Compare commits
1 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6b2d9e6acd |
@@ -172,5 +172,3 @@ tags
|
||||
|
||||
# ruff
|
||||
.ruff_cache
|
||||
|
||||
wandb
|
||||
@@ -15,138 +15,528 @@
|
||||
</a>
|
||||
</p>
|
||||
|
||||
🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or training your own diffusion models, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on [usability over performance](https://huggingface.co/docs/diffusers/conceptual/philosophy#usability-over-performance), [simple over easy](https://huggingface.co/docs/diffusers/conceptual/philosophy#simple-over-easy), and [customizability over abstractions](https://huggingface.co/docs/diffusers/conceptual/philosophy#tweakable-contributorfriendly-over-abstraction).
|
||||
🤗 Diffusers provides pretrained diffusion models across multiple modalities, such as vision and audio, and serves
|
||||
as a modular toolbox for inference and training of diffusion models.
|
||||
|
||||
🤗 Diffusers offers three core components:
|
||||
More precisely, 🤗 Diffusers offers:
|
||||
|
||||
- State-of-the-art [diffusion pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) that can be run in inference with just a few lines of code.
|
||||
- Interchangeable noise [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview) for different diffusion speeds and output quality.
|
||||
- Pretrained [models](https://huggingface.co/docs/diffusers/api/models) that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.
|
||||
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code (see [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines)). Check [this overview](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/README.md#pipelines-summary) to see all supported pipelines and their corresponding official papers.
|
||||
- Various noise schedulers that can be used interchangeably for the preferred speed vs. quality trade-off in inference (see [src/diffusers/schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers)).
|
||||
- Multiple types of models, such as UNet, can be used as building blocks in an end-to-end diffusion system (see [src/diffusers/models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)).
|
||||
- Training examples to show how to train the most popular diffusion model tasks (see [examples](https://github.com/huggingface/diffusers/tree/main/examples), *e.g.* [unconditional-image-generation](https://github.com/huggingface/diffusers/tree/main/examples/unconditional_image_generation)).
|
||||
|
||||
## Installation
|
||||
|
||||
We recommend installing 🤗 Diffusers in a virtual environment from PyPi or Conda. For more details about installing [PyTorch](https://pytorch.org/get-started/locally/) and [Flax](https://flax.readthedocs.io/en/latest/installation.html), please refer to their official documentation.
|
||||
### For PyTorch
|
||||
|
||||
### PyTorch
|
||||
|
||||
With `pip` (official package):
|
||||
**With `pip`** (official package)
|
||||
|
||||
```bash
|
||||
pip install --upgrade diffusers[torch]
|
||||
```
|
||||
|
||||
With `conda` (maintained by the community):
|
||||
**With `conda`** (maintained by the community)
|
||||
|
||||
```sh
|
||||
conda install -c conda-forge diffusers
|
||||
```
|
||||
|
||||
### Flax
|
||||
### For Flax
|
||||
|
||||
With `pip` (official package):
|
||||
**With `pip`**
|
||||
|
||||
```bash
|
||||
pip install --upgrade diffusers[flax]
|
||||
```
|
||||
|
||||
### Apple Silicon (M1/M2) support
|
||||
**Apple Silicon (M1/M2) support**
|
||||
|
||||
Please refer to the [How to use Stable Diffusion in Apple Silicon](https://huggingface.co/docs/diffusers/optimization/mps) guide.
|
||||
Please, refer to [the documentation](https://huggingface.co/docs/diffusers/optimization/mps).
|
||||
|
||||
## Contributing
|
||||
|
||||
We ❤️ contributions from the open-source community!
|
||||
If you want to contribute to this library, please check out our [Contribution guide](https://github.com/huggingface/diffusers/blob/main/CONTRIBUTING.md).
|
||||
You can look out for [issues](https://github.com/huggingface/diffusers/issues) you'd like to tackle to contribute to the library.
|
||||
- See [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute
|
||||
- See [New model/pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) to contribute exciting new diffusion models / diffusion pipelines
|
||||
- See [New scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
|
||||
|
||||
Also, say 👋 in our public Discord channel <a href="https://discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=discord&logoColor=white"></a>. We discuss the hottest trends about diffusion models, help each other with contributions, personal projects or
|
||||
just hang out ☕.
|
||||
|
||||
## Quickstart
|
||||
|
||||
Generating outputs is super easy with 🤗 Diffusers. To generate an image from text, use the `from_pretrained` method to load any pretrained diffusion model (browse the [Hub](https://huggingface.co/models?library=diffusers&sort=downloads) for 4000+ checkpoints):
|
||||
In order to get started, we recommend taking a look at two notebooks:
|
||||
|
||||
- The [Getting started with Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) notebook, which showcases an end-to-end example of usage for diffusion models, schedulers and pipelines.
|
||||
Take a look at this notebook to learn how to use the pipeline abstraction, which takes care of everything (model, scheduler, noise handling) for you, and also to understand each independent building block in the library.
|
||||
- The [Training a diffusers model](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb) notebook summarizes diffusion models training methods. This notebook takes a step-by-step approach to training your
|
||||
diffusion models on an image dataset, with explanatory graphics.
|
||||
|
||||
## Stable Diffusion is fully compatible with `diffusers`!
|
||||
|
||||
Stable Diffusion is a text-to-image latent diffusion model created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [LAION](https://laion.ai/) and [RunwayML](https://runwayml.com/). It's trained on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 4GB VRAM.
|
||||
See the [model card](https://huggingface.co/CompVis/stable-diffusion) for more information.
|
||||
|
||||
|
||||
### Text-to-Image generation with Stable Diffusion
|
||||
|
||||
First let's install
|
||||
|
||||
```bash
|
||||
pip install --upgrade diffusers transformers accelerate
|
||||
```
|
||||
|
||||
We recommend using the model in [half-precision (`fp16`)](https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/) as it gives almost always the same results as full
|
||||
precision while being roughly twice as fast and requiring half the amount of GPU RAM.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
#### Running the model locally
|
||||
|
||||
You can also simply download the model folder and pass the path to the local folder to the `StableDiffusionPipeline`.
|
||||
|
||||
```
|
||||
git lfs install
|
||||
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
|
||||
```
|
||||
|
||||
Assuming the folder is stored locally under `./stable-diffusion-v1-5`, you can run stable diffusion
|
||||
as follows:
|
||||
|
||||
```python
|
||||
pipe = StableDiffusionPipeline.from_pretrained("./stable-diffusion-v1-5")
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
If you are limited by GPU memory, you might want to consider chunking the attention computation in addition
|
||||
to using `fp16`.
|
||||
The following snippet should result in less than 4GB VRAM.
|
||||
|
||||
```python
|
||||
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
pipe.enable_attention_slicing()
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
If you wish to use a different scheduler (e.g.: DDIM, LMS, PNDM/PLMS), you can instantiate
|
||||
it before the pipeline and pass it to `from_pretrained`.
|
||||
|
||||
```python
|
||||
from diffusers import LMSDiscreteScheduler
|
||||
|
||||
pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
image = pipe(prompt).images[0]
|
||||
|
||||
image.save("astronaut_rides_horse.png")
|
||||
```
|
||||
|
||||
If you want to run Stable Diffusion on CPU or you want to have maximum precision on GPU,
|
||||
please run the model in the default *full-precision* setting:
|
||||
|
||||
```python
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
|
||||
|
||||
# disable the following line if you run on CPU
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
image = pipe(prompt).images[0]
|
||||
|
||||
image.save("astronaut_rides_horse.png")
|
||||
```
|
||||
|
||||
### JAX/Flax
|
||||
|
||||
Diffusers offers a JAX / Flax implementation of Stable Diffusion for very fast inference. JAX shines specially on TPU hardware because each TPU server has 8 accelerators working in parallel, but it runs great on GPUs too.
|
||||
|
||||
Running the pipeline with the default PNDMScheduler:
|
||||
|
||||
```python
|
||||
import jax
|
||||
import numpy as np
|
||||
from flax.jax_utils import replicate
|
||||
from flax.training.common_utils import shard
|
||||
|
||||
from diffusers import FlaxStableDiffusionPipeline
|
||||
|
||||
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5", revision="flax", dtype=jax.numpy.bfloat16
|
||||
)
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
|
||||
prng_seed = jax.random.PRNGKey(0)
|
||||
num_inference_steps = 50
|
||||
|
||||
num_samples = jax.device_count()
|
||||
prompt = num_samples * [prompt]
|
||||
prompt_ids = pipeline.prepare_inputs(prompt)
|
||||
|
||||
# shard inputs and rng
|
||||
params = replicate(params)
|
||||
prng_seed = jax.random.split(prng_seed, jax.device_count())
|
||||
prompt_ids = shard(prompt_ids)
|
||||
|
||||
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
|
||||
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
|
||||
```
|
||||
|
||||
**Note**:
|
||||
If you are limited by TPU memory, please make sure to load the `FlaxStableDiffusionPipeline` in `bfloat16` precision instead of the default `float32` precision as done above. You can do so by telling diffusers to load the weights from "bf16" branch.
|
||||
|
||||
```python
|
||||
import jax
|
||||
import numpy as np
|
||||
from flax.jax_utils import replicate
|
||||
from flax.training.common_utils import shard
|
||||
|
||||
from diffusers import FlaxStableDiffusionPipeline
|
||||
|
||||
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5", revision="bf16", dtype=jax.numpy.bfloat16
|
||||
)
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
|
||||
prng_seed = jax.random.PRNGKey(0)
|
||||
num_inference_steps = 50
|
||||
|
||||
num_samples = jax.device_count()
|
||||
prompt = num_samples * [prompt]
|
||||
prompt_ids = pipeline.prepare_inputs(prompt)
|
||||
|
||||
# shard inputs and rng
|
||||
params = replicate(params)
|
||||
prng_seed = jax.random.split(prng_seed, jax.device_count())
|
||||
prompt_ids = shard(prompt_ids)
|
||||
|
||||
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
|
||||
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
|
||||
```
|
||||
|
||||
Diffusers also has a Image-to-Image generation pipeline with Flax/Jax
|
||||
```python
|
||||
import jax
|
||||
import numpy as np
|
||||
import jax.numpy as jnp
|
||||
from flax.jax_utils import replicate
|
||||
from flax.training.common_utils import shard
|
||||
import requests
|
||||
from io import BytesIO
|
||||
from PIL import Image
|
||||
from diffusers import FlaxStableDiffusionImg2ImgPipeline
|
||||
|
||||
def create_key(seed=0):
|
||||
return jax.random.PRNGKey(seed)
|
||||
rng = create_key(0)
|
||||
|
||||
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
response = requests.get(url)
|
||||
init_img = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
init_img = init_img.resize((768, 512))
|
||||
|
||||
prompts = "A fantasy landscape, trending on artstation"
|
||||
|
||||
pipeline, params = FlaxStableDiffusionImg2ImgPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4", revision="flax",
|
||||
dtype=jnp.bfloat16,
|
||||
)
|
||||
|
||||
num_samples = jax.device_count()
|
||||
rng = jax.random.split(rng, jax.device_count())
|
||||
prompt_ids, processed_image = pipeline.prepare_inputs(prompt=[prompts]*num_samples, image = [init_img]*num_samples)
|
||||
p_params = replicate(params)
|
||||
prompt_ids = shard(prompt_ids)
|
||||
processed_image = shard(processed_image)
|
||||
|
||||
output = pipeline(
|
||||
prompt_ids=prompt_ids,
|
||||
image=processed_image,
|
||||
params=p_params,
|
||||
prng_seed=rng,
|
||||
strength=0.75,
|
||||
num_inference_steps=50,
|
||||
jit=True,
|
||||
height=512,
|
||||
width=768).images
|
||||
|
||||
output_images = pipeline.numpy_to_pil(np.asarray(output.reshape((num_samples,) + output.shape[-3:])))
|
||||
```
|
||||
|
||||
Diffusers also has a Text-guided inpainting pipeline with Flax/Jax
|
||||
|
||||
```python
|
||||
import jax
|
||||
import numpy as np
|
||||
from flax.jax_utils import replicate
|
||||
from flax.training.common_utils import shard
|
||||
import PIL
|
||||
import requests
|
||||
from io import BytesIO
|
||||
|
||||
|
||||
from diffusers import FlaxStableDiffusionInpaintPipeline
|
||||
|
||||
def download_image(url):
|
||||
response = requests.get(url)
|
||||
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
||||
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
||||
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
||||
|
||||
init_image = download_image(img_url).resize((512, 512))
|
||||
mask_image = download_image(mask_url).resize((512, 512))
|
||||
|
||||
pipeline, params = FlaxStableDiffusionInpaintPipeline.from_pretrained("xvjiarui/stable-diffusion-2-inpainting")
|
||||
|
||||
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
|
||||
prng_seed = jax.random.PRNGKey(0)
|
||||
num_inference_steps = 50
|
||||
|
||||
num_samples = jax.device_count()
|
||||
prompt = num_samples * [prompt]
|
||||
init_image = num_samples * [init_image]
|
||||
mask_image = num_samples * [mask_image]
|
||||
prompt_ids, processed_masked_images, processed_masks = pipeline.prepare_inputs(prompt, init_image, mask_image)
|
||||
|
||||
|
||||
# shard inputs and rng
|
||||
params = replicate(params)
|
||||
prng_seed = jax.random.split(prng_seed, jax.device_count())
|
||||
prompt_ids = shard(prompt_ids)
|
||||
processed_masked_images = shard(processed_masked_images)
|
||||
processed_masks = shard(processed_masks)
|
||||
|
||||
images = pipeline(prompt_ids, processed_masks, processed_masked_images, params, prng_seed, num_inference_steps, jit=True).images
|
||||
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
|
||||
```
|
||||
|
||||
### Image-to-Image text-guided generation with Stable Diffusion
|
||||
|
||||
The `StableDiffusionImg2ImgPipeline` lets you pass a text prompt and an initial image to condition the generation of new images.
|
||||
|
||||
```python
|
||||
import requests
|
||||
import torch
|
||||
from PIL import Image
|
||||
from io import BytesIO
|
||||
|
||||
from diffusers import StableDiffusionImg2ImgPipeline
|
||||
|
||||
# load the pipeline
|
||||
device = "cuda"
|
||||
model_id_or_path = "runwayml/stable-diffusion-v1-5"
|
||||
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
|
||||
|
||||
# or download via git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
|
||||
# and pass `model_id_or_path="./stable-diffusion-v1-5"`.
|
||||
pipe = pipe.to(device)
|
||||
|
||||
# let's download an initial image
|
||||
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
|
||||
response = requests.get(url)
|
||||
init_image = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
init_image = init_image.resize((768, 512))
|
||||
|
||||
prompt = "A fantasy landscape, trending on artstation"
|
||||
|
||||
images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
|
||||
|
||||
images[0].save("fantasy_landscape.png")
|
||||
```
|
||||
You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
|
||||
|
||||
### In-painting using Stable Diffusion
|
||||
|
||||
The `StableDiffusionInpaintPipeline` lets you edit specific parts of an image by providing a mask and a text prompt.
|
||||
|
||||
```python
|
||||
import PIL
|
||||
import requests
|
||||
import torch
|
||||
from io import BytesIO
|
||||
|
||||
from diffusers import StableDiffusionInpaintPipeline
|
||||
|
||||
def download_image(url):
|
||||
response = requests.get(url)
|
||||
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
||||
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
||||
|
||||
init_image = download_image(img_url).resize((512, 512))
|
||||
mask_image = download_image(mask_url).resize((512, 512))
|
||||
|
||||
pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
|
||||
image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
|
||||
```
|
||||
|
||||
### Tweak prompts reusing seeds and latents
|
||||
|
||||
You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked.
|
||||
Please have a look at [Reusing seeds for deterministic generation](https://huggingface.co/docs/diffusers/main/en/using-diffusers/reusing_seeds).
|
||||
|
||||
## Fine-Tuning Stable Diffusion
|
||||
|
||||
Fine-tuning techniques make it possible to adapt Stable Diffusion to your own dataset, or add new subjects to it. These are some of the techniques supported in `diffusers`:
|
||||
|
||||
Textual Inversion is a technique for capturing novel concepts from a small number of example images in a way that can later be used to control text-to-image pipelines. It does so by learning new 'words' in the embedding space of the pipeline's text encoder. These special words can then be used within text prompts to achieve very fine-grained control of the resulting images.
|
||||
|
||||
- Textual Inversion. Capture novel concepts from a small set of sample images, and associate them with new "words" in the embedding space of the text encoder. Please, refer to [our training examples](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion) or [documentation](https://huggingface.co/docs/diffusers/training/text_inversion) to try for yourself.
|
||||
|
||||
- Dreambooth. Another technique to capture new concepts in Stable Diffusion. This method fine-tunes the UNet (and, optionally, also the text encoder) of the pipeline to achieve impressive results. Please, refer to [our training example](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth) and [training report](https://huggingface.co/blog/dreambooth) for additional details and training recommendations.
|
||||
|
||||
- Full Stable Diffusion fine-tuning. If you have a more sizable dataset with a specific look or style, you can fine-tune Stable Diffusion so that it outputs images following those examples. This was the approach taken to create [a Pokémon Stable Diffusion model](https://huggingface.co/justinpinkney/pokemon-stable-diffusion) (by Justing Pinkney / Lambda Labs), [a Japanese specific version of Stable Diffusion](https://huggingface.co/spaces/rinna/japanese-stable-diffusion) (by [Rinna Co.](https://github.com/rinnakk/japanese-stable-diffusion/) and others. You can start at [our text-to-image fine-tuning example](https://github.com/huggingface/diffusers/tree/main/examples/text_to_image) and go from there.
|
||||
|
||||
|
||||
## Stable Diffusion Community Pipelines
|
||||
|
||||
The release of Stable Diffusion as an open source model has fostered a lot of interesting ideas and experimentation.
|
||||
Our [Community Examples folder](https://github.com/huggingface/diffusers/tree/main/examples/community) contains many ideas worth exploring, like interpolating to create animated videos, using CLIP Guidance for additional prompt fidelity, term weighting, and much more! [Take a look](https://huggingface.co/docs/diffusers/using-diffusers/custom_pipeline_overview) and [contribute your own](https://huggingface.co/docs/diffusers/using-diffusers/contribute_pipeline).
|
||||
|
||||
## Other Examples
|
||||
|
||||
There are many ways to try running Diffusers! Here we outline code-focused tools (primarily using `DiffusionPipeline`s and Google Colab) and interactive web-tools.
|
||||
|
||||
### Running Code
|
||||
|
||||
If you want to run the code yourself 💻, you can try out:
|
||||
- [Text-to-Image Latent Diffusion](https://huggingface.co/CompVis/ldm-text2im-large-256)
|
||||
```python
|
||||
# !pip install diffusers["torch"] transformers
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
|
||||
pipeline.to("cuda")
|
||||
pipeline("An image of a squirrel in Picasso style").images[0]
|
||||
device = "cuda"
|
||||
model_id = "CompVis/ldm-text2im-large-256"
|
||||
|
||||
# load model and scheduler
|
||||
ldm = DiffusionPipeline.from_pretrained(model_id)
|
||||
ldm = ldm.to(device)
|
||||
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
prompt = "A painting of a squirrel eating a burger"
|
||||
image = ldm([prompt], num_inference_steps=50, eta=0.3, guidance_scale=6).images[0]
|
||||
|
||||
# save image
|
||||
image.save("squirrel.png")
|
||||
```
|
||||
|
||||
You can also dig into the models and schedulers toolbox to build your own diffusion system:
|
||||
|
||||
- [Unconditional Diffusion with discrete scheduler](https://huggingface.co/google/ddpm-celebahq-256)
|
||||
```python
|
||||
from diffusers import DDPMScheduler, UNet2DModel
|
||||
from PIL import Image
|
||||
import torch
|
||||
import numpy as np
|
||||
# !pip install diffusers["torch"]
|
||||
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
|
||||
|
||||
scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
|
||||
model = UNet2DModel.from_pretrained("google/ddpm-cat-256").to("cuda")
|
||||
scheduler.set_timesteps(50)
|
||||
model_id = "google/ddpm-celebahq-256"
|
||||
device = "cuda"
|
||||
|
||||
sample_size = model.config.sample_size
|
||||
noise = torch.randn((1, 3, sample_size, sample_size)).to("cuda")
|
||||
input = noise
|
||||
# load model and scheduler
|
||||
ddpm = DDPMPipeline.from_pretrained(model_id) # you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
|
||||
ddpm.to(device)
|
||||
|
||||
for t in scheduler.timesteps:
|
||||
with torch.no_grad():
|
||||
noisy_residual = model(input, t).sample
|
||||
prev_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
|
||||
input = prev_noisy_sample
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
image = ddpm().images[0]
|
||||
|
||||
image = (input / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
|
||||
image = Image.fromarray((image * 255).round().astype("uint8"))
|
||||
image
|
||||
# save image
|
||||
image.save("ddpm_generated_image.png")
|
||||
```
|
||||
- [Unconditional Latent Diffusion](https://huggingface.co/CompVis/ldm-celebahq-256)
|
||||
- [Unconditional Diffusion with continuous scheduler](https://huggingface.co/google/ncsnpp-ffhq-1024)
|
||||
|
||||
Check out the [Quickstart](https://huggingface.co/docs/diffusers/quicktour) to launch your diffusion journey today!
|
||||
**Other Image Notebooks**:
|
||||
* [image-to-image generation with Stable Diffusion](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb) ,
|
||||
* [tweak images via repeated Stable Diffusion seeds](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) ,
|
||||
|
||||
## How to navigate the documentation
|
||||
**Diffusers for Other Modalities**:
|
||||
* [Molecule conformation generation](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/geodiff_molecule_conformation.ipynb) ,
|
||||
* [Model-based reinforcement learning](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/reinforcement_learning_with_diffusers.ipynb) ,
|
||||
|
||||
| **Documentation** | **What can I learn?** |
|
||||
|---------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Tutorial | A basic crash course for learning how to use the library's most important features like using models and schedulers to build your own diffusion system, and training your own diffusion model. |
|
||||
| Loading | Guides for how to load and configure all the components (pipelines, models, and schedulers) of the library, as well as how to use different schedulers. |
|
||||
| Pipelines for inference | Guides for how to use pipelines for different inference tasks, batched generation, controlling generated outputs and randomness, and how to contribute a pipeline to the library. |
|
||||
| Optimization | Guides for how to optimize your diffusion model to run faster and consume less memory. |
|
||||
| [Training](https://huggingface.co/docs/diffusers/training/overview) | Guides for how to train a diffusion model for different tasks with different training techniques. |
|
||||
### Web Demos
|
||||
If you just want to play around with some web demos, you can try out the following 🚀 Spaces:
|
||||
| Model | Hugging Face Spaces |
|
||||
|-------------------------------- |------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Text-to-Image Latent Diffusion | [](https://huggingface.co/spaces/CompVis/text2img-latent-diffusion) |
|
||||
| Faces generator | [](https://huggingface.co/spaces/CompVis/celeba-latent-diffusion) |
|
||||
| DDPM with different schedulers | [](https://huggingface.co/spaces/fusing/celeba-diffusion) |
|
||||
| Conditional generation from sketch | [](https://huggingface.co/spaces/huggingface/diffuse-the-rest) |
|
||||
| Composable diffusion | [](https://huggingface.co/spaces/Shuang59/Composable-Diffusion) |
|
||||
|
||||
## Supported pipelines
|
||||
## Definitions
|
||||
|
||||
| Pipeline | Paper | Tasks |
|
||||
|---|---|:---:|
|
||||
| [alt_diffusion](./api/pipelines/alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
|
||||
| [audio_diffusion](./api/pipelines/audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation |
|
||||
| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
|
||||
| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
|
||||
| [dance_diffusion](./api/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
|
||||
| [ddpm](./api/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
|
||||
| [ddim](./api/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
|
||||
| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
|
||||
| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
|
||||
| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
|
||||
| [paint_by_example](./api/pipelines/paint_by_example) | [**Paint by Example: Exemplar-based Image Editing with Diffusion Models**](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
|
||||
| [pndm](./api/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
|
||||
| [score_sde_ve](./api/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [score_sde_vp](./api/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [**Semantic Guidance**](https://arxiv.org/abs/2301.12247) | Text-Guided Generation |
|
||||
| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation |
|
||||
| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation |
|
||||
| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting |
|
||||
| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [**MultiDiffusion**](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
|
||||
| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [**InstructPix2Pix**](https://github.com/timothybrooks/instruct-pix2pix) | Text-Guided Image Editing|
|
||||
| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [**Zero-shot Image-to-Image Translation**](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
|
||||
| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [**Attend and Excite for Stable Diffusion**](https://attendandexcite.github.io/Attend-and-Excite/) | Text-to-Image Generation |
|
||||
| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [**Self-Attention Guidance**](https://ku-cvlab.github.io/Self-Attention-Guidance) | Text-to-Image Generation |
|
||||
| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [**Stable Diffusion Image Variations**](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
|
||||
| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [**Stable Diffusion Latent Upscaler**](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Depth-Conditional Stable Diffusion**](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
|
||||
| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [**Safe Stable Diffusion**](https://arxiv.org/abs/2211.05105) | Text-Guided Generation |
|
||||
| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Text-to-Image Generation |
|
||||
| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Image-to-Image Text-Guided Generation |
|
||||
| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
|
||||
| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
|
||||
| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
|
||||
**Models**: Neural network that models $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$ (see image below) and is trained end-to-end to *denoise* a noisy input to an image.
|
||||
*Examples*: UNet, Conditioned UNet, 3D UNet, Transformer UNet
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/10695622/174349667-04e9e485-793b-429a-affe-096e8199ad5b.png" width="800"/>
|
||||
<br>
|
||||
<em> Figure from DDPM paper (https://arxiv.org/abs/2006.11239). </em>
|
||||
<p>
|
||||
|
||||
**Schedulers**: Algorithm class for both **inference** and **training**.
|
||||
The class provides functionality to compute previous image according to alpha, beta schedule as well as predict noise for training. Also known as **Samplers**.
|
||||
*Examples*: [DDPM](https://arxiv.org/abs/2006.11239), [DDIM](https://arxiv.org/abs/2010.02502), [PNDM](https://arxiv.org/abs/2202.09778), [DEIS](https://arxiv.org/abs/2204.13902)
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/10695622/174349706-53d58acc-a4d1-4cda-b3e8-432d9dc7ad38.png" width="800"/>
|
||||
<br>
|
||||
<em> Sampling and training algorithms. Figure from DDPM paper (https://arxiv.org/abs/2006.11239). </em>
|
||||
<p>
|
||||
|
||||
|
||||
**Diffusion Pipeline**: End-to-end pipeline that includes multiple diffusion models, possible text encoders, ...
|
||||
*Examples*: Glide, Latent-Diffusion, Imagen, DALL-E 2
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/10695622/174348898-481bd7c2-5457-4830-89bc-f0907756f64c.jpeg" width="550"/>
|
||||
<br>
|
||||
<em> Figure from ImageGen (https://imagen.research.google/). </em>
|
||||
<p>
|
||||
|
||||
## Philosophy
|
||||
|
||||
- Readability and clarity is preferred over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code design. *E.g.*, the provided [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) are separated from the provided [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and provide well-commented code that can be read alongside the original paper.
|
||||
- Diffusers is **modality independent** and focuses on providing pretrained models and tools to build systems that generate **continuous outputs**, *e.g.* vision and audio.
|
||||
- Diffusion models and schedulers are provided as concise, elementary building blocks. In contrast, diffusion pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box, should stay as close as possible to their original implementation and can include components of another library, such as text-encoders. Examples for diffusion pipelines are [Glide](https://github.com/openai/glide-text2im) and [Latent Diffusion](https://github.com/CompVis/latent-diffusion).
|
||||
|
||||
## In the works
|
||||
|
||||
For the first release, 🤗 Diffusers focuses on text-to-image diffusion techniques. However, diffusers can be used for much more than that! Over the upcoming releases, we'll be focusing on:
|
||||
|
||||
- Diffusers for audio
|
||||
- Diffusers for reinforcement learning (initial work happening in https://github.com/huggingface/diffusers/pull/105).
|
||||
- Diffusers for video generation
|
||||
- Diffusers for molecule generation (initial work happening in https://github.com/huggingface/diffusers/pull/54)
|
||||
|
||||
A few pipeline components are already being worked on, namely:
|
||||
|
||||
- BDDMPipeline for spectrogram-to-sound vocoding
|
||||
- GLIDEPipeline to support OpenAI's GLIDE model
|
||||
- Grad-TTS for text to audio generation / conditional audio generation
|
||||
|
||||
We want diffusers to be a toolbox useful for diffusers models in general; if you find yourself limited in any way by the current API, or would like to see additional models, schedulers, or techniques, please open a [GitHub issue](https://github.com/huggingface/diffusers/issues) mentioning what you would like to see.
|
||||
|
||||
## Credits
|
||||
|
||||
@@ -154,7 +544,7 @@ This library concretizes previous work by many different authors and would not h
|
||||
|
||||
- @CompVis' latent diffusion models library, available [here](https://github.com/CompVis/latent-diffusion)
|
||||
- @hojonathanho original DDPM implementation, available [here](https://github.com/hojonathanho/diffusion) as well as the extremely useful translation into PyTorch by @pesser, available [here](https://github.com/pesser/pytorch_diffusion)
|
||||
- @ermongroup's DDIM implementation, available [here](https://github.com/ermongroup/ddim)
|
||||
- @ermongroup's DDIM implementation, available [here](https://github.com/ermongroup/ddim).
|
||||
- @yang-song's Score-VE and Score-VP implementations, available [here](https://github.com/yang-song/score_sde_pytorch)
|
||||
|
||||
We also want to thank @heejkoo for the very helpful overview of papers, code and resources on diffusion models, available [here](https://github.com/heejkoo/Awesome-Diffusion-Models) as well as @crowsonkb and @rromb for useful discussions and insights.
|
||||
|
||||
@@ -27,6 +27,7 @@ RUN python3 -m pip install --no-cache-dir --upgrade pip && \
|
||||
torch \
|
||||
torchvision \
|
||||
torchaudio \
|
||||
--extra-index-url https://download.pytorch.org/whl/cu117 && \
|
||||
python3 -m pip install --no-cache-dir \
|
||||
accelerate \
|
||||
datasets \
|
||||
@@ -39,4 +40,4 @@ RUN python3 -m pip install --no-cache-dir --upgrade pip && \
|
||||
tensorboard \
|
||||
transformers
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
CMD ["/bin/bash"]
|
||||
+22
-32
@@ -9,29 +9,23 @@
|
||||
title: Installation
|
||||
title: Get started
|
||||
- sections:
|
||||
- local: tutorials/tutorial_overview
|
||||
title: Overview
|
||||
- local: using-diffusers/write_own_pipeline
|
||||
title: Understanding models and schedulers
|
||||
- local: tutorials/basic_training
|
||||
title: Train a diffusion model
|
||||
title: Tutorials
|
||||
- sections:
|
||||
- sections:
|
||||
- local: using-diffusers/loading_overview
|
||||
title: Overview
|
||||
- local: using-diffusers/loading
|
||||
title: Load pipelines, models, and schedulers
|
||||
title: Loading Pipelines, Models, and Schedulers
|
||||
- local: using-diffusers/schedulers
|
||||
title: Load and compare different schedulers
|
||||
title: Using different Schedulers
|
||||
- local: using-diffusers/configuration
|
||||
title: Configuring Pipelines, Models, and Schedulers
|
||||
- local: using-diffusers/custom_pipeline_overview
|
||||
title: Load and add custom pipelines
|
||||
title: Loading and Adding Custom Pipelines
|
||||
- local: using-diffusers/kerascv
|
||||
title: Load KerasCV Stable Diffusion checkpoints
|
||||
title: Using KerasCV Stable Diffusion Checkpoints in Diffusers
|
||||
title: Loading & Hub
|
||||
- sections:
|
||||
- local: using-diffusers/pipeline_overview
|
||||
title: Overview
|
||||
- local: using-diffusers/unconditional_image_generation
|
||||
title: Unconditional Image Generation
|
||||
- local: using-diffusers/conditional_image_generation
|
||||
@@ -42,6 +36,8 @@
|
||||
title: Text-Guided Image-Inpainting
|
||||
- local: using-diffusers/depth2img
|
||||
title: Text-Guided Depth-to-Image
|
||||
- local: using-diffusers/controlling_generation
|
||||
title: Controlling generation
|
||||
- local: using-diffusers/reusing_seeds
|
||||
title: Reusing seeds for deterministic generation
|
||||
- local: using-diffusers/reproducibility
|
||||
@@ -55,20 +51,6 @@
|
||||
- local: using-diffusers/weighted_prompts
|
||||
title: Weighting Prompts
|
||||
title: Pipelines for Inference
|
||||
- sections:
|
||||
- local: training/overview
|
||||
title: Overview
|
||||
- local: training/unconditional_training
|
||||
title: Unconditional image generation
|
||||
- local: training/text_inversion
|
||||
title: Textual Inversion
|
||||
- local: training/dreambooth
|
||||
title: DreamBooth
|
||||
- local: training/text2image
|
||||
title: Text-to-image
|
||||
- local: training/lora
|
||||
title: Low-Rank Adaptation of Large Language Models (LoRA)
|
||||
title: Training
|
||||
- sections:
|
||||
- local: using-diffusers/rl
|
||||
title: Reinforcement Learning
|
||||
@@ -79,8 +61,6 @@
|
||||
title: Taking Diffusers Beyond Images
|
||||
title: Using Diffusers
|
||||
- sections:
|
||||
- local: optimization/opt_overview
|
||||
title: Overview
|
||||
- local: optimization/fp16
|
||||
title: Memory and Speed
|
||||
- local: optimization/torch2.0
|
||||
@@ -96,17 +76,27 @@
|
||||
- local: optimization/habana
|
||||
title: Habana Gaudi
|
||||
title: Optimization/Special Hardware
|
||||
- sections:
|
||||
- local: training/overview
|
||||
title: Overview
|
||||
- local: training/unconditional_training
|
||||
title: Unconditional Image Generation
|
||||
- local: training/text_inversion
|
||||
title: Textual Inversion
|
||||
- local: training/dreambooth
|
||||
title: DreamBooth
|
||||
- local: training/text2image
|
||||
title: Text-to-image
|
||||
- local: training/lora
|
||||
title: Low-Rank Adaptation of Large Language Models (LoRA)
|
||||
title: Training
|
||||
- sections:
|
||||
- local: conceptual/philosophy
|
||||
title: Philosophy
|
||||
- local: using-diffusers/controlling_generation
|
||||
title: Controlled generation
|
||||
- local: conceptual/contribution
|
||||
title: How to contribute?
|
||||
- local: conceptual/ethical_guidelines
|
||||
title: Diffusers' Ethical Guidelines
|
||||
- local: conceptual/evaluation
|
||||
title: Evaluating Diffusion Models
|
||||
title: Conceptual Guides
|
||||
- sections:
|
||||
- sections:
|
||||
|
||||
@@ -12,8 +12,8 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# Configuration
|
||||
|
||||
Schedulers from [`~schedulers.scheduling_utils.SchedulerMixin`] and models from [`ModelMixin`] inherit from [`ConfigMixin`] which conveniently takes care of storing all the parameters that are
|
||||
passed to their respective `__init__` methods in a JSON-configuration file.
|
||||
In Diffusers, schedulers of type [`schedulers.scheduling_utils.SchedulerMixin`], and models of type [`ModelMixin`] inherit from [`ConfigMixin`] which conveniently takes care of storing all parameters that are
|
||||
passed to the respective `__init__` methods in a JSON-configuration file.
|
||||
|
||||
## ConfigMixin
|
||||
|
||||
@@ -21,5 +21,3 @@ passed to their respective `__init__` methods in a JSON-configuration file.
|
||||
- load_config
|
||||
- from_config
|
||||
- save_config
|
||||
- to_json_file
|
||||
- to_json_string
|
||||
|
||||
@@ -29,8 +29,4 @@ proposed by Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan
|
||||
- enable_attention_slicing
|
||||
- disable_attention_slicing
|
||||
- enable_xformers_memory_efficient_attention
|
||||
- disable_xformers_memory_efficient_attention
|
||||
|
||||
[[autodoc]] FlaxStableDiffusionImg2ImgPipeline
|
||||
- all
|
||||
- __call__
|
||||
- disable_xformers_memory_efficient_attention
|
||||
@@ -30,8 +30,4 @@ Available checkpoints are:
|
||||
- enable_attention_slicing
|
||||
- disable_attention_slicing
|
||||
- enable_xformers_memory_efficient_attention
|
||||
- disable_xformers_memory_efficient_attention
|
||||
|
||||
[[autodoc]] FlaxStableDiffusionInpaintPipeline
|
||||
- all
|
||||
- __call__
|
||||
- disable_xformers_memory_efficient_attention
|
||||
@@ -39,7 +39,3 @@ Available Checkpoints are:
|
||||
- disable_xformers_memory_efficient_attention
|
||||
- enable_vae_tiling
|
||||
- disable_vae_tiling
|
||||
|
||||
[[autodoc]] FlaxStableDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
@@ -1,565 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Evaluating Diffusion Models
|
||||
|
||||
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/evaluation.ipynb">
|
||||
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
|
||||
</a>
|
||||
|
||||
Evaluation of generative models like [Stable Diffusion](https://huggingface.co/docs/diffusers/stable_diffusion) is subjective in nature. But as practitioners and researchers, we often have to make careful choices amongst many different possibilities. So, when working with different generative models (like GANs, Diffusion, etc.), how do we choose one over the other?
|
||||
|
||||
Qualitative evaluation of such models can be error-prone and might incorrectly influence a decision.
|
||||
However, quantitative metrics don't necessarily correspond to image quality. So, usually, a combination
|
||||
of both qualitative and quantitative evaluations provides a stronger signal when choosing one model
|
||||
over the other.
|
||||
|
||||
In this document, we provide a non-exhaustive overview of qualitative and quantitative methods to evaluate Diffusion models. For quantitative methods, we specifically focus on how to implement them alongside `diffusers`.
|
||||
|
||||
The methods shown in this document can also be used to evaluate different [noise schedulers](https://huggingface.co/docs/diffusers/main/en/api/schedulers/overview) keeping the underlying generation model fixed.
|
||||
|
||||
## Scenarios
|
||||
|
||||
We cover Diffusion models with the following pipelines:
|
||||
|
||||
- Text-guided image generation (such as the [`StableDiffusionPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/text2img)).
|
||||
- Text-guided image generation, additionally conditioned on an input image (such as the [`StableDiffusionImg2ImgPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/img2img), and [`StableDiffusionInstructPix2PixPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/pix2pix)).
|
||||
- Class-conditioned image generation models (such as the [`DiTPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/dit)).
|
||||
|
||||
## Qualitative Evaluation
|
||||
|
||||
Qualitative evaluation typically involves human assessment of generated images. Quality is measured across aspects such as compositionality, image-text alignment, and spatial relations. Common prompts provide a degree of uniformity for subjective metrics. DrawBench and PartiPrompts are prompt datasets used for qualitative benchmarking. DrawBench and PartiPrompts were introduced by [Imagen](https://imagen.research.google/) and [Parti](https://parti.research.google/) respectively.
|
||||
|
||||
From the [official Parti website](https://parti.research.google/):
|
||||
|
||||
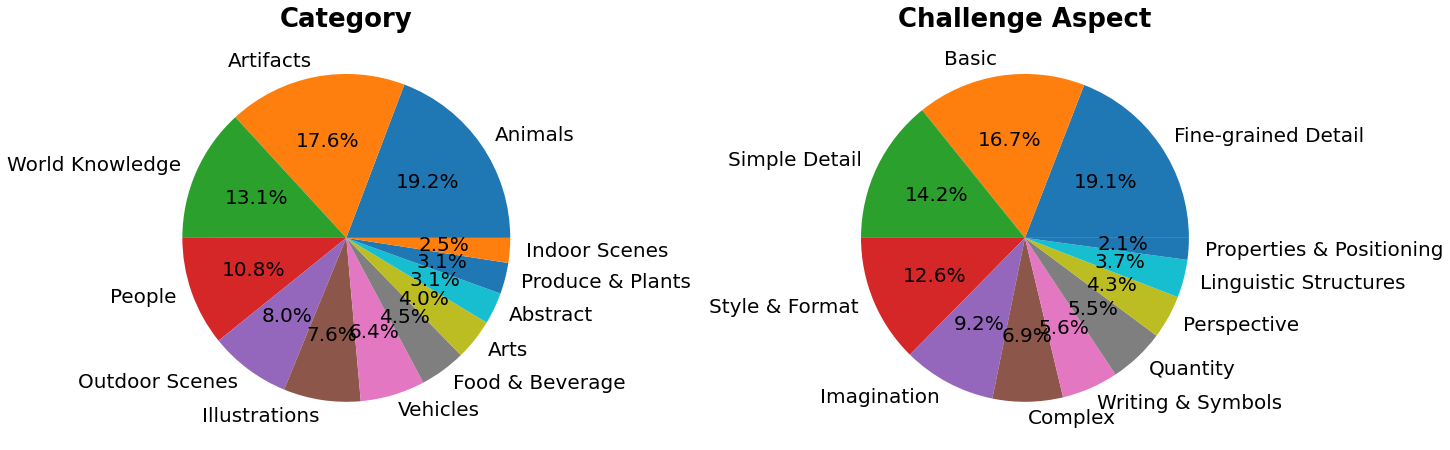
> PartiPrompts (P2) is a rich set of over 1600 prompts in English that we release as part of this work. P2 can be used to measure model capabilities across various categories and challenge aspects.
|
||||
|
||||
|
||||
|
||||
PartiPrompts has the following columns:
|
||||
|
||||
- Prompt
|
||||
- Category of the prompt (such as “Abstract”, “World Knowledge”, etc.)
|
||||
- Challenge reflecting the difficulty (such as “Basic”, “Complex”, “Writing & Symbols”, etc.)
|
||||
|
||||
These benchmarks allow for side-by-side human evaluation of different image generation models. Let’s see how we can use `diffusers` on a couple of PartiPrompts.
|
||||
|
||||
Below we show some prompts sampled across different challenges: Basic, Complex, Linguistic Structures, Imagination, and Writing & Symbols. Here we are using PartiPrompts as a [dataset](https://huggingface.co/datasets/nateraw/parti-prompts).
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
|
||||
# prompts = load_dataset("nateraw/parti-prompts", split="train")
|
||||
# prompts = prompts.shuffle()
|
||||
# sample_prompts = [prompts[i]["Prompt"] for i in range(5)]
|
||||
|
||||
# Fixing these sample prompts in the interest of reproducibility.
|
||||
sample_prompts = [
|
||||
"a corgi",
|
||||
"a hot air balloon with a yin-yang symbol, with the moon visible in the daytime sky",
|
||||
"a car with no windows",
|
||||
"a cube made of porcupine",
|
||||
'The saying "BE EXCELLENT TO EACH OTHER" written on a red brick wall with a graffiti image of a green alien wearing a tuxedo. A yellow fire hydrant is on a sidewalk in the foreground.',
|
||||
]
|
||||
```
|
||||
|
||||
Now we can use these prompts to generate some images using Stable Diffusion ([v1-4 checkpoint](https://huggingface.co/CompVis/stable-diffusion-v1-4)):
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
seed = 0
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
images = sd_pipeline(sample_prompts, num_images_per_prompt=1, generator=generator, output_type="numpy").images
|
||||
```
|
||||
|
||||

|
||||
|
||||
We can also set `num_images_per_prompt` accordingly to compare different images for the same prompt. Running the same pipeline but with a different checkpoint ([v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)), yields:
|
||||
|
||||

|
||||
|
||||
Once several images are generated from all the prompts using multiple models (under evaluation), these results are presented to human evaluators for scoring. For
|
||||
more details on the DrawBench and PartiPrompts benchmarks, refer to their respective papers.
|
||||
|
||||
<Tip>
|
||||
|
||||
It is useful to look at some inference samples while a model is training to measure the
|
||||
training progress. In our [training scripts](https://github.com/huggingface/diffusers/tree/main/examples/), we support this utility with additional support for
|
||||
logging to TensorBoard and Weights & Biases.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Quantitative Evaluation
|
||||
|
||||
In this section, we will walk you through how to evaluate three different diffusion pipelines using:
|
||||
|
||||
- CLIP score
|
||||
- CLIP directional similarity
|
||||
- FID
|
||||
|
||||
### Text-guided image generation
|
||||
|
||||
[CLIP score](https://arxiv.org/abs/2104.08718) measures the compatibility of image-caption pairs. Higher CLIP scores imply higher compatibility 🔼. The CLIP score is a quantitative measurement of the qualitative concept "compatibility". Image-caption pair compatibility can also be thought of as the semantic similarity between the image and the caption. CLIP score was found to have high correlation with human judgement.
|
||||
|
||||
Let's first load a [`StableDiffusionPipeline`]:
|
||||
|
||||
```python
|
||||
from diffusers import StableDiffusionPipeline
|
||||
import torch
|
||||
|
||||
model_ckpt = "CompVis/stable-diffusion-v1-4"
|
||||
sd_pipeline = StableDiffusionPipeline.from_pretrained(model_ckpt, torch_dtype=torch.float16).to("cuda")
|
||||
```
|
||||
|
||||
Generate some images with multiple prompts:
|
||||
|
||||
```python
|
||||
prompts = [
|
||||
"a photo of an astronaut riding a horse on mars",
|
||||
"A high tech solarpunk utopia in the Amazon rainforest",
|
||||
"A pikachu fine dining with a view to the Eiffel Tower",
|
||||
"A mecha robot in a favela in expressionist style",
|
||||
"an insect robot preparing a delicious meal",
|
||||
"A small cabin on top of a snowy mountain in the style of Disney, artstation",
|
||||
]
|
||||
|
||||
images = sd_pipeline(prompts, num_images_per_prompt=1, output_type="numpy").images
|
||||
|
||||
print(images.shape)
|
||||
# (6, 512, 512, 3)
|
||||
```
|
||||
|
||||
And then, we calculate the CLIP score.
|
||||
|
||||
```python
|
||||
from torchmetrics.functional.multimodal import clip_score
|
||||
from functools import partial
|
||||
|
||||
clip_score_fn = partial(clip_score, model_name_or_path="openai/clip-vit-base-patch16")
|
||||
|
||||
|
||||
def calculate_clip_score(images, prompts):
|
||||
images_int = (images * 255).astype("uint8")
|
||||
clip_score = clip_score_fn(torch.from_numpy(images_int).permute(0, 3, 1, 2), prompts).detach()
|
||||
return round(float(clip_score), 4)
|
||||
|
||||
|
||||
sd_clip_score = calculate_clip_score(images, prompts)
|
||||
print(f"CLIP score: {sd_clip_score}")
|
||||
# CLIP score: 35.7038
|
||||
```
|
||||
|
||||
In the above example, we generated one image per prompt. If we generated multiple images per prompt, we would have to take the average score from the generated images per prompt.
|
||||
|
||||
Now, if we wanted to compare two checkpoints compatible with the [`StableDiffusionPipeline`] we should pass a generator while calling the pipeline. First, we generate images with a
|
||||
fixed seed with the [v1-4 Stable Diffusion checkpoint](https://huggingface.co/CompVis/stable-diffusion-v1-4):
|
||||
|
||||
```python
|
||||
seed = 0
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
images = sd_pipeline(prompts, num_images_per_prompt=1, generator=generator, output_type="numpy").images
|
||||
```
|
||||
|
||||
Then we load the [v1-5 checkpoint](https://huggingface.co/runwayml/stable-diffusion-v1-5) to generate images:
|
||||
|
||||
```python
|
||||
model_ckpt_1_5 = "runwayml/stable-diffusion-v1-5"
|
||||
sd_pipeline_1_5 = StableDiffusionPipeline.from_pretrained(model_ckpt_1_5, torch_dtype=weight_dtype).to(device)
|
||||
|
||||
images_1_5 = sd_pipeline_1_5(prompts, num_images_per_prompt=1, generator=generator, output_type="numpy").images
|
||||
```
|
||||
|
||||
And finally, we compare their CLIP scores:
|
||||
|
||||
```python
|
||||
sd_clip_score_1_4 = calculate_clip_score(images, prompts)
|
||||
print(f"CLIP Score with v-1-4: {sd_clip_score_1_4}")
|
||||
# CLIP Score with v-1-4: 34.9102
|
||||
|
||||
sd_clip_score_1_5 = calculate_clip_score(images_1_5, prompts)
|
||||
print(f"CLIP Score with v-1-5: {sd_clip_score_1_5}")
|
||||
# CLIP Score with v-1-5: 36.2137
|
||||
```
|
||||
|
||||
It seems like the [v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) checkpoint performs better than its predecessor. Note, however, that the number of prompts we used to compute the CLIP scores is quite low. For a more practical evaluation, this number should be way higher, and the prompts should be diverse.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
By construction, there are some limitations in this score. The captions in the training dataset
|
||||
were crawled from the web and extracted from `alt` and similar tags associated an image on the internet.
|
||||
They are not necessarily representative of what a human being would use to describe an image. Hence we
|
||||
had to "engineer" some prompts here.
|
||||
|
||||
</Tip>
|
||||
|
||||
### Image-conditioned text-to-image generation
|
||||
|
||||
In this case, we condition the generation pipeline with an input image as well as a text prompt. Let's take the [`StableDiffusionInstructPix2PixPipeline`], as an example. It takes an edit instruction as an input prompt and an input image to be edited.
|
||||
|
||||
Here is one example:
|
||||
|
||||

|
||||
|
||||
One strategy to evaluate such a model is to measure the consistency of the change between the two images (in [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) space) with the change between the two image captions (as shown in [CLIP-Guided Domain Adaptation of Image Generators](https://arxiv.org/abs/2108.00946)). This is referred to as the "**CLIP directional similarity**".
|
||||
|
||||
- Caption 1 corresponds to the input image (image 1) that is to be edited.
|
||||
- Caption 2 corresponds to the edited image (image 2). It should reflect the edit instruction.
|
||||
|
||||
Following is a pictorial overview:
|
||||
|
||||

|
||||
|
||||
We have prepared a mini dataset to implement this metric. Let's first load the dataset.
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
|
||||
dataset = load_dataset("sayakpaul/instructpix2pix-demo", split="train")
|
||||
dataset.features
|
||||
```
|
||||
|
||||
```bash
|
||||
{'input': Value(dtype='string', id=None),
|
||||
'edit': Value(dtype='string', id=None),
|
||||
'output': Value(dtype='string', id=None),
|
||||
'image': Image(decode=True, id=None)}
|
||||
```
|
||||
|
||||
Here we have:
|
||||
|
||||
- `input` is a caption corresponding to the `image`.
|
||||
- `edit` denotes the edit instruction.
|
||||
- `output` denotes the modified caption reflecting the `edit` instruction.
|
||||
|
||||
Let's take a look at a sample.
|
||||
|
||||
```python
|
||||
idx = 0
|
||||
print(f"Original caption: {dataset[idx]['input']}")
|
||||
print(f"Edit instruction: {dataset[idx]['edit']}")
|
||||
print(f"Modified caption: {dataset[idx]['output']}")
|
||||
```
|
||||
|
||||
```bash
|
||||
Original caption: 2. FAROE ISLANDS: An archipelago of 18 mountainous isles in the North Atlantic Ocean between Norway and Iceland, the Faroe Islands has 'everything you could hope for', according to Big 7 Travel. It boasts 'crystal clear waterfalls, rocky cliffs that seem to jut out of nowhere and velvety green hills'
|
||||
Edit instruction: make the isles all white marble
|
||||
Modified caption: 2. WHITE MARBLE ISLANDS: An archipelago of 18 mountainous white marble isles in the North Atlantic Ocean between Norway and Iceland, the White Marble Islands has 'everything you could hope for', according to Big 7 Travel. It boasts 'crystal clear waterfalls, rocky cliffs that seem to jut out of nowhere and velvety green hills'
|
||||
```
|
||||
|
||||
And here is the image:
|
||||
|
||||
```python
|
||||
dataset[idx]["image"]
|
||||
```
|
||||
|
||||

|
||||
|
||||
We will first edit the images of our dataset with the edit instruction and compute the directional similarity.
|
||||
|
||||
Let's first load the [`StableDiffusionInstructPix2PixPipeline`]:
|
||||
|
||||
```python
|
||||
from diffusers import StableDiffusionInstructPix2PixPipeline
|
||||
|
||||
instruct_pix2pix_pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
|
||||
"timbrooks/instruct-pix2pix", torch_dtype=torch.float16
|
||||
).to(device)
|
||||
```
|
||||
|
||||
Now, we perform the edits:
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
|
||||
def edit_image(input_image, instruction):
|
||||
image = instruct_pix2pix_pipeline(
|
||||
instruction,
|
||||
image=input_image,
|
||||
output_type="numpy",
|
||||
generator=generator,
|
||||
).images[0]
|
||||
return image
|
||||
|
||||
|
||||
input_images = []
|
||||
original_captions = []
|
||||
modified_captions = []
|
||||
edited_images = []
|
||||
|
||||
for idx in range(len(dataset)):
|
||||
input_image = dataset[idx]["image"]
|
||||
edit_instruction = dataset[idx]["edit"]
|
||||
edited_image = edit_image(input_image, edit_instruction)
|
||||
|
||||
input_images.append(np.array(input_image))
|
||||
original_captions.append(dataset[idx]["input"])
|
||||
modified_captions.append(dataset[idx]["output"])
|
||||
edited_images.append(edited_image)
|
||||
```
|
||||
|
||||
To measure the directional similarity, we first load CLIP's image and text encoders.
|
||||
|
||||
```python
|
||||
from transformers import (
|
||||
CLIPTokenizer,
|
||||
CLIPTextModelWithProjection,
|
||||
CLIPVisionModelWithProjection,
|
||||
CLIPImageProcessor,
|
||||
)
|
||||
|
||||
clip_id = "openai/clip-vit-large-patch14"
|
||||
tokenizer = CLIPTokenizer.from_pretrained(clip_id)
|
||||
text_encoder = CLIPTextModelWithProjection.from_pretrained(clip_id).to(device)
|
||||
image_processor = CLIPImageProcessor.from_pretrained(clip_id)
|
||||
image_encoder = CLIPVisionModelWithProjection.from_pretrained(clip_id).to(device)
|
||||
```
|
||||
|
||||
Notice that we are using a particular CLIP checkpoint, i.e., `openai/clip-vit-large-patch14`. This is because the Stable Diffusion pre-training was performed with this CLIP variant. For more details, refer to the [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/pix2pix#diffusers.StableDiffusionInstructPix2PixPipeline.text_encoder).
|
||||
|
||||
Next, we prepare a PyTorch `nn.module` to compute directional similarity:
|
||||
|
||||
```python
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
class DirectionalSimilarity(nn.Module):
|
||||
def __init__(self, tokenizer, text_encoder, image_processor, image_encoder):
|
||||
super().__init__()
|
||||
self.tokenizer = tokenizer
|
||||
self.text_encoder = text_encoder
|
||||
self.image_processor = image_processor
|
||||
self.image_encoder = image_encoder
|
||||
|
||||
def preprocess_image(self, image):
|
||||
image = self.image_processor(image, return_tensors="pt")["pixel_values"]
|
||||
return {"pixel_values": image.to(device)}
|
||||
|
||||
def tokenize_text(self, text):
|
||||
inputs = self.tokenizer(
|
||||
text,
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
padding="max_length",
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
return {"input_ids": inputs.input_ids.to(device)}
|
||||
|
||||
def encode_image(self, image):
|
||||
preprocessed_image = self.preprocess_image(image)
|
||||
image_features = self.image_encoder(**preprocessed_image).image_embeds
|
||||
image_features = image_features / image_features.norm(dim=1, keepdim=True)
|
||||
return image_features
|
||||
|
||||
def encode_text(self, text):
|
||||
tokenized_text = self.tokenize_text(text)
|
||||
text_features = self.text_encoder(**tokenized_text).text_embeds
|
||||
text_features = text_features / text_features.norm(dim=1, keepdim=True)
|
||||
return text_features
|
||||
|
||||
def compute_directional_similarity(self, img_feat_one, img_feat_two, text_feat_one, text_feat_two):
|
||||
sim_direction = F.cosine_similarity(img_feat_two - img_feat_one, text_feat_two - text_feat_one)
|
||||
return sim_direction
|
||||
|
||||
def forward(self, image_one, image_two, caption_one, caption_two):
|
||||
img_feat_one = self.encode_image(image_one)
|
||||
img_feat_two = self.encode_image(image_two)
|
||||
text_feat_one = self.encode_text(caption_one)
|
||||
text_feat_two = self.encode_text(caption_two)
|
||||
directional_similarity = self.compute_directional_similarity(
|
||||
img_feat_one, img_feat_two, text_feat_one, text_feat_two
|
||||
)
|
||||
return directional_similarity
|
||||
```
|
||||
|
||||
Let's put `DirectionalSimilarity` to use now.
|
||||
|
||||
```python
|
||||
dir_similarity = DirectionalSimilarity(tokenizer, text_encoder, image_processor, image_encoder)
|
||||
scores = []
|
||||
|
||||
for i in range(len(input_images)):
|
||||
original_image = input_images[i]
|
||||
original_caption = original_captions[i]
|
||||
edited_image = edited_images[i]
|
||||
modified_caption = modified_captions[i]
|
||||
|
||||
similarity_score = dir_similarity(original_image, edited_image, original_caption, modified_caption)
|
||||
scores.append(float(similarity_score.detach().cpu()))
|
||||
|
||||
print(f"CLIP directional similarity: {np.mean(scores)}")
|
||||
# CLIP directional similarity: 0.0797976553440094
|
||||
```
|
||||
|
||||
Like the CLIP Score, the higher the CLIP directional similarity, the better it is.
|
||||
|
||||
It should be noted that the `StableDiffusionInstructPix2PixPipeline` exposes two arguments, namely, `image_guidance_scale` and `guidance_scale` that let you control the quality of the final edited image. We encourage you to experiment with these two arguments and see the impact of that on the directional similarity.
|
||||
|
||||
We can extend the idea of this metric to measure how similar the original image and edited version are. To do that, we can just do `F.cosine_similarity(img_feat_two, img_feat_one)`. For these kinds of edits, we would still want the primary semantics of the images to be preserved as much as possible, i.e., a high similarity score.
|
||||
|
||||
We can use these metrics for similar pipelines such as the[`StableDiffusionPix2PixZeroPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/pix2pix_zero#diffusers.StableDiffusionPix2PixZeroPipeline)`.
|
||||
|
||||
<Tip>
|
||||
|
||||
Both CLIP score and CLIP direction similarity rely on the CLIP model, which can make the evaluations biased.
|
||||
|
||||
</Tip>
|
||||
|
||||
***Extending metrics like IS, FID (discussed later), or KID can be difficult*** when the model under evaluation was pre-trained on a large image-captioning dataset (such as the [LAION-5B dataset](https://laion.ai/blog/laion-5b/)). This is because underlying these metrics is an InceptionNet (pre-trained on the ImageNet-1k dataset) used for extracting intermediate image features. The pre-training dataset of Stable Diffusion may have limited overlap with the pre-training dataset of InceptionNet, so it is not a good candidate here for feature extraction.
|
||||
|
||||
***Using the above metrics helps evaluate models that are class-conditioned. For example, [DiT](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/overview). It was pre-trained being conditioned on the ImageNet-1k classes.***
|
||||
|
||||
### Class-conditioned image generation
|
||||
|
||||
Class-conditioned generative models are usually pre-trained on a class-labeled dataset such as [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k). Popular metrics for evaluating these models include Fréchet Inception Distance (FID), Kernel Inception Distance (KID), and Inception Score (IS). In this document, we focus on FID ([Heusel et al.](https://arxiv.org/abs/1706.08500)). We show how to compute it with the [`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit), which uses the [DiT model](https://arxiv.org/abs/2212.09748) under the hood.
|
||||
|
||||
FID aims to measure how similar are two datasets of images. As per [this resource](https://mmgeneration.readthedocs.io/en/latest/quick_run.html#fid):
|
||||
|
||||
> Fréchet Inception Distance is a measure of similarity between two datasets of images. It was shown to correlate well with the human judgment of visual quality and is most often used to evaluate the quality of samples of Generative Adversarial Networks. FID is calculated by computing the Fréchet distance between two Gaussians fitted to feature representations of the Inception network.
|
||||
|
||||
These two datasets are essentially the dataset of real images and the dataset of fake images (generated images in our case). FID is usually calculated with two large datasets. However, for this document, we will work with two mini datasets.
|
||||
|
||||
Let's first download a few images from the ImageNet-1k training set:
|
||||
|
||||
```python
|
||||
from zipfile import ZipFile
|
||||
import requests
|
||||
|
||||
|
||||
def download(url, local_filepath):
|
||||
r = requests.get(url)
|
||||
with open(local_filepath, "wb") as f:
|
||||
f.write(r.content)
|
||||
return local_filepath
|
||||
|
||||
|
||||
dummy_dataset_url = "https://hf.co/datasets/sayakpaul/sample-datasets/resolve/main/sample-imagenet-images.zip"
|
||||
local_filepath = download(dummy_dataset_url, dummy_dataset_url.split("/")[-1])
|
||||
|
||||
with ZipFile(local_filepath, "r") as zipper:
|
||||
zipper.extractall(".")
|
||||
```
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
import os
|
||||
|
||||
dataset_path = "sample-imagenet-images"
|
||||
image_paths = sorted([os.path.join(dataset_path, x) for x in os.listdir(dataset_path)])
|
||||
|
||||
real_images = [np.array(Image.open(path).convert("RGB")) for path in image_paths]
|
||||
```
|
||||
|
||||
These are 10 images from the following Imagenet-1k classes: "cassette_player", "chain_saw" (x2), "church", "gas_pump" (x3), "parachute" (x2), and "tench".
|
||||
|
||||
<p align="center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/evaluation_diffusion_models/real-images.png" alt="real-images"><br>
|
||||
<em>Real images.</em>
|
||||
</p>
|
||||
|
||||
Now that the images are loaded, let's apply some lightweight pre-processing on them to use them for FID calculation.
|
||||
|
||||
```python
|
||||
from torchvision.transforms import functional as F
|
||||
|
||||
|
||||
def preprocess_image(image):
|
||||
image = torch.tensor(image).unsqueeze(0)
|
||||
image = image.permute(0, 3, 1, 2) / 255.0
|
||||
return F.center_crop(image, (256, 256))
|
||||
|
||||
|
||||
real_images = torch.cat([preprocess_image(image) for image in real_images])
|
||||
print(real_images.shape)
|
||||
# torch.Size([10, 3, 256, 256])
|
||||
```
|
||||
|
||||
We now load the [`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit) to generate images conditioned on the above-mentioned classes.
|
||||
|
||||
```python
|
||||
from diffusers import DiTPipeline, DPMSolverMultistepScheduler
|
||||
|
||||
dit_pipeline = DiTPipeline.from_pretrained("facebook/DiT-XL-2-256", torch_dtype=torch.float16)
|
||||
dit_pipeline.scheduler = DPMSolverMultistepScheduler.from_config(dit_pipeline.scheduler.config)
|
||||
dit_pipeline = dit_pipeline.to("cuda")
|
||||
|
||||
words = [
|
||||
"cassette player",
|
||||
"chainsaw",
|
||||
"chainsaw",
|
||||
"church",
|
||||
"gas pump",
|
||||
"gas pump",
|
||||
"gas pump",
|
||||
"parachute",
|
||||
"parachute",
|
||||
"tench",
|
||||
]
|
||||
|
||||
class_ids = dit_pipeline.get_label_ids(words)
|
||||
output = dit_pipeline(class_labels=class_ids, generator=generator, output_type="numpy")
|
||||
|
||||
fake_images = output.images
|
||||
fake_images = torch.tensor(fake_images)
|
||||
fake_images = fake_images.permute(0, 3, 1, 2)
|
||||
print(fake_images.shape)
|
||||
# torch.Size([10, 3, 256, 256])
|
||||
```
|
||||
|
||||
Now, we can compute the FID using [`torchmetrics`](https://torchmetrics.readthedocs.io/).
|
||||
|
||||
```python
|
||||
from torchmetrics.image.fid import FrechetInceptionDistance
|
||||
|
||||
fid = FrechetInceptionDistance(normalize=True)
|
||||
fid.update(real_images, real=True)
|
||||
fid.update(fake_images, real=False)
|
||||
|
||||
print(f"FID: {float(fid.compute())}")
|
||||
# FID: 177.7147216796875
|
||||
```
|
||||
|
||||
The lower the FID, the better it is. Several things can influence FID here:
|
||||
|
||||
- Number of images (both real and fake)
|
||||
- Randomness induced in the diffusion process
|
||||
- Number of inference steps in the diffusion process
|
||||
- The scheduler being used in the diffusion process
|
||||
|
||||
For the last two points, it is, therefore, a good practice to run the evaluation across different seeds and inference steps, and then report an average result.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
FID results tend to be fragile as they depend on a lot of factors:
|
||||
|
||||
* The specific Inception model used during computation.
|
||||
* The implementation accuracy of the computation.
|
||||
* The image format (not the same if we start from PNGs vs JPGs).
|
||||
|
||||
Keeping that in mind, FID is often most useful when comparing similar runs, but it is
|
||||
hard to to reproduce paper results unless the authors carefully disclose the FID
|
||||
measurement code.
|
||||
|
||||
These points apply to other related metrics too, such as KID and IS.
|
||||
|
||||
</Tip>
|
||||
|
||||
As a final step, let's visually inspect the `fake_images`.
|
||||
|
||||
<p align="center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/evaluation_diffusion_models/fake-images.png" alt="fake-images"><br>
|
||||
<em>Fake images.</em>
|
||||
</p>
|
||||
+52
-67
@@ -16,76 +16,61 @@ specific language governing permissions and limitations under the License.
|
||||
<br>
|
||||
</p>
|
||||
|
||||
# Diffusers
|
||||
# 🧨 Diffusers
|
||||
|
||||
🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or want to train your own diffusion model, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on [usability over performance](conceptual/philosophy#usability-over-performance), [simple over easy](conceptual/philosophy#simple-over-easy), and [customizability over abstractions](conceptual/philosophy#tweakable-contributorfriendly-over-abstraction).
|
||||
🤗 Diffusers provides pretrained vision and audio diffusion models, and serves as a modular toolbox for inference and training.
|
||||
|
||||
The library has three main components:
|
||||
More precisely, 🤗 Diffusers offers:
|
||||
|
||||
- State-of-the-art [diffusion pipelines](api/pipelines/overview) for inference with just a few lines of code.
|
||||
- Interchangeable [noise schedulers](api/schedulers/overview) for balancing trade-offs between generation speed and quality.
|
||||
- Pretrained [models](api/models) that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.
|
||||
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code (see [**Using Diffusers**](./using-diffusers/conditional_image_generation)) or have a look at [**Pipelines**](#pipelines) to get an overview of all supported pipelines and their corresponding papers.
|
||||
- Various noise schedulers that can be used interchangeably for the preferred speed vs. quality trade-off in inference. For more information see [**Schedulers**](./api/schedulers/overview).
|
||||
- Multiple types of models, such as UNet, can be used as building blocks in an end-to-end diffusion system. See [**Models**](./api/models) for more details
|
||||
- Training examples to show how to train the most popular diffusion model tasks. For more information see [**Training**](./training/overview).
|
||||
|
||||
<div class="mt-10">
|
||||
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5">
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./tutorials/tutorial_overview"
|
||||
><div class="w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Tutorials</div>
|
||||
<p class="text-gray-700">Learn the fundamental skills you need to start generating outputs, build your own diffusion system, and train a diffusion model. We recommend starting here if you're using 🤗 Diffusers for the first time!</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./using-diffusers/loading_overview"
|
||||
><div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">How-to guides</div>
|
||||
<p class="text-gray-700">Practical guides for helping you load pipelines, models, and schedulers. You'll also learn how to use pipelines for specific tasks, control how outputs are generated, optimize for inference speed, and different training techniques.</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./conceptual/philosophy"
|
||||
><div class="w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Conceptual guides</div>
|
||||
<p class="text-gray-700">Understand why the library was designed the way it was, and learn more about the ethical guidelines and safety implementations for using the library.</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./api/models"
|
||||
><div class="w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Reference</div>
|
||||
<p class="text-gray-700">Technical descriptions of how 🤗 Diffusers classes and methods work.</p>
|
||||
</a>
|
||||
</div>
|
||||
</div>
|
||||
## 🧨 Diffusers Pipelines
|
||||
|
||||
## Supported pipelines
|
||||
The following table summarizes all officially supported pipelines, their corresponding paper, and if
|
||||
available a colab notebook to directly try them out.
|
||||
|
||||
| Pipeline | Paper/Repository | Tasks |
|
||||
|---|---|:---:|
|
||||
| [alt_diffusion](./api/pipelines/alt_diffusion) | [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
|
||||
| [audio_diffusion](./api/pipelines/audio_diffusion) | [Audio Diffusion](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation |
|
||||
| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
|
||||
| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
|
||||
| [dance_diffusion](./api/pipelines/dance_diffusion) | [Dance Diffusion](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
|
||||
| [ddpm](./api/pipelines/ddpm) | [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
|
||||
| [ddim](./api/pipelines/ddim) | [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
|
||||
| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
|
||||
| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
|
||||
| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
|
||||
| [paint_by_example](./api/pipelines/paint_by_example) | [Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
|
||||
| [pndm](./api/pipelines/pndm) | [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
|
||||
| [score_sde_ve](./api/pipelines/score_sde_ve) | [Score-Based Generative Modeling through Stochastic Differential Equations](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [score_sde_vp](./api/pipelines/score_sde_vp) | [Score-Based Generative Modeling through Stochastic Differential Equations](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [Semantic Guidance](https://arxiv.org/abs/2301.12247) | Text-Guided Generation |
|
||||
| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation |
|
||||
| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation |
|
||||
| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting |
|
||||
| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [MultiDiffusion](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
|
||||
| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://arxiv.org/abs/2211.09800) | Text-Guided Image Editing|
|
||||
| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [Zero-shot Image-to-Image Translation](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
|
||||
| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://arxiv.org/abs/2301.13826) | Text-to-Image Generation |
|
||||
| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [Improving Sample Quality of Diffusion Models Using Self-Attention Guidance](https://arxiv.org/abs/2210.00939) | Text-to-Image Generation |
|
||||
| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [Stable Diffusion Image Variations](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
|
||||
| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [Stable Diffusion Latent Upscaler](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Depth-Conditional Stable Diffusion](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
|
||||
| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [Safe Stable Diffusion](https://arxiv.org/abs/2211.05105) | Text-Guided Generation |
|
||||
| [stable_unclip](./stable_unclip) | Stable unCLIP | Text-to-Image Generation |
|
||||
| [stable_unclip](./stable_unclip) | Stable unCLIP | Image-to-Image Text-Guided Generation |
|
||||
| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
|
||||
| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125)(implementation by [kakaobrain](https://github.com/kakaobrain/karlo)) | Text-to-Image Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
|
||||
| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
|
||||
| Pipeline | Paper | Tasks | Colab
|
||||
|---|---|:---:|:---:|
|
||||
| [alt_diffusion](./api/pipelines/alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
|
||||
| [audio_diffusion](./api/pipelines/audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation | [](https://colab.research.google.com/github/teticio/audio-diffusion/blob/master/notebooks/audio_diffusion_pipeline.ipynb)
|
||||
| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [
|
||||
| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
|
||||
| [dance_diffusion](./api/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
|
||||
| [ddpm](./api/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
|
||||
| [ddim](./api/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
|
||||
| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
|
||||
| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
|
||||
| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
|
||||
| [paint_by_example](./api/pipelines/paint_by_example) | [**Paint by Example: Exemplar-based Image Editing with Diffusion Models**](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
|
||||
| [pndm](./api/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
|
||||
| [score_sde_ve](./api/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [score_sde_vp](./api/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [**Semantic Guidance**](https://arxiv.org/abs/2301.12247) | Text-Guided Generation | [](https://colab.research.google.com/github/ml-research/semantic-image-editing/blob/main/examples/SemanticGuidance.ipynb)
|
||||
| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
|
||||
| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
|
||||
| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
|
||||
| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [**MultiDiffusion**](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
|
||||
| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [**InstructPix2Pix**](https://github.com/timothybrooks/instruct-pix2pix) | Text-Guided Image Editing|
|
||||
| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [**Zero-shot Image-to-Image Translation**](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
|
||||
| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [**Attend and Excite for Stable Diffusion**](https://attendandexcite.github.io/Attend-and-Excite/) | Text-to-Image Generation |
|
||||
| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [**Self-Attention Guidance**](https://ku-cvlab.github.io/Self-Attention-Guidance) | Text-to-Image Generation |
|
||||
| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [**Stable Diffusion Image Variations**](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
|
||||
| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [**Stable Diffusion Latent Upscaler**](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Depth-Conditional Stable Diffusion**](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
|
||||
| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [**Safe Stable Diffusion**](https://arxiv.org/abs/2211.05105) | Text-Guided Generation | [](https://colab.research.google.com/github/ml-research/safe-latent-diffusion/blob/main/examples/Safe%20Latent%20Diffusion.ipynb)
|
||||
| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Text-to-Image Generation |
|
||||
| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Image-to-Image Text-Guided Generation |
|
||||
| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
|
||||
| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
|
||||
| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
|
||||
|
||||
**Note**: Pipelines are simple examples of how to play around with the diffusion systems as described in the corresponding papers.
|
||||
|
||||
@@ -10,30 +10,6 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# OpenVINO
|
||||
|
||||
# How to use OpenVINO for inference
|
||||
|
||||
🤗 [Optimum](https://github.com/huggingface/optimum-intel) provides a Stable Diffusion pipeline compatible with OpenVINO. You can now easily perform inference with OpenVINO Runtime on a variety of Intel processors ([see](https://docs.openvino.ai/latest/openvino_docs_OV_UG_supported_plugins_Supported_Devices.html) the full list of supported devices).
|
||||
|
||||
## Installation
|
||||
|
||||
Install 🤗 Optimum Intel with the following command:
|
||||
|
||||
```
|
||||
pip install optimum["openvino"]
|
||||
```
|
||||
|
||||
## Stable Diffusion Inference
|
||||
|
||||
To load an OpenVINO model and run inference with OpenVINO Runtime, you need to replace `StableDiffusionPipeline` with `OVStableDiffusionPipeline`. In case you want to load a PyTorch model and convert it to the OpenVINO format on-the-fly, you can set `export=True`.
|
||||
|
||||
```python
|
||||
from optimum.intel.openvino import OVStableDiffusionPipeline
|
||||
|
||||
model_id = "runwayml/stable-diffusion-v1-5"
|
||||
pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
images = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
You can find more examples in [optimum documentation](https://huggingface.co/docs/optimum/intel/inference#export-and-inference-of-stable-diffusion-models).
|
||||
Under construction 🚧
|
||||
|
||||
@@ -1,17 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Overview
|
||||
|
||||
Generating high-quality outputs is computationally intensive, especially during each iterative step where you go from a noisy output to a less noisy output. One of 🧨 Diffuser's goal is to make this technology widely accessible to everyone, which includes enabling fast inference on consumer and specialized hardware.
|
||||
|
||||
This section will cover tips and tricks - like half-precision weights and sliced attention - for optimizing inference speed and reducing memory-consumption. You can also learn how to speed up your PyTorch code with [`torch.compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) or [ONNX Runtime](https://onnxruntime.ai/docs/), and enable memory-efficient attention with [xFormers](https://facebookresearch.github.io/xformers/). There are also guides for running inference on specific hardware like Apple Silicon, and Intel or Habana processors.
|
||||
@@ -50,7 +50,7 @@ pip install --pre torch torchvision --index-url https://download.pytorch.org/whl
|
||||
```Python
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
from diffusers.models.attention_processor import AttnProcessor2_0
|
||||
from diffusers.models.cross_attention import AttnProcessor2_0
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
|
||||
pipe.unet.set_attn_processor(AttnProcessor2_0())
|
||||
|
||||
@@ -205,7 +205,7 @@ Schedulers manage going from a noisy sample to a less noisy sample given the mod
|
||||
|
||||
<Tip>
|
||||
|
||||
🧨 Diffusers is a toolbox for building diffusion systems. While the [`DiffusionPipeline`] is a convenient way to get started with a pre-built diffusion system, you can also choose your own model and scheduler components separately to build a custom diffusion system.
|
||||
🧨 Diffusers is a toolbox for building diffusion systems. While the [`DiffusionPipeline`] is a convenient way to get started with a pre-built diffusion system, you can also choose your own the model and scheduler components separately to build a custom diffusion system.
|
||||
|
||||
</Tip>
|
||||
|
||||
@@ -310,4 +310,4 @@ Hopefully you generated some cool images with 🧨 Diffusers in this quicktour!
|
||||
* See example official and community [training or finetuning scripts](https://github.com/huggingface/diffusers/tree/main/examples#-diffusers-examples) for a variety of use cases.
|
||||
* Learn more about loading, accessing, changing and comparing schedulers in the [Using different Schedulers](./using-diffusers/schedulers) guide.
|
||||
* Explore prompt engineering, speed and memory optimizations, and tips and tricks for generating higher quality images with the [Stable Diffusion](./stable_diffusion) guide.
|
||||
* Dive deeper into speeding up 🧨 Diffusers with guides on [optimized PyTorch on a GPU](./optimization/fp16), and inference guides for running [Stable Diffusion on Apple Silicon (M1/M2)](./optimization/mps) and [ONNX Runtime](./optimization/onnx).
|
||||
* Dive deeper into speeding up 🧨 Diffusers with guides on [optimized PyTorch on a GPU](./optimization/fp16), and inference guides for running [Stable Diffusion on Apple Silicon (M1/M2)](./optimization/mps) and [ONNX Runtime](./optimization/onnx).
|
||||
@@ -10,79 +10,29 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Unconditional image generation
|
||||
# Unconditional Image-Generation
|
||||
|
||||
Unconditional image generation is not conditioned on any text or images, unlike text- or image-to-image models. It only generates images that resemble its training data distribution.
|
||||
In this section, we explain how one can train an unconditional image generation diffusion
|
||||
model. "Unconditional" because the model is not conditioned on any context to generate an image - once trained the model will simply generate images that resemble its training data
|
||||
distribution.
|
||||
|
||||
<iframe
|
||||
src="https://stevhliu-ddpm-butterflies-128.hf.space"
|
||||
frameborder="0"
|
||||
width="850"
|
||||
height="550"
|
||||
></iframe>
|
||||
## Installing the dependencies
|
||||
|
||||
|
||||
This guide will show you how to train an unconditional image generation model on existing datasets as well as your own custom dataset. All the training scripts for unconditional image generation can be found [here](https://github.com/huggingface/diffusers/tree/main/examples/unconditional_image_generation) if you're interested in learning more about the training details.
|
||||
|
||||
Before running the script, make sure you install the library's training dependencies:
|
||||
Before running the scripts, make sure to install the library's training dependencies:
|
||||
|
||||
```bash
|
||||
pip install diffusers[training] accelerate datasets
|
||||
```
|
||||
|
||||
Next, initialize an 🤗 [Accelerate](https://github.com/huggingface/accelerate/) environment with:
|
||||
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
To setup a default 🤗 Accelerate environment without choosing any configurations:
|
||||
## Unconditional Flowers
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
Or if your environment doesn't support an interactive shell like a notebook, you can use:
|
||||
|
||||
```bash
|
||||
from accelerate.utils import write_basic_config
|
||||
|
||||
write_basic_config()
|
||||
```
|
||||
|
||||
## Upload model to Hub
|
||||
|
||||
You can upload your model on the Hub by adding the following argument to the training script:
|
||||
|
||||
```bash
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
## Save and load checkpoints
|
||||
|
||||
It is a good idea to regularly save checkpoints in case anything happens during training. To save a checkpoint, pass the following argument to the training script:
|
||||
|
||||
```bash
|
||||
--checkpointing_steps=500
|
||||
```
|
||||
|
||||
The full training state is saved in a subfolder in the `output_dir` every 500 steps, which allows you to load a checkpoint and resume training if you pass the `--resume_from_checkpoint` argument to the training script:
|
||||
|
||||
```bash
|
||||
--resume_from_checkpoint="checkpoint-1500"
|
||||
```
|
||||
|
||||
## Finetuning
|
||||
|
||||
You're ready to launch the [training script](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/train_unconditional.py) now! Specify the dataset name to finetune on with the `--dataset_name` argument and then save it to the path in `--output_dir`.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 A full training run takes 2 hours on 4xV100 GPUs.
|
||||
|
||||
</Tip>
|
||||
|
||||
For example, to finetune on the [Oxford Flowers](https://huggingface.co/datasets/huggan/flowers-102-categories) dataset:
|
||||
The command to train a DDPM UNet model on the Oxford Flowers dataset:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
@@ -97,12 +47,15 @@ accelerate launch train_unconditional.py \
|
||||
--mixed_precision=no \
|
||||
--push_to_hub
|
||||
```
|
||||
An example trained model: https://huggingface.co/anton-l/ddpm-ema-flowers-64
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://user-images.githubusercontent.com/26864830/180248660-a0b143d0-b89a-42c5-8656-2ebf6ece7e52.png"/>
|
||||
</div>
|
||||
A full training run takes 2 hours on 4xV100 GPUs.
|
||||
|
||||
Or if you want to train your model on the [Pokemon](https://huggingface.co/datasets/huggan/pokemon) dataset:
|
||||
<img src="https://user-images.githubusercontent.com/26864830/180248660-a0b143d0-b89a-42c5-8656-2ebf6ece7e52.png" width="700" />
|
||||
|
||||
## Unconditional Pokemon
|
||||
|
||||
The command to train a DDPM UNet model on the Pokemon dataset:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
@@ -117,29 +70,26 @@ accelerate launch train_unconditional.py \
|
||||
--mixed_precision=no \
|
||||
--push_to_hub
|
||||
```
|
||||
An example trained model: https://huggingface.co/anton-l/ddpm-ema-pokemon-64
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://user-images.githubusercontent.com/26864830/180248200-928953b4-db38-48db-b0c6-8b740fe6786f.png"/>
|
||||
</div>
|
||||
A full training run takes 2 hours on 4xV100 GPUs.
|
||||
|
||||
## Finetuning with your own data
|
||||
<img src="https://user-images.githubusercontent.com/26864830/180248200-928953b4-db38-48db-b0c6-8b740fe6786f.png" width="700" />
|
||||
|
||||
There are two ways to finetune a model on your own dataset:
|
||||
|
||||
- provide your own folder of images to the `--train_data_dir` argument
|
||||
- upload your dataset to the Hub and pass the dataset repository id to the `--dataset_name` argument.
|
||||
## Using your own data
|
||||
|
||||
<Tip>
|
||||
To use your own dataset, there are 2 ways:
|
||||
- you can either provide your own folder as `--train_data_dir`
|
||||
- or you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
|
||||
|
||||
💡 Learn more about how to create an image dataset for training in the [Create an image dataset](https://huggingface.co/docs/datasets/image_dataset) guide.
|
||||
|
||||
</Tip>
|
||||
**Note**: If you want to create your own training dataset please have a look at [this document](https://huggingface.co/docs/datasets/image_process#image-datasets).
|
||||
|
||||
Below, we explain both in more detail.
|
||||
|
||||
### Provide the dataset as a folder
|
||||
|
||||
If you provide your own dataset as a folder, the script expects the following directory structure:
|
||||
If you provide your own folders with images, the script expects the following directory structure:
|
||||
|
||||
```bash
|
||||
data_dir/xxx.png
|
||||
@@ -147,7 +97,7 @@ data_dir/xxy.png
|
||||
data_dir/[...]/xxz.png
|
||||
```
|
||||
|
||||
Pass the path to the folder containing the images to the `--train_data_dir` argument and launch the training:
|
||||
In other words, the script will take care of gathering all images inside the folder. You can then run the script like this:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
@@ -155,17 +105,11 @@ accelerate launch train_unconditional.py \
|
||||
<other-arguments>
|
||||
```
|
||||
|
||||
Internally, the script uses the [`ImageFolder`](https://huggingface.co/docs/datasets/image_load#imagefolder) to automatically build a dataset from the folder.
|
||||
Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
|
||||
|
||||
### Upload your data to the Hub
|
||||
### Upload your data to the hub, as a (possibly private) repo
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 For more details and context about creating and uploading a dataset to the Hub, take a look at the [Image search with 🤗 Datasets](https://huggingface.co/blog/image-search-datasets) post.
|
||||
|
||||
</Tip>
|
||||
|
||||
To upload your dataset to the Hub, you can start by creating one with the [`ImageFolder`](https://huggingface.co/docs/datasets/image_load#imagefolder) feature, which creates an `image` column containing the PIL-encoded images, from 🤗 Datasets:
|
||||
It's very easy (and convenient) to upload your image dataset to the hub using the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
@@ -188,7 +132,9 @@ dataset = load_dataset(
|
||||
)
|
||||
```
|
||||
|
||||
Then you can use the [`~datasets.Dataset.push_to_hub`] method to upload it to the Hub:
|
||||
`ImageFolder` will create an `image` column containing the PIL-encoded images.
|
||||
|
||||
Next, push it to the hub!
|
||||
|
||||
```python
|
||||
# assuming you have ran the huggingface-cli login command in a terminal
|
||||
@@ -198,4 +144,6 @@ dataset.push_to_hub("name_of_your_dataset")
|
||||
dataset.push_to_hub("name_of_your_dataset", private=True)
|
||||
```
|
||||
|
||||
Now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the Hub.
|
||||
and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub.
|
||||
|
||||
More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
|
||||
|
||||
@@ -252,7 +252,6 @@ Then, you'll need a way to evaluate the model. For evaluation, you can use the [
|
||||
```py
|
||||
>>> from diffusers import DDPMPipeline
|
||||
>>> import math
|
||||
>>> import os
|
||||
|
||||
|
||||
>>> def make_grid(images, rows, cols):
|
||||
@@ -412,4 +411,4 @@ Unconditional image generation is one example of a task that can be trained. You
|
||||
* [Textual Inversion](./training/text_inversion), an algorithm that teaches a model a specific visual concept and integrates it into the generated image.
|
||||
* [DreamBooth](./training/dreambooth), a technique for generating personalized images of a subject given several input images of the subject.
|
||||
* [Guide](./training/text2image) to finetuning a Stable Diffusion model on your own dataset.
|
||||
* [Guide](./training/lora) to using LoRA, a memory-efficient technique for finetuning really large models faster.
|
||||
* [Guide](./training/lora) to using LoRA, a memory-efficient technique for finetuning really large models faster.
|
||||
@@ -1,23 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Overview
|
||||
|
||||
Welcome to 🧨 Diffusers! If you're new to diffusion models and generative AI, and want to learn more, then you've come to the right place. These beginner-friendly tutorials are designed to provide a gentle introduction to diffusion models and help you understand the library fundamentals - the core components and how 🧨 Diffusers is meant to be used.
|
||||
|
||||
You'll learn how to use a pipeline for inference to rapidly generate things, and then deconstruct that pipeline to really understand how to use the library as a modular toolbox for building your own diffusion systems. In the next lesson, you'll learn how to train your own diffusion model to generate what you want.
|
||||
|
||||
After completing the tutorials, you'll have gained the necessary skills to start exploring the library on your own and see how to use it for your own projects and applications.
|
||||
|
||||
Feel free to join our community on [Discord](https://discord.com/invite/JfAtkvEtRb) or the [forums](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) to connect and collaborate with other users and developers!
|
||||
|
||||
Let's start diffusing! 🧨
|
||||
@@ -12,7 +12,7 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# Conditional Image Generation
|
||||
|
||||
The [`DiffusionPipeline`] is the easiest way to use a pre-trained diffusion system for inference.
|
||||
The [`DiffusionPipeline`] is the easiest way to use a pre-trained diffusion system for inference
|
||||
|
||||
Start by creating an instance of [`DiffusionPipeline`] and specify which pipeline checkpoint you would like to download.
|
||||
You can use the [`DiffusionPipeline`] for any [Diffusers' checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads).
|
||||
|
||||
@@ -0,0 +1,21 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
|
||||
|
||||
# Configuration
|
||||
|
||||
The handling of configurations in Diffusers is with the `ConfigMixin` class.
|
||||
|
||||
[[autodoc]] ConfigMixin
|
||||
|
||||
Under further construction 🚧, open a [PR](https://github.com/huggingface/diffusers/compare) if you want to contribute!
|
||||
@@ -10,7 +10,7 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Controlled generation
|
||||
# Controlling generation of diffusion models
|
||||
|
||||
Controlling outputs generated by diffusion models has been long pursued by the community and is now an active research topic. In many popular diffusion models, subtle changes in inputs, both images and text prompts, can drastically change outputs. In an ideal world we want to be able to control how semantics are preserved and changed.
|
||||
|
||||
@@ -63,7 +63,7 @@ Next, we generate image captions for the concept that shall be edited and for th
|
||||
<Tip>
|
||||
|
||||
Pix2Pix Zero is the first model that allows "zero-shot" image editing. This means that the model
|
||||
can edit an image in less than a minute on a consumer GPU as shown [here](../api/pipelines/stable_diffusion/pix2pix_zero#usage-example).
|
||||
can edit an image in less than a minute on a consumer GPU as shown [here](../api/pipelines/stable_diffusion/pix2pix_zero#usage-example)
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
@@ -41,7 +41,7 @@ is safe 🔒. Make sure to check out the code online before loading & running it
|
||||
|
||||
## Loading official community pipelines
|
||||
|
||||
Community pipelines are summarized in the [community examples folder](https://github.com/huggingface/diffusers/tree/main/examples/community).
|
||||
Community pipelines are summarized in the [community examples folder](https://github.com/huggingface/diffusers/tree/main/examples/community)
|
||||
|
||||
Similarly, you need to pass both the *repo id* from where you wish to load the weights as well as the `custom_pipeline` argument. Here the `custom_pipeline` argument should consist simply of the filename of the community pipeline excluding the `.py` suffix, *e.g.* `clip_guided_stable_diffusion`.
|
||||
|
||||
|
||||
@@ -33,7 +33,7 @@ from io import BytesIO
|
||||
from diffusers import StableDiffusionImg2ImgPipeline
|
||||
```
|
||||
|
||||
Load the pipeline:
|
||||
Load the pipeline
|
||||
|
||||
```python
|
||||
device = "cuda"
|
||||
@@ -42,7 +42,7 @@ pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion
|
||||
)
|
||||
```
|
||||
|
||||
Download an initial image and preprocess it so we can pass it to the pipeline:
|
||||
Download an initial image and preprocess it so we can pass it to the pipeline.
|
||||
|
||||
```python
|
||||
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
@@ -55,7 +55,7 @@ init_image
|
||||
|
||||

|
||||
|
||||
Define the prompt and run the pipeline:
|
||||
Define the prompt and run the pipeline.
|
||||
|
||||
```python
|
||||
prompt = "A fantasy landscape, trending on artstation"
|
||||
@@ -67,7 +67,7 @@ prompt = "A fantasy landscape, trending on artstation"
|
||||
|
||||
</Tip>
|
||||
|
||||
Let's generate two images with same pipeline and seed, but with different values for `strength`:
|
||||
Let's generate two images with same pipeline and seed, but with different values for `strength`
|
||||
|
||||
```python
|
||||
generator = torch.Generator(device=device).manual_seed(1024)
|
||||
@@ -89,9 +89,9 @@ image
|
||||

|
||||
|
||||
|
||||
As you can see, when using a lower value for `strength`, the generated image is more closer to the original `image`.
|
||||
As you can see, when using a lower value for `strength`, the generated image is more closer to the original `image`
|
||||
|
||||
Now let's use a different scheduler - [LMSDiscreteScheduler](https://huggingface.co/docs/diffusers/api/schedulers#diffusers.LMSDiscreteScheduler):
|
||||
Now let's use a different scheduler - [LMSDiscreteScheduler](https://huggingface.co/docs/diffusers/api/schedulers#diffusers.LMSDiscreteScheduler)
|
||||
|
||||
```python
|
||||
from diffusers import LMSDiscreteScheduler
|
||||
|
||||
@@ -97,7 +97,7 @@ Note that we're not specifying the UNet weights here since the UNet is not fine-
|
||||
|
||||
</Tip>
|
||||
|
||||
And that's it! You now have your fine-tuned KerasCV Stable Diffusion model in Diffusers 🧨.
|
||||
And that's it! You now have your fine-tuned KerasCV Stable Diffusion model in Diffusers 🧨
|
||||
|
||||
## Using the Converted Model in Diffusers
|
||||
|
||||
@@ -176,4 +176,4 @@ more details. For inference-specific optimizations, refer [here](https://hugging
|
||||
|
||||
## Known Limitations
|
||||
|
||||
* Only Stable Diffusion v1 checkpoints are supported for conversion in this tool.
|
||||
* Only Stable Diffusion v1 checkpoints are supported for conversion in this tool.
|
||||
@@ -213,7 +213,7 @@ identical to the weights of the "main" checkpoint, just loaded in a different fr
|
||||
|
||||
Also variants do not correspond to different model structures, *e.g.* [stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) is not a variant of [stable-diffusion-2-0](https://huggingface.co/stabilityai/stable-diffusion-2) since the model structure is different (Stable Diffusion 1-5 uses a different `CLIPTextModel` compared to Stable Diffusion 2.0).
|
||||
|
||||
Pipeline checkpoints that are identical in model structure, but have been trained on different datasets, trained with vastly different training setups and thus correspond to different official releases (such as [Stable Diffusion v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4) and [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)) should probably be stored in individual repositories instead of as variations of each other.
|
||||
Pipeline checkpoints that are identical in model structure, but have been trained on different datasets, trained with vastly different training setups and thus correspond to different official releases (such as [Stable Diffusion v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4) and [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)) should probably be stored in individual repositories instead of as variations of eachother.
|
||||
|
||||
#### So what are checkpoint variants then?
|
||||
|
||||
@@ -345,7 +345,7 @@ and
|
||||
pipe = DiffusionPipeline.from_pretrained("diffusers/stable-diffusion-variants", variant="fp16")
|
||||
```
|
||||
|
||||
work.
|
||||
works.
|
||||
|
||||
<Tip>
|
||||
|
||||
@@ -399,7 +399,7 @@ As a class method, [`DiffusionPipeline.from_pretrained`] is responsible for two
|
||||
- Download the latest version of the folder structure required to run the `repo_id` with `diffusers` and cache them. If the latest folder structure is available in the local cache, [`DiffusionPipeline.from_pretrained`] will simply reuse the cache and **not** re-download the files.
|
||||
- Load the cached weights into the _correct_ pipeline class – one of the [officially supported pipeline classes](./api/overview#diffusers-summary) - and return an instance of the class. The _correct_ pipeline class is thereby retrieved from the `model_index.json` file.
|
||||
|
||||
The underlying folder structure of diffusion pipelines corresponds 1-to-1 to their corresponding class instances, *e.g.* [`StableDiffusionPipeline`] for [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5).
|
||||
The underlying folder structure of diffusion pipelines correspond 1-to-1 to their corresponding class instances, *e.g.* [`StableDiffusionPipeline`] for [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5)
|
||||
This can be better understood by looking at an example. Let's load a pipeline class instance `pipe` and print it:
|
||||
|
||||
```python
|
||||
@@ -531,7 +531,7 @@ In the case of `runwayml/stable-diffusion-v1-5` the `model_index.json` is theref
|
||||
"class"
|
||||
]
|
||||
```
|
||||
- The `"name"` field corresponds both to the name of the subfolder in which the configuration and weights are stored as well as the attribute name of the pipeline class (as can be seen [here](https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main/bert) and [here](https://github.com/huggingface/diffusers/blob/cd502b25cf0debac6f98d27a6638ef95208d1ea2/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py#L42))
|
||||
- The `"name"` field corresponds both to the name of the subfolder in which the configuration and weights are stored as well as the attribute name of the pipeline class (as can be seen [here](https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main/bert) and [here](https://github.com/huggingface/diffusers/blob/cd502b25cf0debac6f98d27a6638ef95208d1ea2/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py#L42)
|
||||
- The `"library"` field corresponds to the name of the library, *e.g.* `diffusers` or `transformers` from which the `"class"` should be loaded
|
||||
- The `"class"` field corresponds to the name of the class, *e.g.* [`CLIPTokenizer`](https://huggingface.co/docs/transformers/main/en/model_doc/clip#transformers.CLIPTokenizer) or [`UNet2DConditionModel`]
|
||||
|
||||
@@ -652,6 +652,6 @@ euler_anc = EulerAncestralDiscreteScheduler.from_pretrained(repo_id, subfolder="
|
||||
euler = EulerDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
|
||||
dpm = DPMSolverMultistepScheduler.from_pretrained(repo_id, subfolder="scheduler")
|
||||
|
||||
# replace `dpm` with any of `ddpm`, `ddim`, `pndm`, `lms`, `euler_anc`, `euler`
|
||||
# replace `dpm` with any of `ddpm`, `ddim`, `pndm`, `lms`, `euler`, `euler_anc`
|
||||
pipeline = StableDiffusionPipeline.from_pretrained(repo_id, scheduler=dpm)
|
||||
```
|
||||
|
||||
@@ -1,17 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Overview
|
||||
|
||||
🧨 Diffusers offers many pipelines, models, and schedulers for generative tasks. To make loading these components as simple as possible, we provide a single and unified method - `from_pretrained()` - that loads any of these components from either the Hugging Face [Hub](https://huggingface.co/models?library=diffusers&sort=downloads) or your local machine. Whenever you load a pipeline or model, the latest files are automatically downloaded and cached so you can quickly reuse them next time without redownloading the files.
|
||||
|
||||
This section will show you everything you need to know about loading pipelines, how to load different components in a pipeline, how to load checkpoint variants, and how to load community pipelines. You'll also learn how to load schedulers and compare the speed and quality trade-offs of using different schedulers. Finally, you'll see how to convert and load KerasCV checkpoints so you can use them in PyTorch with 🧨 Diffusers.
|
||||
@@ -1,17 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Overview
|
||||
|
||||
A pipeline is an end-to-end class that provides a quick and easy way to use a diffusion system for inference by bundling independently trained models and schedulers together. Certain combinations of models and schedulers define specific pipeline types, like [`StableDiffusionPipeline`] or [`StableDiffusionControlNetPipeline`], with specific capabilities. All pipeline types inherit from the base [`DiffusionPipeline`] class; pass it any checkpoint, and it'll automatically detect the pipeline type and load the necessary components.
|
||||
|
||||
This section introduces you to some of the tasks supported by our pipelines such as unconditional image generation and different techniques and variations of text-to-image generation. You'll also learn how to gain more control over the generation process by setting a seed for reproducibility and weighting prompts to adjust the influence certain words in the prompt has over the output. Finally, you'll see how you can create a community pipeline for a custom task like generating images from speech.
|
||||
@@ -13,7 +13,7 @@ specific language governing permissions and limitations under the License.
|
||||
# Schedulers
|
||||
|
||||
Diffusion pipelines are inherently a collection of diffusion models and schedulers that are partly independent from each other. This means that one is able to switch out parts of the pipeline to better customize
|
||||
a pipeline to one's use case. The best example of this is the [Schedulers](../api/schedulers/overview.mdx).
|
||||
a pipeline to one's use case. The best example of this are the [Schedulers](../api/schedulers/overview.mdx).
|
||||
|
||||
Whereas diffusion models usually simply define the forward pass from noise to a less noisy sample,
|
||||
schedulers define the whole denoising process, *i.e.*:
|
||||
@@ -24,7 +24,7 @@ schedulers define the whole denoising process, *i.e.*:
|
||||
They can be quite complex and often define a trade-off between **denoising speed** and **denoising quality**.
|
||||
It is extremely difficult to measure quantitatively which scheduler works best for a given diffusion pipeline, so it is often recommended to simply try out which works best.
|
||||
|
||||
The following paragraphs show how to do so with the 🧨 Diffusers library.
|
||||
The following paragraphs shows how to do so with the 🧨 Diffusers library.
|
||||
|
||||
## Load pipeline
|
||||
|
||||
|
||||
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# Unconditional Image Generation
|
||||
|
||||
The [`DiffusionPipeline`] is the easiest way to use a pre-trained diffusion system for inference.
|
||||
The [`DiffusionPipeline`] is the easiest way to use a pre-trained diffusion system for inference
|
||||
|
||||
Start by creating an instance of [`DiffusionPipeline`] and specify which pipeline checkpoint you would like to download.
|
||||
You can use the [`DiffusionPipeline`] for any [Diffusers' checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads).
|
||||
|
||||
@@ -1,290 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Understanding pipelines, models and schedulers
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
🧨 Diffusers is designed to be a user-friendly and flexible toolbox for building diffusion systems tailored to your use-case. At the core of the toolbox are models and schedulers. While the [`DiffusionPipeline`] bundles these components together for convenience, you can also unbundle the pipeline and use the models and schedulers separately to create new diffusion systems.
|
||||
|
||||
In this tutorial, you'll learn how to use models and schedulers to assemble a diffusion system for inference, starting with a basic pipeline and then progressing to the Stable Diffusion pipeline.
|
||||
|
||||
## Deconstruct a basic pipeline
|
||||
|
||||
A pipeline is a quick and easy way to run a model for inference, requiring no more than four lines of code to generate an image:
|
||||
|
||||
```py
|
||||
>>> from diffusers import DDPMPipeline
|
||||
|
||||
>>> ddpm = DDPMPipeline.from_pretrained("google/ddpm-cat-256").to("cuda")
|
||||
>>> image = ddpm(num_inference_steps=25).images[0]
|
||||
>>> image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ddpm-cat.png" alt="Image of cat created from DDPMPipeline"/>
|
||||
</div>
|
||||
|
||||
That was super easy, but how did the pipeline do that? Let's breakdown the pipeline and take a look at what's happening under the hood.
|
||||
|
||||
In the example above, the pipeline contains a UNet model and a DDPM scheduler. The pipeline denoises an image by taking random noise the size of the desired output and passing it through the model several times. At each timestep, the model predicts the *noise residual* and the scheduler uses it to predict a less noisy image. The pipeline repeats this process until it reaches the end of the specified number of inference steps.
|
||||
|
||||
To recreate the pipeline with the model and scheduler separately, let's write our own denoising process.
|
||||
|
||||
1. Load the model and scheduler:
|
||||
|
||||
```py
|
||||
>>> from diffusers import DDPMScheduler, UNet2DModel
|
||||
|
||||
>>> scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
|
||||
>>> model = UNet2DModel.from_pretrained("google/ddpm-cat-256").to("cuda")
|
||||
```
|
||||
|
||||
2. Set the number of timesteps to run the denoising process for:
|
||||
|
||||
```py
|
||||
>>> scheduler.set_timesteps(50)
|
||||
```
|
||||
|
||||
3. Setting the scheduler timesteps creates a tensor with evenly spaced elements in it, 50 in this example. Each element corresponds to a timestep at which the model denoises an image. When you create the denoising loop later, you'll iterate over this tensor to denoise an image:
|
||||
|
||||
```py
|
||||
>>> scheduler.timesteps
|
||||
tensor([980, 960, 940, 920, 900, 880, 860, 840, 820, 800, 780, 760, 740, 720,
|
||||
700, 680, 660, 640, 620, 600, 580, 560, 540, 520, 500, 480, 460, 440,
|
||||
420, 400, 380, 360, 340, 320, 300, 280, 260, 240, 220, 200, 180, 160,
|
||||
140, 120, 100, 80, 60, 40, 20, 0])
|
||||
```
|
||||
|
||||
4. Create some random noise with the same shape as the desired output:
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
|
||||
>>> sample_size = model.config.sample_size
|
||||
>>> noise = torch.randn((1, 3, sample_size, sample_size)).to("cuda")
|
||||
```
|
||||
|
||||
4. Now write a loop to iterate over the timesteps. At each timestep, the model does a [`UNet2DModel.forward`] pass and returns the noisy residual. The scheduler's [`~DDPMScheduler.step`] method takes the noisy residual, timestep, and input and it predicts the image at the previous timestep. This output becomes the next input to the model in the denoising loop, and it'll repeat until it reaches the end of the `timesteps` array.
|
||||
|
||||
```py
|
||||
>>> input = noise
|
||||
|
||||
>>> for t in scheduler.timesteps:
|
||||
... with torch.no_grad():
|
||||
... noisy_residual = model(input, t).sample
|
||||
>>> previous_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
|
||||
>>> input = previous_noisy_sample
|
||||
```
|
||||
|
||||
This is the entire denoising process, and you can use this same pattern to write any diffusion system.
|
||||
|
||||
5. The last step is to convert the denoised output into an image:
|
||||
|
||||
```py
|
||||
>>> from PIL import Image
|
||||
>>> import numpy as np
|
||||
|
||||
>>> image = (input / 2 + 0.5).clamp(0, 1)
|
||||
>>> image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
|
||||
>>> image = Image.fromarray((image * 255)).round().astype("uint8")
|
||||
>>> image
|
||||
```
|
||||
|
||||
In the next section, you'll put your skills to the test and breakdown the more complex Stable Diffusion pipeline. The steps are more or less the same. You'll initialize the necessary components, and set the number of timesteps to create a `timestep` array. The `timestep` array is used in the denoising loop, and for each element in this array, the model predicts a less noisy image. The denoising loop iterates over the `timestep`'s, and at each timestep, it outputs a noisy residual and the scheduler uses it to predict a less noisy image at the previous timestep. This process is repeated until you reach the end of the `timestep` array.
|
||||
|
||||
Let's try it out!
|
||||
|
||||
## Deconstruct the Stable Diffusion pipeline
|
||||
|
||||
Stable Diffusion is a text-to-image *latent diffusion* model. It is called a latent diffusion model because it works with a lower-dimensional representation of the image instead of the actual pixel space, which makes it more memory efficient. The encoder compresses the image into a smaller representation, and a decoder to convert the compressed representation back into an image. For text-to-image models, you'll need a tokenizer and an encoder to generate text embeddings. From the previous example, you already know you need a UNet model and a scheduler.
|
||||
|
||||
As you can see, this is already more complex than the DDPM pipeline which only contains a UNet model. The Stable Diffusion model has three separate pretrained models.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Read the [How does Stable Diffusion work?](https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work) blog for more details about how the VAE, UNet, and text encoder models.
|
||||
|
||||
</Tip>
|
||||
|
||||
Now that you know what you need for the Stable Diffusion pipeline, load all these components with the [`~ModelMixin.from_pretrained`] method. You can find them in the pretrained [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) checkpoint, and each component is stored in a separate subfolder:
|
||||
|
||||
```py
|
||||
>>> from PIL import Image
|
||||
>>> import torch
|
||||
>>> from transformers import CLIPTextModel, CLIPTokenizer
|
||||
>>> from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
|
||||
|
||||
>>> vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
|
||||
>>> tokenizer = CLIPTokenizer.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="tokenizer")
|
||||
>>> text_encoder = CLIPTextModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="text_encoder")
|
||||
>>> unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")
|
||||
```
|
||||
|
||||
Instead of the default [`PNDMScheduler`], exchange it for the [`UniPCMultistepScheduler`] to see how easy it is to plug a different scheduler in:
|
||||
|
||||
```py
|
||||
>>> from diffusers import UniPCMultistepScheduler
|
||||
|
||||
>>> scheduler = UniPCMultistepScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
|
||||
```
|
||||
|
||||
To speed up inference, move the models to a GPU since, unlike the scheduler, they have trainable weights:
|
||||
|
||||
```py
|
||||
>>> torch_device = "cuda"
|
||||
>>> vae.to(torch_device)
|
||||
>>> text_encoder.to(torch_device)
|
||||
>>> unet.to(torch_device)
|
||||
```
|
||||
|
||||
### Create text embeddings
|
||||
|
||||
The next step is to tokenize the text to generate embeddings. The text is used to condition the UNet model and steer the diffusion process towards something that resembles the input prompt.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 The `guidance_scale` parameter determines how much weight should be given to the prompt when generating an image.
|
||||
|
||||
</Tip>
|
||||
|
||||
Feel free to choose any prompt you like if you want to generate something else!
|
||||
|
||||
```py
|
||||
>>> prompt = ["a photograph of an astronaut riding a horse"]
|
||||
>>> height = 512 # default height of Stable Diffusion
|
||||
>>> width = 512 # default width of Stable Diffusion
|
||||
>>> num_inference_steps = 25 # Number of denoising steps
|
||||
>>> guidance_scale = 7.5 # Scale for classifier-free guidance
|
||||
>>> generator = torch.manual_seed(0) # Seed generator to create the inital latent noise
|
||||
>>> batch_size = len(prompt)
|
||||
```
|
||||
|
||||
Tokenize the text and generate the embeddings from the prompt:
|
||||
|
||||
```py
|
||||
>>> text_input = tokenizer(
|
||||
... prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt"
|
||||
... )
|
||||
|
||||
>>> with torch.no_grad():
|
||||
... text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
|
||||
```
|
||||
|
||||
You'll also need to generate the *unconditional text embeddings* which are the embeddings for the padding token. These need to have the same shape (`batch_size` and `seq_length`) as the conditional `text_embeddings`:
|
||||
|
||||
```py
|
||||
>>> max_length = text_input.input_ids.shape[-1]
|
||||
>>> uncond_input = tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt")
|
||||
>>> uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
|
||||
```
|
||||
|
||||
Let's concatenate the conditional and unconditional embeddings into a batch to avoid doing two forward passes:
|
||||
|
||||
```py
|
||||
>>> text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
|
||||
```
|
||||
|
||||
### Create random noise
|
||||
|
||||
Next, generate some initial random noise as a starting point for the diffusion process. This is the latent representation of the image, and it'll be gradually denoised. At this point, the `latent` image is smaller than the final image size but that's okay though because the model will transform it into the final 512x512 image dimensions later.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 The height and width are divided by 8 because the `vae` model has 3 down-sampling layers. You can check by running the following:
|
||||
|
||||
```py
|
||||
2 ** (len(vae.config.block_out_channels) - 1) == 8
|
||||
```
|
||||
|
||||
</Tip>
|
||||
|
||||
```py
|
||||
>>> latents = torch.randn(
|
||||
... (batch_size, unet.in_channels, height // 8, width // 8),
|
||||
... generator=generator,
|
||||
... )
|
||||
>>> latents = latents.to(torch_device)
|
||||
```
|
||||
|
||||
### Denoise the image
|
||||
|
||||
Start by scaling the input with the initial noise distribution, *sigma*, the noise scale value, which is required for improved schedulers like [`UniPCMultistepScheduler`]:
|
||||
|
||||
```py
|
||||
>>> latents = latents * scheduler.init_noise_sigma
|
||||
```
|
||||
|
||||
The last step is to create the denoising loop that'll progressively transform the pure noise in `latents` to an image described by your prompt. Remember, the denoising loop needs to do three things:
|
||||
|
||||
1. Set the scheduler's timesteps to use during denoising.
|
||||
2. Iterate over the timesteps.
|
||||
3. At each timestep, call the UNet model to predict the noise residual and pass it to the scheduler to compute the previous noisy sample.
|
||||
|
||||
```py
|
||||
>>> from tqdm.auto import tqdm
|
||||
|
||||
>>> scheduler.set_timesteps(num_inference_steps)
|
||||
|
||||
>>> for t in tqdm(scheduler.timesteps):
|
||||
... # expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
|
||||
... latent_model_input = torch.cat([latents] * 2)
|
||||
|
||||
... latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
|
||||
|
||||
... # predict the noise residual
|
||||
... with torch.no_grad():
|
||||
... noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
|
||||
|
||||
... # perform guidance
|
||||
... noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
... noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
|
||||
... # compute the previous noisy sample x_t -> x_t-1
|
||||
... latents = scheduler.step(noise_pred, t, latents).prev_sample
|
||||
```
|
||||
|
||||
### Decode the image
|
||||
|
||||
The final step is to use the `vae` to decode the latent representation into an image and get the decoded output with `sample`:
|
||||
|
||||
```py
|
||||
# scale and decode the image latents with vae
|
||||
latents = 1 / 0.18215 * latents
|
||||
with torch.no_grad():
|
||||
image = vae.decode(latents).sample
|
||||
```
|
||||
|
||||
Lastly, convert the image to a `PIL.Image` to see your generated image!
|
||||
|
||||
```py
|
||||
>>> image = (image / 2 + 0.5).clamp(0, 1)
|
||||
>>> image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
|
||||
>>> images = (image * 255).round().astype("uint8")
|
||||
>>> pil_images = [Image.fromarray(image) for image in images]
|
||||
>>> pil_images[0]
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/blog/assets/98_stable_diffusion/stable_diffusion_k_lms.png"/>
|
||||
</div>
|
||||
|
||||
## Next steps
|
||||
|
||||
From basic to complex pipelines, you've seen that all you really need to write your own diffusion system is a denoising loop. The loop should set the scheduler's timesteps, iterate over them, and alternate between calling the UNet model to predict the noise residual and passing it to the scheduler to compute the previous noisy sample.
|
||||
|
||||
This is really what 🧨 Diffusers is designed for: to make it intuitive and easy to write your own diffusion system using models and schedulers.
|
||||
|
||||
For your next steps, feel free to:
|
||||
|
||||
* Learn how to [build and contribute a pipeline](using-diffusers/#contribute_pipeline) to 🧨 Diffusers. We can't wait and see what you'll come up with!
|
||||
* Explore [existing pipelines](./api/pipelines/overview) in the library, and see if you can deconstruct and build a pipeline from scratch using the models and schedulers separately.
|
||||
@@ -1,238 +0,0 @@
|
||||
- sections:
|
||||
- local: index
|
||||
title: 🧨 Diffusers
|
||||
- local: quicktour
|
||||
title: 快速入门
|
||||
- local: stable_diffusion
|
||||
title: Stable Diffusion
|
||||
- local: installation
|
||||
title: 安装
|
||||
title: 开始
|
||||
- sections:
|
||||
- local: tutorials/basic_training
|
||||
title: Train a diffusion model
|
||||
title: Tutorials
|
||||
- sections:
|
||||
- sections:
|
||||
- local: using-diffusers/loading
|
||||
title: Loading Pipelines, Models, and Schedulers
|
||||
- local: using-diffusers/schedulers
|
||||
title: Using different Schedulers
|
||||
- local: using-diffusers/configuration
|
||||
title: Configuring Pipelines, Models, and Schedulers
|
||||
- local: using-diffusers/custom_pipeline_overview
|
||||
title: Loading and Adding Custom Pipelines
|
||||
- local: using-diffusers/kerascv
|
||||
title: Using KerasCV Stable Diffusion Checkpoints in Diffusers
|
||||
title: Loading & Hub
|
||||
- sections:
|
||||
- local: using-diffusers/unconditional_image_generation
|
||||
title: Unconditional Image Generation
|
||||
- local: using-diffusers/conditional_image_generation
|
||||
title: Text-to-Image Generation
|
||||
- local: using-diffusers/img2img
|
||||
title: Text-Guided Image-to-Image
|
||||
- local: using-diffusers/inpaint
|
||||
title: Text-Guided Image-Inpainting
|
||||
- local: using-diffusers/depth2img
|
||||
title: Text-Guided Depth-to-Image
|
||||
- local: using-diffusers/controlling_generation
|
||||
title: Controlling generation
|
||||
- local: using-diffusers/reusing_seeds
|
||||
title: Reusing seeds for deterministic generation
|
||||
- local: using-diffusers/reproducibility
|
||||
title: Reproducibility
|
||||
- local: using-diffusers/custom_pipeline_examples
|
||||
title: Community Pipelines
|
||||
- local: using-diffusers/contribute_pipeline
|
||||
title: How to contribute a Pipeline
|
||||
- local: using-diffusers/using_safetensors
|
||||
title: Using safetensors
|
||||
title: Pipelines for Inference
|
||||
- sections:
|
||||
- local: using-diffusers/rl
|
||||
title: Reinforcement Learning
|
||||
- local: using-diffusers/audio
|
||||
title: Audio
|
||||
- local: using-diffusers/other-modalities
|
||||
title: Other Modalities
|
||||
title: Taking Diffusers Beyond Images
|
||||
title: Using Diffusers
|
||||
- sections:
|
||||
- local: optimization/fp16
|
||||
title: Memory and Speed
|
||||
- local: optimization/torch2.0
|
||||
title: Torch2.0 support
|
||||
- local: optimization/xformers
|
||||
title: xFormers
|
||||
- local: optimization/onnx
|
||||
title: ONNX
|
||||
- local: optimization/open_vino
|
||||
title: OpenVINO
|
||||
- local: optimization/mps
|
||||
title: MPS
|
||||
- local: optimization/habana
|
||||
title: Habana Gaudi
|
||||
title: Optimization/Special Hardware
|
||||
- sections:
|
||||
- local: training/overview
|
||||
title: Overview
|
||||
- local: training/unconditional_training
|
||||
title: Unconditional Image Generation
|
||||
- local: training/text_inversion
|
||||
title: Textual Inversion
|
||||
- local: training/dreambooth
|
||||
title: DreamBooth
|
||||
- local: training/text2image
|
||||
title: Text-to-image
|
||||
- local: training/lora
|
||||
title: Low-Rank Adaptation of Large Language Models (LoRA)
|
||||
title: Training
|
||||
- sections:
|
||||
- local: conceptual/philosophy
|
||||
title: Philosophy
|
||||
- local: conceptual/contribution
|
||||
title: How to contribute?
|
||||
- local: conceptual/ethical_guidelines
|
||||
title: Diffusers' Ethical Guidelines
|
||||
title: Conceptual Guides
|
||||
- sections:
|
||||
- sections:
|
||||
- local: api/models
|
||||
title: Models
|
||||
- local: api/diffusion_pipeline
|
||||
title: Diffusion Pipeline
|
||||
- local: api/logging
|
||||
title: Logging
|
||||
- local: api/configuration
|
||||
title: Configuration
|
||||
- local: api/outputs
|
||||
title: Outputs
|
||||
- local: api/loaders
|
||||
title: Loaders
|
||||
title: Main Classes
|
||||
- sections:
|
||||
- local: api/pipelines/overview
|
||||
title: Overview
|
||||
- local: api/pipelines/alt_diffusion
|
||||
title: AltDiffusion
|
||||
- local: api/pipelines/audio_diffusion
|
||||
title: Audio Diffusion
|
||||
- local: api/pipelines/cycle_diffusion
|
||||
title: Cycle Diffusion
|
||||
- local: api/pipelines/dance_diffusion
|
||||
title: Dance Diffusion
|
||||
- local: api/pipelines/ddim
|
||||
title: DDIM
|
||||
- local: api/pipelines/ddpm
|
||||
title: DDPM
|
||||
- local: api/pipelines/dit
|
||||
title: DiT
|
||||
- local: api/pipelines/latent_diffusion
|
||||
title: Latent Diffusion
|
||||
- local: api/pipelines/paint_by_example
|
||||
title: PaintByExample
|
||||
- local: api/pipelines/pndm
|
||||
title: PNDM
|
||||
- local: api/pipelines/repaint
|
||||
title: RePaint
|
||||
- local: api/pipelines/stable_diffusion_safe
|
||||
title: Safe Stable Diffusion
|
||||
- local: api/pipelines/score_sde_ve
|
||||
title: Score SDE VE
|
||||
- local: api/pipelines/semantic_stable_diffusion
|
||||
title: Semantic Guidance
|
||||
- sections:
|
||||
- local: api/pipelines/stable_diffusion/overview
|
||||
title: Overview
|
||||
- local: api/pipelines/stable_diffusion/text2img
|
||||
title: Text-to-Image
|
||||
- local: api/pipelines/stable_diffusion/img2img
|
||||
title: Image-to-Image
|
||||
- local: api/pipelines/stable_diffusion/inpaint
|
||||
title: Inpaint
|
||||
- local: api/pipelines/stable_diffusion/depth2img
|
||||
title: Depth-to-Image
|
||||
- local: api/pipelines/stable_diffusion/image_variation
|
||||
title: Image-Variation
|
||||
- local: api/pipelines/stable_diffusion/upscale
|
||||
title: Super-Resolution
|
||||
- local: api/pipelines/stable_diffusion/latent_upscale
|
||||
title: Stable-Diffusion-Latent-Upscaler
|
||||
- local: api/pipelines/stable_diffusion/pix2pix
|
||||
title: InstructPix2Pix
|
||||
- local: api/pipelines/stable_diffusion/attend_and_excite
|
||||
title: Attend and Excite
|
||||
- local: api/pipelines/stable_diffusion/pix2pix_zero
|
||||
title: Pix2Pix Zero
|
||||
- local: api/pipelines/stable_diffusion/self_attention_guidance
|
||||
title: Self-Attention Guidance
|
||||
- local: api/pipelines/stable_diffusion/panorama
|
||||
title: MultiDiffusion Panorama
|
||||
- local: api/pipelines/stable_diffusion/controlnet
|
||||
title: Text-to-Image Generation with ControlNet Conditioning
|
||||
title: Stable Diffusion
|
||||
- local: api/pipelines/stable_diffusion_2
|
||||
title: Stable Diffusion 2
|
||||
- local: api/pipelines/stable_unclip
|
||||
title: Stable unCLIP
|
||||
- local: api/pipelines/stochastic_karras_ve
|
||||
title: Stochastic Karras VE
|
||||
- local: api/pipelines/unclip
|
||||
title: UnCLIP
|
||||
- local: api/pipelines/latent_diffusion_uncond
|
||||
title: Unconditional Latent Diffusion
|
||||
- local: api/pipelines/versatile_diffusion
|
||||
title: Versatile Diffusion
|
||||
- local: api/pipelines/vq_diffusion
|
||||
title: VQ Diffusion
|
||||
title: Pipelines
|
||||
- sections:
|
||||
- local: api/schedulers/overview
|
||||
title: Overview
|
||||
- local: api/schedulers/ddim
|
||||
title: DDIM
|
||||
- local: api/schedulers/ddim_inverse
|
||||
title: DDIMInverse
|
||||
- local: api/schedulers/ddpm
|
||||
title: DDPM
|
||||
- local: api/schedulers/deis
|
||||
title: DEIS
|
||||
- local: api/schedulers/dpm_discrete
|
||||
title: DPM Discrete Scheduler
|
||||
- local: api/schedulers/dpm_discrete_ancestral
|
||||
title: DPM Discrete Scheduler with ancestral sampling
|
||||
- local: api/schedulers/euler_ancestral
|
||||
title: Euler Ancestral Scheduler
|
||||
- local: api/schedulers/euler
|
||||
title: Euler scheduler
|
||||
- local: api/schedulers/heun
|
||||
title: Heun Scheduler
|
||||
- local: api/schedulers/ipndm
|
||||
title: IPNDM
|
||||
- local: api/schedulers/lms_discrete
|
||||
title: Linear Multistep
|
||||
- local: api/schedulers/multistep_dpm_solver
|
||||
title: Multistep DPM-Solver
|
||||
- local: api/schedulers/pndm
|
||||
title: PNDM
|
||||
- local: api/schedulers/repaint
|
||||
title: RePaint Scheduler
|
||||
- local: api/schedulers/singlestep_dpm_solver
|
||||
title: Singlestep DPM-Solver
|
||||
- local: api/schedulers/stochastic_karras_ve
|
||||
title: Stochastic Kerras VE
|
||||
- local: api/schedulers/unipc
|
||||
title: UniPCMultistepScheduler
|
||||
- local: api/schedulers/score_sde_ve
|
||||
title: VE-SDE
|
||||
- local: api/schedulers/score_sde_vp
|
||||
title: VP-SDE
|
||||
- local: api/schedulers/vq_diffusion
|
||||
title: VQDiffusionScheduler
|
||||
title: Schedulers
|
||||
- sections:
|
||||
- local: api/experimental/rl
|
||||
title: RL Planning
|
||||
title: Experimental Features
|
||||
title: API
|
||||
@@ -1,78 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<img src="https://raw.githubusercontent.com/huggingface/diffusers/77aadfee6a891ab9fcfb780f87c693f7a5beeb8e/docs/source/imgs/diffusers_library.jpg" width="400"/>
|
||||
<br>
|
||||
</p>
|
||||
|
||||
# 🧨 Diffusers
|
||||
|
||||
🤗Diffusers提供了预训练好的视觉和音频扩散模型,并可以作为推理和训练的模块化工具箱。
|
||||
|
||||
更准确地说,🤗Diffusers提供了:
|
||||
|
||||
- 最先进的扩散管道,可以在推理中仅用几行代码运行(详情看[**Using Diffusers**](./using-diffusers/conditional_image_generation))或看[**管道**](#pipelines) 以获取所有支持的管道及其对应的论文的概述。
|
||||
- 可以在推理中交替使用的各种噪声调度程序,以便在推理过程中权衡如何选择速度和质量。有关更多信息,可以看[**Schedulers**](./api/schedulers/overview)。
|
||||
- 多种类型的模型,如U-Net,可用作端到端扩散系统中的构建模块。有关更多详细信息,可以看 [**Models**](./api/models) 。
|
||||
- 训练示例,展示如何训练最流行的扩散模型任务。更多相关信息,可以看[**Training**](./training/overview)。
|
||||
|
||||
|
||||
## 🧨 Diffusers pipelines
|
||||
|
||||
下表总结了所有官方支持的pipelines及其对应的论文,部分提供了colab,可以直接尝试一下。
|
||||
|
||||
|
||||
| 管道 | 论文 | 任务 | Colab
|
||||
|---|---|:---:|:---:|
|
||||
| [alt_diffusion](./api/pipelines/alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
|
||||
| [audio_diffusion](./api/pipelines/audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation | [](https://colab.research.google.com/github/teticio/audio-diffusion/blob/master/notebooks/audio_diffusion_pipeline.ipynb)
|
||||
| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
|
||||
| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
|
||||
| [dance_diffusion](./api/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
|
||||
| [ddpm](./api/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
|
||||
| [ddim](./api/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
|
||||
| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
|
||||
| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
|
||||
| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
|
||||
| [paint_by_example](./api/pipelines/paint_by_example) | [**Paint by Example: Exemplar-based Image Editing with Diffusion Models**](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
|
||||
| [pndm](./api/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
|
||||
| [score_sde_ve](./api/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [score_sde_vp](./api/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [**Semantic Guidance**](https://arxiv.org/abs/2301.12247) | Text-Guided Generation | [](https://colab.research.google.com/github/ml-research/semantic-image-editing/blob/main/examples/SemanticGuidance.ipynb)
|
||||
| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
|
||||
| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
|
||||
| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
|
||||
| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [**MultiDiffusion**](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
|
||||
| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [**InstructPix2Pix**](https://github.com/timothybrooks/instruct-pix2pix) | Text-Guided Image Editing|
|
||||
| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [**Zero-shot Image-to-Image Translation**](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
|
||||
| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [**Attend and Excite for Stable Diffusion**](https://attendandexcite.github.io/Attend-and-Excite/) | Text-to-Image Generation |
|
||||
| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [**Self-Attention Guidance**](https://ku-cvlab.github.io/Self-Attention-Guidance) | Text-to-Image Generation |
|
||||
| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [**Stable Diffusion Image Variations**](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
|
||||
| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [**Stable Diffusion Latent Upscaler**](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Depth-Conditional Stable Diffusion**](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
|
||||
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
|
||||
| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [**Safe Stable Diffusion**](https://arxiv.org/abs/2211.05105) | Text-Guided Generation | [](https://colab.research.google.com/github/ml-research/safe-latent-diffusion/blob/main/examples/Safe%20Latent%20Diffusion.ipynb)
|
||||
| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Text-to-Image Generation |
|
||||
| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Image-to-Image Text-Guided Generation |
|
||||
| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
|
||||
| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
|
||||
| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
|
||||
| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
|
||||
|
||||
|
||||
**注意**: 管道是如何使用相应论文中提出的扩散模型的简单示例。
|
||||
@@ -1,147 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# 安装
|
||||
|
||||
安装🤗 Diffusers 到你正在使用的任何深度学习框架中。
|
||||
|
||||
🤗 Diffusers已在Python 3.7+、PyTorch 1.7.0+和Flax上进行了测试。按照下面的安装说明,针对你正在使用的深度学习框架进行安装:
|
||||
|
||||
- [PyTorch](https://pytorch.org/get-started/locally/) installation instructions.
|
||||
- [Flax](https://flax.readthedocs.io/en/latest/) installation instructions.
|
||||
|
||||
## 使用pip安装
|
||||
|
||||
你需要在[虚拟环境](https://docs.python.org/3/library/venv.html)中安装🤗 Diffusers 。
|
||||
|
||||
如果你对 Python 虚拟环境不熟悉,可以看看这个[教程](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
|
||||
|
||||
使用虚拟环境你可以轻松管理不同的项目,避免了依赖项之间的兼容性问题。
|
||||
|
||||
首先,在你的项目目录下创建一个虚拟环境:
|
||||
|
||||
```bash
|
||||
python -m venv .env
|
||||
```
|
||||
|
||||
激活虚拟环境:
|
||||
|
||||
```bash
|
||||
source .env/bin/activate
|
||||
```
|
||||
|
||||
现在你就可以安装 🤗 Diffusers了!使用下边这个命令:
|
||||
|
||||
**PyTorch**
|
||||
|
||||
```bash
|
||||
pip install diffusers["torch"]
|
||||
```
|
||||
|
||||
**Flax**
|
||||
|
||||
```bash
|
||||
pip install diffusers["flax"]
|
||||
```
|
||||
|
||||
## 从源代码安装
|
||||
|
||||
在从源代码安装 `diffusers` 之前,你先确定你已经安装了 `torch` 和 `accelerate`。
|
||||
|
||||
`torch`的安装教程可以看 `torch` [文档](https://pytorch.org/get-started/locally/#start-locally).
|
||||
|
||||
安装 `accelerate`
|
||||
|
||||
```bash
|
||||
pip install accelerate
|
||||
```
|
||||
|
||||
从源码安装 🤗 Diffusers 使用以下命令:
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/huggingface/diffusers
|
||||
```
|
||||
|
||||
这个命令安装的是最新的 `main`版本,而不是最近的`stable`版。
|
||||
`main`是一直和最新进展保持一致的。比如,上次正式版发布了,有bug,新的正式版还没推出,但是`main`中可以看到这个bug被修复了。
|
||||
但是这也意味着 `main`版本并不总是稳定的。
|
||||
|
||||
我们努力保持`main`版本正常运行,大多数问题都能在几个小时或一天之内解决
|
||||
|
||||
如果你遇到了问题,可以提 [Issue](https://github.com/huggingface/transformers/issues),这样我们就能更快修复问题了。
|
||||
|
||||
## 可修改安装
|
||||
|
||||
如果你想做以下两件事,那你可能需要一个可修改代码的安装方式:
|
||||
|
||||
* 使用 `main`版本的源代码。
|
||||
* 为 🤗 Diffusers 贡献,需要测试代码中的变化。
|
||||
|
||||
使用以下命令克隆并安装 🤗 Diffusers:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers.git
|
||||
cd diffusers
|
||||
```
|
||||
|
||||
**PyTorch**
|
||||
|
||||
```
|
||||
pip install -e ".[torch]"
|
||||
```
|
||||
|
||||
**Flax**
|
||||
|
||||
```
|
||||
pip install -e ".[flax]"
|
||||
```
|
||||
|
||||
这些命令将连接你克隆的版本库和你的 Python 库路径。
|
||||
现在,除了正常的库路径外,Python 还会在你克隆的文件夹内寻找。
|
||||
例如,如果你的 Python 包通常安装在 `~/anaconda3/envs/main/lib/python3.7/Site-packages/`,Python 也会搜索你克隆到的文件夹。`~/diffusers/`。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
如果你想继续使用这个库,你必须保留 `diffusers` 文件夹。
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
现在你可以用下面的命令轻松地将你克隆的🤗Diffusers仓库更新到最新版本。
|
||||
|
||||
```bash
|
||||
cd ~/diffusers/
|
||||
git pull
|
||||
```
|
||||
|
||||
你的Python环境将在下次运行时找到`main`版本的🤗 Diffusers。
|
||||
|
||||
## 注意遥测日志
|
||||
|
||||
我们的库会在使用`from_pretrained()`请求期间收集信息。这些数据包括Diffusers和PyTorch/Flax的版本,请求的模型或管道,以及预训练检查点的路径(如果它被托管在Hub上)。
|
||||
|
||||
这些使用数据有助于我们调试问题并优先考虑新功能。
|
||||
当从HuggingFace Hub加载模型和管道时才会发送遥测数据,并且在本地使用时不会收集数据。
|
||||
|
||||
我们知道并不是每个人都想分享这些的信息,我们尊重您的隐私,
|
||||
因此您可以通过在终端中设置“DISABLE_TELEMETRY”环境变量来禁用遥测数据的收集:
|
||||
|
||||
|
||||
在Linux/MacOS中:
|
||||
```bash
|
||||
export DISABLE_TELEMETRY=YES
|
||||
```
|
||||
|
||||
在Windows中:
|
||||
```bash
|
||||
set DISABLE_TELEMETRY=YES
|
||||
```
|
||||
@@ -1,331 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
# 快速上手
|
||||
|
||||
训练扩散模型,是为了对随机高斯噪声进行逐步去噪,以生成令人感兴趣的样本,比如图像或者语音。
|
||||
|
||||
扩散模型的发展引起了人们对生成式人工智能的极大兴趣,你可能已经在网上见过扩散生成的图像了。🧨 Diffusers库的目的是让大家更易上手扩散模型。
|
||||
|
||||
无论你是开发人员还是普通用户,本文将向你介绍🧨 Diffusers 并帮助你快速开始生成内容!
|
||||
|
||||
🧨 Diffusers 库的三个主要组件:
|
||||
|
||||
|
||||
无论你是开发者还是普通用户,这个快速指南将向你介绍🧨 Diffusers,并帮助你快速使用和生成!该库三个主要部分如下:
|
||||
|
||||
* [`DiffusionPipeline`]是一个高级的端到端类,旨在通过预训练的扩散模型快速生成样本进行推理。
|
||||
* 作为创建扩散系统做组件的流行的预训练[模型](./api/models)框架和模块。
|
||||
* 许多不同的[调度器](./api/schedulers/overview):控制如何在训练过程中添加噪声的算法,以及如何在推理过程中生成去噪图像的算法。
|
||||
|
||||
快速入门将告诉你如何使用[`DiffusionPipeline`]进行推理,然后指导你如何结合模型和调度器以复现[`DiffusionPipeline`]内部发生的事情。
|
||||
|
||||
<Tip>
|
||||
|
||||
快速入门是🧨[Diffusers入门](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)的简化版,可以帮助你快速上手。如果你想了解更多关于🧨 Diffusers的目标、设计理念以及关于它的核心API的更多细节,可以点击🧨[Diffusers入门](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)查看。
|
||||
|
||||
</Tip>
|
||||
|
||||
在开始之前,确认一下你已经安装好了所需要的库:
|
||||
|
||||
```bash
|
||||
pip install --upgrade diffusers accelerate transformers
|
||||
```
|
||||
|
||||
- [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) 在推理和训练过程中加速模型加载。
|
||||
- [🤗 Transformers](https://huggingface.co/docs/transformers/index) 是运行最流行的扩散模型所必须的库,比如[Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview).
|
||||
|
||||
## 扩散模型管道
|
||||
|
||||
[`DiffusionPipeline`]是用预训练的扩散系统进行推理的最简单方法。它是一个包含模型和调度器的端到端系统。你可以直接使用[`DiffusionPipeline`]完成许多任务。请查看下面的表格以了解一些支持的任务,要获取完整的支持任务列表,请查看[🧨 Diffusers 总结](./api/pipelines/overview#diffusers-summary) 。
|
||||
|
||||
| **任务** | **描述** | **管道**
|
||||
|------------------------------|--------------------------------------------------------------------------------------------------------------|-----------------|
|
||||
| Unconditional Image Generation | 从高斯噪声中生成图片 | [unconditional_image_generation](./using-diffusers/unconditional_image_generation) |
|
||||
| Text-Guided Image Generation | 给定文本提示生成图像 | [conditional_image_generation](./using-diffusers/conditional_image_generation) |
|
||||
| Text-Guided Image-to-Image Translation | 在文本提示的指导下调整图像 | [img2img](./using-diffusers/img2img) |
|
||||
| Text-Guided Image-Inpainting | 给出图像、遮罩和文本提示,填充图像的遮罩部分 | [inpaint](./using-diffusers/inpaint) |
|
||||
| Text-Guided Depth-to-Image Translation | 在文本提示的指导下调整图像的部分内容,同时通过深度估计保留其结构 | [depth2img](./using-diffusers/depth2img) |
|
||||
|
||||
首先创建一个[`DiffusionPipeline`]的实例,并指定要下载的pipeline检查点。
|
||||
你可以使用存储在Hugging Face Hub上的任何[`DiffusionPipeline`][检查点](https://huggingface.co/models?library=diffusers&sort=downloads)。
|
||||
在教程中,你将加载[`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5)检查点,用于文本到图像的生成。
|
||||
|
||||
首先创建一个[DiffusionPipeline]实例,并指定要下载的管道检查点。
|
||||
您可以在Hugging Face Hub上使用[DiffusionPipeline]的任何检查点。
|
||||
在本快速入门中,您将加载stable-diffusion-v1-5检查点,用于文本到图像生成。
|
||||
|
||||
<Tip warning={true}>。
|
||||
|
||||
对于[Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion)模型,在运行该模型之前,请先仔细阅读[许可证](https://huggingface.co/spaces/CompVis/stable-diffusion-license)。🧨 Diffusers实现了一个[`safety_checker`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py),以防止有攻击性的或有害的内容,但Stable Diffusion模型改进图像的生成能力仍有可能产生潜在的有害内容。
|
||||
|
||||
</Tip>
|
||||
|
||||
用[`~DiffusionPipeline.from_pretrained`]方法加载模型。
|
||||
|
||||
```python
|
||||
>>> from diffusers import DiffusionPipeline
|
||||
|
||||
>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
|
||||
```
|
||||
[`DiffusionPipeline`]会下载并缓存所有的建模、标记化和调度组件。你可以看到Stable Diffusion的pipeline是由[`UNet2DConditionModel`]和[`PNDMScheduler`]等组件组成的:
|
||||
|
||||
```py
|
||||
>>> pipeline
|
||||
StableDiffusionPipeline {
|
||||
"_class_name": "StableDiffusionPipeline",
|
||||
"_diffusers_version": "0.13.1",
|
||||
...,
|
||||
"scheduler": [
|
||||
"diffusers",
|
||||
"PNDMScheduler"
|
||||
],
|
||||
...,
|
||||
"unet": [
|
||||
"diffusers",
|
||||
"UNet2DConditionModel"
|
||||
],
|
||||
"vae": [
|
||||
"diffusers",
|
||||
"AutoencoderKL"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
我们强烈建议你在GPU上运行这个pipeline,因为该模型由大约14亿个参数组成。
|
||||
|
||||
你可以像在Pytorch里那样把生成器对象移到GPU上:
|
||||
|
||||
```python
|
||||
>>> pipeline.to("cuda")
|
||||
```
|
||||
|
||||
现在你可以向`pipeline`传递一个文本提示来生成图像,然后获得去噪的图像。默认情况下,图像输出被放在一个[`PIL.Image`](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class)对象中。
|
||||
|
||||
```python
|
||||
>>> image = pipeline("An image of a squirrel in Picasso style").images[0]
|
||||
>>> image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/image_of_squirrel_painting.png"/>
|
||||
</div>
|
||||
|
||||
|
||||
调用`save`保存图像:
|
||||
|
||||
```python
|
||||
>>> image.save("image_of_squirrel_painting.png")
|
||||
```
|
||||
|
||||
### 本地管道
|
||||
|
||||
你也可以在本地使用管道。唯一的区别是你需提前下载权重:
|
||||
|
||||
```
|
||||
git lfs install
|
||||
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
|
||||
```
|
||||
|
||||
将下载好的权重加载到管道中:
|
||||
|
||||
```python
|
||||
>>> pipeline = DiffusionPipeline.from_pretrained("./stable-diffusion-v1-5")
|
||||
```
|
||||
|
||||
现在你可以像上一节中那样运行管道了。
|
||||
|
||||
### 更换调度器
|
||||
|
||||
不同的调度器对去噪速度和质量的权衡是不同的。要想知道哪种调度器最适合你,最好的办法就是试用一下。🧨 Diffusers的主要特点之一是允许你轻松切换不同的调度器。例如,要用[`EulerDiscreteScheduler`]替换默认的[`PNDMScheduler`],用[`~diffusers.ConfigMixin.from_config`]方法加载即可:
|
||||
|
||||
```py
|
||||
>>> from diffusers import EulerDiscreteScheduler
|
||||
|
||||
>>> pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
|
||||
>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
|
||||
```
|
||||
|
||||
|
||||
试着用新的调度器生成一个图像,看看你能否发现不同之处。
|
||||
|
||||
在下一节中,你将仔细观察组成[`DiffusionPipeline`]的组件——模型和调度器,并学习如何使用这些组件来生成猫咪的图像。
|
||||
|
||||
## 模型
|
||||
|
||||
大多数模型取一个噪声样本,在每个时间点预测*噪声残差*(其他模型则直接学习预测前一个样本或速度或[`v-prediction`](https://github.com/huggingface/diffusers/blob/5e5ce13e2f89ac45a0066cb3f369462a3cf1d9ef/src/diffusers/schedulers/scheduling_ddim.py#L110)),即噪声较小的图像与输入图像的差异。你可以混搭模型创建其他扩散系统。
|
||||
|
||||
模型是用[`~ModelMixin.from_pretrained`]方法启动的,该方法还在本地缓存了模型权重,所以下次加载模型时更快。对于快速入门,你默认加载的是[`UNet2DModel`],这是一个基础的无条件图像生成模型,该模型有一个在猫咪图像上训练的检查点:
|
||||
|
||||
|
||||
```py
|
||||
>>> from diffusers import UNet2DModel
|
||||
|
||||
>>> repo_id = "google/ddpm-cat-256"
|
||||
>>> model = UNet2DModel.from_pretrained(repo_id)
|
||||
```
|
||||
|
||||
想知道模型的参数,调用 `model.config`:
|
||||
|
||||
```py
|
||||
>>> model.config
|
||||
```
|
||||
|
||||
模型配置是一个🧊冻结的🧊字典,意思是这些参数在模型创建后就不变了。这是特意设置的,确保在开始时用于定义模型架构的参数保持不变,其他参数仍然可以在推理过程中进行调整。
|
||||
|
||||
一些最重要的参数:
|
||||
|
||||
* `sample_size`:输入样本的高度和宽度尺寸。
|
||||
* `in_channels`:输入样本的输入通道数。
|
||||
* `down_block_types`和`up_block_types`:用于创建U-Net架构的下采样和上采样块的类型。
|
||||
* `block_out_channels`:下采样块的输出通道数;也以相反的顺序用于上采样块的输入通道数。
|
||||
* `layers_per_block`:每个U-Net块中存在的ResNet块的数量。
|
||||
|
||||
为了使用该模型进行推理,用随机高斯噪声生成图像形状。它应该有一个`batch`轴,因为模型可以接收多个随机噪声,一个`channel`轴,对应于输入通道的数量,以及一个`sample_size`轴,对应图像的高度和宽度。
|
||||
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
|
||||
>>> torch.manual_seed(0)
|
||||
|
||||
>>> noisy_sample = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
|
||||
>>> noisy_sample.shape
|
||||
torch.Size([1, 3, 256, 256])
|
||||
```
|
||||
|
||||
对于推理,将噪声图像和一个`timestep`传递给模型。`timestep` 表示输入图像的噪声程度,开始时噪声更多,结束时噪声更少。这有助于模型确定其在扩散过程中的位置,是更接近开始还是结束。使用 `sample` 获得模型输出:
|
||||
|
||||
|
||||
```py
|
||||
>>> with torch.no_grad():
|
||||
... noisy_residual = model(sample=noisy_sample, timestep=2).sample
|
||||
```
|
||||
|
||||
想生成实际的样本,你需要一个调度器指导去噪过程。在下一节中,你将学习如何把模型与调度器结合起来。
|
||||
|
||||
## 调度器
|
||||
|
||||
调度器管理一个噪声样本到一个噪声较小的样本的处理过程,给出模型输出 —— 在这种情况下,它是`noisy_residual`。
|
||||
|
||||
|
||||
|
||||
<Tip>
|
||||
|
||||
🧨 Diffusers是一个用于构建扩散系统的工具箱。预定义好的扩散系统[`DiffusionPipeline`]能方便你快速试用,你也可以单独选择自己的模型和调度器组件来建立一个自定义的扩散系统。
|
||||
|
||||
</Tip>
|
||||
|
||||
在快速入门教程中,你将用它的[`~diffusers.ConfigMixin.from_config`]方法实例化[`DDPMScheduler`]:
|
||||
|
||||
```py
|
||||
>>> from diffusers import DDPMScheduler
|
||||
|
||||
>>> scheduler = DDPMScheduler.from_config(repo_id)
|
||||
>>> scheduler
|
||||
DDPMScheduler {
|
||||
"_class_name": "DDPMScheduler",
|
||||
"_diffusers_version": "0.13.1",
|
||||
"beta_end": 0.02,
|
||||
"beta_schedule": "linear",
|
||||
"beta_start": 0.0001,
|
||||
"clip_sample": true,
|
||||
"clip_sample_range": 1.0,
|
||||
"num_train_timesteps": 1000,
|
||||
"prediction_type": "epsilon",
|
||||
"trained_betas": null,
|
||||
"variance_type": "fixed_small"
|
||||
}
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
|
||||
💡 注意调度器是如何从配置中实例化的。与模型不同,调度器没有可训练的权重,而且是无参数的。
|
||||
|
||||
</Tip>
|
||||
|
||||
* `num_train_timesteps`:去噪过程的长度,或者换句话说,将随机高斯噪声处理成数据样本所需的时间步数。
|
||||
* `beta_schedule`:用于推理和训练的噪声表。
|
||||
* `beta_start`和`beta_end`:噪声表的开始和结束噪声值。
|
||||
|
||||
要预测一个噪音稍小的图像,请将 模型输出、`timestep`和当前`sample` 传递给调度器的[`~diffusers.DDPMScheduler.step`]方法:
|
||||
|
||||
|
||||
```py
|
||||
>>> less_noisy_sample = scheduler.step(model_output=noisy_residual, timestep=2, sample=noisy_sample).prev_sample
|
||||
>>> less_noisy_sample.shape
|
||||
```
|
||||
|
||||
这个 `less_noisy_sample` 去噪样本 可以被传递到下一个`timestep` ,处理后会将变得噪声更小。现在让我们把所有步骤合起来,可视化整个去噪过程。
|
||||
|
||||
首先,创建一个函数,对去噪后的图像进行后处理并显示为`PIL.Image`:
|
||||
|
||||
```py
|
||||
>>> import PIL.Image
|
||||
>>> import numpy as np
|
||||
|
||||
|
||||
>>> def display_sample(sample, i):
|
||||
... image_processed = sample.cpu().permute(0, 2, 3, 1)
|
||||
... image_processed = (image_processed + 1.0) * 127.5
|
||||
... image_processed = image_processed.numpy().astype(np.uint8)
|
||||
|
||||
... image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
... display(f"Image at step {i}")
|
||||
... display(image_pil)
|
||||
```
|
||||
|
||||
将输入和模型移到GPU上加速去噪过程:
|
||||
|
||||
```py
|
||||
>>> model.to("cuda")
|
||||
>>> noisy_sample = noisy_sample.to("cuda")
|
||||
```
|
||||
|
||||
现在创建一个去噪循环,该循环预测噪声较少样本的残差,并使用调度程序计算噪声较少的样本:
|
||||
|
||||
```py
|
||||
>>> import tqdm
|
||||
|
||||
>>> sample = noisy_sample
|
||||
|
||||
>>> for i, t in enumerate(tqdm.tqdm(scheduler.timesteps)):
|
||||
... # 1. predict noise residual
|
||||
... with torch.no_grad():
|
||||
... residual = model(sample, t).sample
|
||||
|
||||
... # 2. compute less noisy image and set x_t -> x_t-1
|
||||
... sample = scheduler.step(residual, t, sample).prev_sample
|
||||
|
||||
... # 3. optionally look at image
|
||||
... if (i + 1) % 50 == 0:
|
||||
... display_sample(sample, i + 1)
|
||||
```
|
||||
|
||||
看!这样就从噪声中生成出一只猫了!😻
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/diffusion-quicktour.png"/>
|
||||
</div>
|
||||
|
||||
## 下一步
|
||||
|
||||
希望你在这次快速入门教程中用🧨Diffuser 生成了一些很酷的图像! 下一步你可以:
|
||||
|
||||
* 在[训练](./tutorials/basic_training)教程中训练或微调一个模型来生成你自己的图像。
|
||||
* 查看官方和社区的[训练或微调脚本](https://github.com/huggingface/diffusers/tree/main/examples#-diffusers-examples)的例子,了解更多使用情况。
|
||||
* 在[使用不同的调度器](./using-diffusers/schedulers)指南中了解更多关于加载、访问、更改和比较调度器的信息。
|
||||
* 在[Stable Diffusion](./stable_diffusion)教程中探索提示工程、速度和内存优化,以及生成更高质量图像的技巧。
|
||||
* 通过[在GPU上优化PyTorch](./optimization/fp16)指南,以及运行[Apple (M1/M2)上的Stable Diffusion](./optimization/mps)和[ONNX Runtime](./optimization/onnx)的教程,更深入地了解如何加速🧨Diffuser。
|
||||
@@ -29,7 +29,7 @@ MagicMix | Diffusion Pipeline for semantic mixing of an image and a text prompt
|
||||
| Stable UnCLIP | Diffusion Pipeline for combining prior model (generate clip image embedding from text, UnCLIPPipeline `"kakaobrain/karlo-v1-alpha"`) and decoder pipeline (decode clip image embedding to image, StableDiffusionImageVariationPipeline `"lambdalabs/sd-image-variations-diffusers"` ). | [Stable UnCLIP](#stable-unclip) | - |[Ray Wang](https://wrong.wang) |
|
||||
| UnCLIP Text Interpolation Pipeline | Diffusion Pipeline that allows passing two prompts and produces images while interpolating between the text-embeddings of the two prompts | [UnCLIP Text Interpolation Pipeline](#unclip-text-interpolation-pipeline) | - | [Naga Sai Abhinay Devarinti](https://github.com/Abhinay1997/) |
|
||||
| UnCLIP Image Interpolation Pipeline | Diffusion Pipeline that allows passing two images/image_embeddings and produces images while interpolating between their image-embeddings | [UnCLIP Image Interpolation Pipeline](#unclip-image-interpolation-pipeline) | - | [Naga Sai Abhinay Devarinti](https://github.com/Abhinay1997/) |
|
||||
| DDIM Noise Comparative Analysis Pipeline | Investigating how the diffusion models learn visual concepts from each noise level (which is a contribution of [P2 weighting (CVPR 2022)](https://arxiv.org/abs/2204.00227)) | [DDIM Noise Comparative Analysis Pipeline](#ddim-noise-comparative-analysis-pipeline) | - |[Aengus (Duc-Anh)](https://github.com/aengusng8) |
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1033,44 +1033,4 @@ The resulting images in order:-
|
||||

|
||||

|
||||
|
||||
### DDIM Noise Comparative Analysis Pipeline
|
||||
#### **Research question: What visual concepts do the diffusion models learn from each noise level during training?**
|
||||
The [P2 weighting (CVPR 2022)](https://arxiv.org/abs/2204.00227) paper proposed an approach to answer the above question, which is their second contribution.
|
||||
The approach consists of the following steps:
|
||||
|
||||
1. The input is an image x0.
|
||||
2. Perturb it to xt using a diffusion process q(xt|x0).
|
||||
- `strength` is a value between 0.0 and 1.0, that controls the amount of noise that is added to the input image. Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input.
|
||||
3. Reconstruct the image with the learned denoising process pθ(ˆx0|xt).
|
||||
4. Compare x0 and ˆx0 among various t to show how each step contributes to the sample.
|
||||
The authors used [openai/guided-diffusion](https://github.com/openai/guided-diffusion) model to denoise images in FFHQ dataset. This pipeline extends their second contribution by investigating DDIM on any input image.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from PIL import Image
|
||||
import numpy as np
|
||||
|
||||
image_path = "path/to/your/image" # images from CelebA-HQ might be better
|
||||
image_pil = Image.open(image_path)
|
||||
image_name = image_path.split("/")[-1].split(".")[0]
|
||||
|
||||
device = torch.device("cpu" if not torch.cuda.is_available() else "cuda")
|
||||
pipe = DiffusionPipeline.from_pretrained(
|
||||
"google/ddpm-ema-celebahq-256",
|
||||
custom_pipeline="ddim_noise_comparative_analysis",
|
||||
)
|
||||
pipe = pipe.to(device)
|
||||
|
||||
for strength in np.linspace(0.1, 1, 25):
|
||||
denoised_image, latent_timestep = pipe(
|
||||
image_pil, strength=strength, return_dict=False
|
||||
)
|
||||
denoised_image = denoised_image[0]
|
||||
denoised_image.save(
|
||||
f"noise_comparative_analysis_{image_name}_{latent_timestep}.png"
|
||||
)
|
||||
```
|
||||
|
||||
Here is the result of this pipeline (which is DDIM) on CelebA-HQ dataset.
|
||||
|
||||

|
||||
|
||||
@@ -1,190 +0,0 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import PIL
|
||||
import torch
|
||||
from torchvision import transforms
|
||||
|
||||
from diffusers.pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
from diffusers.schedulers import DDIMScheduler
|
||||
from diffusers.utils import randn_tensor
|
||||
|
||||
|
||||
trans = transforms.Compose(
|
||||
[
|
||||
transforms.Resize((256, 256)),
|
||||
transforms.ToTensor(),
|
||||
transforms.Normalize([0.5], [0.5]),
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def preprocess(image):
|
||||
if isinstance(image, torch.Tensor):
|
||||
return image
|
||||
elif isinstance(image, PIL.Image.Image):
|
||||
image = [image]
|
||||
|
||||
image = [trans(img.convert("RGB")) for img in image]
|
||||
image = torch.stack(image)
|
||||
return image
|
||||
|
||||
|
||||
class DDIMNoiseComparativeAnalysisPipeline(DiffusionPipeline):
|
||||
r"""
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
Parameters:
|
||||
unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image.
|
||||
scheduler ([`SchedulerMixin`]):
|
||||
A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
|
||||
[`DDPMScheduler`], or [`DDIMScheduler`].
|
||||
"""
|
||||
|
||||
def __init__(self, unet, scheduler):
|
||||
super().__init__()
|
||||
|
||||
# make sure scheduler can always be converted to DDIM
|
||||
scheduler = DDIMScheduler.from_config(scheduler.config)
|
||||
|
||||
self.register_modules(unet=unet, scheduler=scheduler)
|
||||
|
||||
def check_inputs(self, strength):
|
||||
if strength < 0 or strength > 1:
|
||||
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
|
||||
|
||||
def get_timesteps(self, num_inference_steps, strength, device):
|
||||
# get the original timestep using init_timestep
|
||||
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
|
||||
|
||||
t_start = max(num_inference_steps - init_timestep, 0)
|
||||
timesteps = self.scheduler.timesteps[t_start:]
|
||||
|
||||
return timesteps, num_inference_steps - t_start
|
||||
|
||||
def prepare_latents(self, image, timestep, batch_size, dtype, device, generator=None):
|
||||
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
|
||||
raise ValueError(
|
||||
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
|
||||
)
|
||||
|
||||
init_latents = image.to(device=device, dtype=dtype)
|
||||
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
raise ValueError(
|
||||
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
||||
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
||||
)
|
||||
|
||||
shape = init_latents.shape
|
||||
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
|
||||
# get latents
|
||||
print("add noise to latents at timestep", timestep)
|
||||
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
|
||||
latents = init_latents
|
||||
|
||||
return latents
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self,
|
||||
image: Union[torch.FloatTensor, PIL.Image.Image] = None,
|
||||
strength: float = 0.8,
|
||||
batch_size: int = 1,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
eta: float = 0.0,
|
||||
num_inference_steps: int = 50,
|
||||
use_clipped_model_output: Optional[bool] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
) -> Union[ImagePipelineOutput, Tuple]:
|
||||
r"""
|
||||
Args:
|
||||
image (`torch.FloatTensor` or `PIL.Image.Image`):
|
||||
`Image`, or tensor representing an image batch, that will be used as the starting point for the
|
||||
process.
|
||||
strength (`float`, *optional*, defaults to 0.8):
|
||||
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
|
||||
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
|
||||
denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
|
||||
be maximum and the denoising process will run for the full number of iterations specified in
|
||||
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
|
||||
batch_size (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate.
|
||||
generator (`torch.Generator`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
eta (`float`, *optional*, defaults to 0.0):
|
||||
The eta parameter which controls the scale of the variance (0 is DDIM and 1 is one type of DDPM).
|
||||
num_inference_steps (`int`, *optional*, defaults to 50):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
use_clipped_model_output (`bool`, *optional*, defaults to `None`):
|
||||
if `True` or `False`, see documentation for `DDIMScheduler.step`. If `None`, nothing is passed
|
||||
downstream to the scheduler. So use `None` for schedulers which don't support this argument.
|
||||
output_type (`str`, *optional*, defaults to `"pil"`):
|
||||
The output format of the generate image. Choose between
|
||||
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
|
||||
|
||||
Returns:
|
||||
[`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
|
||||
True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
|
||||
"""
|
||||
# 1. Check inputs. Raise error if not correct
|
||||
self.check_inputs(strength)
|
||||
|
||||
# 2. Preprocess image
|
||||
image = preprocess(image)
|
||||
|
||||
# 3. set timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=self.device)
|
||||
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, self.device)
|
||||
latent_timestep = timesteps[:1].repeat(batch_size)
|
||||
|
||||
# 4. Prepare latent variables
|
||||
latents = self.prepare_latents(image, latent_timestep, batch_size, self.unet.dtype, self.device, generator)
|
||||
image = latents
|
||||
|
||||
# 5. Denoising loop
|
||||
for t in self.progress_bar(timesteps):
|
||||
# 1. predict noise model_output
|
||||
model_output = self.unet(image, t).sample
|
||||
|
||||
# 2. predict previous mean of image x_t-1 and add variance depending on eta
|
||||
# eta corresponds to η in paper and should be between [0, 1]
|
||||
# do x_t -> x_t-1
|
||||
image = self.scheduler.step(
|
||||
model_output,
|
||||
t,
|
||||
image,
|
||||
eta=eta,
|
||||
use_clipped_model_output=use_clipped_model_output,
|
||||
generator=generator,
|
||||
).prev_sample
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
if not return_dict:
|
||||
return (image, latent_timestep.item())
|
||||
|
||||
return ImagePipelineOutput(images=image)
|
||||
@@ -713,7 +713,7 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
controlnet_conditioning_scale (`float`, *optional*, defaults to 1.0):
|
||||
|
||||
@@ -868,7 +868,7 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
controlnet_conditioning_scale (`float`, *optional*, defaults to 1.0):
|
||||
|
||||
@@ -911,7 +911,7 @@ class StableDiffusionControlNetInpaintImg2ImgPipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
controlnet_conditioning_scale (`float`, *optional*, defaults to 1.0):
|
||||
|
||||
@@ -1,269 +0,0 @@
|
||||
# ControlNet training example
|
||||
|
||||
[Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
|
||||
|
||||
This example is based on the [training example in the original ControlNet repository](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md). It trains a ControlNet to fill circles using a [small synthetic dataset](https://huggingface.co/datasets/fusing/fill50k).
|
||||
|
||||
## Installing the dependencies
|
||||
|
||||
Before running the scripts, make sure to install the library's training dependencies:
|
||||
|
||||
**Important**
|
||||
|
||||
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
Then cd in the example folder and run
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
Or for a default accelerate configuration without answering questions about your environment
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
Or if your environment doesn't support an interactive shell e.g. a notebook
|
||||
|
||||
```python
|
||||
from accelerate.utils import write_basic_config
|
||||
write_basic_config()
|
||||
```
|
||||
|
||||
## Circle filling dataset
|
||||
|
||||
The original dataset is hosted in the [ControlNet repo](https://huggingface.co/lllyasviel/ControlNet/blob/main/training/fill50k.zip). We re-uploaded it to be compatible with `datasets` [here](https://huggingface.co/datasets/fusing/fill50k). Note that `datasets` handles dataloading within the training script.
|
||||
|
||||
Our training examples use [Stable Diffusion 1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the original set of ControlNet models were trained from it. However, ControlNet can be trained to augment any Stable Diffusion compatible model (such as [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)) or [stabilityai/stable-diffusion-2-1](https://huggingface.co/stabilityai/stable-diffusion-2-1).
|
||||
|
||||
## Training
|
||||
|
||||
Our training examples use two test conditioning images. They can be downloaded by running
|
||||
|
||||
```sh
|
||||
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
|
||||
|
||||
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
|
||||
```
|
||||
|
||||
|
||||
```bash
|
||||
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
|
||||
export OUTPUT_DIR="path to save model"
|
||||
|
||||
accelerate launch train_controlnet.py \
|
||||
--pretrained_model_name_or_path=$MODEL_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--dataset_name=fusing/fill50k \
|
||||
--resolution=512 \
|
||||
--learning_rate=1e-5 \
|
||||
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
|
||||
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
|
||||
--train_batch_size=4
|
||||
```
|
||||
|
||||
This default configuration requires ~38GB VRAM.
|
||||
|
||||
By default, the training script logs outputs to tensorboard. Pass `--report_to wandb` to use weights and
|
||||
biases.
|
||||
|
||||
Gradient accumulation with a smaller batch size can be used to reduce training requirements to ~20 GB VRAM.
|
||||
|
||||
```bash
|
||||
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
|
||||
export OUTPUT_DIR="path to save model"
|
||||
|
||||
accelerate launch train_controlnet.py \
|
||||
--pretrained_model_name_or_path=$MODEL_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--dataset_name=fusing/fill50k \
|
||||
--resolution=512 \
|
||||
--learning_rate=1e-5 \
|
||||
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
|
||||
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4
|
||||
```
|
||||
|
||||
## Example results
|
||||
|
||||
#### After 300 steps with batch size 8
|
||||
|
||||
| | |
|
||||
|-------------------|:-------------------------:|
|
||||
| | red circle with blue background |
|
||||
 |  |
|
||||
| | cyan circle with brown floral background |
|
||||
 |  |
|
||||
|
||||
|
||||
#### After 6000 steps with batch size 8:
|
||||
|
||||
| | |
|
||||
|-------------------|:-------------------------:|
|
||||
| | red circle with blue background |
|
||||
 |  |
|
||||
| | cyan circle with brown floral background |
|
||||
 |  |
|
||||
|
||||
## Training on a 16 GB GPU
|
||||
|
||||
Optimizations:
|
||||
- Gradient checkpointing
|
||||
- bitsandbyte's 8-bit optimizer
|
||||
|
||||
[bitandbytes install instructions](https://github.com/TimDettmers/bitsandbytes#requirements--installation).
|
||||
|
||||
```bash
|
||||
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
|
||||
export OUTPUT_DIR="path to save model"
|
||||
|
||||
accelerate launch train_controlnet.py \
|
||||
--pretrained_model_name_or_path=$MODEL_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--dataset_name=fusing/fill50k \
|
||||
--resolution=512 \
|
||||
--learning_rate=1e-5 \
|
||||
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
|
||||
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--gradient_checkpointing \
|
||||
--use_8bit_adam
|
||||
```
|
||||
|
||||
## Training on a 12 GB GPU
|
||||
|
||||
Optimizations:
|
||||
- Gradient checkpointing
|
||||
- bitsandbyte's 8-bit optimizer
|
||||
- xformers
|
||||
- set grads to none
|
||||
|
||||
```bash
|
||||
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
|
||||
export OUTPUT_DIR="path to save model"
|
||||
|
||||
accelerate launch train_controlnet.py \
|
||||
--pretrained_model_name_or_path=$MODEL_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--dataset_name=fusing/fill50k \
|
||||
--resolution=512 \
|
||||
--learning_rate=1e-5 \
|
||||
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
|
||||
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--gradient_checkpointing \
|
||||
--use_8bit_adam \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--set_grads_to_none
|
||||
```
|
||||
|
||||
When using `enable_xformers_memory_efficient_attention`, please make sure to install `xformers` by `pip install xformers`.
|
||||
|
||||
## Training on an 8 GB GPU
|
||||
|
||||
We have not exhaustively tested DeepSpeed support for ControlNet. While the configuration does
|
||||
save memory, we have not confirmed the configuration to train successfully. You will very likely
|
||||
have to make changes to the config to have a successful training run.
|
||||
|
||||
Optimizations:
|
||||
- Gradient checkpointing
|
||||
- xformers
|
||||
- set grads to none
|
||||
- DeepSpeed stage 2 with parameter and optimizer offloading
|
||||
- fp16 mixed precision
|
||||
|
||||
[DeepSpeed](https://www.deepspeed.ai/) can offload tensors from VRAM to either
|
||||
CPU or NVME. This requires significantly more RAM (about 25 GB).
|
||||
|
||||
Use `accelerate config` to enable DeepSpeed stage 2.
|
||||
|
||||
The relevant parts of the resulting accelerate config file are
|
||||
|
||||
```yaml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config:
|
||||
gradient_accumulation_steps: 4
|
||||
offload_optimizer_device: cpu
|
||||
offload_param_device: cpu
|
||||
zero3_init_flag: false
|
||||
zero_stage: 2
|
||||
distributed_type: DEEPSPEED
|
||||
```
|
||||
|
||||
See [documentation](https://huggingface.co/docs/accelerate/usage_guides/deepspeed) for more DeepSpeed configuration options.
|
||||
|
||||
Changing the default Adam optimizer to DeepSpeed's Adam
|
||||
`deepspeed.ops.adam.DeepSpeedCPUAdam` gives a substantial speedup but
|
||||
it requires CUDA toolchain with the same version as pytorch. 8-bit optimizer
|
||||
does not seem to be compatible with DeepSpeed at the moment.
|
||||
|
||||
```bash
|
||||
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
|
||||
export OUTPUT_DIR="path to save model"
|
||||
|
||||
accelerate launch train_controlnet.py \
|
||||
--pretrained_model_name_or_path=$MODEL_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--dataset_name=fusing/fill50k \
|
||||
--resolution=512 \
|
||||
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
|
||||
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--gradient_checkpointing \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--set_grads_to_none \
|
||||
--mixed_precision fp16
|
||||
```
|
||||
|
||||
## Performing inference with the trained ControlNet
|
||||
|
||||
The trained model can be run the same as the original ControlNet pipeline with the newly trained ControlNet.
|
||||
Set `base_model_path` and `controlnet_path` to the values `--pretrained_model_name_or_path` and
|
||||
`--output_dir` were respectively set to in the training script.
|
||||
|
||||
```py
|
||||
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
|
||||
from diffusers.utils import load_image
|
||||
import torch
|
||||
|
||||
base_model_path = "path to model"
|
||||
controlnet_path = "path to controlnet"
|
||||
|
||||
controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
|
||||
pipe = StableDiffusionControlNetPipeline.from_pretrained(
|
||||
base_model_path, controlnet=controlnet, torch_dtype=torch.float16
|
||||
)
|
||||
|
||||
# speed up diffusion process with faster scheduler and memory optimization
|
||||
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
||||
# remove following line if xformers is not installed
|
||||
pipe.enable_xformers_memory_efficient_attention()
|
||||
|
||||
pipe.enable_model_cpu_offload()
|
||||
|
||||
control_image = load_image("./conditioning_image_1.png")
|
||||
prompt = "pale golden rod circle with old lace background"
|
||||
|
||||
# generate image
|
||||
generator = torch.manual_seed(0)
|
||||
image = pipe(
|
||||
prompt, num_inference_steps=20, generator=generator, image=control_image
|
||||
).images[0]
|
||||
|
||||
image.save("./output.png")
|
||||
```
|
||||
@@ -1,6 +0,0 @@
|
||||
accelerate
|
||||
torchvision
|
||||
transformers>=4.25.1
|
||||
ftfy
|
||||
tensorboard
|
||||
datasets
|
||||
File diff suppressed because it is too large
Load Diff
@@ -454,7 +454,6 @@ class DreamBoothDataset(Dataset):
|
||||
tokenizer,
|
||||
class_data_root=None,
|
||||
class_prompt=None,
|
||||
class_num=None,
|
||||
size=512,
|
||||
center_crop=False,
|
||||
):
|
||||
@@ -475,10 +474,7 @@ class DreamBoothDataset(Dataset):
|
||||
self.class_data_root = Path(class_data_root)
|
||||
self.class_data_root.mkdir(parents=True, exist_ok=True)
|
||||
self.class_images_path = list(self.class_data_root.iterdir())
|
||||
if class_num is not None:
|
||||
self.num_class_images = min(len(self.class_images_path), class_num)
|
||||
else:
|
||||
self.num_class_images = len(self.class_images_path)
|
||||
self.num_class_images = len(self.class_images_path)
|
||||
self._length = max(self.num_class_images, self.num_instance_images)
|
||||
self.class_prompt = class_prompt
|
||||
else:
|
||||
@@ -818,7 +814,6 @@ def main(args):
|
||||
instance_prompt=args.instance_prompt,
|
||||
class_data_root=args.class_data_dir if args.with_prior_preservation else None,
|
||||
class_prompt=args.class_prompt,
|
||||
class_num=args.num_class_images,
|
||||
tokenizer=tokenizer,
|
||||
size=args.resolution,
|
||||
center_crop=args.center_crop,
|
||||
@@ -1000,14 +995,13 @@ def main(args):
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
if accelerator.is_main_process:
|
||||
if global_step % args.checkpointing_steps == 0:
|
||||
if global_step % args.checkpointing_steps == 0:
|
||||
if accelerator.is_main_process:
|
||||
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
|
||||
accelerator.save_state(save_path)
|
||||
logger.info(f"Saved state to {save_path}")
|
||||
|
||||
if args.validation_prompt is not None and global_step % args.validation_steps == 0:
|
||||
log_validation(text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch)
|
||||
if args.validation_prompt is not None and global_step % args.validation_steps == 0:
|
||||
log_validation(text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch)
|
||||
|
||||
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
@@ -231,7 +231,6 @@ class DreamBoothDataset(Dataset):
|
||||
tokenizer,
|
||||
class_data_root=None,
|
||||
class_prompt=None,
|
||||
class_num=None,
|
||||
size=512,
|
||||
center_crop=False,
|
||||
):
|
||||
@@ -252,10 +251,7 @@ class DreamBoothDataset(Dataset):
|
||||
self.class_data_root = Path(class_data_root)
|
||||
self.class_data_root.mkdir(parents=True, exist_ok=True)
|
||||
self.class_images_path = list(self.class_data_root.iterdir())
|
||||
if class_num is not None:
|
||||
self.num_class_images = min(len(self.class_images_path), class_num)
|
||||
else:
|
||||
self.num_class_images = len(self.class_images_path)
|
||||
self.num_class_images = len(self.class_images_path)
|
||||
self._length = max(self.num_class_images, self.num_instance_images)
|
||||
self.class_prompt = class_prompt
|
||||
else:
|
||||
@@ -423,7 +419,6 @@ def main():
|
||||
instance_prompt=args.instance_prompt,
|
||||
class_data_root=args.class_data_dir if args.with_prior_preservation else None,
|
||||
class_prompt=args.class_prompt,
|
||||
class_num=args.num_class_images,
|
||||
tokenizer=tokenizer,
|
||||
size=args.resolution,
|
||||
center_crop=args.center_crop,
|
||||
|
||||
@@ -47,7 +47,7 @@ from diffusers import (
|
||||
UNet2DConditionModel,
|
||||
)
|
||||
from diffusers.loaders import AttnProcsLayers
|
||||
from diffusers.models.attention_processor import LoRAAttnProcessor
|
||||
from diffusers.models.cross_attention import LoRACrossAttnProcessor
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.utils import check_min_version, is_wandb_available
|
||||
from diffusers.utils.import_utils import is_xformers_available
|
||||
@@ -417,7 +417,6 @@ class DreamBoothDataset(Dataset):
|
||||
tokenizer,
|
||||
class_data_root=None,
|
||||
class_prompt=None,
|
||||
class_num=None,
|
||||
size=512,
|
||||
center_crop=False,
|
||||
):
|
||||
@@ -438,10 +437,7 @@ class DreamBoothDataset(Dataset):
|
||||
self.class_data_root = Path(class_data_root)
|
||||
self.class_data_root.mkdir(parents=True, exist_ok=True)
|
||||
self.class_images_path = list(self.class_data_root.iterdir())
|
||||
if class_num is not None:
|
||||
self.num_class_images = min(len(self.class_images_path), class_num)
|
||||
else:
|
||||
self.num_class_images = len(self.class_images_path)
|
||||
self.num_class_images = len(self.class_images_path)
|
||||
self._length = max(self.num_class_images, self.num_instance_images)
|
||||
self.class_prompt = class_prompt
|
||||
else:
|
||||
@@ -723,7 +719,9 @@ def main(args):
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = unet.config.block_out_channels[block_id]
|
||||
|
||||
lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
|
||||
lora_attn_procs[name] = LoRACrossAttnProcessor(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim
|
||||
)
|
||||
|
||||
unet.set_attn_processor(lora_attn_procs)
|
||||
lora_layers = AttnProcsLayers(unet.attn_processors)
|
||||
@@ -773,7 +771,6 @@ def main(args):
|
||||
instance_prompt=args.instance_prompt,
|
||||
class_data_root=args.class_data_dir if args.with_prior_preservation else None,
|
||||
class_prompt=args.class_prompt,
|
||||
class_num=args.num_class_images,
|
||||
tokenizer=tokenizer,
|
||||
size=args.resolution,
|
||||
center_crop=args.center_crop,
|
||||
|
||||
@@ -22,7 +22,7 @@ from transformers import CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionInpaintPipeline, UNet2DConditionModel
|
||||
from diffusers.loaders import AttnProcsLayers
|
||||
from diffusers.models.attention_processor import LoRAAttnProcessor
|
||||
from diffusers.models.cross_attention import LoRACrossAttnProcessor
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.utils import check_min_version
|
||||
from diffusers.utils.import_utils import is_xformers_available
|
||||
@@ -561,7 +561,9 @@ def main():
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = unet.config.block_out_channels[block_id]
|
||||
|
||||
lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
|
||||
lora_attn_procs[name] = LoRACrossAttnProcessor(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim
|
||||
)
|
||||
|
||||
unet.set_attn_processor(lora_attn_procs)
|
||||
lora_layers = AttnProcsLayers(unet.attn_processors)
|
||||
|
||||
@@ -1,83 +0,0 @@
|
||||
# Stable Diffusion text-to-image fine-tuning
|
||||
This extended LoRA training script was authored by [haofanwang](https://github.com/haofanwang).
|
||||
This is an experimental LoRA extension of [this example](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py). We further support add LoRA layers for text encoder.
|
||||
|
||||
## Training with LoRA
|
||||
|
||||
Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
|
||||
|
||||
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
|
||||
|
||||
- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
|
||||
- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
|
||||
- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
|
||||
|
||||
[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
|
||||
|
||||
With LoRA, it's possible to fine-tune Stable Diffusion on a custom image-caption pair dataset
|
||||
on consumer GPUs like Tesla T4, Tesla V100.
|
||||
|
||||
### Training
|
||||
|
||||
First, you need to set up your development environment as is explained in the [installation section](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables. Here, we will use [Stable Diffusion v1-4](https://hf.co/CompVis/stable-diffusion-v1-4) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
|
||||
|
||||
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
|
||||
|
||||
**___Note: It is quite useful to monitor the training progress by regularly generating sample images during training. [Weights and Biases](https://docs.wandb.ai/quickstart) is a nice solution to easily see generating images during training. All you need to do is to run `pip install wandb` before training to automatically log images.___**
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
|
||||
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
|
||||
```
|
||||
|
||||
For this example we want to directly store the trained LoRA embeddings on the Hub, so
|
||||
we need to be logged in and add the `--push_to_hub` flag.
|
||||
|
||||
```bash
|
||||
huggingface-cli login
|
||||
```
|
||||
|
||||
Now we can start training!
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$DATASET_NAME --caption_column="text" \
|
||||
--resolution=512 --random_flip \
|
||||
--train_batch_size=1 \
|
||||
--num_train_epochs=100 --checkpointing_steps=5000 \
|
||||
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
|
||||
--seed=42 \
|
||||
--output_dir="sd-pokemon-model-lora" \
|
||||
--validation_prompt="cute dragon creature" --report_to="wandb"
|
||||
--use_peft \
|
||||
--lora_r=4 --lora_alpha=32 \
|
||||
--lora_text_encoder_r=4 --lora_text_encoder_alpha=32
|
||||
```
|
||||
|
||||
The above command will also run inference as fine-tuning progresses and log the results to Weights and Biases.
|
||||
|
||||
**___Note: When using LoRA we can use a much higher learning rate compared to non-LoRA fine-tuning. Here we use *1e-4* instead of the usual *1e-5*. Also, by using LoRA, it's possible to run `train_text_to_image_lora.py` in consumer GPUs like T4 or V100.___**
|
||||
|
||||
The final LoRA embedding weights have been uploaded to [sayakpaul/sd-model-finetuned-lora-t4](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4). **___Note: [The final weights](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/pytorch_lora_weights.bin) are only 3 MB in size, which is orders of magnitudes smaller than the original model.___**
|
||||
|
||||
You can check some inference samples that were logged during the course of the fine-tuning process [here](https://wandb.ai/sayakpaul/text2image-fine-tune/runs/q4lc0xsw).
|
||||
|
||||
### Inference
|
||||
|
||||
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline` after loading the trained LoRA weights. You
|
||||
need to pass the `output_dir` for loading the LoRA weights which, in this case, is `sd-pokemon-model-lora`.
|
||||
|
||||
```python
|
||||
from diffusers import StableDiffusionPipeline
|
||||
import torch
|
||||
|
||||
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
|
||||
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
|
||||
pipe.unet.load_attn_procs(model_path)
|
||||
pipe.to("cuda")
|
||||
|
||||
prompt = "A pokemon with green eyes and red legs."
|
||||
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
|
||||
image.save("pokemon.png")
|
||||
```
|
||||
@@ -1,8 +0,0 @@
|
||||
accelerate
|
||||
torchvision
|
||||
transformers>=4.25.1
|
||||
datasets
|
||||
ftfy
|
||||
tensorboard
|
||||
Jinja2
|
||||
git+https://github.com/huggingface/peft.git
|
||||
File diff suppressed because it is too large
Load Diff
@@ -864,7 +864,7 @@ def main():
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if accelerator.is_main_process and args.validation_prompt is not None and epoch % args.validation_epochs == 0:
|
||||
if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
|
||||
logger.info(
|
||||
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
|
||||
f" {args.validation_prompt}."
|
||||
|
||||
@@ -790,7 +790,7 @@ def main():
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if accelerator.is_main_process and args.validation_prompt is not None and epoch % args.validation_epochs == 0:
|
||||
if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
|
||||
logger.info(
|
||||
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
|
||||
f" {args.validation_prompt}."
|
||||
|
||||
@@ -41,7 +41,7 @@ from transformers import CLIPTextModel, CLIPTokenizer
|
||||
import diffusers
|
||||
from diffusers import AutoencoderKL, DDPMScheduler, DiffusionPipeline, UNet2DConditionModel
|
||||
from diffusers.loaders import AttnProcsLayers
|
||||
from diffusers.models.attention_processor import LoRAAttnProcessor
|
||||
from diffusers.models.cross_attention import LoRACrossAttnProcessor
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.utils import check_min_version, is_wandb_available
|
||||
from diffusers.utils.import_utils import is_xformers_available
|
||||
@@ -474,7 +474,9 @@ def main():
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = unet.config.block_out_channels[block_id]
|
||||
|
||||
lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
|
||||
lora_attn_procs[name] = LoRACrossAttnProcessor(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim
|
||||
)
|
||||
|
||||
unet.set_attn_processor(lora_attn_procs)
|
||||
|
||||
@@ -798,19 +800,20 @@ def main():
|
||||
pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0]
|
||||
)
|
||||
|
||||
for tracker in accelerator.trackers:
|
||||
if tracker.name == "tensorboard":
|
||||
np_images = np.stack([np.asarray(img) for img in images])
|
||||
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
|
||||
if tracker.name == "wandb":
|
||||
tracker.log(
|
||||
{
|
||||
"validation": [
|
||||
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
|
||||
for i, image in enumerate(images)
|
||||
]
|
||||
}
|
||||
)
|
||||
if accelerator.is_main_process:
|
||||
for tracker in accelerator.trackers:
|
||||
if tracker.name == "tensorboard":
|
||||
np_images = np.stack([np.asarray(img) for img in images])
|
||||
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
|
||||
if tracker.name == "wandb":
|
||||
tracker.log(
|
||||
{
|
||||
"validation": [
|
||||
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
|
||||
for i, image in enumerate(images)
|
||||
]
|
||||
}
|
||||
)
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
@@ -843,14 +843,13 @@ def main():
|
||||
save_path = os.path.join(args.output_dir, f"learned_embeds-steps-{global_step}.bin")
|
||||
save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
if global_step % args.checkpointing_steps == 0:
|
||||
if global_step % args.checkpointing_steps == 0:
|
||||
if accelerator.is_main_process:
|
||||
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
|
||||
accelerator.save_state(save_path)
|
||||
logger.info(f"Saved state to {save_path}")
|
||||
|
||||
if args.validation_prompt is not None and global_step % args.validation_steps == 0:
|
||||
log_validation(text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch)
|
||||
if args.validation_prompt is not None and global_step % args.validation_steps == 0:
|
||||
log_validation(text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch)
|
||||
|
||||
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
@@ -1,91 +0,0 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for stable diffusion checkpoints which _only_ contain a contrlnet. """
|
||||
|
||||
import argparse
|
||||
|
||||
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import download_controlnet_from_original_ckpt
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--original_config_file",
|
||||
type=str,
|
||||
required=True,
|
||||
help="The YAML config file corresponding to the original architecture.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--num_in_channels",
|
||||
default=None,
|
||||
type=int,
|
||||
help="The number of input channels. If `None` number of input channels will be automatically inferred.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--image_size",
|
||||
default=512,
|
||||
type=int,
|
||||
help=(
|
||||
"The image size that the model was trained on. Use 512 for Stable Diffusion v1.X and Stable Siffusion v2"
|
||||
" Base. Use 768 for Stable Diffusion v2."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--extract_ema",
|
||||
action="store_true",
|
||||
help=(
|
||||
"Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights"
|
||||
" or not. Defaults to `False`. Add `--extract_ema` to extract the EMA weights. EMA weights usually yield"
|
||||
" higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--upcast_attention",
|
||||
action="store_true",
|
||||
help=(
|
||||
"Whether the attention computation should always be upcasted. This is necessary when running stable"
|
||||
" diffusion 2.1."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--from_safetensors",
|
||||
action="store_true",
|
||||
help="If `--checkpoint_path` is in `safetensors` format, load checkpoint with safetensors instead of PyTorch.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--to_safetensors",
|
||||
action="store_true",
|
||||
help="Whether to store pipeline in safetensors format or not.",
|
||||
)
|
||||
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
|
||||
parser.add_argument("--device", type=str, help="Device to use (e.g. cpu, cuda:0, cuda:1, etc.)")
|
||||
args = parser.parse_args()
|
||||
|
||||
controlnet = download_controlnet_from_original_ckpt(
|
||||
checkpoint_path=args.checkpoint_path,
|
||||
original_config_file=args.original_config_file,
|
||||
image_size=args.image_size,
|
||||
extract_ema=args.extract_ema,
|
||||
num_in_channels=args.num_in_channels,
|
||||
upcast_attention=args.upcast_attention,
|
||||
from_safetensors=args.from_safetensors,
|
||||
device=args.device,
|
||||
)
|
||||
|
||||
controlnet.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
|
||||
@@ -16,7 +16,7 @@
|
||||
|
||||
import argparse
|
||||
|
||||
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import download_from_original_stable_diffusion_ckpt
|
||||
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import load_pipeline_from_original_stable_diffusion_ckpt
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
@@ -125,7 +125,7 @@ if __name__ == "__main__":
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
pipe = download_from_original_stable_diffusion_ckpt(
|
||||
pipe = load_pipeline_from_original_stable_diffusion_ckpt(
|
||||
checkpoint_path=args.checkpoint_path,
|
||||
original_config_file=args.original_config_file,
|
||||
image_size=args.image_size,
|
||||
|
||||
@@ -86,8 +86,7 @@ _deps = [
|
||||
"filelock",
|
||||
"flax>=0.4.1",
|
||||
"hf-doc-builder>=0.3.0",
|
||||
"huggingface-hub>=0.13.2",
|
||||
"requests-mock==1.10.0",
|
||||
"huggingface-hub>=0.10.0",
|
||||
"importlib_metadata",
|
||||
"isort>=5.5.4",
|
||||
"jax>=0.2.8,!=0.3.2",
|
||||
@@ -193,7 +192,6 @@ extras["test"] = deps_list(
|
||||
"pytest",
|
||||
"pytest-timeout",
|
||||
"pytest-xdist",
|
||||
"requests-mock",
|
||||
"safetensors",
|
||||
"sentencepiece",
|
||||
"scipy",
|
||||
|
||||
@@ -31,15 +31,7 @@ from huggingface_hub.utils import EntryNotFoundError, RepositoryNotFoundError, R
|
||||
from requests import HTTPError
|
||||
|
||||
from . import __version__
|
||||
from .utils import (
|
||||
DIFFUSERS_CACHE,
|
||||
HUGGINGFACE_CO_RESOLVE_ENDPOINT,
|
||||
DummyObject,
|
||||
deprecate,
|
||||
extract_commit_hash,
|
||||
http_user_agent,
|
||||
logging,
|
||||
)
|
||||
from .utils import DIFFUSERS_CACHE, HUGGINGFACE_CO_RESOLVE_ENDPOINT, DummyObject, deprecate, logging
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
@@ -239,11 +231,7 @@ class ConfigMixin:
|
||||
|
||||
@classmethod
|
||||
def load_config(
|
||||
cls,
|
||||
pretrained_model_name_or_path: Union[str, os.PathLike],
|
||||
return_unused_kwargs=False,
|
||||
return_commit_hash=False,
|
||||
**kwargs,
|
||||
cls, pretrained_model_name_or_path: Union[str, os.PathLike], return_unused_kwargs=False, **kwargs
|
||||
) -> Tuple[Dict[str, Any], Dict[str, Any]]:
|
||||
r"""
|
||||
Instantiate a Python class from a config dictionary
|
||||
@@ -283,10 +271,6 @@ class ConfigMixin:
|
||||
subfolder (`str`, *optional*, defaults to `""`):
|
||||
In case the relevant files are located inside a subfolder of the model repo (either remote in
|
||||
huggingface.co or downloaded locally), you can specify the folder name here.
|
||||
return_unused_kwargs (`bool`, *optional*, defaults to `False):
|
||||
Whether unused keyword arguments of the config shall be returned.
|
||||
return_commit_hash (`bool`, *optional*, defaults to `False):
|
||||
Whether the commit_hash of the loaded configuration shall be returned.
|
||||
|
||||
<Tip>
|
||||
|
||||
@@ -311,10 +295,8 @@ class ConfigMixin:
|
||||
revision = kwargs.pop("revision", None)
|
||||
_ = kwargs.pop("mirror", None)
|
||||
subfolder = kwargs.pop("subfolder", None)
|
||||
user_agent = kwargs.pop("user_agent", {})
|
||||
|
||||
user_agent = {**user_agent, "file_type": "config"}
|
||||
user_agent = http_user_agent(user_agent)
|
||||
user_agent = {"file_type": "config"}
|
||||
|
||||
pretrained_model_name_or_path = str(pretrained_model_name_or_path)
|
||||
|
||||
@@ -354,6 +336,7 @@ class ConfigMixin:
|
||||
subfolder=subfolder,
|
||||
revision=revision,
|
||||
)
|
||||
|
||||
except RepositoryNotFoundError:
|
||||
raise EnvironmentError(
|
||||
f"{pretrained_model_name_or_path} is not a local folder and is not a valid model identifier"
|
||||
@@ -395,23 +378,13 @@ class ConfigMixin:
|
||||
try:
|
||||
# Load config dict
|
||||
config_dict = cls._dict_from_json_file(config_file)
|
||||
|
||||
commit_hash = extract_commit_hash(config_file)
|
||||
except (json.JSONDecodeError, UnicodeDecodeError):
|
||||
raise EnvironmentError(f"It looks like the config file at '{config_file}' is not a valid JSON file.")
|
||||
|
||||
if not (return_unused_kwargs or return_commit_hash):
|
||||
return config_dict
|
||||
|
||||
outputs = (config_dict,)
|
||||
|
||||
if return_unused_kwargs:
|
||||
outputs += (kwargs,)
|
||||
return config_dict, kwargs
|
||||
|
||||
if return_commit_hash:
|
||||
outputs += (commit_hash,)
|
||||
|
||||
return outputs
|
||||
return config_dict
|
||||
|
||||
@staticmethod
|
||||
def _get_init_keys(cls):
|
||||
|
||||
@@ -10,8 +10,7 @@ deps = {
|
||||
"filelock": "filelock",
|
||||
"flax": "flax>=0.4.1",
|
||||
"hf-doc-builder": "hf-doc-builder>=0.3.0",
|
||||
"huggingface-hub": "huggingface-hub>=0.13.2",
|
||||
"requests-mock": "requests-mock==1.10.0",
|
||||
"huggingface-hub": "huggingface-hub>=0.10.0",
|
||||
"importlib_metadata": "importlib_metadata",
|
||||
"isort": "isort>=5.5.4",
|
||||
"jax": "jax>=0.2.8,!=0.3.2",
|
||||
|
||||
@@ -1,177 +0,0 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import warnings
|
||||
from typing import Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
from PIL import Image
|
||||
|
||||
from .configuration_utils import ConfigMixin, register_to_config
|
||||
from .utils import CONFIG_NAME, PIL_INTERPOLATION
|
||||
|
||||
|
||||
class VaeImageProcessor(ConfigMixin):
|
||||
"""
|
||||
Image Processor for VAE
|
||||
|
||||
Args:
|
||||
do_resize (`bool`, *optional*, defaults to `True`):
|
||||
Whether to downscale the image's (height, width) dimensions to multiples of `vae_scale_factor`.
|
||||
vae_scale_factor (`int`, *optional*, defaults to `8`):
|
||||
VAE scale factor. If `do_resize` is True, the image will be automatically resized to multiples of this
|
||||
factor.
|
||||
resample (`str`, *optional*, defaults to `lanczos`):
|
||||
Resampling filter to use when resizing the image.
|
||||
do_normalize (`bool`, *optional*, defaults to `True`):
|
||||
Whether to normalize the image to [-1,1]
|
||||
"""
|
||||
|
||||
config_name = CONFIG_NAME
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
do_resize: bool = True,
|
||||
vae_scale_factor: int = 8,
|
||||
resample: str = "lanczos",
|
||||
do_normalize: bool = True,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
@staticmethod
|
||||
def numpy_to_pil(images):
|
||||
"""
|
||||
Convert a numpy image or a batch of images to a PIL image.
|
||||
"""
|
||||
if images.ndim == 3:
|
||||
images = images[None, ...]
|
||||
images = (images * 255).round().astype("uint8")
|
||||
if images.shape[-1] == 1:
|
||||
# special case for grayscale (single channel) images
|
||||
pil_images = [Image.fromarray(image.squeeze(), mode="L") for image in images]
|
||||
else:
|
||||
pil_images = [Image.fromarray(image) for image in images]
|
||||
|
||||
return pil_images
|
||||
|
||||
@staticmethod
|
||||
def numpy_to_pt(images):
|
||||
"""
|
||||
Convert a numpy image to a pytorch tensor
|
||||
"""
|
||||
if images.ndim == 3:
|
||||
images = images[..., None]
|
||||
|
||||
images = torch.from_numpy(images.transpose(0, 3, 1, 2))
|
||||
return images
|
||||
|
||||
@staticmethod
|
||||
def pt_to_numpy(images):
|
||||
"""
|
||||
Convert a numpy image to a pytorch tensor
|
||||
"""
|
||||
images = images.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
return images
|
||||
|
||||
@staticmethod
|
||||
def normalize(images):
|
||||
"""
|
||||
Normalize an image array to [-1,1]
|
||||
"""
|
||||
return 2.0 * images - 1.0
|
||||
|
||||
def resize(self, images: PIL.Image.Image) -> PIL.Image.Image:
|
||||
"""
|
||||
Resize a PIL image. Both height and width will be downscaled to the next integer multiple of `vae_scale_factor`
|
||||
"""
|
||||
w, h = images.size
|
||||
w, h = map(lambda x: x - x % self.vae_scale_factor, (w, h)) # resize to integer multiple of vae_scale_factor
|
||||
images = images.resize((w, h), resample=PIL_INTERPOLATION[self.resample])
|
||||
return images
|
||||
|
||||
def preprocess(
|
||||
self,
|
||||
image: Union[torch.FloatTensor, PIL.Image.Image, np.ndarray],
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Preprocess the image input, accepted formats are PIL images, numpy arrays or pytorch tensors"
|
||||
"""
|
||||
supported_formats = (PIL.Image.Image, np.ndarray, torch.Tensor)
|
||||
if isinstance(image, supported_formats):
|
||||
image = [image]
|
||||
elif not (isinstance(image, list) and all(isinstance(i, supported_formats) for i in image)):
|
||||
raise ValueError(
|
||||
f"Input is in incorrect format: {[type(i) for i in image]}. Currently, we only support {', '.join(supported_formats)}"
|
||||
)
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
if self.do_resize:
|
||||
image = [self.resize(i) for i in image]
|
||||
image = [np.array(i).astype(np.float32) / 255.0 for i in image]
|
||||
image = np.stack(image, axis=0) # to np
|
||||
image = self.numpy_to_pt(image) # to pt
|
||||
|
||||
elif isinstance(image[0], np.ndarray):
|
||||
image = np.concatenate(image, axis=0) if image[0].ndim == 4 else np.stack(image, axis=0)
|
||||
image = self.numpy_to_pt(image)
|
||||
_, _, height, width = image.shape
|
||||
if self.do_resize and (height % self.vae_scale_factor != 0 or width % self.vae_scale_factor != 0):
|
||||
raise ValueError(
|
||||
f"Currently we only support resizing for PIL image - please resize your numpy array to be divisible by {self.vae_scale_factor}"
|
||||
f"currently the sizes are {height} and {width}. You can also pass a PIL image instead to use resize option in VAEImageProcessor"
|
||||
)
|
||||
|
||||
elif isinstance(image[0], torch.Tensor):
|
||||
image = torch.cat(image, axis=0) if image[0].ndim == 4 else torch.stack(image, axis=0)
|
||||
_, _, height, width = image.shape
|
||||
if self.do_resize and (height % self.vae_scale_factor != 0 or width % self.vae_scale_factor != 0):
|
||||
raise ValueError(
|
||||
f"Currently we only support resizing for PIL image - please resize your pytorch tensor to be divisible by {self.vae_scale_factor}"
|
||||
f"currently the sizes are {height} and {width}. You can also pass a PIL image instead to use resize option in VAEImageProcessor"
|
||||
)
|
||||
|
||||
# expected range [0,1], normalize to [-1,1]
|
||||
do_normalize = self.do_normalize
|
||||
if image.min() < 0:
|
||||
warnings.warn(
|
||||
"Passing `image` as torch tensor with value range in [-1,1] is deprecated. The expected value range for image tensor is [0,1] "
|
||||
f"when passing as pytorch tensor or numpy Array. You passed `image` with value range [{image.min()},{image.max()}]",
|
||||
FutureWarning,
|
||||
)
|
||||
do_normalize = False
|
||||
|
||||
if do_normalize:
|
||||
image = self.normalize(image)
|
||||
|
||||
return image
|
||||
|
||||
def postprocess(
|
||||
self,
|
||||
image,
|
||||
output_type: str = "pil",
|
||||
):
|
||||
if isinstance(image, torch.Tensor) and output_type == "pt":
|
||||
return image
|
||||
|
||||
image = self.pt_to_numpy(image)
|
||||
|
||||
if output_type == "np":
|
||||
return image
|
||||
elif output_type == "pil":
|
||||
return self.numpy_to_pil(image)
|
||||
else:
|
||||
raise ValueError(f"Unsupported output_type {output_type}.")
|
||||
+28
-38
@@ -17,9 +17,9 @@ from typing import Callable, Dict, Union
|
||||
|
||||
import torch
|
||||
|
||||
from .models.attention_processor import LoRAAttnProcessor
|
||||
from .models.cross_attention import LoRACrossAttnProcessor
|
||||
from .models.modeling_utils import _get_model_file
|
||||
from .utils import DIFFUSERS_CACHE, HF_HUB_OFFLINE, deprecate, is_safetensors_available, logging
|
||||
from .utils import DIFFUSERS_CACHE, HF_HUB_OFFLINE, is_safetensors_available, logging
|
||||
|
||||
|
||||
if is_safetensors_available():
|
||||
@@ -142,17 +142,6 @@ class UNet2DConditionLoadersMixin:
|
||||
revision = kwargs.pop("revision", None)
|
||||
subfolder = kwargs.pop("subfolder", None)
|
||||
weight_name = kwargs.pop("weight_name", None)
|
||||
use_safetensors = kwargs.pop("use_safetensors", None)
|
||||
|
||||
if use_safetensors and not is_safetensors_available():
|
||||
raise ValueError(
|
||||
"`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
|
||||
)
|
||||
|
||||
allow_pickle = False
|
||||
if use_safetensors is None:
|
||||
use_safetensors = is_safetensors_available()
|
||||
allow_pickle = True
|
||||
|
||||
user_agent = {
|
||||
"file_type": "attn_procs_weights",
|
||||
@@ -161,14 +150,13 @@ class UNet2DConditionLoadersMixin:
|
||||
|
||||
model_file = None
|
||||
if not isinstance(pretrained_model_name_or_path_or_dict, dict):
|
||||
# Let's first try to load .safetensors weights
|
||||
if (use_safetensors and weight_name is None) or (
|
||||
weight_name is not None and weight_name.endswith(".safetensors")
|
||||
):
|
||||
if (is_safetensors_available() and weight_name is None) or weight_name.endswith(".safetensors"):
|
||||
if weight_name is None:
|
||||
weight_name = LORA_WEIGHT_NAME_SAFE
|
||||
try:
|
||||
model_file = _get_model_file(
|
||||
pretrained_model_name_or_path_or_dict,
|
||||
weights_name=weight_name or LORA_WEIGHT_NAME_SAFE,
|
||||
weights_name=weight_name,
|
||||
cache_dir=cache_dir,
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
@@ -180,15 +168,15 @@ class UNet2DConditionLoadersMixin:
|
||||
user_agent=user_agent,
|
||||
)
|
||||
state_dict = safetensors.torch.load_file(model_file, device="cpu")
|
||||
except IOError as e:
|
||||
if not allow_pickle:
|
||||
raise e
|
||||
# try loading non-safetensors weights
|
||||
pass
|
||||
except EnvironmentError:
|
||||
if weight_name == LORA_WEIGHT_NAME_SAFE:
|
||||
weight_name = None
|
||||
if model_file is None:
|
||||
if weight_name is None:
|
||||
weight_name = LORA_WEIGHT_NAME
|
||||
model_file = _get_model_file(
|
||||
pretrained_model_name_or_path_or_dict,
|
||||
weights_name=weight_name or LORA_WEIGHT_NAME,
|
||||
weights_name=weight_name,
|
||||
cache_dir=cache_dir,
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
@@ -219,7 +207,7 @@ class UNet2DConditionLoadersMixin:
|
||||
cross_attention_dim = value_dict["to_k_lora.down.weight"].shape[1]
|
||||
hidden_size = value_dict["to_k_lora.up.weight"].shape[0]
|
||||
|
||||
attn_processors[key] = LoRAAttnProcessor(
|
||||
attn_processors[key] = LoRACrossAttnProcessor(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, rank=rank
|
||||
)
|
||||
attn_processors[key].load_state_dict(value_dict)
|
||||
@@ -237,10 +225,9 @@ class UNet2DConditionLoadersMixin:
|
||||
self,
|
||||
save_directory: Union[str, os.PathLike],
|
||||
is_main_process: bool = True,
|
||||
weight_name: str = None,
|
||||
weights_name: str = None,
|
||||
save_function: Callable = None,
|
||||
safe_serialization: bool = False,
|
||||
**kwargs,
|
||||
):
|
||||
r"""
|
||||
Save an attention processor to a directory, so that it can be re-loaded using the
|
||||
@@ -258,12 +245,6 @@ class UNet2DConditionLoadersMixin:
|
||||
need to replace `torch.save` by another method. Can be configured with the environment variable
|
||||
`DIFFUSERS_SAVE_MODE`.
|
||||
"""
|
||||
weight_name = weight_name or deprecate(
|
||||
"weights_name",
|
||||
"0.18.0",
|
||||
"`weights_name` is deprecated, please use `weight_name` instead.",
|
||||
take_from=kwargs,
|
||||
)
|
||||
if os.path.isfile(save_directory):
|
||||
logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
|
||||
return
|
||||
@@ -284,13 +265,22 @@ class UNet2DConditionLoadersMixin:
|
||||
# Save the model
|
||||
state_dict = model_to_save.state_dict()
|
||||
|
||||
if weight_name is None:
|
||||
# Clean the folder from a previous save
|
||||
for filename in os.listdir(save_directory):
|
||||
full_filename = os.path.join(save_directory, filename)
|
||||
# If we have a shard file that is not going to be replaced, we delete it, but only from the main process
|
||||
# in distributed settings to avoid race conditions.
|
||||
weights_no_suffix = weights_name.replace(".bin", "")
|
||||
if filename.startswith(weights_no_suffix) and os.path.isfile(full_filename) and is_main_process:
|
||||
os.remove(full_filename)
|
||||
|
||||
if weights_name is None:
|
||||
if safe_serialization:
|
||||
weight_name = LORA_WEIGHT_NAME_SAFE
|
||||
weights_name = LORA_WEIGHT_NAME_SAFE
|
||||
else:
|
||||
weight_name = LORA_WEIGHT_NAME
|
||||
weights_name = LORA_WEIGHT_NAME
|
||||
|
||||
# Save the model
|
||||
save_function(state_dict, os.path.join(save_directory, weight_name))
|
||||
save_function(state_dict, os.path.join(save_directory, weights_name))
|
||||
|
||||
logger.info(f"Model weights saved in {os.path.join(save_directory, weight_name)}")
|
||||
logger.info(f"Model weights saved in {os.path.join(save_directory, weights_name)}")
|
||||
|
||||
@@ -19,7 +19,7 @@ import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
from ..utils.import_utils import is_xformers_available
|
||||
from .attention_processor import Attention
|
||||
from .cross_attention import CrossAttention
|
||||
from .embeddings import CombinedTimestepLabelEmbeddings
|
||||
|
||||
|
||||
@@ -220,7 +220,7 @@ class BasicTransformerBlock(nn.Module):
|
||||
)
|
||||
|
||||
# 1. Self-Attn
|
||||
self.attn1 = Attention(
|
||||
self.attn1 = CrossAttention(
|
||||
query_dim=dim,
|
||||
heads=num_attention_heads,
|
||||
dim_head=attention_head_dim,
|
||||
@@ -234,7 +234,7 @@ class BasicTransformerBlock(nn.Module):
|
||||
|
||||
# 2. Cross-Attn
|
||||
if cross_attention_dim is not None:
|
||||
self.attn2 = Attention(
|
||||
self.attn2 = CrossAttention(
|
||||
query_dim=dim,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
heads=num_attention_heads,
|
||||
@@ -271,10 +271,9 @@ class BasicTransformerBlock(nn.Module):
|
||||
def forward(
|
||||
self,
|
||||
hidden_states,
|
||||
attention_mask=None,
|
||||
encoder_hidden_states=None,
|
||||
encoder_attention_mask=None,
|
||||
timestep=None,
|
||||
attention_mask=None,
|
||||
cross_attention_kwargs=None,
|
||||
class_labels=None,
|
||||
):
|
||||
@@ -303,14 +302,12 @@ class BasicTransformerBlock(nn.Module):
|
||||
norm_hidden_states = (
|
||||
self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states)
|
||||
)
|
||||
# TODO (Birch-San): Here we should prepare the encoder_attention mask correctly
|
||||
# prepare attention mask here
|
||||
|
||||
# 2. Cross-Attention
|
||||
attn_output = self.attn2(
|
||||
norm_hidden_states,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
attention_mask=encoder_attention_mask,
|
||||
attention_mask=attention_mask,
|
||||
**cross_attention_kwargs,
|
||||
)
|
||||
hidden_states = attn_output + hidden_states
|
||||
|
||||
@@ -16,7 +16,7 @@ import flax.linen as nn
|
||||
import jax.numpy as jnp
|
||||
|
||||
|
||||
class FlaxAttention(nn.Module):
|
||||
class FlaxCrossAttention(nn.Module):
|
||||
r"""
|
||||
A Flax multi-head attention module as described in: https://arxiv.org/abs/1706.03762
|
||||
|
||||
@@ -118,9 +118,9 @@ class FlaxBasicTransformerBlock(nn.Module):
|
||||
|
||||
def setup(self):
|
||||
# self attention (or cross_attention if only_cross_attention is True)
|
||||
self.attn1 = FlaxAttention(self.dim, self.n_heads, self.d_head, self.dropout, dtype=self.dtype)
|
||||
self.attn1 = FlaxCrossAttention(self.dim, self.n_heads, self.d_head, self.dropout, dtype=self.dtype)
|
||||
# cross attention
|
||||
self.attn2 = FlaxAttention(self.dim, self.n_heads, self.d_head, self.dropout, dtype=self.dtype)
|
||||
self.attn2 = FlaxCrossAttention(self.dim, self.n_heads, self.d_head, self.dropout, dtype=self.dtype)
|
||||
self.ff = FlaxFeedForward(dim=self.dim, dropout=self.dropout, dtype=self.dtype)
|
||||
self.norm1 = nn.LayerNorm(epsilon=1e-5, dtype=self.dtype)
|
||||
self.norm2 = nn.LayerNorm(epsilon=1e-5, dtype=self.dtype)
|
||||
|
||||
@@ -1,695 +0,0 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from typing import Callable, Optional, Union
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
from ..utils import deprecate, logging
|
||||
from ..utils.import_utils import is_xformers_available
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
if is_xformers_available():
|
||||
import xformers
|
||||
import xformers.ops
|
||||
else:
|
||||
xformers = None
|
||||
|
||||
|
||||
class Attention(nn.Module):
|
||||
r"""
|
||||
A cross attention layer.
|
||||
|
||||
Parameters:
|
||||
query_dim (`int`): The number of channels in the query.
|
||||
cross_attention_dim (`int`, *optional*):
|
||||
The number of channels in the encoder_hidden_states. If not given, defaults to `query_dim`.
|
||||
heads (`int`, *optional*, defaults to 8): The number of heads to use for multi-head attention.
|
||||
dim_head (`int`, *optional*, defaults to 64): The number of channels in each head.
|
||||
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
||||
bias (`bool`, *optional*, defaults to False):
|
||||
Set to `True` for the query, key, and value linear layers to contain a bias parameter.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
query_dim: int,
|
||||
cross_attention_dim: Optional[int] = None,
|
||||
heads: int = 8,
|
||||
dim_head: int = 64,
|
||||
dropout: float = 0.0,
|
||||
bias=False,
|
||||
upcast_attention: bool = False,
|
||||
upcast_softmax: bool = False,
|
||||
cross_attention_norm: bool = False,
|
||||
added_kv_proj_dim: Optional[int] = None,
|
||||
norm_num_groups: Optional[int] = None,
|
||||
out_bias: bool = True,
|
||||
scale_qk: bool = True,
|
||||
processor: Optional["AttnProcessor"] = None,
|
||||
):
|
||||
super().__init__()
|
||||
inner_dim = dim_head * heads
|
||||
cross_attention_dim = cross_attention_dim if cross_attention_dim is not None else query_dim
|
||||
self.upcast_attention = upcast_attention
|
||||
self.upcast_softmax = upcast_softmax
|
||||
self.cross_attention_norm = cross_attention_norm
|
||||
|
||||
self.scale = dim_head**-0.5 if scale_qk else 1.0
|
||||
|
||||
self.heads = heads
|
||||
# for slice_size > 0 the attention score computation
|
||||
# is split across the batch axis to save memory
|
||||
# You can set slice_size with `set_attention_slice`
|
||||
self.sliceable_head_dim = heads
|
||||
|
||||
self.added_kv_proj_dim = added_kv_proj_dim
|
||||
|
||||
if norm_num_groups is not None:
|
||||
self.group_norm = nn.GroupNorm(num_channels=inner_dim, num_groups=norm_num_groups, eps=1e-5, affine=True)
|
||||
else:
|
||||
self.group_norm = None
|
||||
|
||||
if cross_attention_norm:
|
||||
self.norm_cross = nn.LayerNorm(cross_attention_dim)
|
||||
|
||||
self.to_q = nn.Linear(query_dim, inner_dim, bias=bias)
|
||||
self.to_k = nn.Linear(cross_attention_dim, inner_dim, bias=bias)
|
||||
self.to_v = nn.Linear(cross_attention_dim, inner_dim, bias=bias)
|
||||
|
||||
if self.added_kv_proj_dim is not None:
|
||||
self.add_k_proj = nn.Linear(added_kv_proj_dim, cross_attention_dim)
|
||||
self.add_v_proj = nn.Linear(added_kv_proj_dim, cross_attention_dim)
|
||||
|
||||
self.to_out = nn.ModuleList([])
|
||||
self.to_out.append(nn.Linear(inner_dim, query_dim, bias=out_bias))
|
||||
self.to_out.append(nn.Dropout(dropout))
|
||||
|
||||
# set attention processor
|
||||
# We use the AttnProcessor2_0 by default when torch 2.x is used which uses
|
||||
# torch.nn.functional.scaled_dot_product_attention for native Flash/memory_efficient_attention
|
||||
# but only if it has the default `scale` argument. TODO remove scale_qk check when we move to torch 2.1
|
||||
if processor is None:
|
||||
processor = (
|
||||
AttnProcessor2_0() if hasattr(F, "scaled_dot_product_attention") and scale_qk else AttnProcessor()
|
||||
)
|
||||
self.set_processor(processor)
|
||||
|
||||
def set_use_memory_efficient_attention_xformers(
|
||||
self, use_memory_efficient_attention_xformers: bool, attention_op: Optional[Callable] = None
|
||||
):
|
||||
is_lora = hasattr(self, "processor") and isinstance(
|
||||
self.processor, (LoRAAttnProcessor, LoRAXFormersAttnProcessor)
|
||||
)
|
||||
|
||||
if use_memory_efficient_attention_xformers:
|
||||
if self.added_kv_proj_dim is not None:
|
||||
# TODO(Anton, Patrick, Suraj, William) - currently xformers doesn't work for UnCLIP
|
||||
# which uses this type of cross attention ONLY because the attention mask of format
|
||||
# [0, ..., -10.000, ..., 0, ...,] is not supported
|
||||
raise NotImplementedError(
|
||||
"Memory efficient attention with `xformers` is currently not supported when"
|
||||
" `self.added_kv_proj_dim` is defined."
|
||||
)
|
||||
elif not is_xformers_available():
|
||||
raise ModuleNotFoundError(
|
||||
(
|
||||
"Refer to https://github.com/facebookresearch/xformers for more information on how to install"
|
||||
" xformers"
|
||||
),
|
||||
name="xformers",
|
||||
)
|
||||
elif not torch.cuda.is_available():
|
||||
raise ValueError(
|
||||
"torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is"
|
||||
" only available for GPU "
|
||||
)
|
||||
else:
|
||||
try:
|
||||
# Make sure we can run the memory efficient attention
|
||||
_ = xformers.ops.memory_efficient_attention(
|
||||
torch.randn((1, 2, 40), device="cuda"),
|
||||
torch.randn((1, 2, 40), device="cuda"),
|
||||
torch.randn((1, 2, 40), device="cuda"),
|
||||
)
|
||||
except Exception as e:
|
||||
raise e
|
||||
|
||||
if is_lora:
|
||||
processor = LoRAXFormersAttnProcessor(
|
||||
hidden_size=self.processor.hidden_size,
|
||||
cross_attention_dim=self.processor.cross_attention_dim,
|
||||
rank=self.processor.rank,
|
||||
attention_op=attention_op,
|
||||
)
|
||||
processor.load_state_dict(self.processor.state_dict())
|
||||
processor.to(self.processor.to_q_lora.up.weight.device)
|
||||
else:
|
||||
processor = XFormersAttnProcessor(attention_op=attention_op)
|
||||
else:
|
||||
if is_lora:
|
||||
processor = LoRAAttnProcessor(
|
||||
hidden_size=self.processor.hidden_size,
|
||||
cross_attention_dim=self.processor.cross_attention_dim,
|
||||
rank=self.processor.rank,
|
||||
)
|
||||
processor.load_state_dict(self.processor.state_dict())
|
||||
processor.to(self.processor.to_q_lora.up.weight.device)
|
||||
else:
|
||||
processor = AttnProcessor()
|
||||
|
||||
self.set_processor(processor)
|
||||
|
||||
def set_attention_slice(self, slice_size):
|
||||
if slice_size is not None and slice_size > self.sliceable_head_dim:
|
||||
raise ValueError(f"slice_size {slice_size} has to be smaller or equal to {self.sliceable_head_dim}.")
|
||||
|
||||
if slice_size is not None and self.added_kv_proj_dim is not None:
|
||||
processor = SlicedAttnAddedKVProcessor(slice_size)
|
||||
elif slice_size is not None:
|
||||
processor = SlicedAttnProcessor(slice_size)
|
||||
elif self.added_kv_proj_dim is not None:
|
||||
processor = AttnAddedKVProcessor()
|
||||
else:
|
||||
processor = AttnProcessor()
|
||||
|
||||
self.set_processor(processor)
|
||||
|
||||
def set_processor(self, processor: "AttnProcessor"):
|
||||
# if current processor is in `self._modules` and if passed `processor` is not, we need to
|
||||
# pop `processor` from `self._modules`
|
||||
if (
|
||||
hasattr(self, "processor")
|
||||
and isinstance(self.processor, torch.nn.Module)
|
||||
and not isinstance(processor, torch.nn.Module)
|
||||
):
|
||||
logger.info(f"You are removing possibly trained weights of {self.processor} with {processor}")
|
||||
self._modules.pop("processor")
|
||||
|
||||
self.processor = processor
|
||||
|
||||
def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, **cross_attention_kwargs):
|
||||
# The `Attention` class can call different attention processors / attention functions
|
||||
# here we simply pass along all tensors to the selected processor class
|
||||
# For standard processors that are defined here, `**cross_attention_kwargs` is empty
|
||||
return self.processor(
|
||||
self,
|
||||
hidden_states,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
**cross_attention_kwargs,
|
||||
)
|
||||
|
||||
def batch_to_head_dim(self, tensor):
|
||||
head_size = self.heads
|
||||
batch_size, seq_len, dim = tensor.shape
|
||||
tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
|
||||
tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size // head_size, seq_len, dim * head_size)
|
||||
return tensor
|
||||
|
||||
def head_to_batch_dim(self, tensor):
|
||||
head_size = self.heads
|
||||
batch_size, seq_len, dim = tensor.shape
|
||||
tensor = tensor.reshape(batch_size, seq_len, head_size, dim // head_size)
|
||||
tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size * head_size, seq_len, dim // head_size)
|
||||
return tensor
|
||||
|
||||
def get_attention_scores(self, query, key, attention_mask=None):
|
||||
dtype = query.dtype
|
||||
if self.upcast_attention:
|
||||
query = query.float()
|
||||
key = key.float()
|
||||
|
||||
if attention_mask is None:
|
||||
baddbmm_input = torch.empty(
|
||||
query.shape[0], query.shape[1], key.shape[1], dtype=query.dtype, device=query.device
|
||||
)
|
||||
beta = 0
|
||||
else:
|
||||
baddbmm_input = attention_mask
|
||||
beta = 1
|
||||
|
||||
attention_scores = torch.baddbmm(
|
||||
baddbmm_input,
|
||||
query,
|
||||
key.transpose(-1, -2),
|
||||
beta=beta,
|
||||
alpha=self.scale,
|
||||
)
|
||||
|
||||
if self.upcast_softmax:
|
||||
attention_scores = attention_scores.float()
|
||||
|
||||
attention_probs = attention_scores.softmax(dim=-1)
|
||||
attention_probs = attention_probs.to(dtype)
|
||||
|
||||
return attention_probs
|
||||
|
||||
def prepare_attention_mask(self, attention_mask, target_length, batch_size=None):
|
||||
if batch_size is None:
|
||||
deprecate(
|
||||
"batch_size=None",
|
||||
"0.0.15",
|
||||
(
|
||||
"Not passing the `batch_size` parameter to `prepare_attention_mask` can lead to incorrect"
|
||||
" attention mask preparation and is deprecated behavior. Please make sure to pass `batch_size` to"
|
||||
" `prepare_attention_mask` when preparing the attention_mask."
|
||||
),
|
||||
)
|
||||
batch_size = 1
|
||||
|
||||
head_size = self.heads
|
||||
if attention_mask is None:
|
||||
return attention_mask
|
||||
|
||||
if attention_mask.shape[-1] != target_length:
|
||||
if attention_mask.device.type == "mps":
|
||||
# HACK: MPS: Does not support padding by greater than dimension of input tensor.
|
||||
# Instead, we can manually construct the padding tensor.
|
||||
padding_shape = (attention_mask.shape[0], attention_mask.shape[1], target_length)
|
||||
padding = torch.zeros(padding_shape, dtype=attention_mask.dtype, device=attention_mask.device)
|
||||
attention_mask = torch.cat([attention_mask, padding], dim=2)
|
||||
else:
|
||||
attention_mask = F.pad(attention_mask, (0, target_length), value=0.0)
|
||||
|
||||
if attention_mask.shape[0] < batch_size * head_size:
|
||||
attention_mask = attention_mask.repeat_interleave(head_size, dim=0)
|
||||
return attention_mask
|
||||
|
||||
|
||||
class AttnProcessor:
|
||||
def __call__(
|
||||
self,
|
||||
attn: Attention,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.cross_attention_norm:
|
||||
encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
|
||||
query = attn.head_to_batch_dim(query)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
||||
hidden_states = torch.bmm(attention_probs, value)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class LoRALinearLayer(nn.Module):
|
||||
def __init__(self, in_features, out_features, rank=4):
|
||||
super().__init__()
|
||||
|
||||
if rank > min(in_features, out_features):
|
||||
raise ValueError(f"LoRA rank {rank} must be less or equal than {min(in_features, out_features)}")
|
||||
|
||||
self.down = nn.Linear(in_features, rank, bias=False)
|
||||
self.up = nn.Linear(rank, out_features, bias=False)
|
||||
|
||||
nn.init.normal_(self.down.weight, std=1 / rank)
|
||||
nn.init.zeros_(self.up.weight)
|
||||
|
||||
def forward(self, hidden_states):
|
||||
orig_dtype = hidden_states.dtype
|
||||
dtype = self.down.weight.dtype
|
||||
|
||||
down_hidden_states = self.down(hidden_states.to(dtype))
|
||||
up_hidden_states = self.up(down_hidden_states)
|
||||
|
||||
return up_hidden_states.to(orig_dtype)
|
||||
|
||||
|
||||
class LoRAAttnProcessor(nn.Module):
|
||||
def __init__(self, hidden_size, cross_attention_dim=None, rank=4):
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.rank = rank
|
||||
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
query = attn.to_q(hidden_states) + scale * self.to_q_lora(hidden_states)
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
|
||||
|
||||
key = attn.to_k(encoder_hidden_states) + scale * self.to_k_lora(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states) + scale * self.to_v_lora(encoder_hidden_states)
|
||||
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
||||
hidden_states = torch.bmm(attention_probs, value)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states) + scale * self.to_out_lora(hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class AttnAddedKVProcessor:
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
residual = hidden_states
|
||||
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
encoder_hidden_states = encoder_hidden_states.transpose(1, 2)
|
||||
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
key = attn.to_k(hidden_states)
|
||||
value = attn.to_v(hidden_states)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
|
||||
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
|
||||
encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj)
|
||||
encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj)
|
||||
|
||||
key = torch.cat([encoder_hidden_states_key_proj, key], dim=1)
|
||||
value = torch.cat([encoder_hidden_states_value_proj, value], dim=1)
|
||||
|
||||
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
||||
hidden_states = torch.bmm(attention_probs, value)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
|
||||
hidden_states = hidden_states + residual
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class XFormersAttnProcessor:
|
||||
def __init__(self, attention_op: Optional[Callable] = None):
|
||||
self.attention_op = attention_op
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.cross_attention_norm:
|
||||
encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
|
||||
query = attn.head_to_batch_dim(query).contiguous()
|
||||
key = attn.head_to_batch_dim(key).contiguous()
|
||||
value = attn.head_to_batch_dim(value).contiguous()
|
||||
|
||||
hidden_states = xformers.ops.memory_efficient_attention(
|
||||
query, key, value, attn_bias=attention_mask, op=self.attention_op, scale=attn.scale
|
||||
)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class AttnProcessor2_0:
|
||||
def __init__(self):
|
||||
if not hasattr(F, "scaled_dot_product_attention"):
|
||||
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
inner_dim = hidden_states.shape[-1]
|
||||
|
||||
if attention_mask is not None:
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
# scaled_dot_product_attention expects attention_mask shape to be
|
||||
# (batch, heads, source_length, target_length)
|
||||
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.cross_attention_norm:
|
||||
encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
|
||||
head_dim = inner_dim // attn.heads
|
||||
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
hidden_states = F.scaled_dot_product_attention(
|
||||
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class LoRAXFormersAttnProcessor(nn.Module):
|
||||
def __init__(self, hidden_size, cross_attention_dim, rank=4, attention_op: Optional[Callable] = None):
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.rank = rank
|
||||
self.attention_op = attention_op
|
||||
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
query = attn.to_q(hidden_states) + scale * self.to_q_lora(hidden_states)
|
||||
query = attn.head_to_batch_dim(query).contiguous()
|
||||
|
||||
encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
|
||||
|
||||
key = attn.to_k(encoder_hidden_states) + scale * self.to_k_lora(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states) + scale * self.to_v_lora(encoder_hidden_states)
|
||||
|
||||
key = attn.head_to_batch_dim(key).contiguous()
|
||||
value = attn.head_to_batch_dim(value).contiguous()
|
||||
|
||||
hidden_states = xformers.ops.memory_efficient_attention(
|
||||
query, key, value, attn_bias=attention_mask, op=self.attention_op, scale=attn.scale
|
||||
)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states) + scale * self.to_out_lora(hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class SlicedAttnProcessor:
|
||||
def __init__(self, slice_size):
|
||||
self.slice_size = slice_size
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
dim = query.shape[-1]
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.cross_attention_norm:
|
||||
encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
batch_size_attention, query_tokens, _ = query.shape
|
||||
hidden_states = torch.zeros(
|
||||
(batch_size_attention, query_tokens, dim // attn.heads), device=query.device, dtype=query.dtype
|
||||
)
|
||||
|
||||
for i in range(batch_size_attention // self.slice_size):
|
||||
start_idx = i * self.slice_size
|
||||
end_idx = (i + 1) * self.slice_size
|
||||
|
||||
query_slice = query[start_idx:end_idx]
|
||||
key_slice = key[start_idx:end_idx]
|
||||
attn_mask_slice = attention_mask[start_idx:end_idx] if attention_mask is not None else None
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
|
||||
|
||||
hidden_states[start_idx:end_idx] = attn_slice
|
||||
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class SlicedAttnAddedKVProcessor:
|
||||
def __init__(self, slice_size):
|
||||
self.slice_size = slice_size
|
||||
|
||||
def __call__(self, attn: "Attention", hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
residual = hidden_states
|
||||
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
|
||||
encoder_hidden_states = encoder_hidden_states.transpose(1, 2)
|
||||
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
dim = query.shape[-1]
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
key = attn.to_k(hidden_states)
|
||||
value = attn.to_v(hidden_states)
|
||||
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
|
||||
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
|
||||
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj)
|
||||
encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj)
|
||||
|
||||
key = torch.cat([encoder_hidden_states_key_proj, key], dim=1)
|
||||
value = torch.cat([encoder_hidden_states_value_proj, value], dim=1)
|
||||
|
||||
batch_size_attention, query_tokens, _ = query.shape
|
||||
hidden_states = torch.zeros(
|
||||
(batch_size_attention, query_tokens, dim // attn.heads), device=query.device, dtype=query.dtype
|
||||
)
|
||||
|
||||
for i in range(batch_size_attention // self.slice_size):
|
||||
start_idx = i * self.slice_size
|
||||
end_idx = (i + 1) * self.slice_size
|
||||
|
||||
query_slice = query[start_idx:end_idx]
|
||||
key_slice = key[start_idx:end_idx]
|
||||
attn_mask_slice = attention_mask[start_idx:end_idx] if attention_mask is not None else None
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
|
||||
|
||||
hidden_states[start_idx:end_idx] = attn_slice
|
||||
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
|
||||
hidden_states = hidden_states + residual
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
AttentionProcessor = Union[
|
||||
AttnProcessor,
|
||||
XFormersAttnProcessor,
|
||||
SlicedAttnProcessor,
|
||||
AttnAddedKVProcessor,
|
||||
SlicedAttnAddedKVProcessor,
|
||||
LoRAAttnProcessor,
|
||||
LoRAXFormersAttnProcessor,
|
||||
]
|
||||
@@ -190,12 +190,12 @@ class AutoencoderKL(ModelMixin, ConfigMixin):
|
||||
return DecoderOutput(sample=decoded)
|
||||
|
||||
def blend_v(self, a, b, blend_extent):
|
||||
for y in range(min(a.shape[2], b.shape[2], blend_extent)):
|
||||
for y in range(blend_extent):
|
||||
b[:, :, y, :] = a[:, :, -blend_extent + y, :] * (1 - y / blend_extent) + b[:, :, y, :] * (y / blend_extent)
|
||||
return b
|
||||
|
||||
def blend_h(self, a, b, blend_extent):
|
||||
for x in range(min(a.shape[3], b.shape[3], blend_extent)):
|
||||
for x in range(blend_extent):
|
||||
b[:, :, :, x] = a[:, :, :, -blend_extent + x] * (1 - x / blend_extent) + b[:, :, :, x] * (x / blend_extent)
|
||||
return b
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ from torch.nn import functional as F
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..utils import BaseOutput, logging
|
||||
from .attention_processor import AttentionProcessor
|
||||
from .cross_attention import AttnProcessor
|
||||
from .embeddings import TimestepEmbedding, Timesteps
|
||||
from .modeling_utils import ModelMixin
|
||||
from .unet_2d_blocks import (
|
||||
@@ -29,7 +29,6 @@ from .unet_2d_blocks import (
|
||||
UNetMidBlock2DCrossAttn,
|
||||
get_down_block,
|
||||
)
|
||||
from .unet_2d_condition import UNet2DConditionModel
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -258,63 +257,9 @@ class ControlNetModel(ModelMixin, ConfigMixin):
|
||||
upcast_attention=upcast_attention,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_unet(
|
||||
cls,
|
||||
unet: UNet2DConditionModel,
|
||||
controlnet_conditioning_channel_order: str = "rgb",
|
||||
conditioning_embedding_out_channels: Optional[Tuple[int]] = (16, 32, 96, 256),
|
||||
load_weights_from_unet: bool = True,
|
||||
):
|
||||
r"""
|
||||
Instantiate Controlnet class from UNet2DConditionModel.
|
||||
|
||||
Parameters:
|
||||
unet (`UNet2DConditionModel`):
|
||||
UNet model which weights are copied to the ControlNet. Note that all configuration options are also
|
||||
copied where applicable.
|
||||
"""
|
||||
controlnet = cls(
|
||||
in_channels=unet.config.in_channels,
|
||||
flip_sin_to_cos=unet.config.flip_sin_to_cos,
|
||||
freq_shift=unet.config.freq_shift,
|
||||
down_block_types=unet.config.down_block_types,
|
||||
only_cross_attention=unet.config.only_cross_attention,
|
||||
block_out_channels=unet.config.block_out_channels,
|
||||
layers_per_block=unet.config.layers_per_block,
|
||||
downsample_padding=unet.config.downsample_padding,
|
||||
mid_block_scale_factor=unet.config.mid_block_scale_factor,
|
||||
act_fn=unet.config.act_fn,
|
||||
norm_num_groups=unet.config.norm_num_groups,
|
||||
norm_eps=unet.config.norm_eps,
|
||||
cross_attention_dim=unet.config.cross_attention_dim,
|
||||
attention_head_dim=unet.config.attention_head_dim,
|
||||
use_linear_projection=unet.config.use_linear_projection,
|
||||
class_embed_type=unet.config.class_embed_type,
|
||||
num_class_embeds=unet.config.num_class_embeds,
|
||||
upcast_attention=unet.config.upcast_attention,
|
||||
resnet_time_scale_shift=unet.config.resnet_time_scale_shift,
|
||||
projection_class_embeddings_input_dim=unet.config.projection_class_embeddings_input_dim,
|
||||
controlnet_conditioning_channel_order=controlnet_conditioning_channel_order,
|
||||
conditioning_embedding_out_channels=conditioning_embedding_out_channels,
|
||||
)
|
||||
|
||||
if load_weights_from_unet:
|
||||
controlnet.conv_in.load_state_dict(unet.conv_in.state_dict())
|
||||
controlnet.time_proj.load_state_dict(unet.time_proj.state_dict())
|
||||
controlnet.time_embedding.load_state_dict(unet.time_embedding.state_dict())
|
||||
|
||||
if controlnet.class_embedding:
|
||||
controlnet.class_embedding.load_state_dict(unet.class_embedding.state_dict())
|
||||
|
||||
controlnet.down_blocks.load_state_dict(unet.down_blocks.state_dict())
|
||||
controlnet.mid_block.load_state_dict(unet.mid_block.state_dict())
|
||||
|
||||
return controlnet
|
||||
|
||||
@property
|
||||
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.attn_processors
|
||||
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
||||
def attn_processors(self) -> Dict[str, AttnProcessor]:
|
||||
r"""
|
||||
Returns:
|
||||
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
||||
@@ -323,7 +268,7 @@ class ControlNetModel(ModelMixin, ConfigMixin):
|
||||
# set recursively
|
||||
processors = {}
|
||||
|
||||
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
||||
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttnProcessor]):
|
||||
if hasattr(module, "set_processor"):
|
||||
processors[f"{name}.processor"] = module.processor
|
||||
|
||||
@@ -338,12 +283,12 @@ class ControlNetModel(ModelMixin, ConfigMixin):
|
||||
return processors
|
||||
|
||||
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attn_processor
|
||||
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
||||
def set_attn_processor(self, processor: Union[AttnProcessor, Dict[str, AttnProcessor]]):
|
||||
r"""
|
||||
Parameters:
|
||||
`processor (`dict` of `AttentionProcessor` or `AttentionProcessor`):
|
||||
`processor (`dict` of `AttnProcessor` or `AttnProcessor`):
|
||||
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
||||
of **all** `Attention` layers.
|
||||
of **all** `CrossAttention` layers.
|
||||
In case `processor` is a dict, the key needs to define the path to the corresponding cross attention processor. This is strongly recommended when setting trainablae attention processors.:
|
||||
|
||||
"""
|
||||
@@ -444,7 +389,6 @@ class ControlNetModel(ModelMixin, ConfigMixin):
|
||||
timestep: Union[torch.Tensor, float, int],
|
||||
encoder_hidden_states: torch.Tensor,
|
||||
controlnet_cond: torch.FloatTensor,
|
||||
conditioning_scale: float = 1.0,
|
||||
class_labels: Optional[torch.Tensor] = None,
|
||||
timestep_cond: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
@@ -548,10 +492,6 @@ class ControlNetModel(ModelMixin, ConfigMixin):
|
||||
|
||||
mid_block_res_sample = self.controlnet_mid_block(sample)
|
||||
|
||||
# 6. scaling
|
||||
down_block_res_samples = [sample * conditioning_scale for sample in down_block_res_samples]
|
||||
mid_block_res_sample *= conditioning_scale
|
||||
|
||||
if not return_dict:
|
||||
return (down_block_res_samples, mid_block_res_sample)
|
||||
|
||||
|
||||
@@ -11,86 +11,671 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from ..utils import deprecate
|
||||
from .attention_processor import ( # noqa: F401
|
||||
Attention,
|
||||
AttentionProcessor,
|
||||
AttnAddedKVProcessor,
|
||||
AttnProcessor2_0,
|
||||
LoRAAttnProcessor,
|
||||
LoRALinearLayer,
|
||||
LoRAXFormersAttnProcessor,
|
||||
SlicedAttnAddedKVProcessor,
|
||||
from typing import Callable, Optional, Union
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
from ..utils import deprecate, logging
|
||||
from ..utils.import_utils import is_xformers_available
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
if is_xformers_available():
|
||||
import xformers
|
||||
import xformers.ops
|
||||
else:
|
||||
xformers = None
|
||||
|
||||
|
||||
class CrossAttention(nn.Module):
|
||||
r"""
|
||||
A cross attention layer.
|
||||
|
||||
Parameters:
|
||||
query_dim (`int`): The number of channels in the query.
|
||||
cross_attention_dim (`int`, *optional*):
|
||||
The number of channels in the encoder_hidden_states. If not given, defaults to `query_dim`.
|
||||
heads (`int`, *optional*, defaults to 8): The number of heads to use for multi-head attention.
|
||||
dim_head (`int`, *optional*, defaults to 64): The number of channels in each head.
|
||||
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
||||
bias (`bool`, *optional*, defaults to False):
|
||||
Set to `True` for the query, key, and value linear layers to contain a bias parameter.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
query_dim: int,
|
||||
cross_attention_dim: Optional[int] = None,
|
||||
heads: int = 8,
|
||||
dim_head: int = 64,
|
||||
dropout: float = 0.0,
|
||||
bias=False,
|
||||
upcast_attention: bool = False,
|
||||
upcast_softmax: bool = False,
|
||||
cross_attention_norm: bool = False,
|
||||
added_kv_proj_dim: Optional[int] = None,
|
||||
norm_num_groups: Optional[int] = None,
|
||||
processor: Optional["AttnProcessor"] = None,
|
||||
):
|
||||
super().__init__()
|
||||
inner_dim = dim_head * heads
|
||||
cross_attention_dim = cross_attention_dim if cross_attention_dim is not None else query_dim
|
||||
self.upcast_attention = upcast_attention
|
||||
self.upcast_softmax = upcast_softmax
|
||||
self.cross_attention_norm = cross_attention_norm
|
||||
|
||||
self.scale = dim_head**-0.5
|
||||
|
||||
self.heads = heads
|
||||
# for slice_size > 0 the attention score computation
|
||||
# is split across the batch axis to save memory
|
||||
# You can set slice_size with `set_attention_slice`
|
||||
self.sliceable_head_dim = heads
|
||||
|
||||
self.added_kv_proj_dim = added_kv_proj_dim
|
||||
|
||||
if norm_num_groups is not None:
|
||||
self.group_norm = nn.GroupNorm(num_channels=inner_dim, num_groups=norm_num_groups, eps=1e-5, affine=True)
|
||||
else:
|
||||
self.group_norm = None
|
||||
|
||||
if cross_attention_norm:
|
||||
self.norm_cross = nn.LayerNorm(cross_attention_dim)
|
||||
|
||||
self.to_q = nn.Linear(query_dim, inner_dim, bias=bias)
|
||||
self.to_k = nn.Linear(cross_attention_dim, inner_dim, bias=bias)
|
||||
self.to_v = nn.Linear(cross_attention_dim, inner_dim, bias=bias)
|
||||
|
||||
if self.added_kv_proj_dim is not None:
|
||||
self.add_k_proj = nn.Linear(added_kv_proj_dim, cross_attention_dim)
|
||||
self.add_v_proj = nn.Linear(added_kv_proj_dim, cross_attention_dim)
|
||||
|
||||
self.to_out = nn.ModuleList([])
|
||||
self.to_out.append(nn.Linear(inner_dim, query_dim))
|
||||
self.to_out.append(nn.Dropout(dropout))
|
||||
|
||||
# set attention processor
|
||||
# We use the AttnProcessor2_0 by default when torch2.x is used which uses
|
||||
# torch.nn.functional.scaled_dot_product_attention for native Flash/memory_efficient_attention
|
||||
if processor is None:
|
||||
processor = AttnProcessor2_0() if hasattr(F, "scaled_dot_product_attention") else CrossAttnProcessor()
|
||||
self.set_processor(processor)
|
||||
|
||||
def set_use_memory_efficient_attention_xformers(
|
||||
self, use_memory_efficient_attention_xformers: bool, attention_op: Optional[Callable] = None
|
||||
):
|
||||
is_lora = hasattr(self, "processor") and isinstance(
|
||||
self.processor, (LoRACrossAttnProcessor, LoRAXFormersCrossAttnProcessor)
|
||||
)
|
||||
|
||||
if use_memory_efficient_attention_xformers:
|
||||
if self.added_kv_proj_dim is not None:
|
||||
# TODO(Anton, Patrick, Suraj, William) - currently xformers doesn't work for UnCLIP
|
||||
# which uses this type of cross attention ONLY because the attention mask of format
|
||||
# [0, ..., -10.000, ..., 0, ...,] is not supported
|
||||
raise NotImplementedError(
|
||||
"Memory efficient attention with `xformers` is currently not supported when"
|
||||
" `self.added_kv_proj_dim` is defined."
|
||||
)
|
||||
elif not is_xformers_available():
|
||||
raise ModuleNotFoundError(
|
||||
(
|
||||
"Refer to https://github.com/facebookresearch/xformers for more information on how to install"
|
||||
" xformers"
|
||||
),
|
||||
name="xformers",
|
||||
)
|
||||
elif not torch.cuda.is_available():
|
||||
raise ValueError(
|
||||
"torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is"
|
||||
" only available for GPU "
|
||||
)
|
||||
else:
|
||||
try:
|
||||
# Make sure we can run the memory efficient attention
|
||||
_ = xformers.ops.memory_efficient_attention(
|
||||
torch.randn((1, 2, 40), device="cuda"),
|
||||
torch.randn((1, 2, 40), device="cuda"),
|
||||
torch.randn((1, 2, 40), device="cuda"),
|
||||
)
|
||||
except Exception as e:
|
||||
raise e
|
||||
|
||||
if is_lora:
|
||||
processor = LoRAXFormersCrossAttnProcessor(
|
||||
hidden_size=self.processor.hidden_size,
|
||||
cross_attention_dim=self.processor.cross_attention_dim,
|
||||
rank=self.processor.rank,
|
||||
attention_op=attention_op,
|
||||
)
|
||||
processor.load_state_dict(self.processor.state_dict())
|
||||
processor.to(self.processor.to_q_lora.up.weight.device)
|
||||
else:
|
||||
processor = XFormersCrossAttnProcessor(attention_op=attention_op)
|
||||
else:
|
||||
if is_lora:
|
||||
processor = LoRACrossAttnProcessor(
|
||||
hidden_size=self.processor.hidden_size,
|
||||
cross_attention_dim=self.processor.cross_attention_dim,
|
||||
rank=self.processor.rank,
|
||||
)
|
||||
processor.load_state_dict(self.processor.state_dict())
|
||||
processor.to(self.processor.to_q_lora.up.weight.device)
|
||||
else:
|
||||
processor = CrossAttnProcessor()
|
||||
|
||||
self.set_processor(processor)
|
||||
|
||||
def set_attention_slice(self, slice_size):
|
||||
if slice_size is not None and slice_size > self.sliceable_head_dim:
|
||||
raise ValueError(f"slice_size {slice_size} has to be smaller or equal to {self.sliceable_head_dim}.")
|
||||
|
||||
if slice_size is not None and self.added_kv_proj_dim is not None:
|
||||
processor = SlicedAttnAddedKVProcessor(slice_size)
|
||||
elif slice_size is not None:
|
||||
processor = SlicedAttnProcessor(slice_size)
|
||||
elif self.added_kv_proj_dim is not None:
|
||||
processor = CrossAttnAddedKVProcessor()
|
||||
else:
|
||||
processor = CrossAttnProcessor()
|
||||
|
||||
self.set_processor(processor)
|
||||
|
||||
def set_processor(self, processor: "AttnProcessor"):
|
||||
# if current processor is in `self._modules` and if passed `processor` is not, we need to
|
||||
# pop `processor` from `self._modules`
|
||||
if (
|
||||
hasattr(self, "processor")
|
||||
and isinstance(self.processor, torch.nn.Module)
|
||||
and not isinstance(processor, torch.nn.Module)
|
||||
):
|
||||
logger.info(f"You are removing possibly trained weights of {self.processor} with {processor}")
|
||||
self._modules.pop("processor")
|
||||
|
||||
self.processor = processor
|
||||
|
||||
def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, **cross_attention_kwargs):
|
||||
# The `CrossAttention` class can call different attention processors / attention functions
|
||||
# here we simply pass along all tensors to the selected processor class
|
||||
# For standard processors that are defined here, `**cross_attention_kwargs` is empty
|
||||
return self.processor(
|
||||
self,
|
||||
hidden_states,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
**cross_attention_kwargs,
|
||||
)
|
||||
|
||||
def batch_to_head_dim(self, tensor):
|
||||
head_size = self.heads
|
||||
batch_size, seq_len, dim = tensor.shape
|
||||
tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
|
||||
tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size // head_size, seq_len, dim * head_size)
|
||||
return tensor
|
||||
|
||||
def head_to_batch_dim(self, tensor):
|
||||
head_size = self.heads
|
||||
batch_size, seq_len, dim = tensor.shape
|
||||
tensor = tensor.reshape(batch_size, seq_len, head_size, dim // head_size)
|
||||
tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size * head_size, seq_len, dim // head_size)
|
||||
return tensor
|
||||
|
||||
def get_attention_scores(self, query, key, attention_mask=None):
|
||||
dtype = query.dtype
|
||||
if self.upcast_attention:
|
||||
query = query.float()
|
||||
key = key.float()
|
||||
|
||||
if attention_mask is None:
|
||||
baddbmm_input = torch.empty(
|
||||
query.shape[0], query.shape[1], key.shape[1], dtype=query.dtype, device=query.device
|
||||
)
|
||||
beta = 0
|
||||
else:
|
||||
baddbmm_input = attention_mask
|
||||
beta = 1
|
||||
|
||||
attention_scores = torch.baddbmm(
|
||||
baddbmm_input,
|
||||
query,
|
||||
key.transpose(-1, -2),
|
||||
beta=beta,
|
||||
alpha=self.scale,
|
||||
)
|
||||
|
||||
if self.upcast_softmax:
|
||||
attention_scores = attention_scores.float()
|
||||
|
||||
attention_probs = attention_scores.softmax(dim=-1)
|
||||
attention_probs = attention_probs.to(dtype)
|
||||
|
||||
return attention_probs
|
||||
|
||||
def prepare_attention_mask(self, attention_mask, target_length, batch_size=None):
|
||||
if batch_size is None:
|
||||
deprecate(
|
||||
"batch_size=None",
|
||||
"0.0.15",
|
||||
(
|
||||
"Not passing the `batch_size` parameter to `prepare_attention_mask` can lead to incorrect"
|
||||
" attention mask preparation and is deprecated behavior. Please make sure to pass `batch_size` to"
|
||||
" `prepare_attention_mask` when preparing the attention_mask."
|
||||
),
|
||||
)
|
||||
batch_size = 1
|
||||
|
||||
head_size = self.heads
|
||||
if attention_mask is None:
|
||||
return attention_mask
|
||||
|
||||
if attention_mask.shape[-1] != target_length:
|
||||
if attention_mask.device.type == "mps":
|
||||
# HACK: MPS: Does not support padding by greater than dimension of input tensor.
|
||||
# Instead, we can manually construct the padding tensor.
|
||||
padding_shape = (attention_mask.shape[0], attention_mask.shape[1], target_length)
|
||||
padding = torch.zeros(padding_shape, dtype=attention_mask.dtype, device=attention_mask.device)
|
||||
attention_mask = torch.cat([attention_mask, padding], dim=2)
|
||||
else:
|
||||
attention_mask = F.pad(attention_mask, (0, target_length), value=0.0)
|
||||
|
||||
if attention_mask.shape[0] < batch_size * head_size:
|
||||
attention_mask = attention_mask.repeat_interleave(head_size, dim=0)
|
||||
return attention_mask
|
||||
|
||||
|
||||
class CrossAttnProcessor:
|
||||
def __call__(
|
||||
self,
|
||||
attn: CrossAttention,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
):
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.cross_attention_norm:
|
||||
encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
|
||||
query = attn.head_to_batch_dim(query)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
||||
hidden_states = torch.bmm(attention_probs, value)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class LoRALinearLayer(nn.Module):
|
||||
def __init__(self, in_features, out_features, rank=4):
|
||||
super().__init__()
|
||||
|
||||
if rank > min(in_features, out_features):
|
||||
raise ValueError(f"LoRA rank {rank} must be less or equal than {min(in_features, out_features)}")
|
||||
|
||||
self.down = nn.Linear(in_features, rank, bias=False)
|
||||
self.up = nn.Linear(rank, out_features, bias=False)
|
||||
|
||||
nn.init.normal_(self.down.weight, std=1 / rank)
|
||||
nn.init.zeros_(self.up.weight)
|
||||
|
||||
def forward(self, hidden_states):
|
||||
orig_dtype = hidden_states.dtype
|
||||
dtype = self.down.weight.dtype
|
||||
|
||||
down_hidden_states = self.down(hidden_states.to(dtype))
|
||||
up_hidden_states = self.up(down_hidden_states)
|
||||
|
||||
return up_hidden_states.to(orig_dtype)
|
||||
|
||||
|
||||
class LoRACrossAttnProcessor(nn.Module):
|
||||
def __init__(self, hidden_size, cross_attention_dim=None, rank=4):
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.rank = rank
|
||||
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
|
||||
def __call__(
|
||||
self, attn: CrossAttention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0
|
||||
):
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
query = attn.to_q(hidden_states) + scale * self.to_q_lora(hidden_states)
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
|
||||
|
||||
key = attn.to_k(encoder_hidden_states) + scale * self.to_k_lora(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states) + scale * self.to_v_lora(encoder_hidden_states)
|
||||
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
||||
hidden_states = torch.bmm(attention_probs, value)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states) + scale * self.to_out_lora(hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class CrossAttnAddedKVProcessor:
|
||||
def __call__(self, attn: CrossAttention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
residual = hidden_states
|
||||
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
encoder_hidden_states = encoder_hidden_states.transpose(1, 2)
|
||||
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
key = attn.to_k(hidden_states)
|
||||
value = attn.to_v(hidden_states)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
|
||||
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
|
||||
encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj)
|
||||
encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj)
|
||||
|
||||
key = torch.cat([encoder_hidden_states_key_proj, key], dim=1)
|
||||
value = torch.cat([encoder_hidden_states_value_proj, value], dim=1)
|
||||
|
||||
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
||||
hidden_states = torch.bmm(attention_probs, value)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
|
||||
hidden_states = hidden_states + residual
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class XFormersCrossAttnProcessor:
|
||||
def __init__(self, attention_op: Optional[Callable] = None):
|
||||
self.attention_op = attention_op
|
||||
|
||||
def __call__(self, attn: CrossAttention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.cross_attention_norm:
|
||||
encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
|
||||
query = attn.head_to_batch_dim(query).contiguous()
|
||||
key = attn.head_to_batch_dim(key).contiguous()
|
||||
value = attn.head_to_batch_dim(value).contiguous()
|
||||
|
||||
hidden_states = xformers.ops.memory_efficient_attention(
|
||||
query, key, value, attn_bias=attention_mask, op=self.attention_op
|
||||
)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class AttnProcessor2_0:
|
||||
def __init__(self):
|
||||
if not hasattr(F, "scaled_dot_product_attention"):
|
||||
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
||||
|
||||
def __call__(self, attn: CrossAttention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
batch_size, sequence_length, inner_dim = hidden_states.shape
|
||||
|
||||
if attention_mask is not None:
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
# scaled_dot_product_attention expects attention_mask shape to be
|
||||
# (batch, heads, source_length, target_length)
|
||||
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.cross_attention_norm:
|
||||
encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
|
||||
head_dim = inner_dim // attn.heads
|
||||
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
||||
hidden_states = F.scaled_dot_product_attention(
|
||||
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class LoRAXFormersCrossAttnProcessor(nn.Module):
|
||||
def __init__(self, hidden_size, cross_attention_dim, rank=4, attention_op: Optional[Callable] = None):
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.rank = rank
|
||||
self.attention_op = attention_op
|
||||
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
|
||||
def __call__(
|
||||
self, attn: CrossAttention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0
|
||||
):
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
query = attn.to_q(hidden_states) + scale * self.to_q_lora(hidden_states)
|
||||
query = attn.head_to_batch_dim(query).contiguous()
|
||||
|
||||
encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
|
||||
|
||||
key = attn.to_k(encoder_hidden_states) + scale * self.to_k_lora(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states) + scale * self.to_v_lora(encoder_hidden_states)
|
||||
|
||||
key = attn.head_to_batch_dim(key).contiguous()
|
||||
value = attn.head_to_batch_dim(value).contiguous()
|
||||
|
||||
hidden_states = xformers.ops.memory_efficient_attention(
|
||||
query, key, value, attn_bias=attention_mask, op=self.attention_op
|
||||
)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states) + scale * self.to_out_lora(hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class SlicedAttnProcessor:
|
||||
def __init__(self, slice_size):
|
||||
self.slice_size = slice_size
|
||||
|
||||
def __call__(self, attn: CrossAttention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
dim = query.shape[-1]
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.cross_attention_norm:
|
||||
encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
batch_size_attention = query.shape[0]
|
||||
hidden_states = torch.zeros(
|
||||
(batch_size_attention, sequence_length, dim // attn.heads), device=query.device, dtype=query.dtype
|
||||
)
|
||||
|
||||
for i in range(hidden_states.shape[0] // self.slice_size):
|
||||
start_idx = i * self.slice_size
|
||||
end_idx = (i + 1) * self.slice_size
|
||||
|
||||
query_slice = query[start_idx:end_idx]
|
||||
key_slice = key[start_idx:end_idx]
|
||||
attn_mask_slice = attention_mask[start_idx:end_idx] if attention_mask is not None else None
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
|
||||
|
||||
hidden_states[start_idx:end_idx] = attn_slice
|
||||
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class SlicedAttnAddedKVProcessor:
|
||||
def __init__(self, slice_size):
|
||||
self.slice_size = slice_size
|
||||
|
||||
def __call__(self, attn: "CrossAttention", hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
residual = hidden_states
|
||||
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
|
||||
encoder_hidden_states = encoder_hidden_states.transpose(1, 2)
|
||||
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
dim = query.shape[-1]
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
key = attn.to_k(hidden_states)
|
||||
value = attn.to_v(hidden_states)
|
||||
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
|
||||
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
|
||||
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj)
|
||||
encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj)
|
||||
|
||||
key = torch.cat([encoder_hidden_states_key_proj, key], dim=1)
|
||||
value = torch.cat([encoder_hidden_states_value_proj, value], dim=1)
|
||||
|
||||
batch_size_attention = query.shape[0]
|
||||
hidden_states = torch.zeros(
|
||||
(batch_size_attention, sequence_length, dim // attn.heads), device=query.device, dtype=query.dtype
|
||||
)
|
||||
|
||||
for i in range(hidden_states.shape[0] // self.slice_size):
|
||||
start_idx = i * self.slice_size
|
||||
end_idx = (i + 1) * self.slice_size
|
||||
|
||||
query_slice = query[start_idx:end_idx]
|
||||
key_slice = key[start_idx:end_idx]
|
||||
attn_mask_slice = attention_mask[start_idx:end_idx] if attention_mask is not None else None
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
|
||||
|
||||
hidden_states[start_idx:end_idx] = attn_slice
|
||||
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
|
||||
hidden_states = hidden_states + residual
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
AttnProcessor = Union[
|
||||
CrossAttnProcessor,
|
||||
XFormersCrossAttnProcessor,
|
||||
SlicedAttnProcessor,
|
||||
XFormersAttnProcessor,
|
||||
)
|
||||
from .attention_processor import ( # noqa: F401
|
||||
AttnProcessor as AttnProcessorRename,
|
||||
)
|
||||
|
||||
|
||||
deprecate(
|
||||
"cross_attention",
|
||||
"0.18.0",
|
||||
"Importing from cross_attention is deprecated. Please import from attention_processor instead.",
|
||||
standard_warn=False,
|
||||
)
|
||||
|
||||
|
||||
AttnProcessor = AttentionProcessor
|
||||
|
||||
|
||||
class CrossAttention(Attention):
|
||||
def __init__(self, *args, **kwargs):
|
||||
deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
|
||||
deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
|
||||
class CrossAttnProcessor(AttnProcessorRename):
|
||||
def __init__(self, *args, **kwargs):
|
||||
deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
|
||||
deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
|
||||
class LoRACrossAttnProcessor(LoRAAttnProcessor):
|
||||
def __init__(self, *args, **kwargs):
|
||||
deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
|
||||
deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
|
||||
class CrossAttnAddedKVProcessor(AttnAddedKVProcessor):
|
||||
def __init__(self, *args, **kwargs):
|
||||
deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
|
||||
deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
|
||||
class XFormersCrossAttnProcessor(XFormersAttnProcessor):
|
||||
def __init__(self, *args, **kwargs):
|
||||
deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
|
||||
deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
|
||||
class LoRAXFormersCrossAttnProcessor(LoRAXFormersAttnProcessor):
|
||||
def __init__(self, *args, **kwargs):
|
||||
deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
|
||||
deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
|
||||
class SlicedCrossAttnProcessor(SlicedAttnProcessor):
|
||||
def __init__(self, *args, **kwargs):
|
||||
deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
|
||||
deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
|
||||
class SlicedCrossAttnAddedKVProcessor(SlicedAttnAddedKVProcessor):
|
||||
def __init__(self, *args, **kwargs):
|
||||
deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
|
||||
deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
|
||||
super().__init__(*args, **kwargs)
|
||||
CrossAttnAddedKVProcessor,
|
||||
SlicedAttnAddedKVProcessor,
|
||||
LoRACrossAttnProcessor,
|
||||
LoRAXFormersCrossAttnProcessor,
|
||||
]
|
||||
|
||||
@@ -114,7 +114,7 @@ class DualTransformer2DModel(nn.Module):
|
||||
timestep ( `torch.long`, *optional*):
|
||||
Optional timestep to be applied as an embedding in AdaLayerNorm's. Used to indicate denoising step.
|
||||
attention_mask (`torch.FloatTensor`, *optional*):
|
||||
Optional attention mask to be applied in Attention
|
||||
Optional attention mask to be applied in CrossAttention
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
|
||||
|
||||
|
||||
@@ -392,10 +392,6 @@ class ModelMixin(torch.nn.Module):
|
||||
variant (`str`, *optional*):
|
||||
If specified load weights from `variant` filename, *e.g.* pytorch_model.<variant>.bin. `variant` is
|
||||
ignored when using `from_flax`.
|
||||
use_safetensors (`bool`, *optional* ):
|
||||
If set to `True`, the pipeline will forcibly load the models from `safetensors` weights. If set to
|
||||
`None` (the default). The pipeline will load using `safetensors` if safetensors weights are available
|
||||
*and* if `safetensors` is installed. If the to `False` the pipeline will *not* use `safetensors`.
|
||||
|
||||
<Tip>
|
||||
|
||||
@@ -427,17 +423,6 @@ class ModelMixin(torch.nn.Module):
|
||||
device_map = kwargs.pop("device_map", None)
|
||||
low_cpu_mem_usage = kwargs.pop("low_cpu_mem_usage", _LOW_CPU_MEM_USAGE_DEFAULT)
|
||||
variant = kwargs.pop("variant", None)
|
||||
use_safetensors = kwargs.pop("use_safetensors", None)
|
||||
|
||||
if use_safetensors and not is_safetensors_available():
|
||||
raise ValueError(
|
||||
"`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
|
||||
)
|
||||
|
||||
allow_pickle = False
|
||||
if use_safetensors is None:
|
||||
use_safetensors = is_safetensors_available()
|
||||
allow_pickle = True
|
||||
|
||||
if low_cpu_mem_usage and not is_accelerate_available():
|
||||
low_cpu_mem_usage = False
|
||||
@@ -473,34 +458,18 @@ class ModelMixin(torch.nn.Module):
|
||||
" dispatching. Please make sure to set `low_cpu_mem_usage=True`."
|
||||
)
|
||||
|
||||
# Load config if we don't provide a configuration
|
||||
config_path = pretrained_model_name_or_path
|
||||
|
||||
user_agent = {
|
||||
"diffusers": __version__,
|
||||
"file_type": "model",
|
||||
"framework": "pytorch",
|
||||
}
|
||||
|
||||
# load config
|
||||
config, unused_kwargs, commit_hash = cls.load_config(
|
||||
config_path,
|
||||
cache_dir=cache_dir,
|
||||
return_unused_kwargs=True,
|
||||
return_commit_hash=True,
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
device_map=device_map,
|
||||
user_agent=user_agent,
|
||||
**kwargs,
|
||||
)
|
||||
# Load config if we don't provide a configuration
|
||||
config_path = pretrained_model_name_or_path
|
||||
|
||||
# This variable will flag if we're loading a sharded checkpoint. In this case the archive file is just the
|
||||
# Load model
|
||||
|
||||
# load model
|
||||
model_file = None
|
||||
if from_flax:
|
||||
model_file = _get_model_file(
|
||||
@@ -515,7 +484,20 @@ class ModelMixin(torch.nn.Module):
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
user_agent=user_agent,
|
||||
commit_hash=commit_hash,
|
||||
)
|
||||
config, unused_kwargs = cls.load_config(
|
||||
config_path,
|
||||
cache_dir=cache_dir,
|
||||
return_unused_kwargs=True,
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
device_map=device_map,
|
||||
**kwargs,
|
||||
)
|
||||
model = cls.from_config(config, **unused_kwargs)
|
||||
|
||||
@@ -524,7 +506,7 @@ class ModelMixin(torch.nn.Module):
|
||||
|
||||
model = load_flax_checkpoint_in_pytorch_model(model, model_file)
|
||||
else:
|
||||
if use_safetensors:
|
||||
if is_safetensors_available():
|
||||
try:
|
||||
model_file = _get_model_file(
|
||||
pretrained_model_name_or_path,
|
||||
@@ -538,11 +520,8 @@ class ModelMixin(torch.nn.Module):
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
user_agent=user_agent,
|
||||
commit_hash=commit_hash,
|
||||
)
|
||||
except IOError as e:
|
||||
if not allow_pickle:
|
||||
raise e
|
||||
except: # noqa: E722
|
||||
pass
|
||||
if model_file is None:
|
||||
model_file = _get_model_file(
|
||||
@@ -557,12 +536,25 @@ class ModelMixin(torch.nn.Module):
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
user_agent=user_agent,
|
||||
commit_hash=commit_hash,
|
||||
)
|
||||
|
||||
if low_cpu_mem_usage:
|
||||
# Instantiate model with empty weights
|
||||
with accelerate.init_empty_weights():
|
||||
config, unused_kwargs = cls.load_config(
|
||||
config_path,
|
||||
cache_dir=cache_dir,
|
||||
return_unused_kwargs=True,
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
device_map=device_map,
|
||||
**kwargs,
|
||||
)
|
||||
model = cls.from_config(config, **unused_kwargs)
|
||||
|
||||
# if device_map is None, load the state dict and move the params from meta device to the cpu
|
||||
@@ -601,6 +593,20 @@ class ModelMixin(torch.nn.Module):
|
||||
"error_msgs": [],
|
||||
}
|
||||
else:
|
||||
config, unused_kwargs = cls.load_config(
|
||||
config_path,
|
||||
cache_dir=cache_dir,
|
||||
return_unused_kwargs=True,
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
device_map=device_map,
|
||||
**kwargs,
|
||||
)
|
||||
model = cls.from_config(config, **unused_kwargs)
|
||||
|
||||
state_dict = load_state_dict(model_file, variant=variant)
|
||||
@@ -797,7 +803,6 @@ def _get_model_file(
|
||||
use_auth_token,
|
||||
user_agent,
|
||||
revision,
|
||||
commit_hash=None,
|
||||
):
|
||||
pretrained_model_name_or_path = str(pretrained_model_name_or_path)
|
||||
if os.path.isfile(pretrained_model_name_or_path):
|
||||
@@ -821,7 +826,7 @@ def _get_model_file(
|
||||
if (
|
||||
revision in DEPRECATED_REVISION_ARGS
|
||||
and (weights_name == WEIGHTS_NAME or weights_name == SAFETENSORS_WEIGHTS_NAME)
|
||||
and version.parse(version.parse(__version__).base_version) >= version.parse("0.17.0")
|
||||
and version.parse(version.parse(__version__).base_version) >= version.parse("0.15.0")
|
||||
):
|
||||
try:
|
||||
model_file = hf_hub_download(
|
||||
@@ -835,7 +840,7 @@ def _get_model_file(
|
||||
use_auth_token=use_auth_token,
|
||||
user_agent=user_agent,
|
||||
subfolder=subfolder,
|
||||
revision=revision or commit_hash,
|
||||
revision=revision,
|
||||
)
|
||||
warnings.warn(
|
||||
f"Loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'` is deprecated. Loading instead from `revision='main'` with `variant={revision}`. Loading model variants via `revision='{revision}'` will be removed in diffusers v1. Please use `variant='{revision}'` instead.",
|
||||
@@ -844,7 +849,7 @@ def _get_model_file(
|
||||
return model_file
|
||||
except: # noqa: E722
|
||||
warnings.warn(
|
||||
f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'`. This behavior is deprecated and will be removed in diffusers v1. One should use `variant='{revision}'` instead. However, it appears that {pretrained_model_name_or_path} currently does not have a {_add_variant(weights_name, revision)} file in the 'main' branch of {pretrained_model_name_or_path}. \n The Diffusers team and community would be very grateful if you could open an issue: https://github.com/huggingface/diffusers/issues/new with the title '{pretrained_model_name_or_path} is missing {_add_variant(weights_name, revision)}' so that the correct variant file can be added.",
|
||||
f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'`. This behavior is deprecated and will be removed in diffusers v1. One should use `variant='{revision}'` instead. However, it appears that {pretrained_model_name_or_path} currently does not have a {_add_variant(weights_name)} file in the 'main' branch of {pretrained_model_name_or_path}. \n The Diffusers team and community would be very grateful if you could open an issue: https://github.com/huggingface/diffusers/issues/new with the title '{pretrained_model_name_or_path} is missing {_add_variant(weights_name)}' so that the correct variant file can be added.",
|
||||
FutureWarning,
|
||||
)
|
||||
try:
|
||||
@@ -860,7 +865,7 @@ def _get_model_file(
|
||||
use_auth_token=use_auth_token,
|
||||
user_agent=user_agent,
|
||||
subfolder=subfolder,
|
||||
revision=revision or commit_hash,
|
||||
revision=revision,
|
||||
)
|
||||
return model_file
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ import torch
|
||||
from torch import nn
|
||||
|
||||
from .attention import AdaGroupNorm, AttentionBlock
|
||||
from .attention_processor import Attention, AttnAddedKVProcessor
|
||||
from .cross_attention import CrossAttention, CrossAttnAddedKVProcessor
|
||||
from .dual_transformer_2d import DualTransformer2DModel
|
||||
from .resnet import Downsample2D, FirDownsample2D, FirUpsample2D, KDownsample2D, KUpsample2D, ResnetBlock2D, Upsample2D
|
||||
from .transformer_2d import Transformer2DModel
|
||||
@@ -591,7 +591,7 @@ class UNetMidBlock2DSimpleCrossAttn(nn.Module):
|
||||
|
||||
for _ in range(num_layers):
|
||||
attentions.append(
|
||||
Attention(
|
||||
CrossAttention(
|
||||
query_dim=in_channels,
|
||||
cross_attention_dim=in_channels,
|
||||
heads=self.num_heads,
|
||||
@@ -600,7 +600,7 @@ class UNetMidBlock2DSimpleCrossAttn(nn.Module):
|
||||
norm_num_groups=resnet_groups,
|
||||
bias=True,
|
||||
upcast_softmax=True,
|
||||
processor=AttnAddedKVProcessor(),
|
||||
processor=CrossAttnAddedKVProcessor(),
|
||||
)
|
||||
)
|
||||
resnets.append(
|
||||
@@ -808,7 +808,7 @@ class CrossAttnDownBlock2D(nn.Module):
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
def forward(
|
||||
self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None, down_block_res=None, cross_attention_kwargs=None
|
||||
self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None, cross_attention_kwargs=None
|
||||
):
|
||||
# TODO(Patrick, William) - attention mask is not used
|
||||
output_states = ()
|
||||
@@ -843,8 +843,6 @@ class CrossAttnDownBlock2D(nn.Module):
|
||||
output_states += (hidden_states,)
|
||||
|
||||
if self.downsamplers is not None:
|
||||
if down_block_res is not None:
|
||||
hidden_states += down_block_res
|
||||
for downsampler in self.downsamplers:
|
||||
hidden_states = downsampler(hidden_states)
|
||||
|
||||
@@ -1367,7 +1365,7 @@ class SimpleCrossAttnDownBlock2D(nn.Module):
|
||||
)
|
||||
)
|
||||
attentions.append(
|
||||
Attention(
|
||||
CrossAttention(
|
||||
query_dim=out_channels,
|
||||
cross_attention_dim=out_channels,
|
||||
heads=self.num_heads,
|
||||
@@ -1376,7 +1374,7 @@ class SimpleCrossAttnDownBlock2D(nn.Module):
|
||||
norm_num_groups=resnet_groups,
|
||||
bias=True,
|
||||
upcast_softmax=True,
|
||||
processor=AttnAddedKVProcessor(),
|
||||
processor=CrossAttnAddedKVProcessor(),
|
||||
)
|
||||
)
|
||||
self.attentions = nn.ModuleList(attentions)
|
||||
@@ -2360,7 +2358,7 @@ class SimpleCrossAttnUpBlock2D(nn.Module):
|
||||
)
|
||||
)
|
||||
attentions.append(
|
||||
Attention(
|
||||
CrossAttention(
|
||||
query_dim=out_channels,
|
||||
cross_attention_dim=out_channels,
|
||||
heads=self.num_heads,
|
||||
@@ -2369,7 +2367,7 @@ class SimpleCrossAttnUpBlock2D(nn.Module):
|
||||
norm_num_groups=resnet_groups,
|
||||
bias=True,
|
||||
upcast_softmax=True,
|
||||
processor=AttnAddedKVProcessor(),
|
||||
processor=CrossAttnAddedKVProcessor(),
|
||||
)
|
||||
)
|
||||
self.attentions = nn.ModuleList(attentions)
|
||||
@@ -2679,7 +2677,7 @@ class KAttentionBlock(nn.Module):
|
||||
# 1. Self-Attn
|
||||
if add_self_attention:
|
||||
self.norm1 = AdaGroupNorm(temb_channels, dim, max(1, dim // group_size))
|
||||
self.attn1 = Attention(
|
||||
self.attn1 = CrossAttention(
|
||||
query_dim=dim,
|
||||
heads=num_attention_heads,
|
||||
dim_head=attention_head_dim,
|
||||
@@ -2691,7 +2689,7 @@ class KAttentionBlock(nn.Module):
|
||||
|
||||
# 2. Cross-Attn
|
||||
self.norm2 = AdaGroupNorm(temb_channels, dim, max(1, dim // group_size))
|
||||
self.attn2 = Attention(
|
||||
self.attn2 = CrossAttention(
|
||||
query_dim=dim,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
heads=num_attention_heads,
|
||||
|
||||
@@ -21,7 +21,7 @@ import torch.utils.checkpoint
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..loaders import UNet2DConditionLoadersMixin
|
||||
from ..utils import BaseOutput, logging
|
||||
from .attention_processor import AttentionProcessor
|
||||
from .cross_attention import AttnProcessor
|
||||
from .embeddings import GaussianFourierProjection, TimestepEmbedding, Timesteps
|
||||
from .modeling_utils import ModelMixin
|
||||
from .unet_2d_blocks import (
|
||||
@@ -362,7 +362,7 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
)
|
||||
|
||||
@property
|
||||
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
||||
def attn_processors(self) -> Dict[str, AttnProcessor]:
|
||||
r"""
|
||||
Returns:
|
||||
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
||||
@@ -371,7 +371,7 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
# set recursively
|
||||
processors = {}
|
||||
|
||||
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
||||
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttnProcessor]):
|
||||
if hasattr(module, "set_processor"):
|
||||
processors[f"{name}.processor"] = module.processor
|
||||
|
||||
@@ -385,12 +385,12 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
|
||||
return processors
|
||||
|
||||
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
||||
def set_attn_processor(self, processor: Union[AttnProcessor, Dict[str, AttnProcessor]]):
|
||||
r"""
|
||||
Parameters:
|
||||
`processor (`dict` of `AttentionProcessor` or `AttentionProcessor`):
|
||||
`processor (`dict` of `AttnProcessor` or `AttnProcessor`):
|
||||
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
||||
of **all** `Attention` layers.
|
||||
of **all** `CrossAttention` layers.
|
||||
In case `processor` is a dict, the key needs to define the path to the corresponding cross attention processor. This is strongly recommended when setting trainablae attention processors.:
|
||||
|
||||
"""
|
||||
@@ -505,7 +505,7 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
|
||||
@@ -576,34 +576,29 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
# 2. pre-process
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
|
||||
is_t2i = mid_block_additional_residual is None and down_block_additional_residuals is not None
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
for downsample_block in self.down_blocks:
|
||||
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
||||
# find out whether `is_t2i` depending on the shape of the residual connections
|
||||
kwargs = {} if not is_t2i else {"down_block_res": down_block_additional_residuals.pop()}
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
**kwargs,
|
||||
)
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
|
||||
down_block_res_samples += res_samples
|
||||
|
||||
if is_controlnet:
|
||||
if down_block_additional_residuals is not None:
|
||||
new_down_block_res_samples = ()
|
||||
|
||||
for down_block_res_sample, down_block_additional_residual in zip(
|
||||
down_block_res_samples, down_block_additional_residuals
|
||||
):
|
||||
down_block_res_sample = down_block_res_sample + down_block_additional_residual
|
||||
down_block_res_sample += down_block_additional_residual
|
||||
new_down_block_res_samples += (down_block_res_sample,)
|
||||
|
||||
down_block_res_samples = new_down_block_res_samples
|
||||
@@ -618,8 +613,8 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
)
|
||||
|
||||
if is_controlnet:
|
||||
sample = sample + mid_block_additional_residual
|
||||
if mid_block_additional_residual is not None:
|
||||
sample += mid_block_additional_residual
|
||||
|
||||
# 5. up
|
||||
for i, upsample_block in enumerate(self.up_blocks):
|
||||
|
||||
@@ -585,7 +585,7 @@ class AltDiffusionPipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
|
||||
|
||||
@@ -24,7 +24,6 @@ from transformers import CLIPFeatureExtractor, XLMRobertaTokenizer
|
||||
from diffusers.utils import is_accelerate_available, is_accelerate_version
|
||||
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import PIL_INTERPOLATION, deprecate, logging, randn_tensor, replace_example_docstring
|
||||
@@ -193,6 +192,7 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
new_config = dict(unet.config)
|
||||
new_config["sample_size"] = 64
|
||||
unet._internal_dict = FrozenDict(new_config)
|
||||
|
||||
self.register_modules(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
@@ -203,11 +203,7 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
feature_extractor=feature_extractor,
|
||||
)
|
||||
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
||||
|
||||
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
|
||||
self.register_to_config(
|
||||
requires_safety_checker=requires_safety_checker,
|
||||
)
|
||||
self.register_to_config(requires_safety_checker=requires_safety_checker)
|
||||
|
||||
def enable_sequential_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
@@ -419,17 +415,21 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
return prompt_embeds
|
||||
|
||||
def run_safety_checker(self, image, device, dtype):
|
||||
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
|
||||
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
|
||||
image, has_nsfw_concept = self.safety_checker(
|
||||
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
|
||||
)
|
||||
if self.safety_checker is not None:
|
||||
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
|
||||
image, has_nsfw_concept = self.safety_checker(
|
||||
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
|
||||
)
|
||||
else:
|
||||
has_nsfw_concept = None
|
||||
return image, has_nsfw_concept
|
||||
|
||||
def decode_latents(self, latents):
|
||||
latents = 1 / self.vae.config.scaling_factor * latents
|
||||
image = self.vae.decode(latents).sample
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
return image
|
||||
|
||||
def prepare_extra_step_kwargs(self, generator, eta):
|
||||
@@ -663,7 +663,7 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
)
|
||||
|
||||
# 4. Preprocess image
|
||||
image = self.image_processor.preprocess(image)
|
||||
image = preprocess(image)
|
||||
|
||||
# 5. set timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
@@ -703,26 +703,15 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
if callback is not None and i % callback_steps == 0:
|
||||
callback(i, t, latents)
|
||||
|
||||
if output_type not in ["latent", "pt", "np", "pil"]:
|
||||
deprecation_message = (
|
||||
f"the output_type {output_type} is outdated. Please make sure to set it to one of these instead: "
|
||||
"`pil`, `np`, `pt`, `latent`"
|
||||
)
|
||||
deprecate("Unsupported output_type", "1.0.0", deprecation_message, standard_warn=False)
|
||||
output_type = "np"
|
||||
|
||||
if output_type == "latent":
|
||||
image = latents
|
||||
has_nsfw_concept = None
|
||||
|
||||
# 9. Post-processing
|
||||
image = self.decode_latents(latents)
|
||||
|
||||
if self.safety_checker is not None:
|
||||
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
|
||||
else:
|
||||
has_nsfw_concept = False
|
||||
# 10. Run safety checker
|
||||
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
|
||||
|
||||
image = self.image_processor.postprocess(image, output_type=output_type)
|
||||
# 11. Convert to PIL
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
# Offload last model to CPU
|
||||
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
|
||||
|
||||
@@ -136,7 +136,7 @@ def prepare_mask_and_masked_image(image, mask):
|
||||
|
||||
class PaintByExamplePipeline(DiffusionPipeline):
|
||||
r"""
|
||||
Pipeline for image-guided image inpainting using Stable Diffusion. *This is an experimental feature*.
|
||||
Pipeline for text-guided image inpainting using Stable Diffusion. *This is an experimental feature*.
|
||||
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
@@ -144,8 +144,10 @@ class PaintByExamplePipeline(DiffusionPipeline):
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
|
||||
image_encoder ([`PaintByExampleImageEncoder`]):
|
||||
Encodes the example input image. The unet is conditioned on the example image instead of a text prompt.
|
||||
text_encoder ([`CLIPTextModel`]):
|
||||
Frozen text-encoder. Stable Diffusion uses the text portion of
|
||||
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
|
||||
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
|
||||
tokenizer (`CLIPTokenizer`):
|
||||
Tokenizer of class
|
||||
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
|
||||
|
||||
@@ -14,7 +14,6 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import fnmatch
|
||||
import importlib
|
||||
import inspect
|
||||
import os
|
||||
@@ -27,7 +26,7 @@ from typing import Any, Callable, Dict, List, Optional, Union
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
from huggingface_hub import hf_hub_download, model_info, snapshot_download
|
||||
from huggingface_hub import model_info, snapshot_download
|
||||
from packaging import version
|
||||
from PIL import Image
|
||||
from tqdm.auto import tqdm
|
||||
@@ -48,6 +47,7 @@ from ..utils import (
|
||||
BaseOutput,
|
||||
deprecate,
|
||||
get_class_from_dynamic_module,
|
||||
http_user_agent,
|
||||
is_accelerate_available,
|
||||
is_accelerate_version,
|
||||
is_safetensors_available,
|
||||
@@ -179,7 +179,8 @@ def is_safetensors_compatible(filenames, variant=None) -> bool:
|
||||
return True
|
||||
|
||||
|
||||
def variant_compatible_siblings(filenames, variant=None) -> Union[List[os.PathLike], str]:
|
||||
def variant_compatible_siblings(info, variant=None) -> Union[List[os.PathLike], str]:
|
||||
filenames = set(sibling.rfilename for sibling in info.siblings)
|
||||
weight_names = [
|
||||
WEIGHTS_NAME,
|
||||
SAFETENSORS_WEIGHTS_NAME,
|
||||
@@ -219,177 +220,6 @@ def variant_compatible_siblings(filenames, variant=None) -> Union[List[os.PathLi
|
||||
return usable_filenames, variant_filenames
|
||||
|
||||
|
||||
def warn_deprecated_model_variant(pretrained_model_name_or_path, use_auth_token, variant, revision, model_filenames):
|
||||
info = model_info(
|
||||
pretrained_model_name_or_path,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=None,
|
||||
)
|
||||
filenames = set(sibling.rfilename for sibling in info.siblings)
|
||||
comp_model_filenames, _ = variant_compatible_siblings(filenames, variant=revision)
|
||||
comp_model_filenames = [".".join(f.split(".")[:1] + f.split(".")[2:]) for f in comp_model_filenames]
|
||||
|
||||
if set(comp_model_filenames) == set(model_filenames):
|
||||
warnings.warn(
|
||||
f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'` even though you can load it via `variant=`{revision}`. Loading model variants via `revision='{revision}'` is deprecated and will be removed in diffusers v1. Please use `variant='{revision}'` instead.",
|
||||
FutureWarning,
|
||||
)
|
||||
else:
|
||||
warnings.warn(
|
||||
f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'`. This behavior is deprecated and will be removed in diffusers v1. One should use `variant='{revision}'` instead. However, it appears that {pretrained_model_name_or_path} currently does not have the required variant filenames in the 'main' branch. \n The Diffusers team and community would be very grateful if you could open an issue: https://github.com/huggingface/diffusers/issues/new with the title '{pretrained_model_name_or_path} is missing {revision} files' so that the correct variant file can be added.",
|
||||
FutureWarning,
|
||||
)
|
||||
|
||||
|
||||
def maybe_raise_or_warn(
|
||||
library_name, library, class_name, importable_classes, passed_class_obj, name, is_pipeline_module
|
||||
):
|
||||
"""Simple helper method to raise or warn in case incorrect module has been passed"""
|
||||
if not is_pipeline_module:
|
||||
library = importlib.import_module(library_name)
|
||||
class_obj = getattr(library, class_name)
|
||||
class_candidates = {c: getattr(library, c, None) for c in importable_classes.keys()}
|
||||
|
||||
expected_class_obj = None
|
||||
for class_name, class_candidate in class_candidates.items():
|
||||
if class_candidate is not None and issubclass(class_obj, class_candidate):
|
||||
expected_class_obj = class_candidate
|
||||
|
||||
if not issubclass(passed_class_obj[name].__class__, expected_class_obj):
|
||||
raise ValueError(
|
||||
f"{passed_class_obj[name]} is of type: {type(passed_class_obj[name])}, but should be"
|
||||
f" {expected_class_obj}"
|
||||
)
|
||||
else:
|
||||
logger.warning(
|
||||
f"You have passed a non-standard module {passed_class_obj[name]}. We cannot verify whether it"
|
||||
" has the correct type"
|
||||
)
|
||||
|
||||
|
||||
def get_class_obj_and_candidates(library_name, class_name, importable_classes, pipelines, is_pipeline_module):
|
||||
"""Simple helper method to retrieve class object of module as well as potential parent class objects"""
|
||||
if is_pipeline_module:
|
||||
pipeline_module = getattr(pipelines, library_name)
|
||||
|
||||
class_obj = getattr(pipeline_module, class_name)
|
||||
class_candidates = {c: class_obj for c in importable_classes.keys()}
|
||||
else:
|
||||
# else we just import it from the library.
|
||||
library = importlib.import_module(library_name)
|
||||
|
||||
class_obj = getattr(library, class_name)
|
||||
class_candidates = {c: getattr(library, c, None) for c in importable_classes.keys()}
|
||||
|
||||
return class_obj, class_candidates
|
||||
|
||||
|
||||
def load_sub_model(
|
||||
library_name: str,
|
||||
class_name: str,
|
||||
importable_classes: List[Any],
|
||||
pipelines: Any,
|
||||
is_pipeline_module: bool,
|
||||
pipeline_class: Any,
|
||||
torch_dtype: torch.dtype,
|
||||
provider: Any,
|
||||
sess_options: Any,
|
||||
device_map: Optional[Union[Dict[str, torch.device], str]],
|
||||
model_variants: Dict[str, str],
|
||||
name: str,
|
||||
from_flax: bool,
|
||||
variant: str,
|
||||
low_cpu_mem_usage: bool,
|
||||
cached_folder: Union[str, os.PathLike],
|
||||
):
|
||||
"""Helper method to load the module `name` from `library_name` and `class_name`"""
|
||||
# retrieve class candidates
|
||||
class_obj, class_candidates = get_class_obj_and_candidates(
|
||||
library_name, class_name, importable_classes, pipelines, is_pipeline_module
|
||||
)
|
||||
|
||||
load_method_name = None
|
||||
# retrive load method name
|
||||
for class_name, class_candidate in class_candidates.items():
|
||||
if class_candidate is not None and issubclass(class_obj, class_candidate):
|
||||
load_method_name = importable_classes[class_name][1]
|
||||
|
||||
# if load method name is None, then we have a dummy module -> raise Error
|
||||
if load_method_name is None:
|
||||
none_module = class_obj.__module__
|
||||
is_dummy_path = none_module.startswith(DUMMY_MODULES_FOLDER) or none_module.startswith(
|
||||
TRANSFORMERS_DUMMY_MODULES_FOLDER
|
||||
)
|
||||
if is_dummy_path and "dummy" in none_module:
|
||||
# call class_obj for nice error message of missing requirements
|
||||
class_obj()
|
||||
|
||||
raise ValueError(
|
||||
f"The component {class_obj} of {pipeline_class} cannot be loaded as it does not seem to have"
|
||||
f" any of the loading methods defined in {ALL_IMPORTABLE_CLASSES}."
|
||||
)
|
||||
|
||||
load_method = getattr(class_obj, load_method_name)
|
||||
|
||||
# add kwargs to loading method
|
||||
loading_kwargs = {}
|
||||
if issubclass(class_obj, torch.nn.Module):
|
||||
loading_kwargs["torch_dtype"] = torch_dtype
|
||||
if issubclass(class_obj, diffusers.OnnxRuntimeModel):
|
||||
loading_kwargs["provider"] = provider
|
||||
loading_kwargs["sess_options"] = sess_options
|
||||
|
||||
is_diffusers_model = issubclass(class_obj, diffusers.ModelMixin)
|
||||
|
||||
if is_transformers_available():
|
||||
transformers_version = version.parse(version.parse(transformers.__version__).base_version)
|
||||
else:
|
||||
transformers_version = "N/A"
|
||||
|
||||
is_transformers_model = (
|
||||
is_transformers_available()
|
||||
and issubclass(class_obj, PreTrainedModel)
|
||||
and transformers_version >= version.parse("4.20.0")
|
||||
)
|
||||
|
||||
# When loading a transformers model, if the device_map is None, the weights will be initialized as opposed to diffusers.
|
||||
# To make default loading faster we set the `low_cpu_mem_usage=low_cpu_mem_usage` flag which is `True` by default.
|
||||
# This makes sure that the weights won't be initialized which significantly speeds up loading.
|
||||
if is_diffusers_model or is_transformers_model:
|
||||
loading_kwargs["device_map"] = device_map
|
||||
loading_kwargs["variant"] = model_variants.pop(name, None)
|
||||
if from_flax:
|
||||
loading_kwargs["from_flax"] = True
|
||||
|
||||
# the following can be deleted once the minimum required `transformers` version
|
||||
# is higher than 4.27
|
||||
if (
|
||||
is_transformers_model
|
||||
and loading_kwargs["variant"] is not None
|
||||
and transformers_version < version.parse("4.27.0")
|
||||
):
|
||||
raise ImportError(
|
||||
f"When passing `variant='{variant}'`, please make sure to upgrade your `transformers` version to at least 4.27.0.dev0"
|
||||
)
|
||||
elif is_transformers_model and loading_kwargs["variant"] is None:
|
||||
loading_kwargs.pop("variant")
|
||||
|
||||
# if `from_flax` and model is transformer model, can currently not load with `low_cpu_mem_usage`
|
||||
if not (from_flax and is_transformers_model):
|
||||
loading_kwargs["low_cpu_mem_usage"] = low_cpu_mem_usage
|
||||
else:
|
||||
loading_kwargs["low_cpu_mem_usage"] = False
|
||||
|
||||
# check if the module is in a subdirectory
|
||||
if os.path.isdir(os.path.join(cached_folder, name)):
|
||||
loaded_sub_model = load_method(os.path.join(cached_folder, name), **loading_kwargs)
|
||||
else:
|
||||
# else load from the root directory
|
||||
loaded_sub_model = load_method(cached_folder, **loading_kwargs)
|
||||
|
||||
return loaded_sub_model
|
||||
|
||||
|
||||
class DiffusionPipeline(ConfigMixin):
|
||||
r"""
|
||||
Base class for all models.
|
||||
@@ -653,9 +483,6 @@ class DiffusionPipeline(ConfigMixin):
|
||||
force_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
|
||||
cached versions if they exist.
|
||||
cache_dir (`Union[str, os.PathLike]`, *optional*):
|
||||
Path to a directory in which a downloaded pretrained model configuration should be cached if the
|
||||
standard cache should not be used.
|
||||
resume_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to delete incompletely received files. Will attempt to resume the download if such a
|
||||
file exists.
|
||||
@@ -694,10 +521,8 @@ class DiffusionPipeline(ConfigMixin):
|
||||
also tries to not use more than 1x model size in CPU memory (including peak memory) while loading the
|
||||
model. This is only supported when torch version >= 1.9.0. If you are using an older version of torch,
|
||||
setting this argument to `True` will raise an error.
|
||||
use_safetensors (`bool`, *optional* ):
|
||||
If set to `True`, the pipeline will be loaded from `safetensors` weights. If set to `None` (the
|
||||
default). The pipeline will load using `safetensors` if the safetensors weights are available *and* if
|
||||
`safetensors` is installed. If the to `False` the pipeline will *not* use `safetensors`.
|
||||
return_cached_folder (`bool`, *optional*, defaults to `False`):
|
||||
If set to `True`, path to downloaded cached folder will be returned in addition to loaded pipeline.
|
||||
kwargs (remaining dictionary of keyword arguments, *optional*):
|
||||
Can be used to overwrite load - and saveable variables - *i.e.* the pipeline components - of the
|
||||
specific pipeline class. The overwritten components are then directly passed to the pipelines
|
||||
@@ -755,13 +580,13 @@ class DiffusionPipeline(ConfigMixin):
|
||||
sess_options = kwargs.pop("sess_options", None)
|
||||
device_map = kwargs.pop("device_map", None)
|
||||
low_cpu_mem_usage = kwargs.pop("low_cpu_mem_usage", _LOW_CPU_MEM_USAGE_DEFAULT)
|
||||
return_cached_folder = kwargs.pop("return_cached_folder", False)
|
||||
variant = kwargs.pop("variant", None)
|
||||
kwargs.pop("use_safetensors", None if is_safetensors_available() else False)
|
||||
|
||||
# 1. Download the checkpoints and configs
|
||||
# use snapshot download here to get it working from from_pretrained
|
||||
if not os.path.isdir(pretrained_model_name_or_path):
|
||||
cached_folder = cls.download(
|
||||
config_dict = cls.load_config(
|
||||
pretrained_model_name_or_path,
|
||||
cache_dir=cache_dir,
|
||||
resume_download=resume_download,
|
||||
@@ -770,18 +595,117 @@ class DiffusionPipeline(ConfigMixin):
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
from_flax=from_flax,
|
||||
custom_pipeline=custom_pipeline,
|
||||
variant=variant,
|
||||
)
|
||||
|
||||
# retrieve all folder_names that contain relevant files
|
||||
folder_names = [k for k, v in config_dict.items() if isinstance(v, list)]
|
||||
|
||||
if not local_files_only:
|
||||
info = model_info(
|
||||
pretrained_model_name_or_path,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
)
|
||||
model_filenames, variant_filenames = variant_compatible_siblings(info, variant=variant)
|
||||
model_folder_names = set([os.path.split(f)[0] for f in model_filenames])
|
||||
|
||||
if revision in DEPRECATED_REVISION_ARGS and version.parse(
|
||||
version.parse(__version__).base_version
|
||||
) >= version.parse("0.15.0"):
|
||||
info = model_info(
|
||||
pretrained_model_name_or_path,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=None,
|
||||
)
|
||||
comp_model_filenames, _ = variant_compatible_siblings(info, variant=revision)
|
||||
comp_model_filenames = [
|
||||
".".join(f.split(".")[:1] + f.split(".")[2:]) for f in comp_model_filenames
|
||||
]
|
||||
|
||||
if set(comp_model_filenames) == set(model_filenames):
|
||||
warnings.warn(
|
||||
f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'` even though you can load it via `variant=`{revision}`. Loading model variants via `revision='{variant}'` is deprecated and will be removed in diffusers v1. Please use `variant='{revision}'` instead.",
|
||||
FutureWarning,
|
||||
)
|
||||
else:
|
||||
warnings.warn(
|
||||
f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'`. This behavior is deprecated and will be removed in diffusers v1. One should use `variant='{revision}'` instead. However, it appears that {pretrained_model_name_or_path} currently does not have the required variant filenames in the 'main' branch. \n The Diffusers team and community would be very grateful if you could open an issue: https://github.com/huggingface/diffusers/issues/new with the title '{pretrained_model_name_or_path} is missing {revision} files' so that the correct variant file can be added.",
|
||||
FutureWarning,
|
||||
)
|
||||
|
||||
# all filenames compatible with variant will be added
|
||||
allow_patterns = list(model_filenames)
|
||||
|
||||
# allow all patterns from non-model folders
|
||||
# this enables downloading schedulers, tokenizers, ...
|
||||
allow_patterns += [os.path.join(k, "*") for k in folder_names if k not in model_folder_names]
|
||||
# also allow downloading config.jsons with the model
|
||||
allow_patterns += [os.path.join(k, "*.json") for k in model_folder_names]
|
||||
|
||||
allow_patterns += [
|
||||
SCHEDULER_CONFIG_NAME,
|
||||
CONFIG_NAME,
|
||||
cls.config_name,
|
||||
CUSTOM_PIPELINE_FILE_NAME,
|
||||
]
|
||||
|
||||
if from_flax:
|
||||
ignore_patterns = ["*.bin", "*.safetensors", "*.onnx", "*.pb"]
|
||||
elif is_safetensors_available() and is_safetensors_compatible(model_filenames, variant=variant):
|
||||
ignore_patterns = ["*.bin", "*.msgpack"]
|
||||
|
||||
safetensors_variant_filenames = set([f for f in variant_filenames if f.endswith(".safetensors")])
|
||||
safetensors_model_filenames = set([f for f in model_filenames if f.endswith(".safetensors")])
|
||||
if (
|
||||
len(safetensors_variant_filenames) > 0
|
||||
and safetensors_model_filenames != safetensors_variant_filenames
|
||||
):
|
||||
logger.warn(
|
||||
f"\nA mixture of {variant} and non-{variant} filenames will be loaded.\nLoaded {variant} filenames:\n[{', '.join(safetensors_variant_filenames)}]\nLoaded non-{variant} filenames:\n[{', '.join(safetensors_model_filenames - safetensors_variant_filenames)}\nIf this behavior is not expected, please check your folder structure."
|
||||
)
|
||||
|
||||
else:
|
||||
ignore_patterns = ["*.safetensors", "*.msgpack"]
|
||||
|
||||
bin_variant_filenames = set([f for f in variant_filenames if f.endswith(".bin")])
|
||||
bin_model_filenames = set([f for f in model_filenames if f.endswith(".bin")])
|
||||
if len(bin_variant_filenames) > 0 and bin_model_filenames != bin_variant_filenames:
|
||||
logger.warn(
|
||||
f"\nA mixture of {variant} and non-{variant} filenames will be loaded.\nLoaded {variant} filenames:\n[{', '.join(bin_variant_filenames)}]\nLoaded non-{variant} filenames:\n[{', '.join(bin_model_filenames - bin_variant_filenames)}\nIf this behavior is not expected, please check your folder structure."
|
||||
)
|
||||
|
||||
else:
|
||||
# allow everything since it has to be downloaded anyways
|
||||
ignore_patterns = allow_patterns = None
|
||||
|
||||
if cls != DiffusionPipeline:
|
||||
requested_pipeline_class = cls.__name__
|
||||
else:
|
||||
requested_pipeline_class = config_dict.get("_class_name", cls.__name__)
|
||||
user_agent = {"pipeline_class": requested_pipeline_class}
|
||||
if custom_pipeline is not None and not custom_pipeline.endswith(".py"):
|
||||
user_agent["custom_pipeline"] = custom_pipeline
|
||||
|
||||
user_agent = http_user_agent(user_agent)
|
||||
|
||||
# download all allow_patterns
|
||||
cached_folder = snapshot_download(
|
||||
pretrained_model_name_or_path,
|
||||
cache_dir=cache_dir,
|
||||
resume_download=resume_download,
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
allow_patterns=allow_patterns,
|
||||
ignore_patterns=ignore_patterns,
|
||||
user_agent=user_agent,
|
||||
)
|
||||
else:
|
||||
cached_folder = pretrained_model_name_or_path
|
||||
config_dict = cls.load_config(cached_folder)
|
||||
|
||||
config_dict = cls.load_config(cached_folder)
|
||||
|
||||
# 2. Define which model components should load variants
|
||||
# We retrieve the information by matching whether variant
|
||||
# model checkpoints exist in the subfolders
|
||||
# retrieve which subfolders should load variants
|
||||
model_variants = {}
|
||||
if variant is not None:
|
||||
for folder in os.listdir(cached_folder):
|
||||
@@ -791,7 +715,7 @@ class DiffusionPipeline(ConfigMixin):
|
||||
if variant_exists:
|
||||
model_variants[folder] = variant
|
||||
|
||||
# 3. Load the pipeline class, if using custom module then load it from the hub
|
||||
# 2. Load the pipeline class, if using custom module then load it from the hub
|
||||
# if we load from explicit class, let's use it
|
||||
if custom_pipeline is not None:
|
||||
if custom_pipeline.endswith(".py"):
|
||||
@@ -811,7 +735,7 @@ class DiffusionPipeline(ConfigMixin):
|
||||
diffusers_module = importlib.import_module(cls.__module__.split(".")[0])
|
||||
pipeline_class = getattr(diffusers_module, config_dict["_class_name"])
|
||||
|
||||
# DEPRECATED: To be removed in 1.0.0
|
||||
# To be removed in 1.0.0
|
||||
if pipeline_class.__name__ == "StableDiffusionInpaintPipeline" and version.parse(
|
||||
version.parse(config_dict["_diffusers_version"]).base_version
|
||||
) <= version.parse("0.5.1"):
|
||||
@@ -830,9 +754,6 @@ class DiffusionPipeline(ConfigMixin):
|
||||
)
|
||||
deprecate("StableDiffusionInpaintPipelineLegacy", "1.0.0", deprecation_message, standard_warn=False)
|
||||
|
||||
# 4. Define expected modules given pipeline signature
|
||||
# and define non-None initialized modules (=`init_kwargs`)
|
||||
|
||||
# some modules can be passed directly to the init
|
||||
# in this case they are already instantiated in `kwargs`
|
||||
# extract them here
|
||||
@@ -864,7 +785,6 @@ class DiffusionPipeline(ConfigMixin):
|
||||
" separately if you need it."
|
||||
)
|
||||
|
||||
# 5. Throw nice warnings / errors for fast accelerate loading
|
||||
if len(unused_kwargs) > 0:
|
||||
logger.warning(
|
||||
f"Keyword arguments {unused_kwargs} are not expected by {pipeline_class.__name__} and will be ignored."
|
||||
@@ -900,50 +820,135 @@ class DiffusionPipeline(ConfigMixin):
|
||||
# import it here to avoid circular import
|
||||
from diffusers import pipelines
|
||||
|
||||
# 6. Load each module in the pipeline
|
||||
# 3. Load each module in the pipeline
|
||||
for name, (library_name, class_name) in init_dict.items():
|
||||
# 6.1 - now that JAX/Flax is an official framework of the library, we might load from Flax names
|
||||
# 3.1 - now that JAX/Flax is an official framework of the library, we might load from Flax names
|
||||
if class_name.startswith("Flax"):
|
||||
class_name = class_name[4:]
|
||||
|
||||
# 6.2 Define all importable classes
|
||||
is_pipeline_module = hasattr(pipelines, library_name)
|
||||
importable_classes = ALL_IMPORTABLE_CLASSES if is_pipeline_module else LOADABLE_CLASSES[library_name]
|
||||
loaded_sub_model = None
|
||||
|
||||
# 6.3 Use passed sub model or load class_name from library_name
|
||||
# if the model is in a pipeline module, then we load it from the pipeline
|
||||
if name in passed_class_obj:
|
||||
# if the model is in a pipeline module, then we load it from the pipeline
|
||||
# check that passed_class_obj has correct parent class
|
||||
maybe_raise_or_warn(
|
||||
library_name, library, class_name, importable_classes, passed_class_obj, name, is_pipeline_module
|
||||
# 1. check that passed_class_obj has correct parent class
|
||||
if not is_pipeline_module:
|
||||
library = importlib.import_module(library_name)
|
||||
class_obj = getattr(library, class_name)
|
||||
importable_classes = LOADABLE_CLASSES[library_name]
|
||||
class_candidates = {c: getattr(library, c, None) for c in importable_classes.keys()}
|
||||
|
||||
expected_class_obj = None
|
||||
for class_name, class_candidate in class_candidates.items():
|
||||
if class_candidate is not None and issubclass(class_obj, class_candidate):
|
||||
expected_class_obj = class_candidate
|
||||
|
||||
if not issubclass(passed_class_obj[name].__class__, expected_class_obj):
|
||||
raise ValueError(
|
||||
f"{passed_class_obj[name]} is of type: {type(passed_class_obj[name])}, but should be"
|
||||
f" {expected_class_obj}"
|
||||
)
|
||||
else:
|
||||
logger.warning(
|
||||
f"You have passed a non-standard module {passed_class_obj[name]}. We cannot verify whether it"
|
||||
" has the correct type"
|
||||
)
|
||||
|
||||
# set passed class object
|
||||
loaded_sub_model = passed_class_obj[name]
|
||||
elif is_pipeline_module:
|
||||
pipeline_module = getattr(pipelines, library_name)
|
||||
class_obj = getattr(pipeline_module, class_name)
|
||||
importable_classes = ALL_IMPORTABLE_CLASSES
|
||||
class_candidates = {c: class_obj for c in importable_classes.keys()}
|
||||
else:
|
||||
# else we just import it from the library.
|
||||
library = importlib.import_module(library_name)
|
||||
|
||||
class_obj = getattr(library, class_name)
|
||||
importable_classes = LOADABLE_CLASSES[library_name]
|
||||
class_candidates = {c: getattr(library, c, None) for c in importable_classes.keys()}
|
||||
|
||||
if loaded_sub_model is None:
|
||||
load_method_name = None
|
||||
for class_name, class_candidate in class_candidates.items():
|
||||
if class_candidate is not None and issubclass(class_obj, class_candidate):
|
||||
load_method_name = importable_classes[class_name][1]
|
||||
|
||||
if load_method_name is None:
|
||||
none_module = class_obj.__module__
|
||||
is_dummy_path = none_module.startswith(DUMMY_MODULES_FOLDER) or none_module.startswith(
|
||||
TRANSFORMERS_DUMMY_MODULES_FOLDER
|
||||
)
|
||||
if is_dummy_path and "dummy" in none_module:
|
||||
# call class_obj for nice error message of missing requirements
|
||||
class_obj()
|
||||
|
||||
raise ValueError(
|
||||
f"The component {class_obj} of {pipeline_class} cannot be loaded as it does not seem to have"
|
||||
f" any of the loading methods defined in {ALL_IMPORTABLE_CLASSES}."
|
||||
)
|
||||
|
||||
load_method = getattr(class_obj, load_method_name)
|
||||
loading_kwargs = {}
|
||||
|
||||
if issubclass(class_obj, torch.nn.Module):
|
||||
loading_kwargs["torch_dtype"] = torch_dtype
|
||||
if issubclass(class_obj, diffusers.OnnxRuntimeModel):
|
||||
loading_kwargs["provider"] = provider
|
||||
loading_kwargs["sess_options"] = sess_options
|
||||
|
||||
is_diffusers_model = issubclass(class_obj, diffusers.ModelMixin)
|
||||
|
||||
if is_transformers_available():
|
||||
transformers_version = version.parse(version.parse(transformers.__version__).base_version)
|
||||
else:
|
||||
transformers_version = "N/A"
|
||||
|
||||
is_transformers_model = (
|
||||
is_transformers_available()
|
||||
and issubclass(class_obj, PreTrainedModel)
|
||||
and transformers_version >= version.parse("4.20.0")
|
||||
)
|
||||
|
||||
loaded_sub_model = passed_class_obj[name]
|
||||
else:
|
||||
# load sub model
|
||||
loaded_sub_model = load_sub_model(
|
||||
library_name=library_name,
|
||||
class_name=class_name,
|
||||
importable_classes=importable_classes,
|
||||
pipelines=pipelines,
|
||||
is_pipeline_module=is_pipeline_module,
|
||||
pipeline_class=pipeline_class,
|
||||
torch_dtype=torch_dtype,
|
||||
provider=provider,
|
||||
sess_options=sess_options,
|
||||
device_map=device_map,
|
||||
model_variants=model_variants,
|
||||
name=name,
|
||||
from_flax=from_flax,
|
||||
variant=variant,
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
cached_folder=cached_folder,
|
||||
)
|
||||
# When loading a transformers model, if the device_map is None, the weights will be initialized as opposed to diffusers.
|
||||
# To make default loading faster we set the `low_cpu_mem_usage=low_cpu_mem_usage` flag which is `True` by default.
|
||||
# This makes sure that the weights won't be initialized which significantly speeds up loading.
|
||||
if is_diffusers_model or is_transformers_model:
|
||||
loading_kwargs["device_map"] = device_map
|
||||
loading_kwargs["variant"] = model_variants.pop(name, None)
|
||||
if from_flax:
|
||||
loading_kwargs["from_flax"] = True
|
||||
|
||||
# the following can be deleted once the minimum required `transformers` version
|
||||
# is higher than 4.27
|
||||
if (
|
||||
is_transformers_model
|
||||
and loading_kwargs["variant"] is not None
|
||||
and transformers_version < version.parse("4.27.0")
|
||||
):
|
||||
raise ImportError(
|
||||
f"When passing `variant='{variant}'`, please make sure to upgrade your `transformers` version to at least 4.27.0.dev0"
|
||||
)
|
||||
elif is_transformers_model and loading_kwargs["variant"] is None:
|
||||
loading_kwargs.pop("variant")
|
||||
|
||||
# if `from_flax` and model is transformer model, can currently not load with `low_cpu_mem_usage`
|
||||
if not (from_flax and is_transformers_model):
|
||||
loading_kwargs["low_cpu_mem_usage"] = low_cpu_mem_usage
|
||||
else:
|
||||
loading_kwargs["low_cpu_mem_usage"] = False
|
||||
|
||||
# check if the module is in a subdirectory
|
||||
if os.path.isdir(os.path.join(cached_folder, name)):
|
||||
loaded_sub_model = load_method(os.path.join(cached_folder, name), **loading_kwargs)
|
||||
else:
|
||||
# else load from the root directory
|
||||
loaded_sub_model = load_method(cached_folder, **loading_kwargs)
|
||||
|
||||
init_kwargs[name] = loaded_sub_model # UNet(...), # DiffusionSchedule(...)
|
||||
|
||||
# 7. Potentially add passed objects if expected
|
||||
# 4. Potentially add passed objects if expected
|
||||
missing_modules = set(expected_modules) - set(init_kwargs.keys())
|
||||
passed_modules = list(passed_class_obj.keys())
|
||||
optional_modules = pipeline_class._optional_components
|
||||
@@ -956,255 +961,13 @@ class DiffusionPipeline(ConfigMixin):
|
||||
f"Pipeline {pipeline_class} expected {expected_modules}, but only {passed_modules} were passed."
|
||||
)
|
||||
|
||||
# 8. Instantiate the pipeline
|
||||
# 5. Instantiate the pipeline
|
||||
model = pipeline_class(**init_kwargs)
|
||||
|
||||
return_cached_folder = kwargs.pop("return_cached_folder", False)
|
||||
if return_cached_folder:
|
||||
message = f"Passing `return_cached_folder=True` is deprecated and will be removed in `diffusers=0.17.0`. Please do the following instead: \n 1. Load the cached_folder via `cached_folder={cls}.download({pretrained_model_name_or_path})`. \n 2. Load the pipeline by loading from the cached folder: `pipeline={cls}.from_pretrained(cached_folder)`."
|
||||
deprecate("return_cached_folder", "0.17.0", message, take_from=kwargs)
|
||||
return model, cached_folder
|
||||
|
||||
return model
|
||||
|
||||
@classmethod
|
||||
def download(cls, pretrained_model_name, **kwargs) -> Union[str, os.PathLike]:
|
||||
r"""
|
||||
Download and cache a PyTorch diffusion pipeline from pre-trained pipeline weights.
|
||||
|
||||
Parameters:
|
||||
pretrained_model_name (`str` or `os.PathLike`, *optional*):
|
||||
Should be a string, the *repo id* of a pretrained pipeline hosted inside a model repo on
|
||||
https://huggingface.co/ Valid repo ids have to be located under a user or organization name, like
|
||||
`CompVis/ldm-text2im-large-256`.
|
||||
custom_pipeline (`str`, *optional*):
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This is an experimental feature and is likely to change in the future.
|
||||
|
||||
</Tip>
|
||||
|
||||
Can be either:
|
||||
|
||||
- A string, the *repo id* of a custom pipeline hosted inside a model repo on
|
||||
https://huggingface.co/. Valid repo ids have to be located under a user or organization name,
|
||||
like `hf-internal-testing/diffusers-dummy-pipeline`.
|
||||
|
||||
<Tip>
|
||||
|
||||
It is required that the model repo has a file, called `pipeline.py` that defines the custom
|
||||
pipeline.
|
||||
|
||||
</Tip>
|
||||
|
||||
- A string, the *file name* of a community pipeline hosted on GitHub under
|
||||
https://github.com/huggingface/diffusers/tree/main/examples/community. Valid file names have to
|
||||
match exactly the file name without `.py` located under the above link, *e.g.*
|
||||
`clip_guided_stable_diffusion`.
|
||||
|
||||
<Tip>
|
||||
|
||||
Community pipelines are always loaded from the current `main` branch of GitHub.
|
||||
|
||||
</Tip>
|
||||
|
||||
- A path to a *directory* containing a custom pipeline, e.g., `./my_pipeline_directory/`.
|
||||
|
||||
<Tip>
|
||||
|
||||
It is required that the directory has a file, called `pipeline.py` that defines the custom
|
||||
pipeline.
|
||||
|
||||
</Tip>
|
||||
|
||||
For more information on how to load and create custom pipelines, please have a look at [Loading and
|
||||
Adding Custom
|
||||
Pipelines](https://huggingface.co/docs/diffusers/using-diffusers/custom_pipeline_overview)
|
||||
|
||||
force_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
|
||||
cached versions if they exist.
|
||||
resume_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to delete incompletely received files. Will attempt to resume the download if such a
|
||||
file exists.
|
||||
proxies (`Dict[str, str]`, *optional*):
|
||||
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
|
||||
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
|
||||
output_loading_info(`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
|
||||
local_files_only(`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to only look at local files (i.e., do not try to download the model).
|
||||
use_auth_token (`str` or *bool*, *optional*):
|
||||
The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
|
||||
when running `huggingface-cli login` (stored in `~/.huggingface`).
|
||||
revision (`str`, *optional*, defaults to `"main"`):
|
||||
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
|
||||
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
|
||||
identifier allowed by git.
|
||||
custom_revision (`str`, *optional*, defaults to `"main"` when loading from the Hub and to local version of
|
||||
`diffusers` when loading from GitHub):
|
||||
The specific model version to use. It can be a branch name, a tag name, or a commit id similar to
|
||||
`revision` when loading a custom pipeline from the Hub. It can be a diffusers version when loading a
|
||||
custom pipeline from GitHub.
|
||||
mirror (`str`, *optional*):
|
||||
Mirror source to accelerate downloads in China. If you are from China and have an accessibility
|
||||
problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
|
||||
Please refer to the mirror site for more information. specify the folder name here.
|
||||
variant (`str`, *optional*):
|
||||
If specified load weights from `variant` filename, *e.g.* pytorch_model.<variant>.bin. `variant` is
|
||||
ignored when using `from_flax`.
|
||||
|
||||
<Tip>
|
||||
|
||||
It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
|
||||
models](https://huggingface.co/docs/hub/models-gated#gated-models)
|
||||
|
||||
</Tip>
|
||||
|
||||
"""
|
||||
cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
|
||||
resume_download = kwargs.pop("resume_download", False)
|
||||
force_download = kwargs.pop("force_download", False)
|
||||
proxies = kwargs.pop("proxies", None)
|
||||
local_files_only = kwargs.pop("local_files_only", HF_HUB_OFFLINE)
|
||||
use_auth_token = kwargs.pop("use_auth_token", None)
|
||||
revision = kwargs.pop("revision", None)
|
||||
from_flax = kwargs.pop("from_flax", False)
|
||||
custom_pipeline = kwargs.pop("custom_pipeline", None)
|
||||
variant = kwargs.pop("variant", None)
|
||||
use_safetensors = kwargs.pop("use_safetensors", None)
|
||||
|
||||
if use_safetensors and not is_safetensors_available():
|
||||
raise ValueError(
|
||||
"`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
|
||||
)
|
||||
|
||||
allow_pickle = False
|
||||
if use_safetensors is None:
|
||||
use_safetensors = is_safetensors_available()
|
||||
allow_pickle = True
|
||||
|
||||
pipeline_is_cached = False
|
||||
allow_patterns = None
|
||||
ignore_patterns = None
|
||||
|
||||
if not local_files_only:
|
||||
config_file = hf_hub_download(
|
||||
pretrained_model_name,
|
||||
cls.config_name,
|
||||
cache_dir=cache_dir,
|
||||
revision=revision,
|
||||
proxies=proxies,
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
use_auth_token=use_auth_token,
|
||||
)
|
||||
info = model_info(
|
||||
pretrained_model_name,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
)
|
||||
|
||||
config_dict = cls._dict_from_json_file(config_file)
|
||||
# retrieve all folder_names that contain relevant files
|
||||
folder_names = [k for k, v in config_dict.items() if isinstance(v, list)]
|
||||
|
||||
filenames = set(sibling.rfilename for sibling in info.siblings)
|
||||
model_filenames, variant_filenames = variant_compatible_siblings(filenames, variant=variant)
|
||||
|
||||
# if the whole pipeline is cached we don't have to ping the Hub
|
||||
if revision in DEPRECATED_REVISION_ARGS and version.parse(
|
||||
version.parse(__version__).base_version
|
||||
) >= version.parse("0.17.0"):
|
||||
warn_deprecated_model_variant(
|
||||
pretrained_model_name, use_auth_token, variant, revision, model_filenames
|
||||
)
|
||||
|
||||
model_folder_names = set([os.path.split(f)[0] for f in model_filenames])
|
||||
|
||||
# all filenames compatible with variant will be added
|
||||
allow_patterns = list(model_filenames)
|
||||
|
||||
# allow all patterns from non-model folders
|
||||
# this enables downloading schedulers, tokenizers, ...
|
||||
allow_patterns += [os.path.join(k, "*") for k in folder_names if k not in model_folder_names]
|
||||
# also allow downloading config.json files with the model
|
||||
allow_patterns += [os.path.join(k, "*.json") for k in model_folder_names]
|
||||
|
||||
allow_patterns += [
|
||||
SCHEDULER_CONFIG_NAME,
|
||||
CONFIG_NAME,
|
||||
cls.config_name,
|
||||
CUSTOM_PIPELINE_FILE_NAME,
|
||||
]
|
||||
|
||||
if (
|
||||
use_safetensors
|
||||
and not allow_pickle
|
||||
and not is_safetensors_compatible(model_filenames, variant=variant)
|
||||
):
|
||||
raise EnvironmentError(
|
||||
f"Could not found the necessary `safetensors` weights in {model_filenames} (variant={variant})"
|
||||
)
|
||||
if from_flax:
|
||||
ignore_patterns = ["*.bin", "*.safetensors", "*.onnx", "*.pb"]
|
||||
elif use_safetensors and is_safetensors_compatible(model_filenames, variant=variant):
|
||||
ignore_patterns = ["*.bin", "*.msgpack"]
|
||||
|
||||
safetensors_variant_filenames = set([f for f in variant_filenames if f.endswith(".safetensors")])
|
||||
safetensors_model_filenames = set([f for f in model_filenames if f.endswith(".safetensors")])
|
||||
if (
|
||||
len(safetensors_variant_filenames) > 0
|
||||
and safetensors_model_filenames != safetensors_variant_filenames
|
||||
):
|
||||
logger.warn(
|
||||
f"\nA mixture of {variant} and non-{variant} filenames will be loaded.\nLoaded {variant} filenames:\n[{', '.join(safetensors_variant_filenames)}]\nLoaded non-{variant} filenames:\n[{', '.join(safetensors_model_filenames - safetensors_variant_filenames)}\nIf this behavior is not expected, please check your folder structure."
|
||||
)
|
||||
else:
|
||||
ignore_patterns = ["*.safetensors", "*.msgpack"]
|
||||
|
||||
bin_variant_filenames = set([f for f in variant_filenames if f.endswith(".bin")])
|
||||
bin_model_filenames = set([f for f in model_filenames if f.endswith(".bin")])
|
||||
if len(bin_variant_filenames) > 0 and bin_model_filenames != bin_variant_filenames:
|
||||
logger.warn(
|
||||
f"\nA mixture of {variant} and non-{variant} filenames will be loaded.\nLoaded {variant} filenames:\n[{', '.join(bin_variant_filenames)}]\nLoaded non-{variant} filenames:\n[{', '.join(bin_model_filenames - bin_variant_filenames)}\nIf this behavior is not expected, please check your folder structure."
|
||||
)
|
||||
|
||||
re_ignore_pattern = [re.compile(fnmatch.translate(p)) for p in ignore_patterns]
|
||||
re_allow_pattern = [re.compile(fnmatch.translate(p)) for p in allow_patterns]
|
||||
|
||||
expected_files = [f for f in filenames if not any(p.match(f) for p in re_ignore_pattern)]
|
||||
expected_files = [f for f in expected_files if any(p.match(f) for p in re_allow_pattern)]
|
||||
|
||||
snapshot_folder = Path(config_file).parent
|
||||
pipeline_is_cached = all((snapshot_folder / f).is_file() for f in expected_files)
|
||||
|
||||
if pipeline_is_cached:
|
||||
# if the pipeline is cached, we can directly return it
|
||||
# else call snapshot_download
|
||||
return snapshot_folder
|
||||
|
||||
user_agent = {"pipeline_class": cls.__name__}
|
||||
if custom_pipeline is not None and not custom_pipeline.endswith(".py"):
|
||||
user_agent["custom_pipeline"] = custom_pipeline
|
||||
|
||||
# download all allow_patterns - ignore_patterns
|
||||
cached_folder = snapshot_download(
|
||||
pretrained_model_name,
|
||||
cache_dir=cache_dir,
|
||||
resume_download=resume_download,
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
allow_patterns=allow_patterns,
|
||||
ignore_patterns=ignore_patterns,
|
||||
user_agent=user_agent,
|
||||
)
|
||||
|
||||
return cached_folder
|
||||
|
||||
@staticmethod
|
||||
def _get_signature_keys(obj):
|
||||
parameters = inspect.signature(obj.__init__).parameters
|
||||
|
||||
@@ -14,8 +14,9 @@
|
||||
# limitations under the License.
|
||||
""" Conversion script for the Stable Diffusion checkpoints."""
|
||||
|
||||
import os
|
||||
import re
|
||||
from io import BytesIO
|
||||
import tempfile
|
||||
from typing import Optional
|
||||
|
||||
import requests
|
||||
@@ -954,26 +955,7 @@ def stable_unclip_image_noising_components(
|
||||
return image_normalizer, image_noising_scheduler
|
||||
|
||||
|
||||
def convert_controlnet_checkpoint(
|
||||
checkpoint, original_config, checkpoint_path, image_size, upcast_attention, extract_ema
|
||||
):
|
||||
ctrlnet_config = create_unet_diffusers_config(original_config, image_size=image_size, controlnet=True)
|
||||
ctrlnet_config["upcast_attention"] = upcast_attention
|
||||
|
||||
ctrlnet_config.pop("sample_size")
|
||||
|
||||
controlnet_model = ControlNetModel(**ctrlnet_config)
|
||||
|
||||
converted_ctrl_checkpoint = convert_ldm_unet_checkpoint(
|
||||
checkpoint, ctrlnet_config, path=checkpoint_path, extract_ema=extract_ema, controlnet=True
|
||||
)
|
||||
|
||||
controlnet_model.load_state_dict(converted_ctrl_checkpoint)
|
||||
|
||||
return controlnet_model
|
||||
|
||||
|
||||
def download_from_original_stable_diffusion_ckpt(
|
||||
def load_pipeline_from_original_stable_diffusion_ckpt(
|
||||
checkpoint_path: str,
|
||||
original_config_file: str = None,
|
||||
image_size: int = 512,
|
||||
@@ -1061,28 +1043,34 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
print("global_step key not found in model")
|
||||
global_step = None
|
||||
|
||||
# NOTE: this while loop isn't great but this controlnet checkpoint has one additional
|
||||
# "state_dict" key https://huggingface.co/thibaud/controlnet-canny-sd21
|
||||
while "state_dict" in checkpoint:
|
||||
if "state_dict" in checkpoint:
|
||||
checkpoint = checkpoint["state_dict"]
|
||||
|
||||
if original_config_file is None:
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
with tempfile.TemporaryDirectory() as tmpdir:
|
||||
if original_config_file is None:
|
||||
key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
|
||||
|
||||
# model_type = "v1"
|
||||
config_url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml"
|
||||
original_config_file = os.path.join(tmpdir, "inference.yaml")
|
||||
if key_name in checkpoint and checkpoint[key_name].shape[-1] == 1024:
|
||||
if not os.path.isfile("v2-inference-v.yaml"):
|
||||
# model_type = "v2"
|
||||
r = requests.get(
|
||||
" https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml"
|
||||
)
|
||||
open(original_config_file, "wb").write(r.content)
|
||||
|
||||
if key_name in checkpoint and checkpoint[key_name].shape[-1] == 1024:
|
||||
# model_type = "v2"
|
||||
config_url = "https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml"
|
||||
if global_step == 110000:
|
||||
# v2.1 needs to upcast attention
|
||||
upcast_attention = True
|
||||
else:
|
||||
if not os.path.isfile("v1-inference.yaml"):
|
||||
# model_type = "v1"
|
||||
r = requests.get(
|
||||
" https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml"
|
||||
)
|
||||
open(original_config_file, "wb").write(r.content)
|
||||
|
||||
if global_step == 110000:
|
||||
# v2.1 needs to upcast attention
|
||||
upcast_attention = True
|
||||
|
||||
original_config_file = BytesIO(requests.get(config_url).content)
|
||||
|
||||
original_config = OmegaConf.load(original_config_file)
|
||||
original_config = OmegaConf.load(original_config_file)
|
||||
|
||||
if num_in_channels is not None:
|
||||
original_config["model"]["params"]["unet_config"]["params"]["in_channels"] = num_in_channels
|
||||
@@ -1105,14 +1093,6 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
if image_size is None:
|
||||
image_size = 512
|
||||
|
||||
if controlnet is None:
|
||||
controlnet = "control_stage_config" in original_config.model.params
|
||||
|
||||
if controlnet:
|
||||
controlnet_model = convert_controlnet_checkpoint(
|
||||
checkpoint, original_config, checkpoint_path, image_size, upcast_attention, extract_ema
|
||||
)
|
||||
|
||||
num_train_timesteps = original_config.model.params.timesteps
|
||||
beta_start = original_config.model.params.linear_start
|
||||
beta_end = original_config.model.params.linear_end
|
||||
@@ -1172,34 +1152,27 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
model_type = original_config.model.params.cond_stage_config.target.split(".")[-1]
|
||||
logger.debug(f"no `model_type` given, `model_type` inferred as: {model_type}")
|
||||
|
||||
if controlnet is None:
|
||||
controlnet = "control_stage_config" in original_config.model.params
|
||||
|
||||
if controlnet and model_type != "FrozenCLIPEmbedder":
|
||||
raise ValueError("`controlnet`=True only supports `model_type`='FrozenCLIPEmbedder'")
|
||||
|
||||
if model_type == "FrozenOpenCLIPEmbedder":
|
||||
text_model = convert_open_clip_checkpoint(checkpoint)
|
||||
tokenizer = CLIPTokenizer.from_pretrained("stabilityai/stable-diffusion-2", subfolder="tokenizer")
|
||||
|
||||
if stable_unclip is None:
|
||||
if controlnet:
|
||||
pipe = StableDiffusionControlNetPipeline(
|
||||
vae=vae,
|
||||
text_encoder=text_model,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
controlnet=controlnet_model,
|
||||
safety_checker=None,
|
||||
feature_extractor=None,
|
||||
requires_safety_checker=False,
|
||||
)
|
||||
else:
|
||||
pipe = StableDiffusionPipeline(
|
||||
vae=vae,
|
||||
text_encoder=text_model,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
safety_checker=None,
|
||||
feature_extractor=None,
|
||||
requires_safety_checker=False,
|
||||
)
|
||||
pipe = StableDiffusionPipeline(
|
||||
vae=vae,
|
||||
text_encoder=text_model,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
safety_checker=None,
|
||||
feature_extractor=None,
|
||||
requires_safety_checker=False,
|
||||
)
|
||||
else:
|
||||
image_normalizer, image_noising_scheduler = stable_unclip_image_noising_components(
|
||||
original_config, clip_stats_path=clip_stats_path, device=device
|
||||
@@ -1274,6 +1247,19 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
feature_extractor = AutoFeatureExtractor.from_pretrained("CompVis/stable-diffusion-safety-checker")
|
||||
|
||||
if controlnet:
|
||||
# Convert the ControlNetModel model.
|
||||
ctrlnet_config = create_unet_diffusers_config(original_config, image_size=image_size, controlnet=True)
|
||||
ctrlnet_config["upcast_attention"] = upcast_attention
|
||||
|
||||
ctrlnet_config.pop("sample_size")
|
||||
|
||||
controlnet_model = ControlNetModel(**ctrlnet_config)
|
||||
|
||||
converted_ctrl_checkpoint = convert_ldm_unet_checkpoint(
|
||||
checkpoint, ctrlnet_config, path=checkpoint_path, extract_ema=extract_ema, controlnet=True
|
||||
)
|
||||
controlnet_model.load_state_dict(converted_ctrl_checkpoint)
|
||||
|
||||
pipe = StableDiffusionControlNetPipeline(
|
||||
vae=vae,
|
||||
text_encoder=text_model,
|
||||
@@ -1301,55 +1287,3 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
pipe = LDMTextToImagePipeline(vqvae=vae, bert=text_model, tokenizer=tokenizer, unet=unet, scheduler=scheduler)
|
||||
|
||||
return pipe
|
||||
|
||||
|
||||
def download_controlnet_from_original_ckpt(
|
||||
checkpoint_path: str,
|
||||
original_config_file: str,
|
||||
image_size: int = 512,
|
||||
extract_ema: bool = False,
|
||||
num_in_channels: Optional[int] = None,
|
||||
upcast_attention: Optional[bool] = None,
|
||||
device: str = None,
|
||||
from_safetensors: bool = False,
|
||||
) -> StableDiffusionPipeline:
|
||||
if not is_omegaconf_available():
|
||||
raise ValueError(BACKENDS_MAPPING["omegaconf"][1])
|
||||
|
||||
from omegaconf import OmegaConf
|
||||
|
||||
if from_safetensors:
|
||||
if not is_safetensors_available():
|
||||
raise ValueError(BACKENDS_MAPPING["safetensors"][1])
|
||||
|
||||
from safetensors import safe_open
|
||||
|
||||
checkpoint = {}
|
||||
with safe_open(checkpoint_path, framework="pt", device="cpu") as f:
|
||||
for key in f.keys():
|
||||
checkpoint[key] = f.get_tensor(key)
|
||||
else:
|
||||
if device is None:
|
||||
device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
checkpoint = torch.load(checkpoint_path, map_location=device)
|
||||
else:
|
||||
checkpoint = torch.load(checkpoint_path, map_location=device)
|
||||
|
||||
# NOTE: this while loop isn't great but this controlnet checkpoint has one additional
|
||||
# "state_dict" key https://huggingface.co/thibaud/controlnet-canny-sd21
|
||||
while "state_dict" in checkpoint:
|
||||
checkpoint = checkpoint["state_dict"]
|
||||
|
||||
original_config = OmegaConf.load(original_config_file)
|
||||
|
||||
if num_in_channels is not None:
|
||||
original_config["model"]["params"]["unet_config"]["params"]["in_channels"] = num_in_channels
|
||||
|
||||
if "control_stage_config" not in original_config.model.params:
|
||||
raise ValueError("`control_stage_config` not present in original config")
|
||||
|
||||
controlnet_model = convert_controlnet_checkpoint(
|
||||
checkpoint, original_config, checkpoint_path, image_size, upcast_attention, extract_ema
|
||||
)
|
||||
|
||||
return controlnet_model
|
||||
|
||||
@@ -33,7 +33,7 @@ from ...schedulers import (
|
||||
FlaxLMSDiscreteScheduler,
|
||||
FlaxPNDMScheduler,
|
||||
)
|
||||
from ...utils import deprecate, logging, replace_example_docstring
|
||||
from ...utils import deprecate, logging
|
||||
from ..pipeline_flax_utils import FlaxDiffusionPipeline
|
||||
from . import FlaxStableDiffusionPipelineOutput
|
||||
from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
|
||||
@@ -44,39 +44,6 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
# Set to True to use python for loop instead of jax.fori_loop for easier debugging
|
||||
DEBUG = False
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> import jax
|
||||
>>> import numpy as np
|
||||
>>> from flax.jax_utils import replicate
|
||||
>>> from flax.training.common_utils import shard
|
||||
|
||||
>>> from diffusers import FlaxStableDiffusionPipeline
|
||||
|
||||
>>> pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
|
||||
... "runwayml/stable-diffusion-v1-5", revision="bf16", dtype=jax.numpy.bfloat16
|
||||
... )
|
||||
|
||||
>>> prompt = "a photo of an astronaut riding a horse on mars"
|
||||
|
||||
>>> prng_seed = jax.random.PRNGKey(0)
|
||||
>>> num_inference_steps = 50
|
||||
|
||||
>>> num_samples = jax.device_count()
|
||||
>>> prompt = num_samples * [prompt]
|
||||
>>> prompt_ids = pipeline.prepare_inputs(prompt)
|
||||
# shard inputs and rng
|
||||
|
||||
>>> params = replicate(params)
|
||||
>>> prng_seed = jax.random.split(prng_seed, jax.device_count())
|
||||
>>> prompt_ids = shard(prompt_ids)
|
||||
|
||||
>>> images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
|
||||
>>> images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
class FlaxStableDiffusionPipeline(FlaxDiffusionPipeline):
|
||||
r"""
|
||||
@@ -305,7 +272,6 @@ class FlaxStableDiffusionPipeline(FlaxDiffusionPipeline):
|
||||
image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
|
||||
return image
|
||||
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt_ids: jnp.array,
|
||||
@@ -350,8 +316,6 @@ class FlaxStableDiffusionPipeline(FlaxDiffusionPipeline):
|
||||
Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
|
||||
a plain tuple.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
|
||||
[`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
|
||||
|
||||
@@ -32,7 +32,7 @@ from ...schedulers import (
|
||||
FlaxLMSDiscreteScheduler,
|
||||
FlaxPNDMScheduler,
|
||||
)
|
||||
from ...utils import PIL_INTERPOLATION, logging, replace_example_docstring
|
||||
from ...utils import PIL_INTERPOLATION, logging
|
||||
from ..pipeline_flax_utils import FlaxDiffusionPipeline
|
||||
from . import FlaxStableDiffusionPipelineOutput
|
||||
from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
|
||||
@@ -43,64 +43,6 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
# Set to True to use python for loop instead of jax.fori_loop for easier debugging
|
||||
DEBUG = False
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> import jax
|
||||
>>> import numpy as np
|
||||
>>> import jax.numpy as jnp
|
||||
>>> from flax.jax_utils import replicate
|
||||
>>> from flax.training.common_utils import shard
|
||||
>>> import requests
|
||||
>>> from io import BytesIO
|
||||
>>> from PIL import Image
|
||||
>>> from diffusers import FlaxStableDiffusionImg2ImgPipeline
|
||||
|
||||
|
||||
>>> def create_key(seed=0):
|
||||
... return jax.random.PRNGKey(seed)
|
||||
|
||||
|
||||
>>> rng = create_key(0)
|
||||
|
||||
>>> url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
>>> response = requests.get(url)
|
||||
>>> init_img = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
>>> init_img = init_img.resize((768, 512))
|
||||
|
||||
>>> prompts = "A fantasy landscape, trending on artstation"
|
||||
|
||||
>>> pipeline, params = FlaxStableDiffusionImg2ImgPipeline.from_pretrained(
|
||||
... "CompVis/stable-diffusion-v1-4",
|
||||
... revision="flax",
|
||||
... dtype=jnp.bfloat16,
|
||||
... )
|
||||
|
||||
>>> num_samples = jax.device_count()
|
||||
>>> rng = jax.random.split(rng, jax.device_count())
|
||||
>>> prompt_ids, processed_image = pipeline.prepare_inputs(
|
||||
... prompt=[prompts] * num_samples, image=[init_img] * num_samples
|
||||
... )
|
||||
>>> p_params = replicate(params)
|
||||
>>> prompt_ids = shard(prompt_ids)
|
||||
>>> processed_image = shard(processed_image)
|
||||
|
||||
>>> output = pipeline(
|
||||
... prompt_ids=prompt_ids,
|
||||
... image=processed_image,
|
||||
... params=p_params,
|
||||
... prng_seed=rng,
|
||||
... strength=0.75,
|
||||
... num_inference_steps=50,
|
||||
... jit=True,
|
||||
... height=512,
|
||||
... width=768,
|
||||
... ).images
|
||||
|
||||
>>> output_images = pipeline.numpy_to_pil(np.asarray(output.reshape((num_samples,) + output.shape[-3:])))
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
class FlaxStableDiffusionImg2ImgPipeline(FlaxDiffusionPipeline):
|
||||
r"""
|
||||
@@ -335,7 +277,6 @@ class FlaxStableDiffusionImg2ImgPipeline(FlaxDiffusionPipeline):
|
||||
image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
|
||||
return image
|
||||
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt_ids: jnp.array,
|
||||
@@ -391,8 +332,6 @@ class FlaxStableDiffusionImg2ImgPipeline(FlaxDiffusionPipeline):
|
||||
Whether to run `pmap` versions of the generation and safety scoring functions. NOTE: This argument
|
||||
exists because `__call__` is not yet end-to-end pmap-able. It will be removed in a future release.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
|
||||
[`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
|
||||
|
||||
@@ -33,7 +33,7 @@ from ...schedulers import (
|
||||
FlaxLMSDiscreteScheduler,
|
||||
FlaxPNDMScheduler,
|
||||
)
|
||||
from ...utils import PIL_INTERPOLATION, deprecate, logging, replace_example_docstring
|
||||
from ...utils import PIL_INTERPOLATION, deprecate, logging
|
||||
from ..pipeline_flax_utils import FlaxDiffusionPipeline
|
||||
from . import FlaxStableDiffusionPipelineOutput
|
||||
from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
|
||||
@@ -44,60 +44,6 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
# Set to True to use python for loop instead of jax.fori_loop for easier debugging
|
||||
DEBUG = False
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> import jax
|
||||
>>> import numpy as np
|
||||
>>> from flax.jax_utils import replicate
|
||||
>>> from flax.training.common_utils import shard
|
||||
>>> import PIL
|
||||
>>> import requests
|
||||
>>> from io import BytesIO
|
||||
>>> from diffusers import FlaxStableDiffusionInpaintPipeline
|
||||
|
||||
|
||||
>>> def download_image(url):
|
||||
... response = requests.get(url)
|
||||
... return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
|
||||
>>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
||||
>>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
||||
|
||||
>>> init_image = download_image(img_url).resize((512, 512))
|
||||
>>> mask_image = download_image(mask_url).resize((512, 512))
|
||||
|
||||
>>> pipeline, params = FlaxStableDiffusionInpaintPipeline.from_pretrained(
|
||||
... "xvjiarui/stable-diffusion-2-inpainting"
|
||||
... )
|
||||
|
||||
>>> prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
|
||||
>>> prng_seed = jax.random.PRNGKey(0)
|
||||
>>> num_inference_steps = 50
|
||||
|
||||
>>> num_samples = jax.device_count()
|
||||
>>> prompt = num_samples * [prompt]
|
||||
>>> init_image = num_samples * [init_image]
|
||||
>>> mask_image = num_samples * [mask_image]
|
||||
>>> prompt_ids, processed_masked_images, processed_masks = pipeline.prepare_inputs(
|
||||
... prompt, init_image, mask_image
|
||||
... )
|
||||
# shard inputs and rng
|
||||
|
||||
>>> params = replicate(params)
|
||||
>>> prng_seed = jax.random.split(prng_seed, jax.device_count())
|
||||
>>> prompt_ids = shard(prompt_ids)
|
||||
>>> processed_masked_images = shard(processed_masked_images)
|
||||
>>> processed_masks = shard(processed_masks)
|
||||
|
||||
>>> images = pipeline(
|
||||
... prompt_ids, processed_masks, processed_masked_images, params, prng_seed, num_inference_steps, jit=True
|
||||
... ).images
|
||||
>>> images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
class FlaxStableDiffusionInpaintPipeline(FlaxDiffusionPipeline):
|
||||
r"""
|
||||
@@ -386,7 +332,6 @@ class FlaxStableDiffusionInpaintPipeline(FlaxDiffusionPipeline):
|
||||
image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
|
||||
return image
|
||||
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt_ids: jnp.array,
|
||||
@@ -433,8 +378,6 @@ class FlaxStableDiffusionInpaintPipeline(FlaxDiffusionPipeline):
|
||||
Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
|
||||
a plain tuple.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
|
||||
[`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
|
||||
|
||||
@@ -588,7 +588,7 @@ class StableDiffusionPipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
|
||||
|
||||
+7
-5
@@ -22,7 +22,7 @@ from torch.nn import functional as F
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.attention_processor import Attention
|
||||
from ...models.cross_attention import CrossAttention
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import is_accelerate_available, is_accelerate_version, logging, randn_tensor, replace_example_docstring
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
@@ -121,13 +121,13 @@ class AttentionStore:
|
||||
self.attn_res = attn_res
|
||||
|
||||
|
||||
class AttendExciteAttnProcessor:
|
||||
class AttendExciteCrossAttnProcessor:
|
||||
def __init__(self, attnstore, place_in_unet):
|
||||
super().__init__()
|
||||
self.attnstore = attnstore
|
||||
self.place_in_unet = place_in_unet
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
def __call__(self, attn: CrossAttention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
@@ -679,7 +679,9 @@ class StableDiffusionAttendAndExcitePipeline(DiffusionPipeline):
|
||||
continue
|
||||
|
||||
cross_att_count += 1
|
||||
attn_procs[name] = AttendExciteAttnProcessor(attnstore=self.attention_store, place_in_unet=place_in_unet)
|
||||
attn_procs[name] = AttendExciteCrossAttnProcessor(
|
||||
attnstore=self.attention_store, place_in_unet=place_in_unet
|
||||
)
|
||||
|
||||
self.unet.set_attn_processor(attn_procs)
|
||||
self.attention_store.num_att_layers = cross_att_count
|
||||
@@ -775,7 +777,7 @@ class StableDiffusionAttendAndExcitePipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
max_iter_to_alter (`int`, *optional*, defaults to `25`):
|
||||
|
||||
@@ -14,18 +14,14 @@
|
||||
|
||||
|
||||
import inspect
|
||||
import os
|
||||
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
|
||||
from typing import Any, Callable, Dict, List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL.Image
|
||||
import torch
|
||||
from torch import nn
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
|
||||
from ...models.controlnet import ControlNetOutput
|
||||
from ...models.modeling_utils import ModelMixin
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
PIL_INTERPOLATION,
|
||||
@@ -89,63 +85,6 @@ EXAMPLE_DOC_STRING = """
|
||||
"""
|
||||
|
||||
|
||||
class MultiControlNetModel(ModelMixin):
|
||||
r"""
|
||||
Multiple `ControlNetModel` wrapper class for Multi-ControlNet
|
||||
|
||||
This module is a wrapper for multiple instances of the `ControlNetModel`. The `forward()` API is designed to be
|
||||
compatible with `ControlNetModel`.
|
||||
|
||||
Args:
|
||||
controlnets (`List[ControlNetModel]`):
|
||||
Provides additional conditioning to the unet during the denoising process. You must set multiple
|
||||
`ControlNetModel` as a list.
|
||||
"""
|
||||
|
||||
def __init__(self, controlnets: Union[List[ControlNetModel], Tuple[ControlNetModel]]):
|
||||
super().__init__()
|
||||
self.nets = nn.ModuleList(controlnets)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
sample: torch.FloatTensor,
|
||||
timestep: Union[torch.Tensor, float, int],
|
||||
encoder_hidden_states: torch.Tensor,
|
||||
controlnet_cond: List[torch.tensor],
|
||||
conditioning_scale: List[float],
|
||||
class_labels: Optional[torch.Tensor] = None,
|
||||
timestep_cond: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
return_dict: bool = True,
|
||||
) -> Union[ControlNetOutput, Tuple]:
|
||||
for i, (image, scale, controlnet) in enumerate(zip(controlnet_cond, conditioning_scale, self.nets)):
|
||||
down_samples, mid_sample = controlnet(
|
||||
sample,
|
||||
timestep,
|
||||
encoder_hidden_states,
|
||||
image,
|
||||
scale,
|
||||
class_labels,
|
||||
timestep_cond,
|
||||
attention_mask,
|
||||
cross_attention_kwargs,
|
||||
return_dict,
|
||||
)
|
||||
|
||||
# merge samples
|
||||
if i == 0:
|
||||
down_block_res_samples, mid_block_res_sample = down_samples, mid_sample
|
||||
else:
|
||||
down_block_res_samples = [
|
||||
samples_prev + samples_curr
|
||||
for samples_prev, samples_curr in zip(down_block_res_samples, down_samples)
|
||||
]
|
||||
mid_block_res_sample += mid_sample
|
||||
|
||||
return down_block_res_samples, mid_block_res_sample
|
||||
|
||||
|
||||
class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
r"""
|
||||
Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
|
||||
@@ -164,10 +103,8 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
Tokenizer of class
|
||||
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
|
||||
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
|
||||
controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
|
||||
Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
|
||||
as a list, the outputs from each ControlNet are added together to create one combined additional
|
||||
conditioning.
|
||||
controlnet ([`ControlNetModel`]):
|
||||
Provides additional conditioning to the unet during the denoising process
|
||||
scheduler ([`SchedulerMixin`]):
|
||||
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
|
||||
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
|
||||
@@ -185,7 +122,7 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
text_encoder: CLIPTextModel,
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
|
||||
controlnet: ControlNetModel,
|
||||
scheduler: KarrasDiffusionSchedulers,
|
||||
safety_checker: StableDiffusionSafetyChecker,
|
||||
feature_extractor: CLIPFeatureExtractor,
|
||||
@@ -209,8 +146,8 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
|
||||
)
|
||||
|
||||
if isinstance(controlnet, (list, tuple)):
|
||||
controlnet = MultiControlNetModel(controlnet)
|
||||
if isinstance(controlnet, list):
|
||||
controlnet = torch.nn.ModuleList(controlnet)
|
||||
|
||||
self.register_modules(
|
||||
vae=vae,
|
||||
@@ -498,7 +435,6 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
negative_prompt=None,
|
||||
prompt_embeds=None,
|
||||
negative_prompt_embeds=None,
|
||||
controlnet_conditioning_scale=1.0,
|
||||
):
|
||||
if height % 8 != 0 or width % 8 != 0:
|
||||
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
|
||||
@@ -537,41 +473,6 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
f" {negative_prompt_embeds.shape}."
|
||||
)
|
||||
|
||||
# Check `image`
|
||||
|
||||
if isinstance(self.controlnet, ControlNetModel):
|
||||
self.check_image(image, prompt, prompt_embeds)
|
||||
elif isinstance(self.controlnet, MultiControlNetModel):
|
||||
if not isinstance(image, list):
|
||||
raise TypeError("For multiple controlnets: `image` must be type `list`")
|
||||
|
||||
if len(image) != len(self.controlnet.nets):
|
||||
raise ValueError(
|
||||
"For multiple controlnets: `image` must have the same length as the number of controlnets."
|
||||
)
|
||||
|
||||
for image_ in image:
|
||||
self.check_image(image_, prompt, prompt_embeds)
|
||||
else:
|
||||
assert False
|
||||
|
||||
# Check `controlnet_conditioning_scale`
|
||||
|
||||
if isinstance(self.controlnet, ControlNetModel):
|
||||
if not isinstance(controlnet_conditioning_scale, float):
|
||||
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
|
||||
elif isinstance(self.controlnet, MultiControlNetModel):
|
||||
if isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
|
||||
self.controlnet.nets
|
||||
):
|
||||
raise ValueError(
|
||||
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
|
||||
" the same length as the number of controlnets"
|
||||
)
|
||||
else:
|
||||
assert False
|
||||
|
||||
def check_image(self, image, prompt, prompt_embeds):
|
||||
image_is_pil = isinstance(image, PIL.Image.Image)
|
||||
image_is_tensor = isinstance(image, torch.Tensor)
|
||||
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
|
||||
@@ -603,25 +504,15 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
|
||||
)
|
||||
|
||||
def prepare_image(
|
||||
self, image, width, height, batch_size, num_images_per_prompt, device, dtype, do_classifier_free_guidance
|
||||
):
|
||||
def prepare_image(self, image, width, height, batch_size, num_images_per_prompt, device, dtype):
|
||||
if not isinstance(image, torch.Tensor):
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
images = []
|
||||
|
||||
for image_ in image:
|
||||
image_ = image_.convert("RGB")
|
||||
image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
|
||||
image_ = np.array(image_)
|
||||
image_ = image_[None, :]
|
||||
images.append(image_)
|
||||
|
||||
image = images
|
||||
|
||||
image = [
|
||||
np.array(i.resize((width, height), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image
|
||||
]
|
||||
image = np.concatenate(image, axis=0)
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
@@ -641,9 +532,6 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
image = torch.cat([image] * 2)
|
||||
|
||||
return image
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
|
||||
@@ -665,10 +553,7 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
return latents
|
||||
|
||||
def _default_height_width(self, height, width, image):
|
||||
# NOTE: It is possible that a list of images have different
|
||||
# dimensions for each image, so just checking the first image
|
||||
# is not _exactly_ correct, but it is simple.
|
||||
while isinstance(image, list):
|
||||
if isinstance(image, list):
|
||||
image = image[0]
|
||||
|
||||
if height is None:
|
||||
@@ -689,18 +574,6 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
|
||||
return height, width
|
||||
|
||||
# override DiffusionPipeline
|
||||
def save_pretrained(
|
||||
self,
|
||||
save_directory: Union[str, os.PathLike],
|
||||
safe_serialization: bool = False,
|
||||
variant: Optional[str] = None,
|
||||
):
|
||||
if isinstance(self.controlnet, ControlNetModel):
|
||||
super().save_pretrained(save_directory, safe_serialization, variant)
|
||||
else:
|
||||
raise NotImplementedError("Currently, the `save_pretrained()` is not implemented for Multi-ControlNet.")
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
@@ -723,7 +596,7 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
||||
callback_steps: int = 1,
|
||||
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
|
||||
controlnet_conditioning_scale: float = 1.0,
|
||||
):
|
||||
r"""
|
||||
Function invoked when calling the pipeline for generation.
|
||||
@@ -732,14 +605,10 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
|
||||
instead.
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
|
||||
`List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]` or `List[PIL.Image.Image]`):
|
||||
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
|
||||
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
|
||||
also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
|
||||
height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
|
||||
specified in init, images must be passed as a list such that each element of the list can be correctly
|
||||
batched for input to a single controlnet.
|
||||
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. PIL.Image.Image` can
|
||||
also be accepted as an image. The control image is automatically resized to fit the output image.
|
||||
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
||||
@@ -789,13 +658,13 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
|
||||
controlnet_conditioning_scale (`float`, *optional*, defaults to 1.0):
|
||||
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
|
||||
to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
|
||||
corresponding scale as a list.
|
||||
to the residual in the original unet.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
@@ -810,15 +679,7 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
|
||||
# 1. Check inputs. Raise error if not correct
|
||||
self.check_inputs(
|
||||
prompt,
|
||||
image,
|
||||
height,
|
||||
width,
|
||||
callback_steps,
|
||||
negative_prompt,
|
||||
prompt_embeds,
|
||||
negative_prompt_embeds,
|
||||
controlnet_conditioning_scale,
|
||||
prompt, image, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
|
||||
)
|
||||
|
||||
# 2. Define call parameters
|
||||
@@ -835,9 +696,6 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
# corresponds to doing no classifier free guidance.
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
if isinstance(self.controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
|
||||
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(self.controlnet.nets)
|
||||
|
||||
# 3. Encode input prompt
|
||||
prompt_embeds = self._encode_prompt(
|
||||
prompt,
|
||||
@@ -850,37 +708,18 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
)
|
||||
|
||||
# 4. Prepare image
|
||||
if isinstance(self.controlnet, ControlNetModel):
|
||||
image = self.prepare_image(
|
||||
image=image,
|
||||
width=width,
|
||||
height=height,
|
||||
batch_size=batch_size * num_images_per_prompt,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
device=device,
|
||||
dtype=self.controlnet.dtype,
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
)
|
||||
elif isinstance(self.controlnet, MultiControlNetModel):
|
||||
images = []
|
||||
image = self.prepare_image(
|
||||
image,
|
||||
width,
|
||||
height,
|
||||
batch_size * num_images_per_prompt,
|
||||
num_images_per_prompt,
|
||||
device,
|
||||
self.controlnet.dtype,
|
||||
)
|
||||
|
||||
for image_ in image:
|
||||
image_ = self.prepare_image(
|
||||
image=image_,
|
||||
width=width,
|
||||
height=height,
|
||||
batch_size=batch_size * num_images_per_prompt,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
device=device,
|
||||
dtype=self.controlnet.dtype,
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
)
|
||||
|
||||
images.append(image_)
|
||||
|
||||
image = images
|
||||
else:
|
||||
assert False
|
||||
if do_classifier_free_guidance:
|
||||
image = torch.cat([image] * 2)
|
||||
|
||||
# 5. Prepare timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
@@ -902,7 +741,16 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
||||
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
||||
|
||||
# 8. Denoising loop
|
||||
# 8. Prepare controlnets for potential multi-controlnet case
|
||||
controlnets = self.controlnet if isinstance(self.controlnet, torch.nn.ModuleList) else [self.controlnet]
|
||||
images_per_controlnet = image.shape[0] // len(controlnets)
|
||||
|
||||
if images_per_controlnet * len(controlnets) != image.shape[0]:
|
||||
raise ValueError(f"You have passed {len(controlnets)} ControlNet models, but {image.shape[0]} conditioned images. Please make sure to pass `n` x {len(controlnets)} images to generate `n` output images.")
|
||||
|
||||
control_images = image[None, :].reshape(len(controlnets), images_per_controlnet, *image.shape[1:])
|
||||
|
||||
# 9. Denoising loop
|
||||
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
||||
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
||||
for i, t in enumerate(timesteps):
|
||||
@@ -910,15 +758,23 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
# controlnet(s) inference
|
||||
down_block_res_samples, mid_block_res_sample = self.controlnet(
|
||||
latent_model_input,
|
||||
t,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
controlnet_cond=image,
|
||||
conditioning_scale=controlnet_conditioning_scale,
|
||||
return_dict=False,
|
||||
)
|
||||
control_down_block_res = control_mid_block_res = 0
|
||||
for image, controlnet in zip(control_images, controlnets):
|
||||
down_res, mid_res = self.controlnet(
|
||||
latent_model_input,
|
||||
t,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
controlnet_cond=image,
|
||||
return_dict=False,
|
||||
)
|
||||
control_down_block_res += down_res
|
||||
control_mid_block_res += mid_res
|
||||
|
||||
control_down_block_res = [
|
||||
down_block_res_sample * controlnet_conditioning_scale
|
||||
for down_block_res_sample in control_down_block_res
|
||||
]
|
||||
control_mid_block_res *= controlnet_conditioning_scale
|
||||
|
||||
# predict the noise residual
|
||||
noise_pred = self.unet(
|
||||
@@ -926,8 +782,8 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline):
|
||||
t,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
down_block_additional_residuals=down_block_res_samples,
|
||||
mid_block_additional_residual=mid_block_res_sample,
|
||||
down_block_additional_residuals=control_down_block_res,
|
||||
mid_block_additional_residual=control_mid_block_res,
|
||||
).sample
|
||||
|
||||
# perform guidance
|
||||
|
||||
@@ -447,7 +447,7 @@ class StableDiffusionDepth2ImgPipeline(DiffusionPipeline):
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
width, height = image[0].size
|
||||
else:
|
||||
height, width = image[0].shape[-2:]
|
||||
width, height = image[0].shape[-2:]
|
||||
|
||||
if depth_map is None:
|
||||
pixel_values = self.feature_extractor(images=image, return_tensors="pt").pixel_values
|
||||
|
||||
@@ -22,7 +22,6 @@ from packaging import version
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
@@ -120,6 +119,7 @@ class StableDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
"""
|
||||
_optional_components = ["safety_checker", "feature_extractor"]
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.__init__
|
||||
def __init__(
|
||||
self,
|
||||
vae: AutoencoderKL,
|
||||
@@ -196,6 +196,7 @@ class StableDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
new_config = dict(unet.config)
|
||||
new_config["sample_size"] = 64
|
||||
unet._internal_dict = FrozenDict(new_config)
|
||||
|
||||
self.register_modules(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
@@ -206,11 +207,7 @@ class StableDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
feature_extractor=feature_extractor,
|
||||
)
|
||||
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
||||
|
||||
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
|
||||
self.register_to_config(
|
||||
requires_safety_checker=requires_safety_checker,
|
||||
)
|
||||
self.register_to_config(requires_safety_checker=requires_safety_checker)
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
|
||||
def enable_sequential_cpu_offload(self, gpu_id=0):
|
||||
@@ -425,18 +422,24 @@ class StableDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
|
||||
return prompt_embeds
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
|
||||
def run_safety_checker(self, image, device, dtype):
|
||||
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
|
||||
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
|
||||
image, has_nsfw_concept = self.safety_checker(
|
||||
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
|
||||
)
|
||||
if self.safety_checker is not None:
|
||||
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
|
||||
image, has_nsfw_concept = self.safety_checker(
|
||||
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
|
||||
)
|
||||
else:
|
||||
has_nsfw_concept = None
|
||||
return image, has_nsfw_concept
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
|
||||
def decode_latents(self, latents):
|
||||
latents = 1 / self.vae.config.scaling_factor * latents
|
||||
image = self.vae.decode(latents).sample
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
return image
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
|
||||
@@ -671,7 +674,7 @@ class StableDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
)
|
||||
|
||||
# 4. Preprocess image
|
||||
image = self.image_processor.preprocess(image)
|
||||
image = preprocess(image)
|
||||
|
||||
# 5. set timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
@@ -711,26 +714,15 @@ class StableDiffusionImg2ImgPipeline(DiffusionPipeline):
|
||||
if callback is not None and i % callback_steps == 0:
|
||||
callback(i, t, latents)
|
||||
|
||||
if output_type not in ["latent", "pt", "np", "pil"]:
|
||||
deprecation_message = (
|
||||
f"the output_type {output_type} is outdated. Please make sure to set it to one of these instead: "
|
||||
"`pil`, `np`, `pt`, `latent`"
|
||||
)
|
||||
deprecate("Unsupported output_type", "1.0.0", deprecation_message, standard_warn=False)
|
||||
output_type = "np"
|
||||
|
||||
if output_type == "latent":
|
||||
image = latents
|
||||
has_nsfw_concept = None
|
||||
|
||||
# 9. Post-processing
|
||||
image = self.decode_latents(latents)
|
||||
|
||||
if self.safety_checker is not None:
|
||||
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
|
||||
else:
|
||||
has_nsfw_concept = False
|
||||
# 10. Run safety checker
|
||||
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
|
||||
|
||||
image = self.image_processor.postprocess(image, output_type=output_type)
|
||||
# 11. Convert to PIL
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
# Offload last model to CPU
|
||||
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
|
||||
|
||||
@@ -525,7 +525,7 @@ class StableDiffusionPanoramaPipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
|
||||
|
||||
@@ -29,7 +29,7 @@ from transformers import (
|
||||
)
|
||||
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.attention_processor import Attention
|
||||
from ...models.cross_attention import CrossAttention
|
||||
from ...schedulers import DDIMScheduler, DDPMScheduler, EulerAncestralDiscreteScheduler, LMSDiscreteScheduler
|
||||
from ...schedulers.scheduling_ddim_inverse import DDIMInverseScheduler
|
||||
from ...utils import (
|
||||
@@ -153,8 +153,6 @@ EXAMPLE_INVERT_DOC_STRING = """
|
||||
>>> source_embeds = pipeline.get_embeds(source_prompts)
|
||||
>>> target_embeds = pipeline.get_embeds(target_prompts)
|
||||
>>> # the latents can then be used to edit a real image
|
||||
>>> # when using Stable Diffusion 2 or other models that use v-prediction
|
||||
>>> # set `cross_attention_guidance_amount` to 0.01 or less to avoid input latent gradient explosion
|
||||
|
||||
>>> image = pipeline(
|
||||
... caption,
|
||||
@@ -200,10 +198,10 @@ def prepare_unet(unet: UNet2DConditionModel):
|
||||
module_name = name.replace(".processor", "")
|
||||
module = unet.get_submodule(module_name)
|
||||
if "attn2" in name:
|
||||
pix2pix_zero_attn_procs[name] = Pix2PixZeroAttnProcessor(is_pix2pix_zero=True)
|
||||
pix2pix_zero_attn_procs[name] = Pix2PixZeroCrossAttnProcessor(is_pix2pix_zero=True)
|
||||
module.requires_grad_(True)
|
||||
else:
|
||||
pix2pix_zero_attn_procs[name] = Pix2PixZeroAttnProcessor(is_pix2pix_zero=False)
|
||||
pix2pix_zero_attn_procs[name] = Pix2PixZeroCrossAttnProcessor(is_pix2pix_zero=False)
|
||||
module.requires_grad_(False)
|
||||
|
||||
unet.set_attn_processor(pix2pix_zero_attn_procs)
|
||||
@@ -218,7 +216,7 @@ class Pix2PixZeroL2Loss:
|
||||
self.loss += ((predictions - targets) ** 2).sum((1, 2)).mean(0)
|
||||
|
||||
|
||||
class Pix2PixZeroAttnProcessor:
|
||||
class Pix2PixZeroCrossAttnProcessor:
|
||||
"""An attention processor class to store the attention weights.
|
||||
In Pix2Pix Zero, it happens during computations in the cross-attention blocks."""
|
||||
|
||||
@@ -229,7 +227,7 @@ class Pix2PixZeroAttnProcessor:
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
attn: Attention,
|
||||
attn: CrossAttention,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
@@ -732,23 +730,6 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline):
|
||||
|
||||
return latents
|
||||
|
||||
def get_epsilon(self, model_output: torch.Tensor, sample: torch.Tensor, timestep: int):
|
||||
pred_type = self.inverse_scheduler.config.prediction_type
|
||||
alpha_prod_t = self.inverse_scheduler.alphas_cumprod[timestep]
|
||||
|
||||
beta_prod_t = 1 - alpha_prod_t
|
||||
|
||||
if pred_type == "epsilon":
|
||||
return model_output
|
||||
elif pred_type == "sample":
|
||||
return (sample - alpha_prod_t ** (0.5) * model_output) / beta_prod_t ** (0.5)
|
||||
elif pred_type == "v_prediction":
|
||||
return (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
|
||||
else:
|
||||
raise ValueError(
|
||||
f"prediction_type given as {pred_type} must be one of `epsilon`, `sample`, or `v_prediction`"
|
||||
)
|
||||
|
||||
def auto_corr_loss(self, hidden_states, generator=None):
|
||||
batch_size, channel, height, width = hidden_states.shape
|
||||
if batch_size > 1:
|
||||
@@ -1175,8 +1156,8 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline):
|
||||
|
||||
# 7. Denoising loop where we obtain the cross-attention maps.
|
||||
num_warmup_steps = len(timesteps) - num_inference_steps * self.inverse_scheduler.order
|
||||
with self.progress_bar(total=num_inference_steps - 1) as progress_bar:
|
||||
for i, t in enumerate(timesteps[:-1]):
|
||||
with self.progress_bar(total=num_inference_steps - 2) as progress_bar:
|
||||
for i, t in enumerate(timesteps[1:-1]):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = self.inverse_scheduler.scale_model_input(latent_model_input, t)
|
||||
@@ -1200,11 +1181,7 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline):
|
||||
if lambda_auto_corr > 0:
|
||||
for _ in range(num_auto_corr_rolls):
|
||||
var = torch.autograd.Variable(noise_pred.detach().clone(), requires_grad=True)
|
||||
|
||||
# Derive epsilon from model output before regularizing to IID standard normal
|
||||
var_epsilon = self.get_epsilon(var, latent_model_input.detach(), t)
|
||||
|
||||
l_ac = self.auto_corr_loss(var_epsilon, generator=generator)
|
||||
l_ac = self.auto_corr_loss(var, generator=generator)
|
||||
l_ac.backward()
|
||||
|
||||
grad = var.grad.detach() / num_auto_corr_rolls
|
||||
@@ -1213,10 +1190,7 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline):
|
||||
if lambda_kl > 0:
|
||||
var = torch.autograd.Variable(noise_pred.detach().clone(), requires_grad=True)
|
||||
|
||||
# Derive epsilon from model output before regularizing to IID standard normal
|
||||
var_epsilon = self.get_epsilon(var, latent_model_input.detach(), t)
|
||||
|
||||
l_kld = self.kl_divergence(var_epsilon)
|
||||
l_kld = self.kl_divergence(var)
|
||||
l_kld.backward()
|
||||
|
||||
grad = var.grad.detach()
|
||||
|
||||
@@ -13,6 +13,7 @@
|
||||
# limitations under the License.
|
||||
|
||||
import inspect
|
||||
import math
|
||||
from typing import Any, Callable, Dict, List, Optional, Union
|
||||
|
||||
import torch
|
||||
@@ -530,7 +531,7 @@ class StableDiffusionSAGPipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
|
||||
@@ -605,73 +606,64 @@ class StableDiffusionSAGPipeline(DiffusionPipeline):
|
||||
store_processor = CrossAttnStoreProcessor()
|
||||
self.unet.mid_block.attentions[0].transformer_blocks[0].attn1.processor = store_processor
|
||||
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
||||
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
||||
for i, t in enumerate(timesteps):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
map_size = None
|
||||
# predict the noise residual
|
||||
noise_pred = self.unet(
|
||||
latent_model_input,
|
||||
t,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
).sample
|
||||
|
||||
def get_map_size(module, input, output):
|
||||
nonlocal map_size
|
||||
map_size = output.sample.shape[-2:]
|
||||
# perform guidance
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
|
||||
with self.unet.mid_block.attentions[0].register_forward_hook(get_map_size):
|
||||
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
||||
for i, t in enumerate(timesteps):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
# predict the noise residual
|
||||
|
||||
noise_pred = self.unet(
|
||||
latent_model_input,
|
||||
t,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
).sample
|
||||
|
||||
# perform guidance
|
||||
# perform self-attention guidance with the stored self-attentnion map
|
||||
if do_self_attention_guidance:
|
||||
# classifier-free guidance produces two chunks of attention map
|
||||
# and we only use unconditional one according to equation (24)
|
||||
# in https://arxiv.org/pdf/2210.00939.pdf
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
# DDIM-like prediction of x0
|
||||
pred_x0 = self.pred_x0(latents, noise_pred_uncond, t)
|
||||
# get the stored attention maps
|
||||
uncond_attn, cond_attn = store_processor.attention_probs.chunk(2)
|
||||
# self-attention-based degrading of latents
|
||||
degraded_latents = self.sag_masking(
|
||||
pred_x0, uncond_attn, t, self.pred_epsilon(latents, noise_pred_uncond, t)
|
||||
)
|
||||
uncond_emb, _ = prompt_embeds.chunk(2)
|
||||
# forward and give guidance
|
||||
degraded_pred = self.unet(degraded_latents, t, encoder_hidden_states=uncond_emb).sample
|
||||
noise_pred += sag_scale * (noise_pred_uncond - degraded_pred)
|
||||
else:
|
||||
# DDIM-like prediction of x0
|
||||
pred_x0 = self.pred_x0(latents, noise_pred, t)
|
||||
# get the stored attention maps
|
||||
cond_attn = store_processor.attention_probs
|
||||
# self-attention-based degrading of latents
|
||||
degraded_latents = self.sag_masking(
|
||||
pred_x0, cond_attn, t, self.pred_epsilon(latents, noise_pred, t)
|
||||
)
|
||||
# forward and give guidance
|
||||
degraded_pred = self.unet(degraded_latents, t, encoder_hidden_states=prompt_embeds).sample
|
||||
noise_pred += sag_scale * (noise_pred - degraded_pred)
|
||||
|
||||
# perform self-attention guidance with the stored self-attentnion map
|
||||
if do_self_attention_guidance:
|
||||
# classifier-free guidance produces two chunks of attention map
|
||||
# and we only use unconditional one according to equation (24)
|
||||
# in https://arxiv.org/pdf/2210.00939.pdf
|
||||
if do_classifier_free_guidance:
|
||||
# DDIM-like prediction of x0
|
||||
pred_x0 = self.pred_x0(latents, noise_pred_uncond, t)
|
||||
# get the stored attention maps
|
||||
uncond_attn, cond_attn = store_processor.attention_probs.chunk(2)
|
||||
# self-attention-based degrading of latents
|
||||
degraded_latents = self.sag_masking(
|
||||
pred_x0, uncond_attn, map_size, t, self.pred_epsilon(latents, noise_pred_uncond, t)
|
||||
)
|
||||
uncond_emb, _ = prompt_embeds.chunk(2)
|
||||
# forward and give guidance
|
||||
degraded_pred = self.unet(degraded_latents, t, encoder_hidden_states=uncond_emb).sample
|
||||
noise_pred += sag_scale * (noise_pred_uncond - degraded_pred)
|
||||
else:
|
||||
# DDIM-like prediction of x0
|
||||
pred_x0 = self.pred_x0(latents, noise_pred, t)
|
||||
# get the stored attention maps
|
||||
cond_attn = store_processor.attention_probs
|
||||
# self-attention-based degrading of latents
|
||||
degraded_latents = self.sag_masking(
|
||||
pred_x0, cond_attn, map_size, t, self.pred_epsilon(latents, noise_pred, t)
|
||||
)
|
||||
# forward and give guidance
|
||||
degraded_pred = self.unet(degraded_latents, t, encoder_hidden_states=prompt_embeds).sample
|
||||
noise_pred += sag_scale * (noise_pred - degraded_pred)
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
|
||||
|
||||
# call the callback, if provided
|
||||
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
||||
progress_bar.update()
|
||||
if callback is not None and i % callback_steps == 0:
|
||||
callback(i, t, latents)
|
||||
# call the callback, if provided
|
||||
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
||||
progress_bar.update()
|
||||
if callback is not None and i % callback_steps == 0:
|
||||
callback(i, t, latents)
|
||||
|
||||
# 8. Post-processing
|
||||
image = self.decode_latents(latents)
|
||||
@@ -688,22 +680,20 @@ class StableDiffusionSAGPipeline(DiffusionPipeline):
|
||||
|
||||
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
||||
|
||||
def sag_masking(self, original_latents, attn_map, map_size, t, eps):
|
||||
def sag_masking(self, original_latents, attn_map, t, eps):
|
||||
# Same masking process as in SAG paper: https://arxiv.org/pdf/2210.00939.pdf
|
||||
bh, hw1, hw2 = attn_map.shape
|
||||
b, latent_channel, latent_h, latent_w = original_latents.shape
|
||||
h = self.unet.attention_head_dim
|
||||
if isinstance(h, list):
|
||||
h = h[-1]
|
||||
map_size = math.isqrt(hw1)
|
||||
|
||||
# Produce attention mask
|
||||
attn_map = attn_map.reshape(b, h, hw1, hw2)
|
||||
attn_mask = attn_map.mean(1, keepdim=False).sum(1, keepdim=False) > 1.0
|
||||
attn_mask = (
|
||||
attn_mask.reshape(b, map_size[0], map_size[1])
|
||||
.unsqueeze(1)
|
||||
.repeat(1, latent_channel, 1, 1)
|
||||
.type(attn_map.dtype)
|
||||
attn_mask.reshape(b, map_size, map_size).unsqueeze(1).repeat(1, latent_channel, 1, 1).type(attn_map.dtype)
|
||||
)
|
||||
attn_mask = F.interpolate(attn_mask, (latent_h, latent_w))
|
||||
|
||||
|
||||
@@ -684,7 +684,7 @@ class StableUnCLIPPipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
noise_level (`int`, *optional*, defaults to `0`):
|
||||
|
||||
@@ -653,7 +653,7 @@ class StableUnCLIPImg2ImgPipeline(DiffusionPipeline):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
noise_level (`int`, *optional*, defaults to `0`):
|
||||
|
||||
@@ -6,8 +6,8 @@ import torch.nn as nn
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...models import ModelMixin
|
||||
from ...models.attention import Attention
|
||||
from ...models.attention_processor import AttentionProcessor, AttnAddedKVProcessor
|
||||
from ...models.attention import CrossAttention
|
||||
from ...models.cross_attention import AttnProcessor, CrossAttnAddedKVProcessor
|
||||
from ...models.dual_transformer_2d import DualTransformer2DModel
|
||||
from ...models.embeddings import GaussianFourierProjection, TimestepEmbedding, Timesteps
|
||||
from ...models.transformer_2d import Transformer2DModel
|
||||
@@ -452,7 +452,7 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
)
|
||||
|
||||
@property
|
||||
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
||||
def attn_processors(self) -> Dict[str, AttnProcessor]:
|
||||
r"""
|
||||
Returns:
|
||||
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
||||
@@ -461,7 +461,7 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
# set recursively
|
||||
processors = {}
|
||||
|
||||
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
||||
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttnProcessor]):
|
||||
if hasattr(module, "set_processor"):
|
||||
processors[f"{name}.processor"] = module.processor
|
||||
|
||||
@@ -475,12 +475,12 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
|
||||
return processors
|
||||
|
||||
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
||||
def set_attn_processor(self, processor: Union[AttnProcessor, Dict[str, AttnProcessor]]):
|
||||
r"""
|
||||
Parameters:
|
||||
`processor (`dict` of `AttentionProcessor` or `AttentionProcessor`):
|
||||
`processor (`dict` of `AttnProcessor` or `AttnProcessor`):
|
||||
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
||||
of **all** `Attention` layers.
|
||||
of **all** `CrossAttention` layers.
|
||||
In case `processor` is a dict, the key needs to define the path to the corresponding cross attention processor. This is strongly recommended when setting trainablae attention processors.:
|
||||
|
||||
"""
|
||||
@@ -595,7 +595,7 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
|
||||
@@ -688,7 +688,7 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
for down_block_res_sample, down_block_additional_residual in zip(
|
||||
down_block_res_samples, down_block_additional_residuals
|
||||
):
|
||||
down_block_res_sample = down_block_res_sample + down_block_additional_residual
|
||||
down_block_res_sample += down_block_additional_residual
|
||||
new_down_block_res_samples += (down_block_res_sample,)
|
||||
|
||||
down_block_res_samples = new_down_block_res_samples
|
||||
@@ -704,7 +704,7 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
)
|
||||
|
||||
if mid_block_additional_residual is not None:
|
||||
sample = sample + mid_block_additional_residual
|
||||
sample += mid_block_additional_residual
|
||||
|
||||
# 5. up
|
||||
for i, upsample_block in enumerate(self.up_blocks):
|
||||
@@ -1425,7 +1425,7 @@ class UNetMidBlockFlatSimpleCrossAttn(nn.Module):
|
||||
|
||||
for _ in range(num_layers):
|
||||
attentions.append(
|
||||
Attention(
|
||||
CrossAttention(
|
||||
query_dim=in_channels,
|
||||
cross_attention_dim=in_channels,
|
||||
heads=self.num_heads,
|
||||
@@ -1434,7 +1434,7 @@ class UNetMidBlockFlatSimpleCrossAttn(nn.Module):
|
||||
norm_num_groups=resnet_groups,
|
||||
bias=True,
|
||||
upcast_softmax=True,
|
||||
processor=AttnAddedKVProcessor(),
|
||||
processor=CrossAttnAddedKVProcessor(),
|
||||
)
|
||||
)
|
||||
resnets.append(
|
||||
|
||||
@@ -301,13 +301,12 @@ class DDIMScheduler(SchedulerMixin, ConfigMixin):
|
||||
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
if self.config.prediction_type == "epsilon":
|
||||
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
|
||||
pred_epsilon = model_output
|
||||
elif self.config.prediction_type == "sample":
|
||||
pred_original_sample = model_output
|
||||
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
|
||||
elif self.config.prediction_type == "v_prediction":
|
||||
pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
|
||||
pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
|
||||
# predict V
|
||||
model_output = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
|
||||
else:
|
||||
raise ValueError(
|
||||
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
|
||||
@@ -329,16 +328,17 @@ class DDIMScheduler(SchedulerMixin, ConfigMixin):
|
||||
std_dev_t = eta * variance ** (0.5)
|
||||
|
||||
if use_clipped_model_output:
|
||||
# the pred_epsilon is always re-derived from the clipped x_0 in Glide
|
||||
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
|
||||
# the model_output is always re-derived from the clipped x_0 in Glide
|
||||
model_output = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
|
||||
|
||||
# 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
|
||||
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * model_output
|
||||
|
||||
# 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
|
||||
|
||||
if eta > 0:
|
||||
device = model_output.device
|
||||
if variance_noise is not None and generator is not None:
|
||||
raise ValueError(
|
||||
"Cannot pass both generator and variance_noise. Please make sure that either `generator` or"
|
||||
@@ -347,7 +347,7 @@ class DDIMScheduler(SchedulerMixin, ConfigMixin):
|
||||
|
||||
if variance_noise is None:
|
||||
variance_noise = randn_tensor(
|
||||
model_output.shape, generator=generator, device=model_output.device, dtype=model_output.dtype
|
||||
model_output.shape, generator=generator, device=device, dtype=model_output.dtype
|
||||
)
|
||||
variance = std_dev_t * variance_noise
|
||||
|
||||
|
||||
@@ -254,13 +254,12 @@ class FlaxDDIMScheduler(FlaxSchedulerMixin, ConfigMixin):
|
||||
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
if self.config.prediction_type == "epsilon":
|
||||
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
|
||||
pred_epsilon = model_output
|
||||
elif self.config.prediction_type == "sample":
|
||||
pred_original_sample = model_output
|
||||
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
|
||||
elif self.config.prediction_type == "v_prediction":
|
||||
pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
|
||||
pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
|
||||
# predict V
|
||||
model_output = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
|
||||
else:
|
||||
raise ValueError(
|
||||
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
|
||||
@@ -273,7 +272,7 @@ class FlaxDDIMScheduler(FlaxSchedulerMixin, ConfigMixin):
|
||||
std_dev_t = eta * variance ** (0.5)
|
||||
|
||||
# 5. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
|
||||
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * model_output
|
||||
|
||||
# 6. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
|
||||
|
||||
@@ -23,7 +23,7 @@ import torch
|
||||
|
||||
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
||||
from diffusers.schedulers.scheduling_utils import SchedulerMixin
|
||||
from diffusers.utils import BaseOutput, deprecate
|
||||
from diffusers.utils import BaseOutput
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -96,17 +96,15 @@ class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
|
||||
trained_betas (`np.ndarray`, optional):
|
||||
option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
|
||||
clip_sample (`bool`, default `True`):
|
||||
option to clip predicted sample for numerical stability.
|
||||
clip_sample_range (`float`, default `1.0`):
|
||||
the maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
|
||||
set_alpha_to_zero (`bool`, default `True`):
|
||||
option to clip predicted sample between -1 and 1 for numerical stability.
|
||||
set_alpha_to_one (`bool`, default `True`):
|
||||
each diffusion step uses the value of alphas product at that step and at the previous one. For the final
|
||||
step there is no previous alpha. When this option is `True` the previous alpha product is fixed to `0`,
|
||||
otherwise it uses the value of alpha at step `num_train_timesteps - 1`.
|
||||
step there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
|
||||
otherwise it uses the value of alpha at step 0.
|
||||
steps_offset (`int`, default `0`):
|
||||
an offset added to the inference steps. You can use a combination of `offset=1` and
|
||||
`set_alpha_to_zero=False`, to make the last step use step `num_train_timesteps - 1` for the previous alpha
|
||||
product.
|
||||
`set_alpha_to_one=False`, to make the last step use step 0 for the previous alpha product, as done in
|
||||
stable diffusion.
|
||||
prediction_type (`str`, default `epsilon`, optional):
|
||||
prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
|
||||
process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
|
||||
@@ -124,18 +122,10 @@ class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
|
||||
beta_schedule: str = "linear",
|
||||
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
|
||||
clip_sample: bool = True,
|
||||
set_alpha_to_zero: bool = True,
|
||||
set_alpha_to_one: bool = True,
|
||||
steps_offset: int = 0,
|
||||
prediction_type: str = "epsilon",
|
||||
clip_sample_range: float = 1.0,
|
||||
**kwargs,
|
||||
):
|
||||
if kwargs.get("set_alpha_to_one", None) is not None:
|
||||
deprecation_message = (
|
||||
"The `set_alpha_to_one` argument is deprecated. Please use `set_alpha_to_zero` instead."
|
||||
)
|
||||
deprecate("set_alpha_to_one", "1.0.0", deprecation_message, standard_warn=False)
|
||||
set_alpha_to_zero = kwargs["set_alpha_to_one"]
|
||||
if trained_betas is not None:
|
||||
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
|
||||
elif beta_schedule == "linear":
|
||||
@@ -154,12 +144,11 @@ class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
|
||||
self.alphas = 1.0 - self.betas
|
||||
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
|
||||
|
||||
# At every step in inverted ddim, we are looking into the next alphas_cumprod
|
||||
# For the final step, there is no next alphas_cumprod, and the index is out of bounds
|
||||
# `set_alpha_to_zero` decides whether we set this parameter simply to zero
|
||||
# in this case, self.step() just output the predicted noise
|
||||
# or whether we use the final alpha of the "non-previous" one.
|
||||
self.final_alpha_cumprod = torch.tensor(0.0) if set_alpha_to_zero else self.alphas_cumprod[-1]
|
||||
# At every step in ddim, we are looking into the previous alphas_cumprod
|
||||
# For the final step, there is no previous alphas_cumprod because we are already at 0
|
||||
# `set_alpha_to_one` decides whether we set this parameter simply to one or
|
||||
# whether we use the final alpha of the "non-previous" one.
|
||||
self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
|
||||
|
||||
# standard deviation of the initial noise distribution
|
||||
self.init_noise_sigma = 1.0
|
||||
@@ -168,7 +157,6 @@ class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
|
||||
self.num_inference_steps = None
|
||||
self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps).copy().astype(np.int64))
|
||||
|
||||
# Copied from diffusers.schedulers.scheduling_ddim.DDIMScheduler.scale_model_input
|
||||
def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
|
||||
"""
|
||||
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
|
||||
@@ -217,52 +205,23 @@ class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
|
||||
variance_noise: Optional[torch.FloatTensor] = None,
|
||||
return_dict: bool = True,
|
||||
) -> Union[DDIMSchedulerOutput, Tuple]:
|
||||
# 1. get previous step value (=t+1)
|
||||
e_t = model_output
|
||||
|
||||
x = sample
|
||||
prev_timestep = timestep + self.config.num_train_timesteps // self.num_inference_steps
|
||||
|
||||
# 2. compute alphas, betas
|
||||
# change original implementation to exactly match noise levels for analogous forward process
|
||||
alpha_prod_t = self.alphas_cumprod[timestep]
|
||||
alpha_prod_t_prev = (
|
||||
self.alphas_cumprod[prev_timestep]
|
||||
if prev_timestep < self.config.num_train_timesteps
|
||||
else self.final_alpha_cumprod
|
||||
)
|
||||
a_t = self.alphas_cumprod[timestep - 1]
|
||||
a_prev = self.alphas_cumprod[prev_timestep - 1] if prev_timestep >= 0 else self.final_alpha_cumprod
|
||||
|
||||
beta_prod_t = 1 - alpha_prod_t
|
||||
pred_x0 = (x - (1 - a_t) ** 0.5 * e_t) / a_t.sqrt()
|
||||
|
||||
# 3. compute predicted original sample from predicted noise also called
|
||||
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
if self.config.prediction_type == "epsilon":
|
||||
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
|
||||
pred_epsilon = model_output
|
||||
elif self.config.prediction_type == "sample":
|
||||
pred_original_sample = model_output
|
||||
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
|
||||
elif self.config.prediction_type == "v_prediction":
|
||||
pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
|
||||
pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
|
||||
else:
|
||||
raise ValueError(
|
||||
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
|
||||
" `v_prediction`"
|
||||
)
|
||||
dir_xt = (1.0 - a_prev).sqrt() * e_t
|
||||
|
||||
# 4. Clip or threshold "predicted x_0"
|
||||
if self.config.clip_sample:
|
||||
pred_original_sample = pred_original_sample.clamp(
|
||||
-self.config.clip_sample_range, self.config.clip_sample_range
|
||||
)
|
||||
|
||||
# 5. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
pred_sample_direction = (1 - alpha_prod_t_prev) ** (0.5) * pred_epsilon
|
||||
|
||||
# 6. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
|
||||
prev_sample = a_prev.sqrt() * pred_x0 + dir_xt
|
||||
|
||||
if not return_dict:
|
||||
return (prev_sample, pred_original_sample)
|
||||
return DDIMSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
|
||||
return (prev_sample, pred_x0)
|
||||
return DDIMSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_x0)
|
||||
|
||||
def __len__(self):
|
||||
return self.config.num_train_timesteps
|
||||
|
||||
@@ -154,13 +154,13 @@ class DEISMultistepScheduler(SchedulerMixin, ConfigMixin):
|
||||
# settings for DEIS
|
||||
if algorithm_type not in ["deis"]:
|
||||
if algorithm_type in ["dpmsolver", "dpmsolver++"]:
|
||||
self.register_to_config(algorithm_type="deis")
|
||||
algorithm_type = "deis"
|
||||
else:
|
||||
raise NotImplementedError(f"{algorithm_type} does is not implemented for {self.__class__}")
|
||||
|
||||
if solver_type not in ["logrho"]:
|
||||
if solver_type in ["midpoint", "heun", "bh1", "bh2"]:
|
||||
self.register_to_config(solver_type="logrho")
|
||||
solver_type = "logrho"
|
||||
else:
|
||||
raise NotImplementedError(f"solver type {solver_type} does is not implemented for {self.__class__}")
|
||||
|
||||
|
||||
@@ -165,13 +165,12 @@ class DPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
|
||||
# settings for DPM-Solver
|
||||
if algorithm_type not in ["dpmsolver", "dpmsolver++"]:
|
||||
if algorithm_type == "deis":
|
||||
self.register_to_config(algorithm_type="dpmsolver++")
|
||||
algorithm_type = "dpmsolver++"
|
||||
else:
|
||||
raise NotImplementedError(f"{algorithm_type} does is not implemented for {self.__class__}")
|
||||
|
||||
if solver_type not in ["midpoint", "heun"]:
|
||||
if solver_type in ["logrho", "bh1", "bh2"]:
|
||||
self.register_to_config(solver_type="midpoint")
|
||||
solver_type = "midpoint"
|
||||
else:
|
||||
raise NotImplementedError(f"{solver_type} does is not implemented for {self.__class__}")
|
||||
|
||||
|
||||
@@ -164,12 +164,12 @@ class DPMSolverSinglestepScheduler(SchedulerMixin, ConfigMixin):
|
||||
# settings for DPM-Solver
|
||||
if algorithm_type not in ["dpmsolver", "dpmsolver++"]:
|
||||
if algorithm_type == "deis":
|
||||
self.register_to_config(algorithm_type="dpmsolver++")
|
||||
algorithm_type = "dpmsolver++"
|
||||
else:
|
||||
raise NotImplementedError(f"{algorithm_type} does is not implemented for {self.__class__}")
|
||||
if solver_type not in ["midpoint", "heun"]:
|
||||
if solver_type in ["logrho", "bh1", "bh2"]:
|
||||
self.register_to_config(solver_type="midpoint")
|
||||
solver_type = "midpoint"
|
||||
else:
|
||||
raise NotImplementedError(f"{solver_type} does is not implemented for {self.__class__}")
|
||||
|
||||
|
||||
@@ -168,7 +168,7 @@ class UniPCMultistepScheduler(SchedulerMixin, ConfigMixin):
|
||||
|
||||
if solver_type not in ["bh1", "bh2"]:
|
||||
if solver_type in ["midpoint", "heun", "logrho"]:
|
||||
self.register_to_config(solver_type="bh1")
|
||||
solver_type = "bh1"
|
||||
else:
|
||||
raise NotImplementedError(f"{solver_type} does is not implemented for {self.__class__}")
|
||||
|
||||
|
||||
@@ -136,11 +136,10 @@ class SchedulerMixin:
|
||||
</Tip>
|
||||
|
||||
"""
|
||||
config, kwargs, commit_hash = cls.load_config(
|
||||
config, kwargs = cls.load_config(
|
||||
pretrained_model_name_or_path=pretrained_model_name_or_path,
|
||||
subfolder=subfolder,
|
||||
return_unused_kwargs=True,
|
||||
return_commit_hash=True,
|
||||
**kwargs,
|
||||
)
|
||||
return cls.from_config(config, return_unused_kwargs=return_unused_kwargs, **kwargs)
|
||||
|
||||
@@ -35,11 +35,7 @@ from .constants import (
|
||||
from .deprecation_utils import deprecate
|
||||
from .doc_utils import replace_example_docstring
|
||||
from .dynamic_modules_utils import get_class_from_dynamic_module
|
||||
from .hub_utils import (
|
||||
HF_HUB_OFFLINE,
|
||||
extract_commit_hash,
|
||||
http_user_agent,
|
||||
)
|
||||
from .hub_utils import HF_HUB_OFFLINE, http_user_agent
|
||||
from .import_utils import (
|
||||
ENV_VARS_TRUE_AND_AUTO_VALUES,
|
||||
ENV_VARS_TRUE_VALUES,
|
||||
|
||||
@@ -15,7 +15,6 @@
|
||||
|
||||
|
||||
import os
|
||||
import re
|
||||
import sys
|
||||
import traceback
|
||||
from pathlib import Path
|
||||
@@ -23,7 +22,6 @@ from typing import Dict, Optional, Union
|
||||
from uuid import uuid4
|
||||
|
||||
from huggingface_hub import HfFolder, ModelCard, ModelCardData, whoami
|
||||
from huggingface_hub.file_download import REGEX_COMMIT_HASH
|
||||
from huggingface_hub.utils import is_jinja_available
|
||||
|
||||
from .. import __version__
|
||||
@@ -134,20 +132,6 @@ def create_model_card(args, model_name):
|
||||
model_card.save(card_path)
|
||||
|
||||
|
||||
def extract_commit_hash(resolved_file: Optional[str], commit_hash: Optional[str] = None):
|
||||
"""
|
||||
Extracts the commit hash from a resolved filename toward a cache file.
|
||||
"""
|
||||
if resolved_file is None or commit_hash is not None:
|
||||
return commit_hash
|
||||
resolved_file = str(Path(resolved_file).as_posix())
|
||||
search = re.search(r"snapshots/([^/]+)/", resolved_file)
|
||||
if search is None:
|
||||
return None
|
||||
commit_hash = search.groups()[0]
|
||||
return commit_hash if REGEX_COMMIT_HASH.match(commit_hash) else None
|
||||
|
||||
|
||||
# Old default cache path, potentially to be migrated.
|
||||
# This logic was more or less taken from `transformers`, with the following differences:
|
||||
# - Diffusers doesn't use custom environment variables to specify the cache path.
|
||||
@@ -166,7 +150,7 @@ def move_cache(old_cache_dir: Optional[str] = None, new_cache_dir: Optional[str]
|
||||
|
||||
old_cache_dir = Path(old_cache_dir).expanduser()
|
||||
new_cache_dir = Path(new_cache_dir).expanduser()
|
||||
for old_blob_path in old_cache_dir.glob("**/blobs/*"):
|
||||
for old_blob_path in old_cache_dir.glob("**/blobs/*"): # move file blob by blob
|
||||
if old_blob_path.is_file() and not old_blob_path.is_symlink():
|
||||
new_blob_path = new_cache_dir / old_blob_path.relative_to(old_cache_dir)
|
||||
new_blob_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
@@ -22,7 +22,7 @@ import torch
|
||||
from parameterized import parameterized
|
||||
|
||||
from diffusers import UNet2DConditionModel
|
||||
from diffusers.models.attention_processor import AttnProcessor, LoRAAttnProcessor
|
||||
from diffusers.models.cross_attention import CrossAttnProcessor, LoRACrossAttnProcessor
|
||||
from diffusers.utils import (
|
||||
floats_tensor,
|
||||
load_hf_numpy,
|
||||
@@ -54,7 +54,9 @@ def create_lora_layers(model):
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = model.config.block_out_channels[block_id]
|
||||
|
||||
lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
|
||||
lora_attn_procs[name] = LoRACrossAttnProcessor(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim
|
||||
)
|
||||
lora_attn_procs[name] = lora_attn_procs[name].to(model.device)
|
||||
|
||||
# add 1 to weights to mock trained weights
|
||||
@@ -116,8 +118,7 @@ class UNet2DConditionModelTests(ModelTesterMixin, unittest.TestCase):
|
||||
model.enable_xformers_memory_efficient_attention()
|
||||
|
||||
assert (
|
||||
model.mid_block.attentions[0].transformer_blocks[0].attn1.processor.__class__.__name__
|
||||
== "XFormersAttnProcessor"
|
||||
model.mid_block.attentions[0].transformer_blocks[0].attn1._use_memory_efficient_attention_xformers
|
||||
), "xformers is not enabled"
|
||||
|
||||
@unittest.skipIf(torch_device == "mps", "Gradient checkpointing skipped on MPS")
|
||||
@@ -322,7 +323,9 @@ class UNet2DConditionModelTests(ModelTesterMixin, unittest.TestCase):
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = model.config.block_out_channels[block_id]
|
||||
|
||||
lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
|
||||
lora_attn_procs[name] = LoRACrossAttnProcessor(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim
|
||||
)
|
||||
|
||||
# add 1 to weights to mock trained weights
|
||||
with torch.no_grad():
|
||||
@@ -409,7 +412,9 @@ class UNet2DConditionModelTests(ModelTesterMixin, unittest.TestCase):
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = model.config.block_out_channels[block_id]
|
||||
|
||||
lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
|
||||
lora_attn_procs[name] = LoRACrossAttnProcessor(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim
|
||||
)
|
||||
lora_attn_procs[name] = lora_attn_procs[name].to(model.device)
|
||||
|
||||
# add 1 to weights to mock trained weights
|
||||
@@ -440,7 +445,7 @@ class UNet2DConditionModelTests(ModelTesterMixin, unittest.TestCase):
|
||||
# LoRA and no LoRA should NOT be the same
|
||||
assert (sample - old_sample).abs().max() > 1e-4
|
||||
|
||||
def test_lora_save_safetensors_load_torch(self):
|
||||
def test_lora_save_load_safetensors_load_torch(self):
|
||||
# enable deterministic behavior for gradient checkpointing
|
||||
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
|
||||
|
||||
@@ -462,7 +467,9 @@ class UNet2DConditionModelTests(ModelTesterMixin, unittest.TestCase):
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = model.config.block_out_channels[block_id]
|
||||
|
||||
lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
|
||||
lora_attn_procs[name] = LoRACrossAttnProcessor(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim
|
||||
)
|
||||
lora_attn_procs[name] = lora_attn_procs[name].to(model.device)
|
||||
|
||||
model.set_attn_processor(lora_attn_procs)
|
||||
@@ -475,43 +482,6 @@ class UNet2DConditionModelTests(ModelTesterMixin, unittest.TestCase):
|
||||
new_model.to(torch_device)
|
||||
new_model.load_attn_procs(tmpdirname, weight_name="pytorch_lora_weights.bin")
|
||||
|
||||
def test_lora_save_torch_force_load_safetensors_error(self):
|
||||
# enable deterministic behavior for gradient checkpointing
|
||||
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
|
||||
|
||||
init_dict["attention_head_dim"] = (8, 16)
|
||||
|
||||
torch.manual_seed(0)
|
||||
model = self.model_class(**init_dict)
|
||||
model.to(torch_device)
|
||||
|
||||
lora_attn_procs = {}
|
||||
for name in model.attn_processors.keys():
|
||||
cross_attention_dim = None if name.endswith("attn1.processor") else model.config.cross_attention_dim
|
||||
if name.startswith("mid_block"):
|
||||
hidden_size = model.config.block_out_channels[-1]
|
||||
elif name.startswith("up_blocks"):
|
||||
block_id = int(name[len("up_blocks.")])
|
||||
hidden_size = list(reversed(model.config.block_out_channels))[block_id]
|
||||
elif name.startswith("down_blocks"):
|
||||
block_id = int(name[len("down_blocks.")])
|
||||
hidden_size = model.config.block_out_channels[block_id]
|
||||
|
||||
lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
|
||||
lora_attn_procs[name] = lora_attn_procs[name].to(model.device)
|
||||
|
||||
model.set_attn_processor(lora_attn_procs)
|
||||
# Saving as torch, properly reloads with directly filename
|
||||
with tempfile.TemporaryDirectory() as tmpdirname:
|
||||
model.save_attn_procs(tmpdirname)
|
||||
self.assertTrue(os.path.isfile(os.path.join(tmpdirname, "pytorch_lora_weights.bin")))
|
||||
torch.manual_seed(0)
|
||||
new_model = self.model_class(**init_dict)
|
||||
new_model.to(torch_device)
|
||||
with self.assertRaises(IOError) as e:
|
||||
new_model.load_attn_procs(tmpdirname, use_safetensors=True)
|
||||
self.assertIn("Error no file named pytorch_lora_weights.safetensors", str(e.exception))
|
||||
|
||||
def test_lora_on_off(self):
|
||||
# enable deterministic behavior for gradient checkpointing
|
||||
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
|
||||
@@ -531,7 +501,7 @@ class UNet2DConditionModelTests(ModelTesterMixin, unittest.TestCase):
|
||||
with torch.no_grad():
|
||||
sample = model(**inputs_dict, cross_attention_kwargs={"scale": 0.0}).sample
|
||||
|
||||
model.set_attn_processor(AttnProcessor())
|
||||
model.set_attn_processor(CrossAttnProcessor())
|
||||
|
||||
with torch.no_grad():
|
||||
new_sample = model(**inputs_dict).sample
|
||||
|
||||
@@ -21,13 +21,7 @@ import numpy as np
|
||||
import torch
|
||||
from transformers import XLMRobertaTokenizer
|
||||
|
||||
from diffusers import (
|
||||
AltDiffusionImg2ImgPipeline,
|
||||
AutoencoderKL,
|
||||
PNDMScheduler,
|
||||
UNet2DConditionModel,
|
||||
)
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from diffusers import AltDiffusionImg2ImgPipeline, AutoencoderKL, PNDMScheduler, UNet2DConditionModel
|
||||
from diffusers.pipelines.alt_diffusion.modeling_roberta_series import (
|
||||
RobertaSeriesConfig,
|
||||
RobertaSeriesModelWithTransformation,
|
||||
@@ -134,7 +128,6 @@ class AltDiffusionImg2ImgPipelineFastTests(unittest.TestCase):
|
||||
safety_checker=None,
|
||||
feature_extractor=self.dummy_extractor,
|
||||
)
|
||||
alt_pipe.image_processor = VaeImageProcessor(vae_scale_factor=alt_pipe.vae_scale_factor, do_normalize=False)
|
||||
alt_pipe = alt_pipe.to(device)
|
||||
alt_pipe.set_progress_bar_config(disable=None)
|
||||
|
||||
@@ -198,7 +191,6 @@ class AltDiffusionImg2ImgPipelineFastTests(unittest.TestCase):
|
||||
safety_checker=None,
|
||||
feature_extractor=self.dummy_extractor,
|
||||
)
|
||||
alt_pipe.image_processor = VaeImageProcessor(vae_scale_factor=alt_pipe.vae_scale_factor, do_normalize=False)
|
||||
alt_pipe = alt_pipe.to(torch_device)
|
||||
alt_pipe.set_progress_bar_config(disable=None)
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user