mirror of
https://github.com/NVIDIA/TensorRT-LLM.git
synced 2026-01-13 22:18:36 +08:00
[None][doc] Replace the relative links with absolute links in README.md. (#8995)
Signed-off-by: nv-guomingz <137257613+nv-guomingz@users.noreply.github.com>
This commit is contained in:
parent
d8ea0b967f
commit
c232ffd122
34
README.md
34
README.md
@ -10,10 +10,10 @@ state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs.<
|
||||
[](https://www.python.org/downloads/release/python-31012/)
|
||||
[](https://developer.nvidia.com/cuda-downloads)
|
||||
[](https://developer.nvidia.com/tensorrt)
|
||||
[](./tensorrt_llm/version.py)
|
||||
[](./LICENSE)
|
||||
[](https://github.com/NVIDIA/TensorRT-LLM/blob/main/tensorrt_llm/version.py)
|
||||
[](https://github.com/NVIDIA/TensorRT-LLM/blob/main/LICENSE)
|
||||
|
||||
[Architecture](./docs/source/torch/arch_overview.md) | [Performance](./docs/source/performance/perf-overview.md) | [Examples](https://nvidia.github.io/TensorRT-LLM/quick-start-guide.html) | [Documentation](https://nvidia.github.io/TensorRT-LLM/) | [Roadmap](https://github.com/NVIDIA/TensorRT-LLM/issues?q=is%3Aissue%20state%3Aopen%20label%3Aroadmap)
|
||||
[Architecture](https://nvidia.github.io/TensorRT-LLM/developer-guide/overview.html) | [Performance](https://nvidia.github.io/TensorRT-LLM/developer-guide/perf-overview.html) | [Examples](https://nvidia.github.io/TensorRT-LLM/quick-start-guide.html) | [Documentation](https://nvidia.github.io/TensorRT-LLM/) | [Roadmap](https://github.com/NVIDIA/TensorRT-LLM/issues?q=is%3Aissue%20state%3Aopen%20label%3Aroadmap)
|
||||
|
||||
---
|
||||
<div align="left">
|
||||
@ -21,40 +21,40 @@ state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs.<
|
||||
## Tech Blogs
|
||||
|
||||
* [10/13] Scaling Expert Parallelism in TensorRT LLM (Part 3: Pushing the Performance Boundary)
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog14_Scaling_Expert_Parallelism_in_TensorRT-LLM_part3.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog14_Scaling_Expert_Parallelism_in_TensorRT-LLM_part3.html)
|
||||
|
||||
* [09/26] Inference Time Compute Implementation in TensorRT LLM
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog13_Inference_Time_Compute_Implementation_in_TensorRT-LLM.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog13_Inference_Time_Compute_Implementation_in_TensorRT-LLM.html)
|
||||
|
||||
* [09/19] Combining Guided Decoding and Speculative Decoding: Making CPU and GPU Cooperate Seamlessly
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog12_Combining_Guided_Decoding_and_Speculative_Decoding.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog12_Combining_Guided_Decoding_and_Speculative_Decoding.html)
|
||||
|
||||
* [08/29] ADP Balance Strategy
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog10_ADP_Balance_Strategy.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog10_ADP_Balance_Strategy.html)
|
||||
|
||||
* [08/05] Running a High-Performance GPT-OSS-120B Inference Server with TensorRT LLM
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog9_Deploying_GPT_OSS_on_TRTLLM.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog9_Deploying_GPT_OSS_on_TRTLLM.html)
|
||||
|
||||
* [08/01] Scaling Expert Parallelism in TensorRT LLM (Part 2: Performance Status and Optimization)
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog8_Scaling_Expert_Parallelism_in_TensorRT-LLM_part2.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog8_Scaling_Expert_Parallelism_in_TensorRT-LLM_part2.html)
|
||||
|
||||
* [07/26] N-Gram Speculative Decoding in TensorRT LLM
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog7_NGram_performance_Analysis_And_Auto_Enablement.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog7_NGram_performance_Analysis_And_Auto_Enablement.html)
|
||||
|
||||
* [06/19] Disaggregated Serving in TensorRT LLM
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog5_Disaggregated_Serving_in_TensorRT-LLM.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog5_Disaggregated_Serving_in_TensorRT-LLM.html)
|
||||
|
||||
* [06/05] Scaling Expert Parallelism in TensorRT LLM (Part 1: Design and Implementation of Large-scale EP)
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog4_Scaling_Expert_Parallelism_in_TensorRT-LLM.html)
|
||||
|
||||
* [05/30] Optimizing DeepSeek R1 Throughput on NVIDIA Blackwell GPUs: A Deep Dive for Developers
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog3_Optimizing_DeepSeek_R1_Throughput_on_NVIDIA_Blackwell_GPUs.html)
|
||||
|
||||
* [05/23] DeepSeek R1 MTP Implementation and Optimization
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog2_DeepSeek_R1_MTP_Implementation_and_Optimization.html)
|
||||
|
||||
* [05/16] Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA B200 GPUs
|
||||
✨ [➡️ link](./docs/source/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/tech_blog/blog1_Pushing_Latency_Boundaries_Optimizing_DeepSeek-R1_Performance_on_NVIDIA_B200_GPUs.html)
|
||||
|
||||
## Latest News
|
||||
* [08/05] 🌟 TensorRT LLM delivers Day-0 support for OpenAI's latest open-weights models: GPT-OSS-120B [➡️ link](https://huggingface.co/openai/gpt-oss-120b) and GPT-OSS-20B [➡️ link](https://huggingface.co/openai/gpt-oss-20b)
|
||||
@ -63,11 +63,11 @@ state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs.<
|
||||
* [05/22] Blackwell Breaks the 1,000 TPS/User Barrier With Meta’s Llama 4 Maverick
|
||||
✨ [➡️ link](https://developer.nvidia.com/blog/blackwell-breaks-the-1000-tps-user-barrier-with-metas-llama-4-maverick/)
|
||||
* [04/10] TensorRT LLM DeepSeek R1 performance benchmarking best practices now published.
|
||||
✨ [➡️ link](./docs/source/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.md)
|
||||
✨ [➡️ link](https://nvidia.github.io/TensorRT-LLM/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.html)
|
||||
|
||||
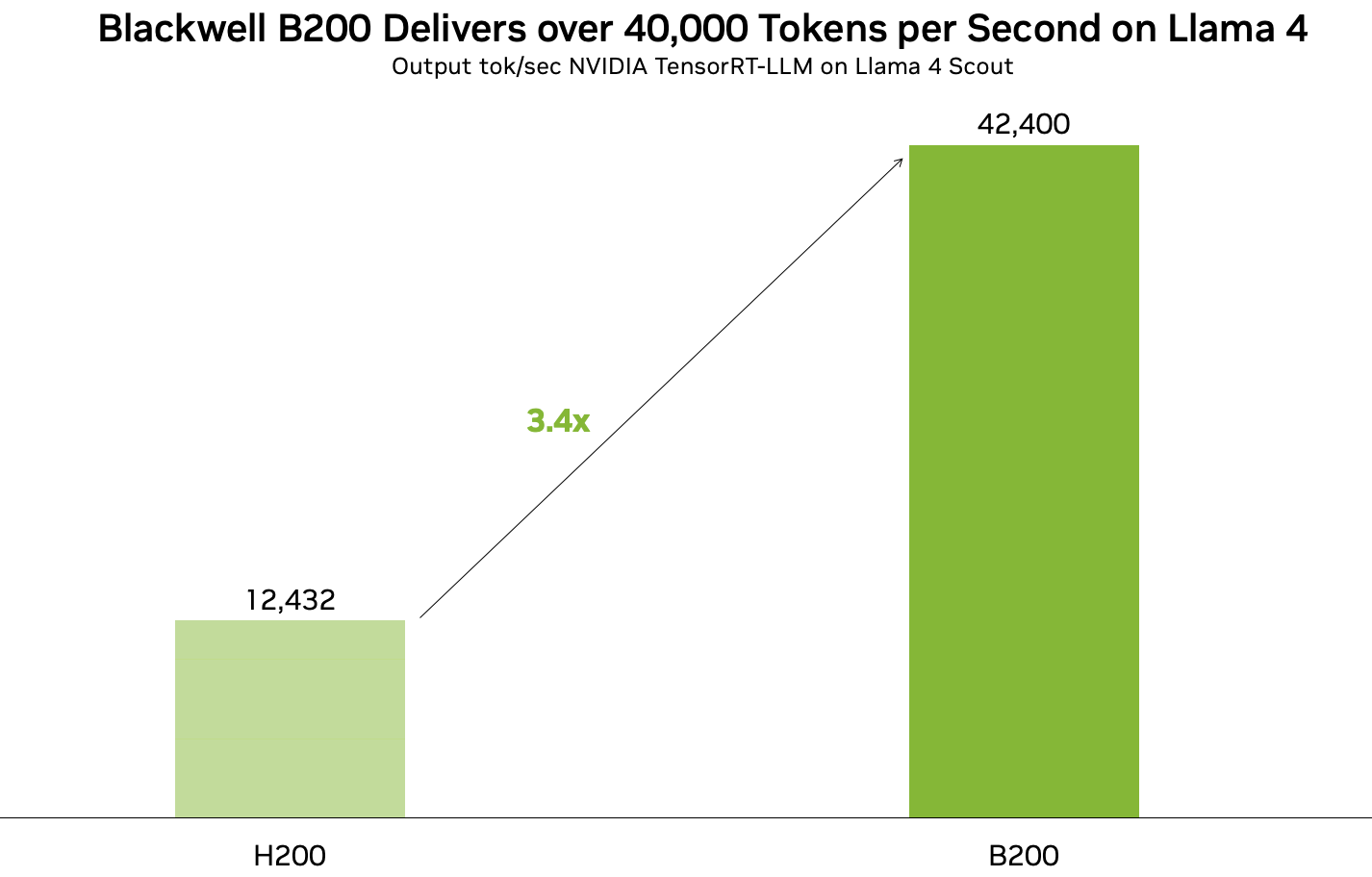
* [04/05] TensorRT LLM can run Llama 4 at over 40,000 tokens per second on B200 GPUs!
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
* [03/22] TensorRT LLM is now fully open-source, with developments moved to GitHub!
|
||||
|
||||
Loading…
Reference in New Issue
Block a user