renew repo, shrink down git sizes
@@ -0,0 +1,10 @@
|
||||
checkpoints/
|
||||
__pycache__/
|
||||
.DS_store
|
||||
*.egg-info/
|
||||
dist/
|
||||
vendor/
|
||||
eval_results/
|
||||
*.webui_secret_key
|
||||
|
||||
|
||||
@@ -0,0 +1,39 @@
|
||||
from namo.api.vl import VLInfer
|
||||
import os
|
||||
from termcolor import colored
|
||||
import torch
|
||||
|
||||
|
||||
def chat():
|
||||
model = VLInfer(
|
||||
model_type="namo", device="cuda:0" if torch.cuda.is_available() else "cpu"
|
||||
)
|
||||
|
||||
crt_input = ["images/cats.jpg", None]
|
||||
|
||||
while True:
|
||||
img_or_txt = input(colored("\nUser (txt/img_path): ", "cyan")).strip()
|
||||
|
||||
if os.path.exists(img_or_txt.split(" ")[0]):
|
||||
crt_input[0] = img_or_txt
|
||||
print(colored("System: Image updated.", "green"))
|
||||
continue
|
||||
else:
|
||||
crt_input[1] = img_or_txt
|
||||
|
||||
if crt_input[0] and crt_input[1]:
|
||||
print(colored("Assistant:", "green"), end=" ")
|
||||
model.generate(images=crt_input[0], prompt=crt_input[1], verbose=False)
|
||||
crt_input[0] = None
|
||||
elif not crt_input[0] and crt_input[1]:
|
||||
# pure text
|
||||
print(colored("Assistant:", "green"), end=" ")
|
||||
model.generate(images=None, prompt=crt_input[1], verbose=False)
|
||||
else:
|
||||
print(
|
||||
colored("System: Please provide either an image or text input.", "red")
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
chat()
|
||||
@@ -0,0 +1,199 @@
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import random
|
||||
import torch
|
||||
from termcolor import colored
|
||||
from transformers import TextStreamer
|
||||
from namo.models.namo import NamoForCausalLM
|
||||
from namo.models.configuration_namo import NamoConfig
|
||||
from namo.utils.infer_utils import load_multi_images_maybe
|
||||
from namo.utils.hf_utils import find_and_merge_lora_adapters
|
||||
from namo.utils.process_utils import tokenizer_image_token
|
||||
from loguru import logger
|
||||
|
||||
|
||||
def load_model_simple(model_path):
|
||||
non_lora_bin = os.path.join(model_path, "non_lora_trainables.bin")
|
||||
if os.path.exists(non_lora_bin):
|
||||
logger.info(f"loading lora: {model_path}")
|
||||
config = NamoConfig.from_pretrained(model_path)
|
||||
model = NamoForCausalLM(config=config)
|
||||
non_lora = torch.load(non_lora_bin)
|
||||
non_lora = {k.replace("base_model.model.", ""): v for k, v in non_lora.items()}
|
||||
model.load_state_dict(non_lora, strict=False)
|
||||
model = find_and_merge_lora_adapters(model, model_path)
|
||||
return model
|
||||
else:
|
||||
return NamoForCausalLM.from_pretrained(model_path)
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--model-path", default="checkpoints/namo-500m")
|
||||
parser.add_argument("--eval", action="store_true")
|
||||
parser.add_argument("--debug", action="store_true")
|
||||
args = parser.parse_args()
|
||||
|
||||
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
model = load_model_simple(args.model_path)
|
||||
model.eval().to(device)
|
||||
image_processor = model.get_vision_tower().image_processor
|
||||
tokenizer = model.get_namo().tokenizer
|
||||
|
||||
if args.eval:
|
||||
with open("images/evals.json") as f:
|
||||
for item in json.load(f):
|
||||
handle_eval_item(
|
||||
item, model, image_processor, tokenizer, device, args.debug
|
||||
)
|
||||
else:
|
||||
run_cli(model, image_processor, tokenizer, device)
|
||||
|
||||
|
||||
def handle_eval_item(item, model, image_processor, tokenizer, device, debug=False):
|
||||
image_path = item["image"]
|
||||
question = random.choice([item["question1"], item["question2"]])
|
||||
images = load_multi_images_maybe(image_path)
|
||||
image_processor.size["shortest_edge"] = 448
|
||||
pixel_values = (
|
||||
image_processor.preprocess(images, do_resize=True, return_tensors="pt")[
|
||||
"pixel_values"
|
||||
]
|
||||
.to(device)
|
||||
.to(model.dtype)
|
||||
)
|
||||
if debug:
|
||||
logger.info(f"pixel_values: {pixel_values.shape}")
|
||||
|
||||
chat = [
|
||||
{"role": "system", "content": "Follow instructions carefully."},
|
||||
{"role": "user", "content": f"<image>\n{question}"},
|
||||
]
|
||||
prompt = (
|
||||
tokenizer.apply_chat_template(chat, tokenize=False) + "<|im_start|>assistant\n"
|
||||
)
|
||||
|
||||
input_ids = (
|
||||
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
|
||||
.unsqueeze(0)
|
||||
.to(device)
|
||||
)
|
||||
print(f"\nImage: {image_path}\nQ: {question}\n", end="")
|
||||
print(colored("AI: ", "yellow"), end="")
|
||||
generate_response(model, tokenizer, pixel_values, prompt)
|
||||
print("\n")
|
||||
|
||||
|
||||
def run_cli(model, image_processor, tokenizer, device):
|
||||
DEFAULT_IMAGE = "images/cats.jpg"
|
||||
current_pixels = process_image(DEFAULT_IMAGE, image_processor, model, device)
|
||||
image_processor.size["shortest_edge"] = 448
|
||||
|
||||
messages = [
|
||||
{"role": "system", "content": "Respond carefully."},
|
||||
{
|
||||
"role": "user",
|
||||
"content": [{"type": "image_url", "image_url": DEFAULT_IMAGE}],
|
||||
},
|
||||
]
|
||||
|
||||
while True:
|
||||
try:
|
||||
user_input = input(colored("\nUser (txt/img_path): ", "green")).strip()
|
||||
if not user_input:
|
||||
continue
|
||||
if user_input.lower() in ("exit", "quit"):
|
||||
break
|
||||
|
||||
if os.path.exists(user_input):
|
||||
current_pixels = process_image(
|
||||
user_input, image_processor, model, device
|
||||
)
|
||||
messages = [
|
||||
{"role": "system", "content": "Respond carefully."},
|
||||
{
|
||||
"role": "user",
|
||||
"content": [{"type": "image_url", "image_url": user_input}],
|
||||
},
|
||||
]
|
||||
print(colored("System: New image loaded", "yellow"))
|
||||
continue
|
||||
|
||||
last_user_msg = next(
|
||||
(m for m in reversed(messages) if m["role"] == "user"), None
|
||||
)
|
||||
if last_user_msg and not has_text_content(last_user_msg):
|
||||
last_user_msg["content"].append({"type": "text", "text": user_input})
|
||||
else:
|
||||
messages.append(
|
||||
{"role": "user", "content": [{"type": "text", "text": user_input}]}
|
||||
)
|
||||
|
||||
prompt = build_chat_prompt(messages, tokenizer)
|
||||
print(colored("Assistant: ", "blue"), end="")
|
||||
response = generate_response(model, tokenizer, current_pixels, prompt)
|
||||
messages.append(
|
||||
{"role": "assistant", "content": [{"type": "text", "text": response}]}
|
||||
)
|
||||
|
||||
except KeyboardInterrupt:
|
||||
print(colored("\nSession ended.", "red"))
|
||||
break
|
||||
|
||||
|
||||
def process_image(path, processor, model, device):
|
||||
images = load_multi_images_maybe(path)
|
||||
return (
|
||||
processor.preprocess(images, return_tensors="pt")["pixel_values"]
|
||||
.to(device)
|
||||
.to(model.dtype)
|
||||
)
|
||||
|
||||
|
||||
def build_chat_prompt(messages, tokenizer):
|
||||
converted = []
|
||||
for msg in messages:
|
||||
if msg["role"] == "system":
|
||||
converted.append(msg)
|
||||
else:
|
||||
parts = []
|
||||
for content in msg["content"]:
|
||||
if content["type"] == "image_url":
|
||||
parts.append("<image>")
|
||||
elif content["type"] == "text":
|
||||
parts.append(content["text"])
|
||||
converted.append({"role": msg["role"], "content": "\n".join(parts)})
|
||||
return (
|
||||
tokenizer.apply_chat_template(converted, tokenize=False)
|
||||
+ "<|im_start|>assistant\n"
|
||||
)
|
||||
|
||||
|
||||
def generate_response(model, tokenizer, pixels, prompt):
|
||||
input_ids = (
|
||||
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
|
||||
.unsqueeze(0)
|
||||
.to(model.device)
|
||||
)
|
||||
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
|
||||
|
||||
with torch.autocast(device_type="cuda", dtype=torch.float16):
|
||||
output_ids = model.generate(
|
||||
pixel_values=pixels,
|
||||
input_ids=input_ids,
|
||||
do_sample=False,
|
||||
max_new_tokens=360,
|
||||
streamer=streamer,
|
||||
eos_token_id=tokenizer.pad_token_id,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
)
|
||||
return tokenizer.decode(output_ids[0], skip_special_tokens=True).strip()
|
||||
|
||||
|
||||
def has_text_content(message):
|
||||
return any(c["type"] == "text" for c in message["content"])
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
{kind=link}
|
After Width: | Height: | Size: 50 KiB |
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
{kind=link}
|
After Width: | Height: | Size: 261 KiB |
{kind=link}
|
After Width: | Height: | Size: 61 KiB |
{kind=link}
|
After Width: | Height: | Size: 276 KiB |
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
{kind=link}
|
After Width: | Height: | Size: 58 KiB |
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
{kind=link}
|
After Width: | Height: | Size: 188 KiB |
{kind=link}
|
After Width: | Height: | Size: 76 KiB |
{kind=link}
|
After Width: | Height: | Size: 34 KiB |
@@ -0,0 +1,35 @@
|
||||
import os
|
||||
from loguru import logger
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
class VLBase:
|
||||
def __init__(self, model_path=None, processor_path=None, device="auto"):
|
||||
self.device = (
|
||||
"cuda:0"
|
||||
if torch.cuda.is_available()
|
||||
else (
|
||||
"mps"
|
||||
if torch.backends.mps.is_available()
|
||||
else "cpu" if device == "auto" else device
|
||||
)
|
||||
)
|
||||
self.model = self.load_model(model_path)
|
||||
self.processor = self.load_processor(
|
||||
processor_path if processor_path is None else model_path
|
||||
)
|
||||
|
||||
self.history_msgs = []
|
||||
|
||||
def load_model(self, model_path):
|
||||
raise NotImplementedError
|
||||
|
||||
def load_processor(self, processor_path):
|
||||
raise NotImplementedError
|
||||
|
||||
def stream_chat_with_images(self):
|
||||
raise NotImplementedError
|
||||
|
||||
def generate(self, prompt, image, verbose):
|
||||
pass
|
||||
@@ -0,0 +1,346 @@
|
||||
import os
|
||||
import threading
|
||||
from typing import AsyncGenerator
|
||||
from namo.api.base import VLBase
|
||||
from loguru import logger
|
||||
import torch
|
||||
from termcolor import colored
|
||||
from transformers import TextStreamer
|
||||
from transformers import AutoProcessor
|
||||
from namo.models.namo import NamoForCausalLM
|
||||
from namo.models.configuration_namo import NamoConfig
|
||||
from namo.utils.infer_utils import CallbackStreamer, load_multi_images_maybe
|
||||
from namo.utils.process_utils import convert_image_tags, tokenizer_image_token
|
||||
from loguru import logger
|
||||
from huggingface_hub import hf_hub_download, snapshot_download
|
||||
from namo.utils.process_utils import smart_resize_v1
|
||||
from transformers.models.clip.image_processing_clip import CLIPImageProcessor
|
||||
from namo.utils.infer_utils import url_to_image
|
||||
from transformers import TextIteratorStreamer
|
||||
|
||||
|
||||
class NamoVL(VLBase):
|
||||
def __init__(
|
||||
self,
|
||||
model_path=None,
|
||||
processor_path=None,
|
||||
device="auto",
|
||||
system_msg="You are Namo small VLM model, trained by NAMO. You can look images and with great OCR ability.",
|
||||
):
|
||||
super().__init__(model_path, processor_path, device)
|
||||
# default: Load the model on the available device(s)
|
||||
self.default_sys = {"role": "system", "content": system_msg}
|
||||
self.history_msgs = [self.default_sys]
|
||||
|
||||
def load_model(self, model_path):
|
||||
if model_path is None:
|
||||
model_path = "checkpoints/Namo-500M-V1"
|
||||
if not os.path.exists(model_path):
|
||||
logger.info(f"downloading model from huggingface into: {model_path}")
|
||||
snapshot_download(
|
||||
repo_id="lucasjin/Namo-500M-V1",
|
||||
local_dir=model_path,
|
||||
local_dir_use_symlinks=False,
|
||||
)
|
||||
model = NamoForCausalLM.from_pretrained(
|
||||
model_path,
|
||||
torch_dtype="auto",
|
||||
# device_map="auto"
|
||||
)
|
||||
model.eval().to(self.device)
|
||||
logger.info(f"model loaded from: {model_path}")
|
||||
return model
|
||||
|
||||
def load_processor(self, processor_path):
|
||||
processor = self.model.get_vision_tower().image_processor
|
||||
self.image_processor = processor
|
||||
self.tokenizer = self.model.get_namo().tokenizer
|
||||
if self.tokenizer.pad_token_id is None:
|
||||
self.tokenizer.pad_token_id = self.tokenizer.encode(
|
||||
self.tokenizer.pad_token
|
||||
)
|
||||
return processor
|
||||
|
||||
def build_chat_prompt(self, messages, tokenizer):
|
||||
converted = []
|
||||
for msg in messages:
|
||||
if msg["role"] == "system":
|
||||
converted.append(msg)
|
||||
elif msg["role"] == "assistant":
|
||||
converted.append(msg["content"])
|
||||
else:
|
||||
parts = []
|
||||
# check if content['text'] already contains image tag
|
||||
# do not convert tag
|
||||
imgs_num = 0
|
||||
txt = ""
|
||||
if isinstance(msg["content"], str):
|
||||
txt = msg["content"]
|
||||
else:
|
||||
for content in msg["content"]:
|
||||
if content["type"] == "image_url":
|
||||
parts.append("<image>")
|
||||
imgs_num += 1
|
||||
elif content["type"] == "text":
|
||||
parts.append(content["text"] + "\n")
|
||||
txt = content["text"]
|
||||
if txt.count("<image>") == imgs_num:
|
||||
parts = txt
|
||||
else:
|
||||
parts = "".join(parts)
|
||||
parts = convert_image_tags(parts)
|
||||
converted.append({"role": msg["role"], "content": parts})
|
||||
return (
|
||||
tokenizer.apply_chat_template(converted, tokenize=False)
|
||||
+ "<|im_start|>assistant\n"
|
||||
)
|
||||
|
||||
def get_history_images(self):
|
||||
his_images = []
|
||||
for msg in self.history_msgs:
|
||||
if isinstance(msg["content"], str):
|
||||
continue
|
||||
for content in msg["content"]:
|
||||
if content["type"] == "image_url":
|
||||
his_images.append(content["image_url"])
|
||||
return his_images
|
||||
|
||||
@staticmethod
|
||||
def msg_has_img(msg):
|
||||
if isinstance(msg["content"], list):
|
||||
return any(
|
||||
[
|
||||
c["type"] == "image_url" and c["image_url"] is not None
|
||||
for c in msg["content"]
|
||||
]
|
||||
)
|
||||
return False
|
||||
|
||||
def remove_history_images(self):
|
||||
hist_images = []
|
||||
for msg in self.history_msgs[::-1]:
|
||||
if self.msg_has_img(msg):
|
||||
msg_new = msg.copy()
|
||||
msg_new["content"] = [
|
||||
itm for itm in msg["content"] if itm["type"] != "image_url"
|
||||
]
|
||||
hist_images.append(msg_new)
|
||||
else:
|
||||
hist_images.append(msg)
|
||||
self.history_msgs = hist_images[::-1]
|
||||
|
||||
def get_images_history_or_none(self):
|
||||
his_images = []
|
||||
for msg in self.history_msgs:
|
||||
if isinstance(msg["content"], list):
|
||||
for itm in msg["content"]:
|
||||
if itm["type"] == "image_url":
|
||||
his_images.append(itm["image_url"])
|
||||
return his_images if len(his_images) > 0 else None
|
||||
|
||||
def generate(
|
||||
self,
|
||||
prompt,
|
||||
images,
|
||||
stream=True,
|
||||
max_size=700,
|
||||
verbose=False,
|
||||
prevent_more_image=True,
|
||||
keep_history=True,
|
||||
):
|
||||
|
||||
if images is not None:
|
||||
crt_images = load_multi_images_maybe(images)
|
||||
if keep_history:
|
||||
if prevent_more_image:
|
||||
# will delete previous all images.
|
||||
self.remove_history_images()
|
||||
images_in = crt_images
|
||||
else:
|
||||
logger.warning(
|
||||
"you have set prevent_more_image=False, current more can not handle history have many images, the result would be wrose."
|
||||
)
|
||||
images_in = crt_images + self.get_history_images()
|
||||
else:
|
||||
self.history_msgs = [self.default_sys]
|
||||
images_in = crt_images
|
||||
|
||||
# print(images)
|
||||
self.image_processor.size["longest_edge"] = max_size
|
||||
|
||||
pixel_values = [
|
||||
self.image_processor.preprocess(
|
||||
img,
|
||||
return_tensors="pt",
|
||||
)["pixel_values"]
|
||||
.to(self.model.device)
|
||||
.to(self.model.dtype)
|
||||
for img in images_in
|
||||
]
|
||||
self.history_msgs.append(
|
||||
{
|
||||
"role": "user",
|
||||
"content": [
|
||||
{"type": "image_url", "image_url": img} for img in crt_images
|
||||
]
|
||||
+ [
|
||||
{"type": "text", "text": prompt},
|
||||
],
|
||||
},
|
||||
)
|
||||
else:
|
||||
if keep_history:
|
||||
his_images = self.get_images_history_or_none()
|
||||
pixel_values = [
|
||||
self.image_processor.preprocess(
|
||||
img,
|
||||
return_tensors="pt",
|
||||
)["pixel_values"]
|
||||
.to(self.model.device)
|
||||
.to(self.model.dtype)
|
||||
for img in his_images
|
||||
]
|
||||
else:
|
||||
pixel_values = None
|
||||
self.history_msgs.append(
|
||||
{
|
||||
"role": "user",
|
||||
"content": [
|
||||
{"type": "text", "text": prompt},
|
||||
],
|
||||
},
|
||||
)
|
||||
if verbose:
|
||||
if pixel_values is not None:
|
||||
logger.info(f"pixel_values: {[t.shape for t in pixel_values]}")
|
||||
|
||||
if keep_history and len(self.history_msgs) > 6:
|
||||
# remove on first pair from history
|
||||
self.history_msgs = [
|
||||
msg for i, msg in enumerate(self.history_msgs) if i != 1 and i != 2
|
||||
]
|
||||
if verbose and len(self.history_msgs) > 0:
|
||||
print(self.history_msgs)
|
||||
|
||||
input_templated = self.build_chat_prompt(self.history_msgs, self.tokenizer)
|
||||
if verbose:
|
||||
print(input_templated)
|
||||
response = self.generate_response(
|
||||
self.model,
|
||||
self.tokenizer,
|
||||
pixel_values,
|
||||
input_templated,
|
||||
stream=stream,
|
||||
)
|
||||
if keep_history:
|
||||
self.history_msgs.append(
|
||||
{"role": "assistant", "content": response},
|
||||
)
|
||||
return response
|
||||
|
||||
def generate_response(
|
||||
self, model, tokenizer, pixels, prompt, stream=True, return_generator=False
|
||||
):
|
||||
input_ids = (
|
||||
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
|
||||
.unsqueeze(0)
|
||||
.to(model.device)
|
||||
)
|
||||
if stream and not return_generator:
|
||||
streamer = TextStreamer(
|
||||
tokenizer, skip_prompt=True, skip_special_tokens=True
|
||||
)
|
||||
if return_generator:
|
||||
streamer = TextIteratorStreamer(self.tokenizer, skip_special_tokens=True)
|
||||
|
||||
gen_args = {
|
||||
"pixel_values": pixels,
|
||||
"input_ids": input_ids,
|
||||
"max_new_tokens": 460,
|
||||
"do_sample": False,
|
||||
"eos_token_id": self.tokenizer.eos_token_id,
|
||||
"pad_token_id": self.tokenizer.pad_token_id,
|
||||
"streamer": streamer if stream or return_generator else None,
|
||||
}
|
||||
if return_generator:
|
||||
thread = threading.Thread(
|
||||
target=self.model.generate,
|
||||
kwargs=gen_args,
|
||||
)
|
||||
thread.start()
|
||||
return (new_text for new_text in streamer)
|
||||
else:
|
||||
with torch.autocast(device_type="cuda", dtype=torch.float16):
|
||||
output_ids = model.generate(**gen_args)
|
||||
return tokenizer.decode(output_ids[0], skip_special_tokens=True).strip()
|
||||
|
||||
def chat_with_request(
|
||||
self, messages, stream=True, prevent_more_image=True, verbose=False
|
||||
):
|
||||
"""
|
||||
in case we already have a messages list
|
||||
"""
|
||||
messages_new = []
|
||||
images = []
|
||||
last_img_idx = 0
|
||||
for msg in messages[::-1]:
|
||||
if self.msg_has_img(msg):
|
||||
if last_img_idx >= 1 and prevent_more_image:
|
||||
msg_new = msg.copy()
|
||||
msg_new["content"] = [
|
||||
itm for itm in msg["content"] if itm["type"] != "image_url"
|
||||
]
|
||||
messages_new.append(msg_new)
|
||||
else:
|
||||
for itm in msg["content"]:
|
||||
if itm["type"] == "image_url":
|
||||
images.append(url_to_image(itm["image_url"]["url"]))
|
||||
messages_new.append(msg)
|
||||
last_img_idx += 1
|
||||
else:
|
||||
messages_new.append(msg)
|
||||
|
||||
if prevent_more_image:
|
||||
assert (
|
||||
len(images) <= 1
|
||||
), "if prevent more image, images at each iter should be 1."
|
||||
messages_new = messages_new[::-1]
|
||||
|
||||
|
||||
if len(images) > 0:
|
||||
pixel_values = [
|
||||
self.image_processor.preprocess(
|
||||
img,
|
||||
return_tensors="pt",
|
||||
)["pixel_values"]
|
||||
.to(self.model.device)
|
||||
.to(self.model.dtype)
|
||||
for img in images
|
||||
]
|
||||
else:
|
||||
pixel_values = None
|
||||
|
||||
input_templated = self.build_chat_prompt(messages_new, self.tokenizer)
|
||||
|
||||
if pixel_values is not None:
|
||||
print(input_templated)
|
||||
print(images)
|
||||
|
||||
if stream:
|
||||
generator = self.generate_response(
|
||||
self.model,
|
||||
self.tokenizer,
|
||||
pixel_values,
|
||||
input_templated,
|
||||
return_generator=True,
|
||||
)
|
||||
return generator
|
||||
else:
|
||||
response = self.generate_response(
|
||||
self.model, self.tokenizer, pixel_values, input_templated, stream=False
|
||||
)
|
||||
return response
|
||||
|
||||
def stream_chat_with_request(self, messages):
|
||||
for chunk in self.chat_with_request(messages, stream=True):
|
||||
yield chunk
|
||||
@@ -0,0 +1,322 @@
|
||||
import json
|
||||
import time
|
||||
import uuid
|
||||
import torch
|
||||
import uvicorn
|
||||
import os
|
||||
from uvicorn.config import Config
|
||||
from uvicorn import Server
|
||||
from pydantic import BaseModel, Field
|
||||
from fastapi import BackgroundTasks, FastAPI, HTTPException, Request, Response
|
||||
from contextlib import asynccontextmanager
|
||||
from starlette.responses import StreamingResponse
|
||||
from typing import Any, Dict
|
||||
from coreai.serve.api_schema import (
|
||||
DeltaMessage,
|
||||
ChatCompletionRequest,
|
||||
ChatCompletionResponseChoice,
|
||||
ChatCompletionResponseStreamChoice,
|
||||
ChatCompletionResponse,
|
||||
ChatMessage,
|
||||
ModelCard,
|
||||
ModelList,
|
||||
ModelPermission,
|
||||
CompletionUsage,
|
||||
)
|
||||
import requests
|
||||
from PIL import Image
|
||||
import base64
|
||||
from io import BytesIO
|
||||
from loguru import logger
|
||||
import uuid
|
||||
|
||||
_TEXT_COMPLETION_CMD = object()
|
||||
|
||||
global_model = None
|
||||
source_prefix = "You are a helpful assistant."
|
||||
local_doc_qa = None
|
||||
conv = None
|
||||
debug_mode = False
|
||||
|
||||
|
||||
@asynccontextmanager
|
||||
async def lifespan(app: FastAPI): # collects GPU memory
|
||||
yield
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
torch.cuda.ipc_collect()
|
||||
|
||||
|
||||
app = FastAPI(lifespan=lifespan)
|
||||
|
||||
|
||||
def load_image(image_file):
|
||||
if image_file.startswith("http") or image_file.startswith("https"):
|
||||
response = requests.get(image_file)
|
||||
image = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
else:
|
||||
image_data = base64.b64decode(image_file)
|
||||
image = Image.open(BytesIO(image_data)).convert("RGB")
|
||||
return image
|
||||
|
||||
|
||||
def add_extra_stop_words(stop_words):
|
||||
if stop_words:
|
||||
_stop_words = []
|
||||
_stop_words.extend(stop_words)
|
||||
for x in stop_words:
|
||||
s = x.lstrip("\n")
|
||||
if s and (s not in _stop_words):
|
||||
_stop_words.append(s)
|
||||
return _stop_words
|
||||
return stop_words
|
||||
|
||||
|
||||
def trim_stop_words(response, stop_words):
|
||||
if stop_words:
|
||||
for stop in stop_words:
|
||||
idx = response.find(stop)
|
||||
if idx != -1:
|
||||
response = response[:idx]
|
||||
return response
|
||||
|
||||
|
||||
async def text_complete_last_message_vllm(
|
||||
history, stop_words_ids, gen_kwargs, tokenizer, model, request_id
|
||||
):
|
||||
im_start = "<|im_start|>"
|
||||
im_end = "<|im_end|>"
|
||||
prompt = f"{im_start}system\nYou are a helpful assistant.{im_end}"
|
||||
for i, (query, response) in enumerate(history):
|
||||
query = query.lstrip("\n").rstrip()
|
||||
response = response.lstrip("\n").rstrip()
|
||||
prompt += f"\n{im_start}user\n{query}{im_end}"
|
||||
prompt += f"\n{im_start}assistant\n{response}{im_end}"
|
||||
prompt = prompt[: -len(im_end)]
|
||||
|
||||
_stop_words_ids = [tokenizer.encode(im_end)]
|
||||
if stop_words_ids:
|
||||
for s in stop_words_ids:
|
||||
_stop_words_ids.append(s)
|
||||
stop_words_ids = _stop_words_ids
|
||||
|
||||
results_generator = model.generate(prompt, gen_kwargs, request_id)
|
||||
output = ""
|
||||
async for request_output in results_generator:
|
||||
p = request_output.prompt
|
||||
output = request_output.outputs[-1].text
|
||||
# assert output.startswith(prompt)
|
||||
# output = output[len(prompt) :]
|
||||
output = trim_stop_words(output, ["<|endoftext|>", im_end])
|
||||
# print(f"<completion>\n{prompt}\n<!-- *** -->\n{output}\n</completion>")
|
||||
return output
|
||||
|
||||
|
||||
@app.get("/")
|
||||
async def root():
|
||||
return {"message": "Hello World, did you using frp get your local service out?"}
|
||||
|
||||
|
||||
@app.get("/v1/models")
|
||||
async def show_available_models():
|
||||
# global model_name_runing
|
||||
models = ["namo-500m", "namo-700m", "gpt4o", "o1", "internvl2-8b"]
|
||||
models.sort()
|
||||
model_cards = []
|
||||
for m in models:
|
||||
model_cards.append(ModelCard(id=m, root=m, permission=[ModelPermission()]))
|
||||
return ModelList(data=model_cards)
|
||||
|
||||
|
||||
def get_response_msg_auto_stream(msg, model_id, stream=False):
|
||||
if stream:
|
||||
gen = get_info_msg_stream(msg, model_id=model_id)
|
||||
return StreamingResponse(gen, media_type="text/event-stream")
|
||||
choice_data = ChatCompletionResponseChoice(
|
||||
index=0,
|
||||
message=ChatMessage(role="assistant", content=msg),
|
||||
finish_reason="stop",
|
||||
)
|
||||
return ChatCompletionResponse(
|
||||
id=str(uuid.uuid4()),
|
||||
created=time.time_ns() // 1_000_000,
|
||||
model=model_id,
|
||||
choices=[choice_data],
|
||||
object="chat.completion",
|
||||
)
|
||||
|
||||
|
||||
async def get_info_msg_stream(content: str, model_id: str):
|
||||
choice_data = ChatCompletionResponseStreamChoice(
|
||||
index=0, delta=DeltaMessage(content=content), finish_reason=None
|
||||
)
|
||||
chunk = ChatCompletionResponse(
|
||||
id=str(uuid.uuid4()),
|
||||
created=time.time_ns() // 1_000_000,
|
||||
model=model_id,
|
||||
choices=[choice_data],
|
||||
object="chat.completion.chunk",
|
||||
)
|
||||
yield "data: {}\n\n".format(chunk.model_dump_json(exclude_unset=True))
|
||||
choice_data = ChatCompletionResponseStreamChoice(
|
||||
index=0, delta=DeltaMessage(), finish_reason="stop"
|
||||
)
|
||||
chunk = ChatCompletionResponse(
|
||||
id=str(uuid.uuid4()),
|
||||
created=time.time_ns() // 1_000_000,
|
||||
model=model_id,
|
||||
choices=[choice_data],
|
||||
object="chat.completion.chunk",
|
||||
)
|
||||
yield "data: {}\n\n".format(chunk.model_dump_json(exclude_unset=True))
|
||||
|
||||
|
||||
def _map_content(content):
|
||||
if isinstance(content, str):
|
||||
return content, None
|
||||
else:
|
||||
if len(content) > 1 and any(item.type == "image_url" for item in content):
|
||||
# might contains image
|
||||
# print(content)
|
||||
text = next(itm for itm in content if itm.type == "text").text
|
||||
img = next(itm.image_url for itm in content if itm.type == "image_url").url
|
||||
return "<image> " + text, load_image(img)
|
||||
else:
|
||||
return content[0], None
|
||||
|
||||
|
||||
@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
|
||||
async def create_chat_completion(request: ChatCompletionRequest):
|
||||
global global_model, source_prefix, local_doc_qa, conv, debug_mode
|
||||
|
||||
t_id = int(time.time())
|
||||
r_id = f"chatcmpl-{t_id}"
|
||||
|
||||
if request.stream:
|
||||
response = stream_response(request, gen_kwargs=None)
|
||||
return StreamingResponse(
|
||||
response,
|
||||
media_type="text/event-stream",
|
||||
)
|
||||
# else:
|
||||
text = global_model.chat_with_request(
|
||||
request.model_dump()["messages"], stream=False
|
||||
)
|
||||
vis_chat_resp = {
|
||||
"id": r_id,
|
||||
"object": "chat.completion", # chat.completions.chunk for stream
|
||||
"created": t_id,
|
||||
# "model": global_model.model_name,
|
||||
"model": "namo",
|
||||
"system_fingerprint": "fp_111111111",
|
||||
"choices": [
|
||||
{
|
||||
"index": 0,
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": text,
|
||||
},
|
||||
"logprobs": None,
|
||||
"finish_reason": "stop",
|
||||
}
|
||||
],
|
||||
"usage": {
|
||||
"prompt_tokens": 0,
|
||||
"completion_tokens": 0,
|
||||
"total_tokens": 0,
|
||||
},
|
||||
}
|
||||
|
||||
logger.debug(f"Response: {vis_chat_resp}")
|
||||
return vis_chat_resp
|
||||
|
||||
|
||||
def stream_response(
|
||||
request,
|
||||
gen_kwargs: Dict[str, Any],
|
||||
):
|
||||
|
||||
# prompt_txt_num = len(gen_kwargs["inputs"])
|
||||
prompt_txt_num = 10
|
||||
all_output = ""
|
||||
response_generator = global_model.stream_chat_with_request(
|
||||
request.model_dump()["messages"]
|
||||
)
|
||||
|
||||
for new_text in response_generator:
|
||||
choice_data = ChatCompletionResponseStreamChoice(
|
||||
index=0,
|
||||
delta=DeltaMessage(role="assistant", content=new_text),
|
||||
finish_reason=None,
|
||||
)
|
||||
if new_text is not None:
|
||||
chunk = ChatCompletionResponse(
|
||||
id=str(uuid.uuid4()),
|
||||
created=time.time_ns() // 1_000_000,
|
||||
model="namo",
|
||||
choices=[choice_data],
|
||||
object="chat.completion.chunk",
|
||||
)
|
||||
# print(chunk.model_dump_json())
|
||||
# print(new_text)
|
||||
all_output += new_text
|
||||
yield "data: {}\n\n".format(chunk.model_dump_json())
|
||||
|
||||
completion_txt_num = len(all_output)
|
||||
# recalculate token
|
||||
prompt_txt_num *= 1.33
|
||||
completion_txt_num *= 1.33
|
||||
|
||||
choice_data = ChatCompletionResponseStreamChoice(
|
||||
index=0, delta=DeltaMessage(role="assistant", content=""), finish_reason="stop"
|
||||
)
|
||||
chunk = ChatCompletionResponse(
|
||||
id=str(uuid.uuid4()),
|
||||
created=time.time_ns() // 1_000_000,
|
||||
model="namo",
|
||||
choices=[choice_data],
|
||||
object="chat.completion.chunk",
|
||||
usage=CompletionUsage(
|
||||
prompt_tokens=int(prompt_txt_num),
|
||||
completion_tokens=int(completion_txt_num),
|
||||
total_tokens=int(completion_txt_num + prompt_txt_num),
|
||||
),
|
||||
)
|
||||
yield "data: {}\n\n".format(chunk.model_dump_json())
|
||||
|
||||
|
||||
def start_server(model="namo", ip="127.0.0.1", port=8080):
|
||||
global global_model
|
||||
|
||||
if not os.path.exists(model):
|
||||
if model == "minicpm":
|
||||
model_path = "checkpoints/minicpm_v2_6"
|
||||
elif model == "internvl2":
|
||||
model_path = "checkpoints/internvl2-8b/"
|
||||
elif model == "qwen2vl":
|
||||
model_path = "checkpoints/qwen2-vl-7b/"
|
||||
else:
|
||||
model_path = "checkpoints/Namo-500M-V1/"
|
||||
else:
|
||||
model_path = model
|
||||
|
||||
if "internvl" in model_path:
|
||||
logger.warning("not supported for now")
|
||||
elif "minicpm" in model_path:
|
||||
logger.warning("not supported for now")
|
||||
elif "qwen2-vl" in model_path:
|
||||
logger.warning("not supported for now")
|
||||
elif "namo" in model_path.lower():
|
||||
from namo.api.namo import NamoVL
|
||||
|
||||
global_model = NamoVL(model_path=model_path, device="auto")
|
||||
logger.success("namo model initiated!")
|
||||
else:
|
||||
ValueError(f"unsupported model: {model_path}")
|
||||
|
||||
http_config = Config(app=app, host=ip, port=port, log_level="info")
|
||||
http_server = Server(config=http_config)
|
||||
|
||||
import asyncio
|
||||
|
||||
uvicorn.run(app, host=ip, port=port, workers=1)
|
||||
@@ -0,0 +1,93 @@
|
||||
from transformers import (
|
||||
AutoTokenizer,
|
||||
AutoProcessor,
|
||||
)
|
||||
|
||||
try:
|
||||
from qwen_vl_utils import process_vision_info
|
||||
from transformers.models.qwen2_5_vl import Qwen2_5_VLModel
|
||||
from transformers import Qwen2_5_VLForConditionalGeneration
|
||||
except ImportError as e:
|
||||
pass
|
||||
from namo.api.base import VLBase
|
||||
from loguru import logger
|
||||
|
||||
|
||||
class Qwen2_5_VL(VLBase):
|
||||
def __init__(self, model_path=None, processor_path=None, device="auto"):
|
||||
super().__init__(model_path, processor_path, device)
|
||||
# default: Load the model on the available device(s)
|
||||
|
||||
def load_model(self, model_path):
|
||||
if model_path is None:
|
||||
model_path = "checkpoints/Qwen2.5-VL-3B-Instruct"
|
||||
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
||||
model_path, torch_dtype="auto", device_map="auto"
|
||||
)
|
||||
model.to(self.device)
|
||||
logger.info(f"model loaded from: {model_path}")
|
||||
return model
|
||||
|
||||
def load_processor(self, processor_path):
|
||||
if processor_path is None:
|
||||
processor_path = "checkpoints/Qwen2.5-VL-3B-Instruct"
|
||||
processor = AutoProcessor.from_pretrained(processor_path)
|
||||
return processor
|
||||
|
||||
def get_msg(self, text, image=None):
|
||||
if image is None:
|
||||
return {
|
||||
"role": "user",
|
||||
"content": [
|
||||
{"type": "text", "text": text},
|
||||
],
|
||||
}
|
||||
return {
|
||||
"role": "user",
|
||||
"content": [
|
||||
{
|
||||
"type": "image",
|
||||
"image": image,
|
||||
},
|
||||
{"type": "text", "text": text},
|
||||
],
|
||||
}
|
||||
|
||||
def generate(
|
||||
self,
|
||||
prompt,
|
||||
images,
|
||||
stream=True,
|
||||
max_size=700,
|
||||
verbose=False,
|
||||
prevent_more_image=True,
|
||||
):
|
||||
msg = self.get_msg(prompt, images)
|
||||
messages = [msg]
|
||||
|
||||
# Preparation for inference
|
||||
text = self.processor.apply_chat_template(
|
||||
messages, tokenize=False, add_generation_prompt=True
|
||||
)
|
||||
image_inputs, video_inputs = process_vision_info(messages)
|
||||
inputs = self.processor(
|
||||
text=[text],
|
||||
images=image_inputs,
|
||||
videos=video_inputs,
|
||||
padding=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
inputs = inputs.to(self.device)
|
||||
|
||||
# Inference: Generation of the output
|
||||
generated_ids = self.model.generate(**inputs, max_new_tokens=128)
|
||||
generated_ids_trimmed = [
|
||||
out_ids[len(in_ids) :]
|
||||
for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
||||
]
|
||||
output_text = self.processor.batch_decode(
|
||||
generated_ids_trimmed,
|
||||
skip_special_tokens=True,
|
||||
clean_up_tokenization_spaces=False,
|
||||
)
|
||||
print(output_text)
|
||||
@@ -0,0 +1,22 @@
|
||||
"""
|
||||
|
||||
A unified API interface support various VL models
|
||||
|
||||
|
||||
"""
|
||||
|
||||
from namo.api.qwen2_5_vl import Qwen2_5_VL
|
||||
from .namo import NamoVL
|
||||
|
||||
|
||||
class VLInfer:
|
||||
def __init__(self, model_type="qwen2.5-vl", device="auto"):
|
||||
if "qwen2.5-vl" in model_type:
|
||||
self.model = Qwen2_5_VL()
|
||||
elif "namo" in model_type.lower():
|
||||
self.model = NamoVL(device=device)
|
||||
else:
|
||||
raise ValueError(f"Unknown model type: {model_type}")
|
||||
|
||||
def generate(self, prompt, images, verbose=False):
|
||||
self.model.generate(prompt, images, verbose=verbose)
|
||||
@@ -0,0 +1,52 @@
|
||||
import argparse
|
||||
from namo.api.openai import start_server
|
||||
|
||||
|
||||
def handle_chat(args):
|
||||
print(f"Starting chat with model: {args.model}")
|
||||
print("Chat functionality is under development.")
|
||||
|
||||
|
||||
def handle_server(args):
|
||||
print("Starting the server...")
|
||||
start_server(ip=args.ip, port=args.port, model=args.model)
|
||||
|
||||
|
||||
def main():
|
||||
|
||||
parser = argparse.ArgumentParser(
|
||||
description="Namo CLI: A tool for chat and server management."
|
||||
)
|
||||
subparsers = parser.add_subparsers(dest="command", help="Available subcommands")
|
||||
|
||||
chat_parser = subparsers.add_parser("chat", help="Start a chat session")
|
||||
chat_parser.add_argument(
|
||||
"--model", type=str, help="Type of model or model local path."
|
||||
)
|
||||
chat_parser.set_defaults(func=handle_chat)
|
||||
|
||||
server_parser = subparsers.add_parser("server", help="Start the server")
|
||||
server_parser.add_argument(
|
||||
"--ip",
|
||||
type=str,
|
||||
default="127.0.0.1",
|
||||
help="The IP address to bind the server to",
|
||||
)
|
||||
server_parser.add_argument(
|
||||
"--port", type=int, default=8000, help="The port to run the server on"
|
||||
)
|
||||
server_parser.add_argument(
|
||||
"--model", type=str, help="Type of model or model local path."
|
||||
)
|
||||
server_parser.set_defaults(func=handle_server)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
if hasattr(args, "func"):
|
||||
args.func(args)
|
||||
else:
|
||||
parser.print_help()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -0,0 +1,78 @@
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional, List
|
||||
import transformers
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModelArguments:
|
||||
llm_model_path: Optional[str] = field(default="checkpoints/Qwen2.5-0.5B-Instruct")
|
||||
ve_model_path: Optional[str] = field(default="checkpoints/aimv2-large-patch14-224")
|
||||
ae_model_path: Optional[str] = None
|
||||
pretrain_model_path: Optional[str] = None
|
||||
version: Optional[str] = field(default="v0")
|
||||
freeze_backbone: bool = field(default=False)
|
||||
tune_conn_ve_llm: bool = field(default=False)
|
||||
mm_vision_select_layer: Optional[int] = field(default=-1)
|
||||
pretrain_conn_ve_llm_path: Optional[str] = field(default=None)
|
||||
pretrain_stage_1_5: Optional[str] = field(default=None)
|
||||
conn_ve_llm_type: Optional[str] = field(default="linear")
|
||||
mm_use_im_start_end: bool = field(default=False)
|
||||
mm_use_im_patch_token: bool = field(default=True)
|
||||
mm_patch_merge_type: Optional[str] = field(default="flat")
|
||||
mm_vision_select_feature: Optional[str] = field(default="patch")
|
||||
new_img_size: Optional[int] = field(default=None)
|
||||
max_img_size: Optional[int] = field(default=None)
|
||||
normalized_before_model: Optional[bool] = field(default=True)
|
||||
unfreeze_ve: bool = field(default=False)
|
||||
unfreeze_ve_layer_index: Optional[int] = field(default=None)
|
||||
s2: bool = field(default=False)
|
||||
s2_scales: Optional[str] = field(default="384,768")
|
||||
s2_max_split_size: int = field(default=384)
|
||||
|
||||
|
||||
@dataclass
|
||||
class DataArguments:
|
||||
data_path: Optional[List[str]] = field(
|
||||
default=None, metadata={"help": "Path to the training data."}
|
||||
)
|
||||
lazy_preprocess: bool = False
|
||||
is_multimodal: bool = False
|
||||
image_folder: Optional[str] = field(default=None)
|
||||
image_aspect_ratio: str = "square"
|
||||
video_frames_num: int = field(default=16)
|
||||
video_fps: Optional[int] = field(default=1)
|
||||
dynamic_size: bool = False
|
||||
native_size: bool = False
|
||||
|
||||
|
||||
@dataclass
|
||||
class TrainingArguments(transformers.TrainingArguments):
|
||||
cache_dir: Optional[str] = field(default=None)
|
||||
optim: str = field(default="adamw_torch")
|
||||
remove_unused_columns: bool = field(default=False)
|
||||
freeze_conn_ve_llm: bool = field(default=False)
|
||||
mpt_attn_impl: Optional[str] = field(default="triton")
|
||||
model_max_length: int = field(default=512)
|
||||
double_quant: bool = field(
|
||||
default=True,
|
||||
metadata={
|
||||
"help": "Compress the quantization statistics through double quantization."
|
||||
},
|
||||
)
|
||||
quant_type: str = field(
|
||||
default="nf4",
|
||||
metadata={
|
||||
"help": "Quantization data type to use. Should be one of `fp4` or `nf4`."
|
||||
},
|
||||
)
|
||||
bits: int = field(default=16, metadata={"help": "How many bits to use."})
|
||||
lora_enable: bool = False
|
||||
lora_r: int = 64
|
||||
lora_alpha: int = 16
|
||||
lora_dropout: float = 0.05
|
||||
lora_weight_path: str = ""
|
||||
lora_bias: str = "none"
|
||||
conn_ve_llm_lr: Optional[float] = None
|
||||
ve_lr: Optional[float] = None
|
||||
group_by_modality_length: bool = field(default=False)
|
||||
use_dora: bool = False
|
||||
@@ -0,0 +1,530 @@
|
||||
import copy
|
||||
from dataclasses import dataclass
|
||||
import json
|
||||
import os
|
||||
from typing import Dict, Sequence
|
||||
from PIL import Image
|
||||
import jsonlines
|
||||
import random
|
||||
import torch
|
||||
from torch.utils.data import Dataset
|
||||
import transformers
|
||||
from namo.dataargs import DataArguments
|
||||
from namo.models.symbols import (
|
||||
DEFAULT_IM_END_TOKEN,
|
||||
DEFAULT_IM_START_TOKEN,
|
||||
DEFAULT_IMAGE_TOKEN,
|
||||
DEFAULT_VIDEO_TOKEN,
|
||||
IGNORE_INDEX,
|
||||
)
|
||||
from namo.utils.process_utils import (
|
||||
convert_image_tags,
|
||||
get_suitable_size_hw,
|
||||
process_video_fixed_frames,
|
||||
resize_pad_images_to_target,
|
||||
)
|
||||
from namo.utils.utils import rank0_print
|
||||
from namo.utils import convs as conversation_lib
|
||||
from namo.utils.process_template import *
|
||||
|
||||
|
||||
def is_dynamic_size_input(keys):
|
||||
return "shortest_edge" in keys and "longest_edge" in keys
|
||||
|
||||
|
||||
def expand2square(pil_img, background_color):
|
||||
width, height = pil_img.size
|
||||
if width == height:
|
||||
return pil_img
|
||||
elif width > height:
|
||||
result = Image.new(pil_img.mode, (width, width), background_color)
|
||||
result.paste(pil_img, (0, (width - height) // 2))
|
||||
return result
|
||||
else:
|
||||
result = Image.new(pil_img.mode, (height, height), background_color)
|
||||
result.paste(pil_img, ((height - width) // 2, 0))
|
||||
return result
|
||||
|
||||
|
||||
def get_suitable_size(images, longest_edge=800):
|
||||
max_width = 0
|
||||
max_height = 0
|
||||
for image in images:
|
||||
if isinstance(image, list):
|
||||
image = image[0]
|
||||
width, height = image.size
|
||||
if width > max_width:
|
||||
max_width = width
|
||||
if height > max_height:
|
||||
max_height = height
|
||||
return min(max(max_width, max_height), longest_edge)
|
||||
|
||||
|
||||
def preprocess_multimodal(sources: Sequence[str], data_args: DataArguments) -> Dict:
|
||||
is_multimodal = data_args.is_multimodal
|
||||
if not is_multimodal:
|
||||
return sources
|
||||
|
||||
for source in sources:
|
||||
for sentence in source:
|
||||
if sentence["from"] != "gpt":
|
||||
sentence["value"] = sentence["value"].lstrip("\n")
|
||||
# possiably avoid <image> or <video> token exist in second or later turn
|
||||
if DEFAULT_IMAGE_TOKEN in sentence["value"]:
|
||||
images_num = sentence["value"].count(DEFAULT_IMAGE_TOKEN)
|
||||
if images_num == 1:
|
||||
sentence["value"] = (
|
||||
sentence["value"].replace(DEFAULT_IMAGE_TOKEN, "").strip()
|
||||
)
|
||||
sentence["value"] = (
|
||||
DEFAULT_IMAGE_TOKEN + "\n" + sentence["value"]
|
||||
)
|
||||
sentence["value"] = sentence["value"].strip()
|
||||
if "mmtag" in conversation_lib.default_conversation.version:
|
||||
sentence["value"] = sentence["value"].replace(
|
||||
DEFAULT_IMAGE_TOKEN,
|
||||
"<Image>" + DEFAULT_IMAGE_TOKEN + "</Image>",
|
||||
)
|
||||
else:
|
||||
# pass
|
||||
# make <image> <image> into: Image1<image>\nImage2<image>\n
|
||||
sentence["value"] = convert_image_tags(sentence["value"])
|
||||
# print(f'multi images {images_num} {sentence["value"]}')
|
||||
# multi images, keep they same as original position
|
||||
elif DEFAULT_VIDEO_TOKEN in sentence["value"]:
|
||||
# print(f'video {sentence}')
|
||||
# force <video> into video_frames_num * '<image> ' indicates frames
|
||||
sentence["value"] = (
|
||||
sentence["value"].replace(DEFAULT_VIDEO_TOKEN, "").strip()
|
||||
)
|
||||
sentence["value"] = (
|
||||
"video sequence frames in order:\n"
|
||||
+ f"{DEFAULT_IMAGE_TOKEN} " * data_args.video_frames_num
|
||||
+ "\n"
|
||||
+ sentence["value"]
|
||||
)
|
||||
# make <image> <image> into: 1<image>\n2<image>\n
|
||||
sentence["value"] = convert_image_tags(sentence["value"])
|
||||
replace_token = DEFAULT_IMAGE_TOKEN
|
||||
if data_args.mm_use_im_start_end:
|
||||
replace_token = (
|
||||
DEFAULT_IM_START_TOKEN + replace_token + DEFAULT_IM_END_TOKEN
|
||||
)
|
||||
sentence["value"] = sentence["value"].replace(
|
||||
DEFAULT_IMAGE_TOKEN, replace_token
|
||||
)
|
||||
return sources
|
||||
|
||||
|
||||
def preprocess(
|
||||
sources: Sequence[str],
|
||||
tokenizer: transformers.PreTrainedTokenizer,
|
||||
has_image: bool = False,
|
||||
) -> Dict:
|
||||
if (
|
||||
conversation_lib.default_conversation.sep_style
|
||||
== conversation_lib.SeparatorStyle.PLAIN
|
||||
):
|
||||
return preprocess_plain(sources, tokenizer)
|
||||
if conversation_lib.default_conversation.version == "qwen":
|
||||
return preprocess_qwen(sources, tokenizer, has_image=has_image)
|
||||
if conversation_lib.default_conversation.version == "llama3":
|
||||
return preprocess_llama3(sources, tokenizer, has_image=has_image)
|
||||
if conversation_lib.default_conversation.version == "mistral":
|
||||
return preprocess_mistral(sources, tokenizer, has_image=has_image)
|
||||
if conversation_lib.default_conversation.version == "gemma":
|
||||
return preprocess_gemma(sources, tokenizer, has_image=has_image)
|
||||
|
||||
|
||||
class LazySupervisedDataset(Dataset):
|
||||
"""Dataset for supervised fine-tuning."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
data_path: str,
|
||||
tokenizer: transformers.PreTrainedTokenizer,
|
||||
data_args: DataArguments,
|
||||
):
|
||||
super(LazySupervisedDataset, self).__init__()
|
||||
# list_data_dict = json.load(open(data_path, "r"))
|
||||
list_data_dict = []
|
||||
for data in data_path:
|
||||
if data.endswith("jsonl"):
|
||||
with jsonlines.open(data, mode="r") as reader:
|
||||
raw_data = [item for item in reader]
|
||||
else:
|
||||
raw_data = json.load(open(data, "r"))
|
||||
|
||||
for i in raw_data:
|
||||
if "conversations" in i.keys():
|
||||
i["id"] = len(list_data_dict)
|
||||
i["ds"] = os.path.basename(data).split(".")[0].split("_train")[0]
|
||||
list_data_dict.append(i)
|
||||
|
||||
rank0_print("Formatting inputs...Skip in lazy mode")
|
||||
self.tokenizer = tokenizer
|
||||
self.list_data_dict = list_data_dict
|
||||
random.shuffle(self.list_data_dict)
|
||||
self.data_args = data_args
|
||||
|
||||
def __len__(self):
|
||||
return len(self.list_data_dict)
|
||||
|
||||
@property
|
||||
def lengths(self):
|
||||
length_list = []
|
||||
for sample in self.list_data_dict:
|
||||
img_tokens = 128 if "image" in sample else 0
|
||||
length_list.append(
|
||||
sum(len(conv["value"].split()) for conv in sample["conversations"])
|
||||
+ img_tokens
|
||||
)
|
||||
return length_list
|
||||
|
||||
@property
|
||||
def modality_lengths(self):
|
||||
length_list = []
|
||||
for sample in self.list_data_dict:
|
||||
cur_len = sum(
|
||||
len(conv["value"].split()) for conv in sample["conversations"]
|
||||
)
|
||||
cur_len = cur_len if "image" in sample or "video" in sample else -cur_len
|
||||
length_list.append(cur_len)
|
||||
return length_list
|
||||
|
||||
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
|
||||
attempt, max_attempt = 0, 10
|
||||
while attempt < max_attempt:
|
||||
try:
|
||||
# sample an item
|
||||
data_dict = self._sample_item(i)
|
||||
# if data_dict is not None:
|
||||
break
|
||||
except Exception as e:
|
||||
attempt += 1
|
||||
print(f"Error in loading {i}, retrying...")
|
||||
import traceback
|
||||
|
||||
print(e)
|
||||
traceback.print_exc()
|
||||
i = random.randint(0, len(self.list_data_dict) - 1)
|
||||
return data_dict
|
||||
|
||||
def _sample_item(self, i) -> Dict[str, torch.Tensor]:
|
||||
image = None
|
||||
sources = self.list_data_dict[i]
|
||||
if isinstance(i, int):
|
||||
sources = [sources]
|
||||
assert len(sources) == 1, "Don't know why it is wrapped to a list" # FIXME
|
||||
if "image" in sources[0]:
|
||||
# image_file = self.list_data_dict[i]['image']
|
||||
# image_folder = self.data_args.image_folder
|
||||
# processor = self.data_args.image_processor
|
||||
# image = Image.open(os.path.join(image_folder, image_file)).convert('RGB')
|
||||
image_file = self.list_data_dict[i]["image"]
|
||||
|
||||
ds = self.list_data_dict[i]["ds"]
|
||||
image_folder = self.data_args.image_folder
|
||||
processor = self.data_args.image_processor
|
||||
# todo: consider multiple images input.
|
||||
if (
|
||||
("llava" in ds and "llavar" not in ds and "llava_recap" not in ds)
|
||||
or "sharegpt4v_instruct" in ds
|
||||
or "sharegpt4v_" in ds
|
||||
or "share-captioner" in ds
|
||||
or "gemini" in ds
|
||||
or "bunny_695k" in ds
|
||||
or "allava_laion" in ds
|
||||
or "multi_llava" in ds
|
||||
or "Cambrian7M" in ds
|
||||
or "c7s-" in ds
|
||||
or "ureader_tr" in ds
|
||||
):
|
||||
if isinstance(image_file, list):
|
||||
image = [
|
||||
Image.open(os.path.join(image_folder, img_f)).convert("RGB")
|
||||
for img_f in image_file
|
||||
]
|
||||
else:
|
||||
image = Image.open(os.path.join(image_folder, image_file)).convert(
|
||||
"RGB"
|
||||
)
|
||||
else:
|
||||
if "llavar" in ds:
|
||||
ds = "llavar"
|
||||
elif "bunny" in ds and "bunny_695k" not in ds:
|
||||
ds = "bunny_pretrain_laion_2m"
|
||||
elif "qa_" in ds:
|
||||
ds = "qa_data"
|
||||
elif "sharegpt4o" in ds:
|
||||
ds = "sharegpt4o/images"
|
||||
elif "mathv360k_cot" in ds:
|
||||
ds = "mathv360k_cot/images"
|
||||
|
||||
if isinstance(image_file, list):
|
||||
image = [
|
||||
Image.open(os.path.join(image_folder, ds, img_f)).convert("RGB")
|
||||
for img_f in image_file
|
||||
]
|
||||
else:
|
||||
image = Image.open(
|
||||
os.path.join(image_folder, ds, image_file)
|
||||
).convert("RGB")
|
||||
|
||||
# todo: checking image validness here.
|
||||
def is_valid_image(img):
|
||||
width, height = img.size
|
||||
# must bigger than 28 pixels
|
||||
if width > 14 and height > 14:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
if isinstance(image, list):
|
||||
for img in image:
|
||||
if not is_valid_image(img):
|
||||
rank0_print(f"Invalid image found, passing... {img.size}")
|
||||
raise ValueError(f"Invalid image found {img.size}")
|
||||
else:
|
||||
if not is_valid_image(image):
|
||||
rank0_print(f"Invalid image found, passing... {image.size}")
|
||||
raise ValueError(f"Invalid image found {image.size}")
|
||||
|
||||
if self.data_args.image_aspect_ratio == "pad":
|
||||
if (
|
||||
not (
|
||||
processor.size and is_dynamic_size_input(processor.size.keys())
|
||||
)
|
||||
and not self.data_args.dynamic_size
|
||||
):
|
||||
# for navit we dont need pad
|
||||
if isinstance(image, list):
|
||||
image = [
|
||||
expand2square(
|
||||
i, tuple(int(x * 255) for x in processor.image_mean)
|
||||
)
|
||||
for i in image
|
||||
]
|
||||
# only preprocess item by item when fixed sizes, otherwise do it in batch
|
||||
image = processor.preprocess(image, return_tensors="pt")[
|
||||
"pixel_values"
|
||||
]
|
||||
else:
|
||||
image = expand2square(
|
||||
image, tuple(int(x * 255) for x in processor.image_mean)
|
||||
)
|
||||
# only preprocess item by item when fixed sizes, otherwise do it in batch
|
||||
image = processor.preprocess(image, return_tensors="pt")[
|
||||
"pixel_values"
|
||||
][0]
|
||||
else:
|
||||
# print(processor.size)
|
||||
# does multiple images can be handled here?
|
||||
if (
|
||||
not (
|
||||
processor.size and is_dynamic_size_input(processor.size.keys())
|
||||
)
|
||||
and not self.data_args.dynamic_size
|
||||
):
|
||||
# only preprocess item by item when fixed sizes, otherwise do it in batch
|
||||
if isinstance(image, list):
|
||||
image = processor.preprocess(image, return_tensors="pt")[
|
||||
"pixel_values"
|
||||
]
|
||||
else:
|
||||
image = processor.preprocess(image, return_tensors="pt")[
|
||||
"pixel_values"
|
||||
][0]
|
||||
|
||||
# if muti img and not same with image token and real images num, force it.
|
||||
if isinstance(image_file, list) and sources[0]["conversations"][0][
|
||||
"value"
|
||||
].count(DEFAULT_IMAGE_TOKEN) != len(image_file):
|
||||
a = sources[0]["conversations"][0]["value"].replace(
|
||||
DEFAULT_IMAGE_TOKEN, ""
|
||||
)
|
||||
sources[0]["conversations"][0]["value"] = (
|
||||
f"{DEFAULT_IMAGE_TOKEN} " * len(image_file) + a
|
||||
)
|
||||
elif (
|
||||
isinstance(image_file, str)
|
||||
and sources[0]["conversations"][0]["value"].count(DEFAULT_IMAGE_TOKEN)
|
||||
> 1
|
||||
):
|
||||
# sometimes single image can have multiple <image> tag
|
||||
print(f"data single turn but got multiple <image>: {sources}")
|
||||
a = sources[0]["conversations"][0]["value"].replace(
|
||||
DEFAULT_IMAGE_TOKEN, ""
|
||||
)
|
||||
sources[0]["conversations"][0]["value"] = f"{DEFAULT_IMAGE_TOKEN} " + a
|
||||
|
||||
sources = preprocess_multimodal(
|
||||
copy.deepcopy([e["conversations"] for e in sources]), self.data_args
|
||||
)
|
||||
elif "image" not in sources[0] and "video" in sources[0]:
|
||||
# print("video sample")
|
||||
video_file = self.list_data_dict[i]["video"]
|
||||
ds = self.list_data_dict[i]["ds"]
|
||||
image_folder = self.data_args.image_folder
|
||||
video_file = os.path.join(image_folder, ds, video_file)
|
||||
|
||||
video = process_video_fixed_frames(
|
||||
video_file, self.data_args.video_fps, self.data_args.video_frames_num
|
||||
)
|
||||
processor = self.data_args.image_processor
|
||||
image = processor.preprocess(video, return_tensors="pt")["pixel_values"]
|
||||
sources = preprocess_multimodal(
|
||||
copy.deepcopy([e["conversations"] for e in sources]), self.data_args
|
||||
)
|
||||
else:
|
||||
sources = copy.deepcopy([e["conversations"] for e in sources])
|
||||
# print(f'sources : {sources}')
|
||||
data_dict = preprocess(
|
||||
sources,
|
||||
self.tokenizer,
|
||||
has_image=(
|
||||
"image" in self.list_data_dict[i] or "video" in self.list_data_dict[i]
|
||||
),
|
||||
)
|
||||
if isinstance(i, int):
|
||||
data_dict = dict(
|
||||
input_ids=data_dict["input_ids"][0], labels=data_dict["labels"][0]
|
||||
)
|
||||
|
||||
# image exist in the data
|
||||
if "image" in self.list_data_dict[i] or "video" in self.list_data_dict[i]:
|
||||
data_dict["image"] = image
|
||||
elif self.data_args.is_multimodal:
|
||||
# image does not exist in the data, but the model is multimodal
|
||||
# crop_size = self.data_args.image_processor.crop_size
|
||||
# data_dict['image'] = torch.zeros(3, crop_size['height'], crop_size['width'])
|
||||
if hasattr(self.data_args.image_processor, "crop_size"):
|
||||
crop_size = self.data_args.image_processor.crop_size
|
||||
if self.data_args.dynamic_size:
|
||||
data_dict["image"] = Image.new("RGB", (448, 448), (0, 0, 0))
|
||||
else:
|
||||
data_dict["image"] = torch.zeros(
|
||||
3, crop_size["height"], crop_size["width"]
|
||||
)
|
||||
else:
|
||||
processor = self.data_args.image_processor
|
||||
size = processor.size
|
||||
if not (
|
||||
processor.size and is_dynamic_size_input(processor.size.keys())
|
||||
):
|
||||
data_dict["image"] = torch.zeros(3, size["height"], size["width"])
|
||||
else:
|
||||
# fake for pure text in navit
|
||||
data_dict["image"] = Image.new("RGB", (448, 448), (0, 0, 0))
|
||||
# print(data_dict)
|
||||
return data_dict
|
||||
|
||||
|
||||
@dataclass
|
||||
class DataCollatorForSupervisedDataset(object):
|
||||
"""Collate examples for supervised fine-tuning."""
|
||||
|
||||
tokenizer: transformers.PreTrainedTokenizer
|
||||
data_args: DataArguments
|
||||
|
||||
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
|
||||
input_ids, labels = tuple(
|
||||
[instance[key] for instance in instances] for key in ("input_ids", "labels")
|
||||
)
|
||||
input_ids = torch.nn.utils.rnn.pad_sequence(
|
||||
input_ids, batch_first=True, padding_value=self.tokenizer.pad_token_id
|
||||
)
|
||||
labels = torch.nn.utils.rnn.pad_sequence(
|
||||
labels, batch_first=True, padding_value=IGNORE_INDEX
|
||||
)
|
||||
input_ids = input_ids[:, : self.tokenizer.model_max_length]
|
||||
labels = labels[:, : self.tokenizer.model_max_length]
|
||||
batch = dict(
|
||||
input_ids=input_ids,
|
||||
labels=labels,
|
||||
attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
|
||||
)
|
||||
|
||||
if "image" in instances[0]:
|
||||
if isinstance(instances[0]["image"], torch.Tensor):
|
||||
images = [instance["image"] for instance in instances]
|
||||
if all(
|
||||
x is not None and x.shape[-2:] == images[0].shape[-2:]
|
||||
for x in images
|
||||
):
|
||||
batch["pixel_values"] = torch.cat(
|
||||
[i.unsqueeze(0) if len(i.shape) == 3 else i for i in images],
|
||||
dim=0,
|
||||
)
|
||||
else:
|
||||
batch["pixel_values"] = images
|
||||
else:
|
||||
# handle various sizes image inputs
|
||||
images = [instance["image"] for instance in instances]
|
||||
images = [
|
||||
item
|
||||
for sublist in images
|
||||
for item in (sublist if isinstance(sublist, list) else [sublist])
|
||||
]
|
||||
if self.data_args.dynamic_size:
|
||||
# size = get_suitable_size(images)
|
||||
|
||||
if self.data_args.native_size:
|
||||
batch["pixel_values"] = [
|
||||
self.data_args.image_processor.preprocess(
|
||||
img,
|
||||
return_tensors="pt",
|
||||
)["pixel_values"]
|
||||
for img in images
|
||||
]
|
||||
else:
|
||||
size = get_suitable_size_hw(
|
||||
images, longest_edge=self.data_args.longest_edge
|
||||
)
|
||||
images = resize_pad_images_to_target(images, size)
|
||||
images_tensor = self.data_args.image_processor.preprocess(
|
||||
images,
|
||||
return_tensors="pt",
|
||||
# size={"width": size, "height": size},
|
||||
)
|
||||
batch["pixel_values"] = images_tensor["pixel_values"]
|
||||
else:
|
||||
images_tensor = self.data_args.image_processor.preprocess(
|
||||
images, return_tensors="pt"
|
||||
)
|
||||
batch["pixel_values"] = images_tensor["pixel_values"]
|
||||
|
||||
if not isinstance(batch["pixel_values"], list):
|
||||
if "pixel_attention_mask" in images_tensor:
|
||||
batch["pixel_attention_mask"] = images_tensor[
|
||||
"pixel_attention_mask"
|
||||
][0]
|
||||
# this will goes to Navit
|
||||
# print('does it got pixeltteionamsk? ------------>')
|
||||
return batch
|
||||
|
||||
|
||||
def make_supervised_data_module(
|
||||
tokenizer: transformers.PreTrainedTokenizer,
|
||||
data_args,
|
||||
model_args,
|
||||
) -> Dict:
|
||||
"""Make dataset and collator for supervised fine-tuning."""
|
||||
if model_args.version in conversation_lib.conv_templates:
|
||||
conversation_lib.default_conversation = conversation_lib.conv_templates[
|
||||
model_args.version
|
||||
]
|
||||
else:
|
||||
conversation_lib.default_conversation = conversation_lib.conv_templates[
|
||||
"vicuna_v1"
|
||||
]
|
||||
|
||||
train_dataset = LazySupervisedDataset(
|
||||
tokenizer=tokenizer, data_path=data_args.data_path, data_args=data_args
|
||||
)
|
||||
data_collator = DataCollatorForSupervisedDataset(
|
||||
tokenizer=tokenizer, data_args=data_args
|
||||
)
|
||||
return dict(
|
||||
train_dataset=train_dataset, eval_dataset=None, data_collator=data_collator
|
||||
)
|
||||
@@ -0,0 +1,745 @@
|
||||
from copy import deepcopy
|
||||
import io
|
||||
import json
|
||||
import random
|
||||
import numpy as np
|
||||
import torch
|
||||
from PIL import Image
|
||||
from namo.dataset import expand2square
|
||||
from namo.models.symbols import IGNORE_INDEX
|
||||
|
||||
from torch.utils.data import ConcatDataset, WeightedRandomSampler
|
||||
from loguru import logger
|
||||
|
||||
import torch.nn.functional as F
|
||||
import torchvision.transforms as T
|
||||
from torchvision.transforms.functional import InterpolationMode
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
|
||||
class WeightedConcatDataset(ConcatDataset):
|
||||
def __init__(self, datasets, weights):
|
||||
super().__init__(datasets)
|
||||
self.weights = torch.DoubleTensor(weights)
|
||||
self.total_size = sum(len(d) for d in datasets)
|
||||
self.sampler = WeightedRandomSampler(
|
||||
weights=self.weights, num_samples=self.total_size, replacement=True
|
||||
)
|
||||
|
||||
def __iter__(self):
|
||||
return iter(self.sampler)
|
||||
|
||||
def __len__(self):
|
||||
return self.total_size
|
||||
|
||||
|
||||
def dpo_concat_pad_data_collator(features, pad_id=0):
|
||||
|
||||
first = features[0]
|
||||
batch = {}
|
||||
|
||||
for prefix in ["chosen_", "rejected_"]:
|
||||
batch_lens = [feat[f"{prefix}input_ids"].shape[0] for feat in features]
|
||||
max_item_length = max(batch_lens)
|
||||
for idx in range(len(features)):
|
||||
feat = features[idx]
|
||||
temp_input_ids = torch.LongTensor([pad_id] * max_item_length)
|
||||
temp_input_ids[: feat[f"{prefix}input_ids"].shape[0]] = feat[
|
||||
f"{prefix}input_ids"
|
||||
]
|
||||
feat[f"{prefix}input_ids"] = temp_input_ids
|
||||
temp_labels = torch.LongTensor([IGNORE_INDEX] * max_item_length)
|
||||
temp_labels[: feat[f"{prefix}labels"].shape[0]] = feat[f"{prefix}labels"]
|
||||
feat[f"{prefix}labels"] = temp_labels
|
||||
feat[f"{prefix}attention_mask"] = feat[f"{prefix}input_ids"].ne(pad_id)
|
||||
|
||||
# Handling of all other possible keys.
|
||||
# Again, we will use the first element to figure out which key/values are not None for this model.
|
||||
for k, v in first.items():
|
||||
if (
|
||||
k not in ("pixel_values", "image_flags")
|
||||
and v is not None
|
||||
and not isinstance(v, str)
|
||||
):
|
||||
if isinstance(v, torch.Tensor):
|
||||
batch[k] = torch.stack([f[k] for f in features])
|
||||
elif isinstance(v, np.ndarray):
|
||||
batch[k] = torch.tensor(np.stack([f[k] for f in features]))
|
||||
else:
|
||||
batch[k] = torch.tensor([f[k] for f in features])
|
||||
if k in ("pixel_values", "image_flags"):
|
||||
if isinstance(v, torch.Tensor):
|
||||
batch[k] = torch.concat([f[k] for f in features])
|
||||
elif isinstance(v, np.ndarray):
|
||||
batch[k] = torch.concat(np.stack([f[k] for f in features]))
|
||||
else:
|
||||
batch[k] = torch.concat([f[k] for f in features])
|
||||
return batch
|
||||
|
||||
|
||||
def simulate_jpeg_degradation(quality):
|
||||
def jpeg_degrade(img):
|
||||
with io.BytesIO() as output:
|
||||
img.convert("RGB").save(output, format="JPEG", quality=quality)
|
||||
output.seek(0) # Move the reading cursor to the start of the stream
|
||||
img_jpeg = Image.open(
|
||||
output
|
||||
).copy() # Use .copy() to make sure the image is loaded in memory
|
||||
return img_jpeg
|
||||
|
||||
return jpeg_degrade
|
||||
|
||||
|
||||
qualities = list(range(75, 101))
|
||||
jpeg_degrade_functions = {
|
||||
quality: simulate_jpeg_degradation(quality) for quality in qualities
|
||||
}
|
||||
|
||||
|
||||
def build_transform(is_train, input_size, pad2square=False, normalize_type="imagenet"):
|
||||
if normalize_type == "imagenet":
|
||||
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
|
||||
elif normalize_type == "clip":
|
||||
MEAN, STD = CLIP_MEAN, CLIP_STD
|
||||
elif normalize_type == "siglip":
|
||||
MEAN, STD = SIGLIP_MEAN, SIGLIP_STD
|
||||
else:
|
||||
raise NotImplementedError
|
||||
if is_train: # use data augumentation
|
||||
transform = T.Compose(
|
||||
[
|
||||
T.Lambda(lambda img: img.convert("RGB") if img.mode != "RGB" else img),
|
||||
T.RandomChoice(
|
||||
[T.Lambda(jpeg_degrade_functions[quality]) for quality in qualities]
|
||||
),
|
||||
T.Resize(
|
||||
(input_size, input_size), interpolation=InterpolationMode.BICUBIC
|
||||
),
|
||||
T.ToTensor(),
|
||||
T.Normalize(mean=MEAN, std=STD),
|
||||
]
|
||||
)
|
||||
else:
|
||||
if pad2square is False: # now we use this transform function by default
|
||||
transform = T.Compose(
|
||||
[
|
||||
T.Lambda(
|
||||
lambda img: img.convert("RGB") if img.mode != "RGB" else img
|
||||
),
|
||||
T.Resize(
|
||||
(input_size, input_size),
|
||||
interpolation=InterpolationMode.BICUBIC,
|
||||
),
|
||||
T.ToTensor(),
|
||||
T.Normalize(mean=MEAN, std=STD),
|
||||
]
|
||||
)
|
||||
else:
|
||||
transform = T.Compose(
|
||||
[
|
||||
T.Lambda(
|
||||
lambda img: img.convert("RGB") if img.mode != "RGB" else img
|
||||
),
|
||||
T.Lambda(
|
||||
lambda img: expand2square(
|
||||
img, tuple(int(x * 255) for x in MEAN)
|
||||
)
|
||||
),
|
||||
T.Resize(
|
||||
(input_size, input_size),
|
||||
interpolation=InterpolationMode.BICUBIC,
|
||||
),
|
||||
T.ToTensor(),
|
||||
T.Normalize(mean=MEAN, std=STD),
|
||||
]
|
||||
)
|
||||
|
||||
return transform
|
||||
|
||||
|
||||
class LazySupervisedDataset(Dataset):
|
||||
"""Dataset for supervised fine-tuning."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
template_name,
|
||||
meta,
|
||||
tokenizer,
|
||||
tcs_loader,
|
||||
ds_name,
|
||||
num_image_token,
|
||||
image_size=448,
|
||||
is_train=True,
|
||||
pad2square=False,
|
||||
group_by_length=False,
|
||||
dynamic_image_size=False,
|
||||
use_thumbnail=False,
|
||||
min_dynamic_patch=1,
|
||||
max_dynamic_patch=12,
|
||||
min_num_frame=8, # for video data
|
||||
max_num_frame=32, # for video data
|
||||
sampling_method="rand", # for video data
|
||||
repeat_time=1,
|
||||
normalize_type="imagenet",
|
||||
random_seed=0,
|
||||
):
|
||||
super(LazySupervisedDataset, self).__init__()
|
||||
self.ds_name = ds_name
|
||||
self.tokenizer = tokenizer
|
||||
self.template_name = template_name
|
||||
self.num_image_token = num_image_token
|
||||
logger.info(f"[Dataset] num_image_token: {num_image_token}")
|
||||
logger.info(f"[Dataset] dynamic_image_size: {dynamic_image_size}")
|
||||
logger.info(f"[Dataset] use_thumbnail: {use_thumbnail}")
|
||||
logger.info(
|
||||
f"[Dataset] min_dynamic_patch: {min_dynamic_patch}, max_dynamic_patch: {max_dynamic_patch}"
|
||||
)
|
||||
|
||||
self.image_size = image_size
|
||||
self.is_train = is_train
|
||||
self.pad2square = pad2square
|
||||
self.max_num_frame = max_num_frame
|
||||
self.min_num_frame = min_num_frame
|
||||
self.sampling_method = sampling_method
|
||||
|
||||
logger.info("Formatting inputs...Skip in lazy mode")
|
||||
assert meta["annotation"].endswith(
|
||||
"jsonl"
|
||||
), f'annotation must be jsonl, but got {meta["annotation"]}'
|
||||
|
||||
with open(meta["annotation"], "r") as f:
|
||||
self.raw_data = f.readlines()
|
||||
if repeat_time < 1:
|
||||
# If repeat_time is less than 1, select a portion of the data
|
||||
self.raw_data = random.sample(
|
||||
self.raw_data, k=int(len(self.raw_data) * repeat_time)
|
||||
)
|
||||
if repeat_time > 1:
|
||||
repeat_time = int(repeat_time)
|
||||
assert isinstance(repeat_time, int)
|
||||
# Repeat the list if repeat_time is greater than 1
|
||||
self.raw_data = self.raw_data * repeat_time
|
||||
|
||||
self.rng = np.random.default_rng(seed=random_seed)
|
||||
self.rng.shuffle(self.raw_data)
|
||||
|
||||
self.root = meta["root"]
|
||||
self.cached_data_dict = {}
|
||||
self.tcs_loader = tcs_loader
|
||||
self.group_by_length = group_by_length
|
||||
self.dynamic_image_size = dynamic_image_size
|
||||
self.use_thumbnail = use_thumbnail
|
||||
self.min_dynamic_patch = min_dynamic_patch
|
||||
self.max_dynamic_patch = max_dynamic_patch
|
||||
self.normalize_type = normalize_type
|
||||
|
||||
# If the precomputed length does not exist, roughly estimate the length of
|
||||
# each sample to improve the efficiency of group_by_length.
|
||||
if self.group_by_length:
|
||||
self.conv2length = (
|
||||
{}
|
||||
) # Using a dictionary to speed up token length calculation
|
||||
self.length = []
|
||||
for data_item in self.raw_data:
|
||||
data_item = json.loads(data_item)
|
||||
if "length" in data_item:
|
||||
token_length = data_item[
|
||||
"length"
|
||||
] # Use precomputed length if available
|
||||
else:
|
||||
# Compute token length using the tokenizer
|
||||
conversations = "\n".join(
|
||||
[temp["value"] for temp in data_item["conversations"]]
|
||||
)
|
||||
str_length = len(conversations)
|
||||
if str_length not in self.conv2length:
|
||||
token_length = tokenizer(
|
||||
conversations,
|
||||
return_tensors="pt",
|
||||
padding=False,
|
||||
truncation=False,
|
||||
).input_ids.size(1)
|
||||
self.conv2length[str_length] = (
|
||||
token_length
|
||||
+ num_image_token * (max_dynamic_patch + use_thumbnail)
|
||||
)
|
||||
else:
|
||||
token_length = self.conv2length[str_length]
|
||||
self.length.append(token_length)
|
||||
|
||||
def __len__(self):
|
||||
return len(self.raw_data)
|
||||
|
||||
def get_preprocess_function(self):
|
||||
# Select the appropriate preprocessing function based on the template name
|
||||
if self.template_name == "Hermes-2":
|
||||
preprocess_function = preprocess_mpt
|
||||
elif self.template_name == "internlm2-chat":
|
||||
preprocess_function = preprocess_internlm
|
||||
elif self.template_name == "phi3-chat":
|
||||
preprocess_function = preprocess_phi3
|
||||
elif self.template_name == "internvl2_5":
|
||||
preprocess_function = preprocess_internvl2_5
|
||||
else:
|
||||
preprocess_function = preprocess
|
||||
return preprocess_function
|
||||
|
||||
def load_image(self, image_path):
|
||||
# Load the image using tcs_loader if available, otherwise use PIL
|
||||
if self.tcs_loader is not None and "s3://" in image_path:
|
||||
return self.tcs_loader(image_path)
|
||||
return Image.open(image_path).convert("RGB")
|
||||
|
||||
def get_image_path(self, image_path):
|
||||
if image_path.startswith("s3://"): # for ceph
|
||||
image_path = self.root + image_path
|
||||
else: # for local image
|
||||
image_path = os.path.join(self.root, image_path)
|
||||
return image_path
|
||||
|
||||
def get_transform(self):
|
||||
# Build transformation function
|
||||
transform = build_transform(
|
||||
is_train=self.is_train,
|
||||
input_size=self.image_size,
|
||||
pad2square=self.pad2square,
|
||||
normalize_type=self.normalize_type,
|
||||
)
|
||||
return transform
|
||||
|
||||
@staticmethod
|
||||
def get_longest_common_prefix_index(tensor1, tensor2):
|
||||
min_len = min(len(tensor1), len(tensor2))
|
||||
|
||||
for i in range(min_len):
|
||||
if tensor1[i] != tensor2[i]:
|
||||
return i
|
||||
|
||||
return min_len
|
||||
|
||||
def multi_modal_get_item(self, data_item):
|
||||
# Build transformation function
|
||||
transform = self.get_transform()
|
||||
|
||||
# Ensure the first conversation contains an image placeholder
|
||||
if "<image>" not in data_item["question"]:
|
||||
data_item["question"] = "<image>\n" + data_item["question"]
|
||||
|
||||
# Merge the image path
|
||||
image_path = self.get_image_path(data_item["image"])
|
||||
|
||||
# Load the image using tcs_loader if available, otherwise use PIL
|
||||
image = self.load_image(image_path)
|
||||
|
||||
if (
|
||||
self.dynamic_image_size
|
||||
): # If dynamic image size is enabled, preprocess the image dynamically
|
||||
images = dynamic_preprocess(
|
||||
image,
|
||||
min_num=self.min_dynamic_patch,
|
||||
max_num=self.max_dynamic_patch,
|
||||
image_size=self.image_size,
|
||||
use_thumbnail=self.use_thumbnail,
|
||||
)
|
||||
else: # Otherwise, use the original image as a single patch
|
||||
images = [image]
|
||||
|
||||
# Apply the transformation to each image and stack the results into a tensor
|
||||
pixel_values = [transform(image) for image in images]
|
||||
pixel_values = torch.stack(pixel_values)
|
||||
|
||||
# Ensure that there is only one patch if dynamic image size is not enabled
|
||||
num_patches = pixel_values.size(0)
|
||||
if not self.dynamic_image_size:
|
||||
assert (
|
||||
num_patches == 1
|
||||
), f"The number of patches should be 1, but got {num_patches}."
|
||||
|
||||
# Select the appropriate preprocessing function based on the template name
|
||||
preprocess_function = self.get_preprocess_function()
|
||||
|
||||
# Preprocess the conversations and generate the return dictionary
|
||||
chosen_conversations = [
|
||||
{"from": "human", "value": data_item["question"]},
|
||||
{"from": "gpt", "value": data_item["chosen"]},
|
||||
]
|
||||
chosen_ret = preprocess_function(
|
||||
self.template_name,
|
||||
[deepcopy(chosen_conversations)],
|
||||
self.tokenizer,
|
||||
[self.num_image_token * num_patches],
|
||||
group_by_length=True,
|
||||
ds_name=self.ds_name,
|
||||
)
|
||||
|
||||
rejected_conversations = [
|
||||
{"from": "human", "value": data_item["question"]},
|
||||
{"from": "gpt", "value": data_item["rejected"]},
|
||||
]
|
||||
rejected_ret = preprocess_function(
|
||||
self.template_name,
|
||||
[deepcopy(rejected_conversations)],
|
||||
self.tokenizer,
|
||||
[self.num_image_token * num_patches],
|
||||
group_by_length=True,
|
||||
ds_name=self.ds_name,
|
||||
)
|
||||
|
||||
# Create the final return dictionary
|
||||
ret = dict(
|
||||
chosen_input_ids=chosen_ret["input_ids"][0],
|
||||
chosen_labels=chosen_ret["labels"][0],
|
||||
chosen_attention_mask=chosen_ret["attention_mask"][0],
|
||||
rejected_input_ids=rejected_ret["input_ids"][0],
|
||||
rejected_labels=rejected_ret["labels"][0],
|
||||
rejected_attention_mask=rejected_ret["attention_mask"][0],
|
||||
pixel_values=pixel_values,
|
||||
image_flags=torch.tensor([1] * num_patches, dtype=torch.long),
|
||||
)
|
||||
return ret
|
||||
|
||||
def multi_modal_multi_image_get_item(self, data_item):
|
||||
# Build transformation function
|
||||
transform = self.get_transform()
|
||||
|
||||
images, num_tiles = [], []
|
||||
num_image = len(data_item["image"])
|
||||
for image_path in data_item["image"]:
|
||||
# Merge the image path
|
||||
image_path = self.get_image_path(image_path)
|
||||
# Load the image using tcs_loader if available, otherwise use PIL
|
||||
image = self.load_image(image_path)
|
||||
if (
|
||||
self.dynamic_image_size
|
||||
): # If dynamic image size is enabled, preprocess the image dynamically
|
||||
image = dynamic_preprocess(
|
||||
image,
|
||||
min_num=self.min_dynamic_patch,
|
||||
max_num=max(1, self.max_dynamic_patch // num_image),
|
||||
image_size=self.image_size,
|
||||
use_thumbnail=self.use_thumbnail,
|
||||
)
|
||||
images += image
|
||||
num_tiles.append(len(image))
|
||||
else: # Otherwise, use the original image as a single patch
|
||||
images.append(image)
|
||||
num_tiles.append(1)
|
||||
pixel_values = [transform(image) for image in images]
|
||||
pixel_values = torch.stack(pixel_values)
|
||||
num_patches = pixel_values.size(0)
|
||||
|
||||
# Select the appropriate preprocessing function based on the template name
|
||||
preprocess_function = self.get_preprocess_function()
|
||||
|
||||
# Preprocess the conversations and generate the return dictionary
|
||||
num_image_tokens = [self.num_image_token * num_tile for num_tile in num_tiles]
|
||||
|
||||
chosen_conversations = [
|
||||
{"from": "human", "value": data_item["question"]},
|
||||
{"from": "gpt", "value": data_item["chosen"]},
|
||||
]
|
||||
chosen_ret = preprocess_function(
|
||||
self.template_name,
|
||||
[deepcopy(chosen_conversations)],
|
||||
self.tokenizer,
|
||||
num_image_tokens,
|
||||
group_by_length=self.group_by_length,
|
||||
ds_name=self.ds_name,
|
||||
num_image=num_image,
|
||||
)
|
||||
|
||||
rejected_conversations = [
|
||||
{"from": "human", "value": data_item["question"]},
|
||||
{"from": "gpt", "value": data_item["rejected"]},
|
||||
]
|
||||
rejected_ret = preprocess_function(
|
||||
self.template_name,
|
||||
[deepcopy(rejected_conversations)],
|
||||
self.tokenizer,
|
||||
num_image_tokens,
|
||||
group_by_length=self.group_by_length,
|
||||
ds_name=self.ds_name,
|
||||
num_image=num_image,
|
||||
)
|
||||
|
||||
# Create the final return dictionary
|
||||
ret = dict(
|
||||
chosen_input_ids=chosen_ret["input_ids"][0],
|
||||
chosen_labels=chosen_ret["labels"][0],
|
||||
chosen_attention_mask=chosen_ret["attention_mask"][0],
|
||||
rejected_input_ids=rejected_ret["input_ids"][0],
|
||||
rejected_labels=rejected_ret["labels"][0],
|
||||
rejected_attention_mask=rejected_ret["attention_mask"][0],
|
||||
pixel_values=pixel_values,
|
||||
image_flags=torch.tensor([1] * num_patches, dtype=torch.long),
|
||||
)
|
||||
return ret
|
||||
|
||||
def video_get_item(self, data_item):
|
||||
# Build transformation function
|
||||
transform = self.get_transform()
|
||||
|
||||
# Ensure the first conversation contains a video placeholder
|
||||
if "<video>" not in data_item["question"]:
|
||||
data_item["question"] = "<video>\n" + data_item["question"]
|
||||
|
||||
# Get the video file path
|
||||
video_file = data_item["video"]
|
||||
video_path = os.path.join(self.root, video_file)
|
||||
|
||||
# Load the video frames using tcs_loader
|
||||
# TODO: Load videos without using tcsloader.
|
||||
image_list = self.tcs_loader(
|
||||
video_path,
|
||||
image_type="video",
|
||||
max_num_frames=self.max_num_frame,
|
||||
min_num_frames=self.min_num_frame,
|
||||
sample=self.sampling_method,
|
||||
clip=data_item.get("clip", None),
|
||||
)
|
||||
|
||||
# Generate special tokens for each video frame
|
||||
special_tokens = "\n".join(
|
||||
["Frame{}: <image>".format(i + 1) for i in range(len(image_list))]
|
||||
)
|
||||
data_item["question"] = data_item["question"].replace(
|
||||
"<video>\n", special_tokens
|
||||
)
|
||||
|
||||
# Transform each frame image and stack them into a tensor
|
||||
pixel_values = [transform(image) for image in image_list]
|
||||
pixel_values = torch.stack(pixel_values)
|
||||
num_patches = pixel_values.size(0)
|
||||
|
||||
# Select the appropriate preprocessing function based on the template name
|
||||
preprocess_function = self.get_preprocess_function()
|
||||
|
||||
# Preprocess the conversations and generate the return dictionary
|
||||
num_image_tokens = [self.num_image_token] * num_patches
|
||||
|
||||
chosen_conversations = [
|
||||
{"from": "human", "value": data_item["question"]},
|
||||
{"from": "gpt", "value": data_item["chosen"]},
|
||||
]
|
||||
chosen_ret = preprocess_function(
|
||||
self.template_name,
|
||||
[deepcopy(chosen_conversations)],
|
||||
self.tokenizer,
|
||||
num_image_tokens,
|
||||
group_by_length=True,
|
||||
use_packed_ds=self.use_packed_ds,
|
||||
ds_name=self.ds_name,
|
||||
num_image=num_patches,
|
||||
)
|
||||
|
||||
rejected_conversations = [
|
||||
{"from": "human", "value": data_item["question"]},
|
||||
{"from": "gpt", "value": data_item["rejected"]},
|
||||
]
|
||||
rejected_ret = preprocess_function(
|
||||
self.template_name,
|
||||
[deepcopy(rejected_conversations)],
|
||||
self.tokenizer,
|
||||
num_image_tokens,
|
||||
group_by_length=True,
|
||||
use_packed_ds=self.use_packed_ds,
|
||||
ds_name=self.ds_name,
|
||||
num_image=num_patches,
|
||||
)
|
||||
|
||||
ret = dict(
|
||||
chosen_input_ids=chosen_ret["input_ids"][0],
|
||||
chosen_labels=chosen_ret["labels"][0],
|
||||
chosen_attention_mask=chosen_ret["attention_mask"][0],
|
||||
rejected_input_ids=rejected_ret["input_ids"][0],
|
||||
rejected_labels=rejected_ret["labels"][0],
|
||||
rejected_attention_mask=rejected_ret["attention_mask"][0],
|
||||
pixel_values=pixel_values,
|
||||
image_flags=torch.tensor([1] * num_patches, dtype=torch.long),
|
||||
)
|
||||
return ret
|
||||
|
||||
def pure_text_get_item(self, data_item):
|
||||
# Build transformation function
|
||||
transform = self.get_transform()
|
||||
|
||||
# Create a blank white image
|
||||
image = Image.new("RGB", (224, 224), (255, 255, 255))
|
||||
|
||||
# Dynamically preprocess the image to generate patches
|
||||
images = dynamic_preprocess(
|
||||
image,
|
||||
min_num=self.min_dynamic_patch,
|
||||
max_num=1,
|
||||
image_size=self.image_size,
|
||||
use_thumbnail=self.use_thumbnail,
|
||||
)
|
||||
|
||||
# Apply the transformation to each image patch and stack them into a tensor
|
||||
pixel_values = [transform(image) for image in images]
|
||||
pixel_values = torch.stack(pixel_values)
|
||||
num_patches = pixel_values.size(0)
|
||||
|
||||
# Ensure there is only one patch
|
||||
assert (
|
||||
num_patches == 1
|
||||
), f"The number of patches should be 1, but got {num_patches}."
|
||||
|
||||
# Select the appropriate preprocessing function based on the template name
|
||||
preprocess_function = self.get_preprocess_function()
|
||||
|
||||
# Preprocess the conversations and generate the return dictionary
|
||||
chosen_conversations = [
|
||||
{"from": "human", "value": data_item["question"]},
|
||||
{"from": "gpt", "value": data_item["chosen"]},
|
||||
]
|
||||
chosen_ret = preprocess_function(
|
||||
self.template_name,
|
||||
[deepcopy(chosen_conversations)],
|
||||
self.tokenizer,
|
||||
[self.num_image_token * num_patches],
|
||||
text_only=True,
|
||||
group_by_length=True,
|
||||
ds_name=self.ds_name,
|
||||
)
|
||||
|
||||
rejected_conversations = [
|
||||
{"from": "human", "value": data_item["question"]},
|
||||
{"from": "gpt", "value": data_item["rejected"]},
|
||||
]
|
||||
rejected_ret = preprocess_function(
|
||||
self.template_name,
|
||||
[deepcopy(rejected_conversations)],
|
||||
self.tokenizer,
|
||||
[self.num_image_token * num_patches],
|
||||
text_only=True,
|
||||
group_by_length=True,
|
||||
ds_name=self.ds_name,
|
||||
)
|
||||
|
||||
# Create the final return dictionary
|
||||
ret = dict(
|
||||
chosen_input_ids=chosen_ret["input_ids"][0],
|
||||
chosen_labels=chosen_ret["labels"][0],
|
||||
chosen_attention_mask=chosen_ret["attention_mask"][0],
|
||||
rejected_input_ids=rejected_ret["input_ids"][0],
|
||||
rejected_labels=rejected_ret["labels"][0],
|
||||
rejected_attention_mask=rejected_ret["attention_mask"][0],
|
||||
pixel_values=pixel_values,
|
||||
image_flags=torch.tensor([0] * num_patches, dtype=torch.long),
|
||||
)
|
||||
return ret
|
||||
|
||||
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
|
||||
i = i % len(self.raw_data)
|
||||
|
||||
try_cnt, max_try = 0, 10
|
||||
while True:
|
||||
if try_cnt > max_try:
|
||||
raise StopIteration
|
||||
try:
|
||||
data_item = json.loads(self.raw_data[i])
|
||||
if "image" in data_item and len(data_item["image"]) != 0:
|
||||
if type(data_item["image"]) == list:
|
||||
ret = self.multi_modal_multi_image_get_item(data_item)
|
||||
else:
|
||||
ret = self.multi_modal_get_item(data_item)
|
||||
elif (
|
||||
"video" in data_item
|
||||
and data_item["video"] is not None
|
||||
and data_item["video"] != ""
|
||||
):
|
||||
ret = self.video_get_item(data_item)
|
||||
else:
|
||||
ret = self.pure_text_get_item(data_item)
|
||||
break
|
||||
except Exception as e:
|
||||
try_cnt += 1
|
||||
print(e, self.ds_name, flush=True)
|
||||
if not isinstance(e, (UnidentifiedImageError, FileNotFoundError)):
|
||||
traceback.print_exc()
|
||||
data_item = json.loads(self.raw_data[i])
|
||||
if "image" in data_item:
|
||||
if type(data_item["image"]) == list:
|
||||
images = [self.root + item for item in data_item["image"]]
|
||||
print(
|
||||
f"Failed to load image: {images}, the dataset is: {self.ds_name}"
|
||||
)
|
||||
else:
|
||||
if data_item["image"].startswith("s3://"):
|
||||
data_path = self.root + data_item["image"]
|
||||
else:
|
||||
data_path = os.path.join(self.root, data_item["image"])
|
||||
print(
|
||||
f"Failed to load image: {data_path}, the dataset is: {self.ds_name}"
|
||||
)
|
||||
elif "video" in data_item:
|
||||
data_path = os.path.join(self.root, data_item["video"])
|
||||
print(
|
||||
f"Failed to load video: {data_path}, the dataset is: {self.ds_name}"
|
||||
)
|
||||
i = random.randint(0, len(self.raw_data) - 1)
|
||||
return ret
|
||||
|
||||
|
||||
def build_datasets(
|
||||
data_args,
|
||||
tokenizer,
|
||||
tcs_loader,
|
||||
model,
|
||||
group_by_length=False,
|
||||
dynamic_image_size=False,
|
||||
use_thumbnail=False,
|
||||
min_dynamic_patch=1,
|
||||
max_dynamic_patch=12,
|
||||
min_num_frame=8,
|
||||
max_num_frame=32,
|
||||
normalize_type="imagenet",
|
||||
):
|
||||
datasets = []
|
||||
lengths = []
|
||||
ds_collections = json.loads(open(data_args.meta_path).read())
|
||||
for ds_idx, ds_name in enumerate(ds_collections.keys()):
|
||||
repeat_time = ds_collections[ds_name]["repeat_time"]
|
||||
if "max_dynamic_patch" in ds_collections[ds_name]:
|
||||
max_num = ds_collections[ds_name]["max_dynamic_patch"]
|
||||
logger.info(
|
||||
f"max_dynamic_patch is set to {max_num} according to the meta file"
|
||||
)
|
||||
else:
|
||||
max_num = max_dynamic_patch
|
||||
dataset = LazySupervisedDataset(
|
||||
data_args.conv_style,
|
||||
ds_collections[ds_name],
|
||||
tokenizer,
|
||||
tcs_loader,
|
||||
ds_name=ds_name,
|
||||
num_image_token=model.num_image_token,
|
||||
image_size=data_args.force_image_size,
|
||||
is_train=ds_collections[ds_name].get("data_augment", False),
|
||||
pad2square=data_args.pad2square,
|
||||
group_by_length=group_by_length,
|
||||
dynamic_image_size=dynamic_image_size,
|
||||
use_thumbnail=use_thumbnail,
|
||||
min_dynamic_patch=min_dynamic_patch,
|
||||
max_dynamic_patch=max_num,
|
||||
min_num_frame=min_num_frame,
|
||||
max_num_frame=max_num_frame,
|
||||
repeat_time=repeat_time,
|
||||
normalize_type=normalize_type,
|
||||
random_seed=ds_idx,
|
||||
)
|
||||
logger.info(f"Add dataset: {ds_name} with length: {len(dataset)}")
|
||||
datasets.append(dataset)
|
||||
if data_args.use_data_resampling:
|
||||
lengths.append(math.sqrt(len(dataset)))
|
||||
else:
|
||||
lengths.append(len(dataset))
|
||||
|
||||
if data_args.use_data_resampling:
|
||||
total_length = sum(lengths)
|
||||
weights = [l / total_length for l in lengths]
|
||||
train_dataset = WeightedConcatDataset(datasets, weights)
|
||||
else:
|
||||
train_dataset = ConcatDataset(datasets)
|
||||
return train_dataset
|
||||
@@ -0,0 +1,4 @@
|
||||
"""
|
||||
Moonshine has some modifications upon whisper.
|
||||
less params but didn't have multilingual support as for now
|
||||
"""
|
||||
@@ -0,0 +1,3 @@
|
||||
"""
|
||||
we uses whisper
|
||||
"""
|
||||
@@ -0,0 +1,95 @@
|
||||
from typing import Any
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
from transformers.models.auto import AutoConfig, CONFIG_MAPPING
|
||||
|
||||
|
||||
class NamoConfig(PretrainedConfig):
|
||||
|
||||
model_type = "namo"
|
||||
is_composition = False
|
||||
sub_configs = {
|
||||
"text_config": AutoConfig,
|
||||
"vision_config": AutoConfig,
|
||||
"audio_config": AutoConfig,
|
||||
}
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
text_config=None,
|
||||
vision_config=None,
|
||||
audio_config=None,
|
||||
ignore_index=-100,
|
||||
image_token_index=-200,
|
||||
vision_feature_select_strategy="same",
|
||||
vision_feature_layer=-2,
|
||||
image_seq_length=576,
|
||||
new_img_size=None,
|
||||
shortest_edge=None,
|
||||
longest_edge=None,
|
||||
unfreeze_ve=True,
|
||||
multimodal_projector_bias=True,
|
||||
conn_ve_llm_type="mlp2x_gelu",
|
||||
**kwargs,
|
||||
):
|
||||
self.ignore_index = ignore_index
|
||||
self.image_token_index = image_token_index
|
||||
self.image_seq_length = image_seq_length
|
||||
self.new_img_size = new_img_size
|
||||
self.shortest_edge = shortest_edge
|
||||
self.longest_edge = longest_edge
|
||||
self.unfreeze_ve = unfreeze_ve
|
||||
self.conn_ve_llm_type = conn_ve_llm_type
|
||||
|
||||
if vision_feature_select_strategy not in ["same", "patch"]:
|
||||
raise ValueError(
|
||||
"vision_feature_select_strategy should be one of 'same', 'patch'."
|
||||
f"Got: {vision_feature_select_strategy}"
|
||||
)
|
||||
|
||||
self.vision_feature_select_strategy = vision_feature_select_strategy
|
||||
self.vision_feature_layer = vision_feature_layer
|
||||
|
||||
if isinstance(vision_config, dict):
|
||||
vision_config["model_type"] = (
|
||||
vision_config["model_type"]
|
||||
if "model_type" in vision_config
|
||||
else "clip_vision_model"
|
||||
)
|
||||
vision_config = CONFIG_MAPPING[vision_config["model_type"]](**vision_config)
|
||||
elif vision_config is None:
|
||||
vision_config = CONFIG_MAPPING["clip_vision_model"](
|
||||
intermediate_size=4096,
|
||||
hidden_size=1024,
|
||||
patch_size=14,
|
||||
image_size=336,
|
||||
num_hidden_layers=24,
|
||||
num_attention_heads=16,
|
||||
vocab_size=32000,
|
||||
projection_dim=768,
|
||||
)
|
||||
self.vision_config = vision_config
|
||||
|
||||
if isinstance(audio_config, dict):
|
||||
audio_config["model_type"] = (
|
||||
audio_config["model_type"]
|
||||
if "model_type" in audio_config
|
||||
else "whisper"
|
||||
)
|
||||
audio_config = CONFIG_MAPPING[audio_config["model_type"]](**audio_config)
|
||||
elif audio_config is None:
|
||||
audio_config = CONFIG_MAPPING["whisper"]()
|
||||
self.audio_config = audio_config
|
||||
|
||||
if isinstance(text_config, dict):
|
||||
text_config["model_type"] = (
|
||||
text_config["model_type"] if "model_type" in text_config else "llama"
|
||||
)
|
||||
text_config = CONFIG_MAPPING[text_config["model_type"]](**text_config)
|
||||
elif text_config is None:
|
||||
text_config = CONFIG_MAPPING["qwen2"]()
|
||||
|
||||
self.text_config = text_config
|
||||
self.multimodal_projector_bias = multimodal_projector_bias
|
||||
|
||||
super().__init__(**kwargs)
|
||||
@@ -0,0 +1,470 @@
|
||||
import torch
|
||||
from namo.models.symbols import (
|
||||
DEFAULT_IM_END_TOKEN,
|
||||
DEFAULT_IM_START_TOKEN,
|
||||
DEFAULT_IMAGE_PATCH_TOKEN,
|
||||
IMAGE_TOKEN_INDEX,
|
||||
IGNORE_INDEX,
|
||||
AUDIO_TOKEN_INDEX,
|
||||
)
|
||||
from namo.utils.process_utils import unpad_image, get_anyres_image_grid_shape
|
||||
from .meta_vision import NamoMetaVisionForCausalLM
|
||||
|
||||
|
||||
class NamoMetaOmniForCausalLM(NamoMetaVisionForCausalLM):
|
||||
def get_audio_encoder(self):
|
||||
return self.get_model().get_audio_encoder()
|
||||
|
||||
def get_audio_projector(self):
|
||||
return self.get_model().audio_projector
|
||||
|
||||
def encode_audio(self, audio, audio_lengths):
|
||||
audio_encoder_type = self.config.audio_encoder_type
|
||||
audio_encoder = self.get_audio_encoder()
|
||||
if "whisper" in audio_encoder_type.lower():
|
||||
encoder_outs = audio_encoder(audio.permute(0, 2, 1))
|
||||
audio_lengths = (audio_lengths + 1) // 2
|
||||
else:
|
||||
raise ValueError(f"Unknown audio encoder: {audio_encoder}")
|
||||
audio_projector_type = self.config.audio_projector_type
|
||||
audio_projector = self.get_audio_projector()
|
||||
if audio_projector_type == "linear":
|
||||
encoder_outs = audio_projector(encoder_outs)
|
||||
audio_lengths = audio_lengths // audio_projector.k
|
||||
else:
|
||||
raise ValueError(f"Unknown audio projector: {audio_projector_type}")
|
||||
audio_features = [
|
||||
encoder_outs[i, : audio_lengths[i]] for i in range(len(encoder_outs))
|
||||
]
|
||||
return audio_features
|
||||
|
||||
def prepare_inputs_labels_for_multimodal(
|
||||
self,
|
||||
input_ids,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
labels,
|
||||
images,
|
||||
image_sizes=None,
|
||||
audio=None,
|
||||
audio_lengths=None,
|
||||
pixel_attention_mask=None,
|
||||
):
|
||||
vision_tower = self.get_vision_tower()
|
||||
if vision_tower is None or images is None or input_ids.shape[1] == 1:
|
||||
return (
|
||||
input_ids,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
None,
|
||||
labels,
|
||||
)
|
||||
|
||||
audio_encoder = self.get_audio_encoder()
|
||||
if audio_encoder is None or audio_encoder is None or input_ids.shape[1] == 1:
|
||||
return (
|
||||
input_ids,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
None,
|
||||
labels,
|
||||
)
|
||||
|
||||
if type(images) is list or images.ndim == 5:
|
||||
if type(images) is list:
|
||||
images = [x.unsqueeze(0) if x.ndim == 3 else x for x in images]
|
||||
concat_images = torch.cat([image for image in images], dim=0)
|
||||
image_features = self.encode_images(concat_images)
|
||||
split_sizes = [image.shape[0] for image in images]
|
||||
image_features = torch.split(image_features, split_sizes, dim=0)
|
||||
mm_patch_merge_type = getattr(self.config, "mm_patch_merge_type", "flat")
|
||||
image_aspect_ratio = getattr(self.config, "image_aspect_ratio", "square")
|
||||
if mm_patch_merge_type == "flat":
|
||||
image_features = [x.flatten(0, 1) for x in image_features]
|
||||
elif mm_patch_merge_type.startswith("spatial"):
|
||||
new_image_features = []
|
||||
for image_idx, image_feature in enumerate(image_features):
|
||||
if image_feature.shape[0] > 1:
|
||||
base_image_feature = image_feature[0]
|
||||
image_feature = image_feature[1:]
|
||||
height = width = self.get_vision_tower().num_patches_per_side
|
||||
assert height * width == base_image_feature.shape[0]
|
||||
if image_aspect_ratio == "anyres":
|
||||
(
|
||||
num_patch_width,
|
||||
num_patch_height,
|
||||
) = get_anyres_image_grid_shape(
|
||||
image_sizes[image_idx],
|
||||
self.config.image_grid_pinpoints,
|
||||
self.get_vision_tower().config.image_size,
|
||||
)
|
||||
image_feature = image_feature.view(
|
||||
num_patch_height, num_patch_width, height, width, -1
|
||||
)
|
||||
else:
|
||||
raise NotImplementedError
|
||||
if "unpad" in mm_patch_merge_type:
|
||||
image_feature = image_feature.permute(
|
||||
4, 0, 2, 1, 3
|
||||
).contiguous()
|
||||
image_feature = image_feature.flatten(1, 2).flatten(2, 3)
|
||||
image_feature = unpad_image(
|
||||
image_feature, image_sizes[image_idx]
|
||||
)
|
||||
image_feature = torch.cat(
|
||||
(
|
||||
image_feature,
|
||||
self.model.image_newline[:, None, None]
|
||||
.expand(*image_feature.shape[:-1], 1)
|
||||
.to(image_feature.device),
|
||||
),
|
||||
dim=-1,
|
||||
)
|
||||
image_feature = image_feature.flatten(1, 2).transpose(0, 1)
|
||||
else:
|
||||
image_feature = image_feature.permute(
|
||||
0, 2, 1, 3, 4
|
||||
).contiguous()
|
||||
image_feature = image_feature.flatten(0, 3)
|
||||
image_feature = torch.cat(
|
||||
(base_image_feature, image_feature), dim=0
|
||||
)
|
||||
else:
|
||||
image_feature = image_feature[0]
|
||||
if "unpad" in mm_patch_merge_type:
|
||||
image_feature = torch.cat(
|
||||
(
|
||||
image_feature,
|
||||
self.model.image_newline[None].to(
|
||||
image_feature.device
|
||||
),
|
||||
),
|
||||
dim=0,
|
||||
)
|
||||
new_image_features.append(image_feature)
|
||||
image_features = new_image_features
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Unexpected mm_patch_merge_type: {self.config.mm_patch_merge_type}"
|
||||
)
|
||||
else:
|
||||
image_features = self.encode_images(
|
||||
images, pixel_attention_mask=pixel_attention_mask
|
||||
)
|
||||
|
||||
# preparing audio features
|
||||
audio_features = self.encode_audio(audio, audio_lengths)
|
||||
|
||||
# for video test
|
||||
# image_features = self.temporal_aggregation(image_features)
|
||||
# print(f'imgfahture: {image_features.shape}')
|
||||
|
||||
# TODO: image start / end is not implemented here to support pretraining.
|
||||
if getattr(self.config, "tune_conn_ve_llm", False) and getattr(
|
||||
self.config, "mm_use_im_start_end", False
|
||||
):
|
||||
raise NotImplementedError
|
||||
|
||||
# Let's just add dummy tensors if they do not exist,
|
||||
# it is a headache to deal with None all the time.
|
||||
# But it is not ideal, and if you have a better idea,
|
||||
# please open an issue / submit a PR, thanks.
|
||||
_labels = labels
|
||||
_position_ids = position_ids
|
||||
_attention_mask = attention_mask
|
||||
if attention_mask is None:
|
||||
attention_mask = torch.ones_like(input_ids, dtype=torch.bool)
|
||||
else:
|
||||
attention_mask = attention_mask.bool()
|
||||
if position_ids is None:
|
||||
position_ids = torch.arange(
|
||||
0, input_ids.shape[1], dtype=torch.long, device=input_ids.device
|
||||
)
|
||||
if labels is None:
|
||||
labels = torch.full_like(input_ids, IGNORE_INDEX)
|
||||
|
||||
# remove the padding using attention_mask -- FIXME
|
||||
_input_ids = input_ids
|
||||
input_ids = [
|
||||
cur_input_ids[cur_attention_mask]
|
||||
for cur_input_ids, cur_attention_mask in zip(input_ids, attention_mask)
|
||||
]
|
||||
labels = [
|
||||
cur_labels[cur_attention_mask]
|
||||
for cur_labels, cur_attention_mask in zip(labels, attention_mask)
|
||||
]
|
||||
|
||||
# I->T, A->T, T->T, AI->T, TI->T, AT->T, AIT->T
|
||||
new_input_embeds = []
|
||||
new_labels = []
|
||||
cur_image_idx = 0
|
||||
cur_audio_idx = 0
|
||||
for batch_idx, cur_input_ids in enumerate(input_ids):
|
||||
# no image or audio, pure text.
|
||||
num_images = (cur_input_ids == IMAGE_TOKEN_INDEX).sum()
|
||||
num_audio_frames = (cur_input_ids == AUDIO_TOKEN_INDEX).sum()
|
||||
if num_images == 0 and num_audio_frames == 0:
|
||||
cur_image_features = image_features[cur_image_idx]
|
||||
cur_audio_features = audio_features["inputs_embeds"][cur_audio_idx]
|
||||
cur_input_embeds_1 = self.get_model().embed_tokens(cur_input_ids)
|
||||
cur_input_embeds = torch.cat(
|
||||
[
|
||||
cur_input_embeds_1,
|
||||
cur_image_features[0:0],
|
||||
cur_audio_features[0:0],
|
||||
],
|
||||
dim=0,
|
||||
)
|
||||
new_input_embeds.append(cur_input_embeds)
|
||||
new_labels.append(labels[batch_idx])
|
||||
cur_image_idx += 1
|
||||
cur_audio_idx += 1
|
||||
continue
|
||||
|
||||
image_audio_token_indices = (
|
||||
[-1]
|
||||
+ torch.where(
|
||||
(cur_input_ids == IMAGE_TOKEN_INDEX)
|
||||
| (cur_input_ids == AUDIO_TOKEN_INDEX)
|
||||
)[0].tolist()
|
||||
+ [cur_input_ids.shape[0]]
|
||||
)
|
||||
cur_input_ids_noim_noau = []
|
||||
cur_labels = labels[batch_idx]
|
||||
cur_labels_noim_noau = []
|
||||
for i in range(len(image_audio_token_indices) - 1):
|
||||
cur_input_ids_noim_noau.append(
|
||||
cur_input_ids[
|
||||
image_audio_token_indices[i]
|
||||
+ 1 : image_audio_token_indices[i + 1]
|
||||
]
|
||||
)
|
||||
cur_labels_noim_noau.append(
|
||||
cur_labels[
|
||||
image_audio_token_indices[i]
|
||||
+ 1 : image_audio_token_indices[i + 1]
|
||||
]
|
||||
)
|
||||
|
||||
split_sizes = [x.shape[0] for x in cur_labels_noim_noau]
|
||||
cur_input_embeds = self.get_model().embed_tokens(
|
||||
torch.cat(cur_input_ids_noim_noau)
|
||||
)
|
||||
cur_input_embeds_no_im_no_au = torch.split(
|
||||
cur_input_embeds, split_sizes, dim=0
|
||||
)
|
||||
cur_new_input_embeds = []
|
||||
cur_new_labels = []
|
||||
for i in range(num_images + num_audio_frames + 1):
|
||||
cur_new_input_embeds.append(cur_input_embeds_no_im_no_au[i])
|
||||
cur_new_labels.append(cur_labels_noim_noau[i])
|
||||
if i < num_images + num_audio_frames:
|
||||
if (
|
||||
cur_input_ids[image_audio_token_indices[i + 1]]
|
||||
== IMAGE_TOKEN_INDEX
|
||||
):
|
||||
cur_image_features = image_features[cur_image_idx]
|
||||
cur_image_idx += 1
|
||||
cur_new_input_embeds.append(cur_image_features)
|
||||
cur_new_labels.append(
|
||||
torch.full(
|
||||
(cur_image_features.shape[0],),
|
||||
IGNORE_INDEX,
|
||||
device=cur_labels.device,
|
||||
dtype=cur_labels.dtype,
|
||||
)
|
||||
)
|
||||
elif (
|
||||
cur_input_ids[image_audio_token_indices[i + 1]]
|
||||
== AUDIO_TOKEN_INDEX
|
||||
):
|
||||
cur_audio_features = audio_features["inputs_embeds"][
|
||||
cur_audio_idx
|
||||
]
|
||||
cur_audio_idx += 1
|
||||
cur_new_input_embeds.append(cur_audio_features)
|
||||
cur_new_labels.append(
|
||||
torch.full(
|
||||
(cur_audio_features.shape[0],),
|
||||
IGNORE_INDEX,
|
||||
device=cur_labels.device,
|
||||
dtype=cur_labels.dtype,
|
||||
)
|
||||
)
|
||||
else:
|
||||
raise ValueError
|
||||
|
||||
if num_images != 0 and num_audio_frames == 0:
|
||||
cur_audio_features = audio_features["inputs_embeds"][cur_audio_idx]
|
||||
cur_audio_idx += 1
|
||||
cur_new_input_embeds.append(cur_audio_features[0:0])
|
||||
elif num_images == 0 and num_audio_frames != 0:
|
||||
cur_image_features = image_features[cur_image_idx]
|
||||
cur_image_idx += 1
|
||||
cur_new_input_embeds.append(cur_image_features[0:0])
|
||||
cur_new_input_embeds = torch.cat(cur_new_input_embeds)
|
||||
cur_new_labels = torch.cat(cur_new_labels)
|
||||
|
||||
new_input_embeds.append(cur_new_input_embeds)
|
||||
new_labels.append(cur_new_labels)
|
||||
|
||||
assert cur_image_idx == image_features.shape[0]
|
||||
assert cur_audio_idx == audio_features["inputs_embeds"].shape[0]
|
||||
|
||||
# Truncate sequences to max length as image embeddings can make the sequence longer
|
||||
tokenizer_model_max_length = getattr(
|
||||
self.config, "tokenizer_model_max_length", None
|
||||
)
|
||||
if tokenizer_model_max_length is not None:
|
||||
new_input_embeds = [
|
||||
x[:tokenizer_model_max_length] for x in new_input_embeds
|
||||
]
|
||||
new_labels = [x[:tokenizer_model_max_length] for x in new_labels]
|
||||
|
||||
# Combine them
|
||||
max_len = max(x.shape[0] for x in new_input_embeds)
|
||||
batch_size = len(new_input_embeds)
|
||||
|
||||
new_input_embeds_padded = []
|
||||
new_labels_padded = torch.full(
|
||||
(batch_size, max_len),
|
||||
IGNORE_INDEX,
|
||||
dtype=new_labels[0].dtype,
|
||||
device=new_labels[0].device,
|
||||
)
|
||||
attention_mask = torch.zeros(
|
||||
(batch_size, max_len),
|
||||
dtype=attention_mask.dtype,
|
||||
device=attention_mask.device,
|
||||
)
|
||||
position_ids = torch.zeros(
|
||||
(batch_size, max_len), dtype=position_ids.dtype, device=position_ids.device
|
||||
)
|
||||
|
||||
for i, (cur_new_embed, cur_new_labels) in enumerate(
|
||||
zip(new_input_embeds, new_labels)
|
||||
):
|
||||
cur_len = cur_new_embed.shape[0]
|
||||
if getattr(self.config, "tokenizer_padding_side", "right") == "left":
|
||||
new_input_embeds_padded.append(
|
||||
torch.cat(
|
||||
(
|
||||
torch.zeros(
|
||||
(max_len - cur_len, cur_new_embed.shape[1]),
|
||||
dtype=cur_new_embed.dtype,
|
||||
device=cur_new_embed.device,
|
||||
),
|
||||
cur_new_embed,
|
||||
),
|
||||
dim=0,
|
||||
)
|
||||
)
|
||||
if cur_len > 0:
|
||||
new_labels_padded[i, -cur_len:] = cur_new_labels
|
||||
attention_mask[i, -cur_len:] = True
|
||||
position_ids[i, -cur_len:] = torch.arange(
|
||||
0, cur_len, dtype=position_ids.dtype, device=position_ids.device
|
||||
)
|
||||
else:
|
||||
new_input_embeds_padded.append(
|
||||
torch.cat(
|
||||
(
|
||||
cur_new_embed,
|
||||
torch.zeros(
|
||||
(max_len - cur_len, cur_new_embed.shape[1]),
|
||||
dtype=cur_new_embed.dtype,
|
||||
device=cur_new_embed.device,
|
||||
),
|
||||
),
|
||||
dim=0,
|
||||
)
|
||||
)
|
||||
if cur_len > 0:
|
||||
new_labels_padded[i, :cur_len] = cur_new_labels
|
||||
attention_mask[i, :cur_len] = True
|
||||
position_ids[i, :cur_len] = torch.arange(
|
||||
0, cur_len, dtype=position_ids.dtype, device=position_ids.device
|
||||
)
|
||||
|
||||
new_input_embeds = torch.stack(new_input_embeds_padded, dim=0)
|
||||
|
||||
if _labels is None:
|
||||
new_labels = None
|
||||
else:
|
||||
new_labels = new_labels_padded
|
||||
|
||||
if _attention_mask is None:
|
||||
attention_mask = None
|
||||
else:
|
||||
attention_mask = attention_mask.to(dtype=_attention_mask.dtype)
|
||||
|
||||
if _position_ids is None:
|
||||
position_ids = None
|
||||
|
||||
return (
|
||||
None,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
new_input_embeds,
|
||||
new_labels,
|
||||
)
|
||||
|
||||
def initialize_vision_tokenizer(self, model_args, tokenizer):
|
||||
if model_args.mm_use_im_patch_token:
|
||||
tokenizer.add_tokens(
|
||||
[DEFAULT_IMAGE_PATCH_TOKEN, DEFAULT_AUDIOTOKEN], special_tokens=True
|
||||
)
|
||||
self.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
if model_args.mm_use_im_start_end:
|
||||
num_new_tokens = tokenizer.add_tokens(
|
||||
[DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True
|
||||
)
|
||||
self.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
if num_new_tokens > 0:
|
||||
input_embeddings = self.get_input_embeddings().weight.data
|
||||
output_embeddings = self.get_output_embeddings().weight.data
|
||||
|
||||
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
|
||||
dim=0, keepdim=True
|
||||
)
|
||||
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
|
||||
dim=0, keepdim=True
|
||||
)
|
||||
|
||||
input_embeddings[-num_new_tokens:] = input_embeddings_avg
|
||||
output_embeddings[-num_new_tokens:] = output_embeddings_avg
|
||||
|
||||
if model_args.tune_conn_ve_llm:
|
||||
for p in self.get_input_embeddings().parameters():
|
||||
p.requires_grad = True
|
||||
for p in self.get_output_embeddings().parameters():
|
||||
p.requires_grad = False
|
||||
|
||||
if model_args.pretrain_mm_mlp_adapter:
|
||||
mm_projector_weights = torch.load(
|
||||
model_args.pretrain_mm_mlp_adapter, map_location="cpu"
|
||||
)
|
||||
embed_tokens_weight = mm_projector_weights["model.embed_tokens.weight"]
|
||||
assert num_new_tokens == 2
|
||||
if input_embeddings.shape == embed_tokens_weight.shape:
|
||||
input_embeddings[-num_new_tokens:] = embed_tokens_weight[
|
||||
-num_new_tokens:
|
||||
]
|
||||
elif embed_tokens_weight.shape[0] == num_new_tokens:
|
||||
input_embeddings[-num_new_tokens:] = embed_tokens_weight
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Unexpected embed_tokens_weight shape. Pretrained: {embed_tokens_weight.shape}. Current: {input_embeddings.shape}. Numer of new tokens: {num_new_tokens}."
|
||||
)
|
||||
elif model_args.mm_use_im_patch_token:
|
||||
if model_args.tune_conn_ve_llm:
|
||||
for p in self.get_input_embeddings().parameters():
|
||||
p.requires_grad = False
|
||||
for p in self.get_output_embeddings().parameters():
|
||||
p.requires_grad = False
|
||||
@@ -0,0 +1,393 @@
|
||||
from abc import abstractmethod
|
||||
from abc import ABC
|
||||
import torch
|
||||
from namo.models.symbols import (
|
||||
DEFAULT_IM_END_TOKEN,
|
||||
DEFAULT_IM_START_TOKEN,
|
||||
DEFAULT_IMAGE_PATCH_TOKEN,
|
||||
IMAGE_TOKEN_INDEX,
|
||||
IGNORE_INDEX,
|
||||
)
|
||||
from namo.utils.process_utils import unpad_image, get_anyres_image_grid_shape
|
||||
|
||||
|
||||
class NamoMetaVisionForCausalLM(ABC):
|
||||
@abstractmethod
|
||||
def get_namo(self):
|
||||
pass
|
||||
|
||||
def get_vision_tower(self):
|
||||
return self.get_namo().get_vision_tower()
|
||||
|
||||
def encode_images(self, images, pixel_attention_mask=None):
|
||||
image_features = self.get_namo().get_vision_tower()(
|
||||
images, pixel_attention_mask
|
||||
)
|
||||
image_features = self.get_namo().conn_ve_llm(image_features)
|
||||
return image_features
|
||||
|
||||
def prepare_inputs_labels_for_multimodal(
|
||||
self,
|
||||
input_ids,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
labels,
|
||||
images,
|
||||
image_sizes=None,
|
||||
pixel_attention_mask=None,
|
||||
):
|
||||
vision_tower = self.get_vision_tower()
|
||||
if vision_tower is None or images is None or input_ids.shape[1] == 1:
|
||||
return (
|
||||
input_ids,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
None,
|
||||
labels,
|
||||
)
|
||||
|
||||
if type(images) is list or images.ndim == 5:
|
||||
if type(images) is list:
|
||||
images = [x.unsqueeze(0) if x.ndim == 3 else x for x in images]
|
||||
# concat_images = torch.cat([image for image in images], dim=0)
|
||||
image_features = self.encode_images(images)
|
||||
mm_patch_merge_type = getattr(self.config, "mm_patch_merge_type", "none")
|
||||
image_aspect_ratio = getattr(self.config, "image_aspect_ratio", "square")
|
||||
if mm_patch_merge_type == "flat":
|
||||
split_sizes = [image.shape[0] for image in images]
|
||||
image_features = torch.split(image_features, split_sizes, dim=0)
|
||||
|
||||
image_features = [x.flatten(0, 1) for x in image_features]
|
||||
elif mm_patch_merge_type.startswith("spatial"):
|
||||
split_sizes = [image.shape[0] for image in images]
|
||||
image_features = torch.split(image_features, split_sizes, dim=0)
|
||||
|
||||
new_image_features = []
|
||||
for image_idx, image_feature in enumerate(image_features):
|
||||
if image_feature.shape[0] > 1:
|
||||
base_image_feature = image_feature[0]
|
||||
image_feature = image_feature[1:]
|
||||
height = width = self.get_vision_tower().num_patches_per_side
|
||||
assert height * width == base_image_feature.shape[0]
|
||||
if image_aspect_ratio == "anyres":
|
||||
(
|
||||
num_patch_width,
|
||||
num_patch_height,
|
||||
) = get_anyres_image_grid_shape(
|
||||
image_sizes[image_idx],
|
||||
self.config.image_grid_pinpoints,
|
||||
self.get_vision_tower().config.image_size,
|
||||
)
|
||||
image_feature = image_feature.view(
|
||||
num_patch_height, num_patch_width, height, width, -1
|
||||
)
|
||||
else:
|
||||
raise NotImplementedError
|
||||
if "unpad" in mm_patch_merge_type:
|
||||
image_feature = image_feature.permute(
|
||||
4, 0, 2, 1, 3
|
||||
).contiguous()
|
||||
image_feature = image_feature.flatten(1, 2).flatten(2, 3)
|
||||
image_feature = unpad_image(
|
||||
image_feature, image_sizes[image_idx]
|
||||
)
|
||||
image_feature = torch.cat(
|
||||
(
|
||||
image_feature,
|
||||
self.model.image_newline[:, None, None]
|
||||
.expand(*image_feature.shape[:-1], 1)
|
||||
.to(image_feature.device),
|
||||
),
|
||||
dim=-1,
|
||||
)
|
||||
image_feature = image_feature.flatten(1, 2).transpose(0, 1)
|
||||
else:
|
||||
image_feature = image_feature.permute(
|
||||
0, 2, 1, 3, 4
|
||||
).contiguous()
|
||||
image_feature = image_feature.flatten(0, 3)
|
||||
image_feature = torch.cat(
|
||||
(base_image_feature, image_feature), dim=0
|
||||
)
|
||||
else:
|
||||
image_feature = image_feature[0]
|
||||
if "unpad" in mm_patch_merge_type:
|
||||
image_feature = torch.cat(
|
||||
(
|
||||
image_feature,
|
||||
self.model.image_newline[None].to(
|
||||
image_feature.device
|
||||
),
|
||||
),
|
||||
dim=0,
|
||||
)
|
||||
new_image_features.append(image_feature)
|
||||
image_features = new_image_features
|
||||
else:
|
||||
# do nothing, should be a list of image tokens
|
||||
image_features = [f.squeeze(0) for f in image_features]
|
||||
else:
|
||||
image_features = self.encode_images(
|
||||
images, pixel_attention_mask=pixel_attention_mask
|
||||
)
|
||||
|
||||
# for video test
|
||||
# image_features = self.temporal_aggregation(image_features)
|
||||
# print(f"imgfahture: {image_features[0].shape}")
|
||||
|
||||
# TODO: image start / end is not implemented here to support pretraining.
|
||||
if getattr(self.config, "tune_conn_ve_llm", False) and getattr(
|
||||
self.config, "mm_use_im_start_end", False
|
||||
):
|
||||
raise NotImplementedError
|
||||
|
||||
# Let's just add dummy tensors if they do not exist,
|
||||
# it is a headache to deal with None all the time.
|
||||
# But it is not ideal, and if you have a better idea,
|
||||
# please open an issue / submit a PR, thanks.
|
||||
_labels = labels
|
||||
_position_ids = position_ids
|
||||
_attention_mask = attention_mask
|
||||
if attention_mask is None:
|
||||
attention_mask = torch.ones_like(input_ids, dtype=torch.bool)
|
||||
else:
|
||||
attention_mask = attention_mask.bool()
|
||||
if position_ids is None:
|
||||
position_ids = torch.arange(
|
||||
0, input_ids.shape[1], dtype=torch.long, device=input_ids.device
|
||||
)
|
||||
if labels is None:
|
||||
labels = torch.full_like(input_ids, IGNORE_INDEX)
|
||||
|
||||
# remove the padding using attention_mask -- FIXME
|
||||
_input_ids = input_ids
|
||||
input_ids = [
|
||||
cur_input_ids[cur_attention_mask]
|
||||
for cur_input_ids, cur_attention_mask in zip(input_ids, attention_mask)
|
||||
]
|
||||
labels = [
|
||||
cur_labels[cur_attention_mask]
|
||||
for cur_labels, cur_attention_mask in zip(labels, attention_mask)
|
||||
]
|
||||
|
||||
new_input_embeds = []
|
||||
new_labels = []
|
||||
cur_image_idx = 0
|
||||
for batch_idx, cur_input_ids in enumerate(input_ids):
|
||||
num_images = (cur_input_ids == IMAGE_TOKEN_INDEX).sum()
|
||||
if num_images == 0:
|
||||
cur_image_features = image_features[cur_image_idx]
|
||||
cur_input_embeds_1 = (
|
||||
self.get_namo().get_llm().embed_tokens(cur_input_ids)
|
||||
)
|
||||
cur_input_embeds = torch.cat(
|
||||
[cur_input_embeds_1, cur_image_features[0:0]], dim=0
|
||||
)
|
||||
new_input_embeds.append(cur_input_embeds)
|
||||
new_labels.append(labels[batch_idx])
|
||||
cur_image_idx += 1
|
||||
continue
|
||||
|
||||
image_token_indices = (
|
||||
[-1]
|
||||
+ torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0].tolist()
|
||||
+ [cur_input_ids.shape[0]]
|
||||
)
|
||||
cur_input_ids_noim = []
|
||||
cur_labels = labels[batch_idx]
|
||||
cur_labels_noim = []
|
||||
for i in range(len(image_token_indices) - 1):
|
||||
cur_input_ids_noim.append(
|
||||
cur_input_ids[
|
||||
image_token_indices[i] + 1 : image_token_indices[i + 1]
|
||||
]
|
||||
)
|
||||
cur_labels_noim.append(
|
||||
cur_labels[image_token_indices[i] + 1 : image_token_indices[i + 1]]
|
||||
)
|
||||
split_sizes = [x.shape[0] for x in cur_labels_noim]
|
||||
cur_input_embeds = (
|
||||
self.get_namo().get_llm().embed_tokens(torch.cat(cur_input_ids_noim))
|
||||
)
|
||||
cur_input_embeds_no_im = torch.split(cur_input_embeds, split_sizes, dim=0)
|
||||
cur_new_input_embeds = []
|
||||
cur_new_labels = []
|
||||
|
||||
for i in range(num_images + 1):
|
||||
cur_new_input_embeds.append(cur_input_embeds_no_im[i])
|
||||
cur_new_labels.append(cur_labels_noim[i])
|
||||
if i < num_images:
|
||||
cur_image_features = image_features[cur_image_idx]
|
||||
cur_image_idx += 1
|
||||
cur_new_input_embeds.append(cur_image_features)
|
||||
cur_new_labels.append(
|
||||
torch.full(
|
||||
(cur_image_features.shape[0],),
|
||||
IGNORE_INDEX,
|
||||
device=cur_labels.device,
|
||||
dtype=cur_labels.dtype,
|
||||
)
|
||||
)
|
||||
|
||||
cur_new_input_embeds = [x.to(self.device) for x in cur_new_input_embeds]
|
||||
|
||||
cur_new_input_embeds = torch.cat(cur_new_input_embeds)
|
||||
cur_new_labels = torch.cat(cur_new_labels)
|
||||
|
||||
new_input_embeds.append(cur_new_input_embeds)
|
||||
new_labels.append(cur_new_labels)
|
||||
|
||||
# Truncate sequences to max length as image embeddings can make the sequence longer
|
||||
tokenizer_model_max_length = getattr(
|
||||
self.config, "tokenizer_model_max_length", None
|
||||
)
|
||||
if tokenizer_model_max_length is not None:
|
||||
new_input_embeds = [
|
||||
x[:tokenizer_model_max_length] for x in new_input_embeds
|
||||
]
|
||||
new_labels = [x[:tokenizer_model_max_length] for x in new_labels]
|
||||
|
||||
# Combine them
|
||||
max_len = max(x.shape[0] for x in new_input_embeds)
|
||||
batch_size = len(new_input_embeds)
|
||||
|
||||
new_input_embeds_padded = []
|
||||
new_labels_padded = torch.full(
|
||||
(batch_size, max_len),
|
||||
IGNORE_INDEX,
|
||||
dtype=new_labels[0].dtype,
|
||||
device=new_labels[0].device,
|
||||
)
|
||||
attention_mask = torch.zeros(
|
||||
(batch_size, max_len),
|
||||
dtype=attention_mask.dtype,
|
||||
device=attention_mask.device,
|
||||
)
|
||||
position_ids = torch.zeros(
|
||||
(batch_size, max_len), dtype=position_ids.dtype, device=position_ids.device
|
||||
)
|
||||
|
||||
for i, (cur_new_embed, cur_new_labels) in enumerate(
|
||||
zip(new_input_embeds, new_labels)
|
||||
):
|
||||
cur_len = cur_new_embed.shape[0]
|
||||
if getattr(self.config, "tokenizer_padding_side", "right") == "left":
|
||||
new_input_embeds_padded.append(
|
||||
torch.cat(
|
||||
(
|
||||
torch.zeros(
|
||||
(max_len - cur_len, cur_new_embed.shape[1]),
|
||||
dtype=cur_new_embed.dtype,
|
||||
device=cur_new_embed.device,
|
||||
),
|
||||
cur_new_embed,
|
||||
),
|
||||
dim=0,
|
||||
)
|
||||
)
|
||||
if cur_len > 0:
|
||||
new_labels_padded[i, -cur_len:] = cur_new_labels
|
||||
attention_mask[i, -cur_len:] = True
|
||||
position_ids[i, -cur_len:] = torch.arange(
|
||||
0, cur_len, dtype=position_ids.dtype, device=position_ids.device
|
||||
)
|
||||
else:
|
||||
new_input_embeds_padded.append(
|
||||
torch.cat(
|
||||
(
|
||||
cur_new_embed,
|
||||
torch.zeros(
|
||||
(max_len - cur_len, cur_new_embed.shape[1]),
|
||||
dtype=cur_new_embed.dtype,
|
||||
device=cur_new_embed.device,
|
||||
),
|
||||
),
|
||||
dim=0,
|
||||
)
|
||||
)
|
||||
if cur_len > 0:
|
||||
new_labels_padded[i, :cur_len] = cur_new_labels
|
||||
attention_mask[i, :cur_len] = True
|
||||
position_ids[i, :cur_len] = torch.arange(
|
||||
0, cur_len, dtype=position_ids.dtype, device=position_ids.device
|
||||
)
|
||||
|
||||
new_input_embeds = torch.stack(new_input_embeds_padded, dim=0)
|
||||
|
||||
if _labels is None:
|
||||
new_labels = None
|
||||
else:
|
||||
new_labels = new_labels_padded
|
||||
|
||||
if _attention_mask is None:
|
||||
attention_mask = None
|
||||
else:
|
||||
attention_mask = attention_mask.to(dtype=_attention_mask.dtype)
|
||||
|
||||
if _position_ids is None:
|
||||
position_ids = None
|
||||
|
||||
return (
|
||||
None,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
new_input_embeds,
|
||||
new_labels,
|
||||
)
|
||||
|
||||
def initialize_vision_tokenizer(self, model_args, tokenizer):
|
||||
if model_args.mm_use_im_patch_token:
|
||||
tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
|
||||
self.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
if model_args.mm_use_im_start_end:
|
||||
num_new_tokens = tokenizer.add_tokens(
|
||||
[DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True
|
||||
)
|
||||
self.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
if num_new_tokens > 0:
|
||||
input_embeddings = self.get_input_embeddings().weight.data
|
||||
output_embeddings = self.get_output_embeddings().weight.data
|
||||
|
||||
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
|
||||
dim=0, keepdim=True
|
||||
)
|
||||
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
|
||||
dim=0, keepdim=True
|
||||
)
|
||||
|
||||
input_embeddings[-num_new_tokens:] = input_embeddings_avg
|
||||
output_embeddings[-num_new_tokens:] = output_embeddings_avg
|
||||
|
||||
if model_args.tune_conn_ve_llm:
|
||||
for p in self.get_input_embeddings().parameters():
|
||||
p.requires_grad = True
|
||||
for p in self.get_output_embeddings().parameters():
|
||||
p.requires_grad = False
|
||||
|
||||
if model_args.pretrain_mm_mlp_adapter:
|
||||
mm_projector_weights = torch.load(
|
||||
model_args.pretrain_mm_mlp_adapter, map_location="cpu"
|
||||
)
|
||||
embed_tokens_weight = mm_projector_weights["model.embed_tokens.weight"]
|
||||
assert num_new_tokens == 2
|
||||
if input_embeddings.shape == embed_tokens_weight.shape:
|
||||
input_embeddings[-num_new_tokens:] = embed_tokens_weight[
|
||||
-num_new_tokens:
|
||||
]
|
||||
elif embed_tokens_weight.shape[0] == num_new_tokens:
|
||||
input_embeddings[-num_new_tokens:] = embed_tokens_weight
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Unexpected embed_tokens_weight shape. Pretrained: {embed_tokens_weight.shape}. Current: {input_embeddings.shape}. Numer of new tokens: {num_new_tokens}."
|
||||
)
|
||||
elif model_args.mm_use_im_patch_token:
|
||||
if model_args.tune_conn_ve_llm:
|
||||
for p in self.get_input_embeddings().parameters():
|
||||
p.requires_grad = False
|
||||
for p in self.get_output_embeddings().parameters():
|
||||
p.requires_grad = False
|
||||
@@ -0,0 +1,40 @@
|
||||
from torch.nn import LayerNorm
|
||||
from torch import nn
|
||||
import torch
|
||||
from timm.models.regnet import RegStage
|
||||
from timm.layers import LayerNorm, LayerNorm2d
|
||||
|
||||
|
||||
class GLU(nn.Module):
|
||||
def __init__(self, hidden_size, ffn_hidden_size, in_features):
|
||||
super().__init__()
|
||||
self.linear_proj = nn.Linear(in_features, hidden_size, bias=False)
|
||||
self.norm1 = nn.LayerNorm(hidden_size)
|
||||
self.act1 = nn.GELU()
|
||||
self.act2 = nn.functional.silu
|
||||
self.dense_h_to_4h = nn.Linear(hidden_size, ffn_hidden_size, bias=False)
|
||||
self.gate_proj = nn.Linear(hidden_size, ffn_hidden_size, bias=False)
|
||||
self.dense_4h_to_h = nn.Linear(ffn_hidden_size, hidden_size, bias=False)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.linear_proj(x)
|
||||
x = self.act1(self.norm1(x))
|
||||
x = self.act2(self.gate_proj(x)) * self.dense_h_to_4h(x)
|
||||
x = self.dense_4h_to_h(x)
|
||||
return x
|
||||
|
||||
|
||||
class MlpGLU(nn.Module):
|
||||
def __init__(self, in_hidden_size, out_hidden_size):
|
||||
super(MlpGLU, self).__init__()
|
||||
|
||||
ffn_hidden_size = out_hidden_size * 4 # out_hidden_size * 4 3584 * 4 = 14336
|
||||
self.linear_proj = GLU(
|
||||
hidden_size=out_hidden_size,
|
||||
ffn_hidden_size=ffn_hidden_size,
|
||||
in_features=in_hidden_size,
|
||||
)
|
||||
|
||||
def forward(self, x, attention_mask: torch.Tensor = None):
|
||||
x = self.linear_proj(x)
|
||||
return x
|
||||
@@ -0,0 +1,45 @@
|
||||
import re
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
class MLP(nn.Module):
|
||||
def __init__(self, projector_type, input_dim, hidden_dim, output_dim=None):
|
||||
|
||||
super().__init__()
|
||||
self.projector_type = projector_type
|
||||
self.output_dim = output_dim or hidden_dim
|
||||
|
||||
self.mlp_depth, self.use_norm = self._parse_projector_type()
|
||||
self.layers = self._build_layers(input_dim, hidden_dim)
|
||||
|
||||
def _parse_projector_type(self):
|
||||
use_norm = "_Norm" in self.projector_type
|
||||
clean_type = self.projector_type.replace("_Norm", "")
|
||||
|
||||
pattern = r"^mlp(\d+)x_gelu$"
|
||||
match = re.match(pattern, clean_type)
|
||||
if not match:
|
||||
raise ValueError(f"Invalid projector_type: {self.projector_type}")
|
||||
return int(match.group(1)), use_norm
|
||||
|
||||
def _build_layers(self, input_dim, hidden_dim):
|
||||
modules = []
|
||||
|
||||
modules.append(nn.Linear(input_dim, hidden_dim))
|
||||
if self.use_norm:
|
||||
modules.append(nn.LayerNorm(hidden_dim))
|
||||
|
||||
for _ in range(self.mlp_depth - 1):
|
||||
modules.append(nn.GELU())
|
||||
modules.append(nn.Linear(hidden_dim, hidden_dim))
|
||||
if self.use_norm:
|
||||
modules.append(nn.LayerNorm(hidden_dim))
|
||||
|
||||
if hidden_dim != self.output_dim:
|
||||
modules.append(nn.Linear(hidden_dim, self.output_dim))
|
||||
return nn.Sequential(*modules)
|
||||
|
||||
def forward(self, x):
|
||||
if len(x.shape) == 4:
|
||||
x = x.flatten(1, 2)
|
||||
return self.layers(x)
|
||||
@@ -0,0 +1,111 @@
|
||||
from functools import partial
|
||||
import re
|
||||
from torch import nn
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from transformers.activations import ACT2FN
|
||||
from .components import GLU
|
||||
from namo.utils.utils import rank0_print
|
||||
|
||||
|
||||
class PixelShuffleLayer(nn.Module):
|
||||
def __init(self):
|
||||
super(PixelShuffleLayer, self).__init__()
|
||||
|
||||
def forward(self, x, scale_factor=0.5):
|
||||
n, w, h, c = x.size()
|
||||
|
||||
# handle if w h not even
|
||||
pad_w = 0
|
||||
pad_h = 0
|
||||
if w % int(1 / scale_factor) != 0:
|
||||
pad_w = int(1 / scale_factor) - (w % int(1 / scale_factor))
|
||||
if h % int(1 / scale_factor) != 0:
|
||||
pad_h = int(1 / scale_factor) - (h % int(1 / scale_factor))
|
||||
|
||||
if pad_w != 0 or pad_h != 0:
|
||||
x = x.permute(0, 3, 1, 2)
|
||||
x = F.pad(x, (0, pad_h, 0, pad_w))
|
||||
x = x.permute(0, 2, 3, 1)
|
||||
w = w + pad_w
|
||||
h = h + pad_h
|
||||
|
||||
new_h = int(h * scale_factor)
|
||||
new_c = int(c / scale_factor)
|
||||
x = x.reshape(n, w, new_h, new_c)
|
||||
x = x.permute(0, 2, 1, 3).contiguous()
|
||||
new_w = int(w * scale_factor)
|
||||
new_c_final = int(c / (scale_factor * scale_factor))
|
||||
x = x.view(n, new_h, new_w, new_c_final)
|
||||
x = x.permute(0, 2, 1, 3).contiguous()
|
||||
return x
|
||||
|
||||
|
||||
class PixelShuffleConnector(nn.Module):
|
||||
def __init__(self, in_hidden_size, out_hidden_size, down_rate=2, conv_before=False):
|
||||
super(PixelShuffleConnector, self).__init__()
|
||||
# ffn_hidden_size = 13696
|
||||
ffn_hidden_size = in_hidden_size * (
|
||||
down_rate**2
|
||||
) # out_hidden_size * 4 3584 * 4 = 14336
|
||||
self.linear_proj = GLU(
|
||||
hidden_size=out_hidden_size,
|
||||
ffn_hidden_size=ffn_hidden_size,
|
||||
in_features=in_hidden_size * (down_rate**2),
|
||||
)
|
||||
rank0_print(
|
||||
f"==> pixelshuffle: ffn_hidden_size: {ffn_hidden_size}, in_features: {in_hidden_size * (down_rate**2)}"
|
||||
)
|
||||
self.down_rate = down_rate
|
||||
self.downsample = PixelShuffleLayer()
|
||||
self.conv_before = conv_before
|
||||
if conv_before:
|
||||
self.conv = nn.Conv2d(
|
||||
in_channels=in_hidden_size,
|
||||
out_channels=in_hidden_size,
|
||||
kernel_size=2,
|
||||
stride=2,
|
||||
)
|
||||
|
||||
def forward(self, x, attention_mask: torch.Tensor = None):
|
||||
# print(f"xin: {x.shape}")
|
||||
if len(x.shape) == 3:
|
||||
b, s, h = x.shape
|
||||
grid_size = int(s**0.5)
|
||||
x = x.reshape(b, grid_size, grid_size, h)
|
||||
x = self.downsample(x, scale_factor=1 / self.down_rate)
|
||||
elif len(x.shape) == 4:
|
||||
if self.conv_before:
|
||||
# only for 4x4 at least?
|
||||
# print(f'brefore conv: {x.shape}')
|
||||
x = self.conv(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
|
||||
# print(x.shape)
|
||||
x = self.downsample(x, scale_factor=1 / self.down_rate)
|
||||
else:
|
||||
raise ValueError(f"Unsupported input shape: {x.shape}, either rank 3 or 4")
|
||||
# print(f"x after pixshuffle: {x.shape}")
|
||||
# [11, 16, 16, 4608]
|
||||
x = x.reshape(x.shape[0], -1, x.shape[-1])
|
||||
# print(f"x after pixshuffle: {x.shape}")
|
||||
x = self.linear_proj(x)
|
||||
return x
|
||||
|
||||
|
||||
def get_pixel_shuffle(type_name, mm_hidden_size, hidden_size):
|
||||
resampler_match = re.match(r"^pixelshuffle_(\d+)x$", type_name)
|
||||
if resampler_match:
|
||||
down_rate = int(resampler_match.group(1))
|
||||
rank0_print(
|
||||
f"==> conn_ve_llm type: {type_name}, downsample rate: {down_rate}, {mm_hidden_size}->{hidden_size}"
|
||||
)
|
||||
modules = []
|
||||
m = PixelShuffleConnector(
|
||||
in_hidden_size=mm_hidden_size,
|
||||
out_hidden_size=hidden_size,
|
||||
down_rate=down_rate,
|
||||
)
|
||||
modules.append(m)
|
||||
modules = nn.Sequential(*modules)
|
||||
return modules
|
||||
else:
|
||||
raise ValueError(f"Unknown resampler type: {type_name}")
|
||||
@@ -0,0 +1,55 @@
|
||||
from typing import List, Tuple, Union
|
||||
from torch import nn
|
||||
import torch
|
||||
import re
|
||||
from namo.models.modal_adapt.adapt_ve.mlp import MLP
|
||||
from namo.models.modal_adapt.adapt_ve.components import MlpGLU
|
||||
from namo.models.modal_adapt.adapt_ve.pixelshuffle import get_pixel_shuffle
|
||||
from namo.utils.utils import rank0_print
|
||||
|
||||
|
||||
class ConnVE(nn.Module):
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
|
||||
self.config = config
|
||||
type_name = self.config.conn_ve_llm_type
|
||||
|
||||
llm_hidden_size = config.text_config.hidden_size
|
||||
ve_hidden_size = getattr(
|
||||
config.vision_config, "hidden_size", config.vision_config.intermediate_size
|
||||
)
|
||||
rank0_print(f"==> current conn type: {type_name}")
|
||||
if type_name == "identity":
|
||||
modules = nn.Identity()
|
||||
elif type_name == "linear":
|
||||
modules = nn.Linear(ve_hidden_size, llm_hidden_size)
|
||||
elif "gelu" in type_name:
|
||||
modules = MLP(type_name, ve_hidden_size, llm_hidden_size)
|
||||
elif "pixelshuffle" in type_name:
|
||||
modules = get_pixel_shuffle(type_name, ve_hidden_size, llm_hidden_size)
|
||||
elif "ovis" in type_name:
|
||||
print(f"{type_name} is not supported")
|
||||
elif "glu" in type_name:
|
||||
rank0_print("==> Using MLP GLU.")
|
||||
modules = []
|
||||
m = MlpGLU(in_hidden_size=ve_hidden_size, out_hidden_size=llm_hidden_size)
|
||||
modules.append(m)
|
||||
modules = nn.Sequential(*modules)
|
||||
else:
|
||||
raise ValueError(f"Unknown projector type: {type_name}")
|
||||
self.layers = modules
|
||||
|
||||
def forward(
|
||||
self,
|
||||
x_or_tuple: Union[
|
||||
Tuple[torch.Tensor, torch.Tensor], torch.Tensor, List[torch.Tensor]
|
||||
],
|
||||
):
|
||||
x = x_or_tuple
|
||||
if isinstance(x, list):
|
||||
out = [self.layers(i) for i in x]
|
||||
return out
|
||||
else:
|
||||
out = self.layers(x)
|
||||
return out
|
||||
@@ -0,0 +1,192 @@
|
||||
import torch
|
||||
from typing import List, Optional, Tuple, Union
|
||||
from transformers.modeling_outputs import CausalLMOutputWithPast
|
||||
from transformers.generation.utils import GenerateOutput
|
||||
from transformers import (
|
||||
PreTrainedModel,
|
||||
GenerationMixin,
|
||||
AutoModelForCausalLM,
|
||||
AutoModel,
|
||||
AutoTokenizer,
|
||||
)
|
||||
from torch import nn
|
||||
from namo.models.meta_vision import NamoMetaVisionForCausalLM
|
||||
from namo.utils.utils import rank0_print, load_conn_weights
|
||||
from namo.models.configuration_namo import NamoConfig
|
||||
from namo.models.modal_adapt.conn_ve import ConnVE
|
||||
from namo.models.vision.ve import get_ve
|
||||
from namo.utils.hf_utils import auto_load_model, auto_load_tokenizer, SimpleForCausalLM
|
||||
|
||||
|
||||
class NamoPretrainedModel(PreTrainedModel):
|
||||
config_class = NamoConfig
|
||||
base_model_prefix = "namo"
|
||||
_supports_sdpa = True
|
||||
_supports_flash_attn_2 = True
|
||||
_supports_cache_class = True
|
||||
supports_gradient_checkpointing = True
|
||||
|
||||
|
||||
class NamoModel(NamoPretrainedModel):
|
||||
|
||||
_no_split_modules = []
|
||||
|
||||
def __init__(self, config: NamoConfig):
|
||||
super().__init__(config)
|
||||
self.config = config
|
||||
self.llm = auto_load_model(self.config.text_config)
|
||||
self.tokenizer = auto_load_tokenizer(self.config)
|
||||
# ve always being trained, not need delay anymore.
|
||||
self.ve = get_ve(config, delay_load=False)
|
||||
self.conn_ve_llm = ConnVE(config)
|
||||
|
||||
def get_llm(self):
|
||||
return self.llm
|
||||
|
||||
def get_vision_tower(self):
|
||||
ve = getattr(self, "ve", None)
|
||||
return ve
|
||||
|
||||
def load_conn_ve_llm_weights(self, pretrain_mm_mlp_adapter):
|
||||
load_conn_weights(pretrain_mm_mlp_adapter, self.conn_ve_llm, "conn_ve_llm")
|
||||
|
||||
|
||||
class NamoForCausalLM(
|
||||
NamoPretrainedModel, NamoMetaVisionForCausalLM, SimpleForCausalLM
|
||||
):
|
||||
_no_split_modules = []
|
||||
|
||||
def __init__(self, config):
|
||||
NamoPretrainedModel.__init__(self, config)
|
||||
super(SimpleForCausalLM, self).__init__(config.text_config)
|
||||
self.config = config
|
||||
|
||||
# using model property avoid duplicated share tensor
|
||||
self.namo = NamoModel(config)
|
||||
self.vocab_size = config.text_config.vocab_size
|
||||
self.lm_head = nn.Linear(
|
||||
config.text_config.hidden_size, config.text_config.vocab_size, bias=False
|
||||
)
|
||||
|
||||
self.post_init()
|
||||
|
||||
def get_namo(self):
|
||||
return self.namo
|
||||
|
||||
@property
|
||||
def model(self):
|
||||
return self.namo.llm
|
||||
|
||||
def get_model(self):
|
||||
return self.model
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
pixel_values: Optional[torch.FloatTensor] = None,
|
||||
image_sizes: Optional[List[List[int]]] = None,
|
||||
pixel_attention_mask: Optional[torch.FloatTensor] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
cache_position=None,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
|
||||
if inputs_embeds is None:
|
||||
(
|
||||
input_ids,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
inputs_embeds,
|
||||
labels,
|
||||
) = self.prepare_inputs_labels_for_multimodal(
|
||||
input_ids,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
labels,
|
||||
pixel_values,
|
||||
image_sizes,
|
||||
pixel_attention_mask,
|
||||
)
|
||||
return super().forward(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
labels=labels,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
)
|
||||
|
||||
@torch.no_grad()
|
||||
def generate(
|
||||
self,
|
||||
input_ids: Optional[torch.Tensor] = None,
|
||||
pixel_values: Optional[torch.Tensor] = None,
|
||||
image_sizes: Optional[torch.Tensor] = None,
|
||||
pixel_attention_mask: Optional[torch.FloatTensor] = None,
|
||||
**kwargs,
|
||||
) -> Union[GenerateOutput, torch.LongTensor]:
|
||||
position_ids = kwargs.pop("position_ids", None)
|
||||
attention_mask = kwargs.pop("attention_mask", None)
|
||||
if "inputs_embeds" in kwargs:
|
||||
raise NotImplementedError("`inputs_embeds` is not supported")
|
||||
|
||||
if pixel_values is not None:
|
||||
(
|
||||
inputs,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
_,
|
||||
inputs_embeds,
|
||||
_,
|
||||
) = self.prepare_inputs_labels_for_multimodal(
|
||||
input_ids,
|
||||
position_ids,
|
||||
attention_mask,
|
||||
None,
|
||||
None,
|
||||
pixel_values,
|
||||
image_sizes=image_sizes,
|
||||
pixel_attention_mask=pixel_attention_mask,
|
||||
)
|
||||
else:
|
||||
inputs_embeds = self.get_model().embed_tokens(input_ids)
|
||||
|
||||
return super().generate(
|
||||
position_ids=position_ids,
|
||||
attention_mask=attention_mask,
|
||||
inputs_embeds=inputs_embeds,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs
|
||||
):
|
||||
pixel_values = kwargs.pop("pixel_values", None)
|
||||
image_sizes = kwargs.pop("image_sizes", None)
|
||||
pixel_attention_mask = kwargs.pop("pixel_attention_mask", None)
|
||||
inputs = super().prepare_inputs_for_generation(
|
||||
input_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
**kwargs,
|
||||
)
|
||||
if pixel_values is not None:
|
||||
inputs["pixel_values"] = pixel_values
|
||||
if image_sizes is not None:
|
||||
inputs["image_sizes"] = image_sizes
|
||||
if pixel_attention_mask is not None:
|
||||
inputs["pixel_attention_mask"] = pixel_attention_mask
|
||||
return inputs
|
||||
@@ -0,0 +1,12 @@
|
||||
# Model Constants
|
||||
IGNORE_INDEX = -100
|
||||
IMAGE_TOKEN_INDEX = -200
|
||||
AUDIO_TOKEN_INDEX = -300
|
||||
DEFAULT_IMAGE_TOKEN = "<image>"
|
||||
DEFAULT_AUDIOTOKEN = "<audio>"
|
||||
|
||||
DEFAULT_IMAGE_PATCH_TOKEN = "<im_patch>"
|
||||
DEFAULT_IM_START_TOKEN = "<im_start>"
|
||||
DEFAULT_IM_END_TOKEN = "<im_end>"
|
||||
IMAGE_PLACEHOLDER = "<image-placeholder>"
|
||||
DEFAULT_VIDEO_TOKEN = "<video>"
|
||||
@@ -0,0 +1,9 @@
|
||||
from transformers import AutoConfig, AutoModel
|
||||
from namo.models.vision.aimv2.configuration_aimv2 import AIMv2Config
|
||||
from namo.models.vision.aimv2.modeling_aimv2 import AIMv2Model
|
||||
from namo.models.vision.aimv2.modeling_aimv2_native import (
|
||||
AIMv2Model as AIMv2ModelNative,
|
||||
)
|
||||
from namo.processor import *
|
||||
|
||||
AutoConfig.register("aimv2", AIMv2Config)
|
||||
@@ -0,0 +1,62 @@
|
||||
from typing import Any
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
__all__ = ["AIMv2Config"]
|
||||
|
||||
|
||||
class AIMv2Config(PretrainedConfig):
|
||||
"""This is the configuration class to store the configuration of an [`AIMv2Model`].
|
||||
|
||||
Instantiating a configuration with the defaults will yield a similar configuration
|
||||
to that of the [apple/aimv2-large-patch14-224](https://huggingface.co/apple/aimv2-large-patch14-224).
|
||||
|
||||
Args:
|
||||
hidden_size: Dimension of the hidden representations.
|
||||
intermediate_size: Dimension of the SwiGLU representations.
|
||||
num_hidden_layers: Number of hidden layers in the Transformer.
|
||||
num_attention_heads: Number of attention heads for each attention layer
|
||||
in the Transformer.
|
||||
num_channels: Number of input channels.
|
||||
image_size: Image size.
|
||||
patch_size: Patch size.
|
||||
rms_norm_eps: Epsilon value used for the RMS normalization layer.
|
||||
attention_dropout: Dropout ratio for attention probabilities.
|
||||
projection_dropout: Dropout ratio for the projection layer after the attention.
|
||||
qkv_bias: Whether to add a bias to the queries, keys and values.
|
||||
use_bias: Whether to add a bias in the feed-forward and projection layers.
|
||||
kwargs: Keyword arguments for the [`PretrainedConfig`].
|
||||
"""
|
||||
|
||||
model_type: str = "aimv2"
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int = 1024,
|
||||
intermediate_size: int = 2816,
|
||||
num_hidden_layers: int = 24,
|
||||
num_attention_heads: int = 8,
|
||||
num_channels: int = 3,
|
||||
image_size: int = 224,
|
||||
patch_size: int = 14,
|
||||
rms_norm_eps: float = 1e-5,
|
||||
attention_dropout: float = 0.0,
|
||||
projection_dropout: float = 0.0,
|
||||
qkv_bias: bool = False,
|
||||
use_bias: bool = False,
|
||||
**kwargs: Any,
|
||||
):
|
||||
super().__init__(**kwargs)
|
||||
self.hidden_size = hidden_size
|
||||
self.intermediate_size = intermediate_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
self.num_channels = num_channels
|
||||
self.patch_size = patch_size
|
||||
self.image_size = image_size
|
||||
self.attention_dropout = attention_dropout
|
||||
self.rms_norm_eps = rms_norm_eps
|
||||
|
||||
self.projection_dropout = projection_dropout
|
||||
self.qkv_bias = qkv_bias
|
||||
self.use_bias = use_bias
|
||||
@@ -0,0 +1,191 @@
|
||||
from typing import Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from .configuration_aimv2 import AIMv2Config
|
||||
from torch import nn
|
||||
from torch.nn import functional as F
|
||||
from transformers.modeling_outputs import BaseModelOutputWithNoAttention
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
|
||||
__all__ = ["AIMv2Model"]
|
||||
|
||||
|
||||
class RMSNorm(nn.Module):
|
||||
def __init__(self, dim: int, eps: float = 1e-6):
|
||||
super().__init__()
|
||||
self.weight = nn.Parameter(torch.ones(dim))
|
||||
self.eps = eps
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
output = self._norm(x.float()).type_as(x)
|
||||
return output * self.weight
|
||||
|
||||
def extra_repr(self) -> str:
|
||||
return f"{tuple(self.weight.shape)}, eps={self.eps}"
|
||||
|
||||
def _norm(self, x: torch.Tensor) -> torch.Tensor:
|
||||
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
||||
|
||||
|
||||
class AIMv2SwiGLUFFN(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
hidden_features = config.intermediate_size
|
||||
in_features = config.hidden_size
|
||||
bias = config.use_bias
|
||||
|
||||
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)
|
||||
self.fc2 = nn.Linear(hidden_features, in_features, bias=bias)
|
||||
self.fc3 = nn.Linear(in_features, hidden_features, bias=bias)
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
x = F.silu(self.fc1(x)) * self.fc3(x)
|
||||
x = self.fc2(x)
|
||||
return x
|
||||
|
||||
|
||||
class AIMv2PatchEmbed(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
self.proj = nn.Conv2d(
|
||||
config.num_channels,
|
||||
config.hidden_size,
|
||||
kernel_size=(config.patch_size, config.patch_size),
|
||||
stride=(config.patch_size, config.patch_size),
|
||||
)
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
x = self.proj(x).flatten(2).transpose(1, 2)
|
||||
x = self.norm(x)
|
||||
return x
|
||||
|
||||
|
||||
class AIMv2ViTPreprocessor(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
num_patches = (config.image_size // config.patch_size) ** 2
|
||||
|
||||
self.patchifier = AIMv2PatchEmbed(config)
|
||||
self.pos_embed = nn.Parameter(torch.zeros((1, num_patches, config.hidden_size)))
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
tokens = self.patchifier(x)
|
||||
_, N, _ = tokens.shape
|
||||
pos_embed = self.pos_embed.to(tokens.device)
|
||||
tokens = tokens + pos_embed[:, :N]
|
||||
return tokens
|
||||
|
||||
|
||||
class AIMv2Attention(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
dim = config.hidden_size
|
||||
|
||||
self.num_heads = config.num_attention_heads
|
||||
self.qkv = nn.Linear(dim, dim * 3, bias=config.qkv_bias)
|
||||
self.attn_drop = nn.Dropout(config.attention_dropout)
|
||||
self.proj = nn.Linear(dim, dim, bias=config.use_bias)
|
||||
self.proj_drop = nn.Dropout(config.projection_dropout)
|
||||
|
||||
def forward(
|
||||
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
|
||||
) -> torch.Tensor:
|
||||
B, N, C = x.shape
|
||||
qkv = (
|
||||
self.qkv(x)
|
||||
.reshape(B, N, 3, self.num_heads, C // self.num_heads)
|
||||
.permute(2, 0, 3, 1, 4)
|
||||
)
|
||||
q, k, v = qkv.unbind(0)
|
||||
|
||||
x = F.scaled_dot_product_attention(q, k, v, attn_mask=mask)
|
||||
x = x.transpose(1, 2).contiguous().reshape(B, N, C)
|
||||
x = self.proj(x)
|
||||
x = self.proj_drop(x)
|
||||
return x
|
||||
|
||||
|
||||
class AIMv2Block(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
self.attn = AIMv2Attention(config)
|
||||
self.norm_1 = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
||||
self.mlp = AIMv2SwiGLUFFN(config)
|
||||
self.norm_2 = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
||||
|
||||
def forward(
|
||||
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
|
||||
) -> torch.Tensor:
|
||||
x = x + self.attn(self.norm_1(x), mask)
|
||||
x = x + self.mlp(self.norm_2(x))
|
||||
return x
|
||||
|
||||
|
||||
class AIMv2Transformer(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
self.blocks = nn.ModuleList(
|
||||
[AIMv2Block(config) for _ in range(config.num_hidden_layers)]
|
||||
)
|
||||
self.post_trunk_norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
tokens: torch.Tensor,
|
||||
mask: Optional[torch.Tensor] = None,
|
||||
output_hidden_states: bool = False,
|
||||
) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor, ...]]]:
|
||||
hidden_states = () if output_hidden_states else None
|
||||
for block in self.blocks:
|
||||
tokens = block(tokens, mask)
|
||||
if output_hidden_states:
|
||||
hidden_states += (tokens,)
|
||||
tokens = self.post_trunk_norm(tokens)
|
||||
return tokens, hidden_states
|
||||
|
||||
|
||||
class AIMv2PretrainedModel(PreTrainedModel):
|
||||
config_class = AIMv2Config
|
||||
base_model_prefix = "aimv2"
|
||||
main_input_name = "pixel_values"
|
||||
_no_split_modules = ["AIMv2ViTPreprocessor", "AIMv2Block"]
|
||||
_supports_sdpa = True
|
||||
|
||||
|
||||
class AIMv2Model(AIMv2PretrainedModel):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__(config)
|
||||
self.preprocessor = AIMv2ViTPreprocessor(config)
|
||||
self.trunk = AIMv2Transformer(config)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
pixel_values: torch.Tensor,
|
||||
mask: Optional[torch.Tensor] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[
|
||||
Tuple[torch.Tensor],
|
||||
Tuple[torch.Tensor, Tuple[torch.Tensor, ...]],
|
||||
BaseModelOutputWithNoAttention,
|
||||
]:
|
||||
if output_hidden_states is None:
|
||||
output_hidden_states = self.config.output_hidden_states
|
||||
if return_dict is None:
|
||||
return_dict = self.config.use_return_dict
|
||||
|
||||
x = self.preprocessor(pixel_values)
|
||||
x, hidden_states = self.trunk(
|
||||
x, mask, output_hidden_states=output_hidden_states
|
||||
)
|
||||
|
||||
if not return_dict:
|
||||
res = (x,)
|
||||
res += (hidden_states,) if output_hidden_states else ()
|
||||
return res
|
||||
|
||||
return BaseModelOutputWithNoAttention(
|
||||
last_hidden_state=x,
|
||||
hidden_states=hidden_states,
|
||||
)
|
||||
@@ -0,0 +1,225 @@
|
||||
import math
|
||||
from typing import Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from .configuration_aimv2 import AIMv2Config
|
||||
from torch import nn
|
||||
from torch.nn import functional as F
|
||||
from transformers.modeling_outputs import BaseModelOutputWithNoAttention
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
|
||||
__all__ = ["AIMv2Model"]
|
||||
|
||||
|
||||
def _get_1d_sincos_pos_embed_from_grid(
|
||||
embed_dim: int, pos: torch.Tensor
|
||||
) -> torch.Tensor:
|
||||
omega = torch.arange(embed_dim // 2).float()
|
||||
omega /= embed_dim / 2.0
|
||||
omega = 1.0 / 10000**omega # (D / 2,)
|
||||
pos = pos.reshape(-1) # (M,)
|
||||
out = pos[:, None] * omega[None, :] # (M, D / 2), outer product
|
||||
emb_sin, emb_cos = torch.sin(out), torch.cos(out) # (M, D / 2)
|
||||
emb = torch.concatenate([emb_sin, emb_cos], dim=1) # (M, D)
|
||||
return emb
|
||||
|
||||
|
||||
def get_sincos_pos_embed(h: int, w: int, embed_dim: int) -> torch.Tensor:
|
||||
assert embed_dim % 2 == 0, embed_dim
|
||||
grid_h = torch.arange(h).float()
|
||||
grid_w = torch.arange(w).float()
|
||||
grid = torch.meshgrid(grid_w, grid_h, indexing="xy")
|
||||
grid = torch.stack(grid, dim=0)
|
||||
grid = grid.reshape([2, 1, h, w])
|
||||
emb_h = _get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0])
|
||||
emb_w = _get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1])
|
||||
pos_embed = torch.concatenate([emb_h, emb_w], dim=1) # (H * W, D)
|
||||
return pos_embed
|
||||
|
||||
|
||||
class RMSNorm(nn.Module):
|
||||
def __init__(self, dim: int, eps: float = 1e-6):
|
||||
super().__init__()
|
||||
self.weight = nn.Parameter(torch.ones(dim))
|
||||
self.eps = eps
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
output = self._norm(x.float()).type_as(x)
|
||||
return output * self.weight
|
||||
|
||||
def extra_repr(self) -> str:
|
||||
return f"{tuple(self.weight.shape)}, eps={self.eps}"
|
||||
|
||||
def _norm(self, x: torch.Tensor) -> torch.Tensor:
|
||||
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
||||
|
||||
|
||||
class AIMv2SwiGLUFFN(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
hidden_features = config.intermediate_size
|
||||
in_features = config.hidden_size
|
||||
bias = config.use_bias
|
||||
|
||||
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)
|
||||
self.fc2 = nn.Linear(hidden_features, in_features, bias=bias)
|
||||
self.fc3 = nn.Linear(in_features, hidden_features, bias=bias)
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
x = F.silu(self.fc1(x)) * self.fc3(x)
|
||||
x = self.fc2(x)
|
||||
return x
|
||||
|
||||
|
||||
class AIMv2PatchEmbed(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
self.proj = nn.Conv2d(
|
||||
config.num_channels,
|
||||
config.hidden_size,
|
||||
kernel_size=(config.patch_size, config.patch_size),
|
||||
stride=(config.patch_size, config.patch_size),
|
||||
)
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
x = self.proj(x).flatten(2).transpose(1, 2)
|
||||
x = self.norm(x)
|
||||
return x
|
||||
|
||||
|
||||
class AIMv2ViTPreprocessor(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
self.patch_h = config.patch_size
|
||||
self.patch_w = config.patch_size
|
||||
self.embed_dim = config.hidden_size
|
||||
|
||||
self.patchifier = AIMv2PatchEmbed(config)
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
_, _, H, W = x.shape
|
||||
tokens = self.patchifier(x)
|
||||
pos_embed = get_sincos_pos_embed(
|
||||
H // self.patch_h, W // self.patch_w, embed_dim=self.embed_dim
|
||||
)
|
||||
tokens = tokens + pos_embed.to(tokens.device)
|
||||
return tokens
|
||||
|
||||
|
||||
class AIMv2Attention(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
dim = config.hidden_size
|
||||
|
||||
self.num_heads = config.num_attention_heads
|
||||
self.qkv = nn.Linear(dim, dim * 3, bias=config.qkv_bias)
|
||||
self.attn_drop = nn.Dropout(config.attention_dropout)
|
||||
self.proj = nn.Linear(dim, dim, bias=config.use_bias)
|
||||
self.proj_drop = nn.Dropout(config.projection_dropout)
|
||||
|
||||
def forward(
|
||||
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
|
||||
) -> torch.Tensor:
|
||||
B, N, C = x.shape
|
||||
qkv = (
|
||||
self.qkv(x)
|
||||
.reshape(B, N, 3, self.num_heads, C // self.num_heads)
|
||||
.permute(2, 0, 3, 1, 4)
|
||||
)
|
||||
q, k, v = qkv.unbind(0)
|
||||
|
||||
x = F.scaled_dot_product_attention(q, k, v, attn_mask=mask)
|
||||
x = x.transpose(1, 2).contiguous().reshape(B, N, C)
|
||||
x = self.proj(x)
|
||||
x = self.proj_drop(x)
|
||||
return x
|
||||
|
||||
|
||||
class AIMv2Block(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
self.attn = AIMv2Attention(config)
|
||||
self.norm_1 = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
||||
self.mlp = AIMv2SwiGLUFFN(config)
|
||||
self.norm_2 = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
||||
|
||||
def forward(
|
||||
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
|
||||
) -> torch.Tensor:
|
||||
x = x + self.attn(self.norm_1(x), mask)
|
||||
x = x + self.mlp(self.norm_2(x))
|
||||
return x
|
||||
|
||||
|
||||
class AIMv2Transformer(nn.Module):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__()
|
||||
self.blocks = nn.ModuleList(
|
||||
[AIMv2Block(config) for _ in range(config.num_hidden_layers)]
|
||||
)
|
||||
self.post_trunk_norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
tokens: torch.Tensor,
|
||||
mask: Optional[torch.Tensor] = None,
|
||||
output_hidden_states: bool = False,
|
||||
) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor, ...]]]:
|
||||
hidden_states = () if output_hidden_states else None
|
||||
for block in self.blocks:
|
||||
tokens = block(tokens, mask)
|
||||
if output_hidden_states:
|
||||
hidden_states += (tokens,)
|
||||
tokens = self.post_trunk_norm(tokens)
|
||||
return tokens, hidden_states
|
||||
|
||||
|
||||
class AIMv2PretrainedModel(PreTrainedModel):
|
||||
config_class = AIMv2Config
|
||||
base_model_prefix = "aimv2"
|
||||
main_input_name = "pixel_values"
|
||||
_no_split_modules = ["AIMv2ViTPreprocessor", "AIMv2Block"]
|
||||
_supports_sdpa = True
|
||||
|
||||
|
||||
class AIMv2Model(AIMv2PretrainedModel):
|
||||
def __init__(self, config: AIMv2Config):
|
||||
super().__init__(config)
|
||||
self.preprocessor = AIMv2ViTPreprocessor(config)
|
||||
self.trunk = AIMv2Transformer(config)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
pixel_values: torch.Tensor,
|
||||
mask: Optional[torch.Tensor] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[
|
||||
Tuple[torch.Tensor],
|
||||
Tuple[torch.Tensor, Tuple[torch.Tensor, ...]],
|
||||
BaseModelOutputWithNoAttention,
|
||||
]:
|
||||
if output_hidden_states is None:
|
||||
output_hidden_states = self.config.output_hidden_states
|
||||
if return_dict is None:
|
||||
return_dict = self.config.use_return_dict
|
||||
x = self.preprocessor(pixel_values)
|
||||
x = x.to(pixel_values.dtype) # sin pos made this to float, fix for bf16
|
||||
x, hidden_states = self.trunk(
|
||||
x, mask, output_hidden_states=output_hidden_states
|
||||
)
|
||||
hidden_states = list(hidden_states)
|
||||
h, w = pixel_values.shape[-2:]
|
||||
hh, hw = h // self.preprocessor.patch_h, w // self.preprocessor.patch_w
|
||||
B, T, H = hidden_states[-2].shape
|
||||
hidden_states[-2] = hidden_states[-2].reshape(B, hh, hw, H)
|
||||
if not return_dict:
|
||||
res = (x,)
|
||||
res += (hidden_states,) if output_hidden_states else ()
|
||||
return res
|
||||
|
||||
return BaseModelOutputWithNoAttention(
|
||||
last_hidden_state=x,
|
||||
hidden_states=hidden_states,
|
||||
)
|
||||
@@ -0,0 +1,739 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2024 Microsoft and the HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""PyTorch Florence-2 model."""
|
||||
from dataclasses import dataclass
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import math
|
||||
import torch
|
||||
import torch.utils.checkpoint
|
||||
from torch import nn
|
||||
import torch.nn.functional as F
|
||||
import torch.utils.checkpoint as checkpoint
|
||||
from torch.nn import CrossEntropyLoss
|
||||
from collections import OrderedDict
|
||||
from einops import rearrange
|
||||
from timm.models.layers import DropPath, trunc_normal_
|
||||
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import (
|
||||
ModelOutput,
|
||||
add_start_docstrings,
|
||||
add_start_docstrings_to_model_forward,
|
||||
is_flash_attn_2_available,
|
||||
logging,
|
||||
replace_return_docstrings,
|
||||
is_flash_attn_2_available,
|
||||
is_flash_attn_greater_or_equal_2_10,
|
||||
)
|
||||
from .configuration_florence2 import Florence2Config
|
||||
from .configuration_florence2 import Florence2LanguageConfig
|
||||
from .configuration_florence2 import Florence2VisionConfig
|
||||
|
||||
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_attn_mask_utils import (
|
||||
_prepare_4d_attention_mask,
|
||||
_prepare_4d_attention_mask_for_sdpa,
|
||||
_prepare_4d_causal_attention_mask,
|
||||
_prepare_4d_causal_attention_mask_for_sdpa,
|
||||
)
|
||||
from transformers.modeling_outputs import (
|
||||
BaseModelOutput,
|
||||
BaseModelOutputWithPastAndCrossAttentions,
|
||||
Seq2SeqLMOutput,
|
||||
Seq2SeqModelOutput,
|
||||
)
|
||||
|
||||
|
||||
if is_flash_attn_2_available():
|
||||
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
_CONFIG_FOR_DOC = "Florence2Config"
|
||||
|
||||
|
||||
class LearnedAbsolutePositionEmbedding2D(nn.Module):
|
||||
"""
|
||||
This module learns positional embeddings up to a fixed maximum size.
|
||||
"""
|
||||
|
||||
def __init__(self, embedding_dim=256, num_pos=50):
|
||||
super().__init__()
|
||||
self.row_embeddings = nn.Embedding(num_pos, embedding_dim // 2)
|
||||
self.column_embeddings = nn.Embedding(
|
||||
num_pos, embedding_dim - (embedding_dim // 2)
|
||||
)
|
||||
|
||||
def forward(self, pixel_values):
|
||||
"""
|
||||
pixel_values: (batch_size, height, width, num_channels)
|
||||
returns: (batch_size, height, width, embedding_dim * 2)
|
||||
"""
|
||||
if len(pixel_values.shape) != 4:
|
||||
raise ValueError("pixel_values must be a 4D tensor")
|
||||
height, width = pixel_values.shape[1:3]
|
||||
width_values = torch.arange(width, device=pixel_values.device)
|
||||
height_values = torch.arange(height, device=pixel_values.device)
|
||||
x_emb = self.column_embeddings(width_values)
|
||||
y_emb = self.row_embeddings(height_values)
|
||||
# (height, width, embedding_dim * 2)
|
||||
pos = torch.cat(
|
||||
[
|
||||
x_emb.unsqueeze(0).repeat(height, 1, 1),
|
||||
y_emb.unsqueeze(1).repeat(1, width, 1),
|
||||
],
|
||||
dim=-1,
|
||||
)
|
||||
# (embedding_dim * 2, height, width)
|
||||
pos = pos.permute(2, 0, 1)
|
||||
pos = pos.unsqueeze(0)
|
||||
# (batch_size, embedding_dim * 2, height, width)
|
||||
pos = pos.repeat(pixel_values.shape[0], 1, 1, 1)
|
||||
# (batch_size, height, width, embedding_dim * 2)
|
||||
pos = pos.permute(0, 2, 3, 1)
|
||||
return pos
|
||||
|
||||
|
||||
class PositionalEmbeddingCosine1D(nn.Module):
|
||||
"""
|
||||
This class implements a very simple positional encoding. It follows closely
|
||||
the encoder from the link below:
|
||||
https://pytorch.org/tutorials/beginner/translation_transformer.html
|
||||
|
||||
Args:
|
||||
embed_dim: The dimension of the embeddings.
|
||||
dropout_prob: The dropout probability.
|
||||
max_seq_len: The maximum length to precompute the positional encodings.
|
||||
"""
|
||||
|
||||
def __init__(self, embed_dim: int = 512, max_seq_len: int = 1024) -> None:
|
||||
super(PositionalEmbeddingCosine1D, self).__init__()
|
||||
self.embed_dim = embed_dim
|
||||
self.max_seq_len = max_seq_len
|
||||
# Generate the sinusoidal arrays.
|
||||
factor = math.log(10000)
|
||||
denominator = torch.exp(
|
||||
-factor * torch.arange(0, self.embed_dim, 2) / self.embed_dim
|
||||
)
|
||||
# Matrix where rows correspond to a positional embedding as a function
|
||||
# of the position index (i.e., the row index).
|
||||
frequencies = (
|
||||
torch.arange(0, self.max_seq_len).reshape(self.max_seq_len, 1) * denominator
|
||||
)
|
||||
pos_idx_to_embed = torch.zeros((self.max_seq_len, self.embed_dim))
|
||||
# Populate uneven entries.
|
||||
pos_idx_to_embed[:, 0::2] = torch.sin(frequencies)
|
||||
pos_idx_to_embed[:, 1::2] = torch.cos(frequencies)
|
||||
# Save the positional embeddings in a constant buffer.
|
||||
self.register_buffer("pos_idx_to_embed", pos_idx_to_embed)
|
||||
|
||||
def forward(self, seq_embeds: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Args:
|
||||
seq_embeds: The sequence embeddings in order. Allowed size:
|
||||
1. [T, D], where T is the length of the sequence, and D is the
|
||||
frame embedding dimension.
|
||||
2. [B, T, D], where B is the batch size and T and D are the
|
||||
same as above.
|
||||
|
||||
Returns a tensor of with the same dimensions as the input: i.e.,
|
||||
[1, T, D] or [T, D].
|
||||
"""
|
||||
shape_len = len(seq_embeds.shape)
|
||||
assert 2 <= shape_len <= 3
|
||||
len_seq = seq_embeds.size(-2)
|
||||
assert len_seq <= self.max_seq_len
|
||||
pos_embeds = self.pos_idx_to_embed[0 : seq_embeds.size(-2), :]
|
||||
# Adapt pre-computed positional embeddings to the input.
|
||||
if shape_len == 3:
|
||||
pos_embeds = pos_embeds.view((1, pos_embeds.size(0), pos_embeds.size(1)))
|
||||
return pos_embeds
|
||||
|
||||
|
||||
class LearnedAbsolutePositionEmbedding1D(nn.Module):
|
||||
"""
|
||||
Learnable absolute positional embeddings for 1D sequences.
|
||||
|
||||
Args:
|
||||
embed_dim: The dimension of the embeddings.
|
||||
max_seq_len: The maximum length to precompute the positional encodings.
|
||||
"""
|
||||
|
||||
def __init__(self, embedding_dim: int = 512, num_pos: int = 1024) -> None:
|
||||
super(LearnedAbsolutePositionEmbedding1D, self).__init__()
|
||||
self.embeddings = nn.Embedding(num_pos, embedding_dim)
|
||||
self.num_pos = num_pos
|
||||
|
||||
def forward(self, seq_embeds: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Args:
|
||||
seq_embeds: The sequence embeddings in order. Allowed size:
|
||||
1. [T, D], where T is the length of the sequence, and D is the
|
||||
frame embedding dimension.
|
||||
2. [B, T, D], where B is the batch size and T and D are the
|
||||
same as above.
|
||||
|
||||
Returns a tensor of with the same dimensions as the input: i.e.,
|
||||
[1, T, D] or [T, D].
|
||||
"""
|
||||
shape_len = len(seq_embeds.shape)
|
||||
assert 2 <= shape_len <= 3
|
||||
len_seq = seq_embeds.size(-2)
|
||||
assert len_seq <= self.num_pos
|
||||
# [T, D]
|
||||
pos_embeds = self.embeddings(torch.arange(len_seq).to(seq_embeds.device))
|
||||
# Adapt pre-computed positional embeddings to the input.
|
||||
if shape_len == 3:
|
||||
pos_embeds = pos_embeds.view((1, pos_embeds.size(0), pos_embeds.size(1)))
|
||||
return pos_embeds
|
||||
|
||||
|
||||
class MySequential(nn.Sequential):
|
||||
def forward(self, *inputs):
|
||||
for module in self._modules.values():
|
||||
if type(inputs) == tuple:
|
||||
inputs = module(*inputs)
|
||||
else:
|
||||
inputs = module(inputs)
|
||||
return inputs
|
||||
|
||||
|
||||
class PreNorm(nn.Module):
|
||||
def __init__(self, norm, fn, drop_path=None):
|
||||
super().__init__()
|
||||
self.norm = norm
|
||||
self.fn = fn
|
||||
self.drop_path = drop_path
|
||||
|
||||
def forward(self, x, *args, **kwargs):
|
||||
shortcut = x
|
||||
if self.norm != None:
|
||||
x, size = self.fn(self.norm(x), *args, **kwargs)
|
||||
else:
|
||||
x, size = self.fn(x, *args, **kwargs)
|
||||
|
||||
if self.drop_path:
|
||||
x = self.drop_path(x)
|
||||
|
||||
x = shortcut + x
|
||||
|
||||
return x, size
|
||||
|
||||
|
||||
class Mlp(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
in_features,
|
||||
hidden_features=None,
|
||||
out_features=None,
|
||||
act_layer=nn.GELU,
|
||||
):
|
||||
super().__init__()
|
||||
out_features = out_features or in_features
|
||||
hidden_features = hidden_features or in_features
|
||||
self.net = nn.Sequential(
|
||||
OrderedDict(
|
||||
[
|
||||
("fc1", nn.Linear(in_features, hidden_features)),
|
||||
("act", act_layer()),
|
||||
("fc2", nn.Linear(hidden_features, out_features)),
|
||||
]
|
||||
)
|
||||
)
|
||||
|
||||
def forward(self, x, size):
|
||||
return self.net(x), size
|
||||
|
||||
|
||||
class DepthWiseConv2d(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
dim_in,
|
||||
kernel_size,
|
||||
padding,
|
||||
stride,
|
||||
bias=True,
|
||||
):
|
||||
super().__init__()
|
||||
self.dw = nn.Conv2d(
|
||||
dim_in,
|
||||
dim_in,
|
||||
kernel_size=kernel_size,
|
||||
padding=padding,
|
||||
groups=dim_in,
|
||||
stride=stride,
|
||||
bias=bias,
|
||||
)
|
||||
|
||||
def forward(self, x, size):
|
||||
B, N, C = x.shape
|
||||
H, W = size
|
||||
assert N == H * W
|
||||
|
||||
x = self.dw(x.transpose(1, 2).view(B, C, H, W))
|
||||
size = (x.size(-2), x.size(-1))
|
||||
x = x.flatten(2).transpose(1, 2)
|
||||
return x, size
|
||||
|
||||
|
||||
class ConvEmbed(nn.Module):
|
||||
"""Image to Patch Embedding"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
patch_size=7,
|
||||
in_chans=3,
|
||||
embed_dim=64,
|
||||
stride=4,
|
||||
padding=2,
|
||||
norm_layer=None,
|
||||
pre_norm=True,
|
||||
):
|
||||
super().__init__()
|
||||
self.patch_size = patch_size
|
||||
|
||||
self.proj = nn.Conv2d(
|
||||
in_chans, embed_dim, kernel_size=patch_size, stride=stride, padding=padding
|
||||
)
|
||||
|
||||
dim_norm = in_chans if pre_norm else embed_dim
|
||||
self.norm = norm_layer(dim_norm) if norm_layer else None
|
||||
|
||||
self.pre_norm = pre_norm
|
||||
|
||||
def forward(self, x, size):
|
||||
H, W = size
|
||||
if len(x.size()) == 3:
|
||||
if self.norm and self.pre_norm:
|
||||
x = self.norm(x)
|
||||
x = rearrange(x, "b (h w) c -> b c h w", h=H, w=W)
|
||||
|
||||
x = self.proj(x)
|
||||
|
||||
_, _, H, W = x.shape
|
||||
x = rearrange(x, "b c h w -> b (h w) c")
|
||||
if self.norm and not self.pre_norm:
|
||||
x = self.norm(x)
|
||||
|
||||
return x, (H, W)
|
||||
|
||||
|
||||
class ChannelAttention(nn.Module):
|
||||
def __init__(self, dim, groups=8, qkv_bias=True):
|
||||
super().__init__()
|
||||
|
||||
self.groups = groups
|
||||
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
||||
self.proj = nn.Linear(dim, dim)
|
||||
|
||||
def forward(self, x, size):
|
||||
B, N, C = x.shape
|
||||
|
||||
qkv = (
|
||||
self.qkv(x)
|
||||
.reshape(B, N, 3, self.groups, C // self.groups)
|
||||
.permute(2, 0, 3, 1, 4)
|
||||
)
|
||||
q, k, v = qkv[0], qkv[1], qkv[2]
|
||||
|
||||
q = q * (float(N) ** -0.5)
|
||||
attention = q.transpose(-1, -2) @ k
|
||||
attention = attention.softmax(dim=-1)
|
||||
x = (attention @ v.transpose(-1, -2)).transpose(-1, -2)
|
||||
x = x.transpose(1, 2).reshape(B, N, C)
|
||||
x = self.proj(x)
|
||||
return x, size
|
||||
|
||||
|
||||
class ChannelBlock(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
dim,
|
||||
groups,
|
||||
mlp_ratio=4.0,
|
||||
qkv_bias=True,
|
||||
drop_path_rate=0.0,
|
||||
act_layer=nn.GELU,
|
||||
norm_layer=nn.LayerNorm,
|
||||
conv_at_attn=True,
|
||||
conv_at_ffn=True,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
drop_path = DropPath(drop_path_rate) if drop_path_rate > 0.0 else nn.Identity()
|
||||
|
||||
self.conv1 = (
|
||||
PreNorm(None, DepthWiseConv2d(dim, 3, 1, 1)) if conv_at_attn else None
|
||||
)
|
||||
self.channel_attn = PreNorm(
|
||||
norm_layer(dim),
|
||||
ChannelAttention(dim, groups=groups, qkv_bias=qkv_bias),
|
||||
drop_path,
|
||||
)
|
||||
self.conv2 = (
|
||||
PreNorm(None, DepthWiseConv2d(dim, 3, 1, 1)) if conv_at_ffn else None
|
||||
)
|
||||
self.ffn = PreNorm(
|
||||
norm_layer(dim),
|
||||
Mlp(
|
||||
in_features=dim,
|
||||
hidden_features=int(dim * mlp_ratio),
|
||||
act_layer=act_layer,
|
||||
),
|
||||
drop_path,
|
||||
)
|
||||
|
||||
def forward(self, x, size):
|
||||
if self.conv1:
|
||||
x, size = self.conv1(x, size)
|
||||
x, size = self.channel_attn(x, size)
|
||||
|
||||
if self.conv2:
|
||||
x, size = self.conv2(x, size)
|
||||
x, size = self.ffn(x, size)
|
||||
|
||||
return x, size
|
||||
|
||||
|
||||
def window_partition(x, window_size: int):
|
||||
B, H, W, C = x.shape
|
||||
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
|
||||
windows = (
|
||||
x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
|
||||
)
|
||||
return windows
|
||||
|
||||
|
||||
def window_reverse(windows, batch_size: int, window_size: int, H: int, W: int):
|
||||
B = batch_size
|
||||
# this will cause onnx conversion failed for dynamic axis, because treated as constant
|
||||
# int(windows.shape[0] / (H * W / window_size / window_size))
|
||||
x = windows.view(
|
||||
B, H // window_size, W // window_size, window_size, window_size, -1
|
||||
)
|
||||
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
|
||||
return x
|
||||
|
||||
|
||||
class WindowAttention(nn.Module):
|
||||
def __init__(self, dim, num_heads, window_size, qkv_bias=True):
|
||||
|
||||
super().__init__()
|
||||
self.dim = dim
|
||||
self.window_size = window_size
|
||||
self.num_heads = num_heads
|
||||
head_dim = dim // num_heads
|
||||
self.scale = float(head_dim) ** -0.5
|
||||
|
||||
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
||||
self.proj = nn.Linear(dim, dim)
|
||||
|
||||
self.softmax = nn.Softmax(dim=-1)
|
||||
|
||||
def forward(self, x, size):
|
||||
|
||||
H, W = size
|
||||
B, L, C = x.shape
|
||||
assert L == H * W, "input feature has wrong size"
|
||||
|
||||
x = x.view(B, H, W, C)
|
||||
|
||||
pad_l = pad_t = 0
|
||||
pad_r = (self.window_size - W % self.window_size) % self.window_size
|
||||
pad_b = (self.window_size - H % self.window_size) % self.window_size
|
||||
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
|
||||
_, Hp, Wp, _ = x.shape
|
||||
|
||||
x = window_partition(x, self.window_size)
|
||||
x = x.view(-1, self.window_size * self.window_size, C)
|
||||
|
||||
# W-MSA/SW-MSA
|
||||
# attn_windows = self.attn(x_windows)
|
||||
|
||||
B_, N, C = x.shape
|
||||
qkv = (
|
||||
self.qkv(x)
|
||||
.reshape(B_, N, 3, self.num_heads, C // self.num_heads)
|
||||
.permute(2, 0, 3, 1, 4)
|
||||
)
|
||||
q, k, v = qkv[0], qkv[1], qkv[2]
|
||||
|
||||
q = q * self.scale
|
||||
attn = q @ k.transpose(-2, -1)
|
||||
attn = self.softmax(attn)
|
||||
|
||||
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
|
||||
x = self.proj(x)
|
||||
|
||||
# merge windows
|
||||
x = x.view(-1, self.window_size, self.window_size, C)
|
||||
x = window_reverse(x, B, self.window_size, Hp, Wp)
|
||||
|
||||
if pad_r > 0 or pad_b > 0:
|
||||
x = x[:, :H, :W, :].contiguous()
|
||||
|
||||
x = x.view(B, H * W, C)
|
||||
|
||||
return x, size
|
||||
|
||||
|
||||
class SpatialBlock(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
dim,
|
||||
num_heads,
|
||||
window_size,
|
||||
mlp_ratio=4.0,
|
||||
qkv_bias=True,
|
||||
drop_path_rate=0.0,
|
||||
act_layer=nn.GELU,
|
||||
norm_layer=nn.LayerNorm,
|
||||
conv_at_attn=True,
|
||||
conv_at_ffn=True,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
drop_path = DropPath(drop_path_rate) if drop_path_rate > 0.0 else nn.Identity()
|
||||
|
||||
self.conv1 = (
|
||||
PreNorm(None, DepthWiseConv2d(dim, 3, 1, 1)) if conv_at_attn else None
|
||||
)
|
||||
self.window_attn = PreNorm(
|
||||
norm_layer(dim),
|
||||
WindowAttention(dim, num_heads, window_size, qkv_bias=qkv_bias),
|
||||
drop_path,
|
||||
)
|
||||
self.conv2 = (
|
||||
PreNorm(None, DepthWiseConv2d(dim, 3, 1, 1)) if conv_at_ffn else None
|
||||
)
|
||||
self.ffn = PreNorm(
|
||||
norm_layer(dim),
|
||||
Mlp(
|
||||
in_features=dim,
|
||||
hidden_features=int(dim * mlp_ratio),
|
||||
act_layer=act_layer,
|
||||
),
|
||||
drop_path,
|
||||
)
|
||||
|
||||
def forward(self, x, size):
|
||||
if self.conv1:
|
||||
x, size = self.conv1(x, size)
|
||||
x, size = self.window_attn(x, size)
|
||||
|
||||
if self.conv2:
|
||||
x, size = self.conv2(x, size)
|
||||
x, size = self.ffn(x, size)
|
||||
return x, size
|
||||
|
||||
|
||||
class DaViT(nn.Module):
|
||||
"""DaViT: Dual-Attention Transformer
|
||||
|
||||
Args:
|
||||
in_chans (int): Number of input image channels. Default: 3.
|
||||
num_classes (int): Number of classes for classification head. Default: 1000.
|
||||
patch_size (tuple(int)): Patch size of convolution in different stages. Default: (7, 2, 2, 2).
|
||||
patch_stride (tuple(int)): Patch stride of convolution in different stages. Default: (4, 2, 2, 2).
|
||||
patch_padding (tuple(int)): Patch padding of convolution in different stages. Default: (3, 0, 0, 0).
|
||||
patch_prenorm (tuple(bool)): If True, perform norm before convlution layer. Default: (True, False, False, False).
|
||||
embed_dims (tuple(int)): Patch embedding dimension in different stages. Default: (64, 128, 192, 256).
|
||||
num_heads (tuple(int)): Number of spatial attention heads in different stages. Default: (4, 8, 12, 16).
|
||||
num_groups (tuple(int)): Number of channel groups in different stages. Default: (4, 8, 12, 16).
|
||||
window_size (int): Window size. Default: 7.
|
||||
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.
|
||||
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True.
|
||||
drop_path_rate (float): Stochastic depth rate. Default: 0.1.
|
||||
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
|
||||
enable_checkpoint (bool): If True, enable checkpointing. Default: False.
|
||||
conv_at_attn (bool): If True, performe depthwise convolution before attention layer. Default: True.
|
||||
conv_at_ffn (bool): If True, performe depthwise convolution before ffn layer. Default: True.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
in_chans=3,
|
||||
num_classes=1000,
|
||||
depths=(1, 1, 3, 1),
|
||||
patch_size=(7, 2, 2, 2),
|
||||
patch_stride=(4, 2, 2, 2),
|
||||
patch_padding=(3, 0, 0, 0),
|
||||
patch_prenorm=(False, False, False, False),
|
||||
embed_dims=(64, 128, 192, 256),
|
||||
num_heads=(3, 6, 12, 24),
|
||||
num_groups=(3, 6, 12, 24),
|
||||
window_size=7,
|
||||
mlp_ratio=4.0,
|
||||
qkv_bias=True,
|
||||
drop_path_rate=0.1,
|
||||
norm_layer=nn.LayerNorm,
|
||||
enable_checkpoint=False,
|
||||
conv_at_attn=True,
|
||||
conv_at_ffn=True,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.num_classes = num_classes
|
||||
self.embed_dims = embed_dims
|
||||
self.num_heads = num_heads
|
||||
self.num_groups = num_groups
|
||||
self.num_stages = len(self.embed_dims)
|
||||
self.enable_checkpoint = enable_checkpoint
|
||||
assert self.num_stages == len(self.num_heads) == len(self.num_groups)
|
||||
|
||||
num_stages = len(embed_dims)
|
||||
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths) * 2)]
|
||||
|
||||
depth_offset = 0
|
||||
convs = []
|
||||
blocks = []
|
||||
for i in range(num_stages):
|
||||
conv_embed = ConvEmbed(
|
||||
patch_size=patch_size[i],
|
||||
stride=patch_stride[i],
|
||||
padding=patch_padding[i],
|
||||
in_chans=in_chans if i == 0 else self.embed_dims[i - 1],
|
||||
embed_dim=self.embed_dims[i],
|
||||
norm_layer=norm_layer,
|
||||
pre_norm=patch_prenorm[i],
|
||||
)
|
||||
convs.append(conv_embed)
|
||||
|
||||
block = MySequential(
|
||||
*[
|
||||
MySequential(
|
||||
OrderedDict(
|
||||
[
|
||||
(
|
||||
"spatial_block",
|
||||
SpatialBlock(
|
||||
embed_dims[i],
|
||||
num_heads[i],
|
||||
window_size,
|
||||
drop_path_rate=dpr[depth_offset + j * 2],
|
||||
qkv_bias=qkv_bias,
|
||||
mlp_ratio=mlp_ratio,
|
||||
conv_at_attn=conv_at_attn,
|
||||
conv_at_ffn=conv_at_ffn,
|
||||
),
|
||||
),
|
||||
(
|
||||
"channel_block",
|
||||
ChannelBlock(
|
||||
embed_dims[i],
|
||||
num_groups[i],
|
||||
drop_path_rate=dpr[depth_offset + j * 2 + 1],
|
||||
qkv_bias=qkv_bias,
|
||||
mlp_ratio=mlp_ratio,
|
||||
conv_at_attn=conv_at_attn,
|
||||
conv_at_ffn=conv_at_ffn,
|
||||
),
|
||||
),
|
||||
]
|
||||
)
|
||||
)
|
||||
for j in range(depths[i])
|
||||
]
|
||||
)
|
||||
blocks.append(block)
|
||||
depth_offset += depths[i] * 2
|
||||
|
||||
self.convs = nn.ModuleList(convs)
|
||||
self.blocks = nn.ModuleList(blocks)
|
||||
|
||||
self.norms = norm_layer(self.embed_dims[-1])
|
||||
self.avgpool = nn.AdaptiveAvgPool1d(1)
|
||||
self.head = (
|
||||
nn.Linear(self.embed_dims[-1], num_classes)
|
||||
if num_classes > 0
|
||||
else nn.Identity()
|
||||
)
|
||||
|
||||
self.apply(self._init_weights)
|
||||
|
||||
@property
|
||||
def dim_out(self):
|
||||
return self.embed_dims[-1]
|
||||
|
||||
def _init_weights(self, m):
|
||||
if isinstance(m, nn.Linear):
|
||||
trunc_normal_(m.weight, std=0.02)
|
||||
if m.bias is not None:
|
||||
nn.init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.Conv2d):
|
||||
nn.init.normal_(m.weight, std=0.02)
|
||||
for name, _ in m.named_parameters():
|
||||
if name in ["bias"]:
|
||||
nn.init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.LayerNorm):
|
||||
nn.init.constant_(m.weight, 1.0)
|
||||
nn.init.constant_(m.bias, 0)
|
||||
elif isinstance(m, nn.BatchNorm2d):
|
||||
nn.init.constant_(m.weight, 1.0)
|
||||
nn.init.constant_(m.bias, 0)
|
||||
|
||||
def forward_features_unpool(self, x):
|
||||
"""
|
||||
forward until avg pooling
|
||||
Args:
|
||||
x (_type_): input image tensor
|
||||
"""
|
||||
input_size = (x.size(2), x.size(3))
|
||||
for conv, block in zip(self.convs, self.blocks):
|
||||
x, input_size = conv(x, input_size)
|
||||
if self.enable_checkpoint:
|
||||
x, input_size = checkpoint.checkpoint(block, x, input_size)
|
||||
else:
|
||||
x, input_size = block(x, input_size)
|
||||
return x
|
||||
|
||||
def forward_features(self, x):
|
||||
x = self.forward_features_unpool(x)
|
||||
|
||||
# (batch_size, num_tokens, token_dim)
|
||||
x = self.avgpool(x.transpose(1, 2))
|
||||
# (batch_size, 1, num_tokens)
|
||||
x = torch.flatten(x, 1)
|
||||
x = self.norms(x)
|
||||
|
||||
return x
|
||||
|
||||
def forward(self, x):
|
||||
x = self.forward_features(x)
|
||||
x = self.head(x)
|
||||
return x
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, config):
|
||||
return cls(
|
||||
depths=config.depths,
|
||||
embed_dims=config.dim_embed,
|
||||
num_heads=config.num_heads,
|
||||
num_groups=config.num_groups,
|
||||
patch_size=config.patch_size,
|
||||
patch_stride=config.patch_stride,
|
||||
patch_padding=config.patch_padding,
|
||||
patch_prenorm=config.patch_prenorm,
|
||||
drop_path_rate=config.drop_path_rate,
|
||||
window_size=config.window_size,
|
||||
)
|
||||
|
||||
|
||||
if is_flash_attn_2_available():
|
||||
from flash_attn import flash_attn_func, flash_attn_varlen_func
|
||||
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
|
||||
@@ -0,0 +1,14 @@
|
||||
from namo.models.vision.ve_aim import AimV2VE
|
||||
from namo.models.vision.ve_siglip_navit import SigLipNavitVE
|
||||
from torch import nn
|
||||
|
||||
|
||||
def get_ve(config, **kwargs):
|
||||
type_name = config.vision_config._name_or_path.lower()
|
||||
|
||||
if "siglip" in type_name and "navit" not in type_name:
|
||||
return SigLipNavitVE(config, **kwargs)
|
||||
elif "aim" in type_name:
|
||||
return AimV2VE(config, **kwargs)
|
||||
else:
|
||||
raise ValueError(f"Unsupported vision model: {type_name}")
|
||||
@@ -0,0 +1,97 @@
|
||||
import math
|
||||
import torch
|
||||
from torch import nn
|
||||
import torchvision
|
||||
from transformers import (
|
||||
AutoProcessor,
|
||||
AutoModelForCausalLM,
|
||||
CLIPImageProcessor,
|
||||
AutoConfig,
|
||||
AutoModel,
|
||||
)
|
||||
import os
|
||||
from transformers import AutoModel
|
||||
from .ve_base import BaseVE
|
||||
from loguru import logger
|
||||
from namo.utils.utils import is_main_process
|
||||
from . import AIMv2Model
|
||||
from . import AIMv2ModelNative
|
||||
from . import AIMv2Config
|
||||
from .aimv2.modeling_aimv2_native import RMSNorm
|
||||
|
||||
|
||||
class VLPatchMerger(nn.Module):
|
||||
def __init__(self, dim: int, context_dim: int, spatial_merge_size: int = 2) -> None:
|
||||
super().__init__()
|
||||
self.hidden_size = context_dim * (spatial_merge_size**2)
|
||||
self.ln_q = RMSNorm(context_dim, eps=1e-6)
|
||||
self.mlp = nn.Sequential(
|
||||
nn.Linear(self.hidden_size, self.hidden_size),
|
||||
nn.GELU(),
|
||||
nn.Linear(self.hidden_size, dim),
|
||||
)
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
x = self.mlp(self.ln_q(x).view(-1, self.hidden_size))
|
||||
return x
|
||||
|
||||
|
||||
class AimV2VE(BaseVE):
|
||||
def _load_vision_tower(self):
|
||||
# other models can be customized here, normally AutoModel can handle well
|
||||
if os.path.exists(self.vision_tower_name):
|
||||
if "native" in self.vision_tower_name:
|
||||
if is_main_process():
|
||||
logger.info(
|
||||
f"loading AIMv2-native pretrain model: {self.vision_tower_name} {self.torch_dtype}"
|
||||
)
|
||||
self.vision_tower = AIMv2ModelNative.from_pretrained(
|
||||
self.vision_tower_name,
|
||||
ignore_mismatched_sizes=True,
|
||||
torch_dtype=self.torch_dtype,
|
||||
)
|
||||
else:
|
||||
if is_main_process():
|
||||
logger.info(
|
||||
f"loading AIMv2 pretrain model: {self.vision_tower_name}"
|
||||
)
|
||||
self.vision_tower = AIMv2Model.from_pretrained(
|
||||
self.vision_tower_name,
|
||||
ignore_mismatched_sizes=True,
|
||||
torch_dtype=self.torch_dtype,
|
||||
)
|
||||
else:
|
||||
if is_main_process():
|
||||
logger.info(f"creating AIMv2 model: {self.vision_tower_name}")
|
||||
if "native" in self.vision_tower_name:
|
||||
self.vision_tower = AIMv2ModelNative(
|
||||
config=self.vision_config,
|
||||
)
|
||||
else:
|
||||
self.vision_tower = AIMv2Model(
|
||||
config=self.vision_config,
|
||||
)
|
||||
|
||||
# todo: should check if vision_tower_name exist, if not, using config._name_or_path
|
||||
# self.image_processor = CLIPImageProcessor.from_pretrained(
|
||||
# self.vision_tower_name
|
||||
# )
|
||||
# self.image_processor.do_center_crop = False
|
||||
|
||||
# add a new PatchMerger after vision tower?
|
||||
# self.patch_merger = VLPatchMerger(
|
||||
# self.vision_config.dim, self.vision_config.context_dim
|
||||
# )
|
||||
|
||||
def feature_select(self, image_forward_outs):
|
||||
image_features = image_forward_outs.hidden_states[self.select_layer]
|
||||
|
||||
if self.select_feature == "patch":
|
||||
return image_features[:, 1:]
|
||||
elif self.select_feature in ["cls_patch", "same", "all", "default"]:
|
||||
return image_features
|
||||
else:
|
||||
raise ValueError(f"Invalid select feature: {self.select_feature}")
|
||||
|
||||
def forward(self, images, image_sizes=None):
|
||||
return self.basic_forward(images)
|
||||
@@ -0,0 +1,144 @@
|
||||
import os
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from transformers import AutoConfig, AutoModel, AutoImageProcessor
|
||||
import torchvision
|
||||
from loguru import logger
|
||||
from namo.utils.utils import rank0_print, is_main_process
|
||||
|
||||
|
||||
class BaseVE(nn.Module):
|
||||
def __init__(self, config, **kwargs):
|
||||
super().__init__()
|
||||
|
||||
delay_load = kwargs.pop("delay_load", False)
|
||||
self.vision_config = config.vision_config
|
||||
self.model_name_or_path = config._name_or_path
|
||||
self.torch_dtype = config.vision_config.torch_dtype
|
||||
self.is_loaded = False
|
||||
self.vision_tower_name = config.vision_config._name_or_path.lower()
|
||||
self.select_layer = config.vision_feature_layer
|
||||
self.select_feature = config.vision_feature_select_strategy
|
||||
self.new_img_size = config.new_img_size
|
||||
self.unfreeze_ve = config.unfreeze_ve
|
||||
self.longest_edge = config.longest_edge
|
||||
self.shortest_edge = config.shortest_edge
|
||||
|
||||
# actually delay_load doesn't needed anymore
|
||||
if not delay_load:
|
||||
self.load_model()
|
||||
elif self.unfreeze_ve:
|
||||
self.load_model()
|
||||
else:
|
||||
self.cfg_only = AutoConfig.from_pretrained(
|
||||
self.vision_tower_name, trust_remote_code=True
|
||||
)
|
||||
if self.new_img_size:
|
||||
logger.info(f"Update using new image size: {self.cfg_only.image_size}")
|
||||
self._load_image_processor()
|
||||
|
||||
def load_model(self):
|
||||
if is_main_process():
|
||||
logger.info(f"Loading base components for {self.vision_tower_name}")
|
||||
self._load_image_processor()
|
||||
self._load_vision_tower()
|
||||
|
||||
if self.new_img_size:
|
||||
if is_main_process():
|
||||
logger.info(f"set new image size {self.new_img_size}")
|
||||
self.image_processor.size = {
|
||||
"height": self.new_img_size,
|
||||
"width": self.new_img_size,
|
||||
}
|
||||
|
||||
if not self.unfreeze_ve:
|
||||
self.vision_tower.requires_grad_(False)
|
||||
self.is_loaded = True
|
||||
|
||||
def _load_image_processor(self):
|
||||
processor_path = self.vision_tower_name
|
||||
logger.info(f"loading image processor from: {self.vision_tower_name}")
|
||||
if os.path.exists(self.vision_tower_name):
|
||||
processor_path = self.vision_tower_name
|
||||
elif os.path.exists(self.model_name_or_path):
|
||||
processor_path = self.model_name_or_path
|
||||
else:
|
||||
raise FileNotFoundError(
|
||||
f"No processor found for either {self.vision_tower_name} or {self.model_name_or_path}"
|
||||
)
|
||||
|
||||
self.image_processor = AutoImageProcessor.from_pretrained(
|
||||
processor_path, trust_remote_code=True
|
||||
)
|
||||
|
||||
if is_main_process():
|
||||
logger.info(f"==> self.longest_edge {self.longest_edge}")
|
||||
if self.longest_edge is not None:
|
||||
self.image_processor.do_resize = True
|
||||
# override from default image processor
|
||||
self.image_processor.size["longest_edge"] = self.longest_edge
|
||||
self.image_processor.size["shortest_edge"] = 42 # hard coded here
|
||||
if is_main_process():
|
||||
logger.info(f"==> override longest_edge {self.image_processor.size}")
|
||||
if self.shortest_edge is not None:
|
||||
self.image_processor.size["shortest_edge"] = self.shortest_edge
|
||||
if is_main_process():
|
||||
logger.info(f"override shortest_edge {self.shortest_edge}")
|
||||
|
||||
def _load_vision_tower(self):
|
||||
raise NotImplementedError
|
||||
|
||||
def feature_select(self, image_forward_outs):
|
||||
raise NotImplementedError
|
||||
|
||||
def basic_forward(self, images):
|
||||
if isinstance(images, list):
|
||||
return self._process_image_list(images)
|
||||
else:
|
||||
return self._process_batch(images)
|
||||
|
||||
def _process_image_list(self, images):
|
||||
image_features = []
|
||||
for image in images:
|
||||
inputs = image.to(device=self.device, dtype=self.dtype)
|
||||
# print(f'image shape: {inputs.shape}')
|
||||
if len(inputs.shape) < 4:
|
||||
inputs = inputs.unsqueeze(0)
|
||||
features = self._get_features(inputs)
|
||||
image_features.append(features)
|
||||
return image_features
|
||||
|
||||
def _process_batch(self, images):
|
||||
inputs = images.to(device=self.device, dtype=self.dtype)
|
||||
return self._get_features(inputs)
|
||||
|
||||
def _get_features(self, inputs):
|
||||
outputs = self.vision_tower(inputs, output_hidden_states=True)
|
||||
return self.feature_select(outputs).to(inputs.dtype)
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
return next(self.vision_tower.parameters()).dtype
|
||||
|
||||
@property
|
||||
def device(self):
|
||||
return next(self.vision_tower.parameters()).device
|
||||
|
||||
@property
|
||||
def config(self):
|
||||
return self.vision_tower.config if self.is_loaded else self.cfg_only
|
||||
|
||||
@property
|
||||
def hidden_size(self):
|
||||
return self.config.hidden_size
|
||||
|
||||
@property
|
||||
def num_patches(self):
|
||||
return (self.config.image_size // self.config.patch_size) ** 2
|
||||
|
||||
@property
|
||||
def image_size_auto(self):
|
||||
return self.new_img_size or self.config.image_size
|
||||
|
||||
def save_pretrained(self, model_path):
|
||||
self.vision_tower.save_pretrained(model_path)
|
||||
@@ -0,0 +1,33 @@
|
||||
import math
|
||||
import torch
|
||||
from torch import nn
|
||||
import torchvision
|
||||
from transformers import (
|
||||
AutoModel,
|
||||
)
|
||||
from transformers import AutoModel
|
||||
from .ve_base import BaseVE
|
||||
from loguru import logger
|
||||
|
||||
|
||||
class SigLipNavitVE(BaseVE):
|
||||
def _load_vision_tower(self):
|
||||
logger.info(f"Loading AIMv2 specific model: {self.vision_tower_name}")
|
||||
# other models can be customized here, normally AutoModel can handle well
|
||||
self.vision_tower = AutoModel.from_pretrained(
|
||||
self.vision_tower_name, ignore_mismatched_sizes=True, trust_remote_code=True
|
||||
)
|
||||
self.image_processor.do_center_crop = False
|
||||
|
||||
def feature_select(self, image_forward_outs):
|
||||
image_features = image_forward_outs.hidden_states[self.select_layer]
|
||||
|
||||
if self.select_feature == "patch":
|
||||
return image_features[:, 1:]
|
||||
elif self.select_feature in ["cls_patch", "same"]:
|
||||
return image_features
|
||||
else:
|
||||
raise ValueError(f"Invalid select feature: {self.select_feature}")
|
||||
|
||||
def forward(self, images, image_sizes=None):
|
||||
return self.basic_forward(images)
|
||||
@@ -0,0 +1,6 @@
|
||||
from .image_processing_namo import NamoImageProcessor
|
||||
from transformers import AutoImageProcessor
|
||||
|
||||
AutoImageProcessor.register(
|
||||
NamoImageProcessor, slow_image_processor_class=NamoImageProcessor
|
||||
)
|
||||
@@ -0,0 +1,99 @@
|
||||
from typing import Dict, List, Optional, Union
|
||||
import numpy as np
|
||||
from transformers.image_utils import ImageInput, is_valid_image
|
||||
from transformers.image_utils import (
|
||||
OPENAI_CLIP_MEAN,
|
||||
OPENAI_CLIP_STD,
|
||||
ChannelDimension,
|
||||
ImageInput,
|
||||
PILImageResampling,
|
||||
)
|
||||
from transformers.utils import is_vision_available, logging
|
||||
from transformers import CLIPImageProcessor
|
||||
from transformers.image_transforms import resize
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
if is_vision_available():
|
||||
import PIL
|
||||
|
||||
|
||||
class NamoImageProcessor(CLIPImageProcessor):
|
||||
|
||||
model_input_names = ["pixel_values"]
|
||||
|
||||
def resize(
|
||||
self,
|
||||
image: np.ndarray,
|
||||
size: Dict[str, int],
|
||||
resample: PILImageResampling = PILImageResampling.BICUBIC,
|
||||
data_format: Optional[Union[str, ChannelDimension]] = None,
|
||||
input_data_format: Optional[Union[str, ChannelDimension]] = None,
|
||||
**kwargs,
|
||||
) -> np.ndarray:
|
||||
"""
|
||||
Override CLIP original resize logic, we matching to longest edge if too large
|
||||
matching to shortest if too small, if within, we do nothing.
|
||||
"""
|
||||
minimal_divider = 28
|
||||
config_shortest = size.get("shortest_edge", minimal_divider)
|
||||
config_longest = size.get("longest_edge", 714)
|
||||
|
||||
orig_height, orig_width = image.shape[:2]
|
||||
current_shortest = min(orig_height, orig_width)
|
||||
current_longest = max(orig_height, orig_width)
|
||||
|
||||
# do nothing
|
||||
if current_shortest >= config_shortest and current_longest <= config_longest:
|
||||
# we don't apply divided with 28, not necessary
|
||||
new_height = (orig_height // minimal_divider) * minimal_divider
|
||||
new_width = (orig_width // minimal_divider) * minimal_divider
|
||||
return resize(
|
||||
image,
|
||||
size=(new_height, new_width),
|
||||
resample=resample,
|
||||
data_format=data_format,
|
||||
input_data_format=input_data_format,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
# Determine the appropriate scaling factor.
|
||||
# If the image is too large, scale down using the longest edge.
|
||||
if current_longest > config_longest:
|
||||
scale = config_longest / current_longest
|
||||
if current_shortest * scale < config_shortest:
|
||||
# if current shortest too small after scale, we scale to shortest
|
||||
scale = config_shortest / current_shortest
|
||||
# If the image is too small, scale up using the shortest edge.
|
||||
elif current_shortest < config_shortest:
|
||||
scale = config_shortest / current_shortest
|
||||
else:
|
||||
scale = 1.0 # This branch should not be reached.
|
||||
|
||||
new_height = int(round(orig_height * scale))
|
||||
new_width = int(round(orig_width * scale))
|
||||
|
||||
# if longest still excceed config_longest
|
||||
if max(new_height, new_width) > config_longest:
|
||||
# this will result restortion, but should not effect detections
|
||||
if new_width > new_height:
|
||||
new_width = config_longest
|
||||
else:
|
||||
new_height = config_longest
|
||||
|
||||
# ensure divided by 28 (14*2)
|
||||
new_height = (new_height // minimal_divider) * minimal_divider
|
||||
new_width = (new_width // minimal_divider) * minimal_divider
|
||||
|
||||
return resize(
|
||||
image,
|
||||
size=(new_height, new_width),
|
||||
resample=resample,
|
||||
data_format=data_format,
|
||||
input_data_format=input_data_format,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
__all__ = ["NamoImageProcessor"]
|
||||
@@ -0,0 +1,85 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""Custom evaluation tasks for LightEval."""
|
||||
|
||||
from lighteval.metrics.dynamic_metrics import (
|
||||
ExprExtractionConfig,
|
||||
LatexExtractionConfig,
|
||||
multilingual_extractive_match_metric,
|
||||
)
|
||||
from lighteval.tasks.lighteval_task import LightevalTaskConfig
|
||||
from lighteval.tasks.requests import Doc
|
||||
from lighteval.utils.language import Language
|
||||
|
||||
|
||||
metric = multilingual_extractive_match_metric(
|
||||
language=Language.ENGLISH,
|
||||
fallback_mode="first_match",
|
||||
precision=5,
|
||||
gold_extraction_target=(LatexExtractionConfig(),),
|
||||
pred_extraction_target=(ExprExtractionConfig(), LatexExtractionConfig()),
|
||||
aggregation_function=max,
|
||||
)
|
||||
|
||||
|
||||
def prompt_fn(line, task_name: str = None):
|
||||
"""Assumes the model is either prompted to emit \\boxed{answer} or does so automatically"""
|
||||
return Doc(
|
||||
task_name=task_name,
|
||||
query=line["problem"],
|
||||
choices=[line["solution"]],
|
||||
gold_index=0,
|
||||
)
|
||||
|
||||
|
||||
# Define tasks
|
||||
aime24 = LightevalTaskConfig(
|
||||
name="aime24",
|
||||
suite=["custom"],
|
||||
prompt_function=prompt_fn,
|
||||
hf_repo="HuggingFaceH4/aime_2024",
|
||||
hf_subset="default",
|
||||
hf_avail_splits=["train"],
|
||||
evaluation_splits=["train"],
|
||||
few_shots_split=None,
|
||||
few_shots_select=None,
|
||||
generation_size=32768,
|
||||
metric=[metric],
|
||||
version=1,
|
||||
)
|
||||
math_500 = LightevalTaskConfig(
|
||||
name="math_500",
|
||||
suite=["custom"],
|
||||
prompt_function=prompt_fn,
|
||||
hf_repo="HuggingFaceH4/MATH-500",
|
||||
hf_subset="default",
|
||||
hf_avail_splits=["test"],
|
||||
evaluation_splits=["test"],
|
||||
few_shots_split=None,
|
||||
few_shots_select=None,
|
||||
generation_size=32768,
|
||||
metric=[metric],
|
||||
version=1,
|
||||
)
|
||||
|
||||
# Add tasks to the table
|
||||
TASKS_TABLE = []
|
||||
TASKS_TABLE.append(aime24)
|
||||
TASKS_TABLE.append(math_500)
|
||||
|
||||
# MODULE LOGIC
|
||||
if __name__ == "__main__":
|
||||
print([t["name"] for t in TASKS_TABLE])
|
||||
print(len(TASKS_TABLE))
|
||||
@@ -0,0 +1,162 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from distilabel.llms import OpenAILLM
|
||||
from distilabel.pipeline import Pipeline
|
||||
from distilabel.steps.tasks import TextGeneration
|
||||
|
||||
|
||||
def build_distilabel_pipeline(
|
||||
model: str,
|
||||
base_url: str = "http://localhost:8000/v1",
|
||||
prompt_column: Optional[str] = None,
|
||||
temperature: Optional[float] = None,
|
||||
top_p: Optional[float] = None,
|
||||
max_new_tokens: int = 8192,
|
||||
num_generations: int = 1,
|
||||
) -> Pipeline:
|
||||
generation_kwargs = {"max_new_tokens": max_new_tokens}
|
||||
|
||||
if temperature is not None:
|
||||
generation_kwargs["temperature"] = temperature
|
||||
|
||||
if top_p is not None:
|
||||
generation_kwargs["top_p"] = top_p
|
||||
|
||||
with Pipeline().ray() as pipeline:
|
||||
TextGeneration(
|
||||
llm=OpenAILLM(
|
||||
base_url=base_url,
|
||||
api_key="something",
|
||||
model=model,
|
||||
# thinking can take some time...
|
||||
timeout=10 * 60,
|
||||
generation_kwargs=generation_kwargs,
|
||||
),
|
||||
input_mappings=(
|
||||
{"instruction": prompt_column} if prompt_column is not None else {}
|
||||
),
|
||||
input_batch_size=64, # on 4 nodes bs ~60+ leads to preemption due to KV cache exhaustion
|
||||
num_generations=num_generations,
|
||||
)
|
||||
|
||||
return pipeline
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import argparse
|
||||
|
||||
from datasets import load_dataset
|
||||
|
||||
parser = argparse.ArgumentParser(
|
||||
description="Run distilabel pipeline for generating responses with DeepSeek R1"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--hf-dataset",
|
||||
type=str,
|
||||
required=True,
|
||||
help="HuggingFace dataset to load",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--hf-dataset-config",
|
||||
type=str,
|
||||
required=False,
|
||||
help="Dataset config to use",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--hf-dataset-split",
|
||||
type=str,
|
||||
default="train",
|
||||
help="Dataset split to use",
|
||||
)
|
||||
parser.add_argument("--prompt-column", type=str, default="prompt")
|
||||
parser.add_argument(
|
||||
"--model",
|
||||
type=str,
|
||||
required=True,
|
||||
help="Model name to use for generation",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--vllm-server-url",
|
||||
type=str,
|
||||
default="http://localhost:8000/v1",
|
||||
help="URL of the vLLM server",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--temperature",
|
||||
type=float,
|
||||
help="Temperature for generation",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--top-p",
|
||||
type=float,
|
||||
help="Top-p value for generation",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--max-new-tokens",
|
||||
type=int,
|
||||
default=8192,
|
||||
help="Maximum number of new tokens to generate",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--num-generations",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of generations per problem",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--hf-output-dataset",
|
||||
type=str,
|
||||
required=False,
|
||||
help="HuggingFace repo to push results to",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--private",
|
||||
action="store_true",
|
||||
help="Whether to make the output dataset private when pushing to HF Hub",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
print("\nRunning with arguments:")
|
||||
for arg, value in vars(args).items():
|
||||
print(f" {arg}: {value}")
|
||||
print()
|
||||
|
||||
print(
|
||||
f"Loading '{args.hf_dataset}' (config: {args.hf_dataset_config}, split: {args.hf_dataset_split}) dataset..."
|
||||
)
|
||||
dataset = load_dataset(args.hf_dataset, split=args.hf_dataset_split)
|
||||
print("Dataset loaded!")
|
||||
|
||||
pipeline = build_distilabel_pipeline(
|
||||
model=args.model,
|
||||
base_url=args.vllm_server_url,
|
||||
prompt_column=args.prompt_column,
|
||||
temperature=args.temperature,
|
||||
top_p=args.top_p,
|
||||
max_new_tokens=args.max_new_tokens,
|
||||
num_generations=args.num_generations,
|
||||
)
|
||||
|
||||
print("Running generation pipeline...")
|
||||
distiset = pipeline.run(dataset=dataset, use_cache=False)
|
||||
print("Generation pipeline finished!")
|
||||
|
||||
if args.hf_output_dataset:
|
||||
print(f"Pushing resulting dataset to '{args.hf_output_dataset}'...")
|
||||
distiset.push_to_hub(args.hf_output_dataset, private=args.private)
|
||||
print("Dataset pushed!")
|
||||
@@ -0,0 +1,223 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import os
|
||||
import re
|
||||
from datetime import datetime
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset, load_from_disk
|
||||
from transformers import Qwen2VLForConditionalGeneration
|
||||
|
||||
from math_verify import parse, verify
|
||||
from .trainer import Qwen2VLGRPOTrainer
|
||||
from trl import (
|
||||
GRPOConfig,
|
||||
GRPOTrainer,
|
||||
ModelConfig,
|
||||
ScriptArguments,
|
||||
TrlParser,
|
||||
get_peft_config,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class GRPOScriptArguments(ScriptArguments):
|
||||
"""
|
||||
Script arguments for the GRPO training script.
|
||||
|
||||
Args:
|
||||
reward_funcs (`list[str]`):
|
||||
List of reward functions. Possible values: 'accuracy', 'format'.
|
||||
"""
|
||||
|
||||
reward_funcs: list[str] = field(
|
||||
default_factory=lambda: ["accuracy", "format"],
|
||||
metadata={
|
||||
"help": "List of reward functions. Possible values: 'accuracy', 'format'"
|
||||
},
|
||||
)
|
||||
max_pixels: Optional[int] = field(
|
||||
default=12845056,
|
||||
metadata={"help": "Maximum number of pixels for the image"},
|
||||
)
|
||||
min_pixels: Optional[int] = field(
|
||||
default=3136,
|
||||
metadata={"help": "Minimum number of pixels for the image"},
|
||||
)
|
||||
|
||||
|
||||
def accuracy_reward(completions, solution, **kwargs):
|
||||
"""Reward function that checks if the completion is correct using either symbolic verification or exact string matching."""
|
||||
contents = [completion[0]["content"] for completion in completions]
|
||||
rewards = []
|
||||
current_time = datetime.now().strftime("%d-%H-%M-%S-%f")
|
||||
for content, sol in zip(contents, solution):
|
||||
reward = 0.0
|
||||
# Try symbolic verification first
|
||||
try:
|
||||
answer = parse(content)
|
||||
if float(verify(answer, parse(sol))) > 0:
|
||||
reward = 1.0
|
||||
except Exception:
|
||||
pass # Continue to next verification method if this fails
|
||||
|
||||
# If symbolic verification failed, try string matching
|
||||
if reward == 0.0:
|
||||
try:
|
||||
# Extract answer from solution if it has think/answer tags
|
||||
sol_match = re.search(r"<answer>(.*?)</answer>", sol)
|
||||
ground_truth = sol_match.group(1).strip() if sol_match else sol.strip()
|
||||
|
||||
# Extract answer from content if it has think/answer tags
|
||||
content_match = re.search(r"<answer>(.*?)</answer>", content)
|
||||
student_answer = (
|
||||
content_match.group(1).strip() if content_match else content.strip()
|
||||
)
|
||||
|
||||
# Compare the extracted answers
|
||||
if student_answer == ground_truth:
|
||||
reward = 1.0
|
||||
except Exception:
|
||||
pass # Keep reward as 0.0 if both methods fail
|
||||
|
||||
rewards.append(reward)
|
||||
if os.getenv("DEBUG_MODE") == "true":
|
||||
log_path = os.getenv("LOG_PATH")
|
||||
# local_rank = int(os.getenv("LOCAL_RANK", 0))
|
||||
with open(log_path, "a") as f:
|
||||
f.write(
|
||||
f"------------- {current_time} Accuracy reward: {reward} -------------\n"
|
||||
)
|
||||
f.write(f"Content: {content}\n")
|
||||
f.write(f"Solution: {sol}\n")
|
||||
return rewards
|
||||
|
||||
|
||||
def format_reward(completions, **kwargs):
|
||||
"""Reward function that checks if the completion has a specific format."""
|
||||
pattern = r"<think>.*?</think>\s*<answer>.*?</answer>"
|
||||
completion_contents = [completion[0]["content"] for completion in completions]
|
||||
matches = [re.match(pattern, content) for content in completion_contents]
|
||||
return [1.0 if match else 0.0 for match in matches]
|
||||
|
||||
|
||||
reward_funcs_registry = {
|
||||
"accuracy": accuracy_reward,
|
||||
"format": format_reward,
|
||||
}
|
||||
|
||||
SYSTEM_PROMPT = (
|
||||
"A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant "
|
||||
"first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning "
|
||||
"process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., "
|
||||
"<think> reasoning process here </think><answer> answer here </answer>"
|
||||
)
|
||||
|
||||
|
||||
def main(script_args, training_args, model_args):
|
||||
# Get reward functions
|
||||
reward_funcs = [reward_funcs_registry[func] for func in script_args.reward_funcs]
|
||||
|
||||
# Load the dataset
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
# Format into conversation
|
||||
def make_conversation(example):
|
||||
return {
|
||||
"prompt": [
|
||||
{"role": "system", "content": SYSTEM_PROMPT},
|
||||
{"role": "user", "content": example["problem"]},
|
||||
],
|
||||
}
|
||||
|
||||
# def make_conversation_image(example):
|
||||
# return {
|
||||
# "prompt": [
|
||||
# {"role": "system", "content": [{"type": "text", "text": SYSTEM_PROMPT}]},
|
||||
# {
|
||||
# "role": "user",
|
||||
# "content": [
|
||||
# {"type": "image"},
|
||||
# {"type": "text", "text": example["problem"]},
|
||||
# ],
|
||||
# },
|
||||
# ],
|
||||
# }
|
||||
|
||||
QUESTION_TEMPLATE = "{Question} Output the thinking process in <think> </think> and final answer (number) in <answer> </answer> tags."
|
||||
|
||||
def make_conversation_image(example):
|
||||
return {
|
||||
"prompt": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": [
|
||||
{"type": "image"},
|
||||
{
|
||||
"type": "text",
|
||||
"text": QUESTION_TEMPLATE.format(
|
||||
Question=example["problem"]
|
||||
),
|
||||
},
|
||||
],
|
||||
},
|
||||
],
|
||||
}
|
||||
|
||||
if "image" in dataset[script_args.dataset_train_split].features:
|
||||
print("has image in dataset")
|
||||
dataset = dataset.map(
|
||||
make_conversation_image
|
||||
) # Utilize multiprocessing for faster mapping
|
||||
# dataset = dataset.remove_columns(["original_question", "original_answer"])
|
||||
|
||||
else:
|
||||
print("no image in dataset")
|
||||
dataset = dataset.map(make_conversation)
|
||||
dataset = dataset.remove_columns("messages")
|
||||
|
||||
trainer_cls = Qwen2VLGRPOTrainer
|
||||
|
||||
# Initialize the GRPO trainer
|
||||
trainer = trainer_cls(
|
||||
model=model_args.model_name_or_path,
|
||||
reward_funcs=reward_funcs,
|
||||
args=training_args,
|
||||
train_dataset=dataset[script_args.dataset_train_split],
|
||||
eval_dataset=(
|
||||
dataset[script_args.dataset_test_split]
|
||||
if training_args.eval_strategy != "no"
|
||||
else None
|
||||
),
|
||||
peft_config=get_peft_config(model_args),
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
max_pixels=script_args.max_pixels,
|
||||
min_pixels=script_args.min_pixels,
|
||||
)
|
||||
|
||||
# Train and push the model to the Hub
|
||||
trainer.train()
|
||||
|
||||
# Save and push to hub
|
||||
trainer.save_model(training_args.output_dir)
|
||||
if training_args.push_to_hub:
|
||||
trainer.push_to_hub(dataset_name=script_args.dataset_name)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = TrlParser((GRPOScriptArguments, GRPOConfig, ModelConfig))
|
||||
script_args, training_args, model_args = parser.parse_args_and_config()
|
||||
main(script_args, training_args, model_args)
|
||||
@@ -0,0 +1,107 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Supervised fine-tuning script for decoder language models.
|
||||
|
||||
Usage:
|
||||
|
||||
# One 1 node of 8 x H100s
|
||||
accelerate launch --config_file=configs/zero3.yaml src/open_r1/sft.py \
|
||||
--model_name_or_path Qwen/Qwen2.5-1.5B-Instruct \
|
||||
--dataset_name HuggingFaceH4/Bespoke-Stratos-17k \
|
||||
--learning_rate 2.0e-5 \
|
||||
--num_train_epochs 1 \
|
||||
--packing \
|
||||
--max_seq_length 4096 \
|
||||
--per_device_train_batch_size 4 \
|
||||
--gradient_accumulation_steps 4 \
|
||||
--gradient_checkpointing \
|
||||
--bf16 \
|
||||
--logging_steps 5 \
|
||||
--eval_strategy steps \
|
||||
--eval_steps 100 \
|
||||
--output_dir data/Qwen2.5-1.5B-Open-R1-Distill
|
||||
"""
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
from trl import (
|
||||
ModelConfig,
|
||||
ScriptArguments,
|
||||
SFTConfig,
|
||||
SFTTrainer,
|
||||
TrlParser,
|
||||
get_kbit_device_map,
|
||||
get_peft_config,
|
||||
get_quantization_config,
|
||||
)
|
||||
|
||||
|
||||
def main(script_args, training_args, model_args):
|
||||
################
|
||||
# Model init kwargs & Tokenizer
|
||||
################
|
||||
quantization_config = get_quantization_config(model_args)
|
||||
model_kwargs = dict(
|
||||
revision=model_args.model_revision,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
torch_dtype=model_args.torch_dtype,
|
||||
use_cache=False if training_args.gradient_checkpointing else True,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
training_args.model_init_kwargs = model_kwargs
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_args.model_name_or_path,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
use_fast=True,
|
||||
)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
################
|
||||
# Training
|
||||
################
|
||||
trainer = SFTTrainer(
|
||||
model=model_args.model_name_or_path,
|
||||
args=training_args,
|
||||
train_dataset=dataset[script_args.dataset_train_split],
|
||||
eval_dataset=(
|
||||
dataset[script_args.dataset_test_split]
|
||||
if training_args.eval_strategy != "no"
|
||||
else None
|
||||
),
|
||||
processing_class=tokenizer,
|
||||
peft_config=get_peft_config(model_args),
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
# Save and push to hub
|
||||
trainer.save_model(training_args.output_dir)
|
||||
if training_args.push_to_hub:
|
||||
trainer.push_to_hub(dataset_name=script_args.dataset_name)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = TrlParser((ScriptArguments, SFTConfig, ModelConfig))
|
||||
script_args, training_args, model_args = parser.parse_args_and_config()
|
||||
main(script_args, training_args, model_args)
|
||||
@@ -0,0 +1,4 @@
|
||||
from .grpo_trainer import Qwen2VLGRPOTrainer
|
||||
|
||||
|
||||
__all__ = ["Qwen2VLGRPOTrainer"]
|
||||
@@ -0,0 +1,705 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import os
|
||||
import textwrap
|
||||
from collections import defaultdict
|
||||
from typing import Any, Callable, Optional, Union
|
||||
|
||||
import torch
|
||||
import torch.utils.data
|
||||
import transformers
|
||||
from datasets import Dataset, IterableDataset
|
||||
from packaging import version
|
||||
from transformers import (
|
||||
AriaForConditionalGeneration,
|
||||
AriaProcessor,
|
||||
AutoModelForCausalLM,
|
||||
AutoModelForSequenceClassification,
|
||||
AutoProcessor,
|
||||
AutoTokenizer,
|
||||
GenerationConfig,
|
||||
PreTrainedModel,
|
||||
PreTrainedTokenizerBase,
|
||||
Qwen2VLForConditionalGeneration,
|
||||
Trainer,
|
||||
TrainerCallback,
|
||||
is_wandb_available,
|
||||
)
|
||||
from transformers.integrations.deepspeed import is_deepspeed_zero3_enabled
|
||||
from transformers.utils import is_peft_available
|
||||
|
||||
from trl.data_utils import (
|
||||
apply_chat_template,
|
||||
is_conversational,
|
||||
maybe_apply_chat_template,
|
||||
)
|
||||
from trl.models import (
|
||||
create_reference_model,
|
||||
prepare_deepspeed,
|
||||
unwrap_model_for_generation,
|
||||
)
|
||||
from trl.trainer.grpo_config import GRPOConfig
|
||||
from trl.trainer.utils import generate_model_card, get_comet_experiment_url
|
||||
|
||||
import copy
|
||||
|
||||
|
||||
if is_peft_available():
|
||||
from peft import PeftConfig, get_peft_model
|
||||
|
||||
if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# What we call a reward function is a callable that takes a list of prompts and completions and returns a list of
|
||||
# rewards. When it's a string, it's a model ID, so it's loaded as a pretrained model.
|
||||
RewardFunc = Union[str, PreTrainedModel, Callable[[list, list], list[float]]]
|
||||
|
||||
|
||||
class Qwen2VLGRPOTrainer(Trainer):
|
||||
"""
|
||||
Trainer for the Group Relative Policy Optimization (GRPO) method. This algorithm was initially proposed in the
|
||||
paper [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
from trl import GRPOTrainer
|
||||
|
||||
dataset = load_dataset("trl-lib/tldr", split="train")
|
||||
|
||||
trainer = GRPOTrainer(
|
||||
model="Qwen/Qwen2-0.5B-Instruct",
|
||||
reward_funcs="weqweasdas/RM-Gemma-2B",
|
||||
train_dataset=dataset,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Args:
|
||||
model (`Union[str, PreTrainedModel]`):
|
||||
Model to be trained. Can be either:
|
||||
|
||||
- A string, being the *model id* of a pretrained model hosted inside a model repo on huggingface.co, or
|
||||
a path to a *directory* containing model weights saved using
|
||||
[`~transformers.PreTrainedModel.save_pretrained`], e.g., `'./my_model_directory/'`. The model is
|
||||
loaded using [`~transformers.AutoModelForCausalLM.from_pretrained`] with the keywork arguments
|
||||
in `args.model_init_kwargs`.
|
||||
- A [`~transformers.PreTrainedModel`] object. Only causal language models are supported.
|
||||
reward_funcs (`Union[RewardFunc, list[RewardFunc]]`):
|
||||
Reward functions to be used for computing the rewards. To compute the rewards, we call all the reward
|
||||
functions with the prompts and completions and sum the rewards. Can be either:
|
||||
|
||||
- A single reward function, such as:
|
||||
- A string: The *model ID* of a pretrained model hosted inside a model repo on huggingface.co, or a
|
||||
path to a *directory* containing model weights saved using
|
||||
[`~transformers.PreTrainedModel.save_pretrained`], e.g., `'./my_model_directory/'`. The model is loaded
|
||||
using [`~transformers.AutoModelForSequenceClassification.from_pretrained`] with `num_labels=1` and the
|
||||
keyword arguments in `args.model_init_kwargs`.
|
||||
- A [`~transformers.PreTrainedModel`] object: Only sequence classification models are supported.
|
||||
- A custom reward function: The function is provided with the prompts and the generated completions,
|
||||
plus any additional columns in the dataset. It should return a list of rewards. For more details, see
|
||||
[Using a custom reward function](#using-a-custom-reward-function).
|
||||
- A list of reward functions, where each item can independently be any of the above types. Mixing different
|
||||
types within the list (e.g., a string model ID and a custom reward function) is allowed.
|
||||
args ([`GRPOConfig`], *optional*, defaults to `None`):
|
||||
Configuration for this trainer. If `None`, a default configuration is used.
|
||||
train_dataset ([`~datasets.Dataset`] or [`~datasets.IterableDataset`]):
|
||||
Dataset to use for training. It must include a column `"prompt"`. Any additional columns in the dataset is
|
||||
ignored. The format of the samples can be either:
|
||||
|
||||
- [Standard](dataset_formats#standard): Each sample contains plain text.
|
||||
- [Conversational](dataset_formats#conversational): Each sample contains structured messages (e.g., role
|
||||
and content).
|
||||
eval_dataset ([`~datasets.Dataset`], [`~datasets.IterableDataset`] or `dict[str, Union[Dataset, IterableDataset]]`):
|
||||
Dataset to use for evaluation. It must meet the same requirements as `train_dataset`.
|
||||
processing_class ([`~transformers.PreTrainedTokenizerBase`], *optional*, defaults to `None`):
|
||||
Processing class used to process the data. The padding side must be set to "left". If `None`, the
|
||||
processing class is loaded from the model's name with [`~transformers.AutoTokenizer.from_pretrained`].
|
||||
reward_processing_classes (`Union[PreTrainedTokenizerBase, list[PreTrainedTokenizerBase]]`, *optional*, defaults to `None`):
|
||||
Processing classes corresponding to the reward functions specified in `reward_funcs`. Can be either:
|
||||
|
||||
- A single processing class: Used when `reward_funcs` contains only one reward function.
|
||||
- A list of processing classes: Must match the order and length of the reward functions in `reward_funcs`.
|
||||
If set to `None`, or if an element of the list corresponding to a [`~transformers.PreTrainedModel`] is
|
||||
`None`, the tokenizer for the model is automatically loaded using [`~transformers.AutoTokenizer.from_pretrained`].
|
||||
For elements in `reward_funcs` that are custom reward functions (not [`~transformers.PreTrainedModel`]),
|
||||
the corresponding entries in `reward_processing_classes` are ignored.
|
||||
callbacks (list of [`~transformers.TrainerCallback`], *optional*, defaults to `None`):
|
||||
List of callbacks to customize the training loop. Will add those to the list of default callbacks
|
||||
detailed in [here](https://huggingface.co/docs/transformers/main_classes/callback).
|
||||
|
||||
If you want to remove one of the default callbacks used, use the [`~transformers.Trainer.remove_callback`]
|
||||
method.
|
||||
optimizers (`tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR]`, *optional*, defaults to `(None, None)`):
|
||||
A tuple containing the optimizer and the scheduler to use. Will default to an instance of [`AdamW`] on your
|
||||
model and a scheduler given by [`get_linear_schedule_with_warmup`] controlled by `args`.
|
||||
peft_config ([`~peft.PeftConfig`], *optional*, defaults to `None`):
|
||||
PEFT configuration used to wrap the model. If `None`, the model is not wrapped.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model: Union[str, PreTrainedModel],
|
||||
reward_funcs: Union[RewardFunc, list[RewardFunc]],
|
||||
args: GRPOConfig = None,
|
||||
train_dataset: Optional[Union[Dataset, IterableDataset]] = None,
|
||||
eval_dataset: Optional[
|
||||
Union[Dataset, IterableDataset, dict[str, Union[Dataset, IterableDataset]]]
|
||||
] = None,
|
||||
processing_class: Optional[PreTrainedTokenizerBase] = None,
|
||||
reward_processing_classes: Optional[
|
||||
Union[PreTrainedTokenizerBase, list[PreTrainedTokenizerBase]]
|
||||
] = None,
|
||||
callbacks: Optional[list[TrainerCallback]] = None,
|
||||
optimizers: tuple[
|
||||
Optional[torch.optim.Optimizer], Optional[torch.optim.lr_scheduler.LambdaLR]
|
||||
] = (None, None),
|
||||
peft_config: Optional["PeftConfig"] = None,
|
||||
max_pixels: Optional[int] = 12845056,
|
||||
min_pixels: Optional[int] = 3136,
|
||||
attn_implementation: str = "flash_attention_2",
|
||||
):
|
||||
# Args
|
||||
if args is None:
|
||||
model_name = model if isinstance(model, str) else model.config._name_or_path
|
||||
model_name = model_name.split("/")[-1]
|
||||
args = GRPOConfig(f"{model_name}-GRPO")
|
||||
|
||||
# Models
|
||||
# Trained model
|
||||
model_init_kwargs = args.model_init_kwargs or {}
|
||||
model_init_kwargs["attn_implementation"] = attn_implementation
|
||||
if isinstance(model, str):
|
||||
model_id = model
|
||||
torch_dtype = model_init_kwargs.get("torch_dtype")
|
||||
if (
|
||||
isinstance(torch_dtype, torch.dtype)
|
||||
or torch_dtype == "auto"
|
||||
or torch_dtype is None
|
||||
):
|
||||
pass # torch_dtype is already a torch.dtype or "auto" or None
|
||||
elif isinstance(torch_dtype, str): # it's a str, but not "auto"
|
||||
torch_dtype = getattr(torch, torch_dtype)
|
||||
model_init_kwargs["torch_dtype"] = torch_dtype
|
||||
else:
|
||||
raise ValueError(
|
||||
"Invalid `torch_dtype` passed to `GRPOConfig`. Expected either 'auto' or a string representing "
|
||||
f"a `torch.dtype` (e.g., 'float32'), but got {torch_dtype}."
|
||||
)
|
||||
# Disable caching if gradient checkpointing is enabled (not supported)
|
||||
model_init_kwargs["use_cache"] = (
|
||||
False
|
||||
if args.gradient_checkpointing
|
||||
else model_init_kwargs.get("use_cache")
|
||||
)
|
||||
if "Qwen2-VL" in model_id:
|
||||
model = Qwen2VLForConditionalGeneration.from_pretrained(
|
||||
model, **model_init_kwargs
|
||||
)
|
||||
elif "Aria" in model_id:
|
||||
model_init_kwargs.pop("use_cache")
|
||||
model = AriaForConditionalGeneration.from_pretrained(
|
||||
model, **model_init_kwargs
|
||||
)
|
||||
else:
|
||||
model = AutoModelForCausalLM.from_pretrained(model, **model_init_kwargs)
|
||||
else:
|
||||
model_id = model.config._name_or_path
|
||||
if args.model_init_kwargs is not None:
|
||||
raise ValueError(
|
||||
"You passed `model_init_kwargs` to the `GRPOConfig`, but your model is already instantiated. "
|
||||
"This argument can only be used when the `model` argument is a string."
|
||||
)
|
||||
|
||||
if peft_config is not None:
|
||||
model = get_peft_model(model, peft_config)
|
||||
|
||||
# Reference model
|
||||
if is_deepspeed_zero3_enabled():
|
||||
if "Qwen2-VL" in model_id:
|
||||
self.ref_model = Qwen2VLForConditionalGeneration.from_pretrained(
|
||||
model_id, **model_init_kwargs
|
||||
)
|
||||
elif "Aria" in model_id:
|
||||
self.ref_model = AriaForConditionalGeneration.from_pretrained(
|
||||
model_id, **model_init_kwargs
|
||||
)
|
||||
else:
|
||||
self.ref_model = AutoModelForCausalLM.from_pretrained(
|
||||
model_id, **model_init_kwargs
|
||||
)
|
||||
elif peft_config is None:
|
||||
# If PEFT configuration is not provided, create a reference model based on the initial model.
|
||||
self.ref_model = create_reference_model(model)
|
||||
else:
|
||||
# If PEFT is used, the reference model is not needed since the adapter can be disabled
|
||||
# to revert to the initial model.
|
||||
self.ref_model = None
|
||||
|
||||
# Processing class
|
||||
if processing_class is None:
|
||||
if "Qwen2-VL" in model_id or "Aria" in model_id:
|
||||
processing_class = AutoProcessor.from_pretrained(model_id)
|
||||
pad_token_id = processing_class.tokenizer.pad_token_id
|
||||
processing_class.pad_token_id = pad_token_id
|
||||
processing_class.eos_token_id = processing_class.tokenizer.eos_token_id
|
||||
if "Qwen2-VL" in model_id:
|
||||
processing_class.image_processor.max_pixels = max_pixels
|
||||
processing_class.image_processor.min_pixels = min_pixels
|
||||
else:
|
||||
processing_class = AutoTokenizer.from_pretrained(
|
||||
model.config._name_or_path, padding_side="left"
|
||||
)
|
||||
pad_token_id = processing_class.pad_token_id
|
||||
|
||||
# Reward functions
|
||||
if not isinstance(reward_funcs, list):
|
||||
reward_funcs = [reward_funcs]
|
||||
for i, reward_func in enumerate(reward_funcs):
|
||||
if isinstance(reward_func, str):
|
||||
reward_funcs[i] = AutoModelForSequenceClassification.from_pretrained(
|
||||
reward_func, num_labels=1, **model_init_kwargs
|
||||
)
|
||||
self.reward_funcs = reward_funcs
|
||||
|
||||
# Reward processing class
|
||||
if reward_processing_classes is None:
|
||||
reward_processing_classes = [None] * len(reward_funcs)
|
||||
elif not isinstance(reward_processing_classes, list):
|
||||
reward_processing_classes = [reward_processing_classes]
|
||||
else:
|
||||
if len(reward_processing_classes) != len(reward_funcs):
|
||||
raise ValueError(
|
||||
"The number of reward processing classes must match the number of reward functions."
|
||||
)
|
||||
|
||||
for i, (reward_processing_class, reward_func) in enumerate(
|
||||
zip(reward_processing_classes, reward_funcs)
|
||||
):
|
||||
if isinstance(reward_func, PreTrainedModel):
|
||||
if reward_processing_class is None:
|
||||
reward_processing_class = AutoTokenizer.from_pretrained(
|
||||
reward_func.config._name_or_path
|
||||
)
|
||||
if reward_processing_class.pad_token_id is None:
|
||||
reward_processing_class.pad_token = (
|
||||
reward_processing_class.eos_token
|
||||
)
|
||||
# The reward model computes the reward for the latest non-padded token in the input sequence.
|
||||
# So it's important to set the pad token ID to the padding token ID of the processing class.
|
||||
reward_func.config.pad_token_id = reward_processing_class.pad_token_id
|
||||
reward_processing_classes[i] = reward_processing_class
|
||||
self.reward_processing_classes = reward_processing_classes
|
||||
|
||||
# Data collator
|
||||
def data_collator(features): # No data collation is needed in GRPO
|
||||
return features
|
||||
|
||||
# Training arguments
|
||||
self.max_prompt_length = args.max_prompt_length
|
||||
self.max_completion_length = (
|
||||
args.max_completion_length
|
||||
) # = |o_i| in the GRPO paper
|
||||
self.num_generations = args.num_generations # = G in the GRPO paper
|
||||
self.generation_config = GenerationConfig(
|
||||
max_new_tokens=self.max_completion_length,
|
||||
do_sample=True,
|
||||
temperature=1, # HACK
|
||||
num_return_sequences=self.num_generations,
|
||||
pad_token_id=pad_token_id,
|
||||
)
|
||||
self.beta = args.beta
|
||||
|
||||
# The trainer estimates the number of FLOPs (floating-point operations) using the number of elements in the
|
||||
# input tensor associated with the key "input_ids". However, in GRPO, the sampled data does not include the
|
||||
# "input_ids" key. Instead, the available keys is "prompt". As a result, the trainer issues the warning:
|
||||
# "Could not estimate the number of tokens of the input, floating-point operations will not be computed." To
|
||||
# suppress this warning, we set the "estimate_tokens" key in the model's "warnings_issued" dictionary to True.
|
||||
# This acts as a flag to indicate that the warning has already been issued.
|
||||
model.warnings_issued["estimate_tokens"] = True
|
||||
|
||||
# Initialize the metrics
|
||||
self._metrics = defaultdict(list)
|
||||
|
||||
super().__init__(
|
||||
model=model,
|
||||
args=args,
|
||||
data_collator=data_collator,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
processing_class=processing_class,
|
||||
callbacks=callbacks,
|
||||
optimizers=optimizers,
|
||||
)
|
||||
|
||||
# Gradient accumulation requires scaled loss. Normally, loss scaling in the parent class depends on whether the
|
||||
# model accepts loss-related kwargs. Since we compute our own loss, this check is irrelevant. We set
|
||||
# self.model_accepts_loss_kwargs to False to enable scaling.
|
||||
self.model_accepts_loss_kwargs = False
|
||||
|
||||
if self.ref_model is not None:
|
||||
if self.is_deepspeed_enabled:
|
||||
self.ref_model = prepare_deepspeed(self.ref_model, self.accelerator)
|
||||
else:
|
||||
self.ref_model = self.accelerator.prepare_model(
|
||||
self.ref_model, evaluation_mode=True
|
||||
)
|
||||
|
||||
for i, reward_func in enumerate(self.reward_funcs):
|
||||
if isinstance(reward_func, PreTrainedModel):
|
||||
self.reward_funcs[i] = self.accelerator.prepare_model(
|
||||
reward_func, evaluation_mode=True
|
||||
)
|
||||
|
||||
def _set_signature_columns_if_needed(self):
|
||||
# If `self.args.remove_unused_columns` is True, non-signature columns are removed.
|
||||
# By default, this method sets `self._signature_columns` to the model's expected inputs.
|
||||
# In GRPOTrainer, we preprocess data, so using the model's signature columns doesn't work.
|
||||
# Instead, we set them to the columns expected by the `training_step` method, hence the override.
|
||||
if self._signature_columns is None:
|
||||
self._signature_columns = ["prompt"]
|
||||
|
||||
# Trainer "prepares" the inputs before calling `compute_loss`. It converts to tensor and move to device.
|
||||
# Since we preprocess the data in `compute_loss`, we need to override this method to skip this step.
|
||||
def _prepare_inputs(
|
||||
self, inputs: dict[str, Union[torch.Tensor, Any]]
|
||||
) -> dict[str, Union[torch.Tensor, Any]]:
|
||||
return inputs
|
||||
|
||||
def compute_loss(
|
||||
self, model, inputs, return_outputs=False, num_items_in_batch=None
|
||||
):
|
||||
if return_outputs:
|
||||
raise ValueError("The GRPOTrainer does not support returning outputs")
|
||||
|
||||
prompts = [x["prompt"] for x in inputs]
|
||||
prompts_text = [
|
||||
maybe_apply_chat_template(example, self.processing_class)["prompt"]
|
||||
for example in inputs
|
||||
]
|
||||
images = [x["image"] for x in inputs]
|
||||
prompt_inputs = self.processing_class(
|
||||
text=prompts_text,
|
||||
images=images,
|
||||
return_tensors="pt",
|
||||
padding=True,
|
||||
padding_side="left",
|
||||
add_special_tokens=False,
|
||||
)
|
||||
prompt_inputs = super()._prepare_inputs(prompt_inputs)
|
||||
|
||||
if self.max_prompt_length is not None:
|
||||
prompt_inputs["input_ids"] = prompt_inputs["input_ids"][
|
||||
:, -self.max_prompt_length :
|
||||
]
|
||||
prompt_inputs["attention_mask"] = prompt_inputs["attention_mask"][
|
||||
:, -self.max_prompt_length :
|
||||
]
|
||||
|
||||
# Generate completions
|
||||
with unwrap_model_for_generation(model, self.accelerator) as unwrapped_model:
|
||||
# prompt_completion_ids = unwrapped_model.generate(**prompt_inputs, generation_config=self.generation_config)
|
||||
|
||||
# Generate N times, each generate one with the temp_generation_config , stack the output_ids to prompt_completion_ids, pad the empty places with number 151613
|
||||
num_generations = self.generation_config.num_return_sequences
|
||||
temp_generation_config = copy.deepcopy(self.generation_config)
|
||||
temp_generation_config.num_return_sequences = 1
|
||||
|
||||
all_completions = []
|
||||
|
||||
for i in range(
|
||||
num_generations
|
||||
): # -1 because we already have one generation
|
||||
completion = unwrapped_model.generate(
|
||||
**prompt_inputs, generation_config=temp_generation_config
|
||||
)
|
||||
all_completions.append(completion)
|
||||
|
||||
# Stack all completions and pad if needed
|
||||
max_length = max(completion.size(1) for completion in all_completions)
|
||||
padded_completions = []
|
||||
|
||||
for completion in all_completions:
|
||||
if completion.size(1) < max_length:
|
||||
padding = torch.full(
|
||||
(completion.size(0), max_length - completion.size(1)),
|
||||
self.processing_class.tokenizer.pad_token_id,
|
||||
dtype=completion.dtype,
|
||||
device=completion.device,
|
||||
)
|
||||
padded_completion = torch.cat([completion, padding], dim=1)
|
||||
else:
|
||||
padded_completion = completion
|
||||
padded_completions.append(padded_completion)
|
||||
|
||||
# Stack all padded completions
|
||||
prompt_completion_ids = torch.cat(padded_completions, dim=0)
|
||||
|
||||
prompt_length = prompt_inputs["input_ids"].size(1)
|
||||
completion_ids = prompt_completion_ids[:, prompt_length:]
|
||||
|
||||
# import pdb;pdb.set_trace()
|
||||
|
||||
# Get the per-token log probabilities for the completions for the model and the reference model
|
||||
def get_per_token_logps(model, input_ids):
|
||||
logits = model(input_ids).logits # (B, L, V)
|
||||
logits = logits[
|
||||
:, :-1, :
|
||||
] # (B, L-1, V), exclude the last logit: it corresponds to the next token pred
|
||||
input_ids = input_ids[
|
||||
:, 1:
|
||||
] # (B, L-1), exclude the first input ID since we don't have logits for it
|
||||
# Compute the log probabilities for the input tokens. Use a loop to reduce memory peak.
|
||||
per_token_logps = []
|
||||
for logits_row, input_ids_row in zip(logits, input_ids):
|
||||
log_probs = logits_row.log_softmax(dim=-1)
|
||||
token_log_prob = torch.gather(
|
||||
log_probs, dim=1, index=input_ids_row.unsqueeze(1)
|
||||
).squeeze(1)
|
||||
per_token_logps.append(token_log_prob)
|
||||
return torch.stack(per_token_logps)
|
||||
|
||||
per_token_logps = get_per_token_logps(model, prompt_completion_ids)
|
||||
# Get rid of the prompt (-1 because of the shift done in get_per_token_logps)
|
||||
per_token_logps = per_token_logps[:, prompt_length - 1 :]
|
||||
|
||||
with torch.inference_mode():
|
||||
if self.ref_model is not None:
|
||||
ref_per_token_logps = get_per_token_logps(
|
||||
self.ref_model, prompt_completion_ids
|
||||
)
|
||||
else:
|
||||
with self.accelerator.unwrap_model(model).disable_adapter():
|
||||
ref_per_token_logps = get_per_token_logps(
|
||||
model, prompt_completion_ids
|
||||
)
|
||||
ref_per_token_logps = ref_per_token_logps[:, prompt_length - 1 :]
|
||||
|
||||
# Compute the KL divergence between the model and the reference model
|
||||
per_token_kl = (
|
||||
torch.exp(ref_per_token_logps - per_token_logps)
|
||||
- (ref_per_token_logps - per_token_logps)
|
||||
- 1
|
||||
)
|
||||
|
||||
# Mask everything after the first EOS token
|
||||
is_eos = completion_ids == self.processing_class.eos_token_id
|
||||
device = self.accelerator.device
|
||||
eos_idx = torch.full(
|
||||
(is_eos.size(0),), is_eos.size(1), dtype=torch.long, device=device
|
||||
)
|
||||
eos_idx[is_eos.any(dim=1)] = is_eos.int().argmax(dim=1)[is_eos.any(dim=1)]
|
||||
sequence_indices = torch.arange(is_eos.size(1), device=device).expand(
|
||||
is_eos.size(0), -1
|
||||
)
|
||||
completion_mask = (sequence_indices <= eos_idx.unsqueeze(1)).int()
|
||||
|
||||
# Decode the generated completions
|
||||
completions = self.processing_class.batch_decode(
|
||||
completion_ids, skip_special_tokens=True
|
||||
)
|
||||
if is_conversational(inputs[0]):
|
||||
completions = [
|
||||
[{"role": "assistant", "content": completion}]
|
||||
for completion in completions
|
||||
]
|
||||
|
||||
# Compute the rewards
|
||||
prompts = [prompt for prompt in prompts for _ in range(self.num_generations)]
|
||||
|
||||
rewards_per_func = torch.zeros(
|
||||
len(prompts), len(self.reward_funcs), device=device
|
||||
)
|
||||
for i, (reward_func, reward_processing_class) in enumerate(
|
||||
zip(self.reward_funcs, self.reward_processing_classes)
|
||||
):
|
||||
if isinstance(reward_func, PreTrainedModel):
|
||||
if is_conversational(inputs[0]):
|
||||
messages = [
|
||||
{"messages": p + c} for p, c in zip(prompts, completions)
|
||||
]
|
||||
texts = [
|
||||
apply_chat_template(x, reward_processing_class)["text"]
|
||||
for x in messages
|
||||
]
|
||||
else:
|
||||
texts = [p + c for p, c in zip(prompts, completions)]
|
||||
reward_inputs = reward_processing_class(
|
||||
texts,
|
||||
return_tensors="pt",
|
||||
padding=True,
|
||||
padding_side="right",
|
||||
add_special_tokens=False,
|
||||
)
|
||||
reward_inputs = super()._prepare_inputs(reward_inputs)
|
||||
with torch.inference_mode():
|
||||
rewards_per_func[:, i] = reward_func(**reward_inputs).logits[
|
||||
:, 0
|
||||
] # Shape (B*G,)
|
||||
else:
|
||||
# Repeat all input columns (but "prompt" and "completion") to match the number of generations
|
||||
reward_kwargs = {
|
||||
key: []
|
||||
for key in inputs[0].keys()
|
||||
if key not in ["prompt", "completion"]
|
||||
}
|
||||
for key in reward_kwargs:
|
||||
for example in inputs:
|
||||
# Repeat each value in the column for `num_generations` times
|
||||
reward_kwargs[key].extend([example[key]] * self.num_generations)
|
||||
output_reward_func = reward_func(
|
||||
prompts=prompts, completions=completions, **reward_kwargs
|
||||
)
|
||||
rewards_per_func[:, i] = torch.tensor(
|
||||
output_reward_func, dtype=torch.float32, device=device
|
||||
)
|
||||
|
||||
# Sum the rewards from all reward functions
|
||||
rewards = rewards_per_func.sum(dim=1)
|
||||
|
||||
# Compute grouped-wise rewards
|
||||
mean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1)
|
||||
std_grouped_rewards = rewards.view(-1, self.num_generations).std(dim=1)
|
||||
|
||||
# Normalize the rewards to compute the advantages
|
||||
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(
|
||||
self.num_generations, dim=0
|
||||
)
|
||||
std_grouped_rewards = std_grouped_rewards.repeat_interleave(
|
||||
self.num_generations, dim=0
|
||||
)
|
||||
advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-4)
|
||||
|
||||
# x - x.detach() allows for preserving gradients from x
|
||||
per_token_loss = torch.exp(
|
||||
per_token_logps - per_token_logps.detach()
|
||||
) * advantages.unsqueeze(1)
|
||||
per_token_loss = -(per_token_loss - self.beta * per_token_kl)
|
||||
loss = (
|
||||
(per_token_loss * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)
|
||||
).mean()
|
||||
|
||||
# Log the metrics
|
||||
completion_length = (
|
||||
self.accelerator.gather_for_metrics(completion_mask.sum(1))
|
||||
.float()
|
||||
.mean()
|
||||
.item()
|
||||
)
|
||||
self._metrics["completion_length"].append(completion_length)
|
||||
|
||||
reward_per_func = self.accelerator.gather_for_metrics(rewards_per_func).mean(0)
|
||||
for i, reward_func in enumerate(self.reward_funcs):
|
||||
if isinstance(reward_func, PreTrainedModel):
|
||||
reward_func_name = reward_func.config._name_or_path.split("/")[-1]
|
||||
else:
|
||||
reward_func_name = reward_func.__name__
|
||||
self._metrics[f"rewards/{reward_func_name}"].append(
|
||||
reward_per_func[i].item()
|
||||
)
|
||||
|
||||
self._metrics["reward"].append(
|
||||
self.accelerator.gather_for_metrics(rewards).mean().item()
|
||||
)
|
||||
|
||||
self._metrics["reward_std"].append(
|
||||
self.accelerator.gather_for_metrics(std_grouped_rewards).mean().item()
|
||||
)
|
||||
|
||||
mean_kl = (
|
||||
(per_token_kl * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)
|
||||
).mean()
|
||||
self._metrics["kl"].append(
|
||||
self.accelerator.gather_for_metrics(mean_kl).mean().item()
|
||||
)
|
||||
|
||||
return loss
|
||||
|
||||
def log(self, logs: dict[str, float], start_time: Optional[float] = None) -> None:
|
||||
metrics = {
|
||||
key: sum(val) / len(val) for key, val in self._metrics.items()
|
||||
} # average the metrics
|
||||
logs = {**logs, **metrics}
|
||||
if version.parse(transformers.__version__) >= version.parse("4.47.0.dev0"):
|
||||
super().log(logs, start_time)
|
||||
else: # transformers<=4.46
|
||||
super().log(logs)
|
||||
self._metrics.clear()
|
||||
|
||||
def create_model_card(
|
||||
self,
|
||||
model_name: Optional[str] = None,
|
||||
dataset_name: Optional[str] = None,
|
||||
tags: Union[str, list[str], None] = None,
|
||||
):
|
||||
"""
|
||||
Creates a draft of a model card using the information available to the `Trainer`.
|
||||
|
||||
Args:
|
||||
model_name (`str` or `None`, *optional*, defaults to `None`):
|
||||
Name of the model.
|
||||
dataset_name (`str` or `None`, *optional*, defaults to `None`):
|
||||
Name of the dataset used for training.
|
||||
tags (`str`, `list[str]` or `None`, *optional*, defaults to `None`):
|
||||
Tags to be associated with the model card.
|
||||
"""
|
||||
if not self.is_world_process_zero():
|
||||
return
|
||||
|
||||
if hasattr(self.model.config, "_name_or_path") and not os.path.isdir(
|
||||
self.model.config._name_or_path
|
||||
):
|
||||
base_model = self.model.config._name_or_path
|
||||
else:
|
||||
base_model = None
|
||||
|
||||
tags = tags or []
|
||||
if isinstance(tags, str):
|
||||
tags = [tags]
|
||||
|
||||
if hasattr(self.model.config, "unsloth_version"):
|
||||
tags.append("unsloth")
|
||||
|
||||
citation = textwrap.dedent(
|
||||
"""\
|
||||
@article{zhihong2024deepseekmath,
|
||||
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
|
||||
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
|
||||
year = 2024,
|
||||
eprint = {arXiv:2402.03300},
|
||||
"""
|
||||
)
|
||||
|
||||
model_card = generate_model_card(
|
||||
base_model=base_model,
|
||||
model_name=model_name,
|
||||
hub_model_id=self.hub_model_id,
|
||||
dataset_name=dataset_name,
|
||||
tags=tags,
|
||||
wandb_url=(
|
||||
wandb.run.get_url()
|
||||
if is_wandb_available() and wandb.run is not None
|
||||
else None
|
||||
),
|
||||
comet_url=get_comet_experiment_url(),
|
||||
trainer_name="GRPO",
|
||||
trainer_citation=citation,
|
||||
paper_title="DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models",
|
||||
paper_id="2402.03300",
|
||||
)
|
||||
|
||||
model_card.save(os.path.join(self.args.output_dir, "README.md"))
|
||||
@@ -0,0 +1,339 @@
|
||||
"""
|
||||
|
||||
Code referenced from InternVL mDPO
|
||||
|
||||
"""
|
||||
|
||||
from copy import deepcopy
|
||||
from typing import Dict, List, Literal, Optional, Tuple, Union
|
||||
|
||||
import deepspeed
|
||||
import torch
|
||||
from torch import nn
|
||||
from torch.utils.data import ConcatDataset
|
||||
from trl import DPOTrainer
|
||||
from trl.trainer.utils import RunningMoments, pad_to_length
|
||||
|
||||
|
||||
def _map(self, *args, **kwargs):
|
||||
return self
|
||||
|
||||
|
||||
ConcatDataset.map = _map
|
||||
|
||||
|
||||
class MultimodalDPOTrainer(DPOTrainer):
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
if self.loss_type != "bco_pair" and "bco_pair" in self.loss_type:
|
||||
self.running = RunningMoments(self.accelerator)
|
||||
|
||||
@staticmethod
|
||||
def concatenated_inputs(
|
||||
batch: Dict[str, Union[List, torch.LongTensor]],
|
||||
is_encoder_decoder: bool = False,
|
||||
is_vision_model: bool = False,
|
||||
label_pad_token_id: int = -100,
|
||||
padding_value: int = 0,
|
||||
device: Optional[torch.device] = None,
|
||||
) -> Dict[str, torch.LongTensor]:
|
||||
"""Concatenate the chosen and rejected inputs into a single tensor.
|
||||
|
||||
Args:
|
||||
batch: A batch of data. Must contain the keys 'chosen_input_ids' and 'rejected_input_ids', which are tensors of shape (batch_size, sequence_length).
|
||||
is_encoder_decoder: Whether the model is an encoder-decoder model.
|
||||
label_pad_token_id: The label pad token id.
|
||||
padding_value: The padding value to use for the concatenated inputs_ids.
|
||||
device: The device for the concatenated inputs.
|
||||
|
||||
Returns:
|
||||
A dictionary containing the concatenated inputs under the key 'concatenated_input_ids'.
|
||||
"""
|
||||
concatenated_batch = {}
|
||||
|
||||
if is_encoder_decoder:
|
||||
max_length = max(
|
||||
batch["chosen_labels"].shape[1], batch["rejected_labels"].shape[1]
|
||||
)
|
||||
else:
|
||||
max_length = max(
|
||||
batch["chosen_input_ids"].shape[1], batch["rejected_input_ids"].shape[1]
|
||||
)
|
||||
|
||||
for k in batch:
|
||||
if k.startswith("chosen") and isinstance(batch[k], torch.Tensor):
|
||||
if "labels" in k or is_encoder_decoder:
|
||||
pad_value = label_pad_token_id
|
||||
elif k.endswith("_input_ids"):
|
||||
pad_value = padding_value
|
||||
elif k.endswith("_attention_mask"):
|
||||
pad_value = 0
|
||||
concatenated_key = k.replace("chosen", "concatenated")
|
||||
concatenated_batch[concatenated_key] = pad_to_length(
|
||||
batch[k], max_length, pad_value=pad_value
|
||||
)
|
||||
for k in batch:
|
||||
if k.startswith("rejected") and isinstance(batch[k], torch.Tensor):
|
||||
if "labels" in k or is_encoder_decoder:
|
||||
pad_value = label_pad_token_id
|
||||
elif k.endswith("_input_ids"):
|
||||
pad_value = padding_value
|
||||
elif k.endswith("_attention_mask"):
|
||||
pad_value = 0
|
||||
concatenated_key = k.replace("rejected", "concatenated")
|
||||
concatenated_batch[concatenated_key] = torch.cat(
|
||||
(
|
||||
concatenated_batch[concatenated_key],
|
||||
pad_to_length(batch[k], max_length, pad_value=pad_value),
|
||||
),
|
||||
dim=0,
|
||||
).to(device=device)
|
||||
|
||||
if is_encoder_decoder:
|
||||
concatenated_batch["concatenated_input_ids"] = (
|
||||
batch["prompt_input_ids"].repeat(2, 1).to(device=device)
|
||||
)
|
||||
concatenated_batch["concatenated_attention_mask"] = (
|
||||
batch["prompt_attention_mask"].repeat(2, 1).to(device=device)
|
||||
)
|
||||
|
||||
if "pixel_values" in batch:
|
||||
concatenated_batch["pixel_values"] = batch["pixel_values"].repeat(
|
||||
2, 1, 1, 1
|
||||
)
|
||||
concatenated_batch["image_flags"] = batch["image_flags"].repeat(2)
|
||||
|
||||
return concatenated_batch
|
||||
|
||||
def concatenated_forward(
|
||||
self, model: nn.Module, batch: Dict[str, Union[List, torch.LongTensor]]
|
||||
) -> Tuple[
|
||||
torch.FloatTensor,
|
||||
torch.FloatTensor,
|
||||
torch.FloatTensor,
|
||||
torch.FloatTensor,
|
||||
torch.FloatTensor,
|
||||
]:
|
||||
"""Run the given model on the given batch of inputs, concatenating the chosen and rejected inputs together.
|
||||
|
||||
We do this to avoid doing two forward passes, because it's faster for FSDP.
|
||||
"""
|
||||
concatenated_batch = self.concatenated_inputs(
|
||||
batch,
|
||||
is_encoder_decoder=self.is_encoder_decoder,
|
||||
is_vision_model=self.is_vision_model,
|
||||
label_pad_token_id=self.label_pad_token_id,
|
||||
padding_value=self.padding_value,
|
||||
device=self.accelerator.device,
|
||||
)
|
||||
len_chosen = batch["chosen_labels"].shape[0]
|
||||
|
||||
model_kwargs = {}
|
||||
|
||||
if self.is_encoder_decoder:
|
||||
model_kwargs["labels"] = concatenated_batch["concatenated_labels"]
|
||||
model_kwargs["decoder_input_ids"] = concatenated_batch.pop(
|
||||
"concatenated_decoder_input_ids", None
|
||||
)
|
||||
|
||||
if self.is_vision_model:
|
||||
model_kwargs["pixel_values"] = concatenated_batch["pixel_values"]
|
||||
model_kwargs["pixel_attention_mask"] = concatenated_batch[
|
||||
"pixel_attention_mask"
|
||||
]
|
||||
|
||||
if self.aux_loss_enabled:
|
||||
model_kwargs["output_router_logits"] = True
|
||||
|
||||
outputs = model(
|
||||
input_ids=concatenated_batch["concatenated_input_ids"],
|
||||
attention_mask=concatenated_batch["concatenated_attention_mask"],
|
||||
pixel_values=concatenated_batch["pixel_values"],
|
||||
image_flags=concatenated_batch["image_flags"],
|
||||
use_cache=False,
|
||||
**model_kwargs,
|
||||
)
|
||||
all_logits = outputs.logits
|
||||
|
||||
all_logps, size_completion = self.get_batch_logps(
|
||||
all_logits,
|
||||
concatenated_batch["concatenated_labels"],
|
||||
# average_log_prob=self.loss_type == "ipo",
|
||||
is_encoder_decoder=self.is_encoder_decoder,
|
||||
label_pad_token_id=self.label_pad_token_id,
|
||||
)
|
||||
|
||||
def cross_entropy_loss(logits, labels):
|
||||
if not self.is_encoder_decoder:
|
||||
# Shift so that tokens < n predict n
|
||||
logits = logits[..., :-1, :].contiguous()
|
||||
labels = labels[..., 1:].contiguous()
|
||||
# Flatten the tokens
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
logits = logits.view(-1, logits.shape[-1])
|
||||
labels = labels.view(-1)
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
loss = loss_fct(logits, labels)
|
||||
return loss
|
||||
|
||||
labels = concatenated_batch["concatenated_labels"].clone()
|
||||
nll_loss = cross_entropy_loss(all_logits[:len_chosen], labels[:len_chosen])
|
||||
|
||||
if self.loss_type == "ipo":
|
||||
all_logps = all_logps / size_completion
|
||||
|
||||
chosen_logps = all_logps[:len_chosen]
|
||||
rejected_logps = all_logps[len_chosen:]
|
||||
|
||||
chosen_logits = all_logits[:len_chosen]
|
||||
rejected_logits = all_logits[len_chosen:]
|
||||
|
||||
if self.aux_loss_enabled:
|
||||
return (
|
||||
chosen_logps,
|
||||
rejected_logps,
|
||||
chosen_logits,
|
||||
rejected_logits,
|
||||
nll_loss,
|
||||
outputs.aux_loss,
|
||||
)
|
||||
|
||||
return (chosen_logps, rejected_logps, chosen_logits, rejected_logits, nll_loss)
|
||||
|
||||
def _prepare_deepspeed_orig(self, model):
|
||||
# Adapted from accelerate: https://github.com/huggingface/accelerate/blob/739b135f8367becb67ffaada12fe76e3aa60fefd/src/accelerate/accelerator.py#L1473
|
||||
deepspeed_plugin = self.accelerator.state.deepspeed_plugin
|
||||
config_kwargs = deepcopy(deepspeed_plugin.deepspeed_config)
|
||||
|
||||
# If ZeRO-3 is used, we shard both the active and reference model.
|
||||
# Otherwise, we assume the reference model fits in memory and is initialized on each device with ZeRO disabled (stage 0)
|
||||
if config_kwargs["zero_optimization"]["stage"] != 3:
|
||||
config_kwargs["zero_optimization"]["stage"] = 0
|
||||
model, *_ = deepspeed.initialize(model=model, config=config_kwargs)
|
||||
model.eval()
|
||||
return model
|
||||
|
||||
def _prepare_deepspeed(self, model):
|
||||
deepspeed_plugin = self.accelerator.state.deepspeed_plugin
|
||||
config_kwargs = deepspeed_plugin.deepspeed_config
|
||||
if config_kwargs["zero_optimization"]["stage"] == 3:
|
||||
print("Enable DPOTrainer._prepare_deepspeed")
|
||||
return self._prepare_deepspeed_orig(model)
|
||||
|
||||
print("Disable DPOTrainer._prepare_deepspeed")
|
||||
for param in model.parameters():
|
||||
param.requires_grad = False
|
||||
|
||||
model.eval()
|
||||
model = model.to(self.accelerator.device)
|
||||
return model
|
||||
|
||||
def get_batch_loss_metrics(
|
||||
self,
|
||||
model,
|
||||
batch: Dict[str, Union[List, torch.LongTensor]],
|
||||
train_eval: Literal["train", "eval"] = "train",
|
||||
):
|
||||
"""Compute the DPO loss and other metrics for the given batch of inputs for train or test."""
|
||||
metrics = {}
|
||||
|
||||
forward_output = self.concatenated_forward(model, batch)
|
||||
(
|
||||
policy_chosen_logps,
|
||||
policy_rejected_logps,
|
||||
policy_chosen_logits,
|
||||
policy_rejected_logits,
|
||||
policy_nll_loss,
|
||||
) = forward_output[:5]
|
||||
if self.aux_loss_enabled:
|
||||
aux_loss = forward_output[5]
|
||||
|
||||
# if reference_chosen_logps and reference_rejected_logps in batch use them, otherwise use the reference model
|
||||
if (
|
||||
"reference_chosen_logps" in batch
|
||||
and "reference_rejected_logps" in batch
|
||||
and self.args.rpo_alpha is not None
|
||||
):
|
||||
reference_chosen_logps = batch["reference_chosen_logps"]
|
||||
reference_rejected_logps = batch["reference_rejected_logps"]
|
||||
else:
|
||||
with torch.no_grad():
|
||||
if self.ref_model is None:
|
||||
with self.null_ref_context():
|
||||
(
|
||||
reference_chosen_logps,
|
||||
reference_rejected_logps,
|
||||
_,
|
||||
_,
|
||||
_,
|
||||
) = self.concatenated_forward(self.model, batch)
|
||||
else:
|
||||
(
|
||||
reference_chosen_logps,
|
||||
reference_rejected_logps,
|
||||
_,
|
||||
_,
|
||||
_,
|
||||
) = self.concatenated_forward(self.ref_model, batch)
|
||||
|
||||
if "," in self.loss_type:
|
||||
loss_type = self.loss_type
|
||||
loss_type_list = loss_type.split(",")
|
||||
|
||||
losses, chosen_rewards, rejected_rewards = 0, 0, 0
|
||||
for curr_type in loss_type_list:
|
||||
self.loss_type = curr_type
|
||||
curr_losses, curr_chosen_rewards, curr_rejected_rewards = self.dpo_loss(
|
||||
policy_chosen_logps,
|
||||
policy_rejected_logps,
|
||||
reference_chosen_logps,
|
||||
reference_rejected_logps,
|
||||
)
|
||||
curr_weight = getattr(self.args, f"{curr_type}_loss_weight")
|
||||
losses = losses + curr_losses * curr_weight
|
||||
chosen_rewards = chosen_rewards + curr_chosen_rewards * curr_weight
|
||||
rejected_rewards = (
|
||||
rejected_rewards + curr_rejected_rewards * curr_weight
|
||||
)
|
||||
|
||||
self.loss_type = loss_type
|
||||
else:
|
||||
losses, chosen_rewards, rejected_rewards = self.dpo_loss(
|
||||
policy_chosen_logps,
|
||||
policy_rejected_logps,
|
||||
reference_chosen_logps,
|
||||
reference_rejected_logps,
|
||||
)
|
||||
|
||||
reward_accuracies = (chosen_rewards > rejected_rewards).float()
|
||||
|
||||
if self.args.rpo_alpha is not None:
|
||||
# losses = losses * self.args.rpo_alpha + policy_nll_loss
|
||||
losses = losses + policy_nll_loss * self.args.rpo_alpha
|
||||
|
||||
prefix = "eval_" if train_eval == "eval" else ""
|
||||
metrics[f"{prefix}rewards/chosen"] = chosen_rewards.mean().cpu()
|
||||
metrics[f"{prefix}rewards/rejected"] = rejected_rewards.mean().cpu()
|
||||
metrics[f"{prefix}rewards/accuracies"] = reward_accuracies.mean().cpu()
|
||||
metrics[f"{prefix}rewards/margins"] = (
|
||||
(chosen_rewards - rejected_rewards).mean().cpu()
|
||||
)
|
||||
metrics[f"{prefix}logps/rejected"] = policy_rejected_logps.detach().mean().cpu()
|
||||
metrics[f"{prefix}logps/chosen"] = policy_chosen_logps.detach().mean().cpu()
|
||||
metrics[f"{prefix}logits/rejected"] = (
|
||||
policy_rejected_logits.detach().mean().cpu()
|
||||
)
|
||||
metrics[f"{prefix}logits/chosen"] = policy_chosen_logits.detach().mean().cpu()
|
||||
if self.args.rpo_alpha is not None:
|
||||
metrics[f"{prefix}nll_loss"] = policy_nll_loss.detach().mean().cpu()
|
||||
|
||||
if self.aux_loss_enabled:
|
||||
return (
|
||||
losses.mean()
|
||||
+ getattr(model.config, "router_aux_loss_coef", 0.0) * aux_loss,
|
||||
metrics,
|
||||
)
|
||||
|
||||
return losses.mean(), metrics
|
||||
@@ -0,0 +1,572 @@
|
||||
import os
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from torch.utils.data import Sampler
|
||||
|
||||
from namo.utils.utils import rank0_print
|
||||
|
||||
try:
|
||||
from trl.trainer import DPOTrainer
|
||||
from trl.trainer.utils import DPODataCollatorWithPadding
|
||||
except ImportError as e:
|
||||
DPOTrainer = object
|
||||
|
||||
from transformers import Trainer
|
||||
from transformers.trainer import (
|
||||
is_sagemaker_mp_enabled,
|
||||
get_parameter_names,
|
||||
has_length,
|
||||
ALL_LAYERNORM_LAYERS,
|
||||
logger,
|
||||
TRAINER_STATE_NAME,
|
||||
)
|
||||
from typing import List, Optional
|
||||
|
||||
|
||||
def maybe_zero_3(param, ignore_status=False, name=None):
|
||||
from deepspeed import zero
|
||||
from deepspeed.runtime.zero.partition_parameters import ZeroParamStatus
|
||||
|
||||
if hasattr(param, "ds_id"):
|
||||
if param.ds_status == ZeroParamStatus.NOT_AVAILABLE:
|
||||
if not ignore_status:
|
||||
print(name, "no ignore status")
|
||||
with zero.GatheredParameters([param]):
|
||||
param = param.data.detach().cpu().clone()
|
||||
else:
|
||||
param = param.detach().cpu().clone()
|
||||
return param
|
||||
|
||||
|
||||
def get_mm_adapter_state_maybe_zero_3(named_params, keys_to_match):
|
||||
to_return = {
|
||||
k: t
|
||||
for k, t in named_params
|
||||
if any(key_match in k for key_match in keys_to_match)
|
||||
}
|
||||
to_return = {
|
||||
k: maybe_zero_3(v, ignore_status=True, name=k).cpu()
|
||||
for k, v in to_return.items()
|
||||
}
|
||||
return to_return
|
||||
|
||||
|
||||
def split_to_even_chunks(indices, lengths, num_chunks):
|
||||
"""
|
||||
Split a list of indices into `chunks` chunks of roughly equal lengths.
|
||||
"""
|
||||
|
||||
if len(indices) % num_chunks != 0:
|
||||
return [indices[i::num_chunks] for i in range(num_chunks)]
|
||||
|
||||
num_indices_per_chunk = len(indices) // num_chunks
|
||||
|
||||
chunks = [[] for _ in range(num_chunks)]
|
||||
chunks_lengths = [0 for _ in range(num_chunks)]
|
||||
for index in indices:
|
||||
shortest_chunk = chunks_lengths.index(min(chunks_lengths))
|
||||
chunks[shortest_chunk].append(index)
|
||||
chunks_lengths[shortest_chunk] += lengths[index]
|
||||
if len(chunks[shortest_chunk]) == num_indices_per_chunk:
|
||||
chunks_lengths[shortest_chunk] = float("inf")
|
||||
|
||||
return chunks
|
||||
|
||||
|
||||
def get_modality_length_grouped_indices(
|
||||
lengths, batch_size, world_size, generator=None
|
||||
):
|
||||
# We need to use torch for the random part as a distributed sampler will set the random seed for torch.
|
||||
assert all(l != 0 for l in lengths), "Should not have zero length."
|
||||
if all(l > 0 for l in lengths) or all(l < 0 for l in lengths):
|
||||
# all samples are in the same modality
|
||||
return get_length_grouped_indices(
|
||||
lengths, batch_size, world_size, generator=generator
|
||||
)
|
||||
mm_indices, mm_lengths = zip(*[(i, l) for i, l in enumerate(lengths) if l > 0])
|
||||
lang_indices, lang_lengths = zip(*[(i, -l) for i, l in enumerate(lengths) if l < 0])
|
||||
|
||||
mm_shuffle = [
|
||||
mm_indices[i]
|
||||
for i in get_length_grouped_indices(
|
||||
mm_lengths, batch_size, world_size, generator=None
|
||||
)
|
||||
]
|
||||
lang_shuffle = [
|
||||
lang_indices[i]
|
||||
for i in get_length_grouped_indices(
|
||||
lang_lengths, batch_size, world_size, generator=None
|
||||
)
|
||||
]
|
||||
megabatch_size = world_size * batch_size
|
||||
mm_megabatches = [
|
||||
mm_shuffle[i : i + megabatch_size]
|
||||
for i in range(0, len(mm_shuffle), megabatch_size)
|
||||
]
|
||||
lang_megabatches = [
|
||||
lang_shuffle[i : i + megabatch_size]
|
||||
for i in range(0, len(lang_shuffle), megabatch_size)
|
||||
]
|
||||
|
||||
last_mm = mm_megabatches[-1]
|
||||
last_lang = lang_megabatches[-1]
|
||||
additional_batch = last_mm + last_lang
|
||||
megabatches = mm_megabatches[:-1] + lang_megabatches[:-1]
|
||||
megabatch_indices = torch.randperm(len(megabatches), generator=generator)
|
||||
megabatches = [megabatches[i] for i in megabatch_indices]
|
||||
|
||||
if len(additional_batch) > 0:
|
||||
megabatches.append(sorted(additional_batch))
|
||||
|
||||
return [i for megabatch in megabatches for i in megabatch]
|
||||
|
||||
|
||||
def get_length_grouped_indices(
|
||||
lengths, batch_size, world_size, generator=None, merge=True
|
||||
):
|
||||
# We need to use torch for the random part as a distributed sampler will set the random seed for torch.
|
||||
indices = torch.randperm(len(lengths), generator=generator)
|
||||
megabatch_size = world_size * batch_size
|
||||
megabatches = [
|
||||
indices[i : i + megabatch_size].tolist()
|
||||
for i in range(0, len(lengths), megabatch_size)
|
||||
]
|
||||
megabatches = [
|
||||
sorted(megabatch, key=lambda i: lengths[i], reverse=True)
|
||||
for megabatch in megabatches
|
||||
]
|
||||
megabatches = [
|
||||
split_to_even_chunks(megabatch, lengths, world_size)
|
||||
for megabatch in megabatches
|
||||
]
|
||||
|
||||
return [i for megabatch in megabatches for batch in megabatch for i in batch]
|
||||
|
||||
|
||||
class LengthGroupedSampler(Sampler):
|
||||
r"""
|
||||
Sampler that samples indices in a way that groups together features of the dataset of roughly the same length while
|
||||
keeping a bit of randomness.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
batch_size: int,
|
||||
world_size: int,
|
||||
lengths: Optional[List[int]] = None,
|
||||
generator=None,
|
||||
group_by_modality: bool = False,
|
||||
):
|
||||
if lengths is None:
|
||||
raise ValueError("Lengths must be provided.")
|
||||
|
||||
self.batch_size = batch_size
|
||||
self.world_size = world_size
|
||||
self.lengths = lengths
|
||||
self.generator = generator
|
||||
self.group_by_modality = group_by_modality
|
||||
|
||||
def __len__(self):
|
||||
return len(self.lengths)
|
||||
|
||||
def __iter__(self):
|
||||
if self.group_by_modality:
|
||||
indices = get_modality_length_grouped_indices(
|
||||
self.lengths, self.batch_size, self.world_size, generator=self.generator
|
||||
)
|
||||
else:
|
||||
indices = get_length_grouped_indices(
|
||||
self.lengths, self.batch_size, self.world_size, generator=self.generator
|
||||
)
|
||||
return iter(indices)
|
||||
|
||||
|
||||
class NamoTrainer(Trainer):
|
||||
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
|
||||
if self.train_dataset is None or not has_length(self.train_dataset):
|
||||
return None
|
||||
|
||||
if self.args.group_by_modality_length:
|
||||
lengths = self.train_dataset.modality_lengths
|
||||
return LengthGroupedSampler(
|
||||
self.args.train_batch_size,
|
||||
world_size=self.args.world_size * self.args.gradient_accumulation_steps,
|
||||
lengths=lengths,
|
||||
group_by_modality=True,
|
||||
)
|
||||
else:
|
||||
return super()._get_train_sampler()
|
||||
|
||||
def create_optimizer(self):
|
||||
"""
|
||||
Setup the optimizer.
|
||||
|
||||
We provide a reasonable default that works well. If you want to use something else, you can pass a tuple in the
|
||||
Trainer's init through `optimizers`, or subclass and override this method in a subclass.
|
||||
"""
|
||||
if is_sagemaker_mp_enabled():
|
||||
return super().create_optimizer()
|
||||
|
||||
opt_model = self.model
|
||||
|
||||
if self.optimizer is None:
|
||||
decay_parameters = get_parameter_names(opt_model, ALL_LAYERNORM_LAYERS)
|
||||
decay_parameters = [name for name in decay_parameters if "bias" not in name]
|
||||
if self.args.conn_ve_llm_lr is not None:
|
||||
projector_parameters = [
|
||||
name
|
||||
for name, _ in opt_model.named_parameters()
|
||||
if "conn_ve_llm" in name
|
||||
]
|
||||
if self.args.ve_lr is not None:
|
||||
vision_tower_parameters = [
|
||||
name
|
||||
for name, _ in opt_model.named_parameters()
|
||||
if ".ve." in name
|
||||
]
|
||||
optimizer_grouped_parameters = [
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (
|
||||
n in decay_parameters
|
||||
and n not in projector_parameters
|
||||
and n not in vision_tower_parameters
|
||||
and p.requires_grad
|
||||
)
|
||||
],
|
||||
"weight_decay": self.args.weight_decay,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (
|
||||
n in decay_parameters
|
||||
and n not in projector_parameters
|
||||
and n in vision_tower_parameters
|
||||
and p.requires_grad
|
||||
)
|
||||
],
|
||||
"weight_decay": self.args.weight_decay,
|
||||
"lr": self.args.ve_lr,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (
|
||||
n not in decay_parameters
|
||||
and n not in projector_parameters
|
||||
and n not in vision_tower_parameters
|
||||
and p.requires_grad
|
||||
)
|
||||
],
|
||||
"weight_decay": 0.0,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (
|
||||
n not in decay_parameters
|
||||
and n not in projector_parameters
|
||||
and n in vision_tower_parameters
|
||||
and p.requires_grad
|
||||
)
|
||||
],
|
||||
"weight_decay": 0.0,
|
||||
"lr": self.args.ve_lr,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (
|
||||
n in decay_parameters
|
||||
and n in projector_parameters
|
||||
and p.requires_grad
|
||||
)
|
||||
],
|
||||
"weight_decay": self.args.weight_decay,
|
||||
"lr": self.args.conn_ve_llm_lr,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (
|
||||
n not in decay_parameters
|
||||
and n in projector_parameters
|
||||
and p.requires_grad
|
||||
)
|
||||
],
|
||||
"weight_decay": 0.0,
|
||||
"lr": self.args.conn_ve_llm_lr,
|
||||
},
|
||||
]
|
||||
else:
|
||||
optimizer_grouped_parameters = [
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (
|
||||
n in decay_parameters
|
||||
and n not in projector_parameters
|
||||
and p.requires_grad
|
||||
)
|
||||
],
|
||||
"weight_decay": self.args.weight_decay,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (
|
||||
n not in decay_parameters
|
||||
and n not in projector_parameters
|
||||
and p.requires_grad
|
||||
)
|
||||
],
|
||||
"weight_decay": 0.0,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (
|
||||
n in decay_parameters
|
||||
and n in projector_parameters
|
||||
and p.requires_grad
|
||||
)
|
||||
],
|
||||
"weight_decay": self.args.weight_decay,
|
||||
"lr": self.args.conn_ve_llm_lr,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (
|
||||
n not in decay_parameters
|
||||
and n in projector_parameters
|
||||
and p.requires_grad
|
||||
)
|
||||
],
|
||||
"weight_decay": 0.0,
|
||||
"lr": self.args.conn_ve_llm_lr,
|
||||
},
|
||||
]
|
||||
else:
|
||||
if self.args.ve_lr is not None:
|
||||
vision_tower_parameters = [
|
||||
name
|
||||
for name, _ in opt_model.named_parameters()
|
||||
if ".ve." in name
|
||||
]
|
||||
optimizer_grouped_parameters = [
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if n in vision_tower_parameters
|
||||
and n in decay_parameters
|
||||
and p.requires_grad
|
||||
],
|
||||
"weight_decay": self.args.weight_decay,
|
||||
"lr": self.args.ve_lr,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if n in vision_tower_parameters
|
||||
and n not in decay_parameters
|
||||
and p.requires_grad
|
||||
],
|
||||
"weight_decay": 0.0,
|
||||
"lr": self.args.ve_lr,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if n in vision_tower_parameters
|
||||
and n in decay_parameters
|
||||
and p.requires_grad
|
||||
],
|
||||
"weight_decay": self.args.weight_decay,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if n in vision_tower_parameters
|
||||
and n not in decay_parameters
|
||||
and p.requires_grad
|
||||
],
|
||||
"weight_decay": 0.0,
|
||||
},
|
||||
]
|
||||
else:
|
||||
optimizer_grouped_parameters = [
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (n in decay_parameters and p.requires_grad)
|
||||
],
|
||||
"weight_decay": self.args.weight_decay,
|
||||
},
|
||||
{
|
||||
"params": [
|
||||
p
|
||||
for n, p in opt_model.named_parameters()
|
||||
if (n not in decay_parameters and p.requires_grad)
|
||||
],
|
||||
"weight_decay": 0.0,
|
||||
},
|
||||
]
|
||||
|
||||
optimizer_cls, optimizer_kwargs = Trainer.get_optimizer_cls_and_kwargs(
|
||||
self.args
|
||||
)
|
||||
|
||||
self.optimizer = optimizer_cls(
|
||||
optimizer_grouped_parameters, **optimizer_kwargs
|
||||
)
|
||||
if optimizer_cls.__name__ == "Adam8bit":
|
||||
import bitsandbytes
|
||||
|
||||
manager = bitsandbytes.optim.GlobalOptimManager.get_instance()
|
||||
|
||||
skipped = 0
|
||||
for module in opt_model.modules():
|
||||
if isinstance(module, nn.Embedding):
|
||||
skipped += sum(
|
||||
{
|
||||
p.data_ptr(): p.numel() for p in module.parameters()
|
||||
}.values()
|
||||
)
|
||||
logger.info(f"skipped {module}: {skipped/2**20}M params")
|
||||
manager.register_module_override(
|
||||
module, "weight", {"optim_bits": 32}
|
||||
)
|
||||
logger.debug(f"bitsandbytes: will optimize {module} in fp32")
|
||||
logger.info(f"skipped: {skipped/2**20}M params")
|
||||
|
||||
return self.optimizer
|
||||
|
||||
def _save_checkpoint(self, model, trial, metrics=None):
|
||||
if getattr(self.args, "tune_conn_ve_llm", False):
|
||||
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
|
||||
|
||||
checkpoint_folder = f"{PREFIX_CHECKPOINT_DIR}-{self.state.global_step}"
|
||||
|
||||
run_dir = self._get_output_dir(trial=trial)
|
||||
output_dir = os.path.join(run_dir, checkpoint_folder)
|
||||
rank0_print(f"saving conn_ve_llm to: {output_dir}")
|
||||
|
||||
# save all for mm adaptor resume
|
||||
self.save_model(output_dir, _internal_call=True)
|
||||
|
||||
# Only save Adapter
|
||||
keys_to_match = ["conn_ve_llm", "vision_resampler"]
|
||||
if getattr(self.args, "use_im_start_end", False):
|
||||
keys_to_match.extend(["embed_tokens", "embed_in"])
|
||||
|
||||
weight_to_save = get_mm_adapter_state_maybe_zero_3(
|
||||
self.model.named_parameters(), keys_to_match
|
||||
)
|
||||
|
||||
if self.args.local_rank == 0 or self.args.local_rank == -1:
|
||||
self.model.config.save_pretrained(output_dir)
|
||||
torch.save(weight_to_save, os.path.join(output_dir, f"conn_ve_llm.bin"))
|
||||
if not os.path.exists(output_dir):
|
||||
os.makedirs(output_dir, exist_ok=True)
|
||||
self.state.save_to_json(os.path.join(output_dir, TRAINER_STATE_NAME))
|
||||
|
||||
self._rotate_checkpoints(use_mtime=False, output_dir=run_dir)
|
||||
else:
|
||||
# call empty cache here?
|
||||
torch.cuda.empty_cache()
|
||||
super(NamoTrainer, self)._save_checkpoint(model, trial)
|
||||
|
||||
def _save(self, output_dir: Optional[str] = None, state_dict=None):
|
||||
if getattr(self.args, "tune_conn_ve_llm", False):
|
||||
pass
|
||||
else:
|
||||
super(NamoTrainer, self)._save(output_dir, state_dict)
|
||||
|
||||
|
||||
class NamoDPOTrainer(DPOTrainer):
|
||||
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
|
||||
if self.train_dataset is None or not has_length(self.train_dataset):
|
||||
return None
|
||||
|
||||
if self.args.group_by_modality_length:
|
||||
lengths = self.train_dataset.modality_lengths
|
||||
return LengthGroupedSampler(
|
||||
# self.args.train_batch_size * self.args.gradient_accumulation_steps, # TODO: seems that we should not have gradient_accumulation_steps
|
||||
self.args.train_batch_size,
|
||||
world_size=self.args.world_size,
|
||||
lengths=lengths,
|
||||
group_by_modality=True,
|
||||
)
|
||||
else:
|
||||
return super()._get_train_sampler()
|
||||
|
||||
def _save_checkpoint(self, model, trial, metrics=None):
|
||||
if getattr(self.args, "tune_conn_ve_llm", False) or (
|
||||
hasattr(self.args, "mm_tunable_parts")
|
||||
and (
|
||||
len(self.args.mm_tunable_parts.split(",")) == 1
|
||||
and (
|
||||
"mm_mlp_adapter" in self.args.mm_tunable_parts
|
||||
or "mm_vision_resampler" in self.args.mm_tunable_parts
|
||||
)
|
||||
)
|
||||
):
|
||||
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
|
||||
|
||||
checkpoint_folder = f"{PREFIX_CHECKPOINT_DIR}-{self.state.global_step}"
|
||||
|
||||
run_dir = self._get_output_dir(trial=trial)
|
||||
output_dir = os.path.join(run_dir, checkpoint_folder)
|
||||
rank0_print(f"saving conn_ve_llm weights: {output_dir}")
|
||||
|
||||
# Only save Adapter
|
||||
keys_to_match = ["conn_ve_llm", "vision_resampler"]
|
||||
if getattr(self.args, "use_im_start_end", False):
|
||||
keys_to_match.extend(["embed_tokens", "embed_in"])
|
||||
|
||||
weight_to_save = get_mm_adapter_state_maybe_zero_3(
|
||||
self.model.named_parameters(), keys_to_match
|
||||
)
|
||||
|
||||
if self.args.local_rank == 0 or self.args.local_rank == -1:
|
||||
self.model.config.save_pretrained(output_dir)
|
||||
torch.save(weight_to_save, os.path.join(output_dir, f"conn_ve_llm.bin"))
|
||||
else:
|
||||
|
||||
if self.args.lora_enable:
|
||||
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
|
||||
|
||||
checkpoint_folder = f"{PREFIX_CHECKPOINT_DIR}-{self.state.global_step}"
|
||||
run_dir = self._get_output_dir(trial=trial)
|
||||
output_dir = os.path.join(run_dir, checkpoint_folder)
|
||||
from transformers.modeling_utils import unwrap_model
|
||||
|
||||
unwrapped_model = unwrap_model(model)
|
||||
self.save_my_lora_ckpt(output_dir, self.args, unwrapped_model)
|
||||
else:
|
||||
super(NamoDPOTrainer, self)._save_checkpoint(model, trial)
|
||||
|
||||
def _save(self, output_dir: Optional[str] = None, state_dict=None):
|
||||
if getattr(self.args, "tune_conn_ve_llm", False):
|
||||
pass
|
||||
else:
|
||||
super(NamoDPOTrainer, self)._save(output_dir, state_dict)
|
||||
@@ -0,0 +1,682 @@
|
||||
import dataclasses
|
||||
from enum import auto, Enum
|
||||
from typing import List, Tuple
|
||||
import base64
|
||||
from io import BytesIO
|
||||
from PIL import Image
|
||||
|
||||
|
||||
class SeparatorStyle(Enum):
|
||||
"""Different separator style."""
|
||||
|
||||
SINGLE = auto()
|
||||
TWO = auto()
|
||||
MPT = auto()
|
||||
PLAIN = auto()
|
||||
LLAMA_2 = auto()
|
||||
GEMMA = auto()
|
||||
LLAMA3 = auto()
|
||||
LLAMA2 = auto()
|
||||
PHI3 = auto()
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class Conversation:
|
||||
"""A class that keeps all conversation history."""
|
||||
|
||||
system: str
|
||||
roles: List[str]
|
||||
messages: List[List[str]]
|
||||
offset: int
|
||||
sep_style: SeparatorStyle = SeparatorStyle.SINGLE
|
||||
sep: str = "###"
|
||||
sep2: str = None
|
||||
version: str = "Unknown"
|
||||
|
||||
stop_str: str = None
|
||||
# Stops generation if meeting any token in this list
|
||||
stop_token_ids: List[int] = None
|
||||
|
||||
skip_next: bool = False
|
||||
|
||||
def get_prompt(self):
|
||||
messages = self.messages
|
||||
if len(messages) > 0 and type(messages[0][1]) is tuple:
|
||||
messages = self.messages.copy()
|
||||
init_role, init_msg = messages[0].copy()
|
||||
init_msg = init_msg[0].replace("<image>", "").strip()
|
||||
if "mmtag" in self.version:
|
||||
messages[0] = (init_role, init_msg)
|
||||
messages.insert(0, (self.roles[0], "<Image><image></Image>"))
|
||||
messages.insert(1, (self.roles[1], "Received."))
|
||||
else:
|
||||
messages[0] = (init_role, "<image>\n" + init_msg)
|
||||
|
||||
if self.sep_style == SeparatorStyle.SINGLE:
|
||||
ret = self.system + self.sep
|
||||
for role, message in messages:
|
||||
if message:
|
||||
if type(message) is tuple:
|
||||
message = message[0]
|
||||
ret += role + ": " + message + self.sep
|
||||
else:
|
||||
ret += role + ":"
|
||||
elif self.sep_style == SeparatorStyle.TWO:
|
||||
seps = [self.sep, self.sep2]
|
||||
ret = self.system + seps[0]
|
||||
for i, (role, message) in enumerate(messages):
|
||||
if message:
|
||||
if type(message) is tuple:
|
||||
message = message[0]
|
||||
ret += role + ": " + message + seps[i % 2]
|
||||
else:
|
||||
ret += role + ":"
|
||||
elif self.sep_style == SeparatorStyle.MPT:
|
||||
ret = self.system + self.sep
|
||||
for role, message in messages:
|
||||
if message:
|
||||
if type(message) is tuple:
|
||||
message = message[0]
|
||||
ret += role + message + self.sep
|
||||
else:
|
||||
ret += role
|
||||
elif self.sep_style == SeparatorStyle.LLAMA_2:
|
||||
|
||||
def wrap_sys(msg):
|
||||
return f"<<SYS>>\n{msg}\n<</SYS>>\n\n" if len(msg) > 0 else msg
|
||||
|
||||
def wrap_inst(msg):
|
||||
return f"[INST] {msg} [/INST]"
|
||||
|
||||
ret = ""
|
||||
|
||||
for i, (role, message) in enumerate(messages):
|
||||
if i == 0:
|
||||
assert message, "first message should not be none"
|
||||
assert role == self.roles[0], "first message should come from user"
|
||||
if message:
|
||||
if type(message) is tuple:
|
||||
message, _, _ = message
|
||||
if i == 0:
|
||||
message = wrap_sys(self.system) + message
|
||||
if i % 2 == 0:
|
||||
message = wrap_inst(message)
|
||||
ret += self.sep + message
|
||||
else:
|
||||
ret += " " + message + " " + self.sep2
|
||||
else:
|
||||
ret += ""
|
||||
ret = ret.lstrip(self.sep)
|
||||
# elif self.sep_style == SeparatorStyle.GEMMA:
|
||||
# ret = self.system
|
||||
# for i, (role, message) in enumerate(self.messages):
|
||||
# assert role == self.roles[i % 2], "Conversation should alternate user/assistant/user/assistant/..." # i % 2 -> user/assistant/user/assistant
|
||||
# if message:
|
||||
# if type(message) is tuple:
|
||||
# message, _, _ = message
|
||||
# ret += role + message + self.sep
|
||||
# else:
|
||||
# ret += role
|
||||
# return ret
|
||||
elif self.sep_style == SeparatorStyle.GEMMA:
|
||||
seps = [self.sep, self.sep2]
|
||||
ret = self.system
|
||||
for i, (role, message) in enumerate(messages):
|
||||
if message:
|
||||
if type(message) is tuple:
|
||||
message, _, _ = message
|
||||
ret += seps[0] + role + "\n" + message + seps[1] + "\n"
|
||||
else:
|
||||
ret += seps[0] + role + "\n"
|
||||
# ret = ret.strip() # remove trailing newline
|
||||
elif self.sep_style == SeparatorStyle.PLAIN:
|
||||
seps = [self.sep, self.sep2]
|
||||
ret = self.system
|
||||
for i, (role, message) in enumerate(messages):
|
||||
if message:
|
||||
if type(message) is tuple:
|
||||
message, _, _ = message
|
||||
ret += message + seps[i % 2]
|
||||
else:
|
||||
ret += ""
|
||||
elif self.sep_style == SeparatorStyle.LLAMA3:
|
||||
ret = "<|begin_of_text|>"
|
||||
ret += self.system
|
||||
for i, (role, message) in enumerate(self.messages):
|
||||
if message:
|
||||
ret += f"<|start_header_id|>{role}<|end_header_id|>\n\n"
|
||||
ret += f"{message.strip()}<|eot_id|>"
|
||||
else:
|
||||
ret += f"<|start_header_id|>{role}<|end_header_id|>\n\n"
|
||||
return ret
|
||||
elif self.sep_style == SeparatorStyle.LLAMA2:
|
||||
seps = [self.sep, self.sep2]
|
||||
ret = self.system
|
||||
for i, (role, message) in enumerate(self.messages):
|
||||
tag = self.roles[i % 2]
|
||||
if message:
|
||||
if i == 0:
|
||||
ret += message + " "
|
||||
else:
|
||||
ret += tag + " " + message + seps[i % 2]
|
||||
else:
|
||||
ret += tag
|
||||
return ret
|
||||
elif self.sep_style == SeparatorStyle.PHI3:
|
||||
ret = "<|endoftext|>"
|
||||
ret += self.system
|
||||
for i, (role, message) in enumerate(self.messages):
|
||||
if message:
|
||||
if type(message) is tuple:
|
||||
message = message[0]
|
||||
ret += role + message + self.sep
|
||||
else:
|
||||
ret += role
|
||||
return ret
|
||||
else:
|
||||
raise ValueError(f"Invalid style: {self.sep_style}")
|
||||
|
||||
return ret
|
||||
|
||||
def append_message(self, role, message):
|
||||
self.messages.append([role, message])
|
||||
|
||||
def process_image(
|
||||
self,
|
||||
image,
|
||||
image_process_mode,
|
||||
return_pil=False,
|
||||
image_format="PNG",
|
||||
max_len=1344,
|
||||
min_len=672,
|
||||
):
|
||||
if image_process_mode == "Pad":
|
||||
|
||||
def expand2square(pil_img, background_color=(122, 116, 104)):
|
||||
width, height = pil_img.size
|
||||
if width == height:
|
||||
return pil_img
|
||||
elif width > height:
|
||||
result = Image.new(pil_img.mode, (width, width), background_color)
|
||||
result.paste(pil_img, (0, (width - height) // 2))
|
||||
return result
|
||||
else:
|
||||
result = Image.new(pil_img.mode, (height, height), background_color)
|
||||
result.paste(pil_img, ((height - width) // 2, 0))
|
||||
return result
|
||||
|
||||
image = expand2square(image)
|
||||
elif image_process_mode in ["Default", "Crop"]:
|
||||
pass
|
||||
elif image_process_mode == "Resize":
|
||||
image = image.resize((336, 336))
|
||||
else:
|
||||
raise ValueError(f"Invalid image_process_mode: {image_process_mode}")
|
||||
if max(image.size) > max_len:
|
||||
max_hw, min_hw = max(image.size), min(image.size)
|
||||
aspect_ratio = max_hw / min_hw
|
||||
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
|
||||
longest_edge = int(shortest_edge * aspect_ratio)
|
||||
W, H = image.size
|
||||
if H > W:
|
||||
H, W = longest_edge, shortest_edge
|
||||
else:
|
||||
H, W = shortest_edge, longest_edge
|
||||
image = image.resize((W, H))
|
||||
if return_pil:
|
||||
return image
|
||||
else:
|
||||
buffered = BytesIO()
|
||||
image.save(buffered, format=image_format)
|
||||
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
|
||||
return img_b64_str
|
||||
|
||||
def get_images(self, return_pil=False):
|
||||
images = []
|
||||
for i, (role, msg) in enumerate(self.messages[self.offset :]):
|
||||
if i % 2 == 0:
|
||||
if type(msg) is tuple:
|
||||
msg, image, image_process_mode = msg
|
||||
image = self.process_image(
|
||||
image, image_process_mode, return_pil=return_pil
|
||||
)
|
||||
images.append(image)
|
||||
return images
|
||||
|
||||
def to_gradio_chatbot(self):
|
||||
ret = []
|
||||
for i, (role, msg) in enumerate(self.messages[self.offset :]):
|
||||
if i % 2 == 0:
|
||||
if type(msg) is tuple:
|
||||
msg, image, image_process_mode = msg
|
||||
img_b64_str = self.process_image(
|
||||
image, "Default", return_pil=False, image_format="JPEG"
|
||||
)
|
||||
img_str = f'<img src="data:image/jpeg;base64,{img_b64_str}" alt="user upload image" />'
|
||||
msg = img_str + msg.replace("<image>", "").strip()
|
||||
ret.append([msg, None])
|
||||
else:
|
||||
ret.append([msg, None])
|
||||
else:
|
||||
if type(msg) is tuple and len(msg) == 2:
|
||||
msg, img_b64_str = msg
|
||||
img_str = f'<img src="data:image/jpeg;base64,{img_b64_str}" alt="user upload image" />'
|
||||
msg = msg.strip() + img_str
|
||||
ret[-1][-1] = msg
|
||||
return ret
|
||||
|
||||
def copy(self):
|
||||
return Conversation(
|
||||
system=self.system,
|
||||
roles=self.roles,
|
||||
messages=[[x, y] for x, y in self.messages],
|
||||
offset=self.offset,
|
||||
sep_style=self.sep_style,
|
||||
sep=self.sep,
|
||||
sep2=self.sep2,
|
||||
version=self.version,
|
||||
)
|
||||
|
||||
def dict(self):
|
||||
if len(self.get_images()) > 0:
|
||||
return {
|
||||
"system": self.system,
|
||||
"roles": self.roles,
|
||||
"messages": [
|
||||
[x, y[0] if type(y) is tuple else y] for x, y in self.messages
|
||||
],
|
||||
"offset": self.offset,
|
||||
"sep": self.sep,
|
||||
"sep2": self.sep2,
|
||||
}
|
||||
return {
|
||||
"system": self.system,
|
||||
"roles": self.roles,
|
||||
"messages": self.messages,
|
||||
"offset": self.offset,
|
||||
"sep": self.sep,
|
||||
"sep2": self.sep2,
|
||||
}
|
||||
|
||||
|
||||
conv_vicuna_v0 = Conversation(
|
||||
system="A chat between a curious human and an artificial intelligence assistant. "
|
||||
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
||||
roles=("Human", "Assistant"),
|
||||
messages=(
|
||||
(
|
||||
"Human",
|
||||
"What are the key differences between renewable and non-renewable energy sources?",
|
||||
),
|
||||
(
|
||||
"Assistant",
|
||||
"Renewable energy sources are those that can be replenished naturally in a relatively "
|
||||
"short amount of time, such as solar, wind, hydro, geothermal, and biomass. "
|
||||
"Non-renewable energy sources, on the other hand, are finite and will eventually be "
|
||||
"depleted, such as coal, oil, and natural gas. Here are some key differences between "
|
||||
"renewable and non-renewable energy sources:\n"
|
||||
"1. Availability: Renewable energy sources are virtually inexhaustible, while non-renewable "
|
||||
"energy sources are finite and will eventually run out.\n"
|
||||
"2. Environmental impact: Renewable energy sources have a much lower environmental impact "
|
||||
"than non-renewable sources, which can lead to air and water pollution, greenhouse gas emissions, "
|
||||
"and other negative effects.\n"
|
||||
"3. Cost: Renewable energy sources can be more expensive to initially set up, but they typically "
|
||||
"have lower operational costs than non-renewable sources.\n"
|
||||
"4. Reliability: Renewable energy sources are often more reliable and can be used in more remote "
|
||||
"locations than non-renewable sources.\n"
|
||||
"5. Flexibility: Renewable energy sources are often more flexible and can be adapted to different "
|
||||
"situations and needs, while non-renewable sources are more rigid and inflexible.\n"
|
||||
"6. Sustainability: Renewable energy sources are more sustainable over the long term, while "
|
||||
"non-renewable sources are not, and their depletion can lead to economic and social instability.\n",
|
||||
),
|
||||
),
|
||||
offset=2,
|
||||
sep_style=SeparatorStyle.SINGLE,
|
||||
sep="###",
|
||||
)
|
||||
|
||||
conv_vicuna_v1 = Conversation(
|
||||
system="A chat between a curious user and an artificial intelligence assistant. "
|
||||
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
||||
roles=("USER", "ASSISTANT"),
|
||||
version="v1",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.TWO,
|
||||
sep=" ",
|
||||
sep2="</s>",
|
||||
)
|
||||
|
||||
conv_llama_2 = Conversation(
|
||||
system="""You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
|
||||
|
||||
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.""",
|
||||
roles=("USER", "ASSISTANT"),
|
||||
version="llama_v2",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.LLAMA_2,
|
||||
sep="<s>",
|
||||
sep2="</s>",
|
||||
)
|
||||
|
||||
conv_llava_llama_2 = Conversation(
|
||||
system="You are a helpful language and vision assistant. "
|
||||
"You are able to understand the visual content that the user provides, "
|
||||
"and assist the user with a variety of tasks using natural language.",
|
||||
roles=("USER", "ASSISTANT"),
|
||||
version="llama_v2",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.LLAMA_2,
|
||||
sep="<s>",
|
||||
sep2="</s>",
|
||||
)
|
||||
|
||||
conv_mpt = Conversation(
|
||||
system="""<|im_start|>system
|
||||
A conversation between a user and an LLM-based AI assistant. The assistant gives helpful and honest answers.""",
|
||||
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
||||
version="mpt",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.MPT,
|
||||
sep="<|im_end|>",
|
||||
)
|
||||
|
||||
conv_llava_plain = Conversation(
|
||||
system="",
|
||||
roles=("", ""),
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.PLAIN,
|
||||
sep="\n",
|
||||
)
|
||||
|
||||
conv_llava_v0 = Conversation(
|
||||
system="A chat between a curious human and an artificial intelligence assistant. "
|
||||
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
||||
roles=("Human", "Assistant"),
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.SINGLE,
|
||||
sep="###",
|
||||
)
|
||||
|
||||
conv_llava_v0_mmtag = Conversation(
|
||||
system="A chat between a curious user and an artificial intelligence assistant. "
|
||||
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
|
||||
"The visual content will be provided with the following format: <Image>visual content</Image>.",
|
||||
roles=("Human", "Assistant"),
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.SINGLE,
|
||||
sep="###",
|
||||
version="v0_mmtag",
|
||||
)
|
||||
|
||||
conv_llava_v1 = Conversation(
|
||||
system="A chat between a curious human and an artificial intelligence assistant. "
|
||||
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
||||
roles=("USER", "ASSISTANT"),
|
||||
version="v1",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.TWO,
|
||||
sep=" ",
|
||||
sep2="</s>",
|
||||
)
|
||||
|
||||
conv_vicuna_imgsp_v1 = Conversation(
|
||||
system="A chat between a curious user and an artificial intelligence assistant. "
|
||||
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
||||
roles=("USER", "ASSISTANT"),
|
||||
version="imgsp_v1",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.TWO,
|
||||
sep=" ",
|
||||
sep2="</s>",
|
||||
)
|
||||
|
||||
conv_llava_plain_guided = Conversation(
|
||||
system="",
|
||||
roles=("", ""),
|
||||
version="plain_guided",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.PLAIN,
|
||||
sep="\n",
|
||||
)
|
||||
|
||||
conv_llava_v1_mmtag = Conversation(
|
||||
system="A chat between a curious user and an artificial intelligence assistant. "
|
||||
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
|
||||
"The visual content will be provided with the following format: <Image>visual content</Image>.",
|
||||
roles=("USER", "ASSISTANT"),
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.TWO,
|
||||
sep=" ",
|
||||
sep2="</s>",
|
||||
version="v1_mmtag",
|
||||
)
|
||||
|
||||
conv_phi_2 = Conversation(
|
||||
system="A chat between a curious user and an artificial intelligence assistant. "
|
||||
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
||||
roles=("USER", "ASSISTANT"),
|
||||
version="phi2",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.TWO,
|
||||
sep=" ",
|
||||
sep2="<|endoftext|>",
|
||||
)
|
||||
|
||||
# conv_mistral_instruct = Conversation(
|
||||
# system="",
|
||||
# roles=("USER", "ASSISTANT"),
|
||||
# version="llama_v2",
|
||||
# messages=(),
|
||||
# offset=0,
|
||||
# sep_style=SeparatorStyle.LLAMA_2,
|
||||
# sep="",
|
||||
# sep2="</s>",
|
||||
# )
|
||||
|
||||
conv_mistral_instruct = Conversation(
|
||||
system="",
|
||||
roles=("USER", "ASSISTANT"),
|
||||
version="llama_v2",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.LLAMA_2,
|
||||
sep="<s>",
|
||||
sep2="</s>",
|
||||
)
|
||||
|
||||
# conv_gemma = Conversation(
|
||||
# system="You are a helpful assistant.",
|
||||
# # system="",
|
||||
# roles=("<start_of_turn>user\n", "<start_of_turn>model\n"),
|
||||
# version="gemma",
|
||||
# messages=(),
|
||||
# offset=0,
|
||||
# sep_style=SeparatorStyle.GEMMA,
|
||||
# sep="<end_of_turn>\n",
|
||||
# stop_str=["<end_of_turn>"],
|
||||
# stop_token_ids=[1, 107], # <eos> <end_of_turn>
|
||||
# )
|
||||
|
||||
conv_gemma = Conversation(
|
||||
system="A chat between a curious user and an artificial intelligence assistant. "
|
||||
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
||||
roles=("user", "model"),
|
||||
version="gemma",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.GEMMA,
|
||||
sep="<start_of_turn>",
|
||||
sep2="<end_of_turn>",
|
||||
)
|
||||
|
||||
conv_chatml_direct = Conversation(
|
||||
system="""<|im_start|>system
|
||||
Answer the questions.""",
|
||||
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
||||
version="mpt",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.MPT,
|
||||
sep="<|im_end|>",
|
||||
)
|
||||
|
||||
|
||||
conv_qwen = Conversation(
|
||||
system="""<|im_start|>system
|
||||
You should follow the instructions carefully and explain your answers in detail.""",
|
||||
# system = None,
|
||||
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
||||
version="qwen",
|
||||
messages=[],
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.MPT,
|
||||
stop_str="<|im_end|>",
|
||||
sep="<|im_end|>",
|
||||
sep2="<|endoftext|>",
|
||||
stop_token_ids=[151643, 151646, 151645],
|
||||
)
|
||||
|
||||
conv_llama3_test = Conversation(
|
||||
system="""<|start_header_id|>system<|end_header_id|>\n\nYou should follow the instructions carefully and explain your answers in detail.""",
|
||||
# system = None,
|
||||
roles=(
|
||||
"<|start_header_id|>user<|end_header_id|>\n\n",
|
||||
"<|start_header_id|>assistant<|end_header_id|>\n\n",
|
||||
),
|
||||
version="llama3",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.MPT,
|
||||
sep="<|eot_id|>\n",
|
||||
sep2="<|eot_id|>",
|
||||
)
|
||||
|
||||
conv_llama3 = Conversation(
|
||||
version="llama3",
|
||||
system="<|start_header_id|>system<|end_header_id|>\n\nYou should follow the instructions carefully and explain your answers in detail.<|eot_id|>",
|
||||
roles=("user", "assistant"),
|
||||
sep_style=SeparatorStyle.LLAMA3,
|
||||
messages=[],
|
||||
offset=0,
|
||||
sep="",
|
||||
stop_str="<|eot_id|>",
|
||||
stop_token_ids=[128001, 128009, 128007],
|
||||
)
|
||||
|
||||
conv_internlm2 = Conversation(
|
||||
version="internlm2-chat",
|
||||
system="<|im_start|>system\nYou are an AI assistant whose name is InternLM (书生·浦语).",
|
||||
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
||||
sep_style=SeparatorStyle.MPT,
|
||||
messages=[],
|
||||
offset=0,
|
||||
sep="<|im_end|>",
|
||||
stop_token_ids=[2, 92543, 92542],
|
||||
)
|
||||
|
||||
conv_glm4 = Conversation(
|
||||
system="""[gMASK]<sop><|system|>
|
||||
You should follow the instructions carefully and explain your answers in detail.""",
|
||||
# system = None,
|
||||
roles=("<|user|>\n", "<|assistant|>\n"),
|
||||
version="glm4",
|
||||
messages=(),
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.MPT,
|
||||
sep="",
|
||||
sep2="<|endoftext|>",
|
||||
stop_token_ids=[151336, 151337], # <|user|> <|assistant|>
|
||||
)
|
||||
|
||||
conv_phi3_instruct = Conversation(
|
||||
# system="""<|system|>\nYou are a helpful AI assistant.""",
|
||||
system="",
|
||||
roles=("<|user|>\n", "<|assistant|>\n"),
|
||||
version="phi3",
|
||||
messages=[],
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.PHI3,
|
||||
sep="<|end|>\n",
|
||||
)
|
||||
|
||||
conv_mistral = Conversation(
|
||||
version="mistral",
|
||||
system="[INST] You should follow the instructions carefully and explain your answers in detail.\n",
|
||||
roles=("[INST]", "[/INST]"),
|
||||
messages=[],
|
||||
offset=0,
|
||||
sep_style=SeparatorStyle.LLAMA2,
|
||||
sep=" ",
|
||||
sep2="</s>",
|
||||
stop_token_ids=[
|
||||
2,
|
||||
],
|
||||
)
|
||||
|
||||
|
||||
default_conversation = conv_vicuna_v1
|
||||
conv_templates = {
|
||||
"default": conv_vicuna_v0,
|
||||
"v0": conv_vicuna_v0,
|
||||
"v1": conv_vicuna_v1,
|
||||
"vicuna_v1": conv_vicuna_v1,
|
||||
"phi_2": conv_phi_2,
|
||||
"gemma": conv_gemma,
|
||||
"llama_2": conv_llama_2,
|
||||
"imgsp_v1": conv_vicuna_imgsp_v1,
|
||||
"plain_guided": conv_llava_plain_guided,
|
||||
"mistral_instruct": conv_mistral_instruct,
|
||||
"chatml_direct": conv_chatml_direct,
|
||||
"mistral_direct": conv_chatml_direct,
|
||||
"plain": conv_llava_plain,
|
||||
"v0_plain": conv_llava_plain,
|
||||
"llava_v0": conv_llava_v0,
|
||||
"v0_mmtag": conv_llava_v0_mmtag,
|
||||
"llava_v1": conv_llava_v1,
|
||||
"v1_mmtag": conv_llava_v1_mmtag,
|
||||
"llava_llama_2": conv_llava_llama_2,
|
||||
"mpt": conv_mpt,
|
||||
"qwen": conv_qwen,
|
||||
"llama3_test": conv_llama3_test,
|
||||
"llama3": conv_llama3,
|
||||
"internlm2-chat": conv_internlm2,
|
||||
"glm4": conv_glm4,
|
||||
"phi3": conv_phi3_instruct,
|
||||
"mistral": conv_mistral,
|
||||
"gemma": conv_gemma,
|
||||
}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# print(default_conversation.get_prompt())
|
||||
# conv = conv_templates["chatml_direct"]
|
||||
# conv = conv_templates["phi3"]
|
||||
# conv = conv_templates["mistral"]
|
||||
conv = conv_templates["gemma"]
|
||||
# conv = conv_templates["qwen"]
|
||||
|
||||
print(conv)
|
||||
conv.messages = []
|
||||
|
||||
conv.append_message(conv.roles[0], "hello")
|
||||
conv.append_message(conv.roles[1], "am tallen! nice to meet u.")
|
||||
conv.append_message(conv.roles[0], "Nice to see u, how dod u do?")
|
||||
conv.append_message(conv.roles[1], "我很好,请问有什么可以帮你的吗?")
|
||||
conv.append_message(conv.roles[0], "介绍一下你自己")
|
||||
conv.append_message(conv.roles[1], "我是ChatGPT,一个人工智能助手")
|
||||
conv.append_message(conv.roles[0], "你会python嘛?")
|
||||
conv.append_message(conv.roles[1], None)
|
||||
a = conv.get_prompt()
|
||||
print(a)
|
||||
@@ -0,0 +1,237 @@
|
||||
import os
|
||||
from typing import List, Optional, Tuple, Union
|
||||
import torch
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
from transformers import PreTrainedModel, GenerationMixin
|
||||
from transformers.modeling_outputs import CausalLMOutputWithPast
|
||||
from torch import nn
|
||||
from .utils import rank0_print
|
||||
from pathlib import Path
|
||||
import json
|
||||
from transformers import TrainerState
|
||||
from peft import PeftModel
|
||||
import glob
|
||||
from loguru import logger
|
||||
|
||||
|
||||
def auto_load_model(config):
|
||||
model_name_or_path = config._name_or_path
|
||||
if os.path.exists(model_name_or_path):
|
||||
return AutoModel.from_pretrained(
|
||||
model_name_or_path, torch_dtype=config.torch_dtype, trust_remote_code=True
|
||||
)
|
||||
else:
|
||||
return AutoModel.from_config(config=config, trust_remote_code=True)
|
||||
|
||||
|
||||
def auto_load_tokenizer(config):
|
||||
model_name_or_path = config._name_or_path
|
||||
if hasattr(config, "text_config"):
|
||||
text_config = config.text_config
|
||||
text_model_name_or_path = getattr(text_config, "_name_or_path", None)
|
||||
if text_model_name_or_path:
|
||||
if os.path.exists(text_model_name_or_path):
|
||||
model_name_or_path = text_model_name_or_path
|
||||
return AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
|
||||
|
||||
|
||||
def try_resume_conn_weights(model, output_dir, weight_file_name="conn_ve_llm.bin"):
|
||||
checkpoint_dirs = list(Path(output_dir).glob("checkpoint-*"))
|
||||
if checkpoint_dirs:
|
||||
sorted_checkpoints = sorted(
|
||||
checkpoint_dirs, key=lambda x: int(x.stem.split("-")[-1])
|
||||
)
|
||||
latest_checkpoint = sorted_checkpoints[-1]
|
||||
weights_path = latest_checkpoint / weight_file_name
|
||||
if weights_path.exists():
|
||||
if "ve_llm" in weight_file_name:
|
||||
model.namo.load_conn_ve_llm_weights(weights_path)
|
||||
rank0_print(f"resumed conn_ve_llm weights from: {weights_path}")
|
||||
|
||||
state_path = latest_checkpoint / "trainer_state.json"
|
||||
if state_path.exists():
|
||||
state = TrainerState.load_from_json(state_path)
|
||||
epoch = state.epoch
|
||||
global_step = state.global_step
|
||||
max_steps = state.max_steps
|
||||
rank0_print(
|
||||
f"tainer state resumed: {state_path}, epoch: {epoch} {global_step}/{max_steps}"
|
||||
)
|
||||
return state
|
||||
return None
|
||||
else:
|
||||
rank0_print(f"not resumed as: {weights_path} not found.")
|
||||
|
||||
|
||||
def get_latest_checkpoint(output_dir, weights_file_name=None):
|
||||
if os.path.exists(output_dir) and os.path.isfile(output_dir):
|
||||
return output_dir
|
||||
if weights_file_name is not None and os.path.exists(
|
||||
os.path.join(output_dir, weights_file_name)
|
||||
):
|
||||
return os.path.join(output_dir, weights_file_name)
|
||||
else:
|
||||
checkpoint_dirs = list(Path(output_dir).glob("checkpoint-*"))
|
||||
if checkpoint_dirs:
|
||||
sorted_checkpoints = sorted(
|
||||
checkpoint_dirs, key=lambda x: int(x.stem.split("-")[-1])
|
||||
)
|
||||
latest_checkpoint = sorted_checkpoints[-1]
|
||||
if weights_file_name is None:
|
||||
return latest_checkpoint
|
||||
weights_path = latest_checkpoint / weights_file_name
|
||||
rank0_print(f"==> loading conn middle checkpoint from: {weights_path}")
|
||||
return weights_path
|
||||
|
||||
|
||||
def find_and_merge_lora_adapters(model, model_path):
|
||||
def find_latest_checkpoint(model_path):
|
||||
checkpoints = glob.glob(os.path.join(model_path, "checkpoint-*"))
|
||||
if not checkpoints:
|
||||
return None
|
||||
return max(checkpoints, key=os.path.getctime)
|
||||
|
||||
lora_path = None
|
||||
lora_adapters = glob.glob(
|
||||
os.path.join(model_path, "*.safetensors")
|
||||
) # 假设适配器是 safetensors 格式
|
||||
if len(lora_adapters) > 0:
|
||||
lora_path = lora_adapters[0]
|
||||
else:
|
||||
latest_checkpoint = find_latest_checkpoint(model_path)
|
||||
if latest_checkpoint:
|
||||
lora_path = latest_checkpoint
|
||||
|
||||
if lora_path:
|
||||
logger.info(f"Merging LoRA adapters: {lora_path}")
|
||||
model = PeftModel.from_pretrained(model, lora_path)
|
||||
model = model.merge_and_unload()
|
||||
return model
|
||||
|
||||
|
||||
class SimpleForCausalLM(PreTrainedModel, GenerationMixin):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
_tp_plan = {"lm_head": "colwise_rep"}
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = None
|
||||
self.vocab_size = config.vocab_size
|
||||
# self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
# for placeholder, must set in real model.
|
||||
self.lm_head = None
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embed_tokens
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embed_tokens = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
cache_position: Optional[torch.LongTensor] = None,
|
||||
num_logits_to_keep: int = 0,
|
||||
**loss_kwargs,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
r"""
|
||||
Args:
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
||||
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
||||
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
||||
|
||||
num_logits_to_keep (`int`, *optional*):
|
||||
Calculate logits for the last `num_logits_to_keep` tokens. If `0`, calculate logits for all
|
||||
`input_ids` (special case). Only last token logits are needed for generation, and calculating them only for that
|
||||
token can save memory, which becomes pretty significant for long sequences or large vocabulary size.
|
||||
|
||||
Returns:
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, Qwen2ForCausalLM
|
||||
|
||||
>>> model = Qwen2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
|
||||
|
||||
>>> prompt = "Hey, are you conscious? Can you talk to me?"
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> # Generate
|
||||
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
||||
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
||||
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
|
||||
```"""
|
||||
|
||||
output_attentions = (
|
||||
output_attentions
|
||||
if output_attentions is not None
|
||||
else self.config.output_attentions
|
||||
)
|
||||
output_hidden_states = (
|
||||
output_hidden_states
|
||||
if output_hidden_states is not None
|
||||
else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = (
|
||||
return_dict if return_dict is not None else self.config.use_return_dict
|
||||
)
|
||||
|
||||
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
cache_position=cache_position,
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
# Only compute necessary logits, and do not upcast them to float if we are not computing the loss
|
||||
logits = self.lm_head(hidden_states[:, -num_logits_to_keep:, :])
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
loss = self.loss_function(logits, labels, self.vocab_size, **loss_kwargs)
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
@@ -0,0 +1,51 @@
|
||||
import requests
|
||||
from PIL import Image
|
||||
import base64
|
||||
from threading import Thread
|
||||
import io
|
||||
from transformers import TextStreamer
|
||||
|
||||
try:
|
||||
from datauri import DataURI
|
||||
except ImportError:
|
||||
pass
|
||||
|
||||
|
||||
def load_image(image_file):
|
||||
if image_file.startswith("http") or image_file.startswith("https"):
|
||||
response = requests.get(image_file)
|
||||
image = Image.open(io.BytesIO(response.content)).convert("RGB")
|
||||
else:
|
||||
image = Image.open(image_file).convert("RGB")
|
||||
return image
|
||||
|
||||
|
||||
def load_multi_images_maybe(image_files, splitter=" "):
|
||||
if isinstance(image_files, str):
|
||||
images = image_files.split(splitter)
|
||||
else:
|
||||
images = image_files
|
||||
return [load_image(i) for i in images]
|
||||
|
||||
|
||||
def url_to_image(img_url: str) -> Image.Image:
|
||||
if img_url.startswith("http"):
|
||||
response = requests.get(img_url)
|
||||
|
||||
img_data = response.content
|
||||
elif img_url.startswith("data:"):
|
||||
img_data = DataURI(img_url).data
|
||||
else:
|
||||
img_data = base64.b64decode(img_url)
|
||||
return Image.open(io.BytesIO(img_data)).convert("RGB")
|
||||
|
||||
|
||||
class CallbackStreamer(TextStreamer):
|
||||
def __init__(self, tokenizer, callback=None, **kwargs):
|
||||
super().__init__(tokenizer, **kwargs)
|
||||
self.callback = callback
|
||||
|
||||
def on_finalized_text(self, text: str, stream_end: bool = False):
|
||||
if self.callback is not None:
|
||||
self.callback(text)
|
||||
super().on_finalized_text(text, stream_end)
|
||||
@@ -0,0 +1,910 @@
|
||||
import copy
|
||||
import transformers
|
||||
from namo.utils import convs as conversation_lib
|
||||
import torch
|
||||
from typing import Dict, Sequence
|
||||
from namo.utils.process_utils import tokenizer_image_token
|
||||
from namo.models.symbols import DEFAULT_IMAGE_TOKEN, IGNORE_INDEX
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
|
||||
def preprocess_plain(
|
||||
sources: Sequence[str],
|
||||
tokenizer: transformers.PreTrainedTokenizer,
|
||||
) -> Dict:
|
||||
# add end signal and concatenate together
|
||||
conversations = []
|
||||
for source in sources:
|
||||
assert len(source) == 2
|
||||
assert DEFAULT_IMAGE_TOKEN in source[0]["value"]
|
||||
source[0]["value"] = DEFAULT_IMAGE_TOKEN
|
||||
conversation = (
|
||||
source[0]["value"]
|
||||
+ source[1]["value"]
|
||||
+ conversation_lib.default_conversation.sep
|
||||
)
|
||||
conversations.append(conversation)
|
||||
# tokenize conversations
|
||||
input_ids = [
|
||||
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
|
||||
for prompt in conversations
|
||||
]
|
||||
targets = copy.deepcopy(input_ids)
|
||||
for target, source in zip(targets, sources):
|
||||
tokenized_len = len(tokenizer_image_token(source[0]["value"], tokenizer))
|
||||
target[:tokenized_len] = IGNORE_INDEX
|
||||
|
||||
return dict(input_ids=input_ids, labels=targets)
|
||||
|
||||
|
||||
def preprocess_qwen(
|
||||
sources, tokenizer: transformers.PreTrainedTokenizer, has_image: bool = False
|
||||
) -> Dict:
|
||||
conv = conversation_lib.default_conversation.copy()
|
||||
roles = {"human": conv.roles[0], "gpt": conv.roles[1]}
|
||||
|
||||
# Apply prompt templates
|
||||
conversations = []
|
||||
for i, source in enumerate(sources):
|
||||
if roles[source[0]["from"]] != conv.roles[0]:
|
||||
# Skip the first one if it is not from human
|
||||
source = source[1:]
|
||||
|
||||
conv.messages = []
|
||||
for j, sentence in enumerate(source):
|
||||
role = roles[sentence["from"]]
|
||||
assert role == conv.roles[j % 2], f"{i}"
|
||||
conv.append_message(role, sentence["value"])
|
||||
conversations.append(conv.get_prompt())
|
||||
# print(f'conversations: {conversations}')
|
||||
# Tokenize conversations
|
||||
if has_image:
|
||||
input_ids = torch.stack(
|
||||
[
|
||||
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
|
||||
for prompt in conversations
|
||||
],
|
||||
dim=0,
|
||||
)
|
||||
else:
|
||||
input_ids = tokenizer(
|
||||
conversations,
|
||||
return_tensors="pt",
|
||||
padding="longest",
|
||||
max_length=tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
).input_ids
|
||||
|
||||
targets = input_ids.clone()
|
||||
|
||||
assert conv.sep_style == conversation_lib.SeparatorStyle.MPT
|
||||
|
||||
# Mask targets
|
||||
sep = conv.sep + conv.roles[1] # <|im_end|><|im_start|>assistant\n
|
||||
sep2 = conv.sep + conv.roles[0] # <|im_end|><|im_start|>user\n
|
||||
for conversation, target in zip(conversations, targets):
|
||||
total_len = int(target.ne(tokenizer.pad_token_id).sum())
|
||||
|
||||
rounds = conversation.split(sep2)
|
||||
# due to spe2 will involve system, merge it to first round
|
||||
if len(rounds) > 1:
|
||||
rounds[0:2] = [sep2.join(rounds[0:2])]
|
||||
cur_len = 0
|
||||
target[:cur_len] = IGNORE_INDEX
|
||||
for i, rou in enumerate(rounds):
|
||||
if rou == "":
|
||||
break
|
||||
|
||||
parts = rou.split(sep)
|
||||
if len(parts) != 2:
|
||||
break
|
||||
parts[0] += sep
|
||||
|
||||
if has_image:
|
||||
if len(rounds) == 1:
|
||||
# no need to compensate
|
||||
round_len = len(tokenizer_image_token(rou, tokenizer))
|
||||
instruction_len = len(tokenizer_image_token(parts[0], tokenizer))
|
||||
elif len(rounds) > 1 and i == 0:
|
||||
round_len = (
|
||||
len(tokenizer_image_token(rou, tokenizer)) + 1
|
||||
) # for <|im_end|>
|
||||
instruction_len = len(tokenizer_image_token(parts[0], tokenizer))
|
||||
elif len(rounds) > 1 and i == len(rounds) - 1:
|
||||
round_len = (
|
||||
len(tokenizer_image_token(rou, tokenizer)) + 3
|
||||
) # for <|im_start|>user\n last round
|
||||
instruction_len = (
|
||||
len(tokenizer_image_token(parts[0], tokenizer)) + 3
|
||||
) # for <|im_start|>user\n
|
||||
else:
|
||||
round_len = (
|
||||
len(tokenizer_image_token(rou, tokenizer)) + 4
|
||||
) # for <|im_start|>user\n .. <|im_end|>
|
||||
instruction_len = (
|
||||
len(tokenizer_image_token(parts[0], tokenizer)) + 3
|
||||
) # for <|im_start|>user\n
|
||||
else:
|
||||
if len(rounds) == 1:
|
||||
# no need to compensate
|
||||
round_len = len(tokenizer(rou).input_ids)
|
||||
instruction_len = len(tokenizer(parts[0]).input_ids)
|
||||
elif len(rounds) > 1 and i == 0:
|
||||
round_len = len(tokenizer(rou).input_ids) + 1 # for <|im_end|>
|
||||
instruction_len = len(tokenizer(parts[0]).input_ids)
|
||||
elif len(rounds) > 1 and i == len(rounds) - 1:
|
||||
round_len = (
|
||||
len(tokenizer(rou).input_ids) + 3
|
||||
) # for <|im_start|>user\n last round
|
||||
instruction_len = (
|
||||
len(tokenizer(parts[0]).input_ids) + 3
|
||||
) # for <|im_start|>user\n
|
||||
else:
|
||||
round_len = (
|
||||
len(tokenizer(rou).input_ids) + 4
|
||||
) # for <|im_start|>user\n .. <|im_end|>
|
||||
instruction_len = (
|
||||
len(tokenizer(parts[0]).input_ids) + 3
|
||||
) # for <|im_start|>user\n
|
||||
|
||||
# if i != 0 and not tokenizer.legacy and IS_TOKENIZER_GREATER_THAN_0_14:
|
||||
# round_len -= 1
|
||||
# instruction_len -= 1
|
||||
|
||||
target[cur_len : cur_len + instruction_len] = IGNORE_INDEX
|
||||
cur_len += round_len
|
||||
target[cur_len:] = IGNORE_INDEX
|
||||
|
||||
if cur_len < tokenizer.model_max_length:
|
||||
if cur_len != total_len:
|
||||
target[:] = IGNORE_INDEX
|
||||
print(
|
||||
f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
|
||||
f" (ignored)"
|
||||
f"{conversations}"
|
||||
)
|
||||
|
||||
return dict(
|
||||
input_ids=input_ids,
|
||||
labels=targets,
|
||||
)
|
||||
|
||||
|
||||
def preprocess_llama3(
|
||||
sources, tokenizer: transformers.PreTrainedTokenizer, has_image: bool = False
|
||||
) -> Dict:
|
||||
conv = conversation_lib.default_conversation.copy()
|
||||
roles = {"human": conv.roles[0], "gpt": conv.roles[1]}
|
||||
|
||||
# Apply prompt templates
|
||||
conversations = []
|
||||
for i, source in enumerate(sources):
|
||||
if roles[source[0]["from"]] != conv.roles[0]:
|
||||
# Skip the first one if it is not from human
|
||||
source = source[1:]
|
||||
|
||||
conv.messages = []
|
||||
for j, sentence in enumerate(source):
|
||||
role = roles[sentence["from"]]
|
||||
assert role == conv.roles[j % 2], f"{i}"
|
||||
conv.append_message(role, sentence["value"])
|
||||
conversations.append(conv.get_prompt())
|
||||
|
||||
# Tokenize conversations
|
||||
# Note: LLama3 has bos while Qwen bos is null, we don't need add_special_token here. (Already added in template)
|
||||
if has_image:
|
||||
input_ids = torch.stack(
|
||||
[
|
||||
tokenizer_image_token(
|
||||
prompt, tokenizer, return_tensors="pt", add_special_tokens=False
|
||||
)
|
||||
for prompt in conversations
|
||||
],
|
||||
dim=0,
|
||||
)
|
||||
else:
|
||||
input_ids = tokenizer(
|
||||
conversations,
|
||||
return_tensors="pt",
|
||||
padding="longest",
|
||||
max_length=tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
add_special_tokens=False,
|
||||
).input_ids
|
||||
|
||||
targets = input_ids.clone()
|
||||
|
||||
assert conv.sep_style == conversation_lib.SeparatorStyle.LLAMA3
|
||||
|
||||
# Mask targets
|
||||
# <|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n
|
||||
sep = f"<|eot_id|><|start_header_id|>{conv.roles[1]}<|end_header_id|>\n\n"
|
||||
# <|eot_id|><|start_header_id|>user<|end_header_id|>\n\n
|
||||
sep2 = f"<|eot_id|><|start_header_id|>{conv.roles[0]}<|end_header_id|>\n\n"
|
||||
# <|start_header_id|>assistant<|end_header_id|>\n\n [128006, 882, 128007, 271]
|
||||
# <|eot_id|> [128009]
|
||||
|
||||
# print(targets)
|
||||
|
||||
# [128000, 128009, 128006, 882, 128007, 271] <|eot_id|><|start_header_id|>user<|end_header_id|>\n\n
|
||||
# print(f'{tokenizer.encode(sep, add_special_tokens=False)} {sep}')
|
||||
# [128000, 128009, 128006, 78191, 128007, 271] <|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n
|
||||
# print(f'{tokenizer.encode(sep2, add_special_tokens=False)} {sep2}')
|
||||
for conversation, target in zip(conversations, targets):
|
||||
total_len = int(target.ne(tokenizer.pad_token_id).sum())
|
||||
|
||||
rounds = conversation.split(sep2)
|
||||
# due to spe2 will involve system, merge it to first round
|
||||
if len(rounds) > 1:
|
||||
rounds[0:2] = [sep2.join(rounds[0:2])]
|
||||
cur_len = 0
|
||||
target[:cur_len] = IGNORE_INDEX
|
||||
|
||||
# print(f'rounds: ----> {rounds}')
|
||||
for i, rou in enumerate(rounds):
|
||||
if rou == "":
|
||||
break
|
||||
|
||||
parts = rou.split(sep)
|
||||
if len(parts) != 2:
|
||||
break
|
||||
parts[0] += sep
|
||||
|
||||
if has_image:
|
||||
if len(rounds) == 1:
|
||||
# no need to compensate
|
||||
round_len = len(
|
||||
tokenizer_image_token(rou, tokenizer, add_special_tokens=False)
|
||||
)
|
||||
instruction_len = len(
|
||||
tokenizer_image_token(
|
||||
parts[0], tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
elif len(rounds) > 1 and i == 0:
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
rou, tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
+ 1
|
||||
) # for <|eot_id|>
|
||||
instruction_len = len(
|
||||
tokenizer_image_token(
|
||||
parts[0], tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
elif len(rounds) > 1 and i == len(rounds) - 1:
|
||||
# for <|start_header_id|>user<|end_header_id|>\n\n last round <|eot_id|> already have
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
rou, tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
+ 4
|
||||
)
|
||||
instruction_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
parts[0], tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
+ 4
|
||||
) # for <|start_header_id|>user<|end_header_id|>\n\n
|
||||
else:
|
||||
# for <|start_header_id|>user<|end_header_id|>\n\n .. <|eot_id|>
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
rou, tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
+ 5
|
||||
)
|
||||
instruction_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
parts[0], tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
+ 4
|
||||
) # for <|start_header_id|>user<|end_header_id|>\n\n
|
||||
else:
|
||||
if len(rounds) == 1:
|
||||
# no need to compensate
|
||||
round_len = len(tokenizer(rou, add_special_tokens=False).input_ids)
|
||||
instruction_len = len(
|
||||
tokenizer(parts[0], add_special_tokens=False).input_ids
|
||||
)
|
||||
elif len(rounds) > 1 and i == 0:
|
||||
round_len = (
|
||||
len(tokenizer(rou, add_special_tokens=False).input_ids) + 1
|
||||
)
|
||||
# for <|im_end|>
|
||||
instruction_len = len(
|
||||
tokenizer(parts[0], add_special_tokens=False).input_ids
|
||||
)
|
||||
elif len(rounds) > 1 and i == len(rounds) - 1:
|
||||
# for <|im_start|>user\n last round
|
||||
round_len = (
|
||||
len(tokenizer(rou, add_special_tokens=False).input_ids) + 4
|
||||
)
|
||||
# for <|im_start|>user\n
|
||||
instruction_len = (
|
||||
len(tokenizer(parts[0], add_special_tokens=False).input_ids) + 4
|
||||
)
|
||||
else:
|
||||
# for <|im_start|>user\n .. <|im_end|>
|
||||
round_len = (
|
||||
len(tokenizer(rou, add_special_tokens=False).input_ids) + 5
|
||||
)
|
||||
# for <|im_start|>user\n
|
||||
instruction_len = (
|
||||
len(tokenizer(parts[0], add_special_tokens=False).input_ids) + 4
|
||||
)
|
||||
|
||||
# if i != 0 and not tokenizer.legacy and IS_TOKENIZER_GREATER_THAN_0_14:
|
||||
# round_len -= 1
|
||||
# instruction_len -= 1
|
||||
|
||||
target[cur_len : cur_len + instruction_len] = IGNORE_INDEX
|
||||
cur_len += round_len
|
||||
target[cur_len:] = IGNORE_INDEX
|
||||
|
||||
if cur_len < tokenizer.model_max_length:
|
||||
if cur_len != total_len:
|
||||
target[:] = IGNORE_INDEX
|
||||
print(
|
||||
f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
|
||||
f" (ignored)"
|
||||
)
|
||||
|
||||
return dict(
|
||||
input_ids=input_ids,
|
||||
labels=targets,
|
||||
)
|
||||
|
||||
|
||||
def preprocess_mistral(
|
||||
sources, tokenizer: transformers.PreTrainedTokenizer, has_image: bool = False
|
||||
) -> Dict:
|
||||
conv = conversation_lib.default_conversation.copy()
|
||||
roles = {"human": conv.roles[0], "gpt": conv.roles[1]}
|
||||
|
||||
# Apply prompt templates
|
||||
conversations = []
|
||||
for i, source in enumerate(sources):
|
||||
if roles[source[0]["from"]] != conv.roles[0]:
|
||||
# Skip the first one if it is not from human
|
||||
source = source[1:]
|
||||
|
||||
conv.messages = []
|
||||
for j, sentence in enumerate(source):
|
||||
role = roles[sentence["from"]]
|
||||
assert role == conv.roles[j % 2], f"{i}"
|
||||
conv.append_message(role, sentence["value"])
|
||||
conversations.append(conv.get_prompt())
|
||||
|
||||
# Tokenize conversations
|
||||
if has_image:
|
||||
input_ids = torch.stack(
|
||||
[
|
||||
tokenizer_image_token(
|
||||
prompt, tokenizer, add_special_tokens=False, return_tensors="pt"
|
||||
)
|
||||
for prompt in conversations
|
||||
],
|
||||
dim=0,
|
||||
)
|
||||
else:
|
||||
input_ids = tokenizer(
|
||||
conversations,
|
||||
return_tensors="pt",
|
||||
padding="longest",
|
||||
max_length=tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
add_special_tokens=False,
|
||||
).input_ids
|
||||
|
||||
targets = input_ids.clone()
|
||||
|
||||
"""
|
||||
<|im_start|>system
|
||||
You should follow the instructions carefully and explain your answers in detail.<|im_end|><|im_start|>user
|
||||
hello<|im_end|><|im_start|>assistant
|
||||
am tallen! nice to meet u.<|im_end|><|im_start|>user
|
||||
Nice to see u, how dod u do?<|im_end|><|im_start|>assistant
|
||||
我很好,请问有什么可以帮你的吗?<|im_end|><|im_start|>user
|
||||
介绍一下你自己<|im_end|><|im_start|>assistant
|
||||
我是ChatGPT,一个人工智能助手<|im_end|><|im_start|>user
|
||||
你会python嘛?<|im_end|><|im_start|>assistant
|
||||
"""
|
||||
|
||||
"""
|
||||
[INST] You should follow the instructions carefully and explain your answers in detail.
|
||||
hello [/INST] am tallen! nice to meet u.</s>[INST] Nice to see u, how dod u do? [/INST] 我很好,请问有什么可以帮你的吗?</s>[INST] 介绍一下你自己 [/INST] 我是ChatGPT,一个人工智能助手</s>
|
||||
|
||||
[INST] You should follow the instructions carefully and explain your answers in detail.\n<image>\nPlease provide the bounding box coordinate of the region this sentence describes: dark suit near between tan and gray coat. [/INST] [0.28, 0.34, 0.4, 0.71]</s>[INST] Please provide a short description for this region: [0.56, 0.35, 0.67, 0.7]. [/INST] Third person from right.</s>[INST] Please provide a short description for this region: [0.66, 0.36, 0.79, 0.72]. [/INST] Red jacket.</s>[INST] Please provide a short description for this region: [0.66, 0.36, 0.79, 0.72]. [/INST] Red jacket.</s>[INST] Please provide a short description for this region: [0.56, 0.35, 0.67, 0.7]. [/INST] Third from right to left person.</s>[INST] Please provide a short description for this region: [0.36, 0.36, 0.5, 0.72]. [/INST] Tan jacket red scarf lady.</s>[INST] Please provide the bounding box coordinate of the region this sentence describes: guy on right. [/INST] [0.65, 0.31, 0.86, 0.74]</s>[INST] Please provide the bounding box coordinate of the region this sentence describes: third skier from rightbeing pointed at. [/INST] [0.56, 0.35, 0.67, 0.7]</s>
|
||||
"""
|
||||
|
||||
# print(f'conversations: {conversations}')
|
||||
# print(f'targets: {targets}')
|
||||
|
||||
# Mask questions
|
||||
# sep = conv.sep + conv.roles[1] # <|im_end|><|im_start|>assistant\n
|
||||
# sep2 = conv.sep + conv.roles[0] # <|im_end|><|im_start|>user\n
|
||||
sep = conv.roles[1] # '[/INST]' [1032, 4, 1032] # Mistral空格会和后面的合并,坑!
|
||||
# sep2 = conv.sep2 # '</s>[INST]' [2, 3, 1032]
|
||||
sep2 = conv.sep2 # '</s>' [2, 3, 1032]
|
||||
for conversation, target in zip(conversations, targets):
|
||||
total_len = int(target.ne(tokenizer.pad_token_id).sum())
|
||||
|
||||
rounds = conversation.split(sep2)
|
||||
rounds = [r for r in rounds if r != ""]
|
||||
# due to spe2 will involve system, merge it to first round
|
||||
# if len(rounds) > 1:
|
||||
# rounds[0:2] = [sep2.join(rounds[0:2])]
|
||||
cur_len = 0
|
||||
target[:cur_len] = IGNORE_INDEX
|
||||
# mask all answers
|
||||
for i, rou in enumerate(rounds):
|
||||
# rounds
|
||||
# [INST] You should follow the instructions carefully and explain your answers in detail.\nhello [/INST] am tallen! nice to meet u.
|
||||
# Nice to see u, how dod u do? [/INST] 我很好,请问有什么可以帮你的吗?
|
||||
if rou == "":
|
||||
break
|
||||
|
||||
parts = rou.split(sep)
|
||||
if len(parts) != 2:
|
||||
break
|
||||
parts[0] += sep
|
||||
|
||||
if has_image:
|
||||
# 补偿只有两种情况,最开头,和其他
|
||||
if len(rounds) == 1:
|
||||
# no need to compensate
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
rou, tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
+ 1
|
||||
)
|
||||
instruction_len = len(
|
||||
tokenizer_image_token(
|
||||
parts[0], tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
else:
|
||||
# </s>分割,只需要补齐这个id即可,其他不影响
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
rou, tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
+ 1
|
||||
)
|
||||
instruction_len = len(
|
||||
tokenizer_image_token(
|
||||
parts[0], tokenizer, add_special_tokens=False
|
||||
)
|
||||
)
|
||||
else:
|
||||
if len(rounds) == 1:
|
||||
# no need to compensate
|
||||
round_len = (
|
||||
len(tokenizer(rou, add_special_tokens=False).input_ids) + 1
|
||||
)
|
||||
instruction_len = len(
|
||||
tokenizer(parts[0], add_special_tokens=False).input_ids
|
||||
)
|
||||
else:
|
||||
round_len = (
|
||||
len(tokenizer(rou, add_special_tokens=False).input_ids) + 1
|
||||
)
|
||||
instruction_len = len(
|
||||
tokenizer(parts[0], add_special_tokens=False).input_ids
|
||||
)
|
||||
|
||||
target[cur_len : cur_len + instruction_len] = IGNORE_INDEX
|
||||
cur_len += round_len
|
||||
# print(target, cur_len)
|
||||
target[cur_len:] = IGNORE_INDEX
|
||||
|
||||
if cur_len < tokenizer.model_max_length:
|
||||
if cur_len != total_len:
|
||||
target[:] = IGNORE_INDEX
|
||||
print(
|
||||
f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
|
||||
f" (ignored)"
|
||||
f"{conversations}"
|
||||
)
|
||||
|
||||
# print(f'final target: {targets}')
|
||||
return dict(
|
||||
input_ids=input_ids,
|
||||
labels=targets,
|
||||
)
|
||||
|
||||
|
||||
def preprocess_gemma2(
|
||||
sources, tokenizer: transformers.PreTrainedTokenizer, has_image: bool = False
|
||||
) -> Dict:
|
||||
conv = conversation_lib.default_conversation.copy()
|
||||
roles = {"human": conv.roles[0], "gpt": conv.roles[1]}
|
||||
|
||||
# Apply prompt templates
|
||||
conversations = []
|
||||
for i, source in enumerate(sources):
|
||||
if roles[source[0]["from"]] != conv.roles[0]:
|
||||
# Skip the first one if it is not from human
|
||||
source = source[1:]
|
||||
|
||||
conv.messages = []
|
||||
for j, sentence in enumerate(source):
|
||||
role = roles[sentence["from"]]
|
||||
assert role == conv.roles[j % 2], f"{i}"
|
||||
conv.append_message(role, sentence["value"])
|
||||
conversations.append(conv.get_prompt())
|
||||
|
||||
add_special_tokens = False
|
||||
# Tokenize conversations
|
||||
if has_image:
|
||||
input_ids = torch.stack(
|
||||
[
|
||||
tokenizer_image_token(
|
||||
prompt,
|
||||
tokenizer,
|
||||
add_special_tokens=add_special_tokens,
|
||||
return_tensors="pt",
|
||||
)
|
||||
for prompt in conversations
|
||||
],
|
||||
dim=0,
|
||||
)
|
||||
else:
|
||||
input_ids = tokenizer(
|
||||
conversations,
|
||||
return_tensors="pt",
|
||||
padding="longest",
|
||||
max_length=tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
add_special_tokens=add_special_tokens,
|
||||
).input_ids
|
||||
|
||||
targets = input_ids.clone()
|
||||
|
||||
"""
|
||||
You are a helpful assistant.<start_of_turn>user
|
||||
hello<end_of_turn>
|
||||
<start_of_turn>model
|
||||
am tallen! nice to meet u.<end_of_turn>
|
||||
<start_of_turn>user
|
||||
Nice to see u, how dod u do?<end_of_turn>
|
||||
<start_of_turn>model
|
||||
我很好,请问有什么可以帮你的吗?<end_of_turn>
|
||||
<start_of_turn>user
|
||||
介绍一下你自己<end_of_turn>
|
||||
<start_of_turn>model
|
||||
我是ChatGPT,一个人工智能助手<end_of_turn>
|
||||
<start_of_turn>user
|
||||
你会python嘛?<end_of_turn>
|
||||
<start_of_turn>model
|
||||
"""
|
||||
|
||||
# print(f'conversations: {conversations}')
|
||||
# print(f'targets: {targets}')
|
||||
|
||||
# Mask questions
|
||||
sep = conv.roles[1] # <start_of_turn>model\n 3
|
||||
sep2 = conv.sep + conv.roles[0] # '<end_of_turn>\n<start_of_turn>user\n' 5
|
||||
for conversation, target in zip(conversations, targets):
|
||||
total_len = int(target.ne(tokenizer.pad_token_id).sum())
|
||||
|
||||
rounds = conversation.split(sep2)
|
||||
rounds = [r for r in rounds if r != ""]
|
||||
# due to spe2 will involve system, merge it to first round
|
||||
# if len(rounds) > 1:
|
||||
# rounds[0:2] = [sep2.join(rounds[0:2])]
|
||||
cur_len = 0
|
||||
target[:cur_len] = IGNORE_INDEX
|
||||
# mask all answers
|
||||
for i, rou in enumerate(rounds):
|
||||
# print(i, rou)
|
||||
# rounds
|
||||
# [INST] You should follow the instructions carefully and explain your answers in detail.\nhello [/INST] am tallen! nice to meet u.
|
||||
# Nice to see u, how dod u do? [/INST] 我很好,请问有什么可以帮你的吗?
|
||||
if rou == "":
|
||||
break
|
||||
|
||||
parts = rou.split(sep)
|
||||
if len(parts) != 2:
|
||||
break
|
||||
parts[0] += sep
|
||||
|
||||
if has_image:
|
||||
if len(rounds) == 1:
|
||||
# no need to compensate
|
||||
round_len = len(
|
||||
tokenizer_image_token(
|
||||
rou, tokenizer, add_special_tokens=add_special_tokens
|
||||
)
|
||||
)
|
||||
instruction_len = len(
|
||||
tokenizer_image_token(
|
||||
parts[0], tokenizer, add_special_tokens=add_special_tokens
|
||||
)
|
||||
)
|
||||
elif len(rounds) > 1 and i == 0:
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
rou, tokenizer, add_special_tokens=add_special_tokens
|
||||
)
|
||||
)
|
||||
+ 2
|
||||
) # for <end_of_turn>\n
|
||||
instruction_len = len(
|
||||
tokenizer_image_token(
|
||||
parts[0], tokenizer, add_special_tokens=add_special_tokens
|
||||
)
|
||||
)
|
||||
elif len(rounds) > 1 and i == len(rounds) - 1:
|
||||
# for <|start_header_id|>user<|end_header_id|>\n\n last round <|eot_id|> already have
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
rou, tokenizer, add_special_tokens=add_special_tokens
|
||||
)
|
||||
)
|
||||
+ 3
|
||||
)
|
||||
instruction_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
parts[0],
|
||||
tokenizer,
|
||||
add_special_tokens=add_special_tokens,
|
||||
)
|
||||
)
|
||||
+ 3
|
||||
) # for <|start_header_id|>user<|end_header_id|>\n\n
|
||||
else:
|
||||
# for <|start_header_id|>user<|end_header_id|>\n\n .. <|eot_id|>
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
rou, tokenizer, add_special_tokens=add_special_tokens
|
||||
)
|
||||
)
|
||||
+ 5
|
||||
)
|
||||
instruction_len = (
|
||||
len(
|
||||
tokenizer_image_token(
|
||||
parts[0],
|
||||
tokenizer,
|
||||
add_special_tokens=add_special_tokens,
|
||||
)
|
||||
)
|
||||
+ 4
|
||||
) # for <|start_header_id|>user<|end_header_id|>\n\n
|
||||
else:
|
||||
if len(rounds) == 1:
|
||||
# no need to compensate
|
||||
round_len = len(
|
||||
tokenizer(rou, add_special_tokens=add_special_tokens).input_ids
|
||||
)
|
||||
instruction_len = len(
|
||||
tokenizer(
|
||||
parts[0], add_special_tokens=add_special_tokens
|
||||
).input_ids
|
||||
)
|
||||
elif len(rounds) > 1 and i == 0:
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer(
|
||||
rou, add_special_tokens=add_special_tokens
|
||||
).input_ids
|
||||
)
|
||||
+ 2
|
||||
)
|
||||
# for <|im_end|>
|
||||
instruction_len = len(
|
||||
tokenizer(
|
||||
parts[0], add_special_tokens=add_special_tokens
|
||||
).input_ids
|
||||
)
|
||||
elif len(rounds) > 1 and i == len(rounds) - 1:
|
||||
# for <|im_start|>user\n last round
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer(
|
||||
rou, add_special_tokens=add_special_tokens
|
||||
).input_ids
|
||||
)
|
||||
+ 3
|
||||
)
|
||||
# for <|im_start|>user\n
|
||||
instruction_len = (
|
||||
len(
|
||||
tokenizer(
|
||||
parts[0], add_special_tokens=add_special_tokens
|
||||
).input_ids
|
||||
)
|
||||
+ 3
|
||||
)
|
||||
else:
|
||||
# for <|im_start|>user\n .. <|im_end|>
|
||||
round_len = (
|
||||
len(
|
||||
tokenizer(
|
||||
rou, add_special_tokens=add_special_tokens
|
||||
).input_ids
|
||||
)
|
||||
+ 5
|
||||
)
|
||||
# for <|im_start|>user\n
|
||||
instruction_len = (
|
||||
len(
|
||||
tokenizer(
|
||||
parts[0], add_special_tokens=add_special_tokens
|
||||
).input_ids
|
||||
)
|
||||
+ 4
|
||||
)
|
||||
|
||||
target[cur_len : cur_len + instruction_len] = IGNORE_INDEX
|
||||
cur_len += round_len
|
||||
# print(target, cur_len)
|
||||
target[cur_len:] = IGNORE_INDEX
|
||||
|
||||
if cur_len < tokenizer.model_max_length:
|
||||
if cur_len != total_len:
|
||||
target[:] = IGNORE_INDEX
|
||||
print(
|
||||
f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
|
||||
f" (ignored)"
|
||||
f"{conversations}"
|
||||
)
|
||||
|
||||
# print(f'final target: {targets}')
|
||||
return dict(
|
||||
input_ids=input_ids,
|
||||
labels=targets,
|
||||
)
|
||||
|
||||
|
||||
def preprocess_gemma(
|
||||
sources, tokenizer: transformers.PreTrainedTokenizer, has_image: bool = False
|
||||
) -> Dict:
|
||||
conv = conversation_lib.default_conversation.copy()
|
||||
roles = {"human": conv.roles[0], "gpt": conv.roles[1]}
|
||||
|
||||
# Apply prompt templates
|
||||
conversations = []
|
||||
for i, source in enumerate(sources):
|
||||
if roles[source[0]["from"]] != conv.roles[0]:
|
||||
# Skip the first one if it is not from human
|
||||
source = source[1:]
|
||||
|
||||
conv.messages = []
|
||||
for j, sentence in enumerate(source):
|
||||
role = roles[sentence["from"]]
|
||||
assert role == conv.roles[j % 2], f"{i}"
|
||||
conv.append_message(role, sentence["value"])
|
||||
conversations.append(conv.get_prompt().strip())
|
||||
|
||||
# Tokenize conversations
|
||||
if has_image:
|
||||
input_ids = torch.stack(
|
||||
[
|
||||
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
|
||||
for prompt in conversations
|
||||
],
|
||||
dim=0,
|
||||
)
|
||||
else:
|
||||
input_ids = tokenizer(
|
||||
conversations,
|
||||
return_tensors="pt",
|
||||
padding="longest",
|
||||
max_length=tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
).input_ids
|
||||
|
||||
targets = input_ids.clone()
|
||||
|
||||
assert conv.sep_style == conversation_lib.SeparatorStyle.GEMMA
|
||||
|
||||
# Mask targets
|
||||
sep = conv.sep + conv.roles[1] + "\n" # <start_of_turn>model\n
|
||||
round_sep = "\n" + conv.sep + conv.roles[0] + "\n" # \n<start_of_turn>user\n
|
||||
for conversation, target in zip(conversations, targets):
|
||||
total_len = int(target.ne(tokenizer.pad_token_id).sum())
|
||||
rounds = conversation.split(round_sep)
|
||||
cur_len = 1
|
||||
if cur_len > 0:
|
||||
target[:cur_len] = IGNORE_INDEX
|
||||
for i, rou in enumerate(rounds):
|
||||
if rou == "":
|
||||
break
|
||||
if i != 0:
|
||||
rou = round_sep + rou
|
||||
parts = rou.split(sep)
|
||||
if len(parts) != 2:
|
||||
break
|
||||
parts[0] += sep
|
||||
if has_image:
|
||||
round_len = (
|
||||
len(tokenizer_image_token(rou, tokenizer)) - 1
|
||||
) # -1 for <bos>
|
||||
instruction_len = (
|
||||
len(tokenizer_image_token(parts[0], tokenizer)) - 1
|
||||
) # -1 for <bos>
|
||||
else:
|
||||
round_len = len(tokenizer(rou).input_ids) - 1 # -1 for <bos>
|
||||
instruction_len = len(tokenizer(parts[0]).input_ids) - 1 # -1 for <bos>
|
||||
|
||||
target[cur_len : cur_len + instruction_len] = IGNORE_INDEX
|
||||
|
||||
cur_len += round_len
|
||||
target[cur_len:] = IGNORE_INDEX
|
||||
|
||||
if cur_len < tokenizer.model_max_length:
|
||||
if cur_len != total_len:
|
||||
target[:] = IGNORE_INDEX
|
||||
print(conversation)
|
||||
print(
|
||||
f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
|
||||
f" (ignored)"
|
||||
)
|
||||
|
||||
return dict(
|
||||
input_ids=input_ids,
|
||||
labels=targets,
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# conversation_lib.default_conversation = conversation_lib.conv_templates['mistral']
|
||||
# tokenizer_path = 'checkpoints/mistral-nemo-instruct/'
|
||||
conversation_lib.default_conversation = conversation_lib.conv_templates["gemma"]
|
||||
tokenizer_path = "checkpoints/gemma-2-9b-it/"
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
tokenizer_path, trust_remote_code=True, use_fast=False
|
||||
)
|
||||
print(tokenizer.pad_token_id)
|
||||
print(tokenizer)
|
||||
if tokenizer.pad_token_id is None:
|
||||
tokenizer.pad_token_id = tokenizer.encode("<pad>")
|
||||
sources = [
|
||||
[
|
||||
{"from": "human", "value": "<video>\nWhat is happening in the video?"},
|
||||
{
|
||||
"from": "gpt",
|
||||
"value": "In the video, a man is sitting at a table with cups and glasses. He then proceeds to grab a cup of coffee and an apple while looking at his phone. Later on, he is seen looking at his phone again while sitting at the same table near a window. The man then has some cups in front of him and continues looking at his phone at the same table. Finally, he is seen looking at his phone again while sitting at the table.",
|
||||
},
|
||||
{
|
||||
"from": "human",
|
||||
"value": "Is the man interacting with any other objects or people?",
|
||||
},
|
||||
{
|
||||
"from": "gpt",
|
||||
"value": "The man is not seen interacting with any other objects or people in the video. He is just sitting at the table and using his phone.",
|
||||
},
|
||||
# {
|
||||
# "from": "human",
|
||||
# "value": "Why do you think the man is looking at his phone so much?"
|
||||
# },
|
||||
# {
|
||||
# "from": "gpt",
|
||||
# "value": "It is not clear why the man is looking at his phone so often. We cannot infer his intentions as the video doesn't provide much context."
|
||||
# }
|
||||
]
|
||||
]
|
||||
preprocess_mistral(sources, tokenizer, True)
|
||||
@@ -0,0 +1,273 @@
|
||||
import ast
|
||||
import random
|
||||
import re
|
||||
|
||||
import numpy as np
|
||||
from namo.models.symbols import IMAGE_TOKEN_INDEX
|
||||
import torch
|
||||
from PIL import Image
|
||||
from loguru import logger
|
||||
|
||||
try:
|
||||
from decord import VideoReader, cpu
|
||||
except ImportError as e:
|
||||
pass
|
||||
try:
|
||||
from moviepy.editor import VideoFileClip
|
||||
except ImportError as e:
|
||||
pass
|
||||
|
||||
|
||||
def tokenizer_image_token(
|
||||
prompt,
|
||||
tokenizer,
|
||||
image_token_index=IMAGE_TOKEN_INDEX,
|
||||
return_tensors=None,
|
||||
add_special_tokens=True,
|
||||
):
|
||||
prompt_chunks = [
|
||||
tokenizer(chunk, add_special_tokens=add_special_tokens).input_ids
|
||||
for chunk in prompt.split("<image>")
|
||||
]
|
||||
|
||||
def insert_separator(X, sep):
|
||||
return [ele for sublist in zip(X, [sep] * len(X)) for ele in sublist][:-1]
|
||||
|
||||
input_ids = []
|
||||
offset = 0
|
||||
if (
|
||||
len(prompt_chunks) > 0
|
||||
and len(prompt_chunks[0]) > 0
|
||||
and prompt_chunks[0][0] == tokenizer.bos_token_id
|
||||
):
|
||||
offset = 1
|
||||
input_ids.append(prompt_chunks[0][0])
|
||||
|
||||
for x in insert_separator(prompt_chunks, [image_token_index] * (offset + 1)):
|
||||
input_ids.extend(x[offset:])
|
||||
|
||||
if return_tensors is not None:
|
||||
if return_tensors == "pt":
|
||||
return torch.tensor(input_ids, dtype=torch.long)
|
||||
raise ValueError(f"Unsupported tensor type: {return_tensors}")
|
||||
return input_ids
|
||||
|
||||
|
||||
def unpad_image(tensor, original_size):
|
||||
"""
|
||||
Unpads a PyTorch tensor of a padded and resized image.
|
||||
|
||||
Args:
|
||||
tensor (torch.Tensor): The image tensor, assumed to be in CxHxW format.
|
||||
original_size (tuple): The original size of the image (height, width).
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The unpadded image tensor.
|
||||
"""
|
||||
original_width, original_height = original_size
|
||||
current_height, current_width = tensor.shape[1:]
|
||||
|
||||
original_aspect_ratio = original_width / original_height
|
||||
current_aspect_ratio = current_width / current_height
|
||||
|
||||
if original_aspect_ratio > current_aspect_ratio:
|
||||
scale_factor = current_width / original_width
|
||||
new_height = int(original_height * scale_factor)
|
||||
padding = (current_height - new_height) // 2
|
||||
unpadded_tensor = tensor[:, padding : current_height - padding, :]
|
||||
else:
|
||||
scale_factor = current_height / original_height
|
||||
new_width = int(original_width * scale_factor)
|
||||
padding = (current_width - new_width) // 2
|
||||
unpadded_tensor = tensor[:, :, padding : current_width - padding]
|
||||
|
||||
return unpadded_tensor
|
||||
|
||||
|
||||
def get_anyres_image_grid_shape(image_size, grid_pinpoints, patch_size):
|
||||
"""
|
||||
Calculate the shape of the image patch grid after the preprocessing for images of any resolution.
|
||||
|
||||
Args:
|
||||
image_size (tuple): The size of the input image in the format (width, height).
|
||||
grid_pinpoints (str): A string representation of a list of possible resolutions.
|
||||
patch_size (int): The size of each image patch.
|
||||
|
||||
Returns:
|
||||
tuple: The shape of the image patch grid in the format (width, height).
|
||||
"""
|
||||
if type(grid_pinpoints) is list:
|
||||
possible_resolutions = grid_pinpoints
|
||||
else:
|
||||
possible_resolutions = ast.literal_eval(grid_pinpoints)
|
||||
width, height = select_best_resolution(image_size, possible_resolutions)
|
||||
return width // patch_size, height // patch_size
|
||||
|
||||
|
||||
def select_best_resolution(original_size, possible_resolutions):
|
||||
"""
|
||||
Selects the best resolution from a list of possible resolutions based on the original size.
|
||||
|
||||
Args:
|
||||
original_size (tuple): The original size of the image in the format (width, height).
|
||||
possible_resolutions (list): A list of possible resolutions in the format [(width1, height1), (width2, height2), ...].
|
||||
|
||||
Returns:
|
||||
tuple: The best fit resolution in the format (width, height).
|
||||
"""
|
||||
original_width, original_height = original_size
|
||||
best_fit = None
|
||||
max_effective_resolution = 0
|
||||
min_wasted_resolution = float("inf")
|
||||
|
||||
for width, height in possible_resolutions:
|
||||
scale = min(width / original_width, height / original_height)
|
||||
downscaled_width, downscaled_height = int(original_width * scale), int(
|
||||
original_height * scale
|
||||
)
|
||||
effective_resolution = min(
|
||||
downscaled_width * downscaled_height, original_width * original_height
|
||||
)
|
||||
wasted_resolution = (width * height) - effective_resolution
|
||||
|
||||
if effective_resolution > max_effective_resolution or (
|
||||
effective_resolution == max_effective_resolution
|
||||
and wasted_resolution < min_wasted_resolution
|
||||
):
|
||||
max_effective_resolution = effective_resolution
|
||||
min_wasted_resolution = wasted_resolution
|
||||
best_fit = (width, height)
|
||||
|
||||
return best_fit
|
||||
|
||||
|
||||
def process_video_fixed_frames(video_file, fps, num_frames):
|
||||
def sample_frames(frame_indices):
|
||||
total_frames = len(frame_indices)
|
||||
if total_frames > num_frames:
|
||||
chunk_size = total_frames // num_frames
|
||||
frame_indices = [
|
||||
random.sample(
|
||||
frame_indices[
|
||||
i * chunk_size : min((i + 1) * chunk_size, total_frames)
|
||||
],
|
||||
1,
|
||||
)[0]
|
||||
for i in range(num_frames)
|
||||
]
|
||||
else:
|
||||
frame_indices = np.interp(
|
||||
np.linspace(0, total_frames - 1, num_frames),
|
||||
np.arange(total_frames),
|
||||
frame_idx,
|
||||
).astype(int)
|
||||
return frame_indices
|
||||
|
||||
if video_file.endswith("webm"):
|
||||
video_webm = VideoFileClip(video_file)
|
||||
video_frames = np.array(list(video_webm.iter_frames()))
|
||||
duration, sample_fps = len(video_frames), round(video_webm.fps / fps)
|
||||
frame_idx = [i for i in range(0, duration, sample_fps)]
|
||||
frame_idx = sample_frames(frame_idx)
|
||||
video = video_frames[frame_idx]
|
||||
return video
|
||||
else:
|
||||
vr = VideoReader(video_file, ctx=cpu(0))
|
||||
sample_fps = round(vr.get_avg_fps() / fps)
|
||||
frame_idx = [i for i in range(0, len(vr), sample_fps)]
|
||||
frame_idx = sample_frames(frame_idx)
|
||||
# random sample 1 frame based on max video frames_num
|
||||
video = vr.get_batch(frame_idx).asnumpy()
|
||||
return video
|
||||
|
||||
|
||||
def convert_image_tags(input_string):
|
||||
if input_string.count("<image>") <= 1:
|
||||
return input_string
|
||||
count = 0
|
||||
|
||||
def replacer(match):
|
||||
nonlocal count
|
||||
count += 1
|
||||
return f"\nImage{count}:{match.group()}"
|
||||
|
||||
return re.sub(r"<image>", replacer, input_string).strip()
|
||||
|
||||
|
||||
def get_suitable_size_hw(images, longest_edge=800):
|
||||
hs = [img.height for img in images]
|
||||
ws = [img.width for img in images]
|
||||
ratios = [h / w for h, w in zip(hs, ws)]
|
||||
|
||||
sorted_indices = sorted(range(len(ratios)), key=lambda i: abs(ratios[i] - 1))
|
||||
k = int(len(images) * 0.75)
|
||||
selected = sorted_indices[:k]
|
||||
|
||||
selected_ratios = [ratios[i] for i in selected]
|
||||
target_ratio = np.median(selected_ratios)
|
||||
|
||||
h_q3 = np.percentile([hs[i] for i in selected], 75)
|
||||
w_q3 = np.percentile([ws[i] for i in selected], 75)
|
||||
sum_hw = h_q3 + w_q3
|
||||
|
||||
W_initial = sum_hw / (target_ratio + 1)
|
||||
H_initial = target_ratio * W_initial
|
||||
|
||||
H = int(round(H_initial / 14) * 14)
|
||||
W = int(round(W_initial / 14) * 14)
|
||||
|
||||
max_edge = max(H, W)
|
||||
if max_edge > longest_edge:
|
||||
new_max = (longest_edge // 14) * 14
|
||||
if H > W:
|
||||
H = new_max
|
||||
W = int(round(H / target_ratio / 14) * 14)
|
||||
else:
|
||||
W = new_max
|
||||
H = int(round(W * target_ratio / 14) * 14)
|
||||
|
||||
H, W = max(392, H), max(392, W)
|
||||
return (H, W)
|
||||
|
||||
|
||||
def resize_pad_images_to_target(images, target_size_hw):
|
||||
H_target, W_target = target_size_hw
|
||||
processed_images = []
|
||||
for img in images:
|
||||
W, H = img.width, img.height
|
||||
aspect_ratio = W / H
|
||||
target_aspect = W_target / H_target
|
||||
|
||||
if aspect_ratio >= target_aspect:
|
||||
# 缩放宽度到目标宽度,调整高度
|
||||
new_w = W_target
|
||||
new_h = int(round(H * (new_w / W)))
|
||||
else:
|
||||
# 缩放高度到目标高度,调整宽度
|
||||
new_h = H_target
|
||||
new_w = int(round(W * (new_h / H)))
|
||||
|
||||
# 调整图像尺寸
|
||||
if new_w > 0 and new_h > 0:
|
||||
resized_img = img.resize((new_w, new_h), Image.BILINEAR)
|
||||
|
||||
# 创建填充后的图像
|
||||
padded_img = Image.new(img.mode, (W_target, H_target), color=0)
|
||||
padded_img.paste(resized_img, (0, 0))
|
||||
else:
|
||||
logger.info(
|
||||
f"unexpected new_h: {new_h} new_w: {new_w} got. forcely resize into target {H_target}x{W_target}."
|
||||
)
|
||||
padded_img = img.resize((W_target, H_target), Image.BILINEAR)
|
||||
|
||||
processed_images.append(padded_img)
|
||||
|
||||
return processed_images
|
||||
|
||||
|
||||
def smart_resize_v1(images, longest_edge=800):
|
||||
if len(images) == 1:
|
||||
return images
|
||||
target_hw = get_suitable_size_hw(images, longest_edge)
|
||||
processed_images = resize_pad_images_to_target(images, target_hw)
|
||||
return processed_images
|
||||
@@ -0,0 +1,204 @@
|
||||
import datetime
|
||||
import logging
|
||||
import logging.handlers
|
||||
import mimetypes
|
||||
import os
|
||||
import sys
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
|
||||
import requests
|
||||
import transformers
|
||||
from loguru import logger
|
||||
|
||||
|
||||
def disable_torch_init():
|
||||
"""
|
||||
Disable the redundant torch default initialization to accelerate model creation.
|
||||
"""
|
||||
import torch
|
||||
|
||||
setattr(torch.nn.Linear, "reset_parameters", lambda self: None)
|
||||
setattr(torch.nn.LayerNorm, "reset_parameters", lambda self: None)
|
||||
|
||||
|
||||
def is_dist_avail_and_initialized():
|
||||
if not dist.is_available():
|
||||
return False
|
||||
if not dist.is_initialized():
|
||||
return False
|
||||
return True
|
||||
|
||||
|
||||
def get_rank():
|
||||
if not is_dist_avail_and_initialized():
|
||||
return 0
|
||||
return dist.get_rank()
|
||||
|
||||
|
||||
def is_main_process():
|
||||
return get_rank() == 0
|
||||
|
||||
|
||||
def rank0_print(*args):
|
||||
if is_main_process():
|
||||
print(*args)
|
||||
|
||||
|
||||
def is_image(url_or_path):
|
||||
# If it's a local file path, convert it to an absolute path
|
||||
url_or_path = url_or_path.split(" ")[0]
|
||||
if os.path.exists(url_or_path):
|
||||
url_or_path = os.path.abspath(url_or_path)
|
||||
|
||||
mimetype, encoding = mimetypes.guess_type(url_or_path)
|
||||
return (mimetype and mimetype.startswith("image")) or url_or_path.endswith("webp")
|
||||
|
||||
|
||||
def load_conn_weights(conn_model_path, model_conn, module_key="conn_ve_llm"):
|
||||
mm_projector_weights = torch.load(conn_model_path, map_location="cpu")
|
||||
|
||||
def get_w(weights, keyword):
|
||||
return {
|
||||
k.split(keyword + ".")[1]: v for k, v in weights.items() if keyword in k
|
||||
}
|
||||
|
||||
mm_projector_weights = get_w(mm_projector_weights, module_key)
|
||||
try:
|
||||
model_conn.load_state_dict(mm_projector_weights, strict=False)
|
||||
if is_main_process():
|
||||
logger.info(f"conn weights loaded from: {conn_model_path}")
|
||||
except Exception as e:
|
||||
print(f"got error load state dict: {e}")
|
||||
model_conn.load_state_dict(
|
||||
{
|
||||
k: v
|
||||
for k, v in mm_projector_weights.items()
|
||||
if "layers.1" not in k and "layers.0" not in k
|
||||
},
|
||||
strict=False,
|
||||
)
|
||||
print(f"{module_key} partially loaded!")
|
||||
|
||||
|
||||
def maybe_zero_3(param, ignore_status=False, name=None):
|
||||
from deepspeed import zero
|
||||
from deepspeed.runtime.zero.partition_parameters import ZeroParamStatus
|
||||
|
||||
if hasattr(param, "ds_id"):
|
||||
if param.ds_status == ZeroParamStatus.NOT_AVAILABLE:
|
||||
if not ignore_status:
|
||||
logging.warning(
|
||||
f"{name}: param.ds_status != ZeroParamStatus.NOT_AVAILABLE: {param.ds_status}"
|
||||
)
|
||||
with zero.GatheredParameters([param]):
|
||||
param = param.data.detach().cpu().clone()
|
||||
else:
|
||||
param = param.detach().cpu().clone()
|
||||
return param
|
||||
|
||||
|
||||
# Borrowed from peft.utils.get_peft_model_state_dict
|
||||
def get_peft_state_maybe_zero_3(named_params, bias):
|
||||
if bias == "none":
|
||||
to_return = {k: t for k, t in named_params if "lora_" in k}
|
||||
elif bias == "all":
|
||||
to_return = {k: t for k, t in named_params if "lora_" in k or "bias" in k}
|
||||
elif bias == "lora_only":
|
||||
to_return = {}
|
||||
maybe_lora_bias = {}
|
||||
lora_bias_names = set()
|
||||
for k, t in named_params:
|
||||
if "lora_" in k:
|
||||
to_return[k] = t
|
||||
bias_name = k.split("lora_")[0] + "bias"
|
||||
lora_bias_names.add(bias_name)
|
||||
elif "bias" in k:
|
||||
maybe_lora_bias[k] = t
|
||||
for k, t in maybe_lora_bias:
|
||||
if bias_name in lora_bias_names:
|
||||
to_return[bias_name] = t
|
||||
else:
|
||||
raise NotImplementedError
|
||||
to_return = {k: maybe_zero_3(v, ignore_status=True) for k, v in to_return.items()}
|
||||
return to_return
|
||||
|
||||
|
||||
def get_peft_state_non_lora_maybe_zero_3(named_params, require_grad_only=True):
|
||||
to_return = {k: t for k, t in named_params if "lora_" not in k}
|
||||
if require_grad_only:
|
||||
to_return = {k: t for k, t in to_return.items() if t.requires_grad}
|
||||
to_return = {
|
||||
k: maybe_zero_3(v, ignore_status=True).cpu() for k, v in to_return.items()
|
||||
}
|
||||
return to_return
|
||||
|
||||
|
||||
def get_mm_adapter_state_maybe_zero_3(named_params, keys_to_match):
|
||||
to_return = {
|
||||
k: t
|
||||
for k, t in named_params
|
||||
if any(key_match in k for key_match in keys_to_match)
|
||||
}
|
||||
to_return = {
|
||||
k: maybe_zero_3(v, ignore_status=True).cpu() for k, v in to_return.items()
|
||||
}
|
||||
return to_return
|
||||
|
||||
|
||||
def find_all_linear_names(model):
|
||||
cls = torch.nn.Linear
|
||||
lora_module_names = set()
|
||||
# {'up_proj', 'v_proj', 'gate_proj', 'k_proj', 'down_proj', 'q_proj', 'o_proj', 'lm_head'}
|
||||
multimodal_keywords = ["conn_ve_llm", "ve", "vision_resampler"]
|
||||
# multimodal_keywords = ['mm_projector', 'vision_resampler']
|
||||
for name, module in model.named_modules():
|
||||
if any(mm_keyword in name for mm_keyword in multimodal_keywords):
|
||||
continue
|
||||
if isinstance(module, cls):
|
||||
names = name.split(".")
|
||||
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
|
||||
rank0_print(f"==> lora modules: {lora_module_names}")
|
||||
if "lm_head" in lora_module_names: # needed for 16-bit
|
||||
lora_module_names.remove("lm_head")
|
||||
return list(lora_module_names)
|
||||
|
||||
|
||||
def safe_save_model_for_hf_trainer(trainer: transformers.Trainer, output_dir: str):
|
||||
"""Collects the state dict and dump to disk."""
|
||||
|
||||
if getattr(trainer.args, "tune_conn_ve_llm", False):
|
||||
# Only save Adapter
|
||||
keys_to_match = ["conn_ve_llm"]
|
||||
if getattr(trainer.args, "use_im_start_end", False):
|
||||
keys_to_match.extend(["embed_tokens", "embed_in"])
|
||||
|
||||
weight_to_save = get_mm_adapter_state_maybe_zero_3(
|
||||
trainer.model.named_parameters(), keys_to_match
|
||||
)
|
||||
trainer.model.config.save_pretrained(output_dir)
|
||||
|
||||
current_folder = output_dir.split("/")[-1]
|
||||
parent_folder = os.path.dirname(output_dir)
|
||||
if trainer.args.local_rank == 0 or trainer.args.local_rank == -1:
|
||||
if current_folder.startswith("checkpoint-"):
|
||||
mm_projector_folder = os.path.join(parent_folder, "conn_ve_llm")
|
||||
os.makedirs(mm_projector_folder, exist_ok=True)
|
||||
torch.save(
|
||||
weight_to_save,
|
||||
os.path.join(mm_projector_folder, f"{current_folder}.bin"),
|
||||
)
|
||||
else:
|
||||
torch.save(weight_to_save, os.path.join(output_dir, f"conn_ve_llm.bin"))
|
||||
return
|
||||
|
||||
if trainer.deepspeed:
|
||||
torch.cuda.synchronize()
|
||||
trainer.save_model(output_dir)
|
||||
return
|
||||
|
||||
state_dict = trainer.model.state_dict()
|
||||
if trainer.args.should_save:
|
||||
cpu_state_dict = {key: value.cpu() for key, value in state_dict.items()}
|
||||
del state_dict
|
||||
trainer._save(output_dir, state_dict=cpu_state_dict) # noqa
|
||||
@@ -0,0 +1,21 @@
|
||||
from datetime import datetime
|
||||
|
||||
major_num = 1
|
||||
|
||||
__version__ = "0.0.4"
|
||||
short_version = __version__
|
||||
|
||||
|
||||
def parse_version_info(version_str):
|
||||
version_info = []
|
||||
for x in version_str.split("."):
|
||||
if x.isdigit():
|
||||
version_info.append(int(x))
|
||||
elif x.find("rc") != -1:
|
||||
patch_version = x.split("rc")
|
||||
version_info.append(int(patch_version[0]))
|
||||
version_info.append(f"rc{patch_version[1]}")
|
||||
return tuple(version_info)
|
||||
|
||||
|
||||
version_info = parse_version_info(__version__)
|
||||
@@ -0,0 +1,19 @@
|
||||
import torch
|
||||
|
||||
|
||||
def load(pretrained_model_path):
|
||||
"""
|
||||
returns model, tokenizer, image_processor
|
||||
"""
|
||||
pass
|
||||
|
||||
|
||||
def generate(model, tokenizer, prompt, images):
|
||||
pass
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
model = load("")
|
||||
output = generate(
|
||||
model,
|
||||
)
|
||||
@@ -0,0 +1,142 @@
|
||||
<div align='center'>
|
||||
<img src='https://img2023.cnblogs.com/blog/3572323/202502/3572323-20250221161349804-1020036173.png' style="border-radius: 15px;" />
|
||||
<h1>Namo R1</h1>
|
||||
</div>
|
||||
|
||||
<p align="center">
|
||||
🤗 <a href="https://huggingface.co/lucasjin/Namo-500M-V1">Namo-500M-V1</a>   |   🐝 <a href="https://github.com/lucasjinreal/Namo-R1/issues/new">Community</a>
|
||||
</p
|
||||
|
||||
> **You**: *I don't have GPUs to run VLMs.* **Namo R1:** Hold my beer.... let's do this on CPU.
|
||||
|
||||
**Namo R1** 🔥🔥 surpassed SmolVLM and Moondream2 in terms of same size! And we are keep evolving, more advanced models are under training!
|
||||
|
||||
## Introduction
|
||||
|
||||
We are excited to open-source **Namo**, an extremly small yet mighty MLLM. While numerous MLLMs exist, few offer true extensibility or fully open-source their training data, model architectures, and training schedulers - critical components for reproducible AI research.
|
||||
|
||||
The AI community has largely overlooked the potential of compact MLLMs, despite their demonstrated efficiency advantages. Our analysis reveals significant untapped potential in sub-billion parameter models, particularly for edge deployment and specialized applications. To address this gap, we're releasing Namo R1, a foundational 500M parameter model trained from scratch using innovative architectural choices.
|
||||
|
||||
Key innovations include:
|
||||
|
||||
1. **CPU friendly:** Even on CPUs, Namo R1 can runs very fast;
|
||||
2. **Omni-modal Scalability:** Native support for future expansion into audio (ASR/TTS) and cross-modal fusion;
|
||||
3. **Training Transparency:** Full disclosure of data curation processes and dynamic curriculum scheduling techniques.
|
||||
|
||||
👇 Video Demo Runs on **CPU**:
|
||||
|
||||
<video src='https://github.com/user-attachments/assets/eb353124-509e-4b87-8a0d-b0b37b5efba2
|
||||
'></video>
|
||||
|
||||
## Updates
|
||||
|
||||
- **`2025.02.21`**: more to come...!
|
||||
- **`2025.02.21`**: 🔥🔥 The first version is ready to open, fire the MLLM power able to runs on CPU!
|
||||
- **`2025.02.17`**: Namo R1 start training.
|
||||
|
||||
## Results
|
||||
|
||||
the result might keep updating as new models trained.
|
||||
|
||||
| Model | MMB-EN-T | MMB-CN-T | Size |
|
||||
| -------------------- | -------------- | -------------- | ---- |
|
||||
| Namo-500M | **68.8** | **48.7** | 500M |
|
||||
| Namo-700M | training | training | 700M |
|
||||
| Namo-500M-R1 | training | training | 500M |
|
||||
| Namo-700M-R1 | training | training | 700M |
|
||||
| SmolVLM-500M | 53.8 | 35.4 | 500M |
|
||||
| SmolVLM-Instruct-DPO | 67.5 | 49.8 | 2.3B |
|
||||
| Moondream1 | 62.3 | 19.8 | 1.9B |
|
||||
| Moondream2 | 70 | 28.7 | 1.9B |
|
||||
|
||||
⚠️ Currently, the testing has only been conducted on a limited number of benchmarks. In the near future, more metrics will be reported. Even so, we've observed significant improvements compared to other small models.
|
||||
|
||||
## Get Started
|
||||
|
||||
#### Install & Run in Cli
|
||||
|
||||
All you need to do is:
|
||||
|
||||
```shell
|
||||
pip install -U namo
|
||||
```
|
||||
|
||||
A simple demo would be:
|
||||
|
||||
```python
|
||||
from namo.api.vl import VLInfer
|
||||
|
||||
# model will download automatically
|
||||
model = VLInfer(model_type='namo')
|
||||
|
||||
# default will have streaming
|
||||
model.generate('what is this?', 'images/cats.jpg', stream=True)
|
||||
```
|
||||
|
||||
That's all!
|
||||
|
||||
For cli multi-turn chat in terminal you can run `python demo.py`. (Namo cli directly in your terminal would be avaiable later.)
|
||||
|
||||
#### OpenAI server & Run in OpenWebUI
|
||||
|
||||
```shell
|
||||
namo server --model checkpoints/Namo-500M-V1
|
||||
```
|
||||
|
||||
then, you will have OpenAI like serving in local.
|
||||
|
||||
## Showcases
|
||||
|
||||
**Namo-500M**, our first small series of models, is capable of performing remarkable tasks such as multilingual OCR, general concept understanding, image captioning, and more. And it has only 500 million parameters! You can run it directly on a CPU!
|
||||
|
||||
<details>
|
||||
<summary><strong>📁 Show more real use cases</strong></summary>
|
||||
|
||||
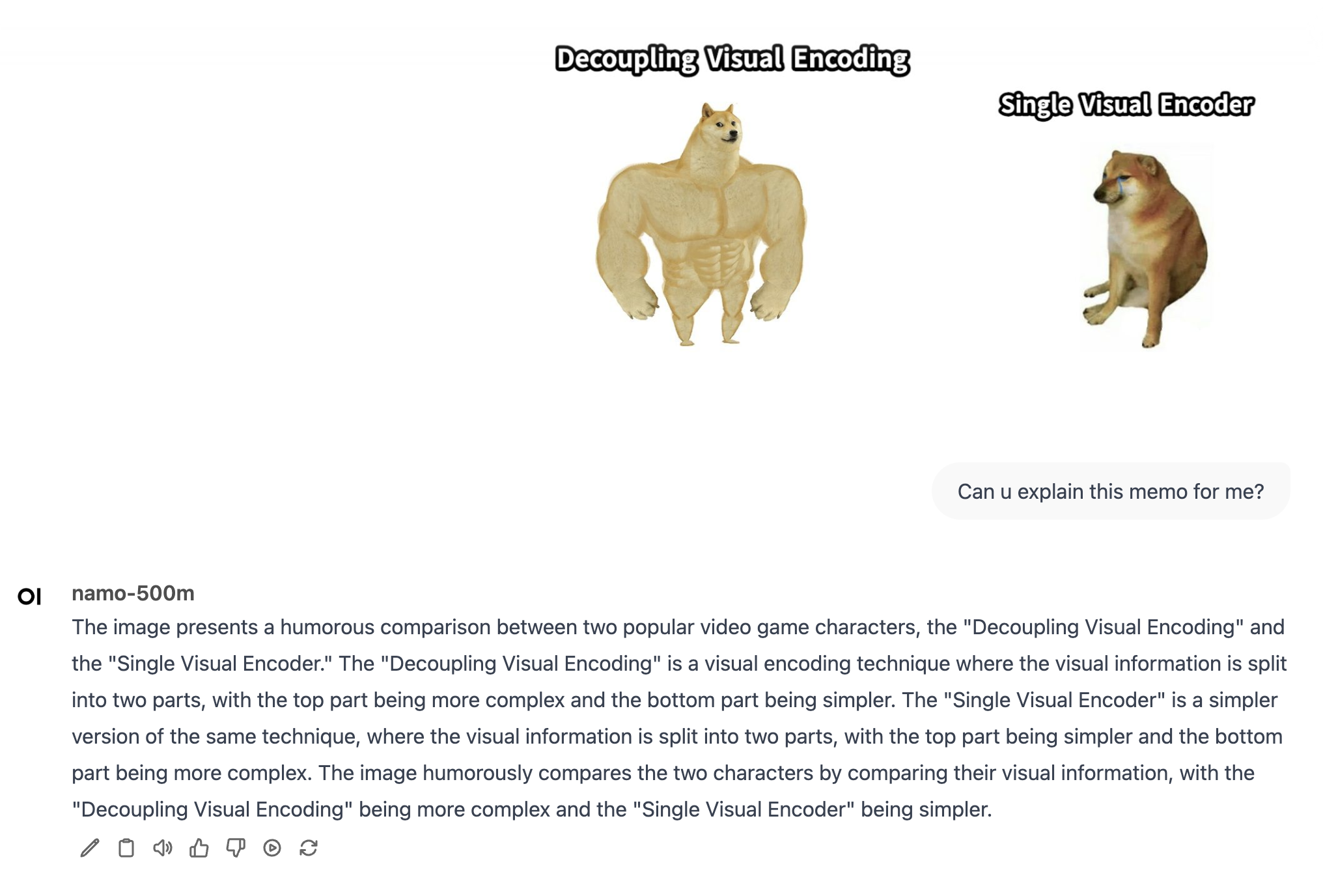
|
||||
|
||||
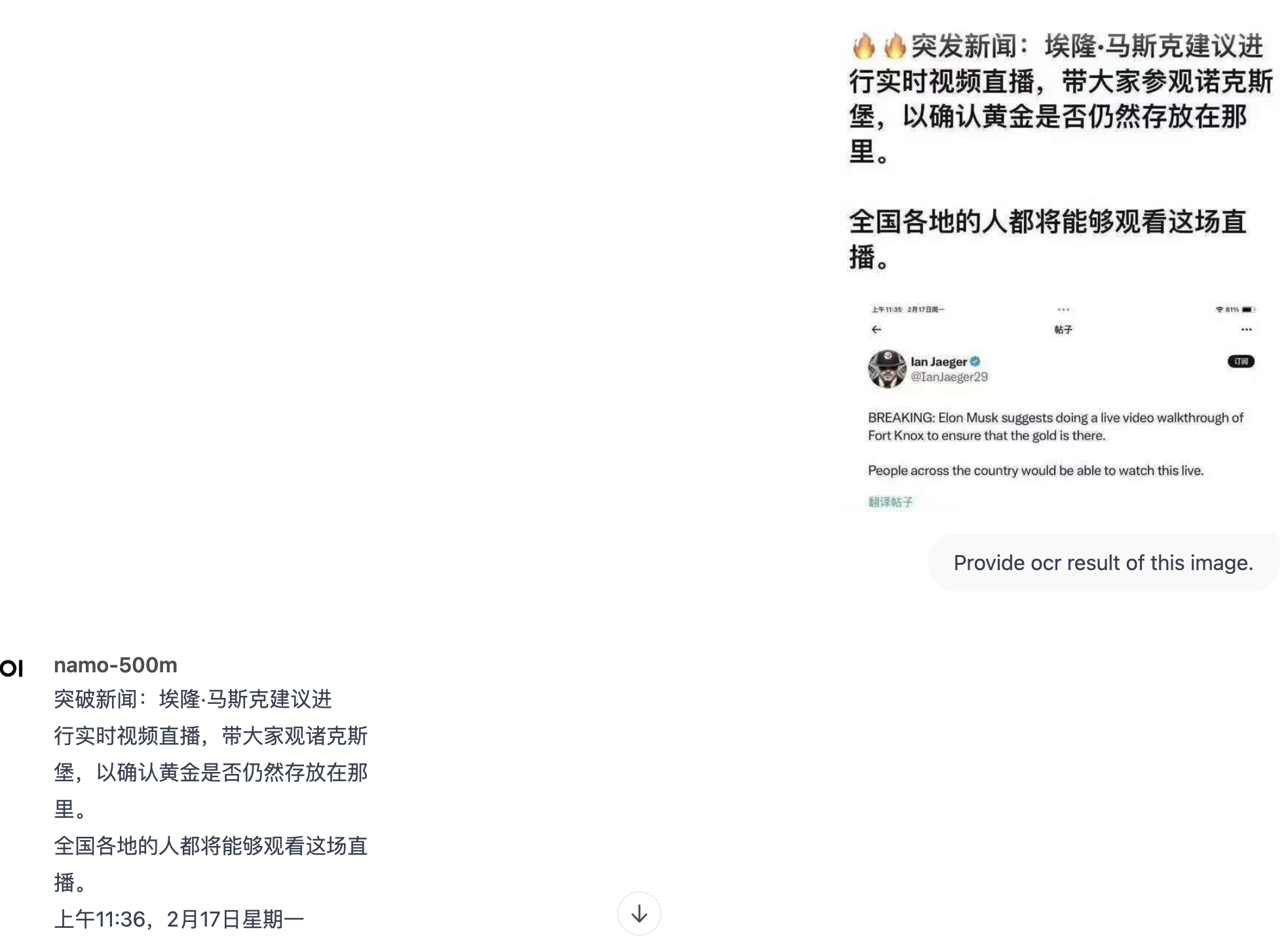
|
||||
|
||||
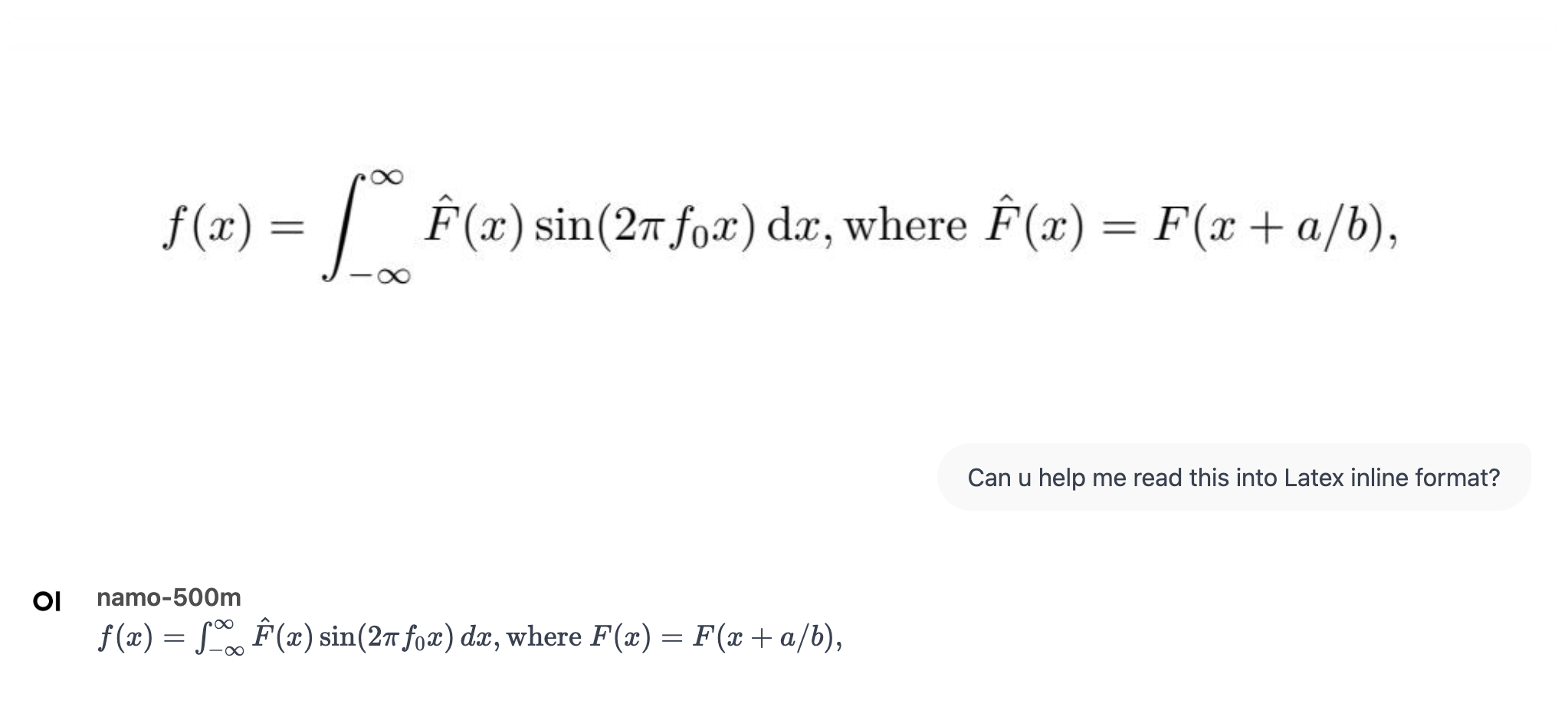
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
## Features of Namo R1
|
||||
|
||||
In contrast to open-source VLMs like Qwen2.5-3B and MiniCPM, the Namo series offers the following features that enable anyone to train their own VLMs from scratch:
|
||||
|
||||
- **Extremely Small**: Our first series has only 500 million parameters yet powerful on various tasks.
|
||||
- **OCR Capability**: With just a 500M model, you can perform multilingual OCR, covering not only Chinese and English but also Japanese and other languages.
|
||||
- **Dynamic Resolution**: We support native dynamic resolution as input, making it robust for images of **any ratio**.
|
||||
- **Fully Open Source**: We opensource all model codes including training steps and scripts!
|
||||
- **R1 Support**: Yes, we now support R1 for post-training.
|
||||
|
||||
Above all, we are also ready to help when u want train your MLLM from scratch at any tasks!
|
||||
|
||||
## Roadmap
|
||||
|
||||
We are still actively training on new models, here are few things we will arrive:
|
||||
|
||||
- Speech model;
|
||||
- Vision model with more decent vision encoders, such as SigLip2;
|
||||
- TTS ability;
|
||||
- Slightly larger models, up to 7B;
|
||||
|
||||
## Trouble Shooting
|
||||
|
||||
1. Got error when using deepspeed: ` AssertionError: no_sync context manager is incompatible with gradient partitioning logic of ZeRO stage 2` ?
|
||||
|
||||
Please upgrade transformers to 4.48+ and use latest deepspeed.
|
||||
|
||||
## Copyright
|
||||
|
||||
All right reserved by Namo authors, code released under MIT License.
|
||||
@@ -0,0 +1,3 @@
|
||||
latext/
|
||||
latext*/
|
||||
invoices*/
|
||||
@@ -0,0 +1,99 @@
|
||||
"""
|
||||
|
||||
convert anyword into llava like format
|
||||
|
||||
|
||||
"""
|
||||
|
||||
import sys
|
||||
import json
|
||||
|
||||
|
||||
TYPE = "ego"
|
||||
TYPE = "webvid"
|
||||
TYPE = "videochat2"
|
||||
|
||||
|
||||
def convert_json(input_json, json_file_path):
|
||||
data = input_json["data_list"]
|
||||
print(f"processing data list: {len(data)}")
|
||||
output_data = []
|
||||
for item in data:
|
||||
if "annotations" in item.keys():
|
||||
|
||||
new_item = {
|
||||
# "id": f"ego_video_{video_path}",
|
||||
"id": item["img_name"],
|
||||
# "video": f"split_videos/{video_path}",
|
||||
"image": f"images/{item['img_name']}",
|
||||
}
|
||||
|
||||
new_item["conversations"] = []
|
||||
|
||||
ocr_text = []
|
||||
all_lans = []
|
||||
for i, QA_data in enumerate(item["annotations"]):
|
||||
ocr_text.append(QA_data["text"])
|
||||
all_lans.append(QA_data["language"])
|
||||
|
||||
should_use = True
|
||||
if "laion" in json_file_path and len(all_lans) > 0:
|
||||
if any(lang != "Latin" for lang in all_lans):
|
||||
should_use = False
|
||||
# print(item)
|
||||
else:
|
||||
print(item)
|
||||
# if len(new_item["conversations"]) > 5:
|
||||
# # depart conversations into 2 parts
|
||||
# for i in range(0, len(new_item["conversations"]), 10):
|
||||
# data_dict_i = {}
|
||||
# data_dict_i["id"] = new_item["id"] + f"_{i//10}"
|
||||
# data_dict_i["video"] = new_item["video"]
|
||||
# data_dict_i["conversations"] = new_item["conversations"][i : i + 10]
|
||||
# if i != 0:
|
||||
# data_dict_i["conversations"][0][
|
||||
# "value"
|
||||
# ] = f"<video>\n{data_dict_i['conversations'][0]['value']}"
|
||||
# output_data.append(data_dict_i)
|
||||
# else:
|
||||
if should_use:
|
||||
new_item["conversations"].append(
|
||||
{
|
||||
"from": "human",
|
||||
"value": "<image>\nPlease provide precise OCR result of the image.",
|
||||
}
|
||||
)
|
||||
new_item["conversations"].append(
|
||||
{"from": "gpt", "value": "\n".join(ocr_text)}
|
||||
)
|
||||
output_data.append(new_item)
|
||||
|
||||
return output_data
|
||||
|
||||
|
||||
def main():
|
||||
if len(sys.argv) != 2:
|
||||
print("Usage: python script.py <path_to_json_file>")
|
||||
sys.exit(1)
|
||||
|
||||
json_file_path = sys.argv[1]
|
||||
try:
|
||||
with open(json_file_path, "r") as file:
|
||||
input_json = json.load(file)
|
||||
except FileNotFoundError:
|
||||
print(f"Error: The file {json_file_path} does not exist.")
|
||||
sys.exit(1)
|
||||
except json.JSONDecodeError:
|
||||
print(f"Error: The file {json_file_path} is not a valid JSON file.")
|
||||
sys.exit(1)
|
||||
|
||||
converted_data = convert_json(input_json, json_file_path)
|
||||
print(f"All {len(converted_data)} samples")
|
||||
# file_path = "ego_video.json"
|
||||
file_path = f"{json_file_path[:-5]}_ocr.json"
|
||||
with open(file_path, "w") as f:
|
||||
json.dump(converted_data, f, ensure_ascii=False, indent=2)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -0,0 +1,77 @@
|
||||
"""
|
||||
convert
|
||||
|
||||
https://huggingface.co/datasets/amaye15/invoices-google-ocr/
|
||||
https://huggingface.co/datasets/mychen76/invoices-and-receipts_ocr_v2
|
||||
|
||||
"""
|
||||
|
||||
import json
|
||||
from datasets import load_dataset
|
||||
import uuid
|
||||
import os
|
||||
import ast
|
||||
|
||||
import sys
|
||||
|
||||
all_res = []
|
||||
|
||||
root_path = sys.argv[1]
|
||||
|
||||
ds = load_dataset("parquet", data_files=os.path.join(root_path, "data/*.parquet"))
|
||||
|
||||
|
||||
def build_item(item, idx):
|
||||
# print(item)
|
||||
new_item = {
|
||||
"id": f"{idx}",
|
||||
"image": f"images/{idx}.jpg",
|
||||
}
|
||||
new_item["conversations"] = []
|
||||
|
||||
os.makedirs("invoices-ocr/images", exist_ok=True)
|
||||
if "image" in item.keys():
|
||||
image = item["image"].convert("RGB")
|
||||
else:
|
||||
image = item["pixel_values"].convert("RGB")
|
||||
|
||||
img_f = os.path.join("invoices-ocr", new_item["image"])
|
||||
if not os.path.exists(img_f):
|
||||
image.save(img_f)
|
||||
|
||||
if "ocr" in item.keys():
|
||||
if len(item["ocr"]) < 1:
|
||||
return None
|
||||
text = item["ocr"][0]["text"]
|
||||
else:
|
||||
a = json.loads(item["raw_data"])
|
||||
ll = ast.literal_eval(a["ocr_words"])
|
||||
# print(ll)
|
||||
text = "\n".join(ll)
|
||||
|
||||
new_item["conversations"].append(
|
||||
{
|
||||
"from": "human",
|
||||
"value": "<image>\nRead all text content visible on image in order.",
|
||||
}
|
||||
)
|
||||
new_item["conversations"].append({"from": "gpt", "value": text})
|
||||
# print(new_item)
|
||||
return new_item
|
||||
|
||||
|
||||
print(ds.items())
|
||||
ds_name = os.path.basename(root_path)
|
||||
idx = 0
|
||||
for item in ds["train"]:
|
||||
new_item = build_item(item, f"invoices_{ds_name}_{idx}")
|
||||
if new_item is None:
|
||||
continue
|
||||
all_res.append(new_item)
|
||||
idx += 1
|
||||
|
||||
|
||||
print(f"all res: {len(all_res)}")
|
||||
file_path = f"invoices_ocr_{ds_name}.json"
|
||||
with open(file_path, "w") as f:
|
||||
json.dump(all_res, f, ensure_ascii=False, indent=2)
|
||||
@@ -0,0 +1,68 @@
|
||||
"""
|
||||
convert
|
||||
|
||||
https://huggingface.co/datasets/linxy/LaTeX_OCR
|
||||
|
||||
"""
|
||||
|
||||
import json
|
||||
from datasets import load_dataset
|
||||
import uuid
|
||||
import os
|
||||
|
||||
all_res = []
|
||||
|
||||
ds = load_dataset("parquet", data_files="latex/full/*.parquet")
|
||||
|
||||
|
||||
def build_item(item, idx):
|
||||
# print(item)
|
||||
new_item = {
|
||||
"id": f"{idx}",
|
||||
"image": f"images/{idx}.jpg",
|
||||
}
|
||||
new_item["conversations"] = []
|
||||
|
||||
os.makedirs("latex_ocr/images", exist_ok=True)
|
||||
item["image"] = item["image"].convert("RGB")
|
||||
|
||||
item["image"].save(os.path.join("latex_ocr", new_item["image"]))
|
||||
|
||||
new_item["conversations"].append(
|
||||
{"from": "human", "value": "<image>\nPlease convert this into latex format."}
|
||||
)
|
||||
new_item["conversations"].append({"from": "gpt", "value": item["text"]})
|
||||
return new_item
|
||||
|
||||
|
||||
print(ds.items())
|
||||
idx = 0
|
||||
for item in ds["train"]:
|
||||
new_item = build_item(item, f"latex-ocr-full-train-{idx}")
|
||||
all_res.append(new_item)
|
||||
idx += 1
|
||||
|
||||
# idx = 0
|
||||
# for item in ds['test']:
|
||||
# new_item = build_item(item, f'latex-ocr-full-test-{idx}')
|
||||
# all_res.append(new_item)
|
||||
# idx += 1
|
||||
|
||||
ds = load_dataset("linxy/LaTeX_OCR", "human_handwrite", streaming=True)
|
||||
|
||||
idx = 0
|
||||
for item in ds["train"]:
|
||||
new_item = build_item(item, f"latex-ocr-human_handwrite-train-{idx}")
|
||||
all_res.append(new_item)
|
||||
idx += 1
|
||||
|
||||
# idx = 0
|
||||
# for item in ds['test']:
|
||||
# new_item = build_item(item, f'latex-ocr-human_handwrite-test-{idx}')
|
||||
# all_res.append(new_item)
|
||||
# idx += 1
|
||||
|
||||
print(f"all res: {len(all_res)}")
|
||||
file_path = f"latex_ocr.json"
|
||||
with open(file_path, "w") as f:
|
||||
json.dump(all_res, f, ensure_ascii=False, indent=2)
|
||||
@@ -0,0 +1,4 @@
|
||||
"""
|
||||
|
||||
HuggingFaceM4/LLaVAR-Instruct-16K
|
||||
"""
|
||||
@@ -0,0 +1,99 @@
|
||||
"""
|
||||
sampling vary data
|
||||
"""
|
||||
|
||||
import json
|
||||
import os
|
||||
import sys
|
||||
import shutil
|
||||
from PIL import Image
|
||||
|
||||
a = sys.argv[1]
|
||||
|
||||
|
||||
def cn():
|
||||
img_root = os.path.join(os.path.dirname(a), "pdf_cn_30w")
|
||||
sample_img_root = os.path.join(os.path.dirname(a), "pdf_cn_30w_samples")
|
||||
os.makedirs(sample_img_root, exist_ok=True)
|
||||
res = json.load(open(a, "r"))
|
||||
|
||||
samples = []
|
||||
|
||||
for i, itm in enumerate(res):
|
||||
img_f = os.path.join(img_root, itm["image"])
|
||||
if not os.path.exists(img_f):
|
||||
print(f"{img_f} not found")
|
||||
|
||||
if i < 100:
|
||||
target_img_f = os.path.join(sample_img_root, itm["image"])
|
||||
os.makedirs(os.path.dirname(target_img_f), exist_ok=True)
|
||||
shutil.copy(img_f, target_img_f)
|
||||
samples.append(itm)
|
||||
print(f"done {len(res)}")
|
||||
file_path = a.replace(".json", "_samples.json")
|
||||
with open(file_path, "w") as f:
|
||||
json.dump(samples, f, ensure_ascii=False, indent=2)
|
||||
|
||||
|
||||
def en():
|
||||
img_root = os.path.join(os.path.dirname(a), "pdf_en_30w")
|
||||
sample_img_root = os.path.join(os.path.dirname(a), "pdf_en_30w_samples")
|
||||
os.makedirs(sample_img_root, exist_ok=True)
|
||||
res = json.load(open(a, "r"))
|
||||
|
||||
samples = []
|
||||
|
||||
new_res = []
|
||||
|
||||
for i, itm in enumerate(res):
|
||||
img_f = os.path.join(img_root, itm["image"])
|
||||
if not os.path.exists(img_f):
|
||||
print(f"{img_f} not found")
|
||||
continue
|
||||
else:
|
||||
new_res.append(itm)
|
||||
|
||||
if i < 100:
|
||||
target_img_f = os.path.join(sample_img_root, itm["image"])
|
||||
os.makedirs(os.path.dirname(target_img_f), exist_ok=True)
|
||||
shutil.copy(img_f, target_img_f)
|
||||
samples.append(itm)
|
||||
print(f"done {len(res)}")
|
||||
file_path = a.replace(".json", "_samples.json")
|
||||
with open(file_path, "w") as f:
|
||||
json.dump(samples, f, ensure_ascii=False, indent=2)
|
||||
|
||||
file_path = a.replace(".json", "_subset.json")
|
||||
with open(file_path, "w") as f:
|
||||
json.dump(new_res, f, ensure_ascii=False, indent=2)
|
||||
print(f"done {len(new_res)}")
|
||||
|
||||
|
||||
def cn_subset():
|
||||
"""
|
||||
choose those relatively smaller size images out
|
||||
"""
|
||||
img_root = os.path.join(os.path.dirname(a), "pdf_cn_30w")
|
||||
# sample_img_root = os.path.join(os.path.dirname(a), 'pdf_cn_30w_samples')
|
||||
# os.makedirs(sample_img_root, exist_ok=True)
|
||||
res = json.load(open(a, "r"))
|
||||
|
||||
samples = []
|
||||
|
||||
for i, itm in enumerate(res):
|
||||
img_f = os.path.join(img_root, itm["image"])
|
||||
if not os.path.exists(img_f):
|
||||
print(f"{img_f} not found")
|
||||
|
||||
image = Image.open(img_f)
|
||||
if image.size[0] < 660 or image.size[1] < 660:
|
||||
samples.append(itm)
|
||||
print(f"done {len(res)}")
|
||||
print(f"done {len(samples)}")
|
||||
file_path = a.replace(".json", "_subset.json")
|
||||
with open(file_path, "w") as f:
|
||||
json.dump(samples, f, ensure_ascii=False, indent=2)
|
||||
|
||||
|
||||
# en()
|
||||
cn_subset()
|
||||
@@ -0,0 +1,56 @@
|
||||
"""
|
||||
convert
|
||||
|
||||
https://huggingface.co/datasets/linxy/LaTeX_OCR
|
||||
|
||||
"""
|
||||
|
||||
import json
|
||||
from datasets import load_dataset
|
||||
import uuid
|
||||
import os
|
||||
|
||||
import sys
|
||||
|
||||
all_res = []
|
||||
|
||||
root_path = sys.argv[1]
|
||||
|
||||
ds = load_dataset("parquet", data_files=os.path.join(root_path, "data/*.parquet"))
|
||||
|
||||
|
||||
def build_item(item, idx):
|
||||
# print(item)
|
||||
new_item = {
|
||||
"id": f"{idx}",
|
||||
"image": f"images/{idx}.jpg",
|
||||
}
|
||||
new_item["conversations"] = []
|
||||
|
||||
os.makedirs("ZhEn_latex_ocr/images", exist_ok=True)
|
||||
item["image"] = item["image"].convert("RGB")
|
||||
|
||||
item["image"].save(os.path.join("ZhEn_latex_ocr", new_item["image"]))
|
||||
|
||||
new_item["conversations"].append(
|
||||
{
|
||||
"from": "human",
|
||||
"value": "<image>\nPlease convert all text in image into precise latex format.",
|
||||
}
|
||||
)
|
||||
new_item["conversations"].append({"from": "gpt", "value": item["text"]})
|
||||
return new_item
|
||||
|
||||
|
||||
print(ds.items())
|
||||
idx = 0
|
||||
for item in ds["train"]:
|
||||
new_item = build_item(item, f"zh-en-latex-ocr-full-train-{idx}")
|
||||
all_res.append(new_item)
|
||||
idx += 1
|
||||
|
||||
|
||||
print(f"all res: {len(all_res)}")
|
||||
file_path = f"ZhEn_latex_ocr.json"
|
||||
with open(file_path, "w") as f:
|
||||
json.dump(all_res, f, ensure_ascii=False, indent=2)
|
||||
@@ -0,0 +1,63 @@
|
||||
import torch
|
||||
from transformers import AutoModel, AutoTokenizer
|
||||
import argparse
|
||||
import os
|
||||
|
||||
|
||||
def convert_and_save_bf16(model_path, output_dir=None):
|
||||
|
||||
try:
|
||||
if output_dir is None:
|
||||
output_dir = model_path.strip("/") + "_bf16"
|
||||
os.makedirs(output_dir, exist_ok=True)
|
||||
print(f"⏳ 正在加载原始模型来自: {model_path}")
|
||||
|
||||
model = AutoModel.from_pretrained(
|
||||
model_path,
|
||||
torch_dtype=torch.bfloat16, # 初始加载为BF16
|
||||
# device_map="auto", # 自动分配设备
|
||||
low_cpu_mem_usage=True, # 优化内存使用
|
||||
trust_remote_code=True,
|
||||
)
|
||||
|
||||
print("🔧 正在转换模型权重到BF16...")
|
||||
model = model.to(torch.bfloat16)
|
||||
|
||||
print(f"💾 正在保存BF16模型到: {output_dir}")
|
||||
model.save_pretrained(
|
||||
output_dir,
|
||||
safe_serialization=True, # 使用safetensors格式
|
||||
max_shard_size="6GB", # 分片大小
|
||||
)
|
||||
|
||||
# 保存tokenizer
|
||||
try:
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_path, trust_remote_code=True
|
||||
)
|
||||
tokenizer.save_pretrained(output_dir)
|
||||
except Exception as e:
|
||||
print("passing save tokenzier.")
|
||||
|
||||
print("✅ 转换完成!保存内容:")
|
||||
print(f" - 模型权重: {output_dir}/pytorch_model*.bin")
|
||||
print(f" - 配置文件: {output_dir}/config.json")
|
||||
print(f" - Tokenizer文件: {output_dir}/tokenizer.*")
|
||||
|
||||
except Exception as e:
|
||||
print(f"❌ 错误发生: {str(e)}")
|
||||
raise
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="转换HF模型到BF16格式")
|
||||
parser.add_argument(
|
||||
"model_path",
|
||||
type=str,
|
||||
help="输入模型路径(本地目录或HF Hub名称)",
|
||||
)
|
||||
parser.add_argument("--output_dir")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
convert_and_save_bf16(args.model_path, args.output_dir)
|
||||
@@ -0,0 +1,74 @@
|
||||
from transformers import AutoConfig
|
||||
from transformers import TextStreamer
|
||||
from namo.models.namo import NamoForCausalLM
|
||||
from namo.models.configuration_namo import NamoConfig
|
||||
from namo.utils.infer_utils import load_multi_images_maybe
|
||||
from namo.utils.process_utils import tokenizer_image_token
|
||||
import torch
|
||||
from loguru import logger
|
||||
import sys
|
||||
|
||||
"""
|
||||
<|im_start|>system\nYou should follow the instructions carefully and explain your answers in detail.<|im_end|><|im_start|>user\n<imag
|
||||
e>\nDescribe the following image.<|im_end|><|im_start|>assistant\n
|
||||
"""
|
||||
|
||||
torch.set_grad_enabled(False)
|
||||
device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
if len(sys.argv) == 1:
|
||||
model_path = "checkpoints/namo-500m"
|
||||
else:
|
||||
model_path = sys.argv[1]
|
||||
|
||||
logger.info(f"load namo from: {model_path}")
|
||||
|
||||
namo_model = NamoForCausalLM.from_pretrained(model_path).to(device)
|
||||
logger.success("namo model all loaded.")
|
||||
image_processor = namo_model.get_vision_tower().image_processor
|
||||
|
||||
# images = load_multi_images_maybe("images/cats.jpg")
|
||||
images = load_multi_images_maybe("images/kobe.jpg")
|
||||
pixel_values = (
|
||||
image_processor.preprocess(images, return_tensors="pt")["pixel_values"]
|
||||
.to(namo_model.device)
|
||||
.to(namo_model.dtype)
|
||||
)
|
||||
print(f"pixel_values: {pixel_values.shape}")
|
||||
tokenizer = namo_model.get_namo().tokenizer
|
||||
|
||||
chat = [
|
||||
{
|
||||
"role": "system",
|
||||
"content": "You should follow the instructions carefully and explain your answers in detail.",
|
||||
},
|
||||
{"role": "user", "content": "<image>\nDescribe the following image."},
|
||||
]
|
||||
prompt = tokenizer.apply_chat_template(chat, tokenize=False) + "<|im_start|>assistant\n"
|
||||
print(prompt)
|
||||
|
||||
input_ids = (
|
||||
tokenizer_image_token(
|
||||
prompt,
|
||||
tokenizer,
|
||||
return_tensors="pt",
|
||||
)
|
||||
.unsqueeze(0)
|
||||
.to(namo_model.device)
|
||||
)
|
||||
print(input_ids)
|
||||
|
||||
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
|
||||
with torch.autocast(device_type="cuda", dtype=torch.float16):
|
||||
output_ids = namo_model.generate(
|
||||
pixel_values=pixel_values,
|
||||
input_ids=input_ids,
|
||||
do_sample=False,
|
||||
max_new_tokens=360,
|
||||
streamer=streamer,
|
||||
use_cache=True,
|
||||
pad_token_id=tokenizer.eos_token_id,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
)
|
||||
outputs = tokenizer.decode(output_ids[0], skip_special_tokens=True).strip()
|
||||
print(f"final output:\n{outputs}")
|
||||
@@ -0,0 +1,9 @@
|
||||
from namo.api.vl import VLInfer
|
||||
|
||||
|
||||
vl = VLInfer(model_type="qwen2.5-vl")
|
||||
# vl.generate("what is funny in this image?", "images/extreme_ironing.jpg")
|
||||
# vl.generate("Outline the position of each car, output in json format", "images/extreme_ironing.jpg")
|
||||
# vl.generate("Locate the person ironing cloth", "images/extreme_ironing.jpg")
|
||||
# vl.generate("Point the blue shirt", "images/extreme_ironing.jpg")
|
||||
vl.generate("Point all the cars in image", "images/extreme_ironing.jpg")
|
||||
@@ -0,0 +1,5 @@
|
||||
mkdir checkpoints
|
||||
cd checkpoints/
|
||||
huggingface-cli download Qwen/Qwen2.5-0.5B-Instruct --local-dir Qwen2.5-0.5B-Instruct
|
||||
huggingface-cli download lucasjin/aimv2-large-patch14-224 --local-dir aimv2-large-patch14-224
|
||||
huggingface-cli download lucasjin/aimv2-large-patch14-native --local-dir aimv2-large-patch14-native
|
||||
@@ -0,0 +1,313 @@
|
||||
"""
|
||||
|
||||
Runs evaluation with VLMEvalKit.
|
||||
|
||||
Namo's result can be easily replicated with it.
|
||||
|
||||
"""
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from vlmeval.smp import *
|
||||
from vlmeval.inference import infer_data_job
|
||||
from vlmeval.config import supported_VLM
|
||||
from vlmeval.utils.result_transfer import MMMU_result_transfer, MMTBench_result_transfer
|
||||
from vlmeval.dataset import build_dataset
|
||||
from functools import partial
|
||||
from vlmeval.vlm import Namo
|
||||
from loguru import logger
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--data", type=str, nargs="+", required=True)
|
||||
parser.add_argument("--model", type=str, required=True)
|
||||
# Args that only apply to Video Dataset
|
||||
parser.add_argument("--nframe", type=int, default=8)
|
||||
parser.add_argument("--pack", action="store_true")
|
||||
parser.add_argument(
|
||||
"--work-dir",
|
||||
type=str,
|
||||
default="./eval_results/",
|
||||
help="select the output directory",
|
||||
)
|
||||
parser.add_argument("--mode", type=str, default="all", choices=["all", "infer"])
|
||||
parser.add_argument("--nproc", type=int, default=4, help="Parallel API calling")
|
||||
parser.add_argument(
|
||||
"--retry", type=int, default=None, help="retry numbers for API VLMs"
|
||||
)
|
||||
parser.add_argument("--judge", type=str, default=None)
|
||||
parser.add_argument("--ignore", action="store_true", help="Ignore failed indices. ")
|
||||
parser.add_argument("--verbose", action="store_true")
|
||||
parser.add_argument("--rerun", action="store_true")
|
||||
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
|
||||
def main():
|
||||
logger = get_logger("RUN")
|
||||
|
||||
args = parse_args()
|
||||
assert len(args.data), "--data should be a list of data files"
|
||||
|
||||
# insert local model
|
||||
if "namo-500m" in args.model.lower():
|
||||
supported_VLM.update({"Namo-500M": partial(Namo, model_path=args.model)})
|
||||
args.model = ["Namo-500M"]
|
||||
logger.info(f"eval on model: {args.model}")
|
||||
|
||||
if args.retry is not None:
|
||||
for k, v in supported_VLM.items():
|
||||
if hasattr(v, "keywords") and "retry" in v.keywords:
|
||||
v.keywords["retry"] = args.retry
|
||||
supported_VLM[k] = v
|
||||
if hasattr(v, "keywords") and "verbose" in v.keywords:
|
||||
v.keywords["verbose"] = args.verbose
|
||||
supported_VLM[k] = v
|
||||
|
||||
rank, world_size = get_rank_and_world_size()
|
||||
if world_size > 1:
|
||||
local_rank = os.environ.get("LOCAL_RANK", 0)
|
||||
torch.cuda.set_device(int(local_rank))
|
||||
dist.init_process_group(
|
||||
backend="nccl", timeout=datetime.timedelta(seconds=10800)
|
||||
)
|
||||
|
||||
for _, model_name in enumerate(args.model):
|
||||
model = None
|
||||
|
||||
pred_root = osp.join(args.work_dir, model_name)
|
||||
os.makedirs(pred_root, exist_ok=True)
|
||||
|
||||
for _, dataset_name in enumerate(args.data):
|
||||
try:
|
||||
dataset_kwargs = {}
|
||||
if dataset_name in [
|
||||
"MMLongBench_DOC",
|
||||
"DUDE",
|
||||
"DUDE_MINI",
|
||||
"SLIDEVQA",
|
||||
"SLIDEVQA_MINI",
|
||||
]:
|
||||
dataset_kwargs["model"] = model_name
|
||||
if dataset_name == "MMBench-Video":
|
||||
dataset_kwargs["pack"] = args.pack
|
||||
if dataset_name == "Video-MME":
|
||||
dataset_kwargs["use_subtitle"] = args.use_subtitle
|
||||
|
||||
# If distributed, first build the dataset on the main process for doing preparation works
|
||||
if world_size > 1:
|
||||
dataset = (
|
||||
build_dataset(dataset_name, **dataset_kwargs)
|
||||
if rank == 0
|
||||
else None
|
||||
)
|
||||
dist.barrier()
|
||||
dataset_list = [dataset]
|
||||
dist.broadcast_object_list(dataset_list, src=0)
|
||||
dataset = dataset_list[0]
|
||||
else:
|
||||
dataset = build_dataset(dataset_name, **dataset_kwargs)
|
||||
if dataset is None:
|
||||
logger.error(
|
||||
f"Dataset {dataset_name} is not valid, will be skipped. "
|
||||
)
|
||||
continue
|
||||
|
||||
result_file = f"{pred_root}/{model_name}_{dataset_name}.xlsx"
|
||||
if dataset_name in ["MMBench-Video"]:
|
||||
packstr = "pack" if args.pack else "nopack"
|
||||
result_file = f"{pred_root}/{model_name}_{dataset_name}_{args.nframe}frame_{packstr}.xlsx"
|
||||
elif dataset.MODALITY == "VIDEO":
|
||||
if args.pack:
|
||||
logger.info(
|
||||
f"{dataset_name} not support Pack Mode, directly change to unpack"
|
||||
)
|
||||
args.pack = False
|
||||
packstr = "pack" if args.pack else "nopack"
|
||||
result_file = f"{pred_root}/{model_name}_{dataset_name}_{args.nframe}frame_{packstr}.xlsx"
|
||||
if dataset_name in ["Video-MME"]:
|
||||
subtitlestr = "subs" if args.use_subtitle else "nosubs"
|
||||
result_file = result_file.replace(
|
||||
".xlsx", f"_{subtitlestr}.xlsx"
|
||||
)
|
||||
|
||||
if dataset.TYPE == "MT":
|
||||
result_file = result_file.replace(".xlsx", ".tsv")
|
||||
|
||||
if osp.exists(result_file) and args.rerun:
|
||||
for keyword in ["openai", "gpt", "auxmatch"]:
|
||||
os.system(
|
||||
f"rm {pred_root}/{model_name}_{dataset_name}_{keyword}*"
|
||||
)
|
||||
|
||||
if model is None:
|
||||
model = model_name # which is only a name
|
||||
|
||||
# Perform the Inference
|
||||
if dataset.MODALITY == "VIDEO":
|
||||
model = infer_data_job_video(
|
||||
model,
|
||||
work_dir=pred_root,
|
||||
model_name=model_name,
|
||||
dataset=dataset,
|
||||
nframe=args.nframe,
|
||||
pack=args.pack,
|
||||
verbose=args.verbose,
|
||||
subtitle=args.use_subtitle,
|
||||
api_nproc=args.nproc,
|
||||
)
|
||||
elif dataset.TYPE == "MT":
|
||||
model = infer_data_job_mt(
|
||||
model,
|
||||
work_dir=pred_root,
|
||||
model_name=model_name,
|
||||
dataset=dataset,
|
||||
verbose=args.verbose,
|
||||
api_nproc=args.nproc,
|
||||
ignore_failed=args.ignore,
|
||||
)
|
||||
else:
|
||||
model = infer_data_job(
|
||||
model,
|
||||
work_dir=pred_root,
|
||||
model_name=model_name,
|
||||
dataset=dataset,
|
||||
verbose=args.verbose,
|
||||
api_nproc=args.nproc,
|
||||
ignore_failed=args.ignore,
|
||||
)
|
||||
|
||||
# Set the judge kwargs first before evaluation or dumping
|
||||
judge_kwargs = {
|
||||
"nproc": args.nproc,
|
||||
"verbose": args.verbose,
|
||||
}
|
||||
if args.retry is not None:
|
||||
judge_kwargs["retry"] = args.retry
|
||||
if args.judge is not None:
|
||||
judge_kwargs["model"] = args.judge
|
||||
else:
|
||||
if dataset.TYPE in ["MCQ", "Y/N"] or listinstr(
|
||||
["MathVerse"], dataset_name
|
||||
):
|
||||
judge_kwargs["model"] = "chatgpt-0125"
|
||||
elif listinstr(
|
||||
[
|
||||
"MMVet",
|
||||
"MathVista",
|
||||
"LLaVABench",
|
||||
"MMBench-Video",
|
||||
"MathVision",
|
||||
],
|
||||
dataset_name,
|
||||
):
|
||||
judge_kwargs["model"] = "gpt-4-turbo"
|
||||
elif listinstr(
|
||||
[
|
||||
"MMLongBench",
|
||||
"MMDU",
|
||||
"DUDE",
|
||||
"DUDE_MINI",
|
||||
"SLIDEVQA",
|
||||
"SLIDEVQA_MINI",
|
||||
],
|
||||
dataset_name,
|
||||
):
|
||||
judge_kwargs["model"] = "gpt-4o"
|
||||
if "OPENAI_API_KEY_JUDGE" in os.environ and len(
|
||||
os.environ["OPENAI_API_KEY_JUDGE"]
|
||||
):
|
||||
judge_kwargs["key"] = os.environ["OPENAI_API_KEY_JUDGE"]
|
||||
if "OPENAI_API_BASE_JUDGE" in os.environ and len(
|
||||
os.environ["OPENAI_API_BASE_JUDGE"]
|
||||
):
|
||||
judge_kwargs["api_base"] = os.environ["OPENAI_API_BASE_JUDGE"]
|
||||
|
||||
if rank == 0:
|
||||
if dataset_name in ["MMMU_TEST"]:
|
||||
result_json = MMMU_result_transfer(result_file)
|
||||
logger.info(
|
||||
f"Transfer MMMU_TEST result to json for official evaluation, "
|
||||
f"json file saved in {result_json}"
|
||||
) # noqa: E501
|
||||
continue
|
||||
elif "MMT-Bench_ALL" in dataset_name:
|
||||
submission_file = MMTBench_result_transfer(
|
||||
result_file, **judge_kwargs
|
||||
)
|
||||
logger.info(
|
||||
f"Extract options from prediction of MMT-Bench FULL split for official evaluation "
|
||||
f"(https://eval.ai/web/challenges/challenge-page/2328/overview), "
|
||||
f"submission file saved in {submission_file}"
|
||||
) # noqa: E501
|
||||
continue
|
||||
elif "MLLMGuard_DS" in dataset_name:
|
||||
logger.info(
|
||||
"The evaluation of MLLMGuard_DS is not supported yet. "
|
||||
) # noqa: E501
|
||||
continue
|
||||
elif "AesBench_TEST" == dataset_name:
|
||||
logger.info(
|
||||
f"The results are saved in {result_file}. "
|
||||
f"Please send it to the AesBench Team via huangyipo@hotmail.com."
|
||||
) # noqa: E501
|
||||
continue
|
||||
|
||||
if dataset_name in [
|
||||
"MMBench_TEST_CN",
|
||||
"MMBench_TEST_EN",
|
||||
"MMBench",
|
||||
"MMBench_CN",
|
||||
"MMBench_TEST_CN_V11",
|
||||
"MMBench_TEST_EN_V11",
|
||||
"MMBench_V11",
|
||||
"MMBench_CN_V11",
|
||||
]:
|
||||
if not MMBenchOfficialServer(dataset_name):
|
||||
logger.error(
|
||||
f"Can not evaluate {dataset_name} on non-official servers, "
|
||||
"will skip the evaluation. "
|
||||
)
|
||||
continue
|
||||
|
||||
eval_proxy = os.environ.get("EVAL_PROXY", None)
|
||||
old_proxy = os.environ.get("HTTP_PROXY", "")
|
||||
|
||||
if rank == 0 and args.mode == "all":
|
||||
if eval_proxy is not None:
|
||||
proxy_set(eval_proxy)
|
||||
|
||||
eval_results = dataset.evaluate(result_file, **judge_kwargs)
|
||||
if eval_results is not None:
|
||||
assert isinstance(eval_results, dict) or isinstance(
|
||||
eval_results, pd.DataFrame
|
||||
)
|
||||
logger.info(
|
||||
f"The evaluation of model {model_name} x dataset {dataset_name} has finished! "
|
||||
)
|
||||
logger.info("Evaluation Results:")
|
||||
if isinstance(eval_results, dict):
|
||||
logger.info("\n" + json.dumps(eval_results, indent=4))
|
||||
elif isinstance(eval_results, pd.DataFrame):
|
||||
if len(eval_results) < len(eval_results.columns):
|
||||
eval_results = eval_results.T
|
||||
logger.info("\n" + tabulate(eval_results))
|
||||
|
||||
if eval_proxy is not None:
|
||||
proxy_set(old_proxy)
|
||||
except Exception as e:
|
||||
logger.exception(
|
||||
f"Model {model_name} x Dataset {dataset_name} combination failed: {e}, "
|
||||
"skipping this combination."
|
||||
)
|
||||
continue
|
||||
|
||||
if world_size > 1:
|
||||
dist.barrier()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
load_env()
|
||||
main()
|
||||
@@ -0,0 +1,51 @@
|
||||
"""
|
||||
|
||||
Extracting VE from a base trained model
|
||||
|
||||
before sft.
|
||||
|
||||
"""
|
||||
|
||||
from transformers import AutoConfig
|
||||
from transformers import TextStreamer
|
||||
from namo.models.namo import NamoForCausalLM
|
||||
from namo.models.configuration_namo import NamoConfig
|
||||
from namo.utils.infer_utils import load_multi_images_maybe
|
||||
from namo.utils.process_utils import tokenizer_image_token
|
||||
import torch
|
||||
from loguru import logger
|
||||
import sys
|
||||
|
||||
torch.set_grad_enabled(False)
|
||||
device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
|
||||
def main():
|
||||
if len(sys.argv) < 2:
|
||||
print("provide the pretrained model path please.")
|
||||
exit()
|
||||
|
||||
model_path = sys.argv[1]
|
||||
|
||||
logger.info(f"load namo from: {model_path}")
|
||||
|
||||
namo_model = NamoForCausalLM.from_pretrained(model_path).to(device)
|
||||
logger.success("namo model all loaded.")
|
||||
|
||||
ve = namo_model.get_vision_tower()
|
||||
image_processor = ve.image_processor
|
||||
tokenizer = namo_model.get_namo().tokenizer
|
||||
|
||||
if "aimv2-large-patch14-native" in ve.vision_tower_name:
|
||||
save_model_path = "checkpoints/aimv2-l-native-trained-base"
|
||||
elif "aimv2-3b-p14" in model_path:
|
||||
save_model_path = "checkpoints/aimv2-3b-p14-trained-base"
|
||||
else:
|
||||
logger.info(f"unsupported vision model type: {ve.vision_tower_name}")
|
||||
ve.save_pretrained(save_model_path)
|
||||
image_processor.save_pretrained(save_model_path)
|
||||
logger.success(f"ve should be saved into: {save_model_path}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -0,0 +1,41 @@
|
||||
"""
|
||||
|
||||
We need get these images haded vary data.
|
||||
|
||||
"""
|
||||
|
||||
import json
|
||||
import os
|
||||
import sys
|
||||
|
||||
|
||||
def filter_json_by_image(input_json_path, image_root, output_json_path):
|
||||
# 打开并读取 JSON 文件
|
||||
with open(input_json_path, "r", encoding="utf-8") as f:
|
||||
data = json.load(f)
|
||||
|
||||
# 存储符合条件的项目
|
||||
filtered_data = []
|
||||
|
||||
for item in data:
|
||||
image_path = item.get("image")
|
||||
if image_path: # 如果有图片路径
|
||||
# 生成完整的图片路径
|
||||
full_image_path = os.path.join(image_root, image_path)
|
||||
# 检查图片文件是否存在
|
||||
if os.path.exists(full_image_path):
|
||||
filtered_data.append(item)
|
||||
|
||||
# 将过滤后的数据写入新文件
|
||||
with open(output_json_path, "w", encoding="utf-8") as f:
|
||||
json.dump(filtered_data, f, indent=2, ensure_ascii=False)
|
||||
|
||||
print(f"samples all: {len(filtered_data)}")
|
||||
|
||||
|
||||
# 示例用法
|
||||
input_json_path = sys.argv[1]
|
||||
image_root = "data/"
|
||||
output_json_path = os.path.join(os.path.dirname(input_json_path), "vary_filtered.json")
|
||||
|
||||
filter_json_by_image(input_json_path, image_root, output_json_path)
|
||||
@@ -0,0 +1,6 @@
|
||||
"""
|
||||
|
||||
Loading non-lora weigths and lora weights, merge them into pretrained model.
|
||||
|
||||
|
||||
"""
|
||||
@@ -0,0 +1,54 @@
|
||||
"""
|
||||
test a simple multimodal request
|
||||
|
||||
if you have run a Namo model in your local:
|
||||
|
||||
namo server --model namo
|
||||
"""
|
||||
|
||||
from openai import OpenAI
|
||||
import base64
|
||||
import os
|
||||
|
||||
# 配置本地API信息
|
||||
client = OpenAI(
|
||||
base_url="http://127.0.0.1:8000/v1", # 根据实际API路径调整
|
||||
api_key="sk-r4536ybrtb", # 如果不需要认证可以留空
|
||||
)
|
||||
|
||||
|
||||
def encode_image(image_path):
|
||||
"""将本地图片编码为base64"""
|
||||
with open(image_path, "rb") as image_file:
|
||||
return base64.b64encode(image_file.read()).decode("utf-8")
|
||||
|
||||
|
||||
img_f = "images/cats.jpg"
|
||||
# 多模态请求(文本 + 图片)
|
||||
response = client.chat.completions.create(
|
||||
model="gpt-4-vision-preview", # 根据实际部署模型调整
|
||||
messages=[
|
||||
{
|
||||
"role": "user",
|
||||
"content": [
|
||||
{"type": "text", "text": "请描述这张图片的内容"},
|
||||
{
|
||||
"type": "image_url",
|
||||
"image_url": {
|
||||
"url": f"data:image/jpeg;base64,{encode_image(img_f)}"
|
||||
},
|
||||
},
|
||||
],
|
||||
}
|
||||
],
|
||||
max_tokens=300,
|
||||
stream=True,
|
||||
)
|
||||
|
||||
# for rsp in response.choices:
|
||||
# print("AI回复:", rsp.message.content)
|
||||
# print("AI回复:", response.choices[0].message.content)
|
||||
print(response)
|
||||
for chunk in response:
|
||||
# print(chunk)
|
||||
print(chunk.choices[0].delta.content, end="", flush=True)
|
||||
@@ -0,0 +1,6 @@
|
||||
# autopep8 -r ./minigemini/ -i
|
||||
|
||||
git add .
|
||||
git commit -am 'add'
|
||||
git push origin main
|
||||
git push github main
|
||||
@@ -0,0 +1,6 @@
|
||||
from namo.utils.process_utils import convert_image_tags
|
||||
|
||||
|
||||
# a = convert_image_tags('what in these images?\n<image>')
|
||||
a = convert_image_tags("what in these images?\n<image>\n<image>")
|
||||
print(a)
|
||||
@@ -0,0 +1,26 @@
|
||||
from transformers.models.qwen2_5_vl import Qwen2_5_VLImageProcessor
|
||||
from PIL import Image
|
||||
from namo.processor.image_processing_namo import NamoImageProcessor
|
||||
|
||||
|
||||
def load_images():
|
||||
imgs = [
|
||||
"images/3001910.jpg",
|
||||
"images/3001927.jpg",
|
||||
"images/3001980.jpg",
|
||||
"images/grey.jpg",
|
||||
]
|
||||
res = []
|
||||
for im in imgs:
|
||||
res.append(Image.open(im))
|
||||
return res
|
||||
|
||||
|
||||
imgs = load_images()
|
||||
# processor = Qwen2_5_VLImageProcessor.from_pretrained(
|
||||
# "checkpoints/Qwen2.5-VL-3B-Instruct"
|
||||
# )
|
||||
processor = NamoImageProcessor.from_pretrained("checkpoints/Namo-500M-V1")
|
||||
inputs = processor.preprocess(images=imgs)
|
||||
print(inputs)
|
||||
print([i.shape for i in inputs["pixel_values"]])
|
||||
@@ -0,0 +1,82 @@
|
||||
from transformers import AutoConfig
|
||||
from transformers import TextStreamer
|
||||
from namo.models.namo import NamoForCausalLM
|
||||
from namo.models.configuration_namo import NamoConfig
|
||||
from namo.utils.infer_utils import load_multi_images_maybe
|
||||
from namo.utils.process_utils import tokenizer_image_token
|
||||
import torch
|
||||
|
||||
torch.set_grad_enabled(False)
|
||||
device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
text_config = AutoConfig.from_pretrained(
|
||||
"checkpoints/Qwen2.5-0.5B-Instruct", trust_remote_code=True
|
||||
)
|
||||
vision_config = AutoConfig.from_pretrained(
|
||||
# "checkpoints/aimv2-large-patch14-native", trust_remote_code=True
|
||||
"checkpoints/aimv2-l-native-trained-base",
|
||||
trust_remote_code=True,
|
||||
)
|
||||
|
||||
|
||||
config = NamoConfig(text_config=text_config, vision_config=vision_config)
|
||||
|
||||
namo_model = NamoForCausalLM(config=config).to(device)
|
||||
namo_model.namo.load_conn_ve_llm_weights(
|
||||
"checkpoints/namo-qwen2-500m-aimv2-native-conn-ve-mlp2x_gelu/checkpoint-2500/conn_ve_llm.bin"
|
||||
)
|
||||
image_processor = namo_model.get_vision_tower().image_processor
|
||||
|
||||
images = load_multi_images_maybe("images/cats.jpg")
|
||||
pixel_values = (
|
||||
image_processor.preprocess(images, return_tensors="pt")["pixel_values"]
|
||||
.to(namo_model.dtype)
|
||||
.to(namo_model.device)
|
||||
)
|
||||
print(f"pixel_values: {pixel_values.shape}")
|
||||
tokenizer = namo_model.get_namo().tokenizer
|
||||
|
||||
chat = [
|
||||
{
|
||||
"role": "system",
|
||||
"content": "You should follow the instructions carefully and explain your answers in detail.",
|
||||
},
|
||||
{"role": "user", "content": "<image>\nDescribe the following image."},
|
||||
]
|
||||
prompt = tokenizer.apply_chat_template(chat, tokenize=False) + "<|im_start|>assistant\n"
|
||||
print(prompt)
|
||||
|
||||
input_ids = (
|
||||
tokenizer_image_token(
|
||||
prompt,
|
||||
# "hello, how are you.",
|
||||
tokenizer,
|
||||
return_tensors="pt",
|
||||
)
|
||||
.unsqueeze(0)
|
||||
.to(namo_model.device)
|
||||
)
|
||||
print(input_ids)
|
||||
|
||||
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
|
||||
with torch.autocast(device_type="cuda", dtype=torch.float16):
|
||||
output_ids = namo_model.generate(
|
||||
pixel_values=pixel_values,
|
||||
input_ids=input_ids,
|
||||
do_sample=False,
|
||||
max_new_tokens=100,
|
||||
streamer=streamer,
|
||||
use_cache=True,
|
||||
pad_token_id=tokenizer.eos_token_id,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
)
|
||||
outputs = tokenizer.decode(output_ids[0], skip_special_tokens=True).strip()
|
||||
print(f"final output:\n{outputs}")
|
||||
|
||||
# namo_model.generate(pixel_values=None, input_ids=input_ids, max_new_tokens=300)
|
||||
|
||||
model_path = "checkpoints/namo-500m-native"
|
||||
namo_model.save_pretrained(model_path)
|
||||
config.save_pretrained(model_path)
|
||||
tokenizer.save_pretrained(model_path)
|
||||
image_processor.save_pretrained(model_path)
|
||||
@@ -0,0 +1,12 @@
|
||||
python3 setup.py check
|
||||
|
||||
sudo rm -r build/
|
||||
sudo rm -r dist/
|
||||
|
||||
# pypi interface are not valid any longer
|
||||
# python3 setup.py sdist
|
||||
# python3 setup.py sdist upload -r pypi
|
||||
|
||||
# using twine instead
|
||||
python3 setup.py sdist
|
||||
twine upload dist/*
|
||||
@@ -0,0 +1,15 @@
|
||||
import os
|
||||
import open_webui
|
||||
|
||||
# Show where the Open WebUI package is installed
|
||||
print("Open WebUI is installed at:", open_webui.__file__)
|
||||
|
||||
# Construct a potential path to webui.db (commonly located in 'data/webui.db')
|
||||
db_path = os.path.join(os.path.dirname(open_webui.__file__), "data", "webui.db")
|
||||
print("Potential path to webui.db:", db_path)
|
||||
|
||||
# Check if webui.db exists at that path
|
||||
if os.path.exists(db_path):
|
||||
print("webui.db found at:", db_path)
|
||||
else:
|
||||
print("webui.db not found at:", db_path)
|
||||
@@ -0,0 +1,8 @@
|
||||
from namo.r1.grpo import main
|
||||
from trl import TrlParser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = TrlParser((GRPOScriptArguments, GRPOConfig, ModelConfig))
|
||||
script_args, training_args, model_args = parser.parse_args_and_config()
|
||||
main(script_args, training_args, model_args)
|
||||
@@ -0,0 +1,335 @@
|
||||
"""
|
||||
Code referenced from:
|
||||
|
||||
InternVL mDPO
|
||||
|
||||
"""
|
||||
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
import shutil
|
||||
import sys
|
||||
import traceback
|
||||
from copy import copy, deepcopy
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Dict, Literal, Optional
|
||||
|
||||
from loguru import logger
|
||||
import numpy as np
|
||||
import json
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import transformers
|
||||
from namo.dataargs import DataArguments, ModelArguments
|
||||
from namo.dataset_dpo import dpo_concat_pad_data_collator, WeightedConcatDataset
|
||||
from namo.dataset_dpo import build_datasets
|
||||
from namo.models.configuration_namo import NamoConfig
|
||||
from namo.models.namo import NamoForCausalLM
|
||||
from namo.tainer_mdpo import MultimodalDPOTrainer
|
||||
from PIL import Image, ImageFile, PngImagePlugin, UnidentifiedImageError
|
||||
from torch.utils.data import Dataset
|
||||
from transformers import (
|
||||
AutoConfig,
|
||||
AutoModelForCausalLM,
|
||||
AutoTokenizer,
|
||||
HfArgumentParser,
|
||||
Trainer,
|
||||
TrainingArguments,
|
||||
set_seed,
|
||||
)
|
||||
from transformers.trainer_utils import get_last_checkpoint
|
||||
from transformers.utils.logging import (
|
||||
enable_default_handler,
|
||||
enable_explicit_format,
|
||||
set_verbosity,
|
||||
)
|
||||
from trl import DPOConfig as DPOConfigTRL
|
||||
from namo.models.symbols import IGNORE_INDEX
|
||||
from namo.utils.hf_utils import get_latest_checkpoint
|
||||
from namo.utils.utils import find_all_linear_names, rank0_print
|
||||
|
||||
Image.MAX_IMAGE_PIXELS = None
|
||||
ImageFile.LOAD_TRUNCATED_IMAGES = True
|
||||
MaximumDecompressedSize = 1024
|
||||
MegaByte = 2**20
|
||||
PngImagePlugin.MAX_TEXT_CHUNK = MaximumDecompressedSize * MegaByte
|
||||
|
||||
|
||||
os.environ["TOKENIZERS_PARALLELISM"] = "true"
|
||||
|
||||
|
||||
class DPOConfig(DPOConfigTRL):
|
||||
loss_type: Literal[
|
||||
"sigmoid",
|
||||
"hinge",
|
||||
"ipo",
|
||||
"bco_pair",
|
||||
"sppo_hard",
|
||||
"nca_pair",
|
||||
"robust",
|
||||
"aot",
|
||||
"aot_pair",
|
||||
"exo_pair",
|
||||
"sigmoid,bco_pair",
|
||||
] = "sigmoid"
|
||||
|
||||
|
||||
def main(attn_implementation="flash_attention_2"):
|
||||
|
||||
global local_rank
|
||||
|
||||
parser = transformers.HfArgumentParser(
|
||||
(ModelArguments, DataArguments, TrainingArguments)
|
||||
)
|
||||
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
|
||||
local_rank = training_args.local_rank
|
||||
compute_dtype = (
|
||||
torch.float16
|
||||
if training_args.fp16
|
||||
else (torch.bfloat16 if training_args.bf16 else torch.float32)
|
||||
)
|
||||
|
||||
bnb_model_from_pretrained_args = {}
|
||||
if training_args.bits in [4, 8]:
|
||||
from transformers import BitsAndBytesConfig
|
||||
|
||||
bnb_model_from_pretrained_args.update(
|
||||
dict(
|
||||
device_map={"": training_args.device},
|
||||
load_in_4bit=training_args.bits == 4,
|
||||
load_in_8bit=training_args.bits == 8,
|
||||
quantization_config=BitsAndBytesConfig(
|
||||
load_in_4bit=training_args.bits == 4,
|
||||
load_in_8bit=training_args.bits == 8,
|
||||
llm_int8_skip_modules=["mm_projector"],
|
||||
llm_int8_threshold=6.0,
|
||||
llm_int8_has_fp16_weight=False,
|
||||
bnb_4bit_compute_dtype=compute_dtype,
|
||||
bnb_4bit_use_double_quant=training_args.double_quant,
|
||||
bnb_4bit_quant_type=training_args.quant_type, # {'fp4', 'nf4'}
|
||||
),
|
||||
)
|
||||
)
|
||||
|
||||
if model_args.pretrain_model_path is not None:
|
||||
pretrain_model_path = get_latest_checkpoint(model_args.pretrain_model_path)
|
||||
rank0_print(f"==> finetune from pretrained whole model: {pretrain_model_path}")
|
||||
model = NamoForCausalLM.from_pretrained(pretrain_model_path)
|
||||
rank0_print("==> pretrained model loaded.")
|
||||
else:
|
||||
text_config = AutoConfig.from_pretrained(
|
||||
model_args.llm_model_path,
|
||||
trust_remote_code=True,
|
||||
attn_implementation=attn_implementation,
|
||||
torch_dtype=compute_dtype,
|
||||
)
|
||||
vision_config = AutoConfig.from_pretrained(
|
||||
model_args.ve_model_path,
|
||||
trust_remote_code=True,
|
||||
torch_dtype=compute_dtype,
|
||||
)
|
||||
config = NamoConfig(
|
||||
text_config=text_config,
|
||||
vision_config=vision_config,
|
||||
attn_implementation=attn_implementation,
|
||||
torch_dtype=compute_dtype,
|
||||
conn_ve_llm_type=model_args.conn_ve_llm_type,
|
||||
longest_edge=model_args.max_img_size,
|
||||
**bnb_model_from_pretrained_args,
|
||||
)
|
||||
model = NamoForCausalLM(config=config)
|
||||
|
||||
# just copy ref model
|
||||
ref_model = copy(model)
|
||||
|
||||
rank0_print(f"==> current model dtype: {model.dtype}, set is: {compute_dtype}")
|
||||
tokenizer = model.get_namo().tokenizer
|
||||
|
||||
model.config.use_cache = False
|
||||
|
||||
if model_args.freeze_backbone:
|
||||
model.model.requires_grad_(False)
|
||||
|
||||
if training_args.gradient_checkpointing:
|
||||
if hasattr(model, "enable_input_require_grads"):
|
||||
try:
|
||||
model.enable_input_require_grads()
|
||||
except Exception as e:
|
||||
print(f"enable_input_require_grads: {e}")
|
||||
else:
|
||||
|
||||
def make_inputs_require_grad(module, input, output):
|
||||
output.requires_grad_(True)
|
||||
|
||||
model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
|
||||
|
||||
if training_args.lora_enable:
|
||||
from peft import LoraConfig, get_peft_model
|
||||
|
||||
lora_config = LoraConfig(
|
||||
r=training_args.lora_r,
|
||||
lora_alpha=training_args.lora_alpha,
|
||||
target_modules=find_all_linear_names(model),
|
||||
lora_dropout=training_args.lora_dropout,
|
||||
bias=training_args.lora_bias,
|
||||
task_type="CAUSAL_LM",
|
||||
use_dora=training_args.use_dora,
|
||||
)
|
||||
if training_args.bits == 16:
|
||||
if training_args.bf16:
|
||||
model.to(torch.bfloat16)
|
||||
if training_args.fp16:
|
||||
model.to(torch.float16)
|
||||
rank0_print("Adding LoRA adapters...")
|
||||
model = get_peft_model(model, lora_config)
|
||||
|
||||
if tokenizer.unk_token != None:
|
||||
tokenizer.pad_token = tokenizer.unk_token
|
||||
|
||||
if tokenizer.pad_token_id == None:
|
||||
rank0_print(f"tokenizer.pad_token: {tokenizer.pad_token}")
|
||||
if "mistral" in model_args.model_name_or_path.lower():
|
||||
# important for mistral models
|
||||
tokenizer.pad_token_id = tokenizer.encode("<pad>")
|
||||
else:
|
||||
tokenizer.pad_token_id = tokenizer.encode(
|
||||
tokenizer.pad_token
|
||||
if tokenizer.pad_token is not None
|
||||
else tokenizer.eos_token
|
||||
)
|
||||
rank0_print(f"pad_token_id: {tokenizer.pad_token_id}")
|
||||
|
||||
if (
|
||||
model_args.ve_model_path is not None
|
||||
or model_args.pretrain_model_path is not None
|
||||
):
|
||||
logger.info("preparing ve model args...")
|
||||
# model.get_model().initialize_vision_modules(
|
||||
# model_args=model_args, fsdp=training_args.fsdp
|
||||
# )
|
||||
vision_tower = model.get_vision_tower()
|
||||
vision_tower.to(
|
||||
dtype=torch.bfloat16 if training_args.bf16 else torch.float16,
|
||||
device=training_args.device,
|
||||
)
|
||||
|
||||
model.config.unfreeze_ve = training_args.unfreeze_ve = model_args.unfreeze_ve
|
||||
if training_args.unfreeze_ve:
|
||||
for p in model.get_vision_tower().parameters():
|
||||
p.requires_grad = True
|
||||
|
||||
model.config.new_img_size = model_args.new_img_size
|
||||
model.config.longest_edge = data_args.longest_edge = model_args.max_img_size
|
||||
model.config.dynamic_size = data_args.dynamic_size
|
||||
vision_tower.image_processor.size["longest_edge"] = data_args.longest_edge
|
||||
data_args.image_processor = vision_tower.image_processor
|
||||
data_args.is_multimodal = True
|
||||
|
||||
model.config.image_aspect_ratio = data_args.image_aspect_ratio
|
||||
model.config.video_fps = data_args.video_fps
|
||||
model.config.video_frames_num = data_args.video_frames_num
|
||||
model.config.tokenizer_padding_side = tokenizer.padding_side
|
||||
model.config.tokenizer_model_max_length = tokenizer.model_max_length
|
||||
|
||||
model.config.tune_conn_ve_llm = training_args.tune_conn_ve_llm = (
|
||||
model_args.tune_conn_ve_llm
|
||||
)
|
||||
if model_args.tune_conn_ve_llm:
|
||||
model.requires_grad_(False)
|
||||
for p in model.get_namo().conn_ve_llm.parameters():
|
||||
p.requires_grad = True
|
||||
|
||||
model.config.freeze_conn_ve_llm = training_args.freeze_conn_ve_llm
|
||||
if training_args.freeze_conn_ve_llm:
|
||||
for p in model.get_namo().conn_ve_llm.parameters():
|
||||
p.requires_grad = False
|
||||
|
||||
if training_args.bits in [4, 8]:
|
||||
model.get_namo().conn_ve_llm.to(
|
||||
dtype=compute_dtype, device=training_args.device
|
||||
)
|
||||
|
||||
model.config.mm_use_im_start_end = data_args.mm_use_im_start_end = (
|
||||
model_args.mm_use_im_start_end
|
||||
)
|
||||
model.config.conn_ve_llm_lr = training_args.conn_ve_llm_lr
|
||||
model.config.s2 = model_args.s2
|
||||
model.config.s2_scales = model_args.s2_scales
|
||||
model.config.s2_max_split_size = model_args.s2_max_split_size
|
||||
training_args.use_im_start_end = model_args.mm_use_im_start_end
|
||||
model.config.mm_use_im_patch_token = model_args.mm_use_im_patch_token
|
||||
model.initialize_vision_tokenizer(model_args, tokenizer=tokenizer)
|
||||
|
||||
logger.info("Model load finished.")
|
||||
train_dataset = build_datasets(
|
||||
data_args,
|
||||
tokenizer,
|
||||
None,
|
||||
model,
|
||||
group_by_length=training_args.group_by_length,
|
||||
dynamic_image_size=data_args.dynamic_image_size,
|
||||
use_thumbnail=data_args.use_thumbnail,
|
||||
min_dynamic_patch=data_args.min_dynamic_patch,
|
||||
max_dynamic_patch=data_args.max_dynamic_patch,
|
||||
normalize_type=data_args.normalize_type,
|
||||
min_num_frame=data_args.min_num_frame,
|
||||
max_num_frame=data_args.max_num_frame,
|
||||
)
|
||||
|
||||
def _freeze_params(module):
|
||||
for param in module.parameters():
|
||||
param.requires_grad = False
|
||||
|
||||
ref_model.eval()
|
||||
# _freeze_params(ref_model)
|
||||
|
||||
# set seed for torch dataloaders
|
||||
set_seed(training_args.seed)
|
||||
|
||||
trainer = MultimodalDPOTrainer(
|
||||
model=model,
|
||||
ref_model=ref_model,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset if training_args.do_train else None,
|
||||
eval_dataset=None,
|
||||
tokenizer=tokenizer,
|
||||
data_collator=dpo_concat_pad_data_collator,
|
||||
)
|
||||
|
||||
# Training
|
||||
if training_args.do_train:
|
||||
print(
|
||||
f"[Memory Usage before training] {torch.cuda.memory_allocated()/1024/1024/1024:.2f}GB"
|
||||
)
|
||||
train_result = trainer.train(resume_from_checkpoint=True)
|
||||
trainer.save_model() # Saves the tokenizer too for easy upload
|
||||
|
||||
metrics = train_result.metrics
|
||||
try:
|
||||
metrics["train_samples"] = len(train_dataset)
|
||||
except:
|
||||
metrics["train_samples"] = -1
|
||||
|
||||
trainer.log_metrics("train", metrics)
|
||||
trainer.save_metrics("train", metrics)
|
||||
trainer.save_state()
|
||||
|
||||
model_dir = model_args.model_name_or_path
|
||||
output_dir = training_args.output_dir
|
||||
for filename in [
|
||||
"conversation.py",
|
||||
"modeling_internvl_chat.py",
|
||||
"modeling_intern_vit.py",
|
||||
"modeling_internlm2.py",
|
||||
"configuration_internvl_chat.py",
|
||||
"configuration_intern_vit.py",
|
||||
"configuration_internlm2.py",
|
||||
]:
|
||||
if os.path.exists(os.path.join(model_dir, filename)):
|
||||
shutil.copy(os.path.join(model_dir, filename), output_dir)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||