mirror of
https://github.com/NVIDIA/TensorRT-LLM.git
synced 2026-01-13 22:18:36 +08:00
Merge branch 'NVIDIA:main' into wg/only_read_cfg_json_once
This commit is contained in:
commit
b93e14ca09
@ -36,9 +36,10 @@
|
||||
// "ms-vscode.makefile-tools",
|
||||
// "ms-vscode.cmake-tools",
|
||||
// Git & Github
|
||||
// "GitHub.vscode-pull-request-github"
|
||||
"GitHub.vscode-pull-request-github",
|
||||
"eamodio.gitlens",
|
||||
// Docs
|
||||
"davidanson.vscode-markdownlint",
|
||||
"ms-vscode.live-server"
|
||||
],
|
||||
"settings": {
|
||||
|
||||
51
.github/CODEOWNERS
vendored
51
.github/CODEOWNERS
vendored
@ -6,6 +6,7 @@
|
||||
/jenkins @NVIDIA/trt-llm-ci-infra-devs @NVIDIA/trt-llm-infra-devs
|
||||
### Setup
|
||||
/docker @NVIDIA/trt-llm-setup-infra-devs @NVIDIA/trt-llm-infra-devs
|
||||
/.pre-commit-config.yaml @NVIDIA/trt-llm-setup-infra-devs @NVIDIA/trt-llm-infra-devs
|
||||
### Github workflows
|
||||
/.github @NVIDIA/trt-llm-gh-workflows-infra-devs @NVIDIA/trt-llm-infra-devs
|
||||
/.coderabbit.yaml @NVIDIA/trt-llm-gh-workflows-infra-devs @NVIDIA/trt-llm-infra-devs
|
||||
@ -151,6 +152,23 @@ docs/source/performance/perf-benchmarking.md @NVIDIA/trtllm-bench-reviewers
|
||||
/cpp/tensorrt_llm/batch_manager/dataTransceiverImpl.h @NVIDIA/trt-llm-disagg-devs
|
||||
/tensorrt_llm/serve/openai_disagg_server.py @NVIDIA/trt-llm-disagg-devs
|
||||
|
||||
## TensorRT-LLM - KV Cache Manager
|
||||
/cpp/tensorrt_llm/batch_manager/kvCacheManager.cpp @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/tensorrt_llm/batch_manager/kvCacheEventManager.cpp @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/tensorrt_llm/batch_manager/kvCacheTransferManager.cpp @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/tensorrt_llm/batch_manager/evictionPolicy.cpp @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/include/tensorrt_llm/batch_manager/kvCacheManager.h @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/include/tensorrt_llm/batch_manager/kvCacheEventManager.h @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/include/tensorrt_llm/batch_manager/kvCacheTransferManager.h @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/include/tensorrt_llm/batch_manager/evictionPolicy.h @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/tensorrt_llm/batch_manager/allocateKvCache.cpp @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/tests/unit_tests/batch_manager/kvCacheManagerTest.cpp @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/tests/unit_tests/batch_manager/kvCacheUtilsTest.cpp @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/tensorrt_llm/_torch/pyexecutor/resource_manager.py @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/tensorrt_llm/nanobind/batch_manager/kvCacheManager.h @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/tensorrt_llm/nanobind/batch_manager/kvCacheManager.cpp @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/tensorrt_llm/pybind/batch_manager/kvCacheManager.h @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
/cpp/tensorrt_llm/pybind/batch_manager/kvCacheManager.cpp @NVIDIA/trt-llm-kv-cache-manager-devs
|
||||
|
||||
# The rule below requires that any PR modifying public APIs must be approved by at least one member
|
||||
# of the NVIDIA/trt-llm-committed-api-review-committee or NVIDIA/trt-llm-noncommitted-api-review-committee team.
|
||||
@ -159,6 +177,39 @@ docs/source/performance/perf-benchmarking.md @NVIDIA/trtllm-bench-reviewers
|
||||
/tests/unittest/api_stability/ @NVIDIA/trt-llm-noncommitted-api-review-committee
|
||||
/tests/unittest/api_stability/references_committed/ @NVIDIA/trt-llm-committed-api-review-committee
|
||||
|
||||
## OSS Compliance & Legal - License/Attribution Protection
|
||||
## IMPORTANT: Changes to any files below may impact legal compliance, attributions, and third-party licenses.
|
||||
## These files require review from the TRTLLM OSS compliance team before merging to ensure proper attribution
|
||||
## and license compliance when adding, removing, or changing versions of dependencies.
|
||||
### License Files
|
||||
/LICENSE @NVIDIA/trt-llm-oss-compliance
|
||||
/jenkins/license_cpp.json @NVIDIA/trt-llm-ci-infra-devs @NVIDIA/trt-llm-infra-devs @NVIDIA/trt-llm-oss-compliance
|
||||
|
||||
### Python Dependency Management
|
||||
/setup.py @NVIDIA/trt-llm-oss-compliance
|
||||
/pyproject.toml @NVIDIA/trt-llm-oss-compliance
|
||||
/requirements.txt @NVIDIA/trt-llm-oss-compliance
|
||||
/requirements-dev.txt @NVIDIA/trt-llm-oss-compliance
|
||||
|
||||
### C++ Build & Dependency Management
|
||||
/cpp/CMakeLists.txt @NVIDIA/trt-llm-oss-compliance
|
||||
/cpp/conanfile.py @NVIDIA/trt-llm-oss-compliance
|
||||
/cpp/cmake/** @NVIDIA/trt-llm-oss-compliance
|
||||
|
||||
### Third-Party Dependencies
|
||||
## Any changes to versions, additions, or removals of third-party libraries
|
||||
/3rdparty/** @NVIDIA/trt-llm-oss-compliance
|
||||
|
||||
### Docker & Installation Scripts
|
||||
## These scripts install and pin dependency versions
|
||||
/docker/common/** @NVIDIA/trt-llm-setup-infra-devs @NVIDIA/trt-llm-infra-devs @NVIDIA/trt-llm-oss-compliance
|
||||
|
||||
### TAVA Architecture Diagram
|
||||
/.github/tava_architecture_diagram.md @NVIDIA/trt-llm-TAVA-design-change
|
||||
|
||||
### CODEOWNERS file itself
|
||||
/.github/CODEOWNERS @NVIDIA/trt-llm-gh-workflows-infra-devs @NVIDIA/trt-llm-infra-devs @NVIDIA/trt-llm-oss-compliance
|
||||
|
||||
# The following rule should only be uncommented on release branches (e.g., release/0.19).
|
||||
# The rule below requires that any PR to release/**/* branches must be approved by at least one member
|
||||
# of the NVIDIA/trt-llm-release-branch-approval team, regardless of who else approves the PR.
|
||||
|
||||
1
.github/pull_request_template.md
vendored
1
.github/pull_request_template.md
vendored
@ -49,6 +49,7 @@ Please review the following before submitting your PR:
|
||||
- Any new dependencies have been scanned for license and vulnerabilities
|
||||
- [CODEOWNERS](https://github.com/NVIDIA/TensorRT-LLM/blob/main/.github/CODEOWNERS) updated if ownership changes
|
||||
- Documentation updated as needed
|
||||
- Update [tava architecture diagram](https://github.com/NVIDIA/TensorRT-LLM/blob/main/.github/tava_architecture_diagram.md) if there is a significant design change in PR.
|
||||
- The reviewers assigned automatically/manually are appropriate for the PR.
|
||||
|
||||
|
||||
|
||||
108
.github/tava_architecture_diagram.md
vendored
Normal file
108
.github/tava_architecture_diagram.md
vendored
Normal file
@ -0,0 +1,108 @@
|
||||
```mermaid
|
||||
graph TB
|
||||
subgraph "User API & CLI Tools"
|
||||
CLI[CLI Tools]
|
||||
LLMAPI[LLM API]
|
||||
CLI --> LLMAPI
|
||||
end
|
||||
|
||||
subgraph "Model Checkpoint"
|
||||
Checkpoint[Huggingface Models]
|
||||
Checkpoint --> CLI
|
||||
Checkpoint --> LLMAPI
|
||||
end
|
||||
|
||||
subgraph "TensorRT_Flow"
|
||||
trtllmExecutor[trtllm.Executor]
|
||||
Engine[TensorRT Engine]
|
||||
TRTGraph[TensorRT Graph]
|
||||
Plugins[TensorRT Plugins]
|
||||
cudaKernel[CUDA Kernel]
|
||||
Executor[Executor]
|
||||
LLMAPI --> trtllmExecutor
|
||||
trtllmExecutor --> |build|Engine
|
||||
trtllmExecutor --> |compile|TRTGraph
|
||||
trtllmExecutor --> |compile|Plugins
|
||||
Engine --> Executor
|
||||
Plugins --> Executor
|
||||
TRTGraph --> Executor
|
||||
Plugins --> cudaKernel
|
||||
end
|
||||
|
||||
subgraph "PyTorch_Flow"
|
||||
PyExecutor[PyExecutor]
|
||||
PyEngine[PyTorch Engine]
|
||||
CustomOps[Custom Ops]
|
||||
PyTorchOps[Pytorch Ops]
|
||||
KernelLibs[Kernel Libs]
|
||||
PyScheduler[Scheduler]
|
||||
PyDecoder[Decoder]
|
||||
CUDAKernel[CUDA Kernel]
|
||||
LLMAPI --> PyExecutor
|
||||
PyExecutor --> PyEngine[PyTorch Engine]
|
||||
PyEngine --> CustomOps
|
||||
PyEngine --> PyTorchOps
|
||||
PyEngine --> KernelLibs
|
||||
PyEngine --> PyScheduler
|
||||
PyEngine --> PyDecoder
|
||||
KernelLibs --> CUDAKernel
|
||||
CustomOps --> CUDAKernel
|
||||
end
|
||||
|
||||
subgraph "Shared_Component"
|
||||
Shared_Decoder[Decoder]
|
||||
Shared_Scheduler[Scheduler]
|
||||
Sampling[Sampling]
|
||||
BatchManager[Batch Manager]
|
||||
KVCache[KV Cache Manager]
|
||||
PyScheduler --> |Pybind|Shared_Scheduler
|
||||
PyDecoder --> |Pybind|Shared_Decoder
|
||||
Executor --> Shared_Decoder
|
||||
Shared_Decoder --> Sampling
|
||||
Executor --> Shared_Scheduler[Scheduler]
|
||||
Shared_Scheduler --> |In-flight Batching| BatchManager
|
||||
BatchManager --> KVCache
|
||||
end
|
||||
|
||||
subgraph "Output_Results"
|
||||
Tokens[Generated Tokens]
|
||||
Stats[Performance Stats]
|
||||
Metrics[Accuracy Metrics]
|
||||
end
|
||||
|
||||
%% PyTorch_Flow ~~~ TensorRT_Flow
|
||||
|
||||
TensorRT_Flow --> Output_Results
|
||||
PyTorch_Flow --> Output_Results
|
||||
|
||||
%% Force Output_Results to be between PyTorch_flow and TensorRT_flow
|
||||
PyTorch_Flow ~~~ Output_Results
|
||||
|
||||
%% Model checkpoint format
|
||||
classDef checkpoint fill:#ff1,stroke:#333,stroke-width:2px;
|
||||
class Checkpoint checkpoint;
|
||||
|
||||
%% CLI tools format
|
||||
classDef cli fill:#f9f,stroke:#333,stroke-width:2px;
|
||||
class CLI cli;
|
||||
|
||||
%% TRT flow format
|
||||
classDef trt fill:#bbf,stroke:#333,stroke-width:2px;
|
||||
class trtllmExecutor,TRTGraph,Plugins,Engine,Executor,cudaKernel trt;
|
||||
|
||||
%% PyTorch flow format
|
||||
classDef pytorch fill:#8bf,stroke:#333,stroke-width:2px;
|
||||
class PyExecutor,PyEngine,CustomOps,PyTorchOps,KernelLibs,PyScheduler,PyDecoder,CUDAKernel pytorch;
|
||||
|
||||
%% Shared Componnet format
|
||||
classDef component fill:#fc8,stroke:#333,stroke-width:2px;
|
||||
class Shared_Decoder,Sampling,Shared_Scheduler,BatchManager,KVCache component;
|
||||
|
||||
%% APIs format
|
||||
classDef api fill:#bfb,stroke:#333,stroke-width:2px;
|
||||
class PythonAPI,CppAPI,LLMAPI api;
|
||||
|
||||
%% Results format
|
||||
classDef result fill:#fbb,stroke:#333,stroke-width:2px;
|
||||
class Tokens,Stats,Metrics result;
|
||||
```
|
||||
@ -3,10 +3,11 @@ name: Close inactive issues
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: "0 * * * *"
|
||||
- cron: "0 3 * * *"
|
||||
|
||||
jobs:
|
||||
stale:
|
||||
if: github.repository == 'NVIDIA/TensorRT-LLM'
|
||||
runs-on: ubuntu-latest
|
||||
permissions:
|
||||
issues: write
|
||||
@ -27,3 +28,4 @@ jobs:
|
||||
labels-to-remove-when-unstale: 'stale,waiting for feedback'
|
||||
stale-issue-label: 'stale'
|
||||
stale-pr-label: 'stale'
|
||||
operations-per-run: 1000
|
||||
|
||||
299
.github/workflows/blossom-ci.yml
vendored
299
.github/workflows/blossom-ci.yml
vendored
@ -40,8 +40,303 @@ jobs:
|
||||
startsWith(github.event.comment.body, '/bot skip --comment') ||
|
||||
startsWith(github.event.comment.body, '/bot reuse-pipeline') ||
|
||||
startsWith(github.event.comment.body, '/bot kill')) && contains(
|
||||
fromJson('["byshiue","chuangz0","funatiq","hypdeb","jdemouth-nvidia","joyang-nv","lowsfer","Tabrizian","yweng0828","Shixiaowei02","MartinMarciniszyn","schetlur-nv","dcampora","pcastonguay","Naveassaf","lfr-0531","nekorobov","PerkzZheng","kaiyux","nv-guomingz","LinPoly","thorjohnsen","jiahanc","latency1024","tburt-nv","zeroepoch","chzblych","niukuo","ZhanruiSunCh","EmmaQiaoCh","yiqingy0","achartier","suyoggupta","amukkara","mk-nvidia","QiJune","lucaslie","davidmlw","hlu1","nvzhou","syuoni","NVGaryJi","symphonylyh","hello-11","zongfeijing","Jackch-NV","jinyangyuan-nvidia","LarryXFly","crazydemo","jaedeok-nvidia","wm2012011492","rosenrodt","zhuoyao1012","xinhe-nv","Yuening-wa","Shunkangz","zhengd-nv","yibinl-nvidia","StanleySun639","KingsleyLiu-NV","kxdc","yingcanw","BestJuly","ChristinaZ","bobboli","xueweilnvidia","kunlunl","cherichy","lucifer1004","Autumn1998","litaotju","peaceh-nv","liji-nv","SimengLiu-nv","yuxianq","yechank-nvidia","vallis-neria","DylanChen-NV","Tracin","zhhuang-nv","ISEEKYAN","xupinjie","tongyuantongyu","laikhtewari","zhuolingwang","dominicshanshan","jershi425","shifangx","StudyingShao","Superjomn","dongjiyingdjy","guangyunh-nv","wili-65535","tiffany940107","DanBlanaru","mikeiovine","djns99","ruodil","xiaoweiw-nv","xuwchen","bashimao","yizhang-nv","hyukn","nvpohanh","yuki-666","juney-nvidia","barry-delaney","Kefeng-Duan","MinaHuai","yilin-void","jhaotingc","jmydurant","katec846","CarstyYou","Njuapp","Jie-Fang","nvbrantz","inocsin","ruoqianguo","chenfeiz0326","ming-wei","eopXD","longlee0622","dongfengy","georgeliu95","evezhier","rakib-hasan","shangz-ai","JyChang012","wangsiping1997","yuanjings-nvda","tomeras91","roikoren755","amirkl94","shaharmor98","danielafrimi","amitz-nv","hijkzzz","rzilberstein-nvidia","dc3671","hchings","yuhengxnv","dongxuy04","qiaoxj07","omera-nv","DomBrown","brb-nv","FrankD412","yuhsuan-t","Fridah-nv","a-mccarthy","HuiGao-NV","alexmsettle","meenchen","sugunav14","cjluo-nv","kyleliang-nv","chang-l","WeiHaocheng","qixiang-99","BatshevaBlack","ebarilanM","xmchen1987","lingjiew","heyuhhh","netanel-haber","jiefangz-nv","wyw1267","yunruis","sklevtsov-nvidia","jgangani","pamelap-nvidia","ixlmar","GalSha","Dido0o0","rabiel","nvzhihanj","milesial","fzmu727","zackyoray","RoeyAzran1992","viraatc","v-shobhit","yuanjingx87","uchihatmtkinu","nvrohanv","vegaluisjose","qsang-nv","ChunhuanLin","timlee0212","venkywonka","zbpatel","tijyojwad","shyeh25","zihaok","nv-yilinf","ttyio","farazkh80","yuantailing","JennyLiu-nv","moraxu","IzzyPutterman","nvchenghaoz","nvxuanyuc","poweiw","stnie","zhanga5","nzmora-nvidia","greg-kwasniewski1","linda-stadter","Tom-Zheng","vanshilshah97","ixlmar","MatthiasKohl","Wanli-Jiang", "arekay", "davidclark-nv", "2ez4bz", "tcherckez-nvidia", "MrGeva", "galagam", "limin2021", "dhansen-nvidia","talorabr","kanghui0204","wu6u3tw","hvagadia","xavier-nvidia","raayandhar","dbari","nvjullin","elvischenv","zhenhuaw-me","weireweire","yifeizhang-c","jiaganc","ziyixiong-nv","FelixXidddd","JunyiXu-nv","bo-nv","zerollzeng","RayenTian","ameynaik-hub","raymochen","shuyixiong","johncalesp","leslie-fang25","reasonsolo","zhou-yuxin","vadiklyutiy","yali-arch","NVShreyas","h-guo18","pengbowang-nv","lancelly","heyuhhh","mayani-nv","flin3500","sunnyqgg","kris1025", "karljang", "ajrasane", "jthomson04", "fredricz-20070104", "aalanwyr", "samuellees", "nvamyt", "jinzh-nvidia", "zheyuf", "yumin066", "sychen52", "xxi-nv", "barneuman", "xuanzic", "yufeiwu-nv", "richardhuo-nv", "dcaox", "tshmilnvidia"]'),
|
||||
github.actor)
|
||||
fromJson('[
|
||||
"2ez4bz",
|
||||
"a-mccarthy",
|
||||
"aalanwyr",
|
||||
"achartier",
|
||||
"ajrasane",
|
||||
"alexmsettle",
|
||||
"ameynaik-hub",
|
||||
"amirkl94",
|
||||
"amitz-nv",
|
||||
"amukkara",
|
||||
"anish-shanbhag",
|
||||
"arekay",
|
||||
"atrifex",
|
||||
"Autumn1998",
|
||||
"baize97",
|
||||
"barneuman",
|
||||
"barry-delaney",
|
||||
"bashimao",
|
||||
"BatshevaBlack",
|
||||
"BestJuly",
|
||||
"bo-nv",
|
||||
"bobboli",
|
||||
"Boreas618",
|
||||
"brb-nv",
|
||||
"byshiue",
|
||||
"CarstyYou",
|
||||
"chang-l",
|
||||
"chenfeiz0326",
|
||||
"cherichy",
|
||||
"cheshirekow",
|
||||
"ChristinaZ",
|
||||
"chuangz0",
|
||||
"ChunhuanLin",
|
||||
"chzblych",
|
||||
"cjluo-nv",
|
||||
"crazydemo",
|
||||
"DanBlanaru",
|
||||
"danielafrimi",
|
||||
"davidclark-nv",
|
||||
"davidmlw",
|
||||
"dbari",
|
||||
"dc3671",
|
||||
"dcampora",
|
||||
"dcaox",
|
||||
"dhansen-nvidia",
|
||||
"Dido0o0",
|
||||
"djns99",
|
||||
"DomBrown",
|
||||
"dominicshanshan",
|
||||
"dongfengy",
|
||||
"dongjiyingdjy",
|
||||
"dongxuy04",
|
||||
"DylanChen-NV",
|
||||
"ebarilanM",
|
||||
"elvischenv",
|
||||
"EmmaQiaoCh",
|
||||
"eopXD",
|
||||
"evezhier",
|
||||
"faradawn",
|
||||
"farazkh80",
|
||||
"FelixXidddd",
|
||||
"flin3500",
|
||||
"FrankD412",
|
||||
"fredricz-20070104",
|
||||
"Fridah-nv",
|
||||
"funatiq",
|
||||
"fzmu727",
|
||||
"galagam",
|
||||
"GalSha",
|
||||
"georgeliu95",
|
||||
"govind-ramnarayan",
|
||||
"greg-kwasniewski1",
|
||||
"guangyunh-nv",
|
||||
"h-guo18",
|
||||
"hchings",
|
||||
"hello-11",
|
||||
"heyuhhh",
|
||||
"hijkzzz",
|
||||
"hlu1",
|
||||
"HuiGao-NV",
|
||||
"hvagadia",
|
||||
"hypdeb",
|
||||
"hyukn",
|
||||
"inocsin",
|
||||
"ISEEKYAN",
|
||||
"ixlmar",
|
||||
"IzzyPutterman",
|
||||
"Jackch-NV",
|
||||
"JadoTu",
|
||||
"jaedeok-nvidia",
|
||||
"jdemouth-nvidia",
|
||||
"JennyLiu-nv",
|
||||
"jershi425",
|
||||
"jgangani",
|
||||
"jhaotingc",
|
||||
"jiaganc",
|
||||
"jiahanc",
|
||||
"Jie-Fang",
|
||||
"jiefangz-nv",
|
||||
"jieli-matrix",
|
||||
"jinyangyuan-nvidia",
|
||||
"jinzh-nvidia",
|
||||
"jmydurant",
|
||||
"johncalesp",
|
||||
"joyang-nv",
|
||||
"jthomson04",
|
||||
"juney-nvidia",
|
||||
"JunyiXu-nv",
|
||||
"JyChang012",
|
||||
"kaiyux",
|
||||
"kanghui0204",
|
||||
"karljang",
|
||||
"katec846",
|
||||
"Kefeng-Duan",
|
||||
"KingsleyLiu-NV",
|
||||
"kris1025",
|
||||
"kunlunl",
|
||||
"kxdc",
|
||||
"kyleliang-nv",
|
||||
"laikhtewari",
|
||||
"lancelly",
|
||||
"LarryXFly",
|
||||
"latency1024",
|
||||
"leslie-fang25",
|
||||
"lfr-0531",
|
||||
"liji-nv",
|
||||
"limin2021",
|
||||
"linda-stadter",
|
||||
"lingjiew",
|
||||
"LinPoly",
|
||||
"litaotju",
|
||||
"liyuhannnnn",
|
||||
"longlee0622",
|
||||
"lowsfer",
|
||||
"lucaslie",
|
||||
"lucifer1004",
|
||||
"MartinMarciniszyn",
|
||||
"MatthiasKohl",
|
||||
"mayani-nv",
|
||||
"meenchen",
|
||||
"mikeiovine",
|
||||
"milesial",
|
||||
"MinaHuai",
|
||||
"ming-wei",
|
||||
"mk-nvidia",
|
||||
"mlefeb01",
|
||||
"moraxu",
|
||||
"MrGeva",
|
||||
"Naveassaf",
|
||||
"nekorobov",
|
||||
"netanel-haber",
|
||||
"niukuo",
|
||||
"Njuapp",
|
||||
"nv-guomingz",
|
||||
"nv-lschneider",
|
||||
"nv-yilinf",
|
||||
"nvamyt",
|
||||
"nvbrantz",
|
||||
"nvchenghaoz",
|
||||
"NVGaryJi",
|
||||
"nvjullin",
|
||||
"nvpohanh",
|
||||
"nvrohanv",
|
||||
"NVShreyas",
|
||||
"nvxuanyuc",
|
||||
"nvyocox",
|
||||
"nvzhihanj",
|
||||
"nvzhou",
|
||||
"nzmora-nvidia",
|
||||
"omera-nv",
|
||||
"pamelap-nvidia",
|
||||
"pcastonguay",
|
||||
"pdrake-nv",
|
||||
"peaceh-nv",
|
||||
"pengbowang-nv",
|
||||
"PerkzZheng",
|
||||
"poweiw",
|
||||
"qiangxu1996",
|
||||
"qiaoxj07",
|
||||
"QiJune",
|
||||
"qixiang-99",
|
||||
"qsang-nv",
|
||||
"raayandhar",
|
||||
"rabiel",
|
||||
"rakib-hasan",
|
||||
"RayenTian",
|
||||
"raymochen",
|
||||
"reasonsolo",
|
||||
"richardhuo-nv",
|
||||
"RoeyAzran1992",
|
||||
"roikoren755",
|
||||
"rosenrodt",
|
||||
"ruodil",
|
||||
"ruoqianguo",
|
||||
"rzilberstein-nvidia",
|
||||
"samuellees",
|
||||
"schetlur-nv",
|
||||
"shaharmor98",
|
||||
"shangz-ai",
|
||||
"shifangx",
|
||||
"Shixiaowei02",
|
||||
"Shunkangz",
|
||||
"shuyixiong",
|
||||
"shyeh25",
|
||||
"SimengLiu-nv",
|
||||
"sklevtsov-nvidia",
|
||||
"StanleySun639",
|
||||
"stnie",
|
||||
"StudyingShao",
|
||||
"sugunav14",
|
||||
"sunnyqgg",
|
||||
"Superjomn",
|
||||
"suyoggupta",
|
||||
"sychen52",
|
||||
"symphonylyh",
|
||||
"syuoni",
|
||||
"Tabrizian",
|
||||
"talorabr",
|
||||
"tburt-nv",
|
||||
"tcherckez-nvidia",
|
||||
"thorjohnsen",
|
||||
"tiffany940107",
|
||||
"tijyojwad",
|
||||
"timlee0212",
|
||||
"timothygao8710",
|
||||
"Tom-Zheng",
|
||||
"tomeras91",
|
||||
"tongyuantongyu",
|
||||
"Tracin",
|
||||
"tshmilnvidia",
|
||||
"ttyio",
|
||||
"uchihatmtkinu",
|
||||
"v-shobhit",
|
||||
"vadiklyutiy",
|
||||
"vallis-neria",
|
||||
"vanshilshah97",
|
||||
"vegaluisjose",
|
||||
"venkywonka",
|
||||
"viraatc",
|
||||
"wangsiping1997",
|
||||
"Wanli-Jiang",
|
||||
"WeiHaocheng",
|
||||
"weireweire",
|
||||
"wili-65535",
|
||||
"wm2012011492",
|
||||
"Wong4j",
|
||||
"wu6u3tw",
|
||||
"wyw1267",
|
||||
"xavier-nvidia",
|
||||
"xiaoweiw-nv",
|
||||
"xinhe-nv",
|
||||
"xmchen1987",
|
||||
"xuanzic",
|
||||
"xueweilnvidia",
|
||||
"xupinjie",
|
||||
"xuwchen",
|
||||
"xxi-nv",
|
||||
"yali-arch",
|
||||
"yechank-nvidia",
|
||||
"yibinl-nvidia",
|
||||
"yifeizhang-c",
|
||||
"yilin-void",
|
||||
"yingcanw",
|
||||
"yingguo-trt",
|
||||
"yiqingy0",
|
||||
"yizhang-nv",
|
||||
"yuanjings-nvda",
|
||||
"yuanjingx87",
|
||||
"yuantailing",
|
||||
"Yuening-wa",
|
||||
"yufeiwu-nv",
|
||||
"yuhengxnv",
|
||||
"yuhsuan-t",
|
||||
"yuki-666",
|
||||
"yumin066",
|
||||
"yunruis",
|
||||
"yuxianq",
|
||||
"yweng0828",
|
||||
"zackyoray",
|
||||
"zbpatel",
|
||||
"zeroepoch",
|
||||
"zerollzeng",
|
||||
"zhanga5",
|
||||
"zhangcl",
|
||||
"ZhanruiSunCh",
|
||||
"zhengd-nv",
|
||||
"zhenhuaw-me",
|
||||
"zheyuf",
|
||||
"zhhuang-nv",
|
||||
"zhou-yuxin",
|
||||
"zhuolingwang",
|
||||
"zhuoyao1012",
|
||||
"zihaok",
|
||||
"ziyixiong-nv",
|
||||
"zongfeijing"
|
||||
]'), github.actor)
|
||||
steps:
|
||||
- name: Check if comment is issued by authorized person
|
||||
run: blossom-ci
|
||||
|
||||
5
.github/workflows/label_issue.yml
vendored
5
.github/workflows/label_issue.yml
vendored
@ -15,10 +15,9 @@ jobs:
|
||||
- name: Checkout private action repository
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
repository: poweiw/goggles_action
|
||||
repository: NVIDIA/goggles_action
|
||||
path: ./.github/actions/goggles_action # local path to store the action
|
||||
token: ${{ secrets.GOGGLES_ACTION_REPO_TOKEN}} # token to access poweiw/goggles_action
|
||||
ref: v1.2.1
|
||||
ref: v1.3.0
|
||||
|
||||
- name: AI Label Issue
|
||||
uses: ./.github/actions/goggles_action/actions/llm_label
|
||||
|
||||
7
.gitignore
vendored
7
.gitignore
vendored
@ -46,6 +46,11 @@ tensorrt_llm/deep_ep_cpp_tllm.pyi
|
||||
tensorrt_llm/deep_gemm/
|
||||
tensorrt_llm/deep_gemm_cpp_tllm.*.so
|
||||
tensorrt_llm/deep_gemm_cpp_tllm.pyi
|
||||
tensorrt_llm/pg_utils_bindings.*.so
|
||||
tensorrt_llm/flash_mla/
|
||||
tensorrt_llm/flash_mla_cpp_tllm.*.so
|
||||
tensorrt_llm/flash_mla_cpp_tllm.pyi
|
||||
tensorrt_llm/scripts
|
||||
*docs/cpp_docs*
|
||||
*docs/source/_cpp_gen*
|
||||
docs/source/**/*.rst
|
||||
@ -68,6 +73,7 @@ cpp/include/tensorrt_llm/executor/version.h
|
||||
cpp/tensorrt_llm/kernels/contextFusedMultiHeadAttention/fmha_v2_cu/
|
||||
cpp/tensorrt_llm/kernels/contextFusedMultiHeadAttention/cubin/fmha_cubin.h
|
||||
.devcontainer/.env
|
||||
/examples/layer_wise_benchmarks/profiles/
|
||||
|
||||
# User config files
|
||||
CMakeUserPresets.json
|
||||
@ -78,4 +84,5 @@ compile_commands.json
|
||||
.devcontainer/docker-compose.override.yml
|
||||
|
||||
# Enroot sqsh files
|
||||
enroot/sw-tensorrt-docker+*.sqsh
|
||||
enroot/tensorrt_llm.devel.sqsh
|
||||
|
||||
32
.gitmodules
vendored
32
.gitmodules
vendored
@ -1,32 +0,0 @@
|
||||
[submodule "3rdparty/cutlass"]
|
||||
path = 3rdparty/cutlass
|
||||
url = https://github.com/NVIDIA/cutlass.git
|
||||
[submodule "3rdparty/json"]
|
||||
path = 3rdparty/json
|
||||
url = https://github.com/nlohmann/json.git
|
||||
[submodule "3rdparty/cxxopts"]
|
||||
path = 3rdparty/cxxopts
|
||||
url = https://github.com/jarro2783/cxxopts
|
||||
branch = v3.1.1
|
||||
[submodule "3rdparty/NVTX"]
|
||||
path = 3rdparty/NVTX
|
||||
url = https://github.com/NVIDIA/NVTX.git
|
||||
[submodule "3rdparty/ucxx"]
|
||||
path = 3rdparty/ucxx
|
||||
url = https://github.com/rapidsai/ucxx.git
|
||||
[submodule "3rdparty/pybind11"]
|
||||
path = 3rdparty/pybind11
|
||||
url = https://github.com/pybind/pybind11.git
|
||||
[submodule "3rdparty/xgrammar"]
|
||||
path = 3rdparty/xgrammar
|
||||
url = https://github.com/mlc-ai/xgrammar.git
|
||||
[submodule "3rdparty/nanobind"]
|
||||
path = 3rdparty/nanobind
|
||||
url = https://github.com/wjakob/nanobind
|
||||
[submodule "3rdparty/cppzmq"]
|
||||
path = 3rdparty/cppzmq
|
||||
url = https://github.com/zeromq/cppzmq.git
|
||||
[submodule "3rdparty/DeepGEMM"]
|
||||
path = 3rdparty/DeepGEMM
|
||||
url = https://github.com/ruoqianguo/DeepGEMM.git
|
||||
branch = swapab_sm100
|
||||
File diff suppressed because it is too large
Load Diff
118
3rdparty/CMakeLists.txt
vendored
Normal file
118
3rdparty/CMakeLists.txt
vendored
Normal file
@ -0,0 +1,118 @@
|
||||
include(ExternalProject)
|
||||
include(FetchContent)
|
||||
|
||||
if(DEFINED ENV{GITHUB_MIRROR} AND NOT "$ENV{GITHUB_MIRROR}" STREQUAL "")
|
||||
set(github_base_url "$ENV{GITHUB_MIRROR}")
|
||||
else()
|
||||
set(github_base_url "https://github.com")
|
||||
endif()
|
||||
|
||||
FetchContent_Declare(
|
||||
cppzmq
|
||||
GIT_REPOSITORY https://github.com/zeromq/cppzmq
|
||||
GIT_TAG v4.10.0 # c94c20743ed7d4aa37835a5c46567ab0790d4acc
|
||||
GIT_SHALLOW TRUE
|
||||
# NOTE: TensorRT-LLM only uses the headers
|
||||
SOURCE_SUBDIR
|
||||
dont-add-this-project-with-add-subdirectory)
|
||||
|
||||
FetchContent_Declare(
|
||||
cutlass
|
||||
GIT_REPOSITORY https://github.com/NVIDIA/cutlass
|
||||
GIT_TAG v4.2.1 # f3fde58372d33e9a5650ba7b80fc48b3b49d40c8
|
||||
GIT_SHALLOW TRUE
|
||||
SOURCE_SUBDIR
|
||||
dont-add-this-project-with-add-subdirectory)
|
||||
|
||||
FetchContent_Declare(
|
||||
cxxopts
|
||||
GIT_REPOSITORY https://github.com/jarro2783/cxxopts
|
||||
GIT_TAG v3.1.1 # eb787304d67ec22f7c3a184ee8b4c481d04357fd
|
||||
GIT_SHALLOW TRUE)
|
||||
|
||||
set(deep_ep_commit 5be51b228a7c82dbdb213ea58e77bffd12b38af8)
|
||||
set_property(GLOBAL PROPERTY DEEP_EP_COMMIT "${deep_ep_commit}")
|
||||
FetchContent_Declare(
|
||||
deep_ep_download
|
||||
URL ${github_base_url}/deepseek-ai/DeepEP/archive/${deep_ep_commit}.tar.gz)
|
||||
|
||||
FetchContent_Declare(
|
||||
deepgemm
|
||||
GIT_REPOSITORY https://github.com/ruoqianguo/DeepGEMM
|
||||
GIT_TAG 6cb8161516302550785d9af924d2778afef1f3f6 # swapab_sm100 branch
|
||||
GIT_SUBMODULES_RECURSE
|
||||
ON
|
||||
SOURCE_SUBDIR
|
||||
dont-add-this-project-with-add-subdirectory)
|
||||
|
||||
FetchContent_Declare(
|
||||
eigen
|
||||
GIT_REPOSITORY https://github.com/libeigen/eigen
|
||||
GIT_TAG 3.4.0
|
||||
GIT_SHALLOW TRUE)
|
||||
|
||||
FetchContent_Declare(
|
||||
flashmla
|
||||
GIT_REPOSITORY https://github.com/deepseek-ai/FlashMLA.git
|
||||
GIT_TAG 1408756a88e52a25196b759eaf8db89d2b51b5a1
|
||||
GIT_SUBMODULES_RECURSE
|
||||
ON
|
||||
SOURCE_SUBDIR
|
||||
dont-add-this-project-with-add-subdirectory)
|
||||
|
||||
FetchContent_Declare(
|
||||
googlebenchmark
|
||||
GIT_REPOSITORY https://github.com/google/benchmark
|
||||
GIT_TAG v1.8.3
|
||||
GIT_SHALLOW TRUE)
|
||||
|
||||
FetchContent_Declare(
|
||||
googletest
|
||||
GIT_REPOSITORY https://github.com/google/googletest
|
||||
GIT_TAG v1.15.2
|
||||
GIT_SHALLOW TRUE)
|
||||
|
||||
FetchContent_Declare(
|
||||
json
|
||||
GIT_REPOSITORY https://github.com/nlohmann/json
|
||||
GIT_TAG v3.12.0 # 55f93686c01528224f448c19128836e7df245f72
|
||||
GIT_SHALLOW TRUE
|
||||
SOURCE_SUBDIR
|
||||
dont-add-this-project-with-add-subdirectory)
|
||||
|
||||
FetchContent_Declare(
|
||||
nanobind
|
||||
GIT_REPOSITORY https://github.com/wjakob/nanobind
|
||||
GIT_TAG a0ed2587f1089ef7657e2ed49ad6756b01c74e9f)
|
||||
|
||||
FetchContent_Declare(
|
||||
nvtx
|
||||
GIT_REPOSITORY https://github.com/NVIDIA/NVTX
|
||||
GIT_TAG v3.1.0-c-cpp # a1ceb0677f67371ed29a2b1c022794f077db5fe7
|
||||
GIT_SHALLOW TRUE
|
||||
# NOTE: TensorRT-LLM only uses the headers
|
||||
SOURCE_SUBDIR
|
||||
dont-add-this-project-with-add-subdirectory)
|
||||
|
||||
FetchContent_Declare(
|
||||
pybind11
|
||||
GIT_REPOSITORY https://github.com/pybind/pybind11
|
||||
GIT_TAG f99ffd7e03001810a3e722bf48ad1a9e08415d7d)
|
||||
|
||||
FetchContent_Declare(
|
||||
ucxx
|
||||
GIT_REPOSITORY https://github.com/rapidsai/ucxx
|
||||
GIT_TAG 16eaa57c8d98c8ef54d666a2d2b11e76cfa565f5
|
||||
# NOTE: See the notes in cpp/CMakeList.txt where this project is build at
|
||||
# configure time and then included via find_package
|
||||
SOURCE_SUBDIR
|
||||
dont-add-this-project-with-add-subdirectory)
|
||||
|
||||
FetchContent_Declare(
|
||||
xgrammar
|
||||
GIT_REPOSITORY https://github.com/mlc-ai/xgrammar
|
||||
GIT_TAG v0.1.25 # e4e816f5f0fe39f5b1601a17a4552307fa3b70ff
|
||||
GIT_SHALLOW TRUE
|
||||
# NOTE: TensorRT-LLM only uses the headers
|
||||
SOURCE_SUBDIR
|
||||
dont-add-this-project-with-add-subdirectory)
|
||||
1
3rdparty/DeepGEMM
vendored
1
3rdparty/DeepGEMM
vendored
@ -1 +0,0 @@
|
||||
Subproject commit 0315934ce27c5c0b05dfff1a5eb101a5f8872cfe
|
||||
1
3rdparty/NVTX
vendored
1
3rdparty/NVTX
vendored
@ -1 +0,0 @@
|
||||
Subproject commit a1ceb0677f67371ed29a2b1c022794f077db5fe7
|
||||
13
3rdparty/README.md
vendored
Normal file
13
3rdparty/README.md
vendored
Normal file
@ -0,0 +1,13 @@
|
||||
# Adding new third-party Dependencies
|
||||
|
||||
The markdown files in this directory contain playbooks for how to add new
|
||||
third-party dependencies. Please see the document that matches the kind of
|
||||
dependency you want to add:
|
||||
|
||||
* For C++ dependencies compiled into the extension modules via the cmake build
|
||||
and re-distributed with the wheel [see here][1]
|
||||
* For python dependencies declared via wheel metadata and installed in the
|
||||
container via pip [see here][2]
|
||||
|
||||
[1]: cpp-thirdparty.md
|
||||
[2]: py-thirdparty.md
|
||||
337
3rdparty/cpp-thirdparty.md
vendored
Normal file
337
3rdparty/cpp-thirdparty.md
vendored
Normal file
@ -0,0 +1,337 @@
|
||||
# Adding new C++ Dependencies
|
||||
|
||||
## Step 1: Make the package available to the build
|
||||
|
||||
First, decide if you must install the package in the container or if you
|
||||
may defer fetching until the build phase. In general, *prefer to fetch
|
||||
packages during the build phase*. You may be required to install
|
||||
packages into the container, however, if there is a runtime component
|
||||
(e.g. shared objects) that cannot be reasonably distributed with the
|
||||
wheel.
|
||||
|
||||
### Install in the container
|
||||
|
||||
#### Debian Packages via os package manager (e.g. apt, dnf)
|
||||
|
||||
Add your package to one of the existing shell scripts used by the docker build
|
||||
under [docker/common/][1] Find the location where the package manager is
|
||||
invoked, and add the name of your package there.
|
||||
|
||||
NOTE: Internal compliance tooling will automatically detect the
|
||||
installation of this package and fetch sources using the source-fetching
|
||||
facilities of the OS package manager.
|
||||
|
||||
[1]: https://github.com/NVIDIA/TensorRT-LLM/tree/main/docker/common.
|
||||
|
||||
#### Python Packages via pip
|
||||
|
||||
If it makes sense, add your package to one of the existing shell scripts used by
|
||||
the docker build under [docker/common/][2]. Grep for "pip3 install" to see
|
||||
existing invocations. If none of the existing shell scripts make sense, add a
|
||||
new shell script to install your package and then invoke that script in
|
||||
Dockerfile.multi.
|
||||
|
||||
NOTE: If the new python package you are adding has a compiled component (e.g. a
|
||||
python extension module), you must coordinate with the [Security Team][20] to
|
||||
ensure that the source for this component is managed correctly.
|
||||
|
||||
[2]: https://github.com/NVIDIA/TensorRT-LLM/tree/main/docker/common
|
||||
|
||||
#### Tarball packages via HTTP/FTP
|
||||
|
||||
Invoke `wget` in a shell script which is called from the docker build file.
|
||||
When it makes sense, please prefer to extend an existing script in
|
||||
[docker/common/][3] rather than creating a new one. If you are downloading a
|
||||
binary package, you must also download the source package that produced that
|
||||
binary.
|
||||
|
||||
Ensure that the source package is copied to /third-party-source and retained
|
||||
after all cleanup within the docker image layer.
|
||||
|
||||
[3]: https://github.com/NVIDIA/TensorRT-LLM/tree/main/docker/common
|
||||
|
||||
### Fetch during the build
|
||||
|
||||
#### Python Packages via pip
|
||||
|
||||
Add an entry to [requirements-dev.txt][4].
|
||||
The package will be installed by build\_wheel.py during virtual
|
||||
environment initialization prior to configuring the build with cmake.
|
||||
Include a comment indicating the intended usage of the package.
|
||||
|
||||
[4]: https://github.com/NVIDIA/TensorRT-LLM/blob/main/requirements-dev.txt
|
||||
|
||||
**Example:**
|
||||
|
||||
`requirements-dev.txt`:
|
||||
|
||||
``` requirements.txt
|
||||
# my-package is needed by <feature> where it is used for <reason>
|
||||
my-package==1.2.24
|
||||
```
|
||||
|
||||
#### C/C++ Packages via conan
|
||||
|
||||
Add a new entry to [conandata.yml][6] indicating the package version for the
|
||||
dependency you are adding. Include a yaml comment indicating the intended usage
|
||||
of the package. Then add a new invocation of `self.require()` within the `def
|
||||
requirements(self)` method of [conanfile.py], referencing the version you added
|
||||
to conandata.
|
||||
|
||||
[6]: https://github.com/NVIDIA/TensorRT-LLM/blob/main/cpp/conandata.yml
|
||||
[7]: https://github.com/NVIDIA/TensorRT-LLM/blob/main/cpp/conanfile.py
|
||||
|
||||
**Example:**
|
||||
|
||||
`conandata.yml`:
|
||||
|
||||
```.yml
|
||||
# my_dependency is needed by <feature> where it is used for <reason>
|
||||
my_dependency: 1.2.24+1
|
||||
```
|
||||
|
||||
`conanfile.py`:
|
||||
|
||||
```.py
|
||||
def requirements(self):
|
||||
...
|
||||
my_dependency_version = self.conandata["my_dependency"]
|
||||
self.requires(f"my_dependency/{my_dependency_version}")
|
||||
```
|
||||
|
||||
#### Source integration via CMake
|
||||
|
||||
If you have a package you need to build from source then use CMake
|
||||
[FetchContent][8] of [ExternalProject][9] to fetch the package sources and
|
||||
integrate it with the build. See the details in the next section.
|
||||
|
||||
[8]: https://cmake.org/cmake/help/latest/module/FetchContent.html
|
||||
[9]: https://cmake.org/cmake/help/latest/module/ExternalProject.html#id1
|
||||
|
||||
#### git Submodule - Don't Use
|
||||
|
||||
Please *avoid use of git-submodule*. If, for some reason, the CMake integrations
|
||||
described below don't work and git-submodule is absolutely required, please add
|
||||
the submodule under the 3rdparty directory.
|
||||
|
||||
**Rationale:**
|
||||
|
||||
For a source-code dependency distributed via git,
|
||||
FetchContent/ExternalProject and git submodules both ultimately contain
|
||||
the same referential information (repository URL, commit sha) and, at
|
||||
the end of the day, do the same things. However
|
||||
FetchContent/ExternalProject have the following advantages:
|
||||
|
||||
1. The git operations happen during the build and are interleaved with the rest
|
||||
of the build processing, rather than requiring an additional step managed
|
||||
outside of CMake.
|
||||
|
||||
2. The fetch, patch, and build steps for the sub project are individually named
|
||||
in the build, so any failures are more clearly identified
|
||||
|
||||
3. The build state is better contained within the build tree where it is less
|
||||
prone to interference by development actions.
|
||||
|
||||
4. For source code that is modified, FetchContent/ExternalProject can manage
|
||||
application of the patches making it clear what modifications are present.
|
||||
|
||||
5. The build does not have to make assumptions about the version control
|
||||
configuration of the source tree, which may be incorrect due to the fact
|
||||
that it is bind-mounted in a container. For example, `git submodule --init`
|
||||
inside a container will corrupt the git configuration outside the container
|
||||
if the source tree is a git worktree.
|
||||
|
||||
6. External project references and their patches are collected under a more
|
||||
narrow surface, rather than being spread across different tools. This makes
|
||||
it easier to track third part dependencies as well as to recognize them
|
||||
during code review.
|
||||
|
||||
**Example:**
|
||||
|
||||
``` bash
|
||||
git submodule add https://github.com/some-organization/some-project.git 3rdparty/some-project
|
||||
```
|
||||
|
||||
|
||||
## Step 2: Integrate the package
|
||||
|
||||
There are many ways to integrate a package with the build through cmake.
|
||||
|
||||
### find\_package for binary packages
|
||||
|
||||
For binary packages (os-provided via apt-get or yum, or conan-provided), prefer
|
||||
the use of [find\_package][10] to integrate the package into the build. Conan
|
||||
will generate a find-script for packages that don't already come with a Cmake
|
||||
configuration file and the conan-specific logic is provided through the
|
||||
conan-generated toolchain already used in our build.
|
||||
|
||||
For any packages which do not have provided find modules (either built-in, or
|
||||
available from conan), please implement one in [cpp/cmake/modules][11]. Please
|
||||
do not add "direct" invocations of `find_library` / `add_library` / `find_file`
|
||||
/ `find_path` outside of a find module the package.
|
||||
|
||||
Please add invocations of `find_package` directly in the root Cmake file.
|
||||
|
||||
[10]: https://cmake.org/cmake/help/latest/command/find_package.html
|
||||
[11]: https://github.com/NVIDIA/TensorRT-LLM/tree/main//cpp/cmake/modules?ref_type=heads
|
||||
|
||||
**Example:**
|
||||
|
||||
cpp/CMakeLists.txt
|
||||
|
||||
```.cmake
|
||||
find_package(NIXL)
|
||||
```
|
||||
|
||||
cpp/cmake/modules/FindNIXL.cmake
|
||||
```.cmake
|
||||
...
|
||||
find_library(
|
||||
NIXL_LIBRARY nixl
|
||||
HINTS
|
||||
${NIXL_ROOT}/lib/${NIXL_TARGET_ARCH}
|
||||
${NIXL_ROOT}/lib64)
|
||||
...
|
||||
add_library(NIXL::nixl SHARED IMPORTED)
|
||||
set_target_properties(
|
||||
NIXL::nixl
|
||||
PROPERTIES
|
||||
INTERFACE_INCLUDE_DIRECTORIES ${NIXL_INCLUDE_DIR}
|
||||
IMPORTED_LOCATION ${NIXL_LIBRARY}
|
||||
${NIXL_BUILD_LIBRARY}
|
||||
${SERDES_LIBRARY}
|
||||
)
|
||||
```
|
||||
|
||||
### FetchContent for source packages with compatible cmake builds
|
||||
|
||||
For source packages that have a compatible cmake (e.g. where add\_subdirectory
|
||||
will work correctly), please use [FetchContent][12] to download the sources and
|
||||
integrate them into the build. Please add new invocations of
|
||||
FetchContent\_Declare in [3rdparty/CMakeLists.txt][13]. Add new invocations for
|
||||
FetchContent\_MakeAvailable wherever it makes sense in the build where you are
|
||||
integrating it, but prefer the root listfile for that build
|
||||
([cpp/CMakeLists.txt][14] for the primary build).
|
||||
|
||||
CODEOWNERS for this file will consist of PLC reviewers who verify that
|
||||
third-party license compliance strategies are being followed.
|
||||
|
||||
If the dependency you are adding has modified sources, please do the
|
||||
following:
|
||||
|
||||
1. Create a repository on gitlab to mirror the upstream source files. If the
|
||||
upstream is also in git, please use the gitlab "mirror" repository option.
|
||||
Otherwise, please use branches/tags to help identify the upstream source
|
||||
versions.
|
||||
|
||||
2. Track nvidia changes in a branch. Use a linear sequence (trunk-based)
|
||||
development strategy. Use meaningful, concise commit message subjects and
|
||||
comprehensive commit messages for the changes applied.
|
||||
|
||||
3. Use `git format-patch \<upstream-commit\>\...HEAD` to create a list of
|
||||
patches, one file per commit,
|
||||
|
||||
4. Add your patches under 3rdparty/patches/\<package-name\>
|
||||
|
||||
5. Use CMake's [PATCH\_COMMAND][15] option to apply the patches during the
|
||||
build process.
|
||||
|
||||
[12]: https://cmake.org/cmake/help/latest/module/FetchContent.html
|
||||
[13]: https://github.com/NVIDIA/TensorRT-LLM/tree/main//3rdparty/CMakeLists.txt?ref_type=heads
|
||||
[14]: https://github.com/NVIDIA/TensorRT-LLM/blob/main/cpp/CMakeLists.txt
|
||||
[15]: https://cmake.org/cmake/help/latest/module/ExternalProject.html#patch-step-options
|
||||
|
||||
**Example:**
|
||||
|
||||
3rdparty/CMakeLists.txt
|
||||
|
||||
```.cmake
|
||||
FetchContent_Declare(
|
||||
pybind11
|
||||
GIT_REPOSITORY https://github.com/pybind/pybind11.git
|
||||
GIT_TAG f99ffd7e03001810a3e722bf48ad1a9e08415d7d
|
||||
)
|
||||
```
|
||||
|
||||
cpp/CmakeLists.txt
|
||||
|
||||
```.cmake
|
||||
FetchContent_MakeAvailable(pybind11)
|
||||
```
|
||||
|
||||
### ExternalProject
|
||||
|
||||
If the package you are adding doesn't support FetchContent (e.g. if it's not
|
||||
built by CMake or if its CMake configuration doesn't nest well), then please use
|
||||
[ExternalProject][16]. In this case that project's build system will be invoked
|
||||
as a build step of the primary build system. Note that, unless both the primary
|
||||
and child build systems are GNU Make, they will not share a job server and will
|
||||
independently schedule parallelism (e.g. -j flags).
|
||||
|
||||
[16]: https://cmake.org/cmake/help/latest/module/ExternalProject.html#id1
|
||||
|
||||
**Example:**
|
||||
|
||||
```.cmake
|
||||
ExternalProject_Add(
|
||||
nvshmem_project
|
||||
URL https://developer.download.nvidia.com/compute/nvshmem/redist/libnvshmem/linux-x86_64/libnvshmem-linux-x86_64-3.2.5_cuda12-archive.tar.xz
|
||||
URL_HASH ${NVSHMEM_URL_HASH}
|
||||
PATCH_COMMAND patch -p1 --forward --batch -i
|
||||
${DEEP_EP_SOURCE_DIR}/third-party/nvshmem.patch
|
||||
...
|
||||
CMAKE_CACHE_ARGS
|
||||
-DCMAKE_C_COMPILER:STRING=${CMAKE_C_COMPILER}
|
||||
-DCMAKE_C_COMPILER_LAUNCHER:STRING=${CMAKE_C_COMPILER_LAUNCHER}
|
||||
...
|
||||
BINARY_DIR ${CMAKE_CURRENT_BINARY_DIR}/nvshmem-build
|
||||
BUILD_BYPRODUCTS
|
||||
${CMAKE_CURRENT_BINARY_DIR}/nvshmem-build/src/lib/libnvshmem.a
|
||||
)
|
||||
add_library(nvshmem_project::nvshmem STATIC IMPORTED)
|
||||
add_dependencies(nvshmem_project::nvshmem nvshmem_project)
|
||||
...
|
||||
set_target_properties(
|
||||
nvshmem_project::nvshmem
|
||||
PROPERTIES IMPORTED_LOCATION
|
||||
${CMAKE_CURRENT_BINARY_DIR}/nvshmem-build/src/lib/libnvshmem.a
|
||||
INTERFACE_INCLUDE_DIRECTORIES
|
||||
${CMAKE_CURRENT_BINARY_DIR}/nvshmem-build/src/include)
|
||||
```
|
||||
|
||||
## Step 3: Update third-party attributions and license tracking
|
||||
|
||||
1. Clone the dependency source code to an NVIDIA-controlled repository. The
|
||||
consumed commit must be stored as-received (ensure the consumed commit-sha
|
||||
is present in the clone). For sources available via git (or git-adaptable)
|
||||
SCM, mirror the repository in the [oss-components][18] gitlab project.
|
||||
|
||||
2. Collect the license text of the consumed commit
|
||||
|
||||
3. If the license does not include a copyright notice, collect any copyright
|
||||
notices that were originally published with the dependency (these may be on
|
||||
individual file levels, in metadata files, or in packaging control files).
|
||||
|
||||
4. Add the license and copyright notices to the ATTRIBUTIONS-CPP-x86\_64.md and
|
||||
ATTRIBUTIONS-CPP-aarch64.md files
|
||||
|
||||
CODEOWNERS for ATTRIBUTIONS-CPP-\*.md are members of the PLC team and modifying
|
||||
this file will signal to reviewers that they are verifying that your change
|
||||
follows the process in this document.
|
||||
|
||||
[18]: https://gitlab.com/nvidia/tensorrt-llm/oss-components
|
||||
|
||||
## Step 4: File a JIRA ticket if you need help from the Security team
|
||||
|
||||
This step is optional, if you need assistance from the Security team.
|
||||
|
||||
File a Jira ticket using the issue template [TRTLLM-8383][19] to request
|
||||
inclusion of this new dependency and initiate license and/or security review.
|
||||
The Security Team will triage and assign the ticket.
|
||||
|
||||
If you don’t have access to the JIRA project, please email the [Security
|
||||
Team][20].
|
||||
|
||||
|
||||
[19]: https://jirasw.nvidia.com/browse/TRTLLM-8383
|
||||
[20]: mailto://TensorRT-LLM-Security@nvidia.com
|
||||
1
3rdparty/cppzmq
vendored
1
3rdparty/cppzmq
vendored
@ -1 +0,0 @@
|
||||
Subproject commit c94c20743ed7d4aa37835a5c46567ab0790d4acc
|
||||
1
3rdparty/cutlass
vendored
1
3rdparty/cutlass
vendored
@ -1 +0,0 @@
|
||||
Subproject commit 57e3cfb47a2d9e0d46eb6335c3dc411498efa198
|
||||
1
3rdparty/cxxopts
vendored
1
3rdparty/cxxopts
vendored
@ -1 +0,0 @@
|
||||
Subproject commit eb787304d67ec22f7c3a184ee8b4c481d04357fd
|
||||
1
3rdparty/json
vendored
1
3rdparty/json
vendored
@ -1 +0,0 @@
|
||||
Subproject commit 55f93686c01528224f448c19128836e7df245f72
|
||||
1
3rdparty/nanobind
vendored
1
3rdparty/nanobind
vendored
@ -1 +0,0 @@
|
||||
Subproject commit a0ed2587f1089ef7657e2ed49ad6756b01c74e9f
|
||||
69
3rdparty/py-thirdparty.md
vendored
Normal file
69
3rdparty/py-thirdparty.md
vendored
Normal file
@ -0,0 +1,69 @@
|
||||
# Adding new python dependencies via pip
|
||||
|
||||
If you add a new python dependency and that dependency will be installed in
|
||||
(and, thus, distributed with) the container, please follow this process.
|
||||
|
||||
## Third-party packages without modification
|
||||
|
||||
If the package you wish to add does not require modification, then please follow
|
||||
these steps:
|
||||
|
||||
1. Add your new dependency to one of the "pip install" invocations among the
|
||||
scripts in docker/common.sh. If none of the existing ones make sense, then
|
||||
add a new script to install your package and add a new line to
|
||||
Dockerfile.multi to run your script.
|
||||
2. Update ATTRIBUTIONS-Python.md to include all new dependencies. Note that this
|
||||
must cover the transitive closure of all dependencies. The dependency you
|
||||
added may have pulled in new transitive dependencies and we must ensure all
|
||||
are attributed in this file.
|
||||
3. Verify that your newly added package is listed in the compliance reports and
|
||||
that sources are pulled via the compliance tooling.
|
||||
|
||||
## Third-party packages with modification
|
||||
|
||||
If you wish to depend on a package with nvidia-contributed modifications that
|
||||
haven't been upstreamed then please follow these steps:
|
||||
|
||||
1. File an OSRB request to fork/contribute to a 3rd party open source package.
|
||||
https://confluence.nvidia.com/display/OSS/Contribution+to+Open+Source
|
||||
2. Clone the original repository to a new public nvidia-controlled location
|
||||
(e.g. https://gitlab.com/nvidia/tensorrt-llm/oss-components/)
|
||||
3. Register this new repository under nspec
|
||||
4. Make modifications in that public repository. Ensure that the clone
|
||||
repository clearly indicates the software license via /LICENSE.txt in the
|
||||
root of the repository. Ensure that this file contains a copyright statement
|
||||
indicating copyright held by the original author(s) and Nvidia.
|
||||
5. Publish the modified package to pypi under a new name (e.g. nvidia-<package>)
|
||||
6. Add your new dependency to one of the "pip install" invocations among the
|
||||
scripts in docker/common.sh. If none of the existing ones make sense, then
|
||||
add a new script to install your package and add a new line to
|
||||
Dockerfile.multi to run your script.
|
||||
7. Update ATTRIBUTIONS-Python.md to include all new dependencies. Note that this
|
||||
must cover the transitive closure of all dependencies. The dependency you
|
||||
added may have pulled in new transitive dependencies and we must ensure all
|
||||
are attributed in this file.
|
||||
8. Verify that your newly added package is listed in the compliance reports and
|
||||
that sources are pulled via the compliance tooling.
|
||||
|
||||
Notes:
|
||||
* For pip/uv-installed versions of TensorRT-LLM, the modified package will be
|
||||
installed as a transitive dependency by the package manager
|
||||
* For the container distribution of TensorRT-LLM, the modified package will be
|
||||
pre-installed from the same pypi location via pip
|
||||
|
||||
## Individual third-party sources with modification
|
||||
|
||||
If you wish to integrate third-party source files with nvidia-contributed
|
||||
modifications that haven't been upstreamed then please follow these steps:
|
||||
|
||||
1. File an OSRB request to use open source:
|
||||
https://confluence.nvidia.com/display/OSS/So+you+want+to+use+open+source+in+your+product
|
||||
2. Clone the original repository to a new nvidia-controlled location
|
||||
(e.g. https://gitlab.com/nvidia/tensorrt-llm/oss-components/)
|
||||
3. Make modifications in that repository on branch so that the versions
|
||||
"as-used" can be easily found and the diff against upstream easily viewed.
|
||||
4. Copy the desired source files into the TensorRT-LLM repository.
|
||||
5. Update ATTRIBUTIONS-Python.md to include attribution for the source files
|
||||
you have added. Note the terms of the license on the original repository
|
||||
and see the examples already in the file to understand what all needs to be
|
||||
stated.
|
||||
1
3rdparty/pybind11
vendored
1
3rdparty/pybind11
vendored
@ -1 +0,0 @@
|
||||
Subproject commit f99ffd7e03001810a3e722bf48ad1a9e08415d7d
|
||||
1
3rdparty/ucxx
vendored
1
3rdparty/ucxx
vendored
@ -1 +0,0 @@
|
||||
Subproject commit 16eaa57c8d98c8ef54d666a2d2b11e76cfa565f5
|
||||
1
3rdparty/xgrammar
vendored
1
3rdparty/xgrammar
vendored
@ -1 +0,0 @@
|
||||
Subproject commit e4e816f5f0fe39f5b1601a17a4552307fa3b70ff
|
||||
15143
ATTRIBUTIONS-CPP-aarch64.md
Executable file
15143
ATTRIBUTIONS-CPP-aarch64.md
Executable file
File diff suppressed because it is too large
Load Diff
14951
ATTRIBUTIONS-CPP-x86_64.md
Executable file
14951
ATTRIBUTIONS-CPP-x86_64.md
Executable file
File diff suppressed because it is too large
Load Diff
45884
ATTRIBUTIONS-Python.md
Normal file
45884
ATTRIBUTIONS-Python.md
Normal file
File diff suppressed because it is too large
Load Diff
4
LICENSE
4
LICENSE
@ -1,3 +1,7 @@
|
||||
Copyright (c) 2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
|
||||
Portions of this project are under the following copyright:
|
||||
- Copyright contributors to the vLLM project
|
||||
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
|
||||
39
README.md
39
README.md
@ -2,54 +2,59 @@
|
||||
|
||||
TensorRT LLM
|
||||
===========================
|
||||
<h4> A TensorRT Toolbox for Optimized Large Language Model Inference</h4>
|
||||
<h4>TensorRT LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and supports
|
||||
state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs.</h4>
|
||||
|
||||
[](https://nvidia.github.io/TensorRT-LLM/)
|
||||
[](https://www.python.org/downloads/release/python-3123/)
|
||||
[](https://www.python.org/downloads/release/python-31012/)
|
||||
[](https://developer.nvidia.com/cuda-downloads)
|
||||
[](https://developer.nvidia.com/tensorrt)
|
||||
[](./tensorrt_llm/version.py)
|
||||
[](./LICENSE)
|
||||
[](https://github.com/NVIDIA/TensorRT-LLM/blob/main/tensorrt_llm/version.py)
|
||||
[](https://github.com/NVIDIA/TensorRT-LLM/blob/main/LICENSE)
|
||||
|
||||
[Architecture](./docs/source/torch/arch_overview.md) | [Performance](./docs/source/performance/perf-overview.md) | [Examples](https://nvidia.github.io/TensorRT-LLM/quick-start-guide.html) | [Documentation](https://nvidia.github.io/TensorRT-LLM/) | [Roadmap](https://github.com/NVIDIA/TensorRT-LLM/issues?q=is%3Aissue%20state%3Aopen%20label%3Aroadmap)
|
||||
[Architecture](https://nvidia.github.io/TensorRT-LLM/developer-guide/overview.html) | [Performance](https://nvidia.github.io/TensorRT-LLM/developer-guide/perf-overview.html) | [Examples](https://nvidia.github.io/TensorRT-LLM/quick-start-guide.html) | [Documentation](https://nvidia.github.io/TensorRT-LLM/) | [Roadmap](https://github.com/NVIDIA/TensorRT-LLM/issues?q=is%3Aissue%20state%3Aopen%20label%3Aroadmap)
|
||||
|
||||
---
|
||||
<div align="left">
|
||||
|
||||
## Tech Blogs
|
||||
|
||||
* [10/13] Scaling Expert Parallelism in TensorRT LLM (Part 3: Pushing the Performance Boundary)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog14_Scaling_Expert_Parallelism_in_TensorRT-LLM_part3.html)
|
||||
|
||||
* [09/26] Inference Time Compute Implementation in TensorRT LLM
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog13_Inference_Time_Compute_Implementation_in_TensorRT-LLM.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog13_Inference_Time_Compute_Implementation_in_TensorRT-LLM.html)
|
||||
|
||||
* [09/19] Combining Guided Decoding and Speculative Decoding: Making CPU and GPU Cooperate Seamlessly
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog12_Combining_Guided_Decoding_and_Speculative_Decoding.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog12_Combining_Guided_Decoding_and_Speculative_Decoding.html)
|
||||
|
||||
* [08/29] ADP Balance Strategy
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog10_ADP_Balance_Strategy.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog10_ADP_Balance_Strategy.html)
|
||||
|
||||
* [08/05] Running a High-Performance GPT-OSS-120B Inference Server with TensorRT LLM
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog9_Deploying_GPT_OSS_on_TRTLLM.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog9_Deploying_GPT_OSS_on_TRTLLM.html)
|
||||
|
||||
* [08/01] Scaling Expert Parallelism in TensorRT LLM (Part 2: Performance Status and Optimization)
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog8_Scaling_Expert_Parallelism_in_TensorRT-LLM_part2.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog8_Scaling_Expert_Parallelism_in_TensorRT-LLM_part2.html)
|
||||
|
||||
* [07/26] N-Gram Speculative Decoding in TensorRT LLM
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog7_NGram_performance_Analysis_And_Auto_Enablement.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog7_NGram_performance_Analysis_And_Auto_Enablement.html)
|
||||
|
||||
* [06/19] Disaggregated Serving in TensorRT LLM
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog5_Disaggregated_Serving_in_TensorRT-LLM.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog5_Disaggregated_Serving_in_TensorRT-LLM.html)
|
||||
|
||||
* [06/05] Scaling Expert Parallelism in TensorRT LLM (Part 1: Design and Implementation of Large-scale EP)
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.html)
|
||||
|
||||
* [05/30] Optimizing DeepSeek R1 Throughput on NVIDIA Blackwell GPUs: A Deep Dive for Developers
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.html)
|
||||
|
||||
* [05/23] DeepSeek R1 MTP Implementation and Optimization
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.html)
|
||||
|
||||
* [05/16] Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA B200 GPUs
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.html)
|
||||
|
||||
## Latest News
|
||||
* [08/05] 🌟 TensorRT LLM delivers Day-0 support for OpenAI's latest open-weights models: GPT-OSS-120B [➡️ link](https://huggingface.co/openai/gpt-oss-120b) and GPT-OSS-20B [➡️ link](https://huggingface.co/openai/gpt-oss-20b)
|
||||
@ -58,11 +63,11 @@ TensorRT LLM
|
||||
* [05/22] Blackwell Breaks the 1,000 TPS/User Barrier With Meta’s Llama 4 Maverick
|
||||
✨ [➡️ link](https://developer.nvidia.com/blog/blackwell-breaks-the-1000-tps-user-barrier-with-metas-llama-4-maverick/)
|
||||
* [04/10] TensorRT LLM DeepSeek R1 performance benchmarking best practices now published.
|
||||
✨ [➡️ link](./docs/source/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.html)
|
||||
|
||||
* [04/05] TensorRT LLM can run Llama 4 at over 40,000 tokens per second on B200 GPUs!
|
||||
|
||||

|
||||
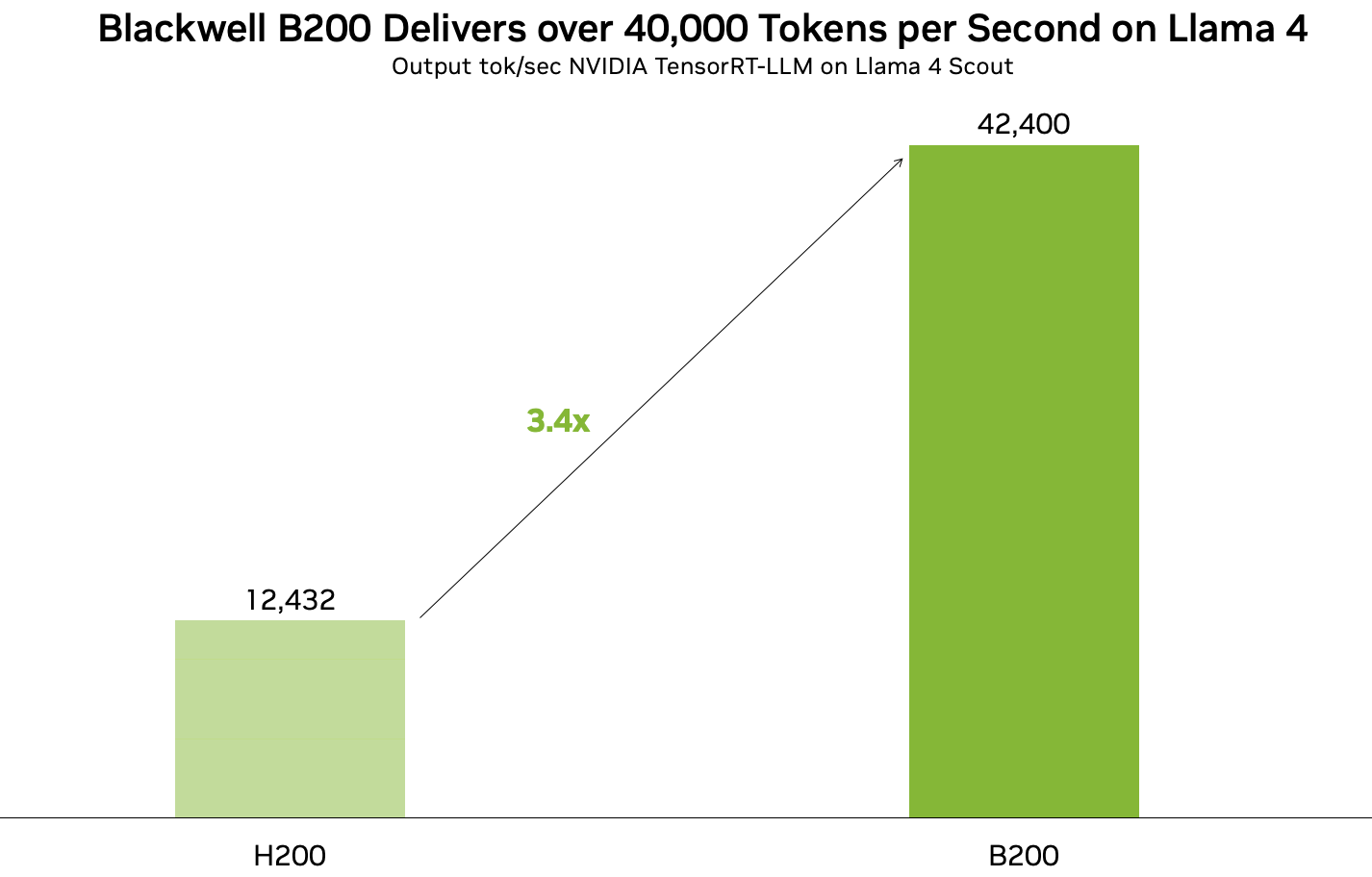
|
||||
|
||||
|
||||
* [03/22] TensorRT LLM is now fully open-source, with developments moved to GitHub!
|
||||
|
||||
@ -20,8 +20,8 @@ set(TOP_LEVEL_DIR "${PROJECT_SOURCE_DIR}/..")
|
||||
add_custom_target(benchmarks)
|
||||
|
||||
if(NOT TARGET cxxopts::cxxopts)
|
||||
set(CXXOPTS_SRC_DIR ${PROJECT_SOURCE_DIR}/../3rdparty/cxxopts)
|
||||
add_subdirectory(${CXXOPTS_SRC_DIR} ${CMAKE_CURRENT_BINARY_DIR}/cxxopts)
|
||||
add_subdirectory(${CMAKE_BINARY_DIR}/_deps/cxxopts-src
|
||||
${CMAKE_CURRENT_BINARY_DIR}/cxxopts)
|
||||
endif()
|
||||
|
||||
function(add_benchmark test_name test_src)
|
||||
|
||||
@ -1,5 +1,2 @@
|
||||
# These vulnerabilities were inherited from the base image (pytorch:25.06-py3) and should be removed when the base image
|
||||
# These vulnerabilities were inherited from the base image (pytorch:25.10-py3) and should be removed when the base image
|
||||
# is updated.
|
||||
|
||||
# WAR against https://github.com/advisories/GHSA-8qvm-5x2c-j2w7
|
||||
protobuf>=4.25.8
|
||||
|
||||
@ -32,6 +32,7 @@ option(BUILD_TESTS "Build Google tests" ON)
|
||||
option(BUILD_BENCHMARKS "Build benchmarks" ON)
|
||||
option(BUILD_DEEP_EP "Build the Deep EP module" ON)
|
||||
option(BUILD_DEEP_GEMM "Build the DeepGEMM module" ON)
|
||||
option(BUILD_FLASH_MLA "Build the FlashMLA module" ON)
|
||||
option(BUILD_MICRO_BENCHMARKS "Build C++ micro benchmarks" OFF)
|
||||
option(NVTX_DISABLE "Disable all NVTX features" ON)
|
||||
option(WARNING_IS_ERROR "Treat all warnings as errors" OFF)
|
||||
@ -54,6 +55,15 @@ option(USING_OSS_CUTLASS_LOW_LATENCY_GEMM
|
||||
"Using open sourced Cutlass low latency gemm kernel" ON)
|
||||
option(USING_OSS_CUTLASS_FP4_GEMM "Using open sourced Cutlass fp4 gemm kernel"
|
||||
ON)
|
||||
option(ENABLE_CUBLASLT_FP4_GEMM "Enable cuBLASLt FP4 GEMM support" ON)
|
||||
if(NOT ${CUDAToolkit_VERSION} VERSION_GREATER_EQUAL "12.8")
|
||||
set(ENABLE_CUBLASLT_FP4_GEMM
|
||||
OFF
|
||||
CACHE BOOL "" FORCE)
|
||||
message(
|
||||
STATUS
|
||||
"CUDA ${CUDAToolkit_VERSION} < 12.8: disabling ENABLE_CUBLASLT_FP4_GEMM")
|
||||
endif()
|
||||
option(USING_OSS_CUTLASS_MOE_GEMM "Using open sourced Cutlass moe gemm kernel"
|
||||
ON)
|
||||
option(USING_OSS_CUTLASS_ALLREDUCE_GEMM
|
||||
@ -233,15 +243,35 @@ set(TRT_LIB TensorRT::NvInfer)
|
||||
get_filename_component(TRT_LLM_ROOT_DIR ${CMAKE_CURRENT_SOURCE_DIR} PATH)
|
||||
|
||||
set(3RDPARTY_DIR ${TRT_LLM_ROOT_DIR}/3rdparty)
|
||||
add_subdirectory(${3RDPARTY_DIR} 3rdparty)
|
||||
|
||||
if(BINDING_TYPE STREQUAL "pybind"
|
||||
OR BUILD_DEEP_EP
|
||||
OR BUILD_DEEP_GEMM)
|
||||
add_subdirectory(${3RDPARTY_DIR}/pybind11
|
||||
${CMAKE_CURRENT_BINARY_DIR}/pybind11)
|
||||
FetchContent_MakeAvailable(pybind11)
|
||||
include_directories(${CMAKE_BINARY_DIR}/_deps/pybind11-src/include)
|
||||
endif()
|
||||
if(BINDING_TYPE STREQUAL "nanobind")
|
||||
add_subdirectory(${3RDPARTY_DIR}/nanobind
|
||||
${CMAKE_CURRENT_BINARY_DIR}/nanobind)
|
||||
FetchContent_MakeAvailable(nanobind)
|
||||
include_directories(${CMAKE_BINARY_DIR}/_deps/nanobind-src/include)
|
||||
endif()
|
||||
|
||||
FetchContent_MakeAvailable(cutlass cxxopts flashmla json xgrammar)
|
||||
|
||||
if(ENABLE_UCX)
|
||||
FetchContent_MakeAvailable(cppzmq ucxx)
|
||||
endif()
|
||||
|
||||
if(NOT NVTX_DISABLE)
|
||||
FetchContent_MakeAvailable(nvtx)
|
||||
endif()
|
||||
|
||||
if(BUILD_DEEP_GEMM)
|
||||
FetchContent_MakeAvailable(deepgemm)
|
||||
endif()
|
||||
|
||||
if(NOT NVTX_DISABLE)
|
||||
set(maybe_nvtx_includedir ${CMAKE_BINARY_DIR}/_deps/nvtx-src/include)
|
||||
endif()
|
||||
|
||||
# include as system to suppress warnings
|
||||
@ -251,18 +281,10 @@ include_directories(
|
||||
${CUDAToolkit_INCLUDE_DIRS}/cccl
|
||||
${CUDNN_ROOT_DIR}/include
|
||||
$<TARGET_PROPERTY:TensorRT::NvInfer,INTERFACE_INCLUDE_DIRECTORIES>
|
||||
${3RDPARTY_DIR}/cutlass/include
|
||||
${3RDPARTY_DIR}/cutlass/tools/util/include
|
||||
${3RDPARTY_DIR}/NVTX/include
|
||||
${3RDPARTY_DIR}/json/include)
|
||||
if(BINDING_TYPE STREQUAL "pybind"
|
||||
OR BUILD_DEEP_EP
|
||||
OR BUILD_DEEP_GEMM)
|
||||
include_directories(${3RDPARTY_DIR}/pybind11/include)
|
||||
endif()
|
||||
if(BINDING_TYPE STREQUAL "nanobind")
|
||||
include_directories(${3RDPARTY_DIR}/nanobind/include)
|
||||
endif()
|
||||
${maybe_nvtx_includedir}
|
||||
${CMAKE_BINARY_DIR}/_deps/cutlass-src/include
|
||||
${CMAKE_BINARY_DIR}/_deps/cutlass-src/tools/util/include
|
||||
${CMAKE_BINARY_DIR}/_deps/json-src/include)
|
||||
|
||||
if(${CUDAToolkit_VERSION} VERSION_GREATER_EQUAL "11")
|
||||
add_definitions("-DENABLE_BF16")
|
||||
@ -476,7 +498,7 @@ print(os.path.dirname(torch.__file__),end='');"
|
||||
endif()
|
||||
list(APPEND CMAKE_PREFIX_PATH ${TORCH_DIR})
|
||||
set(USE_SYSTEM_NVTX ON)
|
||||
set(nvtx3_dir ${3RDPARTY_DIR}/NVTX/include)
|
||||
set(nvtx3_dir ${CMAKE_BINARY_DIR}/_deps/nvtx-src/include)
|
||||
set(CMAKE_CUDA_ARCHITECTURES_BACKUP ${CMAKE_CUDA_ARCHITECTURES})
|
||||
find_package(Torch REQUIRED)
|
||||
set(CMAKE_CUDA_ARCHITECTURES ${CMAKE_CUDA_ARCHITECTURES_BACKUP})
|
||||
@ -528,14 +550,15 @@ if(ENABLE_UCX)
|
||||
if(NOT ${ucx_FOUND})
|
||||
set(ENABLE_UCX 0)
|
||||
else()
|
||||
set(ucxx_source_dir ${CMAKE_BINARY_DIR}/_deps/ucxx-src)
|
||||
if(DEFINED ENV{GITHUB_MIRROR} AND NOT "$ENV{GITHUB_MIRROR}" STREQUAL "")
|
||||
if(EXISTS "${3RDPARTY_DIR}/ucxx/fetch_rapids.cmake")
|
||||
file(READ "${3RDPARTY_DIR}/ucxx/fetch_rapids.cmake" FILE_CONTENTS)
|
||||
if(EXISTS "${ucxx_source_dir}/fetch_rapids.cmake")
|
||||
file(READ "${ucxx_source_dir}/fetch_rapids.cmake" FILE_CONTENTS)
|
||||
string(
|
||||
REPLACE "https://raw.githubusercontent.com/rapidsai/rapids-cmake"
|
||||
"$ENV{GITHUB_MIRROR}/rapidsai/rapids-cmake/raw/refs/heads"
|
||||
FILE_CONTENTS "${FILE_CONTENTS}")
|
||||
file(WRITE "${3RDPARTY_DIR}/ucxx/fetch_rapids.cmake" "${FILE_CONTENTS}")
|
||||
file(WRITE "${ucxx_source_dir}/fetch_rapids.cmake" "${FILE_CONTENTS}")
|
||||
message(WARNING "Replace UCXX fetch_rapids.cmake with internal mirror")
|
||||
endif()
|
||||
endif()
|
||||
@ -546,13 +569,13 @@ if(ENABLE_UCX)
|
||||
execute_process(
|
||||
COMMAND
|
||||
${CMAKE_COMMAND} -E env LIB_BUILD_DIR=${CMAKE_BINARY_DIR}/ucxx/build
|
||||
${3RDPARTY_DIR}/ucxx/build.sh libucxx -n
|
||||
${ucxx_source_dir}/build.sh libucxx -n
|
||||
--cmake-args=\"-DBUILD_SHARED_LIBS=OFF
|
||||
-DCMAKE_CXX_FLAGS=-D_GLIBCXX_USE_CXX11_ABI=${USE_CXX11_ABI}\"
|
||||
OUTPUT_VARIABLE UCXX_BUILD_OUTPUT
|
||||
RESULT_VARIABLE UCXX_BUILD_RESULT)
|
||||
if(UCXX_BUILD_RESULT)
|
||||
message(${UCXX_BUILD_OUTPUT})
|
||||
message("ucxx build: ${UCXX_BUILD_OUTPUT}")
|
||||
message(FATAL_ERROR "ucxx build failed")
|
||||
endif()
|
||||
find_package(ucxx REQUIRED PATHS ${CMAKE_BINARY_DIR}/ucxx/build
|
||||
|
||||
@ -23,9 +23,17 @@
|
||||
#include "tensorrt_llm/executor/cacheCommunicator.h"
|
||||
#include "tensorrt_llm/executor/dataTransceiverState.h"
|
||||
#include "tensorrt_llm/runtime/utils/mpiUtils.h"
|
||||
#include "tensorrt_llm/runtime/utils/pgUtils.h"
|
||||
#include <future>
|
||||
#include <map>
|
||||
#include <memory>
|
||||
#include <mutex>
|
||||
#include <optional>
|
||||
#include <pybind11/pybind11.h>
|
||||
#include <torch/csrc/jit/python/pybind_utils.h>
|
||||
#include <torch/custom_class.h>
|
||||
#include <torch/python.h>
|
||||
#include <type_traits>
|
||||
#include <vector>
|
||||
|
||||
using SizeType32 = tensorrt_llm::runtime::SizeType32;
|
||||
|
||||
@ -43,6 +51,134 @@ class BaseKVCacheManager;
|
||||
class CacheSender;
|
||||
class CacheReceiver;
|
||||
|
||||
class CacheTransceiverComm
|
||||
{
|
||||
public:
|
||||
// Construct from a non-owning raw pointer, won't take ownership of the pointer
|
||||
explicit CacheTransceiverComm(mpi::MpiComm const* mpiComm)
|
||||
: mMpiComm(std::shared_ptr<mpi::MpiComm const>(nullptr), mpiComm)
|
||||
{
|
||||
}
|
||||
|
||||
// Construct from a shared_ptr with shared ownership
|
||||
explicit CacheTransceiverComm(std::shared_ptr<mpi::MpiComm const> mpiComm)
|
||||
: mMpiComm(std::move(mpiComm))
|
||||
{
|
||||
}
|
||||
|
||||
// Construct from a ProcessGroup communicator
|
||||
explicit CacheTransceiverComm(c10::intrusive_ptr<c10d::ProcessGroup> pgComm)
|
||||
: mPgComm(std::move(pgComm))
|
||||
{
|
||||
}
|
||||
|
||||
~CacheTransceiverComm() = default;
|
||||
|
||||
bool isMpi() const noexcept
|
||||
{
|
||||
return mMpiComm != nullptr;
|
||||
}
|
||||
|
||||
int getRank() const
|
||||
{
|
||||
if (isMpi())
|
||||
{
|
||||
return mMpiComm->getRank();
|
||||
}
|
||||
return mPgComm->getRank();
|
||||
}
|
||||
|
||||
int getSize() const
|
||||
{
|
||||
if (isMpi())
|
||||
{
|
||||
return mMpiComm->getSize();
|
||||
}
|
||||
return mPgComm->getSize();
|
||||
}
|
||||
|
||||
void allgather(void const* sendbuf, void* recvbuf, int count, mpi::MpiType dtype) const
|
||||
{
|
||||
if (isMpi())
|
||||
{
|
||||
mMpiComm->allgather(sendbuf, recvbuf, count, dtype);
|
||||
return;
|
||||
}
|
||||
TLLM_THROW("Input arguments only supported in mpi");
|
||||
}
|
||||
|
||||
template <typename Input, typename Output>
|
||||
bool allgather(Input input, Output output, c10d::AllgatherOptions options = c10d::AllgatherOptions()) const
|
||||
{
|
||||
if (isMpi())
|
||||
{
|
||||
TLLM_THROW("Input arguments only supported in pg");
|
||||
}
|
||||
tensorrt_llm::pg_utils::PgHelper pgh{mPgComm};
|
||||
|
||||
PGCHECK_THROW(pgh.allgather(input, output, options));
|
||||
return true;
|
||||
}
|
||||
|
||||
template <typename Input, typename Output>
|
||||
bool allgatherv(Input input, Output output, std::vector<int> const& sizes,
|
||||
c10d::AllgatherOptions options = c10d::AllgatherOptions()) const
|
||||
{
|
||||
if (isMpi())
|
||||
{
|
||||
TLLM_THROW("Input arguments only supported in pg");
|
||||
}
|
||||
tensorrt_llm::pg_utils::PgHelper pgh{mPgComm};
|
||||
PGCHECK_THROW(pgh.allgatherv(input, output, sizes, options));
|
||||
return true;
|
||||
}
|
||||
|
||||
bool allgatherv(void const* sendbuf, int sendcount, mpi::MpiType sendtype, void* recvbuf,
|
||||
std::vector<int> const& recvcounts, std::vector<int> const& displs, mpi::MpiType recvtype) const
|
||||
{
|
||||
if (isMpi())
|
||||
{
|
||||
mMpiComm->allgatherv(sendbuf, sendcount, sendtype, recvbuf, recvcounts, displs, recvtype);
|
||||
return true;
|
||||
}
|
||||
TLLM_THROW("Input arguments only supported in mpi");
|
||||
}
|
||||
|
||||
CacheTransceiverComm split(int color, int key)
|
||||
{
|
||||
if (isMpi())
|
||||
{
|
||||
auto subgroup = mMpiComm->split(color, key);
|
||||
return CacheTransceiverComm(std::make_shared<mpi::MpiComm const>(std::move(subgroup)));
|
||||
}
|
||||
bool const initialized = Py_IsInitialized();
|
||||
TLLM_CHECK_WITH_INFO(initialized, "Trying to use ProcessGroup communicator but Python is not initialized");
|
||||
try
|
||||
{
|
||||
c10::intrusive_ptr<c10d::ProcessGroup> pgSub;
|
||||
{
|
||||
pybind11::gil_scoped_acquire gil;
|
||||
auto const m = pybind11::module::import("tensorrt_llm._torch.distributed.pg_utils");
|
||||
// Properly box the existing intrusive_ptr ProcessGroup into an IValue
|
||||
// and convert to a Python object without constructing a new instance.
|
||||
auto const py_pg = torch::jit::toPyObject(c10::IValue(mPgComm));
|
||||
|
||||
auto const py_sub_pg = m.attr("split")(color, key, py_pg);
|
||||
pgSub = torch::jit::toCustomClass<c10d::ProcessGroup>(py_sub_pg);
|
||||
}
|
||||
return CacheTransceiverComm(pgSub);
|
||||
}
|
||||
catch (...)
|
||||
{
|
||||
TLLM_THROW("Failed to split process group");
|
||||
}
|
||||
}
|
||||
|
||||
private:
|
||||
std::shared_ptr<mpi::MpiComm const> mMpiComm;
|
||||
c10::intrusive_ptr<c10d::ProcessGroup> mPgComm;
|
||||
};
|
||||
|
||||
class CacheTransceiverFactory
|
||||
{
|
||||
public:
|
||||
@ -71,6 +207,8 @@ public:
|
||||
virtual void checkGenTransferStatus(std::optional<int> const& atLeastRequestNum = std::nullopt) = 0;
|
||||
|
||||
[[nodiscard]] virtual bool checkGenTransferComplete() const = 0;
|
||||
|
||||
virtual bool cancelRequest(LlmRequest* llmRequest) = 0;
|
||||
};
|
||||
|
||||
class CacheTransceiver : public BaseCacheTransceiver
|
||||
@ -111,6 +249,8 @@ public:
|
||||
|
||||
[[nodiscard]] bool checkGenTransferComplete() const override;
|
||||
|
||||
virtual bool cancelRequest(LlmRequest* llmRequest) override;
|
||||
|
||||
private:
|
||||
void initializeCommState();
|
||||
|
||||
@ -120,14 +260,17 @@ private:
|
||||
std::unique_ptr<CacheReceiver> mCacheReceiver;
|
||||
std::vector<std::pair<LlmRequest*, std::future<void>>> mSenderFutures;
|
||||
std::vector<std::pair<LlmRequest*, std::future<void>>> mRequesterFutures;
|
||||
mpi::MpiComm const *mMpiGroupComm{nullptr}, *mMpiWorldComm{nullptr};
|
||||
std::shared_ptr<mpi::MpiComm> mMpiGroupTensorParaComm, mMpiGroupPipeParaComm, mMpiGroupDataComm,
|
||||
mMpiGroupTPInDPComm;
|
||||
mpi::MpiComm const* mMpiWorldComm{nullptr};
|
||||
|
||||
std::shared_ptr<CacheTransceiverComm> mGroupComm;
|
||||
std::shared_ptr<CacheTransceiverComm> mGroupTensorParaComm, mGroupPipeParaComm, mGroupDataComm, mGroupTPInDPComm;
|
||||
|
||||
executor::kv_cache::CommState const* mCommState;
|
||||
std::unique_ptr<executor::kv_cache::CacheState> mCacheState;
|
||||
std::unique_ptr<executor::kv_cache::ConnectionManager> mManager;
|
||||
std::optional<executor::CacheTransceiverConfig> mCacheTransceiverConfig;
|
||||
std::unique_ptr<kv_cache_manager::CacheTransBufferManager> mCacheTransBufferManager;
|
||||
std::vector<std::unique_ptr<kv_cache_manager::CacheTransBufferManager>> mCacheTransBufferManagers;
|
||||
std::vector<kv_cache_manager::CacheTransBufferManager*> mCacheTransBufferManagerPtrs;
|
||||
// library handle to the communicator related features,
|
||||
// this is used to defer dependency resolution until needed.
|
||||
static std::mutex mDllMutex;
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2022-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2022-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
@ -20,7 +20,7 @@
|
||||
#include "tensorrt_llm/batch_manager/common.h"
|
||||
#include "tensorrt_llm/common/algorithm.h"
|
||||
#include "tensorrt_llm/common/optionalRef.h"
|
||||
#include "tensorrt_llm/runtime/bufferManager.h"
|
||||
#include "tensorrt_llm/executor/executor.h"
|
||||
#include "tensorrt_llm/runtime/common.h"
|
||||
#include "tensorrt_llm/runtime/iTensor.h"
|
||||
#include "tensorrt_llm/runtime/modelConfig.h"
|
||||
@ -28,11 +28,7 @@
|
||||
|
||||
namespace tensorrt_llm::runtime
|
||||
{
|
||||
class DecodingInput;
|
||||
class DecodingOutput;
|
||||
class GptDecoderBatched;
|
||||
class SamplingConfig;
|
||||
class SpeculativeDecodingMode;
|
||||
|
||||
namespace decoder
|
||||
{
|
||||
@ -56,10 +52,6 @@ public:
|
||||
using CudaStream = tensorrt_llm::runtime::CudaStream;
|
||||
using TensorPtr = runtime::ITensor::SharedPtr;
|
||||
using SharedConstPtr = runtime::ITensor::SharedConstPtr;
|
||||
using DecodingInput = runtime::DecodingInput;
|
||||
using DecodingOutput = runtime::DecodingOutput;
|
||||
using SpeculativeDecodingMode = runtime::SpeculativeDecodingMode;
|
||||
using GptDecoderBatched = runtime::GptDecoderBatched;
|
||||
template <typename T>
|
||||
using OptionalRef = tensorrt_llm::common::OptionalRef<T>;
|
||||
|
||||
@ -70,7 +62,7 @@ public:
|
||||
{
|
||||
}
|
||||
|
||||
std::tuple<TensorPtr, std::vector<runtime::SamplingConfig>, std::vector<runtime::ITensor::SharedConstPtr>,
|
||||
[[nodiscard]] std::tuple<TensorPtr, std::vector<SamplingConfig>, std::vector<SharedConstPtr>,
|
||||
std::vector<executor::LookaheadDecodingConfig>>
|
||||
operator()(runtime::ModelConfig const& modelConfig, runtime::WorldConfig const& worldConfig,
|
||||
executor::DecodingConfig const& decodingConfig, RequestVector const& contextRequests,
|
||||
@ -78,8 +70,7 @@ public:
|
||||
CudaStream const& runtimeStream, CudaStream const& decoderStream, SizeType32 maxSequenceLength,
|
||||
SizeType32 beamWidth, OptionalRef<MedusaBuffers const> medusaBuffers) const;
|
||||
|
||||
[[nodiscard]] std::tuple<std::vector<runtime::ITensor::SharedConstPtr>,
|
||||
std::vector<executor::LookaheadDecodingConfig>>
|
||||
[[nodiscard]] std::tuple<std::vector<SharedConstPtr>, std::vector<executor::LookaheadDecodingConfig>>
|
||||
createDecoderRequests(RequestVector const& finishedContextRequests, TensorPtr const& inputIds,
|
||||
executor::DecodingConfig const& decodingConfig, runtime::decoder::DecoderState& decoderState,
|
||||
nvinfer1::DataType logitsType, runtime::ModelConfig const& modelConfig, runtime::WorldConfig const& worldConfig,
|
||||
|
||||
@ -38,6 +38,7 @@ class DecoderInputBuffers
|
||||
public:
|
||||
using SizeType32 = runtime::SizeType32;
|
||||
using TensorPtr = runtime::ITensor::SharedPtr;
|
||||
using TensorConstPtr = runtime::ITensor::SharedConstPtr;
|
||||
|
||||
explicit DecoderInputBuffers(
|
||||
SizeType32 maxBatchSize, SizeType32 maxDecoderSteps, runtime::BufferManager const& manager);
|
||||
@ -60,13 +61,22 @@ public:
|
||||
//! Requests for considered in decoder forward
|
||||
RequestVector decoderRequests;
|
||||
|
||||
//! Logits of decoder requests
|
||||
std::vector<TensorPtr> decoderLogits;
|
||||
|
||||
//! Maximum number of decoding steps of decoder requests.
|
||||
//! This is only more than 1 for external draft tokens speculative decoding.
|
||||
SizeType32 maxDecoderSteps{1};
|
||||
|
||||
//! Batch slots for all decoder steps, [maxDecoderSteps][maxBatchSize]
|
||||
std::vector<TensorPtr> forwardBatchSlots;
|
||||
|
||||
//! Logits of decoder requests
|
||||
std::vector<TensorPtr> logits;
|
||||
//! Logits for requests in forwardBatchSlots (in the same order).
|
||||
//! [maxDecoderSteps][batchSize][1, beamWidth, vocabSizePadded], on gpu
|
||||
std::vector<std::vector<TensorConstPtr>> batchLogits;
|
||||
|
||||
//! Logits for speculative decoding (Medusa)
|
||||
//! Logits for speculative decoding (Medusa).
|
||||
//! The vector is sparse, only slots in forwardBatchSlots are used.
|
||||
//! [maxBatchSize][maxAcceptedDraftTokensPerStep][maxDraftTokens + 1, vocabSizePadded]
|
||||
std::vector<std::vector<runtime::ITensor::SharedPtr>> predictedDraftLogits;
|
||||
};
|
||||
|
||||
@ -92,13 +92,8 @@ public:
|
||||
bool verifyQueueIntegrity() override;
|
||||
|
||||
private:
|
||||
// Check if the block should be added to mFreeQueues.
|
||||
bool isReleasedLeafBlock(BlockPtr const& block);
|
||||
|
||||
// Queues of available leaf blocks, split by cache level and priority level
|
||||
std::vector<std::vector<FreeBlocksQueue>> mFreeQueues;
|
||||
// All blocks that have been released, along with the amount of released children
|
||||
std::vector<std::unordered_set<SizeType32>> mReleasedBlocks;
|
||||
// Iterators to block entries in mFreeQueues
|
||||
std::vector<std::optional<FreeBlocksQueue::iterator>> mFreeBlockIterators;
|
||||
// Amount of free blocks at each cache level
|
||||
|
||||
@ -41,6 +41,7 @@
|
||||
#include <optional>
|
||||
#include <set>
|
||||
#include <unordered_map>
|
||||
#include <utility>
|
||||
#include <vector>
|
||||
|
||||
namespace kvc = tensorrt_llm::executor::kv_cache;
|
||||
@ -84,6 +85,32 @@ using MmKey = std::pair<std::array<uint8_t, 32>, SizeType32>;
|
||||
template <typename T>
|
||||
using OptionalRef = tensorrt_llm::common::OptionalRef<T>;
|
||||
|
||||
//! \brief Split vector into list of blocks of given size.
|
||||
//! \param vec vector to split
|
||||
//! \param usableSize part of the vector that is processed
|
||||
//! \param elementsPerBlock desired size of blocks
|
||||
//! \param allowPartial whether to append a block smaller than `elementsPerBlock` at the end
|
||||
//! \return list of blocks
|
||||
template <typename T>
|
||||
std::list<std::vector<T>> chopVectorIntoBlocks(
|
||||
std::vector<T> const& vec, SizeType32 usableSize, SizeType32 elementsPerBlock, bool allowPartial)
|
||||
{
|
||||
TLLM_CHECK_WITH_INFO(
|
||||
usableSize <= static_cast<SizeType32>(vec.size()), "usableSize=%d > %ld=vec.size()", usableSize, vec.size());
|
||||
std::list<std::vector<T>> blockedVectors;
|
||||
auto const vecEnd = vec.begin() + usableSize;
|
||||
for (auto begin = vec.begin(); begin < vecEnd; begin += elementsPerBlock)
|
||||
{
|
||||
auto blockSize = std::min(elementsPerBlock, static_cast<SizeType32>(std::distance(begin, vecEnd)));
|
||||
auto end = begin + blockSize;
|
||||
if (blockSize == elementsPerBlock || allowPartial)
|
||||
{
|
||||
blockedVectors.emplace_back(begin, end);
|
||||
}
|
||||
}
|
||||
return blockedVectors;
|
||||
}
|
||||
|
||||
struct TempAttentionWindowInputs
|
||||
{
|
||||
bool pagedContextFMHA;
|
||||
@ -103,17 +130,23 @@ struct WindowSizeMetadata
|
||||
SizeType32 temporaryAttentionWindow; // Temporary kv cache length per sequence.
|
||||
// Only needed when chunked context + sliding window attention are used
|
||||
// together. And it should only be considered when allocating blocks.
|
||||
SizeType32 windowSize;
|
||||
bool isSWA;
|
||||
|
||||
std::string toString()
|
||||
{
|
||||
return tensorrt_llm::common::fmtstr(
|
||||
"WindowSizeMetadata{ .allottedPrimaryBlocks=%d, .allottedSecondaryBlocks=%d, .absolutePoolsOffset=%d, "
|
||||
".numPools=%d, .maxTokenNum=%d, .maxBlocksPerSeq=%d, .maxNumBlocks=%d, .temporaryAttentionWindow=%d }",
|
||||
".numPools=%d, .maxTokenNum=%d, .maxBlocksPerSeq=%d, .maxNumBlocks=%d, .temporaryAttentionWindow=%d, "
|
||||
".windowSize=%d, .isSWA=%d }",
|
||||
allottedPrimaryBlocks, allottedSecondaryBlocks, absolutePoolsOffset, numPools, maxTokenNum, maxBlocksPerSeq,
|
||||
maxNumBlocks, temporaryAttentionWindow);
|
||||
maxNumBlocks, temporaryAttentionWindow, windowSize, isSWA);
|
||||
}
|
||||
};
|
||||
|
||||
std::vector<MmKey> generateBlockHashExtraKeys(
|
||||
tensorrt_llm::batch_manager::LlmRequest const& llmRequest, SizeType32 startTokenIdx, SizeType32 endTokenIdx);
|
||||
|
||||
struct BlockKey
|
||||
{
|
||||
bool usesExtraIds = false;
|
||||
@ -147,11 +180,7 @@ struct BlockKey
|
||||
{
|
||||
}
|
||||
|
||||
bool operator==(BlockKey const& other) const noexcept
|
||||
{
|
||||
return (usesExtraIds == other.usesExtraIds && loraTaskId == other.loraTaskId
|
||||
&& uniqueTokens == other.uniqueTokens && extraKeys == other.extraKeys && cacheSaltID == other.cacheSaltID);
|
||||
}
|
||||
bool operator==(BlockKey const& other) const noexcept;
|
||||
|
||||
int partialMatch(BlockKey const& other) const noexcept
|
||||
{
|
||||
@ -166,6 +195,8 @@ struct BlockKey
|
||||
}
|
||||
};
|
||||
|
||||
std::vector<BlockKey> buildBlockKeys(std::list<VecUniqueTokens>& blockedUniqueTokens, LlmRequest const& llmRequest);
|
||||
|
||||
// Implement hash functor for BlockKey.
|
||||
// This allows us to use unordered_map with BlockKey as key.
|
||||
// Based on https://stackoverflow.com/questions/20511347/a-good-hash-function-for-a-vector/72073933#72073933
|
||||
@ -484,6 +515,8 @@ private:
|
||||
executor::KvCacheRetentionConfig mKvCacheRetentionConfig;
|
||||
// Number of front blocks removed from the sequence
|
||||
SizeType32 mNumFrontBlocksRemoved;
|
||||
// Set of used blocks by the sequence
|
||||
std::set<KVCacheBlock::IdType> mUsedBlocks;
|
||||
};
|
||||
|
||||
// attach metadata to a pool pointer
|
||||
@ -503,10 +536,12 @@ public:
|
||||
|
||||
// FP4 KV caches have extra pools that contain second level scales for dequantization.
|
||||
bool containsBlockScales;
|
||||
bool containsIndexerKCache;
|
||||
|
||||
KVCacheBlockPool(SizeType32 numLayers, SizeType32 kvFactor, SizeType32 numKvHeads, SizeType32 sizePerHead,
|
||||
SizeType32 tokensPerBlock, runtime::ITensor::SharedPtr primaryPtr = nullptr,
|
||||
runtime::ITensor::SharedPtr secondaryPtr = nullptr, bool containsBlockScales = false)
|
||||
runtime::ITensor::SharedPtr secondaryPtr = nullptr, bool containsBlockScales = false,
|
||||
bool containsIndexerKCache = false)
|
||||
: numLayers(numLayers)
|
||||
, kvFactor(kvFactor)
|
||||
, numKvHeads(numKvHeads)
|
||||
@ -516,6 +551,7 @@ public:
|
||||
, primaryPtr(std::move(primaryPtr))
|
||||
, secondaryPtr(std::move(secondaryPtr))
|
||||
, containsBlockScales(containsBlockScales)
|
||||
, containsIndexerKCache(containsIndexerKCache)
|
||||
{
|
||||
}
|
||||
};
|
||||
@ -554,14 +590,32 @@ public:
|
||||
bool onboardBlocks, CacheType cacheType, std::optional<executor::RetentionPriority> secondaryOffloadMinPriority,
|
||||
std::shared_ptr<KVCacheEventManager> eventManager, bool enablePartialReuse, bool copyOnPartialReuse,
|
||||
std::shared_ptr<kv_connector::KvCacheConnectorManager> kvCacheConnectorManager,
|
||||
std::shared_ptr<kvc::BaseLoopbackAgent> loopbackAgent = nullptr);
|
||||
std::shared_ptr<kvc::BaseLoopbackAgent> loopbackAgent = nullptr, bool enableIndexerKCache = false,
|
||||
SizeType32 indexerKCacheQuantBlockSize = 128, SizeType32 indexerKCacheIndexHeadDim = 0);
|
||||
|
||||
~WindowBlockManager();
|
||||
|
||||
[[nodiscard]] bool isEnableIndexerKCache() const
|
||||
{
|
||||
return mEnableIndexerKCache;
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getIndexerKCacheQuantBlockSize() const
|
||||
{
|
||||
return mIndexerKCacheQuantBlockSize;
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getIndexerKCacheIndexHeadDim() const
|
||||
{
|
||||
return mIndexerKCacheIndexHeadDim;
|
||||
}
|
||||
|
||||
void allocatePools(bool useUvm);
|
||||
|
||||
void releasePools();
|
||||
|
||||
void createIndexerKCachePools();
|
||||
|
||||
void startScheduling();
|
||||
|
||||
//! \brief Assign blocks for new sequence. Try to reuse blocks.
|
||||
@ -577,14 +631,18 @@ public:
|
||||
|
||||
void replaceSharedBlock(GenerationRequest& sequence, SizeType32 blockIdx);
|
||||
|
||||
//! \brief Get the ids of all newly allocated (not reused) blocks for the sequence.
|
||||
std::vector<KVCacheBlock::IdType> getNewlyAllocatedBlockIds(GenerationRequest const& sequence) const;
|
||||
[[nodiscard]] std::optional<KVCacheBlock::IdType> storeBlocksForReuse(
|
||||
GenerationRequest& sequence, OptionalRef<LlmRequest const> llmRequest, bool pinBlocks = false);
|
||||
|
||||
void storeNewBlock(GenerationRequest& sequence, OptionalRef<LlmRequest const> llmRequest);
|
||||
|
||||
//! \brief Pin blocks associated with a sequence to prevent eviction.
|
||||
void pinBlocks(GenerationRequest& sequence);
|
||||
|
||||
//! \brief Release blocks of the sequence.
|
||||
//! \details When llmRequest is provided and reuse is enabled, blocks will be stored.
|
||||
void releaseBlocks(GenerationRequest& sequence, OptionalRef<LlmRequest const> llmRequest);
|
||||
std::optional<KVCacheBlock::IdType> releaseBlocks(
|
||||
GenerationRequest& sequence, OptionalRef<LlmRequest const> llmRequest);
|
||||
|
||||
//! \brief Simulate freeing all blocks for that sequence to check impact on number of free blocks
|
||||
void schedulingReleaseBlocks(LlmRequest::RequestIdType requestId);
|
||||
@ -596,15 +654,15 @@ public:
|
||||
void releaseLastBlock(GenerationRequest& sequence);
|
||||
|
||||
//! \brief Detach front block from the sequence
|
||||
void detachFrontBlock(GenerationRequest& sequence, bool isEnableBlockReuse);
|
||||
void detachFrontBlock(GenerationRequest& sequence);
|
||||
|
||||
//! \brief Add/detach block(s) to/from the sequence if needed
|
||||
//! \details When we need a new block, we add it. For sliding window
|
||||
//! attention (SWA), when a block goes out-of-window (OOW), we detach it
|
||||
//! and store it if reuse is enabled. If this called in the first step of
|
||||
//! the generation phase, we may detach more than a single block since
|
||||
//! there may be more than one context block that goes OOW.
|
||||
void adjustBlocksIfNeeded(GenerationRequest& sequence, bool isEnableBlockReuse);
|
||||
//! If this called in the first step of the generation phase, we may detach
|
||||
//! more than a single block since there may be more than one context block
|
||||
//! that goes OOW.
|
||||
void adjustBlocksIfNeeded(GenerationRequest& sequence);
|
||||
|
||||
[[nodiscard]] SizeType32 getWindowSize() const noexcept
|
||||
{
|
||||
@ -684,13 +742,30 @@ public:
|
||||
#endif
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getNumPools(bool includeBlockScalePools = true) const noexcept
|
||||
[[nodiscard]] SizeType32 getNumPools(
|
||||
bool includeBlockScalePools = true, bool includeIndexerKCachePools = true) const noexcept
|
||||
{
|
||||
if (includeBlockScalePools)
|
||||
if (includeBlockScalePools && includeIndexerKCachePools)
|
||||
{
|
||||
return mPools.size();
|
||||
}
|
||||
return std::count_if(mPools.begin(), mPools.end(), [](auto const& pool) { return !pool.containsBlockScales; });
|
||||
SizeType32 count = 0;
|
||||
for (auto const& pool : mPools)
|
||||
{
|
||||
if (includeBlockScalePools && pool.containsBlockScales)
|
||||
{
|
||||
count++;
|
||||
}
|
||||
else if (includeIndexerKCachePools && pool.containsIndexerKCache)
|
||||
{
|
||||
count++;
|
||||
}
|
||||
if (!pool.containsBlockScales && !pool.containsIndexerKCache)
|
||||
{
|
||||
count++;
|
||||
}
|
||||
}
|
||||
return count;
|
||||
}
|
||||
|
||||
[[nodiscard]] KVCacheBlockPool const& getPool(SizeType32 poolIdx) const
|
||||
@ -731,7 +806,7 @@ public:
|
||||
|
||||
//! \brief Bring offloaded block from secondary to primary memory.
|
||||
//! \details Does nothing if block is already in primary memory.
|
||||
void onboardBlock(BlockPtr const& offloadBlock,
|
||||
void onboardBlock(GenerationRequest& sequence, BlockPtr const& offloadBlock,
|
||||
executor::KvCacheTransferMode mode = executor::KvCacheTransferMode::DRAM, std::string const& directory = "");
|
||||
|
||||
//! \brief Bring block from primary to secondary memory.
|
||||
@ -757,8 +832,11 @@ public:
|
||||
//! \brief Store blocks in cached blocks.
|
||||
//! \param blockKeys Key of each block.
|
||||
//! \param blockIds Id of each block.
|
||||
//! \return Number of actual blocks stored.
|
||||
SizeType32 storeBlocks(std::vector<BlockKey> const& blockKeys, std::vector<KVCacheBlock::IdType> const& blockIds);
|
||||
//! \param pinBlocks If true, increment ref count for blocks while storing (pin on store).
|
||||
//! \return Pair of (num blocks stored for reuse, id of the last block stored if any).
|
||||
[[nodiscard]] std::pair<SizeType32, std::optional<KVCacheBlock::IdType>> storeBlocks(
|
||||
std::vector<BlockKey> const& blockKeys, std::vector<KVCacheBlock::IdType> const& blockIds,
|
||||
bool pinBlocks = false);
|
||||
|
||||
[[nodiscard]] bool verifyQueueIntegrity();
|
||||
|
||||
@ -786,6 +864,35 @@ public:
|
||||
return mIsSWA;
|
||||
}
|
||||
|
||||
[[nodiscard]] std::shared_ptr<KVCacheBlock> findBlocksInReuseTreeByBlockKey(BlockKey const& blockKey);
|
||||
|
||||
//! \brief Unpin blocks by starting from a block id and walking prev pointers.
|
||||
void unpinBlocksById(KVCacheBlock::IdType blockId);
|
||||
|
||||
void initializeSequenceStorageValidity(LlmRequest::RequestIdType requestId)
|
||||
{
|
||||
mIsValidStoreForReuseSequence[requestId] = true;
|
||||
}
|
||||
|
||||
void releaseSequenceStorageValidity(LlmRequest::RequestIdType requestId)
|
||||
{
|
||||
mIsValidStoreForReuseSequence.erase(requestId);
|
||||
}
|
||||
|
||||
//! \brief Return whether this sequence is valid for store for reuse
|
||||
[[nodiscard]] bool isSequenceValidForStoreForReuse(LlmRequest::RequestIdType requestId) const
|
||||
{
|
||||
TLLM_CHECK_WITH_INFO(mIsValidStoreForReuseSequence.count(requestId) > 0, "Sequence should be bookkeeped");
|
||||
return mIsValidStoreForReuseSequence.at(requestId);
|
||||
}
|
||||
|
||||
void resetReuseState()
|
||||
{
|
||||
std::lock_guard<std::mutex> lock(mCachedBlocksRootMutex);
|
||||
mCachedBlocksRoot
|
||||
= std::make_shared<KVCacheBlock>(KVCacheBlock::kCachedBlocksRootId, tensorrt_llm::kernels::KVCacheIndex{0});
|
||||
}
|
||||
|
||||
private:
|
||||
//! \brief Add single block to beam of sequence and mAllocatedBlocksPerSeq.
|
||||
void addBlockToBeam(BlockPtr& block, GenerationRequest& sequence, SizeType32 beamIdx);
|
||||
@ -802,18 +909,17 @@ private:
|
||||
executor::KvCacheTransferMode mode = executor::KvCacheTransferMode::DRAM, std::string const& directory = "");
|
||||
|
||||
//! \brief Free block and all it's descendants. This makes block a claimed leaf block.
|
||||
void freeChildren(BlockPtr const& block, executor::RetentionPriority priority,
|
||||
std::optional<std::chrono::milliseconds> durationMs);
|
||||
void freeChildren(BlockPtr const& block);
|
||||
|
||||
//! \brief Find block least likely to be reused, free it if necessary and return.
|
||||
[[nodiscard]] BlockPtr getFreeBlock(
|
||||
//! \param sequence Sequence which the free block is allocated for
|
||||
[[nodiscard]] BlockPtr getFreeBlock(GenerationRequest& sequence,
|
||||
executor::RetentionPriority = executor::KvCacheRetentionConfig::kDefaultRetentionPriority,
|
||||
std::optional<std::chrono::milliseconds> durationMs = std::nullopt,
|
||||
executor::KvCacheTransferMode mode = executor::KvCacheTransferMode::DRAM, std::string const& directory = "");
|
||||
|
||||
//! \brief Free block from previous block and claim it from free blocks list.
|
||||
void claimLeafBlock(BlockPtr const& block, std::optional<executor::RetentionPriority> priority = std::nullopt,
|
||||
std::optional<std::chrono::milliseconds> durationMs = std::nullopt);
|
||||
//! \brief Calls KVCacheBlock::freeLeafBlock to remove block from search tree.
|
||||
void freeLeafBlock(BlockPtr const& block);
|
||||
|
||||
//! \brief For FP4 quantization. Creates pool objects for FP4 block scalars.
|
||||
void createBlockScalePools(SizeType32 blockSize);
|
||||
@ -890,6 +996,24 @@ private:
|
||||
bool mCopyOnPartialReuse;
|
||||
// The kv cache connector manager
|
||||
std::shared_ptr<kv_connector::KvCacheConnectorManager> mKvCacheConnectorManager;
|
||||
|
||||
// Mutex for the cached blocks root
|
||||
std::mutex mCachedBlocksRootMutex;
|
||||
|
||||
// Record which sequence is using the block
|
||||
std::map<KVCacheBlock::IdType, LlmRequest::RequestIdType> mBlockToSequence;
|
||||
// Record whether a sequence has all blocks held valid.
|
||||
// The boolean value is set to true upon first encounter of a new sequence.
|
||||
// It may be invalidated to false when other sequence acquires a block that
|
||||
// is used by another sequence.
|
||||
std::map<LlmRequest::RequestIdType, bool> mIsValidStoreForReuseSequence;
|
||||
|
||||
// Whether to enable indexer K cache
|
||||
bool mEnableIndexerKCache;
|
||||
// Quant block size for indexer K cache
|
||||
SizeType32 mIndexerKCacheQuantBlockSize;
|
||||
// Index head dim for indexer K cache
|
||||
SizeType32 mIndexerKCacheIndexHeadDim;
|
||||
};
|
||||
|
||||
class BlockManager
|
||||
@ -909,7 +1033,23 @@ public:
|
||||
std::shared_ptr<KVCacheEventManager> eventManager = nullptr, bool enablePartialReuse = true,
|
||||
bool copyOnPartialReuse = true,
|
||||
std::shared_ptr<kv_connector::KvCacheConnectorManager> kvCacheConnectorManager = nullptr,
|
||||
std::optional<kvc::BaseAgentConfig> agentConfig = std::nullopt);
|
||||
std::optional<kvc::BaseAgentConfig> agentConfig = std::nullopt, bool enableIndexerKCache = false,
|
||||
SizeType32 indexerKCacheQuantBlockSize = 128, SizeType32 indexerKCacheIndexHeadDim = 0);
|
||||
|
||||
[[nodiscard]] bool isEnableIndexerKCache() const
|
||||
{
|
||||
return mIsEnableIndexerKCache;
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getIndexerKCacheQuantBlockSize() const
|
||||
{
|
||||
return mIndexerKCacheQuantBlockSize;
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getIndexerKCacheIndexHeadDim() const
|
||||
{
|
||||
return mIndexerKCacheIndexHeadDim;
|
||||
}
|
||||
|
||||
BlockManager(BlockManager const&) = delete;
|
||||
BlockManager& operator=(BlockManager const&) = delete;
|
||||
@ -940,13 +1080,20 @@ public:
|
||||
|
||||
void replaceSharedBlock(GenerationRequest& sequence, SizeType32 windowSize, SizeType32 blockIdx);
|
||||
|
||||
std::vector<KVCacheBlock::IdType> getNewlyAllocatedBlockIds(
|
||||
GenerationRequest const& sequence, SizeType32 windowSize) const;
|
||||
std::optional<KVCacheBlock::IdType> releaseBlocks(
|
||||
GenerationRequest& sequence, OptionalRef<LlmRequest const> llmRequest = std::nullopt, bool pinBlocks = false);
|
||||
|
||||
void releaseBlocks(GenerationRequest& sequence, OptionalRef<LlmRequest const> llmRequest = std::nullopt);
|
||||
[[nodiscard]] std::optional<KVCacheBlock::IdType> storeBlocksForReuse(
|
||||
GenerationRequest& sequence, OptionalRef<LlmRequest const> llmRequest = std::nullopt, bool pinBlocks = false);
|
||||
|
||||
void schedulingReleaseBlocks(LlmRequest::RequestIdType requestId);
|
||||
|
||||
/// @brief Pin all blocks associated with a sequence across all window managers.
|
||||
/// @param sequence The generation request whose blocks should be pinned.
|
||||
void pinBlocks(GenerationRequest& sequence);
|
||||
|
||||
void unpinBlocksById(KVCacheBlock::IdType blockId);
|
||||
|
||||
void releaseLastBlock(GenerationRequest& sequence, SizeType32 windowSize);
|
||||
|
||||
void setOffsets(kernels::KVCacheIndex* offsetsPtr, nvinfer1::Dims const& offsetsShape, SizeType32 beamIdx,
|
||||
@ -958,7 +1105,7 @@ public:
|
||||
|
||||
//! \brief Bring block from primary to secondary memory for window size.
|
||||
//! \details Does nothing if block is already in primary memory.
|
||||
void onboardBlock(BlockPtr const& offloadBlock, SizeType32 windowSize,
|
||||
void onboardBlock(GenerationRequest& sequence, BlockPtr const& offloadBlock, SizeType32 windowSize,
|
||||
executor::KvCacheTransferMode mode = executor::KvCacheTransferMode::DRAM, std::string const& directory = "");
|
||||
|
||||
//! \brief Bring block from primary to secondary memory for window size.
|
||||
@ -966,10 +1113,11 @@ public:
|
||||
void offloadBlock(BlockPtr const& block, SizeType32 windowSize,
|
||||
executor::KvCacheTransferMode mode = executor::KvCacheTransferMode::DRAM, std::string const& directory = "");
|
||||
|
||||
void storeBlocks(std::vector<BlockKey> const& blockKeys, std::vector<KVCacheBlock::IdType> const& blockIds,
|
||||
SizeType32 windowSize)
|
||||
[[nodiscard]] std::pair<SizeType32, std::optional<KVCacheBlock::IdType>> storeBlocks(
|
||||
std::vector<BlockKey> const& blockKeys, std::vector<KVCacheBlock::IdType> const& blockIds,
|
||||
SizeType32 windowSize, bool pinBlocks = false)
|
||||
{
|
||||
mWindowBlockManagers.at(windowSize).storeBlocks(blockKeys, blockIds);
|
||||
return mWindowBlockManagers.at(windowSize).storeBlocks(blockKeys, blockIds, pinBlocks);
|
||||
}
|
||||
|
||||
[[nodiscard]] bool verifyQueueIntegrity(SizeType32 windowSize);
|
||||
@ -1003,6 +1151,15 @@ public:
|
||||
return sumWindows([](auto const& manager) { return manager.getNumAllocTotalBlocks(); });
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getFirstWindowSize() const
|
||||
{
|
||||
if (mWindowBlockManagers.empty())
|
||||
{
|
||||
return 0;
|
||||
}
|
||||
return mWindowBlockManagers.begin()->first;
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getNumAllocNewBlocks() const
|
||||
{
|
||||
return sumWindows([](auto const& manager) { return manager.getNumAllocNewBlocks(); });
|
||||
@ -1072,10 +1229,11 @@ public:
|
||||
return getPool(poolIdx).blockSize;
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getNumPools(bool includeBlockScalePools = true) const
|
||||
[[nodiscard]] SizeType32 getNumPools(
|
||||
bool includeBlockScalePools = true, bool includeIndexerKCachePools = true) const
|
||||
{
|
||||
return sumWindows(
|
||||
[includeBlockScalePools](auto const& manager) { return manager.getNumPools(includeBlockScalePools); });
|
||||
return sumWindows([includeBlockScalePools, includeIndexerKCachePools](auto const& manager)
|
||||
{ return manager.getNumPools(includeBlockScalePools, includeIndexerKCachePools); });
|
||||
}
|
||||
|
||||
[[nodiscard]] std::map<SizeType32, WindowSizeMetadata> const& getWindowSizesMetadata() const noexcept
|
||||
@ -1133,6 +1291,12 @@ public:
|
||||
return mWindowBlockManagers.at(windowSize).getBlockById(blockId);
|
||||
}
|
||||
|
||||
[[nodiscard]] std::shared_ptr<KVCacheBlock> findBlocksInReuseTreeByBlockKey(
|
||||
BlockKey const& blockKey, SizeType32 windowSize)
|
||||
{
|
||||
return mWindowBlockManagers.at(windowSize).findBlocksInReuseTreeByBlockKey(blockKey);
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getNumPrimaryBlocks() const
|
||||
{
|
||||
return sumWindows([](auto const& manager) { return manager.getNumPrimaryBlocks(); });
|
||||
@ -1173,10 +1337,60 @@ public:
|
||||
//! \brief Add/detach block(s) to/from the sequence if needed
|
||||
//! \details When we need a new block, we add it. For sliding window
|
||||
//! attention (SWA), when a block goes out-of-window (OOW), we detach it
|
||||
//! and store it if reuse is enabled. If this called in the first step of
|
||||
//! the generation phase, we may detach more than a single block since
|
||||
//! there may be more than one context block that goes OOW.
|
||||
void adjustBlocksIfNeeded(GenerationRequest& sequence, bool isEnableBlockReuse);
|
||||
//! If this called in the first step of the generation phase, we may
|
||||
//! detach more than a single block since there may be more than one
|
||||
//! context block that goes OOW.
|
||||
void adjustBlocksIfNeeded(GenerationRequest& sequence);
|
||||
|
||||
//! \brief Return whether the sequence is already managed by the block manager
|
||||
[[nodiscard]] bool isSequenceHeld(LlmRequest::RequestIdType requestId) const
|
||||
{
|
||||
return mManagedSequences.count(requestId) > 0;
|
||||
}
|
||||
|
||||
//! \brief Add a sequence to the managed sequences
|
||||
//! \details Take the sequence into account for the manager. Initialize
|
||||
//! sequence storage validity under all window sizes.
|
||||
void holdSequence(LlmRequest::RequestIdType requestId)
|
||||
{
|
||||
mManagedSequences.insert(requestId);
|
||||
for (auto const& [windowSize, metadata] : mWindowSizeToMetadata)
|
||||
{
|
||||
mWindowBlockManagers.at(windowSize).initializeSequenceStorageValidity(requestId);
|
||||
}
|
||||
}
|
||||
|
||||
//! \brief Remove a sequence from the managed sequences.
|
||||
//! \details Remove sequence from the managed sequences and remove sequence
|
||||
//! storage
|
||||
void releaseSequence(LlmRequest::RequestIdType requestId)
|
||||
{
|
||||
mManagedSequences.erase(requestId);
|
||||
for (auto const& [windowSize, metadata] : mWindowSizeToMetadata)
|
||||
{
|
||||
mWindowBlockManagers.at(windowSize).releaseSequenceStorageValidity(requestId);
|
||||
}
|
||||
}
|
||||
|
||||
//! \brief Return whether the sequence is still valid for store-for-reuse
|
||||
//! regarding the specific window size.
|
||||
//! \details Currently this utility function is only used under
|
||||
//! kvCacheManagerTest.cpp. Checking for store-for-reuse for each window
|
||||
//! size is done in an iterating fashion under BlockManager::releaseBlocks.
|
||||
bool isSequenceValidForStoreForReuse(LlmRequest::RequestIdType requestId, SizeType32 windowSize) const
|
||||
{
|
||||
TLLM_CHECK_WITH_INFO(
|
||||
mWindowBlockManagers.count(windowSize) > 0, "Querying window size is not found under mWindowBlockManager");
|
||||
return mWindowBlockManagers.at(windowSize).isSequenceValidForStoreForReuse(requestId);
|
||||
}
|
||||
|
||||
void resetReuseState()
|
||||
{
|
||||
for (auto& [windowSize, manager] : mWindowBlockManagers)
|
||||
{
|
||||
manager.resetReuseState();
|
||||
}
|
||||
}
|
||||
|
||||
private:
|
||||
[[nodiscard]] WindowBlockManager const& windowManagerByLayer(SizeType32 layerIdx) const
|
||||
@ -1212,6 +1426,12 @@ private:
|
||||
std::vector<SizeType32> mLayerToWindowSize;
|
||||
std::vector<SizeType32> mAbsolutePoolToWindowSize;
|
||||
std::vector<SizeType32> mAbsolutePoolToRelativePoolIndex;
|
||||
// Record what sequences are currently managed by the block manager
|
||||
std::set<LlmRequest::RequestIdType> mManagedSequences;
|
||||
|
||||
bool mIsEnableIndexerKCache{false};
|
||||
SizeType32 mIndexerKCacheQuantBlockSize{0};
|
||||
SizeType32 mIndexerKCacheIndexHeadDim{0};
|
||||
};
|
||||
|
||||
struct OffsetTableDimensions
|
||||
@ -1274,6 +1494,10 @@ public:
|
||||
[[nodiscard]] virtual SizeType32 getRemainingBlocksToCompletion(LlmRequest const& req, SizeType32 windowSize) const
|
||||
= 0;
|
||||
|
||||
/// @brief Pin blocks associated with a request to prevent eviction.
|
||||
/// @param requestId The ID of the request whose blocks should be pinned.
|
||||
virtual void pinBlocks(LlmRequest::RequestIdType requestId) = 0;
|
||||
|
||||
/// @brief Increase size for request at seqSlotIdx. Allocate new KV cache block(s) if needed.
|
||||
virtual void addToken(LlmRequest::RequestIdType requestId) = 0;
|
||||
|
||||
@ -1287,8 +1511,8 @@ public:
|
||||
OptionalRef<LlmRequest> llmRequest = std::nullopt)
|
||||
= 0;
|
||||
|
||||
virtual void removeSequence(
|
||||
LlmRequest::RequestIdType requestId, OptionalRef<LlmRequest const> llmRequest = std::nullopt)
|
||||
[[nodiscard]] virtual std::optional<KVCacheBlock::IdType> removeSequence(LlmRequest::RequestIdType requestId,
|
||||
OptionalRef<LlmRequest const> llmRequest = std::nullopt, bool pinOnRelease = false)
|
||||
= 0;
|
||||
|
||||
virtual void schedulingRemoveSequence(LlmRequest::RequestIdType requestId) = 0;
|
||||
@ -1310,6 +1534,10 @@ public:
|
||||
|
||||
[[nodiscard]] virtual bool isEnableBlockReuse() const = 0;
|
||||
|
||||
[[nodiscard]] virtual bool isEnableIndexerKCache() const = 0;
|
||||
[[nodiscard]] virtual SizeType32 getIndexerKCacheIndexHeadDim() const = 0;
|
||||
[[nodiscard]] virtual SizeType32 getIndexerKCacheQuantBlockSize() const = 0;
|
||||
|
||||
// void removeToken(SizeType32 seqSlotIdx);
|
||||
virtual void rewindKVCache(LlmRequest::RequestIdType requestId, SizeType32 rewindLengths) = 0;
|
||||
|
||||
@ -1332,6 +1560,11 @@ public:
|
||||
//! \details This block become reusable from next step.
|
||||
virtual void storeNewBlock(LlmRequest const& llmRequest) = 0;
|
||||
|
||||
/// \brief Store blocks for reuse for a given request id
|
||||
[[nodiscard]] virtual std::optional<KVCacheBlock::IdType> storeBlocksForReuse(
|
||||
LlmRequest::RequestIdType requestId, OptionalRef<LlmRequest const> llmRequest, bool pinBlocks = false)
|
||||
= 0;
|
||||
|
||||
//! \brief Get the block ids of a request [per beam] **for a given window size block manager**
|
||||
[[nodiscard]] virtual std::vector<std::vector<SizeType32>> const& getCacheBlockIds(
|
||||
LlmRequest::RequestIdType requestId, SizeType32 windowSize) const
|
||||
@ -1342,16 +1575,18 @@ public:
|
||||
std::vector<LlmRequest::RequestIdType> const& requestIds, SizeType32 windowSize) const
|
||||
= 0;
|
||||
|
||||
[[nodiscard]] virtual std::vector<KVCacheBlock::IdType> getNewlyAllocatedBlockIds(
|
||||
LlmRequest::RequestIdType requestId, SizeType32 windowSize) const
|
||||
/// @brief Get the last block id (beam 0) for a given sequence and window size
|
||||
[[nodiscard]] virtual std::optional<KVCacheBlock::IdType> getLastBlockId(LlmRequest::RequestIdType requestId) const
|
||||
= 0;
|
||||
|
||||
[[nodiscard]] virtual runtime::ITensor::SharedPtr getUniquePrimaryPool() const = 0;
|
||||
[[nodiscard]] virtual runtime::ITensor::SharedPtr getPrimaryPool(SizeType32 layer_idx) const = 0;
|
||||
[[nodiscard]] virtual runtime::ITensor::SharedPtr getIndexerKCachePool() const = 0;
|
||||
[[nodiscard]] virtual SizeType32 getPoolLayerIdx(SizeType32 layer_idx) const = 0;
|
||||
|
||||
virtual void refreshBlocks() = 0;
|
||||
virtual void flushIterationEvents() = 0;
|
||||
virtual void resetReuseState() = 0;
|
||||
|
||||
[[nodiscard]] static SizeType32 getSinkBubbleLength(SizeType32 sinkTokenLen, SizeType32 tokensPerBlock);
|
||||
|
||||
@ -1414,6 +1649,12 @@ public:
|
||||
[[nodiscard]] virtual SizeType32 getMaxCapacityBatchSize(SizeType32 inputLength, SizeType32 outputLength) const = 0;
|
||||
|
||||
[[nodiscard]] virtual CacheType getCacheType() const = 0;
|
||||
|
||||
[[nodiscard]] virtual std::shared_ptr<KVCacheBlock> findBlocksInReuseTreeByBlockKey(
|
||||
BlockKey const& blockKey, SizeType32 windowSize)
|
||||
= 0;
|
||||
|
||||
virtual void unpinBlocksById(KVCacheBlock::IdType blockId) = 0;
|
||||
};
|
||||
|
||||
class KVCacheManager : public BaseKVCacheManager
|
||||
@ -1434,7 +1675,9 @@ public:
|
||||
std::optional<executor::RetentionPriority> secondaryOffloadMinPriority = std::nullopt,
|
||||
std::shared_ptr<KVCacheEventManager> eventManager = nullptr, bool enablePartialReuse = true,
|
||||
bool copyOnpartialReuse = true,
|
||||
std::shared_ptr<kv_connector::KvCacheConnectorManager> kvCacheConnectorManager = nullptr);
|
||||
std::shared_ptr<kv_connector::KvCacheConnectorManager> kvCacheConnectorManager = nullptr,
|
||||
bool enableIndexerKCache = false, SizeType32 indexerKCacheQuantBlockSize = 128,
|
||||
SizeType32 indexerKCacheIndexHeadDim = 0);
|
||||
|
||||
KVCacheManager(std::vector<SizeType32> const& numKvHeadsPerLayer, SizeType32 sizePerHead, SizeType32 tokensPerBlock,
|
||||
BlocksPerWindow const& blocksPerWindow, SizeType32 maxNumSequences, SizeType32 maxBeamWidth,
|
||||
@ -1445,7 +1688,9 @@ public:
|
||||
std::optional<executor::RetentionPriority> secondaryOffloadMinPriority = std::nullopt,
|
||||
std::shared_ptr<KVCacheEventManager> eventManager = nullptr, bool enablePartialReuse = true,
|
||||
bool copyOnpartialReuse = true,
|
||||
std::shared_ptr<kv_connector::KvCacheConnectorManager> kvCacheConnectorManager = nullptr);
|
||||
std::shared_ptr<kv_connector::KvCacheConnectorManager> kvCacheConnectorManager = nullptr,
|
||||
bool enableIndexerKCache = false, SizeType32 indexerKCacheQuantBlockSize = 128,
|
||||
SizeType32 indexerKCacheIndexHeadDim = 0);
|
||||
|
||||
KVCacheManager(SizeType32 numLayers, SizeType32 numKvHeads, SizeType32 sizePerHead, SizeType32 tokensPerBlock,
|
||||
BlocksPerWindow const& blocksPerWindow, SizeType32 maxNumSequences, SizeType32 maxBeamWidth,
|
||||
@ -1456,7 +1701,9 @@ public:
|
||||
std::optional<executor::RetentionPriority> secondaryOffloadMinPriority = std::nullopt,
|
||||
std::shared_ptr<KVCacheEventManager> eventManager = nullptr, bool enablePartialReuse = true,
|
||||
bool copyOnpartialReuse = true,
|
||||
std::shared_ptr<kv_connector::KvCacheConnectorManager> kvCacheConnectorManager = nullptr);
|
||||
std::shared_ptr<kv_connector::KvCacheConnectorManager> kvCacheConnectorManager = nullptr,
|
||||
bool enableIndexerKCache = false, SizeType32 indexerKCacheQuantBlockSize = 128,
|
||||
SizeType32 indexerKCacheIndexHeadDim = 0);
|
||||
|
||||
KVCacheManager(SizeType32 numLayers, SizeType32 numKvHeads, SizeType32 sizePerHead, SizeType32 tokensPerBlock,
|
||||
BlocksPerWindow const& blocksPerWindow, SizeType32 maxNumSequences, SizeType32 maxBeamWidth,
|
||||
@ -1464,7 +1711,8 @@ public:
|
||||
std::optional<TempAttentionWindowInputs> const& tempAttentionWindowInputs, nvinfer1::DataType dtype,
|
||||
SizeType32 sinkTokenLength, int64_t stream, SizeType32 maxSequenceLength, bool enableBlockReuse = false,
|
||||
bool onboardBlocks = true, CacheType cacheType = CacheType::kSELF, bool enablePartialReuse = true,
|
||||
bool copyOnpartialReuse = true);
|
||||
bool copyOnpartialReuse = true, bool enableIndexerKCache = false, SizeType32 indexerKCacheQuantBlockSize = 128,
|
||||
SizeType32 indexerKCacheIndexHeadDim = 0);
|
||||
|
||||
~KVCacheManager() override = default;
|
||||
|
||||
@ -1591,8 +1839,8 @@ public:
|
||||
void addSequence(LlmRequest::RequestIdType requestId, SizeType32 inputLength, SizeType32 beamWidth,
|
||||
OptionalRef<LlmRequest> llmRequest = std::nullopt) override;
|
||||
|
||||
void removeSequence(
|
||||
LlmRequest::RequestIdType requestId, OptionalRef<LlmRequest const> llmRequest = std::nullopt) override;
|
||||
[[nodiscard]] std::optional<KVCacheBlock::IdType> removeSequence(LlmRequest::RequestIdType requestId,
|
||||
OptionalRef<LlmRequest const> llmRequest = std::nullopt, bool pinOnRelease = false) override;
|
||||
|
||||
void schedulingRemoveSequence(LlmRequest::RequestIdType requestId) override;
|
||||
|
||||
@ -1624,6 +1872,21 @@ public:
|
||||
return mEnableBlockReuse;
|
||||
}
|
||||
|
||||
[[nodiscard]] bool isEnableIndexerKCache() const override
|
||||
{
|
||||
return mBlockManager.isEnableIndexerKCache();
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getIndexerKCacheIndexHeadDim() const override
|
||||
{
|
||||
return mBlockManager.getIndexerKCacheIndexHeadDim();
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getIndexerKCacheQuantBlockSize() const override
|
||||
{
|
||||
return mBlockManager.getIndexerKCacheQuantBlockSize();
|
||||
}
|
||||
|
||||
void removeToken(LlmRequest::RequestIdType requestId);
|
||||
void rewindKVCache(LlmRequest::RequestIdType requestId, SizeType32 rewindLengths) override;
|
||||
|
||||
@ -1652,6 +1915,9 @@ public:
|
||||
//! \brief Store newest blocks for reuse
|
||||
void storeNewBlock(LlmRequest const& llmRequest) override;
|
||||
|
||||
[[nodiscard]] std::optional<KVCacheBlock::IdType> storeBlocksForReuse(
|
||||
LlmRequest::RequestIdType requestId, OptionalRef<LlmRequest const> llmRequest, bool pinBlocks = false) override;
|
||||
|
||||
[[nodiscard]] static SizeType32 getSinkBubbleLength(SizeType32 sinkTokenLen, SizeType32 tokensPerBlock);
|
||||
|
||||
[[nodiscard]] SizeType32 getMaxCapacityBatchSize(SizeType32 inputLength, SizeType32 outputLength) const override;
|
||||
@ -1668,6 +1934,12 @@ public:
|
||||
[[nodiscard]] static SizeType32 calculateMaxBlockRequirements(SizeType32 inputLength, SizeType32 outputLength,
|
||||
SizeType32 sinkTokenLength, SizeType32 windowSize, SizeType32 beamWidth, SizeType32 tokensPerBlock);
|
||||
|
||||
void pinBlocks(LlmRequest::RequestIdType requestId) override;
|
||||
|
||||
void unpinBlocksById(KVCacheBlock::IdType blockId) override;
|
||||
|
||||
std::optional<KVCacheBlock::IdType> getLastBlockId(LlmRequest::RequestIdType requestId) const override;
|
||||
|
||||
/// @brief Calculates the number of kv-cache blocks that a sequence will require, for a single beam.
|
||||
///
|
||||
/// @param sequenceLength The total length of the sequence (input and output).
|
||||
@ -1684,11 +1956,9 @@ public:
|
||||
std::vector<std::vector<std::vector<SizeType32>>> getBatchCacheBlockIds(
|
||||
std::vector<LlmRequest::RequestIdType> const& requestIds, SizeType32 windowSize) const override;
|
||||
|
||||
std::vector<SizeType32> getNewlyAllocatedBlockIds(
|
||||
LlmRequest::RequestIdType requestId, SizeType32 windowSize) const override;
|
||||
|
||||
runtime::ITensor::SharedPtr getUniquePrimaryPool() const override;
|
||||
runtime::ITensor::SharedPtr getPrimaryPool(SizeType32 layer_idx) const override;
|
||||
runtime::ITensor::SharedPtr getIndexerKCachePool() const override;
|
||||
|
||||
SizeType32 getPoolLayerIdx(SizeType32 layer_idx) const override
|
||||
{
|
||||
@ -1706,6 +1976,17 @@ public:
|
||||
mBlockManager.flushIterationEvents();
|
||||
}
|
||||
|
||||
std::shared_ptr<KVCacheBlock> findBlocksInReuseTreeByBlockKey(
|
||||
BlockKey const& blockKey, SizeType32 windowSize) override
|
||||
{
|
||||
return mBlockManager.findBlocksInReuseTreeByBlockKey(blockKey, windowSize);
|
||||
}
|
||||
|
||||
void resetReuseState() override
|
||||
{
|
||||
mBlockManager.resetReuseState();
|
||||
}
|
||||
|
||||
/// @brief Finds the maximum attention window that can be used on a sequence, given some kv-cache block capacity.
|
||||
///
|
||||
/// @param inputLength The number of input tokens in the sequence.
|
||||
@ -1744,6 +2025,7 @@ private:
|
||||
runtime::ITensor::SharedPtr mBlockPoolPointers;
|
||||
runtime::ITensor::SharedPtr mLayerToPoolMapping;
|
||||
runtime::ITensor::SharedPtr mBlockScalePoolPointers;
|
||||
runtime::ITensor::SharedPtr mIndexerKCachePoolPointers;
|
||||
// GPU bytes allocated for KV-cache
|
||||
std::size_t mAllocatedBytes{0};
|
||||
};
|
||||
|
||||
@ -17,48 +17,31 @@
|
||||
#pragma once
|
||||
|
||||
#include "tensorrt_llm/batch_manager/kvCacheManager.h"
|
||||
#include "tensorrt_llm/runtime/iTensor.h"
|
||||
|
||||
namespace tensorrt_llm::batch_manager::kv_cache_manager
|
||||
{
|
||||
|
||||
class BlockIterator;
|
||||
|
||||
class BlockRange
|
||||
class BlockRangeForWindow
|
||||
{
|
||||
public:
|
||||
// C++20 std::default_sentinel_t equivalent
|
||||
BlockRangeForWindow(BaseKVCacheManager const* cacheManager, SizeType32 windowSize, std::vector<SizeType32> blockIds,
|
||||
runtime::ITensor::SharedPtr pool)
|
||||
: mCacheManager(cacheManager)
|
||||
, mWindowSize(windowSize)
|
||||
, mBlockIds(std::move(blockIds))
|
||||
, mPool(std::move(pool))
|
||||
{
|
||||
}
|
||||
|
||||
struct Sentinel
|
||||
{
|
||||
};
|
||||
|
||||
static BlockRange fromAllBlockIds(BaseKVCacheManager const& cacheManager, LlmRequest::RequestIdType requestId,
|
||||
SizeType32 beam = kFIRST_AND_ONLY_BEAM)
|
||||
{
|
||||
assert(kFIRST_AND_ONLY_BEAM == beam);
|
||||
auto const windowSize = firstWindowSize(cacheManager);
|
||||
auto const blockIds = cacheManager.getSequence(requestId).getCacheBlockIds(windowSize).at(kFIRST_AND_ONLY_BEAM);
|
||||
return BlockRange(cacheManager, blockIds, requestId);
|
||||
}
|
||||
|
||||
static BlockRange fromNewlyAllocatedBlockIds(
|
||||
BaseKVCacheManager const& cacheManager, LlmRequest::RequestIdType requestId)
|
||||
{
|
||||
auto const windowSize = firstWindowSize(cacheManager);
|
||||
auto const blockIds = cacheManager.getNewlyAllocatedBlockIds(requestId, windowSize);
|
||||
return BlockRange(cacheManager, blockIds, requestId);
|
||||
}
|
||||
|
||||
BlockRange(runtime::ITensor::SharedPtr pool, std::vector<SizeType32> const& blockIds) // Only used in tests
|
||||
: mManager{nullptr}
|
||||
, mPool{std::move(pool)}
|
||||
, mWindowSize{0}
|
||||
, mRequestId{0}
|
||||
, mBlockIds{blockIds}
|
||||
{
|
||||
TLLM_CHECK(mPool);
|
||||
}
|
||||
|
||||
[[nodiscard]] BlockIterator begin() const;
|
||||
friend class BlockIterator;
|
||||
BlockIterator begin() const;
|
||||
|
||||
[[nodiscard]] Sentinel end() const
|
||||
{
|
||||
@ -70,66 +53,163 @@ public:
|
||||
return mBlockIds.size();
|
||||
}
|
||||
|
||||
[[nodiscard]] std::vector<SizeType32> const& getBlockIds() const
|
||||
private:
|
||||
BaseKVCacheManager const* mCacheManager;
|
||||
SizeType32 mWindowSize;
|
||||
std::vector<SizeType32> mBlockIds;
|
||||
runtime::ITensor::SharedPtr mPool;
|
||||
};
|
||||
|
||||
class BlockRange
|
||||
{
|
||||
public:
|
||||
static BlockRange fromAllBlockIds(BaseKVCacheManager const& cacheManager, LlmRequest::RequestIdType requestId)
|
||||
{
|
||||
return mBlockIds;
|
||||
|
||||
return BlockRange(cacheManager, requestId);
|
||||
}
|
||||
|
||||
void setBlockIds(std::vector<SizeType32> blockIds)
|
||||
static BlockRange fromReuseTree(
|
||||
BaseKVCacheManager& cacheManager, BlockKey const& lastBlockKey, int32_t indexFromEnd)
|
||||
{
|
||||
mBlockIds = std::move(blockIds);
|
||||
|
||||
auto poolNum = cacheManager.getBlockManager().getNumPools(
|
||||
/*includeBlockScalePools=*/false, /*includeIndexerKCachePools=*/false);
|
||||
TLLM_CHECK_WITH_INFO(poolNum == 1, "Reuse tree is not supported for multiple pools or variable window size");
|
||||
|
||||
auto windowSize = cacheManager.getBlockManager().getWindowSizesMetadata().begin()->first;
|
||||
// Find the last block in the reuse tree for the provided full sequence of block keys
|
||||
auto lastBlock = cacheManager.findBlocksInReuseTreeByBlockKey(lastBlockKey, windowSize);
|
||||
// TODO: handle the case where the last block is not found
|
||||
TLLM_CHECK_WITH_INFO(lastBlock, "Couldn't find the requested block in the reuse tree");
|
||||
int32_t const numBlocksToCollect = indexFromEnd + 1;
|
||||
|
||||
std::vector<SizeType32> blockIds;
|
||||
blockIds.reserve(numBlocksToCollect);
|
||||
for (int32_t i = 0; i < numBlocksToCollect; ++i)
|
||||
{
|
||||
TLLM_CHECK_WITH_INFO(
|
||||
lastBlock->getBlockId() != KVCacheBlock::kCachedBlocksRootId, "last block has no block id");
|
||||
blockIds.push_back(lastBlock->getBlockId());
|
||||
if (i + 1 < numBlocksToCollect)
|
||||
{
|
||||
TLLM_CHECK_WITH_INFO(lastBlock->getPrevBlock(), "last block has no prev block");
|
||||
lastBlock = lastBlock->getPrevBlock();
|
||||
}
|
||||
}
|
||||
// Reverse to chronological order: oldest to newest
|
||||
std::reverse(blockIds.begin(), blockIds.end());
|
||||
std::unordered_map<SizeType32, std::vector<SizeType32>> blockIdsPerWindow;
|
||||
blockIdsPerWindow[windowSize] = blockIds;
|
||||
return BlockRange(cacheManager, blockIdsPerWindow, 0);
|
||||
}
|
||||
|
||||
[[nodiscard]] std::vector<size_t> getBlockHashes() const
|
||||
void setBlockIdsForWindow(SizeType32 windowSize, std::vector<SizeType32> blockIds)
|
||||
{
|
||||
TLLM_CHECK_WITH_INFO(mBlockIdsPerWindow.find(windowSize) != mBlockIdsPerWindow.end(),
|
||||
"Window size %d should exists", windowSize);
|
||||
mBlockIdsPerWindow[windowSize] = std::move(blockIds);
|
||||
}
|
||||
|
||||
void setBlockIdsForAllWindows(std::unordered_map<SizeType32, std::vector<SizeType32>> blockIdsPerWindow)
|
||||
{
|
||||
for (auto const& [windowSize, blockIds] : blockIdsPerWindow)
|
||||
{
|
||||
TLLM_CHECK_WITH_INFO(
|
||||
mPoolsPerWindow.find(windowSize) != mPoolsPerWindow.end(), "Window size %d should exists", windowSize);
|
||||
}
|
||||
mBlockIdsPerWindow = std::move(blockIdsPerWindow);
|
||||
}
|
||||
|
||||
[[nodiscard]] std::unordered_map<SizeType32, std::vector<size_t>> getBlockHashesPerWindow() const
|
||||
{
|
||||
TLLM_CHECK(mManager);
|
||||
std::vector<size_t> blockHashes;
|
||||
blockHashes.reserve(mBlockIds.size());
|
||||
std::unordered_map<SizeType32, std::vector<size_t>> blockHashesPerWindow;
|
||||
auto& blockManager = mManager->getBlockManager();
|
||||
for (auto id : mBlockIds)
|
||||
for (auto const& [windowSize, blockIds] : mBlockIdsPerWindow)
|
||||
{
|
||||
blockHashes.emplace_back(blockManager.getBlockById(id, mWindowSize)->getHash());
|
||||
for (auto const& blockId : blockIds)
|
||||
{
|
||||
blockHashesPerWindow[windowSize].emplace_back(
|
||||
blockManager.getBlockById(blockId, windowSize)->getHash());
|
||||
}
|
||||
}
|
||||
return blockHashes;
|
||||
return blockHashesPerWindow;
|
||||
}
|
||||
|
||||
void updatePoolIdx(SizeType32 poolIdx)
|
||||
BlockRangeForWindow getBlockRangeForWindow(SizeType32 windowSize, bool useIndexerKCache = false) const
|
||||
{
|
||||
TLLM_CHECK(mManager);
|
||||
mPool = mManager->getBlockManager().getPrimaryPool(poolIdx);
|
||||
auto const newWindowSize = mManager->getBlockManager().getPoolWindowSize(poolIdx);
|
||||
if (newWindowSize != mWindowSize)
|
||||
TLLM_CHECK_WITH_INFO(
|
||||
mPoolsPerWindow.find(windowSize) != mPoolsPerWindow.end(), "Window size %d not found", windowSize);
|
||||
auto pool = mPoolsPerWindow.at(windowSize).front();
|
||||
auto blockIds = mBlockIdsPerWindow.at(windowSize);
|
||||
if (useIndexerKCache)
|
||||
{
|
||||
mWindowSize = newWindowSize;
|
||||
mBlockIds = mManager->getSequence(mRequestId).getCacheBlockIds(mWindowSize).at(kFIRST_AND_ONLY_BEAM);
|
||||
TLLM_CHECK(mIndexerKCachePool);
|
||||
return BlockRangeForWindow(mManager, windowSize, std::move(blockIds), mIndexerKCachePool);
|
||||
}
|
||||
else
|
||||
{
|
||||
return BlockRangeForWindow(mManager, windowSize, std::move(blockIds), std::move(pool));
|
||||
}
|
||||
}
|
||||
|
||||
friend class BlockIterator;
|
||||
std::vector<SizeType32> getWindowSizes() const
|
||||
{
|
||||
std::vector<SizeType32> windowSizes;
|
||||
for (auto const& [windowSize, _] : mPoolsPerWindow)
|
||||
{
|
||||
windowSizes.push_back(windowSize);
|
||||
}
|
||||
return windowSizes;
|
||||
}
|
||||
|
||||
std::unordered_map<SizeType32, std::vector<SizeType32>> const& getBlockIdsPerWindow() const
|
||||
{
|
||||
return mBlockIdsPerWindow;
|
||||
}
|
||||
|
||||
private:
|
||||
BlockRange(
|
||||
BaseKVCacheManager const& cacheManager, std::vector<SizeType32> blockIds, LlmRequest::RequestIdType requestId)
|
||||
BlockRange(BaseKVCacheManager const& cacheManager,
|
||||
std::unordered_map<SizeType32, std::vector<SizeType32>> blockIdsPerWindow, LlmRequest::RequestIdType requestId)
|
||||
: mManager(&cacheManager)
|
||||
, mPool(cacheManager.getBlockManager().getPrimaryPool(kFIRST_POOL_INDEX))
|
||||
, mWindowSize(firstWindowSize(cacheManager))
|
||||
, mRequestId(requestId)
|
||||
, mBlockIds(std::move(blockIds))
|
||||
, mBlockIdsPerWindow(std::move(blockIdsPerWindow))
|
||||
{
|
||||
auto poolNum = mManager->getBlockManager().getNumPools(
|
||||
/*includeBlockScalePools=*/false, /*includeIndexerKCachePools=*/false);
|
||||
for (SizeType32 poolIdx = 0; poolIdx < poolNum; ++poolIdx)
|
||||
{
|
||||
auto windowSize = cacheManager.getBlockManager().getPoolWindowSize(poolIdx);
|
||||
mPoolsPerWindow[windowSize].push_back(cacheManager.getBlockManager().getPrimaryPool(poolIdx));
|
||||
}
|
||||
}
|
||||
|
||||
static SizeType32 firstWindowSize(BaseKVCacheManager const& cacheManager)
|
||||
BlockRange(BaseKVCacheManager const& cacheManager, LlmRequest::RequestIdType requestId)
|
||||
: mManager(&cacheManager)
|
||||
, mRequestId(requestId)
|
||||
{
|
||||
constexpr SizeType32 FIRST_POOL_IDX = 0;
|
||||
return cacheManager.getBlockManager().getPoolWindowSize(FIRST_POOL_IDX);
|
||||
auto poolNum = mManager->getBlockManager().getNumPools(
|
||||
/*includeBlockScalePools=*/false, /*includeIndexerKCachePools=*/false);
|
||||
for (SizeType32 poolIdx = 0; poolIdx < poolNum; ++poolIdx)
|
||||
{
|
||||
auto windowSize = cacheManager.getBlockManager().getPoolWindowSize(poolIdx);
|
||||
mPoolsPerWindow[windowSize].push_back(cacheManager.getBlockManager().getPrimaryPool(poolIdx));
|
||||
mBlockIdsPerWindow[windowSize]
|
||||
= cacheManager.getSequence(mRequestId).getCacheBlockIds(windowSize).at(kFIRST_AND_ONLY_BEAM);
|
||||
}
|
||||
if (cacheManager.isEnableIndexerKCache())
|
||||
{
|
||||
mIndexerKCachePool = cacheManager.getIndexerKCachePool();
|
||||
}
|
||||
}
|
||||
|
||||
private:
|
||||
BaseKVCacheManager const* mManager;
|
||||
runtime::ITensor::SharedPtr mPool;
|
||||
SizeType32 mWindowSize;
|
||||
const LlmRequest::RequestIdType mRequestId;
|
||||
std::vector<SizeType32> mBlockIds;
|
||||
LlmRequest::RequestIdType const mRequestId;
|
||||
std::unordered_map<SizeType32, std::vector<SizeType32>> mBlockIdsPerWindow;
|
||||
std::unordered_map<SizeType32, std::vector<runtime::ITensor::SharedPtr>> mPoolsPerWindow;
|
||||
runtime::ITensor::SharedPtr mIndexerKCachePool;
|
||||
|
||||
static constexpr SizeType32 kFIRST_AND_ONLY_BEAM = 0;
|
||||
static constexpr SizeType32 kFIRST_POOL_INDEX = 0;
|
||||
@ -144,7 +224,7 @@ public:
|
||||
using reference = value_type&;
|
||||
using SizeType32 = tensorrt_llm::runtime::SizeType32;
|
||||
|
||||
BlockIterator(BlockRange const* range, size_t idx)
|
||||
BlockIterator(BlockRangeForWindow const* range, size_t idx)
|
||||
: mRange{range}
|
||||
, mIdx{idx}
|
||||
{
|
||||
@ -187,7 +267,7 @@ public:
|
||||
return mIdx == other.mIdx && mRange == other.mRange;
|
||||
}
|
||||
|
||||
[[nodiscard]] bool operator==(BlockRange::Sentinel other) const
|
||||
[[nodiscard]] bool operator==(BlockRangeForWindow::Sentinel other) const
|
||||
{
|
||||
return mIdx == mRange->mBlockIds.size();
|
||||
}
|
||||
@ -203,16 +283,27 @@ private:
|
||||
{
|
||||
if (mIdx < mRange->mBlockIds.size())
|
||||
{
|
||||
mCurrent = runtime::ITensor::slice(mRange->mPool, mRange->mBlockIds.at(mIdx), 1);
|
||||
if (mRange->mCacheManager != nullptr)
|
||||
{
|
||||
BlockPtr const& block = mRange->mCacheManager->getBlockManager().getBlockById(
|
||||
mRange->mBlockIds.at(mIdx), mRange->mWindowSize);
|
||||
TLLM_CHECK_WITH_INFO(block->isPrimary(), "cache transceiver only supports primary blocks");
|
||||
auto const blockOffset = block->getMemoryPoolBlockIndex();
|
||||
mCurrent = runtime::ITensor::slice(mRange->mPool, blockOffset, 1);
|
||||
}
|
||||
else
|
||||
{
|
||||
mCurrent = runtime::ITensor::slice(mRange->mPool, mRange->mBlockIds.at(mIdx), 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
BlockRange const* mRange;
|
||||
BlockRangeForWindow const* mRange;
|
||||
runtime::ITensor::SharedPtr mCurrent;
|
||||
size_t mIdx;
|
||||
};
|
||||
|
||||
inline BlockIterator BlockRange::begin() const
|
||||
inline BlockIterator BlockRangeForWindow::begin() const
|
||||
{
|
||||
return {this, 0};
|
||||
}
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
/*
|
||||
* Copyright (c) 2022-2024, NVIDIA CORPORATION. All rights reserved.
|
||||
* Copyright (c) 2022-2025, NVIDIA CORPORATION. All rights reserved.
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
@ -29,6 +29,8 @@
|
||||
#include <cassert>
|
||||
#include <chrono>
|
||||
#include <cstdint>
|
||||
#include <cstring>
|
||||
#include <list>
|
||||
#include <memory>
|
||||
#include <optional>
|
||||
#include <utility>
|
||||
@ -56,9 +58,9 @@ enum class LlmRequestState : int32_t
|
||||
/// used in layer-wise transmission
|
||||
kDISAGG_GENERATION_TRANS_COMPLETE = 12, ///< Kv cache transmission are finished
|
||||
kGENERATION_IN_PROGRESS = 13, ///< Generation phase is in progress
|
||||
kGENERATION_TO_COMPLETE = 14, ///< Generation phase is to be completed
|
||||
|
||||
// schedulable states ends
|
||||
kGENERATION_TO_COMPLETE = 14, ///< Generation phase is to be completed
|
||||
kGENERATION_COMPLETE = 20, ///< Generation phase completed
|
||||
kDISAGG_CONTEXT_TRANS_IN_PROGRESS = 21, ///< Waiting context-only request transmitting the kv cache,
|
||||
/// after computation finished
|
||||
@ -101,6 +103,7 @@ public:
|
||||
using RequestPtr = std::shared_ptr<GenericLlmRequest>;
|
||||
using MillisecondsType = std::chrono::milliseconds;
|
||||
using TimePoint = std::chrono::time_point<std::chrono::steady_clock>;
|
||||
using Duration = std::chrono::time_point<std::chrono::steady_clock>::duration;
|
||||
using CacheSaltIDType = runtime::CacheSaltIDType;
|
||||
|
||||
GenericLlmRequest(RequestIdType requestId, SizeType32 maxNewTokens, std::shared_ptr<VecTokens> const& inputTokens,
|
||||
@ -1074,7 +1077,6 @@ public:
|
||||
TLLM_CHECK_WITH_INFO(prepopulatedPromptLen < promptLen,
|
||||
"Invalid state: prepopulatedPromptLen (%d) >= promptLen (%d) for request %lu", prepopulatedPromptLen,
|
||||
promptLen, mRequestId);
|
||||
TLLM_CHECK(prepopulatedPromptLen < promptLen);
|
||||
|
||||
auto& prePromptLen = mUseDraftModel ? mPrepopulatedPromptLenDraft : mPrepopulatedPromptLenTarget;
|
||||
auto& contextCurrentPosition = mUseDraftModel ? mContextCurrentPositionDraft : mContextCurrentPositionTarget;
|
||||
@ -1115,9 +1117,9 @@ public:
|
||||
mDraftLogits = draftLogits;
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getNumDraftTokens() const
|
||||
[[nodiscard]] SizeType32 getNumDraftTokens() const noexcept
|
||||
{
|
||||
return hasDraftTokens() ? mDraftTokens->size() : 0;
|
||||
return hasDraftTokens() ? static_cast<SizeType32>(mDraftTokens->size()) : 0;
|
||||
}
|
||||
|
||||
void discardDraftTokens(SizeType32 numTokensToDiscard)
|
||||
@ -1255,7 +1257,7 @@ public:
|
||||
{
|
||||
if (mPerfMetrics.timingMetrics.firstScheduledTime == executor::RequestPerfMetrics::TimePoint{})
|
||||
{
|
||||
mPerfMetrics.timingMetrics.firstScheduledTime = std::chrono::steady_clock::now();
|
||||
mPerfMetrics.timingMetrics.firstScheduledTime = getSteadyClockNow();
|
||||
}
|
||||
}
|
||||
|
||||
@ -1378,17 +1380,17 @@ public:
|
||||
mGenerationLogitsFragments.push_back(genLogits);
|
||||
}
|
||||
|
||||
SizeType32 getGenerationLogitsFragmentsSize()
|
||||
[[nodiscard]] SizeType32 getGenerationLogitsFragmentsSize() const noexcept
|
||||
{
|
||||
return mGenerationLogitsFragments.size();
|
||||
return static_cast<SizeType32>(mGenerationLogitsFragments.size());
|
||||
}
|
||||
|
||||
void clearGenerationLogitsFragments()
|
||||
void clearGenerationLogitsFragments() noexcept
|
||||
{
|
||||
mGenerationLogitsFragments.clear();
|
||||
}
|
||||
|
||||
bool hasAdditionalOutputs()
|
||||
[[nodiscard]] bool hasAdditionalOutputs() const noexcept
|
||||
{
|
||||
return !mAdditionalContextOutputTensors.empty() || !mAdditionalGenerationOutputTensors.empty();
|
||||
}
|
||||
@ -1689,22 +1691,22 @@ public:
|
||||
mDecodingIter = iter;
|
||||
}
|
||||
|
||||
void setKvCacheTransferStart(std::chrono::time_point<std::chrono::steady_clock> const& time)
|
||||
void setKvCacheTransferStart(TimePoint time) const
|
||||
{
|
||||
mPerfMetrics.timingMetrics.kvCacheTransferStart = time;
|
||||
mPerfMetrics.timingMetrics.kvCacheTransferStart = maybeToGlobalSteadyClock(time);
|
||||
}
|
||||
|
||||
void setKvCacheTransferEnd(std::chrono::time_point<std::chrono::steady_clock> const& time)
|
||||
void setKvCacheTransferEnd(TimePoint time) const
|
||||
{
|
||||
mPerfMetrics.timingMetrics.kvCacheTransferEnd = time;
|
||||
mPerfMetrics.timingMetrics.kvCacheTransferEnd = maybeToGlobalSteadyClock(time);
|
||||
}
|
||||
|
||||
std::chrono::time_point<std::chrono::steady_clock> getKvCacheTransferStart()
|
||||
TimePoint getKvCacheTransferStart() const
|
||||
{
|
||||
return mPerfMetrics.timingMetrics.kvCacheTransferStart;
|
||||
}
|
||||
|
||||
std::chrono::time_point<std::chrono::steady_clock> getKvCacheTransferEnd()
|
||||
TimePoint getKvCacheTransferEnd() const
|
||||
{
|
||||
return mPerfMetrics.timingMetrics.kvCacheTransferEnd;
|
||||
}
|
||||
@ -1788,7 +1790,7 @@ public:
|
||||
if (finishReason == executor::FinishReason::kTIMED_OUT)
|
||||
{
|
||||
TLLM_LOG_DEBUG("Request %ld finished by timeout after %f sec", mRequestId,
|
||||
std::chrono::duration<float>(std::chrono::steady_clock::now() - mStartTime).count());
|
||||
std::chrono::duration<float>(getSteadyClockNow() - mStartTime).count());
|
||||
}
|
||||
if (finishReason == executor::FinishReason::kCANCELLED)
|
||||
{
|
||||
@ -1826,7 +1828,7 @@ public:
|
||||
|
||||
void updatePerfMetrics(executor::IterationType iter)
|
||||
{
|
||||
auto const currentTokenTime = std::chrono::steady_clock::now();
|
||||
auto const currentTokenTime = getSteadyClockNow();
|
||||
|
||||
if (!mPerfMetrics.firstIter)
|
||||
{
|
||||
@ -1843,16 +1845,6 @@ public:
|
||||
}
|
||||
}
|
||||
|
||||
void setRequestedBlockHashes(std::vector<size_t> hashes)
|
||||
{
|
||||
mRequestedBlockHashes = std::move(hashes);
|
||||
}
|
||||
|
||||
[[nodiscard]] std::vector<size_t> const& getRequestedBlockHashes() const
|
||||
{
|
||||
return mRequestedBlockHashes;
|
||||
}
|
||||
|
||||
void setIsDummyRequest(bool isDummyRequest)
|
||||
{
|
||||
mIsDummyRequest = isDummyRequest;
|
||||
@ -1873,6 +1865,13 @@ public:
|
||||
return mUseDraftModel;
|
||||
}
|
||||
|
||||
// If sGlobalSteadyClockOffset is set, return a global steady clock time point, otherwise return local steady clock
|
||||
// time point
|
||||
[[nodiscard]] static TimePoint getSteadyClockNow()
|
||||
{
|
||||
return maybeToGlobalSteadyClock(std::chrono::steady_clock::now());
|
||||
}
|
||||
|
||||
RequestIdType mRequestId;
|
||||
SizeType32 mPromptLen;
|
||||
SizeType32 mMaxNewTokens;
|
||||
@ -1892,6 +1891,9 @@ public:
|
||||
// current position of the prompt tuning table (only used in chunked prefill mode)
|
||||
SizeType32 mPtableCurrentPosition{0};
|
||||
|
||||
// The offset between local steady clock and global steady clock (at rank 0)
|
||||
inline static std::optional<Duration> sGlobalSteadyClockOffset{std::nullopt};
|
||||
|
||||
protected:
|
||||
bool mIsStreaming;
|
||||
|
||||
@ -2024,9 +2026,9 @@ protected:
|
||||
|
||||
std::optional<TensorPtr> mSkipCrossAttnBlocks{std::nullopt};
|
||||
|
||||
// Performance metrics.
|
||||
// Performance metrics. Should be updatable even from a const LlmRequest reference.
|
||||
bool mReturnPerfMetrics{false};
|
||||
executor::RequestPerfMetrics mPerfMetrics;
|
||||
mutable executor::RequestPerfMetrics mPerfMetrics;
|
||||
|
||||
// Guided decoding params.
|
||||
std::optional<executor::GuidedDecodingParams> mGuidedDecodingParams{std::nullopt};
|
||||
@ -2044,9 +2046,6 @@ protected:
|
||||
// Tensors containing the additional generation output.
|
||||
TensorMap mAdditionalGenerationOutputTensors;
|
||||
|
||||
// Context request only. The hashes of the blocks that are requested by the corresponding generation request.
|
||||
std::vector<size_t> mRequestedBlockHashes;
|
||||
|
||||
bool mIsDummyRequest{false};
|
||||
|
||||
bool mUseDraftModel{false};
|
||||
@ -2150,7 +2149,8 @@ private:
|
||||
|
||||
if (mReturnPerfMetrics)
|
||||
{
|
||||
mPerfMetrics.timingMetrics.arrivalTime = arrivalTime.value_or(std::chrono::steady_clock::now());
|
||||
// arrivalTime is assumed to be recorded at the rank 0, so no need to convert it to global clock
|
||||
mPerfMetrics.timingMetrics.arrivalTime = arrivalTime.value_or(getSteadyClockNow());
|
||||
}
|
||||
mStartTime = std::chrono::steady_clock::now();
|
||||
}
|
||||
@ -2180,6 +2180,15 @@ private:
|
||||
|
||||
return tensor;
|
||||
}
|
||||
|
||||
static TimePoint maybeToGlobalSteadyClock(TimePoint const& time_point)
|
||||
{
|
||||
if (sGlobalSteadyClockOffset.has_value())
|
||||
{
|
||||
return time_point + *sGlobalSteadyClockOffset;
|
||||
}
|
||||
return time_point;
|
||||
}
|
||||
};
|
||||
|
||||
class LlmRequest : public GenericLlmRequest<runtime::ITensor::SharedPtr>
|
||||
|
||||
@ -40,19 +40,17 @@ public:
|
||||
constexpr static auto name{"MakeDecodingBatchInputOutput"};
|
||||
|
||||
using SizeType32 = tensorrt_llm::runtime::SizeType32;
|
||||
using TensorPtr = runtime::decoder_batch::Input::TensorPtr;
|
||||
using TensorPtr = runtime::ITensor::SharedPtr;
|
||||
template <typename T>
|
||||
using OptionalRef = tensorrt_llm::common::OptionalRef<T>;
|
||||
|
||||
MakeDecodingBatchInputOutput() = default;
|
||||
|
||||
std::unique_ptr<runtime::decoder_batch::Input> operator()(DecoderInputBuffers& inputBuffers,
|
||||
runtime::decoder::DecoderState& decoderState, runtime::ModelConfig const& modelConfig,
|
||||
SizeType32 maxNumSequences, OptionalRef<RuntimeBuffers> fusedRuntimeBuffers) const;
|
||||
void operator()(DecoderInputBuffers& inputBuffers, runtime::decoder::DecoderState& decoderState,
|
||||
runtime::ModelConfig const& modelConfig, OptionalRef<RuntimeBuffers> fusedRuntimeBuffers) const;
|
||||
|
||||
[[nodiscard]] static std::unique_ptr<runtime::decoder_batch::Input> createDecoderBatchInputs(
|
||||
std::vector<SizeType32> const& activeSlots, runtime::decoder::DecoderState const& decoderState,
|
||||
std::vector<TensorPtr> const& logits, SizeType32 maxNumSequences, std::vector<TensorPtr> const& batchSlots);
|
||||
static void createDecoderBatchInputs(DecoderInputBuffers& inputBuffers, std::vector<SizeType32> const& activeSlots,
|
||||
runtime::decoder::DecoderState const& decoderState);
|
||||
};
|
||||
|
||||
} // namespace tensorrt_llm::batch_manager
|
||||
|
||||
72
cpp/include/tensorrt_llm/common/bindingUtils.h
Normal file
72
cpp/include/tensorrt_llm/common/bindingUtils.h
Normal file
@ -0,0 +1,72 @@
|
||||
/*
|
||||
* Copyright (c) 2025, NVIDIA CORPORATION. All rights reserved.
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
#include "c10/util/intrusive_ptr.h"
|
||||
#include <Python.h>
|
||||
|
||||
namespace tensorrt_llm::common
|
||||
{
|
||||
|
||||
// Adapted from pybind11's example implementation:
|
||||
// https://github.com/pybind/pybind11/blob/master/include/pybind11/conduit/pybind11_conduit_v1.h
|
||||
// Copyright (c) 2024 The pybind Community.
|
||||
|
||||
inline void* get_raw_pointer_ephemeral(
|
||||
PyObject* py_obj, std::type_info const* cpp_type_info, std::string const& pybind11_abi)
|
||||
{
|
||||
PyObject* cpp_type_info_capsule = PyCapsule_New(
|
||||
const_cast<void*>(static_cast<void const*>(cpp_type_info)), typeid(std::type_info).name(), nullptr);
|
||||
if (cpp_type_info_capsule == nullptr)
|
||||
{
|
||||
return nullptr;
|
||||
}
|
||||
PyObject* cpp_conduit = PyObject_CallMethod(
|
||||
py_obj, "_pybind11_conduit_v1_", "yOy", pybind11_abi.c_str(), cpp_type_info_capsule, "raw_pointer_ephemeral");
|
||||
Py_DECREF(cpp_type_info_capsule);
|
||||
if (cpp_conduit == nullptr)
|
||||
{
|
||||
return nullptr;
|
||||
}
|
||||
void* raw_ptr = PyCapsule_GetPointer(cpp_conduit, cpp_type_info->name());
|
||||
Py_DECREF(cpp_conduit);
|
||||
if (PyErr_Occurred())
|
||||
{
|
||||
return nullptr;
|
||||
}
|
||||
return raw_ptr;
|
||||
}
|
||||
|
||||
template <typename T, typename E>
|
||||
T* get_type_pointer_ephemeral(PyObject* py_obj, std::string pybind11_abi)
|
||||
{
|
||||
void* raw_ptr = get_raw_pointer_ephemeral(py_obj, &typeid(T), pybind11_abi);
|
||||
if (raw_ptr == nullptr)
|
||||
{
|
||||
throw E();
|
||||
}
|
||||
return static_cast<T*>(raw_ptr);
|
||||
}
|
||||
|
||||
template <typename T, typename E>
|
||||
c10::intrusive_ptr<T> get_intrusive_ptr(PyObject* py_obj, std::string pybind11_abi)
|
||||
{
|
||||
auto* const p = get_type_pointer_ephemeral<T, E>(py_obj, pybind11_abi);
|
||||
return c10::intrusive_ptr<T>::reclaim_copy(p);
|
||||
}
|
||||
|
||||
} // namespace tensorrt_llm::common
|
||||
@ -19,6 +19,9 @@
|
||||
#include "tensorrt_llm/common/cudaBf16Wrapper.h"
|
||||
#include "tensorrt_llm/common/cudaDriverWrapper.h"
|
||||
#include "tensorrt_llm/common/cudaFp8Utils.h"
|
||||
#if ENABLE_FP4
|
||||
#include <cuda_fp4.h>
|
||||
#endif
|
||||
#include "tensorrt_llm/common/logger.h"
|
||||
#include "tensorrt_llm/common/tllmException.h"
|
||||
#include <algorithm>
|
||||
@ -295,7 +298,11 @@ struct CudaDataType<__nv_bfloat16>
|
||||
};
|
||||
#endif
|
||||
|
||||
inline int getSMVersion()
|
||||
/// @brief Get the SM version of the current device.
|
||||
/// @param queryRealSmArch Whether to query the real SM architecture. example usage: use real sm arch when do LUT tuning
|
||||
/// and use fake sm arch when reuse sm120 code on sm121 devices.
|
||||
/// @return The SM version of the current device.
|
||||
inline int getSMVersion(bool queryRealSmArch = false)
|
||||
{
|
||||
int device{-1};
|
||||
check_cuda_error(cudaGetDevice(&device));
|
||||
@ -304,7 +311,7 @@ inline int getSMVersion()
|
||||
check_cuda_error(cudaDeviceGetAttribute(&sm_major, cudaDevAttrComputeCapabilityMajor, device));
|
||||
check_cuda_error(cudaDeviceGetAttribute(&sm_minor, cudaDevAttrComputeCapabilityMinor, device));
|
||||
int sm = sm_major * 10 + sm_minor;
|
||||
if (sm == 121)
|
||||
if (sm == 121 && !queryRealSmArch)
|
||||
{
|
||||
return 120;
|
||||
}
|
||||
@ -541,6 +548,9 @@ template void printArrayInfo(__nv_bfloat16 const* ptr, uint64_t nElement, std::s
|
||||
#ifdef ENABLE_FP8
|
||||
template void printArrayInfo(__nv_fp8_e4m3 const* ptr, uint64_t nElement, std::string name, bool const bPrintElement);
|
||||
#endif
|
||||
#ifdef ENABLE_FP4
|
||||
template void printArrayInfo(__nv_fp4_e2m1 const* ptr, uint64_t nElement, std::string name, bool const bPrintElement);
|
||||
#endif
|
||||
template void printArrayInfo(uint32_t const* ptr, uint64_t nElement, std::string name, bool const bPrintElement);
|
||||
template void printArrayInfo(uint64_t const* ptr, uint64_t nElement, std::string name, bool const bPrintElement);
|
||||
template void printArrayInfo(int const* ptr, uint64_t nElement, std::string name, bool const bPrintElement);
|
||||
|
||||
@ -50,7 +50,8 @@ public:
|
||||
|
||||
CacheState(ModelConfig modelConfig, runtime::WorldConfig const& worldConfig,
|
||||
std::vector<SizeType32> const& attentionLayerNumPerPP, nvinfer1::DataType dataType,
|
||||
AttentionType attentionType = AttentionType::kDEFAULT, int kvFactor = 2)
|
||||
AttentionType attentionType = AttentionType::kDEFAULT, int kvFactor = 2, bool enableBlockReuse = false,
|
||||
bool hasIndexerKCache = false, SizeType32 indexerDimPerHead = 0, SizeType32 indexerKCacheQuantBlockSize = 128)
|
||||
: mModelConfig(std::move(modelConfig))
|
||||
, mParallelConfig{worldConfig.getTensorParallelism(), worldConfig.getPipelineParallelism(),
|
||||
worldConfig.getContextParallelism(), worldConfig.enableAttentionDP(), worldConfig.getTensorParallelRank(),
|
||||
@ -58,32 +59,46 @@ public:
|
||||
, mDataType{dataType}
|
||||
, mAttentionConfig(attentionType, kvFactor)
|
||||
{
|
||||
mEnableBlockReuse = enableBlockReuse;
|
||||
mHasIndexerKCache = hasIndexerKCache;
|
||||
mIndexerDimPerHead = indexerDimPerHead;
|
||||
mIndexerKCacheQuantBlockSize = indexerKCacheQuantBlockSize;
|
||||
}
|
||||
|
||||
CacheState(std::vector<SizeType32> nbKvHeadPerLayer, SizeType32 sizePerHead, SizeType32 tokensPerBlock,
|
||||
SizeType32 tensorParallelism, SizeType32 pipelineParallelism, SizeType32 contextParallelism,
|
||||
std::vector<SizeType32> const& attentionLayerNumPerPP, nvinfer1::DataType dataType,
|
||||
AttentionType attentionType = AttentionType::kDEFAULT, int kvFactor = 2, bool enableAttentionDP = false,
|
||||
int DPrank = 0, int DPsize = 0)
|
||||
int DPrank = 0, int DPsize = 0, bool enableBlockReuse = false, bool hasIndexerKCache = false,
|
||||
SizeType32 indexerDimPerHead = 0, SizeType32 indexerKCacheQuantBlockSize = 128)
|
||||
: mModelConfig{std::move(nbKvHeadPerLayer), sizePerHead, tokensPerBlock}
|
||||
, mParallelConfig{tensorParallelism, pipelineParallelism, contextParallelism, enableAttentionDP, DPrank, DPsize,
|
||||
attentionLayerNumPerPP}
|
||||
, mDataType{dataType}
|
||||
, mAttentionConfig(attentionType, kvFactor)
|
||||
{
|
||||
mEnableBlockReuse = enableBlockReuse;
|
||||
mHasIndexerKCache = hasIndexerKCache;
|
||||
mIndexerDimPerHead = indexerDimPerHead;
|
||||
mIndexerKCacheQuantBlockSize = indexerKCacheQuantBlockSize;
|
||||
}
|
||||
|
||||
CacheState(SizeType32 nbAttentionLayers, SizeType32 nbKvHeads, SizeType32 sizePerHead, SizeType32 tokensPerBlock,
|
||||
SizeType32 tensorParallelism, SizeType32 pipelineParallelism, SizeType32 contextParallelism,
|
||||
std::vector<SizeType32> const& attentionLayerNumPerPP, nvinfer1::DataType dataType,
|
||||
AttentionType attentionType = AttentionType::kDEFAULT, int kvFactor = 2, bool enableAttentionDP = false,
|
||||
int DPrank = 0, int DPsize = 0)
|
||||
int DPrank = 0, int DPsize = 0, bool enableBlockReuse = false, bool hasIndexerKCache = false,
|
||||
SizeType32 indexerDimPerHead = 0, SizeType32 indexerKCacheQuantBlockSize = 128)
|
||||
: mModelConfig{std::vector(nbAttentionLayers, nbKvHeads), sizePerHead, tokensPerBlock}
|
||||
, mParallelConfig{tensorParallelism, pipelineParallelism, contextParallelism, enableAttentionDP, DPrank, DPsize,
|
||||
attentionLayerNumPerPP}
|
||||
, mDataType{dataType}
|
||||
, mAttentionConfig(attentionType, kvFactor)
|
||||
{
|
||||
mEnableBlockReuse = enableBlockReuse;
|
||||
mHasIndexerKCache = hasIndexerKCache;
|
||||
mIndexerDimPerHead = indexerDimPerHead;
|
||||
mIndexerKCacheQuantBlockSize = indexerKCacheQuantBlockSize;
|
||||
}
|
||||
|
||||
[[nodiscard]] bool operator==(kv_cache::CacheState const& other) const noexcept
|
||||
@ -166,6 +181,26 @@ public:
|
||||
return mDataType;
|
||||
}
|
||||
|
||||
[[nodiscard]] bool getEnableBlockReuse() const
|
||||
{
|
||||
return mEnableBlockReuse;
|
||||
}
|
||||
|
||||
[[nodiscard]] bool getHasIndexerKCache() const
|
||||
{
|
||||
return mHasIndexerKCache;
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getIndexerDimPerHead() const
|
||||
{
|
||||
return mIndexerDimPerHead;
|
||||
}
|
||||
|
||||
[[nodiscard]] SizeType32 getIndexerKCacheQuantBlockSize() const
|
||||
{
|
||||
return mIndexerKCacheQuantBlockSize;
|
||||
}
|
||||
|
||||
[[nodiscard]] std::string toString() const
|
||||
{
|
||||
std::stringstream sstring;
|
||||
@ -185,6 +220,10 @@ public:
|
||||
sstring << "kvFactor:" << mAttentionConfig.mKvFactor << "\n";
|
||||
sstring << "dpRank:" << mParallelConfig.mDPrank << "\n";
|
||||
sstring << "dpSize:" << mParallelConfig.mDPsize << "\n";
|
||||
sstring << "enableBlockReuse:" << mEnableBlockReuse << "\n";
|
||||
sstring << "hasIndexerKCache:" << mHasIndexerKCache << "\n";
|
||||
sstring << "indexerDimPerHead:" << mIndexerDimPerHead << "\n";
|
||||
sstring << "indexerKCacheQuantBlockSize:" << mIndexerKCacheQuantBlockSize << "\n";
|
||||
return sstring.str();
|
||||
}
|
||||
|
||||
@ -194,6 +233,10 @@ private:
|
||||
ParallelConfig mParallelConfig;
|
||||
nvinfer1::DataType mDataType;
|
||||
AttentionConfig mAttentionConfig;
|
||||
bool mEnableBlockReuse{false};
|
||||
bool mHasIndexerKCache{false};
|
||||
SizeType32 mIndexerDimPerHead{0};
|
||||
SizeType32 mIndexerKCacheQuantBlockSize{128};
|
||||
};
|
||||
|
||||
struct MpiState
|
||||
|
||||
@ -71,6 +71,7 @@ public:
|
||||
std::optional<FloatType> const& repetitionPenalty = std::nullopt,
|
||||
std::optional<FloatType> const& presencePenalty = std::nullopt,
|
||||
std::optional<FloatType> const& frequencyPenalty = std::nullopt,
|
||||
std::optional<SizeType32> const& promptIgnoreLength = std::nullopt,
|
||||
std::optional<FloatType> const& lengthPenalty = std::nullopt,
|
||||
std::optional<SizeType32> const& earlyStopping = std::nullopt,
|
||||
std::optional<SizeType32> const& noRepeatNgramSize = std::nullopt,
|
||||
@ -94,6 +95,7 @@ public:
|
||||
[[nodiscard]] std::optional<FloatType> getRepetitionPenalty() const;
|
||||
[[nodiscard]] std::optional<FloatType> getPresencePenalty() const;
|
||||
[[nodiscard]] std::optional<FloatType> getFrequencyPenalty() const;
|
||||
[[nodiscard]] std::optional<SizeType32> getPromptIgnoreLength() const;
|
||||
[[nodiscard]] std::optional<FloatType> getLengthPenalty() const;
|
||||
[[nodiscard]] std::optional<SizeType32> getEarlyStopping() const;
|
||||
[[nodiscard]] std::optional<SizeType32> getNoRepeatNgramSize() const;
|
||||
@ -114,6 +116,7 @@ public:
|
||||
void setRepetitionPenalty(std::optional<FloatType> const& repetitionPenalty);
|
||||
void setPresencePenalty(std::optional<FloatType> const& presencePenalty);
|
||||
void setFrequencyPenalty(std::optional<FloatType> const& frequencyPenalty);
|
||||
void setPromptIgnoreLength(std::optional<SizeType32> const& promptIgnoreLength);
|
||||
void setLengthPenalty(std::optional<FloatType> const& lengthPenalty);
|
||||
void setEarlyStopping(std::optional<SizeType32> const& earlyStopping);
|
||||
void setNoRepeatNgramSize(std::optional<SizeType32> const& noRepeatNgramSize);
|
||||
@ -133,6 +136,8 @@ private:
|
||||
static std::optional<FloatType> const& checkBeamSearchDiversityRate(
|
||||
std::optional<FloatType> const& beamSearchDiversityRate);
|
||||
static std::optional<FloatType> const& checkRepetitionPenalty(std::optional<FloatType> const& repetitionpenalty);
|
||||
static std::optional<SizeType32> const& checkPromptIgnoreLength(
|
||||
std::optional<SizeType32> const& promptIgnoreLength);
|
||||
static std::optional<FloatType> const& checkLengthPenalty(std::optional<FloatType> const& lengthPenalty);
|
||||
static std::optional<SizeType32> const& checkEarlyStopping(std::optional<SizeType32> const& earlyStopping);
|
||||
static std::optional<SizeType32> const& checkNoRepeatNgramSize(std::optional<SizeType32> const& noRepeatNgramSize);
|
||||
@ -174,6 +179,9 @@ private:
|
||||
/// @brief Used to penalize tokens already present in the sequence (dependent on the number of appearances). It can
|
||||
/// have any values. Values < 0.f encourage repetition, values > 0.f discourage it. Default is 0.f
|
||||
std::optional<FloatType> mFrequencyPenalty;
|
||||
/// @brief Controls how many tokens to ignore from the prompt for presence and frequency penalties. Values <= 0 have
|
||||
/// no effect. Values > input (prompt) length will be clamped. Default is 0.
|
||||
std::optional<SizeType32> mPromptIgnoreLength;
|
||||
/// @brief Controls how to penalize longer sequences in beam search. Default is 0.f
|
||||
std::optional<FloatType> mLengthPenalty;
|
||||
/// @brief Controls whether the generation process finishes once beamWidth sentences are generated (ends with
|
||||
@ -1456,15 +1464,20 @@ public:
|
||||
UCX = 2,
|
||||
NIXL = 3
|
||||
};
|
||||
explicit CacheTransceiverConfig(
|
||||
std::optional<BackendType> backendType = std::nullopt, std::optional<size_t> maxNumTokens = std::nullopt);
|
||||
explicit CacheTransceiverConfig(std::optional<BackendType> backendType = std::nullopt,
|
||||
std::optional<size_t> maxNumTokens = std::nullopt, std::optional<int> kvTransferTimeoutMs = std::nullopt,
|
||||
std::optional<int> kvTransferSenderFutureTimeoutMs = std::nullopt);
|
||||
|
||||
bool operator==(CacheTransceiverConfig const& other) const;
|
||||
void setBackendType(std::optional<BackendType> backendType);
|
||||
void setMaxTokensInBuffer(std::optional<size_t> maxTokensInBuffer);
|
||||
void setKvTransferTimeoutMs(std::optional<int> kvTransferTimeoutMs);
|
||||
void setKvTransferSenderFutureTimeoutMs(std::optional<int> kvTransferSenderFutureTimeoutMs);
|
||||
|
||||
[[nodiscard]] std::optional<size_t> getMaxTokensInBuffer() const;
|
||||
[[nodiscard]] std::optional<BackendType> getBackendType() const;
|
||||
[[nodiscard]] std::optional<int> getKvTransferTimeoutMs() const;
|
||||
[[nodiscard]] std::optional<int> getKvTransferSenderFutureTimeoutMs() const;
|
||||
|
||||
private:
|
||||
std::optional<BackendType> mBackendType;
|
||||
@ -1472,13 +1485,18 @@ private:
|
||||
/// kvCache tokens to be transferred for a single request is greater than this value, the performance of the cache
|
||||
/// transfer may be degraded.
|
||||
std::optional<size_t> mMaxTokensInBuffer;
|
||||
std::optional<int> mKvTransferTimeoutMs;
|
||||
// @brief Timeout in milliseconds to wait for the sender future to be ready when scheduled batch size is 0. This
|
||||
// allows the request to be eventually cancelled by the user or because of kv_transfer_timeout_ms
|
||||
std::optional<int> mKvTransferSenderFutureTimeoutMs;
|
||||
};
|
||||
|
||||
/// @brief Configuration class for the model executor
|
||||
class ExecutorConfig
|
||||
{
|
||||
public:
|
||||
static constexpr uint64_t kDefaultMaxSeqIdleMicroseconds = 180000000;
|
||||
static constexpr uint64_t kDefaultMaxSeqIdleMicroseconds
|
||||
= std::chrono::duration_cast<std::chrono::microseconds>(std::chrono::minutes(3)).count();
|
||||
|
||||
static constexpr SizeType32 kDefaultIterStatsMaxIterations = 1000;
|
||||
|
||||
|
||||
@ -16,6 +16,7 @@
|
||||
|
||||
#pragma once
|
||||
|
||||
#include "tensorrt_llm/batch_manager/kvCacheManager.h"
|
||||
#include "tensorrt_llm/executor/dataTransceiverState.h"
|
||||
#include "tensorrt_llm/executor/executor.h"
|
||||
#include "tensorrt_llm/executor/tensor.h"
|
||||
@ -36,6 +37,10 @@ struct SocketState;
|
||||
class Serialization
|
||||
{
|
||||
public:
|
||||
// BlockKey (KV cache)
|
||||
static size_t serializedSize(tensorrt_llm::batch_manager::kv_cache_manager::BlockKey const& key);
|
||||
static void serialize(tensorrt_llm::batch_manager::kv_cache_manager::BlockKey const& key, std::ostream& os);
|
||||
static tensorrt_llm::batch_manager::kv_cache_manager::BlockKey deserializeBlockKey(std::istream& is);
|
||||
// TimePoint
|
||||
[[nodiscard]] static RequestPerfMetrics::TimePoint deserializeTimePoint(std::istream& is);
|
||||
static void serialize(RequestPerfMetrics::TimePoint const& tp, std::ostream& os);
|
||||
|
||||
@ -40,6 +40,8 @@ enum class MemoryType : uint8_t
|
||||
kFILE
|
||||
};
|
||||
|
||||
// `MemoryDesc` is used to describe a memory region, which can then be designated
|
||||
// as the source or destination of read/write operations.
|
||||
class MemoryDesc
|
||||
{
|
||||
public:
|
||||
@ -192,6 +194,8 @@ using RegisterDescs = MemoryDescs;
|
||||
using SyncMessage = std::string;
|
||||
using ConnectionInfoType = std::string;
|
||||
|
||||
// `AgentDesc` represents the unique identifier for reading and writing to the agent.
|
||||
// By accessing this identifier, the backend can establish the correct connection.
|
||||
class AgentDesc final
|
||||
{
|
||||
public:
|
||||
@ -209,15 +213,24 @@ private:
|
||||
std::string mBackendAgentDesc;
|
||||
};
|
||||
|
||||
// `TransferOp` is an enumeration that represents the types of transfer operations.
|
||||
// Currently, it supports two operations: `read` and `write`.
|
||||
enum class TransferOp : uint8_t
|
||||
{
|
||||
kREAD,
|
||||
kWRITE,
|
||||
};
|
||||
|
||||
// `TransferRequest` is used to represent the transfer requests supported by the underlying agent.
|
||||
class TransferRequest
|
||||
{
|
||||
public:
|
||||
/// @brief The constructor of `TransferRequest`.
|
||||
/// @param op Source data arrangement.
|
||||
/// @param srcDescs Description of the source memory region.
|
||||
/// @param dstDescs Description of the destination memory region.
|
||||
/// @param remoteName Name of the remote counterpart.
|
||||
/// @param syncMessage Synchronization information for the end of the transfer.
|
||||
TransferRequest(TransferOp op, TransferDescs srcDescs, TransferDescs dstDescs, std::string const& remoteName,
|
||||
std::optional<SyncMessage> syncMessage = std::nullopt)
|
||||
: mOp{op}
|
||||
@ -261,6 +274,7 @@ private:
|
||||
std::optional<SyncMessage> mSyncMessage;
|
||||
};
|
||||
|
||||
// Data structure for checking the status of active transfer operations.
|
||||
class TransferStatus
|
||||
{
|
||||
public:
|
||||
@ -281,22 +295,52 @@ class BaseTransferAgent
|
||||
public:
|
||||
virtual ~BaseTransferAgent() = default;
|
||||
|
||||
/// @brief Register a memory region.
|
||||
/// @param descs Describe the memory regions to be registered.
|
||||
virtual void registerMemory(RegisterDescs const& descs) = 0;
|
||||
|
||||
/// @brief Unregister a memory region.
|
||||
/// @param descs Describe the memory regions to be unregistered.
|
||||
virtual void deregisterMemory(RegisterDescs const& descs) = 0;
|
||||
|
||||
/// @brief Initialize and establish a connection with a remote agent.
|
||||
/// @param name Specify the name of the remote agent.
|
||||
/// @param agentDesc Provide the necessary communication details for connecting to the remote agent.
|
||||
virtual void loadRemoteAgent(std::string const& name, AgentDesc const& agentDesc) = 0;
|
||||
virtual AgentDesc getLocalAgentDesc() = 0;
|
||||
|
||||
/// @brief Initialize and establish a connection with a remote agent.
|
||||
/// @param name Specify the name of the remote agent.
|
||||
/// @param connectionInfo Provide the necessary communication details for connecting to the remote agent.
|
||||
virtual void loadRemoteAgent(std::string const& name, ConnectionInfoType const& connectionInfo) = 0;
|
||||
|
||||
/// @brief Invalidate a connection with a remote agent.
|
||||
/// @param name Specify the name of the remote agent.
|
||||
virtual void invalidateRemoteAgent(std::string const& name) = 0;
|
||||
|
||||
/// @brief Fetch the descriptor of the local agent.
|
||||
/// @return The descriptor of the local agent.
|
||||
virtual AgentDesc getLocalAgentDesc() = 0;
|
||||
|
||||
/// @brief Fetch the descriptor of the local agent.
|
||||
/// @return The descriptor of the local agent.
|
||||
virtual ConnectionInfoType getLocalConnectionInfo() = 0;
|
||||
|
||||
/// @brief Initiate the transfer by submitting the request.
|
||||
/// @param request Specify the transmission request.
|
||||
/// @return The status of the requests.
|
||||
[[nodiscard]] virtual std::unique_ptr<TransferStatus> submitTransferRequests(TransferRequest const& request) = 0;
|
||||
|
||||
/// @brief Generate a notification, not bound to a transfer, e.g., for control.
|
||||
/// @param name Specify the name of the remote agent to which the information should be sent.
|
||||
/// @param syncMessage The data or message intended for synchronization.
|
||||
virtual void notifySyncMessage(std::string const& name, SyncMessage const& syncMessage) = 0;
|
||||
|
||||
/// @brief Retrieve notification messages sent by other agents.
|
||||
/// @return A mapping from remote agent names to their respective notification messages.
|
||||
virtual std::unordered_map<std::string, std::vector<SyncMessage>> getNotifiedSyncMessages() = 0;
|
||||
|
||||
virtual ConnectionInfoType getConnectionInfo() = 0;
|
||||
virtual void connectRemoteAgent(std::string const& name, ConnectionInfoType const& connectionInfo) = 0;
|
||||
/// @brief Check if metadata is available for a remote agent.
|
||||
/// @return Whether the metadata is available for a remote agent.
|
||||
virtual bool checkRemoteDescs(std::string const& name, MemoryDescs const& memoryDescs) = 0;
|
||||
};
|
||||
|
||||
|
||||
@ -451,7 +451,7 @@ struct RequestPerfMetrics
|
||||
/// @brief End time of the KV cache transfer for disaggregated serving
|
||||
TimePoint kvCacheTransferEnd;
|
||||
/// @brief KV Cache size transfer for disaggregated serving
|
||||
mutable size_t kvCacheSize = 0;
|
||||
size_t kvCacheSize = 0;
|
||||
};
|
||||
|
||||
struct KvCacheMetrics
|
||||
|
||||
@ -56,6 +56,11 @@ public:
|
||||
return 1;
|
||||
}
|
||||
|
||||
[[nodiscard]] __host__ __device__ static constexpr runtime::SizeType32 getPromptIgnoreLength()
|
||||
{
|
||||
return 0;
|
||||
}
|
||||
|
||||
[[nodiscard]] __host__ __device__ static constexpr uint64_t getSeed()
|
||||
{
|
||||
return 0;
|
||||
|
||||
@ -52,8 +52,9 @@ public:
|
||||
|
||||
void disableLookahead(RequestVector const& genRequests, TensorPtr const& batchSlots) override;
|
||||
|
||||
CudaEvent forwardAsync(decoder::DecoderState const& decoderState, decoder_batch::Input const& input) override;
|
||||
void forward(decoder::DecoderState const& decoderState, decoder_batch::Input const& input) override;
|
||||
CudaEvent forwardAsync(
|
||||
decoder::DecoderState const& decoderState, batch_manager::DecoderInputBuffers const& input) override;
|
||||
void forward(decoder::DecoderState const& decoderState, batch_manager::DecoderInputBuffers const& input) override;
|
||||
|
||||
//! @brief Gather final beam search results for request `batchSlot`.
|
||||
//! Result will only be available after event returned.
|
||||
@ -77,7 +78,7 @@ public:
|
||||
|
||||
private:
|
||||
//! @brief Calls decoders for tokens per engine step
|
||||
void forwardDispatch(decoder::DecoderState const& decoderState, decoder_batch::Input const& input);
|
||||
void forwardDispatch(decoder::DecoderState const& decoderState, batch_manager::DecoderInputBuffers const& input);
|
||||
|
||||
private:
|
||||
CudaStreamPtr mRuntimeStream;
|
||||
|
||||
@ -27,8 +27,9 @@
|
||||
|
||||
namespace tensorrt_llm::batch_manager
|
||||
{
|
||||
class DecoderInputBuffers;
|
||||
class LlmRequest;
|
||||
}
|
||||
} // namespace tensorrt_llm::batch_manager
|
||||
|
||||
namespace tensorrt_llm::runtime
|
||||
{
|
||||
@ -39,43 +40,6 @@ namespace decoder
|
||||
class DecoderState;
|
||||
}
|
||||
|
||||
namespace decoder_batch
|
||||
{
|
||||
|
||||
class Input
|
||||
{
|
||||
public:
|
||||
using TensorConstPtr = ITensor::SharedConstPtr;
|
||||
using TensorPtr = ITensor::SharedPtr;
|
||||
|
||||
explicit Input(std::vector<std::vector<TensorConstPtr>> const& logits, SizeType32 maxDecoderSteps)
|
||||
: logits{logits}
|
||||
, maxDecoderSteps{maxDecoderSteps}
|
||||
{
|
||||
TLLM_CHECK_WITH_INFO(
|
||||
logits.size() == static_cast<size_t>(maxDecoderSteps), "logits vector size does not match maxDecoderSteps");
|
||||
}
|
||||
|
||||
explicit Input(std::vector<TensorConstPtr> const& logits)
|
||||
: Input{{logits}, 1}
|
||||
{
|
||||
}
|
||||
|
||||
//! Mandatory parameters
|
||||
//! Logits
|
||||
// FIXME: remove first dimension of tensors
|
||||
//! [maxDecoderSteps][batchSize][1, beamWidth, vocabSizePadded], on gpu
|
||||
std::vector<std::vector<TensorConstPtr>> logits;
|
||||
|
||||
//! Maximum number of decoding tokens of active slots
|
||||
SizeType32 maxDecoderSteps;
|
||||
|
||||
//! Batch of active decoder slots, sorted by slots, [maxDecoderSteps][batchSize]
|
||||
std::vector<TensorPtr> batchSlots;
|
||||
};
|
||||
|
||||
} // namespace decoder_batch
|
||||
|
||||
//! GPT decoder class with support for in-flight batching
|
||||
class IGptDecoderBatched
|
||||
{
|
||||
@ -94,10 +58,13 @@ public:
|
||||
virtual void disableLookahead(RequestVector const& genRequests, TensorPtr const& batchSlots) = 0;
|
||||
|
||||
//! @brief Run one step for all requests without blocking the host process and return the token for synchronization.
|
||||
virtual CudaEvent forwardAsync(decoder::DecoderState const& decoderState, decoder_batch::Input const& input) = 0;
|
||||
virtual CudaEvent forwardAsync(
|
||||
decoder::DecoderState const& decoderState, batch_manager::DecoderInputBuffers const& input)
|
||||
= 0;
|
||||
|
||||
//! @brief Run one step for all requests and wait for completion on the host.
|
||||
virtual void forward(decoder::DecoderState const& decoderState, decoder_batch::Input const& input) = 0;
|
||||
virtual void forward(decoder::DecoderState const& decoderState, batch_manager::DecoderInputBuffers const& input)
|
||||
= 0;
|
||||
|
||||
//! @brief Gather final beam search results for request `batchIdx`.
|
||||
//! Result will only be available after event returned
|
||||
|
||||
@ -19,7 +19,6 @@
|
||||
#include "tensorrt_llm/executor/executor.h"
|
||||
#include "tensorrt_llm/runtime/common.h"
|
||||
#include "tensorrt_llm/runtime/speculativeDecodingModule.h"
|
||||
#include <memory>
|
||||
|
||||
namespace tensorrt_llm::runtime
|
||||
{
|
||||
@ -29,7 +28,6 @@ class LookaheadModule : public SpeculativeDecodingModule
|
||||
public:
|
||||
explicit LookaheadModule(SizeType32 maxDraftPathLen, SizeType32 maxDecodingDraftTokens) noexcept
|
||||
: SpeculativeDecodingModule(maxDraftPathLen, maxDecodingDraftTokens, maxDecodingDraftTokens)
|
||||
, mExecutionConfig()
|
||||
{
|
||||
}
|
||||
|
||||
@ -43,7 +41,7 @@ public:
|
||||
mExecutionConfig = config;
|
||||
}
|
||||
|
||||
executor::LookaheadDecodingConfig const getExecutionConfig() const
|
||||
[[nodiscard]] executor::LookaheadDecodingConfig const& getExecutionConfig() const
|
||||
{
|
||||
return mExecutionConfig;
|
||||
}
|
||||
|
||||
@ -21,6 +21,7 @@
|
||||
#include "tensorrt_llm/runtime/lookaheadModule.h"
|
||||
#include "tensorrt_llm/runtime/loraModule.h"
|
||||
#include "tensorrt_llm/runtime/speculativeDecodingMode.h"
|
||||
#include "tensorrt_llm/runtime/speculativeDecodingModule.h"
|
||||
|
||||
#include <NvInferRuntime.h>
|
||||
#include <array>
|
||||
|
||||
@ -133,6 +133,9 @@ public:
|
||||
frequencyPenalty = fuseValues<FloatType>(
|
||||
configs, [&configs](size_t ci) { return configs[ci].frequencyPenalty; },
|
||||
layers::DefaultDecodingParams::getFrequencyPenalty());
|
||||
promptIgnoreLength = fuseValues<SizeType32>(
|
||||
configs, [&configs](size_t ci) { return configs[ci].promptIgnoreLength; },
|
||||
layers::DefaultDecodingParams::getPromptIgnoreLength());
|
||||
noRepeatNgramSize = fuseValues<SizeType32>(
|
||||
configs, [&configs](size_t ci) { return configs[ci].noRepeatNgramSize; },
|
||||
layers::DefaultDecodingParams::getNoRepeatNgramSize());
|
||||
@ -224,6 +227,7 @@ public:
|
||||
SET_FROM_OPTIONAL(repetitionPenalty, RepetitionPenalty, FloatType)
|
||||
SET_FROM_OPTIONAL(presencePenalty, PresencePenalty, FloatType)
|
||||
SET_FROM_OPTIONAL(frequencyPenalty, FrequencyPenalty, FloatType)
|
||||
SET_FROM_OPTIONAL(promptIgnoreLength, PromptIgnoreLength, SizeType32)
|
||||
SET_FROM_OPTIONAL(lengthPenalty, LengthPenalty, FloatType)
|
||||
SET_FROM_OPTIONAL(earlyStopping, EarlyStopping, SizeType32)
|
||||
SET_FROM_OPTIONAL(noRepeatNgramSize, NoRepeatNgramSize, SizeType32)
|
||||
@ -342,6 +346,7 @@ public:
|
||||
OptVec<FloatType> repetitionPenalty; // [1] or [batchSize]
|
||||
OptVec<FloatType> presencePenalty; // [1] or [batchSize]
|
||||
OptVec<FloatType> frequencyPenalty; // [1] or [batchSize]
|
||||
OptVec<SizeType32> promptIgnoreLength; // [1] or [batchSize]
|
||||
OptVec<SizeType32> noRepeatNgramSize; // [1] or [batchSize]
|
||||
|
||||
// probs
|
||||
@ -377,13 +382,14 @@ public:
|
||||
&& temperature == other.temperature && originalTemperature == other.originalTemperature
|
||||
&& minLength == other.minLength && repetitionPenalty == other.repetitionPenalty
|
||||
&& presencePenalty == other.presencePenalty && frequencyPenalty == other.frequencyPenalty
|
||||
&& noRepeatNgramSize == other.noRepeatNgramSize && topK == other.topK && topP == other.topP
|
||||
&& randomSeed == other.randomSeed && topPDecay == other.topPDecay && topPMin == other.topPMin
|
||||
&& topPResetIds == other.topPResetIds && beamSearchDiversityRate == other.beamSearchDiversityRate
|
||||
&& lengthPenalty == other.lengthPenalty && earlyStopping == other.earlyStopping
|
||||
&& draftAcceptanceThreshold == other.draftAcceptanceThreshold && topKMedusaHeads == other.topKMedusaHeads
|
||||
&& normalizeLogProbs == other.normalizeLogProbs && outputLogProbs == other.outputLogProbs
|
||||
&& cumLogProbs == other.cumLogProbs && minP == other.minP && beamWidthArray == other.beamWidthArray;
|
||||
&& promptIgnoreLength == other.promptIgnoreLength && noRepeatNgramSize == other.noRepeatNgramSize
|
||||
&& topK == other.topK && topP == other.topP && randomSeed == other.randomSeed
|
||||
&& topPDecay == other.topPDecay && topPMin == other.topPMin && topPResetIds == other.topPResetIds
|
||||
&& beamSearchDiversityRate == other.beamSearchDiversityRate && lengthPenalty == other.lengthPenalty
|
||||
&& earlyStopping == other.earlyStopping && draftAcceptanceThreshold == other.draftAcceptanceThreshold
|
||||
&& topKMedusaHeads == other.topKMedusaHeads && normalizeLogProbs == other.normalizeLogProbs
|
||||
&& outputLogProbs == other.outputLogProbs && cumLogProbs == other.cumLogProbs && minP == other.minP
|
||||
&& beamWidthArray == other.beamWidthArray;
|
||||
}
|
||||
|
||||
SizeType32 getNumReturnBeams() const
|
||||
|
||||
@ -35,6 +35,7 @@
|
||||
#include <cstdlib>
|
||||
#include <memory>
|
||||
#include <mutex>
|
||||
#include <optional>
|
||||
#include <thread>
|
||||
|
||||
#if ENABLE_MULTI_DEVICE
|
||||
@ -425,7 +426,29 @@ public:
|
||||
return !(rhs == *this);
|
||||
}
|
||||
|
||||
bool couldUseMPI() const
|
||||
{
|
||||
if (!mDisableMPI.has_value())
|
||||
{
|
||||
char* val = std::getenv("TLLM_DISABLE_MPI");
|
||||
if (val != NULL && std::string(val) == "1")
|
||||
{
|
||||
mDisableMPI = true;
|
||||
}
|
||||
else
|
||||
{
|
||||
mDisableMPI = false;
|
||||
}
|
||||
}
|
||||
if (mDisableMPI.value())
|
||||
{
|
||||
throw std::runtime_error("MPI is disabled, DON\'T USE MPI");
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
private:
|
||||
mutable std::optional<bool> mDisableMPI;
|
||||
//! \brief Corresponds to `world()` by default, but can be overridden per process.
|
||||
static MpiComm& mutableSession();
|
||||
|
||||
|
||||
284
cpp/include/tensorrt_llm/runtime/utils/pgUtils.h
Normal file
284
cpp/include/tensorrt_llm/runtime/utils/pgUtils.h
Normal file
@ -0,0 +1,284 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
#include <algorithm>
|
||||
#include <functional>
|
||||
#include <memory>
|
||||
#include <numeric>
|
||||
#include <torch/csrc/distributed/c10d/ProcessGroup.hpp>
|
||||
#include <torch/torch.h>
|
||||
#include <vector>
|
||||
|
||||
#include "tensorrt_llm/common/assert.h"
|
||||
#include "tensorrt_llm/common/logger.h"
|
||||
#include "tensorrt_llm/common/tllmException.h"
|
||||
|
||||
// Check async op.
|
||||
inline c10::intrusive_ptr<c10d::Work> pgCheckHelper(
|
||||
c10::intrusive_ptr<c10d::Work> work, char const* const file, int const line, char const* info)
|
||||
{
|
||||
if (work == nullptr)
|
||||
{
|
||||
auto const msg = std::string("[TensorRT-LLM][ERROR] empty work returned from: ") + info;
|
||||
tensorrt_llm::common::throwRuntimeError(file, line, msg);
|
||||
}
|
||||
|
||||
try
|
||||
{
|
||||
work->wait();
|
||||
}
|
||||
catch (...)
|
||||
{
|
||||
auto msg = std::string("[TensorRT-LLM][ERROR] Torch distributed operation error: ") + info;
|
||||
std::throw_with_nested(tensorrt_llm::common::TllmException(file, line, msg.c_str()));
|
||||
}
|
||||
|
||||
return work;
|
||||
}
|
||||
|
||||
// Check sync op.
|
||||
inline void pgCheckHelper(bool success, char const* const file, int const line, char const* info)
|
||||
{
|
||||
if (!success)
|
||||
{
|
||||
throw std::runtime_error(std::string("[TensorRT-LLM][ERROR] Torch distributed operation error: ") + info);
|
||||
}
|
||||
}
|
||||
|
||||
#define PGCHECK_THROW(op) pgCheckHelper(op, __FILE__, __LINE__, #op)
|
||||
#define PGCHECK_THROW_WITH_INFO(op, info) pgCheckHelper(op, __FILE__, __LINE__, info)
|
||||
|
||||
inline bool useMPI()
|
||||
{
|
||||
bool useMPI = true;
|
||||
char* val = std::getenv("TLLM_DISABLE_MPI");
|
||||
if (val != nullptr && std::string(val) == "1")
|
||||
{
|
||||
useMPI = false;
|
||||
}
|
||||
return useMPI;
|
||||
}
|
||||
|
||||
namespace tensorrt_llm::pg_utils
|
||||
{
|
||||
|
||||
// ProcessGroup management functions
|
||||
c10::intrusive_ptr<c10d::ProcessGroup> get_world_pg();
|
||||
|
||||
c10::intrusive_ptr<c10d::ProcessGroup> get_local_pg();
|
||||
|
||||
void init_pg(c10::intrusive_ptr<c10d::ProcessGroup> const& process_group_world,
|
||||
c10::intrusive_ptr<c10d::ProcessGroup> const& process_group_local);
|
||||
|
||||
// Tensor wrapping utilities for ProcessGroup operations
|
||||
inline torch::Tensor wrap_tensor(torch::Tensor data)
|
||||
{
|
||||
return data;
|
||||
}
|
||||
|
||||
template <typename T, typename = std::enable_if_t<std::is_arithmetic_v<T>>>
|
||||
torch::Tensor wrap_tensor(T* data, size_t size)
|
||||
{
|
||||
if constexpr (std::is_same_v<std::decay_t<T>, char>)
|
||||
{
|
||||
// `char` does not have a guaranteed specialization in CppTypeToScalarType
|
||||
// across PyTorch builds. Treat `char` as kChar (int8) explicitly.
|
||||
return at::from_blob(data, {static_cast<int64_t>(size)}, c10::TensorOptions{}.dtype(torch::kChar));
|
||||
}
|
||||
else if constexpr (std::is_same_v<std::decay_t<T>, uint64_t>)
|
||||
{
|
||||
// `uint64_t` may not have a guaranteed specialization in CppTypeToScalarType
|
||||
// across PyTorch builds. Treat `uint64_t` as kLong (int64) explicitly.
|
||||
return at::from_blob(data, {static_cast<int64_t>(size)}, c10::TensorOptions{}.dtype(torch::kLong));
|
||||
}
|
||||
else
|
||||
{
|
||||
return at::from_blob(data, {static_cast<int64_t>(size)},
|
||||
c10::TensorOptions{}.dtype(torch::CppTypeToScalarType<std::decay_t<T>>::value));
|
||||
}
|
||||
}
|
||||
|
||||
template <typename T, typename = std::enable_if_t<std::is_void_v<T>>, typename = void>
|
||||
torch::Tensor wrap_tensor(T* data, size_t size)
|
||||
{
|
||||
return at::from_blob(data, {static_cast<int64_t>(size)}, c10::TensorOptions{}.dtype(torch::kChar));
|
||||
}
|
||||
|
||||
template <typename T>
|
||||
torch::Tensor wrap_tensor(T const* data, size_t size)
|
||||
{
|
||||
return wrap_tensor(const_cast<T*>(data), size);
|
||||
}
|
||||
|
||||
template <typename T, typename = std::enable_if_t<std::is_arithmetic_v<T>>>
|
||||
torch::Tensor wrap_tensor(T& data)
|
||||
{
|
||||
return wrap_tensor(&data, 1);
|
||||
}
|
||||
|
||||
template <typename T, typename = std::enable_if_t<std::is_arithmetic_v<T>>>
|
||||
torch::Tensor wrap_tensor(std::reference_wrapper<T> data)
|
||||
{
|
||||
return wrap_tensor(&data.get(), 1);
|
||||
}
|
||||
|
||||
template <typename T, typename = std::enable_if_t<std::is_arithmetic_v<T>>>
|
||||
torch::Tensor wrap_tensor(T* data)
|
||||
{
|
||||
return wrap_tensor(data, 1);
|
||||
}
|
||||
|
||||
template <typename T>
|
||||
torch::Tensor wrap_tensor(std::vector<T>& data)
|
||||
{
|
||||
return wrap_tensor(data.data(), data.size());
|
||||
}
|
||||
|
||||
template <typename T>
|
||||
torch::Tensor wrap_tensor(std::vector<T> const& data)
|
||||
{
|
||||
return wrap_tensor(data.data(), data.size());
|
||||
}
|
||||
|
||||
template <typename T>
|
||||
torch::Tensor wrap_tensor(std::reference_wrapper<std::vector<T>> data)
|
||||
{
|
||||
auto& ref = data.get();
|
||||
return wrap_tensor(ref.data(), ref.size());
|
||||
}
|
||||
|
||||
template <typename T>
|
||||
torch::Tensor wrap_tensor(std::reference_wrapper<std::vector<T> const> data)
|
||||
{
|
||||
auto const& ref = data.get();
|
||||
return wrap_tensor(ref.data(), ref.size());
|
||||
}
|
||||
|
||||
template <typename T>
|
||||
torch::Tensor wrap_tensor(std::vector<T>* data)
|
||||
{
|
||||
return wrap_tensor(data->data(), data->size());
|
||||
}
|
||||
|
||||
// ProcessGroup Helper - convenient wrapper around ProcessGroup operations
|
||||
struct PgHelper
|
||||
{
|
||||
c10::intrusive_ptr<c10d::ProcessGroup> pg;
|
||||
|
||||
PgHelper(c10::intrusive_ptr<c10d::ProcessGroup> pg)
|
||||
: pg(pg)
|
||||
{
|
||||
}
|
||||
|
||||
template <typename Input, typename Output>
|
||||
c10::intrusive_ptr<c10d::Work> allgather(
|
||||
Input input, Output output, c10d::AllgatherOptions options = c10d::AllgatherOptions())
|
||||
{
|
||||
auto inputTensor = wrap_tensor(input);
|
||||
auto outputTensor = wrap_tensor(output);
|
||||
|
||||
return pg->_allgather_base(outputTensor, inputTensor, options);
|
||||
}
|
||||
|
||||
template <typename Input>
|
||||
c10::intrusive_ptr<c10d::Work> allreduce(Input input, c10d::AllreduceOptions options = c10d::AllreduceOptions())
|
||||
{
|
||||
std::vector inputs{wrap_tensor(input)};
|
||||
|
||||
return pg->allreduce(inputs, options);
|
||||
}
|
||||
|
||||
template <typename Input>
|
||||
c10::intrusive_ptr<c10d::Work> send(Input input, int dstRank, int tag)
|
||||
{
|
||||
std::vector inputs{wrap_tensor(input)};
|
||||
|
||||
return pg->send(inputs, dstRank, tag);
|
||||
}
|
||||
|
||||
template <typename Output>
|
||||
c10::intrusive_ptr<c10d::Work> recv(Output output, int srcRank, int tag)
|
||||
{
|
||||
std::vector outputs{wrap_tensor(output)};
|
||||
|
||||
return pg->recv(outputs, srcRank, tag);
|
||||
}
|
||||
|
||||
// Variable-size allgather helper implemented via padding + slicing on Tensors.
|
||||
template <typename Input, typename Output, typename SizeT = int64_t>
|
||||
bool allgatherv(Input input, Output output, std::vector<SizeT> const& sizes,
|
||||
c10d::AllgatherOptions options = c10d::AllgatherOptions())
|
||||
{
|
||||
auto const worldSize = pg->getSize();
|
||||
|
||||
TLLM_CHECK_WITH_INFO(
|
||||
static_cast<int>(sizes.size()) == worldSize, "sizes.size() must equal worldSize in allgatherv");
|
||||
|
||||
at::Tensor inputTensor = wrap_tensor(input);
|
||||
SizeT const localSize = static_cast<SizeT>(inputTensor.numel());
|
||||
TLLM_CHECK_WITH_INFO(
|
||||
sizes[pg->getRank()] == localSize, "sizes[rank] must equal local input size in allgatherv");
|
||||
|
||||
SizeT const maxSize = *std::max_element(sizes.begin(), sizes.end());
|
||||
auto tensorOptions = inputTensor.options();
|
||||
|
||||
at::Tensor paddedInput = at::zeros({static_cast<int64_t>(maxSize)}, tensorOptions);
|
||||
if (localSize > 0)
|
||||
{
|
||||
paddedInput.narrow(0, 0, static_cast<int64_t>(localSize)).copy_(inputTensor);
|
||||
}
|
||||
|
||||
at::Tensor paddedOutput
|
||||
= at::empty({static_cast<int64_t>(maxSize) * static_cast<int64_t>(worldSize)}, tensorOptions);
|
||||
|
||||
PGCHECK_THROW(pg->_allgather_base(paddedOutput, paddedInput, options)->wait());
|
||||
|
||||
// Prepare compact output tensor backed by 'output'
|
||||
SizeT const totalSize = std::accumulate(sizes.begin(), sizes.end(), static_cast<SizeT>(0));
|
||||
at::Tensor outputTensor = wrap_tensor(output);
|
||||
TLLM_CHECK_WITH_INFO(outputTensor.numel() == static_cast<int64_t>(totalSize),
|
||||
"output tensor numel must equal total size in allgatherv");
|
||||
|
||||
// Slice and compact
|
||||
size_t writeOffset = 0;
|
||||
for (int r = 0; r < worldSize; ++r)
|
||||
{
|
||||
int64_t const validCount = static_cast<int64_t>(sizes[static_cast<size_t>(r)]);
|
||||
int64_t const srcOffset = static_cast<int64_t>(r) * static_cast<int64_t>(maxSize);
|
||||
if (validCount > 0)
|
||||
{
|
||||
outputTensor.narrow(0, static_cast<int64_t>(writeOffset), validCount)
|
||||
.copy_(paddedOutput.narrow(0, srcOffset, validCount));
|
||||
writeOffset += static_cast<size_t>(validCount);
|
||||
}
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// Convenience overload to accept sizes passed via std::cref(...)
|
||||
template <typename Input, typename Output, typename SizeT = int64_t>
|
||||
bool allgatherv(Input input, Output output, std::reference_wrapper<std::vector<SizeT> const> sizes,
|
||||
c10d::AllgatherOptions options = c10d::AllgatherOptions())
|
||||
{
|
||||
return allgatherv<Input, Output, SizeT>(input, output, sizes.get(), options);
|
||||
}
|
||||
};
|
||||
|
||||
} // namespace tensorrt_llm::pg_utils
|
||||
Binary file not shown.
@ -1,12 +1,17 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2023-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2023-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
# property and proprietary rights in and to this material, related
|
||||
# documentation and any modifications thereto. Any use, reproduction,
|
||||
# disclosure or distribution of this material and related documentation
|
||||
# without an express license agreement from NVIDIA CORPORATION or
|
||||
# its affiliates is strictly prohibited.
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import subprocess
|
||||
|
||||
|
||||
@ -78,6 +78,10 @@ def test_trtllm_flash_attention_fmha(d, s, dtype, flag, tiled_kernel):
|
||||
# ada fp8 fmha only supports non-tiled kernels currently.
|
||||
if dtype == '-e4m3' and sm_version == 89 and tiled_kernel == "":
|
||||
pytest.skip("ada fp8 fmha only supports non-tiled kernels currently.")
|
||||
# Known accuracy issue in this case.
|
||||
skip_dense_mask_test = False
|
||||
if d == 64 and dtype in ['-fp16-fp32', '-bf16'] and tiled_kernel == "":
|
||||
skip_dense_mask_test = True
|
||||
|
||||
# use higher error tolerance for bf16 and e4m3.
|
||||
epsilon = ''
|
||||
@ -107,10 +111,11 @@ def test_trtllm_flash_attention_fmha(d, s, dtype, flag, tiled_kernel):
|
||||
if "softcapping-scale-bmm1" in flag:
|
||||
pytest.skip("skipping softcapping-scale-bmm1 for sm89 e4m3 fmha.")
|
||||
|
||||
subprocess.run(
|
||||
f"bin/fmha.exe -d {d} -h 16 -b 8 -s {s} -min-s 128 -v {verbose} {dtype} {epsilon} {flag} {tiled_kernel}",
|
||||
shell=True,
|
||||
check=True)
|
||||
if not skip_dense_mask_test:
|
||||
subprocess.run(
|
||||
f"bin/fmha.exe -d {d} -h 16 -b 8 -s {s} -min-s 128 -v {verbose} {dtype} {epsilon} {flag} {tiled_kernel}",
|
||||
shell=True,
|
||||
check=True)
|
||||
subprocess.run(
|
||||
f"bin/fmha.exe -d {d} -h 16 -b 8 -s {s} -min-s 128 -causal-mask -v {verbose} {dtype} {epsilon} {flag} {tiled_kernel}",
|
||||
shell=True,
|
||||
|
||||
@ -1,12 +1,17 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2020-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2020-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
# property and proprietary rights in and to this material, related
|
||||
# documentation and any modifications thereto. Any use, reproduction,
|
||||
# disclosure or distribution of this material and related documentation
|
||||
# without an express license agreement from NVIDIA CORPORATION or
|
||||
# its affiliates is strictly prohibited.
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import os
|
||||
import subprocess
|
||||
@ -3063,7 +3068,9 @@ def get_kernel_traits_code(specs_names):
|
||||
# 2. Hopper sm89 with e4m3/e4m3_fp32 dtype uses cubins for accuracy regressions (will be fixed).
|
||||
# You should set the condition `use_cubin_header` to false if you have modified the source codes of those kernels that use cubins.
|
||||
# This ensures that the kernels will be recompiled using the updated source code rather than relying on precompiled cubins.
|
||||
def use_cubin_header(sm, head_size, dtype):
|
||||
def use_cubin_header(sm, head_size, dtype, output_dtype=None):
|
||||
if 'e4m3' in dtype and output_dtype in ['bf16', 'fp16']:
|
||||
return False
|
||||
return (sm == 90 and head_size == 128) or (sm == 89 and 'e4m3' in dtype)
|
||||
|
||||
|
||||
@ -3074,7 +3081,7 @@ def get_cubin_header(kernel_traits, specs_names):
|
||||
cubin_lens_dict = {}
|
||||
for kspec, fname, lname, kname in specs_names:
|
||||
if generate_cu_trtllm and not use_cubin_header(
|
||||
kspec.sm, kspec.head_size, kspec.dtype):
|
||||
kspec.sm, kspec.head_size, kspec.dtype, kspec.output_dtype):
|
||||
continue
|
||||
name = fname.replace('.', '_')
|
||||
data = 'extern unsigned char cubin_{name}_cubin[];'.format(name=name)
|
||||
@ -3229,7 +3236,8 @@ def get_cubin_header(kernel_traits, specs_names):
|
||||
if generate_cu_trtllm:
|
||||
|
||||
def get_lname_from_kname(kname: str) -> str:
|
||||
if use_cubin_header(int(sm), int(head_size), prec.lower()):
|
||||
if use_cubin_header(int(sm), int(head_size), prec.lower(),
|
||||
output_prec.lower()):
|
||||
return 'nullptr'
|
||||
lname = kname.replace('_kernel', '')
|
||||
mask_types = [
|
||||
@ -3248,8 +3256,9 @@ def get_cubin_header(kernel_traits, specs_names):
|
||||
{cubin_name}_len, \"{kname}\", {smem}, {threads}, {meta_unroll_step}, {attention_mask_type_value}, \
|
||||
{attention_input_layout_value}, {is_il}, {is_flash_atten}, {is_warp_specialization}, {is_fp32_accu}, \
|
||||
{is_alibi_supported}, {is_tiled}, {has_softcapping_scale}, {return_softmax_stats_flag}, {lname}}}\
|
||||
'''.format(**locals()) if use_cubin_header(int(sm), int(head_size),
|
||||
prec.lower()) else '''\
|
||||
'''.format(**locals()) if use_cubin_header(int(sm),
|
||||
int(head_size), prec.lower(),
|
||||
output_prec.lower()) else '''\
|
||||
{{ DATA_TYPE_{prec}, DATA_TYPE_{output_prec}, {seq_len}, {q_step}, {kv_step}, {head_size}, {head_size_v}, \
|
||||
{sage_block_sizes[0]}, {sage_block_sizes[1]}, {sage_block_sizes[2]}, kSM_{sm}, nullptr, \
|
||||
0, \"{kname}\", {smem}, {threads}, {meta_unroll_step}, {attention_mask_type_value}, \
|
||||
@ -3791,7 +3800,7 @@ def enumerate_qgmma_flash_warpspec_kernels(specs,
|
||||
continue
|
||||
# for normal attention, we do not need return softmax for ws fp8 kernels currently.
|
||||
# also fp8 input and bf16 output is only needed for MLA kernel.
|
||||
skip_combination = return_softmax or (output_dtype is not None)
|
||||
skip_combination = return_softmax
|
||||
# for context mla, we need separate qkv as input layout when returning softmax.
|
||||
skip_mla_combination = return_softmax and input_layout != InputLayout.SEPARATE_Q_K_V
|
||||
if not skip_combination:
|
||||
@ -6379,6 +6388,16 @@ def enumerate_kernels():
|
||||
and kspec.version == 2
|
||||
and kspec.cross_mha == False
|
||||
and kspec.flash_attention == False)
|
||||
# Clip/SigLip support.
|
||||
or (kspec.sm == 100
|
||||
and kspec.dtype in ['fp16', 'bf16', 'fp16_fp32', 'e4m3', 'e4m3_fp32']
|
||||
and kspec.head_size == 80
|
||||
and kspec.head_size_v == 0
|
||||
and kspec.sage_block_sizes is None
|
||||
and kspec.version == 2
|
||||
and kspec.cross_mha == False
|
||||
and kspec.flash_attention == True
|
||||
and kspec.input_layout != InputLayout.SEPARATE_Q_K_V)
|
||||
# Deepseek MLA (generation 576/512 paged)
|
||||
or (kspec.sm in [90, 100, 120]
|
||||
and kspec.dtype in ['bf16', 'e4m3_fp32']
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#include <fmha/numeric_types.h>
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,17 +1,23 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
#include <cfloat>
|
||||
#include <fmha/traits.h>
|
||||
#include <fmha/utils.h>
|
||||
|
||||
@ -1250,6 +1256,23 @@ struct Tile_o_normalizer
|
||||
BYTES_PER_ELEMENT = sizeof(float)
|
||||
};
|
||||
|
||||
// Initialize the attention sinks.
|
||||
template <typename Params, typename Block_info>
|
||||
inline __device__ Tile_o_normalizer(Params const& params, Block_info const& binfo)
|
||||
: attention_sink_value_(params.attention_sinks != nullptr ? params.attention_sinks[binfo.bidh] : -FLT_MAX)
|
||||
{
|
||||
}
|
||||
|
||||
// Update the sum when attention sinks are used.
|
||||
inline __device__ void update_sum(float const (&max)[ROWS_PER_THREAD], float (&sum)[ROWS_PER_THREAD])
|
||||
{
|
||||
#pragma unroll
|
||||
for (int i = 0; i < ROWS_PER_THREAD; ++i)
|
||||
{
|
||||
sum[i] += expf(attention_sink_value_ - max[i]);
|
||||
}
|
||||
}
|
||||
|
||||
// Update o.
|
||||
inline __device__ void update(Fragment_accu (&acc_o)[MMAS_M][MMAS_N], float (&curr_max)[ROWS_PER_THREAD],
|
||||
float const (&prev_max)[ROWS_PER_THREAD], float (&sum)[ROWS_PER_THREAD])
|
||||
@ -1331,8 +1354,9 @@ struct Tile_o_normalizer
|
||||
}
|
||||
|
||||
// Update o.
|
||||
inline __device__ void final_update(Fragment_accu (&acc_o)[MMAS_M][MMAS_N], float const (&sum)[ROWS_PER_THREAD])
|
||||
inline __device__ void final_update(Fragment_accu (&acc_o)[MMAS_M][MMAS_N], float (&sum)[ROWS_PER_THREAD])
|
||||
{
|
||||
|
||||
#ifdef HALF_ACCUMULATION_FOR_FLASH_ATTENTION // Half accumulation
|
||||
#pragma unroll
|
||||
for (int mi = 0; mi < MMAS_M; ++mi)
|
||||
@ -1403,6 +1427,9 @@ struct Tile_o_normalizer
|
||||
}
|
||||
#endif // defined HALF_ACCUMULATION_FOR_FLASH_ATTENTION
|
||||
}
|
||||
|
||||
// Attention sink value.
|
||||
float attention_sink_value_;
|
||||
};
|
||||
|
||||
template <typename Traits, typename Cta_tile>
|
||||
@ -1461,6 +1488,23 @@ struct Tile_o_normalizer_fp32
|
||||
BYTES_PER_ELEMENT = sizeof(float)
|
||||
};
|
||||
|
||||
// Initialize the attention sinks.
|
||||
template <typename Params, typename Block_info>
|
||||
inline __device__ Tile_o_normalizer_fp32(Params const& params, Block_info const& binfo)
|
||||
: attention_sink_value_(params.attention_sinks != nullptr ? params.attention_sinks[binfo.bidh] : -FLT_MAX)
|
||||
{
|
||||
}
|
||||
|
||||
// Update the sum when attention sinks are used.
|
||||
inline __device__ void update_sum(float const (&max)[ROWS_PER_THREAD], float (&sum)[ROWS_PER_THREAD])
|
||||
{
|
||||
#pragma unroll
|
||||
for (int i = 0; i < ROWS_PER_THREAD; ++i)
|
||||
{
|
||||
sum[i] += expf(attention_sink_value_ - max[i]);
|
||||
}
|
||||
}
|
||||
|
||||
// Update o.
|
||||
inline __device__ void update(Fragment_accu (&acc_o)[MMAS_M][MMAS_N], float (&curr_max)[ROWS_PER_THREAD],
|
||||
float const (&prev_max)[ROWS_PER_THREAD], float (&sum)[ROWS_PER_THREAD])
|
||||
@ -1501,7 +1545,7 @@ struct Tile_o_normalizer_fp32
|
||||
}
|
||||
|
||||
// Update o after P * V
|
||||
inline __device__ void final_update(Fragment_accu (&acc_o)[MMAS_M][MMAS_N], float const (&sum)[ROWS_PER_THREAD])
|
||||
inline __device__ void final_update(Fragment_accu (&acc_o)[MMAS_M][MMAS_N], float (&sum)[ROWS_PER_THREAD])
|
||||
{
|
||||
|
||||
#pragma unroll
|
||||
@ -1517,9 +1561,7 @@ struct Tile_o_normalizer_fp32
|
||||
int jj = 2 * mi + ii;
|
||||
|
||||
// The diviser.
|
||||
// printf("curr_sum_[ii] %lf %lf \n", curr_sum_[ii], curr_sum_[ii]);
|
||||
beta[ii] = (sum[jj] == 0.f || sum[jj] != sum[jj]) ? 1.f : 1.f / sum[jj];
|
||||
// printf("beta %lf \n", beta[ii]);
|
||||
}
|
||||
|
||||
#pragma unroll
|
||||
@ -1538,6 +1580,9 @@ struct Tile_o_normalizer_fp32
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Attention sink value.
|
||||
float attention_sink_value_;
|
||||
};
|
||||
|
||||
template <typename Cta_tile>
|
||||
@ -1550,8 +1595,12 @@ struct Tile_o_normalizer<Ampere_hmma_fp32_traits, Cta_tile>
|
||||
// The base class.
|
||||
using Base = Tile_o_normalizer_fp32<Traits, Cta_tile>;
|
||||
|
||||
// Default ctor
|
||||
Tile_o_normalizer() = default;
|
||||
// The ctor.
|
||||
template <typename Params, typename Block_info>
|
||||
inline __device__ Tile_o_normalizer(Params const& params, Block_info const& binfo)
|
||||
: Base(params, binfo)
|
||||
{
|
||||
}
|
||||
};
|
||||
|
||||
template <typename Cta_tile>
|
||||
@ -1564,10 +1613,15 @@ struct Tile_o_normalizer<Ampere_hmma_bf16_traits, Cta_tile>
|
||||
// The base class.
|
||||
using Base = Tile_o_normalizer_fp32<Traits, Cta_tile>;
|
||||
|
||||
// Default ctor
|
||||
Tile_o_normalizer() = default;
|
||||
// The ctor.
|
||||
template <typename Params, typename Block_info>
|
||||
inline __device__ Tile_o_normalizer(Params const& params, Block_info const& binfo)
|
||||
: Base(params, binfo)
|
||||
{
|
||||
}
|
||||
};
|
||||
|
||||
// The attention sinks are not enabled for Volta.
|
||||
template <typename Cta_tile>
|
||||
struct Tile_o_normalizer<Volta_hmma_fp16_16x16x16_traits, Cta_tile>
|
||||
{
|
||||
@ -1747,98 +1801,21 @@ struct Tile_o_normalizer<Ada_qmma_e4m3_fp32_traits, Cta_tile>
|
||||
// The base class.
|
||||
using Base = Tile_o_normalizer_fp32<Traits, Cta_tile>;
|
||||
|
||||
// Default ctor
|
||||
Tile_o_normalizer() = default;
|
||||
|
||||
// The fragment accumulator.
|
||||
using Fragment_accu = Fragment_accumulator<Traits>;
|
||||
|
||||
// The Mma tile.
|
||||
using Mma_tile = typename Traits::template Mma_tile<Cta_tile>;
|
||||
|
||||
// The number of MMAs in the M dimension.
|
||||
enum
|
||||
// The ctor.
|
||||
template <typename Params, typename Block_info>
|
||||
inline __device__ Tile_o_normalizer(Params const& params, Block_info const& binfo)
|
||||
: Base(params, binfo)
|
||||
{
|
||||
MMAS_M = Mma_tile::MMAS_M
|
||||
};
|
||||
}
|
||||
|
||||
// The number of MMAs in the N dimension.
|
||||
enum
|
||||
// Update the sum.
|
||||
inline __device__ void update_sum(float const (&max)[Base::ROWS_PER_THREAD], float (&sum)[Base::ROWS_PER_THREAD])
|
||||
{
|
||||
MMAS_N = Mma_tile::VALID_MMAS_N
|
||||
};
|
||||
|
||||
// The number of rows per thread.
|
||||
enum
|
||||
{
|
||||
ROWS_PER_THREAD = 2 * MMAS_M
|
||||
};
|
||||
|
||||
// The number of registers per thread.
|
||||
enum
|
||||
{
|
||||
REGS_PER_THREAD = 8
|
||||
};
|
||||
|
||||
// Warps.
|
||||
enum
|
||||
{
|
||||
WARPS_M = Cta_tile::WARPS_M
|
||||
};
|
||||
|
||||
enum
|
||||
{
|
||||
WARPS_N = Cta_tile::WARPS_N
|
||||
};
|
||||
|
||||
enum
|
||||
{
|
||||
WARPS_K = Cta_tile::WARPS_K
|
||||
};
|
||||
|
||||
// softmax data bytes
|
||||
enum
|
||||
{
|
||||
BYTES_PER_ELEMENT = sizeof(float)
|
||||
};
|
||||
|
||||
// Update o after P * V, the only difference from the basic class is we need to dequant the sum for softmax saver.
|
||||
inline __device__ void final_update(Fragment_accu (&acc_o)[MMAS_M][MMAS_N], float (&sum)[ROWS_PER_THREAD])
|
||||
{
|
||||
|
||||
constexpr float dequant_scale = Traits::SOFTMAX_FP_DEQUANT_SCALE;
|
||||
// Take the log2f(Traits::SOFTMAX_FP_QUANT_SCALE) into account as the same scale has been applied to sum.
|
||||
#pragma unroll
|
||||
for (int mi = 0; mi < MMAS_M; ++mi)
|
||||
for (int i = 0; i < Base::ROWS_PER_THREAD; ++i)
|
||||
{
|
||||
|
||||
// Precompute the scaling factors for the 2 rows.
|
||||
float beta[2];
|
||||
#pragma unroll
|
||||
for (int ii = 0; ii < 2; ++ii)
|
||||
{
|
||||
// The row.
|
||||
int jj = 2 * mi + ii;
|
||||
|
||||
// The diviser.
|
||||
beta[ii] = (sum[jj] == 0.f || sum[jj] != sum[jj]) ? 1.f : 1.f / sum[jj];
|
||||
// softmax saver need the original sum.
|
||||
sum[jj] = sum[jj] * dequant_scale;
|
||||
}
|
||||
|
||||
#pragma unroll
|
||||
for (int ni = 0; ni < MMAS_N; ++ni)
|
||||
{
|
||||
#pragma unroll
|
||||
for (int ii = 0; ii < REGS_PER_THREAD; ++ii)
|
||||
{
|
||||
// The register for O.
|
||||
float acc_o_f = acc_o[mi][ni].elt(ii);
|
||||
// Compute the next accumulator.
|
||||
acc_o_f = acc_o_f * beta[(ii & 2) / 2];
|
||||
// Update the accumulator.
|
||||
acc_o[mi][ni].elt(ii) = acc_o_f;
|
||||
}
|
||||
}
|
||||
sum[i] += expf(this->attention_sink_value_ - max[i]) * Traits::SOFTMAX_FP_QUANT_SCALE;
|
||||
}
|
||||
}
|
||||
};
|
||||
@ -1878,8 +1855,12 @@ struct Tile_o_normalizer<Ada_qmma_e4m3_fp32_traits, Cta_tile, true>
|
||||
REGS_PER_THREAD = 8
|
||||
};
|
||||
|
||||
// Default ctor
|
||||
Tile_o_normalizer() = default;
|
||||
// The ctor.
|
||||
template <typename Params, typename Block_info>
|
||||
inline __device__ Tile_o_normalizer(Params const& params, Block_info const& binfo)
|
||||
: Base(params, binfo)
|
||||
{
|
||||
}
|
||||
|
||||
inline __device__ void merge(Fragment_accu (&acc_dst)[MMAS_M][MMAS_N], Fragment_accu (&acc_src)[MMAS_M][MMAS_N])
|
||||
{
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2023-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2023-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#include <cstdint>
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#include <fmha/hopper/arrive_wait.h>
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
@ -1,13 +1,18 @@
|
||||
/*
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: NVIDIA TensorRT Source Code License Agreement
|
||||
* SPDX-FileCopyrightText: Copyright (c) 2011-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*
|
||||
* NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
|
||||
* property and proprietary rights in and to this material, related
|
||||
* documentation and any modifications thereto. Any use, reproduction,
|
||||
* disclosure or distribution of this material and related documentation
|
||||
* without an express license agreement from NVIDIA CORPORATION or
|
||||
* its affiliates is strictly prohibited.
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
#pragma once
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user