnself
+
+
defupdate_llm_args_with_extra_dict(llm_args:Dict,llm_args_dict:Dict,
@@ -2530,9 +2629,9 @@
diff --git a/latest/_modules/tensorrt_llm/llmapi/mpi_session.html b/latest/_modules/tensorrt_llm/llmapi/mpi_session.html
index 22c585bdba..461af6cf26 100644
--- a/latest/_modules/tensorrt_llm/llmapi/mpi_session.html
+++ b/latest/_modules/tensorrt_llm/llmapi/mpi_session.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1151,9 +1151,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/baichuan/model.html b/latest/_modules/tensorrt_llm/models/baichuan/model.html
index d90b92f478..86f8ddefd8 100644
--- a/latest/_modules/tensorrt_llm/models/baichuan/model.html
+++ b/latest/_modules/tensorrt_llm/models/baichuan/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -880,9 +880,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/bert/model.html b/latest/_modules/tensorrt_llm/models/bert/model.html
index c02ec73408..11df15dc4a 100644
--- a/latest/_modules/tensorrt_llm/models/bert/model.html
+++ b/latest/_modules/tensorrt_llm/models/bert/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1184,9 +1184,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/bloom/model.html b/latest/_modules/tensorrt_llm/models/bloom/model.html
index 3f1e04df38..ff06cb6cac 100644
--- a/latest/_modules/tensorrt_llm/models/bloom/model.html
+++ b/latest/_modules/tensorrt_llm/models/bloom/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -792,9 +792,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/chatglm/config.html b/latest/_modules/tensorrt_llm/models/chatglm/config.html
index 82d441fa93..415a9bad20 100644
--- a/latest/_modules/tensorrt_llm/models/chatglm/config.html
+++ b/latest/_modules/tensorrt_llm/models/chatglm/config.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -809,9 +809,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/chatglm/model.html b/latest/_modules/tensorrt_llm/models/chatglm/model.html
index 079b8e1f18..d92b322f3c 100644
--- a/latest/_modules/tensorrt_llm/models/chatglm/model.html
+++ b/latest/_modules/tensorrt_llm/models/chatglm/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1008,9 +1008,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/clip/model.html b/latest/_modules/tensorrt_llm/models/clip/model.html
index 1a6b4656ce..fab1304486 100644
--- a/latest/_modules/tensorrt_llm/models/clip/model.html
+++ b/latest/_modules/tensorrt_llm/models/clip/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -837,9 +837,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/cogvlm/config.html b/latest/_modules/tensorrt_llm/models/cogvlm/config.html
index 725efe1916..85a3f530d5 100644
--- a/latest/_modules/tensorrt_llm/models/cogvlm/config.html
+++ b/latest/_modules/tensorrt_llm/models/cogvlm/config.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -668,9 +668,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/cogvlm/model.html b/latest/_modules/tensorrt_llm/models/cogvlm/model.html
index 5a72b28a35..909dbe40b5 100644
--- a/latest/_modules/tensorrt_llm/models/cogvlm/model.html
+++ b/latest/_modules/tensorrt_llm/models/cogvlm/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -921,9 +921,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/commandr/model.html b/latest/_modules/tensorrt_llm/models/commandr/model.html
index 344cbc789e..37788273d9 100644
--- a/latest/_modules/tensorrt_llm/models/commandr/model.html
+++ b/latest/_modules/tensorrt_llm/models/commandr/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -819,9 +819,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/dbrx/config.html b/latest/_modules/tensorrt_llm/models/dbrx/config.html
index 914d526e83..56b2c21980 100644
--- a/latest/_modules/tensorrt_llm/models/dbrx/config.html
+++ b/latest/_modules/tensorrt_llm/models/dbrx/config.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -683,9 +683,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/dbrx/model.html b/latest/_modules/tensorrt_llm/models/dbrx/model.html
index abecf36478..72790b59c6 100644
--- a/latest/_modules/tensorrt_llm/models/dbrx/model.html
+++ b/latest/_modules/tensorrt_llm/models/dbrx/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -809,9 +809,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/deepseek_v1/model.html b/latest/_modules/tensorrt_llm/models/deepseek_v1/model.html
index e1e4f5805c..d6222f5b3f 100644
--- a/latest/_modules/tensorrt_llm/models/deepseek_v1/model.html
+++ b/latest/_modules/tensorrt_llm/models/deepseek_v1/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -903,9 +903,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/deepseek_v2/model.html b/latest/_modules/tensorrt_llm/models/deepseek_v2/model.html
index 237dedb2d0..b5804a925f 100644
--- a/latest/_modules/tensorrt_llm/models/deepseek_v2/model.html
+++ b/latest/_modules/tensorrt_llm/models/deepseek_v2/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -985,9 +985,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/dit/model.html b/latest/_modules/tensorrt_llm/models/dit/model.html
index 2e62c27bf2..12659590c4 100644
--- a/latest/_modules/tensorrt_llm/models/dit/model.html
+++ b/latest/_modules/tensorrt_llm/models/dit/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1021,9 +1021,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/eagle/model.html b/latest/_modules/tensorrt_llm/models/eagle/model.html
index 8059e80fca..006c51a970 100644
--- a/latest/_modules/tensorrt_llm/models/eagle/model.html
+++ b/latest/_modules/tensorrt_llm/models/eagle/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1957,9 +1957,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/enc_dec/model.html b/latest/_modules/tensorrt_llm/models/enc_dec/model.html
index fac8df8da0..d1f15c0fe4 100644
--- a/latest/_modules/tensorrt_llm/models/enc_dec/model.html
+++ b/latest/_modules/tensorrt_llm/models/enc_dec/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -2862,9 +2862,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/falcon/config.html b/latest/_modules/tensorrt_llm/models/falcon/config.html
index 11d7eeb7ef..8dc9823266 100644
--- a/latest/_modules/tensorrt_llm/models/falcon/config.html
+++ b/latest/_modules/tensorrt_llm/models/falcon/config.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -744,9 +744,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/falcon/model.html b/latest/_modules/tensorrt_llm/models/falcon/model.html
index 85b1be8036..31f3f8dd7a 100644
--- a/latest/_modules/tensorrt_llm/models/falcon/model.html
+++ b/latest/_modules/tensorrt_llm/models/falcon/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -906,9 +906,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/gemma/config.html b/latest/_modules/tensorrt_llm/models/gemma/config.html
index 961dd54eb6..fb6f1f3cdd 100644
--- a/latest/_modules/tensorrt_llm/models/gemma/config.html
+++ b/latest/_modules/tensorrt_llm/models/gemma/config.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -834,9 +834,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/gemma/model.html b/latest/_modules/tensorrt_llm/models/gemma/model.html
index e80fa36866..7ccac91c80 100644
--- a/latest/_modules/tensorrt_llm/models/gemma/model.html
+++ b/latest/_modules/tensorrt_llm/models/gemma/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1026,9 +1026,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/gpt/config.html b/latest/_modules/tensorrt_llm/models/gpt/config.html
index 20156f06cd..d6f46985a2 100644
--- a/latest/_modules/tensorrt_llm/models/gpt/config.html
+++ b/latest/_modules/tensorrt_llm/models/gpt/config.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -953,9 +953,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/gpt/model.html b/latest/_modules/tensorrt_llm/models/gpt/model.html
index db4d419722..d3da8d1d08 100644
--- a/latest/_modules/tensorrt_llm/models/gpt/model.html
+++ b/latest/_modules/tensorrt_llm/models/gpt/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1062,9 +1062,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/gptj/config.html b/latest/_modules/tensorrt_llm/models/gptj/config.html
index fa05554092..5555ef8050 100644
--- a/latest/_modules/tensorrt_llm/models/gptj/config.html
+++ b/latest/_modules/tensorrt_llm/models/gptj/config.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -682,9 +682,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/gptj/model.html b/latest/_modules/tensorrt_llm/models/gptj/model.html
index 7082784cc5..76da10ab9d 100644
--- a/latest/_modules/tensorrt_llm/models/gptj/model.html
+++ b/latest/_modules/tensorrt_llm/models/gptj/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -834,9 +834,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/gptneox/model.html b/latest/_modules/tensorrt_llm/models/gptneox/model.html
index 03c4ff698e..664578088d 100644
--- a/latest/_modules/tensorrt_llm/models/gptneox/model.html
+++ b/latest/_modules/tensorrt_llm/models/gptneox/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -774,9 +774,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/llama/config.html b/latest/_modules/tensorrt_llm/models/llama/config.html
index 8ec04ebf96..bc40035875 100644
--- a/latest/_modules/tensorrt_llm/models/llama/config.html
+++ b/latest/_modules/tensorrt_llm/models/llama/config.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -908,9 +908,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/llama/model.html b/latest/_modules/tensorrt_llm/models/llama/model.html
index e0986b01f8..92a9b1dc80 100644
--- a/latest/_modules/tensorrt_llm/models/llama/model.html
+++ b/latest/_modules/tensorrt_llm/models/llama/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1256,9 +1256,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/mamba/model.html b/latest/_modules/tensorrt_llm/models/mamba/model.html
index 0440f62009..3000da49f2 100644
--- a/latest/_modules/tensorrt_llm/models/mamba/model.html
+++ b/latest/_modules/tensorrt_llm/models/mamba/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1101,9 +1101,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/medusa/config.html b/latest/_modules/tensorrt_llm/models/medusa/config.html
index 8c12f3cecb..bf0037ebf5 100644
--- a/latest/_modules/tensorrt_llm/models/medusa/config.html
+++ b/latest/_modules/tensorrt_llm/models/medusa/config.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -741,9 +741,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/medusa/model.html b/latest/_modules/tensorrt_llm/models/medusa/model.html
index bc80024bbc..30d46f4f3a 100644
--- a/latest/_modules/tensorrt_llm/models/medusa/model.html
+++ b/latest/_modules/tensorrt_llm/models/medusa/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -891,9 +891,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/mllama/model.html b/latest/_modules/tensorrt_llm/models/mllama/model.html
index 5cbf6a0e7f..4bec8cb69d 100644
--- a/latest/_modules/tensorrt_llm/models/mllama/model.html
+++ b/latest/_modules/tensorrt_llm/models/mllama/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -2202,9 +2202,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/mmdit_sd3/model.html b/latest/_modules/tensorrt_llm/models/mmdit_sd3/model.html
index ce3902bdff..0bf197a2e3 100644
--- a/latest/_modules/tensorrt_llm/models/mmdit_sd3/model.html
+++ b/latest/_modules/tensorrt_llm/models/mmdit_sd3/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1268,9 +1268,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/modeling_utils.html b/latest/_modules/tensorrt_llm/models/modeling_utils.html
index 3ca5f1f7ea..9eb609b2e9 100644
--- a/latest/_modules/tensorrt_llm/models/modeling_utils.html
+++ b/latest/_modules/tensorrt_llm/models/modeling_utils.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -2663,9 +2663,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/mpt/model.html b/latest/_modules/tensorrt_llm/models/mpt/model.html
index 3f9a382258..9dbe1eb463 100644
--- a/latest/_modules/tensorrt_llm/models/mpt/model.html
+++ b/latest/_modules/tensorrt_llm/models/mpt/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -806,9 +806,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/multimodal_encoders/config.html b/latest/_modules/tensorrt_llm/models/multimodal_encoders/config.html
index 7bd34b393a..a49cf6000b 100644
--- a/latest/_modules/tensorrt_llm/models/multimodal_encoders/config.html
+++ b/latest/_modules/tensorrt_llm/models/multimodal_encoders/config.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -740,9 +740,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/multimodal_encoders/model.html b/latest/_modules/tensorrt_llm/models/multimodal_encoders/model.html
index 5fb65b6437..7ac4acc69d 100644
--- a/latest/_modules/tensorrt_llm/models/multimodal_encoders/model.html
+++ b/latest/_modules/tensorrt_llm/models/multimodal_encoders/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -808,9 +808,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/opt/model.html b/latest/_modules/tensorrt_llm/models/opt/model.html
index 64822e5f83..fbca940c38 100644
--- a/latest/_modules/tensorrt_llm/models/opt/model.html
+++ b/latest/_modules/tensorrt_llm/models/opt/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -811,9 +811,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/phi/model.html b/latest/_modules/tensorrt_llm/models/phi/model.html
index b5d512d010..238c3572f3 100644
--- a/latest/_modules/tensorrt_llm/models/phi/model.html
+++ b/latest/_modules/tensorrt_llm/models/phi/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -855,9 +855,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/phi3/model.html b/latest/_modules/tensorrt_llm/models/phi3/model.html
index d9f3c283a4..336e05569f 100644
--- a/latest/_modules/tensorrt_llm/models/phi3/model.html
+++ b/latest/_modules/tensorrt_llm/models/phi3/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -951,9 +951,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/recurrentgemma/model.html b/latest/_modules/tensorrt_llm/models/recurrentgemma/model.html
index 1e6a02647c..45e21a5efb 100644
--- a/latest/_modules/tensorrt_llm/models/recurrentgemma/model.html
+++ b/latest/_modules/tensorrt_llm/models/recurrentgemma/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1254,9 +1254,9 @@
diff --git a/latest/_modules/tensorrt_llm/models/redrafter/model.html b/latest/_modules/tensorrt_llm/models/redrafter/model.html
index ff2ecd37dd..05e9c831a1 100644
--- a/latest/_modules/tensorrt_llm/models/redrafter/model.html
+++ b/latest/_modules/tensorrt_llm/models/redrafter/model.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -926,9 +926,9 @@
diff --git a/latest/_modules/tensorrt_llm/plugin/plugin.html b/latest/_modules/tensorrt_llm/plugin/plugin.html
index ab4d18e833..2eb7c70990 100644
--- a/latest/_modules/tensorrt_llm/plugin/plugin.html
+++ b/latest/_modules/tensorrt_llm/plugin/plugin.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1482,9 +1482,9 @@
diff --git a/latest/_modules/tensorrt_llm/quantization/mode.html b/latest/_modules/tensorrt_llm/quantization/mode.html
index 1a57fca377..4336466ba4 100644
--- a/latest/_modules/tensorrt_llm/quantization/mode.html
+++ b/latest/_modules/tensorrt_llm/quantization/mode.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1034,9 +1034,9 @@
diff --git a/latest/_modules/tensorrt_llm/quantization/quantize_by_modelopt.html b/latest/_modules/tensorrt_llm/quantization/quantize_by_modelopt.html
index bffc8235ee..930a2bef5e 100644
--- a/latest/_modules/tensorrt_llm/quantization/quantize_by_modelopt.html
+++ b/latest/_modules/tensorrt_llm/quantization/quantize_by_modelopt.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1895,9 +1895,9 @@
diff --git a/latest/_modules/tensorrt_llm/runtime/enc_dec_model_runner.html b/latest/_modules/tensorrt_llm/runtime/enc_dec_model_runner.html
index 14a8374cb0..83bf997028 100644
--- a/latest/_modules/tensorrt_llm/runtime/enc_dec_model_runner.html
+++ b/latest/_modules/tensorrt_llm/runtime/enc_dec_model_runner.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1165,9 +1165,9 @@
diff --git a/latest/_modules/tensorrt_llm/runtime/generation.html b/latest/_modules/tensorrt_llm/runtime/generation.html
index f55c97392a..2225cc749f 100644
--- a/latest/_modules/tensorrt_llm/runtime/generation.html
+++ b/latest/_modules/tensorrt_llm/runtime/generation.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -5453,9 +5453,9 @@
diff --git a/latest/_modules/tensorrt_llm/runtime/kv_cache_manager.html b/latest/_modules/tensorrt_llm/runtime/kv_cache_manager.html
index 84659692e3..8e8a516e53 100644
--- a/latest/_modules/tensorrt_llm/runtime/kv_cache_manager.html
+++ b/latest/_modules/tensorrt_llm/runtime/kv_cache_manager.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1112,9 +1112,9 @@
diff --git a/latest/_modules/tensorrt_llm/runtime/model_runner.html b/latest/_modules/tensorrt_llm/runtime/model_runner.html
index 2bb6e85224..faaab88636 100644
--- a/latest/_modules/tensorrt_llm/runtime/model_runner.html
+++ b/latest/_modules/tensorrt_llm/runtime/model_runner.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1624,9 +1624,9 @@
diff --git a/latest/_modules/tensorrt_llm/runtime/model_runner_cpp.html b/latest/_modules/tensorrt_llm/runtime/model_runner_cpp.html
index 5f129f5cef..3d0401e22c 100644
--- a/latest/_modules/tensorrt_llm/runtime/model_runner_cpp.html
+++ b/latest/_modules/tensorrt_llm/runtime/model_runner_cpp.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1828,9 +1828,9 @@
diff --git a/latest/_modules/tensorrt_llm/runtime/multimodal_model_runner.html b/latest/_modules/tensorrt_llm/runtime/multimodal_model_runner.html
index 3418ba3496..b51a6f1121 100644
--- a/latest/_modules/tensorrt_llm/runtime/multimodal_model_runner.html
+++ b/latest/_modules/tensorrt_llm/runtime/multimodal_model_runner.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1440,9 +1440,6 @@
elifself.model_type=='pixtral':# Hold on to pixel_values and input_ids.dtype=str_dtype_to_torch(self.vision_precision)
- pixel_values=image["pixel_values"].to(device="cuda",dtype=dtype)
- input_ids=image["input_ids"].to(device="cuda")
-
# Shape of pixel values from the processor varies with the raw image.# So we create a new tensor with a fixed shape as expected by the vision# encoder and create a corresponding attention mask.
@@ -1450,19 +1447,30 @@
patch_size=self.patch_sized_min=torch.finfo(dtype).minnum_patches=(image_size//patch_size)
- image=torch.full((1,3,image_size,image_size),
- fill_value=0,
- dtype=dtype,
- device="cuda")
- attention_mask=torch.full((1,num_patches,num_patches),
- fill_value=d_min,
- dtype=dtype,
- device="cuda")
- h,w=pixel_values.shape[-2:]
- image[...,:h,:w]=pixel_values
- attention_mask[...,:h//patch_size,:w//patch_size]=0
+ padded_image=torch.full(
+ (self.args.batch_size,3,image_size,image_size),
+ fill_value=0,
+ dtype=dtype,
+ device="cuda")
+ padded_attention_mask=torch.full(
+ (self.args.batch_size,num_patches,num_patches),
+ fill_value=d_min,
+ dtype=dtype,
+ device="cuda")
+ h,w,input_ids=[],[],[]
+ forimg_idxinrange(self.args.batch_size):
+ pixel_values=image["pixel_values"][img_idx]
+ img_h,img_w=pixel_values.shape[-2:]
+ padded_image[img_idx,:,:img_h,:img_w]=pixel_values
+ padded_attention_mask[img_idx,:img_h//patch_size,:img_w//
+ patch_size]=0
+ input_ids.append(image["input_ids"][img_idx])
+ h.append(img_h)
+ w.append(img_w)
+
+ image=padded_imageother_vision_inputs={
- "attention_mask":attention_mask,
+ "attention_mask":padded_attention_mask,}elifself.model_type=='llava_next':input=image
@@ -1681,12 +1689,29 @@
elifself.model_type=='pixtral':relevant_patch_size=self.patch_size*self.spatial_merge_sizeoutput_img_size=self.image_size//relevant_patch_size
- visual_features=visual_features.reshape(
- output_img_size,output_img_size,
- -1)[:h//relevant_patch_size,:w//
- relevant_patch_size].flatten(0,1)
+ # Note: max_h * max_w shall serve as the `tokens_per_task` in ptuning prompt table.
+ max_h=max(h)//relevant_patch_size
+ max_w=max(w)//relevant_patch_size
+ visual_embed_dim=visual_features.shape[-1]
+ relevant_visual_features=torch.zeros(self.args.batch_size,
+ max_h*max_w,
+ visual_embed_dim)
+ forimg_idxinrange(self.args.batch_size):
+ complete_features=visual_features[img_idx]
+ complete_features=complete_features.reshape(
+ output_img_size,output_img_size,visual_embed_dim)
+ relevant_h=h[img_idx]//relevant_patch_size
+ relevant_w=w[img_idx]//relevant_patch_size
+ flattened_features=complete_features[:relevant_h,:
+ relevant_w,:].flatten(
+ 0,1)
+ relevant_visual_features[img_idx,:relevant_h*
+ relevant_w,:]=flattened_features
+ visual_features=relevant_visual_featuresinput_ids=self.ptuning_setup_pixtral(input_ids=input_ids)
- length=input_ids.shape[1]
+ # Note: length is not used for pixtral model downstream. Setting it to a list
+ # of length of input_ids causes errors downstream. So, supplying a placeholder.
+ length=input_ids[0].shape[0]elifself.model_type=='llava_next':visual_features=LlavaNextUtils.rearrange_image_features(
@@ -2329,7 +2354,7 @@
[docs]defget_rope_index(self,
- input_ids:torch.LongTensor,
+ input_ids:torch.IntTensor,image_grid_thw:Optional[torch.LongTensor]=None,video_grid_thw:Optional[torch.LongTensor]=None,attention_mask:Optional[torch.Tensor]=None,
@@ -2361,7 +2386,7 @@
Here we calculate the text start position_ids as the max vision position_ids plus 1. Args:
- input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ input_ids (`torch.IntTensor` of shape `(batch_size, sequence_length)`): Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it. image_grid_thw (`torch.LongTensor` of shape `(num_images, 3)`, *optional*):
@@ -2375,7 +2400,7 @@
- 0 for tokens that are **masked**. Returns:
- position_ids (`torch.LongTensor` of shape `(3, batch_size, sequence_length)`)
+ position_ids (`torch.IntTensor` of shape `(3, batch_size, sequence_length)`) mrope_position_deltas (`torch.Tensor` of shape `(batch_size)`) """spatial_merge_size=self.spatial_merge_size
@@ -2594,16 +2619,19 @@
[docs]defptuning_setup_pixtral(self,input_ids):# input_ids obtained from processor has token_ids for text as well as image tokens
- # where each image token is represented the same image_token_index (10 for this model).
+ # where each image token is represented by the same image_token_index.image_token_index=self.image_token_indexvocab_size=self.vocab_size# Replace all image tokens with a unique token_id > text_vacab_size.# This shall be used to lookup the prompt table.
- replacer=vocab_size
- foriinrange(len(input_ids[0])):
- ifinput_ids[0][i]==image_token_index:
- input_ids[0][i]=replacer
- replacer+=1
+ forimg_idxinrange(self.args.batch_size):
+ # Note: We reset replacer to text_vocab_size for each sample. This is as opposed to doing `replacer = vocab_size + img_idx * tokens_per_task`.
+ # That part of the look-up manipulation is done by the `task_ids` input to PromptEmbedding forward.
+ replacer=vocab_size
+ fortoken_idxinrange(len(input_ids[img_idx])):
+ ifinput_ids[img_idx][token_idx]==image_token_index:
+ input_ids[img_idx][token_idx]=replacer
+ replacer+=1returninput_ids
@@ -2745,7 +2773,24 @@
ifisinstance(image_path,str):image_path=image_path.split(self.args.path_sep)images=load_images(image_path)
-
+ elif"pixtral"inself.model_type:
+ ifimage_pathisNone:
+ image_urls=[
+ "https://storage.googleapis.com/sfr-vision-language-research/LAVIS/assets/merlion.png",
+ "https://www.ilankelman.org/stopsigns/australia.jpg",
+ "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.png",
+ "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
+ ]
+ whilelen(image_urls)<self.args.batch_size:
+ image_urls*=2
+ image_urls=image_urls[:self.args.batch_size]
+ self.args.image_path=",".join(image_urls)
+ images=load_images(image_urls)
+ else:
+ ifisinstance(image_path,str):
+ image_path=image_path.split(self.args.path_sep)
+ images=load_images(image_path)
+ images=[images]ifnotisinstance(images,list)elseimageselif"nougat"inself.model_type:filepath=hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa",
@@ -2998,9 +3043,15 @@
post_prompt="[/INST]"prompt=pre_prompt+input_text+post_promptdtype=str_dtype_to_torch(self.vision_precision)
- image=self.processor(text=prompt,
- images=[raw_image],
- return_tensors="pt").to(dtype)
+ image={'pixel_values':[],'input_ids':[]}
+ forimg_idxinrange(self.args.batch_size):
+ image_info=self.processor(text=prompt,
+ images=[raw_image[img_idx]],
+ return_tensors="pt").to(dtype)
+ image['pixel_values'].append(image_info['pixel_values'].to(
+ self.device))
+ image['input_ids'].append(image_info['input_ids'][0].to(
+ self.device))elif'internvl'inself.model_type:pre_prompt="<|system|>\n你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。<|end|><|user|>\n<image>\n"
@@ -3204,7 +3255,9 @@
image=image.expand(min(self.args.batch_size,len(input_text)),-1,-1,-1).contiguous()
- ifimageisnotNone:
+ # Note: For pixtral model, image is a dict with each value being a list of tensors.
+ # Moving to device is handled above. So, it's safe to skip this for pixtral.
+ ifimageisnotNoneand'pixtral'notinself.model_type:image=image.to(self.device)# Generate decoder_input_ids for enc-dec models# Custom prompts can be added as:
@@ -3354,9 +3407,9 @@
diff --git a/latest/_modules/tensorrt_llm/runtime/session.html b/latest/_modules/tensorrt_llm/runtime/session.html
index 4c54b2be61..bdd196035a 100644
--- a/latest/_modules/tensorrt_llm/runtime/session.html
+++ b/latest/_modules/tensorrt_llm/runtime/session.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -972,9 +972,9 @@
diff --git a/latest/_modules/tensorrt_llm/sampling_params.html b/latest/_modules/tensorrt_llm/sampling_params.html
index 24f7438145..68539fa6ae 100644
--- a/latest/_modules/tensorrt_llm/sampling_params.html
+++ b/latest/_modules/tensorrt_llm/sampling_params.html
@@ -50,7 +50,7 @@
@@ -60,7 +60,7 @@
-
+
@@ -1106,9 +1106,9 @@
diff --git a/latest/_sources/architecture/core-concepts.md.txt b/latest/_sources/architecture/core-concepts.md.txt
index 4534eccf3f..3f7cfd558d 100644
--- a/latest/_sources/architecture/core-concepts.md.txt
+++ b/latest/_sources/architecture/core-concepts.md.txt
@@ -4,24 +4,24 @@
TensorRT-LLM has a Model Definition API that can be used to define
Large Language Models. This API is built on top of the powerful
-[TensorRT Python API](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/index.html#)
+[TensorRT Python API](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/index.html)
to create graph representations of deep neural networks in TensorRT. To become
familiar with the core concepts of the TensorRT API, refer to the
-[Core Concepts](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/coreConcepts.html)
+[Core Concepts](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/coreConcepts.html)
section of the TensorRT documentation before proceeding further.
In TensorRT-LLM, the [`tensorrt_llm.Builder`](source:tensorrt_llm/builder.py) class
contains a
-[`tensorrt.Builder`](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Core/Builder.html#tensorrt.Builder)
+[`tensorrt.Builder`](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/infer/Core/Builder.html#id1)
object. That instance is used in the `tensorrt_llm.Builder.create_network`
method to create an instance of the
-[`tensorrt.INetworkDefinition`](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Graph/Network.html#tensorrt.INetworkDefinition)
+[`tensorrt.INetworkDefinition`](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/infer/Graph/Network.html#tensorrt.INetworkDefinition)
class. The `INetworkDefinition` object can then be populated using the free
functions defined in the
[`tensorrt_llm.functional`](source:tensorrt_llm/functional.py).
A simple example of such a free function is `tensorrt_llm.activation` that inserts a
-[`tensorrt.IActivationLayer`](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Graph/Layers.html#tensorrt.IActivationLayer)
+[`tensorrt.IActivationLayer`](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/infer/Graph/Layers.html#tensorrt.IActivationLayer)
node in the graph of the model:
```python
@@ -56,23 +56,23 @@ def silu(input: Tensor) -> Tensor:
When the TensorRT-LLM's Model Definition API is utilized, a graph of the network is
assembled. The graph can later be traversed or transformed using the graph
traversal API exposed by the
-[`tensorrt.ILayer`](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Graph/LayerBase.html#tensorrt.ILayer)
+[`tensorrt.ILayer`](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/infer/Graph/LayerBase.html#tensorrt.ILayer)
class. That graph will also be optimized by TensorRT during the compilation of
the engine, as explained in the next section.
# Compilation
Once populated, the instance of the
-[`tensorrt.INetworkDefinition`](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Graph/Network.html#tensorrt.INetworkDefinition),
+[`tensorrt.INetworkDefinition`](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/infer/Graph/Network.html#tensorrt.INetworkDefinition),
can be compiled into an efficient engine by the
-[`tensorrt.Builder`](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Core/Builder.html#tensorrt.Builder)
+[`tensorrt.Builder`](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/infer/Core/Builder.html#id1)
In TensorRT-LLM, it is done through the `build_engine` member function of the
`tensorrt_llm.Builder` class that calls the
-[`build_serialized_network`](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Core/Builder.html#tensorrt.Builder.build_serialized_network)
+[`build_serialized_network`](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/infer/Core/Builder.html#tensorrt.Builder.build_serialized_network
method of the
-[`tensorrt.Builder`](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Core/Builder.html#tensorrt.Builder)
+[`tensorrt.Builder`](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/infer/Core/Builder.html#id1)
object. That call, if everything works as expected, produces an instance of the
-[`tensorrt.IHostMemory`](https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/FoundationalTypes/HostMemory.html#tensorrt.IHostMemory)
+[`tensorrt.IHostMemory`](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/infer/FoundationalTypes/HostMemory.html#tensorrt.IHostMemory)
class. That object is an optimized TensorRT engine that can be stored as a
binary file.
diff --git a/latest/_sources/blogs/H100vsA100.md.txt b/latest/_sources/blogs/H100vsA100.md.txt
index bdffe3fe74..bd87dc718a 100644
--- a/latest/_sources/blogs/H100vsA100.md.txt
+++ b/latest/_sources/blogs/H100vsA100.md.txt
@@ -4,7 +4,7 @@
# H100 has 4.6x A100 Performance in TensorRT-LLM, achieving 10,000 tok/s at 100ms to first token
-TensorRT-LLM evaluated on both Hopper and Ampere shows **H100 FP8 is up to 4.6x max throughput and 4.4x faster 1st token latency than A100**. H100 FP8 is able to achieve over 10,000 output tok/s at [peak throughput](https://nvidia.github.io/TensorRT-LLM/performance.html#h100-gpus-fp8) for 64 concurrent requests, while maintaining a 1st token latency of 100ms. For [min-latency](https://nvidia.github.io/TensorRT-LLM/performance.html#id1) applications, TRT-LLM H100 can achieve less than 10ms to 1st token latency.
+TensorRT-LLM evaluated on both Hopper and Ampere shows **H100 FP8 is up to 4.6x max throughput and 4.4x faster 1st token latency than A100**. H100 FP8 is able to achieve over 10,000 output tok/s at peak throughput for 64 concurrent requests, while maintaining a 1st token latency of 100ms. For min-latency applications, TRT-LLM H100 can achieve less than 10ms to 1st token latency.
@@ -28,7 +28,7 @@ TensorRT-LLM evaluated on both Hopper and Ampere shows **H100 FP8 is up to 4.6x
FP8 H100, FP16 A100, SXM 80GB GPUs, TP1, ISL/OSL's provided, TensorRT-LLM v0.5.0., TensorRT 9.1
-The full data behind these charts & tables and including larger models with higher TP values can be found in TensorRT-LLM's [Performance Documentation](https://nvidia.github.io/TensorRT-LLM/performance.html#performance-of-tensorrt-llm)
+The full data behind these charts & tables and including larger models with higher TP values can be found in TensorRT-LLM's [Performance Documentation](https://nvidia.github.io/TensorRT-LLM/latest/performance/perf-overview.html)
Stay tuned for a highlight on Llama coming soon!
diff --git a/latest/_sources/blogs/H200launch.md.txt b/latest/_sources/blogs/H200launch.md.txt
index 58f5c08781..baa4905613 100644
--- a/latest/_sources/blogs/H200launch.md.txt
+++ b/latest/_sources/blogs/H200launch.md.txt
@@ -21,7 +21,7 @@ TensorRT-LLM evaluation of the [new H200 GPU](https://nvidianews.nvidia.com/news
*(1) Largest batch supported on given TP configuration by power of 2.**(2) TP = Tensor Parallelism*
-Additional Performance data is available on the [NVIDIA Data Center Deep Learning Product Performance](https://developer.nvidia.com/deep-learning-performance-training-inference/ai-inference) page, & soon in [TensorRT-LLM's Performance Documentation](https://nvidia.github.io/TensorRT-LLM/performance.html).
+Additional Performance data is available on the [NVIDIA Data Center Deep Learning Product Performance](https://developer.nvidia.com/deep-learning-performance-training-inference/ai-inference) page, & soon in [TensorRT-LLM's Performance Documentation](https://nvidia.github.io/TensorRT-LLM/latest/performance/perf-overview.html).
### H200 vs H100
diff --git a/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt b/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt
index b43b8ed004..201c3781a8 100644
--- a/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt
+++ b/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt
@@ -2,37 +2,39 @@
by NVIDIA TensorRT-LLM team
## Table of Contents
-- [Background](#background)
-- [Implementation Configuration](#implementation-configuration)
- - [Workload Profile](#workload-profile)
- - [Model Architecture](#model-architecture)
- - [Precision Strategy](#precision-strategy)
- - [Parallelism Strategy](#parallelism-strategy)
- - [Everything in One Diagram](#everything-in-one-diagram)
-- [Key Optimizations](#key-optimizations)
- - [System Level optimizations](#system-level-optimizations)
- - [CUDA Graph & Programmatic Dependent Launch](#cuda-graph--programmatic-dependent-launch)
- - [MTP](#mtp)
- - [Autoregressive MTP Layers](#autoregressive-mtp-layers)
- - [Relax Acceptance Verification](#relax-acceptance-verification)
- - [Multi-streams](#multi-streams)
- - [Sparse Experts as GEMMs](#sparse-experts-as-gemms-only-works-when-moe_backendcutlass)
- - [Re-balanced the sparse experts](#re-balanced-the-sparse-experts)
- - [Mixed ETP](#mixed-etp)
- - [Smart Router](#smart-router)
- - [Kernel Level optimizations](#kernel-level-optimizations)
- - [Attention Kernel](#attention-kernel)
- - [Grouped GEMM](#grouped-gemm)
- - [CUTLASS Backend](#cutlass-backend-default-backend)
- - [TRTLLM Backend](#trtllm-backend)
- - [Communication Kernel](#communication-kernel)
- - [Dense GEMM optimization](#dense-gemm-optimization)
- - [Fuse_A_GEMM](#fuse_a_gemm)
- - [RouterGEMM](#routergemm)
- - [Kernel fusion](#kernel-fusion)
-- [How to reproduce](#how-to-reproduce)
-- [Future Works](#future-works)
-- [Acknowledgment](#acknowledgment)
+- [Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA B200 GPUs](#pushing-latency-boundaries-optimizing-deepseek-r1-performance-on-nvidia-b200-gpus)
+ - [Table of Contents](#table-of-contents)
+ - [Background](#background)
+ - [Implementation Configuration](#implementation-configuration)
+ - [Workload Profile](#workload-profile)
+ - [Model Architecture](#model-architecture)
+ - [Precision Strategy](#precision-strategy)
+ - [Parallelism Strategy](#parallelism-strategy)
+ - [Everything in One Diagram](#everything-in-one-diagram)
+ - [Key Optimizations](#key-optimizations)
+ - [System Level optimizations](#system-level-optimizations)
+ - [CUDA Graph \& Programmatic Dependent Launch](#cuda-graph--programmatic-dependent-launch)
+ - [MTP](#mtp)
+ - [Autoregressive MTP Layers](#autoregressive-mtp-layers)
+ - [Relax Acceptance Verification](#relax-acceptance-verification)
+ - [Multi-streams](#multi-streams)
+ - [Sparse Experts as GEMMs (only works when moe\_backend=CUTLASS)](#sparse-experts-as-gemms-only-works-when-moe_backendcutlass)
+ - [Re-balanced the sparse experts](#re-balanced-the-sparse-experts)
+ - [Mixed ETP](#mixed-etp)
+ - [Smart Router](#smart-router)
+ - [Kernel Level optimizations](#kernel-level-optimizations)
+ - [Attention Kernel](#attention-kernel)
+ - [Grouped GEMM](#grouped-gemm)
+ - [CUTLASS Backend (default backend)](#cutlass-backend-default-backend)
+ - [TRTLLM Backend](#trtllm-backend)
+ - [Communication Kernel](#communication-kernel)
+ - [Dense GEMM optimization](#dense-gemm-optimization)
+ - [Fuse\_A\_GEMM](#fuse_a_gemm)
+ - [RouterGEMM](#routergemm)
+ - [Kernel fusion](#kernel-fusion)
+ - [How to reproduce](#how-to-reproduce)
+ - [Future Works](#future-works)
+ - [Acknowledgment](#acknowledgment)
## Background
Recent advancements in Large Language Reasoning Models have demonstrated remarkable success, while creating new deployment challenges. A critical challenge emerges from extended Output Sequence Lengths (OSL) due to complex "thinking and reasoning" processes. Longer OSL demands stricter Token-to-Token Latency (TTL) requirements, often forcing concurrency limitations. The most extreme case, single concurrency (min-latency scenario) , becomes particularly challenging for real-time applications.
diff --git a/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt b/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt
index 0014f1c7f2..8fc2b51643 100644
--- a/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt
+++ b/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt
@@ -1,26 +1,28 @@
# DeepSeek R1 MTP Implementation and Optimization
by NVIDIA TensorRT-LLM team
## Table of Contents
-- [MTP for inference](#mtp-for-inference)
- - [Background](#background)
- - [MTP Vanilla](#mtp-vanilla)
- - [MTP Eagle](#mtp-eagle)
-- [MTP implementation in TensorRT-LLM](#mtp-implementation-in-tensorrt-llm)
- - [Basic Implementation](#basic-implementation)
- - [MTP Modules](#mtp-modules)
- - [Attention for MTP](#attention-for-mtp)
- - [How to run DeepSeek models with MTP](#how-to-run-deepseek-models-with-mtp)
-- [MTP optimization - Relaxed Acceptance](#mtp-optimization---relaxed-acceptance)
- - [Relaxed Acceptance](#relaxed-acceptance)
- - [How to run the DeepSeek-R1 model with Relaxed Acceptance](#how-to-run-the-deepseek-r1-model-with-relaxed-acceptance)
-- [Evaluation](#evaluation)
- - [Achieving speedup with MTP speculative decoding](#achieving-speedup-with-mtp-speculative-decoding)
- - [Accuracy studies for Relaxed Acceptance](#accuracy-studies-for-relaxed-acceptance)
-- [Future Works](#future-works)
- - [Tree-based speculative decoding support](#tree-based-speculative-decoding-support)
- - [Eagle3 support](#eagle3-support)
- - [Fix known issues](#fix-known-issues)
-- [Acknowledgment](#acknowledgment)
+- [DeepSeek R1 MTP Implementation and Optimization](#deepseek-r1-mtp-implementation-and-optimization)
+ - [Table of Contents](#table-of-contents)
+ - [MTP for inference](#mtp-for-inference)
+ - [Background](#background)
+ - [MTP Vanilla](#mtp-vanilla)
+ - [MTP Eagle](#mtp-eagle)
+ - [MTP implementation in TensorRT-LLM](#mtp-implementation-in-tensorrt-llm)
+ - [Basic Implementation](#basic-implementation)
+ - [MTP Modules](#mtp-modules)
+ - [Attention for MTP](#attention-for-mtp)
+ - [How to run DeepSeek models with MTP](#how-to-run-deepseek-models-with-mtp)
+ - [MTP optimization - Relaxed Acceptance](#mtp-optimization---relaxed-acceptance)
+ - [Relaxed Acceptance](#relaxed-acceptance)
+ - [How to run the DeepSeek-R1 model with Relaxed Acceptance](#how-to-run-the-deepseek-r1-model-with-relaxed-acceptance)
+ - [Evaluation](#evaluation)
+ - [Achieving speedup with MTP speculative decoding](#achieving-speedup-with-mtp-speculative-decoding)
+ - [Accuracy studies for Relaxed Acceptance](#accuracy-studies-for-relaxed-acceptance)
+ - [Future Works](#future-works)
+ - [Tree-based speculative decoding support](#tree-based-speculative-decoding-support)
+ - [Eagle3 support](#eagle3-support)
+ - [Fix known issues](#fix-known-issues)
+ - [Acknowledgment](#acknowledgment)
TensorRT-LLM achieves world-record inference performance for DeepSeek-R1 on NVIDIA Blackwell GPUs, where Multi-Token Prediction (MTP) delivers a significant speedup. In our [previous blog post](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md), we discussed the key optimizations that enable the outstanding inference latency of the DeepSeek-R1 model. This article dives deeper into the implementation and optimization of MTP in TensorRT-LLM.
diff --git a/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt b/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt
index 15b418f9b5..0de54f69fb 100644
--- a/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt
+++ b/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt
@@ -2,6 +2,8 @@
By NVIDIA TensorRT-LLM team
## Table of Contents
+- [Optimizing DeepSeek R1 Throughput on NVIDIA Blackwell GPUs: A Deep Dive for Developers](#optimizing-deepseek-r1-throughput-on-nvidia-blackwell-gpus-a-deep-dive-for-developers)
+ - [Table of Contents](#table-of-contents)
- [Introduction](#introduction)
- [Precision strategy](#precision-strategy)
- [Parallel strategy](#parallel-strategy)
diff --git a/latest/_sources/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md.txt b/latest/_sources/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md.txt
new file mode 100644
index 0000000000..a71bc0d037
--- /dev/null
+++ b/latest/_sources/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md.txt
@@ -0,0 +1,715 @@
+# Scaling Expert Parallelism in TensorRT-LLM (Part 1: Design and Implementation of Large-scale EP)
+
+By NVIDIA TensorRT-LLM Team
+
+## Table of Contents
+- [Scaling Expert Parallelism in TensorRT-LLM (Part 1: Design and Implementation of Large-scale EP)](#scaling-expert-parallelism-in-tensorrt-llmpart-1-design-and-implementation-of-large-scale-ep)
+ - [Table of Contents](#table-of-contents)
+ - [Motivation for large-scale EP](#motivation-for-large-scale-ep)
+ - [Observations over one machine translation dataset](#observations-over-one-machine-translation-dataset)
+ - [Observation over GSM8K dataset](#observation-over-gsm8k-dataset)
+ - [High-level design introduction](#high-level-design-introduction)
+ - [EP communication kernels](#ep-communication-kernels)
+ - [Motivation of EP communication kernels for GB200](#motivation-of-ep-communication-kernels-for-gb200)
+ - [EP communication kernels implementation](#ep-communication-kernels-implementation)
+ - [EP Load Balancer](#ep-load-balancer)
+ - [Python Interface](#python-interface)
+ - [C++ extension](#c-extension)
+ - [Core implementations of host side logics](#core-implementations-of-host-side-logics)
+ - [Core implementations of GPU side logics](#core-implementations-of-gpu-side-logics)
+ - [Online EP Load Balancer](#online-ep-load-balancer)
+ - [Offline EP Load Balancer](#offline-ep-load-balancer)
+ - [E2E evaluation](#e2e-evaluation)
+ - [The effect of EP Load Balancer](#the-effect-of-ep-load-balancer)
+ - [Offline EP Load Balancer](#offline-ep-load-balancer-1)
+ - [Online EP Load Balancer](#online-ep-load-balancer-1)
+ - [Performance study](#performance-study)
+ - [Reproducing steps](#reproducing-steps)
+ - [The effect of EP Load Balancer](#the-effect-of-ep-load-balancer-1)
+ - [Step 1: Run inference and collect statistics](#step-1-run-inference-and-collect-statistics)
+ - [Step 2: Generate the EPLB configuration](#step-2-generate-the-eplb-configuration)
+ - [Step 3: Run inference with the EPLB configuration](#step-3-run-inference-with-the-eplb-configuration)
+ - [Miscellaneous](#miscellaneous)
+ - [Expanded thoughts](#expanded-thoughts)
+ - [Acknowledgement](#acknowledgement)
+
+The development of model like DeepSeek-V3/R1, which use large-scale fine-grained Mixture-of-Experts (MoE) designs, has significantly advanced open-source model quality. Newly released open-source models such as LLaMA4 and Qwen3 also adopt a similar large-scale fine-grained MoE design principle. However, large-scale MoE models introduce new challenges for inference systems, including high memory demands and inherent expert-level workload imbalance.
+
+In the past, we have shared TensorRT-LLM’s optimization experience to [push the latency boundary](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md) of DeepSeek R1 model, [the implementation and optimization of MTP](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md)(Multi-Token Prediction) and [the optimizations for DeepSeek R1 throughput oriented performance](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md).
+
+The DeepSeek team has also shared their valuable experience and practice on how to optimize this kind of large-scale Expert Parallelism (EP) model, including [DeepEP](https://github.com/deepseek-ai/DeepEP) and [EPLB](https://github.com/deepseek-ai/EPLB). Also, the DeepSeek team has shared their concrete design considerations in [this](https://arxiv.org/abs/2412.19437) tech report. On top of those great sharings, there are also nice community efforts to implement large-scale EP in other inference engines, such as [this](https://lmsys.org/blog/2025-05-05-large-scale-ep/) effort from the SGLang team.
+
+In this tech blog, we will introduce the details of the design and implementation to support E2E large-scale EP in TensorRT-LLM. This blog post mainly covers the following:
+
+* How to leverage NVIDIA GB200 Multi-Node NVLink (MNNVL) HW features to implement high-performance communication kernels.
+* How to design and implement an online expert workload balancer to dynamically balance the expert load distribution and adapt to the changes of online traffic patterns. We present:
+ * The empirical data analysis demonstrating the need to do so.
+ * The implementation of the online traffic data statistic module.
+ * The design and implementation of the replication/placement strategy.
+ * The MoE weight load/re-distributer to balance the online workload across multiple GPUs.
+ * The changes needed to the MoE router and computation module to adapt to the expert load balancer needs.
+ * Some preliminary data demonstrating the effectiveness of the current implementation in TensorRT-LLM.
+
+In future tech blogs, we will also cover the following topics:
+* The introduction of performance tuning and optimization for TensorRT-LLM large-scale EP GB200 implementation.
+* How to implement efficient large-scale EP support for B200/Hopper and other NVIDIA GPUs without MNNVL.
+* The best practices to leverage large-scale EP and get performance gains.
+* How to combine large-scale EP with other system optimization techniques.
+
+
+Even if, in this tech blog, we focus on TensorRT-LLM, we believe the core ideas and implementation can also be applied to other inference engines to help the inference performance on NVIDIA GPUs. Also, with the help of the community, we would like to figure out how to better modularize the current TensorRT-LLM large-scale EP implementation and make it more easily reusable by the community.
+
+Finally, in this tech blog, there are implementation details which are targeted towards the GB200 system, such as the communication components leveraging the GB200 MNNVL inter-GPU connection, and the MoE weight load/re-distributer module leveraging the high bandwidth C2C connection between Grace CPU and Blackwell GPU. Nevertheless, the overall design principle and software architecture can still apply to non-GB200 NVIDIA GPU systems. To facilitate the extension to other non-GB200 system, we have, on purpose, paid attention to the generalization of the design and implementation. These changes should be easily composable with other existing components.
+
+## Motivation for large-scale EP
+
+
+The main motivation of introducing large-scale EP (here means EP \> 8\) comes from the following system considerations:
+
+* We expect to reduce the execution latency thanks to the increased aggregated memory bandwidth to load the expert weights.
+* We expect to increase the effective batch size to saturate the GPU computing power.
+
+Note that **when the E2E execution time is dominated by the MoE GroupGEMM computation, by introducing large-scale EP, it is expected to see clear performance benefits. But if the E2E execution time is not dominated by the MoE GroupGEMM computation, then large-scale EP may bring limited performance benefit.**
+
+
+Also there isn't free lunch in the system design. When the EP size increases up to greater than 8 (sometimes even less than 8), due to the sparsity execution nature of MoE models, it can inherently trigger the EP-level workload imbalance issue.
+
+And here are some empirical observations based on some datasets (*all the analyses below are done with the **DeepSeek R1 model**, on **32 GB200 GPUs**).*
+
+### Observations over one machine translation dataset
+
+Firstly let’s have an overview of the overall imbalance issues across layers:
+
+
+
+
+
+
+
Figure 1: The routed token count from rank 0 to all the ranks(including rank 0), for decode iteration 1950, and all the MoE layers
+
+In Figure 1, it can be seen clearly that for the MoE in layer 36, many more tokens are sent from **rank 0** to **rank 13\.**
+
+If we zoom on the MoE in the layer 36 and record its activated expert rank distribution, there clearly is a rank that is more heavily activated:
+
+
+
+
+
+
+
Figure 2: The tokens received for each expert rank for layer 36
+
+If we flatten the data to see the routed tokens for each expert, we can see that a few experts are more active than others:
+
+
+
+
+
+
+
Figure 3: The tokens received for each expert for layer 36
+
+It is also interesting to see that this kind of imbalance issue is very stable across multiple iterations, as shown on the following figure:
+
+
+
+
+
+
+
Figure 4: The accumulated token counts received for each expert for layer 36, within 50 decode steps, and the local batch size=256.
+
+Clearly, the hot experts in Figure 4 are actually the same as in Figure 3 which only have data for a single decode iteration.
+We have also done the duration-based analysis for local batch size=1 which correspond to a single request with observing the similar pattern:
+
+
+
+
+
+
+
Figure 5: The accumulated token counts received for each expert for layer 36, within 400 decode iterations, and the local batch size \= 1\.
+
+To conclude the findings from this study over this machine translation dataset, we could say that:
+
+* There are hot spots in some layers where the workload of some EP ranks can be much higher than others.
+* This may be caused by the hottest expert or some hot experts to be located on the same rank.
+* The routed token distributions can be the same for tens to hundreds of iteration steps or even more.
+* For the execution of a single request, it also has the same hot experts between steps.
+
+And another natural question is whether the above observation can change significantly on other datasets. So we have done a similar analysis with the GSM8K dataset.
+
+### Observation over GSM8K dataset
+
+
+
+
+
+
+
Figure 6: The routed token count from rank 0 to all the ranks, for iteration 1950, and all the MoE layers
+
+In Figure 6, compared with Figure 1, it can be seen that for GSM8K, the hot layer becomes layer 57 instead of layer 36\. Then what about the concrete status of layer 36 for the GSM8K dataset?
+
+
+
+
+
+
+
Figure 7: routed token counts from EP rank 0 to other EP ranks, still taking the iteration 1950, MoE layer 36 as the example
+
+Clearly from Figure 7, it can be observed that the workload imbalance is different from what was observed for the different dataset (in Figure 2).
+Based on Figure 8, it can be observed that the workload imbalance is relatively stable across multiple iterations on the GSM8K dataset too. It is the same as the previous machine translation dataset.
+
+
+
+
+
+
+
Figure 8: The accumulated token counts sent from EP Rank 0 to all the ranks, for MoE layer 57 within 50 decode steps, local batch size=256
+
+If we flatten the EP rank level data to expert-level data, we can have the following figure.
+
+
+
+
+
+
+
Figure 9: The accumulated token counts received for each expert for layer 57, within 50 decode steps, and the local batch size=256.
+
+The similar imbalance pattern also exists for a single request.
+
+
+
+
+
+
+
Figure 10: The accumulated token counts received for each expert for layer 57, within 400 decode steps, for a single request
+
+If we use another request, then we can still observe the expert imbalance issue, while the hot experts can be different with some in common (in this example it is expert 10).
+
+
+
+
+
+
+
Figure 11: The accumulated token counts received for each expert for layer 57, within 400 decode steps, for a single request
+
+So combining the data analysis of two datasets, we have the following findings:
+
+* EP level workload imbalance issue is common for large-scale EP inference on multiple datasets. And the EP imbalance severity can be different per layer. Also the EP imbalance issue is dataset sensitive.
+* The EP rank level imbalance issue can be caused by a certain hottest expert or multiple hot experts staying on the same EP rank.
+* The EP rank imbalance distribution is relatively stable across tens to hundreds of iterations.
+* Though there is time-dimension stability of EP rank imbalance distribution, clearly different requests can have different EP imbalance distribution.
+
+Based on these findings, they can lead to our design consideration of TensorRT-LLM’s large-scale EP implementation:
+
+* By design the EP imbalance issue needs to be considered to assure great E2E performance.
+* Online EP Load Balancer(rather than only a Offline EP Load Balancer implementation) based on the real-time online request traffic is essential to ensure the robustness of EP balancer.
+* The time-dimension stability of EP rank imbalance distribution can be leveraged to re-distribute the MoE weights to different EP ranks in an efficient manner.
+
+In the next section we will illustrate the high-level design.
+
+## High-level design introduction
+
+Based on the detailed analysis and study in section [Motivation of large-scale EP](#motivation-of-large-scale-ep), it can clearly be observed that expert imbalance in EP is a common pattern for large-scale EP. This EP imbalance can clearly impede the overall system performance in the following ways:
+
+* The hot EP rank will consume more memory (for activations) which can limit the effective max batch size scheduled during the inference process.
+* More data will be sent to/received from the hot EP rank.
+
+Those issues can clearly result into a system-level congestion effect in which the hot EP rank will delay the overall E2E execution.
+
+To make sure large-scale EP can run well, careful considerations are needed to minimize the EP imbalance issue. The overall design is as follows:
+
+
+
+
+
+
+
Figure 12: the high-level design of TensorRT-LLM large-scale EP
+
+In this design, there are both CPU and GPU side logics:
+
+* CPU side
+ * Implement the Replication \& Placement algorithms **(Replication \& Placement Compute** component) to achieve a more balanced EP strategy. Those are rather classical algorithms for which CPU computation is more suitable. Furthermore, by offloading this computation to the CPU, the interference with the GPU can be reduced. In the future, machine-learning based algorithms may also be explored and additional design consideration may be needed. The **Replication \& Placement Compute** component will generate the **“Placement Info”** which will then be consumed by both the GPU **Routing** logic and the CPU **Update Weights \& Placement** component. The **Replication \& Placement Compute** component will consume the **Statistics Data** generated by the **Statistics** component which runs on the GPU.
+ * Orchestrate the process (**Update Weights \& Placemen**t component) to update and reload the MoE weights from CPU host memory to GPU device memory. This component will also consume the **Placement Info** generated by the **Replication \& Placement Compute** component. Our scalable design allows us to reload the MoE weights from remote GPU memory via MNNVL or NIC.
+
+* GPU side
+ * This is the main execution workflow of inference. The following new GPU components are introduced with our design:
+ * EP communication kernels. In Figure 11, those are the **Dispatch** and **Combine** components.
+ * Online traffic data statistics collector (the **Statistics** component). This component collects the **Statistics Data** which is to be consumed by the **Replication \& Placement Compute** component.
+ * The MoE router logic (the **Routing** component). It sends tokens to the activated experts. It needs to be adjusted to support the dynamic placement of MoE weights. It also consumes the **Placement Info** generated by the **Replication \& Placement Compute** component.
+ * The MoE computation logic (the **MoE** component) also needs to be adjusted correspondingly.
+
+* Careful synchronization between CPU and GPU components is needed to ensure the validity of the entire execution process ; particularly, to avoid hangs, as well as invalid or sub-optimal executions.
+
+For the **Update Weights \& Placemen**t component, we identified two design choices:
+
+* Bulk approach
+ * In this approach, when the MoE weight redistribution logic starts, the inference taking place on the current serving instance will have to be paused until the MoE weight redistribution process finishes. We estimate that it can lead to approximately **0.5 \~** **1 second** online serving stalls ; causing in the worst-cases request timeouts. This kind of timeout or stalls can be mitigated at the system level by routing the requests to other serving instances or just request replays.
+* Layer-wise approach
+ * In this approach, the MoE weight redistribution is done layer by layer such that at each decode iteration only certain layers (it can be configured) will be impacted by a redistribution of their MoE weights. With this design, it will take several iterations to re-balance the MoE weights of all the layers. We expect this approach to have almost no impact on the user experience.
+
+
+
+
+
+
+
Figure 13: One example of the layer-wise MoE weight re-distribution
+
+In our current system, we choose to implement **the layer-wise approach** to minimize the impact on the online user experience. The bulk approach should be much easier to implement and we will not discuss it in this tech blog.
+To implement the layer-wise approach properly, we need to carefully evaluate the capability of different underlying HWs to decide on the concrete implementation.
+Let’s use GB200 as an example. In Figure 14, we illustrate the communication bandwidth of different HW elements in a GB200 node.
+
+
+
+
+
+
+
Figure 14: high-level topology of GB200 system
+
+Using the DeepSeek R1 model as an example, with FP4 precision, each MoE expert occupies 24MiB of memory space. There are 256 experts per layer. In total, that's 58 MoE layers, plus 1 MTP layer. So the maximum amount of MoE weights which need to be redistributed, to achieve EP balance, is 348GiB.
+One GB200 node has 480GB LPDDR5X memory for each Grace CPU. In total, that's 960GB of host memory across a NUMA domain. One GB200 node can host the entire MoE weights of a model like the DeepSeek R1 LLM in its CPU host memory. Based on it, the MoE weight redistribution can be done by moving the corresponding MoE weights from CPU host memory to GPU device memory.
+
+Let's assume that we target **50ms** inter-token-latency (ITL) as our main latency constraint. Using back-of-the-envelope calculation, it can be computed that the amount of expert weights which can be moved from the MoE weight pool (can be kept in Grace CPU memory or GPU memory on another node) to the Blackwell GPU (to do the real MoE inference) for each decode iteration is:
+
+
+
+
+
+
+
Figure 15: The theoretical expert count to be updated for each iteration with following 50ms ITL constraints, by using different HW as pools to store the full MoE weight
+
+Based on this analysis, and, if we rely on the Grace CPU memory on each node to store the MoE weight pool, for each decode iteration, the weights of up to 300 experts can be redistributed to each GPU on the same GB200 node.
+Assuming our goal is to finish the MoE weight re-balancing for the full model within 5 decode iterations, here are some more concrete use-case studies:
+
+* Use-case 1 (with balanced expert placement and no expert replication)
+ * 64 GPUs with 4 Experts per GPU
+ * 58 layers, 232 Experts per GPU
+ * Need 47 Expert Update / Iter, all the methods can satisfy the latency goal.
+* Use-case 2 (with both balanced expert placement and replication)
+ * 64 GPUs or 72 GPUs with 5 Experts per GPU
+ * 58 layers, 290 Experts per GPU
+ * Need 58 Expert Update / Iter, all the methods can satisfy the latency goal.
+* Use-case 3 (with both balanced expert placement and replication)
+ * 36 GPUs with 8 Experts per GPU
+ * 58 layers, 464 Experts per GPU
+ * Need 93 Expert Update / Iter, all the method can satisfy the latency goal.
+
+In summary, based on the theoretical analysis, using Grace CPU memory as the pool to hold the full size MoE weights should allow us to achieve the EP (Expert-Parallelism) re-balancing within 5 decode iterations. If we relax the requirements to 10 or more iterations, there can be even more system implementation flexibility.
+
+Next we will introduce the implementation details of our large-scale EP system.
+
+## EP communication kernels
+
+We have evaluated multiple ways of implementing the EP communication kernels needed by large-scale EP, including DeepEP, other solutions and the development of an approach from scratch.
+
+The current technical decision is:
+
+* For GB200, we implemented a new set of [custom EP communication kernels](https://github.com/NVIDIA/TensorRT-LLM/pull/3504).
+* For non-GB200 systems (such as B200 or Hopper), we chose to integrate DeepEP directly, with some potential enhancement.
+
+ The considerations are:
+
+* DeepEP is a great piece of work done by the DeepSeek team. When we started the TensorRT-LLM large-scale EP efforts, our first focus was on GB200. We chose to implement our own custom EP communication kernels as it was easier to introduce optimizations requiring the GB200 MNNVL capability. Also, based on our current evaluation, DeepEP does not provide CUDA graph compatibility for all the scenarios. We believe that CUDA graph is needed for the scenario we are interested in.
+* When we started the efforts to enable large-scale EP on Hopper, we concluded that DeepEP could be adapted and meet our needs on this platform. We plan to extend DeepEP to work for B200 in the future.
+
+We are also actively evaluating the possibility of consolidating GB200 and non-GB200 EP communication kernels into a single solution to make the system simpler, and we will keep the community posted on the status.
+Now let’s talk a little bit more about the optimizations introduced into the custom EP communication kernel implementations.
+
+### Motivation of EP communication kernels for GB200
+
+In the Decoding Phase with Prefill-Decoding (PD) separation, we observed that the batch size may not be very large, such that latency is a significant concern. In this context, compatibility with CUDA Graph is a strong requirement.
+[NCCL](https://github.com/NVIDIA/nccl) is a great GPU communication library which provides highly efficient communication kernels and primitives.
+For now, its Send and Recv operations require the data size to be explicitly specified when invoking with `ncclSend`/`ncclRecv`.
+However, in large expert parallel (large-EP) scenarios, the data size to be transferred is determined dynamically based on the model's output at each iteration.
+With the current NCCL's communication interface, an explicit synchronization is required to send the communication size back to the CPU and launch NCCL calls from the CPU with the corresponding data size. This would break CUDA Graph compatibility.
+This limitation has forced us to develop high performance communication kernels compatible with CUDA graph and that can accept communication sizes directly from GPU memory.
+We also wanted those kernels, for GB200, to take of advantage of the MNNVL's memory bandwidth.
+
+### EP communication kernels implementation
+Our kernels adopt a communication approach similar to NCCL’s LL128 primitive. As this approach strikes a good balance between latency and bandwidth, it is well-suited for LLM inference.
+Our custom kernels can read the communication size directly from GPU memory and are compatible with CUDA Graph even when the data size varies across runs.
+
+In our implementation, we use the CUDA's Driver API to establish a peer-to-peer (P2P) buffer via MNNVL as a workspace.
+Each GPU can access the workspace of other GPUs. The workspace is divided into multiple channels, each assigned to a remote GPU as a write buffer.
+Those write buffers are used in a FIFO manner, with flags used to synchronize FIFO status and avoid data corruption.
+More details can be found in [PR 3504](https://github.com/NVIDIA/TensorRT-LLM/pull/3504).
+
+## EP Load Balancer
+
+TensorRT-LLM implements a set of functionalities to achieve EP Load Balancing. There are several key components:
+
+### Python Interface
+
+The Python interface layer provides a user-friendly PyTorch/Python native interface to access the MoE Load Balancing implementations, such as the Python wrapper for the GPU/CPU synchronization logics and the online data statistics collection, and other logics implemented in 4.2 to 4.4.
+
+### C++ extension
+
+The C++ extension acts as the bridge between the PyTorch/Python interface and the C++/CUDA core implementations.
+
+### Core implementations of the host logic
+
+The host-side core logic implements the following key parts:
+
+* Load balancing algorithms
+ * Replication algorithm
+ * Placement algorithm
+* Orchestration logic of MoE weight updates
+* MoE weight update logic
+
+### Core implementations of the GPU logic
+
+The GPU core logic contains the following components:
+
+* Online traffic statistics collection
+ * To reduce the CPU-GPU back-and-forth synchronization cost, we choose to implement the online traffic statistic logic on the GPU side.
+* Expert routing logic
+ * The MoE routing logic needs to be enhanced to adapt with the dynamic EP balance impact.
+
+There are GPU/CPU synchronization components implemented. More details can be found in [PR 4384](https://github.com/NVIDIA/TensorRT-LLM/pull/4384) and [PR 4495](https://github.com/NVIDIA/TensorRT-LLM/pull/4495).
+
+Based on these core utilities, there are two versions of EP Load Balancer in TensorRT-LLM: Offline EP Load Balancer and Online EP Load Balancer.
+
+### Online EP Load Balancer
+
+For production deployment needs, Online EP Load Balancer is recommended since it can adapt itself to the change in the online traffic pattern, dynamically, thus with more performance guarantees.
+
+However, the Online EP Load Balancer faces several challenges.
+
+First, load balancing introduces dynamic Expert placement. A single Expert’s location may shift based on current workload. For example, if Expert 0 and Expert 1, originally assigned to Rank 0, both become hot experts, the load balancing policy might redistribute them to different ranks alongside cold experts, which necessitates timely updates to the weight data.
+
+We aim for the Online Load Balancer to react swiftly to changes in request patterns and adjust Expert assignments to avoid load imbalance issues. Importantly, we do not want the balancing process to interfere with the online inference execution process, nor do we want to employ a "Stop-The-World" (Bulk) strategy for updating weights.
+
+In large MoE models (such as DeepSeek R1) during the decoding phase, batch sizes are often small, making CUDA Graph an effective acceleration method; especially when high TPS per user is required. This benefit is even more pronounced on platforms like GB200. For this reason, we want the entire load balancing mechanism to be compatible with CUDA Graph.
+
+To avoid invalidating pre-captured CUDA Graphs, we perform in-place weight updates by writing new Expert weights into the same memory locations, rather than swapping out tensor pointers. This ensures the weights tensor address remains unchanged in the Model Engine.
+
+In this design, each Expert Slot serves as a container for holding an Expert’s weights, decoupled from any specific Expert. The number of Expert Slots must be greater than or equal to the total number of Experts so that each Expert always has at least one available Slot. Hot Experts may occupy multiple Slots. Each Slot is identified by a SlotId.
+
+Since the MoE model's routing logic outputs ExpertIds (not SlotIds), we maintain a routing table from ExpertId to SlotId which is updated by the load balancing policy, periodically. The Load Balancer Routing module uses the current routing table (Expert replication information and slots) to map each token to a suitable Expert Slot.
+
+To make weight updates non-blocking and avoid "Stop-The-World", we use a layer-wise update approach. After a layer’s forward pass completes and before its next forward pass starts, we perform the weight balancing for that layer; the next forward pass for the same layer should wait until the last update is done if it happens at this iteration.
+
+As the forward execution is typically driven by a single Python thread invoking a sequence of PyTorch operations, we offload the weight update routine to a background C++ thread. The Python side only initializes the Expert Slots and registers Expert Weights in shared host memory.
+
+During forward execution, we insert lightweight lock/unlock kernels before and after MoE computations, as well as kernels for collecting statistics and assigning SlotIds to ExpertIds. These kernels must be short and overlap-friendly to minimize performance impact. As long as the CPU weights update thread can finish its work on time, the lock/unlock will be very short. All, except for the routing kernel, are lightweight and can easily overlap with forward kernels in different CUDA streams; the routing kernel is the primary optimization focus.
+
+On GB200, we utilize MNNVL for inter-GPU communication during Expert dispatch and combine. Expert weights reside in host memory and are brought into GPU memory via C2C to support asynchronous updates. A multi-threaded Host Copy Engine manages this process, auto-detecting NUMA topology and choosing optimal CPU cores, enabling full asynchrony with model forward passes.
+
+On servers without C2C but with PCIe, if cross-node communication is required, network and weight updates may compete for PCIe bandwidth, requiring additional tuning and design consideration. We have not implemented the copy engine for PCIe servers yet and it is in list of future tasks.
+
+### Offline EP Load Balancer
+
+Online EP balancer is more suitable for production deployment needs to react timely to online traffic changes. However, Offline EP Balancer provides a lightweight way for performance study/debugging and validation. You can refer to [this PR](https://github.com/NVIDIA/TensorRT-LLM/pull/4695) to learn more about the implementation of the Offline EP Load Balancer. Also there is a tool provided to collect statistics about the expert activation distribution which can be used as the input to deduce the EP balancing placement strategy. You can refer to [this](https://github.com/NVIDIA/TensorRT-LLM/tree/feat/large-ep/examples/ep_load_balancer#offline-ep-load-balancer) doc to learn more details as well as how how to run through the Offline EP Load Balancer in E2E approach.
+
+## E2E evaluation
+
+### The effect of EP Load Balancer
+
+#### Offline EP Load Balancer
+As shown by Figure 1, on the machine translation dataset, MoE layer 36 suffers from extreme expert load imbalance issues, so we use that layer to illustrate the effect of EP Load Balancer. We still run DeepSeek-R1 with 32-way expert parallelism on 32 GB200 GPUs.
+
+
+
+
+
+
+
Figure 16: The routed token count by receiving ranks (x-axis) and iterations (y-axis) at layer 36 (No EPLB)
+
+
+
+
+
+
+
Figure 17: The routed token count by experts (x-axis) and iterations (y-axis) at layer 36 (No EPLB)
+
+Figure 16 displays the routed token count by receiving ranks over 50 iterations, which could represent the workload for each rank. Rank 13 receives significantly more tokens than all other ranks, and such an imbalanced workload distribution is almost constant over iterations. Figure 17 breaks down the workload to experts. Clearly, two hot experts on rank 13 cause the excessive pressure on this rank.
+
+With the above statistics, we can perform offline EPLB. One potential strategy is to maintain the 32-way expert parallelism while increasing expert slots from 8 to 9 per rank. This results in 32 redundant experts and 288 expert slots in total. Figures 18 and 19 show the routed token count after EPLB. Clearly, the per-rank token distribution is much more balanced, and there are no hot experts anymore.
+
+
+
+
+
+
+
Figure 18: The routed token count by receiving ranks (x-axis) and iterations (y-axis) at layer 36 (EPLB with 9 per-rank slots and EP 32)
+
+
+
+
+
+
+
Figure 19: The routed token count by experts (x-axis) and iterations (y-axis) at layer 36 (EPLB with 9 per-rank slots and EP 32)
+
+Another EPLB strategy is to maintain 8 expert slots per rank while increasing expert parallelism to 36 ways. This strategy also results in 32 redundant experts and 288 expert slots in total. As displayed by Figures 20 and 21, the workloads also become balanced across ranks or expert slots.
+
+
+
+
+
+
+
Figure 20: The routed token count by receiving ranks (x-axis) and iterations (y-axis) at layer 36 (EPLB with 8 per-rank slots and EP 36)
+
+
+
+
+
+
+
Figure 21: The routed token count by experts (x-axis) and iterations (y-axis) at layer 36 (EPLB with 8 per-rank slots and EP 36)
+
+For each layer and iteration, the load imbalance can be measured using simple metrics such as the standard deviation or the imbalance ratio. Given the routed token counts for all ranks (or experts), the imbalance ratio is defined as $(max - mean) / mean$, which represents the excessive workload received by the hottest rank (or expert). A perfectly balanced load would have an imbalance ratio of 0.
+
+Table 1 reports the standard deviation and imbalance ratio for the aforementioned cases. Each number is averaged from the per-layer per-iteration metrics. Without EPLB, the load imbalance is significant -- on average, the hottest rank receives 1.56 times more routed tokens than the mean. EPLB can effectively reduced the load imbalance -- on average, the hottest rank receives only about 0.11 times more routed tokens than the mean.
+
+| | By rank | | | By expert slot | | |
+| :---: | :---: | :---: | :---: | :---: | :---: | :---: |
+| | Average | Std. Dev. | Imb. Ratio | Average | Std. Dev. | Imb. Ratio |
+| No EPLB (8 per-rank slots and EP 32) | 1024 | 491.6 | 1.564 | 128 | 164.1 | 10.948 |
+| EPLB (9 per-rank slots and EP 32) | 1024 | 52.0 | 0.109 | 114 | 77.8 | 1.792 |
+| EPLB (8 per-rank slots and EP 36) | 1024 | 53.9 | 0.115 | 128 | 87.5 | 1.791 |
+
+*Table 1: The standard deviation and imbalance ratio (average of per-layer and per-iteration metrics)*
+
+#### Online EP Load Balancer
+
+In the previous section, we demonstrated the impact of the Offline EP Load Balancer. Given our implementation of the Online EP Load Balancer, we further examine the dynamic patterns of EP balancing in online conditions.
+Let’s still use the machine translation dataset, DeepSeek R1 model, layer 36 (which is shown in Figure 1) as the example to understand the online behaviour:
+
+
+
+
+
+
+
Figure 22: The token count sent from rank 0 to all the ranks, run on GB200, with EP32, local batch size=256, with 256 slots(no replication), so each rank hosts 8 experts
+
+From Figure 22, it is clear that from iteration 1963, since the EPLB has taken into effect, the original hottest rank 13 is no longer the hot rank and the original workload sent to rank 13 has been redistributed to rank 0 and rank 1.
+
+In Figure 22, only placement adjustment has been done by the Online EPLB. If we further introduce expert replication, the balancing can be further improved, as shown on the following figure:
+
+
+
+
+
+
+
Figure 23: The token count sent from rank 0 to all the ranks, run on GB200, with EP32, local batch size=256, with 288 slots(with replication), so each rank hosts 9 experts
+
+Clearly, by introducing expert replication when doing the EPLB, the EP balancing can be further improved.
+Further complicated experiments can be designed to observe the Online EPLB taking into effect periodically during the online serving process to balance the EP workload in a dynamic way and we welcome the community to report any interesting EPLB pattern observation to us.
+
+### Performance study
+Note: all the representative workloads illustrated in this section are from the performance traces extracted from DeepSeek R1 inference execution. The E2E performance tuning/optimization is still ongoing and we will discuss them in the future technical blogs.
+
+Let's use some representative workloads to illustrate the performance impact with large-scale EP.
+
+
+
+
+
+
Figure 24: EP impact over MoE Group GEMM and EP communication
+In Figure 24, it can be observed that by increasing the EP size from 4 to 72, the MoE Group GEMM computation time gets reduced, while the EP communication time (for EP4/EP8 Reduce/Scatter is used, while for EP>8 All2All is used) stays almost constant.
+When the EP size increases from 18 to 32, the speed-up diminishes. We are working on optimizing it.
+
+Next, let's use some representative workloads to understand the performance impact with EPLB.
+
+
+
+
+
+
Figure 25: EPLB performance impact
+Clearly in Figure 25, we can see that EPLB brings a clear performance improvement when the EP size increases, for both MoE GroupGEMM and EP communication times.
+
+## Reproducing steps
+Currently to run through the reproducing steps described in this section, please, use this [feature branch](https://github.com/NVIDIA/TensorRT-LLM/tree/feat/large-ep/tensorrt_llm). It will get merged to the main branch soon.
+### The effect of EP Load Balancer
+Please, refer to the [EP Load Balancer example](https://github.com/NVIDIA/TensorRT-LLM/tree/feat/large-ep/examples/ep_load_balancer) for how to reproduce the results for the offline EP Load Balancer.
+
+##### Step 1: Run inference and collect statistics
+
+To generate the necessary statistics for load rebalancing, run your model on a target dataset and count the routed expert IDs during inference. Once the counting process is complete, the statistics will be saved for further processing.
+
+Set up some environment variables:
+
+```bash
+export MODEL_NAME=deepseek-ai/DeepSeek-R1
+export MODEL_PATH=
+# Set the expert statistic data path
+export EXPERT_STATISTIC_PATH=./expert_statistic
+# Enable counting of routed expert IDs from iteration 100 to iteration 200
+export EXPERT_STATISTIC_ITER_RANGE=100-200
+```
+
+Prepare a dataset following the [benchmarking documentation](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/performance/perf-benchmarking.md#preparing-a-dataset) and save it as `./dataset.json`.
+
+Run 32-way expert parallelism inference on the prepared dataset. Please refer to the [LLM API MGMN example](https://github.com/NVIDIA/TensorRT-LLM/blob/main/examples/llm-api/llm_mgmn_trtllm_bench.sh) for details on running `trtllm-bench` on Slurm.
+
+```bash
+cat > ./extra_llm_api_options.yaml < ./extra_llm_api_options_eplb.yaml < **Note:** Counting expert IDs can significantly hurt performance, so remember to disable it by unsetting `EXPERT_STATISTIC_ITER_RANGE` when running inference for benchmarking or production purposes.
+
+### Miscellaneous
+- **GB200 NUMA binding**: Since on GB200, GPU memory are also on NUMA nodes, system can also use GPU's memory. It is suggested to use `numactl -m 0,1` to bind memory to CPU nodes if you don't want that happen.
+- **Shared Memory Clean Up**: To achieve online load balance, all expert weights are stored in shared host memory. 4 ranks on same GB200 node share the same expert weights to save memory. Normally, these shared host memory will be cleaned up at process exit. But if an abnormal exit happens, they may not get chance to be cleaned. In that case, you may need to manually check `/dev/shm` directory and delete `/dev/shm/moe_shared_*` if any.
+
+## Expanded thoughts
+
+We deeply acknowledge the system innovation from the DeepSeek team. The introduction of the large-scale EP support into their in-house inference system and their open spirit of sharing their engineering insights with the community is extremely valuable and has already boost the performance of inference system design.
+**Also we want to point out that there are no magical solutions when doing system design and optimization, such as large-scale EP.**
+Based on our current performance analysis, when you plan to apply large-scale EP, you should take the following factors into considerations:
+
+* Is the MoE GroupGEMM computation time an E2E performance bottleneck?
+ * Large-scale EP mainly helps reduce the MoE GroupGEMM execution time by reducing expert weight loading pressure and, thus, increases the compute intensity of the MoE GroupGEMM layer. For your workload setting, if the MoE GroupGEMM computation is not the bottleneck, then large-scale EP may not help much.
+* The latency constraints.
+ * Large-scale EP mostly helps when there are strict latency constraints, especially on GB200/B200 with more memory capacity. For GPUs with less memory capacity, for scenarios with less latency constraints, large-scale EP can still help as it helps achieve higher concurrency and better tokens/s/GPU.
+* The available HW spec.
+ * The optimal configuration for large-scale EP depends on GPU specifications \- including memory bandwidth, capacity, inter-GPU bandwidth, and compute power \- which determine both whether to employ large-scale EP and the ideal degree of parallelism.
+* System complexity and the production deployment constraints.
+ * Without fault tolerance guarantee, large-scale EP can increase the online system failure ratio. Even if it is possible to do cluster level coordination to route the traffic to other running serving instances when certain large-scale EP serving instances fail, the large number of GPUs required for a single-instance deployment of large-scale EP can increase system level deployment challenges.
+
+**In the future, we plan to summarize and share more of the best practices of deploying with large-scale EP techniques.**
+
+**Please use your own judgement to decide whether to use large-scale EP into your system or not, and when you use it, what is the suitable EP size and concrete deployment settings suitable for your own requirements.**
+
+The current TensorRT-LLM large-scale EP implementation is not perfect and there are still known limitations (community contributions are welcome to help us improve). For example, we need:
+
+* More platforms coverage
+ * Extending the support to cover other non-GB200 NVIDIA GPU HWs. **We are actively working on this now.**
+ * Currently the large-EP support only covers NVFP4 data precision, incremental efforts are needed to cover FP8 and INT8/INT4 data precision.
+* Performance
+ * Further performance tuning and optimizations. **We are actively working on this now.**
+ * More validation with workloads close to production traffic. **Here we highly welcome the community’s feedback to help us calibrate TensorRT-LLM large-scale EP implementation based on more concrete workloads.**
+ * The thorough validation of combination with other inference core features, such as dis-aggregated serving, speculative decoding, validation on more MoE model families, etc. **We are actively working on this now.**
+* Ease-of-use
+ * Easy customization
+ * We believe large-scale EP can be decomposed into at least two layers:
+ * A core layer which developed by inference engine developers. This layer contains the customized EP communication kernels, the synchronization logic between CPU and GPU, the MoE weight re-distributed logic.
+ * A strategy layer which can be co-developed by the inference engine developers as well as machine learning researchers. This part contains tools to collect the online traffic statistics in different approaches, and algorithms for the optimal replication and placement of experts.
+ * Based on this understanding, we plan to make components close to the strategy layer easier to be extended and customized by community users. We hope to encourage better ideas to emerge.
+ * Based on user inputs of the deployment requirements (ISL/OSL, latency constraints, HW spec), we hope to be able to automatically recommend the best EP setting.
+* Fault tolerance
+ * Because large-scale EP deployment solution may lead to an increased fault ratio of the online deployment system, it may increase the need for cross-layer interactions with multiple components of the E2E LLM inference system on NVIDIA GPUs. This includes the low-level communication kernel, the cluster-level orchestrator and scheduler, etc. We are actively working with various NVIDIA engineering teams to push forward on this.
+
+
+We believe the current implementation can be viewed as a reasonable E2E large-scale EP implementation and we encourage the community to try new ideas and performance validation. We encourage the community to share feedback to help us move fast in this area. We are actively tracking the TensorRT-LLM large-scale EP execution in [this](https://github.com/NVIDIA/TensorRT-LLM/issues/4127) GitHub issue to ensure transparency to the community.
+
+
+## Acknowledgement
+
+The large-scale EP work is another great team effort, spanning kernel-level optimizations, runtime enhancements, and systematic performance analysis and tuning. While we cannot individually acknowledge every contributor, we are proud to recognize the dedicated team of engineers whose collective expertise has helped advance the state-of-the-art in terms of performance in TensorRT-LLM.
+Through this collaborative endeavor, we have developed valuable insights to allow us improve GPU utilization for large language model inference. We hope that the techniques and the experience shared in this blog will help the developer community to better leverage NVIDIA GPU capabilities in their mission-critical LLM inference applications.
diff --git a/latest/_sources/torch/adding_new_model.md.txt b/latest/_sources/torch/adding_new_model.md.txt
index 53f2f236ff..4ce5988c99 100644
--- a/latest/_sources/torch/adding_new_model.md.txt
+++ b/latest/_sources/torch/adding_new_model.md.txt
@@ -89,8 +89,8 @@ class MyModel(DecoderModel):
def forward(self,
attn_metadata: AttentionMetadata,
- input_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
+ input_ids: Optional[torch.IntTensor] = None,
+ position_ids: Optional[torch.IntTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None):
# Define the forward computation of the model
...
diff --git a/latest/advanced/disaggregated-service.html b/latest/advanced/disaggregated-service.html
index 34b99a4b6e..105eb9d30b 100644
--- a/latest/advanced/disaggregated-service.html
+++ b/latest/advanced/disaggregated-service.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -808,9 +808,9 @@ export UCX_RNDV_PIPELINE_ERROR_HANDLING=y
diff --git a/latest/advanced/executor.html b/latest/advanced/executor.html
index 7a10cd2e85..9c0d869ecf 100644
--- a/latest/advanced/executor.html
+++ b/latest/advanced/executor.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -813,9 +813,9 @@ the TensorRT-LLM C++ Executor API.
diff --git a/latest/advanced/expert-parallelism.html b/latest/advanced/expert-parallelism.html
index fbd8066e74..881c7a9b01 100644
--- a/latest/advanced/expert-parallelism.html
+++ b/latest/advanced/expert-parallelism.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -680,9 +680,9 @@
diff --git a/latest/advanced/gpt-attention.html b/latest/advanced/gpt-attention.html
index ad3ec90def..8612b7f49c 100644
--- a/latest/advanced/gpt-attention.html
+++ b/latest/advanced/gpt-attention.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -998,9 +998,9 @@ is computed as:
diff --git a/latest/advanced/gpt-runtime.html b/latest/advanced/gpt-runtime.html
index b2d8b3a4b2..07d329d497 100644
--- a/latest/advanced/gpt-runtime.html
+++ b/latest/advanced/gpt-runtime.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -1038,9 +1038,9 @@ The GptDecoder
diff --git a/latest/advanced/graph-rewriting.html b/latest/advanced/graph-rewriting.html
index 2586085da9..c31d4886b8 100644
--- a/latest/advanced/graph-rewriting.html
+++ b/latest/advanced/graph-rewriting.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -859,9 +859,9 @@ techniques to optimize the underlying graph. It provides a wrapper similar to P
diff --git a/latest/advanced/kv-cache-management.html b/latest/advanced/kv-cache-management.html
index 5f5065d0db..ed6b002c42 100644
--- a/latest/advanced/kv-cache-management.html
+++ b/latest/advanced/kv-cache-management.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -764,9 +764,9 @@ An “event” is any significant change in the lifecycle or state of a KV cache
diff --git a/latest/advanced/kv-cache-reuse.html b/latest/advanced/kv-cache-reuse.html
index 619e464383..54d0cd0631 100644
--- a/latest/advanced/kv-cache-reuse.html
+++ b/latest/advanced/kv-cache-reuse.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -737,9 +737,9 @@ Assume vocabulary size is 100, which means normal text token ids are in range [0
diff --git a/latest/advanced/lora.html b/latest/advanced/lora.html
index 81f4f71e6e..722dff5c51 100644
--- a/latest/advanced/lora.html
+++ b/latest/advanced/lora.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -851,9 +851,9 @@ The shape of LoraWe
diff --git a/latest/advanced/lowprecision-pcie-allreduce.html b/latest/advanced/lowprecision-pcie-allreduce.html
index f3b84da6f4..4d53119ac7 100644
--- a/latest/advanced/lowprecision-pcie-allreduce.html
+++ b/latest/advanced/lowprecision-pcie-allreduce.html
@@ -51,7 +51,7 @@
@@ -61,7 +61,7 @@
-
+
@@ -708,9 +708,9 @@ This feature is optimized for PCIe-based GPU topologies and may affect model acc
diff --git a/latest/advanced/speculative-decoding.html b/latest/advanced/speculative-decoding.html
index 06fcd229ad..f4c4862c8c 100644
--- a/latest/advanced/speculative-decoding.html
+++ b/latest/advanced/speculative-decoding.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -839,9 +839,9 @@ However, similar to any new model, you can follow the same approach to define yo
diff --git a/latest/advanced/weight-streaming.html b/latest/advanced/weight-streaming.html
index a6c1605c91..bac3be1c19 100644
--- a/latest/advanced/weight-streaming.html
+++ b/latest/advanced/weight-streaming.html
@@ -51,7 +51,7 @@
@@ -61,7 +61,7 @@
-
+
@@ -688,9 +688,9 @@ python3examples/summarize.py
diff --git a/latest/architecture/add-model.html b/latest/architecture/add-model.html
index 0eb4c03b31..55595d8119 100644
--- a/latest/architecture/add-model.html
+++ b/latest/architecture/add-model.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -750,9 +750,9 @@ python../summarize.py--engine_di
diff --git a/latest/architecture/checkpoint.html b/latest/architecture/checkpoint.html
index d56c1bb644..82688e25ad 100644
--- a/latest/architecture/checkpoint.html
+++ b/latest/architecture/checkpoint.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -1017,9 +1017,9 @@ trtllm-build--checkpoint_dir./op
diff --git a/latest/architecture/core-concepts.html b/latest/architecture/core-concepts.html
index 0b308ed822..9885faf6b4 100644
--- a/latest/architecture/core-concepts.html
+++ b/latest/architecture/core-concepts.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -514,22 +514,22 @@
TensorRT-LLM has a Model Definition API that can be used to define
Large Language Models. This API is built on top of the powerful
-TensorRT Python API
+TensorRT Python API
to create graph representations of deep neural networks in TensorRT. To become
familiar with the core concepts of the TensorRT API, refer to the
-Core Concepts
+Core Concepts
section of the TensorRT documentation before proceeding further.
# In tensorrt_llm.functional:
@@ -558,23 +558,23 @@ functions such as the tensorrt.ILayer
+tensorrt.ILayer
class. That graph will also be optimized by TensorRT during the compilation of
the engine, as explained in the next section.
Once populated, the instance of the
-tensorrt.INetworkDefinition,
+tensorrt.INetworkDefinition,
can be compiled into an efficient engine by the
-tensorrt.Builder
+tensorrt.Builder
In TensorRT-LLM, it is done through the build_engine member function of the
tensorrt_llm.Builder class that calls the
-build_serialized_network
+[build_serialized_network](https://docs.nvidia.com/deeplearning/tensorrt/latest/_static/python-api/infer/Core/Builder.html#tensorrt.Builder.build_serialized_network
method of the
-tensorrt.Builder
+tensorrt.Builder
object. That call, if everything works as expected, produces an instance of the
-tensorrt.IHostMemory
+tensorrt.IHostMemory
class. That object is an optimized TensorRT engine that can be stored as a
binary file.
@@ -1021,9 +1021,9 @@ srun\
diff --git a/latest/architecture/model-weights-loader.html b/latest/architecture/model-weights-loader.html
index bc27b875a5..55642a8f94 100644
--- a/latest/architecture/model-weights-loader.html
+++ b/latest/architecture/model-weights-loader.html
@@ -51,7 +51,7 @@
@@ -61,7 +61,7 @@
-
+
@@ -939,9 +939,9 @@ The support for Qwen-1 is in
diff --git a/latest/architecture/overview.html b/latest/architecture/overview.html
index 2000e1863a..627ebb10d3 100644
--- a/latest/architecture/overview.html
+++ b/latest/architecture/overview.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -668,9 +668,9 @@ Server to easily create web-based services for LLMs. TensorRT-LLM supports m
diff --git a/latest/architecture/workflow.html b/latest/architecture/workflow.html
index 98d35d1308..4ac6b3eaf7 100644
--- a/latest/architecture/workflow.html
+++ b/latest/architecture/workflow.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -847,9 +847,9 @@ The usage of this API looks like this:
diff --git a/latest/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.html b/latest/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.html
index f3c01d3f06..3651e57fa6 100644
--- a/latest/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.html
+++ b/latest/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.html
@@ -51,7 +51,7 @@
@@ -61,7 +61,7 @@
-
+
@@ -1053,9 +1053,9 @@ For more details on
H100 has 4.6x A100 Performance in TensorRT-LLM, achieving 10,000 tok/s at 100ms to first token#
-
TensorRT-LLM evaluated on both Hopper and Ampere shows H100 FP8 is up to 4.6x max throughput and 4.4x faster 1st token latency than A100. H100 FP8 is able to achieve over 10,000 output tok/s at peak throughput for 64 concurrent requests, while maintaining a 1st token latency of 100ms. For min-latency applications, TRT-LLM H100 can achieve less than 10ms to 1st token latency.
+
TensorRT-LLM evaluated on both Hopper and Ampere shows H100 FP8 is up to 4.6x max throughput and 4.4x faster 1st token latency than A100. H100 FP8 is able to achieve over 10,000 output tok/s at peak throughput for 64 concurrent requests, while maintaining a 1st token latency of 100ms. For min-latency applications, TRT-LLM H100 can achieve less than 10ms to 1st token latency.
H200’s HBM3e larger capacity & faster memory enables up to 1.9x performance on LLMs compared to H100. Max throughput improves due to its dependence on memory capacity and bandwidth, benefitting from the new HBM3e. First token latency is compute bound for most ISLs, meaning H200 retains similar time to first token as H100.
TensorRT-LLM achieves world-record inference performance for DeepSeek-R1 on NVIDIA Blackwell GPUs, where Multi-Token Prediction (MTP) delivers a significant speedup. In our previous blog post, we discussed the key optimizations that enable the outstanding inference latency of the DeepSeek-R1 model. This article dives deeper into the implementation and optimization of MTP in TensorRT-LLM.
The development of model like DeepSeek-V3/R1, which use large-scale fine-grained Mixture-of-Experts (MoE) designs, has significantly advanced open-source model quality. Newly released open-source models such as LLaMA4 and Qwen3 also adopt a similar large-scale fine-grained MoE design principle. However, large-scale MoE models introduce new challenges for inference systems, including high memory demands and inherent expert-level workload imbalance.
The DeepSeek team has also shared their valuable experience and practice on how to optimize this kind of large-scale Expert Parallelism (EP) model, including DeepEP and EPLB. Also, the DeepSeek team has shared their concrete design considerations in this tech report. On top of those great sharings, there are also nice community efforts to implement large-scale EP in other inference engines, such as this effort from the SGLang team.
+
In this tech blog, we will introduce the details of the design and implementation to support E2E large-scale EP in TensorRT-LLM. This blog post mainly covers the following:
+
+
How to leverage NVIDIA GB200 Multi-Node NVLink (MNNVL) HW features to implement high-performance communication kernels.
+
How to design and implement an online expert workload balancer to dynamically balance the expert load distribution and adapt to the changes of online traffic patterns. We present:
+
+
The empirical data analysis demonstrating the need to do so.
+
The implementation of the online traffic data statistic module.
+
The design and implementation of the replication/placement strategy.
+
The MoE weight load/re-distributer to balance the online workload across multiple GPUs.
+
The changes needed to the MoE router and computation module to adapt to the expert load balancer needs.
+
Some preliminary data demonstrating the effectiveness of the current implementation in TensorRT-LLM.
+
+
+
+
In future tech blogs, we will also cover the following topics:
+
+
The introduction of performance tuning and optimization for TensorRT-LLM large-scale EP GB200 implementation.
+
How to implement efficient large-scale EP support for B200/Hopper and other NVIDIA GPUs without MNNVL.
+
The best practices to leverage large-scale EP and get performance gains.
+
How to combine large-scale EP with other system optimization techniques.
+
+
Even if, in this tech blog, we focus on TensorRT-LLM, we believe the core ideas and implementation can also be applied to other inference engines to help the inference performance on NVIDIA GPUs. Also, with the help of the community, we would like to figure out how to better modularize the current TensorRT-LLM large-scale EP implementation and make it more easily reusable by the community.
+
Finally, in this tech blog, there are implementation details which are targeted towards the GB200 system, such as the communication components leveraging the GB200 MNNVL inter-GPU connection, and the MoE weight load/re-distributer module leveraging the high bandwidth C2C connection between Grace CPU and Blackwell GPU. Nevertheless, the overall design principle and software architecture can still apply to non-GB200 NVIDIA GPU systems. To facilitate the extension to other non-GB200 system, we have, on purpose, paid attention to the generalization of the design and implementation. These changes should be easily composable with other existing components.
The main motivation of introducing large-scale EP (here means EP > 8) comes from the following system considerations:
+
+
We expect to reduce the execution latency thanks to the increased aggregated memory bandwidth to load the expert weights.
+
We expect to increase the effective batch size to saturate the GPU computing power.
+
+
Note that when the E2E execution time is dominated by the MoE GroupGEMM computation, by introducing large-scale EP, it is expected to see clear performance benefits. But if the E2E execution time is not dominated by the MoE GroupGEMM computation, then large-scale EP may bring limited performance benefit.
+
Also there isn’t free lunch in the system design. When the EP size increases up to greater than 8 (sometimes even less than 8), due to the sparsity execution nature of MoE models, it can inherently trigger the EP-level workload imbalance issue.
+
And here are some empirical observations based on some datasets (all the analyses below are done with the DeepSeek R1 model, on 32 GB200 GPUs).
+
+
Observations over one machine translation dataset#
+
Firstly let’s have an overview of the overall imbalance issues across layers:
+
+
+
+
+
+
Figure 1: The routed token count from rank 0 to all the ranks(including rank 0), for decode iteration 1950, and all the MoE layers
+
In Figure 1, it can be seen clearly that for the MoE in layer 36, many more tokens are sent from rank 0 to rank 13.
+
If we zoom on the MoE in the layer 36 and record its activated expert rank distribution, there clearly is a rank that is more heavily activated:
+
+
+
+
+
+
Figure 2: The tokens received for each expert rank for layer 36
+
If we flatten the data to see the routed tokens for each expert, we can see that a few experts are more active than others:
+
+
+
+
+
+
Figure 3: The tokens received for each expert for layer 36
+
It is also interesting to see that this kind of imbalance issue is very stable across multiple iterations, as shown on the following figure:
+
+
+
+
+
+
Figure 4: The accumulated token counts received for each expert for layer 36, within 50 decode steps, and the local batch size=256.
+
Clearly, the hot experts in Figure 4 are actually the same as in Figure 3 which only have data for a single decode iteration.
+We have also done the duration-based analysis for local batch size=1 which correspond to a single request with observing the similar pattern:
+
+
+
+
+
+
Figure 5: The accumulated token counts received for each expert for layer 36, within 400 decode iterations, and the local batch size \= 1\.
+
To conclude the findings from this study over this machine translation dataset, we could say that:
+
+
There are hot spots in some layers where the workload of some EP ranks can be much higher than others.
+
This may be caused by the hottest expert or some hot experts to be located on the same rank.
+
The routed token distributions can be the same for tens to hundreds of iteration steps or even more.
+
For the execution of a single request, it also has the same hot experts between steps.
+
+
And another natural question is whether the above observation can change significantly on other datasets. So we have done a similar analysis with the GSM8K dataset.
Figure 6: The routed token count from rank 0 to all the ranks, for iteration 1950, and all the MoE layers
+
In Figure 6, compared with Figure 1, it can be seen that for GSM8K, the hot layer becomes layer 57 instead of layer 36. Then what about the concrete status of layer 36 for the GSM8K dataset?
+
+
+
+
+
+
Figure 7: routed token counts from EP rank 0 to other EP ranks, still taking the iteration 1950, MoE layer 36 as the example
+
Clearly from Figure 7, it can be observed that the workload imbalance is different from what was observed for the different dataset (in Figure 2).
+Based on Figure 8, it can be observed that the workload imbalance is relatively stable across multiple iterations on the GSM8K dataset too. It is the same as the previous machine translation dataset.
+
+
+
+
+
+
Figure 8: The accumulated token counts sent from EP Rank 0 to all the ranks, for MoE layer 57 within 50 decode steps, local batch size=256
+
If we flatten the EP rank level data to expert-level data, we can have the following figure.
+
+
+
+
+
+
Figure 9: The accumulated token counts received for each expert for layer 57, within 50 decode steps, and the local batch size=256.
+
The similar imbalance pattern also exists for a single request.
+
+
+
+
+
+
Figure 10: The accumulated token counts received for each expert for layer 57, within 400 decode steps, for a single request
+
If we use another request, then we can still observe the expert imbalance issue, while the hot experts can be different with some in common (in this example it is expert 10).
+
+
+
+
+
+
Figure 11: The accumulated token counts received for each expert for layer 57, within 400 decode steps, for a single request
+
So combining the data analysis of two datasets, we have the following findings:
+
+
EP level workload imbalance issue is common for large-scale EP inference on multiple datasets. And the EP imbalance severity can be different per layer. Also the EP imbalance issue is dataset sensitive.
+
The EP rank level imbalance issue can be caused by a certain hottest expert or multiple hot experts staying on the same EP rank.
+
The EP rank imbalance distribution is relatively stable across tens to hundreds of iterations.
+
Though there is time-dimension stability of EP rank imbalance distribution, clearly different requests can have different EP imbalance distribution.
+
+
Based on these findings, they can lead to our design consideration of TensorRT-LLM’s large-scale EP implementation:
+
+
By design the EP imbalance issue needs to be considered to assure great E2E performance.
+
Online EP Load Balancer(rather than only a Offline EP Load Balancer implementation) based on the real-time online request traffic is essential to ensure the robustness of EP balancer.
+
The time-dimension stability of EP rank imbalance distribution can be leveraged to re-distribute the MoE weights to different EP ranks in an efficient manner.
+
+
In the next section we will illustrate the high-level design.
Based on the detailed analysis and study in section Motivation of large-scale EP, it can clearly be observed that expert imbalance in EP is a common pattern for large-scale EP. This EP imbalance can clearly impede the overall system performance in the following ways:
+
+
The hot EP rank will consume more memory (for activations) which can limit the effective max batch size scheduled during the inference process.
+
More data will be sent to/received from the hot EP rank.
+
+
Those issues can clearly result into a system-level congestion effect in which the hot EP rank will delay the overall E2E execution.
+
To make sure large-scale EP can run well, careful considerations are needed to minimize the EP imbalance issue. The overall design is as follows:
+
+
+
+
+
+
Figure 12: the high-level design of TensorRT-LLM large-scale EP
+
In this design, there are both CPU and GPU side logics:
+
+
CPU side
+
+
Implement the Replication & Placement algorithms (Replication & Placement Compute component) to achieve a more balanced EP strategy. Those are rather classical algorithms for which CPU computation is more suitable. Furthermore, by offloading this computation to the CPU, the interference with the GPU can be reduced. In the future, machine-learning based algorithms may also be explored and additional design consideration may be needed. The Replication & Placement Compute component will generate the “Placement Info” which will then be consumed by both the GPU Routing logic and the CPU Update Weights & Placement component. The Replication & Placement Compute component will consume the Statistics Data generated by the Statistics component which runs on the GPU.
+
Orchestrate the process (Update Weights & Placement component) to update and reload the MoE weights from CPU host memory to GPU device memory. This component will also consume the Placement Info generated by the Replication & Placement Compute component. Our scalable design allows us to reload the MoE weights from remote GPU memory via MNNVL or NIC.
+
+
+
GPU side
+
+
This is the main execution workflow of inference. The following new GPU components are introduced with our design:
+
+
EP communication kernels. In Figure 11, those are the Dispatch and Combine components.
+
Online traffic data statistics collector (the Statistics component). This component collects the Statistics Data which is to be consumed by the Replication & Placement Compute component.
+
The MoE router logic (the Routing component). It sends tokens to the activated experts. It needs to be adjusted to support the dynamic placement of MoE weights. It also consumes the Placement Info generated by the Replication & Placement Compute component.
+
The MoE computation logic (the MoE component) also needs to be adjusted correspondingly.
+
+
+
+
+
Careful synchronization between CPU and GPU components is needed to ensure the validity of the entire execution process ; particularly, to avoid hangs, as well as invalid or sub-optimal executions.
+
+
For the Update Weights & Placement component, we identified two design choices:
+
+
Bulk approach
+
+
In this approach, when the MoE weight redistribution logic starts, the inference taking place on the current serving instance will have to be paused until the MoE weight redistribution process finishes. We estimate that it can lead to approximately 0.5 ~1 second online serving stalls ; causing in the worst-cases request timeouts. This kind of timeout or stalls can be mitigated at the system level by routing the requests to other serving instances or just request replays.
+
+
+
Layer-wise approach
+
+
In this approach, the MoE weight redistribution is done layer by layer such that at each decode iteration only certain layers (it can be configured) will be impacted by a redistribution of their MoE weights. With this design, it will take several iterations to re-balance the MoE weights of all the layers. We expect this approach to have almost no impact on the user experience.
+
+
+
+
+
+
+
+
+
Figure 13: One example of the layer-wise MoE weight re-distribution
+
In our current system, we choose to implement the layer-wise approach to minimize the impact on the online user experience. The bulk approach should be much easier to implement and we will not discuss it in this tech blog.
+To implement the layer-wise approach properly, we need to carefully evaluate the capability of different underlying HWs to decide on the concrete implementation.
+Let’s use GB200 as an example. In Figure 14, we illustrate the communication bandwidth of different HW elements in a GB200 node.
+
+
+
+
+
+
Figure 14: high-level topology of GB200 system
+
Using the DeepSeek R1 model as an example, with FP4 precision, each MoE expert occupies 24MiB of memory space. There are 256 experts per layer. In total, that’s 58 MoE layers, plus 1 MTP layer. So the maximum amount of MoE weights which need to be redistributed, to achieve EP balance, is 348GiB.
+One GB200 node has 480GB LPDDR5X memory for each Grace CPU. In total, that’s 960GB of host memory across a NUMA domain. One GB200 node can host the entire MoE weights of a model like the DeepSeek R1 LLM in its CPU host memory. Based on it, the MoE weight redistribution can be done by moving the corresponding MoE weights from CPU host memory to GPU device memory.
+
Let’s assume that we target 50ms inter-token-latency (ITL) as our main latency constraint. Using back-of-the-envelope calculation, it can be computed that the amount of expert weights which can be moved from the MoE weight pool (can be kept in Grace CPU memory or GPU memory on another node) to the Blackwell GPU (to do the real MoE inference) for each decode iteration is:
+
+
+
+
+
+
Figure 15: The theoretical expert count to be updated for each iteration with following 50ms ITL constraints, by using different HW as pools to store the full MoE weight
+
Based on this analysis, and, if we rely on the Grace CPU memory on each node to store the MoE weight pool, for each decode iteration, the weights of up to 300 experts can be redistributed to each GPU on the same GB200 node.
+Assuming our goal is to finish the MoE weight re-balancing for the full model within 5 decode iterations, here are some more concrete use-case studies:
+
+
Use-case 1 (with balanced expert placement and no expert replication)
+
+
64 GPUs with 4 Experts per GPU
+
58 layers, 232 Experts per GPU
+
Need 47 Expert Update / Iter, all the methods can satisfy the latency goal.
+
+
+
Use-case 2 (with both balanced expert placement and replication)
+
+
64 GPUs or 72 GPUs with 5 Experts per GPU
+
58 layers, 290 Experts per GPU
+
Need 58 Expert Update / Iter, all the methods can satisfy the latency goal.
+
+
+
Use-case 3 (with both balanced expert placement and replication)
+
+
36 GPUs with 8 Experts per GPU
+
58 layers, 464 Experts per GPU
+
Need 93 Expert Update / Iter, all the method can satisfy the latency goal.
+
+
+
+
In summary, based on the theoretical analysis, using Grace CPU memory as the pool to hold the full size MoE weights should allow us to achieve the EP (Expert-Parallelism) re-balancing within 5 decode iterations. If we relax the requirements to 10 or more iterations, there can be even more system implementation flexibility.
+
Next we will introduce the implementation details of our large-scale EP system.
We have evaluated multiple ways of implementing the EP communication kernels needed by large-scale EP, including DeepEP, other solutions and the development of an approach from scratch.
For non-GB200 systems (such as B200 or Hopper), we chose to integrate DeepEP directly, with some potential enhancement.
+
+
The considerations are:
+
+
DeepEP is a great piece of work done by the DeepSeek team. When we started the TensorRT-LLM large-scale EP efforts, our first focus was on GB200. We chose to implement our own custom EP communication kernels as it was easier to introduce optimizations requiring the GB200 MNNVL capability. Also, based on our current evaluation, DeepEP does not provide CUDA graph compatibility for all the scenarios. We believe that CUDA graph is needed for the scenario we are interested in.
+
When we started the efforts to enable large-scale EP on Hopper, we concluded that DeepEP could be adapted and meet our needs on this platform. We plan to extend DeepEP to work for B200 in the future.
+
+
We are also actively evaluating the possibility of consolidating GB200 and non-GB200 EP communication kernels into a single solution to make the system simpler, and we will keep the community posted on the status.
+Now let’s talk a little bit more about the optimizations introduced into the custom EP communication kernel implementations.
In the Decoding Phase with Prefill-Decoding (PD) separation, we observed that the batch size may not be very large, such that latency is a significant concern. In this context, compatibility with CUDA Graph is a strong requirement.
+NCCL is a great GPU communication library which provides highly efficient communication kernels and primitives.
+For now, its Send and Recv operations require the data size to be explicitly specified when invoking with ncclSend/ncclRecv.
+However, in large expert parallel (large-EP) scenarios, the data size to be transferred is determined dynamically based on the model’s output at each iteration.
+With the current NCCL’s communication interface, an explicit synchronization is required to send the communication size back to the CPU and launch NCCL calls from the CPU with the corresponding data size. This would break CUDA Graph compatibility.
+This limitation has forced us to develop high performance communication kernels compatible with CUDA graph and that can accept communication sizes directly from GPU memory.
+We also wanted those kernels, for GB200, to take of advantage of the MNNVL’s memory bandwidth.
Our kernels adopt a communication approach similar to NCCL’s LL128 primitive. As this approach strikes a good balance between latency and bandwidth, it is well-suited for LLM inference.
+Our custom kernels can read the communication size directly from GPU memory and are compatible with CUDA Graph even when the data size varies across runs.
+
In our implementation, we use the CUDA’s Driver API to establish a peer-to-peer (P2P) buffer via MNNVL as a workspace.
+Each GPU can access the workspace of other GPUs. The workspace is divided into multiple channels, each assigned to a remote GPU as a write buffer.
+Those write buffers are used in a FIFO manner, with flags used to synchronize FIFO status and avoid data corruption.
+More details can be found in PR 3504.
The Python interface layer provides a user-friendly PyTorch/Python native interface to access the MoE Load Balancing implementations, such as the Python wrapper for the GPU/CPU synchronization logics and the online data statistics collection, and other logics implemented in 4.2 to 4.4.
For production deployment needs, Online EP Load Balancer is recommended since it can adapt itself to the change in the online traffic pattern, dynamically, thus with more performance guarantees.
+
However, the Online EP Load Balancer faces several challenges.
+
First, load balancing introduces dynamic Expert placement. A single Expert’s location may shift based on current workload. For example, if Expert 0 and Expert 1, originally assigned to Rank 0, both become hot experts, the load balancing policy might redistribute them to different ranks alongside cold experts, which necessitates timely updates to the weight data.
+
We aim for the Online Load Balancer to react swiftly to changes in request patterns and adjust Expert assignments to avoid load imbalance issues. Importantly, we do not want the balancing process to interfere with the online inference execution process, nor do we want to employ a “Stop-The-World” (Bulk) strategy for updating weights.
+
In large MoE models (such as DeepSeek R1) during the decoding phase, batch sizes are often small, making CUDA Graph an effective acceleration method; especially when high TPS per user is required. This benefit is even more pronounced on platforms like GB200. For this reason, we want the entire load balancing mechanism to be compatible with CUDA Graph.
+
To avoid invalidating pre-captured CUDA Graphs, we perform in-place weight updates by writing new Expert weights into the same memory locations, rather than swapping out tensor pointers. This ensures the weights tensor address remains unchanged in the Model Engine.
+
In this design, each Expert Slot serves as a container for holding an Expert’s weights, decoupled from any specific Expert. The number of Expert Slots must be greater than or equal to the total number of Experts so that each Expert always has at least one available Slot. Hot Experts may occupy multiple Slots. Each Slot is identified by a SlotId.
+
Since the MoE model’s routing logic outputs ExpertIds (not SlotIds), we maintain a routing table from ExpertId to SlotId which is updated by the load balancing policy, periodically. The Load Balancer Routing module uses the current routing table (Expert replication information and slots) to map each token to a suitable Expert Slot.
+
To make weight updates non-blocking and avoid “Stop-The-World”, we use a layer-wise update approach. After a layer’s forward pass completes and before its next forward pass starts, we perform the weight balancing for that layer; the next forward pass for the same layer should wait until the last update is done if it happens at this iteration.
+
As the forward execution is typically driven by a single Python thread invoking a sequence of PyTorch operations, we offload the weight update routine to a background C++ thread. The Python side only initializes the Expert Slots and registers Expert Weights in shared host memory.
+
During forward execution, we insert lightweight lock/unlock kernels before and after MoE computations, as well as kernels for collecting statistics and assigning SlotIds to ExpertIds. These kernels must be short and overlap-friendly to minimize performance impact. As long as the CPU weights update thread can finish its work on time, the lock/unlock will be very short. All, except for the routing kernel, are lightweight and can easily overlap with forward kernels in different CUDA streams; the routing kernel is the primary optimization focus.
+
On GB200, we utilize MNNVL for inter-GPU communication during Expert dispatch and combine. Expert weights reside in host memory and are brought into GPU memory via C2C to support asynchronous updates. A multi-threaded Host Copy Engine manages this process, auto-detecting NUMA topology and choosing optimal CPU cores, enabling full asynchrony with model forward passes.
+
On servers without C2C but with PCIe, if cross-node communication is required, network and weight updates may compete for PCIe bandwidth, requiring additional tuning and design consideration. We have not implemented the copy engine for PCIe servers yet and it is in list of future tasks.
Online EP balancer is more suitable for production deployment needs to react timely to online traffic changes. However, Offline EP Balancer provides a lightweight way for performance study/debugging and validation. You can refer to this PR to learn more about the implementation of the Offline EP Load Balancer. Also there is a tool provided to collect statistics about the expert activation distribution which can be used as the input to deduce the EP balancing placement strategy. You can refer to this doc to learn more details as well as how how to run through the Offline EP Load Balancer in E2E approach.
As shown by Figure 1, on the machine translation dataset, MoE layer 36 suffers from extreme expert load imbalance issues, so we use that layer to illustrate the effect of EP Load Balancer. We still run DeepSeek-R1 with 32-way expert parallelism on 32 GB200 GPUs.
+
+
+
+
+
+
Figure 16: The routed token count by receiving ranks (x-axis) and iterations (y-axis) at layer 36 (No EPLB)
+
+
+
+
+
+
Figure 17: The routed token count by experts (x-axis) and iterations (y-axis) at layer 36 (No EPLB)
+
Figure 16 displays the routed token count by receiving ranks over 50 iterations, which could represent the workload for each rank. Rank 13 receives significantly more tokens than all other ranks, and such an imbalanced workload distribution is almost constant over iterations. Figure 17 breaks down the workload to experts. Clearly, two hot experts on rank 13 cause the excessive pressure on this rank.
+
With the above statistics, we can perform offline EPLB. One potential strategy is to maintain the 32-way expert parallelism while increasing expert slots from 8 to 9 per rank. This results in 32 redundant experts and 288 expert slots in total. Figures 18 and 19 show the routed token count after EPLB. Clearly, the per-rank token distribution is much more balanced, and there are no hot experts anymore.
+
+
+
+
+
+
Figure 18: The routed token count by receiving ranks (x-axis) and iterations (y-axis) at layer 36 (EPLB with 9 per-rank slots and EP 32)
+
+
+
+
+
+
Figure 19: The routed token count by experts (x-axis) and iterations (y-axis) at layer 36 (EPLB with 9 per-rank slots and EP 32)
+
Another EPLB strategy is to maintain 8 expert slots per rank while increasing expert parallelism to 36 ways. This strategy also results in 32 redundant experts and 288 expert slots in total. As displayed by Figures 20 and 21, the workloads also become balanced across ranks or expert slots.
+
+
+
+
+
+
Figure 20: The routed token count by receiving ranks (x-axis) and iterations (y-axis) at layer 36 (EPLB with 8 per-rank slots and EP 36)
+
+
+
+
+
+
Figure 21: The routed token count by experts (x-axis) and iterations (y-axis) at layer 36 (EPLB with 8 per-rank slots and EP 36)
+
For each layer and iteration, the load imbalance can be measured using simple metrics such as the standard deviation or the imbalance ratio. Given the routed token counts for all ranks (or experts), the imbalance ratio is defined as $(max - mean) / mean$, which represents the excessive workload received by the hottest rank (or expert). A perfectly balanced load would have an imbalance ratio of 0.
+
Table 1 reports the standard deviation and imbalance ratio for the aforementioned cases. Each number is averaged from the per-layer per-iteration metrics. Without EPLB, the load imbalance is significant – on average, the hottest rank receives 1.56 times more routed tokens than the mean. EPLB can effectively reduced the load imbalance – on average, the hottest rank receives only about 0.11 times more routed tokens than the mean.
+
+
+
+
By rank
+
+
+
By expert slot
+
+
+
+
+
+
+
Average
+
Std. Dev.
+
Imb. Ratio
+
Average
+
Std. Dev.
+
Imb. Ratio
+
+
No EPLB (8 per-rank slots and EP 32)
+
1024
+
491.6
+
1.564
+
128
+
164.1
+
10.948
+
+
EPLB (9 per-rank slots and EP 32)
+
1024
+
52.0
+
0.109
+
114
+
77.8
+
1.792
+
+
EPLB (8 per-rank slots and EP 36)
+
1024
+
53.9
+
0.115
+
128
+
87.5
+
1.791
+
+
+
+
+
Table 1: The standard deviation and imbalance ratio (average of per-layer and per-iteration metrics)
In the previous section, we demonstrated the impact of the Offline EP Load Balancer. Given our implementation of the Online EP Load Balancer, we further examine the dynamic patterns of EP balancing in online conditions.
+Let’s still use the machine translation dataset, DeepSeek R1 model, layer 36 (which is shown in Figure 1) as the example to understand the online behaviour:
+
+
+
+
+
+
Figure 22: The token count sent from rank 0 to all the ranks, run on GB200, with EP32, local batch size=256, with 256 slots(no replication), so each rank hosts 8 experts
+
From Figure 22, it is clear that from iteration 1963, since the EPLB has taken into effect, the original hottest rank 13 is no longer the hot rank and the original workload sent to rank 13 has been redistributed to rank 0 and rank 1.
+
In Figure 22, only placement adjustment has been done by the Online EPLB. If we further introduce expert replication, the balancing can be further improved, as shown on the following figure:
+
+
+
+
+
+
Figure 23: The token count sent from rank 0 to all the ranks, run on GB200, with EP32, local batch size=256, with 288 slots(with replication), so each rank hosts 9 experts
+
Clearly, by introducing expert replication when doing the EPLB, the EP balancing can be further improved.
+Further complicated experiments can be designed to observe the Online EPLB taking into effect periodically during the online serving process to balance the EP workload in a dynamic way and we welcome the community to report any interesting EPLB pattern observation to us.
Note: all the representative workloads illustrated in this section are from the performance traces extracted from DeepSeek R1 inference execution. The E2E performance tuning/optimization is still ongoing and we will discuss them in the future technical blogs.
+
Let’s use some representative workloads to illustrate the performance impact with large-scale EP.
+
+
+
+
+
+
Figure 24: EP impact over MoE Group GEMM and EP communication
+In Figure 24, it can be observed that by increasing the EP size from 4 to 72, the MoE Group GEMM computation time gets reduced, while the EP communication time (for EP4/EP8 Reduce/Scatter is used, while for EP>8 All2All is used) stays almost constant.
+When the EP size increases from 18 to 32, the speed-up diminishes. We are working on optimizing it.
+
Next, let’s use some representative workloads to understand the performance impact with EPLB.
+
+
+
+
+
+
Figure 25: EPLB performance impact
+Clearly in Figure 25, we can see that EPLB brings a clear performance improvement when the EP size increases, for both MoE GroupGEMM and EP communication times.
+
+
+
+
To generate the necessary statistics for load rebalancing, run your model on a target dataset and count the routed expert IDs during inference. Once the counting process is complete, the statistics will be saved for further processing.
+
Set up some environment variables:
+
exportMODEL_NAME=deepseek-ai/DeepSeek-R1
+exportMODEL_PATH=<YOUR_MODEL_PATH>
+# Set the expert statistic data path
+exportEXPERT_STATISTIC_PATH=./expert_statistic
+# Enable counting of routed expert IDs from iteration 100 to iteration 200
+exportEXPERT_STATISTIC_ITER_RANGE=100-200
+
Run 32-way expert parallelism inference on the prepared dataset. Please refer to the LLM API MGMN example for details on running trtllm-bench on Slurm.
After inference, review the dumped statistic files in $EXPERT_STATISTIC_PATH. Run the examples/ep_load_balancer/report_load_statistics.py script to show the standard deviation and imbalance ratio metrics:
Use the provided examples/ep_load_balancer/generate_eplb_config.py script to convert the collected statistics into an EPLB configuration file. Specify the target expert parallelism size (--ep_size) and the total number of slots (--num_slots) that will be used for deployment. For example, if we choose to maintain 8 expert slots per rank while increasing expert parallelism to 36 ways, there should be 32 redundant experts and 288 expert slots in total.
Step 3: Run inference with the EPLB configuration#
+
Set up some environment variables:
+
# Set a new expert statistic data path
+exportEXPERT_STATISTIC_PATH=./expert_statistic_eplb
+# Enable counting of routed expert IDs from iteration 100 to iteration 200
+exportEXPERT_STATISTIC_ITER_RANGE=100-200
+
+
+
Run 36-way expert parallelism inference with the EPLB configuration incorporated:
Note: Counting expert IDs can significantly hurt performance, so remember to disable it by unsetting EXPERT_STATISTIC_ITER_RANGE when running inference for benchmarking or production purposes.
GB200 NUMA binding: Since on GB200, GPU memory are also on NUMA nodes, system can also use GPU’s memory. It is suggested to use numactl-m0,1 to bind memory to CPU nodes if you don’t want that happen.
+
Shared Memory Clean Up: To achieve online load balance, all expert weights are stored in shared host memory. 4 ranks on same GB200 node share the same expert weights to save memory. Normally, these shared host memory will be cleaned up at process exit. But if an abnormal exit happens, they may not get chance to be cleaned. In that case, you may need to manually check /dev/shm directory and delete /dev/shm/moe_shared_* if any.
We deeply acknowledge the system innovation from the DeepSeek team. The introduction of the large-scale EP support into their in-house inference system and their open spirit of sharing their engineering insights with the community is extremely valuable and has already boost the performance of inference system design.
+Also we want to point out that there are no magical solutions when doing system design and optimization, such as large-scale EP.
+Based on our current performance analysis, when you plan to apply large-scale EP, you should take the following factors into considerations:
+
+
Is the MoE GroupGEMM computation time an E2E performance bottleneck?
+
+
Large-scale EP mainly helps reduce the MoE GroupGEMM execution time by reducing expert weight loading pressure and, thus, increases the compute intensity of the MoE GroupGEMM layer. For your workload setting, if the MoE GroupGEMM computation is not the bottleneck, then large-scale EP may not help much.
+
+
+
The latency constraints.
+
+
Large-scale EP mostly helps when there are strict latency constraints, especially on GB200/B200 with more memory capacity. For GPUs with less memory capacity, for scenarios with less latency constraints, large-scale EP can still help as it helps achieve higher concurrency and better tokens/s/GPU.
+
+
+
The available HW spec.
+
+
The optimal configuration for large-scale EP depends on GPU specifications - including memory bandwidth, capacity, inter-GPU bandwidth, and compute power - which determine both whether to employ large-scale EP and the ideal degree of parallelism.
+
+
+
System complexity and the production deployment constraints.
+
+
Without fault tolerance guarantee, large-scale EP can increase the online system failure ratio. Even if it is possible to do cluster level coordination to route the traffic to other running serving instances when certain large-scale EP serving instances fail, the large number of GPUs required for a single-instance deployment of large-scale EP can increase system level deployment challenges.
+
+
+
+
In the future, we plan to summarize and share more of the best practices of deploying with large-scale EP techniques.
+
Please use your own judgement to decide whether to use large-scale EP into your system or not, and when you use it, what is the suitable EP size and concrete deployment settings suitable for your own requirements.
+
The current TensorRT-LLM large-scale EP implementation is not perfect and there are still known limitations (community contributions are welcome to help us improve). For example, we need:
+
+
More platforms coverage
+
+
Extending the support to cover other non-GB200 NVIDIA GPU HWs. We are actively working on this now.
+
Currently the large-EP support only covers NVFP4 data precision, incremental efforts are needed to cover FP8 and INT8/INT4 data precision.
+
+
+
Performance
+
+
Further performance tuning and optimizations. We are actively working on this now.
+
More validation with workloads close to production traffic. Here we highly welcome the community’s feedback to help us calibrate TensorRT-LLM large-scale EP implementation based on more concrete workloads.
+
The thorough validation of combination with other inference core features, such as dis-aggregated serving, speculative decoding, validation on more MoE model families, etc. We are actively working on this now.
+
+
+
Ease-of-use
+
+
Easy customization
+
+
We believe large-scale EP can be decomposed into at least two layers:
+
+
A core layer which developed by inference engine developers. This layer contains the customized EP communication kernels, the synchronization logic between CPU and GPU, the MoE weight re-distributed logic.
+
A strategy layer which can be co-developed by the inference engine developers as well as machine learning researchers. This part contains tools to collect the online traffic statistics in different approaches, and algorithms for the optimal replication and placement of experts.
+
+
+
Based on this understanding, we plan to make components close to the strategy layer easier to be extended and customized by community users. We hope to encourage better ideas to emerge.
+
+
+
Based on user inputs of the deployment requirements (ISL/OSL, latency constraints, HW spec), we hope to be able to automatically recommend the best EP setting.
+
+
+
Fault tolerance
+
+
Because large-scale EP deployment solution may lead to an increased fault ratio of the online deployment system, it may increase the need for cross-layer interactions with multiple components of the E2E LLM inference system on NVIDIA GPUs. This includes the low-level communication kernel, the cluster-level orchestrator and scheduler, etc. We are actively working with various NVIDIA engineering teams to push forward on this.
+
+
+
+
We believe the current implementation can be viewed as a reasonable E2E large-scale EP implementation and we encourage the community to try new ideas and performance validation. We encourage the community to share feedback to help us move fast in this area. We are actively tracking the TensorRT-LLM large-scale EP execution in this GitHub issue to ensure transparency to the community.
The large-scale EP work is another great team effort, spanning kernel-level optimizations, runtime enhancements, and systematic performance analysis and tuning. While we cannot individually acknowledge every contributor, we are proud to recognize the dedicated team of engineers whose collective expertise has helped advance the state-of-the-art in terms of performance in TensorRT-LLM.
+Through this collaborative endeavor, we have developed valuable insights to allow us improve GPU utilization for large language model inference. We hope that the techniques and the experience shared in this blog will help the developer community to better leverage NVIDIA GPU capabilities in their mission-critical LLM inference applications.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ On this page
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/latest/commands/trtllm-build.html b/latest/commands/trtllm-build.html
index 7748f9223a..daf4a71064 100644
--- a/latest/commands/trtllm-build.html
+++ b/latest/commands/trtllm-build.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -1056,9 +1056,9 @@
diff --git a/latest/commands/trtllm-serve.html b/latest/commands/trtllm-serve.html
index 681eef74b6..0d8aba6941 100644
--- a/latest/commands/trtllm-serve.html
+++ b/latest/commands/trtllm-serve.html
@@ -51,7 +51,7 @@
@@ -63,7 +63,7 @@
-
+
@@ -750,6 +750,12 @@ However, for the PyTorch backend, specified with the
+
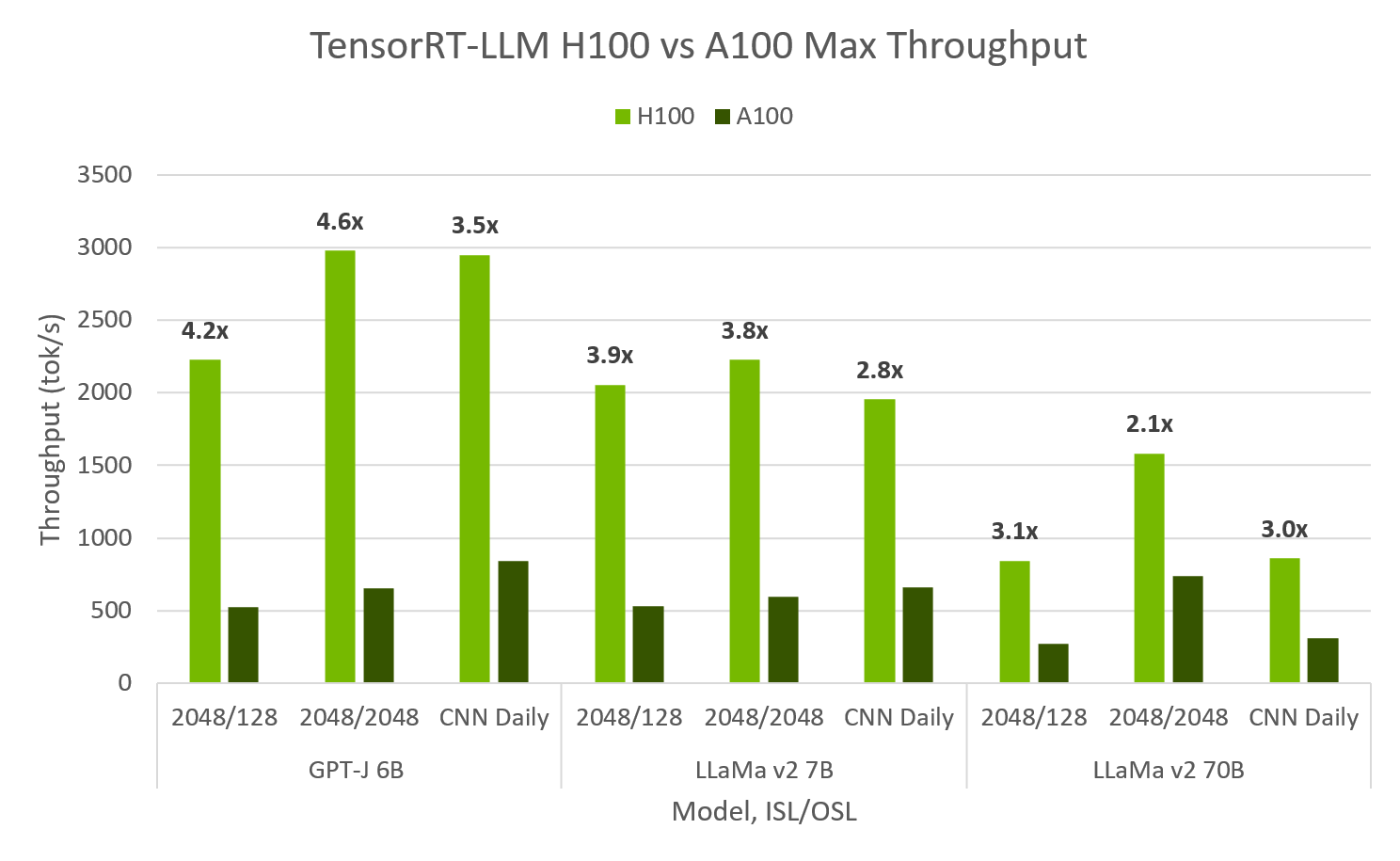 @@ -28,7 +28,7 @@ TensorRT-LLM evaluated on both Hopper and Ampere shows **H100 FP8 is up to 4.6x
FP8 H100, FP16 A100, SXM 80GB GPUs, TP1, ISL/OSL's provided, TensorRT-LLM v0.5.0., TensorRT 9.1
-The full data behind these charts & tables and including larger models with higher TP values can be found in TensorRT-LLM's [Performance Documentation](https://nvidia.github.io/TensorRT-LLM/performance.html#performance-of-tensorrt-llm)
+The full data behind these charts & tables and including larger models with higher TP values can be found in TensorRT-LLM's [Performance Documentation](https://nvidia.github.io/TensorRT-LLM/latest/performance/perf-overview.html)
Stay tuned for a highlight on Llama coming soon!
diff --git a/latest/_sources/blogs/H200launch.md.txt b/latest/_sources/blogs/H200launch.md.txt
index 58f5c08781..baa4905613 100644
--- a/latest/_sources/blogs/H200launch.md.txt
+++ b/latest/_sources/blogs/H200launch.md.txt
@@ -21,7 +21,7 @@ TensorRT-LLM evaluation of the [new H200 GPU](https://nvidianews.nvidia.com/news
*(1) Largest batch supported on given TP configuration by power of 2.* *(2) TP = Tensor Parallelism*
-Additional Performance data is available on the [NVIDIA Data Center Deep Learning Product Performance](https://developer.nvidia.com/deep-learning-performance-training-inference/ai-inference) page, & soon in [TensorRT-LLM's Performance Documentation](https://nvidia.github.io/TensorRT-LLM/performance.html).
+Additional Performance data is available on the [NVIDIA Data Center Deep Learning Product Performance](https://developer.nvidia.com/deep-learning-performance-training-inference/ai-inference) page, & soon in [TensorRT-LLM's Performance Documentation](https://nvidia.github.io/TensorRT-LLM/latest/performance/perf-overview.html).
### H200 vs H100
diff --git a/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt b/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt
index b43b8ed004..201c3781a8 100644
--- a/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt
+++ b/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt
@@ -2,37 +2,39 @@
by NVIDIA TensorRT-LLM team
## Table of Contents
-- [Background](#background)
-- [Implementation Configuration](#implementation-configuration)
- - [Workload Profile](#workload-profile)
- - [Model Architecture](#model-architecture)
- - [Precision Strategy](#precision-strategy)
- - [Parallelism Strategy](#parallelism-strategy)
- - [Everything in One Diagram](#everything-in-one-diagram)
-- [Key Optimizations](#key-optimizations)
- - [System Level optimizations](#system-level-optimizations)
- - [CUDA Graph & Programmatic Dependent Launch](#cuda-graph--programmatic-dependent-launch)
- - [MTP](#mtp)
- - [Autoregressive MTP Layers](#autoregressive-mtp-layers)
- - [Relax Acceptance Verification](#relax-acceptance-verification)
- - [Multi-streams](#multi-streams)
- - [Sparse Experts as GEMMs](#sparse-experts-as-gemms-only-works-when-moe_backendcutlass)
- - [Re-balanced the sparse experts](#re-balanced-the-sparse-experts)
- - [Mixed ETP](#mixed-etp)
- - [Smart Router](#smart-router)
- - [Kernel Level optimizations](#kernel-level-optimizations)
- - [Attention Kernel](#attention-kernel)
- - [Grouped GEMM](#grouped-gemm)
- - [CUTLASS Backend](#cutlass-backend-default-backend)
- - [TRTLLM Backend](#trtllm-backend)
- - [Communication Kernel](#communication-kernel)
- - [Dense GEMM optimization](#dense-gemm-optimization)
- - [Fuse_A_GEMM](#fuse_a_gemm)
- - [RouterGEMM](#routergemm)
- - [Kernel fusion](#kernel-fusion)
-- [How to reproduce](#how-to-reproduce)
-- [Future Works](#future-works)
-- [Acknowledgment](#acknowledgment)
+- [Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA B200 GPUs](#pushing-latency-boundaries-optimizing-deepseek-r1-performance-on-nvidia-b200-gpus)
+ - [Table of Contents](#table-of-contents)
+ - [Background](#background)
+ - [Implementation Configuration](#implementation-configuration)
+ - [Workload Profile](#workload-profile)
+ - [Model Architecture](#model-architecture)
+ - [Precision Strategy](#precision-strategy)
+ - [Parallelism Strategy](#parallelism-strategy)
+ - [Everything in One Diagram](#everything-in-one-diagram)
+ - [Key Optimizations](#key-optimizations)
+ - [System Level optimizations](#system-level-optimizations)
+ - [CUDA Graph \& Programmatic Dependent Launch](#cuda-graph--programmatic-dependent-launch)
+ - [MTP](#mtp)
+ - [Autoregressive MTP Layers](#autoregressive-mtp-layers)
+ - [Relax Acceptance Verification](#relax-acceptance-verification)
+ - [Multi-streams](#multi-streams)
+ - [Sparse Experts as GEMMs (only works when moe\_backend=CUTLASS)](#sparse-experts-as-gemms-only-works-when-moe_backendcutlass)
+ - [Re-balanced the sparse experts](#re-balanced-the-sparse-experts)
+ - [Mixed ETP](#mixed-etp)
+ - [Smart Router](#smart-router)
+ - [Kernel Level optimizations](#kernel-level-optimizations)
+ - [Attention Kernel](#attention-kernel)
+ - [Grouped GEMM](#grouped-gemm)
+ - [CUTLASS Backend (default backend)](#cutlass-backend-default-backend)
+ - [TRTLLM Backend](#trtllm-backend)
+ - [Communication Kernel](#communication-kernel)
+ - [Dense GEMM optimization](#dense-gemm-optimization)
+ - [Fuse\_A\_GEMM](#fuse_a_gemm)
+ - [RouterGEMM](#routergemm)
+ - [Kernel fusion](#kernel-fusion)
+ - [How to reproduce](#how-to-reproduce)
+ - [Future Works](#future-works)
+ - [Acknowledgment](#acknowledgment)
## Background
Recent advancements in Large Language Reasoning Models have demonstrated remarkable success, while creating new deployment challenges. A critical challenge emerges from extended Output Sequence Lengths (OSL) due to complex "thinking and reasoning" processes. Longer OSL demands stricter Token-to-Token Latency (TTL) requirements, often forcing concurrency limitations. The most extreme case, single concurrency (min-latency scenario) , becomes particularly challenging for real-time applications.
diff --git a/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt b/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt
index 0014f1c7f2..8fc2b51643 100644
--- a/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt
+++ b/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt
@@ -1,26 +1,28 @@
# DeepSeek R1 MTP Implementation and Optimization
by NVIDIA TensorRT-LLM team
## Table of Contents
-- [MTP for inference](#mtp-for-inference)
- - [Background](#background)
- - [MTP Vanilla](#mtp-vanilla)
- - [MTP Eagle](#mtp-eagle)
-- [MTP implementation in TensorRT-LLM](#mtp-implementation-in-tensorrt-llm)
- - [Basic Implementation](#basic-implementation)
- - [MTP Modules](#mtp-modules)
- - [Attention for MTP](#attention-for-mtp)
- - [How to run DeepSeek models with MTP](#how-to-run-deepseek-models-with-mtp)
-- [MTP optimization - Relaxed Acceptance](#mtp-optimization---relaxed-acceptance)
- - [Relaxed Acceptance](#relaxed-acceptance)
- - [How to run the DeepSeek-R1 model with Relaxed Acceptance](#how-to-run-the-deepseek-r1-model-with-relaxed-acceptance)
-- [Evaluation](#evaluation)
- - [Achieving speedup with MTP speculative decoding](#achieving-speedup-with-mtp-speculative-decoding)
- - [Accuracy studies for Relaxed Acceptance](#accuracy-studies-for-relaxed-acceptance)
-- [Future Works](#future-works)
- - [Tree-based speculative decoding support](#tree-based-speculative-decoding-support)
- - [Eagle3 support](#eagle3-support)
- - [Fix known issues](#fix-known-issues)
-- [Acknowledgment](#acknowledgment)
+- [DeepSeek R1 MTP Implementation and Optimization](#deepseek-r1-mtp-implementation-and-optimization)
+ - [Table of Contents](#table-of-contents)
+ - [MTP for inference](#mtp-for-inference)
+ - [Background](#background)
+ - [MTP Vanilla](#mtp-vanilla)
+ - [MTP Eagle](#mtp-eagle)
+ - [MTP implementation in TensorRT-LLM](#mtp-implementation-in-tensorrt-llm)
+ - [Basic Implementation](#basic-implementation)
+ - [MTP Modules](#mtp-modules)
+ - [Attention for MTP](#attention-for-mtp)
+ - [How to run DeepSeek models with MTP](#how-to-run-deepseek-models-with-mtp)
+ - [MTP optimization - Relaxed Acceptance](#mtp-optimization---relaxed-acceptance)
+ - [Relaxed Acceptance](#relaxed-acceptance)
+ - [How to run the DeepSeek-R1 model with Relaxed Acceptance](#how-to-run-the-deepseek-r1-model-with-relaxed-acceptance)
+ - [Evaluation](#evaluation)
+ - [Achieving speedup with MTP speculative decoding](#achieving-speedup-with-mtp-speculative-decoding)
+ - [Accuracy studies for Relaxed Acceptance](#accuracy-studies-for-relaxed-acceptance)
+ - [Future Works](#future-works)
+ - [Tree-based speculative decoding support](#tree-based-speculative-decoding-support)
+ - [Eagle3 support](#eagle3-support)
+ - [Fix known issues](#fix-known-issues)
+ - [Acknowledgment](#acknowledgment)
TensorRT-LLM achieves world-record inference performance for DeepSeek-R1 on NVIDIA Blackwell GPUs, where Multi-Token Prediction (MTP) delivers a significant speedup. In our [previous blog post](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md), we discussed the key optimizations that enable the outstanding inference latency of the DeepSeek-R1 model. This article dives deeper into the implementation and optimization of MTP in TensorRT-LLM.
diff --git a/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt b/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt
index 15b418f9b5..0de54f69fb 100644
--- a/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt
+++ b/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt
@@ -2,6 +2,8 @@
By NVIDIA TensorRT-LLM team
## Table of Contents
+- [Optimizing DeepSeek R1 Throughput on NVIDIA Blackwell GPUs: A Deep Dive for Developers](#optimizing-deepseek-r1-throughput-on-nvidia-blackwell-gpus-a-deep-dive-for-developers)
+ - [Table of Contents](#table-of-contents)
- [Introduction](#introduction)
- [Precision strategy](#precision-strategy)
- [Parallel strategy](#parallel-strategy)
diff --git a/latest/_sources/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md.txt b/latest/_sources/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md.txt
new file mode 100644
index 0000000000..a71bc0d037
--- /dev/null
+++ b/latest/_sources/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md.txt
@@ -0,0 +1,715 @@
+# Scaling Expert Parallelism in TensorRT-LLM (Part 1: Design and Implementation of Large-scale EP)
+
+By NVIDIA TensorRT-LLM Team
+
+## Table of Contents
+- [Scaling Expert Parallelism in TensorRT-LLM (Part 1: Design and Implementation of Large-scale EP)](#scaling-expert-parallelism-in-tensorrt-llmpart-1-design-and-implementation-of-large-scale-ep)
+ - [Table of Contents](#table-of-contents)
+ - [Motivation for large-scale EP](#motivation-for-large-scale-ep)
+ - [Observations over one machine translation dataset](#observations-over-one-machine-translation-dataset)
+ - [Observation over GSM8K dataset](#observation-over-gsm8k-dataset)
+ - [High-level design introduction](#high-level-design-introduction)
+ - [EP communication kernels](#ep-communication-kernels)
+ - [Motivation of EP communication kernels for GB200](#motivation-of-ep-communication-kernels-for-gb200)
+ - [EP communication kernels implementation](#ep-communication-kernels-implementation)
+ - [EP Load Balancer](#ep-load-balancer)
+ - [Python Interface](#python-interface)
+ - [C++ extension](#c-extension)
+ - [Core implementations of host side logics](#core-implementations-of-host-side-logics)
+ - [Core implementations of GPU side logics](#core-implementations-of-gpu-side-logics)
+ - [Online EP Load Balancer](#online-ep-load-balancer)
+ - [Offline EP Load Balancer](#offline-ep-load-balancer)
+ - [E2E evaluation](#e2e-evaluation)
+ - [The effect of EP Load Balancer](#the-effect-of-ep-load-balancer)
+ - [Offline EP Load Balancer](#offline-ep-load-balancer-1)
+ - [Online EP Load Balancer](#online-ep-load-balancer-1)
+ - [Performance study](#performance-study)
+ - [Reproducing steps](#reproducing-steps)
+ - [The effect of EP Load Balancer](#the-effect-of-ep-load-balancer-1)
+ - [Step 1: Run inference and collect statistics](#step-1-run-inference-and-collect-statistics)
+ - [Step 2: Generate the EPLB configuration](#step-2-generate-the-eplb-configuration)
+ - [Step 3: Run inference with the EPLB configuration](#step-3-run-inference-with-the-eplb-configuration)
+ - [Miscellaneous](#miscellaneous)
+ - [Expanded thoughts](#expanded-thoughts)
+ - [Acknowledgement](#acknowledgement)
+
+The development of model like DeepSeek-V3/R1, which use large-scale fine-grained Mixture-of-Experts (MoE) designs, has significantly advanced open-source model quality. Newly released open-source models such as LLaMA4 and Qwen3 also adopt a similar large-scale fine-grained MoE design principle. However, large-scale MoE models introduce new challenges for inference systems, including high memory demands and inherent expert-level workload imbalance.
+
+In the past, we have shared TensorRT-LLM’s optimization experience to [push the latency boundary](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md) of DeepSeek R1 model, [the implementation and optimization of MTP](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md)(Multi-Token Prediction) and [the optimizations for DeepSeek R1 throughput oriented performance](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md).
+
+The DeepSeek team has also shared their valuable experience and practice on how to optimize this kind of large-scale Expert Parallelism (EP) model, including [DeepEP](https://github.com/deepseek-ai/DeepEP) and [EPLB](https://github.com/deepseek-ai/EPLB). Also, the DeepSeek team has shared their concrete design considerations in [this](https://arxiv.org/abs/2412.19437) tech report. On top of those great sharings, there are also nice community efforts to implement large-scale EP in other inference engines, such as [this](https://lmsys.org/blog/2025-05-05-large-scale-ep/) effort from the SGLang team.
+
+In this tech blog, we will introduce the details of the design and implementation to support E2E large-scale EP in TensorRT-LLM. This blog post mainly covers the following:
+
+* How to leverage NVIDIA GB200 Multi-Node NVLink (MNNVL) HW features to implement high-performance communication kernels.
+* How to design and implement an online expert workload balancer to dynamically balance the expert load distribution and adapt to the changes of online traffic patterns. We present:
+ * The empirical data analysis demonstrating the need to do so.
+ * The implementation of the online traffic data statistic module.
+ * The design and implementation of the replication/placement strategy.
+ * The MoE weight load/re-distributer to balance the online workload across multiple GPUs.
+ * The changes needed to the MoE router and computation module to adapt to the expert load balancer needs.
+ * Some preliminary data demonstrating the effectiveness of the current implementation in TensorRT-LLM.
+
+In future tech blogs, we will also cover the following topics:
+* The introduction of performance tuning and optimization for TensorRT-LLM large-scale EP GB200 implementation.
+* How to implement efficient large-scale EP support for B200/Hopper and other NVIDIA GPUs without MNNVL.
+* The best practices to leverage large-scale EP and get performance gains.
+* How to combine large-scale EP with other system optimization techniques.
+
+
+Even if, in this tech blog, we focus on TensorRT-LLM, we believe the core ideas and implementation can also be applied to other inference engines to help the inference performance on NVIDIA GPUs. Also, with the help of the community, we would like to figure out how to better modularize the current TensorRT-LLM large-scale EP implementation and make it more easily reusable by the community.
+
+Finally, in this tech blog, there are implementation details which are targeted towards the GB200 system, such as the communication components leveraging the GB200 MNNVL inter-GPU connection, and the MoE weight load/re-distributer module leveraging the high bandwidth C2C connection between Grace CPU and Blackwell GPU. Nevertheless, the overall design principle and software architecture can still apply to non-GB200 NVIDIA GPU systems. To facilitate the extension to other non-GB200 system, we have, on purpose, paid attention to the generalization of the design and implementation. These changes should be easily composable with other existing components.
+
+## Motivation for large-scale EP
+
+
+The main motivation of introducing large-scale EP (here means EP \> 8\) comes from the following system considerations:
+
+* We expect to reduce the execution latency thanks to the increased aggregated memory bandwidth to load the expert weights.
+* We expect to increase the effective batch size to saturate the GPU computing power.
+
+Note that **when the E2E execution time is dominated by the MoE GroupGEMM computation, by introducing large-scale EP, it is expected to see clear performance benefits. But if the E2E execution time is not dominated by the MoE GroupGEMM computation, then large-scale EP may bring limited performance benefit.**
+
+
+Also there isn't free lunch in the system design. When the EP size increases up to greater than 8 (sometimes even less than 8), due to the sparsity execution nature of MoE models, it can inherently trigger the EP-level workload imbalance issue.
+
+And here are some empirical observations based on some datasets (*all the analyses below are done with the **DeepSeek R1 model**, on **32 GB200 GPUs**).*
+
+### Observations over one machine translation dataset
+
+Firstly let’s have an overview of the overall imbalance issues across layers:
+
+
@@ -28,7 +28,7 @@ TensorRT-LLM evaluated on both Hopper and Ampere shows **H100 FP8 is up to 4.6x
FP8 H100, FP16 A100, SXM 80GB GPUs, TP1, ISL/OSL's provided, TensorRT-LLM v0.5.0., TensorRT 9.1
-The full data behind these charts & tables and including larger models with higher TP values can be found in TensorRT-LLM's [Performance Documentation](https://nvidia.github.io/TensorRT-LLM/performance.html#performance-of-tensorrt-llm)
+The full data behind these charts & tables and including larger models with higher TP values can be found in TensorRT-LLM's [Performance Documentation](https://nvidia.github.io/TensorRT-LLM/latest/performance/perf-overview.html)
Stay tuned for a highlight on Llama coming soon!
diff --git a/latest/_sources/blogs/H200launch.md.txt b/latest/_sources/blogs/H200launch.md.txt
index 58f5c08781..baa4905613 100644
--- a/latest/_sources/blogs/H200launch.md.txt
+++ b/latest/_sources/blogs/H200launch.md.txt
@@ -21,7 +21,7 @@ TensorRT-LLM evaluation of the [new H200 GPU](https://nvidianews.nvidia.com/news
*(1) Largest batch supported on given TP configuration by power of 2.* *(2) TP = Tensor Parallelism*
-Additional Performance data is available on the [NVIDIA Data Center Deep Learning Product Performance](https://developer.nvidia.com/deep-learning-performance-training-inference/ai-inference) page, & soon in [TensorRT-LLM's Performance Documentation](https://nvidia.github.io/TensorRT-LLM/performance.html).
+Additional Performance data is available on the [NVIDIA Data Center Deep Learning Product Performance](https://developer.nvidia.com/deep-learning-performance-training-inference/ai-inference) page, & soon in [TensorRT-LLM's Performance Documentation](https://nvidia.github.io/TensorRT-LLM/latest/performance/perf-overview.html).
### H200 vs H100
diff --git a/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt b/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt
index b43b8ed004..201c3781a8 100644
--- a/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt
+++ b/latest/_sources/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md.txt
@@ -2,37 +2,39 @@
by NVIDIA TensorRT-LLM team
## Table of Contents
-- [Background](#background)
-- [Implementation Configuration](#implementation-configuration)
- - [Workload Profile](#workload-profile)
- - [Model Architecture](#model-architecture)
- - [Precision Strategy](#precision-strategy)
- - [Parallelism Strategy](#parallelism-strategy)
- - [Everything in One Diagram](#everything-in-one-diagram)
-- [Key Optimizations](#key-optimizations)
- - [System Level optimizations](#system-level-optimizations)
- - [CUDA Graph & Programmatic Dependent Launch](#cuda-graph--programmatic-dependent-launch)
- - [MTP](#mtp)
- - [Autoregressive MTP Layers](#autoregressive-mtp-layers)
- - [Relax Acceptance Verification](#relax-acceptance-verification)
- - [Multi-streams](#multi-streams)
- - [Sparse Experts as GEMMs](#sparse-experts-as-gemms-only-works-when-moe_backendcutlass)
- - [Re-balanced the sparse experts](#re-balanced-the-sparse-experts)
- - [Mixed ETP](#mixed-etp)
- - [Smart Router](#smart-router)
- - [Kernel Level optimizations](#kernel-level-optimizations)
- - [Attention Kernel](#attention-kernel)
- - [Grouped GEMM](#grouped-gemm)
- - [CUTLASS Backend](#cutlass-backend-default-backend)
- - [TRTLLM Backend](#trtllm-backend)
- - [Communication Kernel](#communication-kernel)
- - [Dense GEMM optimization](#dense-gemm-optimization)
- - [Fuse_A_GEMM](#fuse_a_gemm)
- - [RouterGEMM](#routergemm)
- - [Kernel fusion](#kernel-fusion)
-- [How to reproduce](#how-to-reproduce)
-- [Future Works](#future-works)
-- [Acknowledgment](#acknowledgment)
+- [Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA B200 GPUs](#pushing-latency-boundaries-optimizing-deepseek-r1-performance-on-nvidia-b200-gpus)
+ - [Table of Contents](#table-of-contents)
+ - [Background](#background)
+ - [Implementation Configuration](#implementation-configuration)
+ - [Workload Profile](#workload-profile)
+ - [Model Architecture](#model-architecture)
+ - [Precision Strategy](#precision-strategy)
+ - [Parallelism Strategy](#parallelism-strategy)
+ - [Everything in One Diagram](#everything-in-one-diagram)
+ - [Key Optimizations](#key-optimizations)
+ - [System Level optimizations](#system-level-optimizations)
+ - [CUDA Graph \& Programmatic Dependent Launch](#cuda-graph--programmatic-dependent-launch)
+ - [MTP](#mtp)
+ - [Autoregressive MTP Layers](#autoregressive-mtp-layers)
+ - [Relax Acceptance Verification](#relax-acceptance-verification)
+ - [Multi-streams](#multi-streams)
+ - [Sparse Experts as GEMMs (only works when moe\_backend=CUTLASS)](#sparse-experts-as-gemms-only-works-when-moe_backendcutlass)
+ - [Re-balanced the sparse experts](#re-balanced-the-sparse-experts)
+ - [Mixed ETP](#mixed-etp)
+ - [Smart Router](#smart-router)
+ - [Kernel Level optimizations](#kernel-level-optimizations)
+ - [Attention Kernel](#attention-kernel)
+ - [Grouped GEMM](#grouped-gemm)
+ - [CUTLASS Backend (default backend)](#cutlass-backend-default-backend)
+ - [TRTLLM Backend](#trtllm-backend)
+ - [Communication Kernel](#communication-kernel)
+ - [Dense GEMM optimization](#dense-gemm-optimization)
+ - [Fuse\_A\_GEMM](#fuse_a_gemm)
+ - [RouterGEMM](#routergemm)
+ - [Kernel fusion](#kernel-fusion)
+ - [How to reproduce](#how-to-reproduce)
+ - [Future Works](#future-works)
+ - [Acknowledgment](#acknowledgment)
## Background
Recent advancements in Large Language Reasoning Models have demonstrated remarkable success, while creating new deployment challenges. A critical challenge emerges from extended Output Sequence Lengths (OSL) due to complex "thinking and reasoning" processes. Longer OSL demands stricter Token-to-Token Latency (TTL) requirements, often forcing concurrency limitations. The most extreme case, single concurrency (min-latency scenario) , becomes particularly challenging for real-time applications.
diff --git a/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt b/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt
index 0014f1c7f2..8fc2b51643 100644
--- a/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt
+++ b/latest/_sources/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md.txt
@@ -1,26 +1,28 @@
# DeepSeek R1 MTP Implementation and Optimization
by NVIDIA TensorRT-LLM team
## Table of Contents
-- [MTP for inference](#mtp-for-inference)
- - [Background](#background)
- - [MTP Vanilla](#mtp-vanilla)
- - [MTP Eagle](#mtp-eagle)
-- [MTP implementation in TensorRT-LLM](#mtp-implementation-in-tensorrt-llm)
- - [Basic Implementation](#basic-implementation)
- - [MTP Modules](#mtp-modules)
- - [Attention for MTP](#attention-for-mtp)
- - [How to run DeepSeek models with MTP](#how-to-run-deepseek-models-with-mtp)
-- [MTP optimization - Relaxed Acceptance](#mtp-optimization---relaxed-acceptance)
- - [Relaxed Acceptance](#relaxed-acceptance)
- - [How to run the DeepSeek-R1 model with Relaxed Acceptance](#how-to-run-the-deepseek-r1-model-with-relaxed-acceptance)
-- [Evaluation](#evaluation)
- - [Achieving speedup with MTP speculative decoding](#achieving-speedup-with-mtp-speculative-decoding)
- - [Accuracy studies for Relaxed Acceptance](#accuracy-studies-for-relaxed-acceptance)
-- [Future Works](#future-works)
- - [Tree-based speculative decoding support](#tree-based-speculative-decoding-support)
- - [Eagle3 support](#eagle3-support)
- - [Fix known issues](#fix-known-issues)
-- [Acknowledgment](#acknowledgment)
+- [DeepSeek R1 MTP Implementation and Optimization](#deepseek-r1-mtp-implementation-and-optimization)
+ - [Table of Contents](#table-of-contents)
+ - [MTP for inference](#mtp-for-inference)
+ - [Background](#background)
+ - [MTP Vanilla](#mtp-vanilla)
+ - [MTP Eagle](#mtp-eagle)
+ - [MTP implementation in TensorRT-LLM](#mtp-implementation-in-tensorrt-llm)
+ - [Basic Implementation](#basic-implementation)
+ - [MTP Modules](#mtp-modules)
+ - [Attention for MTP](#attention-for-mtp)
+ - [How to run DeepSeek models with MTP](#how-to-run-deepseek-models-with-mtp)
+ - [MTP optimization - Relaxed Acceptance](#mtp-optimization---relaxed-acceptance)
+ - [Relaxed Acceptance](#relaxed-acceptance)
+ - [How to run the DeepSeek-R1 model with Relaxed Acceptance](#how-to-run-the-deepseek-r1-model-with-relaxed-acceptance)
+ - [Evaluation](#evaluation)
+ - [Achieving speedup with MTP speculative decoding](#achieving-speedup-with-mtp-speculative-decoding)
+ - [Accuracy studies for Relaxed Acceptance](#accuracy-studies-for-relaxed-acceptance)
+ - [Future Works](#future-works)
+ - [Tree-based speculative decoding support](#tree-based-speculative-decoding-support)
+ - [Eagle3 support](#eagle3-support)
+ - [Fix known issues](#fix-known-issues)
+ - [Acknowledgment](#acknowledgment)
TensorRT-LLM achieves world-record inference performance for DeepSeek-R1 on NVIDIA Blackwell GPUs, where Multi-Token Prediction (MTP) delivers a significant speedup. In our [previous blog post](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md), we discussed the key optimizations that enable the outstanding inference latency of the DeepSeek-R1 model. This article dives deeper into the implementation and optimization of MTP in TensorRT-LLM.
diff --git a/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt b/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt
index 15b418f9b5..0de54f69fb 100644
--- a/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt
+++ b/latest/_sources/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md.txt
@@ -2,6 +2,8 @@
By NVIDIA TensorRT-LLM team
## Table of Contents
+- [Optimizing DeepSeek R1 Throughput on NVIDIA Blackwell GPUs: A Deep Dive for Developers](#optimizing-deepseek-r1-throughput-on-nvidia-blackwell-gpus-a-deep-dive-for-developers)
+ - [Table of Contents](#table-of-contents)
- [Introduction](#introduction)
- [Precision strategy](#precision-strategy)
- [Parallel strategy](#parallel-strategy)
diff --git a/latest/_sources/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md.txt b/latest/_sources/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md.txt
new file mode 100644
index 0000000000..a71bc0d037
--- /dev/null
+++ b/latest/_sources/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md.txt
@@ -0,0 +1,715 @@
+# Scaling Expert Parallelism in TensorRT-LLM (Part 1: Design and Implementation of Large-scale EP)
+
+By NVIDIA TensorRT-LLM Team
+
+## Table of Contents
+- [Scaling Expert Parallelism in TensorRT-LLM (Part 1: Design and Implementation of Large-scale EP)](#scaling-expert-parallelism-in-tensorrt-llmpart-1-design-and-implementation-of-large-scale-ep)
+ - [Table of Contents](#table-of-contents)
+ - [Motivation for large-scale EP](#motivation-for-large-scale-ep)
+ - [Observations over one machine translation dataset](#observations-over-one-machine-translation-dataset)
+ - [Observation over GSM8K dataset](#observation-over-gsm8k-dataset)
+ - [High-level design introduction](#high-level-design-introduction)
+ - [EP communication kernels](#ep-communication-kernels)
+ - [Motivation of EP communication kernels for GB200](#motivation-of-ep-communication-kernels-for-gb200)
+ - [EP communication kernels implementation](#ep-communication-kernels-implementation)
+ - [EP Load Balancer](#ep-load-balancer)
+ - [Python Interface](#python-interface)
+ - [C++ extension](#c-extension)
+ - [Core implementations of host side logics](#core-implementations-of-host-side-logics)
+ - [Core implementations of GPU side logics](#core-implementations-of-gpu-side-logics)
+ - [Online EP Load Balancer](#online-ep-load-balancer)
+ - [Offline EP Load Balancer](#offline-ep-load-balancer)
+ - [E2E evaluation](#e2e-evaluation)
+ - [The effect of EP Load Balancer](#the-effect-of-ep-load-balancer)
+ - [Offline EP Load Balancer](#offline-ep-load-balancer-1)
+ - [Online EP Load Balancer](#online-ep-load-balancer-1)
+ - [Performance study](#performance-study)
+ - [Reproducing steps](#reproducing-steps)
+ - [The effect of EP Load Balancer](#the-effect-of-ep-load-balancer-1)
+ - [Step 1: Run inference and collect statistics](#step-1-run-inference-and-collect-statistics)
+ - [Step 2: Generate the EPLB configuration](#step-2-generate-the-eplb-configuration)
+ - [Step 3: Run inference with the EPLB configuration](#step-3-run-inference-with-the-eplb-configuration)
+ - [Miscellaneous](#miscellaneous)
+ - [Expanded thoughts](#expanded-thoughts)
+ - [Acknowledgement](#acknowledgement)
+
+The development of model like DeepSeek-V3/R1, which use large-scale fine-grained Mixture-of-Experts (MoE) designs, has significantly advanced open-source model quality. Newly released open-source models such as LLaMA4 and Qwen3 also adopt a similar large-scale fine-grained MoE design principle. However, large-scale MoE models introduce new challenges for inference systems, including high memory demands and inherent expert-level workload imbalance.
+
+In the past, we have shared TensorRT-LLM’s optimization experience to [push the latency boundary](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md) of DeepSeek R1 model, [the implementation and optimization of MTP](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md)(Multi-Token Prediction) and [the optimizations for DeepSeek R1 throughput oriented performance](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md).
+
+The DeepSeek team has also shared their valuable experience and practice on how to optimize this kind of large-scale Expert Parallelism (EP) model, including [DeepEP](https://github.com/deepseek-ai/DeepEP) and [EPLB](https://github.com/deepseek-ai/EPLB). Also, the DeepSeek team has shared their concrete design considerations in [this](https://arxiv.org/abs/2412.19437) tech report. On top of those great sharings, there are also nice community efforts to implement large-scale EP in other inference engines, such as [this](https://lmsys.org/blog/2025-05-05-large-scale-ep/) effort from the SGLang team.
+
+In this tech blog, we will introduce the details of the design and implementation to support E2E large-scale EP in TensorRT-LLM. This blog post mainly covers the following:
+
+* How to leverage NVIDIA GB200 Multi-Node NVLink (MNNVL) HW features to implement high-performance communication kernels.
+* How to design and implement an online expert workload balancer to dynamically balance the expert load distribution and adapt to the changes of online traffic patterns. We present:
+ * The empirical data analysis demonstrating the need to do so.
+ * The implementation of the online traffic data statistic module.
+ * The design and implementation of the replication/placement strategy.
+ * The MoE weight load/re-distributer to balance the online workload across multiple GPUs.
+ * The changes needed to the MoE router and computation module to adapt to the expert load balancer needs.
+ * Some preliminary data demonstrating the effectiveness of the current implementation in TensorRT-LLM.
+
+In future tech blogs, we will also cover the following topics:
+* The introduction of performance tuning and optimization for TensorRT-LLM large-scale EP GB200 implementation.
+* How to implement efficient large-scale EP support for B200/Hopper and other NVIDIA GPUs without MNNVL.
+* The best practices to leverage large-scale EP and get performance gains.
+* How to combine large-scale EP with other system optimization techniques.
+
+
+Even if, in this tech blog, we focus on TensorRT-LLM, we believe the core ideas and implementation can also be applied to other inference engines to help the inference performance on NVIDIA GPUs. Also, with the help of the community, we would like to figure out how to better modularize the current TensorRT-LLM large-scale EP implementation and make it more easily reusable by the community.
+
+Finally, in this tech blog, there are implementation details which are targeted towards the GB200 system, such as the communication components leveraging the GB200 MNNVL inter-GPU connection, and the MoE weight load/re-distributer module leveraging the high bandwidth C2C connection between Grace CPU and Blackwell GPU. Nevertheless, the overall design principle and software architecture can still apply to non-GB200 NVIDIA GPU systems. To facilitate the extension to other non-GB200 system, we have, on purpose, paid attention to the generalization of the design and implementation. These changes should be easily composable with other existing components.
+
+## Motivation for large-scale EP
+
+
+The main motivation of introducing large-scale EP (here means EP \> 8\) comes from the following system considerations:
+
+* We expect to reduce the execution latency thanks to the increased aggregated memory bandwidth to load the expert weights.
+* We expect to increase the effective batch size to saturate the GPU computing power.
+
+Note that **when the E2E execution time is dominated by the MoE GroupGEMM computation, by introducing large-scale EP, it is expected to see clear performance benefits. But if the E2E execution time is not dominated by the MoE GroupGEMM computation, then large-scale EP may bring limited performance benefit.**
+
+
+Also there isn't free lunch in the system design. When the EP size increases up to greater than 8 (sometimes even less than 8), due to the sparsity execution nature of MoE models, it can inherently trigger the EP-level workload imbalance issue.
+
+And here are some empirical observations based on some datasets (*all the analyses below are done with the **DeepSeek R1 model**, on **32 GB200 GPUs**).*
+
+### Observations over one machine translation dataset
+
+Firstly let’s have an overview of the overall imbalance issues across layers:
+
+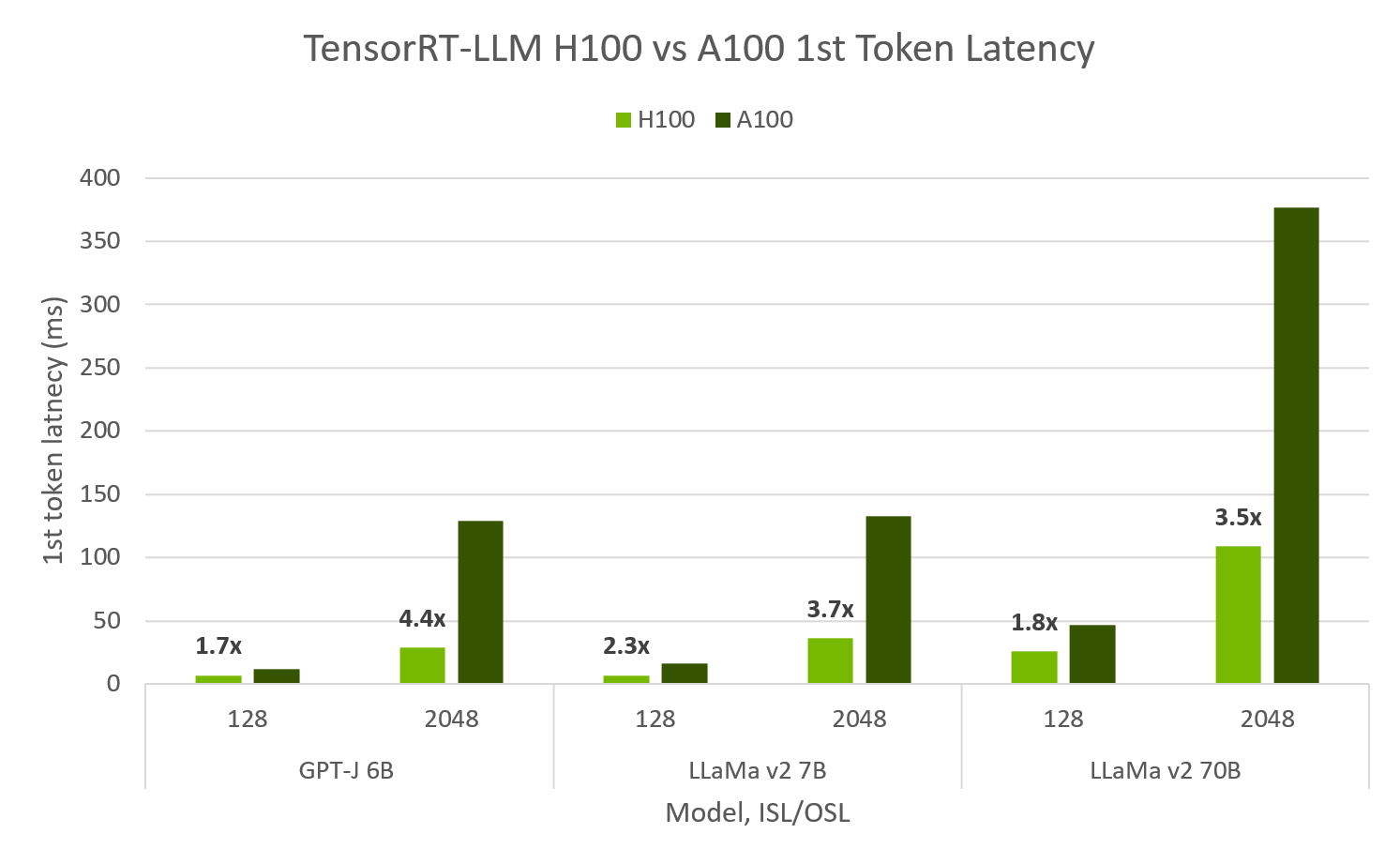
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+