Compare commits
86 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
795f2c90fd | ||
|
|
84e2337807 | ||
|
|
9613576191 | ||
|
|
e4356d6488 | ||
|
|
82441460ef | ||
|
|
3e1097cb63 | ||
|
|
78990dd960 | ||
|
|
405a1facd2 | ||
|
|
3028089e5e | ||
|
|
b536f39818 | ||
|
|
e25e525fde | ||
|
|
de9adb907c | ||
|
|
bf861e65dc | ||
|
|
4da810b943 | ||
|
|
161c6e14b6 | ||
|
|
a6c9015c4e | ||
|
|
e6a5f99e5c | ||
|
|
80ff4ba63e | ||
|
|
b09a2aa308 | ||
|
|
63b6846849 | ||
|
|
139f707e6e | ||
|
|
e4546fd5bb | ||
|
|
d44e31aec2 | ||
|
|
ce9825b56b | ||
|
|
85f9d92883 | ||
|
|
916d9812a8 | ||
|
|
e6a8492242 | ||
|
|
ad0308b3f1 | ||
|
|
e97a633b63 | ||
|
|
01ac37b331 | ||
|
|
6a05b274cc | ||
|
|
98d46a3f08 | ||
|
|
4330a747d4 | ||
|
|
76de6a09fb | ||
|
|
25caf24ef9 | ||
|
|
8db3c9bc9f | ||
|
|
e0e9f81971 | ||
|
|
5d848ec07c | ||
|
|
4974b84564 | ||
|
|
83062fb872 | ||
|
|
b6d7e31d10 | ||
|
|
53e9aacc10 | ||
|
|
41424466e3 | ||
|
|
95de1981c9 | ||
|
|
0b45b58867 | ||
|
|
d3986f18be | ||
|
|
ee6a3a993d | ||
|
|
b300517305 | ||
|
|
ac07b6dc6a | ||
|
|
46ab56a468 | ||
|
|
038ff70023 | ||
|
|
00eca4b887 | ||
|
|
30132aba30 | ||
|
|
a17d6d6858 | ||
|
|
8efd9ce787 | ||
|
|
299c16d0f5 | ||
|
|
69f49195ac | ||
|
|
ed224f94ba | ||
|
|
531e719163 | ||
|
|
4fbd310fd2 | ||
|
|
2ea28d69dc | ||
|
|
a1cb106459 | ||
|
|
5dd8e04d4b | ||
|
|
165af7edd3 | ||
|
|
6c5f0de713 | ||
|
|
e64fdcf2ce | ||
|
|
ec64f371b1 | ||
|
|
cd6e1f1171 | ||
|
|
6f2b310a17 | ||
|
|
e3cd6cae50 | ||
|
|
e5ee05da76 | ||
|
|
e6ff752840 | ||
|
|
3f9c746fb2 | ||
|
|
1f22c98820 | ||
|
|
b4226bd6a7 | ||
|
|
46fac824be | ||
|
|
b33b64f595 | ||
|
|
9d9744075e | ||
|
|
d9a3b69806 | ||
|
|
f7e5954d5e | ||
|
|
8e19c073e5 | ||
|
|
f6df16cbb8 | ||
|
|
b24f78349c | ||
|
|
3ce905c9d0 | ||
|
|
f539497ab4 | ||
|
|
39dfb7abbd |
@@ -1,22 +1,58 @@
|
||||
name: Build Docker images (nightly)
|
||||
name: Test, build, and push Docker images
|
||||
|
||||
on:
|
||||
pull_request: # During PRs, we just check if the changes Dockerfiles can be successfully built
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
- "docker/**"
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: "0 0 * * *" # every day at midnight
|
||||
|
||||
concurrency:
|
||||
group: docker-image-builds
|
||||
cancel-in-progress: false
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
REGISTRY: diffusers
|
||||
CI_SLACK_CHANNEL: ${{ secrets.CI_DOCKER_CHANNEL }}
|
||||
|
||||
jobs:
|
||||
build-docker-images:
|
||||
test-build-docker-images:
|
||||
runs-on: ubuntu-latest
|
||||
if: github.event_name == 'pull_request'
|
||||
steps:
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Find Changed Dockerfiles
|
||||
id: file_changes
|
||||
uses: jitterbit/get-changed-files@v1
|
||||
with:
|
||||
format: 'space-delimited'
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Build Changed Docker Images
|
||||
run: |
|
||||
CHANGED_FILES="${{ steps.file_changes.outputs.all }}"
|
||||
for FILE in $CHANGED_FILES; do
|
||||
if [[ "$FILE" == docker/*Dockerfile ]]; then
|
||||
DOCKER_PATH="${FILE%/Dockerfile}"
|
||||
DOCKER_TAG=$(basename "$DOCKER_PATH")
|
||||
echo "Building Docker image for $DOCKER_TAG"
|
||||
docker build -t "$DOCKER_TAG" "$DOCKER_PATH"
|
||||
fi
|
||||
done
|
||||
if: steps.file_changes.outputs.all != ''
|
||||
|
||||
build-and-push-docker-images:
|
||||
runs-on: ubuntu-latest
|
||||
if: github.event_name != 'pull_request'
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
packages: write
|
||||
|
||||
@@ -12,6 +12,7 @@ env:
|
||||
PYTEST_TIMEOUT: 600
|
||||
RUN_SLOW: yes
|
||||
RUN_NIGHTLY: yes
|
||||
SLACK_API_TOKEN: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
jobs:
|
||||
run_nightly_tests:
|
||||
@@ -64,6 +65,7 @@ jobs:
|
||||
python -m uv pip install -e [quality,test]
|
||||
python -m uv pip install -U transformers@git+https://github.com/huggingface/transformers
|
||||
python -m uv pip install accelerate@git+https://github.com/huggingface/accelerate
|
||||
python -m uv pip install pytest-reportlog
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
@@ -78,7 +80,8 @@ jobs:
|
||||
python -m pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
tests/
|
||||
--report-log=${{ matrix.config.report }}.log \
|
||||
tests/
|
||||
|
||||
- name: Run nightly Flax TPU tests
|
||||
if: ${{ matrix.config.framework == 'flax' }}
|
||||
@@ -89,6 +92,7 @@ jobs:
|
||||
python -m pytest -n 0 \
|
||||
-s -v -k "Flax" \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
--report-log=${{ matrix.config.report }}.log \
|
||||
tests/
|
||||
|
||||
- name: Run nightly ONNXRuntime CUDA tests
|
||||
@@ -100,6 +104,7 @@ jobs:
|
||||
python -m pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "Onnx" \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
--report-log=${{ matrix.config.report }}.log \
|
||||
tests/
|
||||
|
||||
- name: Failure short reports
|
||||
@@ -112,6 +117,12 @@ jobs:
|
||||
with:
|
||||
name: ${{ matrix.config.report }}_test_reports
|
||||
path: reports
|
||||
|
||||
- name: Generate Report and Notify Channel
|
||||
if: always()
|
||||
run: |
|
||||
pip install slack_sdk tabulate
|
||||
python scripts/log_reports.py >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
run_nightly_tests_apple_m1:
|
||||
name: Nightly PyTorch MPS tests on MacOS
|
||||
@@ -140,6 +151,7 @@ jobs:
|
||||
${CONDA_RUN} python -m uv pip install -e [quality,test]
|
||||
${CONDA_RUN} python -m uv pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
|
||||
${CONDA_RUN} python -m uv pip install accelerate@git+https://github.com/huggingface/accelerate
|
||||
${CONDA_RUN} python -m uv pip install pytest-reportlog
|
||||
|
||||
- name: Environment
|
||||
shell: arch -arch arm64 bash {0}
|
||||
@@ -152,7 +164,9 @@ jobs:
|
||||
HF_HOME: /System/Volumes/Data/mnt/cache
|
||||
HUGGING_FACE_HUB_TOKEN: ${{ secrets.HUGGING_FACE_HUB_TOKEN }}
|
||||
run: |
|
||||
${CONDA_RUN} python -m pytest -n 1 -s -v --make-reports=tests_torch_mps tests/
|
||||
${CONDA_RUN} python -m pytest -n 1 -s -v --make-reports=tests_torch_mps \
|
||||
--report-log=tests_torch_mps.log \
|
||||
tests/
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
@@ -164,3 +178,9 @@ jobs:
|
||||
with:
|
||||
name: torch_mps_test_reports
|
||||
path: reports
|
||||
|
||||
- name: Generate Report and Notify Channel
|
||||
if: always()
|
||||
run: |
|
||||
pip install slack_sdk tabulate
|
||||
python scripts/log_reports.py >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
@@ -0,0 +1,23 @@
|
||||
name: Notify Slack about a release
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
release:
|
||||
types: [published]
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '3.8'
|
||||
|
||||
- name: Notify Slack about the release
|
||||
env:
|
||||
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
|
||||
run: pip install requests && python utils/notify_slack_about_release.py
|
||||
@@ -105,4 +105,4 @@ jobs:
|
||||
python -m pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
tests/lora/test_lora_layers_peft.py
|
||||
tests/lora/
|
||||
|
||||
@@ -21,10 +21,7 @@ env:
|
||||
jobs:
|
||||
setup_torch_cuda_pipeline_matrix:
|
||||
name: Setup Torch Pipelines CUDA Slow Tests Matrix
|
||||
runs-on: [single-gpu, nvidia-gpu, t4, ci]
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cpu # this is a CPU image, but we need it to fetch the matrix
|
||||
options: --shm-size "16gb" --ipc host
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
pipeline_test_matrix: ${{ steps.fetch_pipeline_matrix.outputs.pipeline_test_matrix }}
|
||||
steps:
|
||||
@@ -32,24 +29,20 @@ jobs:
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
apt-get update && apt-get install libsndfile1-dev libgl1 -y
|
||||
python -m venv /opt/venv && export PATH="/opt/venv/bin:$PATH"
|
||||
python -m uv pip install -e [quality,test]
|
||||
python -m uv pip install accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
pip install -e .
|
||||
pip install huggingface_hub
|
||||
- name: Fetch Pipeline Matrix
|
||||
id: fetch_pipeline_matrix
|
||||
run: |
|
||||
matrix=$(python utils/fetch_torch_cuda_pipeline_test_matrix.py)
|
||||
echo $matrix
|
||||
echo "pipeline_test_matrix=$matrix" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: Pipeline Tests Artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v2
|
||||
|
||||
@@ -0,0 +1,81 @@
|
||||
# Adapted from https://blog.deepjyoti30.dev/pypi-release-github-action
|
||||
|
||||
name: PyPI release
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
push:
|
||||
tags:
|
||||
- "*"
|
||||
|
||||
jobs:
|
||||
find-and-checkout-latest-branch:
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
latest_branch: ${{ steps.set_latest_branch.outputs.latest_branch }}
|
||||
steps:
|
||||
- name: Checkout Repo
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '3.8'
|
||||
|
||||
- name: Fetch latest branch
|
||||
id: fetch_latest_branch
|
||||
run: |
|
||||
pip install -U requests packaging
|
||||
LATEST_BRANCH=$(python utils/fetch_latest_release_branch.py)
|
||||
echo "Latest branch: $LATEST_BRANCH"
|
||||
echo "latest_branch=$LATEST_BRANCH" >> $GITHUB_ENV
|
||||
|
||||
- name: Set latest branch output
|
||||
id: set_latest_branch
|
||||
run: echo "::set-output name=latest_branch::${{ env.latest_branch }}"
|
||||
|
||||
release:
|
||||
needs: find-and-checkout-latest-branch
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Checkout Repo
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
ref: ${{ needs.find-and-checkout-latest-branch.outputs.latest_branch }}
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.8"
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install -U setuptools wheel twine
|
||||
pip install -U torch --index-url https://download.pytorch.org/whl/cpu
|
||||
pip install -U transformers
|
||||
|
||||
- name: Build the dist files
|
||||
run: python setup.py bdist_wheel && python setup.py sdist
|
||||
|
||||
- name: Publish to the test PyPI
|
||||
env:
|
||||
TWINE_USERNAME: ${{ secrets.TEST_PYPI_USERNAME }}
|
||||
TWINE_PASSWORD: ${{ secrets.TEST_PYPI_PASSWORD }}
|
||||
run: twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/
|
||||
|
||||
- name: Test installing diffusers and importing
|
||||
run: |
|
||||
pip install diffusers && pip uninstall diffusers -y
|
||||
pip install -i https://testpypi.python.org/pypi diffusers
|
||||
python -c "from diffusers import __version__; print(__version__)"
|
||||
python -c "from diffusers import DiffusionPipeline; pipe = DiffusionPipeline.from_pretrained('fusing/unet-ldm-dummy-update'); pipe()"
|
||||
python -c "from diffusers import DiffusionPipeline; pipe = DiffusionPipeline.from_pretrained('hf-internal-testing/tiny-stable-diffusion-pipe', safety_checker=None); pipe('ah suh du')"
|
||||
python -c "from diffusers import *"
|
||||
|
||||
- name: Publish to PyPI
|
||||
env:
|
||||
TWINE_USERNAME: ${{ secrets.PYPI_USERNAME }}
|
||||
TWINE_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
|
||||
run: twine upload dist/* -r pypi
|
||||
@@ -19,6 +19,16 @@ authors:
|
||||
family-names: Rasul
|
||||
- given-names: Mishig
|
||||
family-names: Davaadorj
|
||||
- given-names: Dhruv
|
||||
family-names: Nair
|
||||
- given-names: Sayak
|
||||
family-names: Paul
|
||||
- given-names: Steven
|
||||
family-names: Liu
|
||||
- given-names: William
|
||||
family-names: Berman
|
||||
- given-names: Yiyi
|
||||
family-names: Xu
|
||||
- given-names: Thomas
|
||||
family-names: Wolf
|
||||
repository-code: 'https://github.com/huggingface/diffusers'
|
||||
|
||||
@@ -77,7 +77,7 @@ Please refer to the [How to use Stable Diffusion in Apple Silicon](https://huggi
|
||||
|
||||
## Quickstart
|
||||
|
||||
Generating outputs is super easy with 🤗 Diffusers. To generate an image from text, use the `from_pretrained` method to load any pretrained diffusion model (browse the [Hub](https://huggingface.co/models?library=diffusers&sort=downloads) for 19000+ checkpoints):
|
||||
Generating outputs is super easy with 🤗 Diffusers. To generate an image from text, use the `from_pretrained` method to load any pretrained diffusion model (browse the [Hub](https://huggingface.co/models?library=diffusers&sort=downloads) for 22000+ checkpoints):
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
@@ -219,7 +219,7 @@ Also, say 👋 in our public Discord channel <a href="https://discord.gg/G7tWnz9
|
||||
- https://github.com/deep-floyd/IF
|
||||
- https://github.com/bentoml/BentoML
|
||||
- https://github.com/bmaltais/kohya_ss
|
||||
- +8000 other amazing GitHub repositories 💪
|
||||
- +9000 other amazing GitHub repositories 💪
|
||||
|
||||
Thank you for using us ❤️.
|
||||
|
||||
@@ -238,7 +238,7 @@ We also want to thank @heejkoo for the very helpful overview of papers, code and
|
||||
|
||||
```bibtex
|
||||
@misc{von-platen-etal-2022-diffusers,
|
||||
author = {Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Thomas Wolf},
|
||||
author = {Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Dhruv Nair and Sayak Paul and William Berman and Yiyi Xu and Steven Liu and Thomas Wolf},
|
||||
title = {Diffusers: State-of-the-art diffusion models},
|
||||
year = {2022},
|
||||
publisher = {GitHub},
|
||||
|
||||
@@ -40,6 +40,6 @@ RUN python3 -m pip install --no-cache-dir --upgrade pip uv==0.1.11 && \
|
||||
numpy \
|
||||
scipy \
|
||||
tensorboard \
|
||||
transformers
|
||||
transformers matplotlib
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
|
||||
@@ -18,7 +18,7 @@
|
||||
- local: tutorials/basic_training
|
||||
title: Train a diffusion model
|
||||
- local: tutorials/using_peft_for_inference
|
||||
title: Inference with PEFT
|
||||
title: Load LoRAs for inference
|
||||
- local: tutorials/fast_diffusion
|
||||
title: Accelerate inference of text-to-image diffusion models
|
||||
title: Tutorials
|
||||
@@ -62,6 +62,8 @@
|
||||
title: Textual inversion
|
||||
- local: using-diffusers/ip_adapter
|
||||
title: IP-Adapter
|
||||
- local: using-diffusers/merge_loras
|
||||
title: Merge LoRAs
|
||||
- local: training/distributed_inference
|
||||
title: Distributed inference with multiple GPUs
|
||||
- local: using-diffusers/reusing_seeds
|
||||
@@ -102,6 +104,8 @@
|
||||
title: Latent Consistency Model-LoRA
|
||||
- local: using-diffusers/inference_with_lcm
|
||||
title: Latent Consistency Model
|
||||
- local: using-diffusers/inference_with_tcd_lora
|
||||
title: Trajectory Consistency Distillation-LoRA
|
||||
- local: using-diffusers/svd
|
||||
title: Stable Video Diffusion
|
||||
title: Specific pipeline examples
|
||||
@@ -302,6 +306,8 @@
|
||||
title: Latent Consistency Models
|
||||
- local: api/pipelines/latent_diffusion
|
||||
title: Latent Diffusion
|
||||
- local: api/pipelines/ledits_pp
|
||||
title: LEDITS++
|
||||
- local: api/pipelines/panorama
|
||||
title: MultiDiffusion
|
||||
- local: api/pipelines/musicldm
|
||||
@@ -394,6 +400,10 @@
|
||||
title: DPMSolverSDEScheduler
|
||||
- local: api/schedulers/singlestep_dpm_solver
|
||||
title: DPMSolverSinglestepScheduler
|
||||
- local: api/schedulers/edm_multistep_dpm_solver
|
||||
title: EDMDPMSolverMultistepScheduler
|
||||
- local: api/schedulers/edm_euler
|
||||
title: EDMEulerScheduler
|
||||
- local: api/schedulers/euler_ancestral
|
||||
title: EulerAncestralDiscreteScheduler
|
||||
- local: api/schedulers/euler
|
||||
|
||||
@@ -23,3 +23,7 @@ Learn how to load an IP-Adapter checkpoint and image in the IP-Adapter [loading]
|
||||
## IPAdapterMixin
|
||||
|
||||
[[autodoc]] loaders.ip_adapter.IPAdapterMixin
|
||||
|
||||
## IPAdapterMaskProcessor
|
||||
|
||||
[[autodoc]] image_processor.IPAdapterMaskProcessor
|
||||
@@ -408,6 +408,29 @@ Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers)
|
||||
|
||||
</Tip>
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<th align=center>Without FreeInit enabled</th>
|
||||
<th align=center>With FreeInit enabled</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align=center>
|
||||
panda playing a guitar
|
||||
<br />
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/animatediff-no-freeinit.gif"
|
||||
alt="panda playing a guitar"
|
||||
style="width: 300px;" />
|
||||
</td>
|
||||
<td align=center>
|
||||
panda playing a guitar
|
||||
<br/>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/animatediff-freeinit.gif"
|
||||
alt="panda playing a guitar"
|
||||
style="width: 300px;" />
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## Using AnimateLCM
|
||||
|
||||
[AnimateLCM](https://animatelcm.github.io/) is a motion module checkpoint and an [LCM LoRA](https://huggingface.co/docs/diffusers/using-diffusers/inference_with_lcm_lora) that have been created using a consistency learning strategy that decouples the distillation of the image generation priors and the motion generation priors.
|
||||
|
||||
@@ -0,0 +1,54 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# LEDITS++
|
||||
|
||||
LEDITS++ was proposed in [LEDITS++: Limitless Image Editing using Text-to-Image Models](https://huggingface.co/papers/2311.16711) by Manuel Brack, Felix Friedrich, Katharina Kornmeier, Linoy Tsaban, Patrick Schramowski, Kristian Kersting, Apolinário Passos.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Text-to-image diffusion models have recently received increasing interest for their astonishing ability to produce high-fidelity images from solely text inputs. Subsequent research efforts aim to exploit and apply their capabilities to real image editing. However, existing image-to-image methods are often inefficient, imprecise, and of limited versatility. They either require time-consuming fine-tuning, deviate unnecessarily strongly from the input image, and/or lack support for multiple, simultaneous edits. To address these issues, we introduce LEDITS++, an efficient yet versatile and precise textual image manipulation technique. LEDITS++'s novel inversion approach requires no tuning nor optimization and produces high-fidelity results with a few diffusion steps. Second, our methodology supports multiple simultaneous edits and is architecture-agnostic. Third, we use a novel implicit masking technique that limits changes to relevant image regions. We propose the novel TEdBench++ benchmark as part of our exhaustive evaluation. Our results demonstrate the capabilities of LEDITS++ and its improvements over previous methods. The project page is available at https://leditsplusplus-project.static.hf.space .*
|
||||
|
||||
<Tip>
|
||||
|
||||
You can find additional information about LEDITS++ on the [project page](https://leditsplusplus-project.static.hf.space/index.html) and try it out in a [demo](https://huggingface.co/spaces/editing-images/leditsplusplus).
|
||||
|
||||
</Tip>
|
||||
|
||||
<Tip warning={true}>
|
||||
Due to some backward compatability issues with the current diffusers implementation of [`~schedulers.DPMSolverMultistepScheduler`] this implementation of LEdits++ can no longer guarantee perfect inversion.
|
||||
This issue is unlikely to have any noticeable effects on applied use-cases. However, we provide an alternative implementation that guarantees perfect inversion in a dedicated [GitHub repo](https://github.com/ml-research/ledits_pp).
|
||||
</Tip>
|
||||
|
||||
We provide two distinct pipelines based on different pre-trained models.
|
||||
|
||||
## LEditsPPPipelineStableDiffusion
|
||||
[[autodoc]] pipelines.ledits_pp.LEditsPPPipelineStableDiffusion
|
||||
- all
|
||||
- __call__
|
||||
- invert
|
||||
|
||||
## LEditsPPPipelineStableDiffusionXL
|
||||
[[autodoc]] pipelines.ledits_pp.LEditsPPPipelineStableDiffusionXL
|
||||
- all
|
||||
- __call__
|
||||
- invert
|
||||
|
||||
|
||||
|
||||
## LEditsPPDiffusionPipelineOutput
|
||||
[[autodoc]] pipelines.ledits_pp.pipeline_output.LEditsPPDiffusionPipelineOutput
|
||||
- all
|
||||
|
||||
## LEditsPPInversionPipelineOutput
|
||||
[[autodoc]] pipelines.ledits_pp.pipeline_output.LEditsPPInversionPipelineOutput
|
||||
- all
|
||||
@@ -57,6 +57,7 @@ The table below lists all the pipelines currently available in 🤗 Diffusers an
|
||||
| [Latent Consistency Models](latent_consistency_models) | text2image |
|
||||
| [Latent Diffusion](latent_diffusion) | text2image, super-resolution |
|
||||
| [LDM3D](stable_diffusion/ldm3d_diffusion) | text2image, text-to-3D, text-to-pano, upscaling |
|
||||
| [LEDITS++](ledits_pp) | image editing |
|
||||
| [MultiDiffusion](panorama) | text2image |
|
||||
| [MusicLDM](musicldm) | text2audio |
|
||||
| [Paint by Example](paint_by_example) | inpainting |
|
||||
|
||||
@@ -30,6 +30,6 @@ Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers)
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## StableDiffusionSafePipelineOutput
|
||||
## SemanticStableDiffusionPipelineOutput
|
||||
[[autodoc]] pipelines.semantic_stable_diffusion.pipeline_output.SemanticStableDiffusionPipelineOutput
|
||||
- all
|
||||
|
||||
@@ -12,13 +12,13 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# Stable Cascade
|
||||
|
||||
This model is built upon the [Würstchen](https://openreview.net/forum?id=gU58d5QeGv) architecture and its main
|
||||
difference to other models like Stable Diffusion is that it is working at a much smaller latent space. Why is this
|
||||
important? The smaller the latent space, the **faster** you can run inference and the **cheaper** the training becomes.
|
||||
How small is the latent space? Stable Diffusion uses a compression factor of 8, resulting in a 1024x1024 image being
|
||||
encoded to 128x128. Stable Cascade achieves a compression factor of 42, meaning that it is possible to encode a
|
||||
1024x1024 image to 24x24, while maintaining crisp reconstructions. The text-conditional model is then trained in the
|
||||
highly compressed latent space. Previous versions of this architecture, achieved a 16x cost reduction over Stable
|
||||
This model is built upon the [Würstchen](https://openreview.net/forum?id=gU58d5QeGv) architecture and its main
|
||||
difference to other models like Stable Diffusion is that it is working at a much smaller latent space. Why is this
|
||||
important? The smaller the latent space, the **faster** you can run inference and the **cheaper** the training becomes.
|
||||
How small is the latent space? Stable Diffusion uses a compression factor of 8, resulting in a 1024x1024 image being
|
||||
encoded to 128x128. Stable Cascade achieves a compression factor of 42, meaning that it is possible to encode a
|
||||
1024x1024 image to 24x24, while maintaining crisp reconstructions. The text-conditional model is then trained in the
|
||||
highly compressed latent space. Previous versions of this architecture, achieved a 16x cost reduction over Stable
|
||||
Diffusion 1.5.
|
||||
|
||||
Therefore, this kind of model is well suited for usages where efficiency is important. Furthermore, all known extensions
|
||||
@@ -30,13 +30,154 @@ The original codebase can be found at [Stability-AI/StableCascade](https://githu
|
||||
Stable Cascade consists of three models: Stage A, Stage B and Stage C, representing a cascade to generate images,
|
||||
hence the name "Stable Cascade".
|
||||
|
||||
Stage A & B are used to compress images, similar to what the job of the VAE is in Stable Diffusion.
|
||||
However, with this setup, a much higher compression of images can be achieved. While the Stable Diffusion models use a
|
||||
spatial compression factor of 8, encoding an image with resolution of 1024 x 1024 to 128 x 128, Stable Cascade achieves
|
||||
a compression factor of 42. This encodes a 1024 x 1024 image to 24 x 24, while being able to accurately decode the
|
||||
image. This comes with the great benefit of cheaper training and inference. Furthermore, Stage C is responsible
|
||||
Stage A & B are used to compress images, similar to what the job of the VAE is in Stable Diffusion.
|
||||
However, with this setup, a much higher compression of images can be achieved. While the Stable Diffusion models use a
|
||||
spatial compression factor of 8, encoding an image with resolution of 1024 x 1024 to 128 x 128, Stable Cascade achieves
|
||||
a compression factor of 42. This encodes a 1024 x 1024 image to 24 x 24, while being able to accurately decode the
|
||||
image. This comes with the great benefit of cheaper training and inference. Furthermore, Stage C is responsible
|
||||
for generating the small 24 x 24 latents given a text prompt.
|
||||
|
||||
The Stage C model operates on the small 24 x 24 latents and denoises the latents conditioned on text prompts. The model is also the largest component in the Cascade pipeline and is meant to be used with the `StableCascadePriorPipeline`
|
||||
|
||||
The Stage B and Stage A models are used with the `StableCascadeDecoderPipeline` and are responsible for generating the final image given the small 24 x 24 latents.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
There are some restrictions on data types that can be used with the Stable Cascade models. The official checkpoints for the `StableCascadePriorPipeline` do not support the `torch.float16` data type. Please use `torch.bfloat16` instead.
|
||||
|
||||
In order to use the `torch.bfloat16` data type with the `StableCascadeDecoderPipeline` you need to have PyTorch 2.2.0 or higher installed. This also means that using the `StableCascadeCombinedPipeline` with `torch.bfloat16` requires PyTorch 2.2.0 or higher, since it calls the `StableCascadeDecoderPipeline` internally.
|
||||
|
||||
If it is not possible to install PyTorch 2.2.0 or higher in your environment, the `StableCascadeDecoderPipeline` can be used on its own with the `torch.float16` data type. You can download the full precision or `bf16` variant weights for the pipeline and cast the weights to `torch.float16`.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Usage example
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
|
||||
|
||||
prompt = "an image of a shiba inu, donning a spacesuit and helmet"
|
||||
negative_prompt = ""
|
||||
|
||||
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", variant="bf16", torch_dtype=torch.bfloat16)
|
||||
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", variant="bf16", torch_dtype=torch.float16)
|
||||
|
||||
prior.enable_model_cpu_offload()
|
||||
prior_output = prior(
|
||||
prompt=prompt,
|
||||
height=1024,
|
||||
width=1024,
|
||||
negative_prompt=negative_prompt,
|
||||
guidance_scale=4.0,
|
||||
num_images_per_prompt=1,
|
||||
num_inference_steps=20
|
||||
)
|
||||
|
||||
decoder.enable_model_cpu_offload()
|
||||
decoder_output = decoder(
|
||||
image_embeddings=prior_output.image_embeddings.to(torch.float16),
|
||||
prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
guidance_scale=0.0,
|
||||
output_type="pil",
|
||||
num_inference_steps=10
|
||||
).images[0]
|
||||
decoder_output.save("cascade.png")
|
||||
```
|
||||
|
||||
## Using the Lite Versions of the Stage B and Stage C models
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import (
|
||||
StableCascadeDecoderPipeline,
|
||||
StableCascadePriorPipeline,
|
||||
StableCascadeUNet,
|
||||
)
|
||||
|
||||
prompt = "an image of a shiba inu, donning a spacesuit and helmet"
|
||||
negative_prompt = ""
|
||||
|
||||
prior_unet = StableCascadeUNet.from_pretrained("stabilityai/stable-cascade-prior", subfolder="prior_lite")
|
||||
decoder_unet = StableCascadeUNet.from_pretrained("stabilityai/stable-cascade", subfolder="decoder_lite")
|
||||
|
||||
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", prior=prior_unet)
|
||||
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", decoder=decoder_unet)
|
||||
|
||||
prior.enable_model_cpu_offload()
|
||||
prior_output = prior(
|
||||
prompt=prompt,
|
||||
height=1024,
|
||||
width=1024,
|
||||
negative_prompt=negative_prompt,
|
||||
guidance_scale=4.0,
|
||||
num_images_per_prompt=1,
|
||||
num_inference_steps=20
|
||||
)
|
||||
|
||||
decoder.enable_model_cpu_offload()
|
||||
decoder_output = decoder(
|
||||
image_embeddings=prior_output.image_embeddings,
|
||||
prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
guidance_scale=0.0,
|
||||
output_type="pil",
|
||||
num_inference_steps=10
|
||||
).images[0]
|
||||
decoder_output.save("cascade.png")
|
||||
```
|
||||
|
||||
## Loading original checkpoints with `from_single_file`
|
||||
|
||||
Loading the original format checkpoints is supported via `from_single_file` method in the StableCascadeUNet.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import (
|
||||
StableCascadeDecoderPipeline,
|
||||
StableCascadePriorPipeline,
|
||||
StableCascadeUNet,
|
||||
)
|
||||
|
||||
prompt = "an image of a shiba inu, donning a spacesuit and helmet"
|
||||
negative_prompt = ""
|
||||
|
||||
prior_unet = StableCascadeUNet.from_single_file(
|
||||
"https://huggingface.co/stabilityai/stable-cascade/resolve/main/stage_c_bf16.safetensors",
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
decoder_unet = StableCascadeUNet.from_single_file(
|
||||
"https://huggingface.co/stabilityai/stable-cascade/blob/main/stage_b_bf16.safetensors",
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
|
||||
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", prior=prior_unet, torch_dtype=torch.bfloat16)
|
||||
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", decoder=decoder_unet, torch_dtype=torch.bfloat16)
|
||||
|
||||
prior.enable_model_cpu_offload()
|
||||
prior_output = prior(
|
||||
prompt=prompt,
|
||||
height=1024,
|
||||
width=1024,
|
||||
negative_prompt=negative_prompt,
|
||||
guidance_scale=4.0,
|
||||
num_images_per_prompt=1,
|
||||
num_inference_steps=20
|
||||
)
|
||||
|
||||
decoder.enable_model_cpu_offload()
|
||||
decoder_output = decoder(
|
||||
image_embeddings=prior_output.image_embeddings,
|
||||
prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
guidance_scale=0.0,
|
||||
output_type="pil",
|
||||
num_inference_steps=10
|
||||
).images[0]
|
||||
decoder_output.save("cascade-single-file.png")
|
||||
```
|
||||
|
||||
## Uses
|
||||
|
||||
### Direct Use
|
||||
@@ -53,7 +194,7 @@ Excluded uses are described below.
|
||||
|
||||
### Out-of-Scope Use
|
||||
|
||||
The model was not trained to be factual or true representations of people or events,
|
||||
The model was not trained to be factual or true representations of people or events,
|
||||
and therefore using the model to generate such content is out-of-scope for the abilities of this model.
|
||||
The model should not be used in any way that violates Stability AI's [Acceptable Use Policy](https://stability.ai/use-policy).
|
||||
|
||||
|
||||
@@ -172,3 +172,41 @@ inpaint = StableDiffusionInpaintPipeline(**text2img.components)
|
||||
|
||||
# now you can use text2img(...), img2img(...), inpaint(...) just like the call methods of each respective pipeline
|
||||
```
|
||||
|
||||
### Create web demos using `gradio`
|
||||
|
||||
The Stable Diffusion pipelines are automatically supported in [Gradio](https://github.com/gradio-app/gradio/), a library that makes creating beautiful and user-friendly machine learning apps on the web a breeze. First, make sure you have Gradio installed:
|
||||
|
||||
```
|
||||
pip install -U gradio
|
||||
```
|
||||
|
||||
Then, create a web demo around any Stable Diffusion-based pipeline. For example, you can create an image generation pipeline in a single line of code with Gradio's [`Interface.from_pipeline`](https://www.gradio.app/docs/interface#interface-from-pipeline) function:
|
||||
|
||||
```py
|
||||
from diffusers import StableDiffusionPipeline
|
||||
import gradio as gr
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
|
||||
|
||||
gr.Interface.from_pipeline(pipe).launch()
|
||||
```
|
||||
|
||||
which opens an intuitive drag-and-drop interface in your browser:
|
||||
|
||||
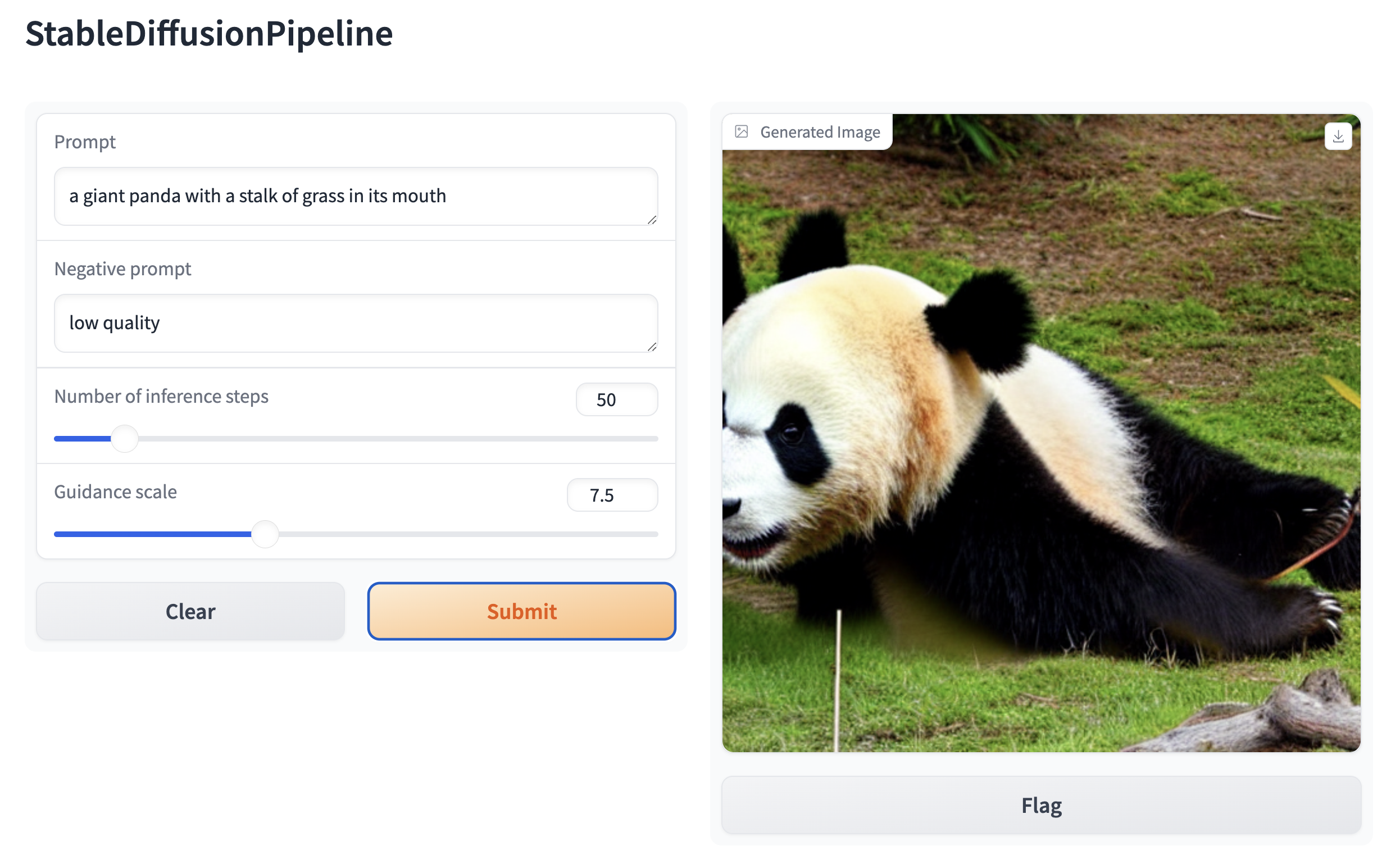
|
||||
|
||||
Similarly, you could create a demo for an image-to-image pipeline with:
|
||||
|
||||
```py
|
||||
from diffusers import StableDiffusionImg2ImgPipeline
|
||||
import gradio as gr
|
||||
|
||||
|
||||
pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
|
||||
|
||||
gr.Interface.from_pipeline(pipe).launch()
|
||||
```
|
||||
|
||||
By default, the web demo runs on a local server. If you'd like to share it with others, you can generate a temporary public
|
||||
link by setting `share=True` in `launch()`. Or, you can host your demo on [Hugging Face Spaces](https://huggingface.co/spaces)https://huggingface.co/spaces for a permanent link.
|
||||
@@ -0,0 +1,22 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# EDMEulerScheduler
|
||||
|
||||
The Karras formulation of the Euler scheduler (Algorithm 2) from the [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364) paper by Karras et al. This is a fast scheduler which can often generate good outputs in 20-30 steps. The scheduler is based on the original [k-diffusion](https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L51) implementation by [Katherine Crowson](https://github.com/crowsonkb/).
|
||||
|
||||
|
||||
## EDMEulerScheduler
|
||||
[[autodoc]] EDMEulerScheduler
|
||||
|
||||
## EDMEulerSchedulerOutput
|
||||
[[autodoc]] schedulers.scheduling_edm_euler.EDMEulerSchedulerOutput
|
||||
@@ -0,0 +1,24 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# EDMDPMSolverMultistepScheduler
|
||||
|
||||
`EDMDPMSolverMultistepScheduler` is a [Karras formulation](https://huggingface.co/papers/2206.00364) of `DPMSolverMultistep`, a multistep scheduler from [DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps](https://huggingface.co/papers/2206.00927) and [DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models](https://huggingface.co/papers/2211.01095) by Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu.
|
||||
|
||||
DPMSolver (and the improved version DPMSolver++) is a fast dedicated high-order solver for diffusion ODEs with convergence order guarantee. Empirically, DPMSolver sampling with only 20 steps can generate high-quality
|
||||
samples, and it can generate quite good samples even in 10 steps.
|
||||
|
||||
## EDMDPMSolverMultistepScheduler
|
||||
[[autodoc]] EDMDPMSolverMultistepScheduler
|
||||
|
||||
## SchedulerOutput
|
||||
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
|
||||
@@ -14,19 +14,17 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# Load LoRAs for inference
|
||||
|
||||
There are many adapters (with LoRAs being the most common type) trained in different styles to achieve different effects. You can even combine multiple adapters to create new and unique images. With the 🤗 [PEFT](https://huggingface.co/docs/peft/index) integration in 🤗 Diffusers, it is really easy to load and manage adapters for inference. In this guide, you'll learn how to use different adapters with [Stable Diffusion XL (SDXL)](../api/pipelines/stable_diffusion/stable_diffusion_xl) for inference.
|
||||
There are many adapter types (with [LoRAs](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) being the most popular) trained in different styles to achieve different effects. You can even combine multiple adapters to create new and unique images.
|
||||
|
||||
Throughout this guide, you'll use LoRA as the main adapter technique, so we'll use the terms LoRA and adapter interchangeably. You should have some familiarity with LoRA, and if you don't, we welcome you to check out the [LoRA guide](https://huggingface.co/docs/peft/conceptual_guides/lora).
|
||||
In this tutorial, you'll learn how to easily load and manage adapters for inference with the 🤗 [PEFT](https://huggingface.co/docs/peft/index) integration in 🤗 Diffusers. You'll use LoRA as the main adapter technique, so you'll see the terms LoRA and adapter used interchangeably.
|
||||
|
||||
Let's first install all the required libraries.
|
||||
|
||||
```bash
|
||||
!pip install -q transformers accelerate
|
||||
!pip install peft
|
||||
!pip install diffusers
|
||||
!pip install -q transformers accelerate peft diffusers
|
||||
```
|
||||
|
||||
Now, let's load a pipeline with a SDXL checkpoint:
|
||||
Now, load a pipeline with a [Stable Diffusion XL (SDXL)](../api/pipelines/stable_diffusion/stable_diffusion_xl) checkpoint:
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
@@ -36,21 +34,18 @@ pipe_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
pipe = DiffusionPipeline.from_pretrained(pipe_id, torch_dtype=torch.float16).to("cuda")
|
||||
```
|
||||
|
||||
|
||||
Next, load a LoRA checkpoint with the [`~diffusers.loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] method.
|
||||
|
||||
With the 🤗 PEFT integration, you can assign a specific `adapter_name` to the checkpoint, which let's you easily switch between different LoRA checkpoints. Let's call this adapter `"toy"`.
|
||||
Next, load a [CiroN2022/toy-face](https://huggingface.co/CiroN2022/toy-face) adapter with the [`~diffusers.loaders.StableDiffusionXLLoraLoaderMixin.load_lora_weights`] method. With the 🤗 PEFT integration, you can assign a specific `adapter_name` to the checkpoint, which let's you easily switch between different LoRA checkpoints. Let's call this adapter `"toy"`.
|
||||
|
||||
```python
|
||||
pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
|
||||
```
|
||||
|
||||
And then perform inference:
|
||||
Make sure to include the token `toy_face` in the prompt and then you can perform inference:
|
||||
|
||||
```python
|
||||
prompt = "toy_face of a hacker with a hoodie"
|
||||
|
||||
lora_scale= 0.9
|
||||
lora_scale = 0.9
|
||||
image = pipe(
|
||||
prompt, num_inference_steps=30, cross_attention_kwargs={"scale": lora_scale}, generator=torch.manual_seed(0)
|
||||
).images[0]
|
||||
@@ -59,17 +54,16 @@ image
|
||||
|
||||

|
||||
|
||||
With the `adapter_name` parameter, it is really easy to use another adapter for inference! Load the [nerijs/pixel-art-xl](https://huggingface.co/nerijs/pixel-art-xl) adapter that has been fine-tuned to generate pixel art images and call it `"pixel"`.
|
||||
|
||||
With the `adapter_name` parameter, it is really easy to use another adapter for inference! Load the [nerijs/pixel-art-xl](https://huggingface.co/nerijs/pixel-art-xl) adapter that has been fine-tuned to generate pixel art images, and let's call it `"pixel"`.
|
||||
|
||||
The pipeline automatically sets the first loaded adapter (`"toy"`) as the active adapter. But you can activate the `"pixel"` adapter with the [`~diffusers.loaders.UNet2DConditionLoadersMixin.set_adapters`] method as shown below:
|
||||
The pipeline automatically sets the first loaded adapter (`"toy"`) as the active adapter, but you can activate the `"pixel"` adapter with the [`~diffusers.loaders.UNet2DConditionLoadersMixin.set_adapters`] method:
|
||||
|
||||
```python
|
||||
pipe.load_lora_weights("nerijs/pixel-art-xl", weight_name="pixel-art-xl.safetensors", adapter_name="pixel")
|
||||
pipe.set_adapters("pixel")
|
||||
```
|
||||
|
||||
Let's now generate an image with the second adapter and check the result:
|
||||
Make sure you include the token `pixel art` in your prompt to generate a pixel art image:
|
||||
|
||||
```python
|
||||
prompt = "a hacker with a hoodie, pixel art"
|
||||
@@ -81,29 +75,25 @@ image
|
||||
|
||||

|
||||
|
||||
## Combine multiple adapters
|
||||
## Merge adapters
|
||||
|
||||
You can also perform multi-adapter inference where you combine different adapter checkpoints for inference.
|
||||
You can also merge different adapter checkpoints for inference to blend their styles together.
|
||||
|
||||
Once again, use the [`~diffusers.loaders.UNet2DConditionLoadersMixin.set_adapters`] method to activate two LoRA checkpoints and specify the weight for how the checkpoints should be combined.
|
||||
Once again, use the [`~diffusers.loaders.UNet2DConditionLoadersMixin.set_adapters`] method to activate the `pixel` and `toy` adapters and specify the weights for how they should be merged.
|
||||
|
||||
```python
|
||||
pipe.set_adapters(["pixel", "toy"], adapter_weights=[0.5, 1.0])
|
||||
```
|
||||
|
||||
Now that we have set these two adapters, let's generate an image from the combined adapters!
|
||||
|
||||
<Tip>
|
||||
|
||||
LoRA checkpoints in the diffusion community are almost always obtained with [DreamBooth](https://huggingface.co/docs/diffusers/main/en/training/dreambooth). DreamBooth training often relies on "trigger" words in the input text prompts in order for the generation results to look as expected. When you combine multiple LoRA checkpoints, it's important to ensure the trigger words for the corresponding LoRA checkpoints are present in the input text prompts.
|
||||
|
||||
</Tip>
|
||||
|
||||
The trigger words for [CiroN2022/toy-face](https://hf.co/CiroN2022/toy-face) and [nerijs/pixel-art-xl](https://hf.co/nerijs/pixel-art-xl) are found in their repositories.
|
||||
|
||||
Remember to use the trigger words for [CiroN2022/toy-face](https://hf.co/CiroN2022/toy-face) and [nerijs/pixel-art-xl](https://hf.co/nerijs/pixel-art-xl) (these are found in their repositories) in the prompt to generate an image.
|
||||
|
||||
```python
|
||||
# Notice how the prompt is constructed.
|
||||
prompt = "toy_face of a hacker with a hoodie, pixel art"
|
||||
image = pipe(
|
||||
prompt, num_inference_steps=30, cross_attention_kwargs={"scale": 1.0}, generator=torch.manual_seed(0)
|
||||
@@ -113,43 +103,39 @@ image
|
||||
|
||||

|
||||
|
||||
Impressive! As you can see, the model was able to generate an image that mixes the characteristics of both adapters.
|
||||
Impressive! As you can see, the model generated an image that mixed the characteristics of both adapters.
|
||||
|
||||
If you want to go back to using only one adapter, use the [`~diffusers.loaders.UNet2DConditionLoadersMixin.set_adapters`] method to activate the `"toy"` adapter:
|
||||
> [!TIP]
|
||||
> Through its PEFT integration, Diffusers also offers more efficient merging methods which you can learn about in the [Merge LoRAs](../using-diffusers/merge_loras) guide!
|
||||
|
||||
To return to only using one adapter, use the [`~diffusers.loaders.UNet2DConditionLoadersMixin.set_adapters`] method to activate the `"toy"` adapter:
|
||||
|
||||
```python
|
||||
# First, set the adapter.
|
||||
pipe.set_adapters("toy")
|
||||
|
||||
# Then, run inference.
|
||||
prompt = "toy_face of a hacker with a hoodie"
|
||||
lora_scale= 0.9
|
||||
lora_scale = 0.9
|
||||
image = pipe(
|
||||
prompt, num_inference_steps=30, cross_attention_kwargs={"scale": lora_scale}, generator=torch.manual_seed(0)
|
||||
).images[0]
|
||||
image
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
If you want to switch to only the base model, disable all LoRAs with the [`~diffusers.loaders.UNet2DConditionLoadersMixin.disable_lora`] method.
|
||||
|
||||
Or to disable all adapters entirely, use the [`~diffusers.loaders.UNet2DConditionLoadersMixin.disable_lora`] method to return the base model.
|
||||
|
||||
```python
|
||||
pipe.disable_lora()
|
||||
|
||||
prompt = "toy_face of a hacker with a hoodie"
|
||||
lora_scale= 0.9
|
||||
image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).images[0]
|
||||
image
|
||||
```
|
||||
|
||||

|
||||
|
||||
## Monitoring active adapters
|
||||
## Manage active adapters
|
||||
|
||||
You have attached multiple adapters in this tutorial, and if you're feeling a bit lost on what adapters have been attached to the pipeline's components, you can easily check the list of active adapters using the [`~diffusers.loaders.LoraLoaderMixin.get_active_adapters`] method:
|
||||
You have attached multiple adapters in this tutorial, and if you're feeling a bit lost on what adapters have been attached to the pipeline's components, use the [`~diffusers.loaders.LoraLoaderMixin.get_active_adapters`] method to check the list of active adapters:
|
||||
|
||||
```py
|
||||
active_adapters = pipe.get_active_adapters()
|
||||
@@ -164,78 +150,3 @@ list_adapters_component_wise = pipe.get_list_adapters()
|
||||
list_adapters_component_wise
|
||||
{"text_encoder": ["toy", "pixel"], "unet": ["toy", "pixel"], "text_encoder_2": ["toy", "pixel"]}
|
||||
```
|
||||
|
||||
## Compatibility with `torch.compile`
|
||||
|
||||
If you want to compile your model with `torch.compile` make sure to first fuse the LoRA weights into the base model and unload them.
|
||||
|
||||
```diff
|
||||
pipe.load_lora_weights("nerijs/pixel-art-xl", weight_name="pixel-art-xl.safetensors", adapter_name="pixel")
|
||||
pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
|
||||
|
||||
pipe.set_adapters(["pixel", "toy"], adapter_weights=[0.5, 1.0])
|
||||
# Fuses the LoRAs into the Unet
|
||||
pipe.fuse_lora()
|
||||
pipe.unload_lora_weights()
|
||||
|
||||
+ pipe.unet.to(memory_format=torch.channels_last)
|
||||
+ pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
|
||||
|
||||
prompt = "toy_face of a hacker with a hoodie, pixel art"
|
||||
image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).images[0]
|
||||
```
|
||||
|
||||
> [!TIP]
|
||||
> You can refer to the `torch.compile()` section [here](https://huggingface.co/docs/diffusers/main/en/optimization/torch2.0#torchcompile) and [here](https://huggingface.co/docs/diffusers/main/en/tutorials/fast_diffusion#torchcompile) for more elaborate examples.
|
||||
|
||||
## Fusing adapters into the model
|
||||
|
||||
You can use PEFT to easily fuse/unfuse multiple adapters directly into the model weights (both UNet and text encoder) using the [`~diffusers.loaders.LoraLoaderMixin.fuse_lora`] method, which can lead to a speed-up in inference and lower VRAM usage.
|
||||
|
||||
```py
|
||||
pipe.load_lora_weights("nerijs/pixel-art-xl", weight_name="pixel-art-xl.safetensors", adapter_name="pixel")
|
||||
pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
|
||||
|
||||
pipe.set_adapters(["pixel", "toy"], adapter_weights=[0.5, 1.0])
|
||||
# Fuses the LoRAs into the Unet
|
||||
pipe.fuse_lora()
|
||||
|
||||
prompt = "toy_face of a hacker with a hoodie, pixel art"
|
||||
image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).images[0]
|
||||
|
||||
# Gets the Unet back to the original state
|
||||
pipe.unfuse_lora()
|
||||
```
|
||||
|
||||
You can also fuse some adapters using `adapter_names` for faster generation:
|
||||
|
||||
```py
|
||||
pipe.load_lora_weights("nerijs/pixel-art-xl", weight_name="pixel-art-xl.safetensors", adapter_name="pixel")
|
||||
pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
|
||||
|
||||
pipe.set_adapters(["pixel"], adapter_weights=[0.5, 1.0])
|
||||
# Fuses the LoRAs into the Unet
|
||||
pipe.fuse_lora(adapter_names=["pixel"])
|
||||
|
||||
prompt = "a hacker with a hoodie, pixel art"
|
||||
image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).images[0]
|
||||
|
||||
# Gets the Unet back to the original state
|
||||
pipe.unfuse_lora()
|
||||
|
||||
# Fuse all adapters
|
||||
pipe.fuse_lora(adapter_names=["pixel", "toy"])
|
||||
|
||||
prompt = "toy_face of a hacker with a hoodie, pixel art"
|
||||
image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).images[0]
|
||||
```
|
||||
|
||||
## Saving a pipeline after fusing the adapters
|
||||
|
||||
To properly save a pipeline after it's been loaded with the adapters, it should be serialized like so:
|
||||
|
||||
```python
|
||||
pipe.fuse_lora(lora_scale=1.0)
|
||||
pipe.unload_lora_weights()
|
||||
pipe.save_pretrained("path-to-pipeline")
|
||||
```
|
||||
|
||||
@@ -12,13 +12,18 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# Pipeline callbacks
|
||||
|
||||
The denoising loop of a pipeline can be modified with custom defined functions using the `callback_on_step_end` parameter. This can be really useful for *dynamically* adjusting certain pipeline attributes, or modifying tensor variables. The flexibility of callbacks opens up some interesting use-cases such as changing the prompt embeddings at each timestep, assigning different weights to the prompt embeddings, and editing the guidance scale.
|
||||
The denoising loop of a pipeline can be modified with custom defined functions using the `callback_on_step_end` parameter. The callback function is executed at the end of each step, and modifies the pipeline attributes and variables for the next step. This is really useful for *dynamically* adjusting certain pipeline attributes or modifying tensor variables. This versatility allows for interesting use-cases such as changing the prompt embeddings at each timestep, assigning different weights to the prompt embeddings, and editing the guidance scale. With callbacks, you can implement new features without modifying the underlying code!
|
||||
|
||||
This guide will show you how to use the `callback_on_step_end` parameter to disable classifier-free guidance (CFG) after 40% of the inference steps to save compute with minimal cost to performance.
|
||||
> [!TIP]
|
||||
> 🤗 Diffusers currently only supports `callback_on_step_end`, but feel free to open a [feature request](https://github.com/huggingface/diffusers/issues/new/choose) if you have a cool use-case and require a callback function with a different execution point!
|
||||
|
||||
The callback function should have the following arguments:
|
||||
This guide will demonstrate how callbacks work by a few features you can implement with them.
|
||||
|
||||
* `pipe` (or the pipeline instance) provides access to useful properties such as `num_timesteps` and `guidance_scale`. You can modify these properties by updating the underlying attributes. For this example, you'll disable CFG by setting `pipe._guidance_scale=0.0`.
|
||||
## Dynamic classifier-free guidance
|
||||
|
||||
Dynamic classifier-free guidance (CFG) is a feature that allows you to disable CFG after a certain number of inference steps which can help you save compute with minimal cost to performance. The callback function for this should have the following arguments:
|
||||
|
||||
* `pipeline` (or the pipeline instance) provides access to important properties such as `num_timesteps` and `guidance_scale`. You can modify these properties by updating the underlying attributes. For this example, you'll disable CFG by setting `pipeline._guidance_scale=0.0`.
|
||||
* `step_index` and `timestep` tell you where you are in the denoising loop. Use `step_index` to turn off CFG after reaching 40% of `num_timesteps`.
|
||||
* `callback_kwargs` is a dict that contains tensor variables you can modify during the denoising loop. It only includes variables specified in the `callback_on_step_end_tensor_inputs` argument, which is passed to the pipeline's `__call__` method. Different pipelines may use different sets of variables, so please check a pipeline's `_callback_tensor_inputs` attribute for the list of variables you can modify. Some common variables include `latents` and `prompt_embeds`. For this function, change the batch size of `prompt_embeds` after setting `guidance_scale=0.0` in order for it to work properly.
|
||||
|
||||
@@ -27,12 +32,12 @@ Your callback function should look something like this:
|
||||
```python
|
||||
def callback_dynamic_cfg(pipe, step_index, timestep, callback_kwargs):
|
||||
# adjust the batch_size of prompt_embeds according to guidance_scale
|
||||
if step_index == int(pipe.num_timesteps * 0.4):
|
||||
if step_index == int(pipeline.num_timesteps * 0.4):
|
||||
prompt_embeds = callback_kwargs["prompt_embeds"]
|
||||
prompt_embeds = prompt_embeds.chunk(2)[-1]
|
||||
|
||||
# update guidance_scale and prompt_embeds
|
||||
pipe._guidance_scale = 0.0
|
||||
pipeline._guidance_scale = 0.0
|
||||
callback_kwargs["prompt_embeds"] = prompt_embeds
|
||||
return callback_kwargs
|
||||
```
|
||||
@@ -43,58 +48,134 @@ Now, you can pass the callback function to the `callback_on_step_end` parameter
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
|
||||
pipe = pipe.to("cuda")
|
||||
pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
|
||||
pipeline = pipeline.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
|
||||
generator = torch.Generator(device="cuda").manual_seed(1)
|
||||
out = pipe(prompt, generator=generator, callback_on_step_end=callback_dynamic_cfg, callback_on_step_end_tensor_inputs=['prompt_embeds'])
|
||||
out = pipeline(
|
||||
prompt,
|
||||
generator=generator,
|
||||
callback_on_step_end=callback_dynamic_cfg,
|
||||
callback_on_step_end_tensor_inputs=['prompt_embeds']
|
||||
)
|
||||
|
||||
out.images[0].save("out_custom_cfg.png")
|
||||
```
|
||||
|
||||
The callback function is executed at the end of each denoising step, and modifies the pipeline attributes and tensor variables for the next denoising step.
|
||||
|
||||
With callbacks, you can implement features such as dynamic CFG without having to modify the underlying code at all!
|
||||
|
||||
<Tip>
|
||||
|
||||
🤗 Diffusers currently only supports `callback_on_step_end`, but feel free to open a [feature request](https://github.com/huggingface/diffusers/issues/new/choose) if you have a cool use-case and require a callback function with a different execution point!
|
||||
|
||||
</Tip>
|
||||
|
||||
## Interrupt the diffusion process
|
||||
|
||||
Interrupting the diffusion process is particularly useful when building UIs that work with Diffusers because it allows users to stop the generation process if they're unhappy with the intermediate results. You can incorporate this into your pipeline with a callback.
|
||||
> [!TIP]
|
||||
> The interruption callback is supported for text-to-image, image-to-image, and inpainting for the [StableDiffusionPipeline](../api/pipelines/stable_diffusion/overview) and [StableDiffusionXLPipeline](../api/pipelines/stable_diffusion/stable_diffusion_xl).
|
||||
|
||||
<Tip>
|
||||
Stopping the diffusion process early is useful when building UIs that work with Diffusers because it allows users to stop the generation process if they're unhappy with the intermediate results. You can incorporate this into your pipeline with a callback.
|
||||
|
||||
The interruption callback is supported for text-to-image, image-to-image, and inpainting for the [StableDiffusionPipeline](../api/pipelines/stable_diffusion/overview) and [StableDiffusionXLPipeline](../api/pipelines/stable_diffusion/stable_diffusion_xl).
|
||||
|
||||
</Tip>
|
||||
|
||||
This callback function should take the following arguments: `pipe`, `i`, `t`, and `callback_kwargs` (this must be returned). Set the pipeline's `_interrupt` attribute to `True` to stop the diffusion process after a certain number of steps. You are also free to implement your own custom stopping logic inside the callback.
|
||||
This callback function should take the following arguments: `pipeline`, `i`, `t`, and `callback_kwargs` (this must be returned). Set the pipeline's `_interrupt` attribute to `True` to stop the diffusion process after a certain number of steps. You are also free to implement your own custom stopping logic inside the callback.
|
||||
|
||||
In this example, the diffusion process is stopped after 10 steps even though `num_inference_steps` is set to 50.
|
||||
|
||||
```python
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
|
||||
pipe.enable_model_cpu_offload()
|
||||
pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
|
||||
pipeline.enable_model_cpu_offload()
|
||||
num_inference_steps = 50
|
||||
|
||||
def interrupt_callback(pipe, i, t, callback_kwargs):
|
||||
def interrupt_callback(pipeline, i, t, callback_kwargs):
|
||||
stop_idx = 10
|
||||
if i == stop_idx:
|
||||
pipe._interrupt = True
|
||||
pipeline._interrupt = True
|
||||
|
||||
return callback_kwargs
|
||||
|
||||
pipe(
|
||||
pipeline(
|
||||
"A photo of a cat",
|
||||
num_inference_steps=num_inference_steps,
|
||||
callback_on_step_end=interrupt_callback,
|
||||
)
|
||||
```
|
||||
|
||||
## Display image after each generation step
|
||||
|
||||
> [!TIP]
|
||||
> This tip was contributed by [asomoza](https://github.com/asomoza).
|
||||
|
||||
Display an image after each generation step by accessing and converting the latents after each step into an image. The latent space is compressed to 128x128, so the images are also 128x128 which is useful for a quick preview.
|
||||
|
||||
1. Use the function below to convert the SDXL latents (4 channels) to RGB tensors (3 channels) as explained in the [Explaining the SDXL latent space](https://huggingface.co/blog/TimothyAlexisVass/explaining-the-sdxl-latent-space) blog post.
|
||||
|
||||
```py
|
||||
def latents_to_rgb(latents):
|
||||
weights = (
|
||||
(60, -60, 25, -70),
|
||||
(60, -5, 15, -50),
|
||||
(60, 10, -5, -35)
|
||||
)
|
||||
|
||||
weights_tensor = torch.t(torch.tensor(weights, dtype=latents.dtype).to(latents.device))
|
||||
biases_tensor = torch.tensor((150, 140, 130), dtype=latents.dtype).to(latents.device)
|
||||
rgb_tensor = torch.einsum("...lxy,lr -> ...rxy", latents, weights_tensor) + biases_tensor.unsqueeze(-1).unsqueeze(-1)
|
||||
image_array = rgb_tensor.clamp(0, 255)[0].byte().cpu().numpy()
|
||||
image_array = image_array.transpose(1, 2, 0)
|
||||
|
||||
return Image.fromarray(image_array)
|
||||
```
|
||||
|
||||
2. Create a function to decode and save the latents into an image.
|
||||
|
||||
```py
|
||||
def decode_tensors(pipe, step, timestep, callback_kwargs):
|
||||
latents = callback_kwargs["latents"]
|
||||
|
||||
image = latents_to_rgb(latents)
|
||||
image.save(f"{step}.png")
|
||||
|
||||
return callback_kwargs
|
||||
```
|
||||
|
||||
3. Pass the `decode_tensors` function to the `callback_on_step_end` parameter to decode the tensors after each step. You also need to specify what you want to modify in the `callback_on_step_end_tensor_inputs` parameter, which in this case are the latents.
|
||||
|
||||
```py
|
||||
from diffusers import AutoPipelineForText2Image
|
||||
import torch
|
||||
from PIL import Image
|
||||
|
||||
pipeline = AutoPipelineForText2Image.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
use_safetensors=True
|
||||
).to("cuda")
|
||||
|
||||
image = pipe(
|
||||
prompt = "A croissant shaped like a cute bear."
|
||||
negative_prompt = "Deformed, ugly, bad anatomy"
|
||||
callback_on_step_end=decode_tensors,
|
||||
callback_on_step_end_tensor_inputs=["latents"],
|
||||
).images[0]
|
||||
```
|
||||
|
||||
<div class="flex gap-4 justify-center">
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/tips_step_0.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">step 0</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/tips_step_19.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">step 19
|
||||
</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/tips_step_29.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">step 29</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/tips_step_39.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">step 39</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/tips_step_49.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">step 49</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
@@ -429,6 +429,27 @@ image = pipe(
|
||||
make_image_grid([original_image, canny_image, image], rows=1, cols=3)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
You can use a refiner model with `StableDiffusionXLControlNetPipeline` to improve image quality, just like you can with a regular `StableDiffusionXLPipeline`.
|
||||
See the [Refine image quality](./sdxl#refine-image-quality) section to learn how to use the refiner model.
|
||||
Make sure to use `StableDiffusionXLControlNetPipeline` and pass `image` and `controlnet_conditioning_scale`.
|
||||
|
||||
```py
|
||||
base = StableDiffusionXLControlNetPipeline(...)
|
||||
image = base(
|
||||
prompt=prompt,
|
||||
controlnet_conditioning_scale=0.5,
|
||||
image=canny_image,
|
||||
num_inference_steps=40,
|
||||
denoising_end=0.8,
|
||||
output_type="latent",
|
||||
).images
|
||||
# rest exactly as with StableDiffusionXLPipeline
|
||||
```
|
||||
|
||||
</Tip>
|
||||
|
||||
## MultiControlNet
|
||||
|
||||
<Tip>
|
||||
|
||||
@@ -239,5 +239,7 @@ pipeline.to("cuda")
|
||||
prompt = "柴犬、カラフルアート"
|
||||
|
||||
image = pipeline(prompt=prompt).images[0]
|
||||
```
|
||||
|
||||
```
|
||||
> [!TIP]
|
||||
> When using `trust_remote_code=True`, it is also strongly encouraged to pass a commit hash as a `revision` to make sure the author of the models did not update the code with some malicious new lines (unless you fully trust the authors of the models).
|
||||
@@ -0,0 +1,438 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
# Trajectory Consistency Distillation-LoRA
|
||||
|
||||
Trajectory Consistency Distillation (TCD) enables a model to generate higher quality and more detailed images with fewer steps. Moreover, owing to the effective error mitigation during the distillation process, TCD demonstrates superior performance even under conditions of large inference steps.
|
||||
|
||||
The major advantages of TCD are:
|
||||
|
||||
- Better than Teacher: TCD demonstrates superior generative quality at both small and large inference steps and exceeds the performance of [DPM-Solver++(2S)](../../api/schedulers/multistep_dpm_solver) with Stable Diffusion XL (SDXL). There is no additional discriminator or LPIPS supervision included during TCD training.
|
||||
|
||||
- Flexible Inference Steps: The inference steps for TCD sampling can be freely adjusted without adversely affecting the image quality.
|
||||
|
||||
- Freely change detail level: During inference, the level of detail in the image can be adjusted with a single hyperparameter, *gamma*.
|
||||
|
||||
> [!TIP]
|
||||
> For more technical details of TCD, please refer to the [paper](https://arxiv.org/abs/2402.19159) or official [project page](https://mhh0318.github.io/tcd/)).
|
||||
|
||||
For large models like SDXL, TCD is trained with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) to reduce memory usage. This is also useful because you can reuse LoRAs between different finetuned models, as long as they share the same base model, without further training.
|
||||
|
||||
|
||||
|
||||
This guide will show you how to perform inference with TCD-LoRAs for a variety of tasks like text-to-image and inpainting, as well as how you can easily combine TCD-LoRAs with other adapters. Choose one of the supported base model and it's corresponding TCD-LoRA checkpoint from the table below to get started.
|
||||
|
||||
| Base model | TCD-LoRA checkpoint |
|
||||
|-------------------------------------------------------------------------------------------------|----------------------------------------------------------------|
|
||||
| [stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) | [TCD-SD15](https://huggingface.co/h1t/TCD-SD15-LoRA) |
|
||||
| [stable-diffusion-2-1-base](https://huggingface.co/stabilityai/stable-diffusion-2-1-base) | [TCD-SD21-base](https://huggingface.co/h1t/TCD-SD21-base-LoRA) |
|
||||
| [stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) | [TCD-SDXL](https://huggingface.co/h1t/TCD-SDXL-LoRA) |
|
||||
|
||||
|
||||
Make sure you have [PEFT](https://github.com/huggingface/peft) installed for better LoRA support.
|
||||
|
||||
```bash
|
||||
pip install -U peft
|
||||
```
|
||||
|
||||
## General tasks
|
||||
|
||||
In this guide, let's use the [`StableDiffusionXLPipeline`] and the [`TCDScheduler`]. Use the [`~StableDiffusionPipeline.load_lora_weights`] method to load the SDXL-compatible TCD-LoRA weights.
|
||||
|
||||
A few tips to keep in mind for TCD-LoRA inference are to:
|
||||
|
||||
- Keep the `num_inference_steps` between 4 and 50
|
||||
- Set `eta` (used to control stochasticity at each step) between 0 and 1. You should use a higher `eta` when increasing the number of inference steps, but the downside is that a larger `eta` in [`TCDScheduler`] leads to blurrier images. A value of 0.3 is recommended to produce good results.
|
||||
|
||||
<hfoptions id="tasks">
|
||||
<hfoption id="text-to-image">
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline, TCDScheduler
|
||||
|
||||
device = "cuda"
|
||||
base_model_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
tcd_lora_id = "h1t/TCD-SDXL-LoRA"
|
||||
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16, variant="fp16").to(device)
|
||||
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
pipe.load_lora_weights(tcd_lora_id)
|
||||
pipe.fuse_lora()
|
||||
|
||||
prompt = "Painting of the orange cat Otto von Garfield, Count of Bismarck-Schönhausen, Duke of Lauenburg, Minister-President of Prussia. Depicted wearing a Prussian Pickelhaube and eating his favorite meal - lasagna."
|
||||
|
||||
image = pipe(
|
||||
prompt=prompt,
|
||||
num_inference_steps=4,
|
||||
guidance_scale=0,
|
||||
eta=0.3,
|
||||
generator=torch.Generator(device=device).manual_seed(0),
|
||||
).images[0]
|
||||
```
|
||||
|
||||

|
||||
|
||||
</hfoption>
|
||||
|
||||
<hfoption id="inpainting">
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import AutoPipelineForInpainting, TCDScheduler
|
||||
from diffusers.utils import load_image, make_image_grid
|
||||
|
||||
device = "cuda"
|
||||
base_model_id = "diffusers/stable-diffusion-xl-1.0-inpainting-0.1"
|
||||
tcd_lora_id = "h1t/TCD-SDXL-LoRA"
|
||||
|
||||
pipe = AutoPipelineForInpainting.from_pretrained(base_model_id, torch_dtype=torch.float16, variant="fp16").to(device)
|
||||
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
pipe.load_lora_weights(tcd_lora_id)
|
||||
pipe.fuse_lora()
|
||||
|
||||
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
||||
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
||||
|
||||
init_image = load_image(img_url).resize((1024, 1024))
|
||||
mask_image = load_image(mask_url).resize((1024, 1024))
|
||||
|
||||
prompt = "a tiger sitting on a park bench"
|
||||
|
||||
image = pipe(
|
||||
prompt=prompt,
|
||||
image=init_image,
|
||||
mask_image=mask_image,
|
||||
num_inference_steps=8,
|
||||
guidance_scale=0,
|
||||
eta=0.3,
|
||||
strength=0.99, # make sure to use `strength` below 1.0
|
||||
generator=torch.Generator(device=device).manual_seed(0),
|
||||
).images[0]
|
||||
|
||||
grid_image = make_image_grid([init_image, mask_image, image], rows=1, cols=3)
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## Community models
|
||||
|
||||
TCD-LoRA also works with many community finetuned models and plugins. For example, load the [animagine-xl-3.0](https://huggingface.co/cagliostrolab/animagine-xl-3.0) checkpoint which is a community finetuned version of SDXL for generating anime images.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline, TCDScheduler
|
||||
|
||||
device = "cuda"
|
||||
base_model_id = "cagliostrolab/animagine-xl-3.0"
|
||||
tcd_lora_id = "h1t/TCD-SDXL-LoRA"
|
||||
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16, variant="fp16").to(device)
|
||||
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
pipe.load_lora_weights(tcd_lora_id)
|
||||
pipe.fuse_lora()
|
||||
|
||||
prompt = "A man, clad in a meticulously tailored military uniform, stands with unwavering resolve. The uniform boasts intricate details, and his eyes gleam with determination. Strands of vibrant, windswept hair peek out from beneath the brim of his cap."
|
||||
|
||||
image = pipe(
|
||||
prompt=prompt,
|
||||
num_inference_steps=8,
|
||||
guidance_scale=0,
|
||||
eta=0.3,
|
||||
generator=torch.Generator(device=device).manual_seed(0),
|
||||
).images[0]
|
||||
```
|
||||
|
||||

|
||||
|
||||
TCD-LoRA also supports other LoRAs trained on different styles. For example, let's load the [TheLastBen/Papercut_SDXL](https://huggingface.co/TheLastBen/Papercut_SDXL) LoRA and fuse it with the TCD-LoRA with the [`~loaders.UNet2DConditionLoadersMixin.set_adapters`] method.
|
||||
|
||||
> [!TIP]
|
||||
> Check out the [Merge LoRAs](merge_loras) guide to learn more about efficient merging methods.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
from scheduling_tcd import TCDScheduler
|
||||
|
||||
device = "cuda"
|
||||
base_model_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
tcd_lora_id = "h1t/TCD-SDXL-LoRA"
|
||||
styled_lora_id = "TheLastBen/Papercut_SDXL"
|
||||
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16, variant="fp16").to(device)
|
||||
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
pipe.load_lora_weights(tcd_lora_id, adapter_name="tcd")
|
||||
pipe.load_lora_weights(styled_lora_id, adapter_name="style")
|
||||
pipe.set_adapters(["tcd", "style"], adapter_weights=[1.0, 1.0])
|
||||
|
||||
prompt = "papercut of a winter mountain, snow"
|
||||
|
||||
image = pipe(
|
||||
prompt=prompt,
|
||||
num_inference_steps=4,
|
||||
guidance_scale=0,
|
||||
eta=0.3,
|
||||
generator=torch.Generator(device=device).manual_seed(0),
|
||||
).images[0]
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
## Adapters
|
||||
|
||||
TCD-LoRA is very versatile, and it can be combined with other adapter types like ControlNets, IP-Adapter, and AnimateDiff.
|
||||
|
||||
<hfoptions id="adapters">
|
||||
<hfoption id="ControlNet">
|
||||
|
||||
### Depth ControlNet
|
||||
|
||||
```python
|
||||
import torch
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
from transformers import DPTFeatureExtractor, DPTForDepthEstimation
|
||||
from diffusers import ControlNetModel, StableDiffusionXLControlNetPipeline
|
||||
from diffusers.utils import load_image, make_image_grid
|
||||
from scheduling_tcd import TCDScheduler
|
||||
|
||||
device = "cuda"
|
||||
depth_estimator = DPTForDepthEstimation.from_pretrained("Intel/dpt-hybrid-midas").to(device)
|
||||
feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-hybrid-midas")
|
||||
|
||||
def get_depth_map(image):
|
||||
image = feature_extractor(images=image, return_tensors="pt").pixel_values.to(device)
|
||||
with torch.no_grad(), torch.autocast(device):
|
||||
depth_map = depth_estimator(image).predicted_depth
|
||||
|
||||
depth_map = torch.nn.functional.interpolate(
|
||||
depth_map.unsqueeze(1),
|
||||
size=(1024, 1024),
|
||||
mode="bicubic",
|
||||
align_corners=False,
|
||||
)
|
||||
depth_min = torch.amin(depth_map, dim=[1, 2, 3], keepdim=True)
|
||||
depth_max = torch.amax(depth_map, dim=[1, 2, 3], keepdim=True)
|
||||
depth_map = (depth_map - depth_min) / (depth_max - depth_min)
|
||||
image = torch.cat([depth_map] * 3, dim=1)
|
||||
|
||||
image = image.permute(0, 2, 3, 1).cpu().numpy()[0]
|
||||
image = Image.fromarray((image * 255.0).clip(0, 255).astype(np.uint8))
|
||||
return image
|
||||
|
||||
base_model_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
controlnet_id = "diffusers/controlnet-depth-sdxl-1.0"
|
||||
tcd_lora_id = "h1t/TCD-SDXL-LoRA"
|
||||
|
||||
controlnet = ControlNetModel.from_pretrained(
|
||||
controlnet_id,
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
).to(device)
|
||||
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
|
||||
base_model_id,
|
||||
controlnet=controlnet,
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
).to(device)
|
||||
pipe.enable_model_cpu_offload()
|
||||
|
||||
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
pipe.load_lora_weights(tcd_lora_id)
|
||||
pipe.fuse_lora()
|
||||
|
||||
prompt = "stormtrooper lecture, photorealistic"
|
||||
|
||||
image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-depth/resolve/main/images/stormtrooper.png")
|
||||
depth_image = get_depth_map(image)
|
||||
|
||||
controlnet_conditioning_scale = 0.5 # recommended for good generalization
|
||||
|
||||
image = pipe(
|
||||
prompt,
|
||||
image=depth_image,
|
||||
num_inference_steps=4,
|
||||
guidance_scale=0,
|
||||
eta=0.3,
|
||||
controlnet_conditioning_scale=controlnet_conditioning_scale,
|
||||
generator=torch.Generator(device=device).manual_seed(0),
|
||||
).images[0]
|
||||
|
||||
grid_image = make_image_grid([depth_image, image], rows=1, cols=2)
|
||||
```
|
||||
|
||||

|
||||
|
||||
### Canny ControlNet
|
||||
```python
|
||||
import torch
|
||||
from diffusers import ControlNetModel, StableDiffusionXLControlNetPipeline
|
||||
from diffusers.utils import load_image, make_image_grid
|
||||
from scheduling_tcd import TCDScheduler
|
||||
|
||||
device = "cuda"
|
||||
base_model_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
controlnet_id = "diffusers/controlnet-canny-sdxl-1.0"
|
||||
tcd_lora_id = "h1t/TCD-SDXL-LoRA"
|
||||
|
||||
controlnet = ControlNetModel.from_pretrained(
|
||||
controlnet_id,
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
).to(device)
|
||||
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
|
||||
base_model_id,
|
||||
controlnet=controlnet,
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
).to(device)
|
||||
pipe.enable_model_cpu_offload()
|
||||
|
||||
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
pipe.load_lora_weights(tcd_lora_id)
|
||||
pipe.fuse_lora()
|
||||
|
||||
prompt = "ultrarealistic shot of a furry blue bird"
|
||||
|
||||
canny_image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png")
|
||||
|
||||
controlnet_conditioning_scale = 0.5 # recommended for good generalization
|
||||
|
||||
image = pipe(
|
||||
prompt,
|
||||
image=canny_image,
|
||||
num_inference_steps=4,
|
||||
guidance_scale=0,
|
||||
eta=0.3,
|
||||
controlnet_conditioning_scale=controlnet_conditioning_scale,
|
||||
generator=torch.Generator(device=device).manual_seed(0),
|
||||
).images[0]
|
||||
|
||||
grid_image = make_image_grid([canny_image, image], rows=1, cols=2)
|
||||
```
|
||||

|
||||
|
||||
<Tip>
|
||||
The inference parameters in this example might not work for all examples, so we recommend you to try different values for `num_inference_steps`, `guidance_scale`, `controlnet_conditioning_scale` and `cross_attention_kwargs` parameters and choose the best one.
|
||||
</Tip>
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="IP-Adapter">
|
||||
|
||||
This example shows how to use the TCD-LoRA with the [IP-Adapter](https://github.com/tencent-ailab/IP-Adapter/tree/main) and SDXL.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
from diffusers.utils import load_image, make_image_grid
|
||||
|
||||
from ip_adapter import IPAdapterXL
|
||||
from scheduling_tcd import TCDScheduler
|
||||
|
||||
device = "cuda"
|
||||
base_model_path = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
image_encoder_path = "sdxl_models/image_encoder"
|
||||
ip_ckpt = "sdxl_models/ip-adapter_sdxl.bin"
|
||||
tcd_lora_id = "h1t/TCD-SDXL-LoRA"
|
||||
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(
|
||||
base_model_path,
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16"
|
||||
)
|
||||
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
pipe.load_lora_weights(tcd_lora_id)
|
||||
pipe.fuse_lora()
|
||||
|
||||
ip_model = IPAdapterXL(pipe, image_encoder_path, ip_ckpt, device)
|
||||
|
||||
ref_image = load_image("https://raw.githubusercontent.com/tencent-ailab/IP-Adapter/main/assets/images/woman.png").resize((512, 512))
|
||||
|
||||
prompt = "best quality, high quality, wearing sunglasses"
|
||||
|
||||
image = ip_model.generate(
|
||||
pil_image=ref_image,
|
||||
prompt=prompt,
|
||||
scale=0.5,
|
||||
num_samples=1,
|
||||
num_inference_steps=4,
|
||||
guidance_scale=0,
|
||||
eta=0.3,
|
||||
seed=0,
|
||||
)[0]
|
||||
|
||||
grid_image = make_image_grid([ref_image, image], rows=1, cols=2)
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="AnimateDiff">
|
||||
|
||||
[`AnimateDiff`] allows animating images using Stable Diffusion models. TCD-LoRA can substantially accelerate the process without degrading image quality. The quality of animation with TCD-LoRA and AnimateDiff has a more lucid outcome.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import MotionAdapter, AnimateDiffPipeline, DDIMScheduler
|
||||
from scheduling_tcd import TCDScheduler
|
||||
from diffusers.utils import export_to_gif
|
||||
|
||||
adapter = MotionAdapter.from_pretrained("guoyww/animatediff-motion-adapter-v1-5")
|
||||
pipe = AnimateDiffPipeline.from_pretrained(
|
||||
"frankjoshua/toonyou_beta6",
|
||||
motion_adapter=adapter,
|
||||
).to("cuda")
|
||||
|
||||
# set TCDScheduler
|
||||
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
# load TCD LoRA
|
||||
pipe.load_lora_weights("h1t/TCD-SD15-LoRA", adapter_name="tcd")
|
||||
pipe.load_lora_weights("guoyww/animatediff-motion-lora-zoom-in", weight_name="diffusion_pytorch_model.safetensors", adapter_name="motion-lora")
|
||||
|
||||
pipe.set_adapters(["tcd", "motion-lora"], adapter_weights=[1.0, 1.2])
|
||||
|
||||
prompt = "best quality, masterpiece, 1girl, looking at viewer, blurry background, upper body, contemporary, dress"
|
||||
generator = torch.manual_seed(0)
|
||||
frames = pipe(
|
||||
prompt=prompt,
|
||||
num_inference_steps=5,
|
||||
guidance_scale=0,
|
||||
cross_attention_kwargs={"scale": 1},
|
||||
num_frames=24,
|
||||
eta=0.3,
|
||||
generator=generator
|
||||
).frames[0]
|
||||
export_to_gif(frames, "animation.gif")
|
||||
```
|
||||
|
||||

|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
@@ -25,6 +25,9 @@ Let's take a look at how to use IP-Adapter's image prompting capabilities with t
|
||||
|
||||
In all the following examples, you'll see the [`~loaders.IPAdapterMixin.set_ip_adapter_scale`] method. This method controls the amount of text or image conditioning to apply to the model. A value of `1.0` means the model is only conditioned on the image prompt. Lowering this value encourages the model to produce more diverse images, but they may not be as aligned with the image prompt. Typically, a value of `0.5` achieves a good balance between the two prompt types and produces good results.
|
||||
|
||||
> [!TIP]
|
||||
> In the examples below, try adding `low_cpu_mem_usage=True` to the [`~loaders.IPAdapterMixin.load_ip_adapter`] method to speed up the loading time.
|
||||
|
||||
<hfoptions id="tasks">
|
||||
<hfoption id="Text-to-image">
|
||||
|
||||
@@ -231,10 +234,21 @@ export_to_gif(frames, "gummy_bear.gif")
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
> [!TIP]
|
||||
> While calling `load_ip_adapter()`, pass `low_cpu_mem_usage=True` to speed up the loading time.
|
||||
## Configure parameters
|
||||
|
||||
All the pipelines supporting IP-Adapter accept a `ip_adapter_image_embeds` argument. If you need to run the IP-Adapter multiple times with the same image, you can encode the image once and save the embedding to the disk.
|
||||
There are a couple of IP-Adapter parameters that are useful to know about and can help you with your image generation tasks. These parameters can make your workflow more efficient or give you more control over image generation.
|
||||
|
||||
### Image embeddings
|
||||
|
||||
IP-Adapter enabled pipelines provide the `ip_adapter_image_embeds` parameter to accept precomputed image embeddings. This is particularly useful in scenarios where you need to run the IP-Adapter pipeline multiple times because you have more than one image. For example, [multi IP-Adapter](#multi-ip-adapter) is a specific use case where you provide multiple styling images to generate a specific image in a specific style. Loading and encoding multiple images each time you use the pipeline would be inefficient. Instead, you can precompute and save the image embeddings to disk (which can save a lot of space if you're using high-quality images) and load them when you need them.
|
||||
|
||||
> [!TIP]
|
||||
> This parameter also gives you the flexibility to load embeddings from other sources. For example, ComfyUI image embeddings for IP-Adapters are compatible with Diffusers and should work ouf-of-the-box!
|
||||
|
||||
Call the [`~StableDiffusionPipeline.prepare_ip_adapter_image_embeds`] method to encode and generate the image embeddings. Then you can save them to disk with `torch.save`.
|
||||
|
||||
> [!TIP]
|
||||
> If you're using IP-Adapter with `ip_adapter_image_embedding` instead of `ip_adapter_image`', you can set `load_ip_adapter(image_encoder_folder=None,...)` because you don't need to load an encoder to generate the image embeddings.
|
||||
|
||||
```py
|
||||
image_embeds = pipeline.prepare_ip_adapter_image_embeds(
|
||||
@@ -248,10 +262,7 @@ image_embeds = pipeline.prepare_ip_adapter_image_embeds(
|
||||
torch.save(image_embeds, "image_embeds.ipadpt")
|
||||
```
|
||||
|
||||
Load the image embedding and pass it to the pipeline as `ip_adapter_image_embeds`
|
||||
|
||||
> [!TIP]
|
||||
> ComfyUI image embeddings for IP-Adapters are fully compatible in Diffusers and should work out-of-box.
|
||||
Now load the image embeddings by passing them to the `ip_adapter_image_embeds` parameter.
|
||||
|
||||
```py
|
||||
image_embeds = torch.load("image_embeds.ipadpt")
|
||||
@@ -264,8 +275,86 @@ images = pipeline(
|
||||
).images
|
||||
```
|
||||
|
||||
> [!TIP]
|
||||
> If you use IP-Adapter with `ip_adapter_image_embedding` instead of `ip_adapter_image`, you can choose not to load an image encoder by passing `image_encoder_folder=None` to `load_ip_adapter()`.
|
||||
### IP-Adapter masking
|
||||
|
||||
Binary masks specify which portion of the output image should be assigned to an IP-Adapter. This is useful for composing more than one IP-Adapter image. For each input IP-Adapter image, you must provide a binary mask an an IP-Adapter.
|
||||
|
||||
To start, preprocess the input IP-Adapter images with the [`~image_processor.IPAdapterMaskProcessor.preprocess()`] to generate their masks. For optimal results, provide the output height and width to [`~image_processor.IPAdapterMaskProcessor.preprocess()`]. This ensures masks with different aspect ratios are appropriately stretched. If the input masks already match the aspect ratio of the generated image, you don't have to set the `height` and `width`.
|
||||
|
||||
```py
|
||||
from diffusers.image_processor import IPAdapterMaskProcessor
|
||||
|
||||
mask1 = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_mask_mask1.png")
|
||||
mask2 = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_mask_mask2.png")
|
||||
|
||||
output_height = 1024
|
||||
output_width = 1024
|
||||
|
||||
processor = IPAdapterMaskProcessor()
|
||||
masks = processor.preprocess([mask1, mask2], height=output_height, width=output_width)
|
||||
```
|
||||
|
||||
<div class="flex flex-row gap-4">
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_mask1.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">mask one</figcaption>
|
||||
</div>
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_mask2.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">mask two</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
When there is more than one input IP-Adapter image, load them as a list to ensure each image is assigned to a different IP-Adapter. Each of the input IP-Adapter images here correspond to the masks generated above.
|
||||
|
||||
```py
|
||||
face_image1 = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_mask_girl1.png")
|
||||
face_image2 = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_mask_girl2.png")
|
||||
|
||||
ip_images = [[face_image1], [face_image2]]
|
||||
```
|
||||
|
||||
<div class="flex flex-row gap-4">
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_girl1.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">IP-Adapter image one</figcaption>
|
||||
</div>
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_girl2.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">IP-Adapter image two</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
Now pass the preprocessed masks to `cross_attention_kwargs` in the pipeline call.
|
||||
|
||||
```py
|
||||
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name=["ip-adapter-plus-face_sdxl_vit-h.safetensors"] * 2)
|
||||
pipeline.set_ip_adapter_scale([0.7] * 2)
|
||||
generator = torch.Generator(device="cpu").manual_seed(0)
|
||||
num_images = 1
|
||||
|
||||
image = pipeline(
|
||||
prompt="2 girls",
|
||||
ip_adapter_image=ip_images,
|
||||
negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",
|
||||
num_inference_steps=20,
|
||||
num_images_per_prompt=num_images,
|
||||
generator=generator,
|
||||
cross_attention_kwargs={"ip_adapter_masks": masks}
|
||||
).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex flex-row gap-4">
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_adapter_attention_mask_result_seed_0.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">IP-Adapter masking applied</figcaption>
|
||||
</div>
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_adapter_no_attention_mask_result_seed_0.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">no IP-Adapter masking applied</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
## Specific use cases
|
||||
|
||||
@@ -279,6 +368,7 @@ Generating accurate faces is challenging because they are complex and nuanced. D
|
||||
* [ip-adapter-plus-face_sd15.safetensors](https://huggingface.co/h94/IP-Adapter/blob/main/models/ip-adapter-plus-face_sd15.safetensors) uses patch embeddings and is conditioned with images of cropped faces
|
||||
|
||||
> [!TIP]
|
||||
>
|
||||
> [IP-Adapter-FaceID](https://huggingface.co/h94/IP-Adapter-FaceID) is a face-specific IP-Adapter trained with face ID embeddings instead of CLIP image embeddings, allowing you to generate more consistent faces in different contexts and styles. Try out this popular [community pipeline](https://github.com/huggingface/diffusers/tree/main/examples/community#ip-adapter-face-id) and see how it compares to the other face IP-Adapters.
|
||||
|
||||
For face models, use the [h94/IP-Adapter](https://huggingface.co/h94/IP-Adapter) checkpoint. It is also recommended to use [`DDIMScheduler`] or [`EulerDiscreteScheduler`] for face models.
|
||||
@@ -502,82 +592,3 @@ image
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ipa-controlnet-out.png" />
|
||||
</div>
|
||||
|
||||
### IP-Adapter masking
|
||||
|
||||
Binary masks can be used to specify which portion of the output image should be assigned to an IP-Adapter.
|
||||
For each input IP-Adapter image, a binary mask and an IP-Adapter must be provided.
|
||||
|
||||
Before passing the masks to the pipeline, it's essential to preprocess them using [`IPAdapterMaskProcessor.preprocess()`].
|
||||
|
||||
> [!TIP]
|
||||
> For optimal results, provide the output height and width to [`IPAdapterMaskProcessor.preprocess()`]. This ensures that masks with differing aspect ratios are appropriately stretched. If the input masks already match the aspect ratio of the generated image, specifying height and width can be omitted.
|
||||
|
||||
Here an example with two masks:
|
||||
|
||||
```py
|
||||
from diffusers.image_processor import IPAdapterMaskProcessor
|
||||
|
||||
mask1 = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_mask1.png")
|
||||
mask2 = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_mask2.png")
|
||||
|
||||
output_height = 1024
|
||||
output_width = 1024
|
||||
|
||||
processor = IPAdapterMaskProcessor()
|
||||
masks = processor.preprocess([mask1, mask2], height=output_height, width=output_width)
|
||||
```
|
||||
|
||||
<div class="flex flex-row gap-4">
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_mask1.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">mask one</figcaption>
|
||||
</div>
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_mask2.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">mask two</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
If you have more than one IP-Adapter image, load them into a list, ensuring each image is assigned to a different IP-Adapter.
|
||||
|
||||
```py
|
||||
face_image1 = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_girl1.png")
|
||||
face_image2 = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_girl2.png")
|
||||
|
||||
ip_images = [[face_image1], [face_image2]]
|
||||
```
|
||||
|
||||
<div class="flex flex-row gap-4">
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_girl1.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">ip adapter image one</figcaption>
|
||||
</div>
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/ip_mask_girl2.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">ip adapter image two</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
Pass preprocessed masks to the pipeline using `cross_attention_kwargs` as shown below:
|
||||
|
||||
```py
|
||||
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name=["ip-adapter-plus-face_sdxl_vit-h.safetensors"] * 2)
|
||||
pipeline.set_ip_adapter_scale([0.7] * 2)
|
||||
generator = torch.Generator(device="cpu").manual_seed(0)
|
||||
num_images = 1
|
||||
|
||||
image = pipeline(
|
||||
prompt="2 girls",
|
||||
ip_adapter_image=ip_images,
|
||||
negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",
|
||||
num_inference_steps=20, num_images_per_prompt=num_images,
|
||||
generator=generator, cross_attention_kwargs={"ip_adapter_masks": masks}
|
||||
).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_adapter_attention_mask_result_seed_0.png" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">output image</figcaption>
|
||||
</div>
|
||||
|
||||
@@ -60,6 +60,23 @@ repo_id = "runwayml/stable-diffusion-v1-5"
|
||||
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(repo_id)
|
||||
```
|
||||
|
||||
You can use the Space below to gauge the memory requirements of a pipeline you want to load beforehand without downloading the pipeline checkpoints:
|
||||
|
||||
<div class="block dark:hidden">
|
||||
<iframe
|
||||
src="https://diffusers-compute-pipeline-size.hf.space?__theme=light"
|
||||
width="850"
|
||||
height="1600"
|
||||
></iframe>
|
||||
</div>
|
||||
<div class="hidden dark:block">
|
||||
<iframe
|
||||
src="https://diffusers-compute-pipeline-size.hf.space?__theme=dark"
|
||||
width="850"
|
||||
height="1600"
|
||||
></iframe>
|
||||
</div>
|
||||
|
||||
### Local pipeline
|
||||
|
||||
To load a diffusion pipeline locally, use [`git-lfs`](https://git-lfs.github.com/) to manually download the checkpoint (in this case, [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5)) to your local disk. This creates a local folder, `./stable-diffusion-v1-5`, on your disk:
|
||||
|
||||
@@ -103,7 +103,7 @@ image
|
||||
|
||||
<Tip>
|
||||
|
||||
LoRA is a very general training technique that can be used with other training methods. For example, it is common to train a model with DreamBooth and LoRA.
|
||||
LoRA is a very general training technique that can be used with other training methods. For example, it is common to train a model with DreamBooth and LoRA. It is also increasingly common to load and merge multiple LoRAs to create new and unique images. You can learn more about it in the in-depth [Merge LoRAs](merge_loras) guide since merging is outside the scope of this loading guide.
|
||||
|
||||
</Tip>
|
||||
|
||||
@@ -165,101 +165,14 @@ To unload the LoRA weights, use the [`~loaders.LoraLoaderMixin.unload_lora_weigh
|
||||
pipeline.unload_lora_weights()
|
||||
```
|
||||
|
||||
### Load multiple LoRAs
|
||||
|
||||
It can be fun to use multiple LoRAs together to create something entirely new and unique. The [`~loaders.LoraLoaderMixin.fuse_lora`] method allows you to fuse the LoRA weights with the original weights of the underlying model.
|
||||
|
||||
<Tip>
|
||||
|
||||
Fusing the weights can lead to a speedup in inference latency because you don't need to separately load the base model and LoRA! You can save your fused pipeline with [`~DiffusionPipeline.save_pretrained`] to avoid loading and fusing the weights every time you want to use the model.
|
||||
|
||||
</Tip>
|
||||
|
||||
Load an initial model:
|
||||
|
||||
```py
|
||||
from diffusers import StableDiffusionXLPipeline, AutoencoderKL
|
||||
import torch
|
||||
|
||||
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
vae=vae,
|
||||
torch_dtype=torch.float16,
|
||||
).to("cuda")
|
||||
```
|
||||
|
||||
Next, load the LoRA checkpoint and fuse it with the original weights. The `lora_scale` parameter controls how much to scale the output by with the LoRA weights. It is important to make the `lora_scale` adjustments in the [`~loaders.LoraLoaderMixin.fuse_lora`] method because it won't work if you try to pass `scale` to the `cross_attention_kwargs` in the pipeline.
|
||||
|
||||
If you need to reset the original model weights for any reason (use a different `lora_scale`), you should use the [`~loaders.LoraLoaderMixin.unfuse_lora`] method.
|
||||
|
||||
```py
|
||||
pipeline.load_lora_weights("ostris/ikea-instructions-lora-sdxl")
|
||||
pipeline.fuse_lora(lora_scale=0.7)
|
||||
|
||||
# to unfuse the LoRA weights
|
||||
pipeline.unfuse_lora()
|
||||
```
|
||||
|
||||
Then fuse this pipeline with the next set of LoRA weights:
|
||||
|
||||
```py
|
||||
pipeline.load_lora_weights("ostris/super-cereal-sdxl-lora")
|
||||
pipeline.fuse_lora(lora_scale=0.7)
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
You can't unfuse multiple LoRA checkpoints, so if you need to reset the model to its original weights, you'll need to reload it.
|
||||
|
||||
</Tip>
|
||||
|
||||
Now you can generate an image that uses the weights from both LoRAs:
|
||||
|
||||
```py
|
||||
prompt = "A cute brown bear eating a slice of pizza, stunning color scheme, masterpiece, illustration"
|
||||
image = pipeline(prompt).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
### 🤗 PEFT
|
||||
|
||||
<Tip>
|
||||
|
||||
Read the [Inference with 🤗 PEFT](../tutorials/using_peft_for_inference) tutorial to learn more about its integration with 🤗 Diffusers and how you can easily work with and juggle multiple adapters. You'll need to install 🤗 Diffusers and PEFT from source to run the example in this section.
|
||||
|
||||
</Tip>
|
||||
|
||||
Another way you can load and use multiple LoRAs is to specify the `adapter_name` parameter in [`~loaders.LoraLoaderMixin.load_lora_weights`]. This method takes advantage of the 🤗 PEFT integration. For example, load and name both LoRA weights:
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
|
||||
pipeline.load_lora_weights("ostris/ikea-instructions-lora-sdxl", weight_name="ikea_instructions_xl_v1_5.safetensors", adapter_name="ikea")
|
||||
pipeline.load_lora_weights("ostris/super-cereal-sdxl-lora", weight_name="cereal_box_sdxl_v1.safetensors", adapter_name="cereal")
|
||||
```
|
||||
|
||||
Now use the [`~loaders.UNet2DConditionLoadersMixin.set_adapters`] to activate both LoRAs, and you can configure how much weight each LoRA should have on the output:
|
||||
|
||||
```py
|
||||
pipeline.set_adapters(["ikea", "cereal"], adapter_weights=[0.7, 0.5])
|
||||
```
|
||||
|
||||
Then, generate an image:
|
||||
|
||||
```py
|
||||
prompt = "A cute brown bear eating a slice of pizza, stunning color scheme, masterpiece, illustration"
|
||||
image = pipeline(prompt, num_inference_steps=30, cross_attention_kwargs={"scale": 1.0}).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
### Kohya and TheLastBen
|
||||
|
||||
Other popular LoRA trainers from the community include those by [Kohya](https://github.com/kohya-ss/sd-scripts/) and [TheLastBen](https://github.com/TheLastBen/fast-stable-diffusion). These trainers create different LoRA checkpoints than those trained by 🤗 Diffusers, but they can still be loaded in the same way.
|
||||
|
||||
Let's download the [Blueprintify SD XL 1.0](https://civitai.com/models/150986/blueprintify-sd-xl-10) checkpoint from [Civitai](https://civitai.com/):
|
||||
<hfoptions id="other-trainers">
|
||||
<hfoption id="Kohya">
|
||||
|
||||
To load a Kohya LoRA, let's download the [Blueprintify SD XL 1.0](https://civitai.com/models/150986/blueprintify-sd-xl-10) checkpoint from [Civitai](https://civitai.com/) as an example:
|
||||
|
||||
```sh
|
||||
!wget https://civitai.com/api/download/models/168776 -O blueprintify-sd-xl-10.safetensors
|
||||
@@ -293,6 +206,9 @@ Some limitations of using Kohya LoRAs with 🤗 Diffusers include:
|
||||
|
||||
</Tip>
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="TheLastBen">
|
||||
|
||||
Loading a checkpoint from TheLastBen is very similar. For example, to load the [TheLastBen/William_Eggleston_Style_SDXL](https://huggingface.co/TheLastBen/William_Eggleston_Style_SDXL) checkpoint:
|
||||
|
||||
```py
|
||||
@@ -308,6 +224,9 @@ image = pipeline(prompt=prompt).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## IP-Adapter
|
||||
|
||||
[IP-Adapter](https://ip-adapter.github.io/) is a lightweight adapter that enables image prompting for any diffusion model. This adapter works by decoupling the cross-attention layers of the image and text features. All the other model components are frozen and only the embedded image features in the UNet are trained. As a result, IP-Adapter files are typically only ~100MBs.
|
||||
|
||||
@@ -0,0 +1,266 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Merge LoRAs
|
||||
|
||||
It can be fun and creative to use multiple [LoRAs]((https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora)) together to generate something entirely new and unique. This works by merging multiple LoRA weights together to produce images that are a blend of different styles. Diffusers provides a few methods to merge LoRAs depending on *how* you want to merge their weights, which can affect image quality.
|
||||
|
||||
This guide will show you how to merge LoRAs using the [`~loaders.UNet2DConditionLoadersMixin.set_adapters`] and [`~peft.LoraModel.add_weighted_adapter`] methods. To improve inference speed and reduce memory-usage of merged LoRAs, you'll also see how to use the [`~loaders.LoraLoaderMixin.fuse_lora`] method to fuse the LoRA weights with the original weights of the underlying model.
|
||||
|
||||
For this guide, load a Stable Diffusion XL (SDXL) checkpoint and the [KappaNeuro/studio-ghibli-style]() and [Norod78/sdxl-chalkboarddrawing-lora]() LoRAs with the [`~loaders.LoraLoaderMixin.load_lora_weights`] method. You'll need to assign each LoRA an `adapter_name` to combine them later.
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
|
||||
pipeline.load_lora_weights("ostris/ikea-instructions-lora-sdxl", weight_name="ikea_instructions_xl_v1_5.safetensors", adapter_name="ikea")
|
||||
pipeline.load_lora_weights("lordjia/by-feng-zikai", weight_name="fengzikai_v1.0_XL.safetensors", adapter_name="feng")
|
||||
```
|
||||
|
||||
## set_adapters
|
||||
|
||||
The [`~loaders.UNet2DConditionLoadersMixin.set_adapters`] method merges LoRA adapters by concatenating their weighted matrices. Use the adapter name to specify which LoRAs to merge, and the `adapter_weights` parameter to control the scaling for each LoRA. For example, if `adapter_weights=[0.5, 0.5]`, then the merged LoRA output is an average of both LoRAs. Try adjusting the adapter weights to see how it affects the generated image!
|
||||
|
||||
```py
|
||||
pipeline.set_adapters(["ikea", "feng"], adapter_weights=[0.7, 0.8])
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
prompt = "A bowl of ramen shaped like a cute kawaii bear, by Feng Zikai"
|
||||
image = pipeline(prompt, generator=generator, cross_attention_kwargs={"scale": 1.0}).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/lora_merge_set_adapters.png"/>
|
||||
</div>
|
||||
|
||||
## add_weighted_adapter
|
||||
|
||||
> [!WARNING]
|
||||
> This is an experimental method that adds PEFTs [`~peft.LoraModel.add_weighted_adapter`] method to Diffusers to enable more efficient merging methods. Check out this [issue](https://github.com/huggingface/diffusers/issues/6892) if you're interested in learning more about the motivation and design behind this integration.
|
||||
|
||||
The [`~peft.LoraModel.add_weighted_adapter`] method provides access to more efficient merging method such as [TIES and DARE](https://huggingface.co/docs/peft/developer_guides/model_merging). To use these merging methods, make sure you have the latest stable version of Diffusers and PEFT installed.
|
||||
|
||||
```bash
|
||||
pip install -U diffusers peft
|
||||
```
|
||||
|
||||
There are three steps to merge LoRAs with the [`~peft.LoraModel.add_weighted_adapter`] method:
|
||||
|
||||
1. Create a [`~peft.PeftModel`] from the underlying model and LoRA checkpoint.
|
||||
2. Load a base UNet model and the LoRA adapters.
|
||||
3. Merge the adapters using the [`~peft.LoraModel.add_weighted_adapter`] method and the merging method of your choice.
|
||||
|
||||
Let's dive deeper into what these steps entail.
|
||||
|
||||
1. Load a UNet that corresponds to the UNet in the LoRA checkpoint. In this case, both LoRAs use the SDXL UNet as their base model.
|
||||
|
||||
```python
|
||||
from diffusers import UNet2DConditionModel
|
||||
import torch
|
||||
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
use_safetensors=True,
|
||||
variant="fp16",
|
||||
subfolder="unet",
|
||||
).to("cuda")
|
||||
```
|
||||
|
||||
Load the SDXL pipeline and the LoRA checkpoints, starting with the [ostris/ikea-instructions-lora-sdxl](https://huggingface.co/ostris/ikea-instructions-lora-sdxl) LoRA.
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
variant="fp16",
|
||||
torch_dtype=torch.float16,
|
||||
unet=unet
|
||||
).to("cuda")
|
||||
pipeline.load_lora_weights("ostris/ikea-instructions-lora-sdxl", weight_name="ikea_instructions_xl_v1_5.safetensors", adapter_name="ikea")
|
||||
```
|
||||
|
||||
Now you'll create a [`~peft.PeftModel`] from the loaded LoRA checkpoint by combining the SDXL UNet and the LoRA UNet from the pipeline.
|
||||
|
||||
```python
|
||||
from peft import get_peft_model, LoraConfig
|
||||
import copy
|
||||
|
||||
sdxl_unet = copy.deepcopy(unet)
|
||||
ikea_peft_model = get_peft_model(
|
||||
sdxl_unet,
|
||||
pipeline.unet.peft_config["ikea"],
|
||||
adapter_name="ikea"
|
||||
)
|
||||
|
||||
original_state_dict = {f"base_model.model.{k}": v for k, v in pipeline.unet.state_dict().items()}
|
||||
ikea_peft_model.load_state_dict(original_state_dict, strict=True)
|
||||
```
|
||||
|
||||
> [!TIP]
|
||||
> You can optionally push the ikea_peft_model to the Hub by calling `ikea_peft_model.push_to_hub("ikea_peft_model", token=TOKEN)`.
|
||||
|
||||
Repeat this process to create a [`~peft.PeftModel`] from the [lordjia/by-feng-zikai](https://huggingface.co/lordjia/by-feng-zikai) LoRA.
|
||||
|
||||
```python
|
||||
pipeline.delete_adapters("ikea")
|
||||
sdxl_unet.delete_adapters("ikea")
|
||||
|
||||
pipeline.load_lora_weights("lordjia/by-feng-zikai", weight_name="fengzikai_v1.0_XL.safetensors", adapter_name="feng")
|
||||
pipeline.set_adapters(adapter_names="feng")
|
||||
|
||||
feng_peft_model = get_peft_model(
|
||||
sdxl_unet,
|
||||
pipeline.unet.peft_config["feng"],
|
||||
adapter_name="feng"
|
||||
)
|
||||
|
||||
original_state_dict = {f"base_model.model.{k}": v for k, v in pipe.unet.state_dict().items()}
|
||||
feng_peft_model.load_state_dict(original_state_dict, strict=True)
|
||||
```
|
||||
|
||||
2. Load a base UNet model and then load the adapters onto it.
|
||||
|
||||
```python
|
||||
from peft import PeftModel
|
||||
|
||||
base_unet = UNet2DConditionModel.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
use_safetensors=True,
|
||||
variant="fp16",
|
||||
subfolder="unet",
|
||||
).to("cuda")
|
||||
|
||||
model = PeftModel.from_pretrained(base_unet, "stevhliu/ikea_peft_model", use_safetensors=True, subfolder="ikea", adapter_name="ikea")
|
||||
model.load_adapter("stevhliu/feng_peft_model", use_safetensors=True, subfolder="feng", adapter_name="feng")
|
||||
```
|
||||
|
||||
3. Merge the adapters using the [`~peft.LoraModel.add_weighted_adapter`] method and the merging method of your choice (learn more about other merging methods in this [blog post](https://huggingface.co/blog/peft_merging)). For this example, let's use the `"dare_linear"` method to merge the LoRAs.
|
||||
|
||||
> [!WARNING]
|
||||
> Keep in mind the LoRAs need to have the same rank to be merged!
|
||||
|
||||
```python
|
||||
model.add_weighted_adapter(
|
||||
adapters=["ikea", "feng"],
|
||||
weights=[1.0, 1.0],
|
||||
combination_type="dare_linear",
|
||||
adapter_name="ikea-feng"
|
||||
)
|
||||
model.set_adapters("ikea-feng")
|
||||
```
|
||||
|
||||
Now you can generate an image with the merged LoRA.
|
||||
|
||||
```python
|
||||
model = model.to(dtype=torch.float16, device="cuda")
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", unet=model, variant="fp16", torch_dtype=torch.float16,
|
||||
).to("cuda")
|
||||
|
||||
image = pipeline("A bowl of ramen shaped like a cute kawaii bear, by Feng Zikai", generator=torch.manual_seed(0)).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ikea-feng-dare-linear.png"/>
|
||||
</div>
|
||||
|
||||
## fuse_lora
|
||||
|
||||
Both the [`~loaders.UNet2DConditionLoadersMixin.set_adapters`] and [`~peft.LoraModel.add_weighted_adapter`] methods require loading the base model and the LoRA adapters separately which incurs some overhead. The [`~loaders.LoraLoaderMixin.fuse_lora`] method allows you to fuse the LoRA weights directly with the original weights of the underlying model. This way, you're only loading the model once which can increase inference and lower memory-usage.
|
||||
|
||||
You can use PEFT to easily fuse/unfuse multiple adapters directly into the model weights (both UNet and text encoder) using the [`~loaders.LoraLoaderMixin.fuse_lora`] method, which can lead to a speed-up in inference and lower VRAM usage.
|
||||
|
||||
For example, if you have a base model and adapters loaded and set as active with the following adapter weights:
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
|
||||
pipeline.load_lora_weights("ostris/ikea-instructions-lora-sdxl", weight_name="ikea_instructions_xl_v1_5.safetensors", adapter_name="ikea")
|
||||
pipeline.load_lora_weights("lordjia/by-feng-zikai", weight_name="fengzikai_v1.0_XL.safetensors", adapter_name="feng")
|
||||
|
||||
pipeline.set_adapters(["ikea", "feng"], adapter_weights=[0.7, 0.8])
|
||||
```
|
||||
|
||||
Fuse these LoRAs into the UNet with the [`~loaders.LoraLoaderMixin.fuse_lora`] method. The `lora_scale` parameter controls how much to scale the output by with the LoRA weights. It is important to make the `lora_scale` adjustments in the [`~loaders.LoraLoaderMixin.fuse_lora`] method because it won’t work if you try to pass `scale` to the `cross_attention_kwargs` in the pipeline.
|
||||
|
||||
```py
|
||||
pipeline.fuse_lora(adapter_names=["ikea", "feng"], lora_scale=1.0)
|
||||
```
|
||||
|
||||
Then you should use [`~loaders.LoraLoaderMixin.unload_lora_weights`] to unload the LoRA weights since they've already been fused with the underlying base model. Finally, call [`~DiffusionPipeline.save_pretrained`] to save the fused pipeline locally or you could call [`~DiffusionPipeline.push_to_hub`] to push the fused pipeline to the Hub.
|
||||
|
||||
```py
|
||||
pipeline.unload_lora_weights()
|
||||
# save locally
|
||||
pipeline.save_pretrained("path/to/fused-pipeline")
|
||||
# save to the Hub
|
||||
pipeline.push_to_hub("fused-ikea-feng")
|
||||
```
|
||||
|
||||
Now you can quickly load the fused pipeline and use it for inference without needing to separately load the LoRA adapters.
|
||||
|
||||
```py
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"username/fused-ikea-feng", torch_dtype=torch.float16,
|
||||
).to("cuda")
|
||||
|
||||
image = pipeline("A bowl of ramen shaped like a cute kawaii bear, by Feng Zikai", generator=torch.manual_seed(0)).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
You can call [`~loaders.LoraLoaderMixin.unfuse_lora`] to restore the original model's weights (for example, if you want to use a different `lora_scale` value). However, this only works if you've only fused one LoRA adapter to the original model. If you've fused multiple LoRAs, you'll need to reload the model.
|
||||
|
||||
```py
|
||||
pipeline.unfuse_lora()
|
||||
```
|
||||
|
||||
### torch.compile
|
||||
|
||||
[torch.compile](../optimization/torch2.0#torchcompile) can speed up your pipeline even more, but the LoRA weights must be fused first and then unloaded. Typically, the UNet is compiled because it is such a computationally intensive component of the pipeline.
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
# load base model and LoRAs
|
||||
pipeline = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
|
||||
pipeline.load_lora_weights("ostris/ikea-instructions-lora-sdxl", weight_name="ikea_instructions_xl_v1_5.safetensors", adapter_name="ikea")
|
||||
pipeline.load_lora_weights("lordjia/by-feng-zikai", weight_name="fengzikai_v1.0_XL.safetensors", adapter_name="feng")
|
||||
|
||||
# activate both LoRAs and set adapter weights
|
||||
pipeline.set_adapters(["ikea", "feng"], adapter_weights=[0.7, 0.8])
|
||||
|
||||
# fuse LoRAs and unload weights
|
||||
pipeline.fuse_lora(adapter_names=["ikea", "feng"], lora_scale=1.0)
|
||||
pipeline.unload_lora_weights()
|
||||
|
||||
# torch.compile
|
||||
pipeline.unet.to(memory_format=torch.channels_last)
|
||||
pipeline.unet = torch.compile(pipeline.unet, mode="reduce-overhead", fullgraph=True)
|
||||
|
||||
image = pipeline("A bowl of ramen shaped like a cute kawaii bear, by Feng Zikai", generator=torch.manual_seed(0)).images[0]
|
||||
```
|
||||
|
||||
Learn more about torch.compile in the [Accelerate inference of text-to-image diffusion models](../tutorials/fast_diffusion#torchcompile) guide.
|
||||
|
||||
## Next steps
|
||||
|
||||
For more conceptual details about how each merging method works, take a look at the [🤗 PEFT welcomes new merging methods](https://huggingface.co/blog/peft_merging#concatenation-cat) blog post!
|
||||
@@ -21,7 +21,7 @@ This guide will show you how to use SVD to generate short videos from images.
|
||||
Before you begin, make sure you have the following libraries installed:
|
||||
|
||||
```py
|
||||
!pip install -q -U diffusers transformers accelerate
|
||||
!pip install -q -U diffusers transformers accelerate
|
||||
```
|
||||
|
||||
The are two variants of this model, [SVD](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid) and [SVD-XT](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt). The SVD checkpoint is trained to generate 14 frames and the SVD-XT checkpoint is further finetuned to generate 25 frames.
|
||||
@@ -86,7 +86,7 @@ Video generation is very memory intensive because you're essentially generating
|
||||
+ frames = pipe(image, decode_chunk_size=2, generator=generator, num_frames=25).frames[0]
|
||||
```
|
||||
|
||||
Using all these tricks togethere should lower the memory requirement to less than 8GB VRAM.
|
||||
Using all these tricks together should lower the memory requirement to less than 8GB VRAM.
|
||||
|
||||
## Micro-conditioning
|
||||
|
||||
|
||||
@@ -273,7 +273,6 @@ Lastly, convert the image to a `PIL.Image` to see your generated image!
|
||||
```py
|
||||
>>> image = (image / 2 + 0.5).clamp(0, 1).squeeze()
|
||||
>>> image = (image.permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
|
||||
>>> image = (image * 255).round().astype("uint8")
|
||||
>>> image = Image.fromarray(image)
|
||||
>>> image
|
||||
```
|
||||
|
||||
@@ -12,7 +12,7 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# 메모리와 속도
|
||||
|
||||
메모리 또는 속도에 대해 🤗 Diffusers *추론*을 최적화하기 위한 몇 가지 기술과 아이디어를 제시합니다.
|
||||
메모리 또는 속도에 대해 🤗 Diffusers *추론*을 최적화하기 위한 몇 가지 기술과 아이디어를 제시합니다.
|
||||
일반적으로, memory-efficient attention을 위해 [xFormers](https://github.com/facebookresearch/xformers) 사용을 추천하기 때문에, 추천하는 [설치 방법](xformers)을 보고 설치해 보세요.
|
||||
|
||||
다음 설정이 성능과 메모리에 미치는 영향에 대해 설명합니다.
|
||||
@@ -27,7 +27,7 @@ specific language governing permissions and limitations under the License.
|
||||
| memory-efficient attention | 2.63s | x3.61 |
|
||||
|
||||
<em>
|
||||
NVIDIA TITAN RTX에서 50 DDIM 스텝의 "a photo of an astronaut riding a horse on mars" 프롬프트로 512x512 크기의 단일 이미지를 생성하였습니다.
|
||||
NVIDIA TITAN RTX에서 50 DDIM 스텝의 "a photo of an astronaut riding a horse on mars" 프롬프트로 512x512 크기의 단일 이미지를 생성하였습니다.
|
||||
</em>
|
||||
|
||||
## cuDNN auto-tuner 활성화하기
|
||||
@@ -44,11 +44,11 @@ torch.backends.cudnn.benchmark = True
|
||||
|
||||
### fp32 대신 tf32 사용하기 (Ampere 및 이후 CUDA 장치들에서)
|
||||
|
||||
Ampere 및 이후 CUDA 장치에서 행렬곱 및 컨볼루션은 TensorFloat32(TF32) 모드를 사용하여 더 빠르지만 약간 덜 정확할 수 있습니다.
|
||||
기본적으로 PyTorch는 컨볼루션에 대해 TF32 모드를 활성화하지만 행렬 곱셈은 활성화하지 않습니다.
|
||||
네트워크에 완전한 float32 정밀도가 필요한 경우가 아니면 행렬 곱셈에 대해서도 이 설정을 활성화하는 것이 좋습니다.
|
||||
이는 일반적으로 무시할 수 있는 수치의 정확도 손실이 있지만, 계산 속도를 크게 높일 수 있습니다.
|
||||
그것에 대해 [여기](https://huggingface.co/docs/transformers/v4.18.0/en/performance#tf32)서 더 읽을 수 있습니다.
|
||||
Ampere 및 이후 CUDA 장치에서 행렬곱 및 컨볼루션은 TensorFloat32(TF32) 모드를 사용하여 더 빠르지만 약간 덜 정확할 수 있습니다.
|
||||
기본적으로 PyTorch는 컨볼루션에 대해 TF32 모드를 활성화하지만 행렬 곱셈은 활성화하지 않습니다.
|
||||
네트워크에 완전한 float32 정밀도가 필요한 경우가 아니면 행렬 곱셈에 대해서도 이 설정을 활성화하는 것이 좋습니다.
|
||||
이는 일반적으로 무시할 수 있는 수치의 정확도 손실이 있지만, 계산 속도를 크게 높일 수 있습니다.
|
||||
그것에 대해 [여기](https://huggingface.co/docs/transformers/v4.18.0/en/performance#tf32)서 더 읽을 수 있습니다.
|
||||
추론하기 전에 다음을 추가하기만 하면 됩니다:
|
||||
|
||||
```python
|
||||
@@ -59,13 +59,13 @@ torch.backends.cuda.matmul.allow_tf32 = True
|
||||
|
||||
## 반정밀도 가중치
|
||||
|
||||
더 많은 GPU 메모리를 절약하고 더 빠른 속도를 얻기 위해 모델 가중치를 반정밀도(half precision)로 직접 불러오고 실행할 수 있습니다.
|
||||
더 많은 GPU 메모리를 절약하고 더 빠른 속도를 얻기 위해 모델 가중치를 반정밀도(half precision)로 직접 불러오고 실행할 수 있습니다.
|
||||
여기에는 `fp16`이라는 브랜치에 저장된 float16 버전의 가중치를 불러오고, 그 때 `float16` 유형을 사용하도록 PyTorch에 지시하는 작업이 포함됩니다.
|
||||
|
||||
```Python
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
|
||||
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
pipe = pipe.to("cuda")
|
||||
@@ -75,7 +75,7 @@ image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
어떤 파이프라인에서도 [`torch.autocast`](https://pytorch.org/docs/stable/amp.html#torch.autocast) 를 사용하는 것은 검은색 이미지를 생성할 수 있고, 순수한 float16 정밀도를 사용하는 것보다 항상 느리기 때문에 사용하지 않는 것이 좋습니다.
|
||||
어떤 파이프라인에서도 [`torch.autocast`](https://pytorch.org/docs/stable/amp.html#torch.autocast) 를 사용하는 것은 검은색 이미지를 생성할 수 있고, 순수한 float16 정밀도를 사용하는 것보다 항상 느리기 때문에 사용하지 않는 것이 좋습니다.
|
||||
</Tip>
|
||||
|
||||
## 추가 메모리 절약을 위한 슬라이스 어텐션
|
||||
@@ -95,7 +95,7 @@ from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
|
||||
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
pipe = pipe.to("cuda")
|
||||
@@ -122,7 +122,7 @@ from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
|
||||
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
pipe = pipe.to("cuda")
|
||||
@@ -148,7 +148,7 @@ from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
|
||||
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
|
||||
@@ -165,7 +165,7 @@ image = pipe(prompt).images[0]
|
||||
또 다른 최적화 방법인 <a href="#model_offloading">모델 오프로딩</a>을 사용하는 것을 고려하십시오. 이는 훨씬 빠르지만 메모리 절약이 크지는 않습니다.
|
||||
</Tip>
|
||||
|
||||
또한 ttention slicing과 연결해서 최소 메모리(< 2GB)로도 동작할 수 있습니다.
|
||||
또한 ttention slicing과 연결해서 최소 메모리(< 2GB)로도 동작할 수 있습니다.
|
||||
|
||||
|
||||
```Python
|
||||
@@ -174,7 +174,7 @@ from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
|
||||
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
|
||||
@@ -204,7 +204,7 @@ import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
|
||||
@@ -355,7 +355,7 @@ unet_traced = torch.jit.load("unet_traced.pt")
|
||||
class TracedUNet(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.in_channels = pipe.unet.in_channels
|
||||
self.in_channels = pipe.unet.config.in_channels
|
||||
self.device = pipe.unet.device
|
||||
|
||||
def forward(self, latent_model_input, t, encoder_hidden_states):
|
||||
@@ -387,7 +387,7 @@ with torch.inference_mode():
|
||||
| A100-SXM4-40GB | 18.6it/s | 29.it/s |
|
||||
| A100-SXM-80GB | 18.7it/s | 29.5it/s |
|
||||
|
||||
이를 활용하려면 다음을 만족해야 합니다:
|
||||
이를 활용하려면 다음을 만족해야 합니다:
|
||||
- PyTorch > 1.12
|
||||
- Cuda 사용 가능
|
||||
- [xformers 라이브러리를 설치함](xformers)
|
||||
|
||||
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
🧨 Diffusers는 사용자 친화적이며 유연한 도구 상자로, 사용사례에 맞게 diffusion 시스템을 구축 할 수 있도록 설계되었습니다. 이 도구 상자의 핵심은 모델과 스케줄러입니다. [`DiffusionPipeline`]은 편의를 위해 이러한 구성 요소를 번들로 제공하지만, 파이프라인을 분리하고 모델과 스케줄러를 개별적으로 사용해 새로운 diffusion 시스템을 만들 수도 있습니다.
|
||||
🧨 Diffusers는 사용자 친화적이며 유연한 도구 상자로, 사용사례에 맞게 diffusion 시스템을 구축 할 수 있도록 설계되었습니다. 이 도구 상자의 핵심은 모델과 스케줄러입니다. [`DiffusionPipeline`]은 편의를 위해 이러한 구성 요소를 번들로 제공하지만, 파이프라인을 분리하고 모델과 스케줄러를 개별적으로 사용해 새로운 diffusion 시스템을 만들 수도 있습니다.
|
||||
|
||||
이 튜토리얼에서는 기본 파이프라인부터 시작해 Stable Diffusion 파이프라인까지 진행하며 모델과 스케줄러를 사용해 추론을 위한 diffusion 시스템을 조립하는 방법을 배웁니다.
|
||||
|
||||
@@ -36,7 +36,7 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
정말 쉽습니다. 그런데 파이프라인은 어떻게 이렇게 할 수 있었을까요? 파이프라인을 세분화하여 내부에서 어떤 일이 일어나고 있는지 살펴보겠습니다.
|
||||
|
||||
위 예시에서 파이프라인에는 [`UNet2DModel`] 모델과 [`DDPMScheduler`]가 포함되어 있습니다. 파이프라인은 원하는 출력 크기의 랜덤 노이즈를 받아 모델을 여러번 통과시켜 이미지의 노이즈를 제거합니다. 각 timestep에서 모델은 *noise residual*을 예측하고 스케줄러는 이를 사용하여 노이즈가 적은 이미지를 예측합니다. 파이프라인은 지정된 추론 스텝수에 도달할 때까지 이 과정을 반복합니다.
|
||||
위 예시에서 파이프라인에는 [`UNet2DModel`] 모델과 [`DDPMScheduler`]가 포함되어 있습니다. 파이프라인은 원하는 출력 크기의 랜덤 노이즈를 받아 모델을 여러번 통과시켜 이미지의 노이즈를 제거합니다. 각 timestep에서 모델은 *noise residual*을 예측하고 스케줄러는 이를 사용하여 노이즈가 적은 이미지를 예측합니다. 파이프라인은 지정된 추론 스텝수에 도달할 때까지 이 과정을 반복합니다.
|
||||
|
||||
모델과 스케줄러를 별도로 사용하여 파이프라인을 다시 생성하기 위해 자체적인 노이즈 제거 프로세스를 작성해 보겠습니다.
|
||||
|
||||
@@ -210,7 +210,7 @@ Stable Diffusion 은 text-to-image *latent diffusion* 모델입니다. latent di
|
||||
|
||||
```py
|
||||
>>> latents = torch.randn(
|
||||
... (batch_size, unet.in_channels, height // 8, width // 8),
|
||||
... (batch_size, unet.config.in_channels, height // 8, width // 8),
|
||||
... generator=generator,
|
||||
... device=torch_device,
|
||||
... )
|
||||
|
||||
@@ -259,6 +259,50 @@ pip install git+https://github.com/huggingface/peft.git
|
||||
**Inference**
|
||||
The inference is the same as if you train a regular LoRA 🤗
|
||||
|
||||
## Conducting EDM-style training
|
||||
|
||||
It's now possible to perform EDM-style training as proposed in [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364).
|
||||
|
||||
simply set:
|
||||
|
||||
```diff
|
||||
+ --do_edm_style_training \
|
||||
```
|
||||
|
||||
Other SDXL-like models that use the EDM formulation, such as [playgroundai/playground-v2.5-1024px-aesthetic](https://huggingface.co/playgroundai/playground-v2.5-1024px-aesthetic), can also be DreamBooth'd with the script. Below is an example command:
|
||||
|
||||
```bash
|
||||
accelerate launch train_dreambooth_lora_sdxl_advanced.py \
|
||||
--pretrained_model_name_or_path="playgroundai/playground-v2.5-1024px-aesthetic" \
|
||||
--dataset_name="linoyts/3d_icon" \
|
||||
--instance_prompt="3d icon in the style of TOK" \
|
||||
--validation_prompt="a TOK icon of an astronaut riding a horse, in the style of TOK" \
|
||||
--output_dir="3d-icon-SDXL-LoRA" \
|
||||
--do_edm_style_training \
|
||||
--caption_column="prompt" \
|
||||
--mixed_precision="bf16" \
|
||||
--resolution=1024 \
|
||||
--train_batch_size=3 \
|
||||
--repeats=1 \
|
||||
--report_to="wandb"\
|
||||
--gradient_accumulation_steps=1 \
|
||||
--gradient_checkpointing \
|
||||
--learning_rate=1.0 \
|
||||
--text_encoder_lr=1.0 \
|
||||
--optimizer="prodigy"\
|
||||
--train_text_encoder_ti\
|
||||
--train_text_encoder_ti_frac=0.5\
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--rank=8 \
|
||||
--max_train_steps=1000 \
|
||||
--checkpointing_steps=2000 \
|
||||
--seed="0" \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
> [!CAUTION]
|
||||
> Min-SNR gamma is not supported with the EDM-style training yet. When training with the PlaygroundAI model, it's recommended to not pass any "variant".
|
||||
|
||||
### Tips and Tricks
|
||||
Check out [these recommended practices](https://huggingface.co/blog/sdxl_lora_advanced_script#additional-good-practices)
|
||||
|
||||
@@ -70,7 +70,7 @@ from diffusers.utils.import_utils import is_xformers_available
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -1215,7 +1215,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, "
|
||||
"please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
@@ -1366,14 +1366,14 @@ def main(args):
|
||||
|
||||
# Optimizer creation
|
||||
if not (args.optimizer.lower() == "prodigy" or args.optimizer.lower() == "adamw"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
f"Unsupported choice of optimizer: {args.optimizer}.Supported optimizers include [adamW, prodigy]."
|
||||
"Defaulting to adamW"
|
||||
)
|
||||
args.optimizer = "adamw"
|
||||
|
||||
if args.use_8bit_adam and not args.optimizer.lower() == "adamw":
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
f"use_8bit_adam is ignored when optimizer is not set to 'AdamW'. Optimizer was "
|
||||
f"set to {args.optimizer.lower()}"
|
||||
)
|
||||
@@ -1407,11 +1407,11 @@ def main(args):
|
||||
optimizer_class = prodigyopt.Prodigy
|
||||
|
||||
if args.learning_rate <= 0.1:
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"Learning rate is too low. When using prodigy, it's generally better to set learning rate around 1.0"
|
||||
)
|
||||
if args.train_text_encoder and args.text_encoder_lr:
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
f"Learning rates were provided both for the unet and the text encoder- e.g. text_encoder_lr:"
|
||||
f" {args.text_encoder_lr} and learning_rate: {args.learning_rate}. "
|
||||
f"When using prodigy only learning_rate is used as the initial learning rate."
|
||||
|
||||
@@ -14,9 +14,11 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
|
||||
import argparse
|
||||
import contextlib
|
||||
import gc
|
||||
import hashlib
|
||||
import itertools
|
||||
import json
|
||||
import logging
|
||||
import math
|
||||
import os
|
||||
@@ -37,7 +39,7 @@ import transformers
|
||||
from accelerate import Accelerator
|
||||
from accelerate.logging import get_logger
|
||||
from accelerate.utils import DistributedDataParallelKwargs, ProjectConfiguration, set_seed
|
||||
from huggingface_hub import create_repo, upload_folder
|
||||
from huggingface_hub import create_repo, hf_hub_download, upload_folder
|
||||
from packaging import version
|
||||
from peft import LoraConfig, set_peft_model_state_dict
|
||||
from peft.utils import get_peft_model_state_dict
|
||||
@@ -55,6 +57,8 @@ from diffusers import (
|
||||
AutoencoderKL,
|
||||
DDPMScheduler,
|
||||
DPMSolverMultistepScheduler,
|
||||
EDMEulerScheduler,
|
||||
EulerDiscreteScheduler,
|
||||
StableDiffusionXLPipeline,
|
||||
UNet2DConditionModel,
|
||||
)
|
||||
@@ -74,11 +78,25 @@ from diffusers.utils.torch_utils import is_compiled_module
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
def determine_scheduler_type(pretrained_model_name_or_path, revision):
|
||||
model_index_filename = "model_index.json"
|
||||
if os.path.isdir(pretrained_model_name_or_path):
|
||||
model_index = os.path.join(pretrained_model_name_or_path, model_index_filename)
|
||||
else:
|
||||
model_index = hf_hub_download(
|
||||
repo_id=pretrained_model_name_or_path, filename=model_index_filename, revision=revision
|
||||
)
|
||||
|
||||
with open(model_index, "r") as f:
|
||||
scheduler_type = json.load(f)["scheduler"][1]
|
||||
return scheduler_type
|
||||
|
||||
|
||||
def save_model_card(
|
||||
repo_id: str,
|
||||
use_dora: bool,
|
||||
@@ -370,6 +388,11 @@ def parse_args(input_args=None):
|
||||
" `args.validation_prompt` multiple times: `args.num_validation_images`."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--do_edm_style_training",
|
||||
action="store_true",
|
||||
help="Flag to conduct training using the EDM formulation as introduced in https://arxiv.org/abs/2206.00364.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--with_prior_preservation",
|
||||
default=False,
|
||||
@@ -1117,6 +1140,8 @@ def main(args):
|
||||
"You cannot use both --report_to=wandb and --hub_token due to a security risk of exposing your token."
|
||||
" Please use `huggingface-cli login` to authenticate with the Hub."
|
||||
)
|
||||
if args.do_edm_style_training and args.snr_gamma is not None:
|
||||
raise ValueError("Min-SNR formulation is not supported when conducting EDM-style training.")
|
||||
|
||||
logging_dir = Path(args.output_dir, args.logging_dir)
|
||||
|
||||
@@ -1234,7 +1259,19 @@ def main(args):
|
||||
)
|
||||
|
||||
# Load scheduler and models
|
||||
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
|
||||
scheduler_type = determine_scheduler_type(args.pretrained_model_name_or_path, args.revision)
|
||||
if "EDM" in scheduler_type:
|
||||
args.do_edm_style_training = True
|
||||
noise_scheduler = EDMEulerScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
|
||||
logger.info("Performing EDM-style training!")
|
||||
elif args.do_edm_style_training:
|
||||
noise_scheduler = EulerDiscreteScheduler.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="scheduler"
|
||||
)
|
||||
logger.info("Performing EDM-style training!")
|
||||
else:
|
||||
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
|
||||
|
||||
text_encoder_one = text_encoder_cls_one.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
|
||||
)
|
||||
@@ -1252,7 +1289,12 @@ def main(args):
|
||||
revision=args.revision,
|
||||
variant=args.variant,
|
||||
)
|
||||
vae_scaling_factor = vae.config.scaling_factor
|
||||
latents_mean = latents_std = None
|
||||
if hasattr(vae.config, "latents_mean") and vae.config.latents_mean is not None:
|
||||
latents_mean = torch.tensor(vae.config.latents_mean).view(1, 4, 1, 1)
|
||||
if hasattr(vae.config, "latents_std") and vae.config.latents_std is not None:
|
||||
latents_std = torch.tensor(vae.config.latents_std).view(1, 4, 1, 1)
|
||||
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
|
||||
)
|
||||
@@ -1317,7 +1359,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, "
|
||||
"please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
@@ -1522,14 +1564,14 @@ def main(args):
|
||||
|
||||
# Optimizer creation
|
||||
if not (args.optimizer.lower() == "prodigy" or args.optimizer.lower() == "adamw"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
f"Unsupported choice of optimizer: {args.optimizer}.Supported optimizers include [adamW, prodigy]."
|
||||
"Defaulting to adamW"
|
||||
)
|
||||
args.optimizer = "adamw"
|
||||
|
||||
if args.use_8bit_adam and not args.optimizer.lower() == "adamw":
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
f"use_8bit_adam is ignored when optimizer is not set to 'AdamW'. Optimizer was "
|
||||
f"set to {args.optimizer.lower()}"
|
||||
)
|
||||
@@ -1563,11 +1605,11 @@ def main(args):
|
||||
optimizer_class = prodigyopt.Prodigy
|
||||
|
||||
if args.learning_rate <= 0.1:
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"Learning rate is too low. When using prodigy, it's generally better to set learning rate around 1.0"
|
||||
)
|
||||
if args.train_text_encoder and args.text_encoder_lr:
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
f"Learning rates were provided both for the unet and the text encoder- e.g. text_encoder_lr:"
|
||||
f" {args.text_encoder_lr} and learning_rate: {args.learning_rate}. "
|
||||
f"When using prodigy only learning_rate is used as the initial learning rate."
|
||||
@@ -1790,6 +1832,19 @@ def main(args):
|
||||
disable=not accelerator.is_local_main_process,
|
||||
)
|
||||
|
||||
def get_sigmas(timesteps, n_dim=4, dtype=torch.float32):
|
||||
# TODO: revisit other sampling algorithms
|
||||
sigmas = noise_scheduler.sigmas.to(device=accelerator.device, dtype=dtype)
|
||||
schedule_timesteps = noise_scheduler.timesteps.to(accelerator.device)
|
||||
timesteps = timesteps.to(accelerator.device)
|
||||
|
||||
step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps]
|
||||
|
||||
sigma = sigmas[step_indices].flatten()
|
||||
while len(sigma.shape) < n_dim:
|
||||
sigma = sigma.unsqueeze(-1)
|
||||
return sigma
|
||||
|
||||
if args.train_text_encoder:
|
||||
num_train_epochs_text_encoder = int(args.train_text_encoder_frac * args.num_train_epochs)
|
||||
elif args.train_text_encoder_ti: # args.train_text_encoder_ti
|
||||
@@ -1841,9 +1896,15 @@ def main(args):
|
||||
pixel_values = batch["pixel_values"].to(dtype=vae.dtype)
|
||||
model_input = vae.encode(pixel_values).latent_dist.sample()
|
||||
|
||||
model_input = model_input * vae_scaling_factor
|
||||
if args.pretrained_vae_model_name_or_path is None:
|
||||
model_input = model_input.to(weight_dtype)
|
||||
if latents_mean is None and latents_std is None:
|
||||
model_input = model_input * vae.config.scaling_factor
|
||||
if args.pretrained_vae_model_name_or_path is None:
|
||||
model_input = model_input.to(weight_dtype)
|
||||
else:
|
||||
latents_mean = latents_mean.to(device=model_input.device, dtype=model_input.dtype)
|
||||
latents_std = latents_std.to(device=model_input.device, dtype=model_input.dtype)
|
||||
model_input = (model_input - latents_mean) * vae.config.scaling_factor / latents_std
|
||||
model_input = model_input.to(dtype=weight_dtype)
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(model_input)
|
||||
@@ -1854,15 +1915,32 @@ def main(args):
|
||||
)
|
||||
|
||||
bsz = model_input.shape[0]
|
||||
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(
|
||||
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=model_input.device
|
||||
)
|
||||
timesteps = timesteps.long()
|
||||
if not args.do_edm_style_training:
|
||||
timesteps = torch.randint(
|
||||
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=model_input.device
|
||||
)
|
||||
timesteps = timesteps.long()
|
||||
else:
|
||||
# in EDM formulation, the model is conditioned on the pre-conditioned noise levels
|
||||
# instead of discrete timesteps, so here we sample indices to get the noise levels
|
||||
# from `scheduler.timesteps`
|
||||
indices = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,))
|
||||
timesteps = noise_scheduler.timesteps[indices].to(device=model_input.device)
|
||||
|
||||
# Add noise to the model input according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_model_input = noise_scheduler.add_noise(model_input, noise, timesteps)
|
||||
# For EDM-style training, we first obtain the sigmas based on the continuous timesteps.
|
||||
# We then precondition the final model inputs based on these sigmas instead of the timesteps.
|
||||
# Follow: Section 5 of https://arxiv.org/abs/2206.00364.
|
||||
if args.do_edm_style_training:
|
||||
sigmas = get_sigmas(timesteps, len(noisy_model_input.shape), noisy_model_input.dtype)
|
||||
if "EDM" in scheduler_type:
|
||||
inp_noisy_latents = noise_scheduler.precondition_inputs(noisy_model_input, sigmas)
|
||||
else:
|
||||
inp_noisy_latents = noisy_model_input / ((sigmas**2 + 1) ** 0.5)
|
||||
|
||||
# time ids
|
||||
add_time_ids = torch.cat(
|
||||
@@ -1888,7 +1966,7 @@ def main(args):
|
||||
}
|
||||
prompt_embeds_input = prompt_embeds.repeat(elems_to_repeat_text_embeds, 1, 1)
|
||||
model_pred = unet(
|
||||
noisy_model_input,
|
||||
inp_noisy_latents if args.do_edm_style_training else noisy_model_input,
|
||||
timesteps,
|
||||
prompt_embeds_input,
|
||||
added_cond_kwargs=unet_added_conditions,
|
||||
@@ -1906,14 +1984,42 @@ def main(args):
|
||||
)
|
||||
prompt_embeds_input = prompt_embeds.repeat(elems_to_repeat_text_embeds, 1, 1)
|
||||
model_pred = unet(
|
||||
noisy_model_input, timesteps, prompt_embeds_input, added_cond_kwargs=unet_added_conditions
|
||||
inp_noisy_latents if args.do_edm_style_training else noisy_model_input,
|
||||
timesteps,
|
||||
prompt_embeds_input,
|
||||
added_cond_kwargs=unet_added_conditions,
|
||||
).sample
|
||||
|
||||
weighting = None
|
||||
if args.do_edm_style_training:
|
||||
# Similar to the input preconditioning, the model predictions are also preconditioned
|
||||
# on noised model inputs (before preconditioning) and the sigmas.
|
||||
# Follow: Section 5 of https://arxiv.org/abs/2206.00364.
|
||||
if "EDM" in scheduler_type:
|
||||
model_pred = noise_scheduler.precondition_outputs(noisy_model_input, model_pred, sigmas)
|
||||
else:
|
||||
if noise_scheduler.config.prediction_type == "epsilon":
|
||||
model_pred = model_pred * (-sigmas) + noisy_model_input
|
||||
elif noise_scheduler.config.prediction_type == "v_prediction":
|
||||
model_pred = model_pred * (-sigmas / (sigmas**2 + 1) ** 0.5) + (
|
||||
noisy_model_input / (sigmas**2 + 1)
|
||||
)
|
||||
# We are not doing weighting here because it tends result in numerical problems.
|
||||
# See: https://github.com/huggingface/diffusers/pull/7126#issuecomment-1968523051
|
||||
# There might be other alternatives for weighting as well:
|
||||
# https://github.com/huggingface/diffusers/pull/7126#discussion_r1505404686
|
||||
if "EDM" not in scheduler_type:
|
||||
weighting = (sigmas**-2.0).float()
|
||||
|
||||
# Get the target for loss depending on the prediction type
|
||||
if noise_scheduler.config.prediction_type == "epsilon":
|
||||
target = noise
|
||||
target = model_input if args.do_edm_style_training else noise
|
||||
elif noise_scheduler.config.prediction_type == "v_prediction":
|
||||
target = noise_scheduler.get_velocity(model_input, noise, timesteps)
|
||||
target = (
|
||||
model_input
|
||||
if args.do_edm_style_training
|
||||
else noise_scheduler.get_velocity(model_input, noise, timesteps)
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
|
||||
|
||||
@@ -1923,10 +2029,28 @@ def main(args):
|
||||
target, target_prior = torch.chunk(target, 2, dim=0)
|
||||
|
||||
# Compute prior loss
|
||||
prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
|
||||
if weighting is not None:
|
||||
prior_loss = torch.mean(
|
||||
(weighting.float() * (model_pred_prior.float() - target_prior.float()) ** 2).reshape(
|
||||
target_prior.shape[0], -1
|
||||
),
|
||||
1,
|
||||
)
|
||||
prior_loss = prior_loss.mean()
|
||||
else:
|
||||
prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
|
||||
|
||||
if args.snr_gamma is None:
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
if weighting is not None:
|
||||
loss = torch.mean(
|
||||
(weighting.float() * (model_pred.float() - target.float()) ** 2).reshape(
|
||||
target.shape[0], -1
|
||||
),
|
||||
1,
|
||||
)
|
||||
loss = loss.mean()
|
||||
else:
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
else:
|
||||
# Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
|
||||
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
|
||||
@@ -2049,17 +2173,18 @@ def main(args):
|
||||
# We train on the simplified learning objective. If we were previously predicting a variance, we need the scheduler to ignore it
|
||||
scheduler_args = {}
|
||||
|
||||
if "variance_type" in pipeline.scheduler.config:
|
||||
variance_type = pipeline.scheduler.config.variance_type
|
||||
if not args.do_edm_style_training:
|
||||
if "variance_type" in pipeline.scheduler.config:
|
||||
variance_type = pipeline.scheduler.config.variance_type
|
||||
|
||||
if variance_type in ["learned", "learned_range"]:
|
||||
variance_type = "fixed_small"
|
||||
if variance_type in ["learned", "learned_range"]:
|
||||
variance_type = "fixed_small"
|
||||
|
||||
scheduler_args["variance_type"] = variance_type
|
||||
scheduler_args["variance_type"] = variance_type
|
||||
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(
|
||||
pipeline.scheduler.config, **scheduler_args
|
||||
)
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(
|
||||
pipeline.scheduler.config, **scheduler_args
|
||||
)
|
||||
|
||||
pipeline = pipeline.to(accelerator.device)
|
||||
pipeline.set_progress_bar_config(disable=True)
|
||||
@@ -2067,8 +2192,13 @@ def main(args):
|
||||
# run inference
|
||||
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
|
||||
pipeline_args = {"prompt": args.validation_prompt}
|
||||
inference_ctx = (
|
||||
contextlib.nullcontext()
|
||||
if "playground" in args.pretrained_model_name_or_path
|
||||
else torch.cuda.amp.autocast()
|
||||
)
|
||||
|
||||
with torch.cuda.amp.autocast():
|
||||
with inference_ctx:
|
||||
images = [
|
||||
pipeline(**pipeline_args, generator=generator).images[0]
|
||||
for _ in range(args.num_validation_images)
|
||||
@@ -2144,15 +2274,18 @@ def main(args):
|
||||
# We train on the simplified learning objective. If we were previously predicting a variance, we need the scheduler to ignore it
|
||||
scheduler_args = {}
|
||||
|
||||
if "variance_type" in pipeline.scheduler.config:
|
||||
variance_type = pipeline.scheduler.config.variance_type
|
||||
if not args.do_edm_style_training:
|
||||
if "variance_type" in pipeline.scheduler.config:
|
||||
variance_type = pipeline.scheduler.config.variance_type
|
||||
|
||||
if variance_type in ["learned", "learned_range"]:
|
||||
variance_type = "fixed_small"
|
||||
if variance_type in ["learned", "learned_range"]:
|
||||
variance_type = "fixed_small"
|
||||
|
||||
scheduler_args["variance_type"] = variance_type
|
||||
scheduler_args["variance_type"] = variance_type
|
||||
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config, **scheduler_args)
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(
|
||||
pipeline.scheduler.config, **scheduler_args
|
||||
)
|
||||
|
||||
# load attention processors
|
||||
pipeline.load_lora_weights(args.output_dir)
|
||||
|
||||
@@ -1,10 +1,12 @@
|
||||
# Community Examples
|
||||
# Community Pipeline Examples
|
||||
|
||||
> **For more information about community pipelines, please have a look at [this issue](https://github.com/huggingface/diffusers/issues/841).**
|
||||
|
||||
**Community** examples consist of both inference and training examples that have been added by the community.
|
||||
Please have a look at the following table to get an overview of all community examples. Click on the **Code Example** to get a copy-and-paste ready code example that you can try out.
|
||||
If a community doesn't work as expected, please open an issue and ping the author on it.
|
||||
**Community pipeline** examples consist pipelines that have been added by the community.
|
||||
Please have a look at the following tables to get an overview of all community examples. Click on the **Code Example** to get a copy-and-paste ready code example that you can try out.
|
||||
If a community pipeline doesn't work as expected, please open an issue and ping the author on it.
|
||||
|
||||
Please also check out our [Community Scripts](https://github.com/huggingface/diffusers/blob/main/examples/community/README_community_scripts.md) examples for tips and tricks that you can use with diffusers without having to run a community pipeline.
|
||||
|
||||
| Example | Description | Code Example | Colab | Author |
|
||||
|:--------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------:|
|
||||
@@ -105,7 +107,7 @@ pipeline_output = pipe(
|
||||
# processing_res=768, # (optional) Maximum resolution of processing. If set to 0: will not resize at all. Defaults to 768.
|
||||
# match_input_res=True, # (optional) Resize depth prediction to match input resolution.
|
||||
# batch_size=0, # (optional) Inference batch size, no bigger than `num_ensemble`. If set to 0, the script will automatically decide the proper batch size. Defaults to 0.
|
||||
# color_map="Spectral", # (optional) Colormap used to colorize the depth map. Defaults to "Spectral".
|
||||
# color_map="Spectral", # (optional) Colormap used to colorize the depth map. Defaults to "Spectral". Set to `None` to skip colormap generation.
|
||||
# show_progress_bar=True, # (optional) If true, will show progress bars of the inference progress.
|
||||
)
|
||||
|
||||
@@ -1887,7 +1889,7 @@ In the above code, the `prompt2` is appended to the `prompt`, which is more than
|
||||
|
||||
For more results, checkout [PR #6114](https://github.com/huggingface/diffusers/pull/6114).
|
||||
|
||||
## Example Images Mixing (with CoCa)
|
||||
### Example Images Mixing (with CoCa)
|
||||
```python
|
||||
import requests
|
||||
from io import BytesIO
|
||||
@@ -2934,7 +2936,7 @@ pipe(prompt =prompt, rp_args = rp_args)
|
||||
|
||||
The Pipeline supports `compel` syntax. Input prompts using the `compel` structure will be automatically applied and processed.
|
||||
|
||||
## Diffusion Posterior Sampling Pipeline
|
||||
### Diffusion Posterior Sampling Pipeline
|
||||
* Reference paper
|
||||
```
|
||||
@article{chung2022diffusion,
|
||||
@@ -3414,15 +3416,13 @@ pipeline(prompt, uncond, inverted_latent, guidance_scale=7.5, num_inference_step
|
||||
|
||||
### Rerender A Video
|
||||
|
||||
This is the Diffusers implementation of zero-shot video-to-video translation pipeline [Rerender A Video](https://github.com/williamyang1991/Rerender_A_Video) (without Ebsynth postprocessing). To run the code, please install gmflow. Then modify the path in `examples/community/rerender_a_video.py`:
|
||||
This is the Diffusers implementation of zero-shot video-to-video translation pipeline [Rerender A Video](https://github.com/williamyang1991/Rerender_A_Video) (without Ebsynth postprocessing). To run the code, please install gmflow. Then modify the path in `gmflow_dir`. After that, you can run the pipeline with:
|
||||
|
||||
```py
|
||||
import sys
|
||||
gmflow_dir = "/path/to/gmflow"
|
||||
```
|
||||
sys.path.insert(0, gmflow_dir)
|
||||
|
||||
After that, you can run the pipeline with:
|
||||
|
||||
```py
|
||||
from diffusers import ControlNetModel, AutoencoderKL, DDIMScheduler
|
||||
from diffusers.utils import export_to_video
|
||||
import numpy as np
|
||||
|
||||
@@ -0,0 +1,232 @@
|
||||
# Community Scripts
|
||||
|
||||
**Community scripts** consist of inference examples using Diffusers pipelines that have been added by the community.
|
||||
Please have a look at the following table to get an overview of all community examples. Click on the **Code Example** to get a copy-and-paste code example that you can try out.
|
||||
If a community script doesn't work as expected, please open an issue and ping the author on it.
|
||||
|
||||
| Example | Description | Code Example | Colab | Author |
|
||||
|:--------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------:|
|
||||
| Using IP-Adapter with negative noise | Using negative noise with IP-adapter to better control the generation (see the [original post](https://github.com/huggingface/diffusers/discussions/7167) on the forum for more details) | [IP-Adapter Negative Noise](#ip-adapter-negative-noise) | | [Álvaro Somoza](https://github.com/asomoza)|
|
||||
| asymmetric tiling |configure seamless image tiling independently for the X and Y axes | [Asymmetric Tiling](#asymmetric-tiling ) | | [alexisrolland](https://github.com/alexisrolland)|
|
||||
|
||||
|
||||
## Example usages
|
||||
|
||||
### IP Adapter Negative Noise
|
||||
|
||||
Diffusers pipelines are fully integrated with IP-Adapter, which allows you to prompt the diffusion model with an image. However, it does not support negative image prompts (there is no `negative_ip_adapter_image` argument) the same way it supports negative text prompts. When you pass an `ip_adapter_image,` it will create a zero-filled tensor as a negative image. This script shows you how to create a negative noise from `ip_adapter_image` and use it to significantly improve the generation quality while preserving the composition of images.
|
||||
|
||||
[cubiq](https://github.com/cubiq) initially developed this feature in his [repository](https://github.com/cubiq/ComfyUI_IPAdapter_plus). The community script was contributed by [asomoza](https://github.com/Somoza). You can find more details about this experimentation [this discussion](https://github.com/huggingface/diffusers/discussions/7167)
|
||||
|
||||
IP-Adapter without negative noise
|
||||
|source|result|
|
||||
|---|---|
|
||||
|||
|
||||
|
||||
IP-Adapter with negative noise
|
||||
|source|result|
|
||||
|---|---|
|
||||
|||
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
from diffusers import AutoencoderKL, DPMSolverMultistepScheduler, StableDiffusionXLPipeline
|
||||
from diffusers.models import ImageProjection
|
||||
from diffusers.utils import load_image
|
||||
|
||||
|
||||
def encode_image(
|
||||
image_encoder,
|
||||
feature_extractor,
|
||||
image,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
output_hidden_states=None,
|
||||
negative_image=None,
|
||||
):
|
||||
dtype = next(image_encoder.parameters()).dtype
|
||||
|
||||
if not isinstance(image, torch.Tensor):
|
||||
image = feature_extractor(image, return_tensors="pt").pixel_values
|
||||
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
if output_hidden_states:
|
||||
image_enc_hidden_states = image_encoder(image, output_hidden_states=True).hidden_states[-2]
|
||||
image_enc_hidden_states = image_enc_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
if negative_image is None:
|
||||
uncond_image_enc_hidden_states = image_encoder(
|
||||
torch.zeros_like(image), output_hidden_states=True
|
||||
).hidden_states[-2]
|
||||
else:
|
||||
if not isinstance(negative_image, torch.Tensor):
|
||||
negative_image = feature_extractor(negative_image, return_tensors="pt").pixel_values
|
||||
negative_image = negative_image.to(device=device, dtype=dtype)
|
||||
uncond_image_enc_hidden_states = image_encoder(negative_image, output_hidden_states=True).hidden_states[-2]
|
||||
|
||||
uncond_image_enc_hidden_states = uncond_image_enc_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
return image_enc_hidden_states, uncond_image_enc_hidden_states
|
||||
else:
|
||||
image_embeds = image_encoder(image).image_embeds
|
||||
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
uncond_image_embeds = torch.zeros_like(image_embeds)
|
||||
|
||||
return image_embeds, uncond_image_embeds
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def prepare_ip_adapter_image_embeds(
|
||||
unet,
|
||||
image_encoder,
|
||||
feature_extractor,
|
||||
ip_adapter_image,
|
||||
do_classifier_free_guidance,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
ip_adapter_negative_image=None,
|
||||
):
|
||||
if not isinstance(ip_adapter_image, list):
|
||||
ip_adapter_image = [ip_adapter_image]
|
||||
|
||||
if len(ip_adapter_image) != len(unet.encoder_hid_proj.image_projection_layers):
|
||||
raise ValueError(
|
||||
f"`ip_adapter_image` must have same length as the number of IP Adapters. Got {len(ip_adapter_image)} images and {len(unet.encoder_hid_proj.image_projection_layers)} IP Adapters."
|
||||
)
|
||||
|
||||
image_embeds = []
|
||||
for single_ip_adapter_image, image_proj_layer in zip(
|
||||
ip_adapter_image, unet.encoder_hid_proj.image_projection_layers
|
||||
):
|
||||
output_hidden_state = not isinstance(image_proj_layer, ImageProjection)
|
||||
single_image_embeds, single_negative_image_embeds = encode_image(
|
||||
image_encoder,
|
||||
feature_extractor,
|
||||
single_ip_adapter_image,
|
||||
device,
|
||||
1,
|
||||
output_hidden_state,
|
||||
negative_image=ip_adapter_negative_image,
|
||||
)
|
||||
single_image_embeds = torch.stack([single_image_embeds] * num_images_per_prompt, dim=0)
|
||||
single_negative_image_embeds = torch.stack([single_negative_image_embeds] * num_images_per_prompt, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
single_image_embeds = torch.cat([single_negative_image_embeds, single_image_embeds])
|
||||
single_image_embeds = single_image_embeds.to(device)
|
||||
|
||||
image_embeds.append(single_image_embeds)
|
||||
|
||||
return image_embeds
|
||||
|
||||
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
"madebyollin/sdxl-vae-fp16-fix",
|
||||
torch_dtype=torch.float16,
|
||||
).to("cuda")
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"RunDiffusion/Juggernaut-XL-v9",
|
||||
torch_dtype=torch.float16,
|
||||
vae=vae,
|
||||
variant="fp16",
|
||||
).to("cuda")
|
||||
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline.scheduler.config.use_karras_sigmas = True
|
||||
|
||||
pipeline.load_ip_adapter(
|
||||
"h94/IP-Adapter",
|
||||
subfolder="sdxl_models",
|
||||
weight_name="ip-adapter-plus_sdxl_vit-h.safetensors",
|
||||
image_encoder_folder="models/image_encoder",
|
||||
)
|
||||
pipeline.set_ip_adapter_scale(0.7)
|
||||
|
||||
ip_image = load_image("source.png")
|
||||
negative_ip_image = load_image("noise.png")
|
||||
|
||||
image_embeds = prepare_ip_adapter_image_embeds(
|
||||
unet=pipeline.unet,
|
||||
image_encoder=pipeline.image_encoder,
|
||||
feature_extractor=pipeline.feature_extractor,
|
||||
ip_adapter_image=[[ip_image]],
|
||||
do_classifier_free_guidance=True,
|
||||
device="cuda",
|
||||
num_images_per_prompt=1,
|
||||
ip_adapter_negative_image=negative_ip_image,
|
||||
)
|
||||
|
||||
|
||||
prompt = "cinematic photo of a cyborg in the city, 4k, high quality, intricate, highly detailed"
|
||||
negative_prompt = "blurry, smooth, plastic"
|
||||
|
||||
image = pipeline(
|
||||
prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
ip_adapter_image_embeds=image_embeds,
|
||||
guidance_scale=6.0,
|
||||
num_inference_steps=25,
|
||||
generator=torch.Generator(device="cpu").manual_seed(1556265306),
|
||||
).images[0]
|
||||
|
||||
image.save("result.png")
|
||||
```
|
||||
|
||||
### Asymmetric Tiling
|
||||
Stable Diffusion is not trained to generate seamless textures. However, you can use this simple script to add tiling to your generation. This script is contributed by [alexisrolland](https://github.com/alexisrolland). See more details in the [this issue](https://github.com/huggingface/diffusers/issues/556)
|
||||
|
||||
|
||||
|Generated|Tiled|
|
||||
|---|---|
|
||||
|||
|
||||
|
||||
|
||||
```py
|
||||
import torch
|
||||
from typing import Optional
|
||||
from diffusers import StableDiffusionPipeline
|
||||
from diffusers.models.lora import LoRACompatibleConv
|
||||
|
||||
def seamless_tiling(pipeline, x_axis, y_axis):
|
||||
def asymmetric_conv2d_convforward(self, input: torch.Tensor, weight: torch.Tensor, bias: Optional[torch.Tensor] = None):
|
||||
self.paddingX = (self._reversed_padding_repeated_twice[0], self._reversed_padding_repeated_twice[1], 0, 0)
|
||||
self.paddingY = (0, 0, self._reversed_padding_repeated_twice[2], self._reversed_padding_repeated_twice[3])
|
||||
working = torch.nn.functional.pad(input, self.paddingX, mode=x_mode)
|
||||
working = torch.nn.functional.pad(working, self.paddingY, mode=y_mode)
|
||||
return torch.nn.functional.conv2d(working, weight, bias, self.stride, torch.nn.modules.utils._pair(0), self.dilation, self.groups)
|
||||
x_mode = 'circular' if x_axis else 'constant'
|
||||
y_mode = 'circular' if y_axis else 'constant'
|
||||
targets = [pipeline.vae, pipeline.text_encoder, pipeline.unet]
|
||||
convolution_layers = []
|
||||
for target in targets:
|
||||
for module in target.modules():
|
||||
if isinstance(module, torch.nn.Conv2d):
|
||||
convolution_layers.append(module)
|
||||
for layer in convolution_layers:
|
||||
if isinstance(layer, LoRACompatibleConv) and layer.lora_layer is None:
|
||||
layer.lora_layer = lambda * x: 0
|
||||
layer._conv_forward = asymmetric_conv2d_convforward.__get__(layer, torch.nn.Conv2d)
|
||||
return pipeline
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True)
|
||||
pipeline.enable_model_cpu_offload()
|
||||
prompt = ["texture of a red brick wall"]
|
||||
seed = 123456
|
||||
generator = torch.Generator(device='cuda').manual_seed(seed)
|
||||
|
||||
pipeline = seamless_tiling(pipeline=pipeline, x_axis=True, y_axis=True)
|
||||
image = pipeline(
|
||||
prompt=prompt,
|
||||
width=512,
|
||||
height=512,
|
||||
num_inference_steps=20,
|
||||
guidance_scale=7,
|
||||
num_images_per_prompt=1,
|
||||
generator=generator
|
||||
).images[0]
|
||||
seamless_tiling(pipeline=pipeline, x_axis=False, y_axis=False)
|
||||
|
||||
torch.cuda.empty_cache()
|
||||
image.save('image.png')
|
||||
```
|
||||
@@ -1,7 +1,8 @@
|
||||
"""
|
||||
modeled after the textual_inversion.py / train_dreambooth.py and the work
|
||||
of justinpinkney here: https://github.com/justinpinkney/stable-diffusion/blob/main/notebooks/imagic.ipynb
|
||||
modeled after the textual_inversion.py / train_dreambooth.py and the work
|
||||
of justinpinkney here: https://github.com/justinpinkney/stable-diffusion/blob/main/notebooks/imagic.ipynb
|
||||
"""
|
||||
|
||||
import inspect
|
||||
import warnings
|
||||
from typing import List, Optional, Union
|
||||
|
||||
@@ -440,7 +440,7 @@ def betas_for_alpha_bar(
|
||||
return math.exp(t * -12.0)
|
||||
|
||||
else:
|
||||
raise ValueError(f"Unsupported alpha_tranform_type: {alpha_transform_type}")
|
||||
raise ValueError(f"Unsupported alpha_transform_type: {alpha_transform_type}")
|
||||
|
||||
betas = []
|
||||
for i in range(num_diffusion_timesteps):
|
||||
@@ -513,9 +513,7 @@ class LCMSchedulerWithTimestamp(SchedulerMixin, ConfigMixin):
|
||||
there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
|
||||
otherwise it uses the alpha value at step 0.
|
||||
steps_offset (`int`, defaults to 0):
|
||||
An offset added to the inference steps. You can use a combination of `offset=1` and
|
||||
`set_alpha_to_one=False` to make the last step use step 0 for the previous alpha product like in Stable
|
||||
Diffusion.
|
||||
An offset added to the inference steps, as required by some model families.
|
||||
prediction_type (`str`, defaults to `epsilon`, *optional*):
|
||||
Prediction type of the scheduler function; can be `epsilon` (predicts the noise of the diffusion process),
|
||||
`sample` (directly predicts the noisy sample`) or `v_prediction` (see section 2.4 of [Imagen
|
||||
|
||||
@@ -348,7 +348,7 @@ def betas_for_alpha_bar(
|
||||
return math.exp(t * -12.0)
|
||||
|
||||
else:
|
||||
raise ValueError(f"Unsupported alpha_tranform_type: {alpha_transform_type}")
|
||||
raise ValueError(f"Unsupported alpha_transform_type: {alpha_transform_type}")
|
||||
|
||||
betas = []
|
||||
for i in range(num_diffusion_timesteps):
|
||||
@@ -418,9 +418,7 @@ class LCMScheduler(SchedulerMixin, ConfigMixin):
|
||||
there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
|
||||
otherwise it uses the alpha value at step 0.
|
||||
steps_offset (`int`, defaults to 0):
|
||||
An offset added to the inference steps. You can use a combination of `offset=1` and
|
||||
`set_alpha_to_one=False` to make the last step use step 0 for the previous alpha product like in Stable
|
||||
Diffusion.
|
||||
An offset added to the inference steps, as required by some model families.
|
||||
prediction_type (`str`, defaults to `epsilon`, *optional*):
|
||||
Prediction type of the scheduler function; can be `epsilon` (predicts the noise of the diffusion process),
|
||||
`sample` (directly predicts the noisy sample`) or `v_prediction` (see section 2.4 of [Imagen
|
||||
|
||||
@@ -40,7 +40,7 @@ from diffusers.utils import BaseOutput, check_min_version
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
|
||||
class MarigoldDepthOutput(BaseOutput):
|
||||
@@ -50,14 +50,14 @@ class MarigoldDepthOutput(BaseOutput):
|
||||
Args:
|
||||
depth_np (`np.ndarray`):
|
||||
Predicted depth map, with depth values in the range of [0, 1].
|
||||
depth_colored (`PIL.Image.Image`):
|
||||
depth_colored (`None` or `PIL.Image.Image`):
|
||||
Colorized depth map, with the shape of [3, H, W] and values in [0, 1].
|
||||
uncertainty (`None` or `np.ndarray`):
|
||||
Uncalibrated uncertainty(MAD, median absolute deviation) coming from ensembling.
|
||||
"""
|
||||
|
||||
depth_np: np.ndarray
|
||||
depth_colored: Image.Image
|
||||
depth_colored: Union[None, Image.Image]
|
||||
uncertainty: Union[None, np.ndarray]
|
||||
|
||||
|
||||
@@ -139,14 +139,15 @@ class MarigoldPipeline(DiffusionPipeline):
|
||||
If set to 0, the script will automatically decide the proper batch size.
|
||||
show_progress_bar (`bool`, *optional*, defaults to `True`):
|
||||
Display a progress bar of diffusion denoising.
|
||||
color_map (`str`, *optional*, defaults to `"Spectral"`):
|
||||
color_map (`str`, *optional*, defaults to `"Spectral"`, pass `None` to skip colorized depth map generation):
|
||||
Colormap used to colorize the depth map.
|
||||
ensemble_kwargs (`dict`, *optional*, defaults to `None`):
|
||||
Arguments for detailed ensembling settings.
|
||||
Returns:
|
||||
`MarigoldDepthOutput`: Output class for Marigold monocular depth prediction pipeline, including:
|
||||
- **depth_np** (`np.ndarray`) Predicted depth map, with depth values in the range of [0, 1]
|
||||
- **depth_colored** (`PIL.Image.Image`) Colorized depth map, with the shape of [3, H, W] and values in [0, 1]
|
||||
- **depth_colored** (`None` or `PIL.Image.Image`) Colorized depth map, with the shape of [3, H, W] and
|
||||
values in [0, 1]. None if `color_map` is `None`
|
||||
- **uncertainty** (`None` or `np.ndarray`) Uncalibrated uncertainty(MAD, median absolute deviation)
|
||||
coming from ensembling. None if `ensemble_size = 1`
|
||||
"""
|
||||
@@ -233,12 +234,15 @@ class MarigoldPipeline(DiffusionPipeline):
|
||||
depth_pred = depth_pred.clip(0, 1)
|
||||
|
||||
# Colorize
|
||||
depth_colored = self.colorize_depth_maps(
|
||||
depth_pred, 0, 1, cmap=color_map
|
||||
).squeeze() # [3, H, W], value in (0, 1)
|
||||
depth_colored = (depth_colored * 255).astype(np.uint8)
|
||||
depth_colored_hwc = self.chw2hwc(depth_colored)
|
||||
depth_colored_img = Image.fromarray(depth_colored_hwc)
|
||||
if color_map is not None:
|
||||
depth_colored = self.colorize_depth_maps(
|
||||
depth_pred, 0, 1, cmap=color_map
|
||||
).squeeze() # [3, H, W], value in (0, 1)
|
||||
depth_colored = (depth_colored * 255).astype(np.uint8)
|
||||
depth_colored_hwc = self.chw2hwc(depth_colored)
|
||||
depth_colored_img = Image.fromarray(depth_colored_hwc)
|
||||
else:
|
||||
depth_colored_img = None
|
||||
return MarigoldDepthOutput(
|
||||
depth_np=depth_pred,
|
||||
depth_colored=depth_colored_img,
|
||||
|
||||
@@ -13,7 +13,6 @@
|
||||
# limitations under the License.
|
||||
|
||||
import inspect
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
@@ -27,6 +26,7 @@ from diffusers.loaders import IPAdapterMixin, LoraLoaderMixin, TextualInversionL
|
||||
from diffusers.models import AutoencoderKL, ControlNetModel, ImageProjection, UNet2DConditionModel, UNetMotionModel
|
||||
from diffusers.models.lora import adjust_lora_scale_text_encoder
|
||||
from diffusers.models.unets.unet_motion_model import MotionAdapter
|
||||
from diffusers.pipelines.animatediff.pipeline_output import AnimateDiffPipelineOutput
|
||||
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
|
||||
from diffusers.pipelines.pipeline_utils import DiffusionPipeline, StableDiffusionMixin
|
||||
from diffusers.schedulers import (
|
||||
@@ -37,7 +37,7 @@ from diffusers.schedulers import (
|
||||
LMSDiscreteScheduler,
|
||||
PNDMScheduler,
|
||||
)
|
||||
from diffusers.utils import USE_PEFT_BACKEND, BaseOutput, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from diffusers.utils import USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from diffusers.utils.torch_utils import is_compiled_module, randn_tensor
|
||||
|
||||
|
||||
@@ -91,10 +91,8 @@ EXAMPLE_DOC_STRING = """
|
||||
"""
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.animatediff.pipeline_animatediff.tensor2vid
|
||||
def tensor2vid(video: torch.Tensor, processor, output_type="np"):
|
||||
# Based on:
|
||||
# https://github.com/modelscope/modelscope/blob/1509fdb973e5871f37148a4b5e5964cafd43e64d/modelscope/pipelines/multi_modal/text_to_video_synthesis_pipeline.py#L78
|
||||
|
||||
batch_size, channels, num_frames, height, width = video.shape
|
||||
outputs = []
|
||||
for batch_idx in range(batch_size):
|
||||
@@ -103,14 +101,18 @@ def tensor2vid(video: torch.Tensor, processor, output_type="np"):
|
||||
|
||||
outputs.append(batch_output)
|
||||
|
||||
if output_type == "np":
|
||||
outputs = np.stack(outputs)
|
||||
|
||||
elif output_type == "pt":
|
||||
outputs = torch.stack(outputs)
|
||||
|
||||
elif not output_type == "pil":
|
||||
raise ValueError(f"{output_type} does not exist. Please choose one of ['np', 'pt', 'pil']")
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
@dataclass
|
||||
class AnimateDiffControlNetPipelineOutput(BaseOutput):
|
||||
frames: Union[torch.Tensor, np.ndarray]
|
||||
|
||||
|
||||
class AnimateDiffControlNetPipeline(
|
||||
DiffusionPipeline, StableDiffusionMixin, TextualInversionLoaderMixin, IPAdapterMixin, LoraLoaderMixin
|
||||
):
|
||||
@@ -843,8 +845,8 @@ class AnimateDiffControlNetPipeline(
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.text_to_video_synthesis.TextToVideoSDPipelineOutput`] or `tuple`:
|
||||
If `return_dict` is `True`, [`~pipelines.text_to_video_synthesis.TextToVideoSDPipelineOutput`] is
|
||||
[`~pipelines.animatediff.pipeline_output.AnimateDiffPipelineOutput`] or `tuple`:
|
||||
If `return_dict` is `True`, [`~pipelines.animatediff.pipeline_output.AnimateDiffPipelineOutput`] is
|
||||
returned, otherwise a `tuple` is returned where the first element is a list with the generated frames.
|
||||
"""
|
||||
|
||||
@@ -1020,7 +1022,7 @@ class AnimateDiffControlNetPipeline(
|
||||
]
|
||||
controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps)
|
||||
|
||||
# Denoising loop
|
||||
# 8. Denoising loop
|
||||
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
||||
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
||||
for i, t in enumerate(timesteps):
|
||||
@@ -1096,21 +1098,17 @@ class AnimateDiffControlNetPipeline(
|
||||
if callback is not None and i % callback_steps == 0:
|
||||
callback(i, t, latents)
|
||||
|
||||
# 9. Post processing
|
||||
if output_type == "latent":
|
||||
return AnimateDiffControlNetPipelineOutput(frames=latents)
|
||||
|
||||
# Post-processing
|
||||
video_tensor = self.decode_latents(latents)
|
||||
|
||||
if output_type == "pt":
|
||||
video = video_tensor
|
||||
video = latents
|
||||
else:
|
||||
video_tensor = self.decode_latents(latents)
|
||||
video = tensor2vid(video_tensor, self.image_processor, output_type=output_type)
|
||||
|
||||
# Offload all models
|
||||
# 10. Offload all models
|
||||
self.maybe_free_model_hooks()
|
||||
|
||||
if not return_dict:
|
||||
return (video,)
|
||||
|
||||
return AnimateDiffControlNetPipelineOutput(frames=video)
|
||||
return AnimateDiffPipelineOutput(frames=video)
|
||||
|
||||
@@ -158,10 +158,8 @@ def slerp(
|
||||
return v2
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.animatediff.pipeline_animatediff.tensor2vid
|
||||
def tensor2vid(video: torch.Tensor, processor, output_type="np"):
|
||||
# Based on:
|
||||
# https://github.com/modelscope/modelscope/blob/1509fdb973e5871f37148a4b5e5964cafd43e64d/modelscope/pipelines/multi_modal/text_to_video_synthesis_pipeline.py#L78
|
||||
|
||||
batch_size, channels, num_frames, height, width = video.shape
|
||||
outputs = []
|
||||
for batch_idx in range(batch_size):
|
||||
@@ -170,6 +168,15 @@ def tensor2vid(video: torch.Tensor, processor, output_type="np"):
|
||||
|
||||
outputs.append(batch_output)
|
||||
|
||||
if output_type == "np":
|
||||
outputs = np.stack(outputs)
|
||||
|
||||
elif output_type == "pt":
|
||||
outputs = torch.stack(outputs)
|
||||
|
||||
elif not output_type == "pil":
|
||||
raise ValueError(f"{output_type} does not exist. Please choose one of ['np', 'pt', 'pil']")
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
@@ -826,8 +833,8 @@ class AnimateDiffImgToVideoPipeline(
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`AnimateDiffPipelineOutput`] or `tuple`:
|
||||
If `return_dict` is `True`, [`AnimateDiffPipelineOutput`] is
|
||||
[`~pipelines.animatediff.pipeline_output.AnimateDiffPipelineOutput`] or `tuple`:
|
||||
If `return_dict` is `True`, [`~pipelines.animatediff.pipeline_output.AnimateDiffPipelineOutput`] is
|
||||
returned, otherwise a `tuple` is returned where the first element is a list with the generated frames.
|
||||
"""
|
||||
# 0. Default height and width to unet
|
||||
@@ -958,11 +965,10 @@ class AnimateDiffImgToVideoPipeline(
|
||||
return AnimateDiffPipelineOutput(frames=latents)
|
||||
|
||||
# 10. Post-processing
|
||||
video_tensor = self.decode_latents(latents)
|
||||
|
||||
if output_type == "pt":
|
||||
video = video_tensor
|
||||
if output_type == "latent":
|
||||
video = latents
|
||||
else:
|
||||
video_tensor = self.decode_latents(latents)
|
||||
video = tensor2vid(video_tensor, self.image_processor, output_type=output_type)
|
||||
|
||||
# 11. Offload all models
|
||||
|
||||
@@ -206,7 +206,7 @@ def prepare_mask_and_masked_image(image, mask, height, width, return_image: bool
|
||||
dimensions: ``batch x channels x height x width``.
|
||||
"""
|
||||
|
||||
# checkpoint. TOD(Yiyi) - need to clean this up later
|
||||
# checkpoint. #TODO(Yiyi) - need to clean this up later
|
||||
if image is None:
|
||||
raise ValueError("`image` input cannot be undefined.")
|
||||
|
||||
@@ -277,7 +277,7 @@ def prepare_mask_and_masked_image(image, mask, height, width, return_image: bool
|
||||
# images are in latent space and thus can't
|
||||
# be masked set masked_image to None
|
||||
# we assume that the checkpoint is not an inpainting
|
||||
# checkpoint. TOD(Yiyi) - need to clean this up later
|
||||
# checkpoint. #TODO(Yiyi) - need to clean this up later
|
||||
masked_image = None
|
||||
else:
|
||||
masked_image = image * (mask < 0.5)
|
||||
|
||||
@@ -452,7 +452,7 @@ class StableDiffusionXLInstantIDPipeline(StableDiffusionXLControlNetPipeline):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
self.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -12,7 +12,6 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import sys
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
|
||||
|
||||
@@ -21,6 +20,7 @@ import PIL.Image
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import torchvision.transforms as T
|
||||
from gmflow.gmflow import GMFlow
|
||||
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
@@ -34,13 +34,6 @@ from diffusers.utils import BaseOutput, deprecate, logging
|
||||
from diffusers.utils.torch_utils import is_compiled_module, randn_tensor
|
||||
|
||||
|
||||
gmflow_dir = "/path/to/gmflow"
|
||||
sys.path.insert(0, gmflow_dir)
|
||||
from gmflow.gmflow import GMFlow # noqa: E402
|
||||
|
||||
from utils.utils import InputPadder # noqa: E402
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
@@ -119,11 +112,11 @@ def forward_backward_consistency_check(fwd_flow, bwd_flow, alpha=0.01, beta=0.5)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def get_warped_and_mask(flow_model, image1, image2, image3=None, pixel_consistency=False):
|
||||
def get_warped_and_mask(flow_model, image1, image2, image3=None, pixel_consistency=False, device=None):
|
||||
if image3 is None:
|
||||
image3 = image1
|
||||
padder = InputPadder(image1.shape, padding_factor=8)
|
||||
image1, image2 = padder.pad(image1[None].cuda(), image2[None].cuda())
|
||||
image1, image2 = padder.pad(image1[None].to(device), image2[None].to(device))
|
||||
results_dict = flow_model(
|
||||
image1, image2, attn_splits_list=[2], corr_radius_list=[-1], prop_radius_list=[-1], pred_bidir_flow=True
|
||||
)
|
||||
@@ -307,6 +300,7 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
|
||||
feature_extractor: CLIPImageProcessor,
|
||||
image_encoder=None,
|
||||
requires_safety_checker: bool = True,
|
||||
device=None,
|
||||
):
|
||||
super().__init__(
|
||||
vae,
|
||||
@@ -320,6 +314,7 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
|
||||
image_encoder,
|
||||
requires_safety_checker,
|
||||
)
|
||||
self.to(device)
|
||||
|
||||
if safety_checker is None and requires_safety_checker:
|
||||
logger.warning(
|
||||
@@ -374,7 +369,7 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
|
||||
attention_type="swin",
|
||||
ffn_dim_expansion=4,
|
||||
num_transformer_layers=6,
|
||||
).to("cuda")
|
||||
).to(self.device)
|
||||
|
||||
checkpoint = torch.utils.model_zoo.load_url(
|
||||
"https://huggingface.co/Anonymous-sub/Rerender/resolve/main/models/gmflow_sintel-0c07dcb3.pth",
|
||||
@@ -928,13 +923,13 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
|
||||
prev_image = self.image_processor.preprocess(prev_image).to(dtype=torch.float32)
|
||||
|
||||
warped_0, bwd_occ_0, bwd_flow_0 = get_warped_and_mask(
|
||||
self.flow_model, first_image, image[0], first_result, False
|
||||
self.flow_model, first_image, image[0], first_result, False, self.device
|
||||
)
|
||||
blend_mask_0 = blur(F.max_pool2d(bwd_occ_0, kernel_size=9, stride=1, padding=4))
|
||||
blend_mask_0 = torch.clamp(blend_mask_0 + bwd_occ_0, 0, 1)
|
||||
|
||||
warped_pre, bwd_occ_pre, bwd_flow_pre = get_warped_and_mask(
|
||||
self.flow_model, prev_image[0], image[0], prev_result, False
|
||||
self.flow_model, prev_image[0], image[0], prev_result, False, self.device
|
||||
)
|
||||
blend_mask_pre = blur(F.max_pool2d(bwd_occ_pre, kernel_size=9, stride=1, padding=4))
|
||||
blend_mask_pre = torch.clamp(blend_mask_pre + bwd_occ_pre, 0, 1)
|
||||
@@ -1176,3 +1171,24 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
|
||||
return output_frames
|
||||
|
||||
return TextToVideoSDPipelineOutput(frames=output_frames)
|
||||
|
||||
|
||||
class InputPadder:
|
||||
"""Pads images such that dimensions are divisible by 8"""
|
||||
|
||||
def __init__(self, dims, mode="sintel", padding_factor=8):
|
||||
self.ht, self.wd = dims[-2:]
|
||||
pad_ht = (((self.ht // padding_factor) + 1) * padding_factor - self.ht) % padding_factor
|
||||
pad_wd = (((self.wd // padding_factor) + 1) * padding_factor - self.wd) % padding_factor
|
||||
if mode == "sintel":
|
||||
self._pad = [pad_wd // 2, pad_wd - pad_wd // 2, pad_ht // 2, pad_ht - pad_ht // 2]
|
||||
else:
|
||||
self._pad = [pad_wd // 2, pad_wd - pad_wd // 2, 0, pad_ht]
|
||||
|
||||
def pad(self, *inputs):
|
||||
return [F.pad(x, self._pad, mode="replicate") for x in inputs]
|
||||
|
||||
def unpad(self, x):
|
||||
ht, wd = x.shape[-2:]
|
||||
c = [self._pad[2], ht - self._pad[3], self._pad[0], wd - self._pad[1]]
|
||||
return x[..., c[0] : c[1], c[2] : c[3]]
|
||||
|
||||
@@ -81,7 +81,7 @@ def betas_for_alpha_bar(
|
||||
return math.exp(t * -12.0)
|
||||
|
||||
else:
|
||||
raise ValueError(f"Unsupported alpha_tranform_type: {alpha_transform_type}")
|
||||
raise ValueError(f"Unsupported alpha_transform_type: {alpha_transform_type}")
|
||||
|
||||
betas = []
|
||||
for i in range(num_diffusion_timesteps):
|
||||
@@ -171,9 +171,7 @@ class UFOGenScheduler(SchedulerMixin, ConfigMixin):
|
||||
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
|
||||
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
|
||||
steps_offset (`int`, defaults to 0):
|
||||
An offset added to the inference steps. You can use a combination of `offset=1` and
|
||||
`set_alpha_to_one=False` to make the last step use step 0 for the previous alpha product like in Stable
|
||||
Diffusion.
|
||||
An offset added to the inference steps, as required by some model families.
|
||||
rescale_betas_zero_snr (`bool`, defaults to `False`):
|
||||
Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
|
||||
dark samples instead of limiting it to samples with medium brightness. Loosely related to
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
"""
|
||||
modified based on diffusion library from Huggingface: https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
|
||||
modified based on diffusion library from Huggingface: https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
|
||||
"""
|
||||
|
||||
import inspect
|
||||
from typing import Callable, List, Optional, Union
|
||||
|
||||
|
||||
@@ -224,7 +224,7 @@ class StableDiffusionIPEXPipeline(
|
||||
# 5. Prepare latent variables
|
||||
latents = self.prepare_latents(
|
||||
batch_size * num_images_per_prompt,
|
||||
self.unet.in_channels,
|
||||
self.unet.config.in_channels,
|
||||
height,
|
||||
width,
|
||||
prompt_embeds.dtype,
|
||||
@@ -679,7 +679,7 @@ class StableDiffusionIPEXPipeline(
|
||||
timesteps = self.scheduler.timesteps
|
||||
|
||||
# 5. Prepare latent variables
|
||||
num_channels_latents = self.unet.in_channels
|
||||
num_channels_latents = self.unet.config.in_channels
|
||||
latents = self.prepare_latents(
|
||||
batch_size * num_images_per_prompt,
|
||||
num_channels_latents,
|
||||
|
||||
@@ -917,7 +917,7 @@ class TensorRTStableDiffusionPipeline(StableDiffusionPipeline):
|
||||
text_embeddings = self.__encode_prompt(prompt, negative_prompt)
|
||||
|
||||
# Pre-initialize latents
|
||||
num_channels_latents = self.unet.in_channels
|
||||
num_channels_latents = self.unet.config.in_channels
|
||||
latents = self.prepare_latents(
|
||||
batch_size,
|
||||
num_channels_latents,
|
||||
|
||||
@@ -35,7 +35,6 @@ def slerp(val, low, high):
|
||||
|
||||
|
||||
class UnCLIPTextInterpolationPipeline(DiffusionPipeline):
|
||||
|
||||
"""
|
||||
Pipeline for prompt-to-prompt interpolation on CLIP text embeddings and using the UnCLIP / Dall-E to decode them to images.
|
||||
|
||||
@@ -49,7 +48,7 @@ class UnCLIPTextInterpolationPipeline(DiffusionPipeline):
|
||||
Tokenizer of class
|
||||
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
|
||||
prior ([`PriorTransformer`]):
|
||||
The canonincal unCLIP prior to approximate the image embedding from the text embedding.
|
||||
The canonical unCLIP prior to approximate the image embedding from the text embedding.
|
||||
text_proj ([`UnCLIPTextProjModel`]):
|
||||
Utility class to prepare and combine the embeddings before they are passed to the decoder.
|
||||
decoder ([`UNet2DConditionModel`]):
|
||||
|
||||
@@ -72,7 +72,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -308,7 +308,7 @@ def log_validation(vae, unet, args, accelerator, weight_dtype, step):
|
||||
|
||||
tracker.log({"validation": formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
gc.collect()
|
||||
@@ -1068,7 +1068,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -65,7 +65,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -180,7 +180,7 @@ def log_validation(vae, args, accelerator, weight_dtype, step, unet=None, is_fin
|
||||
logger_name = "test" if is_final_validation else "validation"
|
||||
tracker.log({logger_name: formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
gc.collect()
|
||||
@@ -928,7 +928,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -78,7 +78,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -325,7 +325,7 @@ def log_validation(vae, unet, args, accelerator, weight_dtype, step):
|
||||
|
||||
tracker.log({"validation": formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
gc.collect()
|
||||
@@ -1083,7 +1083,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -71,7 +71,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -285,7 +285,7 @@ def log_validation(vae, unet, args, accelerator, weight_dtype, step, name="targe
|
||||
|
||||
tracker.log({f"validation/{name}": formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
gc.collect()
|
||||
@@ -1023,7 +1023,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -77,7 +77,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -303,7 +303,7 @@ def log_validation(vae, unet, args, accelerator, weight_dtype, step, name="targe
|
||||
|
||||
tracker.log({f"validation/{name}": formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
gc.collect()
|
||||
@@ -1083,7 +1083,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -60,7 +60,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -178,7 +178,7 @@ def log_validation(
|
||||
|
||||
tracker.log({tracker_key: formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
gc.collect()
|
||||
@@ -861,7 +861,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -60,7 +60,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -128,7 +128,7 @@ def log_validation(pipeline, pipeline_params, controlnet_params, tokenizer, args
|
||||
|
||||
wandb.log({"validation": formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {args.report_to}")
|
||||
logger.warning(f"image logging not implemented for {args.report_to}")
|
||||
|
||||
return image_logs
|
||||
|
||||
|
||||
@@ -61,7 +61,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -178,7 +178,7 @@ def log_validation(vae, unet, controlnet, args, accelerator, weight_dtype, step,
|
||||
|
||||
tracker.log({tracker_key: formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
gc.collect()
|
||||
@@ -929,7 +929,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -63,7 +63,7 @@ from diffusers.utils.import_utils import is_xformers_available
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -904,7 +904,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
attention_class = CustomDiffusionXFormersAttnProcessor
|
||||
@@ -1178,7 +1178,7 @@ def main(args):
|
||||
grads_text_encoder = text_encoder.get_input_embeddings().weight.grad
|
||||
# Get the index for tokens that we want to zero the grads for
|
||||
index_grads_to_zero = torch.arange(len(tokenizer)) != modifier_token_id[0]
|
||||
for i in range(len(modifier_token_id[1:])):
|
||||
for i in range(1, len(modifier_token_id)):
|
||||
index_grads_to_zero = index_grads_to_zero & (
|
||||
torch.arange(len(tokenizer)) != modifier_token_id[i]
|
||||
)
|
||||
|
||||
@@ -63,7 +63,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -987,7 +987,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -35,7 +35,7 @@ from diffusers.utils import check_min_version
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
# Cache compiled models across invocations of this script.
|
||||
cc.initialize_cache(os.path.expanduser("~/.cache/jax/compilation_cache"))
|
||||
|
||||
@@ -70,7 +70,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -895,7 +895,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -75,7 +75,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -114,7 +114,7 @@ def save_model_card(
|
||||
)
|
||||
|
||||
model_description = f"""
|
||||
# {'SDXL' if 'playgroundai' not in base_model else 'Playground'} LoRA DreamBooth - {repo_id}
|
||||
# {'SDXL' if 'playground' not in base_model else 'Playground'} LoRA DreamBooth - {repo_id}
|
||||
|
||||
<Gallery />
|
||||
|
||||
@@ -139,7 +139,7 @@ Weights for this model are available in Safetensors format.
|
||||
[Download]({repo_id}/tree/main) them in the Files & versions tab.
|
||||
|
||||
"""
|
||||
if "playgroundai" in args.pretrained_model_name_or_path:
|
||||
if "playground" in base_model:
|
||||
model_description += """\n
|
||||
## License
|
||||
|
||||
@@ -148,7 +148,7 @@ Please adhere to the licensing terms as described [here](https://huggingface.co/
|
||||
model_card = load_or_create_model_card(
|
||||
repo_id_or_path=repo_id,
|
||||
from_training=True,
|
||||
license="openrail++" if "playgroundai" not in base_model else "playground-v2dot5-community",
|
||||
license="openrail++" if "playground" not in base_model else "playground-v2dot5-community",
|
||||
base_model=base_model,
|
||||
prompt=instance_prompt,
|
||||
model_description=model_description,
|
||||
@@ -162,7 +162,7 @@ Please adhere to the licensing terms as described [here](https://huggingface.co/
|
||||
"lora" if not use_dora else "dora",
|
||||
"template:sd-lora",
|
||||
]
|
||||
if "playgroundai" in base_model:
|
||||
if "playground" in base_model:
|
||||
tags.extend(["playground", "playground-diffusers"])
|
||||
else:
|
||||
tags.extend(["stable-diffusion-xl", "stable-diffusion-xl-diffusers"])
|
||||
@@ -206,7 +206,7 @@ def log_validation(
|
||||
# Currently the context determination is a bit hand-wavy. We can improve it in the future if there's a better
|
||||
# way to condition it. Reference: https://github.com/huggingface/diffusers/pull/7126#issuecomment-1968523051
|
||||
inference_ctx = (
|
||||
contextlib.nullcontext() if "playgroundai" in args.pretrained_model_name_or_path else torch.cuda.amp.autocast()
|
||||
contextlib.nullcontext() if "playground" in args.pretrained_model_name_or_path else torch.cuda.amp.autocast()
|
||||
)
|
||||
|
||||
with inference_ctx:
|
||||
@@ -1141,7 +1141,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, "
|
||||
"please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
@@ -1317,14 +1317,14 @@ def main(args):
|
||||
|
||||
# Optimizer creation
|
||||
if not (args.optimizer.lower() == "prodigy" or args.optimizer.lower() == "adamw"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
f"Unsupported choice of optimizer: {args.optimizer}.Supported optimizers include [adamW, prodigy]."
|
||||
"Defaulting to adamW"
|
||||
)
|
||||
args.optimizer = "adamw"
|
||||
|
||||
if args.use_8bit_adam and not args.optimizer.lower() == "adamw":
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
f"use_8bit_adam is ignored when optimizer is not set to 'AdamW'. Optimizer was "
|
||||
f"set to {args.optimizer.lower()}"
|
||||
)
|
||||
@@ -1358,11 +1358,11 @@ def main(args):
|
||||
optimizer_class = prodigyopt.Prodigy
|
||||
|
||||
if args.learning_rate <= 0.1:
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"Learning rate is too low. When using prodigy, it's generally better to set learning rate around 1.0"
|
||||
)
|
||||
if args.train_text_encoder and args.text_encoder_lr:
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
f"Learning rates were provided both for the unet and the text encoder- e.g. text_encoder_lr:"
|
||||
f" {args.text_encoder_lr} and learning_rate: {args.learning_rate}. "
|
||||
f"When using prodigy only learning_rate is used as the initial learning rate."
|
||||
@@ -1509,7 +1509,7 @@ def main(args):
|
||||
if accelerator.is_main_process:
|
||||
tracker_name = (
|
||||
"dreambooth-lora-sd-xl"
|
||||
if "playgroundai" not in args.pretrained_model_name_or_path
|
||||
if "playground" not in args.pretrained_model_name_or_path
|
||||
else "dreambooth-lora-playground"
|
||||
)
|
||||
accelerator.init_trackers(tracker_name, config=vars(args))
|
||||
|
||||
@@ -53,7 +53,7 @@ from diffusers.utils.torch_utils import is_compiled_module
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
@@ -488,7 +488,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -59,7 +59,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
@@ -580,7 +580,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -52,7 +52,7 @@ if is_wandb_available():
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
@@ -177,7 +177,7 @@ def log_validation(vae, image_encoder, image_processor, unet, args, accelerator,
|
||||
}
|
||||
)
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
@@ -534,7 +534,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -46,7 +46,7 @@ from diffusers.utils import check_min_version, is_wandb_available
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
|
||||
@@ -46,7 +46,7 @@ from diffusers.utils import check_min_version, is_wandb_available
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
|
||||
@@ -51,7 +51,7 @@ if is_wandb_available():
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
@@ -180,7 +180,7 @@ def log_validation(
|
||||
}
|
||||
)
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
@@ -219,7 +219,7 @@ def log_validation(unet, scheduler, args, accelerator, weight_dtype, step, name=
|
||||
if args.num_classes is not None:
|
||||
class_labels = list(range(args.num_classes))
|
||||
else:
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"The model is class-conditional but the number of classes is not set. The generated images will be"
|
||||
" unconditional rather than class-conditional."
|
||||
)
|
||||
@@ -266,7 +266,7 @@ def log_validation(unet, scheduler, args, accelerator, weight_dtype, step, name=
|
||||
|
||||
tracker.log({f"validation/{name}": formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
gc.collect()
|
||||
@@ -863,14 +863,14 @@ def main(args):
|
||||
elif args.model_config_name_or_path is None:
|
||||
# TODO: use default architectures from iCT paper
|
||||
if not args.class_conditional and (args.num_classes is not None or args.class_embed_type is not None):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
f"`--class_conditional` is set to `False` but `--num_classes` is set to {args.num_classes} and"
|
||||
f" `--class_embed_type` is set to {args.class_embed_type}. These values will be overridden to `None`."
|
||||
)
|
||||
args.num_classes = None
|
||||
args.class_embed_type = None
|
||||
elif args.class_conditional and args.num_classes is None and args.class_embed_type is None:
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"`--class_conditional` is set to `True` but neither `--num_classes` nor `--class_embed_type` is set."
|
||||
"`class_conditional` will be overridden to `False`."
|
||||
)
|
||||
@@ -996,7 +996,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -407,7 +407,7 @@ def log_validation(vae, unet, controlnet, args, accelerator, weight_dtype, step)
|
||||
|
||||
tracker.log({"validation": formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
gc.collect()
|
||||
@@ -1057,7 +1057,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -574,7 +574,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -672,7 +672,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -516,7 +516,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -608,7 +608,7 @@ def main():
|
||||
# Create the pipeline using using the trained modules and save it.
|
||||
if accelerator.is_main_process:
|
||||
if args.push_to_hub and args.only_save_embeds:
|
||||
logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
logger.warning("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
save_full_model = True
|
||||
else:
|
||||
save_full_model = not args.only_save_embeds
|
||||
|
||||
@@ -541,7 +541,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -23,6 +23,7 @@ TODO:
|
||||
6. Integrate to training x
|
||||
7. Test
|
||||
"""
|
||||
|
||||
import copy
|
||||
import random
|
||||
|
||||
|
||||
@@ -645,7 +645,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
@@ -901,7 +901,7 @@ def main():
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
if args.push_to_hub and args.only_save_embeds:
|
||||
logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
logger.warning("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
save_full_model = True
|
||||
else:
|
||||
save_full_model = not args.only_save_embeds
|
||||
|
||||
@@ -108,7 +108,7 @@ def log_validation(vae, text_encoder, tokenizer, unet, args, accelerator, weight
|
||||
}
|
||||
)
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
@@ -523,7 +523,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -687,7 +687,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
@@ -916,7 +916,7 @@ def main():
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
if args.push_to_hub and not args.save_as_full_pipeline:
|
||||
logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
logger.warning("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
save_full_model = True
|
||||
else:
|
||||
save_full_model = args.save_as_full_pipeline
|
||||
|
||||
+2
-2
@@ -410,7 +410,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
model.enable_xformers_memory_efficient_attention()
|
||||
@@ -637,7 +637,7 @@ def main(args):
|
||||
generator=generator,
|
||||
batch_size=args.eval_batch_size,
|
||||
num_inference_steps=args.ddpm_num_inference_steps,
|
||||
output_type="numpy",
|
||||
output_type="np",
|
||||
).images
|
||||
|
||||
if args.use_ema:
|
||||
|
||||
+1
-1
@@ -12,7 +12,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for stable diffusion checkpoints which _only_ contain a controlnet. """
|
||||
"""Conversion script for stable diffusion checkpoints which _only_ contain a controlnet."""
|
||||
|
||||
import argparse
|
||||
import re
|
||||
|
||||
@@ -629,7 +629,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -60,7 +60,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -167,7 +167,7 @@ def log_validation(vae, unet, adapter, args, accelerator, weight_dtype, step):
|
||||
|
||||
tracker.log({"validation": formatted_images})
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
gc.collect()
|
||||
@@ -932,7 +932,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -56,7 +56,7 @@ if is_wandb_available():
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
@@ -183,7 +183,7 @@ def log_validation(vae, text_encoder, tokenizer, unet, args, accelerator, weight
|
||||
}
|
||||
)
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
@@ -608,7 +608,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -49,7 +49,7 @@ from diffusers.utils import check_min_version
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
@@ -52,7 +52,7 @@ from diffusers.utils.torch_utils import is_compiled_module
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
@@ -497,7 +497,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
|
||||
@@ -64,7 +64,7 @@ from diffusers.utils.torch_utils import is_compiled_module
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -425,6 +425,11 @@ def parse_args(input_args=None):
|
||||
default=4,
|
||||
help=("The dimension of the LoRA update matrices."),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--debug_loss",
|
||||
action="store_true",
|
||||
help="debug loss for each image, if filenames are awailable in the dataset",
|
||||
)
|
||||
|
||||
if input_args is not None:
|
||||
args = parser.parse_args(input_args)
|
||||
@@ -603,6 +608,7 @@ def main(args):
|
||||
# Move unet, vae and text_encoder to device and cast to weight_dtype
|
||||
# The VAE is in float32 to avoid NaN losses.
|
||||
unet.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
if args.pretrained_vae_model_name_or_path is None:
|
||||
vae.to(accelerator.device, dtype=torch.float32)
|
||||
else:
|
||||
@@ -616,7 +622,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
@@ -890,13 +896,17 @@ def main(args):
|
||||
tokens_one, tokens_two = tokenize_captions(examples)
|
||||
examples["input_ids_one"] = tokens_one
|
||||
examples["input_ids_two"] = tokens_two
|
||||
if args.debug_loss:
|
||||
fnames = [os.path.basename(image.filename) for image in examples[image_column] if image.filename]
|
||||
if fnames:
|
||||
examples["filenames"] = fnames
|
||||
return examples
|
||||
|
||||
with accelerator.main_process_first():
|
||||
if args.max_train_samples is not None:
|
||||
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
|
||||
# Set the training transforms
|
||||
train_dataset = dataset["train"].with_transform(preprocess_train)
|
||||
train_dataset = dataset["train"].with_transform(preprocess_train, output_all_columns=True)
|
||||
|
||||
def collate_fn(examples):
|
||||
pixel_values = torch.stack([example["pixel_values"] for example in examples])
|
||||
@@ -905,7 +915,7 @@ def main(args):
|
||||
crop_top_lefts = [example["crop_top_lefts"] for example in examples]
|
||||
input_ids_one = torch.stack([example["input_ids_one"] for example in examples])
|
||||
input_ids_two = torch.stack([example["input_ids_two"] for example in examples])
|
||||
return {
|
||||
result = {
|
||||
"pixel_values": pixel_values,
|
||||
"input_ids_one": input_ids_one,
|
||||
"input_ids_two": input_ids_two,
|
||||
@@ -913,6 +923,11 @@ def main(args):
|
||||
"crop_top_lefts": crop_top_lefts,
|
||||
}
|
||||
|
||||
filenames = [example["filenames"] for example in examples if "filenames" in example]
|
||||
if filenames:
|
||||
result["filenames"] = filenames
|
||||
return result
|
||||
|
||||
# DataLoaders creation:
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset,
|
||||
@@ -1105,7 +1120,9 @@ def main(args):
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
|
||||
loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
|
||||
loss = loss.mean()
|
||||
|
||||
if args.debug_loss and "filenames" in batch:
|
||||
for fname in batch["filenames"]:
|
||||
accelerator.log({"loss_for_" + fname: loss}, step=global_step)
|
||||
# Gather the losses across all processes for logging (if we use distributed training).
|
||||
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
|
||||
train_loss += avg_loss.item() / args.gradient_accumulation_steps
|
||||
|
||||
@@ -54,7 +54,7 @@ from diffusers.utils.torch_utils import is_compiled_module
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -712,7 +712,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
@@ -911,6 +911,7 @@ def main(args):
|
||||
)
|
||||
precomputed_dataset = precomputed_dataset.with_transform(preprocess_train)
|
||||
|
||||
del compute_vae_encodings_fn, compute_embeddings_fn, text_encoder_one, text_encoder_two
|
||||
del text_encoders, tokenizers, vae
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
@@ -80,7 +80,7 @@ else:
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -708,7 +708,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
@@ -966,7 +966,7 @@ def main():
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
if args.push_to_hub and not args.save_as_full_pipeline:
|
||||
logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
logger.warning("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
save_full_model = True
|
||||
else:
|
||||
save_full_model = args.save_as_full_pipeline
|
||||
|
||||
@@ -56,7 +56,7 @@ else:
|
||||
# ------------------------------------------------------------------------------
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
@@ -76,7 +76,7 @@ else:
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
@@ -711,7 +711,7 @@ def main():
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
@@ -1022,7 +1022,7 @@ def main():
|
||||
)
|
||||
|
||||
if args.push_to_hub and not args.save_as_full_pipeline:
|
||||
logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
logger.warning("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
save_full_model = True
|
||||
else:
|
||||
save_full_model = args.save_as_full_pipeline
|
||||
|
||||
@@ -29,7 +29,7 @@ from diffusers.utils.import_utils import is_xformers_available
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
@@ -408,7 +408,7 @@ def main(args):
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
model.enable_xformers_memory_efficient_attention()
|
||||
@@ -648,7 +648,7 @@ def main(args):
|
||||
generator=generator,
|
||||
batch_size=args.eval_batch_size,
|
||||
num_inference_steps=args.ddpm_num_inference_steps,
|
||||
output_type="numpy",
|
||||
output_type="np",
|
||||
).images
|
||||
|
||||
if args.use_ema:
|
||||
|
||||
@@ -50,7 +50,7 @@ if is_wandb_available():
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
@@ -184,7 +184,7 @@ def log_validation(text_encoder, tokenizer, prior, args, accelerator, weight_dty
|
||||
}
|
||||
)
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
@@ -51,7 +51,7 @@ if is_wandb_available():
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.27.0.dev0")
|
||||
check_min_version("0.28.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
@@ -182,7 +182,7 @@ def log_validation(text_encoder, tokenizer, prior, args, accelerator, weight_dty
|
||||
}
|
||||
)
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
logger.warning(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
@@ -12,7 +12,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for the LDM checkpoints. """
|
||||
"""Conversion script for the LDM checkpoints."""
|
||||
|
||||
import argparse
|
||||
import json
|
||||
|
||||
@@ -12,7 +12,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for the LDM checkpoints. """
|
||||
"""Conversion script for the LDM checkpoints."""
|
||||
|
||||
import argparse
|
||||
|
||||
|
||||
@@ -1195,9 +1195,9 @@ def superres_check_against_original(dump_path, unet_checkpoint_path):
|
||||
if_II_model = IFStageIII(device="cuda", dir_or_name=orig_path, model_kwargs={"precision": "fp32"}).model
|
||||
|
||||
batch_size = 1
|
||||
channels = model.in_channels // 2
|
||||
height = model.sample_size
|
||||
width = model.sample_size
|
||||
channels = model.config.in_channels // 2
|
||||
height = model.config.sample_size
|
||||
width = model.config.sample_size
|
||||
height = 1024
|
||||
width = 1024
|
||||
|
||||
|
||||
@@ -12,7 +12,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for the LDM checkpoints. """
|
||||
"""Conversion script for the LDM checkpoints."""
|
||||
|
||||
import argparse
|
||||
import json
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user