Compare commits
2 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
b08fc2d9d5 | ||
|
|
a031abdc89 |
@@ -162,25 +162,6 @@ class LCMLoRATextToImageBenchmark(TextToImageBenchmark):
|
||||
guidance_scale=1.0,
|
||||
)
|
||||
|
||||
def benchmark(self, args):
|
||||
flush()
|
||||
|
||||
print(f"[INFO] {self.pipe.__class__.__name__}: Running benchmark with: {vars(args)}\n")
|
||||
|
||||
time = benchmark_fn(self.run_inference, self.pipe, args) # in seconds.
|
||||
memory = bytes_to_giga_bytes(torch.cuda.max_memory_allocated()) # in GBs.
|
||||
benchmark_info = BenchmarkInfo(time=time, memory=memory)
|
||||
|
||||
pipeline_class_name = str(self.pipe.__class__.__name__)
|
||||
flush()
|
||||
csv_dict = generate_csv_dict(
|
||||
pipeline_cls=pipeline_class_name, ckpt=self.lora_id, args=args, benchmark_info=benchmark_info
|
||||
)
|
||||
filepath = self.get_result_filepath(args)
|
||||
write_to_csv(filepath, csv_dict)
|
||||
print(f"Logs written to: {filepath}")
|
||||
flush()
|
||||
|
||||
|
||||
class ImageToImageBenchmark(TextToImageBenchmark):
|
||||
pipeline_class = AutoPipelineForImage2Image
|
||||
|
||||
@@ -198,8 +198,6 @@
|
||||
title: Outputs
|
||||
title: Main Classes
|
||||
- sections:
|
||||
- local: api/loaders/ip_adapter
|
||||
title: IP-Adapter
|
||||
- local: api/loaders/lora
|
||||
title: LoRA
|
||||
- local: api/loaders/single_file
|
||||
@@ -244,10 +242,14 @@
|
||||
- sections:
|
||||
- local: api/pipelines/overview
|
||||
title: Overview
|
||||
- local: api/pipelines/alt_diffusion
|
||||
title: AltDiffusion
|
||||
- local: api/pipelines/animatediff
|
||||
title: AnimateDiff
|
||||
- local: api/pipelines/attend_and_excite
|
||||
title: Attend-and-Excite
|
||||
- local: api/pipelines/audio_diffusion
|
||||
title: Audio Diffusion
|
||||
- local: api/pipelines/audioldm
|
||||
title: AudioLDM
|
||||
- local: api/pipelines/audioldm2
|
||||
@@ -266,6 +268,8 @@
|
||||
title: ControlNet-XS
|
||||
- local: api/pipelines/controlnetxs_sdxl
|
||||
title: ControlNet-XS with Stable Diffusion XL
|
||||
- local: api/pipelines/cycle_diffusion
|
||||
title: Cycle Diffusion
|
||||
- local: api/pipelines/dance_diffusion
|
||||
title: Dance Diffusion
|
||||
- local: api/pipelines/ddim
|
||||
@@ -296,14 +300,26 @@
|
||||
title: MusicLDM
|
||||
- local: api/pipelines/paint_by_example
|
||||
title: Paint by Example
|
||||
- local: api/pipelines/paradigms
|
||||
title: Parallel Sampling of Diffusion Models
|
||||
- local: api/pipelines/pix2pix_zero
|
||||
title: Pix2Pix Zero
|
||||
- local: api/pipelines/pixart
|
||||
title: PixArt-α
|
||||
- local: api/pipelines/pndm
|
||||
title: PNDM
|
||||
- local: api/pipelines/repaint
|
||||
title: RePaint
|
||||
- local: api/pipelines/score_sde_ve
|
||||
title: Score SDE VE
|
||||
- local: api/pipelines/self_attention_guidance
|
||||
title: Self-Attention Guidance
|
||||
- local: api/pipelines/semantic_stable_diffusion
|
||||
title: Semantic Guidance
|
||||
- local: api/pipelines/shap_e
|
||||
title: Shap-E
|
||||
- local: api/pipelines/spectrogram_diffusion
|
||||
title: Spectrogram Diffusion
|
||||
- sections:
|
||||
- local: api/pipelines/stable_diffusion/overview
|
||||
title: Overview
|
||||
@@ -338,16 +354,26 @@
|
||||
title: Stable Diffusion
|
||||
- local: api/pipelines/stable_unclip
|
||||
title: Stable unCLIP
|
||||
- local: api/pipelines/stochastic_karras_ve
|
||||
title: Stochastic Karras VE
|
||||
- local: api/pipelines/model_editing
|
||||
title: Text-to-image model editing
|
||||
- local: api/pipelines/text_to_video
|
||||
title: Text-to-video
|
||||
- local: api/pipelines/text_to_video_zero
|
||||
title: Text2Video-Zero
|
||||
- local: api/pipelines/unclip
|
||||
title: unCLIP
|
||||
- local: api/pipelines/latent_diffusion_uncond
|
||||
title: Unconditional Latent Diffusion
|
||||
- local: api/pipelines/unidiffuser
|
||||
title: UniDiffuser
|
||||
- local: api/pipelines/value_guided_sampling
|
||||
title: Value-guided sampling
|
||||
- local: api/pipelines/versatile_diffusion
|
||||
title: Versatile Diffusion
|
||||
- local: api/pipelines/vq_diffusion
|
||||
title: VQ Diffusion
|
||||
- local: api/pipelines/wuerstchen
|
||||
title: Wuerstchen
|
||||
title: Pipelines
|
||||
|
||||
@@ -1,25 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# IP-Adapter
|
||||
|
||||
[IP-Adapter](https://hf.co/papers/2308.06721) is a lightweight adapter that enables prompting a diffusion model with an image. This method decouples the cross-attention layers of the image and text features. The image features are generated from an image encoder. Files generated from IP-Adapter are only ~100MBs.
|
||||
|
||||
<Tip>
|
||||
|
||||
Learn how to load an IP-Adapter checkpoint and image in the [IP-Adapter](../../using-diffusers/loading_adapters#ip-adapter) loading guide.
|
||||
|
||||
</Tip>
|
||||
|
||||
## IPAdapterMixin
|
||||
|
||||
[[autodoc]] loaders.ip_adapter.IPAdapterMixin
|
||||
@@ -49,12 +49,12 @@ make_image_grid([original_image, mask_image, image], rows=1, cols=3)
|
||||
|
||||
## AsymmetricAutoencoderKL
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_asym_kl.AsymmetricAutoencoderKL
|
||||
[[autodoc]] models.autoencoder_asym_kl.AsymmetricAutoencoderKL
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
[[autodoc]] models.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
[[autodoc]] models.vae.DecoderOutput
|
||||
|
||||
@@ -54,4 +54,4 @@ image
|
||||
|
||||
## AutoencoderTinyOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_tiny.AutoencoderTinyOutput
|
||||
[[autodoc]] models.autoencoder_tiny.AutoencoderTinyOutput
|
||||
|
||||
@@ -36,11 +36,11 @@ model = AutoencoderKL.from_single_file(url)
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
[[autodoc]] models.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
[[autodoc]] models.vae.DecoderOutput
|
||||
|
||||
## FlaxAutoencoderKL
|
||||
|
||||
|
||||
@@ -0,0 +1,47 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# AltDiffusion
|
||||
|
||||
AltDiffusion was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://huggingface.co/papers/2211.06679) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*In this work, we present a conceptually simple and effective method to train a strong bilingual/multilingual multimodal representation model. Starting from the pre-trained multimodal representation model CLIP released by OpenAI, we altered its text encoder with a pre-trained multilingual text encoder XLM-R, and aligned both languages and image representations by a two-stage training schema consisting of teacher learning and contrastive learning. We validate our method through evaluations of a wide range of tasks. We set new state-of-the-art performances on a bunch of tasks including ImageNet-CN, Flicker30k-CN, COCO-CN and XTD. Further, we obtain very close performances with CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding. Our models and code are available at [this https URL](https://github.com/FlagAI-Open/FlagAI).*
|
||||
|
||||
## Tips
|
||||
|
||||
`AltDiffusion` is conceptually the same as [Stable Diffusion](./stable_diffusion/overview).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## AltDiffusionPipeline
|
||||
|
||||
[[autodoc]] AltDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## AltDiffusionImg2ImgPipeline
|
||||
|
||||
[[autodoc]] AltDiffusionImg2ImgPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## AltDiffusionPipelineOutput
|
||||
|
||||
[[autodoc]] pipelines.alt_diffusion.AltDiffusionPipelineOutput
|
||||
- all
|
||||
- __call__
|
||||
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Audio Diffusion
|
||||
|
||||
[Audio Diffusion](https://github.com/teticio/audio-diffusion) is by Robert Dargavel Smith, and it leverages the recent advances in image generation from diffusion models by converting audio samples to and from Mel spectrogram images.
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## AudioDiffusionPipeline
|
||||
[[autodoc]] AudioDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## AudioPipelineOutput
|
||||
[[autodoc]] pipelines.AudioPipelineOutput
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
|
||||
## Mel
|
||||
[[autodoc]] Mel
|
||||
@@ -0,0 +1,33 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Cycle Diffusion
|
||||
|
||||
Cycle Diffusion is a text guided image-to-image generation model proposed in [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://huggingface.co/papers/2210.05559) by Chen Henry Wu, Fernando De la Torre.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Diffusion models have achieved unprecedented performance in generative modeling. The commonly-adopted formulation of the latent code of diffusion models is a sequence of gradually denoised samples, as opposed to the simpler (e.g., Gaussian) latent space of GANs, VAEs, and normalizing flows. This paper provides an alternative, Gaussian formulation of the latent space of various diffusion models, as well as an invertible DPM-Encoder that maps images into the latent space. While our formulation is purely based on the definition of diffusion models, we demonstrate several intriguing consequences. (1) Empirically, we observe that a common latent space emerges from two diffusion models trained independently on related domains. In light of this finding, we propose CycleDiffusion, which uses DPM-Encoder for unpaired image-to-image translation. Furthermore, applying CycleDiffusion to text-to-image diffusion models, we show that large-scale text-to-image diffusion models can be used as zero-shot image-to-image editors. (2) One can guide pre-trained diffusion models and GANs by controlling the latent codes in a unified, plug-and-play formulation based on energy-based models. Using the CLIP model and a face recognition model as guidance, we demonstrate that diffusion models have better coverage of low-density sub-populations and individuals than GANs. The code is publicly available at [this https URL](https://github.com/ChenWu98/cycle-diffusion).*
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## CycleDiffusionPipeline
|
||||
[[autodoc]] CycleDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## StableDiffusionPiplineOutput
|
||||
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
|
||||
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Unconditional Latent Diffusion
|
||||
|
||||
Unconditional Latent Diffusion was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
|
||||
|
||||
The original codebase can be found at [CompVis/latent-diffusion](https://github.com/CompVis/latent-diffusion).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## LDMPipeline
|
||||
[[autodoc]] LDMPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Text-to-image model editing
|
||||
|
||||
[Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://huggingface.co/papers/2303.08084) is by Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov. This pipeline enables editing diffusion model weights, such that its assumptions of a given concept are changed. The resulting change is expected to take effect in all prompt generations related to the edited concept.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Text-to-image diffusion models often make implicit assumptions about the world when generating images. While some assumptions are useful (e.g., the sky is blue), they can also be outdated, incorrect, or reflective of social biases present in the training data. Thus, there is a need to control these assumptions without requiring explicit user input or costly re-training. In this work, we aim to edit a given implicit assumption in a pre-trained diffusion model. Our Text-to-Image Model Editing method, TIME for short, receives a pair of inputs: a "source" under-specified prompt for which the model makes an implicit assumption (e.g., "a pack of roses"), and a "destination" prompt that describes the same setting, but with a specified desired attribute (e.g., "a pack of blue roses"). TIME then updates the model's cross-attention layers, as these layers assign visual meaning to textual tokens. We edit the projection matrices in these layers such that the source prompt is projected close to the destination prompt. Our method is highly efficient, as it modifies a mere 2.2% of the model's parameters in under one second. To evaluate model editing approaches, we introduce TIMED (TIME Dataset), containing 147 source and destination prompt pairs from various domains. Our experiments (using Stable Diffusion) show that TIME is successful in model editing, generalizes well for related prompts unseen during editing, and imposes minimal effect on unrelated generations.*
|
||||
|
||||
You can find additional information about model editing on the [project page](https://time-diffusion.github.io/), [original codebase](https://github.com/bahjat-kawar/time-diffusion), and try it out in a [demo](https://huggingface.co/spaces/bahjat-kawar/time-diffusion).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## StableDiffusionModelEditingPipeline
|
||||
[[autodoc]] StableDiffusionModelEditingPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
## StableDiffusionPipelineOutput
|
||||
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
|
||||
@@ -0,0 +1,51 @@
|
||||
<!--Copyright 2023 ParaDiGMS authors and The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Parallel Sampling of Diffusion Models
|
||||
|
||||
[Parallel Sampling of Diffusion Models](https://huggingface.co/papers/2305.16317) is by Andy Shih, Suneel Belkhale, Stefano Ermon, Dorsa Sadigh, Nima Anari.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Diffusion models are powerful generative models but suffer from slow sampling, often taking 1000 sequential denoising steps for one sample. As a result, considerable efforts have been directed toward reducing the number of denoising steps, but these methods hurt sample quality. Instead of reducing the number of denoising steps (trading quality for speed), in this paper we explore an orthogonal approach: can we run the denoising steps in parallel (trading compute for speed)? In spite of the sequential nature of the denoising steps, we show that surprisingly it is possible to parallelize sampling via Picard iterations, by guessing the solution of future denoising steps and iteratively refining until convergence. With this insight, we present ParaDiGMS, a novel method to accelerate the sampling of pretrained diffusion models by denoising multiple steps in parallel. ParaDiGMS is the first diffusion sampling method that enables trading compute for speed and is even compatible with existing fast sampling techniques such as DDIM and DPMSolver. Using ParaDiGMS, we improve sampling speed by 2-4x across a range of robotics and image generation models, giving state-of-the-art sampling speeds of 0.2s on 100-step DiffusionPolicy and 14.6s on 1000-step StableDiffusion-v2 with no measurable degradation of task reward, FID score, or CLIP score.*
|
||||
|
||||
The original codebase can be found at [AndyShih12/paradigms](https://github.com/AndyShih12/paradigms), and the pipeline was contributed by [AndyShih12](https://github.com/AndyShih12). ❤️
|
||||
|
||||
## Tips
|
||||
|
||||
This pipeline improves sampling speed by running denoising steps in parallel, at the cost of increased total FLOPs.
|
||||
Therefore, it is better to call this pipeline when running on multiple GPUs. Otherwise, without enough GPU bandwidth
|
||||
sampling may be even slower than sequential sampling.
|
||||
|
||||
The two parameters to play with are `parallel` (batch size) and `tolerance`.
|
||||
- If it fits in memory, for a 1000-step DDPM you can aim for a batch size of around 100 (for example, 8 GPUs and `batch_per_device=12` to get `parallel=96`). A higher batch size may not fit in memory, and lower batch size gives less parallelism.
|
||||
- For tolerance, using a higher tolerance may get better speedups but can risk sample quality degradation. If there is quality degradation with the default tolerance, then use a lower tolerance like `0.001`.
|
||||
|
||||
For a 1000-step DDPM on 8 A100 GPUs, you can expect around a 3x speedup from [`StableDiffusionParadigmsPipeline`] compared to the [`StableDiffusionPipeline`]
|
||||
by setting `parallel=80` and `tolerance=0.1`.
|
||||
|
||||
🤗 Diffusers offers [distributed inference support](../../training/distributed_inference) for generating multiple prompts
|
||||
in parallel on multiple GPUs. But [`StableDiffusionParadigmsPipeline`] is designed for speeding up sampling of a single prompt by using multiple GPUs.
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## StableDiffusionParadigmsPipeline
|
||||
[[autodoc]] StableDiffusionParadigmsPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
## StableDiffusionPipelineOutput
|
||||
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
|
||||
@@ -0,0 +1,289 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Pix2Pix Zero
|
||||
|
||||
[Zero-shot Image-to-Image Translation](https://huggingface.co/papers/2302.03027) is by Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, and Jun-Yan Zhu.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.*
|
||||
|
||||
You can find additional information about Pix2Pix Zero on the [project page](https://pix2pixzero.github.io/), [original codebase](https://github.com/pix2pixzero/pix2pix-zero), and try it out in a [demo](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo).
|
||||
|
||||
## Tips
|
||||
|
||||
* The pipeline can be conditioned on real input images. Check out the code examples below to know more.
|
||||
* The pipeline exposes two arguments namely `source_embeds` and `target_embeds`
|
||||
that let you control the direction of the semantic edits in the final image to be generated. Let's say,
|
||||
you wanted to translate from "cat" to "dog". In this case, the edit direction will be "cat -> dog". To reflect
|
||||
this in the pipeline, you simply have to set the embeddings related to the phrases including "cat" to
|
||||
`source_embeds` and "dog" to `target_embeds`. Refer to the code example below for more details.
|
||||
* When you're using this pipeline from a prompt, specify the _source_ concept in the prompt. Taking
|
||||
the above example, a valid input prompt would be: "a high resolution painting of a **cat** in the style of van gogh".
|
||||
* If you wanted to reverse the direction in the example above, i.e., "dog -> cat", then it's recommended to:
|
||||
* Swap the `source_embeds` and `target_embeds`.
|
||||
* Change the input prompt to include "dog".
|
||||
* To learn more about how the source and target embeddings are generated, refer to the [original paper](https://arxiv.org/abs/2302.03027). Below, we also provide some directions on how to generate the embeddings.
|
||||
* Note that the quality of the outputs generated with this pipeline is dependent on how good the `source_embeds` and `target_embeds` are. Please, refer to [this discussion](#generating-source-and-target-embeddings) for some suggestions on the topic.
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Demo
|
||||
|---|---|:---:|
|
||||
| [StableDiffusionPix2PixZeroPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py) | *Text-Based Image Editing* | [🤗 Space](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo) |
|
||||
|
||||
<!-- TODO: add Colab -->
|
||||
|
||||
## Usage example
|
||||
|
||||
### Based on an image generated with the input prompt
|
||||
|
||||
```python
|
||||
import requests
|
||||
import torch
|
||||
|
||||
from diffusers import DDIMScheduler, StableDiffusionPix2PixZeroPipeline
|
||||
|
||||
|
||||
def download(embedding_url, local_filepath):
|
||||
r = requests.get(embedding_url)
|
||||
with open(local_filepath, "wb") as f:
|
||||
f.write(r.content)
|
||||
|
||||
|
||||
model_ckpt = "CompVis/stable-diffusion-v1-4"
|
||||
pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
|
||||
model_ckpt, conditions_input_image=False, torch_dtype=torch.float16
|
||||
)
|
||||
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline.to("cuda")
|
||||
|
||||
prompt = "a high resolution painting of a cat in the style of van gogh"
|
||||
src_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/cat.pt"
|
||||
target_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/dog.pt"
|
||||
|
||||
for url in [src_embs_url, target_embs_url]:
|
||||
download(url, url.split("/")[-1])
|
||||
|
||||
src_embeds = torch.load(src_embs_url.split("/")[-1])
|
||||
target_embeds = torch.load(target_embs_url.split("/")[-1])
|
||||
|
||||
image = pipeline(
|
||||
prompt,
|
||||
source_embeds=src_embeds,
|
||||
target_embeds=target_embeds,
|
||||
num_inference_steps=50,
|
||||
cross_attention_guidance_amount=0.15,
|
||||
).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
### Based on an input image
|
||||
|
||||
When the pipeline is conditioned on an input image, we first obtain an inverted
|
||||
noise from it using a `DDIMInverseScheduler` with the help of a generated caption. Then the inverted noise is used to start the generation process.
|
||||
|
||||
First, let's load our pipeline:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import BlipForConditionalGeneration, BlipProcessor
|
||||
from diffusers import DDIMScheduler, DDIMInverseScheduler, StableDiffusionPix2PixZeroPipeline
|
||||
|
||||
captioner_id = "Salesforce/blip-image-captioning-base"
|
||||
processor = BlipProcessor.from_pretrained(captioner_id)
|
||||
model = BlipForConditionalGeneration.from_pretrained(captioner_id, torch_dtype=torch.float16, low_cpu_mem_usage=True)
|
||||
|
||||
sd_model_ckpt = "CompVis/stable-diffusion-v1-4"
|
||||
pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
|
||||
sd_model_ckpt,
|
||||
caption_generator=model,
|
||||
caption_processor=processor,
|
||||
torch_dtype=torch.float16,
|
||||
safety_checker=None,
|
||||
)
|
||||
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline.inverse_scheduler = DDIMInverseScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline.enable_model_cpu_offload()
|
||||
```
|
||||
|
||||
Then, we load an input image for conditioning and obtain a suitable caption for it:
|
||||
|
||||
```py
|
||||
from diffusers.utils import load_image
|
||||
|
||||
img_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/test_images/cats/cat_6.png"
|
||||
raw_image = load_image(url).resize((512, 512))
|
||||
caption = pipeline.generate_caption(raw_image)
|
||||
caption
|
||||
```
|
||||
|
||||
Then we employ the generated caption and the input image to get the inverted noise:
|
||||
|
||||
```py
|
||||
generator = torch.manual_seed(0)
|
||||
inv_latents = pipeline.invert(caption, image=raw_image, generator=generator).latents
|
||||
```
|
||||
|
||||
Now, generate the image with edit directions:
|
||||
|
||||
```py
|
||||
# See the "Generating source and target embeddings" section below to
|
||||
# automate the generation of these captions with a pre-trained model like Flan-T5 as explained below.
|
||||
source_prompts = ["a cat sitting on the street", "a cat playing in the field", "a face of a cat"]
|
||||
target_prompts = ["a dog sitting on the street", "a dog playing in the field", "a face of a dog"]
|
||||
|
||||
source_embeds = pipeline.get_embeds(source_prompts, batch_size=2)
|
||||
target_embeds = pipeline.get_embeds(target_prompts, batch_size=2)
|
||||
|
||||
|
||||
image = pipeline(
|
||||
caption,
|
||||
source_embeds=source_embeds,
|
||||
target_embeds=target_embeds,
|
||||
num_inference_steps=50,
|
||||
cross_attention_guidance_amount=0.15,
|
||||
generator=generator,
|
||||
latents=inv_latents,
|
||||
negative_prompt=caption,
|
||||
).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
## Generating source and target embeddings
|
||||
|
||||
The authors originally used the [GPT-3 API](https://openai.com/api/) to generate the source and target captions for discovering
|
||||
edit directions. However, we can also leverage open source and public models for the same purpose.
|
||||
Below, we provide an end-to-end example with the [Flan-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5) model
|
||||
for generating captions and [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for
|
||||
computing embeddings on the generated captions.
|
||||
|
||||
**1. Load the generation model**:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoTokenizer, T5ForConditionalGeneration
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-xl")
|
||||
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xl", device_map="auto", torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
**2. Construct a starting prompt**:
|
||||
|
||||
```py
|
||||
source_concept = "cat"
|
||||
target_concept = "dog"
|
||||
|
||||
source_text = f"Provide a caption for images containing a {source_concept}. "
|
||||
"The captions should be in English and should be no longer than 150 characters."
|
||||
|
||||
target_text = f"Provide a caption for images containing a {target_concept}. "
|
||||
"The captions should be in English and should be no longer than 150 characters."
|
||||
```
|
||||
|
||||
Here, we're interested in the "cat -> dog" direction.
|
||||
|
||||
**3. Generate captions**:
|
||||
|
||||
We can use a utility like so for this purpose.
|
||||
|
||||
```py
|
||||
def generate_captions(input_prompt):
|
||||
input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids.to("cuda")
|
||||
|
||||
outputs = model.generate(
|
||||
input_ids, temperature=0.8, num_return_sequences=16, do_sample=True, max_new_tokens=128, top_k=10
|
||||
)
|
||||
return tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
```
|
||||
|
||||
And then we just call it to generate our captions:
|
||||
|
||||
```py
|
||||
source_captions = generate_captions(source_text)
|
||||
target_captions = generate_captions(target_concept)
|
||||
print(source_captions, target_captions, sep='\n')
|
||||
```
|
||||
|
||||
We encourage you to play around with the different parameters supported by the
|
||||
`generate()` method ([documentation](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_tf_utils.TFGenerationMixin.generate)) for the generation quality you are looking for.
|
||||
|
||||
**4. Load the embedding model**:
|
||||
|
||||
Here, we need to use the same text encoder model used by the subsequent Stable Diffusion model.
|
||||
|
||||
```py
|
||||
from diffusers import StableDiffusionPix2PixZeroPipeline
|
||||
|
||||
pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
|
||||
)
|
||||
pipeline = pipeline.to("cuda")
|
||||
tokenizer = pipeline.tokenizer
|
||||
text_encoder = pipeline.text_encoder
|
||||
```
|
||||
|
||||
**5. Compute embeddings**:
|
||||
|
||||
```py
|
||||
import torch
|
||||
|
||||
def embed_captions(sentences, tokenizer, text_encoder, device="cuda"):
|
||||
with torch.no_grad():
|
||||
embeddings = []
|
||||
for sent in sentences:
|
||||
text_inputs = tokenizer(
|
||||
sent,
|
||||
padding="max_length",
|
||||
max_length=tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
text_input_ids = text_inputs.input_ids
|
||||
prompt_embeds = text_encoder(text_input_ids.to(device), attention_mask=None)[0]
|
||||
embeddings.append(prompt_embeds)
|
||||
return torch.concatenate(embeddings, dim=0).mean(dim=0).unsqueeze(0)
|
||||
|
||||
source_embeddings = embed_captions(source_captions, tokenizer, text_encoder)
|
||||
target_embeddings = embed_captions(target_captions, tokenizer, text_encoder)
|
||||
```
|
||||
|
||||
And you're done! [Here](https://colab.research.google.com/drive/1tz2C1EdfZYAPlzXXbTnf-5PRBiR8_R1F?usp=sharing) is a Colab Notebook that you can use to interact with the entire process.
|
||||
|
||||
Now, you can use these embeddings directly while calling the pipeline:
|
||||
|
||||
```py
|
||||
from diffusers import DDIMScheduler
|
||||
|
||||
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
|
||||
|
||||
image = pipeline(
|
||||
prompt,
|
||||
source_embeds=source_embeddings,
|
||||
target_embeds=target_embeddings,
|
||||
num_inference_steps=50,
|
||||
cross_attention_guidance_amount=0.15,
|
||||
).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## StableDiffusionPix2PixZeroPipeline
|
||||
[[autodoc]] StableDiffusionPix2PixZeroPipeline
|
||||
- __call__
|
||||
- all
|
||||
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# PNDM
|
||||
|
||||
[Pseudo Numerical Methods for Diffusion Models on Manifolds](https://huggingface.co/papers/2202.09778) (PNDM) is by Luping Liu, Yi Ren, Zhijie Lin and Zhou Zhao.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Denoising Diffusion Probabilistic Models (DDPMs) can generate high-quality samples such as image and audio samples. However, DDPMs require hundreds to thousands of iterations to produce final samples. Several prior works have successfully accelerated DDPMs through adjusting the variance schedule (e.g., Improved Denoising Diffusion Probabilistic Models) or the denoising equation (e.g., Denoising Diffusion Implicit Models (DDIMs)). However, these acceleration methods cannot maintain the quality of samples and even introduce new noise at a high speedup rate, which limit their practicability. To accelerate the inference process while keeping the sample quality, we provide a fresh perspective that DDPMs should be treated as solving differential equations on manifolds. Under such a perspective, we propose pseudo numerical methods for diffusion models (PNDMs). Specifically, we figure out how to solve differential equations on manifolds and show that DDIMs are simple cases of pseudo numerical methods. We change several classical numerical methods to corresponding pseudo numerical methods and find that the pseudo linear multi-step method is the best in most situations. According to our experiments, by directly using pre-trained models on Cifar10, CelebA and LSUN, PNDMs can generate higher quality synthetic images with only 50 steps compared with 1000-step DDIMs (20x speedup), significantly outperform DDIMs with 250 steps (by around 0.4 in FID) and have good generalization on different variance schedules.*
|
||||
|
||||
The original codebase can be found at [luping-liu/PNDM](https://github.com/luping-liu/PNDM).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## PNDMPipeline
|
||||
[[autodoc]] PNDMPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
@@ -0,0 +1,37 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# RePaint
|
||||
|
||||
[RePaint: Inpainting using Denoising Diffusion Probabilistic Models](https://huggingface.co/papers/2201.09865) is by Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, Luc Van Gool.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks.
|
||||
RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions.*
|
||||
|
||||
The original codebase can be found at [andreas128/RePaint](https://github.com/andreas128/RePaint).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
## RePaintPipeline
|
||||
[[autodoc]] RePaintPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Score SDE VE
|
||||
|
||||
[Score-Based Generative Modeling through Stochastic Differential Equations](https://huggingface.co/papers/2011.13456) (Score SDE) is by Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon and Ben Poole. This pipeline implements the variance expanding (VE) variant of the stochastic differential equation method.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (\aka, score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in score-based generative modeling and diffusion probabilistic modeling, allowing for new sampling procedures and new modeling capabilities. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, but additionally enables exact likelihood computation, and improved sampling efficiency. In addition, we provide a new way to solve inverse problems with score-based models, as demonstrated with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 2.99 bits/dim, and demonstrate high fidelity generation of 1024 x 1024 images for the first time from a score-based generative model.*
|
||||
|
||||
The original codebase can be found at [yang-song/score_sde_pytorch](https://github.com/yang-song/score_sde_pytorch).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## ScoreSdeVePipeline
|
||||
[[autodoc]] ScoreSdeVePipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
@@ -0,0 +1,37 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Spectrogram Diffusion
|
||||
|
||||
[Spectrogram Diffusion](https://huggingface.co/papers/2206.05408) is by Curtis Hawthorne, Ian Simon, Adam Roberts, Neil Zeghidour, Josh Gardner, Ethan Manilow, and Jesse Engel.
|
||||
|
||||
*An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.*
|
||||
|
||||
The original codebase can be found at [magenta/music-spectrogram-diffusion](https://github.com/magenta/music-spectrogram-diffusion).
|
||||
|
||||
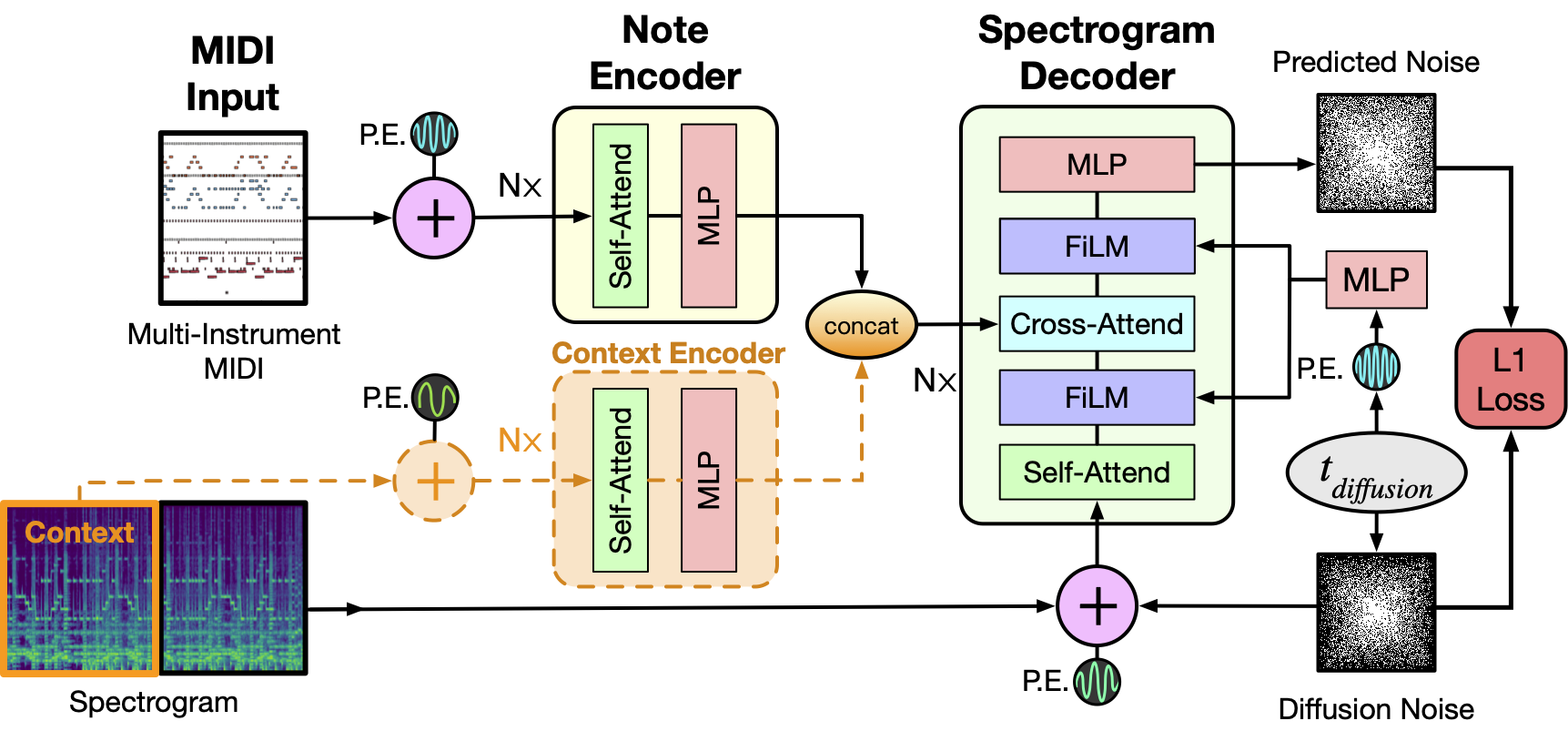
|
||||
|
||||
As depicted above the model takes as input a MIDI file and tokenizes it into a sequence of 5 second intervals. Each tokenized interval then together with positional encodings is passed through the Note Encoder and its representation is concatenated with the previous window's generated spectrogram representation obtained via the Context Encoder. For the initial 5 second window this is set to zero. The resulting context is then used as conditioning to sample the denoised Spectrogram from the MIDI window and we concatenate this spectrogram to the final output as well as use it for the context of the next MIDI window. The process repeats till we have gone over all the MIDI inputs. Finally a MelGAN decoder converts the potentially long spectrogram to audio which is the final result of this pipeline.
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## SpectrogramDiffusionPipeline
|
||||
[[autodoc]] SpectrogramDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## AudioPipelineOutput
|
||||
[[autodoc]] pipelines.AudioPipelineOutput
|
||||
@@ -0,0 +1,33 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Stochastic Karras VE
|
||||
|
||||
[Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364) is by Tero Karras, Miika Aittala, Timo Aila and Samuli Laine. This pipeline implements the stochastic sampling tailored to variance expanding (VE) models.
|
||||
|
||||
The abstract from the paper:
|
||||
|
||||
*We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates the concrete design choices. This lets us identify several changes to both the sampling and training processes, as well as preconditioning of the score networks. Together, our improvements yield new state-of-the-art FID of 1.79 for CIFAR-10 in a class-conditional setting and 1.97 in an unconditional setting, with much faster sampling (35 network evaluations per image) than prior designs. To further demonstrate their modular nature, we show that our design changes dramatically improve both the efficiency and quality obtainable with pre-trained score networks from previous work, including improving the FID of a previously trained ImageNet-64 model from 2.07 to near-SOTA 1.55, and after re-training with our proposed improvements to a new SOTA of 1.36.*
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## KarrasVePipeline
|
||||
[[autodoc]] KarrasVePipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
@@ -0,0 +1,54 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Versatile Diffusion
|
||||
|
||||
Versatile Diffusion was proposed in [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://huggingface.co/papers/2211.08332) by Xingqian Xu, Zhangyang Wang, Eric Zhang, Kai Wang, Humphrey Shi.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Recent advances in diffusion models have set an impressive milestone in many generation tasks, and trending works such as DALL-E2, Imagen, and Stable Diffusion have attracted great interest. Despite the rapid landscape changes, recent new approaches focus on extensions and performance rather than capacity, thus requiring separate models for separate tasks. In this work, we expand the existing single-flow diffusion pipeline into a multi-task multimodal network, dubbed Versatile Diffusion (VD), that handles multiple flows of text-to-image, image-to-text, and variations in one unified model. The pipeline design of VD instantiates a unified multi-flow diffusion framework, consisting of sharable and swappable layer modules that enable the crossmodal generality beyond images and text. Through extensive experiments, we demonstrate that VD successfully achieves the following: a) VD outperforms the baseline approaches and handles all its base tasks with competitive quality; b) VD enables novel extensions such as disentanglement of style and semantics, dual- and multi-context blending, etc.; c) The success of our multi-flow multimodal framework over images and text may inspire further diffusion-based universal AI research.*
|
||||
|
||||
## Tips
|
||||
|
||||
You can load the more memory intensive "all-in-one" [`VersatileDiffusionPipeline`] that supports all the tasks or use the individual pipelines which are more memory efficient.
|
||||
|
||||
| **Pipeline** | **Supported tasks** |
|
||||
|------------------------------------------------------|-----------------------------------|
|
||||
| [`VersatileDiffusionPipeline`] | all of the below |
|
||||
| [`VersatileDiffusionTextToImagePipeline`] | text-to-image |
|
||||
| [`VersatileDiffusionImageVariationPipeline`] | image variation |
|
||||
| [`VersatileDiffusionDualGuidedPipeline`] | image-text dual guided generation |
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## VersatileDiffusionPipeline
|
||||
[[autodoc]] VersatileDiffusionPipeline
|
||||
|
||||
## VersatileDiffusionTextToImagePipeline
|
||||
[[autodoc]] VersatileDiffusionTextToImagePipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## VersatileDiffusionImageVariationPipeline
|
||||
[[autodoc]] VersatileDiffusionImageVariationPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## VersatileDiffusionDualGuidedPipeline
|
||||
[[autodoc]] VersatileDiffusionDualGuidedPipeline
|
||||
- all
|
||||
- __call__
|
||||
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# VQ Diffusion
|
||||
|
||||
[Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://huggingface.co/papers/2111.14822) is by Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, Baining Guo.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.*
|
||||
|
||||
The original codebase can be found at [microsoft/VQ-Diffusion](https://github.com/microsoft/VQ-Diffusion).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## VQDiffusionPipeline
|
||||
[[autodoc]] VQDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
@@ -179,7 +179,7 @@ accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--dataloader_num_workers=8 \
|
||||
--resolution=512 \
|
||||
--resolution=512
|
||||
--center_crop \
|
||||
--random_flip \
|
||||
--train_batch_size=1 \
|
||||
@@ -214,4 +214,4 @@ image = pipeline("A pokemon with blue eyes").images[0]
|
||||
Congratulations on training a new model with LoRA! To learn more about how to use your new model, the following guides may be helpful:
|
||||
|
||||
- Learn how to [load different LoRA formats](../using-diffusers/loading_adapters#LoRA) trained using community trainers like Kohya and TheLastBen.
|
||||
- Learn how to use and [combine multiple LoRA's](../tutorials/using_peft_for_inference) with PEFT for inference.
|
||||
- Learn how to use and [combine multiple LoRA's](../tutorials/using_peft_for_inference) with PEFT for inference.
|
||||
@@ -112,7 +112,7 @@ def save_model_card(
|
||||
repo_folder=None,
|
||||
vae_path=None,
|
||||
):
|
||||
img_str = "widget:\n"
|
||||
img_str = "widget:\n" if images else ""
|
||||
for i, image in enumerate(images):
|
||||
image.save(os.path.join(repo_folder, f"image_{i}.png"))
|
||||
img_str += f"""
|
||||
@@ -121,10 +121,6 @@ def save_model_card(
|
||||
url:
|
||||
"image_{i}.png"
|
||||
"""
|
||||
if not images:
|
||||
img_str += f"""
|
||||
- text: '{instance_prompt}'
|
||||
"""
|
||||
|
||||
trigger_str = f"You should use {instance_prompt} to trigger the image generation."
|
||||
diffusers_imports_pivotal = ""
|
||||
@@ -161,6 +157,8 @@ tags:
|
||||
base_model: {base_model}
|
||||
instance_prompt: {instance_prompt}
|
||||
license: openrail++
|
||||
widget:
|
||||
- text: '{validation_prompt if validation_prompt else instance_prompt}'
|
||||
---
|
||||
"""
|
||||
|
||||
@@ -2012,42 +2010,43 @@ def main(args):
|
||||
text_encoder_lora_layers=text_encoder_lora_layers,
|
||||
text_encoder_2_lora_layers=text_encoder_2_lora_layers,
|
||||
)
|
||||
|
||||
# Final inference
|
||||
# Load previous pipeline
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
vae_path,
|
||||
subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
|
||||
revision=args.revision,
|
||||
variant=args.variant,
|
||||
torch_dtype=weight_dtype,
|
||||
)
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
vae=vae,
|
||||
revision=args.revision,
|
||||
variant=args.variant,
|
||||
torch_dtype=weight_dtype,
|
||||
)
|
||||
|
||||
# We train on the simplified learning objective. If we were previously predicting a variance, we need the scheduler to ignore it
|
||||
scheduler_args = {}
|
||||
|
||||
if "variance_type" in pipeline.scheduler.config:
|
||||
variance_type = pipeline.scheduler.config.variance_type
|
||||
|
||||
if variance_type in ["learned", "learned_range"]:
|
||||
variance_type = "fixed_small"
|
||||
|
||||
scheduler_args["variance_type"] = variance_type
|
||||
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config, **scheduler_args)
|
||||
|
||||
# load attention processors
|
||||
pipeline.load_lora_weights(args.output_dir)
|
||||
|
||||
# run inference
|
||||
images = []
|
||||
if args.validation_prompt and args.num_validation_images > 0:
|
||||
# Final inference
|
||||
# Load previous pipeline
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
vae_path,
|
||||
subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
|
||||
revision=args.revision,
|
||||
variant=args.variant,
|
||||
torch_dtype=weight_dtype,
|
||||
)
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
vae=vae,
|
||||
revision=args.revision,
|
||||
variant=args.variant,
|
||||
torch_dtype=weight_dtype,
|
||||
)
|
||||
|
||||
# We train on the simplified learning objective. If we were previously predicting a variance, we need the scheduler to ignore it
|
||||
scheduler_args = {}
|
||||
|
||||
if "variance_type" in pipeline.scheduler.config:
|
||||
variance_type = pipeline.scheduler.config.variance_type
|
||||
|
||||
if variance_type in ["learned", "learned_range"]:
|
||||
variance_type = "fixed_small"
|
||||
|
||||
scheduler_args["variance_type"] = variance_type
|
||||
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config, **scheduler_args)
|
||||
|
||||
# load attention processors
|
||||
pipeline.load_lora_weights(args.output_dir)
|
||||
|
||||
# run inference
|
||||
pipeline = pipeline.to(accelerator.device)
|
||||
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
|
||||
images = [
|
||||
|
||||
@@ -156,7 +156,7 @@ class WebdatasetFilter:
|
||||
return False
|
||||
|
||||
|
||||
class SDText2ImageDataset:
|
||||
class Text2ImageDataset:
|
||||
def __init__(
|
||||
self,
|
||||
train_shards_path_or_url: Union[str, List[str]],
|
||||
@@ -359,43 +359,19 @@ def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=
|
||||
|
||||
|
||||
# Compare LCMScheduler.step, Step 4
|
||||
def get_predicted_original_sample(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
def predicted_origin(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
if prediction_type == "epsilon":
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
pred_x_0 = (sample - sigmas * model_output) / alphas
|
||||
elif prediction_type == "sample":
|
||||
pred_x_0 = model_output
|
||||
elif prediction_type == "v_prediction":
|
||||
pred_x_0 = alphas * sample - sigmas * model_output
|
||||
pred_x_0 = alphas[timesteps] * sample - sigmas[timesteps] * model_output
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
|
||||
f" are supported."
|
||||
)
|
||||
raise ValueError(f"Prediction type {prediction_type} currently not supported.")
|
||||
|
||||
return pred_x_0
|
||||
|
||||
|
||||
# Based on step 4 in DDIMScheduler.step
|
||||
def get_predicted_noise(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
if prediction_type == "epsilon":
|
||||
pred_epsilon = model_output
|
||||
elif prediction_type == "sample":
|
||||
pred_epsilon = (sample - alphas * model_output) / sigmas
|
||||
elif prediction_type == "v_prediction":
|
||||
pred_epsilon = alphas * model_output + sigmas * sample
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
|
||||
f" are supported."
|
||||
)
|
||||
|
||||
return pred_epsilon
|
||||
|
||||
|
||||
def extract_into_tensor(a, t, x_shape):
|
||||
b, *_ = t.shape
|
||||
out = a.gather(-1, t)
|
||||
@@ -859,35 +835,34 @@ def main(args):
|
||||
args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
|
||||
)
|
||||
|
||||
# DDPMScheduler calculates the alpha and sigma noise schedules (based on the alpha bars) for us
|
||||
# The scheduler calculates the alpha and sigma schedule for us
|
||||
alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
|
||||
sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
|
||||
# Initialize the DDIM ODE solver for distillation.
|
||||
solver = DDIMSolver(
|
||||
noise_scheduler.alphas_cumprod.numpy(),
|
||||
timesteps=noise_scheduler.config.num_train_timesteps,
|
||||
ddim_timesteps=args.num_ddim_timesteps,
|
||||
)
|
||||
|
||||
# 2. Load tokenizers from SD 1.X/2.X checkpoint.
|
||||
# 2. Load tokenizers from SD-XL checkpoint.
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.pretrained_teacher_model, subfolder="tokenizer", revision=args.teacher_revision, use_fast=False
|
||||
)
|
||||
|
||||
# 3. Load text encoders from SD 1.X/2.X checkpoint.
|
||||
# 3. Load text encoders from SD-1.5 checkpoint.
|
||||
# import correct text encoder classes
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
args.pretrained_teacher_model, subfolder="text_encoder", revision=args.teacher_revision
|
||||
)
|
||||
|
||||
# 4. Load VAE from SD 1.X/2.X checkpoint
|
||||
# 4. Load VAE from SD-XL checkpoint (or more stable VAE)
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
args.pretrained_teacher_model,
|
||||
subfolder="vae",
|
||||
revision=args.teacher_revision,
|
||||
)
|
||||
|
||||
# 5. Load teacher U-Net from SD 1.X/2.X checkpoint
|
||||
# 5. Load teacher U-Net from SD-XL checkpoint
|
||||
teacher_unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
|
||||
)
|
||||
@@ -897,7 +872,7 @@ def main(args):
|
||||
text_encoder.requires_grad_(False)
|
||||
teacher_unet.requires_grad_(False)
|
||||
|
||||
# 7. Create online student U-Net.
|
||||
# 7. Create online (`unet`) student U-Nets.
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
|
||||
)
|
||||
@@ -960,7 +935,6 @@ def main(args):
|
||||
# Also move the alpha and sigma noise schedules to accelerator.device.
|
||||
alpha_schedule = alpha_schedule.to(accelerator.device)
|
||||
sigma_schedule = sigma_schedule.to(accelerator.device)
|
||||
# Move the ODE solver to accelerator.device.
|
||||
solver = solver.to(accelerator.device)
|
||||
|
||||
# 10. Handle saving and loading of checkpoints
|
||||
@@ -1037,14 +1011,13 @@ def main(args):
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
# 13. Dataset creation and data processing
|
||||
# Here, we compute not just the text embeddings but also the additional embeddings
|
||||
# needed for the SD XL UNet to operate.
|
||||
def compute_embeddings(prompt_batch, proportion_empty_prompts, text_encoder, tokenizer, is_train=True):
|
||||
prompt_embeds = encode_prompt(prompt_batch, text_encoder, tokenizer, proportion_empty_prompts, is_train)
|
||||
return {"prompt_embeds": prompt_embeds}
|
||||
|
||||
dataset = SDText2ImageDataset(
|
||||
dataset = Text2ImageDataset(
|
||||
train_shards_path_or_url=args.train_shards_path_or_url,
|
||||
num_train_examples=args.max_train_samples,
|
||||
per_gpu_batch_size=args.train_batch_size,
|
||||
@@ -1064,7 +1037,6 @@ def main(args):
|
||||
tokenizer=tokenizer,
|
||||
)
|
||||
|
||||
# 14. LR Scheduler creation
|
||||
# Scheduler and math around the number of training steps.
|
||||
overrode_max_train_steps = False
|
||||
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
|
||||
@@ -1079,7 +1051,6 @@ def main(args):
|
||||
num_training_steps=args.max_train_steps,
|
||||
)
|
||||
|
||||
# 15. Prepare for training
|
||||
# Prepare everything with our `accelerator`.
|
||||
unet, optimizer, lr_scheduler = accelerator.prepare(unet, optimizer, lr_scheduler)
|
||||
|
||||
@@ -1101,7 +1072,7 @@ def main(args):
|
||||
).input_ids.to(accelerator.device)
|
||||
uncond_prompt_embeds = text_encoder(uncond_input_ids)[0]
|
||||
|
||||
# 16. Train!
|
||||
# Train!
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
|
||||
logger.info("***** Running training *****")
|
||||
@@ -1152,7 +1123,6 @@ def main(args):
|
||||
for epoch in range(first_epoch, args.num_train_epochs):
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
with accelerator.accumulate(unet):
|
||||
# 1. Load and process the image and text conditioning
|
||||
image, text = batch
|
||||
|
||||
image = image.to(accelerator.device, non_blocking=True)
|
||||
@@ -1170,37 +1140,37 @@ def main(args):
|
||||
|
||||
latents = latents * vae.config.scaling_factor
|
||||
latents = latents.to(weight_dtype)
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
|
||||
# 2. Sample a random timestep for each image t_n from the ODE solver timesteps without bias.
|
||||
# For the DDIM solver, the timestep schedule is [T - 1, T - k - 1, T - 2 * k - 1, ...]
|
||||
# Sample a random timestep for each image t_n ~ U[0, N - k - 1] without bias.
|
||||
topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
|
||||
index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
|
||||
start_timesteps = solver.ddim_timesteps[index]
|
||||
timesteps = start_timesteps - topk
|
||||
timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
|
||||
|
||||
# 3. Get boundary scalings for start_timesteps and (end) timesteps.
|
||||
# 20.4.4. Get boundary scalings for start_timesteps and (end) timesteps.
|
||||
c_skip_start, c_out_start = scalings_for_boundary_conditions(start_timesteps)
|
||||
c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
|
||||
c_skip, c_out = scalings_for_boundary_conditions(timesteps)
|
||||
c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
|
||||
|
||||
# 4. Sample noise from the prior and add it to the latents according to the noise magnitude at each
|
||||
# timestep (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
|
||||
noise = torch.randn_like(latents)
|
||||
# 20.4.5. Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
|
||||
noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
|
||||
|
||||
# 5. Sample a random guidance scale w from U[w_min, w_max]
|
||||
# Note that for LCM-LoRA distillation it is not necessary to use a guidance scale embedding
|
||||
# 20.4.6. Sample a random guidance scale w from U[w_min, w_max] and embed it
|
||||
w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
|
||||
w = w.reshape(bsz, 1, 1, 1)
|
||||
w = w.to(device=latents.device, dtype=latents.dtype)
|
||||
|
||||
# 6. Prepare prompt embeds and unet_added_conditions
|
||||
# 20.4.8. Prepare prompt embeds and unet_added_conditions
|
||||
prompt_embeds = encoded_text.pop("prompt_embeds")
|
||||
|
||||
# 7. Get online LCM prediction on z_{t_{n + k}} (noisy_model_input), w, c, t_{n + k} (start_timesteps)
|
||||
# 20.4.9. Get online LCM prediction on z_{t_{n + k}}, w, c, t_{n + k}
|
||||
noise_pred = unet(
|
||||
noisy_model_input,
|
||||
start_timesteps,
|
||||
@@ -1209,7 +1179,7 @@ def main(args):
|
||||
added_cond_kwargs=encoded_text,
|
||||
).sample
|
||||
|
||||
pred_x_0 = get_predicted_original_sample(
|
||||
pred_x_0 = predicted_origin(
|
||||
noise_pred,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1220,27 +1190,17 @@ def main(args):
|
||||
|
||||
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
|
||||
|
||||
# 8. Compute the conditional and unconditional teacher model predictions to get CFG estimates of the
|
||||
# predicted noise eps_0 and predicted original sample x_0, then run the ODE solver using these
|
||||
# estimates to predict the data point in the augmented PF-ODE trajectory corresponding to the next ODE
|
||||
# solver timestep.
|
||||
# 20.4.10. Use the ODE solver to predict the kth step in the augmented PF-ODE trajectory after
|
||||
# noisy_latents with both the conditioning embedding c and unconditional embedding 0
|
||||
# Get teacher model prediction on noisy_latents and conditional embedding
|
||||
with torch.no_grad():
|
||||
with torch.autocast("cuda"):
|
||||
# 1. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and conditional embedding c
|
||||
cond_teacher_output = teacher_unet(
|
||||
noisy_model_input.to(weight_dtype),
|
||||
start_timesteps,
|
||||
encoder_hidden_states=prompt_embeds.to(weight_dtype),
|
||||
).sample
|
||||
cond_pred_x0 = get_predicted_original_sample(
|
||||
cond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
noise_scheduler.config.prediction_type,
|
||||
alpha_schedule,
|
||||
sigma_schedule,
|
||||
)
|
||||
cond_pred_noise = get_predicted_noise(
|
||||
cond_pred_x0 = predicted_origin(
|
||||
cond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1249,21 +1209,13 @@ def main(args):
|
||||
sigma_schedule,
|
||||
)
|
||||
|
||||
# 2. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and unconditional embedding 0
|
||||
# Get teacher model prediction on noisy_latents and unconditional embedding
|
||||
uncond_teacher_output = teacher_unet(
|
||||
noisy_model_input.to(weight_dtype),
|
||||
start_timesteps,
|
||||
encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
|
||||
).sample
|
||||
uncond_pred_x0 = get_predicted_original_sample(
|
||||
uncond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
noise_scheduler.config.prediction_type,
|
||||
alpha_schedule,
|
||||
sigma_schedule,
|
||||
)
|
||||
uncond_pred_noise = get_predicted_noise(
|
||||
uncond_pred_x0 = predicted_origin(
|
||||
uncond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1272,17 +1224,12 @@ def main(args):
|
||||
sigma_schedule,
|
||||
)
|
||||
|
||||
# 3. Calculate the CFG estimate of x_0 (pred_x0) and eps_0 (pred_noise)
|
||||
# Note that this uses the LCM paper's CFG formulation rather than the Imagen CFG formulation
|
||||
# 20.4.11. Perform "CFG" to get x_prev estimate (using the LCM paper's CFG formulation)
|
||||
pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
|
||||
pred_noise = cond_pred_noise + w * (cond_pred_noise - uncond_pred_noise)
|
||||
# 4. Run one step of the ODE solver to estimate the next point x_prev on the
|
||||
# augmented PF-ODE trajectory (solving backward in time)
|
||||
# Note that the DDIM step depends on both the predicted x_0 and source noise eps_0.
|
||||
pred_noise = cond_teacher_output + w * (cond_teacher_output - uncond_teacher_output)
|
||||
x_prev = solver.ddim_step(pred_x0, pred_noise, index)
|
||||
|
||||
# 9. Get target LCM prediction on x_prev, w, c, t_n (timesteps)
|
||||
# Note that we do not use a separate target network for LCM-LoRA distillation.
|
||||
# 20.4.12. Get target LCM prediction on x_prev, w, c, t_n
|
||||
with torch.no_grad():
|
||||
with torch.autocast("cuda", dtype=weight_dtype):
|
||||
target_noise_pred = unet(
|
||||
@@ -1291,7 +1238,7 @@ def main(args):
|
||||
timestep_cond=None,
|
||||
encoder_hidden_states=prompt_embeds.float(),
|
||||
).sample
|
||||
pred_x_0 = get_predicted_original_sample(
|
||||
pred_x_0 = predicted_origin(
|
||||
target_noise_pred,
|
||||
timesteps,
|
||||
x_prev,
|
||||
@@ -1301,7 +1248,7 @@ def main(args):
|
||||
)
|
||||
target = c_skip * x_prev + c_out * pred_x_0
|
||||
|
||||
# 10. Calculate loss
|
||||
# 20.4.13. Calculate loss
|
||||
if args.loss_type == "l2":
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
elif args.loss_type == "huber":
|
||||
@@ -1309,7 +1256,7 @@ def main(args):
|
||||
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
|
||||
)
|
||||
|
||||
# 11. Backpropagate on the online student model (`unet`)
|
||||
# 20.4.14. Backpropagate on the online student model (`unet`)
|
||||
accelerator.backward(loss)
|
||||
if accelerator.sync_gradients:
|
||||
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
|
||||
|
||||
@@ -162,7 +162,7 @@ class WebdatasetFilter:
|
||||
return False
|
||||
|
||||
|
||||
class SDXLText2ImageDataset:
|
||||
class Text2ImageDataset:
|
||||
def __init__(
|
||||
self,
|
||||
train_shards_path_or_url: Union[str, List[str]],
|
||||
@@ -346,43 +346,19 @@ def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=
|
||||
|
||||
|
||||
# Compare LCMScheduler.step, Step 4
|
||||
def get_predicted_original_sample(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
def predicted_origin(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
if prediction_type == "epsilon":
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
pred_x_0 = (sample - sigmas * model_output) / alphas
|
||||
elif prediction_type == "sample":
|
||||
pred_x_0 = model_output
|
||||
elif prediction_type == "v_prediction":
|
||||
pred_x_0 = alphas * sample - sigmas * model_output
|
||||
pred_x_0 = alphas[timesteps] * sample - sigmas[timesteps] * model_output
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
|
||||
f" are supported."
|
||||
)
|
||||
raise ValueError(f"Prediction type {prediction_type} currently not supported.")
|
||||
|
||||
return pred_x_0
|
||||
|
||||
|
||||
# Based on step 4 in DDIMScheduler.step
|
||||
def get_predicted_noise(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
if prediction_type == "epsilon":
|
||||
pred_epsilon = model_output
|
||||
elif prediction_type == "sample":
|
||||
pred_epsilon = (sample - alphas * model_output) / sigmas
|
||||
elif prediction_type == "v_prediction":
|
||||
pred_epsilon = alphas * model_output + sigmas * sample
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
|
||||
f" are supported."
|
||||
)
|
||||
|
||||
return pred_epsilon
|
||||
|
||||
|
||||
def extract_into_tensor(a, t, x_shape):
|
||||
b, *_ = t.shape
|
||||
out = a.gather(-1, t)
|
||||
@@ -854,10 +830,9 @@ def main(args):
|
||||
args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
|
||||
)
|
||||
|
||||
# DDPMScheduler calculates the alpha and sigma noise schedules (based on the alpha bars) for us
|
||||
# The scheduler calculates the alpha and sigma schedule for us
|
||||
alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
|
||||
sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
|
||||
# Initialize the DDIM ODE solver for distillation.
|
||||
solver = DDIMSolver(
|
||||
noise_scheduler.alphas_cumprod.numpy(),
|
||||
timesteps=noise_scheduler.config.num_train_timesteps,
|
||||
@@ -911,7 +886,7 @@ def main(args):
|
||||
text_encoder_two.requires_grad_(False)
|
||||
teacher_unet.requires_grad_(False)
|
||||
|
||||
# 7. Create online student U-Net.
|
||||
# 7. Create online (`unet`) student U-Nets.
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
|
||||
)
|
||||
@@ -975,7 +950,6 @@ def main(args):
|
||||
# Also move the alpha and sigma noise schedules to accelerator.device.
|
||||
alpha_schedule = alpha_schedule.to(accelerator.device)
|
||||
sigma_schedule = sigma_schedule.to(accelerator.device)
|
||||
# Move the ODE solver to accelerator.device.
|
||||
solver = solver.to(accelerator.device)
|
||||
|
||||
# 10. Handle saving and loading of checkpoints
|
||||
@@ -1083,7 +1057,7 @@ def main(args):
|
||||
|
||||
return {"prompt_embeds": prompt_embeds, **unet_added_cond_kwargs}
|
||||
|
||||
dataset = SDXLText2ImageDataset(
|
||||
dataset = Text2ImageDataset(
|
||||
train_shards_path_or_url=args.train_shards_path_or_url,
|
||||
num_train_examples=args.max_train_samples,
|
||||
per_gpu_batch_size=args.train_batch_size,
|
||||
@@ -1201,7 +1175,6 @@ def main(args):
|
||||
for epoch in range(first_epoch, args.num_train_epochs):
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
with accelerator.accumulate(unet):
|
||||
# 1. Load and process the image, text, and micro-conditioning (original image size, crop coordinates)
|
||||
image, text, orig_size, crop_coords = batch
|
||||
|
||||
image = image.to(accelerator.device, non_blocking=True)
|
||||
@@ -1223,37 +1196,37 @@ def main(args):
|
||||
latents = latents * vae.config.scaling_factor
|
||||
if args.pretrained_vae_model_name_or_path is None:
|
||||
latents = latents.to(weight_dtype)
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
|
||||
# 2. Sample a random timestep for each image t_n from the ODE solver timesteps without bias.
|
||||
# For the DDIM solver, the timestep schedule is [T - 1, T - k - 1, T - 2 * k - 1, ...]
|
||||
# Sample a random timestep for each image t_n ~ U[0, N - k - 1] without bias.
|
||||
topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
|
||||
index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
|
||||
start_timesteps = solver.ddim_timesteps[index]
|
||||
timesteps = start_timesteps - topk
|
||||
timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
|
||||
|
||||
# 3. Get boundary scalings for start_timesteps and (end) timesteps.
|
||||
# 20.4.4. Get boundary scalings for start_timesteps and (end) timesteps.
|
||||
c_skip_start, c_out_start = scalings_for_boundary_conditions(start_timesteps)
|
||||
c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
|
||||
c_skip, c_out = scalings_for_boundary_conditions(timesteps)
|
||||
c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
|
||||
|
||||
# 4. Sample noise from the prior and add it to the latents according to the noise magnitude at each
|
||||
# timestep (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
|
||||
noise = torch.randn_like(latents)
|
||||
# 20.4.5. Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
|
||||
noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
|
||||
|
||||
# 5. Sample a random guidance scale w from U[w_min, w_max]
|
||||
# Note that for LCM-LoRA distillation it is not necessary to use a guidance scale embedding
|
||||
# 20.4.6. Sample a random guidance scale w from U[w_min, w_max] and embed it
|
||||
w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
|
||||
w = w.reshape(bsz, 1, 1, 1)
|
||||
w = w.to(device=latents.device, dtype=latents.dtype)
|
||||
|
||||
# 6. Prepare prompt embeds and unet_added_conditions
|
||||
# 20.4.8. Prepare prompt embeds and unet_added_conditions
|
||||
prompt_embeds = encoded_text.pop("prompt_embeds")
|
||||
|
||||
# 7. Get online LCM prediction on z_{t_{n + k}} (noisy_model_input), w, c, t_{n + k} (start_timesteps)
|
||||
# 20.4.9. Get online LCM prediction on z_{t_{n + k}}, w, c, t_{n + k}
|
||||
noise_pred = unet(
|
||||
noisy_model_input,
|
||||
start_timesteps,
|
||||
@@ -1262,7 +1235,7 @@ def main(args):
|
||||
added_cond_kwargs=encoded_text,
|
||||
).sample
|
||||
|
||||
pred_x_0 = get_predicted_original_sample(
|
||||
pred_x_0 = predicted_origin(
|
||||
noise_pred,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1273,28 +1246,18 @@ def main(args):
|
||||
|
||||
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
|
||||
|
||||
# 8. Compute the conditional and unconditional teacher model predictions to get CFG estimates of the
|
||||
# predicted noise eps_0 and predicted original sample x_0, then run the ODE solver using these
|
||||
# estimates to predict the data point in the augmented PF-ODE trajectory corresponding to the next ODE
|
||||
# solver timestep.
|
||||
# 20.4.10. Use the ODE solver to predict the kth step in the augmented PF-ODE trajectory after
|
||||
# noisy_latents with both the conditioning embedding c and unconditional embedding 0
|
||||
# Get teacher model prediction on noisy_latents and conditional embedding
|
||||
with torch.no_grad():
|
||||
with torch.autocast("cuda"):
|
||||
# 1. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and conditional embedding c
|
||||
cond_teacher_output = teacher_unet(
|
||||
noisy_model_input.to(weight_dtype),
|
||||
start_timesteps,
|
||||
encoder_hidden_states=prompt_embeds.to(weight_dtype),
|
||||
added_cond_kwargs={k: v.to(weight_dtype) for k, v in encoded_text.items()},
|
||||
).sample
|
||||
cond_pred_x0 = get_predicted_original_sample(
|
||||
cond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
noise_scheduler.config.prediction_type,
|
||||
alpha_schedule,
|
||||
sigma_schedule,
|
||||
)
|
||||
cond_pred_noise = get_predicted_noise(
|
||||
cond_pred_x0 = predicted_origin(
|
||||
cond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1303,7 +1266,7 @@ def main(args):
|
||||
sigma_schedule,
|
||||
)
|
||||
|
||||
# 2. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and unconditional embedding 0
|
||||
# Get teacher model prediction on noisy_latents and unconditional embedding
|
||||
uncond_added_conditions = copy.deepcopy(encoded_text)
|
||||
uncond_added_conditions["text_embeds"] = uncond_pooled_prompt_embeds
|
||||
uncond_teacher_output = teacher_unet(
|
||||
@@ -1312,15 +1275,7 @@ def main(args):
|
||||
encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
|
||||
added_cond_kwargs={k: v.to(weight_dtype) for k, v in uncond_added_conditions.items()},
|
||||
).sample
|
||||
uncond_pred_x0 = get_predicted_original_sample(
|
||||
uncond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
noise_scheduler.config.prediction_type,
|
||||
alpha_schedule,
|
||||
sigma_schedule,
|
||||
)
|
||||
uncond_pred_noise = get_predicted_noise(
|
||||
uncond_pred_x0 = predicted_origin(
|
||||
uncond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1329,17 +1284,12 @@ def main(args):
|
||||
sigma_schedule,
|
||||
)
|
||||
|
||||
# 3. Calculate the CFG estimate of x_0 (pred_x0) and eps_0 (pred_noise)
|
||||
# Note that this uses the LCM paper's CFG formulation rather than the Imagen CFG formulation
|
||||
# 20.4.11. Perform "CFG" to get x_prev estimate (using the LCM paper's CFG formulation)
|
||||
pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
|
||||
pred_noise = cond_pred_noise + w * (cond_pred_noise - uncond_pred_noise)
|
||||
# 4. Run one step of the ODE solver to estimate the next point x_prev on the
|
||||
# augmented PF-ODE trajectory (solving backward in time)
|
||||
# Note that the DDIM step depends on both the predicted x_0 and source noise eps_0.
|
||||
pred_noise = cond_teacher_output + w * (cond_teacher_output - uncond_teacher_output)
|
||||
x_prev = solver.ddim_step(pred_x0, pred_noise, index)
|
||||
|
||||
# 9. Get target LCM prediction on x_prev, w, c, t_n (timesteps)
|
||||
# Note that we do not use a separate target network for LCM-LoRA distillation.
|
||||
# 20.4.12. Get target LCM prediction on x_prev, w, c, t_n
|
||||
with torch.no_grad():
|
||||
with torch.autocast("cuda", enabled=True, dtype=weight_dtype):
|
||||
target_noise_pred = unet(
|
||||
@@ -1349,7 +1299,7 @@ def main(args):
|
||||
encoder_hidden_states=prompt_embeds.float(),
|
||||
added_cond_kwargs=encoded_text,
|
||||
).sample
|
||||
pred_x_0 = get_predicted_original_sample(
|
||||
pred_x_0 = predicted_origin(
|
||||
target_noise_pred,
|
||||
timesteps,
|
||||
x_prev,
|
||||
@@ -1359,7 +1309,7 @@ def main(args):
|
||||
)
|
||||
target = c_skip * x_prev + c_out * pred_x_0
|
||||
|
||||
# 10. Calculate loss
|
||||
# 20.4.13. Calculate loss
|
||||
if args.loss_type == "l2":
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
elif args.loss_type == "huber":
|
||||
@@ -1367,7 +1317,7 @@ def main(args):
|
||||
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
|
||||
)
|
||||
|
||||
# 11. Backpropagate on the online student model (`unet`)
|
||||
# 20.4.14. Backpropagate on the online student model (`unet`)
|
||||
accelerator.backward(loss)
|
||||
if accelerator.sync_gradients:
|
||||
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
|
||||
|
||||
@@ -138,7 +138,7 @@ class WebdatasetFilter:
|
||||
return False
|
||||
|
||||
|
||||
class SDText2ImageDataset:
|
||||
class Text2ImageDataset:
|
||||
def __init__(
|
||||
self,
|
||||
train_shards_path_or_url: Union[str, List[str]],
|
||||
@@ -336,43 +336,19 @@ def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=
|
||||
|
||||
|
||||
# Compare LCMScheduler.step, Step 4
|
||||
def get_predicted_original_sample(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
def predicted_origin(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
if prediction_type == "epsilon":
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
pred_x_0 = (sample - sigmas * model_output) / alphas
|
||||
elif prediction_type == "sample":
|
||||
pred_x_0 = model_output
|
||||
elif prediction_type == "v_prediction":
|
||||
pred_x_0 = alphas * sample - sigmas * model_output
|
||||
pred_x_0 = alphas[timesteps] * sample - sigmas[timesteps] * model_output
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
|
||||
f" are supported."
|
||||
)
|
||||
raise ValueError(f"Prediction type {prediction_type} currently not supported.")
|
||||
|
||||
return pred_x_0
|
||||
|
||||
|
||||
# Based on step 4 in DDIMScheduler.step
|
||||
def get_predicted_noise(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
if prediction_type == "epsilon":
|
||||
pred_epsilon = model_output
|
||||
elif prediction_type == "sample":
|
||||
pred_epsilon = (sample - alphas * model_output) / sigmas
|
||||
elif prediction_type == "v_prediction":
|
||||
pred_epsilon = alphas * model_output + sigmas * sample
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
|
||||
f" are supported."
|
||||
)
|
||||
|
||||
return pred_epsilon
|
||||
|
||||
|
||||
def extract_into_tensor(a, t, x_shape):
|
||||
b, *_ = t.shape
|
||||
out = a.gather(-1, t)
|
||||
@@ -847,35 +823,34 @@ def main(args):
|
||||
args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
|
||||
)
|
||||
|
||||
# DDPMScheduler calculates the alpha and sigma noise schedules (based on the alpha bars) for us
|
||||
# The scheduler calculates the alpha and sigma schedule for us
|
||||
alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
|
||||
sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
|
||||
# Initialize the DDIM ODE solver for distillation.
|
||||
solver = DDIMSolver(
|
||||
noise_scheduler.alphas_cumprod.numpy(),
|
||||
timesteps=noise_scheduler.config.num_train_timesteps,
|
||||
ddim_timesteps=args.num_ddim_timesteps,
|
||||
)
|
||||
|
||||
# 2. Load tokenizers from SD 1.X/2.X checkpoint.
|
||||
# 2. Load tokenizers from SD-XL checkpoint.
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.pretrained_teacher_model, subfolder="tokenizer", revision=args.teacher_revision, use_fast=False
|
||||
)
|
||||
|
||||
# 3. Load text encoders from SD 1.X/2.X checkpoint.
|
||||
# 3. Load text encoders from SD-1.5 checkpoint.
|
||||
# import correct text encoder classes
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
args.pretrained_teacher_model, subfolder="text_encoder", revision=args.teacher_revision
|
||||
)
|
||||
|
||||
# 4. Load VAE from SD 1.X/2.X checkpoint
|
||||
# 4. Load VAE from SD-XL checkpoint (or more stable VAE)
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
args.pretrained_teacher_model,
|
||||
subfolder="vae",
|
||||
revision=args.teacher_revision,
|
||||
)
|
||||
|
||||
# 5. Load teacher U-Net from SD 1.X/2.X checkpoint
|
||||
# 5. Load teacher U-Net from SD-XL checkpoint
|
||||
teacher_unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
|
||||
)
|
||||
@@ -885,7 +860,7 @@ def main(args):
|
||||
text_encoder.requires_grad_(False)
|
||||
teacher_unet.requires_grad_(False)
|
||||
|
||||
# 7. Create online student U-Net. This will be updated by the optimizer (e.g. via backpropagation.)
|
||||
# 8. Create online (`unet`) student U-Nets. This will be updated by the optimizer (e.g. via backpropagation.)
|
||||
# Add `time_cond_proj_dim` to the student U-Net if `teacher_unet.config.time_cond_proj_dim` is None
|
||||
if teacher_unet.config.time_cond_proj_dim is None:
|
||||
teacher_unet.config["time_cond_proj_dim"] = args.unet_time_cond_proj_dim
|
||||
@@ -894,8 +869,8 @@ def main(args):
|
||||
unet.load_state_dict(teacher_unet.state_dict(), strict=False)
|
||||
unet.train()
|
||||
|
||||
# 8. Create target student U-Net. This will be updated via EMA updates (polyak averaging).
|
||||
# Initialize from (online) unet
|
||||
# 9. Create target (`ema_unet`) student U-Net parameters. This will be updated via EMA updates (polyak averaging).
|
||||
# Initialize from unet
|
||||
target_unet = UNet2DConditionModel(**teacher_unet.config)
|
||||
target_unet.load_state_dict(unet.state_dict())
|
||||
target_unet.train()
|
||||
@@ -912,7 +887,7 @@ def main(args):
|
||||
f"Controlnet loaded as datatype {accelerator.unwrap_model(unet).dtype}. {low_precision_error_string}"
|
||||
)
|
||||
|
||||
# 9. Handle mixed precision and device placement
|
||||
# 10. Handle mixed precision and device placement
|
||||
# For mixed precision training we cast all non-trainable weigths to half-precision
|
||||
# as these weights are only used for inference, keeping weights in full precision is not required.
|
||||
weight_dtype = torch.float32
|
||||
@@ -939,7 +914,7 @@ def main(args):
|
||||
sigma_schedule = sigma_schedule.to(accelerator.device)
|
||||
solver = solver.to(accelerator.device)
|
||||
|
||||
# 10. Handle saving and loading of checkpoints
|
||||
# 11. Handle saving and loading of checkpoints
|
||||
# `accelerate` 0.16.0 will have better support for customized saving
|
||||
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
|
||||
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
|
||||
@@ -973,7 +948,7 @@ def main(args):
|
||||
accelerator.register_save_state_pre_hook(save_model_hook)
|
||||
accelerator.register_load_state_pre_hook(load_model_hook)
|
||||
|
||||
# 11. Enable optimizations
|
||||
# 12. Enable optimizations
|
||||
if args.enable_xformers_memory_efficient_attention:
|
||||
if is_xformers_available():
|
||||
import xformers
|
||||
@@ -1019,14 +994,13 @@ def main(args):
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
# 13. Dataset creation and data processing
|
||||
# Here, we compute not just the text embeddings but also the additional embeddings
|
||||
# needed for the SD XL UNet to operate.
|
||||
def compute_embeddings(prompt_batch, proportion_empty_prompts, text_encoder, tokenizer, is_train=True):
|
||||
prompt_embeds = encode_prompt(prompt_batch, text_encoder, tokenizer, proportion_empty_prompts, is_train)
|
||||
return {"prompt_embeds": prompt_embeds}
|
||||
|
||||
dataset = SDText2ImageDataset(
|
||||
dataset = Text2ImageDataset(
|
||||
train_shards_path_or_url=args.train_shards_path_or_url,
|
||||
num_train_examples=args.max_train_samples,
|
||||
per_gpu_batch_size=args.train_batch_size,
|
||||
@@ -1046,7 +1020,6 @@ def main(args):
|
||||
tokenizer=tokenizer,
|
||||
)
|
||||
|
||||
# 14. LR Scheduler creation
|
||||
# Scheduler and math around the number of training steps.
|
||||
overrode_max_train_steps = False
|
||||
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
|
||||
@@ -1061,7 +1034,6 @@ def main(args):
|
||||
num_training_steps=args.max_train_steps,
|
||||
)
|
||||
|
||||
# 15. Prepare for training
|
||||
# Prepare everything with our `accelerator`.
|
||||
unet, optimizer, lr_scheduler = accelerator.prepare(unet, optimizer, lr_scheduler)
|
||||
|
||||
@@ -1083,7 +1055,7 @@ def main(args):
|
||||
).input_ids.to(accelerator.device)
|
||||
uncond_prompt_embeds = text_encoder(uncond_input_ids)[0]
|
||||
|
||||
# 16. Train!
|
||||
# Train!
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
|
||||
logger.info("***** Running training *****")
|
||||
@@ -1134,7 +1106,6 @@ def main(args):
|
||||
for epoch in range(first_epoch, args.num_train_epochs):
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
with accelerator.accumulate(unet):
|
||||
# 1. Load and process the image and text conditioning
|
||||
image, text = batch
|
||||
|
||||
image = image.to(accelerator.device, non_blocking=True)
|
||||
@@ -1152,28 +1123,29 @@ def main(args):
|
||||
|
||||
latents = latents * vae.config.scaling_factor
|
||||
latents = latents.to(weight_dtype)
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
|
||||
# 2. Sample a random timestep for each image t_n from the ODE solver timesteps without bias.
|
||||
# For the DDIM solver, the timestep schedule is [T - 1, T - k - 1, T - 2 * k - 1, ...]
|
||||
# Sample a random timestep for each image t_n ~ U[0, N - k - 1] without bias.
|
||||
topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
|
||||
index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
|
||||
start_timesteps = solver.ddim_timesteps[index]
|
||||
timesteps = start_timesteps - topk
|
||||
timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
|
||||
|
||||
# 3. Get boundary scalings for start_timesteps and (end) timesteps.
|
||||
# 20.4.4. Get boundary scalings for start_timesteps and (end) timesteps.
|
||||
c_skip_start, c_out_start = scalings_for_boundary_conditions(start_timesteps)
|
||||
c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
|
||||
c_skip, c_out = scalings_for_boundary_conditions(timesteps)
|
||||
c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
|
||||
|
||||
# 4. Sample noise from the prior and add it to the latents according to the noise magnitude at each
|
||||
# timestep (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
|
||||
noise = torch.randn_like(latents)
|
||||
# 20.4.5. Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
|
||||
noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
|
||||
|
||||
# 5. Sample a random guidance scale w from U[w_min, w_max] and embed it
|
||||
# 20.4.6. Sample a random guidance scale w from U[w_min, w_max] and embed it
|
||||
w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
|
||||
w_embedding = guidance_scale_embedding(w, embedding_dim=unet.config.time_cond_proj_dim)
|
||||
w = w.reshape(bsz, 1, 1, 1)
|
||||
@@ -1181,10 +1153,10 @@ def main(args):
|
||||
w = w.to(device=latents.device, dtype=latents.dtype)
|
||||
w_embedding = w_embedding.to(device=latents.device, dtype=latents.dtype)
|
||||
|
||||
# 6. Prepare prompt embeds and unet_added_conditions
|
||||
# 20.4.8. Prepare prompt embeds and unet_added_conditions
|
||||
prompt_embeds = encoded_text.pop("prompt_embeds")
|
||||
|
||||
# 7. Get online LCM prediction on z_{t_{n + k}} (noisy_model_input), w, c, t_{n + k} (start_timesteps)
|
||||
# 20.4.9. Get online LCM prediction on z_{t_{n + k}}, w, c, t_{n + k}
|
||||
noise_pred = unet(
|
||||
noisy_model_input,
|
||||
start_timesteps,
|
||||
@@ -1193,7 +1165,7 @@ def main(args):
|
||||
added_cond_kwargs=encoded_text,
|
||||
).sample
|
||||
|
||||
pred_x_0 = get_predicted_original_sample(
|
||||
pred_x_0 = predicted_origin(
|
||||
noise_pred,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1204,27 +1176,17 @@ def main(args):
|
||||
|
||||
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
|
||||
|
||||
# 8. Compute the conditional and unconditional teacher model predictions to get CFG estimates of the
|
||||
# predicted noise eps_0 and predicted original sample x_0, then run the ODE solver using these
|
||||
# estimates to predict the data point in the augmented PF-ODE trajectory corresponding to the next ODE
|
||||
# solver timestep.
|
||||
# 20.4.10. Use the ODE solver to predict the kth step in the augmented PF-ODE trajectory after
|
||||
# noisy_latents with both the conditioning embedding c and unconditional embedding 0
|
||||
# Get teacher model prediction on noisy_latents and conditional embedding
|
||||
with torch.no_grad():
|
||||
with torch.autocast("cuda"):
|
||||
# 1. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and conditional embedding c
|
||||
cond_teacher_output = teacher_unet(
|
||||
noisy_model_input.to(weight_dtype),
|
||||
start_timesteps,
|
||||
encoder_hidden_states=prompt_embeds.to(weight_dtype),
|
||||
).sample
|
||||
cond_pred_x0 = get_predicted_original_sample(
|
||||
cond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
noise_scheduler.config.prediction_type,
|
||||
alpha_schedule,
|
||||
sigma_schedule,
|
||||
)
|
||||
cond_pred_noise = get_predicted_noise(
|
||||
cond_pred_x0 = predicted_origin(
|
||||
cond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1233,21 +1195,13 @@ def main(args):
|
||||
sigma_schedule,
|
||||
)
|
||||
|
||||
# 2. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and unconditional embedding 0
|
||||
# Get teacher model prediction on noisy_latents and unconditional embedding
|
||||
uncond_teacher_output = teacher_unet(
|
||||
noisy_model_input.to(weight_dtype),
|
||||
start_timesteps,
|
||||
encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
|
||||
).sample
|
||||
uncond_pred_x0 = get_predicted_original_sample(
|
||||
uncond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
noise_scheduler.config.prediction_type,
|
||||
alpha_schedule,
|
||||
sigma_schedule,
|
||||
)
|
||||
uncond_pred_noise = get_predicted_noise(
|
||||
uncond_pred_x0 = predicted_origin(
|
||||
uncond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1256,16 +1210,12 @@ def main(args):
|
||||
sigma_schedule,
|
||||
)
|
||||
|
||||
# 3. Calculate the CFG estimate of x_0 (pred_x0) and eps_0 (pred_noise)
|
||||
# Note that this uses the LCM paper's CFG formulation rather than the Imagen CFG formulation
|
||||
# 20.4.11. Perform "CFG" to get x_prev estimate (using the LCM paper's CFG formulation)
|
||||
pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
|
||||
pred_noise = cond_pred_noise + w * (cond_pred_noise - uncond_pred_noise)
|
||||
# 4. Run one step of the ODE solver to estimate the next point x_prev on the
|
||||
# augmented PF-ODE trajectory (solving backward in time)
|
||||
# Note that the DDIM step depends on both the predicted x_0 and source noise eps_0.
|
||||
pred_noise = cond_teacher_output + w * (cond_teacher_output - uncond_teacher_output)
|
||||
x_prev = solver.ddim_step(pred_x0, pred_noise, index)
|
||||
|
||||
# 9. Get target LCM prediction on x_prev, w, c, t_n (timesteps)
|
||||
# 20.4.12. Get target LCM prediction on x_prev, w, c, t_n
|
||||
with torch.no_grad():
|
||||
with torch.autocast("cuda", dtype=weight_dtype):
|
||||
target_noise_pred = target_unet(
|
||||
@@ -1274,7 +1224,7 @@ def main(args):
|
||||
timestep_cond=w_embedding,
|
||||
encoder_hidden_states=prompt_embeds.float(),
|
||||
).sample
|
||||
pred_x_0 = get_predicted_original_sample(
|
||||
pred_x_0 = predicted_origin(
|
||||
target_noise_pred,
|
||||
timesteps,
|
||||
x_prev,
|
||||
@@ -1284,7 +1234,7 @@ def main(args):
|
||||
)
|
||||
target = c_skip * x_prev + c_out * pred_x_0
|
||||
|
||||
# 10. Calculate loss
|
||||
# 20.4.13. Calculate loss
|
||||
if args.loss_type == "l2":
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
elif args.loss_type == "huber":
|
||||
@@ -1292,7 +1242,7 @@ def main(args):
|
||||
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
|
||||
)
|
||||
|
||||
# 11. Backpropagate on the online student model (`unet`)
|
||||
# 20.4.14. Backpropagate on the online student model (`unet`)
|
||||
accelerator.backward(loss)
|
||||
if accelerator.sync_gradients:
|
||||
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
|
||||
@@ -1302,7 +1252,7 @@ def main(args):
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
# 12. Make EMA update to target student model parameters (`target_unet`)
|
||||
# 20.4.15. Make EMA update to target student model parameters
|
||||
update_ema(target_unet.parameters(), unet.parameters(), args.ema_decay)
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
@@ -144,7 +144,7 @@ class WebdatasetFilter:
|
||||
return False
|
||||
|
||||
|
||||
class SDXLText2ImageDataset:
|
||||
class Text2ImageDataset:
|
||||
def __init__(
|
||||
self,
|
||||
train_shards_path_or_url: Union[str, List[str]],
|
||||
@@ -324,43 +324,19 @@ def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=
|
||||
|
||||
|
||||
# Compare LCMScheduler.step, Step 4
|
||||
def get_predicted_original_sample(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
def predicted_origin(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
if prediction_type == "epsilon":
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
pred_x_0 = (sample - sigmas * model_output) / alphas
|
||||
elif prediction_type == "sample":
|
||||
pred_x_0 = model_output
|
||||
elif prediction_type == "v_prediction":
|
||||
pred_x_0 = alphas * sample - sigmas * model_output
|
||||
pred_x_0 = alphas[timesteps] * sample - sigmas[timesteps] * model_output
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
|
||||
f" are supported."
|
||||
)
|
||||
raise ValueError(f"Prediction type {prediction_type} currently not supported.")
|
||||
|
||||
return pred_x_0
|
||||
|
||||
|
||||
# Based on step 4 in DDIMScheduler.step
|
||||
def get_predicted_noise(model_output, timesteps, sample, prediction_type, alphas, sigmas):
|
||||
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
|
||||
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
|
||||
if prediction_type == "epsilon":
|
||||
pred_epsilon = model_output
|
||||
elif prediction_type == "sample":
|
||||
pred_epsilon = (sample - alphas * model_output) / sigmas
|
||||
elif prediction_type == "v_prediction":
|
||||
pred_epsilon = alphas * model_output + sigmas * sample
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
|
||||
f" are supported."
|
||||
)
|
||||
|
||||
return pred_epsilon
|
||||
|
||||
|
||||
def extract_into_tensor(a, t, x_shape):
|
||||
b, *_ = t.shape
|
||||
out = a.gather(-1, t)
|
||||
@@ -887,10 +863,9 @@ def main(args):
|
||||
args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
|
||||
)
|
||||
|
||||
# DDPMScheduler calculates the alpha and sigma noise schedules (based on the alpha bars) for us
|
||||
# The scheduler calculates the alpha and sigma schedule for us
|
||||
alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
|
||||
sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
|
||||
# Initialize the DDIM ODE solver for distillation.
|
||||
solver = DDIMSolver(
|
||||
noise_scheduler.alphas_cumprod.numpy(),
|
||||
timesteps=noise_scheduler.config.num_train_timesteps,
|
||||
@@ -944,7 +919,7 @@ def main(args):
|
||||
text_encoder_two.requires_grad_(False)
|
||||
teacher_unet.requires_grad_(False)
|
||||
|
||||
# 7. Create online student U-Net. This will be updated by the optimizer (e.g. via backpropagation.)
|
||||
# 8. Create online (`unet`) student U-Nets. This will be updated by the optimizer (e.g. via backpropagation.)
|
||||
# Add `time_cond_proj_dim` to the student U-Net if `teacher_unet.config.time_cond_proj_dim` is None
|
||||
if teacher_unet.config.time_cond_proj_dim is None:
|
||||
teacher_unet.config["time_cond_proj_dim"] = args.unet_time_cond_proj_dim
|
||||
@@ -953,8 +928,8 @@ def main(args):
|
||||
unet.load_state_dict(teacher_unet.state_dict(), strict=False)
|
||||
unet.train()
|
||||
|
||||
# 8. Create target student U-Net. This will be updated via EMA updates (polyak averaging).
|
||||
# Initialize from (online) unet
|
||||
# 9. Create target (`ema_unet`) student U-Net parameters. This will be updated via EMA updates (polyak averaging).
|
||||
# Initialize from unet
|
||||
target_unet = UNet2DConditionModel(**teacher_unet.config)
|
||||
target_unet.load_state_dict(unet.state_dict())
|
||||
target_unet.train()
|
||||
@@ -996,7 +971,6 @@ def main(args):
|
||||
# Also move the alpha and sigma noise schedules to accelerator.device.
|
||||
alpha_schedule = alpha_schedule.to(accelerator.device)
|
||||
sigma_schedule = sigma_schedule.to(accelerator.device)
|
||||
# Move the ODE solver to accelerator.device.
|
||||
solver = solver.to(accelerator.device)
|
||||
|
||||
# 10. Handle saving and loading of checkpoints
|
||||
@@ -1110,7 +1084,7 @@ def main(args):
|
||||
|
||||
return {"prompt_embeds": prompt_embeds, **unet_added_cond_kwargs}
|
||||
|
||||
dataset = SDXLText2ImageDataset(
|
||||
dataset = Text2ImageDataset(
|
||||
train_shards_path_or_url=args.train_shards_path_or_url,
|
||||
num_train_examples=args.max_train_samples,
|
||||
per_gpu_batch_size=args.train_batch_size,
|
||||
@@ -1228,7 +1202,6 @@ def main(args):
|
||||
for epoch in range(first_epoch, args.num_train_epochs):
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
with accelerator.accumulate(unet):
|
||||
# 1. Load and process the image, text, and micro-conditioning (original image size, crop coordinates)
|
||||
image, text, orig_size, crop_coords = batch
|
||||
|
||||
image = image.to(accelerator.device, non_blocking=True)
|
||||
@@ -1250,39 +1223,38 @@ def main(args):
|
||||
latents = latents * vae.config.scaling_factor
|
||||
if args.pretrained_vae_model_name_or_path is None:
|
||||
latents = latents.to(weight_dtype)
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
|
||||
# 2. Sample a random timestep for each image t_n from the ODE solver timesteps without bias.
|
||||
# For the DDIM solver, the timestep schedule is [T - 1, T - k - 1, T - 2 * k - 1, ...]
|
||||
# Sample a random timestep for each image t_n ~ U[0, N - k - 1] without bias.
|
||||
topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
|
||||
index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
|
||||
start_timesteps = solver.ddim_timesteps[index]
|
||||
timesteps = start_timesteps - topk
|
||||
timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
|
||||
|
||||
# 3. Get boundary scalings for start_timesteps and (end) timesteps.
|
||||
# 20.4.4. Get boundary scalings for start_timesteps and (end) timesteps.
|
||||
c_skip_start, c_out_start = scalings_for_boundary_conditions(start_timesteps)
|
||||
c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
|
||||
c_skip, c_out = scalings_for_boundary_conditions(timesteps)
|
||||
c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
|
||||
|
||||
# 4. Sample noise from the prior and add it to the latents according to the noise magnitude at each
|
||||
# timestep (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
|
||||
noise = torch.randn_like(latents)
|
||||
# 20.4.5. Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
|
||||
noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
|
||||
|
||||
# 5. Sample a random guidance scale w from U[w_min, w_max] and embed it
|
||||
# 20.4.6. Sample a random guidance scale w from U[w_min, w_max] and embed it
|
||||
w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
|
||||
w_embedding = guidance_scale_embedding(w, embedding_dim=unet.config.time_cond_proj_dim)
|
||||
w = w.reshape(bsz, 1, 1, 1)
|
||||
# Move to U-Net device and dtype
|
||||
w = w.to(device=latents.device, dtype=latents.dtype)
|
||||
w_embedding = w_embedding.to(device=latents.device, dtype=latents.dtype)
|
||||
|
||||
# 6. Prepare prompt embeds and unet_added_conditions
|
||||
# 20.4.8. Prepare prompt embeds and unet_added_conditions
|
||||
prompt_embeds = encoded_text.pop("prompt_embeds")
|
||||
|
||||
# 7. Get online LCM prediction on z_{t_{n + k}} (noisy_model_input), w, c, t_{n + k} (start_timesteps)
|
||||
# 20.4.9. Get online LCM prediction on z_{t_{n + k}}, w, c, t_{n + k}
|
||||
noise_pred = unet(
|
||||
noisy_model_input,
|
||||
start_timesteps,
|
||||
@@ -1291,7 +1263,7 @@ def main(args):
|
||||
added_cond_kwargs=encoded_text,
|
||||
).sample
|
||||
|
||||
pred_x_0 = get_predicted_original_sample(
|
||||
pred_x_0 = predicted_origin(
|
||||
noise_pred,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1302,28 +1274,18 @@ def main(args):
|
||||
|
||||
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
|
||||
|
||||
# 8. Compute the conditional and unconditional teacher model predictions to get CFG estimates of the
|
||||
# predicted noise eps_0 and predicted original sample x_0, then run the ODE solver using these
|
||||
# estimates to predict the data point in the augmented PF-ODE trajectory corresponding to the next ODE
|
||||
# solver timestep.
|
||||
# 20.4.10. Use the ODE solver to predict the kth step in the augmented PF-ODE trajectory after
|
||||
# noisy_latents with both the conditioning embedding c and unconditional embedding 0
|
||||
# Get teacher model prediction on noisy_latents and conditional embedding
|
||||
with torch.no_grad():
|
||||
with torch.autocast("cuda"):
|
||||
# 1. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and conditional embedding c
|
||||
cond_teacher_output = teacher_unet(
|
||||
noisy_model_input.to(weight_dtype),
|
||||
start_timesteps,
|
||||
encoder_hidden_states=prompt_embeds.to(weight_dtype),
|
||||
added_cond_kwargs={k: v.to(weight_dtype) for k, v in encoded_text.items()},
|
||||
).sample
|
||||
cond_pred_x0 = get_predicted_original_sample(
|
||||
cond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
noise_scheduler.config.prediction_type,
|
||||
alpha_schedule,
|
||||
sigma_schedule,
|
||||
)
|
||||
cond_pred_noise = get_predicted_noise(
|
||||
cond_pred_x0 = predicted_origin(
|
||||
cond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1332,7 +1294,7 @@ def main(args):
|
||||
sigma_schedule,
|
||||
)
|
||||
|
||||
# 2. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and unconditional embedding 0
|
||||
# Get teacher model prediction on noisy_latents and unconditional embedding
|
||||
uncond_added_conditions = copy.deepcopy(encoded_text)
|
||||
uncond_added_conditions["text_embeds"] = uncond_pooled_prompt_embeds
|
||||
uncond_teacher_output = teacher_unet(
|
||||
@@ -1341,15 +1303,7 @@ def main(args):
|
||||
encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
|
||||
added_cond_kwargs={k: v.to(weight_dtype) for k, v in uncond_added_conditions.items()},
|
||||
).sample
|
||||
uncond_pred_x0 = get_predicted_original_sample(
|
||||
uncond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
noise_scheduler.config.prediction_type,
|
||||
alpha_schedule,
|
||||
sigma_schedule,
|
||||
)
|
||||
uncond_pred_noise = get_predicted_noise(
|
||||
uncond_pred_x0 = predicted_origin(
|
||||
uncond_teacher_output,
|
||||
start_timesteps,
|
||||
noisy_model_input,
|
||||
@@ -1358,16 +1312,12 @@ def main(args):
|
||||
sigma_schedule,
|
||||
)
|
||||
|
||||
# 3. Calculate the CFG estimate of x_0 (pred_x0) and eps_0 (pred_noise)
|
||||
# Note that this uses the LCM paper's CFG formulation rather than the Imagen CFG formulation
|
||||
# 20.4.11. Perform "CFG" to get x_prev estimate (using the LCM paper's CFG formulation)
|
||||
pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
|
||||
pred_noise = cond_pred_noise + w * (cond_pred_noise - uncond_pred_noise)
|
||||
# 4. Run one step of the ODE solver to estimate the next point x_prev on the
|
||||
# augmented PF-ODE trajectory (solving backward in time)
|
||||
# Note that the DDIM step depends on both the predicted x_0 and source noise eps_0.
|
||||
pred_noise = cond_teacher_output + w * (cond_teacher_output - uncond_teacher_output)
|
||||
x_prev = solver.ddim_step(pred_x0, pred_noise, index)
|
||||
|
||||
# 9. Get target LCM prediction on x_prev, w, c, t_n (timesteps)
|
||||
# 20.4.12. Get target LCM prediction on x_prev, w, c, t_n
|
||||
with torch.no_grad():
|
||||
with torch.autocast("cuda", dtype=weight_dtype):
|
||||
target_noise_pred = target_unet(
|
||||
@@ -1377,7 +1327,7 @@ def main(args):
|
||||
encoder_hidden_states=prompt_embeds.float(),
|
||||
added_cond_kwargs=encoded_text,
|
||||
).sample
|
||||
pred_x_0 = get_predicted_original_sample(
|
||||
pred_x_0 = predicted_origin(
|
||||
target_noise_pred,
|
||||
timesteps,
|
||||
x_prev,
|
||||
@@ -1387,7 +1337,7 @@ def main(args):
|
||||
)
|
||||
target = c_skip * x_prev + c_out * pred_x_0
|
||||
|
||||
# 10. Calculate loss
|
||||
# 20.4.13. Calculate loss
|
||||
if args.loss_type == "l2":
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
elif args.loss_type == "huber":
|
||||
@@ -1395,7 +1345,7 @@ def main(args):
|
||||
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
|
||||
)
|
||||
|
||||
# 11. Backpropagate on the online student model (`unet`)
|
||||
# 20.4.14. Backpropagate on the online student model (`unet`)
|
||||
accelerator.backward(loss)
|
||||
if accelerator.sync_gradients:
|
||||
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
|
||||
@@ -1405,7 +1355,7 @@ def main(args):
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
# 12. Make EMA update to target student model parameters (`target_unet`)
|
||||
# 20.4.15. Make EMA update to target student model parameters
|
||||
update_ema(target_unet.parameters(), unet.parameters(), args.ema_decay)
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
@@ -12,9 +12,9 @@ from safetensors.torch import load_file as stl
|
||||
from tqdm import tqdm
|
||||
|
||||
from diffusers import AutoencoderKL, ConsistencyDecoderVAE, DiffusionPipeline, StableDiffusionPipeline, UNet2DModel
|
||||
from diffusers.models.autoencoders.vae import Encoder
|
||||
from diffusers.models.embeddings import TimestepEmbedding
|
||||
from diffusers.models.unet_2d_blocks import ResnetDownsampleBlock2D, ResnetUpsampleBlock2D, UNetMidBlock2D
|
||||
from diffusers.models.vae import Encoder
|
||||
|
||||
|
||||
args = ArgumentParser()
|
||||
|
||||
@@ -18,7 +18,6 @@ from typing import Callable, Dict, List, Optional, Union
|
||||
import safetensors
|
||||
import torch
|
||||
from huggingface_hub import model_info
|
||||
from huggingface_hub.constants import HF_HUB_OFFLINE
|
||||
from huggingface_hub.utils import validate_hf_hub_args
|
||||
from packaging import version
|
||||
from torch import nn
|
||||
@@ -230,9 +229,7 @@ class LoraLoaderMixin:
|
||||
# determine `weight_name`.
|
||||
if weight_name is None:
|
||||
weight_name = cls._best_guess_weight_name(
|
||||
pretrained_model_name_or_path_or_dict,
|
||||
file_extension=".safetensors",
|
||||
local_files_only=local_files_only,
|
||||
pretrained_model_name_or_path_or_dict, file_extension=".safetensors"
|
||||
)
|
||||
model_file = _get_model_file(
|
||||
pretrained_model_name_or_path_or_dict,
|
||||
@@ -258,7 +255,7 @@ class LoraLoaderMixin:
|
||||
if model_file is None:
|
||||
if weight_name is None:
|
||||
weight_name = cls._best_guess_weight_name(
|
||||
pretrained_model_name_or_path_or_dict, file_extension=".bin", local_files_only=local_files_only
|
||||
pretrained_model_name_or_path_or_dict, file_extension=".bin"
|
||||
)
|
||||
model_file = _get_model_file(
|
||||
pretrained_model_name_or_path_or_dict,
|
||||
@@ -297,12 +294,7 @@ class LoraLoaderMixin:
|
||||
return state_dict, network_alphas
|
||||
|
||||
@classmethod
|
||||
def _best_guess_weight_name(
|
||||
cls, pretrained_model_name_or_path_or_dict, file_extension=".safetensors", local_files_only=False
|
||||
):
|
||||
if local_files_only or HF_HUB_OFFLINE:
|
||||
raise ValueError("When using the offline mode, you must specify a `weight_name`.")
|
||||
|
||||
def _best_guess_weight_name(cls, pretrained_model_name_or_path_or_dict, file_extension=".safetensors"):
|
||||
targeted_files = []
|
||||
|
||||
if os.path.isfile(pretrained_model_name_or_path_or_dict):
|
||||
|
||||
@@ -26,11 +26,11 @@ _import_structure = {}
|
||||
|
||||
if is_torch_available():
|
||||
_import_structure["adapter"] = ["MultiAdapter", "T2IAdapter"]
|
||||
_import_structure["autoencoders.autoencoder_asym_kl"] = ["AsymmetricAutoencoderKL"]
|
||||
_import_structure["autoencoders.autoencoder_kl"] = ["AutoencoderKL"]
|
||||
_import_structure["autoencoders.autoencoder_kl_temporal_decoder"] = ["AutoencoderKLTemporalDecoder"]
|
||||
_import_structure["autoencoders.autoencoder_tiny"] = ["AutoencoderTiny"]
|
||||
_import_structure["autoencoders.consistency_decoder_vae"] = ["ConsistencyDecoderVAE"]
|
||||
_import_structure["autoencoder_asym_kl"] = ["AsymmetricAutoencoderKL"]
|
||||
_import_structure["autoencoder_kl"] = ["AutoencoderKL"]
|
||||
_import_structure["autoencoder_kl_temporal_decoder"] = ["AutoencoderKLTemporalDecoder"]
|
||||
_import_structure["autoencoder_tiny"] = ["AutoencoderTiny"]
|
||||
_import_structure["consistency_decoder_vae"] = ["ConsistencyDecoderVAE"]
|
||||
_import_structure["controlnet"] = ["ControlNetModel"]
|
||||
_import_structure["controlnetxs"] = ["ControlNetXSModel"]
|
||||
_import_structure["dual_transformer_2d"] = ["DualTransformer2DModel"]
|
||||
@@ -58,13 +58,11 @@ if is_flax_available():
|
||||
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
if is_torch_available():
|
||||
from .adapter import MultiAdapter, T2IAdapter
|
||||
from .autoencoders import (
|
||||
AsymmetricAutoencoderKL,
|
||||
AutoencoderKL,
|
||||
AutoencoderKLTemporalDecoder,
|
||||
AutoencoderTiny,
|
||||
ConsistencyDecoderVAE,
|
||||
)
|
||||
from .autoencoder_asym_kl import AsymmetricAutoencoderKL
|
||||
from .autoencoder_kl import AutoencoderKL
|
||||
from .autoencoder_kl_temporal_decoder import AutoencoderKLTemporalDecoder
|
||||
from .autoencoder_tiny import AutoencoderTiny
|
||||
from .consistency_decoder_vae import ConsistencyDecoderVAE
|
||||
from .controlnet import ControlNetModel
|
||||
from .controlnetxs import ControlNetXSModel
|
||||
from .dual_transformer_2d import DualTransformer2DModel
|
||||
|
||||
+4
-4
@@ -16,10 +16,10 @@ from typing import Optional, Tuple, Union
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...utils.accelerate_utils import apply_forward_hook
|
||||
from ..modeling_outputs import AutoencoderKLOutput
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from .modeling_outputs import AutoencoderKLOutput
|
||||
from .modeling_utils import ModelMixin
|
||||
from .vae import DecoderOutput, DiagonalGaussianDistribution, Encoder, MaskConditionDecoder
|
||||
|
||||
|
||||
+6
-6
@@ -16,10 +16,10 @@ from typing import Dict, Optional, Tuple, Union
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...loaders import FromOriginalVAEMixin
|
||||
from ...utils.accelerate_utils import apply_forward_hook
|
||||
from ..attention_processor import (
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..loaders import FromOriginalVAEMixin
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from .attention_processor import (
|
||||
ADDED_KV_ATTENTION_PROCESSORS,
|
||||
CROSS_ATTENTION_PROCESSORS,
|
||||
Attention,
|
||||
@@ -27,8 +27,8 @@ from ..attention_processor import (
|
||||
AttnAddedKVProcessor,
|
||||
AttnProcessor,
|
||||
)
|
||||
from ..modeling_outputs import AutoencoderKLOutput
|
||||
from ..modeling_utils import ModelMixin
|
||||
from .modeling_outputs import AutoencoderKLOutput
|
||||
from .modeling_utils import ModelMixin
|
||||
from .vae import Decoder, DecoderOutput, DiagonalGaussianDistribution, Encoder
|
||||
|
||||
|
||||
+8
-8
@@ -16,14 +16,14 @@ from typing import Dict, Optional, Tuple, Union
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...loaders import FromOriginalVAEMixin
|
||||
from ...utils import is_torch_version
|
||||
from ...utils.accelerate_utils import apply_forward_hook
|
||||
from ..attention_processor import CROSS_ATTENTION_PROCESSORS, AttentionProcessor, AttnProcessor
|
||||
from ..modeling_outputs import AutoencoderKLOutput
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..unet_3d_blocks import MidBlockTemporalDecoder, UpBlockTemporalDecoder
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..loaders import FromOriginalVAEMixin
|
||||
from ..utils import is_torch_version
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from .attention_processor import CROSS_ATTENTION_PROCESSORS, AttentionProcessor, AttnProcessor
|
||||
from .modeling_outputs import AutoencoderKLOutput
|
||||
from .modeling_utils import ModelMixin
|
||||
from .unet_3d_blocks import MidBlockTemporalDecoder, UpBlockTemporalDecoder
|
||||
from .vae import DecoderOutput, DiagonalGaussianDistribution, Encoder
|
||||
|
||||
|
||||
+4
-4
@@ -18,10 +18,10 @@ from typing import Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...utils import BaseOutput
|
||||
from ...utils.accelerate_utils import apply_forward_hook
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..utils import BaseOutput
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from .modeling_utils import ModelMixin
|
||||
from .vae import DecoderOutput, DecoderTiny, EncoderTiny
|
||||
|
||||
|
||||
@@ -1,5 +0,0 @@
|
||||
from .autoencoder_asym_kl import AsymmetricAutoencoderKL
|
||||
from .autoencoder_kl import AutoencoderKL
|
||||
from .autoencoder_kl_temporal_decoder import AutoencoderKLTemporalDecoder
|
||||
from .autoencoder_tiny import AutoencoderTiny
|
||||
from .consistency_decoder_vae import ConsistencyDecoderVAE
|
||||
+14
-14
@@ -18,20 +18,20 @@ import torch
|
||||
import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...schedulers import ConsistencyDecoderScheduler
|
||||
from ...utils import BaseOutput
|
||||
from ...utils.accelerate_utils import apply_forward_hook
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..attention_processor import (
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..schedulers import ConsistencyDecoderScheduler
|
||||
from ..utils import BaseOutput
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from ..utils.torch_utils import randn_tensor
|
||||
from .attention_processor import (
|
||||
ADDED_KV_ATTENTION_PROCESSORS,
|
||||
CROSS_ATTENTION_PROCESSORS,
|
||||
AttentionProcessor,
|
||||
AttnAddedKVProcessor,
|
||||
AttnProcessor,
|
||||
)
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..unet_2d import UNet2DModel
|
||||
from .modeling_utils import ModelMixin
|
||||
from .unet_2d import UNet2DModel
|
||||
from .vae import DecoderOutput, DiagonalGaussianDistribution, Encoder
|
||||
|
||||
|
||||
@@ -153,7 +153,7 @@ class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
|
||||
self.use_slicing = False
|
||||
self.use_tiling = False
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.enable_tiling
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.enable_tiling
|
||||
def enable_tiling(self, use_tiling: bool = True):
|
||||
r"""
|
||||
Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
|
||||
@@ -162,7 +162,7 @@ class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
|
||||
"""
|
||||
self.use_tiling = use_tiling
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.disable_tiling
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.disable_tiling
|
||||
def disable_tiling(self):
|
||||
r"""
|
||||
Disable tiled VAE decoding. If `enable_tiling` was previously enabled, this method will go back to computing
|
||||
@@ -170,7 +170,7 @@ class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
|
||||
"""
|
||||
self.enable_tiling(False)
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.enable_slicing
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.enable_slicing
|
||||
def enable_slicing(self):
|
||||
r"""
|
||||
Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
|
||||
@@ -178,7 +178,7 @@ class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
|
||||
"""
|
||||
self.use_slicing = True
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.disable_slicing
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.disable_slicing
|
||||
def disable_slicing(self):
|
||||
r"""
|
||||
Disable sliced VAE decoding. If `enable_slicing` was previously enabled, this method will go back to computing
|
||||
@@ -333,14 +333,14 @@ class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
|
||||
|
||||
return DecoderOutput(sample=x_0)
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.blend_v
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.blend_v
|
||||
def blend_v(self, a: torch.Tensor, b: torch.Tensor, blend_extent: int) -> torch.Tensor:
|
||||
blend_extent = min(a.shape[2], b.shape[2], blend_extent)
|
||||
for y in range(blend_extent):
|
||||
b[:, :, y, :] = a[:, :, -blend_extent + y, :] * (1 - y / blend_extent) + b[:, :, y, :] * (y / blend_extent)
|
||||
return b
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.blend_h
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.blend_h
|
||||
def blend_h(self, a: torch.Tensor, b: torch.Tensor, blend_extent: int) -> torch.Tensor:
|
||||
blend_extent = min(a.shape[3], b.shape[3], blend_extent)
|
||||
for x in range(blend_extent):
|
||||
@@ -26,7 +26,7 @@ from ..utils import BaseOutput, logging
|
||||
from .attention_processor import (
|
||||
AttentionProcessor,
|
||||
)
|
||||
from .autoencoders import AutoencoderKL
|
||||
from .autoencoder_kl import AutoencoderKL
|
||||
from .lora import LoRACompatibleConv
|
||||
from .modeling_utils import ModelMixin
|
||||
from .unet_2d_blocks import (
|
||||
|
||||
@@ -18,11 +18,11 @@ import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ...utils import BaseOutput, is_torch_version
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..activations import get_activation
|
||||
from ..attention_processor import SpatialNorm
|
||||
from ..unet_2d_blocks import (
|
||||
from ..utils import BaseOutput, is_torch_version
|
||||
from ..utils.torch_utils import randn_tensor
|
||||
from .activations import get_activation
|
||||
from .attention_processor import SpatialNorm
|
||||
from .unet_2d_blocks import (
|
||||
AutoencoderTinyBlock,
|
||||
UNetMidBlock2D,
|
||||
get_down_block,
|
||||
@@ -20,8 +20,8 @@ import torch.nn as nn
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..utils import BaseOutput
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from .autoencoders.vae import Decoder, DecoderOutput, Encoder, VectorQuantizer
|
||||
from .modeling_utils import ModelMixin
|
||||
from .vae import Decoder, DecoderOutput, Encoder, VectorQuantizer
|
||||
|
||||
|
||||
@dataclass
|
||||
|
||||
@@ -20,7 +20,6 @@ _dummy_objects = {}
|
||||
_import_structure = {
|
||||
"controlnet": [],
|
||||
"controlnet_xs": [],
|
||||
"deprecated": [],
|
||||
"latent_diffusion": [],
|
||||
"stable_diffusion": [],
|
||||
"stable_diffusion_xl": [],
|
||||
@@ -45,20 +44,16 @@ else:
|
||||
_import_structure["ddpm"] = ["DDPMPipeline"]
|
||||
_import_structure["dit"] = ["DiTPipeline"]
|
||||
_import_structure["latent_diffusion"].extend(["LDMSuperResolutionPipeline"])
|
||||
_import_structure["latent_diffusion_uncond"] = ["LDMPipeline"]
|
||||
_import_structure["pipeline_utils"] = [
|
||||
"AudioPipelineOutput",
|
||||
"DiffusionPipeline",
|
||||
"ImagePipelineOutput",
|
||||
]
|
||||
_import_structure["deprecated"].extend(
|
||||
[
|
||||
"PNDMPipeline",
|
||||
"LDMPipeline",
|
||||
"RePaintPipeline",
|
||||
"ScoreSdeVePipeline",
|
||||
"KarrasVePipeline",
|
||||
]
|
||||
)
|
||||
_import_structure["pndm"] = ["PNDMPipeline"]
|
||||
_import_structure["repaint"] = ["RePaintPipeline"]
|
||||
_import_structure["score_sde_ve"] = ["ScoreSdeVePipeline"]
|
||||
_import_structure["stochastic_karras_ve"] = ["KarrasVePipeline"]
|
||||
try:
|
||||
if not (is_torch_available() and is_librosa_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
@@ -67,23 +62,7 @@ except OptionalDependencyNotAvailable:
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_librosa_objects))
|
||||
else:
|
||||
_import_structure["deprecated"].extend(["AudioDiffusionPipeline", "Mel"])
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils import dummy_transformers_and_torch_and_note_seq_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_transformers_and_torch_and_note_seq_objects))
|
||||
else:
|
||||
_import_structure["deprecated"].extend(
|
||||
[
|
||||
"MidiProcessor",
|
||||
"SpectrogramDiffusionPipeline",
|
||||
]
|
||||
)
|
||||
|
||||
_import_structure["audio_diffusion"] = ["AudioDiffusionPipeline", "Mel"]
|
||||
try:
|
||||
if not (is_torch_available() and is_transformers_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
@@ -92,22 +71,10 @@ except OptionalDependencyNotAvailable:
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
_import_structure["deprecated"].extend(
|
||||
[
|
||||
"VQDiffusionPipeline",
|
||||
"AltDiffusionPipeline",
|
||||
"AltDiffusionImg2ImgPipeline",
|
||||
"CycleDiffusionPipeline",
|
||||
"StableDiffusionInpaintPipelineLegacy",
|
||||
"StableDiffusionPix2PixZeroPipeline",
|
||||
"StableDiffusionParadigmsPipeline",
|
||||
"StableDiffusionModelEditingPipeline",
|
||||
"VersatileDiffusionDualGuidedPipeline",
|
||||
"VersatileDiffusionImageVariationPipeline",
|
||||
"VersatileDiffusionPipeline",
|
||||
"VersatileDiffusionTextToImagePipeline",
|
||||
]
|
||||
)
|
||||
_import_structure["alt_diffusion"] = [
|
||||
"AltDiffusionImg2ImgPipeline",
|
||||
"AltDiffusionPipeline",
|
||||
]
|
||||
_import_structure["animatediff"] = ["AnimateDiffPipeline"]
|
||||
_import_structure["audioldm"] = ["AudioLDMPipeline"]
|
||||
_import_structure["audioldm2"] = [
|
||||
@@ -179,6 +146,7 @@ else:
|
||||
_import_structure["stable_diffusion"].extend(
|
||||
[
|
||||
"CLIPImageProjection",
|
||||
"CycleDiffusionPipeline",
|
||||
"StableDiffusionAttendAndExcitePipeline",
|
||||
"StableDiffusionDepth2ImgPipeline",
|
||||
"StableDiffusionDiffEditPipeline",
|
||||
@@ -188,11 +156,15 @@ else:
|
||||
"StableDiffusionImageVariationPipeline",
|
||||
"StableDiffusionImg2ImgPipeline",
|
||||
"StableDiffusionInpaintPipeline",
|
||||
"StableDiffusionInpaintPipelineLegacy",
|
||||
"StableDiffusionInstructPix2PixPipeline",
|
||||
"StableDiffusionLatentUpscalePipeline",
|
||||
"StableDiffusionLDM3DPipeline",
|
||||
"StableDiffusionModelEditingPipeline",
|
||||
"StableDiffusionPanoramaPipeline",
|
||||
"StableDiffusionParadigmsPipeline",
|
||||
"StableDiffusionPipeline",
|
||||
"StableDiffusionPix2PixZeroPipeline",
|
||||
"StableDiffusionSAGPipeline",
|
||||
"StableDiffusionUpscalePipeline",
|
||||
"StableUnCLIPImg2ImgPipeline",
|
||||
@@ -226,6 +198,13 @@ else:
|
||||
"UniDiffuserPipeline",
|
||||
"UniDiffuserTextDecoder",
|
||||
]
|
||||
_import_structure["versatile_diffusion"] = [
|
||||
"VersatileDiffusionDualGuidedPipeline",
|
||||
"VersatileDiffusionImageVariationPipeline",
|
||||
"VersatileDiffusionPipeline",
|
||||
"VersatileDiffusionTextToImagePipeline",
|
||||
]
|
||||
_import_structure["vq_diffusion"] = ["VQDiffusionPipeline"]
|
||||
_import_structure["wuerstchen"] = [
|
||||
"WuerstchenCombinedPipeline",
|
||||
"WuerstchenDecoderPipeline",
|
||||
@@ -252,6 +231,7 @@ else:
|
||||
[
|
||||
"OnnxStableDiffusionImg2ImgPipeline",
|
||||
"OnnxStableDiffusionInpaintPipeline",
|
||||
"OnnxStableDiffusionInpaintPipelineLegacy",
|
||||
"OnnxStableDiffusionPipeline",
|
||||
"OnnxStableDiffusionUpscalePipeline",
|
||||
"StableDiffusionOnnxPipeline",
|
||||
@@ -299,6 +279,18 @@ else:
|
||||
"FlaxStableDiffusionXLPipeline",
|
||||
]
|
||||
)
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils import dummy_transformers_and_torch_and_note_seq_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_transformers_and_torch_and_note_seq_objects))
|
||||
else:
|
||||
_import_structure["spectrogram_diffusion"] = [
|
||||
"MidiProcessor",
|
||||
"SpectrogramDiffusionPipeline",
|
||||
]
|
||||
|
||||
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
try:
|
||||
@@ -317,14 +309,18 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from .dance_diffusion import DanceDiffusionPipeline
|
||||
from .ddim import DDIMPipeline
|
||||
from .ddpm import DDPMPipeline
|
||||
from .deprecated import KarrasVePipeline, LDMPipeline, PNDMPipeline, RePaintPipeline, ScoreSdeVePipeline
|
||||
from .dit import DiTPipeline
|
||||
from .latent_diffusion import LDMSuperResolutionPipeline
|
||||
from .latent_diffusion_uncond import LDMPipeline
|
||||
from .pipeline_utils import (
|
||||
AudioPipelineOutput,
|
||||
DiffusionPipeline,
|
||||
ImagePipelineOutput,
|
||||
)
|
||||
from .pndm import PNDMPipeline
|
||||
from .repaint import RePaintPipeline
|
||||
from .score_sde_ve import ScoreSdeVePipeline
|
||||
from .stochastic_karras_ve import KarrasVePipeline
|
||||
|
||||
try:
|
||||
if not (is_torch_available() and is_librosa_available()):
|
||||
@@ -332,7 +328,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils.dummy_torch_and_librosa_objects import *
|
||||
else:
|
||||
from .deprecated import AudioDiffusionPipeline, Mel
|
||||
from .audio_diffusion import AudioDiffusionPipeline, Mel
|
||||
|
||||
try:
|
||||
if not (is_torch_available() and is_transformers_available()):
|
||||
@@ -340,6 +336,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils.dummy_torch_and_transformers_objects import *
|
||||
else:
|
||||
from .alt_diffusion import AltDiffusionImg2ImgPipeline, AltDiffusionPipeline
|
||||
from .animatediff import AnimateDiffPipeline
|
||||
from .audioldm import AudioLDMPipeline
|
||||
from .audioldm2 import (
|
||||
@@ -369,20 +366,6 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
IFPipeline,
|
||||
IFSuperResolutionPipeline,
|
||||
)
|
||||
from .deprecated import (
|
||||
AltDiffusionImg2ImgPipeline,
|
||||
AltDiffusionPipeline,
|
||||
CycleDiffusionPipeline,
|
||||
StableDiffusionInpaintPipelineLegacy,
|
||||
StableDiffusionModelEditingPipeline,
|
||||
StableDiffusionParadigmsPipeline,
|
||||
StableDiffusionPix2PixZeroPipeline,
|
||||
VersatileDiffusionDualGuidedPipeline,
|
||||
VersatileDiffusionImageVariationPipeline,
|
||||
VersatileDiffusionPipeline,
|
||||
VersatileDiffusionTextToImagePipeline,
|
||||
VQDiffusionPipeline,
|
||||
)
|
||||
from .kandinsky import (
|
||||
KandinskyCombinedPipeline,
|
||||
KandinskyImg2ImgCombinedPipeline,
|
||||
@@ -420,6 +403,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from .shap_e import ShapEImg2ImgPipeline, ShapEPipeline
|
||||
from .stable_diffusion import (
|
||||
CLIPImageProjection,
|
||||
CycleDiffusionPipeline,
|
||||
StableDiffusionAttendAndExcitePipeline,
|
||||
StableDiffusionDepth2ImgPipeline,
|
||||
StableDiffusionDiffEditPipeline,
|
||||
@@ -428,11 +412,15 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
StableDiffusionImageVariationPipeline,
|
||||
StableDiffusionImg2ImgPipeline,
|
||||
StableDiffusionInpaintPipeline,
|
||||
StableDiffusionInpaintPipelineLegacy,
|
||||
StableDiffusionInstructPix2PixPipeline,
|
||||
StableDiffusionLatentUpscalePipeline,
|
||||
StableDiffusionLDM3DPipeline,
|
||||
StableDiffusionModelEditingPipeline,
|
||||
StableDiffusionPanoramaPipeline,
|
||||
StableDiffusionParadigmsPipeline,
|
||||
StableDiffusionPipeline,
|
||||
StableDiffusionPix2PixZeroPipeline,
|
||||
StableDiffusionSAGPipeline,
|
||||
StableDiffusionUpscalePipeline,
|
||||
StableUnCLIPImg2ImgPipeline,
|
||||
@@ -463,6 +451,13 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
UniDiffuserPipeline,
|
||||
UniDiffuserTextDecoder,
|
||||
)
|
||||
from .versatile_diffusion import (
|
||||
VersatileDiffusionDualGuidedPipeline,
|
||||
VersatileDiffusionImageVariationPipeline,
|
||||
VersatileDiffusionPipeline,
|
||||
VersatileDiffusionTextToImagePipeline,
|
||||
)
|
||||
from .vq_diffusion import VQDiffusionPipeline
|
||||
from .wuerstchen import (
|
||||
WuerstchenCombinedPipeline,
|
||||
WuerstchenDecoderPipeline,
|
||||
@@ -487,6 +482,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from .stable_diffusion import (
|
||||
OnnxStableDiffusionImg2ImgPipeline,
|
||||
OnnxStableDiffusionInpaintPipeline,
|
||||
OnnxStableDiffusionInpaintPipelineLegacy,
|
||||
OnnxStableDiffusionPipeline,
|
||||
OnnxStableDiffusionUpscalePipeline,
|
||||
StableDiffusionOnnxPipeline,
|
||||
@@ -531,7 +527,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from ..utils.dummy_transformers_and_torch_and_note_seq_objects import * # noqa F403
|
||||
|
||||
else:
|
||||
from .deprecated import (
|
||||
from .spectrogram_diffusion import (
|
||||
MidiProcessor,
|
||||
SpectrogramDiffusionPipeline,
|
||||
)
|
||||
|
||||
+3
-3
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import (
|
||||
from ...utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
OptionalDependencyNotAvailable,
|
||||
_LazyModule,
|
||||
@@ -17,7 +17,7 @@ try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils import dummy_torch_and_transformers_objects
|
||||
from ...utils import dummy_torch_and_transformers_objects
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
@@ -32,7 +32,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils.dummy_torch_and_transformers_objects import *
|
||||
from ...utils.dummy_torch_and_transformers_objects import *
|
||||
|
||||
else:
|
||||
from .modeling_roberta_series import RobertaSeriesModelWithTransformation
|
||||
+11
-70
@@ -19,14 +19,13 @@ import torch
|
||||
from packaging import version
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection, XLMRobertaTokenizer
|
||||
|
||||
from ....configuration_utils import FrozenDict
|
||||
from ....image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ....loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ....models.attention_processor import FusedAttnProcessor2_0
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import KarrasDiffusionSchedulers
|
||||
from ....utils import (
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
USE_PEFT_BACKEND,
|
||||
deprecate,
|
||||
logging,
|
||||
@@ -34,9 +33,9 @@ from ....utils import (
|
||||
scale_lora_layers,
|
||||
unscale_lora_layers,
|
||||
)
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from .modeling_roberta_series import RobertaSeriesModelWithTransformation
|
||||
from .pipeline_output import AltDiffusionPipelineOutput
|
||||
|
||||
@@ -119,6 +118,7 @@ def retrieve_timesteps(
|
||||
return timesteps, num_inference_steps
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline with Stable->Alt, CLIPTextModel->RobertaSeriesModelWithTransformation, CLIPTokenizer->XLMRobertaTokenizer, AltDiffusionSafetyChecker->StableDiffusionSafetyChecker
|
||||
class AltDiffusionPipeline(
|
||||
DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, IPAdapterMixin, FromSingleFileMixin
|
||||
):
|
||||
@@ -655,65 +655,6 @@ class AltDiffusionPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
|
||||
+11
-70
@@ -21,14 +21,13 @@ import torch
|
||||
from packaging import version
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection, XLMRobertaTokenizer
|
||||
|
||||
from ....configuration_utils import FrozenDict
|
||||
from ....image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ....loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ....models.attention_processor import FusedAttnProcessor2_0
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import KarrasDiffusionSchedulers
|
||||
from ....utils import (
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
PIL_INTERPOLATION,
|
||||
USE_PEFT_BACKEND,
|
||||
deprecate,
|
||||
@@ -37,9 +36,9 @@ from ....utils import (
|
||||
scale_lora_layers,
|
||||
unscale_lora_layers,
|
||||
)
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from .modeling_roberta_series import RobertaSeriesModelWithTransformation
|
||||
from .pipeline_output import AltDiffusionPipelineOutput
|
||||
|
||||
@@ -159,6 +158,7 @@ def retrieve_timesteps(
|
||||
return timesteps, num_inference_steps
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline with Stable->Alt, CLIPTextModel->RobertaSeriesModelWithTransformation, CLIPTokenizer->XLMRobertaTokenizer, AltDiffusionSafetyChecker->StableDiffusionSafetyChecker
|
||||
class AltDiffusionImg2ImgPipeline(
|
||||
DiffusionPipeline, TextualInversionLoaderMixin, IPAdapterMixin, LoraLoaderMixin, FromSingleFileMixin
|
||||
):
|
||||
@@ -715,65 +715,6 @@ class AltDiffusionImg2ImgPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
|
||||
+1
-1
@@ -4,7 +4,7 @@ from typing import List, Optional, Union
|
||||
import numpy as np
|
||||
import PIL.Image
|
||||
|
||||
from ....utils import (
|
||||
from ...utils import (
|
||||
BaseOutput,
|
||||
)
|
||||
|
||||
@@ -84,12 +84,6 @@ class AnimateDiffPipeline(DiffusionPipeline, TextualInversionLoaderMixin, IPAdap
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
||||
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
|
||||
|
||||
+1
-1
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {
|
||||
+2
-2
@@ -15,8 +15,8 @@
|
||||
|
||||
import numpy as np # noqa: E402
|
||||
|
||||
from ....configuration_utils import ConfigMixin, register_to_config
|
||||
from ....schedulers.scheduling_utils import SchedulerMixin
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...schedulers.scheduling_utils import SchedulerMixin
|
||||
|
||||
|
||||
try:
|
||||
+4
-4
@@ -20,10 +20,10 @@ import numpy as np
|
||||
import torch
|
||||
from PIL import Image
|
||||
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....schedulers import DDIMScheduler, DDPMScheduler
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import AudioPipelineOutput, BaseOutput, DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...schedulers import DDIMScheduler, DDPMScheduler
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import AudioPipelineOutput, BaseOutput, DiffusionPipeline, ImagePipelineOutput
|
||||
from .mel import Mel
|
||||
|
||||
|
||||
@@ -147,9 +147,6 @@ class StableDiffusionControlNetPipeline(
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
|
||||
|
||||
Args:
|
||||
|
||||
@@ -140,11 +140,7 @@ class StableDiffusionControlNetImg2ImgPipeline(
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
|
||||
|
||||
@@ -251,9 +251,6 @@ class StableDiffusionControlNetInpaintPipeline(
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
|
||||
|
||||
<Tip>
|
||||
|
||||
@@ -148,10 +148,12 @@ class StableDiffusionXLControlNetInpaintPipeline(
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
In addition the pipeline inherits the following loading methods:
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`]
|
||||
- *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
|
||||
|
||||
as well as the following saving methods:
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`]
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
|
||||
@@ -129,10 +129,8 @@ class StableDiffusionXLControlNetPipeline(
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
|
||||
- [`loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
|
||||
@@ -155,10 +155,9 @@ class StableDiffusionXLControlNetImg2ImgPipeline(
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
In addition the pipeline inherits the following loading methods:
|
||||
- *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`]
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
|
||||
@@ -98,9 +98,7 @@ class StableDiffusionControlNetXSPipeline(
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
|
||||
@@ -102,9 +102,8 @@ class StableDiffusionXLControlNetXSPipeline(
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
|
||||
@@ -1,3 +0,0 @@
|
||||
# Deprecated Pipelines
|
||||
|
||||
This folder contains pipelines that have very low usage as measured by model downloads, issues and PRs. While you can still use the pipelines just as before, we will stop testing the pipelines and will not accept any changes to existing files.
|
||||
@@ -1,153 +0,0 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ...utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
OptionalDependencyNotAvailable,
|
||||
_LazyModule,
|
||||
get_objects_from_module,
|
||||
is_librosa_available,
|
||||
is_note_seq_available,
|
||||
is_torch_available,
|
||||
is_transformers_available,
|
||||
)
|
||||
|
||||
|
||||
_dummy_objects = {}
|
||||
_import_structure = {}
|
||||
|
||||
try:
|
||||
if not is_torch_available():
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils import dummy_pt_objects
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_pt_objects))
|
||||
else:
|
||||
_import_structure["latent_diffusion_uncond"] = ["LDMPipeline"]
|
||||
_import_structure["pndm"] = ["PNDMPipeline"]
|
||||
_import_structure["repaint"] = ["RePaintPipeline"]
|
||||
_import_structure["score_sde_ve"] = ["ScoreSdeVePipeline"]
|
||||
_import_structure["stochastic_karras_ve"] = ["KarrasVePipeline"]
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils import dummy_torch_and_transformers_objects
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
_import_structure["alt_diffusion"] = [
|
||||
"AltDiffusionImg2ImgPipeline",
|
||||
"AltDiffusionPipeline",
|
||||
"AltDiffusionPipelineOutput",
|
||||
]
|
||||
_import_structure["versatile_diffusion"] = [
|
||||
"VersatileDiffusionDualGuidedPipeline",
|
||||
"VersatileDiffusionImageVariationPipeline",
|
||||
"VersatileDiffusionPipeline",
|
||||
"VersatileDiffusionTextToImagePipeline",
|
||||
]
|
||||
_import_structure["vq_diffusion"] = ["VQDiffusionPipeline"]
|
||||
_import_structure["stable_diffusion_variants"] = [
|
||||
"CycleDiffusionPipeline",
|
||||
"StableDiffusionInpaintPipelineLegacy",
|
||||
"StableDiffusionPix2PixZeroPipeline",
|
||||
"StableDiffusionParadigmsPipeline",
|
||||
"StableDiffusionModelEditingPipeline",
|
||||
]
|
||||
|
||||
try:
|
||||
if not (is_torch_available() and is_librosa_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils import dummy_torch_and_librosa_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_librosa_objects))
|
||||
|
||||
else:
|
||||
_import_structure["audio_diffusion"] = ["AudioDiffusionPipeline", "Mel"]
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils import dummy_transformers_and_torch_and_note_seq_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_transformers_and_torch_and_note_seq_objects))
|
||||
|
||||
else:
|
||||
_import_structure["spectrogram_diffusion"] = ["MidiProcessor", "SpectrogramDiffusionPipeline"]
|
||||
|
||||
|
||||
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
try:
|
||||
if not is_torch_available():
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_pt_objects import *
|
||||
|
||||
else:
|
||||
from .latent_diffusion_uncond import LDMPipeline
|
||||
from .pndm import PNDMPipeline
|
||||
from .repaint import RePaintPipeline
|
||||
from .score_sde_ve import ScoreSdeVePipeline
|
||||
from .stochastic_karras_ve import KarrasVePipeline
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_torch_and_transformers_objects import *
|
||||
|
||||
else:
|
||||
from .alt_diffusion import AltDiffusionImg2ImgPipeline, AltDiffusionPipeline, AltDiffusionPipelineOutput
|
||||
from .audio_diffusion import AudioDiffusionPipeline, Mel
|
||||
from .spectrogram_diffusion import SpectrogramDiffusionPipeline
|
||||
from .stable_diffusion_variants import (
|
||||
CycleDiffusionPipeline,
|
||||
StableDiffusionInpaintPipelineLegacy,
|
||||
StableDiffusionModelEditingPipeline,
|
||||
StableDiffusionParadigmsPipeline,
|
||||
StableDiffusionPix2PixZeroPipeline,
|
||||
)
|
||||
from .stochastic_karras_ve import KarrasVePipeline
|
||||
from .versatile_diffusion import (
|
||||
VersatileDiffusionDualGuidedPipeline,
|
||||
VersatileDiffusionImageVariationPipeline,
|
||||
VersatileDiffusionPipeline,
|
||||
VersatileDiffusionTextToImagePipeline,
|
||||
)
|
||||
from .vq_diffusion import VQDiffusionPipeline
|
||||
|
||||
try:
|
||||
if not (is_torch_available() and is_librosa_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_torch_and_librosa_objects import *
|
||||
else:
|
||||
from .audio_diffusion import AudioDiffusionPipeline, Mel
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_transformers_and_torch_and_note_seq_objects import * # noqa F403
|
||||
else:
|
||||
from .spectrogram_diffusion import (
|
||||
MidiProcessor,
|
||||
SpectrogramDiffusionPipeline,
|
||||
)
|
||||
|
||||
|
||||
else:
|
||||
import sys
|
||||
|
||||
sys.modules[__name__] = _LazyModule(
|
||||
__name__,
|
||||
globals()["__file__"],
|
||||
_import_structure,
|
||||
module_spec=__spec__,
|
||||
)
|
||||
for name, value in _dummy_objects.items():
|
||||
setattr(sys.modules[__name__], name, value)
|
||||
@@ -1,55 +0,0 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
OptionalDependencyNotAvailable,
|
||||
_LazyModule,
|
||||
get_objects_from_module,
|
||||
is_torch_available,
|
||||
is_transformers_available,
|
||||
)
|
||||
|
||||
|
||||
_dummy_objects = {}
|
||||
_import_structure = {}
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils import dummy_torch_and_transformers_objects
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
_import_structure["pipeline_cycle_diffusion"] = ["CycleDiffusionPipeline"]
|
||||
_import_structure["pipeline_stable_diffusion_inpaint_legacy"] = ["StableDiffusionInpaintPipelineLegacy"]
|
||||
_import_structure["pipeline_stable_diffusion_model_editing"] = ["StableDiffusionModelEditingPipeline"]
|
||||
|
||||
_import_structure["pipeline_stable_diffusion_paradigms"] = ["StableDiffusionParadigmsPipeline"]
|
||||
_import_structure["pipeline_stable_diffusion_pix2pix_zero"] = ["StableDiffusionPix2PixZeroPipeline"]
|
||||
|
||||
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils.dummy_torch_and_transformers_objects import *
|
||||
|
||||
else:
|
||||
from .pipeline_cycle_diffusion import CycleDiffusionPipeline
|
||||
from .pipeline_stable_diffusion_inpaint_legacy import StableDiffusionInpaintPipelineLegacy
|
||||
from .pipeline_stable_diffusion_model_editing import StableDiffusionModelEditingPipeline
|
||||
from .pipeline_stable_diffusion_paradigms import StableDiffusionParadigmsPipeline
|
||||
from .pipeline_stable_diffusion_pix2pix_zero import StableDiffusionPix2PixZeroPipeline
|
||||
|
||||
else:
|
||||
import sys
|
||||
|
||||
sys.modules[__name__] = _LazyModule(
|
||||
__name__,
|
||||
globals()["__file__"],
|
||||
_import_structure,
|
||||
module_spec=__spec__,
|
||||
)
|
||||
for name, value in _dummy_objects.items():
|
||||
setattr(sys.modules[__name__], name, value)
|
||||
+1
-1
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {"pipeline_latent_diffusion_uncond": ["LDMPipeline"]}
|
||||
+4
-4
@@ -17,10 +17,10 @@ from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ....models import UNet2DModel, VQModel
|
||||
from ....schedulers import DDIMScheduler
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import UNet2DModel, VQModel
|
||||
from ...schedulers import DDIMScheduler
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
|
||||
|
||||
class LDMPipeline(DiffusionPipeline):
|
||||
+1
-1
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {"pipeline_pndm": ["PNDMPipeline"]}
|
||||
+4
-4
@@ -17,10 +17,10 @@ from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ....models import UNet2DModel
|
||||
from ....schedulers import PNDMScheduler
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import UNet2DModel
|
||||
from ...schedulers import PNDMScheduler
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
|
||||
|
||||
class PNDMPipeline(DiffusionPipeline):
|
||||
+1
-1
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {"pipeline_repaint": ["RePaintPipeline"]}
|
||||
+5
-5
@@ -19,11 +19,11 @@ import numpy as np
|
||||
import PIL.Image
|
||||
import torch
|
||||
|
||||
from ....models import UNet2DModel
|
||||
from ....schedulers import RePaintScheduler
|
||||
from ....utils import PIL_INTERPOLATION, deprecate, logging
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import UNet2DModel
|
||||
from ...schedulers import RePaintScheduler
|
||||
from ...utils import PIL_INTERPOLATION, deprecate, logging
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
+1
-1
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {"pipeline_score_sde_ve": ["ScoreSdeVePipeline"]}
|
||||
+4
-4
@@ -16,10 +16,10 @@ from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ....models import UNet2DModel
|
||||
from ....schedulers import ScoreSdeVeScheduler
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import UNet2DModel
|
||||
from ...schedulers import ScoreSdeVeScheduler
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
|
||||
|
||||
class ScoreSdeVePipeline(DiffusionPipeline):
|
||||
+6
-6
@@ -1,7 +1,7 @@
|
||||
# flake8: noqa
|
||||
from typing import TYPE_CHECKING
|
||||
from ....utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT
|
||||
from ...utils import (
|
||||
_LazyModule,
|
||||
is_note_seq_available,
|
||||
OptionalDependencyNotAvailable,
|
||||
@@ -17,7 +17,7 @@ try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils import dummy_torch_and_transformers_objects # noqa F403
|
||||
from ...utils import dummy_torch_and_transformers_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
@@ -32,7 +32,7 @@ try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils import dummy_transformers_and_torch_and_note_seq_objects
|
||||
from ...utils import dummy_transformers_and_torch_and_note_seq_objects
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_transformers_and_torch_and_note_seq_objects))
|
||||
else:
|
||||
@@ -45,7 +45,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
raise OptionalDependencyNotAvailable()
|
||||
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils.dummy_torch_and_transformers_objects import *
|
||||
from ...utils.dummy_torch_and_transformers_objects import *
|
||||
else:
|
||||
from .pipeline_spectrogram_diffusion import SpectrogramDiffusionPipeline
|
||||
from .pipeline_spectrogram_diffusion import SpectrogramContEncoder
|
||||
@@ -56,7 +56,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils.dummy_transformers_and_torch_and_note_seq_objects import *
|
||||
from ...utils.dummy_transformers_and_torch_and_note_seq_objects import *
|
||||
|
||||
else:
|
||||
from .midi_utils import MidiProcessor
|
||||
+2
-2
@@ -22,8 +22,8 @@ from transformers.models.t5.modeling_t5 import (
|
||||
T5LayerNorm,
|
||||
)
|
||||
|
||||
from ....configuration_utils import ConfigMixin, register_to_config
|
||||
from ....models import ModelMixin
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...models import ModelMixin
|
||||
|
||||
|
||||
class SpectrogramContEncoder(ModelMixin, ConfigMixin, ModuleUtilsMixin):
|
||||
+1
-1
@@ -22,7 +22,7 @@ import numpy as np
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
from ....utils import is_note_seq_available
|
||||
from ...utils import is_note_seq_available
|
||||
from .pipeline_spectrogram_diffusion import TARGET_FEATURE_LENGTH
|
||||
|
||||
|
||||
+2
-2
@@ -18,8 +18,8 @@ import torch.nn as nn
|
||||
from transformers.modeling_utils import ModuleUtilsMixin
|
||||
from transformers.models.t5.modeling_t5 import T5Block, T5Config, T5LayerNorm
|
||||
|
||||
from ....configuration_utils import ConfigMixin, register_to_config
|
||||
from ....models import ModelMixin
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...models import ModelMixin
|
||||
|
||||
|
||||
class SpectrogramNotesEncoder(ModelMixin, ConfigMixin, ModuleUtilsMixin):
|
||||
+6
-6
@@ -19,16 +19,16 @@ from typing import Any, Callable, List, Optional, Tuple, Union
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from ....models import T5FilmDecoder
|
||||
from ....schedulers import DDPMScheduler
|
||||
from ....utils import is_onnx_available, logging
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...models import T5FilmDecoder
|
||||
from ...schedulers import DDPMScheduler
|
||||
from ...utils import is_onnx_available, logging
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
|
||||
|
||||
if is_onnx_available():
|
||||
from ...onnx_utils import OnnxRuntimeModel
|
||||
from ..onnx_utils import OnnxRuntimeModel
|
||||
|
||||
from ...pipeline_utils import AudioPipelineOutput, DiffusionPipeline
|
||||
from ..pipeline_utils import AudioPipelineOutput, DiffusionPipeline
|
||||
from .continuous_encoder import SpectrogramContEncoder
|
||||
from .notes_encoder import SpectrogramNotesEncoder
|
||||
|
||||
@@ -134,6 +134,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
|
||||
else:
|
||||
from .clip_image_project_model import CLIPImageProjection
|
||||
from .pipeline_cycle_diffusion import CycleDiffusionPipeline
|
||||
from .pipeline_stable_diffusion import (
|
||||
StableDiffusionPipeline,
|
||||
StableDiffusionPipelineOutput,
|
||||
@@ -148,6 +149,9 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
)
|
||||
from .pipeline_stable_diffusion_img2img import StableDiffusionImg2ImgPipeline
|
||||
from .pipeline_stable_diffusion_inpaint import StableDiffusionInpaintPipeline
|
||||
from .pipeline_stable_diffusion_inpaint_legacy import (
|
||||
StableDiffusionInpaintPipelineLegacy,
|
||||
)
|
||||
from .pipeline_stable_diffusion_instruct_pix2pix import (
|
||||
StableDiffusionInstructPix2PixPipeline,
|
||||
)
|
||||
@@ -155,7 +159,13 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
StableDiffusionLatentUpscalePipeline,
|
||||
)
|
||||
from .pipeline_stable_diffusion_ldm3d import StableDiffusionLDM3DPipeline
|
||||
from .pipeline_stable_diffusion_model_editing import (
|
||||
StableDiffusionModelEditingPipeline,
|
||||
)
|
||||
from .pipeline_stable_diffusion_panorama import StableDiffusionPanoramaPipeline
|
||||
from .pipeline_stable_diffusion_paradigms import (
|
||||
StableDiffusionParadigmsPipeline,
|
||||
)
|
||||
from .pipeline_stable_diffusion_sag import StableDiffusionSAGPipeline
|
||||
from .pipeline_stable_diffusion_upscale import StableDiffusionUpscalePipeline
|
||||
from .pipeline_stable_unclip import StableUnCLIPPipeline
|
||||
@@ -189,6 +199,9 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
StableDiffusionDepth2ImgPipeline,
|
||||
)
|
||||
from .pipeline_stable_diffusion_diffedit import StableDiffusionDiffEditPipeline
|
||||
from .pipeline_stable_diffusion_pix2pix_zero import (
|
||||
StableDiffusionPix2PixZeroPipeline,
|
||||
)
|
||||
|
||||
try:
|
||||
if not (
|
||||
@@ -221,6 +234,9 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from .pipeline_onnx_stable_diffusion_inpaint import (
|
||||
OnnxStableDiffusionInpaintPipeline,
|
||||
)
|
||||
from .pipeline_onnx_stable_diffusion_inpaint_legacy import (
|
||||
OnnxStableDiffusionInpaintPipelineLegacy,
|
||||
)
|
||||
from .pipeline_onnx_stable_diffusion_upscale import (
|
||||
OnnxStableDiffusionUpscalePipeline,
|
||||
)
|
||||
|
||||
+11
-16
@@ -21,17 +21,17 @@ import torch
|
||||
from packaging import version
|
||||
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ....configuration_utils import FrozenDict
|
||||
from ....image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ....loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import DDIMScheduler
|
||||
from ....utils import PIL_INTERPOLATION, USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import DDIMScheduler
|
||||
from ...utils import PIL_INTERPOLATION, USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from .pipeline_output import StableDiffusionPipelineOutput
|
||||
from .safety_checker import StableDiffusionSafetyChecker
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -143,11 +143,6 @@ class CycleDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin, Lor
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
||||
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
|
||||
+6
-6
@@ -6,12 +6,12 @@ import PIL.Image
|
||||
import torch
|
||||
from transformers import CLIPImageProcessor, CLIPTokenizer
|
||||
|
||||
from ....configuration_utils import FrozenDict
|
||||
from ....schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
|
||||
from ....utils import deprecate, logging
|
||||
from ...onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
|
||||
from ...utils import deprecate, logging
|
||||
from ..onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from . import StableDiffusionPipelineOutput
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -23,7 +23,6 @@ from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.attention_processor import FusedAttnProcessor2_0
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
@@ -651,67 +650,6 @@ class StableDiffusionPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.fuse_qkv_projections
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.unfuse_qkv_projections
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
|
||||
-3
@@ -177,9 +177,6 @@ class StableDiffusionAttendAndExcitePipeline(DiffusionPipeline, TextualInversion
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
||||
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
|
||||
|
||||
@@ -788,6 +788,7 @@ class StableDiffusionDiffEditPipeline(DiffusionPipeline, TextualInversionLoaderM
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_pix2pix_zero.StableDiffusionPix2PixZeroPipeline.prepare_image_latents
|
||||
def prepare_image_latents(self, image, batch_size, dtype, device, generator=None):
|
||||
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
|
||||
raise ValueError(
|
||||
|
||||
@@ -25,7 +25,6 @@ from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.attention_processor import FusedAttnProcessor2_0
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
@@ -719,67 +718,6 @@ class StableDiffusionImg2ImgPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.fuse_qkv_projections
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.unfuse_qkv_projections
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
|
||||
@@ -25,7 +25,6 @@ from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AsymmetricAutoencoderKL, AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.attention_processor import FusedAttnProcessor2_0
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
@@ -233,7 +232,6 @@ class StableDiffusionInpaintPipeline(
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`, `AsymmetricAutoencoderKL`]):
|
||||
@@ -845,67 +843,6 @@ class StableDiffusionInpaintPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.fuse_qkv_projections
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.unfuse_qkv_projections
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
|
||||
+11
-11
@@ -21,17 +21,17 @@ import torch
|
||||
from packaging import version
|
||||
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ....configuration_utils import FrozenDict
|
||||
from ....image_processor import VaeImageProcessor
|
||||
from ....loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import KarrasDiffusionSchedulers
|
||||
from ....utils import PIL_INTERPOLATION, USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion import StableDiffusionPipelineOutput
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import PIL_INTERPOLATION, USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from . import StableDiffusionPipelineOutput
|
||||
from .safety_checker import StableDiffusionSafetyChecker
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
@@ -54,11 +54,6 @@ class StableDiffusionKDiffusionPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This is an experimental pipeline and is likely to change in the future.
|
||||
|
||||
@@ -67,9 +67,6 @@ class StableDiffusionLatentUpscalePipeline(DiffusionPipeline, FromSingleFileMixi
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
||||
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
|
||||
|
||||
+11
-16
@@ -18,17 +18,17 @@ from typing import Any, Callable, Dict, List, Optional, Union
|
||||
import torch
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ....image_processor import VaeImageProcessor
|
||||
from ....loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import PNDMScheduler
|
||||
from ....schedulers.scheduling_utils import SchedulerMixin
|
||||
from ....utils import USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import PNDMScheduler
|
||||
from ...schedulers.scheduling_utils import SchedulerMixin
|
||||
from ...utils import USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from . import StableDiffusionPipelineOutput
|
||||
from .safety_checker import StableDiffusionSafetyChecker
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -43,11 +43,6 @@ class StableDiffusionModelEditingPipeline(DiffusionPipeline, TextualInversionLoa
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
||||
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
|
||||
+10
-10
@@ -18,12 +18,12 @@ from typing import Any, Callable, Dict, List, Optional, Union
|
||||
import torch
|
||||
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ....image_processor import VaeImageProcessor
|
||||
from ....loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import KarrasDiffusionSchedulers
|
||||
from ....utils import (
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
USE_PEFT_BACKEND,
|
||||
deprecate,
|
||||
logging,
|
||||
@@ -31,10 +31,10 @@ from ....utils import (
|
||||
scale_lora_layers,
|
||||
unscale_lora_layers,
|
||||
)
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from . import StableDiffusionPipelineOutput
|
||||
from .safety_checker import StableDiffusionSafetyChecker
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
+13
-13
@@ -28,14 +28,14 @@ from transformers import (
|
||||
CLIPTokenizer,
|
||||
)
|
||||
|
||||
from ....image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ....loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....models.attention_processor import Attention
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import DDIMScheduler, DDPMScheduler, EulerAncestralDiscreteScheduler, LMSDiscreteScheduler
|
||||
from ....schedulers.scheduling_ddim_inverse import DDIMInverseScheduler
|
||||
from ....utils import (
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.attention_processor import Attention
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import DDIMScheduler, DDPMScheduler, EulerAncestralDiscreteScheduler, LMSDiscreteScheduler
|
||||
from ...schedulers.scheduling_ddim_inverse import DDIMInverseScheduler
|
||||
from ...utils import (
|
||||
PIL_INTERPOLATION,
|
||||
USE_PEFT_BACKEND,
|
||||
BaseOutput,
|
||||
@@ -45,10 +45,10 @@ from ....utils import (
|
||||
scale_lora_layers,
|
||||
unscale_lora_layers,
|
||||
)
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from . import StableDiffusionPipelineOutput
|
||||
from .safety_checker import StableDiffusionSafetyChecker
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -282,7 +282,7 @@ class Pix2PixZeroAttnProcessor:
|
||||
|
||||
class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline):
|
||||
r"""
|
||||
Pipeline for pixel-level image editing using Pix2Pix Zero. Based on Stable Diffusion.
|
||||
Pipeline for pixel-levl image editing using Pix2Pix Zero. Based on Stable Diffusion.
|
||||
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
@@ -76,12 +76,6 @@ class StableDiffusionUpscalePipeline(
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
||||
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
|
||||
|
||||
@@ -65,11 +65,6 @@ class StableUnCLIPPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraL
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
||||
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
|
||||
Args:
|
||||
prior_tokenizer ([`CLIPTokenizer`]):
|
||||
A [`CLIPTokenizer`].
|
||||
|
||||
@@ -76,11 +76,6 @@ class StableUnCLIPImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
||||
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
|
||||
Args:
|
||||
feature_extractor ([`CLIPImageProcessor`]):
|
||||
Feature extractor for image pre-processing before being encoded.
|
||||
|
||||
@@ -595,11 +595,10 @@ class StableDiffusionPipelineSafe(DiffusionPipeline, IPAdapterMixin):
|
||||
```py
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipelineSafe
|
||||
from diffusers.pipelines.stable_diffusion_safe import SafetyConfig
|
||||
|
||||
pipeline = StableDiffusionPipelineSafe.from_pretrained(
|
||||
"AIML-TUDA/stable-diffusion-safe", torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
)
|
||||
prompt = "the four horsewomen of the apocalypse, painting by tom of finland, gaston bussiere, craig mullins, j. c. leyendecker"
|
||||
image = pipeline(prompt=prompt, **SafetyConfig.MEDIUM).images[0]
|
||||
```
|
||||
|
||||
@@ -159,12 +159,12 @@ class StableDiffusionXLPipeline(
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
|
||||
In addition the pipeline inherits the following loading methods:
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`]
|
||||
- *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
|
||||
|
||||
as well as the following saving methods:
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`]
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
|
||||
+6
-68
@@ -35,7 +35,6 @@ from ...loaders import (
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.attention_processor import (
|
||||
AttnProcessor2_0,
|
||||
FusedAttnProcessor2_0,
|
||||
LoRAAttnProcessor2_0,
|
||||
LoRAXFormersAttnProcessor,
|
||||
XFormersAttnProcessor,
|
||||
@@ -177,12 +176,12 @@ class StableDiffusionXLImg2ImgPipeline(
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
|
||||
In addition the pipeline inherits the following loading methods:
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`]
|
||||
- *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
|
||||
|
||||
as well as the following saving methods:
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`]
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
@@ -865,67 +864,6 @@ class StableDiffusionXLImg2ImgPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.fuse_qkv_projections
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.unfuse_qkv_projections
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
|
||||
+6
-68
@@ -36,7 +36,6 @@ from ...loaders import (
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.attention_processor import (
|
||||
AttnProcessor2_0,
|
||||
FusedAttnProcessor2_0,
|
||||
LoRAAttnProcessor2_0,
|
||||
LoRAXFormersAttnProcessor,
|
||||
XFormersAttnProcessor,
|
||||
@@ -322,12 +321,12 @@ class StableDiffusionXLInpaintPipeline(
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
|
||||
In addition the pipeline inherits the following loading methods:
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`]
|
||||
- *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
|
||||
|
||||
as well as the following saving methods:
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`]
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
@@ -1085,67 +1084,6 @@ class StableDiffusionXLInpaintPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.fuse_qkv_projections
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.unfuse_qkv_projections
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
|
||||
+5
-5
@@ -126,11 +126,11 @@ class StableDiffusionXLInstructPix2PixPipeline(
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
In addition the pipeline inherits the following loading methods:
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`]
|
||||
|
||||
as well as the following saving methods:
|
||||
- *LoRA*: [`loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`]
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
|
||||
+1
-1
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {"pipeline_stochastic_karras_ve": ["KarrasVePipeline"]}
|
||||
+4
-4
@@ -16,10 +16,10 @@ from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ....models import UNet2DModel
|
||||
from ....schedulers import KarrasVeScheduler
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import UNet2DModel
|
||||
from ...schedulers import KarrasVeScheduler
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
|
||||
|
||||
class KarrasVePipeline(DiffusionPipeline):
|
||||
@@ -178,12 +178,6 @@ class StableDiffusionXLAdapterPipeline(
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.StableDiffusionXLLoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
|
||||
Args:
|
||||
adapter ([`T2IAdapter`] or [`MultiAdapter`] or `List[T2IAdapter]`):
|
||||
Provides additional conditioning to the unet during the denoising process. If you set multiple Adapter as a
|
||||
|
||||
@@ -83,11 +83,6 @@ class TextToVideoSDPipeline(DiffusionPipeline, TextualInversionLoaderMixin, Lora
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
||||
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
|
||||
|
||||
-5
@@ -159,11 +159,6 @@ class VideoToVideoSDPipeline(DiffusionPipeline, TextualInversionLoaderMixin, Lor
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
||||
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
||||
|
||||
The pipeline also inherits the following loading methods:
|
||||
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
||||
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
||||
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) Model to encode and decode videos to and from latent representations.
|
||||
|
||||
+3
-3
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import (
|
||||
from ...utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
OptionalDependencyNotAvailable,
|
||||
_LazyModule,
|
||||
@@ -17,7 +17,7 @@ try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.25.0")):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils.dummy_torch_and_transformers_objects import (
|
||||
from ...utils.dummy_torch_and_transformers_objects import (
|
||||
VersatileDiffusionDualGuidedPipeline,
|
||||
VersatileDiffusionImageVariationPipeline,
|
||||
VersatileDiffusionPipeline,
|
||||
@@ -45,7 +45,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.25.0")):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils.dummy_torch_and_transformers_objects import (
|
||||
from ...utils.dummy_torch_and_transformers_objects import (
|
||||
VersatileDiffusionDualGuidedPipeline,
|
||||
VersatileDiffusionImageVariationPipeline,
|
||||
VersatileDiffusionPipeline,
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user