Compare commits
581 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
3f55d1359f | ||
|
|
195ebe5a02 | ||
|
|
1e98723e12 | ||
|
|
4e2c1f3a4d | ||
|
|
5e6417e988 | ||
|
|
234e90cca7 | ||
|
|
f6fb3282b1 | ||
|
|
1a79969d23 | ||
|
|
f55190b275 | ||
|
|
f8325cfd7b | ||
|
|
8d9c4a531b | ||
|
|
7bcc873bb5 | ||
|
|
43c585111d | ||
|
|
46013e8e3f | ||
|
|
e7457b377d | ||
|
|
1d7adf1329 | ||
|
|
f4a785cec7 | ||
|
|
5dda1735fd | ||
|
|
98f346835a | ||
|
|
6b9906f6c2 | ||
|
|
a353c46ec0 | ||
|
|
c29d81c3e3 | ||
|
|
a127363dca | ||
|
|
b8894f181d | ||
|
|
e6110f6856 | ||
|
|
cee3aa0dd4 | ||
|
|
8ff777d3c1 | ||
|
|
1a431ae886 | ||
|
|
8d14edf27f | ||
|
|
58d627aed6 | ||
|
|
65ed5d2845 | ||
|
|
44091d8b2a | ||
|
|
e0d836c813 | ||
|
|
8603ca6b09 | ||
|
|
fead3ba386 | ||
|
|
492f5c9a6c | ||
|
|
71d737bfe2 | ||
|
|
5b4f5951a9 | ||
|
|
3dcc5e9a5a | ||
|
|
9288fb1df8 | ||
|
|
a0592a13ee | ||
|
|
cdb371f07b | ||
|
|
8ef1ee812d | ||
|
|
ac84c2fa5a | ||
|
|
5a38033de4 | ||
|
|
7bd50cabaf | ||
|
|
5c4ea00de7 | ||
|
|
56c003705f | ||
|
|
7a1229fa29 | ||
|
|
f085d2f5c6 | ||
|
|
be52be7215 | ||
|
|
3c1cdd3359 | ||
|
|
07f8ebd543 | ||
|
|
ada09bd3f0 | ||
|
|
cc59b05635 | ||
|
|
daddd98b88 | ||
|
|
55d6453fce | ||
|
|
9ea9c6d1c2 | ||
|
|
5791f4acde | ||
|
|
878af0e113 | ||
|
|
dea5ec508f | ||
|
|
6c0ca5efa6 | ||
|
|
cab7650524 | ||
|
|
ed8ef6226d | ||
|
|
59c1af77e8 | ||
|
|
fd76845651 | ||
|
|
b1fe170642 | ||
|
|
9b704f7688 | ||
|
|
e49dd03d2d | ||
|
|
7b628a225a | ||
|
|
033b77ebc4 | ||
|
|
e54206d095 | ||
|
|
6b5baa9332 | ||
|
|
66fd3ec70d | ||
|
|
3a536ac8f1 | ||
|
|
30e7c78ac3 | ||
|
|
d0d3e24ec1 | ||
|
|
5164c9faa9 | ||
|
|
93debd301d | ||
|
|
1b1d6444c6 | ||
|
|
4724250980 | ||
|
|
64270eff34 | ||
|
|
3c138a4d2b | ||
|
|
2fa4476525 | ||
|
|
d799084a9a | ||
|
|
1e5d91d577 | ||
|
|
d8f8b9aac9 | ||
|
|
4d1b1b46f4 | ||
|
|
1f196a09fe | ||
|
|
034673bbeb | ||
|
|
17b8adeb0e | ||
|
|
e8140304b9 | ||
|
|
bc2ad5a661 | ||
|
|
f3937bc8f3 | ||
|
|
384fcac6df | ||
|
|
0b1a843d32 | ||
|
|
2299951e6d | ||
|
|
ab7857019a | ||
|
|
c7a3b2ed31 | ||
|
|
b64c522759 | ||
|
|
7eb6dfc607 | ||
|
|
06bc1daf6c | ||
|
|
7e1b202d5e | ||
|
|
170af08e7f | ||
|
|
76985bc87a | ||
|
|
851b968630 | ||
|
|
3a5eff9022 | ||
|
|
6e808719d2 | ||
|
|
eb64e201b8 | ||
|
|
a4d5b59f13 | ||
|
|
5e84353eba | ||
|
|
efa773afd2 | ||
|
|
da7d4cf200 | ||
|
|
9e1b1ca49d | ||
|
|
16172c1c7e | ||
|
|
28f730520e | ||
|
|
5cbed8e0d1 | ||
|
|
11133dcca1 | ||
|
|
bb4d605dfc | ||
|
|
e5b5deaea6 | ||
|
|
bfe37f3159 | ||
|
|
89793a97e2 | ||
|
|
365f75233f | ||
|
|
c1efda70b5 | ||
|
|
47893164ab | ||
|
|
102cabeb23 | ||
|
|
511bd3aaf2 | ||
|
|
4674fdf807 | ||
|
|
6028d58cb0 | ||
|
|
60a147343f | ||
|
|
eb5267f377 | ||
|
|
db5fa43079 | ||
|
|
0ab948568d | ||
|
|
ebd80e2618 | ||
|
|
89509230db | ||
|
|
577a6a65d6 | ||
|
|
62b3efe351 | ||
|
|
21ceda3f6c | ||
|
|
5321f3e203 | ||
|
|
3f1861ee46 | ||
|
|
6a03060c45 | ||
|
|
2b7669183e | ||
|
|
e7b69cbe19 | ||
|
|
3cde81408f | ||
|
|
71ba8aec55 | ||
|
|
89e9521048 | ||
|
|
65ea7d6b62 | ||
|
|
e30e1b89d0 | ||
|
|
df90f0ce98 | ||
|
|
ed22b4fd07 | ||
|
|
f9522d825c | ||
|
|
80e0c8ba9e | ||
|
|
3cd20d59d7 | ||
|
|
e36a36788e | ||
|
|
4b02f53e62 | ||
|
|
27d11a0094 | ||
|
|
554e67cb06 | ||
|
|
45cb500667 | ||
|
|
8c78e73fef | ||
|
|
c1b378db69 | ||
|
|
b50a9ae383 | ||
|
|
ea2e177c1d | ||
|
|
513f1fbfb0 | ||
|
|
d7b692083c | ||
|
|
9070c394aa | ||
|
|
194ed794d8 | ||
|
|
051b34635f | ||
|
|
5f25818a0f | ||
|
|
c25d8c905c | ||
|
|
5782e0393d | ||
|
|
92b6dbba1a | ||
|
|
c72e343085 | ||
|
|
3228eb1609 | ||
|
|
c1488ff348 | ||
|
|
b344c953a8 | ||
|
|
dd10da76a7 | ||
|
|
543ee1e092 | ||
|
|
75b6c16567 | ||
|
|
c4ae7c2421 | ||
|
|
a2090375ca | ||
|
|
c4a3b09a36 | ||
|
|
616c3a42cb | ||
|
|
d23cf98769 | ||
|
|
eeb9264acd | ||
|
|
b6447fa87e | ||
|
|
b6cadcef98 | ||
|
|
3100bc9670 | ||
|
|
e05f03ae41 | ||
|
|
6c15636b0b | ||
|
|
89f2011ced | ||
|
|
0f8547c2af | ||
|
|
343180c2cf | ||
|
|
27782bc18e | ||
|
|
cde0ed162a | ||
|
|
570d3f1eb9 | ||
|
|
85244d4a59 | ||
|
|
1a84bd2a0f | ||
|
|
3247eadde4 | ||
|
|
a487b5095a | ||
|
|
04fa7baea8 | ||
|
|
9a04a8a6a8 | ||
|
|
a05a5fb9ba | ||
|
|
71faf347fd | ||
|
|
2f1f7b01d6 | ||
|
|
5311f564ed | ||
|
|
3b7f514a1c | ||
|
|
7c0a861894 | ||
|
|
a73ae3e5b0 | ||
|
|
06505ba4b4 | ||
|
|
13457002c0 | ||
|
|
302b86bd0b | ||
|
|
d87d5edf66 | ||
|
|
e795a4c6f8 | ||
|
|
4293b9f54f | ||
|
|
0e5f2daee7 | ||
|
|
416749ff96 | ||
|
|
b1b99b59ac | ||
|
|
606ac57e50 | ||
|
|
394243ce98 | ||
|
|
fe98574622 | ||
|
|
c5c9399610 | ||
|
|
836f3f35c2 | ||
|
|
9c3820d05a | ||
|
|
13e37cabe0 | ||
|
|
760dcb1ffc | ||
|
|
889aa6008c | ||
|
|
76f9b52289 | ||
|
|
6b275fca49 | ||
|
|
1b42732ced | ||
|
|
9e9d2dbc59 | ||
|
|
8b4371f70f | ||
|
|
919e27d357 | ||
|
|
ad9d252596 | ||
|
|
7e11392dfd | ||
|
|
1f49a343b5 | ||
|
|
936cd08488 | ||
|
|
3a32b8c916 | ||
|
|
c3a15437f8 | ||
|
|
8c31925b3b | ||
|
|
33344ed916 | ||
|
|
7353b74ec2 | ||
|
|
44bb38fd8b | ||
|
|
2ea64a08ed | ||
|
|
37fe8e00b2 | ||
|
|
0ea78f0d3b | ||
|
|
0e5a99bb5a | ||
|
|
e3c982ee29 | ||
|
|
ab00f5d3e1 | ||
|
|
3f0b44b322 | ||
|
|
cb90fd69b4 | ||
|
|
f794432e81 | ||
|
|
182b164f32 | ||
|
|
8b42c7cecc | ||
|
|
66d5a1804c | ||
|
|
d5acb4110a | ||
|
|
6cabc599a2 | ||
|
|
36b459f6e6 | ||
|
|
1820024005 | ||
|
|
ffe7b93b60 | ||
|
|
f82ebb9a03 | ||
|
|
63c68d979a | ||
|
|
ba3c9a9a3a | ||
|
|
b5c684f042 | ||
|
|
da8e87e201 | ||
|
|
43bbc78123 | ||
|
|
1c14ce9509 | ||
|
|
29628acbec | ||
|
|
9d2fc6b535 | ||
|
|
3f1e95928e | ||
|
|
87060e6a9c | ||
|
|
e5f3415fbd | ||
|
|
f5ca5af6ce | ||
|
|
2ac19ff190 | ||
|
|
badc5517ff | ||
|
|
a8fc1560c6 | ||
|
|
f448360bd0 | ||
|
|
97e1e3ba76 | ||
|
|
dacabaa47f | ||
|
|
6d5ef87e6b | ||
|
|
e7fe901e5e | ||
|
|
c3d78cd306 | ||
|
|
2a69c0b7b8 | ||
|
|
c8c0c0e846 | ||
|
|
5e12d5c691 | ||
|
|
8aed37c1bd | ||
|
|
06c79730d0 | ||
|
|
ea8d58ea91 | ||
|
|
c352faeae3 | ||
|
|
107986639d | ||
|
|
d9316bf8bc | ||
|
|
3abf4bc439 | ||
|
|
94566e6dd8 | ||
|
|
4e2674934f | ||
|
|
53a42d0a0c | ||
|
|
321f9791d6 | ||
|
|
c524244f49 | ||
|
|
d224c6373f | ||
|
|
44705a648b | ||
|
|
a7b0047e0f | ||
|
|
dcb9070bc2 | ||
|
|
11667d08d3 | ||
|
|
221de0edee | ||
|
|
0eac7bd682 | ||
|
|
1e7e23a9c6 | ||
|
|
b8415bb480 | ||
|
|
3a15afacab | ||
|
|
571e4062e5 | ||
|
|
14bd3567b0 | ||
|
|
c2bc59d2b1 | ||
|
|
ab946575b1 | ||
|
|
1468f754e0 | ||
|
|
fa7443c899 | ||
|
|
8d7771d8b0 | ||
|
|
a1b5ef5ddc | ||
|
|
f26d3011c7 | ||
|
|
9da575d63c | ||
|
|
979c48be04 | ||
|
|
099d3eab49 | ||
|
|
61dc657461 | ||
|
|
23904d54d0 | ||
|
|
c691bb2f42 | ||
|
|
4c293e0e1b | ||
|
|
516cb9e7f8 | ||
|
|
60a981343e | ||
|
|
db5a05742e | ||
|
|
0dbc4779c8 | ||
|
|
5018abff6e | ||
|
|
f1aade0596 | ||
|
|
abedfb08f1 | ||
|
|
61ea57c5a7 | ||
|
|
810c0e4fda | ||
|
|
db7ec72dd8 | ||
|
|
52e0c5b294 | ||
|
|
fb188cd3f5 | ||
|
|
efe1e60e12 | ||
|
|
fd6f93b2b1 | ||
|
|
db934c6750 | ||
|
|
185347e411 | ||
|
|
c1c4dea98d | ||
|
|
f4cd5a20d0 | ||
|
|
3dbd6a8f4d | ||
|
|
c54f36f087 | ||
|
|
8b0bc596de | ||
|
|
f35387b33f | ||
|
|
3e2cff4da2 | ||
|
|
639b861129 | ||
|
|
663393e28a | ||
|
|
c50d997591 | ||
|
|
f1cb807496 | ||
|
|
13ac40ed8e | ||
|
|
ebe683432f | ||
|
|
b897008122 | ||
|
|
8830af1168 | ||
|
|
81e7144783 | ||
|
|
c9bd4d4338 | ||
|
|
7e0fd19ffe | ||
|
|
21aac1aca9 | ||
|
|
b65eb377dd | ||
|
|
26ce60c46d | ||
|
|
358531be9d | ||
|
|
66ee73eebc | ||
|
|
32b93da875 | ||
|
|
597b7ae2fb | ||
|
|
519bd41ff3 | ||
|
|
eb90d3be13 | ||
|
|
df2e145e5f | ||
|
|
046dc43075 | ||
|
|
c174bcf4bf | ||
|
|
466214d2d6 | ||
|
|
4e125f72ab | ||
|
|
0926dc2418 | ||
|
|
8cba133f36 | ||
|
|
f47066f707 | ||
|
|
859ffea2b1 | ||
|
|
65788e46ed | ||
|
|
eceeb97242 | ||
|
|
333a8da678 | ||
|
|
814133ec9c | ||
|
|
f15ab901a0 | ||
|
|
d1f2e3e47b | ||
|
|
1899457b24 | ||
|
|
ebf3717c37 | ||
|
|
976173a4bf | ||
|
|
bae04ea9d8 | ||
|
|
0b7daa6de9 | ||
|
|
99568c5a39 | ||
|
|
2ac9b02609 | ||
|
|
17e5b4921a | ||
|
|
36e1893c6f | ||
|
|
4d1536bb2e | ||
|
|
e5d9baf0fe | ||
|
|
c482d7bd4f | ||
|
|
e47c97a451 | ||
|
|
740326d2a2 | ||
|
|
31d1f3c8c0 | ||
|
|
635da72374 | ||
|
|
79db3eb6ca | ||
|
|
e372767c4d | ||
|
|
c45fd7498c | ||
|
|
9dccc7dc42 | ||
|
|
52b3ff5eb9 | ||
|
|
fff981df2f | ||
|
|
a42b900d27 | ||
|
|
bdecc3cffd | ||
|
|
0efac0aac9 | ||
|
|
d74b804d05 | ||
|
|
a859b1992b | ||
|
|
22b63d155a | ||
|
|
85d991a12a | ||
|
|
3a5c87055c | ||
|
|
a2b72faff7 | ||
|
|
c9504bba10 | ||
|
|
26ea58d4e1 | ||
|
|
d1fb309381 | ||
|
|
7b9b946cb2 | ||
|
|
b9de7172ba | ||
|
|
4261c3aadf | ||
|
|
932ce05d97 | ||
|
|
4e08e0ca42 | ||
|
|
af6c143919 | ||
|
|
07ff0abff4 | ||
|
|
3286dac6bf | ||
|
|
1cf7933ea2 | ||
|
|
d726857f7e | ||
|
|
ee010726ab | ||
|
|
abcb25978a | ||
|
|
183056f243 | ||
|
|
dc7c49e4e4 | ||
|
|
c991ffd4f0 | ||
|
|
3986741b8b | ||
|
|
0e13d3293c | ||
|
|
3f9e3d8ad6 | ||
|
|
e13ee8b5b3 | ||
|
|
0027993e91 | ||
|
|
6846ee2ac4 | ||
|
|
c7a39d38ad | ||
|
|
02a76c2c81 | ||
|
|
9b9afc9726 | ||
|
|
b7f0ce5b39 | ||
|
|
6921393ae2 | ||
|
|
17bf65e186 | ||
|
|
014ebc594d | ||
|
|
168e5b7ffa | ||
|
|
43bf361a7a | ||
|
|
8199f09c22 | ||
|
|
7c120874be | ||
|
|
3562a3e661 | ||
|
|
1a0331a78a | ||
|
|
fbb103deb6 | ||
|
|
45a09bebf3 | ||
|
|
0183bf13c7 | ||
|
|
f6e8c8c09c | ||
|
|
9a4d53a476 | ||
|
|
ba264419f4 | ||
|
|
dc6d028654 | ||
|
|
d5c527a499 | ||
|
|
135acd83af | ||
|
|
433cb3f801 | ||
|
|
de810814da | ||
|
|
bc2d586dcb | ||
|
|
49a81f9f1a | ||
|
|
78e99a997b | ||
|
|
fc67917a18 | ||
|
|
7ca832cac9 | ||
|
|
b296f2d4f3 | ||
|
|
ac796924df | ||
|
|
3618d33039 | ||
|
|
c3c1bdf8e2 | ||
|
|
bd9c9fbfbe | ||
|
|
f941fc9917 | ||
|
|
e29fc44635 | ||
|
|
7b4e049eb0 | ||
|
|
4fbf8c815e | ||
|
|
0244e2af4c | ||
|
|
6e456b7a7a | ||
|
|
3a17775454 | ||
|
|
40e28e8bf4 | ||
|
|
fc596c8625 | ||
|
|
48269070d2 | ||
|
|
c31736a4a4 | ||
|
|
7b43035bcb | ||
|
|
e45dae7dc0 | ||
|
|
d0032c6095 | ||
|
|
33abc79515 | ||
|
|
0d80fe9327 | ||
|
|
848c86ca0a | ||
|
|
320506c75a | ||
|
|
30fbd39f0c | ||
|
|
62c2c547db | ||
|
|
9e31c6a749 | ||
|
|
e3bf932404 | ||
|
|
dc966cc447 | ||
|
|
ac00dad756 | ||
|
|
072d75196c | ||
|
|
da4aebeda7 | ||
|
|
71289ba06e | ||
|
|
bfb4ddca35 | ||
|
|
c982fb8262 | ||
|
|
0417baf23d | ||
|
|
9c82c32ba7 | ||
|
|
1a099e5e0e | ||
|
|
b09b152f77 | ||
|
|
a2117cb797 | ||
|
|
ee902ddf3a | ||
|
|
e1ef122260 | ||
|
|
4497e78d00 | ||
|
|
49718b4704 | ||
|
|
77aadfee6a | ||
|
|
452339e20e | ||
|
|
80898b5234 | ||
|
|
e5675fad5d | ||
|
|
27359ae049 | ||
|
|
95a45f5b3a | ||
|
|
646e16fe06 | ||
|
|
08c852290a | ||
|
|
2b8bc91cf8 | ||
|
|
5b8ce1e7e6 | ||
|
|
05e265fbc8 | ||
|
|
694ad9849b | ||
|
|
808b49a7dc | ||
|
|
1c953bc3ea | ||
|
|
e007c797b1 | ||
|
|
44e64f9464 | ||
|
|
a677565f16 | ||
|
|
ff885b0e26 | ||
|
|
b4e6a7403d | ||
|
|
d182a6ad91 | ||
|
|
12da0fe10d | ||
|
|
cf6cd39572 | ||
|
|
eef2327a47 | ||
|
|
9c96682a51 | ||
|
|
1997b90838 | ||
|
|
b2274ece73 | ||
|
|
7dc71897b3 | ||
|
|
800b27703e | ||
|
|
d76bc43720 | ||
|
|
de22d4cd5d | ||
|
|
8c1f51978c | ||
|
|
dcb23b2d72 | ||
|
|
13a78b3cd3 | ||
|
|
fe7d136324 | ||
|
|
e660a05fed | ||
|
|
5e6f500038 | ||
|
|
0ffda1dfcc | ||
|
|
20c722c601 | ||
|
|
7cabc0cddc | ||
|
|
c2e48b23f8 | ||
|
|
ace07110c1 | ||
|
|
988369a01c | ||
|
|
5a3467e623 | ||
|
|
e26782759c | ||
|
|
1d2551d716 | ||
|
|
8007393614 | ||
|
|
cdf26c55f5 | ||
|
|
bed32182f6 | ||
|
|
cf3fdb8479 | ||
|
|
d2940c23fe | ||
|
|
13f003c9bd | ||
|
|
a1e1806575 | ||
|
|
cc45831ec6 | ||
|
|
2d8d82f93e | ||
|
|
71ecc7aed8 | ||
|
|
3f2d46a14e | ||
|
|
ebbba62c36 | ||
|
|
7b55d334d5 | ||
|
|
986cc9b2f4 | ||
|
|
c3cc8eb23c | ||
|
|
926658665f | ||
|
|
acb2faaefa | ||
|
|
4c16b3a5fd | ||
|
|
c5e54c200a | ||
|
|
4bf6bea52a | ||
|
|
7d4bafa8a4 | ||
|
|
57aba1ef50 | ||
|
|
71c6b36254 | ||
|
|
1112699149 | ||
|
|
52a9acfa8e | ||
|
|
611163405f | ||
|
|
e3c8af2618 | ||
|
|
ca9f7ac2df | ||
|
|
3d335f833c |
@@ -0,0 +1,36 @@
|
||||
name: "\U0001F41B Bug Report"
|
||||
description: Report a bug on diffusers
|
||||
labels: [ "bug" ]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this bug report!
|
||||
- type: textarea
|
||||
id: bug-description
|
||||
attributes:
|
||||
label: Describe the bug
|
||||
description: A clear and concise description of what the bug is. If you intend to submit a pull request for this issue, tell us in the description. Thanks!
|
||||
placeholder: Bug description
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
id: reproduction
|
||||
attributes:
|
||||
label: Reproduction
|
||||
description: Please provide a minimal reproducible code which we can copy/paste and reproduce the issue.
|
||||
placeholder: Reproduction
|
||||
- type: textarea
|
||||
id: logs
|
||||
attributes:
|
||||
label: Logs
|
||||
description: "Please include the Python logs if you can."
|
||||
render: shell
|
||||
- type: textarea
|
||||
id: system-info
|
||||
attributes:
|
||||
label: System Info
|
||||
description: Please share your system info with us. You can run the command `diffusers-cli env` and copy-paste its output below.
|
||||
placeholder: diffusers version, platform, python version, ...
|
||||
validations:
|
||||
required: true
|
||||
@@ -0,0 +1,7 @@
|
||||
contact_links:
|
||||
- name: Forum
|
||||
url: https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63
|
||||
about: General usage questions and community discussions
|
||||
- name: Blank issue
|
||||
url: https://github.com/huggingface/diffusers/issues/new
|
||||
about: Please note that the Forum is in most places the right place for discussions
|
||||
@@ -0,0 +1,20 @@
|
||||
---
|
||||
name: "\U0001F680 Feature request"
|
||||
about: Suggest an idea for this project
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
**Is your feature request related to a problem? Please describe.**
|
||||
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
|
||||
|
||||
**Describe the solution you'd like**
|
||||
A clear and concise description of what you want to happen.
|
||||
|
||||
**Describe alternatives you've considered**
|
||||
A clear and concise description of any alternative solutions or features you've considered.
|
||||
|
||||
**Additional context**
|
||||
Add any other context or screenshots about the feature request here.
|
||||
@@ -0,0 +1,12 @@
|
||||
---
|
||||
name: "💬 Feedback about API Design"
|
||||
about: Give feedback about the current API design
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
**What API design would you like to have changed or added to the library? Why?**
|
||||
|
||||
**What use case would this enable or better enable? Can you give us a code example?**
|
||||
@@ -0,0 +1,31 @@
|
||||
name: "\U0001F31F New model/pipeline/scheduler addition"
|
||||
description: Submit a proposal/request to implement a new diffusion model / pipeline / scheduler
|
||||
labels: [ "New model/pipeline/scheduler" ]
|
||||
|
||||
body:
|
||||
- type: textarea
|
||||
id: description-request
|
||||
validations:
|
||||
required: true
|
||||
attributes:
|
||||
label: Model/Pipeline/Scheduler description
|
||||
description: |
|
||||
Put any and all important information relative to the model/pipeline/scheduler
|
||||
|
||||
- type: checkboxes
|
||||
id: information-tasks
|
||||
attributes:
|
||||
label: Open source status
|
||||
description: |
|
||||
Please note that if the model implementation isn't available or if the weights aren't open-source, we are less likely to implement it in `diffusers`.
|
||||
options:
|
||||
- label: "The model implementation is available"
|
||||
- label: "The model weights are available (Only relevant if addition is not a scheduler)."
|
||||
|
||||
- type: textarea
|
||||
id: additional-info
|
||||
attributes:
|
||||
label: Provide useful links for the implementation
|
||||
description: |
|
||||
Please provide information regarding the implementation, the weights, and the authors.
|
||||
Please mention the authors by @gh-username if you're aware of their usernames.
|
||||
@@ -0,0 +1,17 @@
|
||||
name: Build documentation
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
- doc-builder*
|
||||
- v*-release
|
||||
|
||||
jobs:
|
||||
build:
|
||||
uses: huggingface/doc-builder/.github/workflows/build_main_documentation.yml@main
|
||||
with:
|
||||
commit_sha: ${{ github.sha }}
|
||||
package: diffusers
|
||||
secrets:
|
||||
token: ${{ secrets.HUGGINGFACE_PUSH }}
|
||||
@@ -0,0 +1,16 @@
|
||||
name: Build PR Documentation
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
build:
|
||||
uses: huggingface/doc-builder/.github/workflows/build_pr_documentation.yml@main
|
||||
with:
|
||||
commit_sha: ${{ github.event.pull_request.head.sha }}
|
||||
pr_number: ${{ github.event.number }}
|
||||
package: diffusers
|
||||
@@ -0,0 +1,13 @@
|
||||
name: Delete dev documentation
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
types: [ closed ]
|
||||
|
||||
|
||||
jobs:
|
||||
delete:
|
||||
uses: huggingface/doc-builder/.github/workflows/delete_doc_comment.yml@main
|
||||
with:
|
||||
pr_number: ${{ github.event.number }}
|
||||
package: diffusers
|
||||
@@ -0,0 +1,33 @@
|
||||
name: Run code quality checks
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
branches:
|
||||
- main
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
check_code_quality:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.7"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install .[quality]
|
||||
- name: Check quality
|
||||
run: |
|
||||
black --check --preview examples tests src utils scripts
|
||||
isort --check-only examples tests src utils scripts
|
||||
flake8 examples tests src utils scripts
|
||||
doc-builder style src/diffusers docs/source --max_len 119 --check_only --path_to_docs docs/source
|
||||
@@ -0,0 +1,44 @@
|
||||
name: Run non-slow tests
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
branches:
|
||||
- main
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
HF_HOME: /mnt/cache
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
PYTEST_TIMEOUT: 60
|
||||
|
||||
jobs:
|
||||
run_tests_cpu:
|
||||
name: Diffusers tests
|
||||
runs-on: [ self-hosted, docker-gpu ]
|
||||
container:
|
||||
image: python:3.7
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install torch --extra-index-url https://download.pytorch.org/whl/cpu
|
||||
python -m pip install -e .[quality,test]
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run all non-slow selected tests on CPU
|
||||
run: |
|
||||
python -m pytest -n 2 --max-worker-restart=0 --dist=loadfile -s tests/
|
||||
@@ -0,0 +1,52 @@
|
||||
name: Run all tests
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
|
||||
env:
|
||||
HF_HOME: /mnt/cache
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
PYTEST_TIMEOUT: 1000
|
||||
RUN_SLOW: yes
|
||||
|
||||
jobs:
|
||||
run_tests_single_gpu:
|
||||
name: Diffusers tests
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
machine_type: [ single-gpu ]
|
||||
runs-on: [ self-hosted, docker-gpu, '${{ matrix.machine_type }}' ]
|
||||
container:
|
||||
image: nvcr.io/nvidia/pytorch:22.07-py3
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip uninstall -y torch torchvision torchtext
|
||||
python -m pip install torch --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
python -m pip install -e .[quality,test]
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run all (incl. slow) tests on GPU
|
||||
env:
|
||||
HUGGING_FACE_HUB_TOKEN: ${{ secrets.HUGGING_FACE_HUB_TOKEN }}
|
||||
run: |
|
||||
python -m pytest -n 1 --max-worker-restart=0 --dist=loadfile -s tests/
|
||||
@@ -0,0 +1,129 @@
|
||||
|
||||
# Contributor Covenant Code of Conduct
|
||||
|
||||
## Our Pledge
|
||||
|
||||
We as members, contributors, and leaders pledge to make participation in our
|
||||
community a harassment-free experience for everyone, regardless of age, body
|
||||
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
||||
identity and expression, level of experience, education, socio-economic status,
|
||||
nationality, personal appearance, race, religion, or sexual identity
|
||||
and orientation.
|
||||
|
||||
We pledge to act and interact in ways that contribute to an open, welcoming,
|
||||
diverse, inclusive, and healthy community.
|
||||
|
||||
## Our Standards
|
||||
|
||||
Examples of behavior that contributes to a positive environment for our
|
||||
community include:
|
||||
|
||||
* Demonstrating empathy and kindness toward other people
|
||||
* Being respectful of differing opinions, viewpoints, and experiences
|
||||
* Giving and gracefully accepting constructive feedback
|
||||
* Accepting responsibility and apologizing to those affected by our mistakes,
|
||||
and learning from the experience
|
||||
* Focusing on what is best not just for us as individuals, but for the
|
||||
overall community
|
||||
|
||||
Examples of unacceptable behavior include:
|
||||
|
||||
* The use of sexualized language or imagery, and sexual attention or
|
||||
advances of any kind
|
||||
* Trolling, insulting or derogatory comments, and personal or political attacks
|
||||
* Public or private harassment
|
||||
* Publishing others' private information, such as a physical or email
|
||||
address, without their explicit permission
|
||||
* Other conduct which could reasonably be considered inappropriate in a
|
||||
professional setting
|
||||
|
||||
## Enforcement Responsibilities
|
||||
|
||||
Community leaders are responsible for clarifying and enforcing our standards of
|
||||
acceptable behavior and will take appropriate and fair corrective action in
|
||||
response to any behavior that they deem inappropriate, threatening, offensive,
|
||||
or harmful.
|
||||
|
||||
Community leaders have the right and responsibility to remove, edit, or reject
|
||||
comments, commits, code, wiki edits, issues, and other contributions that are
|
||||
not aligned to this Code of Conduct, and will communicate reasons for moderation
|
||||
decisions when appropriate.
|
||||
|
||||
## Scope
|
||||
|
||||
This Code of Conduct applies within all community spaces, and also applies when
|
||||
an individual is officially representing the community in public spaces.
|
||||
Examples of representing our community include using an official e-mail address,
|
||||
posting via an official social media account, or acting as an appointed
|
||||
representative at an online or offline event.
|
||||
|
||||
## Enforcement
|
||||
|
||||
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
||||
reported to the community leaders responsible for enforcement at
|
||||
feedback@huggingface.co.
|
||||
All complaints will be reviewed and investigated promptly and fairly.
|
||||
|
||||
All community leaders are obligated to respect the privacy and security of the
|
||||
reporter of any incident.
|
||||
|
||||
## Enforcement Guidelines
|
||||
|
||||
Community leaders will follow these Community Impact Guidelines in determining
|
||||
the consequences for any action they deem in violation of this Code of Conduct:
|
||||
|
||||
### 1. Correction
|
||||
|
||||
**Community Impact**: Use of inappropriate language or other behavior deemed
|
||||
unprofessional or unwelcome in the community.
|
||||
|
||||
**Consequence**: A private, written warning from community leaders, providing
|
||||
clarity around the nature of the violation and an explanation of why the
|
||||
behavior was inappropriate. A public apology may be requested.
|
||||
|
||||
### 2. Warning
|
||||
|
||||
**Community Impact**: A violation through a single incident or series
|
||||
of actions.
|
||||
|
||||
**Consequence**: A warning with consequences for continued behavior. No
|
||||
interaction with the people involved, including unsolicited interaction with
|
||||
those enforcing the Code of Conduct, for a specified period of time. This
|
||||
includes avoiding interactions in community spaces as well as external channels
|
||||
like social media. Violating these terms may lead to a temporary or
|
||||
permanent ban.
|
||||
|
||||
### 3. Temporary Ban
|
||||
|
||||
**Community Impact**: A serious violation of community standards, including
|
||||
sustained inappropriate behavior.
|
||||
|
||||
**Consequence**: A temporary ban from any sort of interaction or public
|
||||
communication with the community for a specified period of time. No public or
|
||||
private interaction with the people involved, including unsolicited interaction
|
||||
with those enforcing the Code of Conduct, is allowed during this period.
|
||||
Violating these terms may lead to a permanent ban.
|
||||
|
||||
### 4. Permanent Ban
|
||||
|
||||
**Community Impact**: Demonstrating a pattern of violation of community
|
||||
standards, including sustained inappropriate behavior, harassment of an
|
||||
individual, or aggression toward or disparagement of classes of individuals.
|
||||
|
||||
**Consequence**: A permanent ban from any sort of public interaction within
|
||||
the community.
|
||||
|
||||
## Attribution
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
||||
version 2.0, available at
|
||||
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
||||
|
||||
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
||||
enforcement ladder](https://github.com/mozilla/diversity).
|
||||
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
|
||||
For answers to common questions about this code of conduct, see the FAQ at
|
||||
https://www.contributor-covenant.org/faq. Translations are available at
|
||||
https://www.contributor-covenant.org/translations.
|
||||
+294
@@ -0,0 +1,294 @@
|
||||
<!---
|
||||
Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
|
||||
# How to contribute to diffusers?
|
||||
|
||||
Everyone is welcome to contribute, and we value everybody's contribution. Code
|
||||
is thus not the only way to help the community. Answering questions, helping
|
||||
others, reaching out and improving the documentations are immensely valuable to
|
||||
the community.
|
||||
|
||||
It also helps us if you spread the word: reference the library from blog posts
|
||||
on the awesome projects it made possible, shout out on Twitter every time it has
|
||||
helped you, or simply star the repo to say "thank you".
|
||||
|
||||
Whichever way you choose to contribute, please be mindful to respect our
|
||||
[code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md).
|
||||
|
||||
## You can contribute in so many ways!
|
||||
|
||||
There are 4 ways you can contribute to diffusers:
|
||||
* Fixing outstanding issues with the existing code;
|
||||
* Implementing [new diffusion pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines#contribution), [new schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) or [new models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)
|
||||
* [Contributing to the examples](https://github.com/huggingface/diffusers/tree/main/examples) or to the documentation;
|
||||
* Submitting issues related to bugs or desired new features.
|
||||
|
||||
In particular there is a special [Good First Issue](https://github.com/huggingface/diffusers/contribute) listing.
|
||||
It will give you a list of open Issues that are open to anybody to work on. Just comment in the issue that you'd like to work on it.
|
||||
In that same listing you will also find some Issues with `Good Second Issue` label. These are
|
||||
typically slightly more complicated than the Issues with just `Good First Issue` label. But if you
|
||||
feel you know what you're doing, go for it.
|
||||
|
||||
*All are equally valuable to the community.*
|
||||
|
||||
## Submitting a new issue or feature request
|
||||
|
||||
Do your best to follow these guidelines when submitting an issue or a feature
|
||||
request. It will make it easier for us to come back to you quickly and with good
|
||||
feedback.
|
||||
|
||||
### Did you find a bug?
|
||||
|
||||
The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
|
||||
the problems they encounter. So thank you for reporting an issue.
|
||||
|
||||
First, we would really appreciate it if you could **make sure the bug was not
|
||||
already reported** (use the search bar on Github under Issues).
|
||||
|
||||
### Do you want to implement a new diffusion pipeline / diffusion model?
|
||||
|
||||
Awesome! Please provide the following information:
|
||||
|
||||
* Short description of the diffusion pipeline and link to the paper;
|
||||
* Link to the implementation if it is open-source;
|
||||
* Link to the model weights if they are available.
|
||||
|
||||
If you are willing to contribute the model yourself, let us know so we can best
|
||||
guide you.
|
||||
|
||||
### Do you want a new feature (that is not a model)?
|
||||
|
||||
A world-class feature request addresses the following points:
|
||||
|
||||
1. Motivation first:
|
||||
* Is it related to a problem/frustration with the library? If so, please explain
|
||||
why. Providing a code snippet that demonstrates the problem is best.
|
||||
* Is it related to something you would need for a project? We'd love to hear
|
||||
about it!
|
||||
* Is it something you worked on and think could benefit the community?
|
||||
Awesome! Tell us what problem it solved for you.
|
||||
2. Write a *full paragraph* describing the feature;
|
||||
3. Provide a **code snippet** that demonstrates its future use;
|
||||
4. In case this is related to a paper, please attach a link;
|
||||
5. Attach any additional information (drawings, screenshots, etc.) you think may help.
|
||||
|
||||
If your issue is well written we're already 80% of the way there by the time you
|
||||
post it.
|
||||
|
||||
## Start contributing! (Pull Requests)
|
||||
|
||||
Before writing code, we strongly advise you to search through the existing PRs or
|
||||
issues to make sure that nobody is already working on the same thing. If you are
|
||||
unsure, it is always a good idea to open an issue to get some feedback.
|
||||
|
||||
You will need basic `git` proficiency to be able to contribute to
|
||||
🧨 Diffusers. `git` is not the easiest tool to use but it has the greatest
|
||||
manual. Type `git --help` in a shell and enjoy. If you prefer books, [Pro
|
||||
Git](https://git-scm.com/book/en/v2) is a very good reference.
|
||||
|
||||
Follow these steps to start contributing ([supported Python versions](https://github.com/huggingface/diffusers/blob/main/setup.py#L426)):
|
||||
|
||||
1. Fork the [repository](https://github.com/huggingface/diffusers) by
|
||||
clicking on the 'Fork' button on the repository's page. This creates a copy of the code
|
||||
under your GitHub user account.
|
||||
|
||||
2. Clone your fork to your local disk, and add the base repository as a remote:
|
||||
|
||||
```bash
|
||||
$ git clone git@github.com:<your Github handle>/diffusers.git
|
||||
$ cd diffusers
|
||||
$ git remote add upstream https://github.com/huggingface/diffusers.git
|
||||
```
|
||||
|
||||
3. Create a new branch to hold your development changes:
|
||||
|
||||
```bash
|
||||
$ git checkout -b a-descriptive-name-for-my-changes
|
||||
```
|
||||
|
||||
**Do not** work on the `main` branch.
|
||||
|
||||
4. Set up a development environment by running the following command in a virtual environment:
|
||||
|
||||
```bash
|
||||
$ pip install -e ".[dev]"
|
||||
```
|
||||
|
||||
(If diffusers was already installed in the virtual environment, remove
|
||||
it with `pip uninstall diffusers` before reinstalling it in editable
|
||||
mode with the `-e` flag.)
|
||||
|
||||
To run the full test suite, you might need the additional dependency on `transformers` and `datasets` which requires a separate source
|
||||
install:
|
||||
|
||||
```bash
|
||||
$ git clone https://github.com/huggingface/transformers
|
||||
$ cd transformers
|
||||
$ pip install -e .
|
||||
```
|
||||
|
||||
```bash
|
||||
$ git clone https://github.com/huggingface/datasets
|
||||
$ cd datasets
|
||||
$ pip install -e .
|
||||
```
|
||||
|
||||
If you have already cloned that repo, you might need to `git pull` to get the most recent changes in the `datasets`
|
||||
library.
|
||||
|
||||
5. Develop the features on your branch.
|
||||
|
||||
As you work on the features, you should make sure that the test suite
|
||||
passes. You should run the tests impacted by your changes like this:
|
||||
|
||||
```bash
|
||||
$ pytest tests/<TEST_TO_RUN>.py
|
||||
```
|
||||
|
||||
You can also run the full suite with the following command, but it takes
|
||||
a beefy machine to produce a result in a decent amount of time now that
|
||||
Diffusers has grown a lot. Here is the command for it:
|
||||
|
||||
```bash
|
||||
$ make test
|
||||
```
|
||||
|
||||
For more information about tests, check out the
|
||||
[dedicated documentation](https://huggingface.co/docs/diffusers/testing)
|
||||
|
||||
🧨 Diffusers relies on `black` and `isort` to format its source code
|
||||
consistently. After you make changes, apply automatic style corrections and code verifications
|
||||
that can't be automated in one go with:
|
||||
|
||||
```bash
|
||||
$ make style
|
||||
```
|
||||
|
||||
🧨 Diffusers also uses `flake8` and a few custom scripts to check for coding mistakes. Quality
|
||||
control runs in CI, however you can also run the same checks with:
|
||||
|
||||
```bash
|
||||
$ make quality
|
||||
```
|
||||
|
||||
Once you're happy with your changes, add changed files using `git add` and
|
||||
make a commit with `git commit` to record your changes locally:
|
||||
|
||||
```bash
|
||||
$ git add modified_file.py
|
||||
$ git commit
|
||||
```
|
||||
|
||||
It is a good idea to sync your copy of the code with the original
|
||||
repository regularly. This way you can quickly account for changes:
|
||||
|
||||
```bash
|
||||
$ git fetch upstream
|
||||
$ git rebase upstream/main
|
||||
```
|
||||
|
||||
Push the changes to your account using:
|
||||
|
||||
```bash
|
||||
$ git push -u origin a-descriptive-name-for-my-changes
|
||||
```
|
||||
|
||||
6. Once you are satisfied (**and the checklist below is happy too**), go to the
|
||||
webpage of your fork on GitHub. Click on 'Pull request' to send your changes
|
||||
to the project maintainers for review.
|
||||
|
||||
7. It's ok if maintainers ask you for changes. It happens to core contributors
|
||||
too! So everyone can see the changes in the Pull request, work in your local
|
||||
branch and push the changes to your fork. They will automatically appear in
|
||||
the pull request.
|
||||
|
||||
|
||||
### Checklist
|
||||
|
||||
1. The title of your pull request should be a summary of its contribution;
|
||||
2. If your pull request addresses an issue, please mention the issue number in
|
||||
the pull request description to make sure they are linked (and people
|
||||
consulting the issue know you are working on it);
|
||||
3. To indicate a work in progress please prefix the title with `[WIP]`. These
|
||||
are useful to avoid duplicated work, and to differentiate it from PRs ready
|
||||
to be merged;
|
||||
4. Make sure existing tests pass;
|
||||
5. Add high-coverage tests. No quality testing = no merge.
|
||||
- If you are adding new `@slow` tests, make sure they pass using
|
||||
`RUN_SLOW=1 python -m pytest tests/test_my_new_model.py`.
|
||||
- If you are adding a new tokenizer, write tests, and make sure
|
||||
`RUN_SLOW=1 python -m pytest tests/test_tokenization_{your_model_name}.py` passes.
|
||||
CircleCI does not run the slow tests, but github actions does every night!
|
||||
6. All public methods must have informative docstrings that work nicely with sphinx. See `modeling_bert.py` for an
|
||||
example.
|
||||
7. Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
|
||||
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
|
||||
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
|
||||
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
|
||||
to this dataset.
|
||||
|
||||
### Tests
|
||||
|
||||
An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
|
||||
the [tests folder](https://github.com/huggingface/diffusers/tree/main/tests).
|
||||
|
||||
We like `pytest` and `pytest-xdist` because it's faster. From the root of the
|
||||
repository, here's how to run tests with `pytest` for the library:
|
||||
|
||||
```bash
|
||||
$ python -m pytest -n auto --dist=loadfile -s -v ./tests/
|
||||
```
|
||||
|
||||
In fact, that's how `make test` is implemented (sans the `pip install` line)!
|
||||
|
||||
You can specify a smaller set of tests in order to test only the feature
|
||||
you're working on.
|
||||
|
||||
By default, slow tests are skipped. Set the `RUN_SLOW` environment variable to
|
||||
`yes` to run them. This will download many gigabytes of models — make sure you
|
||||
have enough disk space and a good Internet connection, or a lot of patience!
|
||||
|
||||
```bash
|
||||
$ RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/
|
||||
```
|
||||
|
||||
This means `unittest` is fully supported. Here's how to run tests with
|
||||
`unittest`:
|
||||
|
||||
```bash
|
||||
$ python -m unittest discover -s tests -t . -v
|
||||
$ python -m unittest discover -s examples -t examples -v
|
||||
```
|
||||
|
||||
|
||||
### Style guide
|
||||
|
||||
For documentation strings, 🧨 Diffusers follows the [google style](https://google.github.io/styleguide/pyguide.html).
|
||||
|
||||
**This guide was heavily inspired by the awesome [scikit-learn guide to contributing](https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md).**
|
||||
|
||||
### Syncing forked main with upstream (HuggingFace) main
|
||||
|
||||
To avoid pinging the upstream repository which adds reference notes to each upstream PR and sends unnecessary notifications to the developers involved in these PRs,
|
||||
when syncing the main branch of a forked repository, please, follow these steps:
|
||||
1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead merge directly into the forked main.
|
||||
2. If a PR is absolutely necessary, use the following steps after checking out your branch:
|
||||
```
|
||||
$ git checkout -b your-branch-for-syncing
|
||||
$ git pull --squash --no-commit upstream main
|
||||
$ git commit -m '<your message without GitHub references>'
|
||||
$ git push --set-upstream origin your-branch-for-syncing
|
||||
```
|
||||
@@ -0,0 +1 @@
|
||||
include src/diffusers/utils/model_card_template.md
|
||||
@@ -3,7 +3,7 @@
|
||||
# make sure to test the local checkout in scripts and not the pre-installed one (don't use quotes!)
|
||||
export PYTHONPATH = src
|
||||
|
||||
check_dirs := examples tests src utils
|
||||
check_dirs := examples scripts src tests utils
|
||||
|
||||
modified_only_fixup:
|
||||
$(eval modified_py_files := $(shell python utils/get_modified_files.py $(check_dirs)))
|
||||
@@ -34,30 +34,23 @@ autogenerate_code: deps_table_update
|
||||
# Check that the repo is in a good state
|
||||
|
||||
repo-consistency:
|
||||
python utils/check_copies.py
|
||||
python utils/check_table.py
|
||||
python utils/check_dummies.py
|
||||
python utils/check_repo.py
|
||||
python utils/check_inits.py
|
||||
python utils/check_config_docstrings.py
|
||||
python utils/tests_fetcher.py --sanity_check
|
||||
|
||||
# this target runs checks on all files
|
||||
|
||||
quality:
|
||||
black --check --preview $(check_dirs)
|
||||
isort --check-only $(check_dirs)
|
||||
python utils/custom_init_isort.py --check_only
|
||||
python utils/sort_auto_mappings.py --check_only
|
||||
flake8 $(check_dirs)
|
||||
doc-builder style src/transformers docs/source --max_len 119 --check_only --path_to_docs docs/source
|
||||
doc-builder style src/diffusers docs/source --max_len 119 --check_only --path_to_docs docs/source
|
||||
|
||||
# Format source code automatically and check is there are any problems left that need manual fixing
|
||||
|
||||
extra_style_checks:
|
||||
python utils/custom_init_isort.py
|
||||
python utils/sort_auto_mappings.py
|
||||
doc-builder style src/transformers docs/source --max_len 119 --path_to_docs docs/source
|
||||
doc-builder style src/diffusers docs/source --max_len 119 --path_to_docs docs/source
|
||||
|
||||
# this target runs checks on all files and potentially modifies some of them
|
||||
|
||||
@@ -74,8 +67,6 @@ fixup: modified_only_fixup extra_style_checks autogenerate_code repo-consistency
|
||||
# Make marked copies of snippets of codes conform to the original
|
||||
|
||||
fix-copies:
|
||||
python utils/check_copies.py --fix_and_overwrite
|
||||
python utils/check_table.py --fix_and_overwrite
|
||||
python utils/check_dummies.py --fix_and_overwrite
|
||||
|
||||
# Run tests for the library
|
||||
@@ -88,11 +79,6 @@ test:
|
||||
test-examples:
|
||||
python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/
|
||||
|
||||
# Run tests for SageMaker DLC release
|
||||
|
||||
test-sagemaker: # install sagemaker dependencies in advance with pip install .[sagemaker]
|
||||
TEST_SAGEMAKER=True python -m pytest -n auto -s -v ./tests/sagemaker
|
||||
|
||||
|
||||
# Release stuff
|
||||
|
||||
|
||||
@@ -20,266 +20,360 @@ as a modular toolbox for inference and training of diffusion models.
|
||||
|
||||
More precisely, 🤗 Diffusers offers:
|
||||
|
||||
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code (see [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines)).
|
||||
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code (see [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines)). Check [this overview](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/README.md#pipelines-summary) to see all supported pipelines and their corresponding official papers.
|
||||
- Various noise schedulers that can be used interchangeably for the prefered speed vs. quality trade-off in inference (see [src/diffusers/schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers)).
|
||||
- Multiple types of models, such as UNet, that can be used as building blocks in an end-to-end diffusion system (see [src/diffusers/models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)).
|
||||
- Training examples to show how to train the most popular diffusion models (see [examples](https://github.com/huggingface/diffusers/tree/main/examples)).
|
||||
- Multiple types of models, such as UNet, can be used as building blocks in an end-to-end diffusion system (see [src/diffusers/models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)).
|
||||
- Training examples to show how to train the most popular diffusion model tasks (see [examples](https://github.com/huggingface/diffusers/tree/main/examples), *e.g.* [unconditional-image-generation](https://github.com/huggingface/diffusers/tree/main/examples/unconditional_image_generation)).
|
||||
|
||||
## Installation
|
||||
|
||||
**With `pip`**
|
||||
|
||||
```bash
|
||||
pip install --upgrade diffusers
|
||||
```
|
||||
|
||||
**With `conda`**
|
||||
|
||||
```sh
|
||||
conda install -c conda-forge diffusers
|
||||
```
|
||||
|
||||
**Apple Silicon (M1/M2) support**
|
||||
|
||||
Please, refer to [the documentation](https://huggingface.co/docs/diffusers/optimization/mps).
|
||||
|
||||
## Contributing
|
||||
|
||||
We ❤️ contributions from the open-source community!
|
||||
If you want to contribute to this library, please check out our [Contribution guide](https://github.com/huggingface/diffusers/blob/main/CONTRIBUTING.md).
|
||||
You can look out for [issues](https://github.com/huggingface/diffusers/issues) you'd like to tackle to contribute to the library.
|
||||
- See [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute
|
||||
- See [New model/pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) to contribute exciting new diffusion models / diffusion pipelines
|
||||
- See [New scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
|
||||
|
||||
Also, say 👋 in our public Discord channel <a href="https://discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=discord&logoColor=white"></a>. We discuss the hottest trends about diffusion models, help each other with contributions, personal projects or
|
||||
just hang out ☕.
|
||||
|
||||
## Quickstart
|
||||
|
||||
In order to get started, we recommend taking a look at two notebooks:
|
||||
|
||||
- The [Getting started with Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) notebook, which showcases an end-to-end example of usage for diffusion models, schedulers and pipelines.
|
||||
Take a look at this notebook to learn how to use the pipeline abstraction, which takes care of everything (model, scheduler, noise handling) for you, and also to understand each independent building block in the library.
|
||||
- The [Training a diffusers model](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb) notebook summarizes diffusion models training methods. This notebook takes a step-by-step approach to training your
|
||||
diffusion models on an image dataset, with explanatory graphics.
|
||||
|
||||
## **New** Stable Diffusion is now fully compatible with `diffusers`!
|
||||
|
||||
Stable Diffusion is a text-to-image latent diffusion model created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/). It's trained on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
|
||||
See the [model card](https://huggingface.co/CompVis/stable-diffusion) for more information.
|
||||
|
||||
You need to accept the model license before downloading or using the Stable Diffusion weights. Please, visit the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4), read the license and tick the checkbox if you agree. You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section](https://huggingface.co/docs/hub/security-tokens) of the documentation.
|
||||
|
||||
|
||||
### Text-to-Image generation with Stable Diffusion
|
||||
|
||||
```python
|
||||
# make sure you're logged in with `huggingface-cli login`
|
||||
from torch import autocast
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
with autocast("cuda"):
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
**Note**: If you don't want to use the token, you can also simply download the model weights
|
||||
(after having [accepted the license](https://huggingface.co/CompVis/stable-diffusion-v1-4)) and pass
|
||||
the path to the local folder to the `StableDiffusionPipeline`.
|
||||
|
||||
```
|
||||
git lfs install
|
||||
git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
|
||||
```
|
||||
|
||||
Assuming the folder is stored locally under `./stable-diffusion-v1-4`, you can also run stable diffusion
|
||||
without requiring an authentication token:
|
||||
|
||||
```python
|
||||
pipe = StableDiffusionPipeline.from_pretrained("./stable-diffusion-v1-4")
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
with autocast("cuda"):
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
If you are limited by GPU memory, you might want to consider using the model in `fp16` as
|
||||
well as chunking the attention computation.
|
||||
The following snippet should result in less than 4GB VRAM.
|
||||
|
||||
```python
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
revision="fp16",
|
||||
torch_dtype=torch.float16,
|
||||
use_auth_token=True
|
||||
)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
pipe.enable_attention_slicing()
|
||||
with autocast("cuda"):
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
Finally, if you wish to use a different scheduler, you can simply instantiate
|
||||
it before the pipeline and pass it to `from_pretrained`.
|
||||
|
||||
```python
|
||||
from diffusers import LMSDiscreteScheduler
|
||||
|
||||
lms = LMSDiscreteScheduler(
|
||||
beta_start=0.00085,
|
||||
beta_end=0.012,
|
||||
beta_schedule="scaled_linear"
|
||||
)
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
revision="fp16",
|
||||
torch_dtype=torch.float16,
|
||||
scheduler=lms,
|
||||
use_auth_token=True
|
||||
)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
with autocast("cuda"):
|
||||
image = pipe(prompt).images[0]
|
||||
|
||||
image.save("astronaut_rides_horse.png")
|
||||
```
|
||||
|
||||
### Image-to-Image text-guided generation with Stable Diffusion
|
||||
|
||||
The `StableDiffusionImg2ImgPipeline` lets you pass a text prompt and an initial image to condition the generation of new images.
|
||||
|
||||
```python
|
||||
from torch import autocast
|
||||
import requests
|
||||
import torch
|
||||
from PIL import Image
|
||||
from io import BytesIO
|
||||
|
||||
from diffusers import StableDiffusionImg2ImgPipeline
|
||||
|
||||
# load the pipeline
|
||||
device = "cuda"
|
||||
model_id_or_path = "CompVis/stable-diffusion-v1-4"
|
||||
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
|
||||
model_id_or_path,
|
||||
revision="fp16",
|
||||
torch_dtype=torch.float16,
|
||||
use_auth_token=True
|
||||
)
|
||||
# or download via git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
|
||||
# and pass `model_id_or_path="./stable-diffusion-v1-4"` without having to use `use_auth_token=True`.
|
||||
pipe = pipe.to(device)
|
||||
|
||||
# let's download an initial image
|
||||
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
|
||||
response = requests.get(url)
|
||||
init_image = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
init_image = init_image.resize((768, 512))
|
||||
|
||||
prompt = "A fantasy landscape, trending on artstation"
|
||||
|
||||
with autocast("cuda"):
|
||||
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5).images
|
||||
|
||||
images[0].save("fantasy_landscape.png")
|
||||
```
|
||||
You can also run this example on colab [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/image_2_image_using_diffusers.ipynb)
|
||||
|
||||
### In-painting using Stable Diffusion
|
||||
|
||||
The `StableDiffusionInpaintPipeline` lets you edit specific parts of an image by providing a mask and text prompt.
|
||||
|
||||
```python
|
||||
from io import BytesIO
|
||||
|
||||
from torch import autocast
|
||||
import torch
|
||||
import requests
|
||||
import PIL
|
||||
|
||||
from diffusers import StableDiffusionInpaintPipeline
|
||||
|
||||
def download_image(url):
|
||||
response = requests.get(url)
|
||||
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
||||
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
||||
|
||||
init_image = download_image(img_url).resize((512, 512))
|
||||
mask_image = download_image(mask_url).resize((512, 512))
|
||||
|
||||
device = "cuda"
|
||||
model_id_or_path = "CompVis/stable-diffusion-v1-4"
|
||||
pipe = StableDiffusionInpaintPipeline.from_pretrained(
|
||||
model_id_or_path,
|
||||
revision="fp16",
|
||||
torch_dtype=torch.float16,
|
||||
use_auth_token=True
|
||||
)
|
||||
# or download via git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
|
||||
# and pass `model_id_or_path="./stable-diffusion-v1-4"` without having to use `use_auth_token=True`.
|
||||
pipe = pipe.to(device)
|
||||
|
||||
prompt = "a cat sitting on a bench"
|
||||
with autocast("cuda"):
|
||||
images = pipe(prompt=prompt, init_image=init_image, mask_image=mask_image, strength=0.75).images
|
||||
|
||||
images[0].save("cat_on_bench.png")
|
||||
```
|
||||
|
||||
### Tweak prompts reusing seeds and latents
|
||||
|
||||
You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked. [This notebook](https://github.com/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb).
|
||||
|
||||
|
||||
For more details, check out [the Stable Diffusion notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb)
|
||||
and have a look into the [release notes](https://github.com/huggingface/diffusers/releases/tag/v0.2.0).
|
||||
|
||||
## Examples
|
||||
|
||||
There are many ways to try running Diffusers! Here we outline code-focused tools (primarily using `DiffusionPipeline`s and Google Colab) and interactive web-tools.
|
||||
|
||||
### Running Code
|
||||
|
||||
If you want to run the code yourself 💻, you can try out:
|
||||
- [Text-to-Image Latent Diffusion](https://huggingface.co/CompVis/ldm-text2im-large-256)
|
||||
```python
|
||||
# !pip install diffusers transformers
|
||||
from torch import autocast
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
device = "cuda"
|
||||
model_id = "CompVis/ldm-text2im-large-256"
|
||||
|
||||
# load model and scheduler
|
||||
ldm = DiffusionPipeline.from_pretrained(model_id)
|
||||
ldm = ldm.to(device)
|
||||
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
prompt = "A painting of a squirrel eating a burger"
|
||||
with autocast(device):
|
||||
image = ldm([prompt], num_inference_steps=50, eta=0.3, guidance_scale=6).images[0]
|
||||
|
||||
# save image
|
||||
image.save("squirrel.png")
|
||||
```
|
||||
- [Unconditional Diffusion with discrete scheduler](https://huggingface.co/google/ddpm-celebahq-256)
|
||||
```python
|
||||
# !pip install diffusers
|
||||
from torch import autocast
|
||||
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
|
||||
|
||||
model_id = "google/ddpm-celebahq-256"
|
||||
device = "cuda"
|
||||
|
||||
# load model and scheduler
|
||||
ddpm = DDPMPipeline.from_pretrained(model_id) # you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
|
||||
ddpm.to(device)
|
||||
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
with autocast("cuda"):
|
||||
image = ddpm().images[0]
|
||||
|
||||
# save image
|
||||
image.save("ddpm_generated_image.png")
|
||||
```
|
||||
- [Unconditional Latent Diffusion](https://huggingface.co/CompVis/ldm-celebahq-256)
|
||||
- [Unconditional Diffusion with continous scheduler](https://huggingface.co/google/ncsnpp-ffhq-1024)
|
||||
|
||||
**Other Notebooks**:
|
||||
* [image-to-image generation with Stable Diffusion](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/image_2_image_using_diffusers.ipynb) ,
|
||||
* [tweak images via repeated Stable Diffusion seeds](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) ,
|
||||
|
||||
### Web Demos
|
||||
If you just want to play around with some web demos, you can try out the following 🚀 Spaces:
|
||||
| Model | Hugging Face Spaces |
|
||||
|-------------------------------- |------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Text-to-Image Latent Diffusion | [](https://huggingface.co/spaces/CompVis/text2img-latent-diffusion) |
|
||||
| Faces generator | [](https://huggingface.co/spaces/CompVis/celeba-latent-diffusion) |
|
||||
| DDPM with different schedulers | [](https://huggingface.co/spaces/fusing/celeba-diffusion) |
|
||||
| Conditional generation from sketch | [](https://huggingface.co/spaces/huggingface/diffuse-the-rest) |
|
||||
| Composable diffusion | [](https://huggingface.co/spaces/Shuang59/Composable-Diffusion) |
|
||||
|
||||
## Definitions
|
||||
|
||||
**Models**: Neural network that models **p_θ(x_t-1|x_t)** (see image below) and is trained end-to-end to *denoise* a noisy input to an image.
|
||||
**Models**: Neural network that models $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$ (see image below) and is trained end-to-end to *denoise* a noisy input to an image.
|
||||
*Examples*: UNet, Conditioned UNet, 3D UNet, Transformer UNet
|
||||
|
||||
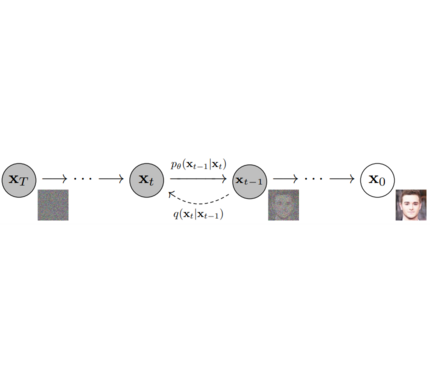
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/10695622/174349667-04e9e485-793b-429a-affe-096e8199ad5b.png" width="800"/>
|
||||
<br>
|
||||
<em> Figure from DDPM paper (https://arxiv.org/abs/2006.11239). </em>
|
||||
<p>
|
||||
|
||||
**Schedulers**: Algorithm class for both **inference** and **training**.
|
||||
The class provides functionality to compute previous image according to alpha, beta schedule as well as predict noise for training.
|
||||
*Examples*: [DDPM](https://arxiv.org/abs/2006.11239), [DDIM](https://arxiv.org/abs/2010.02502), [PNDM](https://arxiv.org/abs/2202.09778), [DEIS](https://arxiv.org/abs/2204.13902)
|
||||
|
||||

|
||||

|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/10695622/174349706-53d58acc-a4d1-4cda-b3e8-432d9dc7ad38.png" width="800"/>
|
||||
<br>
|
||||
<em> Sampling and training algorithms. Figure from DDPM paper (https://arxiv.org/abs/2006.11239). </em>
|
||||
<p>
|
||||
|
||||
|
||||
**Diffusion Pipeline**: End-to-end pipeline that includes multiple diffusion models, possible text encoders, ...
|
||||
*Examples*: GLIDE, Latent-Diffusion, Imagen, DALL-E 2
|
||||
|
||||
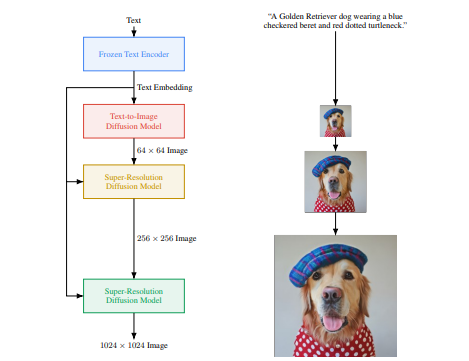
|
||||
|
||||
*Examples*: Glide, Latent-Diffusion, Imagen, DALL-E 2
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/10695622/174348898-481bd7c2-5457-4830-89bc-f0907756f64c.jpeg" width="550"/>
|
||||
<br>
|
||||
<em> Figure from ImageGen (https://imagen.research.google/). </em>
|
||||
<p>
|
||||
|
||||
## Philosophy
|
||||
|
||||
- Readability and clarity is prefered over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code desgin. *E.g.*, the provided [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) are separated from the provided [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and provide well-commented code that can be read alongside the original paper.
|
||||
- Diffusers is **modality independent** and focusses on providing pretrained models and tools to build systems that generate **continous outputs**, *e.g.* vision and audio.
|
||||
- Diffusion models and schedulers are provided as consise, elementary building blocks whereas diffusion pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box, should stay as close as possible to their original implementation and can include components of other library, such as text-encoders. Examples for diffusion pipelines are [Glide](https://github.com/openai/glide-text2im) and [Latent Diffusion](https://github.com/CompVis/latent-diffusion).
|
||||
- Readability and clarity is prefered over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code design. *E.g.*, the provided [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) are separated from the provided [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and provide well-commented code that can be read alongside the original paper.
|
||||
- Diffusers is **modality independent** and focuses on providing pretrained models and tools to build systems that generate **continous outputs**, *e.g.* vision and audio.
|
||||
- Diffusion models and schedulers are provided as concise, elementary building blocks. In contrast, diffusion pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box, should stay as close as possible to their original implementation and can include components of another library, such as text-encoders. Examples for diffusion pipelines are [Glide](https://github.com/openai/glide-text2im) and [Latent Diffusion](https://github.com/CompVis/latent-diffusion).
|
||||
|
||||
## Quickstart
|
||||
## In the works
|
||||
|
||||
### Installation
|
||||
For the first release, 🤗 Diffusers focuses on text-to-image diffusion techniques. However, diffusers can be used for much more than that! Over the upcoming releases, we'll be focusing on:
|
||||
|
||||
**Note**: If you want to run PyTorch on GPU on a CUDA-compatible machine, please make sure to install the corresponding `torch` version from the
|
||||
[official website](https://pytorch.org/).
|
||||
```
|
||||
git clone https://github.com/huggingface/diffusers.git
|
||||
cd diffusers && pip install -e .
|
||||
```
|
||||
- Diffusers for audio
|
||||
- Diffusers for reinforcement learning (initial work happening in https://github.com/huggingface/diffusers/pull/105).
|
||||
- Diffusers for video generation
|
||||
- Diffusers for molecule generation (initial work happening in https://github.com/huggingface/diffusers/pull/54)
|
||||
|
||||
### 1. `diffusers` as a toolbox for schedulers and models.
|
||||
A few pipeline components are already being worked on, namely:
|
||||
|
||||
`diffusers` is more modularized than `transformers`. The idea is that researchers and engineers can use only parts of the library easily for the own use cases.
|
||||
It could become a central place for all kinds of models, schedulers, training utils and processors that one can mix and match for one's own use case.
|
||||
Both models and schedulers should be load- and saveable from the Hub.
|
||||
- BDDMPipeline for spectrogram-to-sound vocoding
|
||||
- GLIDEPipeline to support OpenAI's GLIDE model
|
||||
- Grad-TTS for text to audio generation / conditional audio generation
|
||||
|
||||
For more examples see [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) and [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)
|
||||
We want diffusers to be a toolbox useful for diffusers models in general; if you find yourself limited in any way by the current API, or would like to see additional models, schedulers, or techniques, please open a [GitHub issue](https://github.com/huggingface/diffusers/issues) mentioning what you would like to see.
|
||||
|
||||
#### **Example for [DDPM](https://arxiv.org/abs/2006.11239):**
|
||||
## Credits
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import UNetModel, DDPMScheduler
|
||||
import PIL
|
||||
import numpy as np
|
||||
import tqdm
|
||||
This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
- @CompVis' latent diffusion models library, available [here](https://github.com/CompVis/latent-diffusion)
|
||||
- @hojonathanho original DDPM implementation, available [here](https://github.com/hojonathanho/diffusion) as well as the extremely useful translation into PyTorch by @pesser, available [here](https://github.com/pesser/pytorch_diffusion)
|
||||
- @ermongroup's DDIM implementation, available [here](https://github.com/ermongroup/ddim).
|
||||
- @yang-song's Score-VE and Score-VP implementations, available [here](https://github.com/yang-song/score_sde_pytorch)
|
||||
|
||||
# 1. Load models
|
||||
noise_scheduler = DDPMScheduler.from_config("fusing/ddpm-lsun-church", tensor_format="pt")
|
||||
unet = UNetModel.from_pretrained("fusing/ddpm-lsun-church").to(torch_device)
|
||||
|
||||
# 2. Sample gaussian noise
|
||||
image = torch.randn(
|
||||
(1, unet.in_channels, unet.resolution, unet.resolution),
|
||||
generator=generator,
|
||||
)
|
||||
image = image.to(torch_device)
|
||||
|
||||
# 3. Denoise
|
||||
num_prediction_steps = len(noise_scheduler)
|
||||
for t in tqdm.tqdm(reversed(range(num_prediction_steps)), total=num_prediction_steps):
|
||||
# predict noise residual
|
||||
with torch.no_grad():
|
||||
residual = unet(image, t)
|
||||
|
||||
# predict previous mean of image x_t-1
|
||||
pred_prev_image = noise_scheduler.step(residual, image, t)
|
||||
|
||||
# optionally sample variance
|
||||
variance = 0
|
||||
if t > 0:
|
||||
noise = torch.randn(image.shape, generator=generator).to(image.device)
|
||||
variance = noise_scheduler.get_variance(t).sqrt() * noise
|
||||
|
||||
# set current image to prev_image: x_t -> x_t-1
|
||||
image = pred_prev_image + variance
|
||||
|
||||
# 5. process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# 6. save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
#### **Example for [DDIM](https://arxiv.org/abs/2010.02502):**
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import UNetModel, DDIMScheduler
|
||||
import PIL
|
||||
import numpy as np
|
||||
import tqdm
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
# 1. Load models
|
||||
noise_scheduler = DDIMScheduler.from_config("fusing/ddpm-celeba-hq", tensor_format="pt")
|
||||
unet = UNetModel.from_pretrained("fusing/ddpm-celeba-hq").to(torch_device)
|
||||
|
||||
# 2. Sample gaussian noise
|
||||
image = torch.randn(
|
||||
(1, unet.in_channels, unet.resolution, unet.resolution),
|
||||
generator=generator,
|
||||
)
|
||||
image = image.to(torch_device)
|
||||
|
||||
# 3. Denoise
|
||||
num_inference_steps = 50
|
||||
eta = 0.0 # <- deterministic sampling
|
||||
|
||||
for t in tqdm.tqdm(reversed(range(num_inference_steps)), total=num_inference_steps):
|
||||
# 1. predict noise residual
|
||||
orig_t = noise_scheduler.get_orig_t(t, num_inference_steps)
|
||||
with torch.no_grad():
|
||||
residual = unet(image, orig_t)
|
||||
|
||||
# 2. predict previous mean of image x_t-1
|
||||
pred_prev_image = noise_scheduler.step(residual, image, t, num_inference_steps, eta)
|
||||
|
||||
# 3. optionally sample variance
|
||||
variance = 0
|
||||
if eta > 0:
|
||||
noise = torch.randn(image.shape, generator=generator).to(image.device)
|
||||
variance = noise_scheduler.get_variance(t).sqrt() * eta * noise
|
||||
|
||||
# 4. set current image to prev_image: x_t -> x_t-1
|
||||
image = pred_prev_image + variance
|
||||
|
||||
# 5. process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# 6. save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
### 2. `diffusers` as a collection of popula Diffusion systems (GLIDE, Dalle, ...)
|
||||
|
||||
For more examples see [pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
|
||||
|
||||
#### **Example image generation with PNDM**
|
||||
|
||||
```python
|
||||
from diffusers import PNDM, UNetModel, PNDMScheduler
|
||||
import PIL.Image
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
model_id = "fusing/ddim-celeba-hq"
|
||||
|
||||
model = UNetModel.from_pretrained(model_id)
|
||||
scheduler = PNDMScheduler()
|
||||
|
||||
# load model and scheduler
|
||||
ddpm = PNDM(unet=model, noise_scheduler=scheduler)
|
||||
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
with torch.no_grad():
|
||||
image = ddpm()
|
||||
|
||||
# process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) / 2
|
||||
image_processed = torch.clamp(image_processed, 0.0, 1.0)
|
||||
image_processed = image_processed * 255
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
#### **Text to Image generation with Latent Diffusion**
|
||||
|
||||
_Note: To use latent diffusion install transformers from [this branch](https://github.com/patil-suraj/transformers/tree/ldm-bert)._
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
ldm = DiffusionPipeline.from_pretrained("fusing/latent-diffusion-text2im-large")
|
||||
|
||||
generator = torch.manual_seed(42)
|
||||
|
||||
prompt = "A painting of a squirrel eating a burger"
|
||||
image = ldm([prompt], generator=generator, eta=0.3, guidance_scale=6.0, num_inference_steps=50)
|
||||
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = image_processed * 255.
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
#### **Text to speech with BDDM**
|
||||
|
||||
_Follow the isnstructions [here](https://pytorch.org/hub/nvidia_deeplearningexamples_tacotron2/) to load tacotron2 model._
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import BDDM, DiffusionPipeline
|
||||
|
||||
torch_device = "cuda"
|
||||
|
||||
# load the BDDM pipeline
|
||||
bddm = DiffusionPipeline.from_pretrained("fusing/diffwave-vocoder-ljspeech")
|
||||
|
||||
# load tacotron2 to get the mel spectograms
|
||||
tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp16')
|
||||
tacotron2 = tacotron2.to(torch_device).eval()
|
||||
|
||||
text = "Hello world, I missed you so much."
|
||||
|
||||
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')
|
||||
sequences, lengths = utils.prepare_input_sequence([text])
|
||||
|
||||
# generate mel spectograms using text
|
||||
with torch.no_grad():
|
||||
mel_spec, _, _ = tacotron2.infer(sequences, lengths)
|
||||
|
||||
# generate the speech by passing mel spectograms to BDDM pipeline
|
||||
generator = torch.manual_seed(0)
|
||||
audio = bddm(mel_spec, generator, torch_device)
|
||||
|
||||
# save generated audio
|
||||
from scipy.io.wavfile import write as wavwrite
|
||||
sampling_rate = 22050
|
||||
wavwrite("generated_audio.wav", sampling_rate, audio.squeeze().cpu().numpy())
|
||||
```
|
||||
|
||||
## TODO
|
||||
|
||||
- Create common API for models [ ]
|
||||
- Add tests for models [ ]
|
||||
- Adapt schedulers for training [ ]
|
||||
- Write google colab for training [ ]
|
||||
- Write docs / Think about how to structure docs [ ]
|
||||
- Add tests to circle ci [ ]
|
||||
- Add more vision models [ ]
|
||||
- Add more speech models [ ]
|
||||
- Add RL model [ ]
|
||||
We also want to thank @heejkoo for the very helpful overview of papers, code and resources on diffusion models, available [here](https://github.com/heejkoo/Awesome-Diffusion-Models) as well as @crowsonkb and @rromb for useful discussions and insights.
|
||||
|
||||
@@ -0,0 +1,92 @@
|
||||
- sections:
|
||||
- local: index
|
||||
title: "🧨 Diffusers"
|
||||
- local: quicktour
|
||||
title: "Quicktour"
|
||||
- local: installation
|
||||
title: "Installation"
|
||||
title: "Get started"
|
||||
- sections:
|
||||
- sections:
|
||||
- local: using-diffusers/loading
|
||||
title: "Loading Pipelines, Models, and Schedulers"
|
||||
- local: using-diffusers/configuration
|
||||
title: "Configuring Pipelines, Models, and Schedulers"
|
||||
title: "Loading"
|
||||
- sections:
|
||||
- local: using-diffusers/unconditional_image_generation
|
||||
title: "Unconditional Image Generation"
|
||||
- local: using-diffusers/conditional_image_generation
|
||||
title: "Text-to-Image Generation"
|
||||
- local: using-diffusers/img2img
|
||||
title: "Text-Guided Image-to-Image"
|
||||
- local: using-diffusers/inpaint
|
||||
title: "Text-Guided Image-Inpainting"
|
||||
- local: using-diffusers/custom
|
||||
title: "Create a custom pipeline"
|
||||
title: "Pipelines for Inference"
|
||||
title: "Using Diffusers"
|
||||
- sections:
|
||||
- local: optimization/fp16
|
||||
title: "Memory and Speed"
|
||||
- local: optimization/onnx
|
||||
title: "ONNX"
|
||||
- local: optimization/open_vino
|
||||
title: "Open Vino"
|
||||
- local: optimization/mps
|
||||
title: "MPS"
|
||||
title: "Optimization/Special Hardware"
|
||||
- sections:
|
||||
- local: training/overview
|
||||
title: "Overview"
|
||||
- local: training/unconditional_training
|
||||
title: "Unconditional Image Generation"
|
||||
- local: training/text_inversion
|
||||
title: "Text Inversion"
|
||||
- local: training/text2image
|
||||
title: "Text-to-image"
|
||||
title: "Training"
|
||||
- sections:
|
||||
- local: conceptual/stable_diffusion
|
||||
title: "Stable Diffusion"
|
||||
- local: conceptual/philosophy
|
||||
title: "Philosophy"
|
||||
- local: conceptual/contribution
|
||||
title: "How to contribute?"
|
||||
title: "Conceptual Guides"
|
||||
- sections:
|
||||
- sections:
|
||||
- local: api/models
|
||||
title: "Models"
|
||||
- local: api/schedulers
|
||||
title: "Schedulers"
|
||||
- local: api/diffusion_pipeline
|
||||
title: "Diffusion Pipeline"
|
||||
- local: api/logging
|
||||
title: "Logging"
|
||||
- local: api/configuration
|
||||
title: "Configuration"
|
||||
- local: api/outputs
|
||||
title: "Outputs"
|
||||
title: "Main Classes"
|
||||
- sections:
|
||||
- local: api/pipelines/overview
|
||||
title: "Overview"
|
||||
- local: api/pipelines/ddim
|
||||
title: "DDIM"
|
||||
- local: api/pipelines/ddpm
|
||||
title: "DDPM"
|
||||
- local: api/pipelines/latent_diffusion
|
||||
title: "Latent Diffusion"
|
||||
- local: api/pipelines/latent_diffusion_uncond
|
||||
title: "Unconditional Latent Diffusion"
|
||||
- local: api/pipelines/pndm
|
||||
title: "PNDM"
|
||||
- local: api/pipelines/score_sde_ve
|
||||
title: "Score SDE VE"
|
||||
- local: api/pipelines/stable_diffusion
|
||||
title: "Stable Diffusion"
|
||||
- local: api/pipelines/stochastic_karras_ve
|
||||
title: "Stochastic Karras VE"
|
||||
title: "Pipelines"
|
||||
title: "API"
|
||||
@@ -0,0 +1,23 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Configuration
|
||||
|
||||
In Diffusers, schedulers of type [`schedulers.scheduling_utils.SchedulerMixin`], and models of type [`ModelMixin`] inherit from [`ConfigMixin`] which conveniently takes care of storing all parameters that are
|
||||
passed to the respective `__init__` methods in a JSON-configuration file.
|
||||
|
||||
TODO(PVP) - add example and better info here
|
||||
|
||||
## ConfigMixin
|
||||
[[autodoc]] ConfigMixin
|
||||
- from_config
|
||||
- save_config
|
||||
@@ -0,0 +1,39 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Pipelines
|
||||
|
||||
The [`DiffusionPipeline`] is the easiest way to load any pretrained diffusion pipeline from the [Hub](https://huggingface.co/models?library=diffusers) and to use it in inference.
|
||||
|
||||
<Tip>
|
||||
|
||||
One should not use the Diffusion Pipeline class for training or fine-tuning a diffusion model. Individual
|
||||
components of diffusion pipelines are usually trained individually, so we suggest to directly work
|
||||
with [`UNetModel`] and [`UNetConditionModel`].
|
||||
|
||||
</Tip>
|
||||
|
||||
Any diffusion pipeline that is loaded with [`~DiffusionPipeline.from_pretrained`] will automatically
|
||||
detect the pipeline type, *e.g.* [`StableDiffusionPipeline`] and consequently load each component of the
|
||||
pipeline and pass them into the `__init__` function of the pipeline, *e.g.* [`~StableDiffusionPipeline.__init__`].
|
||||
|
||||
Any pipeline object can be saved locally with [`~DiffusionPipeline.save_pretrained`].
|
||||
|
||||
## DiffusionPipeline
|
||||
[[autodoc]] DiffusionPipeline
|
||||
- from_pretrained
|
||||
- save_pretrained
|
||||
|
||||
## ImagePipelineOutput
|
||||
By default diffusion pipelines return an object of class
|
||||
|
||||
[[autodoc]] pipeline_utils.ImagePipelineOutput
|
||||
@@ -0,0 +1,98 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Logging
|
||||
|
||||
🧨 Diffusers has a centralized logging system, so that you can setup the verbosity of the library easily.
|
||||
|
||||
Currently the default verbosity of the library is `WARNING`.
|
||||
|
||||
To change the level of verbosity, just use one of the direct setters. For instance, here is how to change the verbosity
|
||||
to the INFO level.
|
||||
|
||||
```python
|
||||
import diffusers
|
||||
|
||||
diffusers.logging.set_verbosity_info()
|
||||
```
|
||||
|
||||
You can also use the environment variable `DIFFUSERS_VERBOSITY` to override the default verbosity. You can set it
|
||||
to one of the following: `debug`, `info`, `warning`, `error`, `critical`. For example:
|
||||
|
||||
```bash
|
||||
DIFFUSERS_VERBOSITY=error ./myprogram.py
|
||||
```
|
||||
|
||||
Additionally, some `warnings` can be disabled by setting the environment variable
|
||||
`DIFFUSERS_NO_ADVISORY_WARNINGS` to a true value, like *1*. This will disable any warning that is logged using
|
||||
[`logger.warning_advice`]. For example:
|
||||
|
||||
```bash
|
||||
DIFFUSERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
|
||||
```
|
||||
|
||||
Here is an example of how to use the same logger as the library in your own module or script:
|
||||
|
||||
```python
|
||||
from diffusers.utils import logging
|
||||
|
||||
logging.set_verbosity_info()
|
||||
logger = logging.get_logger("diffusers")
|
||||
logger.info("INFO")
|
||||
logger.warning("WARN")
|
||||
```
|
||||
|
||||
|
||||
All the methods of this logging module are documented below, the main ones are
|
||||
[`logging.get_verbosity`] to get the current level of verbosity in the logger and
|
||||
[`logging.set_verbosity`] to set the verbosity to the level of your choice. In order (from the least
|
||||
verbose to the most verbose), those levels (with their corresponding int values in parenthesis) are:
|
||||
|
||||
- `diffusers.logging.CRITICAL` or `diffusers.logging.FATAL` (int value, 50): only report the most
|
||||
critical errors.
|
||||
- `diffusers.logging.ERROR` (int value, 40): only report errors.
|
||||
- `diffusers.logging.WARNING` or `diffusers.logging.WARN` (int value, 30): only reports error and
|
||||
warnings. This the default level used by the library.
|
||||
- `diffusers.logging.INFO` (int value, 20): reports error, warnings and basic information.
|
||||
- `diffusers.logging.DEBUG` (int value, 10): report all information.
|
||||
|
||||
By default, `tqdm` progress bars will be displayed during model download. [`logging.disable_progress_bar`] and [`logging.enable_progress_bar`] can be used to suppress or unsuppress this behavior.
|
||||
|
||||
## Base setters
|
||||
|
||||
[[autodoc]] logging.set_verbosity_error
|
||||
|
||||
[[autodoc]] logging.set_verbosity_warning
|
||||
|
||||
[[autodoc]] logging.set_verbosity_info
|
||||
|
||||
[[autodoc]] logging.set_verbosity_debug
|
||||
|
||||
## Other functions
|
||||
|
||||
[[autodoc]] logging.get_verbosity
|
||||
|
||||
[[autodoc]] logging.set_verbosity
|
||||
|
||||
[[autodoc]] logging.get_logger
|
||||
|
||||
[[autodoc]] logging.enable_default_handler
|
||||
|
||||
[[autodoc]] logging.disable_default_handler
|
||||
|
||||
[[autodoc]] logging.enable_explicit_format
|
||||
|
||||
[[autodoc]] logging.reset_format
|
||||
|
||||
[[autodoc]] logging.enable_progress_bar
|
||||
|
||||
[[autodoc]] logging.disable_progress_bar
|
||||
@@ -0,0 +1,47 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Models
|
||||
|
||||
Diffusers contains pretrained models for popular algorithms and modules for creating the next set of diffusion models.
|
||||
The primary function of these models is to denoise an input sample, by modeling the distribution $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$.
|
||||
The models are built on the base class ['ModelMixin'] that is a `torch.nn.module` with basic functionality for saving and loading models both locally and from the HuggingFace hub.
|
||||
|
||||
## ModelMixin
|
||||
[[autodoc]] ModelMixin
|
||||
|
||||
## UNet2DOutput
|
||||
[[autodoc]] models.unet_2d.UNet2DOutput
|
||||
|
||||
## UNet2DModel
|
||||
[[autodoc]] UNet2DModel
|
||||
|
||||
## UNet2DConditionOutput
|
||||
[[autodoc]] models.unet_2d_condition.UNet2DConditionOutput
|
||||
|
||||
## UNet2DConditionModel
|
||||
[[autodoc]] UNet2DConditionModel
|
||||
|
||||
## DecoderOutput
|
||||
[[autodoc]] models.vae.DecoderOutput
|
||||
|
||||
## VQEncoderOutput
|
||||
[[autodoc]] models.vae.VQEncoderOutput
|
||||
|
||||
## VQModel
|
||||
[[autodoc]] VQModel
|
||||
|
||||
## AutoencoderKLOutput
|
||||
[[autodoc]] models.vae.AutoencoderKLOutput
|
||||
|
||||
## AutoencoderKL
|
||||
[[autodoc]] AutoencoderKL
|
||||
@@ -0,0 +1,55 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# BaseOutputs
|
||||
|
||||
All models have outputs that are instances of subclasses of [`~utils.BaseOutput`]. Those are
|
||||
data structures containing all the information returned by the model, but that can also be used as tuples or
|
||||
dictionaries.
|
||||
|
||||
Let's see how this looks in an example:
|
||||
|
||||
```python
|
||||
from diffusers import DDIMPipeline
|
||||
|
||||
pipeline = DDIMPipeline.from_pretrained("google/ddpm-cifar10-32")
|
||||
outputs = pipeline()
|
||||
```
|
||||
|
||||
The `outputs` object is a [`~pipeline_utils.ImagePipelineOutput`], as we can see in the
|
||||
documentation of that class below, it means it has an image attribute.
|
||||
|
||||
You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you will get `None`:
|
||||
|
||||
```python
|
||||
outputs.images
|
||||
```
|
||||
|
||||
or via keyword lookup
|
||||
|
||||
```python
|
||||
outputs["images"]
|
||||
```
|
||||
|
||||
When considering our `outputs` object as tuple, it only considers the attributes that don't have `None` values.
|
||||
Here for instance, we could retrieve images via indexing:
|
||||
|
||||
```python
|
||||
outputs[:1]
|
||||
```
|
||||
|
||||
which will return the tuple `(outputs.images)` for instance.
|
||||
|
||||
## BaseOutput
|
||||
|
||||
[[autodoc]] utils.BaseOutput
|
||||
- to_tuple
|
||||
@@ -0,0 +1,22 @@
|
||||
# DDIM
|
||||
|
||||
## Overview
|
||||
|
||||
[Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) (DDIM) by Jiaming Song, Chenlin Meng and Stefano Ermon.
|
||||
|
||||
The abstract of the paper is the following:
|
||||
|
||||
Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a sample. To accelerate sampling, we present denoising diffusion implicit models (DDIMs), a more efficient class of iterative implicit probabilistic models with the same training procedure as DDPMs. In DDPMs, the generative process is defined as the reverse of a Markovian diffusion process. We construct a class of non-Markovian diffusion processes that lead to the same training objective, but whose reverse process can be much faster to sample from. We empirically demonstrate that DDIMs can produce high quality samples 10× to 50× faster in terms of wall-clock time compared to DDPMs, allow us to trade off computation for sample quality, and can perform semantically meaningful image interpolation directly in the latent space.
|
||||
|
||||
The original codebase of this paper can be found [here](https://github.com/ermongroup/ddim).
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Colab
|
||||
|---|---|:---:|
|
||||
| [pipeline_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddim/pipeline_ddim.py) | *Unconditional Image Generation* | - |
|
||||
|
||||
|
||||
## DDIMPipeline
|
||||
[[autodoc]] DDIMPipeline
|
||||
- __call__
|
||||
@@ -0,0 +1,24 @@
|
||||
# DDPM
|
||||
|
||||
## Overview
|
||||
|
||||
[Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
|
||||
(DDPM) by Jonathan Ho, Ajay Jain and Pieter Abbeel proposes the diffusion based model of the same name, but in the context of the 🤗 Diffusers library, DDPM refers to the discrete denoising scheduler from the paper as well as the pipeline.
|
||||
|
||||
The abstract of the paper is the following:
|
||||
|
||||
We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.
|
||||
|
||||
The original codebase of this paper can be found [here](https://github.com/hojonathanho/diffusion).
|
||||
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Colab
|
||||
|---|---|:---:|
|
||||
| [pipeline_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddpm/pipeline_ddpm.py) | *Unconditional Image Generation* | - |
|
||||
|
||||
|
||||
# DDPMPipeline
|
||||
[[autodoc]] DDPMPipeline
|
||||
- __call__
|
||||
@@ -0,0 +1,30 @@
|
||||
# Latent Diffusion
|
||||
|
||||
## Overview
|
||||
|
||||
Latent Diffusion was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer.
|
||||
|
||||
The abstract of the paper is the following:
|
||||
|
||||
*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
|
||||
|
||||
The original codebase can be found [here](https://github.com/CompVis/latent-diffusion).
|
||||
|
||||
## Tips:
|
||||
|
||||
-
|
||||
-
|
||||
-
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Colab
|
||||
|---|---|:---:|
|
||||
| [pipeline_latent_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py) | *Text-to-Image Generation* | - |
|
||||
|
||||
## Examples:
|
||||
|
||||
|
||||
## LDMTextToImagePipeline
|
||||
[[autodoc]] pipelines.latent_diffusion.pipeline_latent_diffusion.LDMTextToImagePipeline
|
||||
- __call__
|
||||
@@ -0,0 +1,29 @@
|
||||
# Unconditional Latent Diffusion
|
||||
|
||||
## Overview
|
||||
|
||||
Unconditional Latent Diffusion was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer.
|
||||
|
||||
The abstract of the paper is the following:
|
||||
|
||||
*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
|
||||
|
||||
The original codebase can be found [here](https://github.com/CompVis/latent-diffusion).
|
||||
|
||||
## Tips:
|
||||
|
||||
-
|
||||
-
|
||||
-
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Colab
|
||||
|---|---|:---:|
|
||||
| [pipeline_latent_diffusion_uncond.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion_uncond/pipeline_latent_diffusion_uncond.py) | *Unconditional Image Generation* | - |
|
||||
|
||||
## Examples:
|
||||
|
||||
## LDMPipeline
|
||||
[[autodoc]] LDMPipeline
|
||||
- __call__
|
||||
@@ -0,0 +1,190 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Pipelines
|
||||
|
||||
Pipelines provide a simple way to run state-of-the-art diffusion models in inference.
|
||||
Most diffusion systems consist of multiple independently-trained models and highly adaptable scheduler
|
||||
components - all of which are needed to have a functioning end-to-end diffusion system.
|
||||
|
||||
As an example, [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) has three independently trained models:
|
||||
- [Autoencoder](./api/models#vae)
|
||||
- [Conditional Unet](./api/models#UNet2DConditionModel)
|
||||
- [CLIP text encoder](https://huggingface.co/docs/transformers/v4.21.2/en/model_doc/clip#transformers.CLIPTextModel)
|
||||
- a scheduler component, [scheduler](./api/scheduler#pndm),
|
||||
- a [CLIPFeatureExtractor](https://huggingface.co/docs/transformers/v4.21.2/en/model_doc/clip#transformers.CLIPFeatureExtractor),
|
||||
- as well as a [safety checker](./stable_diffusion#safety_checker).
|
||||
All of these components are necessary to run stable diffusion in inference even though they were trained
|
||||
or created independently from each other.
|
||||
|
||||
To that end, we strive to offer all open-sourced, state-of-the-art diffusion system under a unified API.
|
||||
More specifically, we strive to provide pipelines that
|
||||
- 1. can load the officially published weights and yield 1-to-1 the same outputs as the original implementation according to the corresponding paper (*e.g.* [LatentDiffusionPipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/latent_diffusion), uses the officially released weights of [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)),
|
||||
- 2. have a simple user interface to run the model in inference (see the [Pipelines API](#pipelines-api) section),
|
||||
- 3. are easy to understand with code that is self-explanatory and can be read along-side the official paper (see [Pipelines summary](#pipelines-summary)),
|
||||
- 4. can easily be contributed by the community (see the [Contribution](#contribution) section).
|
||||
|
||||
**Note** that pipelines do not (and should not) offer any training functionality.
|
||||
If you are looking for *official* training examples, please have a look at [examples](https://github.com/huggingface/diffusers/tree/main/examples).
|
||||
|
||||
## 🧨 Diffusers Summary
|
||||
|
||||
The following table summarizes all officially supported pipelines, their corresponding paper, and if
|
||||
available a colab notebook to directly try them out.
|
||||
|
||||
| Pipeline | Paper | Tasks | Colab
|
||||
|---|---|:---:|:---:|
|
||||
| [ddpm](./ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
|
||||
| [ddim](./ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
|
||||
| [latent_diffusion](./latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
|
||||
| [latent_diffusion_uncond](./latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
|
||||
| [pndm](./pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
|
||||
| [score_sde_ve](./score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [score_sde_vp](./score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [stable_diffusion](./stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
|
||||
| [stable_diffusion](./stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/image_2_image_using_diffusers.ipynb)
|
||||
| [stable_diffusion](./stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/in_painting_with_stable_diffusion_using_diffusers.ipynb)
|
||||
| [stochatic_karras_ve](./stochatic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
|
||||
|
||||
**Note**: Pipelines are simple examples of how to play around with the diffusion systems as described in the corresponding papers.
|
||||
|
||||
However, most of them can be adapted to use different scheduler components or even different model components. Some pipeline examples are shown in the [Examples](#examples) below.
|
||||
|
||||
## Pipelines API
|
||||
|
||||
Diffusion models often consist of multiple independently-trained models or other previously existing components.
|
||||
|
||||
|
||||
Each model has been trained independently on a different task and the scheduler can easily be swapped out and replaced with a different one.
|
||||
During inference, we however want to be able to easily load all components and use them in inference - even if one component, *e.g.* CLIP's text encoder, originates from a different library, such as [Transformers](https://github.com/huggingface/transformers). To that end, all pipelines provide the following functionality:
|
||||
|
||||
- [`from_pretrained` method](../diffusion_pipeline) that accepts a Hugging Face Hub repository id, *e.g.* [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4) or a path to a local directory, *e.g.*
|
||||
"./stable-diffusion". To correctly retrieve which models and components should be loaded, one has to provide a `model_index.json` file, *e.g.* [CompVis/stable-diffusion-v1-4/model_index.json](https://huggingface.co/CompVis/stable-diffusion-v1-4/blob/main/model_index.json), which defines all components that should be
|
||||
loaded into the pipelines. More specifically, for each model/component one needs to define the format `<name>: ["<library>", "<class name>"]`. `<name>` is the attribute name given to the loaded instance of `<class name>` which can be found in the library or pipeline folder called `"<library>"`.
|
||||
- [`save_pretrained`](../diffusion_pipeline) that accepts a local path, *e.g.* `./stable-diffusion` under which all models/components of the pipeline will be saved. For each component/model a folder is created inside the local path that is named after the given attribute name, *e.g.* `./stable_diffusion/unet`.
|
||||
In addition, a `model_index.json` file is created at the root of the local path, *e.g.* `./stable_diffusion/model_index.json` so that the complete pipeline can again be instantiated
|
||||
from the local path.
|
||||
- [`to`](../diffusion_pipeline) which accepts a `string` or `torch.device` to move all models that are of type `torch.nn.Module` to the passed device. The behavior is fully analogous to [PyTorch's `to` method](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.to).
|
||||
- [`__call__`] method to use the pipeline in inference. `__call__` defines inference logic of the pipeline and should ideally encompass all aspects of it, from pre-processing to forwarding tensors to the different models and schedulers, as well as post-processing. The API of the `__call__` method can strongly vary from pipeline to pipeline. *E.g.* a text-to-image pipeline, such as [`StableDiffusionPipeline`](./stable_diffusion) should accept among other things the text prompt to generate the image. A pure image generation pipeline, such as [DDPMPipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/ddpm) on the other hand can be run without providing any inputs. To better understand what inputs can be adapted for
|
||||
each pipeline, one should look directly into the respective pipeline.
|
||||
|
||||
**Note**: All pipelines have PyTorch's autograd disabled by decorating the `__call__` method with a [`torch.no_grad`](https://pytorch.org/docs/stable/generated/torch.no_grad.html) decorator because pipelines should
|
||||
not be used for training. If you want to store the gradients during the forward pass, we recommend writing your own pipeline, see also our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community)
|
||||
|
||||
## Contribution
|
||||
|
||||
We are more than happy about any contribution to the officially supported pipelines 🤗. We aspire
|
||||
all of our pipelines to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
|
||||
|
||||
- **Self-contained**: A pipeline shall be as self-contained as possible. More specifically, this means that all functionality should be either directly defined in the pipeline file iteslf, should be inherited from (and only from) the [`DiffusionPipeline` class](.../diffusion_pipeline) or be directly attached to the model and scheduler components of the pipeline.
|
||||
- **Easy-to-use**: Pipelines should be extremely easy to use - one should be able to load the pipeline and
|
||||
use it for its designated task, *e.g.* text-to-image generation, in just a couple of lines of code. Most
|
||||
logic including pre-processing, an unrolled diffusion loop, and post-processing should all happen inside the `__call__` method.
|
||||
- **Easy-to-tweak**: Certain pipelines will not be able to handle all use cases and tasks that you might like them to. If you want to use a certain pipeline for a specific use case that is not yet supported, you might have to copy the pipeline file and tweak the code to your needs. We try to make the pipeline code as readable as possible so that each part –from pre-processing to diffusing to post-processing– can easily be adapted. If you would like the community to benefit from your customized pipeline, we would love to see a contribution to our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community). If you feel that an important pipeline should be part of the official pipelines but isn't, a contribution to the [official pipelines](./overview) would be even better.
|
||||
- **One-purpose-only**: Pipelines should be used for one task and one task only. Even if two tasks are very similar from a modeling point of view, *e.g.* image2image translation and in-painting, pipelines shall be used for one task only to keep them *easy-to-tweak* and *readable*.
|
||||
|
||||
## Examples
|
||||
|
||||
### Text-to-Image generation with Stable Diffusion
|
||||
|
||||
```python
|
||||
# make sure you're logged in with `huggingface-cli login`
|
||||
from torch import autocast
|
||||
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
with autocast("cuda"):
|
||||
image = pipe(prompt).images[0]
|
||||
|
||||
image.save("astronaut_rides_horse.png")
|
||||
```
|
||||
|
||||
### Image-to-Image text-guided generation with Stable Diffusion
|
||||
|
||||
The `StableDiffusionImg2ImgPipeline` lets you pass a text prompt and an initial image to condition the generation of new images.
|
||||
|
||||
```python
|
||||
from torch import autocast
|
||||
import requests
|
||||
from PIL import Image
|
||||
from io import BytesIO
|
||||
|
||||
from diffusers import StableDiffusionImg2ImgPipeline
|
||||
|
||||
# load the pipeline
|
||||
device = "cuda"
|
||||
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16, use_auth_token=True
|
||||
).to(device)
|
||||
|
||||
# let's download an initial image
|
||||
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
|
||||
response = requests.get(url)
|
||||
init_image = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
init_image = init_image.resize((768, 512))
|
||||
|
||||
prompt = "A fantasy landscape, trending on artstation"
|
||||
|
||||
with autocast("cuda"):
|
||||
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5).images
|
||||
|
||||
images[0].save("fantasy_landscape.png")
|
||||
```
|
||||
You can also run this example on colab [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/image_2_image_using_diffusers.ipynb)
|
||||
|
||||
### Tweak prompts reusing seeds and latents
|
||||
|
||||
You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked. [This notebook](https://github.com/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb).
|
||||
|
||||
|
||||
### In-painting using Stable Diffusion
|
||||
|
||||
The `StableDiffusionInpaintPipeline` lets you edit specific parts of an image by providing a mask and text prompt.
|
||||
|
||||
```python
|
||||
from io import BytesIO
|
||||
|
||||
from torch import autocast
|
||||
import requests
|
||||
import PIL
|
||||
|
||||
from diffusers import StableDiffusionInpaintPipeline
|
||||
|
||||
|
||||
def download_image(url):
|
||||
response = requests.get(url)
|
||||
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
|
||||
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
||||
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
||||
|
||||
init_image = download_image(img_url).resize((512, 512))
|
||||
mask_image = download_image(mask_url).resize((512, 512))
|
||||
|
||||
device = "cuda"
|
||||
pipe = StableDiffusionInpaintPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16, use_auth_token=True
|
||||
).to(device)
|
||||
|
||||
prompt = "a cat sitting on a bench"
|
||||
with autocast("cuda"):
|
||||
images = pipe(prompt=prompt, init_image=init_image, mask_image=mask_image, strength=0.75).images
|
||||
|
||||
images[0].save("cat_on_bench.png")
|
||||
```
|
||||
|
||||
You can also run this example on colab [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/in_painting_with_stable_diffusion_using_diffusers.ipynb)
|
||||
@@ -0,0 +1,23 @@
|
||||
# PNDM
|
||||
|
||||
## Overview
|
||||
|
||||
[Pseudo Numerical methods for Diffusion Models on manifolds](https://arxiv.org/abs/2202.09778) (PNDM) by Luping Liu, Yi Ren, Zhijie Lin and Zhou Zhao.
|
||||
|
||||
The abstract of the paper is the following:
|
||||
|
||||
Denoising Diffusion Probabilistic Models (DDPMs) can generate high-quality samples such as image and audio samples. However, DDPMs require hundreds to thousands of iterations to produce final samples. Several prior works have successfully accelerated DDPMs through adjusting the variance schedule (e.g., Improved Denoising Diffusion Probabilistic Models) or the denoising equation (e.g., Denoising Diffusion Implicit Models (DDIMs)). However, these acceleration methods cannot maintain the quality of samples and even introduce new noise at a high speedup rate, which limit their practicability. To accelerate the inference process while keeping the sample quality, we provide a fresh perspective that DDPMs should be treated as solving differential equations on manifolds. Under such a perspective, we propose pseudo numerical methods for diffusion models (PNDMs). Specifically, we figure out how to solve differential equations on manifolds and show that DDIMs are simple cases of pseudo numerical methods. We change several classical numerical methods to corresponding pseudo numerical methods and find that the pseudo linear multi-step method is the best in most situations. According to our experiments, by directly using pre-trained models on Cifar10, CelebA and LSUN, PNDMs can generate higher quality synthetic images with only 50 steps compared with 1000-step DDIMs (20x speedup), significantly outperform DDIMs with 250 steps (by around 0.4 in FID) and have good generalization on different variance schedules.
|
||||
|
||||
The original codebase can be found [here](https://github.com/luping-liu/PNDM).
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Colab
|
||||
|---|---|:---:|
|
||||
| [pipeline_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pndm/pipeline_pndm.py) | *Unconditional Image Generation* | - |
|
||||
|
||||
|
||||
## PNDMPipeline
|
||||
[[autodoc]] pipelines.pndm.pipeline_pndm.PNDMPipeline
|
||||
- __call__
|
||||
|
||||
@@ -0,0 +1,24 @@
|
||||
# Score SDE VE
|
||||
|
||||
## Overview
|
||||
|
||||
[Score-Based Generative Modeling through Stochastic Differential Equations](https://arxiv.org/abs/2011.13456) (Score SDE) by Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon and Ben Poole.
|
||||
|
||||
The abstract of the paper is the following:
|
||||
|
||||
Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (\aka, score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in score-based generative modeling and diffusion probabilistic modeling, allowing for new sampling procedures and new modeling capabilities. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, but additionally enables exact likelihood computation, and improved sampling efficiency. In addition, we provide a new way to solve inverse problems with score-based models, as demonstrated with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 2.99 bits/dim, and demonstrate high fidelity generation of 1024 x 1024 images for the first time from a score-based generative model.
|
||||
|
||||
The original codebase can be found [here](https://github.com/yang-song/score_sde_pytorch).
|
||||
|
||||
This pipeline implements the Variance Expanding (VE) variant of the method.
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Colab
|
||||
|---|---|:---:|
|
||||
| [pipeline_score_sde_ve.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/score_sde_ve/pipeline_score_sde_ve.py) | *Unconditional Image Generation* | - |
|
||||
|
||||
## ScoreSdeVePipeline
|
||||
[[autodoc]] ScoreSdeVePipeline
|
||||
- __call__
|
||||
|
||||
@@ -0,0 +1,38 @@
|
||||
# Stable diffusion pipelines
|
||||
|
||||
Stable Diffusion is a text-to-image _latent diffusion_ model created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/). It's trained on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) dataset. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and can run on consumer GPUs.
|
||||
|
||||
Latent diffusion is the research on top of which Stable Diffusion was built. It was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer. You can learn more details about it in the [specific pipeline for latent diffusion](pipelines/latent_diffusion) that is part of 🤗 Diffusers.
|
||||
|
||||
For more details about how Stable Diffusion works and how it differs from the base latent diffusion model, please refer to the official [launch announcement post](https://stability.ai/blog/stable-diffusion-announcement) and [this section of our own blog post](https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work).
|
||||
|
||||
*Tips*:
|
||||
- To tweak your prompts on a specific result you liked, you can generate your own latents, as demonstrated in the following notebook: [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
|
||||
|
||||
*Overview*:
|
||||
| Pipeline | Tasks | Colab | Demo
|
||||
|---|---|:---:|:---:|
|
||||
| [pipeline_stable_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb) | [🤗 Stable Diffusion](https://huggingface.co/spaces/stabilityai/stable-diffusion)
|
||||
| [pipeline_stable_diffusion_img2img.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py) | *Image-to-Image Text-Guided Generation* | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/image_2_image_using_diffusers.ipynb) | [🤗 Diffuse the Rest](https://huggingface.co/spaces/huggingface/diffuse-the-rest)
|
||||
| [pipeline_stable_diffusion_inpaint.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py) | **Experimental** – *Text-Guided Image Inpainting* | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/in_painting_with_stable_diffusion_using_diffusers.ipynb) | Coming soon
|
||||
|
||||
## StableDiffusionPipelineOutput
|
||||
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
|
||||
|
||||
## StableDiffusionPipeline
|
||||
[[autodoc]] StableDiffusionPipeline
|
||||
- __call__
|
||||
- enable_attention_slicing
|
||||
- disable_attention_slicing
|
||||
|
||||
## StableDiffusionImg2ImgPipeline
|
||||
[[autodoc]] StableDiffusionImg2ImgPipeline
|
||||
- __call__
|
||||
- enable_attention_slicing
|
||||
- disable_attention_slicing
|
||||
|
||||
## StableDiffusionInpaintPipeline
|
||||
[[autodoc]] StableDiffusionInpaintPipeline
|
||||
- __call__
|
||||
- enable_attention_slicing
|
||||
- disable_attention_slicing
|
||||
@@ -0,0 +1,23 @@
|
||||
# Stochastic Karras VE
|
||||
|
||||
## Overview
|
||||
|
||||
[Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364) by Tero Karras, Miika Aittala, Timo Aila and Samuli Laine.
|
||||
|
||||
The abstract of the paper is the following:
|
||||
|
||||
We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates the concrete design choices. This lets us identify several changes to both the sampling and training processes, as well as preconditioning of the score networks. Together, our improvements yield new state-of-the-art FID of 1.79 for CIFAR-10 in a class-conditional setting and 1.97 in an unconditional setting, with much faster sampling (35 network evaluations per image) than prior designs. To further demonstrate their modular nature, we show that our design changes dramatically improve both the efficiency and quality obtainable with pre-trained score networks from previous work, including improving the FID of an existing ImageNet-64 model from 2.07 to near-SOTA 1.55.
|
||||
|
||||
This pipeline implements the Stochastic sampling tailored to the Variance-Expanding (VE) models.
|
||||
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Colab
|
||||
|---|---|:---:|
|
||||
| [pipeline_stochastic_karras_ve.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stochastic_karras_ve/pipeline_stochastic_karras_ve.py) | *Unconditional Image Generation* | - |
|
||||
|
||||
|
||||
## KarrasVePipeline
|
||||
[[autodoc]] KarrasVePipeline
|
||||
- __call__
|
||||
@@ -0,0 +1,109 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Schedulers
|
||||
|
||||
Diffusers contains multiple pre-built schedule functions for the diffusion process.
|
||||
|
||||
## What is a scheduler?
|
||||
|
||||
The schedule functions, denoted *Schedulers* in the library take in the output of a trained model, a sample which the diffusion process is iterating on, and a timestep to return a denoised sample.
|
||||
|
||||
- Schedulers define the methodology for iteratively adding noise to an image or for updating a sample based on model outputs.
|
||||
- adding noise in different manners represent the algorithmic processes to train a diffusion model by adding noise to images.
|
||||
- for inference, the scheduler defines how to update a sample based on an output from a pretrained model.
|
||||
- Schedulers are often defined by a *noise schedule* and an *update rule* to solve the differential equation solution.
|
||||
|
||||
### Discrete versus continuous schedulers
|
||||
|
||||
All schedulers take in a timestep to predict the updated version of the sample being diffused.
|
||||
The timesteps dictate where in the diffusion process the step is, where data is generated by iterating forward in time and inference is executed by propagating backwards through timesteps.
|
||||
Different algorithms use timesteps that both discrete (accepting `int` inputs), such as the [`DDPMScheduler`] or [`PNDMScheduler`], and continuous (accepting `float` inputs), such as the score-based schedulers [`ScoreSdeVeScheduler`] or [`ScoreSdeVpScheduler`].
|
||||
|
||||
## Designing Re-usable schedulers
|
||||
|
||||
The core design principle between the schedule functions is to be model, system, and framework independent.
|
||||
This allows for rapid experimentation and cleaner abstractions in the code, where the model prediction is separated from the sample update.
|
||||
To this end, the design of schedulers is such that:
|
||||
|
||||
- Schedulers can be used interchangeably between diffusion models in inference to find the preferred trade-off between speed and generation quality.
|
||||
- Schedulers are currently by default in PyTorch, but are designed to be framework independent (partial Numpy support currently exists).
|
||||
|
||||
|
||||
## API
|
||||
|
||||
The core API for any new scheduler must follow a limited structure.
|
||||
- Schedulers should provide one or more `def step(...)` functions that should be called to update the generated sample iteratively.
|
||||
- Schedulers should provide a `set_timesteps(...)` method that configures the parameters of a schedule function for a specific inference task.
|
||||
- Schedulers should be framework-agonstic, but provide a simple functionality to convert the scheduler into a specific framework, such as PyTorch
|
||||
with a `set_format(...)` method.
|
||||
|
||||
The base class [`SchedulerMixin`] implements low level utilities used by multiple schedulers.
|
||||
|
||||
### SchedulerMixin
|
||||
[[autodoc]] SchedulerMixin
|
||||
|
||||
### SchedulerOutput
|
||||
The class [`SchedulerOutput`] contains the ouputs from any schedulers `step(...)` call.
|
||||
|
||||
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
|
||||
|
||||
### Implemented Schedulers
|
||||
|
||||
#### Denoising diffusion implicit models (DDIM)
|
||||
|
||||
Original paper can be found here.
|
||||
|
||||
[[autodoc]] DDIMScheduler
|
||||
|
||||
#### Denoising diffusion probabilistic models (DDPM)
|
||||
|
||||
Original paper can be found [here](https://arxiv.org/abs/2010.02502).
|
||||
|
||||
[[autodoc]] DDPMScheduler
|
||||
|
||||
#### Varience exploding, stochastic sampling from Karras et. al
|
||||
|
||||
Original paper can be found [here](https://arxiv.org/abs/2006.11239).
|
||||
|
||||
[[autodoc]] KarrasVeScheduler
|
||||
|
||||
#### Linear multistep scheduler for discrete beta schedules
|
||||
|
||||
Original implementation can be found [here](https://arxiv.org/abs/2206.00364).
|
||||
|
||||
|
||||
[[autodoc]] LMSDiscreteScheduler
|
||||
|
||||
#### Pseudo numerical methods for diffusion models (PNDM)
|
||||
|
||||
Original implementation can be found [here](https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L181).
|
||||
|
||||
[[autodoc]] PNDMScheduler
|
||||
|
||||
#### variance exploding stochastic differential equation (SDE) scheduler
|
||||
|
||||
Original paper can be found [here](https://arxiv.org/abs/2011.13456).
|
||||
|
||||
[[autodoc]] ScoreSdeVeScheduler
|
||||
|
||||
#### variance preserving stochastic differential equation (SDE) scheduler
|
||||
|
||||
Original paper can be found [here](https://arxiv.org/abs/2011.13456).
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Score SDE-VP is under construction.
|
||||
|
||||
</Tip>
|
||||
|
||||
[[autodoc]] schedulers.scheduling_sde_vp.ScoreSdeVpScheduler
|
||||
@@ -0,0 +1,291 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# How to contribute to Diffusers 🧨
|
||||
|
||||
We ❤️ contributions from the open-source community! Everyone is welcome, and all types of participation –not just code– are valued and appreciated. Answering questions, helping others, reaching out and improving the documentation are all immensely valuable to the community, so don't be afraid and get involved if you're up for it!
|
||||
|
||||
It also helps us if you spread the word: reference the library from blog posts
|
||||
on the awesome projects it made possible, shout out on Twitter every time it has
|
||||
helped you, or simply star the repo to say "thank you".
|
||||
|
||||
We encourage everyone to start by saying 👋 in our public Discord channel. We discuss the hottest trends about diffusion models, ask questions, show-off personal projects, help each other with contributions, or just hang out ☕. <a href="https://discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=discord&logoColor=white"></a>
|
||||
|
||||
Whichever way you choose to contribute, we strive to be part of an open, welcoming and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions.
|
||||
|
||||
|
||||
## Overview
|
||||
|
||||
You can contribute in so many ways! Just to name a few:
|
||||
|
||||
* Fixing outstanding issues with the existing code.
|
||||
* Implementing [new diffusion pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines#contribution), [new schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) or [new models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models).
|
||||
* [Contributing to the examples](https://github.com/huggingface/diffusers/tree/main/examples).
|
||||
* [Contributing to the documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
|
||||
* Submitting issues related to bugs or desired new features.
|
||||
|
||||
*All are equally valuable to the community.*
|
||||
|
||||
### Browse GitHub issues for suggestions
|
||||
|
||||
If you need inspiration, you can look out for [issues](https://github.com/huggingface/diffusers/issues) you'd like to tackle to contribute to the library. There are a few filters that can be helpful:
|
||||
|
||||
- See [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute and getting started with the codebase.
|
||||
- See [New pipeline/model](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) to contribute exciting new diffusion models or diffusion pipelines.
|
||||
- See [New scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) to work on new samplers and schedulers.
|
||||
|
||||
|
||||
## Submitting a new issue or feature request
|
||||
|
||||
Do your best to follow these guidelines when submitting an issue or a feature
|
||||
request. It will make it easier for us to come back to you quickly and with good
|
||||
feedback.
|
||||
|
||||
### Did you find a bug?
|
||||
|
||||
The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
|
||||
the problems they encounter. So thank you for reporting an issue.
|
||||
|
||||
First, we would really appreciate it if you could **make sure the bug was not
|
||||
already reported** (use the search bar on GitHub under Issues).
|
||||
|
||||
### Do you want to implement a new diffusion pipeline / diffusion model?
|
||||
|
||||
Awesome! Please provide the following information:
|
||||
|
||||
* Short description of the diffusion pipeline and link to the paper;
|
||||
* Link to the implementation if it is open-source;
|
||||
* Link to the model weights if they are available.
|
||||
|
||||
If you are willing to contribute the model yourself, let us know so we can best
|
||||
guide you.
|
||||
|
||||
### Do you want a new feature (that is not a model)?
|
||||
|
||||
A world-class feature request addresses the following points:
|
||||
|
||||
1. Motivation first:
|
||||
* Is it related to a problem/frustration with the library? If so, please explain
|
||||
why. Providing a code snippet that demonstrates the problem is best.
|
||||
* Is it related to something you would need for a project? We'd love to hear
|
||||
about it!
|
||||
* Is it something you worked on and think could benefit the community?
|
||||
Awesome! Tell us what problem it solved for you.
|
||||
2. Write a *full paragraph* describing the feature;
|
||||
3. Provide a **code snippet** that demonstrates its future use;
|
||||
4. In case this is related to a paper, please attach a link;
|
||||
5. Attach any additional information (drawings, screenshots, etc.) you think may help.
|
||||
|
||||
If your issue is well written we're already 80% of the way there by the time you
|
||||
post it.
|
||||
|
||||
## Start contributing! (Pull Requests)
|
||||
|
||||
Before writing code, we strongly advise you to search through the existing PRs or
|
||||
issues to make sure that nobody is already working on the same thing. If you are
|
||||
unsure, it is always a good idea to open an issue to get some feedback.
|
||||
|
||||
You will need basic `git` proficiency to be able to contribute to
|
||||
🧨 Diffusers. `git` is not the easiest tool to use but it has the greatest
|
||||
manual. Type `git --help` in a shell and enjoy. If you prefer books, [Pro
|
||||
Git](https://git-scm.com/book/en/v2) is a very good reference.
|
||||
|
||||
Follow these steps to start contributing ([supported Python versions](https://github.com/huggingface/diffusers/blob/main/setup.py#L212)):
|
||||
|
||||
1. Fork the [repository](https://github.com/huggingface/diffusers) by
|
||||
clicking on the 'Fork' button on the repository's page. This creates a copy of the code
|
||||
under your GitHub user account.
|
||||
|
||||
2. Clone your fork to your local disk, and add the base repository as a remote:
|
||||
|
||||
```bash
|
||||
$ git clone git@github.com:<your Github handle>/diffusers.git
|
||||
$ cd diffusers
|
||||
$ git remote add upstream https://github.com/huggingface/diffusers.git
|
||||
```
|
||||
|
||||
3. Create a new branch to hold your development changes:
|
||||
|
||||
```bash
|
||||
$ git checkout -b a-descriptive-name-for-my-changes
|
||||
```
|
||||
|
||||
**Do not** work on the `main` branch.
|
||||
|
||||
4. Set up a development environment by running the following command in a virtual environment:
|
||||
|
||||
```bash
|
||||
$ pip install -e ".[dev]"
|
||||
```
|
||||
|
||||
(If Diffusers was already installed in the virtual environment, remove
|
||||
it with `pip uninstall diffusers` before reinstalling it in editable
|
||||
mode with the `-e` flag.)
|
||||
|
||||
To run the full test suite, you might need the additional dependency on `transformers` and `datasets` which requires a separate source
|
||||
install:
|
||||
|
||||
```bash
|
||||
$ git clone https://github.com/huggingface/transformers
|
||||
$ cd transformers
|
||||
$ pip install -e .
|
||||
```
|
||||
|
||||
```bash
|
||||
$ git clone https://github.com/huggingface/datasets
|
||||
$ cd datasets
|
||||
$ pip install -e .
|
||||
```
|
||||
|
||||
If you have already cloned that repo, you might need to `git pull` to get the most recent changes in the `datasets`
|
||||
library.
|
||||
|
||||
5. Develop the features on your branch.
|
||||
|
||||
As you work on the features, you should make sure that the test suite
|
||||
passes. You should run the tests impacted by your changes like this:
|
||||
|
||||
```bash
|
||||
$ pytest tests/<TEST_TO_RUN>.py
|
||||
```
|
||||
|
||||
You can also run the full suite with the following command, but it takes
|
||||
a beefy machine to produce a result in a decent amount of time now that
|
||||
Diffusers has grown a lot. Here is the command for it:
|
||||
|
||||
```bash
|
||||
$ make test
|
||||
```
|
||||
|
||||
For more information about tests, check out the
|
||||
[dedicated documentation](https://huggingface.co/docs/diffusers/testing)
|
||||
|
||||
🧨 Diffusers relies on `black` and `isort` to format its source code
|
||||
consistently. After you make changes, apply automatic style corrections and code verifications
|
||||
that can't be automated in one go with:
|
||||
|
||||
```bash
|
||||
$ make style
|
||||
```
|
||||
|
||||
🧨 Diffusers also uses `flake8` and a few custom scripts to check for coding mistakes. Quality
|
||||
control runs in CI, however you can also run the same checks with:
|
||||
|
||||
```bash
|
||||
$ make quality
|
||||
```
|
||||
|
||||
Once you're happy with your changes, add changed files using `git add` and
|
||||
make a commit with `git commit` to record your changes locally:
|
||||
|
||||
```bash
|
||||
$ git add modified_file.py
|
||||
$ git commit
|
||||
```
|
||||
|
||||
It is a good idea to sync your copy of the code with the original
|
||||
repository regularly. This way you can quickly account for changes:
|
||||
|
||||
```bash
|
||||
$ git fetch upstream
|
||||
$ git rebase upstream/main
|
||||
```
|
||||
|
||||
Push the changes to your account using:
|
||||
|
||||
```bash
|
||||
$ git push -u origin a-descriptive-name-for-my-changes
|
||||
```
|
||||
|
||||
6. Once you are satisfied (**and the checklist below is happy too**), go to the
|
||||
webpage of your fork on GitHub. Click on 'Pull request' to send your changes
|
||||
to the project maintainers for review.
|
||||
|
||||
7. It's ok if maintainers ask you for changes. It happens to core contributors
|
||||
too! So everyone can see the changes in the Pull request, work in your local
|
||||
branch and push the changes to your fork. They will automatically appear in
|
||||
the pull request.
|
||||
|
||||
|
||||
### Checklist
|
||||
|
||||
1. The title of your pull request should be a summary of its contribution;
|
||||
2. If your pull request addresses an issue, please mention the issue number in
|
||||
the pull request description to make sure they are linked (and people
|
||||
consulting the issue know you are working on it);
|
||||
3. To indicate a work in progress please prefix the title with `[WIP]`. These
|
||||
are useful to avoid duplicated work, and to differentiate it from PRs ready
|
||||
to be merged;
|
||||
4. Make sure existing tests pass;
|
||||
5. Add high-coverage tests. No quality testing = no merge.
|
||||
- If you are adding new `@slow` tests, make sure they pass using
|
||||
`RUN_SLOW=1 python -m pytest tests/test_my_new_model.py`.
|
||||
- If you are adding a new tokenizer, write tests, and make sure
|
||||
`RUN_SLOW=1 python -m pytest tests/test_tokenization_{your_model_name}.py` passes.
|
||||
CircleCI does not run the slow tests, but GitHub actions does every night!
|
||||
6. All public methods must have informative docstrings that work nicely with sphinx. See `[pipeline_latent_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py)` for an example.
|
||||
7. Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
|
||||
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference or [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
|
||||
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
|
||||
to this dataset.
|
||||
|
||||
### Tests
|
||||
|
||||
An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
|
||||
the [tests folder](https://github.com/huggingface/diffusers/tree/main/tests).
|
||||
|
||||
We like `pytest` and `pytest-xdist` because it's faster. From the root of the
|
||||
repository, here's how to run tests with `pytest` for the library:
|
||||
|
||||
```bash
|
||||
$ python -m pytest -n auto --dist=loadfile -s -v ./tests/
|
||||
```
|
||||
|
||||
In fact, that's how `make test` is implemented!
|
||||
|
||||
You can specify a smaller set of tests in order to test only the feature
|
||||
you're working on.
|
||||
|
||||
By default, slow tests are skipped. Set the `RUN_SLOW` environment variable to
|
||||
`yes` to run them. This will download many gigabytes of models — make sure you
|
||||
have enough disk space and a good Internet connection, or a lot of patience!
|
||||
|
||||
```bash
|
||||
$ RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/
|
||||
```
|
||||
|
||||
`unittest` is fully supported, here's how to run tests with it:
|
||||
|
||||
```bash
|
||||
$ python -m unittest discover -s tests -t . -v
|
||||
$ python -m unittest discover -s examples -t examples -v
|
||||
```
|
||||
|
||||
### Syncing forked main with upstream (HuggingFace) main
|
||||
|
||||
To avoid pinging the upstream repository which adds reference notes to each upstream PR and sends unnecessary notifications to the developers involved in these PRs,
|
||||
when syncing the main branch of a forked repository, please, follow these steps:
|
||||
1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
|
||||
2. If a PR is absolutely necessary, use the following steps after checking out your branch:
|
||||
```
|
||||
$ git checkout -b your-branch-for-syncing
|
||||
$ git pull --squash --no-commit upstream main
|
||||
$ git commit -m '<your message without GitHub references>'
|
||||
$ git push --set-upstream origin your-branch-for-syncing
|
||||
```
|
||||
|
||||
### Style guide
|
||||
|
||||
For documentation strings, 🧨 Diffusers follows the [google style](https://google.github.io/styleguide/pyguide.html).
|
||||
|
||||
|
||||
**This guide was heavily inspired by the awesome [scikit-learn guide to contributing](https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md).**
|
||||
@@ -0,0 +1,17 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Philosophy
|
||||
|
||||
- Readability and clarity are preferred over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code design. *E.g.*, the provided [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) are separated from the provided [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and use well-commented code that can be read alongside the original paper.
|
||||
- Diffusers is **modality independent** and focuses on providing pretrained models and tools to build systems that generate **continuous outputs**, *e.g.* vision and audio. This is one of the guiding goals even if the initial pipelines are devoted to vision tasks.
|
||||
- Diffusion models and schedulers are provided as concise, elementary building blocks. In contrast, diffusion pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box, should stay as close as possible to their original implementations and can include components of other libraries, such as text encoders. Examples of diffusion pipelines are [Glide](https://github.com/openai/glide-text2im), [Latent Diffusion](https://github.com/CompVis/latent-diffusion) and [Stable Diffusion](https://github.com/compvis/stable-diffusion).
|
||||
@@ -0,0 +1,17 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Stable Diffusion
|
||||
|
||||
Under construction 🚧
|
||||
|
||||
For now please visit this [very in-detail blog post](https://huggingface.co/blog/stable_diffusion)
|
||||
@@ -0,0 +1,49 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<img src="https://raw.githubusercontent.com/huggingface/diffusers/77aadfee6a891ab9fcfb780f87c693f7a5beeb8e/docs/source/imgs/diffusers_library.jpg" width="400"/>
|
||||
<br>
|
||||
</p>
|
||||
|
||||
# 🧨 Diffusers
|
||||
|
||||
🤗 Diffusers provides pretrained vision diffusion models, and serves as a modular toolbox for inference and training.
|
||||
|
||||
More precisely, 🤗 Diffusers offers:
|
||||
|
||||
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code (see [**Using Diffusers**](./using-diffusers/conditional_image_generation)) or have a look at [**Pipelines**](#pipelines) to get an overview of all supported pipelines and their corresponding papers.
|
||||
- Various noise schedulers that can be used interchangeably for the preferred speed vs. quality trade-off in inference. For more information see [**Schedulers**](./api/schedulers).
|
||||
- Multiple types of models, such as UNet, can be used as building blocks in an end-to-end diffusion system. See [**Models**](./api/models) for more details
|
||||
- Training examples to show how to train the most popular diffusion model tasks. For more information see [**Training**](./training/overview).
|
||||
|
||||
## 🧨 Diffusers Pipelines
|
||||
|
||||
The following table summarizes all officially supported pipelines, their corresponding paper, and if
|
||||
available a colab notebook to directly try them out.
|
||||
|
||||
| Pipeline | Paper | Tasks | Colab
|
||||
|---|---|:---:|:---:|
|
||||
| [ddpm](./api/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
|
||||
| [ddim](./api/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
|
||||
| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
|
||||
| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
|
||||
| [pndm](./api/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
|
||||
| [score_sde_ve](./api/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [score_sde_vp](./api/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
|
||||
| [stable_diffusion](./api/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
|
||||
| [stable_diffusion](./api/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/image_2_image_using_diffusers.ipynb)
|
||||
| [stable_diffusion](./api/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/in_painting_with_stable_diffusion_using_diffusers.ipynb)
|
||||
| [stochatic_karras_ve](./api/pipelines/stochatic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
|
||||
|
||||
**Note**: Pipelines are simple examples of how to play around with the diffusion systems as described in the corresponding papers.
|
||||
@@ -0,0 +1,90 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Installation
|
||||
|
||||
Install Diffusers for with PyTorch. Support for other libraries will come in the future
|
||||
|
||||
🤗 Diffusers is tested on Python 3.7+, and PyTorch 1.7.0+.
|
||||
|
||||
## Install with pip
|
||||
|
||||
You should install 🤗 Diffusers in a [virtual environment](https://docs.python.org/3/library/venv.html).
|
||||
If you're unfamiliar with Python virtual environments, take a look at this [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
|
||||
A virtual environment makes it easier to manage different projects, and avoid compatibility issues between dependencies.
|
||||
|
||||
Start by creating a virtual environment in your project directory:
|
||||
|
||||
```bash
|
||||
python -m venv .env
|
||||
```
|
||||
|
||||
Activate the virtual environment:
|
||||
|
||||
```bash
|
||||
source .env/bin/activate
|
||||
```
|
||||
|
||||
Now you're ready to install 🤗 Diffusers with the following command:
|
||||
|
||||
```bash
|
||||
pip install diffusers
|
||||
```
|
||||
|
||||
## Install from source
|
||||
|
||||
Install 🤗 Diffusers from source with the following command:
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/huggingface/diffusers
|
||||
```
|
||||
|
||||
This command installs the bleeding edge `main` version rather than the latest `stable` version.
|
||||
The `main` version is useful for staying up-to-date with the latest developments.
|
||||
For instance, if a bug has been fixed since the last official release but a new release hasn't been rolled out yet.
|
||||
However, this means the `main` version may not always be stable.
|
||||
We strive to keep the `main` version operational, and most issues are usually resolved within a few hours or a day.
|
||||
If you run into a problem, please open an [Issue](https://github.com/huggingface/transformers/issues) so we can fix it even sooner!
|
||||
|
||||
## Editable install
|
||||
|
||||
You will need an editable install if you'd like to:
|
||||
|
||||
* Use the `main` version of the source code.
|
||||
* Contribute to 🤗 Diffusers and need to test changes in the code.
|
||||
|
||||
Clone the repository and install 🤗 Diffusers with the following commands:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers.git
|
||||
cd transformers
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
These commands will link the folder you cloned the repository to and your Python library paths.
|
||||
Python will now look inside the folder you cloned to in addition to the normal library paths.
|
||||
For example, if your Python packages are typically installed in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python will also search the folder you cloned to: `~/diffusers/`.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
You must keep the `diffusers` folder if you want to keep using the library.
|
||||
|
||||
</Tip>
|
||||
|
||||
Now you can easily update your clone to the latest version of 🤗 Diffusers with the following command:
|
||||
|
||||
```bash
|
||||
cd ~/diffusers/
|
||||
git pull
|
||||
```
|
||||
|
||||
Your Python environment will find the `main` version of 🤗 Diffusers on the next run.
|
||||
@@ -0,0 +1,76 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Memory and speed
|
||||
|
||||
We present some techniques and ideas to optimize 🤗 Diffusers _inference_ for memory or speed.
|
||||
|
||||
## CUDA `autocast`
|
||||
|
||||
If you use a CUDA GPU, you can take advantage of `torch.autocast` to perform inference roughly twice as fast at the cost of slightly lower precision. All you need to do is put your inference call inside an `autocast` context manager. The following example shows how to do it using Stable Diffusion text-to-image generation as an example:
|
||||
|
||||
```Python
|
||||
from torch import autocast
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
with autocast("cuda"):
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
Despite the precision loss, in our experience the final image results look the same as the `float32` versions. Feel free to experiment and report back!
|
||||
|
||||
## Half precision weights
|
||||
|
||||
To save more GPU memory, you can load the model weights directly in half precision. This involves loading the float16 version of the weights, which was saved to a branch named `fp16`, and telling PyTorch to use the `float16` type when loading them:
|
||||
|
||||
```Python
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
revision="fp16",
|
||||
torch_dtype=torch.float16,
|
||||
use_auth_token=True
|
||||
)
|
||||
```
|
||||
|
||||
## Sliced attention for additional memory savings
|
||||
|
||||
For even additional memory savings, you can use a sliced version of attention that performs the computation in steps instead of all at once.
|
||||
|
||||
<Tip>
|
||||
Attention slicing is useful even if a batch size of just 1 is used - as long as the model uses more than one attention head. If there is more than one attention head the *QK^T* attention matrix can be computed sequentially for each head which can save a significant amount of memory.
|
||||
</Tip>
|
||||
|
||||
To perform the attention computation sequentially over each head, you only need to invoke [`~StableDiffusionPipeline.enable_attention_slicing`] in your pipeline before inference, like here:
|
||||
|
||||
```Python
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
revision="fp16",
|
||||
torch_dtype=torch.float16,
|
||||
use_auth_token=True
|
||||
)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
pipe.enable_attention_slicing()
|
||||
with torch.autocast("cuda"):
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
There's a small performance penalty of about 10% slower inference times, but this method allows you to use Stable Diffusion in as little as 3.2 GB of VRAM!
|
||||
@@ -0,0 +1,58 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# How to use Stable Diffusion in Apple Silicon (M1/M2)
|
||||
|
||||
🤗 Diffusers is compatible with Apple silicon for Stable Diffusion inference, using the PyTorch `mps` device. These are the steps you need to follow to use your M1 or M2 computer with Stable Diffusion.
|
||||
|
||||
## Requirements
|
||||
|
||||
- Mac computer with Apple silicon (M1/M2) hardware.
|
||||
- macOS 12.3 or later.
|
||||
- arm64 version of Python.
|
||||
- PyTorch [Preview (Nightly)](https://pytorch.org/get-started/locally/), version `1.13.0.dev20220830` or later.
|
||||
|
||||
## Inference Pipeline
|
||||
|
||||
The snippet below demonstrates how to use the `mps` backend using the familiar `to()` interface to move the Stable Diffusion pipeline to your M1 or M2 device.
|
||||
|
||||
We recommend to "prime" the pipeline using an additional one-time pass through it. This is a temporary workaround for a weird issue we have detected: the first inference pass produces slightly different results than subsequent ones. You only need to do this pass once, and it's ok to use just one inference step and discard the result.
|
||||
|
||||
```python
|
||||
# make sure you're logged in with `huggingface-cli login`
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
|
||||
pipe = pipe.to("mps")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
|
||||
# First-time "warmup" pass (see explanation above)
|
||||
_ = pipe(prompt, num_inference_steps=1)
|
||||
|
||||
# Results match those from the CPU device after the warmup pass.
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
## Known Issues
|
||||
|
||||
- As mentioned above, we are investigating a strange [first-time inference issue](https://github.com/huggingface/diffusers/issues/372).
|
||||
- Generating multiple prompts in a batch [crashes or doesn't work reliably](https://github.com/huggingface/diffusers/issues/363). We believe this might be related to the [`mps` backend in PyTorch](https://github.com/pytorch/pytorch/issues/84039#issuecomment-1237735249), but we need to investigate in more depth. For now, we recommend to iterate instead of batching.
|
||||
|
||||
## Performance
|
||||
|
||||
These are the results we got on a M1 Max MacBook Pro with 64 GB of RAM, running macOS Ventura Version 13.0 Beta (22A5331f). We performed Stable Diffusion text-to-image generation of the same prompt for 50 inference steps, using a guidance scale of 7.5.
|
||||
|
||||
| Device | Steps | Time |
|
||||
|--------|-------|---------|
|
||||
| CPU | 50 | 213.46s |
|
||||
| MPS | 50 | 30.81s |
|
||||
@@ -0,0 +1,43 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
|
||||
# How to use the ONNX Runtime for inference
|
||||
|
||||
🤗 Diffusers provides a Stable Diffusion pipeline compatible with the ONNX Runtime. This allows you to run Stable Diffusion on any hardware that supports ONNX (including CPUs), and where an accelerated version of PyTorch is not available.
|
||||
|
||||
## Installation
|
||||
|
||||
- TODO
|
||||
|
||||
## Stable Diffusion Inference
|
||||
|
||||
The snippet below demonstrates how to use the ONNX runtime. You need to use `StableDiffusionOnnxPipeline` instead of `StableDiffusionPipeline`. You also need to download the weights from the `onnx` branch of the repository, and indicate the runtime provider you want to use.
|
||||
|
||||
```python
|
||||
# make sure you're logged in with `huggingface-cli login`
|
||||
from diffusers import StableDiffusionOnnxPipeline
|
||||
|
||||
pipe = StableDiffusionOnnxPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
revision="onnx",
|
||||
provider="CUDAExecutionProvider",
|
||||
use_auth_token=True,
|
||||
)
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
## Known Issues
|
||||
|
||||
- Generating multiple prompts in a batch seems to take too much memory. While we look into it, you may need to iterate instead of batching.
|
||||
@@ -0,0 +1,15 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# OpenVINO
|
||||
|
||||
Under construction 🚧
|
||||
@@ -0,0 +1,146 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Quicktour
|
||||
|
||||
Get up and running with 🧨 Diffusers quickly!
|
||||
Whether you're a developer or an everyday user, this quick tour will help you get started and show you how to use [`DiffusionPipeline`] for inference.
|
||||
|
||||
Before you begin, make sure you have all the necessary libraries installed:
|
||||
|
||||
```bash
|
||||
pip install --upgrade diffusers
|
||||
```
|
||||
|
||||
## DiffusionPipeline
|
||||
|
||||
The [`DiffusionPipeline`] is the easiest way to use a pre-trained diffusion system for inference. You can use the [`DiffusionPipeline`] out-of-the-box for many tasks across different modalities. Take a look at the table below for some supported tasks:
|
||||
|
||||
| **Task** | **Description** | **Pipeline**
|
||||
|------------------------------|--------------------------------------------------------------------------------------------------------------|-----------------|
|
||||
| Unconditional Image Generation | generate an image from gaussian noise | [unconditional_image_generation](./using-diffusers/unconditional_image_generation`) |
|
||||
| Text-Guided Image Generation | generate an image given a text prompt | [conditional_image_generation](./using-diffusers/conditional_image_generation) |
|
||||
| Text-Guided Image-to-Image Translation | generate an image given an original image and a text prompt | [img2img](./using-diffusers/img2img) |
|
||||
| Text-Guided Image-Inpainting | fill the masked part of an image given the image, the mask and a text prompt | [inpaint](./using-diffusers/inpaint) |
|
||||
|
||||
For more in-detail information on how diffusion pipelines function for the different tasks, please have a look at the [**Using Diffusers**](./using-diffusers/overview) section.
|
||||
|
||||
As an example, start by creating an instance of [`DiffusionPipeline`] and specify which pipeline checkpoint you would like to download.
|
||||
You can use the [`DiffusionPipeline`] for any [Diffusers' checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads).
|
||||
In this guide though, you'll use [`DiffusionPipeline`] for text-to-image generation with [Latent Diffusion](https://huggingface.co/CompVis/ldm-text2im-large-256):
|
||||
|
||||
```python
|
||||
>>> from diffusers import DiffusionPipeline
|
||||
|
||||
>>> generator = DiffusionPipeline.from_pretrained("CompVis/ldm-text2im-large-256")
|
||||
```
|
||||
|
||||
The [`DiffusionPipeline`] downloads and caches all modeling, tokenization, and scheduling components.
|
||||
Because the model consists of roughly 1.4 billion parameters, we strongly recommend running it on GPU.
|
||||
You can move the generator object to GPU, just like you would in PyTorch.
|
||||
|
||||
```python
|
||||
>>> generator.to("cuda")
|
||||
```
|
||||
|
||||
Now you can use the `generator` on your text prompt:
|
||||
|
||||
```python
|
||||
>>> image = generator("An image of a squirrel in Picasso style").images[0]
|
||||
```
|
||||
|
||||
The output is by default wrapped into a [PIL Image object](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class).
|
||||
|
||||
You can save the image by simply calling:
|
||||
|
||||
```python
|
||||
>>> image.save("image_of_squirrel_painting.png")
|
||||
```
|
||||
|
||||
More advanced models, like [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion) require you to accept a [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) before running the model.
|
||||
This is due to the improved image generation capabilities of the model and the potentially harmful content that could be produced with it.
|
||||
Long story short: Head over to your stable diffusion model of choice, *e.g.* [`CompVis/stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4), read through the license and click-accept to get
|
||||
access to the model.
|
||||
You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
|
||||
Having "click-accepted" the license, you can save your token:
|
||||
|
||||
```python
|
||||
AUTH_TOKEN = "<please-fill-with-your-token>"
|
||||
```
|
||||
|
||||
You can then load [`CompVis/stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4)
|
||||
just like we did before only that now you need to pass your `AUTH_TOKEN`:
|
||||
|
||||
```python
|
||||
>>> from diffusers import DiffusionPipeline
|
||||
|
||||
>>> generator = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=AUTH_TOKEN)
|
||||
```
|
||||
|
||||
If you do not pass your authentification token you will see that the diffusion system will not be correctly
|
||||
downloaded. Forcing the user to pass an authentification token ensures that it can be verified that the
|
||||
user has indeed read and accepted the license, which also means that an internet connection is required.
|
||||
|
||||
**Note**: If you do not want to be forced to pass an authentification token, you can also simply download
|
||||
the weights locally via:
|
||||
|
||||
```
|
||||
git lfs install
|
||||
git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
|
||||
```
|
||||
|
||||
and then load locally saved weights into the pipeline. This way, you do not need to pass an authentification
|
||||
token. Assuming that `"./stable-diffusion-v1-4"` is the local path to the cloned stable-diffusion-v1-4 repo,
|
||||
you can also load the pipeline as follows:
|
||||
|
||||
```python
|
||||
>>> generator = DiffusionPipeline.from_pretrained("./stable-diffusion-v1-4")
|
||||
```
|
||||
|
||||
Running the pipeline is then identical to the code above as it's the same model architecture.
|
||||
|
||||
```python
|
||||
>>> generator.to("cuda")
|
||||
>>> image = generator("An image of a squirrel in Picasso style").images[0]
|
||||
>>> image.save("image_of_squirrel_painting.png")
|
||||
```
|
||||
|
||||
Diffusion systems can be used with multiple different [schedulers]("api/schedulers") each with their
|
||||
pros and cons. By default, Stable Diffusion runs with [`PNDMScheduler`], but it's very simple to
|
||||
use a different scheduler. *E.g.* if you would instead like to use the [`LMSDiscreteScheduler`] scheduler,
|
||||
you could use it as follows:
|
||||
|
||||
```python
|
||||
>>> from diffusers import LMSDiscreteScheduler
|
||||
|
||||
>>> scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear")
|
||||
|
||||
>>> generator = StableDiffusionPipeline.from_pretrained(
|
||||
... "CompVis/stable-diffusion-v1-4", scheduler=scheduler, use_auth_token=AUTH_TOKEN
|
||||
... )
|
||||
```
|
||||
|
||||
[Stability AI's](https://stability.ai/) Stable Diffusion model is an impressive image generation model
|
||||
and can do much more than just generating images from text. We have dedicated a whole documentation page,
|
||||
just for Stable Diffusion [here]("./conceptual/stable_diffusion").
|
||||
|
||||
If you want to know how to optimize Stable Diffusion to run on less memory, higher inference speeds, on specific hardware, such as Mac, or with [ONNX Runtime](https://onnxruntime.ai/), please have a look at our
|
||||
optimization pages:
|
||||
|
||||
- [Optimized PyTorch on GPU]("./optimization/fp16")
|
||||
- [Mac OS with PyTorch]("./optimization/mps")
|
||||
- [ONNX]("./optimization/onnx)
|
||||
- [OpenVINO]("./optimization/open_vino)
|
||||
|
||||
If you want to fine-tune or train your diffusion model, please have a look at the [**training section**](./training/overview)
|
||||
|
||||
Finally, please be considerate when distributing generated images publicly 🤗.
|
||||
@@ -0,0 +1,69 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# 🧨 Diffusers Training Examples
|
||||
|
||||
Diffusers examples are a collection of scripts to demonstrate how to effectively use the `diffusers` library
|
||||
for a variety of use cases.
|
||||
|
||||
**Note**: If you are looking for **official** examples on how to use `diffusers` for inference,
|
||||
please have a look at [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines)
|
||||
|
||||
Our examples aspire to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
|
||||
More specifically, this means:
|
||||
|
||||
- **Self-contained**: An example script shall only depend on "pip-install-able" Python packages that can be found in a `requirements.txt` file. Example scripts shall **not** depend on any local files. This means that one can simply download an example script, *e.g.* [train_unconditional.py](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/train_unconditional.py), install the required dependencies, *e.g.* [requirements.txt](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/requirements.txt) and execute the example script.
|
||||
- **Easy-to-tweak**: While we strive to present as many use cases as possible, the example scripts are just that - examples. It is expected that they won't work out-of-the box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs. To help you with that, most of the examples fully expose the preprocessing of the data and the training loop to allow you to tweak and edit them as required.
|
||||
- **Beginner-friendly**: We do not aim for providing state-of-the-art training scripts for the newest models, but rather examples that can be used as a way to better understand diffusion models and how to use them with the `diffusers` library. We often purposefully leave out certain state-of-the-art methods if we consider them too complex for beginners.
|
||||
- **One-purpose-only**: Examples should show one task and one task only. Even if a task is from a modeling
|
||||
point of view very similar, *e.g.* image super-resolution and image modification tend to use the same model and training method, we want examples to showcase only one task to keep them as readable and easy-to-understand as possible.
|
||||
|
||||
We provide **official** examples that cover the most popular tasks of diffusion models.
|
||||
*Official* examples are **actively** maintained by the `diffusers` maintainers and we try to rigorously follow our example philosophy as defined above.
|
||||
If you feel like another important example should exist, we are more than happy to welcome a [Feature Request](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=) or directly a [Pull Request](https://github.com/huggingface/diffusers/compare) from you!
|
||||
|
||||
Training examples show how to pretrain or fine-tune diffusion models for a variety of tasks. Currently we support:
|
||||
|
||||
- [Unconditional Training](./unconditional_training)
|
||||
- [Text-to-Image Training](./text2image)
|
||||
- [Text Inversion](./text_inversion)
|
||||
|
||||
|
||||
| Task | 🤗 Accelerate | 🤗 Datasets | Colab
|
||||
|---|---|:---:|:---:|
|
||||
| [**Unconditional Image Generation**](./unconditional_training) | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
|
||||
| [**Text-to-Image**](./text2image) | - | - |
|
||||
| [**Text-Inversion**](./text_inversion) | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
|
||||
|
||||
## Community
|
||||
|
||||
In addition, we provide **community** examples, which are examples added and maintained by our community.
|
||||
Community examples can consist of both *training* examples or *inference* pipelines.
|
||||
For such examples, we are more lenient regarding the philosophy defined above and also cannot guarantee to provide maintenance for every issue.
|
||||
Examples that are useful for the community, but are either not yet deemed popular or not yet following our above philosophy should go into the [community examples](https://github.com/huggingface/diffusers/tree/main/examples/community) folder. The community folder therefore includes training examples and inference pipelines.
|
||||
**Note**: Community examples can be a [great first contribution](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) to show to the community how you like to use `diffusers` 🪄.
|
||||
|
||||
## Important note
|
||||
|
||||
To make sure you can successfully run the latest versions of the example scripts, you have to **install the library from source** and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
|
||||
Then cd in the example folder of your choice and run
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
@@ -0,0 +1,16 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
|
||||
# Text-to-Image Training
|
||||
|
||||
Under construction 🚧
|
||||
@@ -0,0 +1,124 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
|
||||
|
||||
# Textual Inversion
|
||||
|
||||
Textual Inversion is a technique for capturing novel concepts from a small number of example images in a way that can later be used to control text-to-image pipelines. It does so by learning new 'words' in the embedding space of the pipeline's text encoder. These special words can then be used within text prompts to achieve very fine-grained control of the resulting images.
|
||||
|
||||

|
||||
_By using just 3-5 images you can teach new concepts to a model such as Stable Diffusion for personalized image generation ([image source](https://github.com/rinongal/textual_inversion))._
|
||||
|
||||
This technique was introduced in [An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion](https://arxiv.org/abs/2208.01618). The paper demonstrated the concept using a [latent diffusion model](https://github.com/CompVis/latent-diffusion) but the idea has since been applied to other variants such as [Stable Diffusion](https://huggingface.co/docs/diffusers/main/en/conceptual/stable_diffusion).
|
||||
|
||||
|
||||
## How It Works
|
||||
|
||||

|
||||
_Architecture Overview from the [textual inversion blog post](https://textual-inversion.github.io/)_
|
||||
|
||||
Before a text prompt can be used in a diffusion model, it must first be processed into a numerical representation. This typically involves tokenizing the text, converting each token to an embedding and then feeding those embeddings through a model (typically a transformer) whose output will be used as the conditioning for the diffusion model.
|
||||
|
||||
Textual inversion learns a new token embedding (v* in the diagram above). A prompt (that includes a token which will be mapped to this new embedding) is used in conjunction with a noised version of one or more training images as inputs to the generator model, which attempts to predict the denoised version of the image. The embedding is optimized based on how well the model does at this task - an embedding that better captures the object or style shown by the training images will give more useful information to the diffusion model and thus result in a lower denoising loss. After many steps (typically several thousand) with a variety of prompt and image variants the learned embedding should hopefully capture the essence of the new concept being taught.
|
||||
|
||||
## Usage
|
||||
|
||||
To train your own textual inversions, see the [example script here](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion).
|
||||
|
||||
There is also a notebook for training:
|
||||
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
|
||||
|
||||
And one for inference:
|
||||
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
|
||||
|
||||
In addition to using concepts you have trained yourself, there is a community-created collection of trained textual inversions in the new [Stable Diffusion public concepts library](https://huggingface.co/sd-concepts-library) which you can also use from the inference notebook above. Over time this will hopefully grow into a useful resource as more examples are added.
|
||||
|
||||
## Example: Running locally
|
||||
|
||||
The `textual_inversion.py` script [here](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion) shows how to implement the training procedure and adapt it for stable diffusion.
|
||||
|
||||
### Installing the dependencies
|
||||
|
||||
Before running the scipts, make sure to install the library's training dependencies:
|
||||
|
||||
```bash
|
||||
pip install diffusers[training] accelerate transformers
|
||||
```
|
||||
|
||||
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
|
||||
### Cat toy example
|
||||
|
||||
You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-4`, so you'll need to visit [its card](https://huggingface.co/CompVis/stable-diffusion-v1-4), read the license and tick the checkbox if you agree.
|
||||
|
||||
You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
|
||||
|
||||
Run the following command to autheticate your token
|
||||
|
||||
```bash
|
||||
huggingface-cli login
|
||||
```
|
||||
|
||||
If you have already cloned the repo, then you won't need to go through these steps. You can simple remove the `--use_auth_token` arg from the following command.
|
||||
|
||||
<br>
|
||||
|
||||
Now let's get our dataset.Download 3-4 images from [here](https://drive.google.com/drive/folders/1fmJMs25nxS_rSNqS5hTcRdLem_YQXbq5) and save them in a directory. This will be our training data.
|
||||
|
||||
And launch the training using
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
|
||||
export DATA_DIR="path-to-dir-containing-images"
|
||||
|
||||
accelerate launch textual_inversion.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME --use_auth_token \
|
||||
--train_data_dir=$DATA_DIR \
|
||||
--learnable_property="object" \
|
||||
--placeholder_token="<cat-toy>" --initializer_token="toy" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--max_train_steps=3000 \
|
||||
--learning_rate=5.0e-04 --scale_lr \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--output_dir="textual_inversion_cat"
|
||||
```
|
||||
|
||||
A full training run takes ~1 hour on one V100 GPU.
|
||||
|
||||
|
||||
### Inference
|
||||
|
||||
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `placeholder_token` in your prompt.
|
||||
|
||||
```python
|
||||
from torch import autocast
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
model_id = "path-to-your-trained-model"
|
||||
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
|
||||
|
||||
prompt = "A <cat-toy> backpack"
|
||||
|
||||
with autocast("cuda"):
|
||||
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
|
||||
|
||||
image.save("cat-backpack.png")
|
||||
```
|
||||
@@ -0,0 +1,149 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Unconditional Image-Generation
|
||||
|
||||
In this section, we explain how one can train an unconditional image generation diffusion
|
||||
model. "Unconditional" because the model is not conditioned on any context to generate an image - once trained the model will simply generate images that resemble its training data
|
||||
distribution.
|
||||
|
||||
## Installing the dependencies
|
||||
|
||||
Before running the scipts, make sure to install the library's training dependencies:
|
||||
|
||||
```bash
|
||||
pip install diffusers[training] accelerate datasets
|
||||
```
|
||||
|
||||
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
## Unconditional Flowers
|
||||
|
||||
The command to train a DDPM UNet model on the Oxford Flowers dataset:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
--dataset_name="huggan/flowers-102-categories" \
|
||||
--resolution=64 \
|
||||
--output_dir="ddpm-ema-flowers-64" \
|
||||
--train_batch_size=16 \
|
||||
--num_epochs=100 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-4 \
|
||||
--lr_warmup_steps=500 \
|
||||
--mixed_precision=no \
|
||||
--push_to_hub
|
||||
```
|
||||
An example trained model: https://huggingface.co/anton-l/ddpm-ema-flowers-64
|
||||
|
||||
A full training run takes 2 hours on 4xV100 GPUs.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26864830/180248660-a0b143d0-b89a-42c5-8656-2ebf6ece7e52.png" width="700" />
|
||||
|
||||
## Unconditional Pokemon
|
||||
|
||||
The command to train a DDPM UNet model on the Pokemon dataset:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
--dataset_name="huggan/pokemon" \
|
||||
--resolution=64 \
|
||||
--output_dir="ddpm-ema-pokemon-64" \
|
||||
--train_batch_size=16 \
|
||||
--num_epochs=100 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-4 \
|
||||
--lr_warmup_steps=500 \
|
||||
--mixed_precision=no \
|
||||
--push_to_hub
|
||||
```
|
||||
An example trained model: https://huggingface.co/anton-l/ddpm-ema-pokemon-64
|
||||
|
||||
A full training run takes 2 hours on 4xV100 GPUs.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26864830/180248200-928953b4-db38-48db-b0c6-8b740fe6786f.png" width="700" />
|
||||
|
||||
|
||||
## Using your own data
|
||||
|
||||
To use your own dataset, there are 2 ways:
|
||||
- you can either provide your own folder as `--train_data_dir`
|
||||
- or you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
|
||||
|
||||
**Note**: If you want to create your own training dataset please have a look at [this document](https://huggingface.co/docs/datasets/image_process#image-datasets).
|
||||
|
||||
Below, we explain both in more detail.
|
||||
|
||||
### Provide the dataset as a folder
|
||||
|
||||
If you provide your own folders with images, the script expects the following directory structure:
|
||||
|
||||
```bash
|
||||
data_dir/xxx.png
|
||||
data_dir/xxy.png
|
||||
data_dir/[...]/xxz.png
|
||||
```
|
||||
|
||||
In other words, the script will take care of gathering all images inside the folder. You can then run the script like this:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
--train_data_dir <path-to-train-directory> \
|
||||
<other-arguments>
|
||||
```
|
||||
|
||||
Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
|
||||
|
||||
### Upload your data to the hub, as a (possibly private) repo
|
||||
|
||||
It's very easy (and convenient) to upload your image dataset to the hub using the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
|
||||
# example 1: local folder
|
||||
dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
|
||||
|
||||
# example 2: local files (suppoted formats are tar, gzip, zip, xz, rar, zstd)
|
||||
dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
|
||||
|
||||
# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
|
||||
dataset = load_dataset(
|
||||
"imagefolder",
|
||||
data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip",
|
||||
)
|
||||
|
||||
# example 4: providing several splits
|
||||
dataset = load_dataset(
|
||||
"imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]}
|
||||
)
|
||||
```
|
||||
|
||||
`ImageFolder` will create an `image` column containing the PIL-encoded images.
|
||||
|
||||
Next, push it to the hub!
|
||||
|
||||
```python
|
||||
# assuming you have ran the huggingface-cli login command in a terminal
|
||||
dataset.push_to_hub("name_of_your_dataset")
|
||||
|
||||
# if you want to push to a private repo, simply pass private=True:
|
||||
dataset.push_to_hub("name_of_your_dataset", private=True)
|
||||
```
|
||||
|
||||
and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub.
|
||||
|
||||
More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
|
||||
@@ -0,0 +1,48 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Conditional Image Generation
|
||||
|
||||
The [`DiffusionPipeline`] is the easiest way to use a pre-trained diffusion system for inference
|
||||
|
||||
Start by creating an instance of [`DiffusionPipeline`] and specify which pipeline checkpoint you would like to download.
|
||||
You can use the [`DiffusionPipeline`] for any [Diffusers' checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads).
|
||||
In this guide though, you'll use [`DiffusionPipeline`] for text-to-image generation with [Latent Diffusion](https://huggingface.co/CompVis/ldm-text2im-large-256):
|
||||
|
||||
```python
|
||||
>>> from diffusers import DiffusionPipeline
|
||||
|
||||
>>> generator = DiffusionPipeline.from_pretrained("CompVis/ldm-text2im-large-256")
|
||||
```
|
||||
The [`DiffusionPipeline`] downloads and caches all modeling, tokenization, and scheduling components.
|
||||
Because the model consists of roughly 1.4 billion parameters, we strongly recommend running it on GPU.
|
||||
You can move the generator object to GPU, just like you would in PyTorch.
|
||||
|
||||
```python
|
||||
>>> generator.to("cuda")
|
||||
```
|
||||
|
||||
Now you can use the `generator` on your text prompt:
|
||||
|
||||
```python
|
||||
>>> image = generator("An image of a squirrel in Picasso style").images[0]
|
||||
```
|
||||
|
||||
The output is by default wrapped into a [PIL Image object](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class).
|
||||
|
||||
You can save the image by simply calling:
|
||||
|
||||
```python
|
||||
>>> image.save("image_of_squirrel_painting.png")
|
||||
```
|
||||
|
||||
|
||||
@@ -0,0 +1,32 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
|
||||
|
||||
# Quicktour
|
||||
|
||||
Start using Diffusers🧨 quickly!
|
||||
To start, use the [`DiffusionPipeline`] for quick inference and sample generations!
|
||||
|
||||
```
|
||||
pip install diffusers
|
||||
```
|
||||
|
||||
## Main classes
|
||||
|
||||
### Models
|
||||
|
||||
### Schedulers
|
||||
|
||||
### Pipeliens
|
||||
|
||||
|
||||
@@ -0,0 +1,15 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Custom Pipeline
|
||||
|
||||
Under construction 🚧
|
||||
@@ -0,0 +1,46 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Text-Guided Image-to-Image Generation
|
||||
|
||||
The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images.
|
||||
|
||||
```python
|
||||
from torch import autocast
|
||||
import requests
|
||||
from PIL import Image
|
||||
from io import BytesIO
|
||||
|
||||
from diffusers import StableDiffusionImg2ImgPipeline
|
||||
|
||||
# load the pipeline
|
||||
device = "cuda"
|
||||
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16, use_auth_token=True
|
||||
).to(device)
|
||||
|
||||
# let's download an initial image
|
||||
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
|
||||
response = requests.get(url)
|
||||
init_image = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
init_image = init_image.resize((768, 512))
|
||||
|
||||
prompt = "A fantasy landscape, trending on artstation"
|
||||
|
||||
with autocast("cuda"):
|
||||
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5).images
|
||||
|
||||
images[0].save("fantasy_landscape.png")
|
||||
```
|
||||
You can also run this example on colab [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/image_2_image_using_diffusers.ipynb)
|
||||
|
||||
@@ -0,0 +1,50 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Text-Guided Image-Inpainting
|
||||
|
||||
The [`StableDiffusionInpaintPipeline`] lets you edit specific parts of an image by providing a mask and text prompt.
|
||||
|
||||
```python
|
||||
from io import BytesIO
|
||||
|
||||
from torch import autocast
|
||||
import requests
|
||||
import PIL
|
||||
|
||||
from diffusers import StableDiffusionInpaintPipeline
|
||||
|
||||
|
||||
def download_image(url):
|
||||
response = requests.get(url)
|
||||
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
|
||||
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
||||
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
||||
|
||||
init_image = download_image(img_url).resize((512, 512))
|
||||
mask_image = download_image(mask_url).resize((512, 512))
|
||||
|
||||
device = "cuda"
|
||||
pipe = StableDiffusionInpaintPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16, use_auth_token=True
|
||||
).to(device)
|
||||
|
||||
prompt = "a cat sitting on a bench"
|
||||
with autocast("cuda"):
|
||||
images = pipe(prompt=prompt, init_image=init_image, mask_image=mask_image, strength=0.75).images
|
||||
|
||||
images[0].save("cat_on_bench.png")
|
||||
```
|
||||
|
||||
You can also run this example on colab [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/in_painting_with_stable_diffusion_using_diffusers.ipynb)
|
||||
@@ -0,0 +1,15 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Loading
|
||||
|
||||
Under construction 🚧
|
||||
@@ -0,0 +1,52 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
|
||||
|
||||
# Unonditional Image Generation
|
||||
|
||||
The [`DiffusionPipeline`] is the easiest way to use a pre-trained diffusion system for inference
|
||||
|
||||
Start by creating an instance of [`DiffusionPipeline`] and specify which pipeline checkpoint you would like to download.
|
||||
You can use the [`DiffusionPipeline`] for any [Diffusers' checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads).
|
||||
In this guide though, you'll use [`DiffusionPipeline`] for unconditional image generation with [DDPM](https://arxiv.org/abs/2006.11239):
|
||||
|
||||
```python
|
||||
>>> from diffusers import DiffusionPipeline
|
||||
|
||||
>>> generator = DiffusionPipeline.from_pretrained("google/ddpm-celebahq-256")
|
||||
```
|
||||
The [`DiffusionPipeline`] downloads and caches all modeling, tokenization, and scheduling components.
|
||||
Because the model consists of roughly 1.4 billion parameters, we strongly recommend running it on GPU.
|
||||
You can move the generator object to GPU, just like you would in PyTorch.
|
||||
|
||||
```python
|
||||
>>> generator.to("cuda")
|
||||
```
|
||||
|
||||
Now you can use the `generator` on your text prompt:
|
||||
|
||||
```python
|
||||
>>> image = generator().images[0]
|
||||
```
|
||||
|
||||
The output is by default wrapped into a [PIL Image object](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class).
|
||||
|
||||
You can save the image by simply calling:
|
||||
|
||||
```python
|
||||
>>> image.save("generated_image.png")
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -0,0 +1,62 @@
|
||||
<!---
|
||||
Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
|
||||
# 🧨 Diffusers Examples
|
||||
|
||||
Diffusers examples are a collection of scripts to demonstrate how to effectively use the `diffusers` library
|
||||
for a variety of use cases.
|
||||
|
||||
**Note**: If you are looking for **official** examples on how to use `diffusers` for inference,
|
||||
please have a look at [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines)
|
||||
|
||||
Our examples aspire to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
|
||||
More specifically, this means:
|
||||
|
||||
- **Self-contained**: An example script shall only depend on "pip-install-able" Python packages that can be found in a `requirements.txt` file. Example scripts shall **not** depend on any local files. This means that one can simply download an example script, *e.g.* [train_unconditional.py](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/train_unconditional.py), install the required dependencies, *e.g.* [requirements.txt](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/requirements.txt) and execute the example script.
|
||||
- **Easy-to-tweak**: While we strive to present as many use cases as possible, the example scripts are just that - examples. It is expected that they won't work out-of-the box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs. To help you with that, most of the examples fully expose the preprocessing of the data and the training loop to allow you to tweak and edit them as required.
|
||||
- **Beginner-friendly**: We do not aim for providing state-of-the-art training scripts for the newest models, but rather examples that can be used as a way to better understand diffusion models and how to use them with the `diffusers` library. We often purposefully leave out certain state-of-the-art methods if we consider them too complex for beginners.
|
||||
- **One-purpose-only**: Examples should show one task and one task only. Even if a task is from a modeling
|
||||
point of view very similar, *e.g.* image super-resolution and image modification tend to use the same model and training method, we want examples to showcase only one task to keep them as readable and easy-to-understand as possible.
|
||||
|
||||
We provide **official** examples that cover the most popular tasks of diffusion models.
|
||||
*Official* examples are **actively** maintained by the `diffusers` maintainers and we try to rigorously follow our example philosophy as defined above.
|
||||
If you feel like another important example should exist, we are more than happy to welcome a [Feature Request](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=) or directly a [Pull Request](https://github.com/huggingface/diffusers/compare) from you!
|
||||
|
||||
Training examples show how to pretrain or fine-tune diffusion models for a variety of tasks. Currently we support:
|
||||
|
||||
| Task | 🤗 Accelerate | 🤗 Datasets | Colab
|
||||
|---|---|:---:|:---:|
|
||||
| [**Unconditional Image Generation**](https://github.com/huggingface/transformers/tree/main/examples/training/train_unconditional.py) | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
|
||||
|
||||
## Community
|
||||
|
||||
In addition, we provide **community** examples, which are examples added and maintained by our community.
|
||||
Community examples can consist of both *training* examples or *inference* pipelines.
|
||||
For such examples, we are more lenient regarding the philosophy defined above and also cannot guarantee to provide maintenance for every issue.
|
||||
Examples that are useful for the community, but are either not yet deemed popular or not yet following our above philosophy should go into the [community examples](https://github.com/huggingface/diffusers/tree/main/examples/community) folder. The community folder therefore includes training examples and inference pipelines.
|
||||
**Note**: Community examples can be a [great first contribution](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) to show to the community how you like to use `diffusers` 🪄.
|
||||
|
||||
## Important note
|
||||
|
||||
To make sure you can successfully run the latest versions of the example scripts, you have to **install the library from source** and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
Then cd in the example folder of your choice and run
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
@@ -0,0 +1,6 @@
|
||||
# Community Examples
|
||||
|
||||
**Community** examples consist of both inference and training examples that have been added by the community.
|
||||
|
||||
| Example | Description | Author | |
|
||||
|:----------|:-------------|:-------------|------:|
|
||||
@@ -0,0 +1,8 @@
|
||||
# Inference Examples
|
||||
|
||||
**The inference examples folder is deprecated and will be removed in a future version**.
|
||||
**Officially supported inference examples can be found in the [Pipelines folder](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines)**.
|
||||
|
||||
- For `Image-to-Image text-guided generation with Stable Diffusion`, please have a look at the official [Pipeline examples](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines#examples)
|
||||
- For `In-painting using Stable Diffusion`, please have a look at the official [Pipeline examples](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines#examples)
|
||||
- For `Tweak prompts reusing seeds and latents`, please have a look at the official [Pipeline examples](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines#examples)
|
||||
@@ -0,0 +1,9 @@
|
||||
import warnings
|
||||
|
||||
from diffusers import StableDiffusionImg2ImgPipeline # noqa F401
|
||||
|
||||
|
||||
warnings.warn(
|
||||
"The `image_to_image.py` script is outdated. Please use directly `from diffusers import"
|
||||
" StableDiffusionImg2ImgPipeline` instead."
|
||||
)
|
||||
@@ -0,0 +1,9 @@
|
||||
import warnings
|
||||
|
||||
from diffusers import StableDiffusionInpaintPipeline as StableDiffusionInpaintPipeline # noqa F401
|
||||
|
||||
|
||||
warnings.warn(
|
||||
"The `inpainting.py` script is outdated. Please use directly `from diffusers import"
|
||||
" StableDiffusionInpaintPipeline` instead."
|
||||
)
|
||||
@@ -0,0 +1,90 @@
|
||||
## Textual Inversion fine-tuning example
|
||||
|
||||
[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
|
||||
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
|
||||
|
||||
## Running on Colab
|
||||
|
||||
Colab for training
|
||||
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
|
||||
|
||||
Colab for inference
|
||||
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
|
||||
|
||||
## Running locally
|
||||
### Installing the dependencies
|
||||
|
||||
Before running the scipts, make sure to install the library's training dependencies:
|
||||
|
||||
```bash
|
||||
pip install diffusers[training] accelerate transformers
|
||||
```
|
||||
|
||||
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
|
||||
### Cat toy example
|
||||
|
||||
You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-4`, so you'll need to visit [its card](https://huggingface.co/CompVis/stable-diffusion-v1-4), read the license and tick the checkbox if you agree.
|
||||
|
||||
You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
|
||||
|
||||
Run the following command to autheticate your token
|
||||
|
||||
```bash
|
||||
huggingface-cli login
|
||||
```
|
||||
|
||||
If you have already cloned the repo, then you won't need to go through these steps. You can simple remove the `--use_auth_token` arg from the following command.
|
||||
|
||||
<br>
|
||||
|
||||
Now let's get our dataset.Download 3-4 images from [here](https://drive.google.com/drive/folders/1fmJMs25nxS_rSNqS5hTcRdLem_YQXbq5) and save them in a directory. This will be our training data.
|
||||
|
||||
And launch the training using
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
|
||||
export DATA_DIR="path-to-dir-containing-images"
|
||||
|
||||
accelerate launch textual_inversion.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME --use_auth_token \
|
||||
--train_data_dir=$DATA_DIR \
|
||||
--learnable_property="object" \
|
||||
--placeholder_token="<cat-toy>" --initializer_token="toy" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--max_train_steps=3000 \
|
||||
--learning_rate=5.0e-04 --scale_lr \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--output_dir="textual_inversion_cat"
|
||||
```
|
||||
|
||||
A full training run takes ~1 hour on one V100 GPU.
|
||||
|
||||
|
||||
### Inference
|
||||
|
||||
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `placeholder_token` in your prompt.
|
||||
|
||||
```python
|
||||
|
||||
from torch import autocast
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
model_id = "path-to-your-trained-model"
|
||||
pipe = StableDiffusionPipeline.from_pretrained(model_id,torch_dtype=torch.float16).to("cuda")
|
||||
|
||||
prompt = "A <cat-toy> backpack"
|
||||
|
||||
with autocast("cuda"):
|
||||
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
|
||||
|
||||
image.save("cat-backpack.png")
|
||||
```
|
||||
@@ -0,0 +1,3 @@
|
||||
accelerate
|
||||
torchvision
|
||||
transformers
|
||||
@@ -0,0 +1,579 @@
|
||||
import argparse
|
||||
import itertools
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import torch.utils.checkpoint
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
import PIL
|
||||
from accelerate import Accelerator
|
||||
from accelerate.logging import get_logger
|
||||
from accelerate.utils import set_seed
|
||||
from diffusers import AutoencoderKL, DDPMScheduler, PNDMScheduler, StableDiffusionPipeline, UNet2DConditionModel
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
|
||||
from huggingface_hub import HfFolder, Repository, whoami
|
||||
from PIL import Image
|
||||
from torchvision import transforms
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(description="Simple example of a training script.")
|
||||
parser.add_argument(
|
||||
"--pretrained_model_name_or_path",
|
||||
type=str,
|
||||
default=None,
|
||||
required=True,
|
||||
help="Path to pretrained model or model identifier from huggingface.co/models.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tokenizer_name",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Pretrained tokenizer name or path if not the same as model_name",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--placeholder_token",
|
||||
type=str,
|
||||
default=None,
|
||||
required=True,
|
||||
help="A token to use as a placeholder for the concept.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
|
||||
)
|
||||
parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
|
||||
parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
|
||||
parser.add_argument(
|
||||
"--output_dir",
|
||||
type=str,
|
||||
default="text-inversion-model",
|
||||
help="The output directory where the model predictions and checkpoints will be written.",
|
||||
)
|
||||
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
|
||||
parser.add_argument(
|
||||
"--resolution",
|
||||
type=int,
|
||||
default=512,
|
||||
help=(
|
||||
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
|
||||
" resolution"
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
|
||||
)
|
||||
parser.add_argument("--num_train_epochs", type=int, default=100)
|
||||
parser.add_argument(
|
||||
"--max_train_steps",
|
||||
type=int,
|
||||
default=5000,
|
||||
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--gradient_accumulation_steps",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of updates steps to accumulate before performing a backward/update pass.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--learning_rate",
|
||||
type=float,
|
||||
default=1e-4,
|
||||
help="Initial learning rate (after the potential warmup period) to use.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--scale_lr",
|
||||
action="store_true",
|
||||
default=True,
|
||||
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lr_scheduler",
|
||||
type=str,
|
||||
default="constant",
|
||||
help=(
|
||||
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
|
||||
' "constant", "constant_with_warmup"]'
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
|
||||
)
|
||||
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
|
||||
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
|
||||
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
|
||||
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
|
||||
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
|
||||
parser.add_argument(
|
||||
"--use_auth_token",
|
||||
action="store_true",
|
||||
help=(
|
||||
"Will use the token generated when running `huggingface-cli login` (necessary to use this script with"
|
||||
" private models)."
|
||||
),
|
||||
)
|
||||
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
|
||||
parser.add_argument(
|
||||
"--hub_model_id",
|
||||
type=str,
|
||||
default=None,
|
||||
help="The name of the repository to keep in sync with the local `output_dir`.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--logging_dir",
|
||||
type=str,
|
||||
default="logs",
|
||||
help=(
|
||||
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
|
||||
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="no",
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help=(
|
||||
"Whether to use mixed precision. Choose"
|
||||
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
|
||||
"and an Nvidia Ampere GPU."
|
||||
),
|
||||
)
|
||||
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
|
||||
|
||||
args = parser.parse_args()
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
if env_local_rank != -1 and env_local_rank != args.local_rank:
|
||||
args.local_rank = env_local_rank
|
||||
|
||||
if args.train_data_dir is None:
|
||||
raise ValueError("You must specify a train data directory.")
|
||||
|
||||
return args
|
||||
|
||||
|
||||
imagenet_templates_small = [
|
||||
"a photo of a {}",
|
||||
"a rendering of a {}",
|
||||
"a cropped photo of the {}",
|
||||
"the photo of a {}",
|
||||
"a photo of a clean {}",
|
||||
"a photo of a dirty {}",
|
||||
"a dark photo of the {}",
|
||||
"a photo of my {}",
|
||||
"a photo of the cool {}",
|
||||
"a close-up photo of a {}",
|
||||
"a bright photo of the {}",
|
||||
"a cropped photo of a {}",
|
||||
"a photo of the {}",
|
||||
"a good photo of the {}",
|
||||
"a photo of one {}",
|
||||
"a close-up photo of the {}",
|
||||
"a rendition of the {}",
|
||||
"a photo of the clean {}",
|
||||
"a rendition of a {}",
|
||||
"a photo of a nice {}",
|
||||
"a good photo of a {}",
|
||||
"a photo of the nice {}",
|
||||
"a photo of the small {}",
|
||||
"a photo of the weird {}",
|
||||
"a photo of the large {}",
|
||||
"a photo of a cool {}",
|
||||
"a photo of a small {}",
|
||||
]
|
||||
|
||||
imagenet_style_templates_small = [
|
||||
"a painting in the style of {}",
|
||||
"a rendering in the style of {}",
|
||||
"a cropped painting in the style of {}",
|
||||
"the painting in the style of {}",
|
||||
"a clean painting in the style of {}",
|
||||
"a dirty painting in the style of {}",
|
||||
"a dark painting in the style of {}",
|
||||
"a picture in the style of {}",
|
||||
"a cool painting in the style of {}",
|
||||
"a close-up painting in the style of {}",
|
||||
"a bright painting in the style of {}",
|
||||
"a cropped painting in the style of {}",
|
||||
"a good painting in the style of {}",
|
||||
"a close-up painting in the style of {}",
|
||||
"a rendition in the style of {}",
|
||||
"a nice painting in the style of {}",
|
||||
"a small painting in the style of {}",
|
||||
"a weird painting in the style of {}",
|
||||
"a large painting in the style of {}",
|
||||
]
|
||||
|
||||
|
||||
class TextualInversionDataset(Dataset):
|
||||
def __init__(
|
||||
self,
|
||||
data_root,
|
||||
tokenizer,
|
||||
learnable_property="object", # [object, style]
|
||||
size=512,
|
||||
repeats=100,
|
||||
interpolation="bicubic",
|
||||
flip_p=0.5,
|
||||
set="train",
|
||||
placeholder_token="*",
|
||||
center_crop=False,
|
||||
):
|
||||
|
||||
self.data_root = data_root
|
||||
self.tokenizer = tokenizer
|
||||
self.learnable_property = learnable_property
|
||||
self.size = size
|
||||
self.placeholder_token = placeholder_token
|
||||
self.center_crop = center_crop
|
||||
self.flip_p = flip_p
|
||||
|
||||
self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
|
||||
|
||||
self.num_images = len(self.image_paths)
|
||||
self._length = self.num_images
|
||||
|
||||
if set == "train":
|
||||
self._length = self.num_images * repeats
|
||||
|
||||
self.interpolation = {
|
||||
"linear": PIL.Image.LINEAR,
|
||||
"bilinear": PIL.Image.BILINEAR,
|
||||
"bicubic": PIL.Image.BICUBIC,
|
||||
"lanczos": PIL.Image.LANCZOS,
|
||||
}[interpolation]
|
||||
|
||||
self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
|
||||
self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
|
||||
|
||||
def __len__(self):
|
||||
return self._length
|
||||
|
||||
def __getitem__(self, i):
|
||||
example = {}
|
||||
image = Image.open(self.image_paths[i % self.num_images])
|
||||
|
||||
if not image.mode == "RGB":
|
||||
image = image.convert("RGB")
|
||||
|
||||
placeholder_string = self.placeholder_token
|
||||
text = random.choice(self.templates).format(placeholder_string)
|
||||
|
||||
example["input_ids"] = self.tokenizer(
|
||||
text,
|
||||
padding="max_length",
|
||||
truncation=True,
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
return_tensors="pt",
|
||||
).input_ids[0]
|
||||
|
||||
# default to score-sde preprocessing
|
||||
img = np.array(image).astype(np.uint8)
|
||||
|
||||
if self.center_crop:
|
||||
crop = min(img.shape[0], img.shape[1])
|
||||
h, w, = (
|
||||
img.shape[0],
|
||||
img.shape[1],
|
||||
)
|
||||
img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
|
||||
|
||||
image = Image.fromarray(img)
|
||||
image = image.resize((self.size, self.size), resample=self.interpolation)
|
||||
|
||||
image = self.flip_transform(image)
|
||||
image = np.array(image).astype(np.uint8)
|
||||
image = (image / 127.5 - 1.0).astype(np.float32)
|
||||
|
||||
example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
|
||||
return example
|
||||
|
||||
|
||||
def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
|
||||
if token is None:
|
||||
token = HfFolder.get_token()
|
||||
if organization is None:
|
||||
username = whoami(token)["name"]
|
||||
return f"{username}/{model_id}"
|
||||
else:
|
||||
return f"{organization}/{model_id}"
|
||||
|
||||
|
||||
def freeze_params(params):
|
||||
for param in params:
|
||||
param.requires_grad = False
|
||||
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
logging_dir = os.path.join(args.output_dir, args.logging_dir)
|
||||
|
||||
accelerator = Accelerator(
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
mixed_precision=args.mixed_precision,
|
||||
log_with="tensorboard",
|
||||
logging_dir=logging_dir,
|
||||
)
|
||||
|
||||
# If passed along, set the training seed now.
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed)
|
||||
|
||||
# Handle the repository creation
|
||||
if accelerator.is_main_process:
|
||||
if args.push_to_hub:
|
||||
if args.hub_model_id is None:
|
||||
repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
|
||||
else:
|
||||
repo_name = args.hub_model_id
|
||||
repo = Repository(args.output_dir, clone_from=repo_name)
|
||||
|
||||
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
|
||||
if "step_*" not in gitignore:
|
||||
gitignore.write("step_*\n")
|
||||
if "epoch_*" not in gitignore:
|
||||
gitignore.write("epoch_*\n")
|
||||
elif args.output_dir is not None:
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
|
||||
# Load the tokenizer and add the placeholder token as a additional special token
|
||||
if args.tokenizer_name:
|
||||
tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
|
||||
elif args.pretrained_model_name_or_path:
|
||||
tokenizer = CLIPTokenizer.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="tokenizer", use_auth_token=args.use_auth_token
|
||||
)
|
||||
|
||||
# Add the placeholder token in tokenizer
|
||||
num_added_tokens = tokenizer.add_tokens(args.placeholder_token)
|
||||
if num_added_tokens == 0:
|
||||
raise ValueError(
|
||||
f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
|
||||
" `placeholder_token` that is not already in the tokenizer."
|
||||
)
|
||||
|
||||
# Convert the initializer_token, placeholder_token to ids
|
||||
token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
|
||||
# Check if initializer_token is a single token or a sequence of tokens
|
||||
if len(token_ids) > 1:
|
||||
raise ValueError("The initializer token must be a single token.")
|
||||
|
||||
initializer_token_id = token_ids[0]
|
||||
placeholder_token_id = tokenizer.convert_tokens_to_ids(args.placeholder_token)
|
||||
|
||||
# Load models and create wrapper for stable diffusion
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="text_encoder", use_auth_token=args.use_auth_token
|
||||
)
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="vae", use_auth_token=args.use_auth_token
|
||||
)
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="unet", use_auth_token=args.use_auth_token
|
||||
)
|
||||
|
||||
# Resize the token embeddings as we are adding new special tokens to the tokenizer
|
||||
text_encoder.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
# Initialise the newly added placeholder token with the embeddings of the initializer token
|
||||
token_embeds = text_encoder.get_input_embeddings().weight.data
|
||||
token_embeds[placeholder_token_id] = token_embeds[initializer_token_id]
|
||||
|
||||
# Freeze vae and unet
|
||||
freeze_params(vae.parameters())
|
||||
freeze_params(unet.parameters())
|
||||
# Freeze all parameters except for the token embeddings in text encoder
|
||||
params_to_freeze = itertools.chain(
|
||||
text_encoder.text_model.encoder.parameters(),
|
||||
text_encoder.text_model.final_layer_norm.parameters(),
|
||||
text_encoder.text_model.embeddings.position_embedding.parameters(),
|
||||
)
|
||||
freeze_params(params_to_freeze)
|
||||
|
||||
if args.scale_lr:
|
||||
args.learning_rate = (
|
||||
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
|
||||
)
|
||||
|
||||
# Initialize the optimizer
|
||||
optimizer = torch.optim.AdamW(
|
||||
text_encoder.get_input_embeddings().parameters(), # only optimize the embeddings
|
||||
lr=args.learning_rate,
|
||||
betas=(args.adam_beta1, args.adam_beta2),
|
||||
weight_decay=args.adam_weight_decay,
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
# TODO (patil-suraj): laod scheduler using args
|
||||
noise_scheduler = DDPMScheduler(
|
||||
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000, tensor_format="pt"
|
||||
)
|
||||
|
||||
train_dataset = TextualInversionDataset(
|
||||
data_root=args.train_data_dir,
|
||||
tokenizer=tokenizer,
|
||||
size=args.resolution,
|
||||
placeholder_token=args.placeholder_token,
|
||||
repeats=args.repeats,
|
||||
learnable_property=args.learnable_property,
|
||||
center_crop=args.center_crop,
|
||||
set="train",
|
||||
)
|
||||
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=args.train_batch_size, shuffle=True)
|
||||
|
||||
# Scheduler and math around the number of training steps.
|
||||
overrode_max_train_steps = False
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
if args.max_train_steps is None:
|
||||
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
|
||||
overrode_max_train_steps = True
|
||||
|
||||
lr_scheduler = get_scheduler(
|
||||
args.lr_scheduler,
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
|
||||
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
|
||||
)
|
||||
|
||||
text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
text_encoder, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
# Move vae and unet to device
|
||||
vae.to(accelerator.device)
|
||||
unet.to(accelerator.device)
|
||||
|
||||
# Keep vae and unet in eval model as we don't train these
|
||||
vae.eval()
|
||||
unet.eval()
|
||||
|
||||
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
if overrode_max_train_steps:
|
||||
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
|
||||
# Afterwards we recalculate our number of training epochs
|
||||
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
|
||||
# We need to initialize the trackers we use, and also store our configuration.
|
||||
# The trackers initializes automatically on the main process.
|
||||
if accelerator.is_main_process:
|
||||
accelerator.init_trackers("textual_inversion", config=vars(args))
|
||||
|
||||
# Train!
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
|
||||
logger.info("***** Running training *****")
|
||||
logger.info(f" Num examples = {len(train_dataset)}")
|
||||
logger.info(f" Num Epochs = {args.num_train_epochs}")
|
||||
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
|
||||
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
|
||||
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
|
||||
logger.info(f" Total optimization steps = {args.max_train_steps}")
|
||||
# Only show the progress bar once on each machine.
|
||||
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
|
||||
progress_bar.set_description("Steps")
|
||||
global_step = 0
|
||||
|
||||
for epoch in range(args.num_train_epochs):
|
||||
text_encoder.train()
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
with accelerator.accumulate(text_encoder):
|
||||
# Convert images to latent space
|
||||
latents = vae.encode(batch["pixel_values"]).latent_dist.sample().detach()
|
||||
latents = latents * 0.18215
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn(latents.shape).to(latents.device)
|
||||
bsz = latents.shape[0]
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bsz,), device=latents.device).long()
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
|
||||
# Get the text embedding for conditioning
|
||||
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
|
||||
|
||||
# Predict the noise residual
|
||||
noise_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
|
||||
|
||||
loss = F.mse_loss(noise_pred, noise, reduction="none").mean([1, 2, 3]).mean()
|
||||
accelerator.backward(loss)
|
||||
|
||||
# Zero out the gradients for all token embeddings except the newly added
|
||||
# embeddings for the concept, as we only want to optimize the concept embeddings
|
||||
if accelerator.num_processes > 1:
|
||||
grads = text_encoder.module.get_input_embeddings().weight.grad
|
||||
else:
|
||||
grads = text_encoder.get_input_embeddings().weight.grad
|
||||
# Get the index for tokens that we want to zero the grads for
|
||||
index_grads_to_zero = torch.arange(len(tokenizer)) != placeholder_token_id
|
||||
grads.data[index_grads_to_zero, :] = grads.data[index_grads_to_zero, :].fill_(0)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# Create the pipeline using using the trained modules and save it.
|
||||
if accelerator.is_main_process:
|
||||
pipeline = StableDiffusionPipeline(
|
||||
text_encoder=accelerator.unwrap_model(text_encoder),
|
||||
vae=vae,
|
||||
unet=unet,
|
||||
tokenizer=tokenizer,
|
||||
scheduler=PNDMScheduler(
|
||||
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", skip_prk_steps=True
|
||||
),
|
||||
safety_checker=StableDiffusionSafetyChecker.from_pretrained("CompVis/stable-diffusion-safety-checker"),
|
||||
feature_extractor=CLIPFeatureExtractor.from_pretrained("openai/clip-vit-base-patch32"),
|
||||
)
|
||||
pipeline.save_pretrained(args.output_dir)
|
||||
# Also save the newly trained embeddings
|
||||
learned_embeds = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[placeholder_token_id]
|
||||
learned_embeds_dict = {args.placeholder_token: learned_embeds.detach().cpu()}
|
||||
torch.save(learned_embeds_dict, os.path.join(args.output_dir, "learned_embeds.bin"))
|
||||
|
||||
if args.push_to_hub:
|
||||
repo.push_to_hub(
|
||||
args, pipeline, repo, commit_message="End of training", blocking=False, auto_lfs_prune=True
|
||||
)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -1,159 +0,0 @@
|
||||
import argparse
|
||||
import os
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
import PIL.Image
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from diffusers import DDPM, DDPMScheduler, UNetModel
|
||||
from torchvision.transforms import (
|
||||
CenterCrop,
|
||||
Compose,
|
||||
InterpolationMode,
|
||||
Lambda,
|
||||
RandomHorizontalFlip,
|
||||
Resize,
|
||||
ToTensor,
|
||||
)
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import get_linear_schedule_with_warmup
|
||||
|
||||
|
||||
def main(args):
|
||||
accelerator = Accelerator(mixed_precision=args.mixed_precision)
|
||||
|
||||
model = UNetModel(
|
||||
attn_resolutions=(16,),
|
||||
ch=128,
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
dropout=0.0,
|
||||
num_res_blocks=2,
|
||||
resamp_with_conv=True,
|
||||
resolution=args.resolution,
|
||||
)
|
||||
noise_scheduler = DDPMScheduler(timesteps=1000)
|
||||
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
|
||||
|
||||
augmentations = Compose(
|
||||
[
|
||||
Resize(args.resolution, interpolation=InterpolationMode.BILINEAR),
|
||||
CenterCrop(args.resolution),
|
||||
RandomHorizontalFlip(),
|
||||
ToTensor(),
|
||||
Lambda(lambda x: x * 2 - 1),
|
||||
]
|
||||
)
|
||||
dataset = load_dataset(args.dataset, split="train")
|
||||
|
||||
def transforms(examples):
|
||||
images = [augmentations(image.convert("RGB")) for image in examples["image"]]
|
||||
return {"input": images}
|
||||
|
||||
dataset.set_transform(transforms)
|
||||
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=args.batch_size, shuffle=True)
|
||||
|
||||
lr_scheduler = get_linear_schedule_with_warmup(
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.warmup_steps,
|
||||
num_training_steps=(len(train_dataloader) * args.num_epochs) // args.gradient_accumulation_steps,
|
||||
)
|
||||
|
||||
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
for epoch in range(args.num_epochs):
|
||||
model.train()
|
||||
with tqdm(total=len(train_dataloader), unit="ba") as pbar:
|
||||
pbar.set_description(f"Epoch {epoch}")
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
clean_images = batch["input"]
|
||||
noisy_images = torch.empty_like(clean_images)
|
||||
noise_samples = torch.empty_like(clean_images)
|
||||
bsz = clean_images.shape[0]
|
||||
|
||||
timesteps = torch.randint(0, noise_scheduler.timesteps, (bsz,), device=clean_images.device).long()
|
||||
for idx in range(bsz):
|
||||
noise = torch.randn(clean_images.shape[1:]).to(clean_images.device)
|
||||
noise_samples[idx] = noise
|
||||
noisy_images[idx] = noise_scheduler.forward_step(clean_images[idx], noise, timesteps[idx])
|
||||
|
||||
if step % args.gradient_accumulation_steps != 0:
|
||||
with accelerator.no_sync(model):
|
||||
output = model(noisy_images, timesteps)
|
||||
# predict the noise residual
|
||||
loss = F.mse_loss(output, noise_samples)
|
||||
accelerator.backward(loss)
|
||||
else:
|
||||
output = model(noisy_images, timesteps)
|
||||
# predict the noise residual
|
||||
loss = F.mse_loss(output, noise_samples)
|
||||
accelerator.backward(loss)
|
||||
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
pbar.update(1)
|
||||
pbar.set_postfix(loss=loss.detach().item(), lr=optimizer.param_groups[0]["lr"])
|
||||
|
||||
optimizer.step()
|
||||
|
||||
# Generate a sample image for visual inspection
|
||||
torch.distributed.barrier()
|
||||
if args.local_rank in [-1, 0]:
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
if isinstance(model, torch.nn.parallel.DistributedDataParallel):
|
||||
pipeline = DDPM(unet=model.module, noise_scheduler=noise_scheduler)
|
||||
else:
|
||||
pipeline = DDPM(unet=model, noise_scheduler=noise_scheduler)
|
||||
pipeline.save_pretrained(args.output_path)
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
image = pipeline(generator=generator)
|
||||
|
||||
# process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.type(torch.uint8).numpy()
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
test_dir = os.path.join(args.output_path, "test_samples")
|
||||
os.makedirs(test_dir, exist_ok=True)
|
||||
image_pil.save(f"{test_dir}/{epoch}.png")
|
||||
torch.distributed.barrier()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Simple example of a training script.")
|
||||
parser.add_argument("--local_rank", type=int)
|
||||
parser.add_argument("--dataset", type=str, default="huggan/flowers-102-categories")
|
||||
parser.add_argument("--resolution", type=int, default=64)
|
||||
parser.add_argument("--output_path", type=str, default="ddpm-model")
|
||||
parser.add_argument("--batch_size", type=int, default=16)
|
||||
parser.add_argument("--num_epochs", type=int, default=100)
|
||||
parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
|
||||
parser.add_argument("--lr", type=float, default=1e-4)
|
||||
parser.add_argument("--warmup_steps", type=int, default=500)
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="no",
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help=(
|
||||
"Whether to use mixed precision. Choose"
|
||||
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
|
||||
"and an Nvidia Ampere GPU."
|
||||
),
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
if env_local_rank != -1 and env_local_rank != args.local_rank:
|
||||
args.local_rank = env_local_rank
|
||||
|
||||
main(args)
|
||||
@@ -0,0 +1,129 @@
|
||||
## Training examples
|
||||
|
||||
Creating a training image set is [described in a different document](https://huggingface.co/docs/datasets/image_process#image-datasets).
|
||||
|
||||
### Installing the dependencies
|
||||
|
||||
Before running the scipts, make sure to install the library's training dependencies:
|
||||
|
||||
```bash
|
||||
pip install diffusers[training] accelerate datasets
|
||||
```
|
||||
|
||||
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
### Unconditional Flowers
|
||||
|
||||
The command to train a DDPM UNet model on the Oxford Flowers dataset:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
--dataset_name="huggan/flowers-102-categories" \
|
||||
--resolution=64 \
|
||||
--output_dir="ddpm-ema-flowers-64" \
|
||||
--train_batch_size=16 \
|
||||
--num_epochs=100 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-4 \
|
||||
--lr_warmup_steps=500 \
|
||||
--mixed_precision=no \
|
||||
--push_to_hub
|
||||
```
|
||||
An example trained model: https://huggingface.co/anton-l/ddpm-ema-flowers-64
|
||||
|
||||
A full training run takes 2 hours on 4xV100 GPUs.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26864830/180248660-a0b143d0-b89a-42c5-8656-2ebf6ece7e52.png" width="700" />
|
||||
|
||||
|
||||
### Unconditional Pokemon
|
||||
|
||||
The command to train a DDPM UNet model on the Pokemon dataset:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
--dataset_name="huggan/pokemon" \
|
||||
--resolution=64 \
|
||||
--output_dir="ddpm-ema-pokemon-64" \
|
||||
--train_batch_size=16 \
|
||||
--num_epochs=100 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-4 \
|
||||
--lr_warmup_steps=500 \
|
||||
--mixed_precision=no \
|
||||
--push_to_hub
|
||||
```
|
||||
An example trained model: https://huggingface.co/anton-l/ddpm-ema-pokemon-64
|
||||
|
||||
A full training run takes 2 hours on 4xV100 GPUs.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26864830/180248200-928953b4-db38-48db-b0c6-8b740fe6786f.png" width="700" />
|
||||
|
||||
|
||||
### Using your own data
|
||||
|
||||
To use your own dataset, there are 2 ways:
|
||||
- you can either provide your own folder as `--train_data_dir`
|
||||
- or you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
|
||||
|
||||
Below, we explain both in more detail.
|
||||
|
||||
#### Provide the dataset as a folder
|
||||
|
||||
If you provide your own folders with images, the script expects the following directory structure:
|
||||
|
||||
```bash
|
||||
data_dir/xxx.png
|
||||
data_dir/xxy.png
|
||||
data_dir/[...]/xxz.png
|
||||
```
|
||||
|
||||
In other words, the script will take care of gathering all images inside the folder. You can then run the script like this:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
--train_data_dir <path-to-train-directory> \
|
||||
<other-arguments>
|
||||
```
|
||||
|
||||
Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
|
||||
|
||||
#### Upload your data to the hub, as a (possibly private) repo
|
||||
|
||||
It's very easy (and convenient) to upload your image dataset to the hub using the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
|
||||
# example 1: local folder
|
||||
dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
|
||||
|
||||
# example 2: local files (suppoted formats are tar, gzip, zip, xz, rar, zstd)
|
||||
dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
|
||||
|
||||
# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
|
||||
dataset = load_dataset("imagefolder", data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip")
|
||||
|
||||
# example 4: providing several splits
|
||||
dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
|
||||
```
|
||||
|
||||
`ImageFolder` will create an `image` column containing the PIL-encoded images.
|
||||
|
||||
Next, push it to the hub!
|
||||
|
||||
```python
|
||||
# assuming you have ran the huggingface-cli login command in a terminal
|
||||
dataset.push_to_hub("name_of_your_dataset")
|
||||
|
||||
# if you want to push to a private repo, simply pass private=True:
|
||||
dataset.push_to_hub("name_of_your_dataset", private=True)
|
||||
```
|
||||
|
||||
and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub.
|
||||
|
||||
More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
|
||||
@@ -0,0 +1,3 @@
|
||||
accelerate
|
||||
torchvision
|
||||
datasets
|
||||
@@ -0,0 +1,249 @@
|
||||
import argparse
|
||||
import math
|
||||
import os
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
from accelerate import Accelerator
|
||||
from accelerate.logging import get_logger
|
||||
from datasets import load_dataset
|
||||
from diffusers import DDPMPipeline, DDPMScheduler, UNet2DModel
|
||||
from diffusers.hub_utils import init_git_repo, push_to_hub
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.training_utils import EMAModel
|
||||
from torchvision.transforms import (
|
||||
CenterCrop,
|
||||
Compose,
|
||||
InterpolationMode,
|
||||
Normalize,
|
||||
RandomHorizontalFlip,
|
||||
Resize,
|
||||
ToTensor,
|
||||
)
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
def main(args):
|
||||
logging_dir = os.path.join(args.output_dir, args.logging_dir)
|
||||
accelerator = Accelerator(
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
mixed_precision=args.mixed_precision,
|
||||
log_with="tensorboard",
|
||||
logging_dir=logging_dir,
|
||||
)
|
||||
|
||||
model = UNet2DModel(
|
||||
sample_size=args.resolution,
|
||||
in_channels=3,
|
||||
out_channels=3,
|
||||
layers_per_block=2,
|
||||
block_out_channels=(128, 128, 256, 256, 512, 512),
|
||||
down_block_types=(
|
||||
"DownBlock2D",
|
||||
"DownBlock2D",
|
||||
"DownBlock2D",
|
||||
"DownBlock2D",
|
||||
"AttnDownBlock2D",
|
||||
"DownBlock2D",
|
||||
),
|
||||
up_block_types=(
|
||||
"UpBlock2D",
|
||||
"AttnUpBlock2D",
|
||||
"UpBlock2D",
|
||||
"UpBlock2D",
|
||||
"UpBlock2D",
|
||||
"UpBlock2D",
|
||||
),
|
||||
)
|
||||
noise_scheduler = DDPMScheduler(num_train_timesteps=1000, tensor_format="pt")
|
||||
optimizer = torch.optim.AdamW(
|
||||
model.parameters(),
|
||||
lr=args.learning_rate,
|
||||
betas=(args.adam_beta1, args.adam_beta2),
|
||||
weight_decay=args.adam_weight_decay,
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
augmentations = Compose(
|
||||
[
|
||||
Resize(args.resolution, interpolation=InterpolationMode.BILINEAR),
|
||||
CenterCrop(args.resolution),
|
||||
RandomHorizontalFlip(),
|
||||
ToTensor(),
|
||||
Normalize([0.5], [0.5]),
|
||||
]
|
||||
)
|
||||
|
||||
if args.dataset_name is not None:
|
||||
dataset = load_dataset(
|
||||
args.dataset_name,
|
||||
args.dataset_config_name,
|
||||
cache_dir=args.cache_dir,
|
||||
use_auth_token=True if args.use_auth_token else None,
|
||||
split="train",
|
||||
)
|
||||
else:
|
||||
dataset = load_dataset("imagefolder", data_dir=args.train_data_dir, cache_dir=args.cache_dir, split="train")
|
||||
|
||||
def transforms(examples):
|
||||
images = [augmentations(image.convert("RGB")) for image in examples["image"]]
|
||||
return {"input": images}
|
||||
|
||||
dataset.set_transform(transforms)
|
||||
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=args.train_batch_size, shuffle=True)
|
||||
|
||||
lr_scheduler = get_scheduler(
|
||||
args.lr_scheduler,
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.lr_warmup_steps,
|
||||
num_training_steps=(len(train_dataloader) * args.num_epochs) // args.gradient_accumulation_steps,
|
||||
)
|
||||
|
||||
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
|
||||
ema_model = EMAModel(model, inv_gamma=args.ema_inv_gamma, power=args.ema_power, max_value=args.ema_max_decay)
|
||||
|
||||
if args.push_to_hub:
|
||||
repo = init_git_repo(args, at_init=True)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
run = os.path.split(__file__)[-1].split(".")[0]
|
||||
accelerator.init_trackers(run)
|
||||
|
||||
global_step = 0
|
||||
for epoch in range(args.num_epochs):
|
||||
model.train()
|
||||
progress_bar = tqdm(total=num_update_steps_per_epoch, disable=not accelerator.is_local_main_process)
|
||||
progress_bar.set_description(f"Epoch {epoch}")
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
clean_images = batch["input"]
|
||||
# Sample noise that we'll add to the images
|
||||
noise = torch.randn(clean_images.shape).to(clean_images.device)
|
||||
bsz = clean_images.shape[0]
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(
|
||||
0, noise_scheduler.num_train_timesteps, (bsz,), device=clean_images.device
|
||||
).long()
|
||||
|
||||
# Add noise to the clean images according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
|
||||
|
||||
with accelerator.accumulate(model):
|
||||
# Predict the noise residual
|
||||
noise_pred = model(noisy_images, timesteps).sample
|
||||
loss = F.mse_loss(noise_pred, noise)
|
||||
accelerator.backward(loss)
|
||||
|
||||
accelerator.clip_grad_norm_(model.parameters(), 1.0)
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
if args.use_ema:
|
||||
ema_model.step(model)
|
||||
optimizer.zero_grad()
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
|
||||
if args.use_ema:
|
||||
logs["ema_decay"] = ema_model.decay
|
||||
progress_bar.set_postfix(**logs)
|
||||
accelerator.log(logs, step=global_step)
|
||||
progress_bar.close()
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# Generate sample images for visual inspection
|
||||
if accelerator.is_main_process:
|
||||
if epoch % args.save_images_epochs == 0 or epoch == args.num_epochs - 1:
|
||||
pipeline = DDPMPipeline(
|
||||
unet=accelerator.unwrap_model(ema_model.averaged_model if args.use_ema else model),
|
||||
scheduler=noise_scheduler,
|
||||
)
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
images = pipeline(generator=generator, batch_size=args.eval_batch_size, output_type="numpy").images
|
||||
|
||||
# denormalize the images and save to tensorboard
|
||||
images_processed = (images * 255).round().astype("uint8")
|
||||
accelerator.trackers[0].writer.add_images(
|
||||
"test_samples", images_processed.transpose(0, 3, 1, 2), epoch
|
||||
)
|
||||
|
||||
if epoch % args.save_model_epochs == 0 or epoch == args.num_epochs - 1:
|
||||
# save the model
|
||||
if args.push_to_hub:
|
||||
push_to_hub(args, pipeline, repo, commit_message=f"Epoch {epoch}", blocking=False)
|
||||
else:
|
||||
pipeline.save_pretrained(args.output_dir)
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Simple example of a training script.")
|
||||
parser.add_argument("--local_rank", type=int, default=-1)
|
||||
parser.add_argument("--dataset_name", type=str, default=None)
|
||||
parser.add_argument("--dataset_config_name", type=str, default=None)
|
||||
parser.add_argument("--train_data_dir", type=str, default=None, help="A folder containing the training data.")
|
||||
parser.add_argument("--output_dir", type=str, default="ddpm-model-64")
|
||||
parser.add_argument("--overwrite_output_dir", action="store_true")
|
||||
parser.add_argument("--cache_dir", type=str, default=None)
|
||||
parser.add_argument("--resolution", type=int, default=64)
|
||||
parser.add_argument("--train_batch_size", type=int, default=16)
|
||||
parser.add_argument("--eval_batch_size", type=int, default=16)
|
||||
parser.add_argument("--num_epochs", type=int, default=100)
|
||||
parser.add_argument("--save_images_epochs", type=int, default=10)
|
||||
parser.add_argument("--save_model_epochs", type=int, default=10)
|
||||
parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
|
||||
parser.add_argument("--learning_rate", type=float, default=1e-4)
|
||||
parser.add_argument("--lr_scheduler", type=str, default="cosine")
|
||||
parser.add_argument("--lr_warmup_steps", type=int, default=500)
|
||||
parser.add_argument("--adam_beta1", type=float, default=0.95)
|
||||
parser.add_argument("--adam_beta2", type=float, default=0.999)
|
||||
parser.add_argument("--adam_weight_decay", type=float, default=1e-6)
|
||||
parser.add_argument("--adam_epsilon", type=float, default=1e-08)
|
||||
parser.add_argument("--use_ema", action="store_true", default=True)
|
||||
parser.add_argument("--ema_inv_gamma", type=float, default=1.0)
|
||||
parser.add_argument("--ema_power", type=float, default=3 / 4)
|
||||
parser.add_argument("--ema_max_decay", type=float, default=0.9999)
|
||||
parser.add_argument("--push_to_hub", action="store_true")
|
||||
parser.add_argument("--use_auth_token", action="store_true")
|
||||
parser.add_argument("--hub_token", type=str, default=None)
|
||||
parser.add_argument("--hub_model_id", type=str, default=None)
|
||||
parser.add_argument("--hub_private_repo", action="store_true")
|
||||
parser.add_argument("--logging_dir", type=str, default="logs")
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="no",
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help=(
|
||||
"Whether to use mixed precision. Choose"
|
||||
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
|
||||
"and an Nvidia Ampere GPU."
|
||||
),
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
if env_local_rank != -1 and env_local_rank != args.local_rank:
|
||||
args.local_rank = env_local_rank
|
||||
|
||||
if args.dataset_name is None and args.train_data_dir is None:
|
||||
raise ValueError("You must specify either a dataset name from the hub or a train data directory.")
|
||||
|
||||
main(args)
|
||||
@@ -0,0 +1,113 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for the LDM checkpoints. """
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
|
||||
import torch
|
||||
|
||||
from diffusers import UNet2DConditionModel, UNet2DModel
|
||||
from transformers.file_utils import has_file
|
||||
|
||||
|
||||
do_only_config = False
|
||||
do_only_weights = True
|
||||
do_only_renaming = False
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--repo_path",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="The config json file corresponding to the architecture.",
|
||||
)
|
||||
|
||||
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
config_parameters_to_change = {
|
||||
"image_size": "sample_size",
|
||||
"num_res_blocks": "layers_per_block",
|
||||
"block_channels": "block_out_channels",
|
||||
"down_blocks": "down_block_types",
|
||||
"up_blocks": "up_block_types",
|
||||
"downscale_freq_shift": "freq_shift",
|
||||
"resnet_num_groups": "norm_num_groups",
|
||||
"resnet_act_fn": "act_fn",
|
||||
"resnet_eps": "norm_eps",
|
||||
"num_head_channels": "attention_head_dim",
|
||||
}
|
||||
|
||||
key_parameters_to_change = {
|
||||
"time_steps": "time_proj",
|
||||
"mid": "mid_block",
|
||||
"downsample_blocks": "down_blocks",
|
||||
"upsample_blocks": "up_blocks",
|
||||
}
|
||||
|
||||
subfolder = "" if has_file(args.repo_path, "config.json") else "unet"
|
||||
|
||||
with open(os.path.join(args.repo_path, subfolder, "config.json"), "r", encoding="utf-8") as reader:
|
||||
text = reader.read()
|
||||
config = json.loads(text)
|
||||
|
||||
if do_only_config:
|
||||
for key in config_parameters_to_change.keys():
|
||||
config.pop(key, None)
|
||||
|
||||
if has_file(args.repo_path, "config.json"):
|
||||
model = UNet2DModel(**config)
|
||||
else:
|
||||
class_name = UNet2DConditionModel if "ldm-text2im-large-256" in args.repo_path else UNet2DModel
|
||||
model = class_name(**config)
|
||||
|
||||
if do_only_config:
|
||||
model.save_config(os.path.join(args.repo_path, subfolder))
|
||||
|
||||
config = dict(model.config)
|
||||
|
||||
if do_only_renaming:
|
||||
for key, value in config_parameters_to_change.items():
|
||||
if key in config:
|
||||
config[value] = config[key]
|
||||
del config[key]
|
||||
|
||||
config["down_block_types"] = [k.replace("UNetRes", "") for k in config["down_block_types"]]
|
||||
config["up_block_types"] = [k.replace("UNetRes", "") for k in config["up_block_types"]]
|
||||
|
||||
if do_only_weights:
|
||||
state_dict = torch.load(os.path.join(args.repo_path, subfolder, "diffusion_pytorch_model.bin"))
|
||||
|
||||
new_state_dict = {}
|
||||
for param_key, param_value in state_dict.items():
|
||||
if param_key.endswith(".op.bias") or param_key.endswith(".op.weight"):
|
||||
continue
|
||||
has_changed = False
|
||||
for key, new_key in key_parameters_to_change.items():
|
||||
if not has_changed and param_key.split(".")[0] == key:
|
||||
new_state_dict[".".join([new_key] + param_key.split(".")[1:])] = param_value
|
||||
has_changed = True
|
||||
if not has_changed:
|
||||
new_state_dict[param_key] = param_value
|
||||
|
||||
model.load_state_dict(new_state_dict)
|
||||
model.save_pretrained(os.path.join(args.repo_path, subfolder))
|
||||
@@ -0,0 +1,56 @@
|
||||
import argparse
|
||||
|
||||
import torch
|
||||
|
||||
import OmegaConf
|
||||
from diffusers import DDIMScheduler, LDMPipeline, UNetLDMModel, VQModel
|
||||
|
||||
|
||||
def convert_ldm_original(checkpoint_path, config_path, output_path):
|
||||
config = OmegaConf.load(config_path)
|
||||
state_dict = torch.load(checkpoint_path, map_location="cpu")["model"]
|
||||
keys = list(state_dict.keys())
|
||||
|
||||
# extract state_dict for VQVAE
|
||||
first_stage_dict = {}
|
||||
first_stage_key = "first_stage_model."
|
||||
for key in keys:
|
||||
if key.startswith(first_stage_key):
|
||||
first_stage_dict[key.replace(first_stage_key, "")] = state_dict[key]
|
||||
|
||||
# extract state_dict for UNetLDM
|
||||
unet_state_dict = {}
|
||||
unet_key = "model.diffusion_model."
|
||||
for key in keys:
|
||||
if key.startswith(unet_key):
|
||||
unet_state_dict[key.replace(unet_key, "")] = state_dict[key]
|
||||
|
||||
vqvae_init_args = config.model.params.first_stage_config.params
|
||||
unet_init_args = config.model.params.unet_config.params
|
||||
|
||||
vqvae = VQModel(**vqvae_init_args).eval()
|
||||
vqvae.load_state_dict(first_stage_dict)
|
||||
|
||||
unet = UNetLDMModel(**unet_init_args).eval()
|
||||
unet.load_state_dict(unet_state_dict)
|
||||
|
||||
noise_scheduler = DDIMScheduler(
|
||||
timesteps=config.model.params.timesteps,
|
||||
beta_schedule="scaled_linear",
|
||||
beta_start=config.model.params.linear_start,
|
||||
beta_end=config.model.params.linear_end,
|
||||
clip_sample=False,
|
||||
)
|
||||
|
||||
pipeline = LDMPipeline(vqvae, unet, noise_scheduler)
|
||||
pipeline.save_pretrained(output_path)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--checkpoint_path", type=str, required=True)
|
||||
parser.add_argument("--config_path", type=str, required=True)
|
||||
parser.add_argument("--output_path", type=str, required=True)
|
||||
args = parser.parse_args()
|
||||
|
||||
convert_ldm_original(args.checkpoint_path, args.config_path, args.output_path)
|
||||
@@ -0,0 +1,431 @@
|
||||
import argparse
|
||||
import json
|
||||
|
||||
import torch
|
||||
|
||||
from diffusers import AutoencoderKL, DDPMPipeline, DDPMScheduler, UNet2DModel, VQModel
|
||||
|
||||
|
||||
def shave_segments(path, n_shave_prefix_segments=1):
|
||||
"""
|
||||
Removes segments. Positive values shave the first segments, negative shave the last segments.
|
||||
"""
|
||||
if n_shave_prefix_segments >= 0:
|
||||
return ".".join(path.split(".")[n_shave_prefix_segments:])
|
||||
else:
|
||||
return ".".join(path.split(".")[:n_shave_prefix_segments])
|
||||
|
||||
|
||||
def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
|
||||
mapping = []
|
||||
for old_item in old_list:
|
||||
new_item = old_item
|
||||
new_item = new_item.replace("block.", "resnets.")
|
||||
new_item = new_item.replace("conv_shorcut", "conv1")
|
||||
new_item = new_item.replace("nin_shortcut", "conv_shortcut")
|
||||
new_item = new_item.replace("temb_proj", "time_emb_proj")
|
||||
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
|
||||
mapping.append({"old": old_item, "new": new_item})
|
||||
|
||||
return mapping
|
||||
|
||||
|
||||
def renew_attention_paths(old_list, n_shave_prefix_segments=0, in_mid=False):
|
||||
mapping = []
|
||||
for old_item in old_list:
|
||||
new_item = old_item
|
||||
|
||||
# In `model.mid`, the layer is called `attn`.
|
||||
if not in_mid:
|
||||
new_item = new_item.replace("attn", "attentions")
|
||||
new_item = new_item.replace(".k.", ".key.")
|
||||
new_item = new_item.replace(".v.", ".value.")
|
||||
new_item = new_item.replace(".q.", ".query.")
|
||||
|
||||
new_item = new_item.replace("proj_out", "proj_attn")
|
||||
new_item = new_item.replace("norm", "group_norm")
|
||||
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
mapping.append({"old": old_item, "new": new_item})
|
||||
|
||||
return mapping
|
||||
|
||||
|
||||
def assign_to_checkpoint(
|
||||
paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
|
||||
):
|
||||
assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
|
||||
|
||||
if attention_paths_to_split is not None:
|
||||
if config is None:
|
||||
raise ValueError("Please specify the config if setting 'attention_paths_to_split' to 'True'.")
|
||||
|
||||
for path, path_map in attention_paths_to_split.items():
|
||||
old_tensor = old_checkpoint[path]
|
||||
channels = old_tensor.shape[0] // 3
|
||||
|
||||
target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
|
||||
|
||||
num_heads = old_tensor.shape[0] // config.get("num_head_channels", 1) // 3
|
||||
|
||||
old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
|
||||
query, key, value = old_tensor.split(channels // num_heads, dim=1)
|
||||
|
||||
checkpoint[path_map["query"]] = query.reshape(target_shape).squeeze()
|
||||
checkpoint[path_map["key"]] = key.reshape(target_shape).squeeze()
|
||||
checkpoint[path_map["value"]] = value.reshape(target_shape).squeeze()
|
||||
|
||||
for path in paths:
|
||||
new_path = path["new"]
|
||||
|
||||
if attention_paths_to_split is not None and new_path in attention_paths_to_split:
|
||||
continue
|
||||
|
||||
new_path = new_path.replace("down.", "down_blocks.")
|
||||
new_path = new_path.replace("up.", "up_blocks.")
|
||||
|
||||
if additional_replacements is not None:
|
||||
for replacement in additional_replacements:
|
||||
new_path = new_path.replace(replacement["old"], replacement["new"])
|
||||
|
||||
if "attentions" in new_path:
|
||||
checkpoint[new_path] = old_checkpoint[path["old"]].squeeze()
|
||||
else:
|
||||
checkpoint[new_path] = old_checkpoint[path["old"]]
|
||||
|
||||
|
||||
def convert_ddpm_checkpoint(checkpoint, config):
|
||||
"""
|
||||
Takes a state dict and a config, and returns a converted checkpoint.
|
||||
"""
|
||||
new_checkpoint = {}
|
||||
|
||||
new_checkpoint["time_embedding.linear_1.weight"] = checkpoint["temb.dense.0.weight"]
|
||||
new_checkpoint["time_embedding.linear_1.bias"] = checkpoint["temb.dense.0.bias"]
|
||||
new_checkpoint["time_embedding.linear_2.weight"] = checkpoint["temb.dense.1.weight"]
|
||||
new_checkpoint["time_embedding.linear_2.bias"] = checkpoint["temb.dense.1.bias"]
|
||||
|
||||
new_checkpoint["conv_norm_out.weight"] = checkpoint["norm_out.weight"]
|
||||
new_checkpoint["conv_norm_out.bias"] = checkpoint["norm_out.bias"]
|
||||
|
||||
new_checkpoint["conv_in.weight"] = checkpoint["conv_in.weight"]
|
||||
new_checkpoint["conv_in.bias"] = checkpoint["conv_in.bias"]
|
||||
new_checkpoint["conv_out.weight"] = checkpoint["conv_out.weight"]
|
||||
new_checkpoint["conv_out.bias"] = checkpoint["conv_out.bias"]
|
||||
|
||||
num_down_blocks = len({".".join(layer.split(".")[:2]) for layer in checkpoint if "down" in layer})
|
||||
down_blocks = {
|
||||
layer_id: [key for key in checkpoint if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
|
||||
}
|
||||
|
||||
num_up_blocks = len({".".join(layer.split(".")[:2]) for layer in checkpoint if "up" in layer})
|
||||
up_blocks = {layer_id: [key for key in checkpoint if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)}
|
||||
|
||||
for i in range(num_down_blocks):
|
||||
block_id = (i - 1) // (config["layers_per_block"] + 1)
|
||||
|
||||
if any("downsample" in layer for layer in down_blocks[i]):
|
||||
new_checkpoint[f"down_blocks.{i}.downsamplers.0.conv.weight"] = checkpoint[
|
||||
f"down.{i}.downsample.op.weight"
|
||||
]
|
||||
new_checkpoint[f"down_blocks.{i}.downsamplers.0.conv.bias"] = checkpoint[f"down.{i}.downsample.op.bias"]
|
||||
# new_checkpoint[f'down_blocks.{i}.downsamplers.0.op.weight'] = checkpoint[f'down.{i}.downsample.conv.weight']
|
||||
# new_checkpoint[f'down_blocks.{i}.downsamplers.0.op.bias'] = checkpoint[f'down.{i}.downsample.conv.bias']
|
||||
|
||||
if any("block" in layer for layer in down_blocks[i]):
|
||||
num_blocks = len(
|
||||
{".".join(shave_segments(layer, 2).split(".")[:2]) for layer in down_blocks[i] if "block" in layer}
|
||||
)
|
||||
blocks = {
|
||||
layer_id: [key for key in down_blocks[i] if f"block.{layer_id}" in key]
|
||||
for layer_id in range(num_blocks)
|
||||
}
|
||||
|
||||
if num_blocks > 0:
|
||||
for j in range(config["layers_per_block"]):
|
||||
paths = renew_resnet_paths(blocks[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint)
|
||||
|
||||
if any("attn" in layer for layer in down_blocks[i]):
|
||||
num_attn = len(
|
||||
{".".join(shave_segments(layer, 2).split(".")[:2]) for layer in down_blocks[i] if "attn" in layer}
|
||||
)
|
||||
attns = {
|
||||
layer_id: [key for key in down_blocks[i] if f"attn.{layer_id}" in key]
|
||||
for layer_id in range(num_blocks)
|
||||
}
|
||||
|
||||
if num_attn > 0:
|
||||
for j in range(config["layers_per_block"]):
|
||||
paths = renew_attention_paths(attns[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, config=config)
|
||||
|
||||
mid_block_1_layers = [key for key in checkpoint if "mid.block_1" in key]
|
||||
mid_block_2_layers = [key for key in checkpoint if "mid.block_2" in key]
|
||||
mid_attn_1_layers = [key for key in checkpoint if "mid.attn_1" in key]
|
||||
|
||||
# Mid new 2
|
||||
paths = renew_resnet_paths(mid_block_1_layers)
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
checkpoint,
|
||||
additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "block_1", "new": "resnets.0"}],
|
||||
)
|
||||
|
||||
paths = renew_resnet_paths(mid_block_2_layers)
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
checkpoint,
|
||||
additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "block_2", "new": "resnets.1"}],
|
||||
)
|
||||
|
||||
paths = renew_attention_paths(mid_attn_1_layers, in_mid=True)
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
checkpoint,
|
||||
additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "attn_1", "new": "attentions.0"}],
|
||||
)
|
||||
|
||||
for i in range(num_up_blocks):
|
||||
block_id = num_up_blocks - 1 - i
|
||||
|
||||
if any("upsample" in layer for layer in up_blocks[i]):
|
||||
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = checkpoint[
|
||||
f"up.{i}.upsample.conv.weight"
|
||||
]
|
||||
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = checkpoint[f"up.{i}.upsample.conv.bias"]
|
||||
|
||||
if any("block" in layer for layer in up_blocks[i]):
|
||||
num_blocks = len(
|
||||
{".".join(shave_segments(layer, 2).split(".")[:2]) for layer in up_blocks[i] if "block" in layer}
|
||||
)
|
||||
blocks = {
|
||||
layer_id: [key for key in up_blocks[i] if f"block.{layer_id}" in key] for layer_id in range(num_blocks)
|
||||
}
|
||||
|
||||
if num_blocks > 0:
|
||||
for j in range(config["layers_per_block"] + 1):
|
||||
replace_indices = {"old": f"up_blocks.{i}", "new": f"up_blocks.{block_id}"}
|
||||
paths = renew_resnet_paths(blocks[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[replace_indices])
|
||||
|
||||
if any("attn" in layer for layer in up_blocks[i]):
|
||||
num_attn = len(
|
||||
{".".join(shave_segments(layer, 2).split(".")[:2]) for layer in up_blocks[i] if "attn" in layer}
|
||||
)
|
||||
attns = {
|
||||
layer_id: [key for key in up_blocks[i] if f"attn.{layer_id}" in key] for layer_id in range(num_blocks)
|
||||
}
|
||||
|
||||
if num_attn > 0:
|
||||
for j in range(config["layers_per_block"] + 1):
|
||||
replace_indices = {"old": f"up_blocks.{i}", "new": f"up_blocks.{block_id}"}
|
||||
paths = renew_attention_paths(attns[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[replace_indices])
|
||||
|
||||
new_checkpoint = {k.replace("mid_new_2", "mid_block"): v for k, v in new_checkpoint.items()}
|
||||
return new_checkpoint
|
||||
|
||||
|
||||
def convert_vq_autoenc_checkpoint(checkpoint, config):
|
||||
"""
|
||||
Takes a state dict and a config, and returns a converted checkpoint.
|
||||
"""
|
||||
new_checkpoint = {}
|
||||
|
||||
new_checkpoint["encoder.conv_norm_out.weight"] = checkpoint["encoder.norm_out.weight"]
|
||||
new_checkpoint["encoder.conv_norm_out.bias"] = checkpoint["encoder.norm_out.bias"]
|
||||
|
||||
new_checkpoint["encoder.conv_in.weight"] = checkpoint["encoder.conv_in.weight"]
|
||||
new_checkpoint["encoder.conv_in.bias"] = checkpoint["encoder.conv_in.bias"]
|
||||
new_checkpoint["encoder.conv_out.weight"] = checkpoint["encoder.conv_out.weight"]
|
||||
new_checkpoint["encoder.conv_out.bias"] = checkpoint["encoder.conv_out.bias"]
|
||||
|
||||
new_checkpoint["decoder.conv_norm_out.weight"] = checkpoint["decoder.norm_out.weight"]
|
||||
new_checkpoint["decoder.conv_norm_out.bias"] = checkpoint["decoder.norm_out.bias"]
|
||||
|
||||
new_checkpoint["decoder.conv_in.weight"] = checkpoint["decoder.conv_in.weight"]
|
||||
new_checkpoint["decoder.conv_in.bias"] = checkpoint["decoder.conv_in.bias"]
|
||||
new_checkpoint["decoder.conv_out.weight"] = checkpoint["decoder.conv_out.weight"]
|
||||
new_checkpoint["decoder.conv_out.bias"] = checkpoint["decoder.conv_out.bias"]
|
||||
|
||||
num_down_blocks = len({".".join(layer.split(".")[:3]) for layer in checkpoint if "down" in layer})
|
||||
down_blocks = {
|
||||
layer_id: [key for key in checkpoint if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
|
||||
}
|
||||
|
||||
num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in checkpoint if "up" in layer})
|
||||
up_blocks = {layer_id: [key for key in checkpoint if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)}
|
||||
|
||||
for i in range(num_down_blocks):
|
||||
block_id = (i - 1) // (config["layers_per_block"] + 1)
|
||||
|
||||
if any("downsample" in layer for layer in down_blocks[i]):
|
||||
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = checkpoint[
|
||||
f"encoder.down.{i}.downsample.conv.weight"
|
||||
]
|
||||
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = checkpoint[
|
||||
f"encoder.down.{i}.downsample.conv.bias"
|
||||
]
|
||||
|
||||
if any("block" in layer for layer in down_blocks[i]):
|
||||
num_blocks = len(
|
||||
{".".join(shave_segments(layer, 3).split(".")[:3]) for layer in down_blocks[i] if "block" in layer}
|
||||
)
|
||||
blocks = {
|
||||
layer_id: [key for key in down_blocks[i] if f"block.{layer_id}" in key]
|
||||
for layer_id in range(num_blocks)
|
||||
}
|
||||
|
||||
if num_blocks > 0:
|
||||
for j in range(config["layers_per_block"]):
|
||||
paths = renew_resnet_paths(blocks[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint)
|
||||
|
||||
if any("attn" in layer for layer in down_blocks[i]):
|
||||
num_attn = len(
|
||||
{".".join(shave_segments(layer, 3).split(".")[:3]) for layer in down_blocks[i] if "attn" in layer}
|
||||
)
|
||||
attns = {
|
||||
layer_id: [key for key in down_blocks[i] if f"attn.{layer_id}" in key]
|
||||
for layer_id in range(num_blocks)
|
||||
}
|
||||
|
||||
if num_attn > 0:
|
||||
for j in range(config["layers_per_block"]):
|
||||
paths = renew_attention_paths(attns[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, config=config)
|
||||
|
||||
mid_block_1_layers = [key for key in checkpoint if "mid.block_1" in key]
|
||||
mid_block_2_layers = [key for key in checkpoint if "mid.block_2" in key]
|
||||
mid_attn_1_layers = [key for key in checkpoint if "mid.attn_1" in key]
|
||||
|
||||
# Mid new 2
|
||||
paths = renew_resnet_paths(mid_block_1_layers)
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
checkpoint,
|
||||
additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "block_1", "new": "resnets.0"}],
|
||||
)
|
||||
|
||||
paths = renew_resnet_paths(mid_block_2_layers)
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
checkpoint,
|
||||
additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "block_2", "new": "resnets.1"}],
|
||||
)
|
||||
|
||||
paths = renew_attention_paths(mid_attn_1_layers, in_mid=True)
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
checkpoint,
|
||||
additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "attn_1", "new": "attentions.0"}],
|
||||
)
|
||||
|
||||
for i in range(num_up_blocks):
|
||||
block_id = num_up_blocks - 1 - i
|
||||
|
||||
if any("upsample" in layer for layer in up_blocks[i]):
|
||||
new_checkpoint[f"decoder.up_blocks.{block_id}.upsamplers.0.conv.weight"] = checkpoint[
|
||||
f"decoder.up.{i}.upsample.conv.weight"
|
||||
]
|
||||
new_checkpoint[f"decoder.up_blocks.{block_id}.upsamplers.0.conv.bias"] = checkpoint[
|
||||
f"decoder.up.{i}.upsample.conv.bias"
|
||||
]
|
||||
|
||||
if any("block" in layer for layer in up_blocks[i]):
|
||||
num_blocks = len(
|
||||
{".".join(shave_segments(layer, 3).split(".")[:3]) for layer in up_blocks[i] if "block" in layer}
|
||||
)
|
||||
blocks = {
|
||||
layer_id: [key for key in up_blocks[i] if f"block.{layer_id}" in key] for layer_id in range(num_blocks)
|
||||
}
|
||||
|
||||
if num_blocks > 0:
|
||||
for j in range(config["layers_per_block"] + 1):
|
||||
replace_indices = {"old": f"up_blocks.{i}", "new": f"up_blocks.{block_id}"}
|
||||
paths = renew_resnet_paths(blocks[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[replace_indices])
|
||||
|
||||
if any("attn" in layer for layer in up_blocks[i]):
|
||||
num_attn = len(
|
||||
{".".join(shave_segments(layer, 3).split(".")[:3]) for layer in up_blocks[i] if "attn" in layer}
|
||||
)
|
||||
attns = {
|
||||
layer_id: [key for key in up_blocks[i] if f"attn.{layer_id}" in key] for layer_id in range(num_blocks)
|
||||
}
|
||||
|
||||
if num_attn > 0:
|
||||
for j in range(config["layers_per_block"] + 1):
|
||||
replace_indices = {"old": f"up_blocks.{i}", "new": f"up_blocks.{block_id}"}
|
||||
paths = renew_attention_paths(attns[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[replace_indices])
|
||||
|
||||
new_checkpoint = {k.replace("mid_new_2", "mid_block"): v for k, v in new_checkpoint.items()}
|
||||
new_checkpoint["quant_conv.weight"] = checkpoint["quant_conv.weight"]
|
||||
new_checkpoint["quant_conv.bias"] = checkpoint["quant_conv.bias"]
|
||||
if "quantize.embedding.weight" in checkpoint:
|
||||
new_checkpoint["quantize.embedding.weight"] = checkpoint["quantize.embedding.weight"]
|
||||
new_checkpoint["post_quant_conv.weight"] = checkpoint["post_quant_conv.weight"]
|
||||
new_checkpoint["post_quant_conv.bias"] = checkpoint["post_quant_conv.bias"]
|
||||
|
||||
return new_checkpoint
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--config_file",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="The config json file corresponding to the architecture.",
|
||||
)
|
||||
|
||||
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
|
||||
|
||||
args = parser.parse_args()
|
||||
checkpoint = torch.load(args.checkpoint_path)
|
||||
|
||||
with open(args.config_file) as f:
|
||||
config = json.loads(f.read())
|
||||
|
||||
# unet case
|
||||
key_prefix_set = set(key.split(".")[0] for key in checkpoint.keys())
|
||||
if "encoder" in key_prefix_set and "decoder" in key_prefix_set:
|
||||
converted_checkpoint = convert_vq_autoenc_checkpoint(checkpoint, config)
|
||||
else:
|
||||
converted_checkpoint = convert_ddpm_checkpoint(checkpoint, config)
|
||||
|
||||
if "ddpm" in config:
|
||||
del config["ddpm"]
|
||||
|
||||
if config["_class_name"] == "VQModel":
|
||||
model = VQModel(**config)
|
||||
model.load_state_dict(converted_checkpoint)
|
||||
model.save_pretrained(args.dump_path)
|
||||
elif config["_class_name"] == "AutoencoderKL":
|
||||
model = AutoencoderKL(**config)
|
||||
model.load_state_dict(converted_checkpoint)
|
||||
model.save_pretrained(args.dump_path)
|
||||
else:
|
||||
model = UNet2DModel(**config)
|
||||
model.load_state_dict(converted_checkpoint)
|
||||
|
||||
scheduler = DDPMScheduler.from_config("/".join(args.checkpoint_path.split("/")[:-1]))
|
||||
|
||||
pipe = DDPMPipeline(unet=model, scheduler=scheduler)
|
||||
pipe.save_pretrained(args.dump_path)
|
||||
@@ -0,0 +1,358 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for the LDM checkpoints. """
|
||||
|
||||
import argparse
|
||||
import json
|
||||
|
||||
import torch
|
||||
|
||||
from diffusers import DDPMScheduler, LDMPipeline, UNet2DModel, VQModel
|
||||
|
||||
|
||||
def shave_segments(path, n_shave_prefix_segments=1):
|
||||
"""
|
||||
Removes segments. Positive values shave the first segments, negative shave the last segments.
|
||||
"""
|
||||
if n_shave_prefix_segments >= 0:
|
||||
return ".".join(path.split(".")[n_shave_prefix_segments:])
|
||||
else:
|
||||
return ".".join(path.split(".")[:n_shave_prefix_segments])
|
||||
|
||||
|
||||
def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
|
||||
"""
|
||||
Updates paths inside resnets to the new naming scheme (local renaming)
|
||||
"""
|
||||
mapping = []
|
||||
for old_item in old_list:
|
||||
new_item = old_item.replace("in_layers.0", "norm1")
|
||||
new_item = new_item.replace("in_layers.2", "conv1")
|
||||
|
||||
new_item = new_item.replace("out_layers.0", "norm2")
|
||||
new_item = new_item.replace("out_layers.3", "conv2")
|
||||
|
||||
new_item = new_item.replace("emb_layers.1", "time_emb_proj")
|
||||
new_item = new_item.replace("skip_connection", "conv_shortcut")
|
||||
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
|
||||
mapping.append({"old": old_item, "new": new_item})
|
||||
|
||||
return mapping
|
||||
|
||||
|
||||
def renew_attention_paths(old_list, n_shave_prefix_segments=0):
|
||||
"""
|
||||
Updates paths inside attentions to the new naming scheme (local renaming)
|
||||
"""
|
||||
mapping = []
|
||||
for old_item in old_list:
|
||||
new_item = old_item
|
||||
|
||||
new_item = new_item.replace("norm.weight", "group_norm.weight")
|
||||
new_item = new_item.replace("norm.bias", "group_norm.bias")
|
||||
|
||||
new_item = new_item.replace("proj_out.weight", "proj_attn.weight")
|
||||
new_item = new_item.replace("proj_out.bias", "proj_attn.bias")
|
||||
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
|
||||
mapping.append({"old": old_item, "new": new_item})
|
||||
|
||||
return mapping
|
||||
|
||||
|
||||
def assign_to_checkpoint(
|
||||
paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
|
||||
):
|
||||
"""
|
||||
This does the final conversion step: take locally converted weights and apply a global renaming
|
||||
to them. It splits attention layers, and takes into account additional replacements
|
||||
that may arise.
|
||||
|
||||
Assigns the weights to the new checkpoint.
|
||||
"""
|
||||
assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
|
||||
|
||||
# Splits the attention layers into three variables.
|
||||
if attention_paths_to_split is not None:
|
||||
for path, path_map in attention_paths_to_split.items():
|
||||
old_tensor = old_checkpoint[path]
|
||||
channels = old_tensor.shape[0] // 3
|
||||
|
||||
target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
|
||||
|
||||
num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
|
||||
|
||||
old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
|
||||
query, key, value = old_tensor.split(channels // num_heads, dim=1)
|
||||
|
||||
checkpoint[path_map["query"]] = query.reshape(target_shape)
|
||||
checkpoint[path_map["key"]] = key.reshape(target_shape)
|
||||
checkpoint[path_map["value"]] = value.reshape(target_shape)
|
||||
|
||||
for path in paths:
|
||||
new_path = path["new"]
|
||||
|
||||
# These have already been assigned
|
||||
if attention_paths_to_split is not None and new_path in attention_paths_to_split:
|
||||
continue
|
||||
|
||||
# Global renaming happens here
|
||||
new_path = new_path.replace("middle_block.0", "mid.resnets.0")
|
||||
new_path = new_path.replace("middle_block.1", "mid.attentions.0")
|
||||
new_path = new_path.replace("middle_block.2", "mid.resnets.1")
|
||||
|
||||
if additional_replacements is not None:
|
||||
for replacement in additional_replacements:
|
||||
new_path = new_path.replace(replacement["old"], replacement["new"])
|
||||
|
||||
# proj_attn.weight has to be converted from conv 1D to linear
|
||||
if "proj_attn.weight" in new_path:
|
||||
checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
|
||||
else:
|
||||
checkpoint[new_path] = old_checkpoint[path["old"]]
|
||||
|
||||
|
||||
def convert_ldm_checkpoint(checkpoint, config):
|
||||
"""
|
||||
Takes a state dict and a config, and returns a converted checkpoint.
|
||||
"""
|
||||
new_checkpoint = {}
|
||||
|
||||
new_checkpoint["time_embedding.linear_1.weight"] = checkpoint["time_embed.0.weight"]
|
||||
new_checkpoint["time_embedding.linear_1.bias"] = checkpoint["time_embed.0.bias"]
|
||||
new_checkpoint["time_embedding.linear_2.weight"] = checkpoint["time_embed.2.weight"]
|
||||
new_checkpoint["time_embedding.linear_2.bias"] = checkpoint["time_embed.2.bias"]
|
||||
|
||||
new_checkpoint["conv_in.weight"] = checkpoint["input_blocks.0.0.weight"]
|
||||
new_checkpoint["conv_in.bias"] = checkpoint["input_blocks.0.0.bias"]
|
||||
|
||||
new_checkpoint["conv_norm_out.weight"] = checkpoint["out.0.weight"]
|
||||
new_checkpoint["conv_norm_out.bias"] = checkpoint["out.0.bias"]
|
||||
new_checkpoint["conv_out.weight"] = checkpoint["out.2.weight"]
|
||||
new_checkpoint["conv_out.bias"] = checkpoint["out.2.bias"]
|
||||
|
||||
# Retrieves the keys for the input blocks only
|
||||
num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in checkpoint if "input_blocks" in layer})
|
||||
input_blocks = {
|
||||
layer_id: [key for key in checkpoint if f"input_blocks.{layer_id}" in key]
|
||||
for layer_id in range(num_input_blocks)
|
||||
}
|
||||
|
||||
# Retrieves the keys for the middle blocks only
|
||||
num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in checkpoint if "middle_block" in layer})
|
||||
middle_blocks = {
|
||||
layer_id: [key for key in checkpoint if f"middle_block.{layer_id}" in key]
|
||||
for layer_id in range(num_middle_blocks)
|
||||
}
|
||||
|
||||
# Retrieves the keys for the output blocks only
|
||||
num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in checkpoint if "output_blocks" in layer})
|
||||
output_blocks = {
|
||||
layer_id: [key for key in checkpoint if f"output_blocks.{layer_id}" in key]
|
||||
for layer_id in range(num_output_blocks)
|
||||
}
|
||||
|
||||
for i in range(1, num_input_blocks):
|
||||
block_id = (i - 1) // (config["num_res_blocks"] + 1)
|
||||
layer_in_block_id = (i - 1) % (config["num_res_blocks"] + 1)
|
||||
|
||||
resnets = [key for key in input_blocks[i] if f"input_blocks.{i}.0" in key]
|
||||
attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
|
||||
|
||||
if f"input_blocks.{i}.0.op.weight" in checkpoint:
|
||||
new_checkpoint[f"downsample_blocks.{block_id}.downsamplers.0.conv.weight"] = checkpoint[
|
||||
f"input_blocks.{i}.0.op.weight"
|
||||
]
|
||||
new_checkpoint[f"downsample_blocks.{block_id}.downsamplers.0.conv.bias"] = checkpoint[
|
||||
f"input_blocks.{i}.0.op.bias"
|
||||
]
|
||||
|
||||
paths = renew_resnet_paths(resnets)
|
||||
meta_path = {"old": f"input_blocks.{i}.0", "new": f"downsample_blocks.{block_id}.resnets.{layer_in_block_id}"}
|
||||
resnet_op = {"old": "resnets.2.op", "new": "downsamplers.0.op"}
|
||||
assign_to_checkpoint(
|
||||
paths, new_checkpoint, checkpoint, additional_replacements=[meta_path, resnet_op], config=config
|
||||
)
|
||||
|
||||
if len(attentions):
|
||||
paths = renew_attention_paths(attentions)
|
||||
meta_path = {
|
||||
"old": f"input_blocks.{i}.1",
|
||||
"new": f"downsample_blocks.{block_id}.attentions.{layer_in_block_id}",
|
||||
}
|
||||
to_split = {
|
||||
f"input_blocks.{i}.1.qkv.bias": {
|
||||
"key": f"downsample_blocks.{block_id}.attentions.{layer_in_block_id}.key.bias",
|
||||
"query": f"downsample_blocks.{block_id}.attentions.{layer_in_block_id}.query.bias",
|
||||
"value": f"downsample_blocks.{block_id}.attentions.{layer_in_block_id}.value.bias",
|
||||
},
|
||||
f"input_blocks.{i}.1.qkv.weight": {
|
||||
"key": f"downsample_blocks.{block_id}.attentions.{layer_in_block_id}.key.weight",
|
||||
"query": f"downsample_blocks.{block_id}.attentions.{layer_in_block_id}.query.weight",
|
||||
"value": f"downsample_blocks.{block_id}.attentions.{layer_in_block_id}.value.weight",
|
||||
},
|
||||
}
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
checkpoint,
|
||||
additional_replacements=[meta_path],
|
||||
attention_paths_to_split=to_split,
|
||||
config=config,
|
||||
)
|
||||
|
||||
resnet_0 = middle_blocks[0]
|
||||
attentions = middle_blocks[1]
|
||||
resnet_1 = middle_blocks[2]
|
||||
|
||||
resnet_0_paths = renew_resnet_paths(resnet_0)
|
||||
assign_to_checkpoint(resnet_0_paths, new_checkpoint, checkpoint, config=config)
|
||||
|
||||
resnet_1_paths = renew_resnet_paths(resnet_1)
|
||||
assign_to_checkpoint(resnet_1_paths, new_checkpoint, checkpoint, config=config)
|
||||
|
||||
attentions_paths = renew_attention_paths(attentions)
|
||||
to_split = {
|
||||
"middle_block.1.qkv.bias": {
|
||||
"key": "mid_block.attentions.0.key.bias",
|
||||
"query": "mid_block.attentions.0.query.bias",
|
||||
"value": "mid_block.attentions.0.value.bias",
|
||||
},
|
||||
"middle_block.1.qkv.weight": {
|
||||
"key": "mid_block.attentions.0.key.weight",
|
||||
"query": "mid_block.attentions.0.query.weight",
|
||||
"value": "mid_block.attentions.0.value.weight",
|
||||
},
|
||||
}
|
||||
assign_to_checkpoint(
|
||||
attentions_paths, new_checkpoint, checkpoint, attention_paths_to_split=to_split, config=config
|
||||
)
|
||||
|
||||
for i in range(num_output_blocks):
|
||||
block_id = i // (config["num_res_blocks"] + 1)
|
||||
layer_in_block_id = i % (config["num_res_blocks"] + 1)
|
||||
output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
|
||||
output_block_list = {}
|
||||
|
||||
for layer in output_block_layers:
|
||||
layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
|
||||
if layer_id in output_block_list:
|
||||
output_block_list[layer_id].append(layer_name)
|
||||
else:
|
||||
output_block_list[layer_id] = [layer_name]
|
||||
|
||||
if len(output_block_list) > 1:
|
||||
resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
|
||||
attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
|
||||
|
||||
resnet_0_paths = renew_resnet_paths(resnets)
|
||||
paths = renew_resnet_paths(resnets)
|
||||
|
||||
meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[meta_path], config=config)
|
||||
|
||||
if ["conv.weight", "conv.bias"] in output_block_list.values():
|
||||
index = list(output_block_list.values()).index(["conv.weight", "conv.bias"])
|
||||
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = checkpoint[
|
||||
f"output_blocks.{i}.{index}.conv.weight"
|
||||
]
|
||||
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = checkpoint[
|
||||
f"output_blocks.{i}.{index}.conv.bias"
|
||||
]
|
||||
|
||||
# Clear attentions as they have been attributed above.
|
||||
if len(attentions) == 2:
|
||||
attentions = []
|
||||
|
||||
if len(attentions):
|
||||
paths = renew_attention_paths(attentions)
|
||||
meta_path = {
|
||||
"old": f"output_blocks.{i}.1",
|
||||
"new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
|
||||
}
|
||||
to_split = {
|
||||
f"output_blocks.{i}.1.qkv.bias": {
|
||||
"key": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.key.bias",
|
||||
"query": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.query.bias",
|
||||
"value": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.value.bias",
|
||||
},
|
||||
f"output_blocks.{i}.1.qkv.weight": {
|
||||
"key": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.key.weight",
|
||||
"query": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.query.weight",
|
||||
"value": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.value.weight",
|
||||
},
|
||||
}
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
checkpoint,
|
||||
additional_replacements=[meta_path],
|
||||
attention_paths_to_split=to_split if any("qkv" in key for key in attentions) else None,
|
||||
config=config,
|
||||
)
|
||||
else:
|
||||
resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
|
||||
for path in resnet_0_paths:
|
||||
old_path = ".".join(["output_blocks", str(i), path["old"]])
|
||||
new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
|
||||
|
||||
new_checkpoint[new_path] = checkpoint[old_path]
|
||||
|
||||
return new_checkpoint
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--config_file",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="The config json file corresponding to the architecture.",
|
||||
)
|
||||
|
||||
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
checkpoint = torch.load(args.checkpoint_path)
|
||||
|
||||
with open(args.config_file) as f:
|
||||
config = json.loads(f.read())
|
||||
|
||||
converted_checkpoint = convert_ldm_checkpoint(checkpoint, config)
|
||||
|
||||
if "ldm" in config:
|
||||
del config["ldm"]
|
||||
|
||||
model = UNet2DModel(**config)
|
||||
model.load_state_dict(converted_checkpoint)
|
||||
|
||||
try:
|
||||
scheduler = DDPMScheduler.from_config("/".join(args.checkpoint_path.split("/")[:-1]))
|
||||
vqvae = VQModel.from_pretrained("/".join(args.checkpoint_path.split("/")[:-1]))
|
||||
|
||||
pipe = LDMPipeline(unet=model, scheduler=scheduler, vae=vqvae)
|
||||
pipe.save_pretrained(args.dump_path)
|
||||
except:
|
||||
model.save_pretrained(args.dump_path)
|
||||
@@ -0,0 +1,185 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for the NCSNPP checkpoints. """
|
||||
|
||||
import argparse
|
||||
import json
|
||||
|
||||
import torch
|
||||
|
||||
from diffusers import ScoreSdeVePipeline, ScoreSdeVeScheduler, UNet2DModel
|
||||
|
||||
|
||||
def convert_ncsnpp_checkpoint(checkpoint, config):
|
||||
"""
|
||||
Takes a state dict and the path to
|
||||
"""
|
||||
new_model_architecture = UNet2DModel(**config)
|
||||
new_model_architecture.time_proj.W.data = checkpoint["all_modules.0.W"].data
|
||||
new_model_architecture.time_proj.weight.data = checkpoint["all_modules.0.W"].data
|
||||
new_model_architecture.time_embedding.linear_1.weight.data = checkpoint["all_modules.1.weight"].data
|
||||
new_model_architecture.time_embedding.linear_1.bias.data = checkpoint["all_modules.1.bias"].data
|
||||
|
||||
new_model_architecture.time_embedding.linear_2.weight.data = checkpoint["all_modules.2.weight"].data
|
||||
new_model_architecture.time_embedding.linear_2.bias.data = checkpoint["all_modules.2.bias"].data
|
||||
|
||||
new_model_architecture.conv_in.weight.data = checkpoint["all_modules.3.weight"].data
|
||||
new_model_architecture.conv_in.bias.data = checkpoint["all_modules.3.bias"].data
|
||||
|
||||
new_model_architecture.conv_norm_out.weight.data = checkpoint[list(checkpoint.keys())[-4]].data
|
||||
new_model_architecture.conv_norm_out.bias.data = checkpoint[list(checkpoint.keys())[-3]].data
|
||||
new_model_architecture.conv_out.weight.data = checkpoint[list(checkpoint.keys())[-2]].data
|
||||
new_model_architecture.conv_out.bias.data = checkpoint[list(checkpoint.keys())[-1]].data
|
||||
|
||||
module_index = 4
|
||||
|
||||
def set_attention_weights(new_layer, old_checkpoint, index):
|
||||
new_layer.query.weight.data = old_checkpoint[f"all_modules.{index}.NIN_0.W"].data.T
|
||||
new_layer.key.weight.data = old_checkpoint[f"all_modules.{index}.NIN_1.W"].data.T
|
||||
new_layer.value.weight.data = old_checkpoint[f"all_modules.{index}.NIN_2.W"].data.T
|
||||
|
||||
new_layer.query.bias.data = old_checkpoint[f"all_modules.{index}.NIN_0.b"].data
|
||||
new_layer.key.bias.data = old_checkpoint[f"all_modules.{index}.NIN_1.b"].data
|
||||
new_layer.value.bias.data = old_checkpoint[f"all_modules.{index}.NIN_2.b"].data
|
||||
|
||||
new_layer.proj_attn.weight.data = old_checkpoint[f"all_modules.{index}.NIN_3.W"].data.T
|
||||
new_layer.proj_attn.bias.data = old_checkpoint[f"all_modules.{index}.NIN_3.b"].data
|
||||
|
||||
new_layer.group_norm.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.weight"].data
|
||||
new_layer.group_norm.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.bias"].data
|
||||
|
||||
def set_resnet_weights(new_layer, old_checkpoint, index):
|
||||
new_layer.conv1.weight.data = old_checkpoint[f"all_modules.{index}.Conv_0.weight"].data
|
||||
new_layer.conv1.bias.data = old_checkpoint[f"all_modules.{index}.Conv_0.bias"].data
|
||||
new_layer.norm1.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.weight"].data
|
||||
new_layer.norm1.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.bias"].data
|
||||
|
||||
new_layer.conv2.weight.data = old_checkpoint[f"all_modules.{index}.Conv_1.weight"].data
|
||||
new_layer.conv2.bias.data = old_checkpoint[f"all_modules.{index}.Conv_1.bias"].data
|
||||
new_layer.norm2.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_1.weight"].data
|
||||
new_layer.norm2.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_1.bias"].data
|
||||
|
||||
new_layer.time_emb_proj.weight.data = old_checkpoint[f"all_modules.{index}.Dense_0.weight"].data
|
||||
new_layer.time_emb_proj.bias.data = old_checkpoint[f"all_modules.{index}.Dense_0.bias"].data
|
||||
|
||||
if new_layer.in_channels != new_layer.out_channels or new_layer.up or new_layer.down:
|
||||
new_layer.conv_shortcut.weight.data = old_checkpoint[f"all_modules.{index}.Conv_2.weight"].data
|
||||
new_layer.conv_shortcut.bias.data = old_checkpoint[f"all_modules.{index}.Conv_2.bias"].data
|
||||
|
||||
for i, block in enumerate(new_model_architecture.downsample_blocks):
|
||||
has_attentions = hasattr(block, "attentions")
|
||||
for j in range(len(block.resnets)):
|
||||
set_resnet_weights(block.resnets[j], checkpoint, module_index)
|
||||
module_index += 1
|
||||
if has_attentions:
|
||||
set_attention_weights(block.attentions[j], checkpoint, module_index)
|
||||
module_index += 1
|
||||
|
||||
if hasattr(block, "downsamplers") and block.downsamplers is not None:
|
||||
set_resnet_weights(block.resnet_down, checkpoint, module_index)
|
||||
module_index += 1
|
||||
block.skip_conv.weight.data = checkpoint[f"all_modules.{module_index}.Conv_0.weight"].data
|
||||
block.skip_conv.bias.data = checkpoint[f"all_modules.{module_index}.Conv_0.bias"].data
|
||||
module_index += 1
|
||||
|
||||
set_resnet_weights(new_model_architecture.mid_block.resnets[0], checkpoint, module_index)
|
||||
module_index += 1
|
||||
set_attention_weights(new_model_architecture.mid_block.attentions[0], checkpoint, module_index)
|
||||
module_index += 1
|
||||
set_resnet_weights(new_model_architecture.mid_block.resnets[1], checkpoint, module_index)
|
||||
module_index += 1
|
||||
|
||||
for i, block in enumerate(new_model_architecture.up_blocks):
|
||||
has_attentions = hasattr(block, "attentions")
|
||||
for j in range(len(block.resnets)):
|
||||
set_resnet_weights(block.resnets[j], checkpoint, module_index)
|
||||
module_index += 1
|
||||
if has_attentions:
|
||||
set_attention_weights(
|
||||
block.attentions[0], checkpoint, module_index
|
||||
) # why can there only be a single attention layer for up?
|
||||
module_index += 1
|
||||
|
||||
if hasattr(block, "resnet_up") and block.resnet_up is not None:
|
||||
block.skip_norm.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
|
||||
block.skip_norm.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
|
||||
module_index += 1
|
||||
block.skip_conv.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
|
||||
block.skip_conv.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
|
||||
module_index += 1
|
||||
set_resnet_weights(block.resnet_up, checkpoint, module_index)
|
||||
module_index += 1
|
||||
|
||||
new_model_architecture.conv_norm_out.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
|
||||
new_model_architecture.conv_norm_out.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
|
||||
module_index += 1
|
||||
new_model_architecture.conv_out.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
|
||||
new_model_architecture.conv_out.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
|
||||
|
||||
return new_model_architecture.state_dict()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--checkpoint_path",
|
||||
default="/Users/arthurzucker/Work/diffusers/ArthurZ/diffusion_pytorch_model.bin",
|
||||
type=str,
|
||||
required=False,
|
||||
help="Path to the checkpoint to convert.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--config_file",
|
||||
default="/Users/arthurzucker/Work/diffusers/ArthurZ/config.json",
|
||||
type=str,
|
||||
required=False,
|
||||
help="The config json file corresponding to the architecture.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--dump_path",
|
||||
default="/Users/arthurzucker/Work/diffusers/ArthurZ/diffusion_model_new.pt",
|
||||
type=str,
|
||||
required=False,
|
||||
help="Path to the output model.",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
checkpoint = torch.load(args.checkpoint_path, map_location="cpu")
|
||||
|
||||
with open(args.config_file) as f:
|
||||
config = json.loads(f.read())
|
||||
|
||||
converted_checkpoint = convert_ncsnpp_checkpoint(
|
||||
checkpoint,
|
||||
config,
|
||||
)
|
||||
|
||||
if "sde" in config:
|
||||
del config["sde"]
|
||||
|
||||
model = UNet2DModel(**config)
|
||||
model.load_state_dict(converted_checkpoint)
|
||||
|
||||
try:
|
||||
scheduler = ScoreSdeVeScheduler.from_config("/".join(args.checkpoint_path.split("/")[:-1]))
|
||||
|
||||
pipe = ScoreSdeVePipeline(unet=model, scheduler=scheduler)
|
||||
pipe.save_pretrained(args.dump_path)
|
||||
except:
|
||||
model.save_pretrained(args.dump_path)
|
||||
@@ -0,0 +1,196 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
from torch.onnx import export
|
||||
|
||||
from diffusers import StableDiffusionOnnxPipeline, StableDiffusionPipeline
|
||||
from diffusers.onnx_utils import OnnxRuntimeModel
|
||||
from packaging import version
|
||||
|
||||
|
||||
is_torch_less_than_1_11 = version.parse(version.parse(torch.__version__).base_version) < version.parse("1.11")
|
||||
|
||||
|
||||
def onnx_export(
|
||||
model,
|
||||
model_args: tuple,
|
||||
output_path: Path,
|
||||
ordered_input_names,
|
||||
output_names,
|
||||
dynamic_axes,
|
||||
opset,
|
||||
use_external_data_format=False,
|
||||
):
|
||||
output_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
# PyTorch deprecated the `enable_onnx_checker` and `use_external_data_format` arguments in v1.11,
|
||||
# so we check the torch version for backwards compatibility
|
||||
if is_torch_less_than_1_11:
|
||||
export(
|
||||
model,
|
||||
model_args,
|
||||
f=output_path.as_posix(),
|
||||
input_names=ordered_input_names,
|
||||
output_names=output_names,
|
||||
dynamic_axes=dynamic_axes,
|
||||
do_constant_folding=True,
|
||||
use_external_data_format=use_external_data_format,
|
||||
enable_onnx_checker=True,
|
||||
opset_version=opset,
|
||||
)
|
||||
else:
|
||||
export(
|
||||
model,
|
||||
model_args,
|
||||
f=output_path.as_posix(),
|
||||
input_names=ordered_input_names,
|
||||
output_names=output_names,
|
||||
dynamic_axes=dynamic_axes,
|
||||
do_constant_folding=True,
|
||||
opset_version=opset,
|
||||
)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def convert_models(model_path: str, output_path: str, opset: int):
|
||||
pipeline = StableDiffusionPipeline.from_pretrained(model_path, use_auth_token=True)
|
||||
output_path = Path(output_path)
|
||||
|
||||
# TEXT ENCODER
|
||||
text_input = pipeline.tokenizer(
|
||||
"A sample prompt",
|
||||
padding="max_length",
|
||||
max_length=pipeline.tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
onnx_export(
|
||||
pipeline.text_encoder,
|
||||
# casting to torch.int32 until the CLIP fix is released: https://github.com/huggingface/transformers/pull/18515/files
|
||||
model_args=(text_input.input_ids.to(torch.int32)),
|
||||
output_path=output_path / "text_encoder" / "model.onnx",
|
||||
ordered_input_names=["input_ids"],
|
||||
output_names=["last_hidden_state", "pooler_output"],
|
||||
dynamic_axes={
|
||||
"input_ids": {0: "batch", 1: "sequence"},
|
||||
},
|
||||
opset=opset,
|
||||
)
|
||||
|
||||
# UNET
|
||||
onnx_export(
|
||||
pipeline.unet,
|
||||
model_args=(torch.randn(2, 4, 64, 64), torch.LongTensor([0, 1]), torch.randn(2, 77, 768), False),
|
||||
output_path=output_path / "unet" / "model.onnx",
|
||||
ordered_input_names=["sample", "timestep", "encoder_hidden_states", "return_dict"],
|
||||
output_names=["out_sample"], # has to be different from "sample" for correct tracing
|
||||
dynamic_axes={
|
||||
"sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
|
||||
"timestep": {0: "batch"},
|
||||
"encoder_hidden_states": {0: "batch", 1: "sequence"},
|
||||
},
|
||||
opset=opset,
|
||||
use_external_data_format=True, # UNet is > 2GB, so the weights need to be split
|
||||
)
|
||||
|
||||
# VAE ENCODER
|
||||
vae_encoder = pipeline.vae
|
||||
# need to get the raw tensor output (sample) from the encoder
|
||||
vae_encoder.forward = lambda sample, return_dict: vae_encoder.encode(sample, return_dict)[0].sample()
|
||||
onnx_export(
|
||||
vae_encoder,
|
||||
model_args=(torch.randn(1, 3, 512, 512), False),
|
||||
output_path=output_path / "vae_encoder" / "model.onnx",
|
||||
ordered_input_names=["sample", "return_dict"],
|
||||
output_names=["latent_sample"],
|
||||
dynamic_axes={
|
||||
"sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
|
||||
},
|
||||
opset=opset,
|
||||
)
|
||||
|
||||
# VAE DECODER
|
||||
vae_decoder = pipeline.vae
|
||||
# forward only through the decoder part
|
||||
vae_decoder.forward = vae_encoder.decode
|
||||
onnx_export(
|
||||
vae_decoder,
|
||||
model_args=(torch.randn(1, 4, 64, 64), False),
|
||||
output_path=output_path / "vae_decoder" / "model.onnx",
|
||||
ordered_input_names=["latent_sample", "return_dict"],
|
||||
output_names=["sample"],
|
||||
dynamic_axes={
|
||||
"latent_sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
|
||||
},
|
||||
opset=opset,
|
||||
)
|
||||
|
||||
# SAFETY CHECKER
|
||||
safety_checker = pipeline.safety_checker
|
||||
safety_checker.forward = safety_checker.forward_onnx
|
||||
onnx_export(
|
||||
pipeline.safety_checker,
|
||||
model_args=(torch.randn(1, 3, 224, 224), torch.randn(1, 512, 512, 3)),
|
||||
output_path=output_path / "safety_checker" / "model.onnx",
|
||||
ordered_input_names=["clip_input", "images"],
|
||||
output_names=["out_images", "has_nsfw_concepts"],
|
||||
dynamic_axes={
|
||||
"clip_input": {0: "batch", 1: "channels", 2: "height", 3: "width"},
|
||||
"images": {0: "batch", 1: "channels", 2: "height", 3: "width"},
|
||||
},
|
||||
opset=opset,
|
||||
)
|
||||
|
||||
onnx_pipeline = StableDiffusionOnnxPipeline(
|
||||
vae_decoder=OnnxRuntimeModel.from_pretrained(output_path / "vae_decoder"),
|
||||
text_encoder=OnnxRuntimeModel.from_pretrained(output_path / "text_encoder"),
|
||||
tokenizer=pipeline.tokenizer,
|
||||
unet=OnnxRuntimeModel.from_pretrained(output_path / "unet"),
|
||||
scheduler=pipeline.scheduler,
|
||||
safety_checker=OnnxRuntimeModel.from_pretrained(output_path / "safety_checker"),
|
||||
feature_extractor=pipeline.feature_extractor,
|
||||
)
|
||||
|
||||
onnx_pipeline.save_pretrained(output_path)
|
||||
print("ONNX pipeline saved to", output_path)
|
||||
|
||||
_ = StableDiffusionOnnxPipeline.from_pretrained(output_path, provider="CPUExecutionProvider")
|
||||
print("ONNX pipeline is loadable")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--model_path",
|
||||
type=str,
|
||||
required=True,
|
||||
help="Path to the `diffusers` checkpoint to convert (either a local directory or on the Hub).",
|
||||
)
|
||||
|
||||
parser.add_argument("--output_path", type=str, required=True, help="Path to the output model.")
|
||||
|
||||
parser.add_argument(
|
||||
"--opset",
|
||||
default=14,
|
||||
type=str,
|
||||
help="The version of the ONNX operator set to use.",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
convert_models(args.model_path, args.output_path, args.opset)
|
||||
@@ -0,0 +1,127 @@
|
||||
import random
|
||||
|
||||
import torch
|
||||
|
||||
from diffusers import UNet2DModel
|
||||
from huggingface_hub import HfApi
|
||||
|
||||
|
||||
api = HfApi()
|
||||
|
||||
results = {}
|
||||
# fmt: off
|
||||
results["google_ddpm_cifar10_32"] = torch.tensor([
|
||||
-0.7515, -1.6883, 0.2420, 0.0300, 0.6347, 1.3433, -1.1743, -3.7467,
|
||||
1.2342, -2.2485, 0.4636, 0.8076, -0.7991, 0.3969, 0.8498, 0.9189,
|
||||
-1.8887, -3.3522, 0.7639, 0.2040, 0.6271, -2.7148, -1.6316, 3.0839,
|
||||
0.3186, 0.2721, -0.9759, -1.2461, 2.6257, 1.3557
|
||||
])
|
||||
results["google_ddpm_ema_bedroom_256"] = torch.tensor([
|
||||
-2.3639, -2.5344, 0.0054, -0.6674, 1.5990, 1.0158, 0.3124, -2.1436,
|
||||
1.8795, -2.5429, -0.1566, -0.3973, 1.2490, 2.6447, 1.2283, -0.5208,
|
||||
-2.8154, -3.5119, 2.3838, 1.2033, 1.7201, -2.1256, -1.4576, 2.7948,
|
||||
2.4204, -0.9752, -1.2546, 0.8027, 3.2758, 3.1365
|
||||
])
|
||||
results["CompVis_ldm_celebahq_256"] = torch.tensor([
|
||||
-0.6531, -0.6891, -0.3172, -0.5375, -0.9140, -0.5367, -0.1175, -0.7869,
|
||||
-0.3808, -0.4513, -0.2098, -0.0083, 0.3183, 0.5140, 0.2247, -0.1304,
|
||||
-0.1302, -0.2802, -0.2084, -0.2025, -0.4967, -0.4873, -0.0861, 0.6925,
|
||||
0.0250, 0.1290, -0.1543, 0.6316, 1.0460, 1.4943
|
||||
])
|
||||
results["google_ncsnpp_ffhq_1024"] = torch.tensor([
|
||||
0.0911, 0.1107, 0.0182, 0.0435, -0.0805, -0.0608, 0.0381, 0.2172,
|
||||
-0.0280, 0.1327, -0.0299, -0.0255, -0.0050, -0.1170, -0.1046, 0.0309,
|
||||
0.1367, 0.1728, -0.0533, -0.0748, -0.0534, 0.1624, 0.0384, -0.1805,
|
||||
-0.0707, 0.0642, 0.0220, -0.0134, -0.1333, -0.1505
|
||||
])
|
||||
results["google_ncsnpp_bedroom_256"] = torch.tensor([
|
||||
0.1321, 0.1337, 0.0440, 0.0622, -0.0591, -0.0370, 0.0503, 0.2133,
|
||||
-0.0177, 0.1415, -0.0116, -0.0112, 0.0044, -0.0980, -0.0789, 0.0395,
|
||||
0.1502, 0.1785, -0.0488, -0.0514, -0.0404, 0.1539, 0.0454, -0.1559,
|
||||
-0.0665, 0.0659, 0.0383, -0.0005, -0.1266, -0.1386
|
||||
])
|
||||
results["google_ncsnpp_celebahq_256"] = torch.tensor([
|
||||
0.1154, 0.1218, 0.0307, 0.0526, -0.0711, -0.0541, 0.0366, 0.2078,
|
||||
-0.0267, 0.1317, -0.0226, -0.0193, -0.0014, -0.1055, -0.0902, 0.0330,
|
||||
0.1391, 0.1709, -0.0562, -0.0693, -0.0560, 0.1482, 0.0381, -0.1683,
|
||||
-0.0681, 0.0661, 0.0331, -0.0046, -0.1268, -0.1431
|
||||
])
|
||||
results["google_ncsnpp_church_256"] = torch.tensor([
|
||||
0.1192, 0.1240, 0.0414, 0.0606, -0.0557, -0.0412, 0.0430, 0.2042,
|
||||
-0.0200, 0.1385, -0.0115, -0.0132, 0.0017, -0.0965, -0.0802, 0.0398,
|
||||
0.1433, 0.1747, -0.0458, -0.0533, -0.0407, 0.1545, 0.0419, -0.1574,
|
||||
-0.0645, 0.0626, 0.0341, -0.0010, -0.1199, -0.1390
|
||||
])
|
||||
results["google_ncsnpp_ffhq_256"] = torch.tensor([
|
||||
0.1075, 0.1074, 0.0205, 0.0431, -0.0774, -0.0607, 0.0298, 0.2042,
|
||||
-0.0320, 0.1267, -0.0281, -0.0250, -0.0064, -0.1091, -0.0946, 0.0290,
|
||||
0.1328, 0.1650, -0.0580, -0.0738, -0.0586, 0.1440, 0.0337, -0.1746,
|
||||
-0.0712, 0.0605, 0.0250, -0.0099, -0.1316, -0.1473
|
||||
])
|
||||
results["google_ddpm_cat_256"] = torch.tensor([
|
||||
-1.4572, -2.0481, -0.0414, -0.6005, 1.4136, 0.5848, 0.4028, -2.7330,
|
||||
1.2212, -2.1228, 0.2155, 0.4039, 0.7662, 2.0535, 0.7477, -0.3243,
|
||||
-2.1758, -2.7648, 1.6947, 0.7026, 1.2338, -1.6078, -0.8682, 2.2810,
|
||||
1.8574, -0.5718, -0.5586, -0.0186, 2.3415, 2.1251])
|
||||
results["google_ddpm_celebahq_256"] = torch.tensor([
|
||||
-1.3690, -1.9720, -0.4090, -0.6966, 1.4660, 0.9938, -0.1385, -2.7324,
|
||||
0.7736, -1.8917, 0.2923, 0.4293, 0.1693, 1.4112, 1.1887, -0.3181,
|
||||
-2.2160, -2.6381, 1.3170, 0.8163, 0.9240, -1.6544, -0.6099, 2.5259,
|
||||
1.6430, -0.9090, -0.9392, -0.0126, 2.4268, 2.3266
|
||||
])
|
||||
results["google_ddpm_ema_celebahq_256"] = torch.tensor([
|
||||
-1.3525, -1.9628, -0.3956, -0.6860, 1.4664, 1.0014, -0.1259, -2.7212,
|
||||
0.7772, -1.8811, 0.2996, 0.4388, 0.1704, 1.4029, 1.1701, -0.3027,
|
||||
-2.2053, -2.6287, 1.3350, 0.8131, 0.9274, -1.6292, -0.6098, 2.5131,
|
||||
1.6505, -0.8958, -0.9298, -0.0151, 2.4257, 2.3355
|
||||
])
|
||||
results["google_ddpm_church_256"] = torch.tensor([
|
||||
-2.0585, -2.7897, -0.2850, -0.8940, 1.9052, 0.5702, 0.6345, -3.8959,
|
||||
1.5932, -3.2319, 0.1974, 0.0287, 1.7566, 2.6543, 0.8387, -0.5351,
|
||||
-3.2736, -4.3375, 2.9029, 1.6390, 1.4640, -2.1701, -1.9013, 2.9341,
|
||||
3.4981, -0.6255, -1.1644, -0.1591, 3.7097, 3.2066
|
||||
])
|
||||
results["google_ddpm_bedroom_256"] = torch.tensor([
|
||||
-2.3139, -2.5594, -0.0197, -0.6785, 1.7001, 1.1606, 0.3075, -2.1740,
|
||||
1.8071, -2.5630, -0.0926, -0.3811, 1.2116, 2.6246, 1.2731, -0.5398,
|
||||
-2.8153, -3.6140, 2.3893, 1.3262, 1.6258, -2.1856, -1.3267, 2.8395,
|
||||
2.3779, -1.0623, -1.2468, 0.8959, 3.3367, 3.2243
|
||||
])
|
||||
results["google_ddpm_ema_church_256"] = torch.tensor([
|
||||
-2.0628, -2.7667, -0.2089, -0.8263, 2.0539, 0.5992, 0.6495, -3.8336,
|
||||
1.6025, -3.2817, 0.1721, -0.0633, 1.7516, 2.7039, 0.8100, -0.5908,
|
||||
-3.2113, -4.4343, 2.9257, 1.3632, 1.5562, -2.1489, -1.9894, 3.0560,
|
||||
3.3396, -0.7328, -1.0417, 0.0383, 3.7093, 3.2343
|
||||
])
|
||||
results["google_ddpm_ema_cat_256"] = torch.tensor([
|
||||
-1.4574, -2.0569, -0.0473, -0.6117, 1.4018, 0.5769, 0.4129, -2.7344,
|
||||
1.2241, -2.1397, 0.2000, 0.3937, 0.7616, 2.0453, 0.7324, -0.3391,
|
||||
-2.1746, -2.7744, 1.6963, 0.6921, 1.2187, -1.6172, -0.8877, 2.2439,
|
||||
1.8471, -0.5839, -0.5605, -0.0464, 2.3250, 2.1219
|
||||
])
|
||||
# fmt: on
|
||||
|
||||
models = api.list_models(filter="diffusers")
|
||||
for mod in models:
|
||||
if "google" in mod.author or mod.modelId == "CompVis/ldm-celebahq-256":
|
||||
local_checkpoint = "/home/patrick/google_checkpoints/" + mod.modelId.split("/")[-1]
|
||||
|
||||
print(f"Started running {mod.modelId}!!!")
|
||||
|
||||
if mod.modelId.startswith("CompVis"):
|
||||
model = UNet2DModel.from_pretrained(local_checkpoint, subfolder="unet")
|
||||
else:
|
||||
model = UNet2DModel.from_pretrained(local_checkpoint)
|
||||
|
||||
torch.manual_seed(0)
|
||||
random.seed(0)
|
||||
|
||||
noise = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
|
||||
time_step = torch.tensor([10] * noise.shape[0])
|
||||
with torch.no_grad():
|
||||
logits = model(noise, time_step).sample
|
||||
|
||||
assert torch.allclose(
|
||||
logits[0, 0, 0, :30], results["_".join("_".join(mod.modelId.split("/")).split("-"))], atol=1e-3
|
||||
)
|
||||
print(f"{mod.modelId} has passed succesfully!!!")
|
||||
@@ -17,3 +17,4 @@ use_parentheses = True
|
||||
[flake8]
|
||||
ignore = E203, E722, E501, E741, W503, W605
|
||||
max-line-length = 119
|
||||
per-file-ignores = __init__.py:F401
|
||||
|
||||
@@ -77,16 +77,26 @@ from setuptools import find_packages, setup
|
||||
# 2. once modified, run: `make deps_table_update` to update src/diffusers/dependency_versions_table.py
|
||||
_deps = [
|
||||
"Pillow",
|
||||
"black~=22.0,>=22.3",
|
||||
"accelerate>=0.11.0",
|
||||
"black==22.3",
|
||||
"datasets",
|
||||
"filelock",
|
||||
"flake8>=3.8.3",
|
||||
"huggingface-hub",
|
||||
"hf-doc-builder>=0.3.0",
|
||||
"huggingface-hub>=0.8.1",
|
||||
"importlib_metadata",
|
||||
"isort>=5.5.4",
|
||||
"modelcards==0.1.4",
|
||||
"numpy",
|
||||
"pytest",
|
||||
"pytest-timeout",
|
||||
"pytest-xdist",
|
||||
"scipy",
|
||||
"regex!=2019.12.17",
|
||||
"requests",
|
||||
"tensorboard",
|
||||
"torch>=1.4",
|
||||
"transformers>=4.21.0",
|
||||
]
|
||||
|
||||
# this is a lookup table with items like:
|
||||
@@ -157,14 +167,14 @@ extras = {}
|
||||
|
||||
|
||||
extras = {}
|
||||
extras["quality"] = ["black ~= 22.0", "isort >= 5.5.4", "flake8 >= 3.8.3"]
|
||||
extras["docs"] = []
|
||||
extras["test"] = [
|
||||
"pytest",
|
||||
]
|
||||
extras["dev"] = extras["quality"] + extras["test"]
|
||||
extras["quality"] = ["black==22.3", "isort>=5.5.4", "flake8>=3.8.3", "hf-doc-builder"]
|
||||
extras["docs"] = ["hf-doc-builder"]
|
||||
extras["training"] = ["accelerate", "datasets", "tensorboard", "modelcards"]
|
||||
extras["test"] = ["datasets", "onnxruntime", "pytest", "pytest-timeout", "pytest-xdist", "scipy", "transformers"]
|
||||
extras["dev"] = extras["quality"] + extras["test"] + extras["training"] + extras["docs"]
|
||||
|
||||
install_requires = [
|
||||
deps["importlib_metadata"],
|
||||
deps["filelock"],
|
||||
deps["huggingface-hub"],
|
||||
deps["numpy"],
|
||||
@@ -176,7 +186,7 @@ install_requires = [
|
||||
|
||||
setup(
|
||||
name="diffusers",
|
||||
version="0.0.3",
|
||||
version="0.3.0", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)
|
||||
description="Diffusers",
|
||||
long_description=open("README.md", "r", encoding="utf-8").read(),
|
||||
long_description_content_type="text/markdown",
|
||||
@@ -187,9 +197,11 @@ setup(
|
||||
url="https://github.com/huggingface/diffusers",
|
||||
package_dir={"": "src"},
|
||||
packages=find_packages("src"),
|
||||
include_package_data=True,
|
||||
python_requires=">=3.6.0",
|
||||
install_requires=install_requires,
|
||||
extras_require=extras,
|
||||
entry_points={"console_scripts": ["diffusers-cli=diffusers.commands.diffusers_cli:main"]},
|
||||
classifiers=[
|
||||
"Development Status :: 5 - Production/Stable",
|
||||
"Intended Audience :: Developers",
|
||||
@@ -198,7 +210,6 @@ setup(
|
||||
"License :: OSI Approved :: Apache Software License",
|
||||
"Operating System :: OS Independent",
|
||||
"Programming Language :: Python :: 3",
|
||||
"Programming Language :: Python :: 3.6",
|
||||
"Programming Language :: Python :: 3.7",
|
||||
"Programming Language :: Python :: 3.8",
|
||||
"Programming Language :: Python :: 3.9",
|
||||
|
||||
+56
-11
@@ -1,15 +1,60 @@
|
||||
# flake8: noqa
|
||||
# There's no way to ignore "F401 '...' imported but unused" warnings in this
|
||||
# module, but to preserve other warnings. So, don't check this module at all.
|
||||
from .utils import (
|
||||
is_inflect_available,
|
||||
is_onnx_available,
|
||||
is_scipy_available,
|
||||
is_transformers_available,
|
||||
is_unidecode_available,
|
||||
)
|
||||
|
||||
__version__ = "0.0.3"
|
||||
|
||||
__version__ = "0.3.0"
|
||||
|
||||
from .configuration_utils import ConfigMixin
|
||||
from .modeling_utils import ModelMixin
|
||||
from .models.unet import UNetModel
|
||||
from .models.unet_glide import GLIDESuperResUNetModel, GLIDETextToImageUNetModel, GLIDEUNetModel
|
||||
from .models.unet_grad_tts import UNetGradTTSModel
|
||||
from .models.unet_ldm import UNetLDMModel
|
||||
from .models import AutoencoderKL, UNet2DConditionModel, UNet2DModel, VQModel
|
||||
from .onnx_utils import OnnxRuntimeModel
|
||||
from .optimization import (
|
||||
get_constant_schedule,
|
||||
get_constant_schedule_with_warmup,
|
||||
get_cosine_schedule_with_warmup,
|
||||
get_cosine_with_hard_restarts_schedule_with_warmup,
|
||||
get_linear_schedule_with_warmup,
|
||||
get_polynomial_decay_schedule_with_warmup,
|
||||
get_scheduler,
|
||||
)
|
||||
from .pipeline_utils import DiffusionPipeline
|
||||
from .pipelines import BDDM, DDIM, DDPM, GLIDE, PNDM, LatentDiffusion
|
||||
from .schedulers import DDIMScheduler, DDPMScheduler, PNDMScheduler, SchedulerMixin
|
||||
from .schedulers.classifier_free_guidance import ClassifierFreeGuidanceScheduler
|
||||
from .pipelines import DDIMPipeline, DDPMPipeline, KarrasVePipeline, LDMPipeline, PNDMPipeline, ScoreSdeVePipeline
|
||||
from .schedulers import (
|
||||
DDIMScheduler,
|
||||
DDPMScheduler,
|
||||
KarrasVeScheduler,
|
||||
PNDMScheduler,
|
||||
SchedulerMixin,
|
||||
ScoreSdeVeScheduler,
|
||||
)
|
||||
from .utils import logging
|
||||
|
||||
|
||||
if is_scipy_available():
|
||||
from .schedulers import LMSDiscreteScheduler
|
||||
else:
|
||||
from .utils.dummy_scipy_objects import * # noqa F403
|
||||
|
||||
from .training_utils import EMAModel
|
||||
|
||||
|
||||
if is_transformers_available():
|
||||
from .pipelines import (
|
||||
LDMTextToImagePipeline,
|
||||
StableDiffusionImg2ImgPipeline,
|
||||
StableDiffusionInpaintPipeline,
|
||||
StableDiffusionPipeline,
|
||||
)
|
||||
else:
|
||||
from .utils.dummy_transformers_objects import * # noqa F403
|
||||
|
||||
|
||||
if is_transformers_available() and is_onnx_available():
|
||||
from .pipelines import StableDiffusionOnnxPipeline
|
||||
else:
|
||||
from .utils.dummy_transformers_and_onnx_objects import * # noqa F403
|
||||
|
||||
@@ -0,0 +1,27 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
from argparse import ArgumentParser
|
||||
|
||||
|
||||
class BaseDiffusersCLICommand(ABC):
|
||||
@staticmethod
|
||||
@abstractmethod
|
||||
def register_subcommand(parser: ArgumentParser):
|
||||
raise NotImplementedError()
|
||||
|
||||
@abstractmethod
|
||||
def run(self):
|
||||
raise NotImplementedError()
|
||||
@@ -0,0 +1,41 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from argparse import ArgumentParser
|
||||
|
||||
from .env import EnvironmentCommand
|
||||
|
||||
|
||||
def main():
|
||||
parser = ArgumentParser("Diffusers CLI tool", usage="diffusers-cli <command> [<args>]")
|
||||
commands_parser = parser.add_subparsers(help="diffusers-cli command helpers")
|
||||
|
||||
# Register commands
|
||||
EnvironmentCommand.register_subcommand(commands_parser)
|
||||
|
||||
# Let's go
|
||||
args = parser.parse_args()
|
||||
|
||||
if not hasattr(args, "func"):
|
||||
parser.print_help()
|
||||
exit(1)
|
||||
|
||||
# Run
|
||||
service = args.func(args)
|
||||
service.run()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -0,0 +1,70 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import platform
|
||||
from argparse import ArgumentParser
|
||||
|
||||
import huggingface_hub
|
||||
|
||||
from .. import __version__ as version
|
||||
from ..utils import is_torch_available, is_transformers_available
|
||||
from . import BaseDiffusersCLICommand
|
||||
|
||||
|
||||
def info_command_factory(_):
|
||||
return EnvironmentCommand()
|
||||
|
||||
|
||||
class EnvironmentCommand(BaseDiffusersCLICommand):
|
||||
@staticmethod
|
||||
def register_subcommand(parser: ArgumentParser):
|
||||
download_parser = parser.add_parser("env")
|
||||
download_parser.set_defaults(func=info_command_factory)
|
||||
|
||||
def run(self):
|
||||
hub_version = huggingface_hub.__version__
|
||||
|
||||
pt_version = "not installed"
|
||||
pt_cuda_available = "NA"
|
||||
if is_torch_available():
|
||||
import torch
|
||||
|
||||
pt_version = torch.__version__
|
||||
pt_cuda_available = torch.cuda.is_available()
|
||||
|
||||
transformers_version = "not installed"
|
||||
if is_transformers_available:
|
||||
import transformers
|
||||
|
||||
transformers_version = transformers.__version__
|
||||
|
||||
info = {
|
||||
"`diffusers` version": version,
|
||||
"Platform": platform.platform(),
|
||||
"Python version": platform.python_version(),
|
||||
"PyTorch version (GPU?)": f"{pt_version} ({pt_cuda_available})",
|
||||
"Huggingface_hub version": hub_version,
|
||||
"Transformers version": transformers_version,
|
||||
"Using GPU in script?": "<fill in>",
|
||||
"Using distributed or parallel set-up in script?": "<fill in>",
|
||||
}
|
||||
|
||||
print("\nCopy-and-paste the text below in your GitHub issue and FILL OUT the two last points.\n")
|
||||
print(self.format_dict(info))
|
||||
|
||||
return info
|
||||
|
||||
@staticmethod
|
||||
def format_dict(d):
|
||||
return "\n".join([f"- {prop}: {val}" for prop, val in d.items()]) + "\n"
|
||||
@@ -14,27 +14,20 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" ConfigMixinuration base class and utilities."""
|
||||
|
||||
|
||||
import copy
|
||||
import functools
|
||||
import inspect
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
from collections import OrderedDict
|
||||
from typing import Any, Dict, Tuple, Union
|
||||
|
||||
from huggingface_hub import hf_hub_download
|
||||
from huggingface_hub.utils import EntryNotFoundError, RepositoryNotFoundError, RevisionNotFoundError
|
||||
from requests import HTTPError
|
||||
|
||||
from . import __version__
|
||||
from .utils import (
|
||||
DIFFUSERS_CACHE,
|
||||
HUGGINGFACE_CO_RESOLVE_ENDPOINT,
|
||||
EntryNotFoundError,
|
||||
RepositoryNotFoundError,
|
||||
RevisionNotFoundError,
|
||||
logging,
|
||||
)
|
||||
from .utils import DIFFUSERS_CACHE, HUGGINGFACE_CO_RESOLVE_ENDPOINT, logging
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
@@ -44,13 +37,21 @@ _re_configuration_file = re.compile(r"config\.(.*)\.json")
|
||||
|
||||
class ConfigMixin:
|
||||
r"""
|
||||
Base class for all configuration classes. Handles a few parameters common to all models' configurations as well as
|
||||
methods for loading/downloading/saving configurations.
|
||||
Base class for all configuration classes. Stores all configuration parameters under `self.config` Also handles all
|
||||
methods for loading/downloading/saving classes inheriting from [`ConfigMixin`] with
|
||||
- [`~ConfigMixin.from_config`]
|
||||
- [`~ConfigMixin.save_config`]
|
||||
|
||||
Class attributes:
|
||||
- **config_name** (`str`) -- A filename under which the config should stored when calling
|
||||
[`~ConfigMixin.save_config`] (should be overriden by parent class).
|
||||
- **ignore_for_config** (`List[str]`) -- A list of attributes that should not be saved in the config (should be
|
||||
overriden by parent class).
|
||||
"""
|
||||
config_name = None
|
||||
ignore_for_config = []
|
||||
|
||||
def register(self, **kwargs):
|
||||
def register_to_config(self, **kwargs):
|
||||
if self.config_name is None:
|
||||
raise NotImplementedError(f"Make sure that {self.__class__} has defined a class name `config_name`")
|
||||
kwargs["_class_name"] = self.__class__.__name__
|
||||
@@ -63,10 +64,14 @@ class ConfigMixin:
|
||||
logger.error(f"Can't set {key} with value {value} for {self}")
|
||||
raise err
|
||||
|
||||
if not hasattr(self, "_dict_to_save"):
|
||||
self._dict_to_save = {}
|
||||
if not hasattr(self, "_internal_dict"):
|
||||
internal_dict = kwargs
|
||||
else:
|
||||
previous_dict = dict(self._internal_dict)
|
||||
internal_dict = {**self._internal_dict, **kwargs}
|
||||
logger.debug(f"Updating config from {previous_dict} to {internal_dict}")
|
||||
|
||||
self._dict_to_save.update(kwargs)
|
||||
self._internal_dict = FrozenDict(internal_dict)
|
||||
|
||||
def save_config(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
|
||||
"""
|
||||
@@ -76,8 +81,6 @@ class ConfigMixin:
|
||||
Args:
|
||||
save_directory (`str` or `os.PathLike`):
|
||||
Directory where the configuration JSON file will be saved (will be created if it does not exist).
|
||||
kwargs:
|
||||
Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
|
||||
"""
|
||||
if os.path.isfile(save_directory):
|
||||
raise AssertionError(f"Provided path ({save_directory}) should be a directory, not a file")
|
||||
@@ -92,6 +95,64 @@ class ConfigMixin:
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, pretrained_model_name_or_path: Union[str, os.PathLike], return_unused_kwargs=False, **kwargs):
|
||||
r"""
|
||||
Instantiate a Python class from a pre-defined JSON-file.
|
||||
|
||||
Parameters:
|
||||
pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
|
||||
Can be either:
|
||||
|
||||
- A string, the *model id* of a model repo on huggingface.co. Valid model ids should have an
|
||||
organization name, like `google/ddpm-celebahq-256`.
|
||||
- A path to a *directory* containing model weights saved using [`~ConfigMixin.save_config`], e.g.,
|
||||
`./my_model_directory/`.
|
||||
|
||||
cache_dir (`Union[str, os.PathLike]`, *optional*):
|
||||
Path to a directory in which a downloaded pretrained model configuration should be cached if the
|
||||
standard cache should not be used.
|
||||
ignore_mismatched_sizes (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to raise an error if some of the weights from the checkpoint do not have the same size
|
||||
as the weights of the model (if for instance, you are instantiating a model with 10 labels from a
|
||||
checkpoint with 3 labels).
|
||||
force_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
|
||||
cached versions if they exist.
|
||||
resume_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to delete incompletely received files. Will attempt to resume the download if such a
|
||||
file exists.
|
||||
proxies (`Dict[str, str]`, *optional*):
|
||||
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
|
||||
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
|
||||
output_loading_info(`bool`, *optional*, defaults to `False`):
|
||||
Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
|
||||
local_files_only(`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to only look at local files (i.e., do not try to download the model).
|
||||
use_auth_token (`str` or *bool*, *optional*):
|
||||
The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
|
||||
when running `transformers-cli login` (stored in `~/.huggingface`).
|
||||
revision (`str`, *optional*, defaults to `"main"`):
|
||||
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
|
||||
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
|
||||
identifier allowed by git.
|
||||
mirror (`str`, *optional*):
|
||||
Mirror source to accelerate downloads in China. If you are from China and have an accessibility
|
||||
problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
|
||||
Please refer to the mirror site for more information.
|
||||
|
||||
<Tip>
|
||||
|
||||
Passing `use_auth_token=True`` is required when you want to use a private model.
|
||||
|
||||
</Tip>
|
||||
|
||||
<Tip>
|
||||
|
||||
Activate the special ["offline-mode"](https://huggingface.co/transformers/installation.html#offline-mode) to
|
||||
use this method in a firewalled environment.
|
||||
|
||||
</Tip>
|
||||
|
||||
"""
|
||||
config_dict = cls.get_config_dict(pretrained_model_name_or_path=pretrained_model_name_or_path, **kwargs)
|
||||
|
||||
init_dict, unused_kwargs = cls.extract_init_dict(config_dict, **kwargs)
|
||||
@@ -114,6 +175,7 @@ class ConfigMixin:
|
||||
use_auth_token = kwargs.pop("use_auth_token", None)
|
||||
local_files_only = kwargs.pop("local_files_only", False)
|
||||
revision = kwargs.pop("revision", None)
|
||||
subfolder = kwargs.pop("subfolder", None)
|
||||
|
||||
user_agent = {"file_type": "config"}
|
||||
|
||||
@@ -131,6 +193,10 @@ class ConfigMixin:
|
||||
if os.path.isfile(os.path.join(pretrained_model_name_or_path, cls.config_name)):
|
||||
# Load from a PyTorch checkpoint
|
||||
config_file = os.path.join(pretrained_model_name_or_path, cls.config_name)
|
||||
elif subfolder is not None and os.path.isfile(
|
||||
os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
|
||||
):
|
||||
config_file = os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
|
||||
else:
|
||||
raise EnvironmentError(
|
||||
f"Error no file named {cls.config_name} found in directory {pretrained_model_name_or_path}."
|
||||
@@ -148,14 +214,16 @@ class ConfigMixin:
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
user_agent=user_agent,
|
||||
subfolder=subfolder,
|
||||
revision=revision,
|
||||
)
|
||||
|
||||
except RepositoryNotFoundError:
|
||||
raise EnvironmentError(
|
||||
f"{pretrained_model_name_or_path} is not a local folder and is not a valid model identifier listed"
|
||||
" on 'https://huggingface.co/models'\nIf this is a private repository, make sure to pass a token"
|
||||
" having permission to this repo with `use_auth_token` or log in with `huggingface-cli login` and"
|
||||
" pass `use_auth_token=True`."
|
||||
f"{pretrained_model_name_or_path} is not a local folder and is not a valid model identifier"
|
||||
" listed on 'https://huggingface.co/models'\nIf this is a private repository, make sure to pass a"
|
||||
" token having permission to this repo with `use_auth_token` or log in with `huggingface-cli"
|
||||
" login` and pass `use_auth_token=True`."
|
||||
)
|
||||
except RevisionNotFoundError:
|
||||
raise EnvironmentError(
|
||||
@@ -200,6 +268,12 @@ class ConfigMixin:
|
||||
def extract_init_dict(cls, config_dict, **kwargs):
|
||||
expected_keys = set(dict(inspect.signature(cls.__init__).parameters).keys())
|
||||
expected_keys.remove("self")
|
||||
# remove general kwargs if present in dict
|
||||
if "kwargs" in expected_keys:
|
||||
expected_keys.remove("kwargs")
|
||||
# remove keys to be ignored
|
||||
if len(cls.ignore_for_config) > 0:
|
||||
expected_keys = expected_keys - set(cls.ignore_for_config)
|
||||
init_dict = {}
|
||||
for key in expected_keys:
|
||||
if key in kwargs:
|
||||
@@ -230,8 +304,7 @@ class ConfigMixin:
|
||||
|
||||
@property
|
||||
def config(self) -> Dict[str, Any]:
|
||||
output = copy.deepcopy(self._dict_to_save)
|
||||
return output
|
||||
return self._internal_dict
|
||||
|
||||
def to_json_string(self) -> str:
|
||||
"""
|
||||
@@ -240,7 +313,7 @@ class ConfigMixin:
|
||||
Returns:
|
||||
`str`: String containing all the attributes that make up this configuration instance in JSON format.
|
||||
"""
|
||||
config_dict = self._dict_to_save
|
||||
config_dict = self._internal_dict if hasattr(self, "_internal_dict") else {}
|
||||
return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
|
||||
|
||||
def to_json_file(self, json_file_path: Union[str, os.PathLike]):
|
||||
@@ -253,3 +326,78 @@ class ConfigMixin:
|
||||
"""
|
||||
with open(json_file_path, "w", encoding="utf-8") as writer:
|
||||
writer.write(self.to_json_string())
|
||||
|
||||
|
||||
class FrozenDict(OrderedDict):
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
for key, value in self.items():
|
||||
setattr(self, key, value)
|
||||
|
||||
self.__frozen = True
|
||||
|
||||
def __delitem__(self, *args, **kwargs):
|
||||
raise Exception(f"You cannot use ``__delitem__`` on a {self.__class__.__name__} instance.")
|
||||
|
||||
def setdefault(self, *args, **kwargs):
|
||||
raise Exception(f"You cannot use ``setdefault`` on a {self.__class__.__name__} instance.")
|
||||
|
||||
def pop(self, *args, **kwargs):
|
||||
raise Exception(f"You cannot use ``pop`` on a {self.__class__.__name__} instance.")
|
||||
|
||||
def update(self, *args, **kwargs):
|
||||
raise Exception(f"You cannot use ``update`` on a {self.__class__.__name__} instance.")
|
||||
|
||||
def __setattr__(self, name, value):
|
||||
if hasattr(self, "__frozen") and self.__frozen:
|
||||
raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
|
||||
super().__setattr__(name, value)
|
||||
|
||||
def __setitem__(self, name, value):
|
||||
if hasattr(self, "__frozen") and self.__frozen:
|
||||
raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
|
||||
super().__setitem__(name, value)
|
||||
|
||||
|
||||
def register_to_config(init):
|
||||
r"""
|
||||
Decorator to apply on the init of classes inheriting from [`ConfigMixin`] so that all the arguments are
|
||||
automatically sent to `self.register_for_config`. To ignore a specific argument accepted by the init but that
|
||||
shouldn't be registered in the config, use the `ignore_for_config` class variable
|
||||
|
||||
Warning: Once decorated, all private arguments (beginning with an underscore) are trashed and not sent to the init!
|
||||
"""
|
||||
|
||||
@functools.wraps(init)
|
||||
def inner_init(self, *args, **kwargs):
|
||||
# Ignore private kwargs in the init.
|
||||
init_kwargs = {k: v for k, v in kwargs.items() if not k.startswith("_")}
|
||||
init(self, *args, **init_kwargs)
|
||||
if not isinstance(self, ConfigMixin):
|
||||
raise RuntimeError(
|
||||
f"`@register_for_config` was applied to {self.__class__.__name__} init method, but this class does "
|
||||
"not inherit from `ConfigMixin`."
|
||||
)
|
||||
|
||||
ignore = getattr(self, "ignore_for_config", [])
|
||||
# Get positional arguments aligned with kwargs
|
||||
new_kwargs = {}
|
||||
signature = inspect.signature(init)
|
||||
parameters = {
|
||||
name: p.default for i, (name, p) in enumerate(signature.parameters.items()) if i > 0 and name not in ignore
|
||||
}
|
||||
for arg, name in zip(args, parameters.keys()):
|
||||
new_kwargs[name] = arg
|
||||
|
||||
# Then add all kwargs
|
||||
new_kwargs.update(
|
||||
{
|
||||
k: init_kwargs.get(k, default)
|
||||
for k, default in parameters.items()
|
||||
if k not in ignore and k not in new_kwargs
|
||||
}
|
||||
)
|
||||
getattr(self, "register_to_config")(**new_kwargs)
|
||||
|
||||
return inner_init
|
||||
|
||||
@@ -3,14 +3,24 @@
|
||||
# 2. run `make deps_table_update``
|
||||
deps = {
|
||||
"Pillow": "Pillow",
|
||||
"black": "black~=22.0,>=22.3",
|
||||
"accelerate": "accelerate>=0.11.0",
|
||||
"black": "black==22.3",
|
||||
"datasets": "datasets",
|
||||
"filelock": "filelock",
|
||||
"flake8": "flake8>=3.8.3",
|
||||
"huggingface-hub": "huggingface-hub",
|
||||
"hf-doc-builder": "hf-doc-builder>=0.3.0",
|
||||
"huggingface-hub": "huggingface-hub>=0.8.1",
|
||||
"importlib_metadata": "importlib_metadata",
|
||||
"isort": "isort>=5.5.4",
|
||||
"modelcards": "modelcards==0.1.4",
|
||||
"numpy": "numpy",
|
||||
"pytest": "pytest",
|
||||
"pytest-timeout": "pytest-timeout",
|
||||
"pytest-xdist": "pytest-xdist",
|
||||
"scipy": "scipy",
|
||||
"regex": "regex!=2019.12.17",
|
||||
"requests": "requests",
|
||||
"tensorboard": "tensorboard",
|
||||
"torch": "torch>=1.4",
|
||||
"transformers": "transformers>=4.21.0",
|
||||
}
|
||||
|
||||
@@ -0,0 +1,197 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import os
|
||||
import shutil
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from huggingface_hub import HfFolder, Repository, whoami
|
||||
|
||||
from .pipeline_utils import DiffusionPipeline
|
||||
from .utils import is_modelcards_available, logging
|
||||
|
||||
|
||||
if is_modelcards_available():
|
||||
from modelcards import CardData, ModelCard
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
MODEL_CARD_TEMPLATE_PATH = Path(__file__).parent / "utils" / "model_card_template.md"
|
||||
|
||||
|
||||
def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
|
||||
if token is None:
|
||||
token = HfFolder.get_token()
|
||||
if organization is None:
|
||||
username = whoami(token)["name"]
|
||||
return f"{username}/{model_id}"
|
||||
else:
|
||||
return f"{organization}/{model_id}"
|
||||
|
||||
|
||||
def init_git_repo(args, at_init: bool = False):
|
||||
"""
|
||||
Args:
|
||||
Initializes a git repo in `args.hub_model_id`.
|
||||
at_init (`bool`, *optional*, defaults to `False`):
|
||||
Whether this function is called before any training or not. If `self.args.overwrite_output_dir` is `True`
|
||||
and `at_init` is `True`, the path to the repo (which is `self.args.output_dir`) might be wiped out.
|
||||
"""
|
||||
if hasattr(args, "local_rank") and args.local_rank not in [-1, 0]:
|
||||
return
|
||||
hub_token = args.hub_token if hasattr(args, "hub_token") else None
|
||||
use_auth_token = True if hub_token is None else hub_token
|
||||
if not hasattr(args, "hub_model_id") or args.hub_model_id is None:
|
||||
repo_name = Path(args.output_dir).absolute().name
|
||||
else:
|
||||
repo_name = args.hub_model_id
|
||||
if "/" not in repo_name:
|
||||
repo_name = get_full_repo_name(repo_name, token=hub_token)
|
||||
|
||||
try:
|
||||
repo = Repository(
|
||||
args.output_dir,
|
||||
clone_from=repo_name,
|
||||
use_auth_token=use_auth_token,
|
||||
private=args.hub_private_repo,
|
||||
)
|
||||
except EnvironmentError:
|
||||
if args.overwrite_output_dir and at_init:
|
||||
# Try again after wiping output_dir
|
||||
shutil.rmtree(args.output_dir)
|
||||
repo = Repository(
|
||||
args.output_dir,
|
||||
clone_from=repo_name,
|
||||
use_auth_token=use_auth_token,
|
||||
)
|
||||
else:
|
||||
raise
|
||||
|
||||
repo.git_pull()
|
||||
|
||||
# By default, ignore the checkpoint folders
|
||||
if not os.path.exists(os.path.join(args.output_dir, ".gitignore")):
|
||||
with open(os.path.join(args.output_dir, ".gitignore"), "w", encoding="utf-8") as writer:
|
||||
writer.writelines(["checkpoint-*/"])
|
||||
|
||||
return repo
|
||||
|
||||
|
||||
def push_to_hub(
|
||||
args,
|
||||
pipeline: DiffusionPipeline,
|
||||
repo: Repository,
|
||||
commit_message: Optional[str] = "End of training",
|
||||
blocking: bool = True,
|
||||
**kwargs,
|
||||
) -> str:
|
||||
"""
|
||||
Parameters:
|
||||
Upload *self.model* and *self.tokenizer* to the 🤗 model hub on the repo *self.args.hub_model_id*.
|
||||
commit_message (`str`, *optional*, defaults to `"End of training"`):
|
||||
Message to commit while pushing.
|
||||
blocking (`bool`, *optional*, defaults to `True`):
|
||||
Whether the function should return only when the `git push` has finished.
|
||||
kwargs:
|
||||
Additional keyword arguments passed along to [`create_model_card`].
|
||||
Returns:
|
||||
The url of the commit of your model in the given repository if `blocking=False`, a tuple with the url of the
|
||||
commit and an object to track the progress of the commit if `blocking=True`
|
||||
"""
|
||||
|
||||
if not hasattr(args, "hub_model_id") or args.hub_model_id is None:
|
||||
model_name = Path(args.output_dir).name
|
||||
else:
|
||||
model_name = args.hub_model_id.split("/")[-1]
|
||||
|
||||
output_dir = args.output_dir
|
||||
os.makedirs(output_dir, exist_ok=True)
|
||||
logger.info(f"Saving pipeline checkpoint to {output_dir}")
|
||||
pipeline.save_pretrained(output_dir)
|
||||
|
||||
# Only push from one node.
|
||||
if hasattr(args, "local_rank") and args.local_rank not in [-1, 0]:
|
||||
return
|
||||
|
||||
# Cancel any async push in progress if blocking=True. The commits will all be pushed together.
|
||||
if (
|
||||
blocking
|
||||
and len(repo.command_queue) > 0
|
||||
and repo.command_queue[-1] is not None
|
||||
and not repo.command_queue[-1].is_done
|
||||
):
|
||||
repo.command_queue[-1]._process.kill()
|
||||
|
||||
git_head_commit_url = repo.push_to_hub(commit_message=commit_message, blocking=blocking, auto_lfs_prune=True)
|
||||
# push separately the model card to be independent from the rest of the model
|
||||
create_model_card(args, model_name=model_name)
|
||||
try:
|
||||
repo.push_to_hub(commit_message="update model card README.md", blocking=blocking, auto_lfs_prune=True)
|
||||
except EnvironmentError as exc:
|
||||
logger.error(f"Error pushing update to the model card. Please read logs and retry.\n${exc}")
|
||||
|
||||
return git_head_commit_url
|
||||
|
||||
|
||||
def create_model_card(args, model_name):
|
||||
if not is_modelcards_available:
|
||||
raise ValueError(
|
||||
"Please make sure to have `modelcards` installed when using the `create_model_card` function. You can"
|
||||
" install the package with `pip install modelcards`."
|
||||
)
|
||||
|
||||
if hasattr(args, "local_rank") and args.local_rank not in [-1, 0]:
|
||||
return
|
||||
|
||||
hub_token = args.hub_token if hasattr(args, "hub_token") else None
|
||||
repo_name = get_full_repo_name(model_name, token=hub_token)
|
||||
|
||||
model_card = ModelCard.from_template(
|
||||
card_data=CardData( # Card metadata object that will be converted to YAML block
|
||||
language="en",
|
||||
license="apache-2.0",
|
||||
library_name="diffusers",
|
||||
tags=[],
|
||||
datasets=args.dataset_name,
|
||||
metrics=[],
|
||||
),
|
||||
template_path=MODEL_CARD_TEMPLATE_PATH,
|
||||
model_name=model_name,
|
||||
repo_name=repo_name,
|
||||
dataset_name=args.dataset_name if hasattr(args, "dataset_name") else None,
|
||||
learning_rate=args.learning_rate,
|
||||
train_batch_size=args.train_batch_size,
|
||||
eval_batch_size=args.eval_batch_size,
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps
|
||||
if hasattr(args, "gradient_accumulation_steps")
|
||||
else None,
|
||||
adam_beta1=args.adam_beta1 if hasattr(args, "adam_beta1") else None,
|
||||
adam_beta2=args.adam_beta2 if hasattr(args, "adam_beta2") else None,
|
||||
adam_weight_decay=args.adam_weight_decay if hasattr(args, "adam_weight_decay") else None,
|
||||
adam_epsilon=args.adam_epsilon if hasattr(args, "adam_epsilon") else None,
|
||||
lr_scheduler=args.lr_scheduler if hasattr(args, "lr_scheduler") else None,
|
||||
lr_warmup_steps=args.lr_warmup_steps if hasattr(args, "lr_warmup_steps") else None,
|
||||
ema_inv_gamma=args.ema_inv_gamma if hasattr(args, "ema_inv_gamma") else None,
|
||||
ema_power=args.ema_power if hasattr(args, "ema_power") else None,
|
||||
ema_max_decay=args.ema_max_decay if hasattr(args, "ema_max_decay") else None,
|
||||
mixed_precision=args.mixed_precision,
|
||||
)
|
||||
|
||||
card_path = os.path.join(args.output_dir, "README.md")
|
||||
model_card.save(card_path)
|
||||
@@ -21,20 +21,13 @@ import torch
|
||||
from torch import Tensor, device
|
||||
|
||||
from huggingface_hub import hf_hub_download
|
||||
from huggingface_hub.utils import EntryNotFoundError, RepositoryNotFoundError, RevisionNotFoundError
|
||||
from requests import HTTPError
|
||||
|
||||
from .utils import (
|
||||
CONFIG_NAME,
|
||||
DIFFUSERS_CACHE,
|
||||
HUGGINGFACE_CO_RESOLVE_ENDPOINT,
|
||||
EntryNotFoundError,
|
||||
RepositoryNotFoundError,
|
||||
RevisionNotFoundError,
|
||||
logging,
|
||||
)
|
||||
from .utils import CONFIG_NAME, DIFFUSERS_CACHE, HUGGINGFACE_CO_RESOLVE_ENDPOINT, logging
|
||||
|
||||
|
||||
WEIGHTS_NAME = "diffusion_model.pt"
|
||||
WEIGHTS_NAME = "diffusion_pytorch_model.bin"
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
@@ -123,30 +116,14 @@ class ModelMixin(torch.nn.Module):
|
||||
r"""
|
||||
Base class for all models.
|
||||
|
||||
[`ModelMixin`] takes care of storing the configuration of the models and handles methods for loading,
|
||||
downloading and saving models as well as a few methods common to all models to:
|
||||
[`ModelMixin`] takes care of storing the configuration of the models and handles methods for loading, downloading
|
||||
and saving models.
|
||||
|
||||
- resize the input embeddings,
|
||||
- prune heads in the self-attention heads.
|
||||
|
||||
Class attributes (overridden by derived classes):
|
||||
|
||||
- **config_class** ([`ConfigMixin`]) -- A subclass of [`ConfigMixin`] to use as configuration class
|
||||
for this model architecture.
|
||||
- **load_tf_weights** (`Callable`) -- A python *method* for loading a TensorFlow checkpoint in a PyTorch model,
|
||||
taking as arguments:
|
||||
|
||||
- **model** ([`ModelMixin`]) -- An instance of the model on which to load the TensorFlow checkpoint.
|
||||
- **config** ([`PreTrainedConfigMixin`]) -- An instance of the configuration associated to the model.
|
||||
- **path** (`str`) -- A path to the TensorFlow checkpoint.
|
||||
|
||||
- **base_model_prefix** (`str`) -- A string indicating the attribute associated to the base model in derived
|
||||
classes of the same architecture adding modules on top of the base model.
|
||||
- **is_parallelizable** (`bool`) -- A flag indicating whether this model supports model parallelization.
|
||||
- **main_input_name** (`str`) -- The name of the principal input to the model (often `input_ids` for NLP
|
||||
models, `pixel_values` for vision models and `input_values` for speech models).
|
||||
- **config_name** ([`str`]) -- A filename under which the model should be stored when calling
|
||||
[`~modeling_utils.ModelMixin.save_pretrained`].
|
||||
"""
|
||||
config_name = CONFIG_NAME
|
||||
_automatically_saved_args = ["_diffusers_version", "_class_name", "_name_or_path"]
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
@@ -156,11 +133,10 @@ class ModelMixin(torch.nn.Module):
|
||||
save_directory: Union[str, os.PathLike],
|
||||
is_main_process: bool = True,
|
||||
save_function: Callable = torch.save,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Save a model and its configuration file to a directory, so that it can be re-loaded using the
|
||||
`[`~ModelMixin.from_pretrained`]` class method.
|
||||
`[`~modeling_utils.ModelMixin.from_pretrained`]` class method.
|
||||
|
||||
Arguments:
|
||||
save_directory (`str` or `os.PathLike`):
|
||||
@@ -172,9 +148,6 @@ class ModelMixin(torch.nn.Module):
|
||||
save_function (`Callable`):
|
||||
The function to use to save the state dictionary. Useful on distributed training like TPUs when one
|
||||
need to replace `torch.save` by another method.
|
||||
|
||||
kwargs:
|
||||
Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
|
||||
"""
|
||||
if os.path.isfile(save_directory):
|
||||
logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
|
||||
@@ -225,39 +198,16 @@ class ModelMixin(torch.nn.Module):
|
||||
Can be either:
|
||||
|
||||
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
|
||||
Valid model ids can be located at the root-level, like `bert-base-uncased`, or namespaced under a
|
||||
user or organization name, like `dbmdz/bert-base-german-cased`.
|
||||
- A path to a *directory* containing model weights saved using
|
||||
[`~ModelMixin.save_pretrained`], e.g., `./my_model_directory/`.
|
||||
Valid model ids should have an organization name, like `google/ddpm-celebahq-256`.
|
||||
- A path to a *directory* containing model weights saved using [`~ModelMixin.save_config`], e.g.,
|
||||
`./my_model_directory/`.
|
||||
|
||||
config (`Union[ConfigMixin, str, os.PathLike]`, *optional*):
|
||||
Can be either:
|
||||
|
||||
- an instance of a class derived from [`ConfigMixin`],
|
||||
- a string or path valid as input to [`~ConfigMixin.from_pretrained`].
|
||||
|
||||
ConfigMixinuration for the model to use instead of an automatically loaded configuration. ConfigMixinuration can
|
||||
be automatically loaded when:
|
||||
|
||||
- The model is a model provided by the library (loaded with the *model id* string of a pretrained
|
||||
model).
|
||||
- The model was saved using [`~ModelMixin.save_pretrained`] and is reloaded by supplying the
|
||||
save directory.
|
||||
- The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
|
||||
configuration JSON file named *config.json* is found in the directory.
|
||||
cache_dir (`Union[str, os.PathLike]`, *optional*):
|
||||
Path to a directory in which a downloaded pretrained model configuration should be cached if the
|
||||
standard cache should not be used.
|
||||
from_tf (`bool`, *optional*, defaults to `False`):
|
||||
Load the model weights from a TensorFlow checkpoint save file (see docstring of
|
||||
`pretrained_model_name_or_path` argument).
|
||||
from_flax (`bool`, *optional*, defaults to `False`):
|
||||
Load the model weights from a Flax checkpoint save file (see docstring of
|
||||
`pretrained_model_name_or_path` argument).
|
||||
ignore_mismatched_sizes (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to raise an error if some of the weights from the checkpoint do not have the same size
|
||||
as the weights of the model (if for instance, you are instantiating a model with 10 labels from a
|
||||
checkpoint with 3 labels).
|
||||
torch_dtype (`str` or `torch.dtype`, *optional*):
|
||||
Override the default `torch.dtype` and load the model under this dtype. If `"auto"` is passed the dtype
|
||||
will be automatically derived from the model's weights.
|
||||
force_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
|
||||
cached versions if they exist.
|
||||
@@ -273,7 +223,7 @@ class ModelMixin(torch.nn.Module):
|
||||
Whether or not to only look at local files (i.e., do not try to download the model).
|
||||
use_auth_token (`str` or *bool*, *optional*):
|
||||
The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
|
||||
when running `transformers-cli login` (stored in `~/.huggingface`).
|
||||
when running `diffusers-cli login` (stored in `~/.huggingface`).
|
||||
revision (`str`, *optional*, defaults to `"main"`):
|
||||
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
|
||||
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
|
||||
@@ -283,20 +233,6 @@ class ModelMixin(torch.nn.Module):
|
||||
problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
|
||||
Please refer to the mirror site for more information.
|
||||
|
||||
kwargs (remaining dictionary of keyword arguments, *optional*):
|
||||
Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
|
||||
`output_attentions=True`). Behaves differently depending on whether a `config` is provided or
|
||||
automatically loaded:
|
||||
|
||||
- If a configuration is provided with `config`, `**kwargs` will be directly passed to the
|
||||
underlying model's `__init__` method (we assume all relevant updates to the configuration have
|
||||
already been done)
|
||||
- If a configuration is not provided, `kwargs` will be first passed to the configuration class
|
||||
initialization function ([`~ConfigMixin.from_pretrained`]). Each key of `kwargs` that
|
||||
corresponds to a configuration attribute will be used to override said attribute with the
|
||||
supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
|
||||
will be passed to the underlying model's `__init__` function.
|
||||
|
||||
<Tip>
|
||||
|
||||
Passing `use_auth_token=True`` is required when you want to use a private model.
|
||||
@@ -305,8 +241,8 @@ class ModelMixin(torch.nn.Module):
|
||||
|
||||
<Tip>
|
||||
|
||||
Activate the special ["offline-mode"](https://huggingface.co/transformers/installation.html#offline-mode) to
|
||||
use this method in a firewalled environment.
|
||||
Activate the special ["offline-mode"](https://huggingface.co/diffusers/installation.html#offline-mode) to use
|
||||
this method in a firewalled environment.
|
||||
|
||||
</Tip>
|
||||
|
||||
@@ -321,6 +257,8 @@ class ModelMixin(torch.nn.Module):
|
||||
use_auth_token = kwargs.pop("use_auth_token", None)
|
||||
revision = kwargs.pop("revision", None)
|
||||
from_auto_class = kwargs.pop("_from_auto", False)
|
||||
torch_dtype = kwargs.pop("torch_dtype", None)
|
||||
subfolder = kwargs.pop("subfolder", None)
|
||||
|
||||
user_agent = {"file_type": "model", "framework": "pytorch", "from_auto_class": from_auto_class}
|
||||
|
||||
@@ -336,9 +274,18 @@ class ModelMixin(torch.nn.Module):
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
**kwargs,
|
||||
)
|
||||
model.register(name_or_path=pretrained_model_name_or_path)
|
||||
|
||||
if torch_dtype is not None and not isinstance(torch_dtype, torch.dtype):
|
||||
raise ValueError(
|
||||
f"{torch_dtype} needs to be of type `torch.dtype`, e.g. `torch.float16`, but is {type(torch_dtype)}."
|
||||
)
|
||||
elif torch_dtype is not None:
|
||||
model = model.to(torch_dtype)
|
||||
|
||||
model.register_to_config(_name_or_path=pretrained_model_name_or_path)
|
||||
# This variable will flag if we're loading a sharded checkpoint. In this case the archive file is just the
|
||||
# Load model
|
||||
pretrained_model_name_or_path = str(pretrained_model_name_or_path)
|
||||
@@ -346,6 +293,10 @@ class ModelMixin(torch.nn.Module):
|
||||
if os.path.isfile(os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)):
|
||||
# Load from a PyTorch checkpoint
|
||||
model_file = os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)
|
||||
elif subfolder is not None and os.path.isfile(
|
||||
os.path.join(pretrained_model_name_or_path, subfolder, WEIGHTS_NAME)
|
||||
):
|
||||
model_file = os.path.join(pretrained_model_name_or_path, subfolder, WEIGHTS_NAME)
|
||||
else:
|
||||
raise EnvironmentError(
|
||||
f"Error no file named {WEIGHTS_NAME} found in directory {pretrained_model_name_or_path}."
|
||||
@@ -363,6 +314,8 @@ class ModelMixin(torch.nn.Module):
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
user_agent=user_agent,
|
||||
subfolder=subfolder,
|
||||
revision=revision,
|
||||
)
|
||||
|
||||
except RepositoryNotFoundError:
|
||||
@@ -380,7 +333,7 @@ class ModelMixin(torch.nn.Module):
|
||||
)
|
||||
except EntryNotFoundError:
|
||||
raise EnvironmentError(
|
||||
f"{pretrained_model_name_or_path} does not appear to have a file named {model_file}."
|
||||
f"{pretrained_model_name_or_path} does not appear to have a file named {WEIGHTS_NAME}."
|
||||
)
|
||||
except HTTPError as err:
|
||||
raise EnvironmentError(
|
||||
@@ -393,7 +346,7 @@ class ModelMixin(torch.nn.Module):
|
||||
f" in the cached files and it looks like {pretrained_model_name_or_path} is not the path to a"
|
||||
f" directory containing a file named {WEIGHTS_NAME} or"
|
||||
" \nCheckout your internet connection or see how to run the library in"
|
||||
" offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'."
|
||||
" offline mode at 'https://huggingface.co/docs/diffusers/installation#offline-mode'."
|
||||
)
|
||||
except EnvironmentError:
|
||||
raise EnvironmentError(
|
||||
@@ -490,19 +443,20 @@ class ModelMixin(torch.nn.Module):
|
||||
raise RuntimeError(f"Error(s) in loading state_dict for {model.__class__.__name__}:\n\t{error_msg}")
|
||||
|
||||
if len(unexpected_keys) > 0:
|
||||
logger.warninging(
|
||||
logger.warning(
|
||||
f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
|
||||
f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
|
||||
f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
|
||||
" with another architecture (e.g. initializing a BertForSequenceClassification model from a"
|
||||
f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task"
|
||||
" or with another architecture (e.g. initializing a BertForSequenceClassification model from a"
|
||||
" BertForPreTraining model).\n- This IS NOT expected if you are initializing"
|
||||
f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly identical"
|
||||
" (initializing a BertForSequenceClassification model from a BertForSequenceClassification model)."
|
||||
f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly"
|
||||
" identical (initializing a BertForSequenceClassification model from a"
|
||||
" BertForSequenceClassification model)."
|
||||
)
|
||||
else:
|
||||
logger.info(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
|
||||
if len(missing_keys) > 0:
|
||||
logger.warninging(
|
||||
logger.warning(
|
||||
f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
|
||||
f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
|
||||
" TRAIN this model on a down-stream task to be able to use it for predictions and inference."
|
||||
@@ -510,9 +464,9 @@ class ModelMixin(torch.nn.Module):
|
||||
elif len(mismatched_keys) == 0:
|
||||
logger.info(
|
||||
f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
|
||||
f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
|
||||
f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
|
||||
" training."
|
||||
f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the"
|
||||
f" checkpoint was trained on, you can already use {model.__class__.__name__} for predictions"
|
||||
" without further training."
|
||||
)
|
||||
if len(mismatched_keys) > 0:
|
||||
mismatched_warning = "\n".join(
|
||||
@@ -521,11 +475,11 @@ class ModelMixin(torch.nn.Module):
|
||||
for key, shape1, shape2 in mismatched_keys
|
||||
]
|
||||
)
|
||||
logger.warninging(
|
||||
logger.warning(
|
||||
f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
|
||||
f" {pretrained_model_name_or_path} and are newly initialized because the shapes did not"
|
||||
f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be able"
|
||||
" to use it for predictions and inference."
|
||||
f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be"
|
||||
" able to use it for predictions and inference."
|
||||
)
|
||||
|
||||
return model, missing_keys, unexpected_keys, mismatched_keys, error_msgs
|
||||
@@ -572,3 +526,17 @@ class ModelMixin(torch.nn.Module):
|
||||
return sum(p.numel() for p in non_embedding_parameters if p.requires_grad or not only_trainable)
|
||||
else:
|
||||
return sum(p.numel() for p in self.parameters() if p.requires_grad or not only_trainable)
|
||||
|
||||
|
||||
def unwrap_model(model: torch.nn.Module) -> torch.nn.Module:
|
||||
"""
|
||||
Recursively unwraps a model from potential containers (as used in distributed training).
|
||||
|
||||
Args:
|
||||
model (`torch.nn.Module`): The model to unwrap.
|
||||
"""
|
||||
# since there could be multiple levels of wrapping, unwrap recursively
|
||||
if hasattr(model, "module"):
|
||||
return unwrap_model(model.module)
|
||||
else:
|
||||
return model
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Models
|
||||
|
||||
- Models: Neural network that models p_θ(x_t-1|x_t) (see image below) and is trained end-to-end to denoise a noisy input to an image. Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet
|
||||
- Models: Neural network that models $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$ (see image below) and is trained end-to-end to denoise a noisy input to an image. Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet
|
||||
|
||||
## API
|
||||
|
||||
|
||||
@@ -1,7 +1,3 @@
|
||||
# flake8: noqa
|
||||
# There's no way to ignore "F401 '...' imported but unused" warnings in this
|
||||
# module, but to preserve other warnings. So, don't check this module at all.
|
||||
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
@@ -16,7 +12,6 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from .unet import UNetModel
|
||||
from .unet_glide import GLIDESuperResUNetModel, GLIDETextToImageUNetModel, GLIDEUNetModel
|
||||
from .unet_grad_tts import UNetGradTTSModel
|
||||
from .unet_ldm import UNetLDMModel
|
||||
from .unet_2d import UNet2DModel
|
||||
from .unet_2d_condition import UNet2DConditionModel
|
||||
from .vae import AutoencoderKL, VQModel
|
||||
|
||||
@@ -0,0 +1,333 @@
|
||||
import math
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
|
||||
class AttentionBlock(nn.Module):
|
||||
"""
|
||||
An attention block that allows spatial positions to attend to each other. Originally ported from here, but adapted
|
||||
to the N-d case.
|
||||
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
|
||||
Uses three q, k, v linear layers to compute attention.
|
||||
|
||||
Parameters:
|
||||
channels (:obj:`int`): The number of channels in the input and output.
|
||||
num_head_channels (:obj:`int`, *optional*):
|
||||
The number of channels in each head. If None, then `num_heads` = 1.
|
||||
num_groups (:obj:`int`, *optional*, defaults to 32): The number of groups to use for group norm.
|
||||
rescale_output_factor (:obj:`float`, *optional*, defaults to 1.0): The factor to rescale the output by.
|
||||
eps (:obj:`float`, *optional*, defaults to 1e-5): The epsilon value to use for group norm.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
channels: int,
|
||||
num_head_channels: Optional[int] = None,
|
||||
num_groups: int = 32,
|
||||
rescale_output_factor: float = 1.0,
|
||||
eps: float = 1e-5,
|
||||
):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
|
||||
self.num_heads = channels // num_head_channels if num_head_channels is not None else 1
|
||||
self.num_head_size = num_head_channels
|
||||
self.group_norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, eps=eps, affine=True)
|
||||
|
||||
# define q,k,v as linear layers
|
||||
self.query = nn.Linear(channels, channels)
|
||||
self.key = nn.Linear(channels, channels)
|
||||
self.value = nn.Linear(channels, channels)
|
||||
|
||||
self.rescale_output_factor = rescale_output_factor
|
||||
self.proj_attn = nn.Linear(channels, channels, 1)
|
||||
|
||||
def transpose_for_scores(self, projection: torch.Tensor) -> torch.Tensor:
|
||||
new_projection_shape = projection.size()[:-1] + (self.num_heads, -1)
|
||||
# move heads to 2nd position (B, T, H * D) -> (B, T, H, D) -> (B, H, T, D)
|
||||
new_projection = projection.view(new_projection_shape).permute(0, 2, 1, 3)
|
||||
return new_projection
|
||||
|
||||
def forward(self, hidden_states):
|
||||
residual = hidden_states
|
||||
batch, channel, height, width = hidden_states.shape
|
||||
|
||||
# norm
|
||||
hidden_states = self.group_norm(hidden_states)
|
||||
|
||||
hidden_states = hidden_states.view(batch, channel, height * width).transpose(1, 2)
|
||||
|
||||
# proj to q, k, v
|
||||
query_proj = self.query(hidden_states)
|
||||
key_proj = self.key(hidden_states)
|
||||
value_proj = self.value(hidden_states)
|
||||
|
||||
# transpose
|
||||
query_states = self.transpose_for_scores(query_proj)
|
||||
key_states = self.transpose_for_scores(key_proj)
|
||||
value_states = self.transpose_for_scores(value_proj)
|
||||
|
||||
# get scores
|
||||
scale = 1 / math.sqrt(math.sqrt(self.channels / self.num_heads))
|
||||
|
||||
attention_scores = torch.matmul(query_states * scale, key_states.transpose(-1, -2) * scale)
|
||||
attention_probs = torch.softmax(attention_scores.float(), dim=-1).type(attention_scores.dtype)
|
||||
|
||||
# compute attention output
|
||||
hidden_states = torch.matmul(attention_probs, value_states)
|
||||
|
||||
hidden_states = hidden_states.permute(0, 2, 1, 3).contiguous()
|
||||
new_hidden_states_shape = hidden_states.size()[:-2] + (self.channels,)
|
||||
hidden_states = hidden_states.view(new_hidden_states_shape)
|
||||
|
||||
# compute next hidden_states
|
||||
hidden_states = self.proj_attn(hidden_states)
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(batch, channel, height, width)
|
||||
|
||||
# res connect and rescale
|
||||
hidden_states = (hidden_states + residual) / self.rescale_output_factor
|
||||
return hidden_states
|
||||
|
||||
|
||||
class SpatialTransformer(nn.Module):
|
||||
"""
|
||||
Transformer block for image-like data. First, project the input (aka embedding) and reshape to b, t, d. Then apply
|
||||
standard transformer action. Finally, reshape to image.
|
||||
|
||||
Parameters:
|
||||
in_channels (:obj:`int`): The number of channels in the input and output.
|
||||
n_heads (:obj:`int`): The number of heads to use for multi-head attention.
|
||||
d_head (:obj:`int`): The number of channels in each head.
|
||||
depth (:obj:`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
|
||||
dropout (:obj:`float`, *optional*, defaults to 0.1): The dropout probability to use.
|
||||
context_dim (:obj:`int`, *optional*): The number of context dimensions to use.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
in_channels: int,
|
||||
n_heads: int,
|
||||
d_head: int,
|
||||
depth: int = 1,
|
||||
dropout: float = 0.0,
|
||||
context_dim: Optional[int] = None,
|
||||
):
|
||||
super().__init__()
|
||||
self.n_heads = n_heads
|
||||
self.d_head = d_head
|
||||
self.in_channels = in_channels
|
||||
inner_dim = n_heads * d_head
|
||||
self.norm = torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
||||
|
||||
self.proj_in = nn.Conv2d(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
self.transformer_blocks = nn.ModuleList(
|
||||
[
|
||||
BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
|
||||
for d in range(depth)
|
||||
]
|
||||
)
|
||||
|
||||
self.proj_out = nn.Conv2d(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def _set_attention_slice(self, slice_size):
|
||||
for block in self.transformer_blocks:
|
||||
block._set_attention_slice(slice_size)
|
||||
|
||||
def forward(self, x, context=None):
|
||||
# note: if no context is given, cross-attention defaults to self-attention
|
||||
b, c, h, w = x.shape
|
||||
x_in = x
|
||||
x = self.norm(x)
|
||||
x = self.proj_in(x)
|
||||
x = x.permute(0, 2, 3, 1).reshape(b, h * w, c)
|
||||
for block in self.transformer_blocks:
|
||||
x = block(x, context=context)
|
||||
x = x.reshape(b, h, w, c).permute(0, 3, 1, 2)
|
||||
x = self.proj_out(x)
|
||||
return x + x_in
|
||||
|
||||
|
||||
class BasicTransformerBlock(nn.Module):
|
||||
r"""
|
||||
A basic Transformer block.
|
||||
|
||||
Parameters:
|
||||
dim (:obj:`int`): The number of channels in the input and output.
|
||||
n_heads (:obj:`int`): The number of heads to use for multi-head attention.
|
||||
d_head (:obj:`int`): The number of channels in each head.
|
||||
dropout (:obj:`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
||||
context_dim (:obj:`int`, *optional*): The size of the context vector for cross attention.
|
||||
gated_ff (:obj:`bool`, *optional*, defaults to :obj:`False`): Whether to use a gated feed-forward network.
|
||||
checkpoint (:obj:`bool`, *optional*, defaults to :obj:`False`): Whether to use checkpointing.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
dim: int,
|
||||
n_heads: int,
|
||||
d_head: int,
|
||||
dropout=0.0,
|
||||
context_dim: Optional[int] = None,
|
||||
gated_ff: bool = True,
|
||||
checkpoint: bool = True,
|
||||
):
|
||||
super().__init__()
|
||||
self.attn1 = CrossAttention(
|
||||
query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout
|
||||
) # is a self-attention
|
||||
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
|
||||
self.attn2 = CrossAttention(
|
||||
query_dim=dim, context_dim=context_dim, heads=n_heads, dim_head=d_head, dropout=dropout
|
||||
) # is self-attn if context is none
|
||||
self.norm1 = nn.LayerNorm(dim)
|
||||
self.norm2 = nn.LayerNorm(dim)
|
||||
self.norm3 = nn.LayerNorm(dim)
|
||||
self.checkpoint = checkpoint
|
||||
|
||||
def _set_attention_slice(self, slice_size):
|
||||
self.attn1._slice_size = slice_size
|
||||
self.attn2._slice_size = slice_size
|
||||
|
||||
def forward(self, x, context=None):
|
||||
x = x.contiguous() if x.device.type == "mps" else x
|
||||
x = self.attn1(self.norm1(x)) + x
|
||||
x = self.attn2(self.norm2(x), context=context) + x
|
||||
x = self.ff(self.norm3(x)) + x
|
||||
return x
|
||||
|
||||
|
||||
class CrossAttention(nn.Module):
|
||||
r"""
|
||||
A cross attention layer.
|
||||
|
||||
Parameters:
|
||||
query_dim (:obj:`int`): The number of channels in the query.
|
||||
context_dim (:obj:`int`, *optional*):
|
||||
The number of channels in the context. If not given, defaults to `query_dim`.
|
||||
heads (:obj:`int`, *optional*, defaults to 8): The number of heads to use for multi-head attention.
|
||||
dim_head (:obj:`int`, *optional*, defaults to 64): The number of channels in each head.
|
||||
dropout (:obj:`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self, query_dim: int, context_dim: Optional[int] = None, heads: int = 8, dim_head: int = 64, dropout: int = 0.0
|
||||
):
|
||||
super().__init__()
|
||||
inner_dim = dim_head * heads
|
||||
context_dim = context_dim if context_dim is not None else query_dim
|
||||
|
||||
self.scale = dim_head**-0.5
|
||||
self.heads = heads
|
||||
# for slice_size > 0 the attention score computation
|
||||
# is split across the batch axis to save memory
|
||||
# You can set slice_size with `set_attention_slice`
|
||||
self._slice_size = None
|
||||
|
||||
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
|
||||
self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
|
||||
self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
|
||||
|
||||
self.to_out = nn.Sequential(nn.Linear(inner_dim, query_dim), nn.Dropout(dropout))
|
||||
|
||||
def reshape_heads_to_batch_dim(self, tensor):
|
||||
batch_size, seq_len, dim = tensor.shape
|
||||
head_size = self.heads
|
||||
tensor = tensor.reshape(batch_size, seq_len, head_size, dim // head_size)
|
||||
tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size * head_size, seq_len, dim // head_size)
|
||||
return tensor
|
||||
|
||||
def reshape_batch_dim_to_heads(self, tensor):
|
||||
batch_size, seq_len, dim = tensor.shape
|
||||
head_size = self.heads
|
||||
tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
|
||||
tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size // head_size, seq_len, dim * head_size)
|
||||
return tensor
|
||||
|
||||
def forward(self, x, context=None, mask=None):
|
||||
batch_size, sequence_length, dim = x.shape
|
||||
|
||||
q = self.to_q(x)
|
||||
context = context if context is not None else x
|
||||
k = self.to_k(context)
|
||||
v = self.to_v(context)
|
||||
|
||||
q = self.reshape_heads_to_batch_dim(q)
|
||||
k = self.reshape_heads_to_batch_dim(k)
|
||||
v = self.reshape_heads_to_batch_dim(v)
|
||||
|
||||
# TODO(PVP) - mask is currently never used. Remember to re-implement when used
|
||||
|
||||
# attention, what we cannot get enough of
|
||||
hidden_states = self._attention(q, k, v, sequence_length, dim)
|
||||
|
||||
return self.to_out(hidden_states)
|
||||
|
||||
def _attention(self, query, key, value, sequence_length, dim):
|
||||
batch_size_attention = query.shape[0]
|
||||
hidden_states = torch.zeros(
|
||||
(batch_size_attention, sequence_length, dim // self.heads), device=query.device, dtype=query.dtype
|
||||
)
|
||||
slice_size = self._slice_size if self._slice_size is not None else hidden_states.shape[0]
|
||||
for i in range(hidden_states.shape[0] // slice_size):
|
||||
start_idx = i * slice_size
|
||||
end_idx = (i + 1) * slice_size
|
||||
attn_slice = (
|
||||
torch.einsum("b i d, b j d -> b i j", query[start_idx:end_idx], key[start_idx:end_idx]) * self.scale
|
||||
)
|
||||
attn_slice = attn_slice.softmax(dim=-1)
|
||||
attn_slice = torch.einsum("b i j, b j d -> b i d", attn_slice, value[start_idx:end_idx])
|
||||
|
||||
hidden_states[start_idx:end_idx] = attn_slice
|
||||
|
||||
# reshape hidden_states
|
||||
hidden_states = self.reshape_batch_dim_to_heads(hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class FeedForward(nn.Module):
|
||||
r"""
|
||||
A feed-forward layer.
|
||||
|
||||
Parameters:
|
||||
dim (:obj:`int`): The number of channels in the input.
|
||||
dim_out (:obj:`int`, *optional*): The number of channels in the output. If not given, defaults to `dim`.
|
||||
mult (:obj:`int`, *optional*, defaults to 4): The multiplier to use for the hidden dimension.
|
||||
glu (:obj:`bool`, *optional*, defaults to :obj:`False`): Whether to use GLU activation.
|
||||
dropout (:obj:`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self, dim: int, dim_out: Optional[int] = None, mult: int = 4, glu: bool = False, dropout: float = 0.0
|
||||
):
|
||||
super().__init__()
|
||||
inner_dim = int(dim * mult)
|
||||
dim_out = dim_out if dim_out is not None else dim
|
||||
project_in = GEGLU(dim, inner_dim)
|
||||
|
||||
self.net = nn.Sequential(project_in, nn.Dropout(dropout), nn.Linear(inner_dim, dim_out))
|
||||
|
||||
def forward(self, x):
|
||||
return self.net(x)
|
||||
|
||||
|
||||
# feedforward
|
||||
class GEGLU(nn.Module):
|
||||
r"""
|
||||
A variant of the gated linear unit activation function from https://arxiv.org/abs/2002.05202.
|
||||
|
||||
Parameters:
|
||||
dim_in (:obj:`int`): The number of channels in the input.
|
||||
dim_out (:obj:`int`): The number of channels in the output.
|
||||
"""
|
||||
|
||||
def __init__(self, dim_in: int, dim_out: int):
|
||||
super().__init__()
|
||||
self.proj = nn.Linear(dim_in, dim_out * 2)
|
||||
|
||||
def forward(self, x):
|
||||
x, gate = self.proj(x).chunk(2, dim=-1)
|
||||
return x * F.gelu(gate)
|
||||
@@ -0,0 +1,115 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import math
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
|
||||
def get_timestep_embedding(
|
||||
timesteps: torch.Tensor,
|
||||
embedding_dim: int,
|
||||
flip_sin_to_cos: bool = False,
|
||||
downscale_freq_shift: float = 1,
|
||||
scale: float = 1,
|
||||
max_period: int = 10000,
|
||||
):
|
||||
"""
|
||||
This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
|
||||
|
||||
:param timesteps: a 1-D Tensor of N indices, one per batch element.
|
||||
These may be fractional.
|
||||
:param embedding_dim: the dimension of the output. :param max_period: controls the minimum frequency of the
|
||||
embeddings. :return: an [N x dim] Tensor of positional embeddings.
|
||||
"""
|
||||
assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
|
||||
|
||||
half_dim = embedding_dim // 2
|
||||
exponent = -math.log(max_period) * torch.arange(start=0, end=half_dim, dtype=torch.float32)
|
||||
exponent = exponent / (half_dim - downscale_freq_shift)
|
||||
|
||||
emb = torch.exp(exponent).to(device=timesteps.device)
|
||||
emb = timesteps[:, None].float() * emb[None, :]
|
||||
|
||||
# scale embeddings
|
||||
emb = scale * emb
|
||||
|
||||
# concat sine and cosine embeddings
|
||||
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
|
||||
|
||||
# flip sine and cosine embeddings
|
||||
if flip_sin_to_cos:
|
||||
emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1)
|
||||
|
||||
# zero pad
|
||||
if embedding_dim % 2 == 1:
|
||||
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
||||
return emb
|
||||
|
||||
|
||||
class TimestepEmbedding(nn.Module):
|
||||
def __init__(self, channel: int, time_embed_dim: int, act_fn: str = "silu"):
|
||||
super().__init__()
|
||||
|
||||
self.linear_1 = nn.Linear(channel, time_embed_dim)
|
||||
self.act = None
|
||||
if act_fn == "silu":
|
||||
self.act = nn.SiLU()
|
||||
self.linear_2 = nn.Linear(time_embed_dim, time_embed_dim)
|
||||
|
||||
def forward(self, sample):
|
||||
sample = self.linear_1(sample)
|
||||
|
||||
if self.act is not None:
|
||||
sample = self.act(sample)
|
||||
|
||||
sample = self.linear_2(sample)
|
||||
return sample
|
||||
|
||||
|
||||
class Timesteps(nn.Module):
|
||||
def __init__(self, num_channels: int, flip_sin_to_cos: bool, downscale_freq_shift: float):
|
||||
super().__init__()
|
||||
self.num_channels = num_channels
|
||||
self.flip_sin_to_cos = flip_sin_to_cos
|
||||
self.downscale_freq_shift = downscale_freq_shift
|
||||
|
||||
def forward(self, timesteps):
|
||||
t_emb = get_timestep_embedding(
|
||||
timesteps,
|
||||
self.num_channels,
|
||||
flip_sin_to_cos=self.flip_sin_to_cos,
|
||||
downscale_freq_shift=self.downscale_freq_shift,
|
||||
)
|
||||
return t_emb
|
||||
|
||||
|
||||
class GaussianFourierProjection(nn.Module):
|
||||
"""Gaussian Fourier embeddings for noise levels."""
|
||||
|
||||
def __init__(self, embedding_size: int = 256, scale: float = 1.0):
|
||||
super().__init__()
|
||||
self.weight = nn.Parameter(torch.randn(embedding_size) * scale, requires_grad=False)
|
||||
|
||||
# to delete later
|
||||
self.W = nn.Parameter(torch.randn(embedding_size) * scale, requires_grad=False)
|
||||
|
||||
self.weight = self.W
|
||||
|
||||
def forward(self, x):
|
||||
x = torch.log(x)
|
||||
x_proj = x[:, None] * self.weight[None, :] * 2 * np.pi
|
||||
out = torch.cat([torch.sin(x_proj), torch.cos(x_proj)], dim=-1)
|
||||
return out
|
||||
@@ -0,0 +1,483 @@
|
||||
from functools import partial
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
class Upsample2D(nn.Module):
|
||||
"""
|
||||
An upsampling layer with an optional convolution.
|
||||
|
||||
:param channels: channels in the inputs and outputs. :param use_conv: a bool determining if a convolution is
|
||||
applied. :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
|
||||
upsampling occurs in the inner-two dimensions.
|
||||
"""
|
||||
|
||||
def __init__(self, channels, use_conv=False, use_conv_transpose=False, out_channels=None, name="conv"):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
self.out_channels = out_channels or channels
|
||||
self.use_conv = use_conv
|
||||
self.use_conv_transpose = use_conv_transpose
|
||||
self.name = name
|
||||
|
||||
conv = None
|
||||
if use_conv_transpose:
|
||||
conv = nn.ConvTranspose2d(channels, self.out_channels, 4, 2, 1)
|
||||
elif use_conv:
|
||||
conv = nn.Conv2d(self.channels, self.out_channels, 3, padding=1)
|
||||
|
||||
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
||||
if name == "conv":
|
||||
self.conv = conv
|
||||
else:
|
||||
self.Conv2d_0 = conv
|
||||
|
||||
def forward(self, x):
|
||||
assert x.shape[1] == self.channels
|
||||
if self.use_conv_transpose:
|
||||
return self.conv(x)
|
||||
|
||||
x = F.interpolate(x, scale_factor=2.0, mode="nearest")
|
||||
|
||||
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
||||
if self.use_conv:
|
||||
if self.name == "conv":
|
||||
x = self.conv(x)
|
||||
else:
|
||||
x = self.Conv2d_0(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
class Downsample2D(nn.Module):
|
||||
"""
|
||||
A downsampling layer with an optional convolution.
|
||||
|
||||
:param channels: channels in the inputs and outputs. :param use_conv: a bool determining if a convolution is
|
||||
applied. :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
|
||||
downsampling occurs in the inner-two dimensions.
|
||||
"""
|
||||
|
||||
def __init__(self, channels, use_conv=False, out_channels=None, padding=1, name="conv"):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
self.out_channels = out_channels or channels
|
||||
self.use_conv = use_conv
|
||||
self.padding = padding
|
||||
stride = 2
|
||||
self.name = name
|
||||
|
||||
if use_conv:
|
||||
conv = nn.Conv2d(self.channels, self.out_channels, 3, stride=stride, padding=padding)
|
||||
else:
|
||||
assert self.channels == self.out_channels
|
||||
conv = nn.AvgPool2d(kernel_size=stride, stride=stride)
|
||||
|
||||
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
||||
if name == "conv":
|
||||
self.Conv2d_0 = conv
|
||||
self.conv = conv
|
||||
elif name == "Conv2d_0":
|
||||
self.conv = conv
|
||||
else:
|
||||
self.conv = conv
|
||||
|
||||
def forward(self, x):
|
||||
assert x.shape[1] == self.channels
|
||||
if self.use_conv and self.padding == 0:
|
||||
pad = (0, 1, 0, 1)
|
||||
x = F.pad(x, pad, mode="constant", value=0)
|
||||
|
||||
assert x.shape[1] == self.channels
|
||||
x = self.conv(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
class FirUpsample2D(nn.Module):
|
||||
def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
|
||||
super().__init__()
|
||||
out_channels = out_channels if out_channels else channels
|
||||
if use_conv:
|
||||
self.Conv2d_0 = nn.Conv2d(channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
self.use_conv = use_conv
|
||||
self.fir_kernel = fir_kernel
|
||||
self.out_channels = out_channels
|
||||
|
||||
def _upsample_2d(self, x, weight=None, kernel=None, factor=2, gain=1):
|
||||
"""Fused `upsample_2d()` followed by `Conv2d()`.
|
||||
|
||||
Args:
|
||||
Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
|
||||
efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of arbitrary:
|
||||
order.
|
||||
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
|
||||
C]`.
|
||||
weight: Weight tensor of the shape `[filterH, filterW, inChannels,
|
||||
outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] // numGroups`.
|
||||
kernel: FIR filter of the shape `[firH, firW]` or `[firN]`
|
||||
(separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
|
||||
factor: Integer upsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
|
||||
|
||||
Returns:
|
||||
Tensor of the shape `[N, C, H * factor, W * factor]` or `[N, H * factor, W * factor, C]`, and same datatype as
|
||||
`x`.
|
||||
"""
|
||||
|
||||
assert isinstance(factor, int) and factor >= 1
|
||||
|
||||
# Setup filter kernel.
|
||||
if kernel is None:
|
||||
kernel = [1] * factor
|
||||
|
||||
# setup kernel
|
||||
kernel = np.asarray(kernel, dtype=np.float32)
|
||||
if kernel.ndim == 1:
|
||||
kernel = np.outer(kernel, kernel)
|
||||
kernel /= np.sum(kernel)
|
||||
|
||||
kernel = kernel * (gain * (factor**2))
|
||||
|
||||
if self.use_conv:
|
||||
convH = weight.shape[2]
|
||||
convW = weight.shape[3]
|
||||
inC = weight.shape[1]
|
||||
|
||||
p = (kernel.shape[0] - factor) - (convW - 1)
|
||||
|
||||
stride = (factor, factor)
|
||||
# Determine data dimensions.
|
||||
stride = [1, 1, factor, factor]
|
||||
output_shape = ((x.shape[2] - 1) * factor + convH, (x.shape[3] - 1) * factor + convW)
|
||||
output_padding = (
|
||||
output_shape[0] - (x.shape[2] - 1) * stride[0] - convH,
|
||||
output_shape[1] - (x.shape[3] - 1) * stride[1] - convW,
|
||||
)
|
||||
assert output_padding[0] >= 0 and output_padding[1] >= 0
|
||||
inC = weight.shape[1]
|
||||
num_groups = x.shape[1] // inC
|
||||
|
||||
# Transpose weights.
|
||||
weight = torch.reshape(weight, (num_groups, -1, inC, convH, convW))
|
||||
weight = weight[..., ::-1, ::-1].permute(0, 2, 1, 3, 4)
|
||||
weight = torch.reshape(weight, (num_groups * inC, -1, convH, convW))
|
||||
|
||||
x = F.conv_transpose2d(x, weight, stride=stride, output_padding=output_padding, padding=0)
|
||||
|
||||
x = upfirdn2d_native(x, torch.tensor(kernel, device=x.device), pad=((p + 1) // 2 + factor - 1, p // 2 + 1))
|
||||
else:
|
||||
p = kernel.shape[0] - factor
|
||||
x = upfirdn2d_native(
|
||||
x, torch.tensor(kernel, device=x.device), up=factor, pad=((p + 1) // 2 + factor - 1, p // 2)
|
||||
)
|
||||
|
||||
return x
|
||||
|
||||
def forward(self, x):
|
||||
if self.use_conv:
|
||||
height = self._upsample_2d(x, self.Conv2d_0.weight, kernel=self.fir_kernel)
|
||||
height = height + self.Conv2d_0.bias.reshape(1, -1, 1, 1)
|
||||
else:
|
||||
height = self._upsample_2d(x, kernel=self.fir_kernel, factor=2)
|
||||
|
||||
return height
|
||||
|
||||
|
||||
class FirDownsample2D(nn.Module):
|
||||
def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
|
||||
super().__init__()
|
||||
out_channels = out_channels if out_channels else channels
|
||||
if use_conv:
|
||||
self.Conv2d_0 = nn.Conv2d(channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
self.fir_kernel = fir_kernel
|
||||
self.use_conv = use_conv
|
||||
self.out_channels = out_channels
|
||||
|
||||
def _downsample_2d(self, x, weight=None, kernel=None, factor=2, gain=1):
|
||||
"""Fused `Conv2d()` followed by `downsample_2d()`.
|
||||
|
||||
Args:
|
||||
Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
|
||||
efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of arbitrary:
|
||||
order.
|
||||
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`. w: Weight tensor of the shape `[filterH,
|
||||
filterW, inChannels, outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] //
|
||||
numGroups`. k: FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] *
|
||||
factor`, which corresponds to average pooling. factor: Integer downsampling factor (default: 2). gain:
|
||||
Scaling factor for signal magnitude (default: 1.0).
|
||||
|
||||
Returns:
|
||||
Tensor of the shape `[N, C, H // factor, W // factor]` or `[N, H // factor, W // factor, C]`, and same
|
||||
datatype as `x`.
|
||||
"""
|
||||
|
||||
assert isinstance(factor, int) and factor >= 1
|
||||
if kernel is None:
|
||||
kernel = [1] * factor
|
||||
|
||||
# setup kernel
|
||||
kernel = np.asarray(kernel, dtype=np.float32)
|
||||
if kernel.ndim == 1:
|
||||
kernel = np.outer(kernel, kernel)
|
||||
kernel /= np.sum(kernel)
|
||||
|
||||
kernel = kernel * gain
|
||||
|
||||
if self.use_conv:
|
||||
_, _, convH, convW = weight.shape
|
||||
p = (kernel.shape[0] - factor) + (convW - 1)
|
||||
s = [factor, factor]
|
||||
x = upfirdn2d_native(x, torch.tensor(kernel, device=x.device), pad=((p + 1) // 2, p // 2))
|
||||
x = F.conv2d(x, weight, stride=s, padding=0)
|
||||
else:
|
||||
p = kernel.shape[0] - factor
|
||||
x = upfirdn2d_native(x, torch.tensor(kernel, device=x.device), down=factor, pad=((p + 1) // 2, p // 2))
|
||||
|
||||
return x
|
||||
|
||||
def forward(self, x):
|
||||
if self.use_conv:
|
||||
x = self._downsample_2d(x, weight=self.Conv2d_0.weight, kernel=self.fir_kernel)
|
||||
x = x + self.Conv2d_0.bias.reshape(1, -1, 1, 1)
|
||||
else:
|
||||
x = self._downsample_2d(x, kernel=self.fir_kernel, factor=2)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
class ResnetBlock2D(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
in_channels,
|
||||
out_channels=None,
|
||||
conv_shortcut=False,
|
||||
dropout=0.0,
|
||||
temb_channels=512,
|
||||
groups=32,
|
||||
groups_out=None,
|
||||
pre_norm=True,
|
||||
eps=1e-6,
|
||||
non_linearity="swish",
|
||||
time_embedding_norm="default",
|
||||
kernel=None,
|
||||
output_scale_factor=1.0,
|
||||
use_nin_shortcut=None,
|
||||
up=False,
|
||||
down=False,
|
||||
):
|
||||
super().__init__()
|
||||
self.pre_norm = pre_norm
|
||||
self.pre_norm = True
|
||||
self.in_channels = in_channels
|
||||
out_channels = in_channels if out_channels is None else out_channels
|
||||
self.out_channels = out_channels
|
||||
self.use_conv_shortcut = conv_shortcut
|
||||
self.time_embedding_norm = time_embedding_norm
|
||||
self.up = up
|
||||
self.down = down
|
||||
self.output_scale_factor = output_scale_factor
|
||||
|
||||
if groups_out is None:
|
||||
groups_out = groups
|
||||
|
||||
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
|
||||
|
||||
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
if temb_channels is not None:
|
||||
self.time_emb_proj = torch.nn.Linear(temb_channels, out_channels)
|
||||
else:
|
||||
self.time_emb_proj = None
|
||||
|
||||
self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
|
||||
self.dropout = torch.nn.Dropout(dropout)
|
||||
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
if non_linearity == "swish":
|
||||
self.nonlinearity = lambda x: F.silu(x)
|
||||
elif non_linearity == "mish":
|
||||
self.nonlinearity = Mish()
|
||||
elif non_linearity == "silu":
|
||||
self.nonlinearity = nn.SiLU()
|
||||
|
||||
self.upsample = self.downsample = None
|
||||
if self.up:
|
||||
if kernel == "fir":
|
||||
fir_kernel = (1, 3, 3, 1)
|
||||
self.upsample = lambda x: upsample_2d(x, kernel=fir_kernel)
|
||||
elif kernel == "sde_vp":
|
||||
self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
|
||||
else:
|
||||
self.upsample = Upsample2D(in_channels, use_conv=False)
|
||||
elif self.down:
|
||||
if kernel == "fir":
|
||||
fir_kernel = (1, 3, 3, 1)
|
||||
self.downsample = lambda x: downsample_2d(x, kernel=fir_kernel)
|
||||
elif kernel == "sde_vp":
|
||||
self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
|
||||
else:
|
||||
self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
|
||||
|
||||
self.use_nin_shortcut = self.in_channels != self.out_channels if use_nin_shortcut is None else use_nin_shortcut
|
||||
|
||||
self.conv_shortcut = None
|
||||
if self.use_nin_shortcut:
|
||||
self.conv_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x, temb):
|
||||
hidden_states = x
|
||||
|
||||
# make sure hidden states is in float32
|
||||
# when running in half-precision
|
||||
hidden_states = self.norm1(hidden_states.float()).type(hidden_states.dtype)
|
||||
hidden_states = self.nonlinearity(hidden_states)
|
||||
|
||||
if self.upsample is not None:
|
||||
x = self.upsample(x)
|
||||
hidden_states = self.upsample(hidden_states)
|
||||
elif self.downsample is not None:
|
||||
x = self.downsample(x)
|
||||
hidden_states = self.downsample(hidden_states)
|
||||
|
||||
hidden_states = self.conv1(hidden_states)
|
||||
|
||||
if temb is not None:
|
||||
temb = self.time_emb_proj(self.nonlinearity(temb))[:, :, None, None]
|
||||
hidden_states = hidden_states + temb
|
||||
|
||||
# make sure hidden states is in float32
|
||||
# when running in half-precision
|
||||
hidden_states = self.norm2(hidden_states.float()).type(hidden_states.dtype)
|
||||
hidden_states = self.nonlinearity(hidden_states)
|
||||
|
||||
hidden_states = self.dropout(hidden_states)
|
||||
hidden_states = self.conv2(hidden_states)
|
||||
|
||||
if self.conv_shortcut is not None:
|
||||
x = self.conv_shortcut(x)
|
||||
|
||||
out = (x + hidden_states) / self.output_scale_factor
|
||||
|
||||
return out
|
||||
|
||||
|
||||
class Mish(torch.nn.Module):
|
||||
def forward(self, x):
|
||||
return x * torch.tanh(torch.nn.functional.softplus(x))
|
||||
|
||||
|
||||
def upsample_2d(x, kernel=None, factor=2, gain=1):
|
||||
r"""Upsample2D a batch of 2D images with the given filter.
|
||||
|
||||
Args:
|
||||
Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and upsamples each image with the given
|
||||
filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the specified
|
||||
`gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its shape is a:
|
||||
multiple of the upsampling factor.
|
||||
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
|
||||
C]`.
|
||||
k: FIR filter of the shape `[firH, firW]` or `[firN]`
|
||||
(separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
|
||||
factor: Integer upsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
|
||||
|
||||
Returns:
|
||||
Tensor of the shape `[N, C, H * factor, W * factor]`
|
||||
"""
|
||||
assert isinstance(factor, int) and factor >= 1
|
||||
if kernel is None:
|
||||
kernel = [1] * factor
|
||||
|
||||
kernel = np.asarray(kernel, dtype=np.float32)
|
||||
if kernel.ndim == 1:
|
||||
kernel = np.outer(kernel, kernel)
|
||||
kernel /= np.sum(kernel)
|
||||
|
||||
kernel = kernel * (gain * (factor**2))
|
||||
p = kernel.shape[0] - factor
|
||||
return upfirdn2d_native(
|
||||
x, torch.tensor(kernel, device=x.device), up=factor, pad=((p + 1) // 2 + factor - 1, p // 2)
|
||||
)
|
||||
|
||||
|
||||
def downsample_2d(x, kernel=None, factor=2, gain=1):
|
||||
r"""Downsample2D a batch of 2D images with the given filter.
|
||||
|
||||
Args:
|
||||
Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and downsamples each image with the
|
||||
given filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the
|
||||
specified `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its
|
||||
shape is a multiple of the downsampling factor.
|
||||
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
|
||||
C]`.
|
||||
kernel: FIR filter of the shape `[firH, firW]` or `[firN]`
|
||||
(separable). The default is `[1] * factor`, which corresponds to average pooling.
|
||||
factor: Integer downsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
|
||||
|
||||
Returns:
|
||||
Tensor of the shape `[N, C, H // factor, W // factor]`
|
||||
"""
|
||||
|
||||
assert isinstance(factor, int) and factor >= 1
|
||||
if kernel is None:
|
||||
kernel = [1] * factor
|
||||
|
||||
kernel = np.asarray(kernel, dtype=np.float32)
|
||||
if kernel.ndim == 1:
|
||||
kernel = np.outer(kernel, kernel)
|
||||
kernel /= np.sum(kernel)
|
||||
|
||||
kernel = kernel * gain
|
||||
p = kernel.shape[0] - factor
|
||||
return upfirdn2d_native(x, torch.tensor(kernel, device=x.device), down=factor, pad=((p + 1) // 2, p // 2))
|
||||
|
||||
|
||||
def upfirdn2d_native(input, kernel, up=1, down=1, pad=(0, 0)):
|
||||
up_x = up_y = up
|
||||
down_x = down_y = down
|
||||
pad_x0 = pad_y0 = pad[0]
|
||||
pad_x1 = pad_y1 = pad[1]
|
||||
|
||||
_, channel, in_h, in_w = input.shape
|
||||
input = input.reshape(-1, in_h, in_w, 1)
|
||||
|
||||
_, in_h, in_w, minor = input.shape
|
||||
kernel_h, kernel_w = kernel.shape
|
||||
|
||||
out = input.view(-1, in_h, 1, in_w, 1, minor)
|
||||
|
||||
# Temporary workaround for mps specific issue: https://github.com/pytorch/pytorch/issues/84535
|
||||
if input.device.type == "mps":
|
||||
out = out.to("cpu")
|
||||
out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
|
||||
out = out.view(-1, in_h * up_y, in_w * up_x, minor)
|
||||
|
||||
out = F.pad(out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)])
|
||||
out = out.to(input.device) # Move back to mps if necessary
|
||||
out = out[
|
||||
:,
|
||||
max(-pad_y0, 0) : out.shape[1] - max(-pad_y1, 0),
|
||||
max(-pad_x0, 0) : out.shape[2] - max(-pad_x1, 0),
|
||||
:,
|
||||
]
|
||||
|
||||
out = out.permute(0, 3, 1, 2)
|
||||
out = out.reshape([-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1])
|
||||
w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
|
||||
out = F.conv2d(out, w)
|
||||
out = out.reshape(
|
||||
-1,
|
||||
minor,
|
||||
in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
|
||||
in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
|
||||
)
|
||||
out = out.permute(0, 2, 3, 1)
|
||||
out = out[:, ::down_y, ::down_x, :]
|
||||
|
||||
out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
|
||||
out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
|
||||
|
||||
return out.view(-1, channel, out_h, out_w)
|
||||
@@ -1,332 +0,0 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
|
||||
# limitations under the License.
|
||||
|
||||
# helpers functions
|
||||
|
||||
import copy
|
||||
import math
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
from torch.cuda.amp import GradScaler, autocast
|
||||
from torch.optim import Adam
|
||||
from torch.utils import data
|
||||
|
||||
from PIL import Image
|
||||
from tqdm import tqdm
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from ..modeling_utils import ModelMixin
|
||||
|
||||
|
||||
def get_timestep_embedding(timesteps, embedding_dim):
|
||||
"""
|
||||
This matches the implementation in Denoising Diffusion Probabilistic Models:
|
||||
From Fairseq.
|
||||
Build sinusoidal embeddings.
|
||||
This matches the implementation in tensor2tensor, but differs slightly
|
||||
from the description in Section 3.5 of "Attention Is All You Need".
|
||||
"""
|
||||
assert len(timesteps.shape) == 1
|
||||
|
||||
half_dim = embedding_dim // 2
|
||||
emb = math.log(10000) / (half_dim - 1)
|
||||
emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb)
|
||||
emb = emb.to(device=timesteps.device)
|
||||
emb = timesteps.float()[:, None] * emb[None, :]
|
||||
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
|
||||
if embedding_dim % 2 == 1: # zero pad
|
||||
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
||||
return emb
|
||||
|
||||
|
||||
def nonlinearity(x):
|
||||
# swish
|
||||
return x * torch.sigmoid(x)
|
||||
|
||||
|
||||
def Normalize(in_channels):
|
||||
return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
||||
|
||||
|
||||
class Upsample(nn.Module):
|
||||
def __init__(self, in_channels, with_conv):
|
||||
super().__init__()
|
||||
self.with_conv = with_conv
|
||||
if self.with_conv:
|
||||
self.conv = torch.nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, x):
|
||||
x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
|
||||
if self.with_conv:
|
||||
x = self.conv(x)
|
||||
return x
|
||||
|
||||
|
||||
class Downsample(nn.Module):
|
||||
def __init__(self, in_channels, with_conv):
|
||||
super().__init__()
|
||||
self.with_conv = with_conv
|
||||
if self.with_conv:
|
||||
# no asymmetric padding in torch conv, must do it ourselves
|
||||
self.conv = torch.nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=2, padding=0)
|
||||
|
||||
def forward(self, x):
|
||||
if self.with_conv:
|
||||
pad = (0, 1, 0, 1)
|
||||
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
|
||||
x = self.conv(x)
|
||||
else:
|
||||
x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
|
||||
return x
|
||||
|
||||
|
||||
class ResnetBlock(nn.Module):
|
||||
def __init__(self, *, in_channels, out_channels=None, conv_shortcut=False, dropout, temb_channels=512):
|
||||
super().__init__()
|
||||
self.in_channels = in_channels
|
||||
out_channels = in_channels if out_channels is None else out_channels
|
||||
self.out_channels = out_channels
|
||||
self.use_conv_shortcut = conv_shortcut
|
||||
|
||||
self.norm1 = Normalize(in_channels)
|
||||
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
|
||||
self.norm2 = Normalize(out_channels)
|
||||
self.dropout = torch.nn.Dropout(dropout)
|
||||
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
if self.in_channels != self.out_channels:
|
||||
if self.use_conv_shortcut:
|
||||
self.conv_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
else:
|
||||
self.nin_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x, temb):
|
||||
h = x
|
||||
h = self.norm1(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.conv1(h)
|
||||
|
||||
h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
|
||||
|
||||
h = self.norm2(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.dropout(h)
|
||||
h = self.conv2(h)
|
||||
|
||||
if self.in_channels != self.out_channels:
|
||||
if self.use_conv_shortcut:
|
||||
x = self.conv_shortcut(x)
|
||||
else:
|
||||
x = self.nin_shortcut(x)
|
||||
|
||||
return x + h
|
||||
|
||||
|
||||
class AttnBlock(nn.Module):
|
||||
def __init__(self, in_channels):
|
||||
super().__init__()
|
||||
self.in_channels = in_channels
|
||||
|
||||
self.norm = Normalize(in_channels)
|
||||
self.q = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.k = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.v = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.proj_out = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x):
|
||||
h_ = x
|
||||
h_ = self.norm(h_)
|
||||
q = self.q(h_)
|
||||
k = self.k(h_)
|
||||
v = self.v(h_)
|
||||
|
||||
# compute attention
|
||||
b, c, h, w = q.shape
|
||||
q = q.reshape(b, c, h * w)
|
||||
q = q.permute(0, 2, 1) # b,hw,c
|
||||
k = k.reshape(b, c, h * w) # b,c,hw
|
||||
w_ = torch.bmm(q, k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
|
||||
w_ = w_ * (int(c) ** (-0.5))
|
||||
w_ = torch.nn.functional.softmax(w_, dim=2)
|
||||
|
||||
# attend to values
|
||||
v = v.reshape(b, c, h * w)
|
||||
w_ = w_.permute(0, 2, 1) # b,hw,hw (first hw of k, second of q)
|
||||
h_ = torch.bmm(v, w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
|
||||
h_ = h_.reshape(b, c, h, w)
|
||||
|
||||
h_ = self.proj_out(h_)
|
||||
|
||||
return x + h_
|
||||
|
||||
|
||||
class UNetModel(ModelMixin, ConfigMixin):
|
||||
def __init__(
|
||||
self,
|
||||
ch=128,
|
||||
out_ch=3,
|
||||
ch_mult=(1, 1, 2, 2, 4, 4),
|
||||
num_res_blocks=2,
|
||||
attn_resolutions=(16,),
|
||||
dropout=0.0,
|
||||
resamp_with_conv=True,
|
||||
in_channels=3,
|
||||
resolution=256,
|
||||
):
|
||||
super().__init__()
|
||||
self.register(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
ch_mult=ch_mult,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
dropout=dropout,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
)
|
||||
ch_mult = tuple(ch_mult)
|
||||
self.ch = ch
|
||||
self.temb_ch = self.ch * 4
|
||||
self.num_resolutions = len(ch_mult)
|
||||
self.num_res_blocks = num_res_blocks
|
||||
self.resolution = resolution
|
||||
self.in_channels = in_channels
|
||||
|
||||
# timestep embedding
|
||||
self.temb = nn.Module()
|
||||
self.temb.dense = nn.ModuleList(
|
||||
[
|
||||
torch.nn.Linear(self.ch, self.temb_ch),
|
||||
torch.nn.Linear(self.temb_ch, self.temb_ch),
|
||||
]
|
||||
)
|
||||
|
||||
# downsampling
|
||||
self.conv_in = torch.nn.Conv2d(in_channels, self.ch, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
curr_res = resolution
|
||||
in_ch_mult = (1,) + ch_mult
|
||||
self.down = nn.ModuleList()
|
||||
for i_level in range(self.num_resolutions):
|
||||
block = nn.ModuleList()
|
||||
attn = nn.ModuleList()
|
||||
block_in = ch * in_ch_mult[i_level]
|
||||
block_out = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks):
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_out, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
down = nn.Module()
|
||||
down.block = block
|
||||
down.attn = attn
|
||||
if i_level != self.num_resolutions - 1:
|
||||
down.downsample = Downsample(block_in, resamp_with_conv)
|
||||
curr_res = curr_res // 2
|
||||
self.down.append(down)
|
||||
|
||||
# middle
|
||||
self.mid = nn.Module()
|
||||
self.mid.block_1 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
self.mid.attn_1 = AttnBlock(block_in)
|
||||
self.mid.block_2 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
|
||||
# upsampling
|
||||
self.up = nn.ModuleList()
|
||||
for i_level in reversed(range(self.num_resolutions)):
|
||||
block = nn.ModuleList()
|
||||
attn = nn.ModuleList()
|
||||
block_out = ch * ch_mult[i_level]
|
||||
skip_in = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
if i_block == self.num_res_blocks:
|
||||
skip_in = ch * in_ch_mult[i_level]
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
in_channels=block_in + skip_in,
|
||||
out_channels=block_out,
|
||||
temb_channels=self.temb_ch,
|
||||
dropout=dropout,
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
up = nn.Module()
|
||||
up.block = block
|
||||
up.attn = attn
|
||||
if i_level != 0:
|
||||
up.upsample = Upsample(block_in, resamp_with_conv)
|
||||
curr_res = curr_res * 2
|
||||
self.up.insert(0, up) # prepend to get consistent order
|
||||
|
||||
# end
|
||||
self.norm_out = Normalize(block_in)
|
||||
self.conv_out = torch.nn.Conv2d(block_in, out_ch, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, x, t):
|
||||
assert x.shape[2] == x.shape[3] == self.resolution
|
||||
|
||||
if not torch.is_tensor(t):
|
||||
t = torch.tensor([t], dtype=torch.long, device=x.device)
|
||||
|
||||
# timestep embedding
|
||||
temb = get_timestep_embedding(t, self.ch)
|
||||
temb = self.temb.dense[0](temb)
|
||||
temb = nonlinearity(temb)
|
||||
temb = self.temb.dense[1](temb)
|
||||
|
||||
# downsampling
|
||||
hs = [self.conv_in(x)]
|
||||
for i_level in range(self.num_resolutions):
|
||||
for i_block in range(self.num_res_blocks):
|
||||
h = self.down[i_level].block[i_block](hs[-1], temb)
|
||||
if len(self.down[i_level].attn) > 0:
|
||||
h = self.down[i_level].attn[i_block](h)
|
||||
hs.append(h)
|
||||
if i_level != self.num_resolutions - 1:
|
||||
hs.append(self.down[i_level].downsample(hs[-1]))
|
||||
|
||||
# middle
|
||||
h = hs[-1]
|
||||
h = self.mid.block_1(h, temb)
|
||||
h = self.mid.attn_1(h)
|
||||
h = self.mid.block_2(h, temb)
|
||||
|
||||
# upsampling
|
||||
for i_level in reversed(range(self.num_resolutions)):
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
h = self.up[i_level].block[i_block](torch.cat([h, hs.pop()], dim=1), temb)
|
||||
if len(self.up[i_level].attn) > 0:
|
||||
h = self.up[i_level].attn[i_block](h)
|
||||
if i_level != 0:
|
||||
h = self.up[i_level].upsample(h)
|
||||
|
||||
# end
|
||||
h = self.norm_out(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.conv_out(h)
|
||||
return h
|
||||
@@ -0,0 +1,246 @@
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..utils import BaseOutput
|
||||
from .embeddings import GaussianFourierProjection, TimestepEmbedding, Timesteps
|
||||
from .unet_blocks import UNetMidBlock2D, get_down_block, get_up_block
|
||||
|
||||
|
||||
@dataclass
|
||||
class UNet2DOutput(BaseOutput):
|
||||
"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
||||
Hidden states output. Output of last layer of model.
|
||||
"""
|
||||
|
||||
sample: torch.FloatTensor
|
||||
|
||||
|
||||
class UNet2DModel(ModelMixin, ConfigMixin):
|
||||
r"""
|
||||
UNet2DModel is a 2D UNet model that takes in a noisy sample and a timestep and returns sample shaped output.
|
||||
|
||||
This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
|
||||
implements for all the model (such as downloading or saving, etc.)
|
||||
|
||||
Parameters:
|
||||
sample_size (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`, *optional*):
|
||||
Input sample size.
|
||||
in_channels (`int`, *optional*, defaults to 3): Number of channels in the input image.
|
||||
out_channels (`int`, *optional*, defaults to 3): Number of channels in the output.
|
||||
center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
|
||||
time_embedding_type (`str`, *optional*, defaults to `"positional"`): Type of time embedding to use.
|
||||
freq_shift (`int`, *optional*, defaults to 0): Frequency shift for fourier time embedding.
|
||||
flip_sin_to_cos (`bool`, *optional*, defaults to :
|
||||
obj:`False`): Whether to flip sin to cos for fourier time embedding.
|
||||
down_block_types (`Tuple[str]`, *optional*, defaults to :
|
||||
obj:`("DownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D")`): Tuple of downsample block
|
||||
types.
|
||||
up_block_types (`Tuple[str]`, *optional*, defaults to :
|
||||
obj:`("AttnUpBlock2D", "AttnUpBlock2D", "AttnUpBlock2D", "UpBlock2D")`): Tuple of upsample block types.
|
||||
block_out_channels (`Tuple[int]`, *optional*, defaults to :
|
||||
obj:`(224, 448, 672, 896)`): Tuple of block output channels.
|
||||
layers_per_block (`int`, *optional*, defaults to `2`): The number of layers per block.
|
||||
mid_block_scale_factor (`float`, *optional*, defaults to `1`): The scale factor for the mid block.
|
||||
downsample_padding (`int`, *optional*, defaults to `1`): The padding for the downsample convolution.
|
||||
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
||||
attention_head_dim (`int`, *optional*, defaults to `8`): The attention head dimension.
|
||||
norm_num_groups (`int`, *optional*, defaults to `32`): The number of groups for the normalization.
|
||||
norm_eps (`float`, *optional*, defaults to `1e-5`): The epsilon for the normalization.
|
||||
"""
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
sample_size: Optional[int] = None,
|
||||
in_channels: int = 3,
|
||||
out_channels: int = 3,
|
||||
center_input_sample: bool = False,
|
||||
time_embedding_type: str = "positional",
|
||||
freq_shift: int = 0,
|
||||
flip_sin_to_cos: bool = True,
|
||||
down_block_types: Tuple[str] = ("DownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D"),
|
||||
up_block_types: Tuple[str] = ("AttnUpBlock2D", "AttnUpBlock2D", "AttnUpBlock2D", "UpBlock2D"),
|
||||
block_out_channels: Tuple[int] = (224, 448, 672, 896),
|
||||
layers_per_block: int = 2,
|
||||
mid_block_scale_factor: float = 1,
|
||||
downsample_padding: int = 1,
|
||||
act_fn: str = "silu",
|
||||
attention_head_dim: int = 8,
|
||||
norm_num_groups: int = 32,
|
||||
norm_eps: float = 1e-5,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.sample_size = sample_size
|
||||
time_embed_dim = block_out_channels[0] * 4
|
||||
|
||||
# input
|
||||
self.conv_in = nn.Conv2d(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
|
||||
|
||||
# time
|
||||
if time_embedding_type == "fourier":
|
||||
self.time_proj = GaussianFourierProjection(embedding_size=block_out_channels[0], scale=16)
|
||||
timestep_input_dim = 2 * block_out_channels[0]
|
||||
elif time_embedding_type == "positional":
|
||||
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
||||
timestep_input_dim = block_out_channels[0]
|
||||
|
||||
self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
|
||||
|
||||
self.down_blocks = nn.ModuleList([])
|
||||
self.mid_block = None
|
||||
self.up_blocks = nn.ModuleList([])
|
||||
|
||||
# down
|
||||
output_channel = block_out_channels[0]
|
||||
for i, down_block_type in enumerate(down_block_types):
|
||||
input_channel = output_channel
|
||||
output_channel = block_out_channels[i]
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
down_block = get_down_block(
|
||||
down_block_type,
|
||||
num_layers=layers_per_block,
|
||||
in_channels=input_channel,
|
||||
out_channels=output_channel,
|
||||
temb_channels=time_embed_dim,
|
||||
add_downsample=not is_final_block,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
downsample_padding=downsample_padding,
|
||||
)
|
||||
self.down_blocks.append(down_block)
|
||||
|
||||
# mid
|
||||
self.mid_block = UNetMidBlock2D(
|
||||
in_channels=block_out_channels[-1],
|
||||
temb_channels=time_embed_dim,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=mid_block_scale_factor,
|
||||
resnet_time_scale_shift="default",
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
resnet_groups=norm_num_groups,
|
||||
)
|
||||
|
||||
# up
|
||||
reversed_block_out_channels = list(reversed(block_out_channels))
|
||||
output_channel = reversed_block_out_channels[0]
|
||||
for i, up_block_type in enumerate(up_block_types):
|
||||
prev_output_channel = output_channel
|
||||
output_channel = reversed_block_out_channels[i]
|
||||
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
||||
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
up_block = get_up_block(
|
||||
up_block_type,
|
||||
num_layers=layers_per_block + 1,
|
||||
in_channels=input_channel,
|
||||
out_channels=output_channel,
|
||||
prev_output_channel=prev_output_channel,
|
||||
temb_channels=time_embed_dim,
|
||||
add_upsample=not is_final_block,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
)
|
||||
self.up_blocks.append(up_block)
|
||||
prev_output_channel = output_channel
|
||||
|
||||
# out
|
||||
num_groups_out = norm_num_groups if norm_num_groups is not None else min(block_out_channels[0] // 4, 32)
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=num_groups_out, eps=norm_eps)
|
||||
self.conv_act = nn.SiLU()
|
||||
self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, 3, padding=1)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
sample: torch.FloatTensor,
|
||||
timestep: Union[torch.Tensor, float, int],
|
||||
return_dict: bool = True,
|
||||
) -> Union[UNet2DOutput, Tuple]:
|
||||
"""r
|
||||
Args:
|
||||
sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
|
||||
timestep (`torch.FloatTensor` or `float` or `int): (batch) timesteps
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~models.unet_2d.UNet2DOutput`] instead of a plain tuple.
|
||||
|
||||
Returns:
|
||||
[`~models.unet_2d.UNet2DOutput`] or `tuple`: [`~models.unet_2d.UNet2DOutput`] if `return_dict` is True,
|
||||
otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
|
||||
"""
|
||||
# 0. center input if necessary
|
||||
if self.config.center_input_sample:
|
||||
sample = 2 * sample - 1.0
|
||||
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
if not torch.is_tensor(timesteps):
|
||||
timesteps = torch.tensor([timesteps], dtype=torch.long, device=sample.device)
|
||||
elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:
|
||||
timesteps = timesteps[None].to(sample.device)
|
||||
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timesteps = timesteps * torch.ones(sample.shape[0], dtype=timesteps.dtype, device=timesteps.device)
|
||||
|
||||
t_emb = self.time_proj(timesteps)
|
||||
emb = self.time_embedding(t_emb)
|
||||
|
||||
# 2. pre-process
|
||||
skip_sample = sample
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
for downsample_block in self.down_blocks:
|
||||
if hasattr(downsample_block, "skip_conv"):
|
||||
sample, res_samples, skip_sample = downsample_block(
|
||||
hidden_states=sample, temb=emb, skip_sample=skip_sample
|
||||
)
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
|
||||
down_block_res_samples += res_samples
|
||||
|
||||
# 4. mid
|
||||
sample = self.mid_block(sample, emb)
|
||||
|
||||
# 5. up
|
||||
skip_sample = None
|
||||
for upsample_block in self.up_blocks:
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
||||
|
||||
if hasattr(upsample_block, "skip_conv"):
|
||||
sample, skip_sample = upsample_block(sample, res_samples, emb, skip_sample)
|
||||
else:
|
||||
sample = upsample_block(sample, res_samples, emb)
|
||||
|
||||
# 6. post-process
|
||||
# make sure hidden states is in float32
|
||||
# when running in half-precision
|
||||
sample = self.conv_norm_out(sample.float()).type(sample.dtype)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
if skip_sample is not None:
|
||||
sample += skip_sample
|
||||
|
||||
if self.config.time_embedding_type == "fourier":
|
||||
timesteps = timesteps.reshape((sample.shape[0], *([1] * len(sample.shape[1:]))))
|
||||
sample = sample / timesteps
|
||||
|
||||
if not return_dict:
|
||||
return (sample,)
|
||||
|
||||
return UNet2DOutput(sample=sample)
|
||||
@@ -0,0 +1,270 @@
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..utils import BaseOutput
|
||||
from .embeddings import TimestepEmbedding, Timesteps
|
||||
from .unet_blocks import UNetMidBlock2DCrossAttn, get_down_block, get_up_block
|
||||
|
||||
|
||||
@dataclass
|
||||
class UNet2DConditionOutput(BaseOutput):
|
||||
"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
||||
Hidden states conditioned on `encoder_hidden_states` input. Output of last layer of model.
|
||||
"""
|
||||
|
||||
sample: torch.FloatTensor
|
||||
|
||||
|
||||
class UNet2DConditionModel(ModelMixin, ConfigMixin):
|
||||
r"""
|
||||
UNet2DConditionModel is a conditional 2D UNet model that takes in a noisy sample, conditional state, and a timestep
|
||||
and returns sample shaped output.
|
||||
|
||||
This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
|
||||
implements for all the model (such as downloading or saving, etc.)
|
||||
|
||||
Parameters:
|
||||
sample_size (`int`, *optional*): The size of the input sample.
|
||||
in_channels (`int`, *optional*, defaults to 4): The number of channels in the input sample.
|
||||
out_channels (`int`, *optional*, defaults to 4): The number of channels in the output.
|
||||
center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
|
||||
flip_sin_to_cos (`bool`, *optional*, defaults to `False`):
|
||||
Whether to flip the sin to cos in the time embedding.
|
||||
freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
|
||||
down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
|
||||
The tuple of downsample blocks to use.
|
||||
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D",)`):
|
||||
The tuple of upsample blocks to use.
|
||||
block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
|
||||
The tuple of output channels for each block.
|
||||
layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
|
||||
downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
|
||||
mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
|
||||
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
||||
norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
|
||||
norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
|
||||
cross_attention_dim (`int`, *optional*, defaults to 1280): The dimension of the cross attention features.
|
||||
attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
|
||||
"""
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
sample_size: Optional[int] = None,
|
||||
in_channels: int = 4,
|
||||
out_channels: int = 4,
|
||||
center_input_sample: bool = False,
|
||||
flip_sin_to_cos: bool = True,
|
||||
freq_shift: int = 0,
|
||||
down_block_types: Tuple[str] = (
|
||||
"CrossAttnDownBlock2D",
|
||||
"CrossAttnDownBlock2D",
|
||||
"CrossAttnDownBlock2D",
|
||||
"DownBlock2D",
|
||||
),
|
||||
up_block_types: Tuple[str] = ("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
|
||||
block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
|
||||
layers_per_block: int = 2,
|
||||
downsample_padding: int = 1,
|
||||
mid_block_scale_factor: float = 1,
|
||||
act_fn: str = "silu",
|
||||
norm_num_groups: int = 32,
|
||||
norm_eps: float = 1e-5,
|
||||
cross_attention_dim: int = 1280,
|
||||
attention_head_dim: int = 8,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.sample_size = sample_size
|
||||
time_embed_dim = block_out_channels[0] * 4
|
||||
|
||||
# input
|
||||
self.conv_in = nn.Conv2d(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
|
||||
|
||||
# time
|
||||
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
||||
timestep_input_dim = block_out_channels[0]
|
||||
|
||||
self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
|
||||
|
||||
self.down_blocks = nn.ModuleList([])
|
||||
self.mid_block = None
|
||||
self.up_blocks = nn.ModuleList([])
|
||||
|
||||
# down
|
||||
output_channel = block_out_channels[0]
|
||||
for i, down_block_type in enumerate(down_block_types):
|
||||
input_channel = output_channel
|
||||
output_channel = block_out_channels[i]
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
down_block = get_down_block(
|
||||
down_block_type,
|
||||
num_layers=layers_per_block,
|
||||
in_channels=input_channel,
|
||||
out_channels=output_channel,
|
||||
temb_channels=time_embed_dim,
|
||||
add_downsample=not is_final_block,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
downsample_padding=downsample_padding,
|
||||
)
|
||||
self.down_blocks.append(down_block)
|
||||
|
||||
# mid
|
||||
self.mid_block = UNetMidBlock2DCrossAttn(
|
||||
in_channels=block_out_channels[-1],
|
||||
temb_channels=time_embed_dim,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=mid_block_scale_factor,
|
||||
resnet_time_scale_shift="default",
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
resnet_groups=norm_num_groups,
|
||||
)
|
||||
|
||||
# up
|
||||
reversed_block_out_channels = list(reversed(block_out_channels))
|
||||
output_channel = reversed_block_out_channels[0]
|
||||
for i, up_block_type in enumerate(up_block_types):
|
||||
prev_output_channel = output_channel
|
||||
output_channel = reversed_block_out_channels[i]
|
||||
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
||||
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
up_block = get_up_block(
|
||||
up_block_type,
|
||||
num_layers=layers_per_block + 1,
|
||||
in_channels=input_channel,
|
||||
out_channels=output_channel,
|
||||
prev_output_channel=prev_output_channel,
|
||||
temb_channels=time_embed_dim,
|
||||
add_upsample=not is_final_block,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
)
|
||||
self.up_blocks.append(up_block)
|
||||
prev_output_channel = output_channel
|
||||
|
||||
# out
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps)
|
||||
self.conv_act = nn.SiLU()
|
||||
self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, 3, padding=1)
|
||||
|
||||
def set_attention_slice(self, slice_size):
|
||||
if slice_size is not None and self.config.attention_head_dim % slice_size != 0:
|
||||
raise ValueError(
|
||||
f"Make sure slice_size {slice_size} is a divisor of "
|
||||
f"the number of heads used in cross_attention {self.config.attention_head_dim}"
|
||||
)
|
||||
if slice_size is not None and slice_size > self.config.attention_head_dim:
|
||||
raise ValueError(
|
||||
f"Chunk_size {slice_size} has to be smaller or equal to "
|
||||
f"the number of heads used in cross_attention {self.config.attention_head_dim}"
|
||||
)
|
||||
|
||||
for block in self.down_blocks:
|
||||
if hasattr(block, "attentions") and block.attentions is not None:
|
||||
block.set_attention_slice(slice_size)
|
||||
|
||||
self.mid_block.set_attention_slice(slice_size)
|
||||
|
||||
for block in self.up_blocks:
|
||||
if hasattr(block, "attentions") and block.attentions is not None:
|
||||
block.set_attention_slice(slice_size)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
sample: torch.FloatTensor,
|
||||
timestep: Union[torch.Tensor, float, int],
|
||||
encoder_hidden_states: torch.Tensor,
|
||||
return_dict: bool = True,
|
||||
) -> Union[UNet2DConditionOutput, Tuple]:
|
||||
"""r
|
||||
Args:
|
||||
sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
|
||||
timestep (`torch.FloatTensor` or `float` or `int): (batch) timesteps
|
||||
encoder_hidden_states (`torch.FloatTensor`): (batch, channel, height, width) encoder hidden states
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
|
||||
|
||||
Returns:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`. When
|
||||
returning a tuple, the first element is the sample tensor.
|
||||
"""
|
||||
# 0. center input if necessary
|
||||
if self.config.center_input_sample:
|
||||
sample = 2 * sample - 1.0
|
||||
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
if not torch.is_tensor(timesteps):
|
||||
timesteps = torch.tensor([timesteps], dtype=torch.long, device=sample.device)
|
||||
elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:
|
||||
timesteps = timesteps.to(dtype=torch.float32)
|
||||
timesteps = timesteps[None].to(device=sample.device)
|
||||
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timesteps = timesteps.expand(sample.shape[0])
|
||||
|
||||
t_emb = self.time_proj(timesteps)
|
||||
emb = self.time_embedding(t_emb)
|
||||
|
||||
# 2. pre-process
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
for downsample_block in self.down_blocks:
|
||||
if hasattr(downsample_block, "attentions") and downsample_block.attentions is not None:
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample, temb=emb, encoder_hidden_states=encoder_hidden_states
|
||||
)
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
|
||||
down_block_res_samples += res_samples
|
||||
|
||||
# 4. mid
|
||||
sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states)
|
||||
|
||||
# 5. up
|
||||
for upsample_block in self.up_blocks:
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
||||
|
||||
if hasattr(upsample_block, "attentions") and upsample_block.attentions is not None:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
res_hidden_states_tuple=res_samples,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
)
|
||||
else:
|
||||
sample = upsample_block(hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples)
|
||||
|
||||
# 6. post-process
|
||||
# make sure hidden states is in float32
|
||||
# when running in half-precision
|
||||
sample = self.conv_norm_out(sample.float()).type(sample.dtype)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
if not return_dict:
|
||||
return (sample,)
|
||||
|
||||
return UNet2DConditionOutput(sample=sample)
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,820 +0,0 @@
|
||||
import math
|
||||
from abc import abstractmethod
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from ..modeling_utils import ModelMixin
|
||||
|
||||
|
||||
def convert_module_to_f16(l):
|
||||
"""
|
||||
Convert primitive modules to float16.
|
||||
"""
|
||||
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Conv3d)):
|
||||
l.weight.data = l.weight.data.half()
|
||||
if l.bias is not None:
|
||||
l.bias.data = l.bias.data.half()
|
||||
|
||||
|
||||
def convert_module_to_f32(l):
|
||||
"""
|
||||
Convert primitive modules to float32, undoing convert_module_to_f16().
|
||||
"""
|
||||
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Conv3d)):
|
||||
l.weight.data = l.weight.data.float()
|
||||
if l.bias is not None:
|
||||
l.bias.data = l.bias.data.float()
|
||||
|
||||
|
||||
def avg_pool_nd(dims, *args, **kwargs):
|
||||
"""
|
||||
Create a 1D, 2D, or 3D average pooling module.
|
||||
"""
|
||||
if dims == 1:
|
||||
return nn.AvgPool1d(*args, **kwargs)
|
||||
elif dims == 2:
|
||||
return nn.AvgPool2d(*args, **kwargs)
|
||||
elif dims == 3:
|
||||
return nn.AvgPool3d(*args, **kwargs)
|
||||
raise ValueError(f"unsupported dimensions: {dims}")
|
||||
|
||||
|
||||
def conv_nd(dims, *args, **kwargs):
|
||||
"""
|
||||
Create a 1D, 2D, or 3D convolution module.
|
||||
"""
|
||||
if dims == 1:
|
||||
return nn.Conv1d(*args, **kwargs)
|
||||
elif dims == 2:
|
||||
return nn.Conv2d(*args, **kwargs)
|
||||
elif dims == 3:
|
||||
return nn.Conv3d(*args, **kwargs)
|
||||
raise ValueError(f"unsupported dimensions: {dims}")
|
||||
|
||||
|
||||
def linear(*args, **kwargs):
|
||||
"""
|
||||
Create a linear module.
|
||||
"""
|
||||
return nn.Linear(*args, **kwargs)
|
||||
|
||||
|
||||
class GroupNorm32(nn.GroupNorm):
|
||||
def __init__(self, num_groups, num_channels, swish, eps=1e-5):
|
||||
super().__init__(num_groups=num_groups, num_channels=num_channels, eps=eps)
|
||||
self.swish = swish
|
||||
|
||||
def forward(self, x):
|
||||
y = super().forward(x.float()).to(x.dtype)
|
||||
if self.swish == 1.0:
|
||||
y = F.silu(y)
|
||||
elif self.swish:
|
||||
y = y * F.sigmoid(y * float(self.swish))
|
||||
return y
|
||||
|
||||
|
||||
def normalization(channels, swish=0.0):
|
||||
"""
|
||||
Make a standard normalization layer, with an optional swish activation.
|
||||
|
||||
:param channels: number of input channels.
|
||||
:return: an nn.Module for normalization.
|
||||
"""
|
||||
return GroupNorm32(num_channels=channels, num_groups=32, swish=swish)
|
||||
|
||||
|
||||
def timestep_embedding(timesteps, dim, max_period=10000):
|
||||
"""
|
||||
Create sinusoidal timestep embeddings.
|
||||
|
||||
:param timesteps: a 1-D Tensor of N indices, one per batch element.
|
||||
These may be fractional.
|
||||
:param dim: the dimension of the output.
|
||||
:param max_period: controls the minimum frequency of the embeddings.
|
||||
:return: an [N x dim] Tensor of positional embeddings.
|
||||
"""
|
||||
half = dim // 2
|
||||
freqs = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(
|
||||
device=timesteps.device
|
||||
)
|
||||
args = timesteps[:, None].float() * freqs[None]
|
||||
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
|
||||
if dim % 2:
|
||||
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
|
||||
return embedding
|
||||
|
||||
|
||||
def zero_module(module):
|
||||
"""
|
||||
Zero out the parameters of a module and return it.
|
||||
"""
|
||||
for p in module.parameters():
|
||||
p.detach().zero_()
|
||||
return module
|
||||
|
||||
|
||||
class TimestepBlock(nn.Module):
|
||||
"""
|
||||
Any module where forward() takes timestep embeddings as a second argument.
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def forward(self, x, emb):
|
||||
"""
|
||||
Apply the module to `x` given `emb` timestep embeddings.
|
||||
"""
|
||||
|
||||
|
||||
class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
|
||||
"""
|
||||
A sequential module that passes timestep embeddings to the children that
|
||||
support it as an extra input.
|
||||
"""
|
||||
|
||||
def forward(self, x, emb, encoder_out=None):
|
||||
for layer in self:
|
||||
if isinstance(layer, TimestepBlock):
|
||||
x = layer(x, emb)
|
||||
elif isinstance(layer, AttentionBlock):
|
||||
x = layer(x, encoder_out)
|
||||
else:
|
||||
x = layer(x)
|
||||
return x
|
||||
|
||||
|
||||
class Upsample(nn.Module):
|
||||
"""
|
||||
An upsampling layer with an optional convolution.
|
||||
|
||||
:param channels: channels in the inputs and outputs.
|
||||
:param use_conv: a bool determining if a convolution is applied.
|
||||
:param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
|
||||
upsampling occurs in the inner-two dimensions.
|
||||
"""
|
||||
|
||||
def __init__(self, channels, use_conv, dims=2, out_channels=None):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
self.out_channels = out_channels or channels
|
||||
self.use_conv = use_conv
|
||||
self.dims = dims
|
||||
if use_conv:
|
||||
self.conv = conv_nd(dims, self.channels, self.out_channels, 3, padding=1)
|
||||
|
||||
def forward(self, x):
|
||||
assert x.shape[1] == self.channels
|
||||
if self.dims == 3:
|
||||
x = F.interpolate(x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest")
|
||||
else:
|
||||
x = F.interpolate(x, scale_factor=2, mode="nearest")
|
||||
if self.use_conv:
|
||||
x = self.conv(x)
|
||||
return x
|
||||
|
||||
|
||||
class Downsample(nn.Module):
|
||||
"""
|
||||
A downsampling layer with an optional convolution.
|
||||
|
||||
:param channels: channels in the inputs and outputs.
|
||||
:param use_conv: a bool determining if a convolution is applied.
|
||||
:param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
|
||||
downsampling occurs in the inner-two dimensions.
|
||||
"""
|
||||
|
||||
def __init__(self, channels, use_conv, dims=2, out_channels=None):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
self.out_channels = out_channels or channels
|
||||
self.use_conv = use_conv
|
||||
self.dims = dims
|
||||
stride = 2 if dims != 3 else (1, 2, 2)
|
||||
if use_conv:
|
||||
self.op = conv_nd(dims, self.channels, self.out_channels, 3, stride=stride, padding=1)
|
||||
else:
|
||||
assert self.channels == self.out_channels
|
||||
self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
|
||||
|
||||
def forward(self, x):
|
||||
assert x.shape[1] == self.channels
|
||||
return self.op(x)
|
||||
|
||||
|
||||
class ResBlock(TimestepBlock):
|
||||
"""
|
||||
A residual block that can optionally change the number of channels.
|
||||
|
||||
:param channels: the number of input channels.
|
||||
:param emb_channels: the number of timestep embedding channels.
|
||||
:param dropout: the rate of dropout.
|
||||
:param out_channels: if specified, the number of out channels.
|
||||
:param use_conv: if True and out_channels is specified, use a spatial
|
||||
convolution instead of a smaller 1x1 convolution to change the
|
||||
channels in the skip connection.
|
||||
:param dims: determines if the signal is 1D, 2D, or 3D.
|
||||
:param use_checkpoint: if True, use gradient checkpointing on this module.
|
||||
:param up: if True, use this block for upsampling.
|
||||
:param down: if True, use this block for downsampling.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
channels,
|
||||
emb_channels,
|
||||
dropout,
|
||||
out_channels=None,
|
||||
use_conv=False,
|
||||
use_scale_shift_norm=False,
|
||||
dims=2,
|
||||
use_checkpoint=False,
|
||||
up=False,
|
||||
down=False,
|
||||
):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
self.emb_channels = emb_channels
|
||||
self.dropout = dropout
|
||||
self.out_channels = out_channels or channels
|
||||
self.use_conv = use_conv
|
||||
self.use_checkpoint = use_checkpoint
|
||||
self.use_scale_shift_norm = use_scale_shift_norm
|
||||
|
||||
self.in_layers = nn.Sequential(
|
||||
normalization(channels, swish=1.0),
|
||||
nn.Identity(),
|
||||
conv_nd(dims, channels, self.out_channels, 3, padding=1),
|
||||
)
|
||||
|
||||
self.updown = up or down
|
||||
|
||||
if up:
|
||||
self.h_upd = Upsample(channels, False, dims)
|
||||
self.x_upd = Upsample(channels, False, dims)
|
||||
elif down:
|
||||
self.h_upd = Downsample(channels, False, dims)
|
||||
self.x_upd = Downsample(channels, False, dims)
|
||||
else:
|
||||
self.h_upd = self.x_upd = nn.Identity()
|
||||
|
||||
self.emb_layers = nn.Sequential(
|
||||
nn.SiLU(),
|
||||
linear(
|
||||
emb_channels,
|
||||
2 * self.out_channels if use_scale_shift_norm else self.out_channels,
|
||||
),
|
||||
)
|
||||
self.out_layers = nn.Sequential(
|
||||
normalization(self.out_channels, swish=0.0 if use_scale_shift_norm else 1.0),
|
||||
nn.SiLU() if use_scale_shift_norm else nn.Identity(),
|
||||
nn.Dropout(p=dropout),
|
||||
zero_module(conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)),
|
||||
)
|
||||
|
||||
if self.out_channels == channels:
|
||||
self.skip_connection = nn.Identity()
|
||||
elif use_conv:
|
||||
self.skip_connection = conv_nd(dims, channels, self.out_channels, 3, padding=1)
|
||||
else:
|
||||
self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
|
||||
|
||||
def forward(self, x, emb):
|
||||
"""
|
||||
Apply the block to a Tensor, conditioned on a timestep embedding.
|
||||
|
||||
:param x: an [N x C x ...] Tensor of features.
|
||||
:param emb: an [N x emb_channels] Tensor of timestep embeddings.
|
||||
:return: an [N x C x ...] Tensor of outputs.
|
||||
"""
|
||||
if self.updown:
|
||||
in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
|
||||
h = in_rest(x)
|
||||
h = self.h_upd(h)
|
||||
x = self.x_upd(x)
|
||||
h = in_conv(h)
|
||||
else:
|
||||
h = self.in_layers(x)
|
||||
emb_out = self.emb_layers(emb).type(h.dtype)
|
||||
while len(emb_out.shape) < len(h.shape):
|
||||
emb_out = emb_out[..., None]
|
||||
if self.use_scale_shift_norm:
|
||||
out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
|
||||
scale, shift = torch.chunk(emb_out, 2, dim=1)
|
||||
h = out_norm(h) * (1 + scale) + shift
|
||||
h = out_rest(h)
|
||||
else:
|
||||
h = h + emb_out
|
||||
h = self.out_layers(h)
|
||||
return self.skip_connection(x) + h
|
||||
|
||||
|
||||
class AttentionBlock(nn.Module):
|
||||
"""
|
||||
An attention block that allows spatial positions to attend to each other.
|
||||
|
||||
Originally ported from here, but adapted to the N-d case.
|
||||
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
channels,
|
||||
num_heads=1,
|
||||
num_head_channels=-1,
|
||||
use_checkpoint=False,
|
||||
encoder_channels=None,
|
||||
):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
if num_head_channels == -1:
|
||||
self.num_heads = num_heads
|
||||
else:
|
||||
assert (
|
||||
channels % num_head_channels == 0
|
||||
), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
|
||||
self.num_heads = channels // num_head_channels
|
||||
self.use_checkpoint = use_checkpoint
|
||||
self.norm = normalization(channels, swish=0.0)
|
||||
self.qkv = conv_nd(1, channels, channels * 3, 1)
|
||||
self.attention = QKVAttention(self.num_heads)
|
||||
|
||||
if encoder_channels is not None:
|
||||
self.encoder_kv = conv_nd(1, encoder_channels, channels * 2, 1)
|
||||
self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
|
||||
|
||||
def forward(self, x, encoder_out=None):
|
||||
b, c, *spatial = x.shape
|
||||
qkv = self.qkv(self.norm(x).view(b, c, -1))
|
||||
if encoder_out is not None:
|
||||
encoder_out = self.encoder_kv(encoder_out)
|
||||
h = self.attention(qkv, encoder_out)
|
||||
else:
|
||||
h = self.attention(qkv)
|
||||
h = self.proj_out(h)
|
||||
return x + h.reshape(b, c, *spatial)
|
||||
|
||||
|
||||
class QKVAttention(nn.Module):
|
||||
"""
|
||||
A module which performs QKV attention. Matches legacy QKVAttention + input/ouput heads shaping
|
||||
"""
|
||||
|
||||
def __init__(self, n_heads):
|
||||
super().__init__()
|
||||
self.n_heads = n_heads
|
||||
|
||||
def forward(self, qkv, encoder_kv=None):
|
||||
"""
|
||||
Apply QKV attention.
|
||||
|
||||
:param qkv: an [N x (H * 3 * C) x T] tensor of Qs, Ks, and Vs.
|
||||
:return: an [N x (H * C) x T] tensor after attention.
|
||||
"""
|
||||
bs, width, length = qkv.shape
|
||||
assert width % (3 * self.n_heads) == 0
|
||||
ch = width // (3 * self.n_heads)
|
||||
q, k, v = qkv.reshape(bs * self.n_heads, ch * 3, length).split(ch, dim=1)
|
||||
if encoder_kv is not None:
|
||||
assert encoder_kv.shape[1] == self.n_heads * ch * 2
|
||||
ek, ev = encoder_kv.reshape(bs * self.n_heads, ch * 2, -1).split(ch, dim=1)
|
||||
k = torch.cat([ek, k], dim=-1)
|
||||
v = torch.cat([ev, v], dim=-1)
|
||||
scale = 1 / math.sqrt(math.sqrt(ch))
|
||||
weight = torch.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
|
||||
weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
|
||||
a = torch.einsum("bts,bcs->bct", weight, v)
|
||||
return a.reshape(bs, -1, length)
|
||||
|
||||
|
||||
class GLIDEUNetModel(ModelMixin, ConfigMixin):
|
||||
"""
|
||||
The full UNet model with attention and timestep embedding.
|
||||
|
||||
:param in_channels: channels in the input Tensor.
|
||||
:param model_channels: base channel count for the model.
|
||||
:param out_channels: channels in the output Tensor.
|
||||
:param num_res_blocks: number of residual blocks per downsample.
|
||||
:param attention_resolutions: a collection of downsample rates at which
|
||||
attention will take place. May be a set, list, or tuple.
|
||||
For example, if this contains 4, then at 4x downsampling, attention
|
||||
will be used.
|
||||
:param dropout: the dropout probability.
|
||||
:param channel_mult: channel multiplier for each level of the UNet.
|
||||
:param conv_resample: if True, use learned convolutions for upsampling and
|
||||
downsampling.
|
||||
:param dims: determines if the signal is 1D, 2D, or 3D.
|
||||
:param num_classes: if specified (as an int), then this model will be
|
||||
class-conditional with `num_classes` classes.
|
||||
:param use_checkpoint: use gradient checkpointing to reduce memory usage.
|
||||
:param num_heads: the number of attention heads in each attention layer.
|
||||
:param num_heads_channels: if specified, ignore num_heads and instead use
|
||||
a fixed channel width per attention head.
|
||||
:param num_heads_upsample: works with num_heads to set a different number
|
||||
of heads for upsampling. Deprecated.
|
||||
:param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
|
||||
:param resblock_updown: use residual blocks for up/downsampling.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=3,
|
||||
resolution=64,
|
||||
model_channels=192,
|
||||
out_channels=6,
|
||||
num_res_blocks=3,
|
||||
attention_resolutions=(2, 4, 8),
|
||||
dropout=0,
|
||||
channel_mult=(1, 2, 4, 8),
|
||||
conv_resample=True,
|
||||
dims=2,
|
||||
use_checkpoint=False,
|
||||
use_fp16=False,
|
||||
num_heads=1,
|
||||
num_head_channels=-1,
|
||||
num_heads_upsample=-1,
|
||||
use_scale_shift_norm=False,
|
||||
resblock_updown=False,
|
||||
transformer_dim=None,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
if num_heads_upsample == -1:
|
||||
num_heads_upsample = num_heads
|
||||
|
||||
self.in_channels = in_channels
|
||||
self.resolution = resolution
|
||||
self.model_channels = model_channels
|
||||
self.out_channels = out_channels
|
||||
self.num_res_blocks = num_res_blocks
|
||||
self.attention_resolutions = attention_resolutions
|
||||
self.dropout = dropout
|
||||
self.channel_mult = channel_mult
|
||||
self.conv_resample = conv_resample
|
||||
self.use_checkpoint = use_checkpoint
|
||||
# self.dtype = torch.float16 if use_fp16 else torch.float32
|
||||
self.num_heads = num_heads
|
||||
self.num_head_channels = num_head_channels
|
||||
self.num_heads_upsample = num_heads_upsample
|
||||
|
||||
time_embed_dim = model_channels * 4
|
||||
self.time_embed = nn.Sequential(
|
||||
linear(model_channels, time_embed_dim),
|
||||
nn.SiLU(),
|
||||
linear(time_embed_dim, time_embed_dim),
|
||||
)
|
||||
|
||||
ch = input_ch = int(channel_mult[0] * model_channels)
|
||||
self.input_blocks = nn.ModuleList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
|
||||
self._feature_size = ch
|
||||
input_block_chans = [ch]
|
||||
ds = 1
|
||||
for level, mult in enumerate(channel_mult):
|
||||
for _ in range(num_res_blocks):
|
||||
layers = [
|
||||
ResBlock(
|
||||
ch,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
out_channels=int(mult * model_channels),
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
)
|
||||
]
|
||||
ch = int(mult * model_channels)
|
||||
if ds in attention_resolutions:
|
||||
layers.append(
|
||||
AttentionBlock(
|
||||
ch,
|
||||
use_checkpoint=use_checkpoint,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
encoder_channels=transformer_dim,
|
||||
)
|
||||
)
|
||||
self.input_blocks.append(TimestepEmbedSequential(*layers))
|
||||
self._feature_size += ch
|
||||
input_block_chans.append(ch)
|
||||
if level != len(channel_mult) - 1:
|
||||
out_ch = ch
|
||||
self.input_blocks.append(
|
||||
TimestepEmbedSequential(
|
||||
ResBlock(
|
||||
ch,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
out_channels=out_ch,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
down=True,
|
||||
)
|
||||
if resblock_updown
|
||||
else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)
|
||||
)
|
||||
)
|
||||
ch = out_ch
|
||||
input_block_chans.append(ch)
|
||||
ds *= 2
|
||||
self._feature_size += ch
|
||||
|
||||
self.middle_block = TimestepEmbedSequential(
|
||||
ResBlock(
|
||||
ch,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
),
|
||||
AttentionBlock(
|
||||
ch,
|
||||
use_checkpoint=use_checkpoint,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
encoder_channels=transformer_dim,
|
||||
),
|
||||
ResBlock(
|
||||
ch,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
),
|
||||
)
|
||||
self._feature_size += ch
|
||||
|
||||
self.output_blocks = nn.ModuleList([])
|
||||
for level, mult in list(enumerate(channel_mult))[::-1]:
|
||||
for i in range(num_res_blocks + 1):
|
||||
ich = input_block_chans.pop()
|
||||
layers = [
|
||||
ResBlock(
|
||||
ch + ich,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
out_channels=int(model_channels * mult),
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
)
|
||||
]
|
||||
ch = int(model_channels * mult)
|
||||
if ds in attention_resolutions:
|
||||
layers.append(
|
||||
AttentionBlock(
|
||||
ch,
|
||||
use_checkpoint=use_checkpoint,
|
||||
num_heads=num_heads_upsample,
|
||||
num_head_channels=num_head_channels,
|
||||
encoder_channels=transformer_dim,
|
||||
)
|
||||
)
|
||||
if level and i == num_res_blocks:
|
||||
out_ch = ch
|
||||
layers.append(
|
||||
ResBlock(
|
||||
ch,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
out_channels=out_ch,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
up=True,
|
||||
)
|
||||
if resblock_updown
|
||||
else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch)
|
||||
)
|
||||
ds //= 2
|
||||
self.output_blocks.append(TimestepEmbedSequential(*layers))
|
||||
self._feature_size += ch
|
||||
|
||||
self.out = nn.Sequential(
|
||||
normalization(ch, swish=1.0),
|
||||
nn.Identity(),
|
||||
zero_module(conv_nd(dims, input_ch, out_channels, 3, padding=1)),
|
||||
)
|
||||
self.use_fp16 = use_fp16
|
||||
|
||||
def convert_to_fp16(self):
|
||||
"""
|
||||
Convert the torso of the model to float16.
|
||||
"""
|
||||
self.input_blocks.apply(convert_module_to_f16)
|
||||
self.middle_block.apply(convert_module_to_f16)
|
||||
self.output_blocks.apply(convert_module_to_f16)
|
||||
|
||||
def convert_to_fp32(self):
|
||||
"""
|
||||
Convert the torso of the model to float32.
|
||||
"""
|
||||
self.input_blocks.apply(convert_module_to_f32)
|
||||
self.middle_block.apply(convert_module_to_f32)
|
||||
self.output_blocks.apply(convert_module_to_f32)
|
||||
|
||||
def forward(self, x, timesteps):
|
||||
"""
|
||||
Apply the model to an input batch.
|
||||
|
||||
:param x: an [N x C x ...] Tensor of inputs.
|
||||
:param timesteps: a 1-D batch of timesteps.
|
||||
:param y: an [N] Tensor of labels, if class-conditional.
|
||||
:return: an [N x C x ...] Tensor of outputs.
|
||||
"""
|
||||
|
||||
hs = []
|
||||
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
|
||||
|
||||
h = x.type(self.dtype)
|
||||
for module in self.input_blocks:
|
||||
h = module(h, emb)
|
||||
hs.append(h)
|
||||
h = self.middle_block(h, emb)
|
||||
for module in self.output_blocks:
|
||||
h = torch.cat([h, hs.pop()], dim=1)
|
||||
h = module(h, emb)
|
||||
h = h.type(x.dtype)
|
||||
return self.out(h)
|
||||
|
||||
|
||||
class GLIDETextToImageUNetModel(GLIDEUNetModel):
|
||||
"""
|
||||
A UNetModel that performs super-resolution.
|
||||
|
||||
Expects an extra kwarg `low_res` to condition on a low-resolution image.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=3,
|
||||
resolution=64,
|
||||
model_channels=192,
|
||||
out_channels=6,
|
||||
num_res_blocks=3,
|
||||
attention_resolutions=(2, 4, 8),
|
||||
dropout=0,
|
||||
channel_mult=(1, 2, 4, 8),
|
||||
conv_resample=True,
|
||||
dims=2,
|
||||
use_checkpoint=False,
|
||||
use_fp16=False,
|
||||
num_heads=1,
|
||||
num_head_channels=-1,
|
||||
num_heads_upsample=-1,
|
||||
use_scale_shift_norm=False,
|
||||
resblock_updown=False,
|
||||
transformer_dim=512,
|
||||
):
|
||||
super().__init__(
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
model_channels=model_channels,
|
||||
out_channels=out_channels,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attention_resolutions=attention_resolutions,
|
||||
dropout=dropout,
|
||||
channel_mult=channel_mult,
|
||||
conv_resample=conv_resample,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_fp16=use_fp16,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
num_heads_upsample=num_heads_upsample,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
resblock_updown=resblock_updown,
|
||||
transformer_dim=transformer_dim,
|
||||
)
|
||||
self.register(
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
model_channels=model_channels,
|
||||
out_channels=out_channels,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attention_resolutions=attention_resolutions,
|
||||
dropout=dropout,
|
||||
channel_mult=channel_mult,
|
||||
conv_resample=conv_resample,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_fp16=use_fp16,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
num_heads_upsample=num_heads_upsample,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
resblock_updown=resblock_updown,
|
||||
transformer_dim=transformer_dim,
|
||||
)
|
||||
|
||||
self.transformer_proj = nn.Linear(transformer_dim, self.model_channels * 4)
|
||||
|
||||
def forward(self, x, timesteps, transformer_out=None):
|
||||
hs = []
|
||||
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
|
||||
|
||||
# project the last token
|
||||
transformer_proj = self.transformer_proj(transformer_out[:, -1])
|
||||
transformer_out = transformer_out.permute(0, 2, 1) # NLC -> NCL
|
||||
|
||||
emb = emb + transformer_proj.to(emb)
|
||||
|
||||
h = x
|
||||
for module in self.input_blocks:
|
||||
h = module(h, emb, transformer_out)
|
||||
hs.append(h)
|
||||
h = self.middle_block(h, emb, transformer_out)
|
||||
for module in self.output_blocks:
|
||||
other = hs.pop()
|
||||
h = torch.cat([h, other], dim=1)
|
||||
h = module(h, emb, transformer_out)
|
||||
return self.out(h)
|
||||
|
||||
|
||||
class GLIDESuperResUNetModel(GLIDEUNetModel):
|
||||
"""
|
||||
A UNetModel that performs super-resolution.
|
||||
|
||||
Expects an extra kwarg `low_res` to condition on a low-resolution image.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=3,
|
||||
resolution=256,
|
||||
model_channels=192,
|
||||
out_channels=6,
|
||||
num_res_blocks=3,
|
||||
attention_resolutions=(2, 4, 8),
|
||||
dropout=0,
|
||||
channel_mult=(1, 2, 4, 8),
|
||||
conv_resample=True,
|
||||
dims=2,
|
||||
use_checkpoint=False,
|
||||
use_fp16=False,
|
||||
num_heads=1,
|
||||
num_head_channels=-1,
|
||||
num_heads_upsample=-1,
|
||||
use_scale_shift_norm=False,
|
||||
resblock_updown=False,
|
||||
):
|
||||
super().__init__(
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
model_channels=model_channels,
|
||||
out_channels=out_channels,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attention_resolutions=attention_resolutions,
|
||||
dropout=dropout,
|
||||
channel_mult=channel_mult,
|
||||
conv_resample=conv_resample,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_fp16=use_fp16,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
num_heads_upsample=num_heads_upsample,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
resblock_updown=resblock_updown,
|
||||
)
|
||||
self.register(
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
model_channels=model_channels,
|
||||
out_channels=out_channels,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attention_resolutions=attention_resolutions,
|
||||
dropout=dropout,
|
||||
channel_mult=channel_mult,
|
||||
conv_resample=conv_resample,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_fp16=use_fp16,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
num_heads_upsample=num_heads_upsample,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
resblock_updown=resblock_updown,
|
||||
)
|
||||
|
||||
def forward(self, x, timesteps, low_res=None):
|
||||
_, _, new_height, new_width = x.shape
|
||||
upsampled = F.interpolate(low_res, (new_height, new_width), mode="bilinear")
|
||||
x = torch.cat([x, upsampled], dim=1)
|
||||
|
||||
hs = []
|
||||
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
|
||||
|
||||
h = x
|
||||
for module in self.input_blocks:
|
||||
h = module(h, emb)
|
||||
hs.append(h)
|
||||
h = self.middle_block(h, emb)
|
||||
for module in self.output_blocks:
|
||||
h = torch.cat([h, hs.pop()], dim=1)
|
||||
h = module(h, emb)
|
||||
|
||||
return self.out(h)
|
||||
@@ -1,233 +0,0 @@
|
||||
import math
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
try:
|
||||
from einops import rearrange, repeat
|
||||
except:
|
||||
print("Einops is not installed")
|
||||
pass
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from ..modeling_utils import ModelMixin
|
||||
|
||||
|
||||
class Mish(torch.nn.Module):
|
||||
def forward(self, x):
|
||||
return x * torch.tanh(torch.nn.functional.softplus(x))
|
||||
|
||||
|
||||
class Upsample(torch.nn.Module):
|
||||
def __init__(self, dim):
|
||||
super(Upsample, self).__init__()
|
||||
self.conv = torch.nn.ConvTranspose2d(dim, dim, 4, 2, 1)
|
||||
|
||||
def forward(self, x):
|
||||
return self.conv(x)
|
||||
|
||||
|
||||
class Downsample(torch.nn.Module):
|
||||
def __init__(self, dim):
|
||||
super(Downsample, self).__init__()
|
||||
self.conv = torch.nn.Conv2d(dim, dim, 3, 2, 1)
|
||||
|
||||
def forward(self, x):
|
||||
return self.conv(x)
|
||||
|
||||
|
||||
class Rezero(torch.nn.Module):
|
||||
def __init__(self, fn):
|
||||
super(Rezero, self).__init__()
|
||||
self.fn = fn
|
||||
self.g = torch.nn.Parameter(torch.zeros(1))
|
||||
|
||||
def forward(self, x):
|
||||
return self.fn(x) * self.g
|
||||
|
||||
|
||||
class Block(torch.nn.Module):
|
||||
def __init__(self, dim, dim_out, groups=8):
|
||||
super(Block, self).__init__()
|
||||
self.block = torch.nn.Sequential(
|
||||
torch.nn.Conv2d(dim, dim_out, 3, padding=1), torch.nn.GroupNorm(groups, dim_out), Mish()
|
||||
)
|
||||
|
||||
def forward(self, x, mask):
|
||||
output = self.block(x * mask)
|
||||
return output * mask
|
||||
|
||||
|
||||
class ResnetBlock(torch.nn.Module):
|
||||
def __init__(self, dim, dim_out, time_emb_dim, groups=8):
|
||||
super(ResnetBlock, self).__init__()
|
||||
self.mlp = torch.nn.Sequential(Mish(), torch.nn.Linear(time_emb_dim, dim_out))
|
||||
|
||||
self.block1 = Block(dim, dim_out, groups=groups)
|
||||
self.block2 = Block(dim_out, dim_out, groups=groups)
|
||||
if dim != dim_out:
|
||||
self.res_conv = torch.nn.Conv2d(dim, dim_out, 1)
|
||||
else:
|
||||
self.res_conv = torch.nn.Identity()
|
||||
|
||||
def forward(self, x, mask, time_emb):
|
||||
h = self.block1(x, mask)
|
||||
h += self.mlp(time_emb).unsqueeze(-1).unsqueeze(-1)
|
||||
h = self.block2(h, mask)
|
||||
output = h + self.res_conv(x * mask)
|
||||
return output
|
||||
|
||||
|
||||
class LinearAttention(torch.nn.Module):
|
||||
def __init__(self, dim, heads=4, dim_head=32):
|
||||
super(LinearAttention, self).__init__()
|
||||
self.heads = heads
|
||||
hidden_dim = dim_head * heads
|
||||
self.to_qkv = torch.nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
|
||||
self.to_out = torch.nn.Conv2d(hidden_dim, dim, 1)
|
||||
|
||||
def forward(self, x):
|
||||
b, c, h, w = x.shape
|
||||
qkv = self.to_qkv(x)
|
||||
q, k, v = rearrange(qkv, "b (qkv heads c) h w -> qkv b heads c (h w)", heads=self.heads, qkv=3)
|
||||
k = k.softmax(dim=-1)
|
||||
context = torch.einsum("bhdn,bhen->bhde", k, v)
|
||||
out = torch.einsum("bhde,bhdn->bhen", context, q)
|
||||
out = rearrange(out, "b heads c (h w) -> b (heads c) h w", heads=self.heads, h=h, w=w)
|
||||
return self.to_out(out)
|
||||
|
||||
|
||||
class Residual(torch.nn.Module):
|
||||
def __init__(self, fn):
|
||||
super(Residual, self).__init__()
|
||||
self.fn = fn
|
||||
|
||||
def forward(self, x, *args, **kwargs):
|
||||
output = self.fn(x, *args, **kwargs) + x
|
||||
return output
|
||||
|
||||
|
||||
class SinusoidalPosEmb(torch.nn.Module):
|
||||
def __init__(self, dim):
|
||||
super(SinusoidalPosEmb, self).__init__()
|
||||
self.dim = dim
|
||||
|
||||
def forward(self, x, scale=1000):
|
||||
device = x.device
|
||||
half_dim = self.dim // 2
|
||||
emb = math.log(10000) / (half_dim - 1)
|
||||
emb = torch.exp(torch.arange(half_dim, device=device).float() * -emb)
|
||||
emb = scale * x.unsqueeze(1) * emb.unsqueeze(0)
|
||||
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
|
||||
return emb
|
||||
|
||||
|
||||
class UNetGradTTSModel(ModelMixin, ConfigMixin):
|
||||
def __init__(self, dim, dim_mults=(1, 2, 4), groups=8, n_spks=None, spk_emb_dim=64, n_feats=80, pe_scale=1000):
|
||||
super(UNetGradTTSModel, self).__init__()
|
||||
|
||||
self.register(
|
||||
dim=dim,
|
||||
dim_mults=dim_mults,
|
||||
groups=groups,
|
||||
n_spks=n_spks,
|
||||
spk_emb_dim=spk_emb_dim,
|
||||
n_feats=n_feats,
|
||||
pe_scale=pe_scale,
|
||||
)
|
||||
|
||||
self.dim = dim
|
||||
self.dim_mults = dim_mults
|
||||
self.groups = groups
|
||||
self.n_spks = n_spks if not isinstance(n_spks, type(None)) else 1
|
||||
self.spk_emb_dim = spk_emb_dim
|
||||
self.pe_scale = pe_scale
|
||||
|
||||
if n_spks > 1:
|
||||
self.spk_mlp = torch.nn.Sequential(
|
||||
torch.nn.Linear(spk_emb_dim, spk_emb_dim * 4), Mish(), torch.nn.Linear(spk_emb_dim * 4, n_feats)
|
||||
)
|
||||
self.time_pos_emb = SinusoidalPosEmb(dim)
|
||||
self.mlp = torch.nn.Sequential(torch.nn.Linear(dim, dim * 4), Mish(), torch.nn.Linear(dim * 4, dim))
|
||||
|
||||
dims = [2 + (1 if n_spks > 1 else 0), *map(lambda m: dim * m, dim_mults)]
|
||||
in_out = list(zip(dims[:-1], dims[1:]))
|
||||
self.downs = torch.nn.ModuleList([])
|
||||
self.ups = torch.nn.ModuleList([])
|
||||
num_resolutions = len(in_out)
|
||||
|
||||
for ind, (dim_in, dim_out) in enumerate(in_out):
|
||||
is_last = ind >= (num_resolutions - 1)
|
||||
self.downs.append(
|
||||
torch.nn.ModuleList(
|
||||
[
|
||||
ResnetBlock(dim_in, dim_out, time_emb_dim=dim),
|
||||
ResnetBlock(dim_out, dim_out, time_emb_dim=dim),
|
||||
Residual(Rezero(LinearAttention(dim_out))),
|
||||
Downsample(dim_out) if not is_last else torch.nn.Identity(),
|
||||
]
|
||||
)
|
||||
)
|
||||
|
||||
mid_dim = dims[-1]
|
||||
self.mid_block1 = ResnetBlock(mid_dim, mid_dim, time_emb_dim=dim)
|
||||
self.mid_attn = Residual(Rezero(LinearAttention(mid_dim)))
|
||||
self.mid_block2 = ResnetBlock(mid_dim, mid_dim, time_emb_dim=dim)
|
||||
|
||||
for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):
|
||||
self.ups.append(
|
||||
torch.nn.ModuleList(
|
||||
[
|
||||
ResnetBlock(dim_out * 2, dim_in, time_emb_dim=dim),
|
||||
ResnetBlock(dim_in, dim_in, time_emb_dim=dim),
|
||||
Residual(Rezero(LinearAttention(dim_in))),
|
||||
Upsample(dim_in),
|
||||
]
|
||||
)
|
||||
)
|
||||
self.final_block = Block(dim, dim)
|
||||
self.final_conv = torch.nn.Conv2d(dim, 1, 1)
|
||||
|
||||
def forward(self, x, mask, mu, t, spk=None):
|
||||
if not isinstance(spk, type(None)):
|
||||
s = self.spk_mlp(spk)
|
||||
|
||||
t = self.time_pos_emb(t, scale=self.pe_scale)
|
||||
t = self.mlp(t)
|
||||
|
||||
if self.n_spks < 2:
|
||||
x = torch.stack([mu, x], 1)
|
||||
else:
|
||||
s = s.unsqueeze(-1).repeat(1, 1, x.shape[-1])
|
||||
x = torch.stack([mu, x, s], 1)
|
||||
mask = mask.unsqueeze(1)
|
||||
|
||||
hiddens = []
|
||||
masks = [mask]
|
||||
for resnet1, resnet2, attn, downsample in self.downs:
|
||||
mask_down = masks[-1]
|
||||
x = resnet1(x, mask_down, t)
|
||||
x = resnet2(x, mask_down, t)
|
||||
x = attn(x)
|
||||
hiddens.append(x)
|
||||
x = downsample(x * mask_down)
|
||||
masks.append(mask_down[:, :, :, ::2])
|
||||
|
||||
masks = masks[:-1]
|
||||
mask_mid = masks[-1]
|
||||
x = self.mid_block1(x, mask_mid, t)
|
||||
x = self.mid_attn(x)
|
||||
x = self.mid_block2(x, mask_mid, t)
|
||||
|
||||
for resnet1, resnet2, attn, upsample in self.ups:
|
||||
mask_up = masks.pop()
|
||||
x = torch.cat((x, hiddens.pop()), dim=1)
|
||||
x = resnet1(x, mask_up, t)
|
||||
x = resnet2(x, mask_up, t)
|
||||
x = attn(x)
|
||||
x = upsample(x * mask_up)
|
||||
|
||||
x = self.final_block(x, mask)
|
||||
output = self.final_conv(x * mask)
|
||||
|
||||
return (output * mask).squeeze(1)
|
||||
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,581 @@
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..utils import BaseOutput
|
||||
from .unet_blocks import UNetMidBlock2D, get_down_block, get_up_block
|
||||
|
||||
|
||||
@dataclass
|
||||
class DecoderOutput(BaseOutput):
|
||||
"""
|
||||
Output of decoding method.
|
||||
|
||||
Args:
|
||||
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
||||
Decoded output sample of the model. Output of the last layer of the model.
|
||||
"""
|
||||
|
||||
sample: torch.FloatTensor
|
||||
|
||||
|
||||
@dataclass
|
||||
class VQEncoderOutput(BaseOutput):
|
||||
"""
|
||||
Output of VQModel encoding method.
|
||||
|
||||
Args:
|
||||
latents (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
||||
Encoded output sample of the model. Output of the last layer of the model.
|
||||
"""
|
||||
|
||||
latents: torch.FloatTensor
|
||||
|
||||
|
||||
@dataclass
|
||||
class AutoencoderKLOutput(BaseOutput):
|
||||
"""
|
||||
Output of AutoencoderKL encoding method.
|
||||
|
||||
Args:
|
||||
latent_dist (`DiagonalGaussianDistribution`):
|
||||
Encoded outputs of `Encoder` represented as the mean and logvar of `DiagonalGaussianDistribution`.
|
||||
`DiagonalGaussianDistribution` allows for sampling latents from the distribution.
|
||||
"""
|
||||
|
||||
latent_dist: "DiagonalGaussianDistribution"
|
||||
|
||||
|
||||
class Encoder(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=3,
|
||||
out_channels=3,
|
||||
down_block_types=("DownEncoderBlock2D",),
|
||||
block_out_channels=(64,),
|
||||
layers_per_block=2,
|
||||
act_fn="silu",
|
||||
double_z=True,
|
||||
):
|
||||
super().__init__()
|
||||
self.layers_per_block = layers_per_block
|
||||
|
||||
self.conv_in = torch.nn.Conv2d(in_channels, block_out_channels[0], kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.mid_block = None
|
||||
self.down_blocks = nn.ModuleList([])
|
||||
|
||||
# down
|
||||
output_channel = block_out_channels[0]
|
||||
for i, down_block_type in enumerate(down_block_types):
|
||||
input_channel = output_channel
|
||||
output_channel = block_out_channels[i]
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
down_block = get_down_block(
|
||||
down_block_type,
|
||||
num_layers=self.layers_per_block,
|
||||
in_channels=input_channel,
|
||||
out_channels=output_channel,
|
||||
add_downsample=not is_final_block,
|
||||
resnet_eps=1e-6,
|
||||
downsample_padding=0,
|
||||
resnet_act_fn=act_fn,
|
||||
attn_num_head_channels=None,
|
||||
temb_channels=None,
|
||||
)
|
||||
self.down_blocks.append(down_block)
|
||||
|
||||
# mid
|
||||
self.mid_block = UNetMidBlock2D(
|
||||
in_channels=block_out_channels[-1],
|
||||
resnet_eps=1e-6,
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=1,
|
||||
resnet_time_scale_shift="default",
|
||||
attn_num_head_channels=None,
|
||||
resnet_groups=32,
|
||||
temb_channels=None,
|
||||
)
|
||||
|
||||
# out
|
||||
num_groups_out = 32
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[-1], num_groups=num_groups_out, eps=1e-6)
|
||||
self.conv_act = nn.SiLU()
|
||||
|
||||
conv_out_channels = 2 * out_channels if double_z else out_channels
|
||||
self.conv_out = nn.Conv2d(block_out_channels[-1], conv_out_channels, 3, padding=1)
|
||||
|
||||
def forward(self, x):
|
||||
sample = x
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
# down
|
||||
for down_block in self.down_blocks:
|
||||
sample = down_block(sample)
|
||||
|
||||
# middle
|
||||
sample = self.mid_block(sample)
|
||||
|
||||
# post-process
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
return sample
|
||||
|
||||
|
||||
class Decoder(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=3,
|
||||
out_channels=3,
|
||||
up_block_types=("UpDecoderBlock2D",),
|
||||
block_out_channels=(64,),
|
||||
layers_per_block=2,
|
||||
act_fn="silu",
|
||||
):
|
||||
super().__init__()
|
||||
self.layers_per_block = layers_per_block
|
||||
|
||||
self.conv_in = nn.Conv2d(in_channels, block_out_channels[-1], kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.mid_block = None
|
||||
self.up_blocks = nn.ModuleList([])
|
||||
|
||||
# mid
|
||||
self.mid_block = UNetMidBlock2D(
|
||||
in_channels=block_out_channels[-1],
|
||||
resnet_eps=1e-6,
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=1,
|
||||
resnet_time_scale_shift="default",
|
||||
attn_num_head_channels=None,
|
||||
resnet_groups=32,
|
||||
temb_channels=None,
|
||||
)
|
||||
|
||||
# up
|
||||
reversed_block_out_channels = list(reversed(block_out_channels))
|
||||
output_channel = reversed_block_out_channels[0]
|
||||
for i, up_block_type in enumerate(up_block_types):
|
||||
prev_output_channel = output_channel
|
||||
output_channel = reversed_block_out_channels[i]
|
||||
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
up_block = get_up_block(
|
||||
up_block_type,
|
||||
num_layers=self.layers_per_block + 1,
|
||||
in_channels=prev_output_channel,
|
||||
out_channels=output_channel,
|
||||
prev_output_channel=None,
|
||||
add_upsample=not is_final_block,
|
||||
resnet_eps=1e-6,
|
||||
resnet_act_fn=act_fn,
|
||||
attn_num_head_channels=None,
|
||||
temb_channels=None,
|
||||
)
|
||||
self.up_blocks.append(up_block)
|
||||
prev_output_channel = output_channel
|
||||
|
||||
# out
|
||||
num_groups_out = 32
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=num_groups_out, eps=1e-6)
|
||||
self.conv_act = nn.SiLU()
|
||||
self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, 3, padding=1)
|
||||
|
||||
def forward(self, z):
|
||||
sample = z
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
# middle
|
||||
sample = self.mid_block(sample)
|
||||
|
||||
# up
|
||||
for up_block in self.up_blocks:
|
||||
sample = up_block(sample)
|
||||
|
||||
# post-process
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
return sample
|
||||
|
||||
|
||||
class VectorQuantizer(nn.Module):
|
||||
"""
|
||||
Improved version over VectorQuantizer, can be used as a drop-in replacement. Mostly avoids costly matrix
|
||||
multiplications and allows for post-hoc remapping of indices.
|
||||
"""
|
||||
|
||||
# NOTE: due to a bug the beta term was applied to the wrong term. for
|
||||
# backwards compatibility we use the buggy version by default, but you can
|
||||
# specify legacy=False to fix it.
|
||||
def __init__(self, n_e, e_dim, beta, remap=None, unknown_index="random", sane_index_shape=False, legacy=True):
|
||||
super().__init__()
|
||||
self.n_e = n_e
|
||||
self.e_dim = e_dim
|
||||
self.beta = beta
|
||||
self.legacy = legacy
|
||||
|
||||
self.embedding = nn.Embedding(self.n_e, self.e_dim)
|
||||
self.embedding.weight.data.uniform_(-1.0 / self.n_e, 1.0 / self.n_e)
|
||||
|
||||
self.remap = remap
|
||||
if self.remap is not None:
|
||||
self.register_buffer("used", torch.tensor(np.load(self.remap)))
|
||||
self.re_embed = self.used.shape[0]
|
||||
self.unknown_index = unknown_index # "random" or "extra" or integer
|
||||
if self.unknown_index == "extra":
|
||||
self.unknown_index = self.re_embed
|
||||
self.re_embed = self.re_embed + 1
|
||||
print(
|
||||
f"Remapping {self.n_e} indices to {self.re_embed} indices. "
|
||||
f"Using {self.unknown_index} for unknown indices."
|
||||
)
|
||||
else:
|
||||
self.re_embed = n_e
|
||||
|
||||
self.sane_index_shape = sane_index_shape
|
||||
|
||||
def remap_to_used(self, inds):
|
||||
ishape = inds.shape
|
||||
assert len(ishape) > 1
|
||||
inds = inds.reshape(ishape[0], -1)
|
||||
used = self.used.to(inds)
|
||||
match = (inds[:, :, None] == used[None, None, ...]).long()
|
||||
new = match.argmax(-1)
|
||||
unknown = match.sum(2) < 1
|
||||
if self.unknown_index == "random":
|
||||
new[unknown] = torch.randint(0, self.re_embed, size=new[unknown].shape).to(device=new.device)
|
||||
else:
|
||||
new[unknown] = self.unknown_index
|
||||
return new.reshape(ishape)
|
||||
|
||||
def unmap_to_all(self, inds):
|
||||
ishape = inds.shape
|
||||
assert len(ishape) > 1
|
||||
inds = inds.reshape(ishape[0], -1)
|
||||
used = self.used.to(inds)
|
||||
if self.re_embed > self.used.shape[0]: # extra token
|
||||
inds[inds >= self.used.shape[0]] = 0 # simply set to zero
|
||||
back = torch.gather(used[None, :][inds.shape[0] * [0], :], 1, inds)
|
||||
return back.reshape(ishape)
|
||||
|
||||
def forward(self, z):
|
||||
# reshape z -> (batch, height, width, channel) and flatten
|
||||
z = z.permute(0, 2, 3, 1).contiguous()
|
||||
z_flattened = z.view(-1, self.e_dim)
|
||||
# distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
|
||||
|
||||
d = (
|
||||
torch.sum(z_flattened**2, dim=1, keepdim=True)
|
||||
+ torch.sum(self.embedding.weight**2, dim=1)
|
||||
- 2 * torch.einsum("bd,dn->bn", z_flattened, self.embedding.weight.t())
|
||||
)
|
||||
|
||||
min_encoding_indices = torch.argmin(d, dim=1)
|
||||
z_q = self.embedding(min_encoding_indices).view(z.shape)
|
||||
perplexity = None
|
||||
min_encodings = None
|
||||
|
||||
# compute loss for embedding
|
||||
if not self.legacy:
|
||||
loss = self.beta * torch.mean((z_q.detach() - z) ** 2) + torch.mean((z_q - z.detach()) ** 2)
|
||||
else:
|
||||
loss = torch.mean((z_q.detach() - z) ** 2) + self.beta * torch.mean((z_q - z.detach()) ** 2)
|
||||
|
||||
# preserve gradients
|
||||
z_q = z + (z_q - z).detach()
|
||||
|
||||
# reshape back to match original input shape
|
||||
z_q = z_q.permute(0, 3, 1, 2).contiguous()
|
||||
|
||||
if self.remap is not None:
|
||||
min_encoding_indices = min_encoding_indices.reshape(z.shape[0], -1) # add batch axis
|
||||
min_encoding_indices = self.remap_to_used(min_encoding_indices)
|
||||
min_encoding_indices = min_encoding_indices.reshape(-1, 1) # flatten
|
||||
|
||||
if self.sane_index_shape:
|
||||
min_encoding_indices = min_encoding_indices.reshape(z_q.shape[0], z_q.shape[2], z_q.shape[3])
|
||||
|
||||
return z_q, loss, (perplexity, min_encodings, min_encoding_indices)
|
||||
|
||||
def get_codebook_entry(self, indices, shape):
|
||||
# shape specifying (batch, height, width, channel)
|
||||
if self.remap is not None:
|
||||
indices = indices.reshape(shape[0], -1) # add batch axis
|
||||
indices = self.unmap_to_all(indices)
|
||||
indices = indices.reshape(-1) # flatten again
|
||||
|
||||
# get quantized latent vectors
|
||||
z_q = self.embedding(indices)
|
||||
|
||||
if shape is not None:
|
||||
z_q = z_q.view(shape)
|
||||
# reshape back to match original input shape
|
||||
z_q = z_q.permute(0, 3, 1, 2).contiguous()
|
||||
|
||||
return z_q
|
||||
|
||||
|
||||
class DiagonalGaussianDistribution(object):
|
||||
def __init__(self, parameters, deterministic=False):
|
||||
self.parameters = parameters
|
||||
self.mean, self.logvar = torch.chunk(parameters, 2, dim=1)
|
||||
self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
|
||||
self.deterministic = deterministic
|
||||
self.std = torch.exp(0.5 * self.logvar)
|
||||
self.var = torch.exp(self.logvar)
|
||||
if self.deterministic:
|
||||
self.var = self.std = torch.zeros_like(self.mean).to(device=self.parameters.device)
|
||||
|
||||
def sample(self, generator: Optional[torch.Generator] = None) -> torch.FloatTensor:
|
||||
device = self.parameters.device
|
||||
sample_device = "cpu" if device.type == "mps" else device
|
||||
sample = torch.randn(self.mean.shape, generator=generator, device=sample_device).to(device)
|
||||
x = self.mean + self.std * sample
|
||||
return x
|
||||
|
||||
def kl(self, other=None):
|
||||
if self.deterministic:
|
||||
return torch.Tensor([0.0])
|
||||
else:
|
||||
if other is None:
|
||||
return 0.5 * torch.sum(torch.pow(self.mean, 2) + self.var - 1.0 - self.logvar, dim=[1, 2, 3])
|
||||
else:
|
||||
return 0.5 * torch.sum(
|
||||
torch.pow(self.mean - other.mean, 2) / other.var
|
||||
+ self.var / other.var
|
||||
- 1.0
|
||||
- self.logvar
|
||||
+ other.logvar,
|
||||
dim=[1, 2, 3],
|
||||
)
|
||||
|
||||
def nll(self, sample, dims=[1, 2, 3]):
|
||||
if self.deterministic:
|
||||
return torch.Tensor([0.0])
|
||||
logtwopi = np.log(2.0 * np.pi)
|
||||
return 0.5 * torch.sum(logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var, dim=dims)
|
||||
|
||||
def mode(self):
|
||||
return self.mean
|
||||
|
||||
|
||||
class VQModel(ModelMixin, ConfigMixin):
|
||||
r"""VQ-VAE model from the paper Neural Discrete Representation Learning by Aaron van den Oord, Oriol Vinyals and Koray
|
||||
Kavukcuoglu.
|
||||
|
||||
This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
|
||||
implements for all the model (such as downloading or saving, etc.)
|
||||
|
||||
Parameters:
|
||||
in_channels (int, *optional*, defaults to 3): Number of channels in the input image.
|
||||
out_channels (int, *optional*, defaults to 3): Number of channels in the output.
|
||||
down_block_types (`Tuple[str]`, *optional*, defaults to :
|
||||
obj:`("DownEncoderBlock2D",)`): Tuple of downsample block types.
|
||||
up_block_types (`Tuple[str]`, *optional*, defaults to :
|
||||
obj:`("UpDecoderBlock2D",)`): Tuple of upsample block types.
|
||||
block_out_channels (`Tuple[int]`, *optional*, defaults to :
|
||||
obj:`(64,)`): Tuple of block output channels.
|
||||
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
||||
latent_channels (`int`, *optional*, defaults to `3`): Number of channels in the latent space.
|
||||
sample_size (`int`, *optional*, defaults to `32`): TODO
|
||||
num_vq_embeddings (`int`, *optional*, defaults to `256`): Number of codebook vectors in the VQ-VAE.
|
||||
"""
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
in_channels: int = 3,
|
||||
out_channels: int = 3,
|
||||
down_block_types: Tuple[str] = ("DownEncoderBlock2D",),
|
||||
up_block_types: Tuple[str] = ("UpDecoderBlock2D",),
|
||||
block_out_channels: Tuple[int] = (64,),
|
||||
layers_per_block: int = 1,
|
||||
act_fn: str = "silu",
|
||||
latent_channels: int = 3,
|
||||
sample_size: int = 32,
|
||||
num_vq_embeddings: int = 256,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
# pass init params to Encoder
|
||||
self.encoder = Encoder(
|
||||
in_channels=in_channels,
|
||||
out_channels=latent_channels,
|
||||
down_block_types=down_block_types,
|
||||
block_out_channels=block_out_channels,
|
||||
layers_per_block=layers_per_block,
|
||||
act_fn=act_fn,
|
||||
double_z=False,
|
||||
)
|
||||
|
||||
self.quant_conv = torch.nn.Conv2d(latent_channels, latent_channels, 1)
|
||||
self.quantize = VectorQuantizer(
|
||||
num_vq_embeddings, latent_channels, beta=0.25, remap=None, sane_index_shape=False
|
||||
)
|
||||
self.post_quant_conv = torch.nn.Conv2d(latent_channels, latent_channels, 1)
|
||||
|
||||
# pass init params to Decoder
|
||||
self.decoder = Decoder(
|
||||
in_channels=latent_channels,
|
||||
out_channels=out_channels,
|
||||
up_block_types=up_block_types,
|
||||
block_out_channels=block_out_channels,
|
||||
layers_per_block=layers_per_block,
|
||||
act_fn=act_fn,
|
||||
)
|
||||
|
||||
def encode(self, x: torch.FloatTensor, return_dict: bool = True) -> VQEncoderOutput:
|
||||
h = self.encoder(x)
|
||||
h = self.quant_conv(h)
|
||||
|
||||
if not return_dict:
|
||||
return (h,)
|
||||
|
||||
return VQEncoderOutput(latents=h)
|
||||
|
||||
def decode(
|
||||
self, h: torch.FloatTensor, force_not_quantize: bool = False, return_dict: bool = True
|
||||
) -> Union[DecoderOutput, torch.FloatTensor]:
|
||||
# also go through quantization layer
|
||||
if not force_not_quantize:
|
||||
quant, emb_loss, info = self.quantize(h)
|
||||
else:
|
||||
quant = h
|
||||
quant = self.post_quant_conv(quant)
|
||||
dec = self.decoder(quant)
|
||||
|
||||
if not return_dict:
|
||||
return (dec,)
|
||||
|
||||
return DecoderOutput(sample=dec)
|
||||
|
||||
def forward(self, sample: torch.FloatTensor, return_dict: bool = True) -> Union[DecoderOutput, torch.FloatTensor]:
|
||||
r"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor`): Input sample.
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`DecoderOutput`] instead of a plain tuple.
|
||||
"""
|
||||
x = sample
|
||||
h = self.encode(x).latents
|
||||
dec = self.decode(h).sample
|
||||
|
||||
if not return_dict:
|
||||
return (dec,)
|
||||
|
||||
return DecoderOutput(sample=dec)
|
||||
|
||||
|
||||
class AutoencoderKL(ModelMixin, ConfigMixin):
|
||||
r"""Variational Autoencoder (VAE) model with KL loss from the paper Auto-Encoding Variational Bayes by Diederik P. Kingma
|
||||
and Max Welling.
|
||||
|
||||
This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
|
||||
implements for all the model (such as downloading or saving, etc.)
|
||||
|
||||
Parameters:
|
||||
in_channels (int, *optional*, defaults to 3): Number of channels in the input image.
|
||||
out_channels (int, *optional*, defaults to 3): Number of channels in the output.
|
||||
down_block_types (`Tuple[str]`, *optional*, defaults to :
|
||||
obj:`("DownEncoderBlock2D",)`): Tuple of downsample block types.
|
||||
up_block_types (`Tuple[str]`, *optional*, defaults to :
|
||||
obj:`("UpDecoderBlock2D",)`): Tuple of upsample block types.
|
||||
block_out_channels (`Tuple[int]`, *optional*, defaults to :
|
||||
obj:`(64,)`): Tuple of block output channels.
|
||||
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
||||
latent_channels (`int`, *optional*, defaults to `4`): Number of channels in the latent space.
|
||||
sample_size (`int`, *optional*, defaults to `32`): TODO
|
||||
"""
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
in_channels: int = 3,
|
||||
out_channels: int = 3,
|
||||
down_block_types: Tuple[str] = ("DownEncoderBlock2D",),
|
||||
up_block_types: Tuple[str] = ("UpDecoderBlock2D",),
|
||||
block_out_channels: Tuple[int] = (64,),
|
||||
layers_per_block: int = 1,
|
||||
act_fn: str = "silu",
|
||||
latent_channels: int = 4,
|
||||
sample_size: int = 32,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
# pass init params to Encoder
|
||||
self.encoder = Encoder(
|
||||
in_channels=in_channels,
|
||||
out_channels=latent_channels,
|
||||
down_block_types=down_block_types,
|
||||
block_out_channels=block_out_channels,
|
||||
layers_per_block=layers_per_block,
|
||||
act_fn=act_fn,
|
||||
double_z=True,
|
||||
)
|
||||
|
||||
# pass init params to Decoder
|
||||
self.decoder = Decoder(
|
||||
in_channels=latent_channels,
|
||||
out_channels=out_channels,
|
||||
up_block_types=up_block_types,
|
||||
block_out_channels=block_out_channels,
|
||||
layers_per_block=layers_per_block,
|
||||
act_fn=act_fn,
|
||||
)
|
||||
|
||||
self.quant_conv = torch.nn.Conv2d(2 * latent_channels, 2 * latent_channels, 1)
|
||||
self.post_quant_conv = torch.nn.Conv2d(latent_channels, latent_channels, 1)
|
||||
|
||||
def encode(self, x: torch.FloatTensor, return_dict: bool = True) -> AutoencoderKLOutput:
|
||||
h = self.encoder(x)
|
||||
moments = self.quant_conv(h)
|
||||
posterior = DiagonalGaussianDistribution(moments)
|
||||
|
||||
if not return_dict:
|
||||
return (posterior,)
|
||||
|
||||
return AutoencoderKLOutput(latent_dist=posterior)
|
||||
|
||||
def decode(self, z: torch.FloatTensor, return_dict: bool = True) -> Union[DecoderOutput, torch.FloatTensor]:
|
||||
z = self.post_quant_conv(z)
|
||||
dec = self.decoder(z)
|
||||
|
||||
if not return_dict:
|
||||
return (dec,)
|
||||
|
||||
return DecoderOutput(sample=dec)
|
||||
|
||||
def forward(
|
||||
self, sample: torch.FloatTensor, sample_posterior: bool = False, return_dict: bool = True
|
||||
) -> Union[DecoderOutput, torch.FloatTensor]:
|
||||
r"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor`): Input sample.
|
||||
sample_posterior (`bool`, *optional*, defaults to `False`):
|
||||
Whether to sample from the posterior.
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`DecoderOutput`] instead of a plain tuple.
|
||||
"""
|
||||
x = sample
|
||||
posterior = self.encode(x).latent_dist
|
||||
if sample_posterior:
|
||||
z = posterior.sample()
|
||||
else:
|
||||
z = posterior.mode()
|
||||
dec = self.decode(z).sample
|
||||
|
||||
if not return_dict:
|
||||
return (dec,)
|
||||
|
||||
return DecoderOutput(sample=dec)
|
||||
@@ -0,0 +1,189 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import os
|
||||
import shutil
|
||||
from pathlib import Path
|
||||
from typing import Optional, Union
|
||||
|
||||
import numpy as np
|
||||
|
||||
from huggingface_hub import hf_hub_download
|
||||
|
||||
from .utils import is_onnx_available, logging
|
||||
|
||||
|
||||
if is_onnx_available():
|
||||
import onnxruntime as ort
|
||||
|
||||
|
||||
ONNX_WEIGHTS_NAME = "model.onnx"
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class OnnxRuntimeModel:
|
||||
base_model_prefix = "onnx_model"
|
||||
|
||||
def __init__(self, model=None, **kwargs):
|
||||
logger.info("`diffusers.OnnxRuntimeModel` is experimental and might change in the future.")
|
||||
self.model = model
|
||||
self.model_save_dir = kwargs.get("model_save_dir", None)
|
||||
self.latest_model_name = kwargs.get("latest_model_name", "model.onnx")
|
||||
|
||||
def __call__(self, **kwargs):
|
||||
inputs = {k: np.array(v) for k, v in kwargs.items()}
|
||||
return self.model.run(None, inputs)
|
||||
|
||||
@staticmethod
|
||||
def load_model(path: Union[str, Path], provider=None):
|
||||
"""
|
||||
Loads an ONNX Inference session with an ExecutionProvider. Default provider is `CPUExecutionProvider`
|
||||
|
||||
Arguments:
|
||||
path (`str` or `Path`):
|
||||
Directory from which to load
|
||||
provider(`str`, *optional*):
|
||||
Onnxruntime execution provider to use for loading the model, defaults to `CPUExecutionProvider`
|
||||
"""
|
||||
if provider is None:
|
||||
logger.info("No onnxruntime provider specified, using CPUExecutionProvider")
|
||||
provider = "CPUExecutionProvider"
|
||||
|
||||
return ort.InferenceSession(path, providers=[provider])
|
||||
|
||||
def _save_pretrained(self, save_directory: Union[str, Path], file_name: Optional[str] = None, **kwargs):
|
||||
"""
|
||||
Save a model and its configuration file to a directory, so that it can be re-loaded using the
|
||||
[`~optimum.onnxruntime.modeling_ort.ORTModel.from_pretrained`] class method. It will always save the
|
||||
latest_model_name.
|
||||
|
||||
Arguments:
|
||||
save_directory (`str` or `Path`):
|
||||
Directory where to save the model file.
|
||||
file_name(`str`, *optional*):
|
||||
Overwrites the default model file name from `"model.onnx"` to `file_name`. This allows you to save the
|
||||
model with a different name.
|
||||
"""
|
||||
model_file_name = file_name if file_name is not None else ONNX_WEIGHTS_NAME
|
||||
|
||||
src_path = self.model_save_dir.joinpath(self.latest_model_name)
|
||||
dst_path = Path(save_directory).joinpath(model_file_name)
|
||||
if not src_path.samefile(dst_path):
|
||||
shutil.copyfile(src_path, dst_path)
|
||||
|
||||
def save_pretrained(
|
||||
self,
|
||||
save_directory: Union[str, os.PathLike],
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Save a model to a directory, so that it can be re-loaded using the [`~OnnxModel.from_pretrained`] class
|
||||
method.:
|
||||
|
||||
Arguments:
|
||||
save_directory (`str` or `os.PathLike`):
|
||||
Directory to which to save. Will be created if it doesn't exist.
|
||||
"""
|
||||
if os.path.isfile(save_directory):
|
||||
logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
|
||||
return
|
||||
|
||||
os.makedirs(save_directory, exist_ok=True)
|
||||
|
||||
# saving model weights/files
|
||||
self._save_pretrained(save_directory, **kwargs)
|
||||
|
||||
@classmethod
|
||||
def _from_pretrained(
|
||||
cls,
|
||||
model_id: Union[str, Path],
|
||||
use_auth_token: Optional[Union[bool, str, None]] = None,
|
||||
revision: Optional[Union[str, None]] = None,
|
||||
force_download: bool = False,
|
||||
cache_dir: Optional[str] = None,
|
||||
file_name: Optional[str] = None,
|
||||
provider: Optional[str] = None,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Load a model from a directory or the HF Hub.
|
||||
|
||||
Arguments:
|
||||
model_id (`str` or `Path`):
|
||||
Directory from which to load
|
||||
use_auth_token (`str` or `bool`):
|
||||
Is needed to load models from a private or gated repository
|
||||
revision (`str`):
|
||||
Revision is the specific model version to use. It can be a branch name, a tag name, or a commit id
|
||||
cache_dir (`Union[str, Path]`, *optional*):
|
||||
Path to a directory in which a downloaded pretrained model configuration should be cached if the
|
||||
standard cache should not be used.
|
||||
force_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
|
||||
cached versions if they exist.
|
||||
file_name(`str`):
|
||||
Overwrites the default model file name from `"model.onnx"` to `file_name`. This allows you to load
|
||||
different model files from the same repository or directory.
|
||||
provider(`str`):
|
||||
The ONNX runtime provider, e.g. `CPUExecutionProvider` or `CUDAExecutionProvider`.
|
||||
kwargs (`Dict`, *optional*):
|
||||
kwargs will be passed to the model during initialization
|
||||
"""
|
||||
model_file_name = file_name if file_name is not None else ONNX_WEIGHTS_NAME
|
||||
# load model from local directory
|
||||
if os.path.isdir(model_id):
|
||||
model = OnnxRuntimeModel.load_model(os.path.join(model_id, model_file_name), provider=provider)
|
||||
kwargs["model_save_dir"] = Path(model_id)
|
||||
# load model from hub
|
||||
else:
|
||||
# download model
|
||||
model_cache_path = hf_hub_download(
|
||||
repo_id=model_id,
|
||||
filename=model_file_name,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
cache_dir=cache_dir,
|
||||
force_download=force_download,
|
||||
)
|
||||
kwargs["model_save_dir"] = Path(model_cache_path).parent
|
||||
kwargs["latest_model_name"] = Path(model_cache_path).name
|
||||
model = OnnxRuntimeModel.load_model(model_cache_path, provider=provider)
|
||||
return cls(model=model, **kwargs)
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(
|
||||
cls,
|
||||
model_id: Union[str, Path],
|
||||
force_download: bool = True,
|
||||
use_auth_token: Optional[str] = None,
|
||||
cache_dir: Optional[str] = None,
|
||||
**model_kwargs,
|
||||
):
|
||||
revision = None
|
||||
if len(str(model_id).split("@")) == 2:
|
||||
model_id, revision = model_id.split("@")
|
||||
|
||||
return cls._from_pretrained(
|
||||
model_id=model_id,
|
||||
revision=revision,
|
||||
cache_dir=cache_dir,
|
||||
force_download=force_download,
|
||||
use_auth_token=use_auth_token,
|
||||
**model_kwargs,
|
||||
)
|
||||
@@ -0,0 +1,275 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""PyTorch optimization for diffusion models."""
|
||||
|
||||
import math
|
||||
from enum import Enum
|
||||
from typing import Optional, Union
|
||||
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import LambdaLR
|
||||
|
||||
from .utils import logging
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class SchedulerType(Enum):
|
||||
LINEAR = "linear"
|
||||
COSINE = "cosine"
|
||||
COSINE_WITH_RESTARTS = "cosine_with_restarts"
|
||||
POLYNOMIAL = "polynomial"
|
||||
CONSTANT = "constant"
|
||||
CONSTANT_WITH_WARMUP = "constant_with_warmup"
|
||||
|
||||
|
||||
def get_constant_schedule(optimizer: Optimizer, last_epoch: int = -1):
|
||||
"""
|
||||
Create a schedule with a constant learning rate, using the learning rate set in optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
"""
|
||||
return LambdaLR(optimizer, lambda _: 1, last_epoch=last_epoch)
|
||||
|
||||
|
||||
def get_constant_schedule_with_warmup(optimizer: Optimizer, num_warmup_steps: int, last_epoch: int = -1):
|
||||
"""
|
||||
Create a schedule with a constant learning rate preceded by a warmup period during which the learning rate
|
||||
increases linearly between 0 and the initial lr set in the optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
num_warmup_steps (`int`):
|
||||
The number of steps for the warmup phase.
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
"""
|
||||
|
||||
def lr_lambda(current_step: int):
|
||||
if current_step < num_warmup_steps:
|
||||
return float(current_step) / float(max(1.0, num_warmup_steps))
|
||||
return 1.0
|
||||
|
||||
return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
|
||||
|
||||
|
||||
def get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps, last_epoch=-1):
|
||||
"""
|
||||
Create a schedule with a learning rate that decreases linearly from the initial lr set in the optimizer to 0, after
|
||||
a warmup period during which it increases linearly from 0 to the initial lr set in the optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
num_warmup_steps (`int`):
|
||||
The number of steps for the warmup phase.
|
||||
num_training_steps (`int`):
|
||||
The total number of training steps.
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
"""
|
||||
|
||||
def lr_lambda(current_step: int):
|
||||
if current_step < num_warmup_steps:
|
||||
return float(current_step) / float(max(1, num_warmup_steps))
|
||||
return max(
|
||||
0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps))
|
||||
)
|
||||
|
||||
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||
|
||||
|
||||
def get_cosine_schedule_with_warmup(
|
||||
optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: float = 0.5, last_epoch: int = -1
|
||||
):
|
||||
"""
|
||||
Create a schedule with a learning rate that decreases following the values of the cosine function between the
|
||||
initial lr set in the optimizer to 0, after a warmup period during which it increases linearly between 0 and the
|
||||
initial lr set in the optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
num_warmup_steps (`int`):
|
||||
The number of steps for the warmup phase.
|
||||
num_training_steps (`int`):
|
||||
The total number of training steps.
|
||||
num_cycles (`float`, *optional*, defaults to 0.5):
|
||||
The number of waves in the cosine schedule (the defaults is to just decrease from the max value to 0
|
||||
following a half-cosine).
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
"""
|
||||
|
||||
def lr_lambda(current_step):
|
||||
if current_step < num_warmup_steps:
|
||||
return float(current_step) / float(max(1, num_warmup_steps))
|
||||
progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
|
||||
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
|
||||
|
||||
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||
|
||||
|
||||
def get_cosine_with_hard_restarts_schedule_with_warmup(
|
||||
optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: int = 1, last_epoch: int = -1
|
||||
):
|
||||
"""
|
||||
Create a schedule with a learning rate that decreases following the values of the cosine function between the
|
||||
initial lr set in the optimizer to 0, with several hard restarts, after a warmup period during which it increases
|
||||
linearly between 0 and the initial lr set in the optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
num_warmup_steps (`int`):
|
||||
The number of steps for the warmup phase.
|
||||
num_training_steps (`int`):
|
||||
The total number of training steps.
|
||||
num_cycles (`int`, *optional*, defaults to 1):
|
||||
The number of hard restarts to use.
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
"""
|
||||
|
||||
def lr_lambda(current_step):
|
||||
if current_step < num_warmup_steps:
|
||||
return float(current_step) / float(max(1, num_warmup_steps))
|
||||
progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
|
||||
if progress >= 1.0:
|
||||
return 0.0
|
||||
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * ((float(num_cycles) * progress) % 1.0))))
|
||||
|
||||
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||
|
||||
|
||||
def get_polynomial_decay_schedule_with_warmup(
|
||||
optimizer, num_warmup_steps, num_training_steps, lr_end=1e-7, power=1.0, last_epoch=-1
|
||||
):
|
||||
"""
|
||||
Create a schedule with a learning rate that decreases as a polynomial decay from the initial lr set in the
|
||||
optimizer to end lr defined by *lr_end*, after a warmup period during which it increases linearly from 0 to the
|
||||
initial lr set in the optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
num_warmup_steps (`int`):
|
||||
The number of steps for the warmup phase.
|
||||
num_training_steps (`int`):
|
||||
The total number of training steps.
|
||||
lr_end (`float`, *optional*, defaults to 1e-7):
|
||||
The end LR.
|
||||
power (`float`, *optional*, defaults to 1.0):
|
||||
Power factor.
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Note: *power* defaults to 1.0 as in the fairseq implementation, which in turn is based on the original BERT
|
||||
implementation at
|
||||
https://github.com/google-research/bert/blob/f39e881b169b9d53bea03d2d341b31707a6c052b/optimization.py#L37
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
|
||||
"""
|
||||
|
||||
lr_init = optimizer.defaults["lr"]
|
||||
if not (lr_init > lr_end):
|
||||
raise ValueError(f"lr_end ({lr_end}) must be be smaller than initial lr ({lr_init})")
|
||||
|
||||
def lr_lambda(current_step: int):
|
||||
if current_step < num_warmup_steps:
|
||||
return float(current_step) / float(max(1, num_warmup_steps))
|
||||
elif current_step > num_training_steps:
|
||||
return lr_end / lr_init # as LambdaLR multiplies by lr_init
|
||||
else:
|
||||
lr_range = lr_init - lr_end
|
||||
decay_steps = num_training_steps - num_warmup_steps
|
||||
pct_remaining = 1 - (current_step - num_warmup_steps) / decay_steps
|
||||
decay = lr_range * pct_remaining**power + lr_end
|
||||
return decay / lr_init # as LambdaLR multiplies by lr_init
|
||||
|
||||
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||
|
||||
|
||||
TYPE_TO_SCHEDULER_FUNCTION = {
|
||||
SchedulerType.LINEAR: get_linear_schedule_with_warmup,
|
||||
SchedulerType.COSINE: get_cosine_schedule_with_warmup,
|
||||
SchedulerType.COSINE_WITH_RESTARTS: get_cosine_with_hard_restarts_schedule_with_warmup,
|
||||
SchedulerType.POLYNOMIAL: get_polynomial_decay_schedule_with_warmup,
|
||||
SchedulerType.CONSTANT: get_constant_schedule,
|
||||
SchedulerType.CONSTANT_WITH_WARMUP: get_constant_schedule_with_warmup,
|
||||
}
|
||||
|
||||
|
||||
def get_scheduler(
|
||||
name: Union[str, SchedulerType],
|
||||
optimizer: Optimizer,
|
||||
num_warmup_steps: Optional[int] = None,
|
||||
num_training_steps: Optional[int] = None,
|
||||
):
|
||||
"""
|
||||
Unified API to get any scheduler from its name.
|
||||
|
||||
Args:
|
||||
name (`str` or `SchedulerType`):
|
||||
The name of the scheduler to use.
|
||||
optimizer (`torch.optim.Optimizer`):
|
||||
The optimizer that will be used during training.
|
||||
num_warmup_steps (`int`, *optional*):
|
||||
The number of warmup steps to do. This is not required by all schedulers (hence the argument being
|
||||
optional), the function will raise an error if it's unset and the scheduler type requires it.
|
||||
num_training_steps (`int``, *optional*):
|
||||
The number of training steps to do. This is not required by all schedulers (hence the argument being
|
||||
optional), the function will raise an error if it's unset and the scheduler type requires it.
|
||||
"""
|
||||
name = SchedulerType(name)
|
||||
schedule_func = TYPE_TO_SCHEDULER_FUNCTION[name]
|
||||
if name == SchedulerType.CONSTANT:
|
||||
return schedule_func(optimizer)
|
||||
|
||||
# All other schedulers require `num_warmup_steps`
|
||||
if num_warmup_steps is None:
|
||||
raise ValueError(f"{name} requires `num_warmup_steps`, please provide that argument.")
|
||||
|
||||
if name == SchedulerType.CONSTANT_WITH_WARMUP:
|
||||
return schedule_func(optimizer, num_warmup_steps=num_warmup_steps)
|
||||
|
||||
# All other schedulers require `num_training_steps`
|
||||
if num_training_steps is None:
|
||||
raise ValueError(f"{name} requires `num_training_steps`, please provide that argument.")
|
||||
|
||||
return schedule_func(optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps)
|
||||
+258
-49
@@ -15,17 +15,25 @@
|
||||
# limitations under the License.
|
||||
|
||||
import importlib
|
||||
import inspect
|
||||
import os
|
||||
from typing import Optional, Union
|
||||
from dataclasses import dataclass
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
import diffusers
|
||||
import PIL
|
||||
from huggingface_hub import snapshot_download
|
||||
from PIL import Image
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
from .configuration_utils import ConfigMixin
|
||||
from .dynamic_modules_utils import get_class_from_dynamic_module
|
||||
from .utils import DIFFUSERS_CACHE, logging
|
||||
from .utils import DIFFUSERS_CACHE, BaseOutput, logging
|
||||
|
||||
|
||||
INDEX_FILE = "diffusion_model.pt"
|
||||
INDEX_FILE = "diffusion_pytorch_model.bin"
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
@@ -36,12 +44,13 @@ LOADABLE_CLASSES = {
|
||||
"ModelMixin": ["save_pretrained", "from_pretrained"],
|
||||
"SchedulerMixin": ["save_config", "from_config"],
|
||||
"DiffusionPipeline": ["save_pretrained", "from_pretrained"],
|
||||
"ClassifierFreeGuidanceScheduler": ["save_config", "from_config"],
|
||||
"OnnxRuntimeModel": ["save_pretrained", "from_pretrained"],
|
||||
},
|
||||
"transformers": {
|
||||
"PreTrainedTokenizer": ["save_pretrained", "from_pretrained"],
|
||||
"PreTrainedTokenizerFast": ["save_pretrained", "from_pretrained"],
|
||||
"PreTrainedModel": ["save_pretrained", "from_pretrained"],
|
||||
"FeatureExtractionMixin": ["save_pretrained", "from_pretrained"],
|
||||
},
|
||||
}
|
||||
|
||||
@@ -50,8 +59,35 @@ for library in LOADABLE_CLASSES:
|
||||
ALL_IMPORTABLE_CLASSES.update(LOADABLE_CLASSES[library])
|
||||
|
||||
|
||||
class DiffusionPipeline(ConfigMixin):
|
||||
@dataclass
|
||||
class ImagePipelineOutput(BaseOutput):
|
||||
"""
|
||||
Output class for image pipelines.
|
||||
|
||||
Args:
|
||||
images (`List[PIL.Image.Image]` or `np.ndarray`)
|
||||
List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
|
||||
num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
|
||||
"""
|
||||
|
||||
images: Union[List[PIL.Image.Image], np.ndarray]
|
||||
|
||||
|
||||
class DiffusionPipeline(ConfigMixin):
|
||||
r"""
|
||||
Base class for all models.
|
||||
|
||||
[`DiffusionPipeline`] takes care of storing all components (models, schedulers, processors) for diffusion pipelines
|
||||
and handles methods for loading, downloading and saving models as well as a few methods common to all pipelines to:
|
||||
|
||||
- move all PyTorch modules to the device of your choice
|
||||
- enabling/disabling the progress bar for the denoising iteration
|
||||
|
||||
Class attributes:
|
||||
|
||||
- **config_name** ([`str`]) -- name of the config file that will store the class and module names of all
|
||||
compenents of the diffusion pipeline.
|
||||
"""
|
||||
config_name = "model_index.json"
|
||||
|
||||
def register_modules(self, **kwargs):
|
||||
@@ -59,17 +95,19 @@ class DiffusionPipeline(ConfigMixin):
|
||||
from diffusers import pipelines
|
||||
|
||||
for name, module in kwargs.items():
|
||||
# check if the module is a pipeline module
|
||||
is_pipeline_module = hasattr(pipelines, module.__module__.split(".")[-1])
|
||||
|
||||
# retrive library
|
||||
library = module.__module__.split(".")[0]
|
||||
|
||||
# check if the module is a pipeline module
|
||||
pipeline_dir = module.__module__.split(".")[-2]
|
||||
path = module.__module__.split(".")
|
||||
is_pipeline_module = pipeline_dir in path and hasattr(pipelines, pipeline_dir)
|
||||
|
||||
# if library is not in LOADABLE_CLASSES, then it is a custom module.
|
||||
# Or if it's a pipeline module, then the module is inside the pipeline
|
||||
# so we set the library to module name.
|
||||
# folder so we set the library to module name.
|
||||
if library not in LOADABLE_CLASSES or is_pipeline_module:
|
||||
library = module.__module__.split(".")[-1]
|
||||
library = pipeline_dir
|
||||
|
||||
# retrive class_name
|
||||
class_name = module.__class__.__name__
|
||||
@@ -77,21 +115,27 @@ class DiffusionPipeline(ConfigMixin):
|
||||
register_dict = {name: (library, class_name)}
|
||||
|
||||
# save model index config
|
||||
self.register(**register_dict)
|
||||
self.register_to_config(**register_dict)
|
||||
|
||||
# set models
|
||||
setattr(self, name, module)
|
||||
|
||||
register_dict = {"_module": self.__module__.split(".")[-1]}
|
||||
self.register(**register_dict)
|
||||
|
||||
def save_pretrained(self, save_directory: Union[str, os.PathLike]):
|
||||
"""
|
||||
Save all variables of the pipeline that can be saved and loaded as well as the pipelines configuration file to
|
||||
a directory. A pipeline variable can be saved and loaded if its class implements both a save and loading
|
||||
method. The pipeline can easily be re-loaded using the `[`~DiffusionPipeline.from_pretrained`]` class method.
|
||||
|
||||
Arguments:
|
||||
save_directory (`str` or `os.PathLike`):
|
||||
Directory to which to save. Will be created if it doesn't exist.
|
||||
"""
|
||||
self.save_config(save_directory)
|
||||
|
||||
model_index_dict = self.config
|
||||
model_index_dict = dict(self.config)
|
||||
model_index_dict.pop("_class_name")
|
||||
model_index_dict.pop("_diffusers_version")
|
||||
model_index_dict.pop("_module")
|
||||
model_index_dict.pop("_module", None)
|
||||
|
||||
for pipeline_component_name in model_index_dict.keys():
|
||||
sub_model = getattr(self, pipeline_component_name)
|
||||
@@ -113,16 +157,130 @@ class DiffusionPipeline(ConfigMixin):
|
||||
save_method = getattr(sub_model, save_method_name)
|
||||
save_method(os.path.join(save_directory, pipeline_component_name))
|
||||
|
||||
def to(self, torch_device: Optional[Union[str, torch.device]] = None):
|
||||
if torch_device is None:
|
||||
return self
|
||||
|
||||
module_names, _ = self.extract_init_dict(dict(self.config))
|
||||
for name in module_names.keys():
|
||||
module = getattr(self, name)
|
||||
if isinstance(module, torch.nn.Module):
|
||||
module.to(torch_device)
|
||||
return self
|
||||
|
||||
@property
|
||||
def device(self) -> torch.device:
|
||||
r"""
|
||||
Returns:
|
||||
`torch.device`: The torch device on which the pipeline is located.
|
||||
"""
|
||||
module_names, _ = self.extract_init_dict(dict(self.config))
|
||||
for name in module_names.keys():
|
||||
module = getattr(self, name)
|
||||
if isinstance(module, torch.nn.Module):
|
||||
return module.device
|
||||
return torch.device("cpu")
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], **kwargs):
|
||||
r"""
|
||||
Add docstrings
|
||||
Instantiate a PyTorch diffusion pipeline from pre-trained pipeline weights.
|
||||
|
||||
The pipeline is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated).
|
||||
|
||||
The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
|
||||
pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
|
||||
task.
|
||||
|
||||
The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
|
||||
weights are discarded.
|
||||
|
||||
Parameters:
|
||||
pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
|
||||
Can be either:
|
||||
|
||||
- A string, the *repo id* of a pretrained pipeline hosted inside a model repo on
|
||||
https://huggingface.co/ Valid repo ids have to be located under a user or organization name, like
|
||||
`CompVis/ldm-text2im-large-256`.
|
||||
- A path to a *directory* containing pipeline weights saved using
|
||||
[`~DiffusionPipeline.save_pretrained`], e.g., `./my_pipeline_directory/`.
|
||||
torch_dtype (`str` or `torch.dtype`, *optional*):
|
||||
Override the default `torch.dtype` and load the model under this dtype. If `"auto"` is passed the dtype
|
||||
will be automatically derived from the model's weights.
|
||||
force_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
|
||||
cached versions if they exist.
|
||||
resume_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to delete incompletely received files. Will attempt to resume the download if such a
|
||||
file exists.
|
||||
proxies (`Dict[str, str]`, *optional*):
|
||||
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
|
||||
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
|
||||
output_loading_info(`bool`, *optional*, defaults to `False`):
|
||||
Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
|
||||
local_files_only(`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to only look at local files (i.e., do not try to download the model).
|
||||
use_auth_token (`str` or *bool*, *optional*):
|
||||
The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
|
||||
when running `huggingface-cli login` (stored in `~/.huggingface`).
|
||||
revision (`str`, *optional*, defaults to `"main"`):
|
||||
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
|
||||
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
|
||||
identifier allowed by git.
|
||||
mirror (`str`, *optional*):
|
||||
Mirror source to accelerate downloads in China. If you are from China and have an accessibility
|
||||
problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
|
||||
Please refer to the mirror site for more information. specify the folder name here.
|
||||
|
||||
kwargs (remaining dictionary of keyword arguments, *optional*):
|
||||
Can be used to overwrite load - and saveable variables - *i.e.* the pipeline components - of the
|
||||
speficic pipeline class. The overritten components are then directly passed to the pipelines `__init__`
|
||||
method. See example below for more information.
|
||||
|
||||
<Tip>
|
||||
|
||||
Passing `use_auth_token=True`` is required when you want to use a private model, *e.g.*
|
||||
`"CompVis/stable-diffusion-v1-4"`
|
||||
|
||||
</Tip>
|
||||
|
||||
<Tip>
|
||||
|
||||
Activate the special ["offline-mode"](https://huggingface.co/diffusers/installation.html#offline-mode) to use
|
||||
this method in a firewalled environment.
|
||||
|
||||
</Tip>
|
||||
|
||||
Examples:
|
||||
|
||||
```py
|
||||
>>> from diffusers import DiffusionPipeline
|
||||
|
||||
>>> # Download pipeline from huggingface.co and cache.
|
||||
>>> pipeline = DiffusionPipeline.from_pretrained("CompVis/ldm-text2im-large-256")
|
||||
|
||||
>>> # Download pipeline that requires an authorization token
|
||||
>>> # For more information on access tokens, please refer to this section
|
||||
>>> # of the documentation](https://huggingface.co/docs/hub/security-tokens)
|
||||
>>> pipeline = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
|
||||
|
||||
>>> # Download pipeline, but overwrite scheduler
|
||||
>>> from diffusers import LMSDiscreteScheduler
|
||||
|
||||
>>> scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear")
|
||||
>>> pipeline = DiffusionPipeline.from_pretrained(
|
||||
... "CompVis/stable-diffusion-v1-4", scheduler=scheduler, use_auth_token=True
|
||||
... )
|
||||
```
|
||||
"""
|
||||
cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
|
||||
resume_download = kwargs.pop("resume_download", False)
|
||||
proxies = kwargs.pop("proxies", None)
|
||||
local_files_only = kwargs.pop("local_files_only", False)
|
||||
use_auth_token = kwargs.pop("use_auth_token", None)
|
||||
revision = kwargs.pop("revision", None)
|
||||
torch_dtype = kwargs.pop("torch_dtype", None)
|
||||
provider = kwargs.pop("provider", None)
|
||||
|
||||
# 1. Download the checkpoints and configs
|
||||
# use snapshot download here to get it working from from_pretrained
|
||||
@@ -134,17 +292,14 @@ class DiffusionPipeline(ConfigMixin):
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
)
|
||||
else:
|
||||
cached_folder = pretrained_model_name_or_path
|
||||
|
||||
config_dict = cls.get_config_dict(cached_folder)
|
||||
|
||||
# 2. Get class name and module candidates to load custom models
|
||||
module_candidate_name = config_dict["_module"]
|
||||
module_candidate = module_candidate_name + ".py"
|
||||
|
||||
# 3. Load the pipeline class, if using custom module then load it from the hub
|
||||
# 2. Load the pipeline class, if using custom module then load it from the hub
|
||||
# if we load from explicit class, let's use it
|
||||
if cls != DiffusionPipeline:
|
||||
pipeline_class = cls
|
||||
@@ -152,10 +307,11 @@ class DiffusionPipeline(ConfigMixin):
|
||||
diffusers_module = importlib.import_module(cls.__module__.split(".")[0])
|
||||
pipeline_class = getattr(diffusers_module, config_dict["_class_name"])
|
||||
|
||||
# (TODO - we should allow to load custom pipelines
|
||||
# else we need to load the correct module from the Hub
|
||||
# module = module_candidate
|
||||
# pipeline_class = get_class_from_dynamic_module(cached_folder, module, class_name_, cached_folder)
|
||||
# some modules can be passed directly to the init
|
||||
# in this case they are already instantiated in `kwargs`
|
||||
# extract them here
|
||||
expected_modules = set(inspect.signature(pipeline_class.__init__).parameters.keys())
|
||||
passed_class_obj = {k: kwargs.pop(k) for k in expected_modules if k in kwargs}
|
||||
|
||||
init_dict, _ = pipeline_class.extract_init_dict(config_dict, **kwargs)
|
||||
|
||||
@@ -164,22 +320,43 @@ class DiffusionPipeline(ConfigMixin):
|
||||
# import it here to avoid circular import
|
||||
from diffusers import pipelines
|
||||
|
||||
# 4. Load each module in the pipeline
|
||||
# 3. Load each module in the pipeline
|
||||
for name, (library_name, class_name) in init_dict.items():
|
||||
is_pipeline_module = hasattr(pipelines, library_name)
|
||||
loaded_sub_model = None
|
||||
|
||||
# if the model is in a pipeline module, then we load it from the pipeline
|
||||
if is_pipeline_module:
|
||||
if name in passed_class_obj:
|
||||
# 1. check that passed_class_obj has correct parent class
|
||||
if not is_pipeline_module:
|
||||
library = importlib.import_module(library_name)
|
||||
class_obj = getattr(library, class_name)
|
||||
importable_classes = LOADABLE_CLASSES[library_name]
|
||||
class_candidates = {c: getattr(library, c) for c in importable_classes.keys()}
|
||||
|
||||
expected_class_obj = None
|
||||
for class_name, class_candidate in class_candidates.items():
|
||||
if issubclass(class_obj, class_candidate):
|
||||
expected_class_obj = class_candidate
|
||||
|
||||
if not issubclass(passed_class_obj[name].__class__, expected_class_obj):
|
||||
raise ValueError(
|
||||
f"{passed_class_obj[name]} is of type: {type(passed_class_obj[name])}, but should be"
|
||||
f" {expected_class_obj}"
|
||||
)
|
||||
else:
|
||||
logger.warn(
|
||||
f"You have passed a non-standard module {passed_class_obj[name]}. We cannot verify whether it"
|
||||
" has the correct type"
|
||||
)
|
||||
|
||||
# set passed class object
|
||||
loaded_sub_model = passed_class_obj[name]
|
||||
elif is_pipeline_module:
|
||||
pipeline_module = getattr(pipelines, library_name)
|
||||
class_obj = getattr(pipeline_module, class_name)
|
||||
importable_classes = ALL_IMPORTABLE_CLASSES
|
||||
class_candidates = {c: class_obj for c in ALL_IMPORTABLE_CLASSES.keys()}
|
||||
elif library_name == module_candidate_name:
|
||||
# if the model is not in diffusers or transformers, we need to load it from the hub
|
||||
# assumes that it's a subclass of ModelMixin
|
||||
class_obj = get_class_from_dynamic_module(cached_folder, module_candidate, class_name, cached_folder)
|
||||
# since it's not from a library, we need to check class candidates for all importable classes
|
||||
importable_classes = ALL_IMPORTABLE_CLASSES
|
||||
class_candidates = {c: class_obj for c in ALL_IMPORTABLE_CLASSES.keys()}
|
||||
class_candidates = {c: class_obj for c in importable_classes.keys()}
|
||||
else:
|
||||
# else we just import it from the library.
|
||||
library = importlib.import_module(library_name)
|
||||
@@ -187,22 +364,54 @@ class DiffusionPipeline(ConfigMixin):
|
||||
importable_classes = LOADABLE_CLASSES[library_name]
|
||||
class_candidates = {c: getattr(library, c) for c in importable_classes.keys()}
|
||||
|
||||
load_method_name = None
|
||||
for class_name, class_candidate in class_candidates.items():
|
||||
if issubclass(class_obj, class_candidate):
|
||||
load_method_name = importable_classes[class_name][1]
|
||||
if loaded_sub_model is None:
|
||||
load_method_name = None
|
||||
for class_name, class_candidate in class_candidates.items():
|
||||
if issubclass(class_obj, class_candidate):
|
||||
load_method_name = importable_classes[class_name][1]
|
||||
|
||||
load_method = getattr(class_obj, load_method_name)
|
||||
load_method = getattr(class_obj, load_method_name)
|
||||
|
||||
# check if the module is in a subdirectory
|
||||
if os.path.isdir(os.path.join(cached_folder, name)):
|
||||
loaded_sub_model = load_method(os.path.join(cached_folder, name))
|
||||
else:
|
||||
# else load from the root directory
|
||||
loaded_sub_model = load_method(cached_folder)
|
||||
loading_kwargs = {}
|
||||
if issubclass(class_obj, torch.nn.Module):
|
||||
loading_kwargs["torch_dtype"] = torch_dtype
|
||||
if issubclass(class_obj, diffusers.OnnxRuntimeModel):
|
||||
loading_kwargs["provider"] = provider
|
||||
|
||||
# check if the module is in a subdirectory
|
||||
if os.path.isdir(os.path.join(cached_folder, name)):
|
||||
loaded_sub_model = load_method(os.path.join(cached_folder, name), **loading_kwargs)
|
||||
else:
|
||||
# else load from the root directory
|
||||
loaded_sub_model = load_method(cached_folder, **loading_kwargs)
|
||||
|
||||
init_kwargs[name] = loaded_sub_model # UNet(...), # DiffusionSchedule(...)
|
||||
|
||||
# 5. Instantiate the pipeline
|
||||
# 4. Instantiate the pipeline
|
||||
model = pipeline_class(**init_kwargs)
|
||||
return model
|
||||
|
||||
@staticmethod
|
||||
def numpy_to_pil(images):
|
||||
"""
|
||||
Convert a numpy image or a batch of images to a PIL image.
|
||||
"""
|
||||
if images.ndim == 3:
|
||||
images = images[None, ...]
|
||||
images = (images * 255).round().astype("uint8")
|
||||
pil_images = [Image.fromarray(image) for image in images]
|
||||
|
||||
return pil_images
|
||||
|
||||
def progress_bar(self, iterable):
|
||||
if not hasattr(self, "_progress_bar_config"):
|
||||
self._progress_bar_config = {}
|
||||
elif not isinstance(self._progress_bar_config, dict):
|
||||
raise ValueError(
|
||||
f"`self._progress_bar_config` should be of type `dict`, but is {type(self._progress_bar_config)}."
|
||||
)
|
||||
|
||||
return tqdm(iterable, **self._progress_bar_config)
|
||||
|
||||
def set_progress_bar_config(self, **kwargs):
|
||||
self._progress_bar_config = kwargs
|
||||
|
||||
@@ -1,19 +0,0 @@
|
||||
# Pipelines
|
||||
|
||||
- Pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box
|
||||
- Pipelines should stay as close as possible to their original implementation
|
||||
- Pipelines can include components of other library, such as text-encoders.
|
||||
|
||||
## API
|
||||
|
||||
TODO(Patrick, Anton, Suraj)
|
||||
|
||||
## Examples
|
||||
|
||||
- DDPM for unconditional image generation in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddpm.py).
|
||||
- DDIM for unconditional image generation in [pipeline_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddim.py).
|
||||
- PNDM for unconditional image generation in [pipeline_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_pndm.py).
|
||||
- Latent diffusion for text to image generation / conditional image generation in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
- Glide for text to image generation / conditional image generation in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
- BDDM for spectrogram-to-sound vocoding in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
- Grad-TTS for text to audio generation / conditional audio generation in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user