mirror of
https://github.com/lucasjinreal/Namo-R1.git
synced 2026-01-13 22:07:17 +08:00
151 lines
6.3 KiB
Markdown
151 lines
6.3 KiB
Markdown
<div align='center'>
|
|
<img src='https://img2023.cnblogs.com/blog/3572323/202502/3572323-20250221161349804-1020036173.png' style="border-radius: 15px;" />
|
|
<h1>Namo R1</h1>
|
|
</div>
|
|
|
|
<p align="center">
|
|
🤗 <a href="https://huggingface.co/lucasjin/Namo-500M-V1">Namo-500M-V1</a>   |   🐝 <a href="https://discord.gg/5ftPBVspXj">Community</a>
|
|
</p
|
|
|
|
> **You**: *I don't have GPUs to run VLMs.* **Namo R1:** Hold my beer.... let's do this on CPU.
|
|
|
|
**Namo R1** 🔥🔥 surpassed SmolVLM and Moondream2 in terms of same size! And we are keep evolving, more advanced models are under training!
|
|
|
|
## Introduction
|
|
|
|
We are excited to open-source **Namo**, an extremly small yet mighty MLLM. While numerous MLLMs exist, few offer true extensibility or fully open-source their training data, model architectures, and training schedulers - critical components for reproducible AI research.
|
|
|
|
The AI community has largely overlooked the potential of compact MLLMs, despite their demonstrated efficiency advantages. Our analysis reveals significant untapped potential in sub-billion parameter models, particularly for edge deployment and specialized applications. To address this gap, we're releasing Namo R1, a foundational 500M parameter model trained from scratch using innovative architectural choices.
|
|
|
|
Key innovations include:
|
|
|
|
1. **CPU friendly:** Even on CPUs, Namo R1 can runs very fast;
|
|
2. **Omni-modal Scalability:** Native support for future expansion into audio (ASR/TTS) and cross-modal fusion;
|
|
3. **Training Transparency:** Full disclosure of data curation processes and dynamic curriculum scheduling techniques.
|
|
|
|
👇 Video Demo Runs on **CPU**:
|
|
|
|
<video src='https://github.com/user-attachments/assets/eb353124-509e-4b87-8a0d-b0b37b5efba2
|
|
'></video>
|
|
|
|
Please join us in discord! https://discord.gg/5ftPBVspXj . For Chinese users, we will publish WeChat group in discord as well.
|
|
|
|
|
|
## Updates
|
|
|
|
- **`2025.02.22`**: more to come...!
|
|
- **`2025.02.22`**: 🔥🔥 SigLIP2 added! You can now training with SigLIP2 as vision encoder, Join us in [discord](https://discord.gg/5ftPBVspXj);
|
|
- **`2025.02.21`**: 🔥🔥 The first version is ready to open, fire the MLLM power able to runs on CPU!
|
|
- **`2025.02.17`**: Namo R1 start training.
|
|
|
|
## Results
|
|
|
|
the result might keep updating as new models trained.
|
|
|
|
| Model | MMB-EN-T | MMB-CN-T | Size |
|
|
| -------------------- | -------------- | -------------- | ---- |
|
|
| Namo-500M | **68.8** | **48.7** | 500M |
|
|
| Namo-700M | training | training | 700M |
|
|
| Namo-500M-R1 | training | training | 500M |
|
|
| Namo-700M-R1 | training | training | 700M |
|
|
| SmolVLM-500M | 53.8 | 35.4 | 500M |
|
|
| SmolVLM-Instruct-DPO | 67.5 | 49.8 | 2.3B |
|
|
| Moondream1 | 62.3 | 19.8 | 1.9B |
|
|
| Moondream2 | 70 | 28.7 | 1.9B |
|
|
|
|
⚠️ Currently, the testing has only been conducted on a limited number of benchmarks. In the near future, more metrics will be reported. Even so, we've observed significant improvements compared to other small models.
|
|
|
|
## Get Started
|
|
|
|
#### Install & Run in Cli
|
|
|
|
All you need to do is:
|
|
|
|
```shell
|
|
pip install -U namo
|
|
```
|
|
|
|
A simple demo would be:
|
|
|
|
```python
|
|
import torch
|
|
from namo.api.vl import VLInfer
|
|
|
|
# model will download automatically
|
|
model = VLInfer(
|
|
model_type="namo", device="cuda:0" if torch.cuda.is_available() else "cpu"
|
|
)
|
|
|
|
# default will have streaming
|
|
# this method accepts a single path, url, or PIL image, or an array of same.
|
|
model.generate(images=['images/cats.jpg'], prompt='what is this?')
|
|
```
|
|
|
|
That's all!
|
|
|
|
For cli multi-turn chat in terminal you can run `python demo.py`. (Namo cli directly in your terminal would be available later.)
|
|
|
|
#### OpenAI server & Run in OpenWebUI
|
|
|
|
```shell
|
|
namo server --model checkpoints/Namo-500M-V1
|
|
```
|
|
|
|
then, you will have OpenAI like serving in local.
|
|
|
|
## Showcases
|
|
|
|
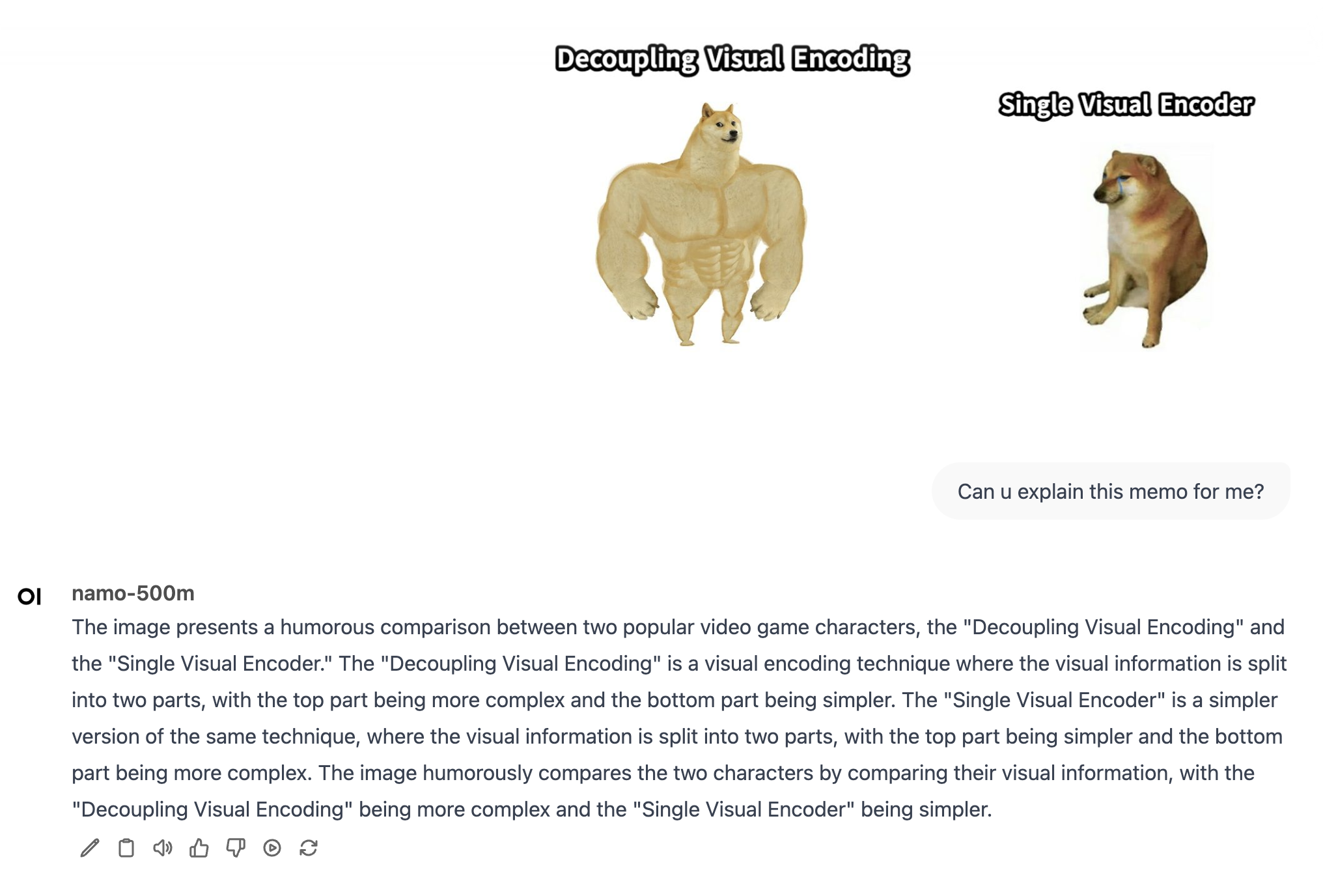
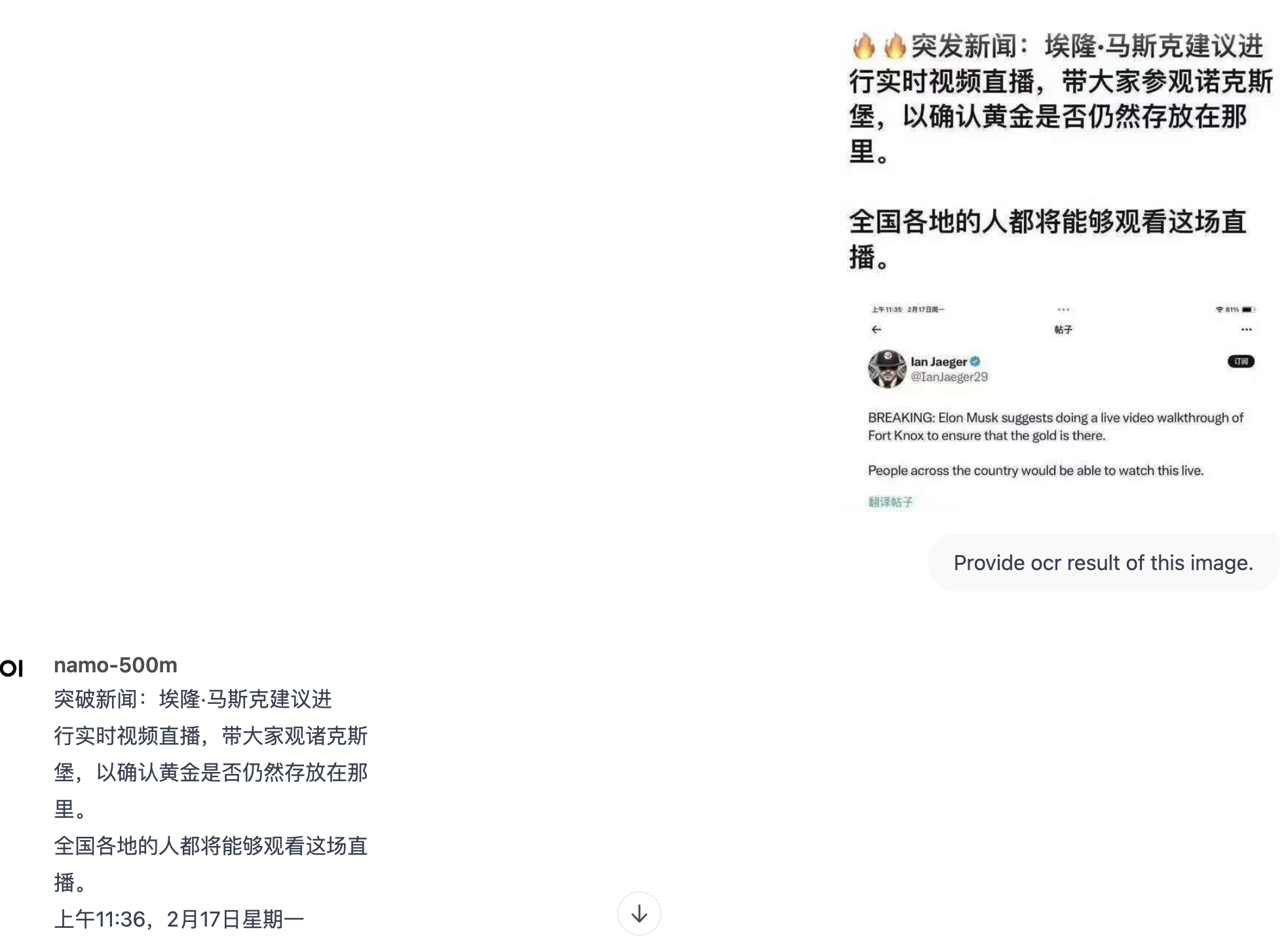
**Namo-500M**, our first small series of models, is capable of performing remarkable tasks such as multilingual OCR, general concept understanding, image captioning, and more. And it has only 500 million parameters! You can run it directly on a CPU!
|
|
|
|
<details>
|
|
<summary><strong>📁 Show more real use cases</strong></summary>
|
|
|
|
|
|
|
|
|
|
|
|
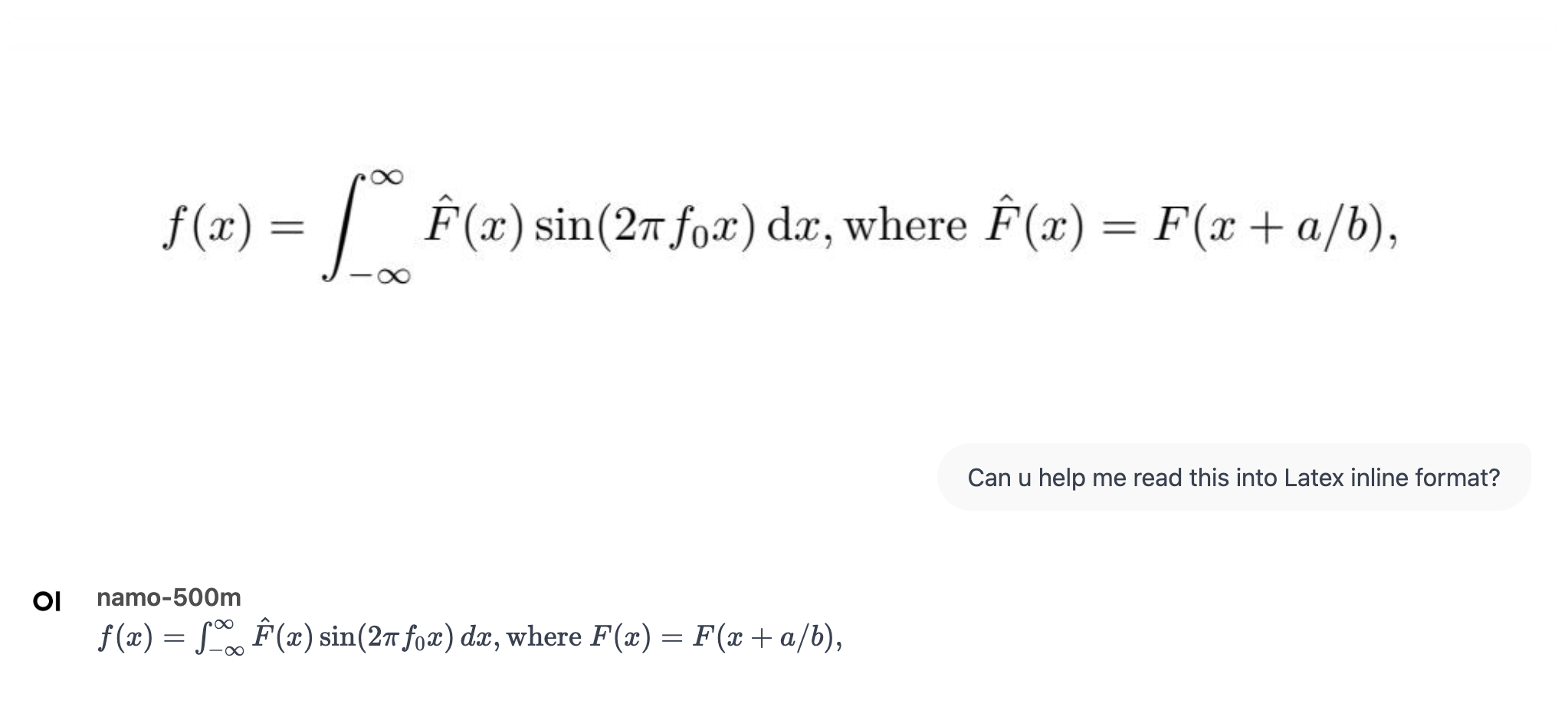
|
|
|
|

|
|
|
|

|
|
|
|

|
|
|
|

|
|
|
|

|
|
|
|
</details>
|
|
|
|
## Features of Namo R1
|
|
|
|
In contrast to open-source VLMs like Qwen2.5-3B and MiniCPM, the Namo series offers the following features that enable anyone to train their own VLMs from scratch:
|
|
|
|
- **Extremely Small**: Our first series has only 500 million parameters yet powerful on various tasks.
|
|
- **OCR Capability**: With just a 500M model, you can perform multilingual OCR, covering not only Chinese and English but also Japanese and other languages.
|
|
- **Dynamic Resolution**: We support native dynamic resolution as input, making it robust for images of **any ratio**.
|
|
- **Fully Open Source**: We opensource all model codes including training steps and scripts!
|
|
- **R1 Support**: Yes, we now support R1 for post-training.
|
|
|
|
Above all, we are also ready to help when u want train your MLLM from scratch at any tasks!
|
|
|
|
## Roadmap
|
|
|
|
We are still actively training on new models, here are few things we will arrive:
|
|
|
|
- Speech model;
|
|
- Vision model with more decent vision encoders, such as SigLip2;
|
|
- TTS ability;
|
|
- Slightly larger models, up to 7B;
|
|
|
|
## Trouble Shooting
|
|
|
|
1. Got error when using deepspeed: ` AssertionError: no_sync context manager is incompatible with gradient partitioning logic of ZeRO stage 2` ?
|
|
|
|
Please upgrade transformers to 4.48+ and use latest deepspeed.
|
|
|
|
## Copyright
|
|
|
|
All right reserved by Namo authors, code released under MIT License.
|